
A Semi-Supervised-Learning-Aided Explainable Belief Rule-Based Approach to Predict the Energy Consumption of Buildings



Abstract
1. Introduction
- How to address the scarcity of supervised labeled training data of energy consumption? We employ SSL to overcome the scarcity of labeled energy data with weakly and strongly augmented pseudo-labeled data.
- What is the benefit of predicting with BRBES? The benefit is prediction based on knowledge of the energy domain while dealing with data uncertainties.
- Why and how to integrate self-training model with BRBES? For the SSL model, we employ self-training to obtain pseudo-labels of unlabeled energy data with the BRBES only. A mathematical model is proposed to combine self-training with the BRBES.
- How to make the output of BRBES trustworthy to a human user? We make the predictive energy consumption output of the semi-supervised BRBES trustworthy by explaining it in nontechnical human language to a user through a user interface. This explanation is based on knowledge of the concerned domain.
2. Related Work
2.1. SSL Methods
2.2. Labeling the Unlabeled Data
2.3. Type of Data and Predictive Output
2.4. Motivation
3. Method
3.1. Self-Training Method
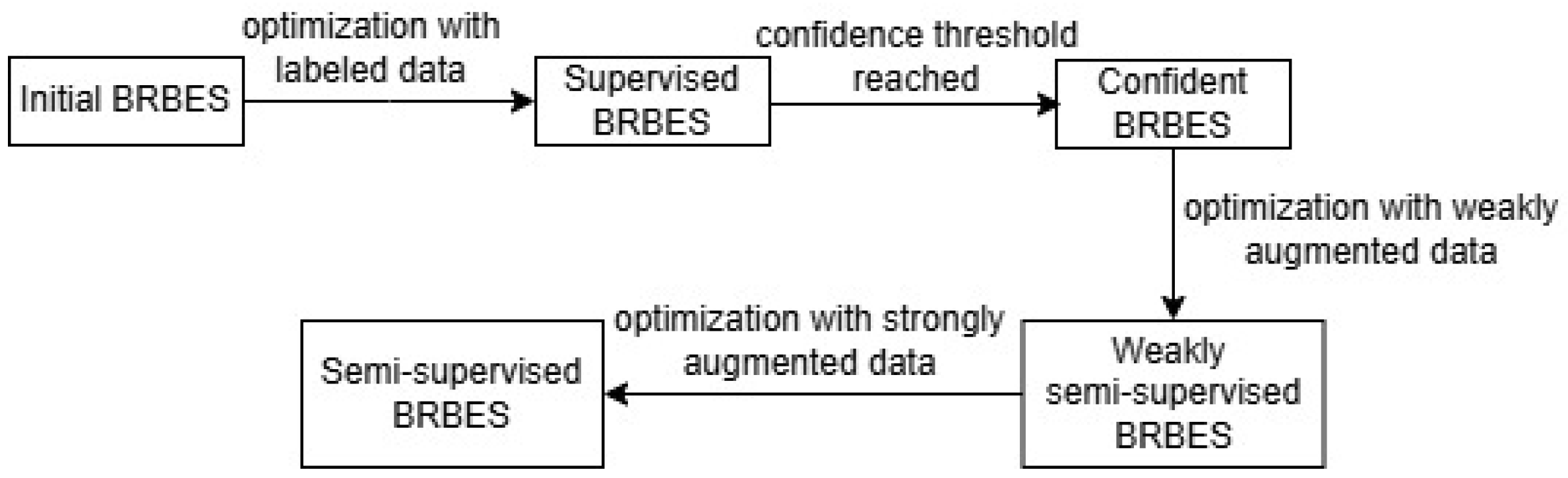
- Prediction Model: For the prediction model, we use the BRBES, a symbolic AI model, to provide domain knowledge based prediction while handling associated uncertainties (Figure 1a). We then optimize the initial BRBES with supervised labeled training data using JOPS. Such optimization makes the initial BRBES supervised. We optimize the supervised BRBES unless its accuracy reaches the confidence threshold. If the accuracy reaches this threshold, the supervised BRBES will become a confident BRBES. This confident BRBES will be able to predict pseudo-labels for the unlabeled data points with due confidence. (Figure 1b).
- Data Augmentation: To overcome the shortage of labeled data, we synthetically generate unlabeled data. For this purpose, we leverage two kinds of augmentations: “weak” and “strong”. Theses two types of augmentations are briefly mentioned below.Weak Augmentation: For weak augmentation, we generate unlabeled integer values for relevant antecedent attributes of BRBES. We predict labels for these weakly augmented unlabeled data points with confident BRBES. We then train the confident BRBES with both labeled and weakly augmented pseudo-labeled datasets. If training with this weakly augmented pseudo-labeled dataset improves the accuracy, the confident BRBES will transition to a weakly semi-supervised BRBES (Figure 1c–g).Strong Augmentation: A dataset has two types of noise: class noise and attribute noise [61]. Class noise is triggered against incorrectly assigned class label to a data instance. On the other hand, attribute noise reflects erroneous or missing values for one or more input features (independent variables) of the dataset [61]. To reduce both the class and attribute noise of the weakly augmented pseudo-labeled dataset, we apply strong augmentation. For strong augmentation, we synthetically generate unlabeled float values for the same antecedent attributes of BRBES as weak augmentation. We then predict labels for these strongly augmented unlabeled data points with a weakly semi-supervised BRBES. We optimize the weakly semi-supervised BRBES with labeled, as well as weakly and strongly augmented pseudo-labeled, datasets. If training with the strongly augmented pseudo-labeled dataset improves the accuracy, weakly semi-supervised BRBES will transition to a semi-supervised BRBES (Figure 1h–l).
- Prediction and Explanation: This semi-supervised BRBES provides more accurate prediction, along with an explanation and counterfactual, through a user interface (Figure 1m,n).
3.2. Proposed Semi-Supervised Explainable BRBES Framework
3.3. Framework Evaluation
4. Results
4.1. Experimental Configuration
4.2. Dataset
4.3. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Nichols, B.G.; Kockelman, K.M. Life-cycle energy implications of different residential settings: Recognizing buildings, travel, and public infrastructure. Energy Policy 2014, 68, 232–242. [Google Scholar] [CrossRef]
- Geng, Y.; Ji, W.; Wang, Z.; Lin, B.; Zhu, Y. A review of operating performance in green buildings: Energy use, indoor environmental quality and occupant satisfaction. Energy Build. 2019, 183, 500–514. [Google Scholar] [CrossRef]
- Aversa, P.; Donatelli, A.; Piccoli, G.; Luprano, V.A.M. Improved Thermal Transmittance Measurement with HFM Technique on Building Envelopes in the Mediterranean Area. Sel. Sci. Pap. J. Civ. Eng. 2016, 11, 39–52. [Google Scholar] [CrossRef]
- Cao, X.; Dai, X.; Liu, J. Building energy-consumption status worldwide and the state-of-the-art technologies for zero-energy buildings during the past decade. Energy Build. 2016, 128, 198–213. [Google Scholar] [CrossRef]
- Pham, A.-D.; Ngo, N.-T.; Truong, T.T.H.; Huynh, N.-T.; Truong, N.-S. Predicting energy consumption in multiple buildings using machine learning for improving energy efficiency and sustainability. J. Clean. Prod. 2020, 260, 121082. [Google Scholar] [CrossRef]
- McNeil, M.A.; Karali, N.; Letschert, V. Forecasting Indonesia’s electricity load through 2030 and peak demand reductions from appliance and lighting efficiency. Energy Sustain. Dev. 2019, 49, 65–77. [Google Scholar] [CrossRef]
- Qiao, R.; Liu, T. Impact of building greening on building energy consumption: A quantitative computational approach. J. Clean. Prod. 2020, 246, 119020. [Google Scholar] [CrossRef]
- Kabir, S.; Islam, R.U.; Hossain, M.S.; Andersson, K. An integrated approach of belief rule base and deep learning to predict air pollution. Sensors 2020, 20, 1956. [Google Scholar] [CrossRef]
- Caruana, R.; Niculescu-Mizil, A. An empirical comparison of supervised learning algorithms. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 161–168. [Google Scholar]
- Wei, X.; Li, Y.; Zhang, M.; Chen, Q.; Wang, H. Data-driven energy consumption prediction: Challenges and solutions. Energy Inform. 2022, 5, 18–32. [Google Scholar]
- Sahoo, P.; Roy, I.; Ahlawat, R.; Irtiza, S.; Khan, L. Potential diagnosis of COVID-19 from chest X-ray and CT findings using semi-supervised learning. Phys. Eng. Sci. Med. 2021, 45, 31–42. [Google Scholar] [CrossRef]
- Sahoo, P.; Roy, I.; Wang, Z.; Mi, F.; Yu, L.; Balasubramani, P.; Khan, L.; Stoddart, J.F. MultiCon: A semi-supervised approach for predicting drug function from chemical structure analysis. J. Chem. Inf. Model. 2020, 60, 5995–6006. [Google Scholar] [CrossRef]
- Zhu, X.J. Semi-Supervised Learning Literature Survey; University of Wisconsin-Madison Department of Computer Sciences: Madison, WI, USA, 2005. [Google Scholar]
- Chapelle, O.; Scholkopf, B.; Zien Eds, A. Semi-Supervised Learning (Chapelle, O. et al., Eds.; 2006) [Book reviews]. IEEE Trans. Neural Network 2009, 20, 542. [Google Scholar] [CrossRef]
- Lee, D.-H. Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks. In Proceedings of the Workshop on Challenges in Representation Learning, ICML, Atlanta, GA, USA, 21 June 2013; Volume 2. [Google Scholar]
- Miyato, T.; Maeda, S.; Koyama, M.; Ishii, S. Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1979–1993. [Google Scholar] [CrossRef]
- Yang, X.; Song, Z.; King, I.; Xu, Z. A survey on deep semi-supervised learning. IEEE Trans. Knowl. Data Eng. 2022, 35, 8934–8954. [Google Scholar] [CrossRef]
- Luo, X.; Zhao, Y.; Qin, Y.; Ju, W.; Zhang, M. Towards semi-supervised universal graph classification. IEEE Trans. Knowl. Data Eng. 2023, 36, 416–428. [Google Scholar] [CrossRef]
- Luo, X.; Zhao, Y.; Mao, Z.; Qin, Y.; Ju, W.; Zhang, M.; Sun, Y. Rignn: A rationale perspective for semi-supervised open-world graph classification. Trans. Mach. Learn. Res. 2023, 2, 1–20. [Google Scholar] [CrossRef]
- Liu, Z.; Li, Y.; Wang, Y.; Wang, Z. Hypergraph-enhanced dual semi-supervised graph classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 7603–7611. [Google Scholar]
- Verma, V.; Kawaguchi, K.; Lamb, A.; Kannala, J.; Solin, A.; Bengio, Y.; Lopez-Paz, D. Interpolation consistency training for semi-supervised learning. Neural Netw. 2022, 145, 90–106. [Google Scholar] [CrossRef]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C.A. Mixmatch: A holistic approach to semi-supervised learning. Adv. Neural Inf. Process. Syst. 2019, 32, 5049–5059. [Google Scholar]
- Berthelot, D. ReMixMatch: Semi-supervised learning with distribution matching and augmentation anchoring. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Cubuk, E.D.; Kurakin, A.; Li, C.-L. FixMatch: Simplifying semi-supervised learning with consistency and confidence. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver BC Canada, 6–12 December 2020. [Google Scholar]
- Bai, Y.; Zhao, H.; Zhang, Y.; Liu, Y.; Xie, L. Semi-supervised Active Learning for Graph-level Classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 7520–7528. [Google Scholar]
- Zhang, M.; Song, L.; Yang, C.; Liu, Z. Towards Effective Semi-supervised Node Classification with Hybrid Curriculum Pseudo-labeling. In Proceedings of the NeurIPS Conference, New Orleans, LA, USA, 28 November 2022; Volume 35, pp. 2175–2185. [Google Scholar] [CrossRef]
- Liu, J.W.; Liu, Y.; Luo, X.L. Semi-supervised Learning Method. Chin. J. Comput. 2015, 38, 1592–1617. [Google Scholar]
- Ahmad, T.; Chen, H. Empirical performance evaluation of machine learning techniques for building energy consumption forecasting. Energy Build. 2018, 165, 121–130. [Google Scholar] [CrossRef]
- Han, S.; Han, Q.H. Review of Semi-supervised Learning Research. Comput. Eng. Appl. 2020, 56, 19–27. [Google Scholar]
- Chen, L.; Nugent, C.D.; Wang, H. A Knowledge-Driven Approach to Activity Recognition in Smart Homes. IEEE Trans. Knowl. Data Eng. 2011, 24, 961–974. [Google Scholar] [CrossRef]
- Bhavsar, H.; Ganatra, A. A comparative study of training algorithms for supervised machine learning. Int. J. Soft Comput. Eng. 2012, 2, 74–81. [Google Scholar]
- Cireşan, D.C.; Meier, U.; Gambardella, L.M.; Schmidhuber, J. Deep, Big, Simple Neural Nets for Handwritten Digit Recognition. Neural Comput. 2010, 22, 3207–3220. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, F.; Wen, Y.; Nee, B. Toward explainable and interpretable building energy modelling: An explainable artificial intelligence approach. In Proceedings of the 8th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, Coimbra, Portugal, 17–18 November 2021; pp. 255–258. [Google Scholar]
- Zhang, Y.; Teoh, B.K.; Wu, M.; Chen, J.; Zhang, L. Data-driven estimation of building energy consumption and GHG emissions using explainable artificial intelligence. Energy 2023, 262, 125468. [Google Scholar] [CrossRef]
- Biessmann, F.; Kamble, B.; Streblow, R. An Automated Machine Learning Approach towards Energy Saving Estimates in Public Buildings. Energies 2023, 16, 6799. [Google Scholar] [CrossRef]
- Tsoka, T.; Ye, X.; Chen, Y.; Gong, D.; Xia, X. Explainable artificial intelligence for building energy performance certificate labelling classification. J. Clean. Prod. 2022, 355, 131626. [Google Scholar] [CrossRef]
- Kabir, S.; Hossain, M.S.; Andersson, K. An Advanced Explainable Belief Rule-Based Framework to Predict the Energy Consumption of Buildings. Energies 2024, 17, 1797. [Google Scholar] [CrossRef]
- Sun, R. Robust reasoning: Integrating rule-based and similarity-based reasoning. Artif. Intell. 1995, 75, 241–295. [Google Scholar] [CrossRef]
- Buchanan, B.G.; Shortliffe, E.H. Rule Based Expert Systems: The Mycin Experiments of the Stanford Heuristic Programming Project. In The Addison-Wesley Series in Artificial Intelligence; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1984. [Google Scholar]
- Bourgeois, J.; Bacha, S. The fuzzy logic method to efficiently optimize electricity consumption in individual housing. Energies 2017, 10, 1701. [Google Scholar] [CrossRef]
- Gorzałczany, M.B.; Rudziński, F. Energy Consumption Prediction in Residential Buildings—An Accurate and Interpretable Machine Learning Approach Combining Fuzzy Systems with Evolutionary Optimization. Energies 2024, 17, 3242. [Google Scholar] [CrossRef]
- Chen, X.; Singh, M.M.; Geyer, P. Utilizing domain knowledge: Robust machine learning for building energy performance prediction with small, inconsistent datasets. Knowl.-Based Syst. 2024, 294, 111774. [Google Scholar] [CrossRef]
- Islam, R.U.; Hossain, M.S.; Andersson, K. A novel anomaly detection algorithm for sensor data under uncertainty. Soft Comput. 2018, 22, 1623–1639. [Google Scholar] [CrossRef]
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1988. [Google Scholar]
- Zadeh, L.A. Fuzzy logic. Computer 1988, 21, 83–93. [Google Scholar] [CrossRef]
- Yang, J.-B.; Liu, J.; Wang, J.; Sii, H.-S.; Wang, H.-W. Belief rule-base inference methodology using the evidential reasoning Approach-RIMER. IEEE Trans. Syst. Man Cybern. Part A Syst. Humans 2006, 36, 266–285. [Google Scholar] [CrossRef]
- Hossain, M.S.; Rahaman, S.; Mustafa, R.; Andersson, K. A belief rule-based expert system to assess suspicion of acute coronary syndrome (ACS) under uncertainty. Soft Comput. 2018, 22, 7571–7586. [Google Scholar] [CrossRef]
- Yang, J.-B.; Singh, M. An evidential reasoning approach for multiple-attribute decision making with uncertainty. IEEE Trans. Syst. Man Cybern. 1994, 24, 1–18. [Google Scholar] [CrossRef]
- Yang, L.H.; Wang, Y.M.; Liu, J.; Martínez, L. A joint optimization method on parameter and structure for belief-rule-based systems. Knowl. Based Syst. 2018, 142, 220–240. [Google Scholar] [CrossRef]
- Prakash, V.J.; Nithya, D.L. A survey on semi-supervised learning techniques. Int. J. Comput. Trends Technol. 2014, 8, 148–153. [Google Scholar] [CrossRef]
- Hernández-García, A.; König, P. Data augmentation instead of explicit regularization. arXiv 2018, arXiv:1806.03852. [Google Scholar]
- Kaur, P.; Khehra, B.S.; Mavi, E.B.S. Data augmentation for object detection: A review. In Proceedings of the IEEE International Midwest Symposium on Circuits and Systems (MWSCAS), Lansing, MI, USA, 9–11 August 2021; pp. 537–543. [Google Scholar]
- Li, X.; Khan, L.; Zamani, M.; Wickramasuriya, S.; Hamlen, K.W.; Thuraisingham, B. Mcom: A semi-supervised method for imbalanced tabular security data. In Proceedings of the IFIP Annual Conference on Data and Applications Security and Privacy, Newark, NJ, USA, 18–20 July 2022; Springer International Publishing: Cham, Switzerland, 2022; pp. 48–67. [Google Scholar]
- Silva, C.; Santos, J.S.; Wanner, E.F.; Carrano, E.G.; Takahashi, R.H. Semi-supervised training of least squares support vector machine using a multiobjective evolutionary algorithm. In Proceedings of the IEEE Congress on Evolutionary Computation, Trondheim, Norway, 18–21 May 2009; pp. 2996–3002. [Google Scholar]
- Donyavi, Z.; Asadi, S. Diverse training dataset generation based on a multi-objective optimization for semi-supervised classification. Pattern Recognit. 2020, 108, 107543. [Google Scholar] [CrossRef]
- Jin, H.; Li, Z.; Chen, X.; Qian, B.; Yang, B.; Yang, J. Evolutionary optimization based pseudo labeling for semi-supervised soft sensor development of industrial processes. Chem. Eng. Sci. 2021, 237, 116560. [Google Scholar] [CrossRef]
- Gao, F.; Gao, W.; Huang, L.; Xie, J.; Gong, M. An effective knowledge transfer method based on semi-supervised learning for evolutionary optimization. Inf. Sci. 2022, 612, 1127–1144. [Google Scholar] [CrossRef]
- Cococcioni, M.; Lazzerini, B.; Pistolesi, F. A semi-supervised learning-aided evolutionary approach to occupational safety improvement. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 3695–3701. [Google Scholar]
- Triguero, I.; García, S.; Herrera, F. Self-labeled techniques for semi-supervised learning: Taxonomy, software and empirical study. Knowl. Inf. Syst. 2015, 42, 245–284. [Google Scholar] [CrossRef]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Gupta, S.; Gupta, A. Dealing with noise problem in machine learning data-sets: A systematic review. In Proceedings of the fifth Information Systems International Conference, Surabaya, Indonesia, 23–24 July 2019; Volume 161, pp. 466–474. [Google Scholar]
- Alexander, P.A.; Judy, J.E. The interaction of domain-specific and strategic knowledge in academic performance. Rev. Educ. Res. 1988, 58, 375–404. [Google Scholar] [CrossRef]
- Alexander, P.A. Domain Knowledge: Evolving Themes and Emerging Concerns. Educ. Psychol. 1992, 27, 33–51. [Google Scholar] [CrossRef]
- Wang, Y.M.; Yang, J.B.; Xu, D.L. Environmental impact assessment using the evidential reasoning approach. Eur. J. Oper. Res. 2006, 174, 1885–1913. [Google Scholar] [CrossRef]
- Kabir, S.; Islam, R.U.; Hossain, M.S.; Andersson, K. An integrated approach of Belief Rule Base and Convolutional Neural Network to monitor air quality in Shanghai. Expert Syst. Appl. 2022, 206, 117905. [Google Scholar] [CrossRef]
- Brange, L.; Englund, J.; Lauenburg, P. Prosumers in district heating networks—A Swedish case study. Appl. Energy 2016, 164, 492–500. [Google Scholar] [CrossRef]
- Dosilovic, F.K.; Brcic, M.; Hlupic, N. Explainable artificial intelligence: A survey. In Proceedings of the IEEE 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 0210–0215. [Google Scholar]
- Hossain, M.S.; Rahaman, S.; Kor, A.L.; Andersson, K.; Pattinson, C. A Belief Rule Based Expert System for Datacenter PUE Prediction under Uncertainty. IEEE Trans. Sustain. Comput. 2017, 2, 140–153. [Google Scholar] [CrossRef]
- Islam, R.U.; Hossain, M.S.; Andersson, K. A learning mechanism for brbes using enhanced belief rule-based adaptive differential evolution. In Proceedings of the 2020 4th IEEE International Conference on Imaging, Vision & Pattern Recognition (icIVPR), Kitakyushu, Japan, 26–29 August 2020; pp. 1–10. [Google Scholar]
- Yang, J.B.; Liu, J.; Xu, D.L.; Wang, J.; Wang, H. Optimization models for training belief-rule-based systems. IEEE Trans. Syst. Man Cybern.-Part A Syst. Humans 2007, 37, 569–585. [Google Scholar] [CrossRef]
- Chang, L.; Sun, J.; Jiang, J.; Li, M. Parameter learning for the belief rule base system in the residual life probability prediction of metalized film capacitor. Knowl.-Based Syst. 2015, 73, 69–80. [Google Scholar] [CrossRef]
- Chang, L.L.; Zhou, Z.J.; Chen, Y.W.; Liao, T.J.; Hu, Y.; Yang, L.H. Belief rule base structure and parameter joint optimization under disjunctive assumption for nonlinear complex system modeling. IEEE Trans. Syst. Man Cybern. Syst. 2018, 48, 1542–1554. [Google Scholar] [CrossRef]
- Blum, C.; Roli, A. Metaheuristics in combinatorial optimization: Overview and conceptual comparison. ACM Comput. Surv. 2003, 35, 268–308. [Google Scholar] [CrossRef]
- Al-Dabbagh, R.D.; Neri, F.; Idris, N.; Baba, M.S. Algorithmic design issues in adaptive differential evolution schemes: Review and taxonomy. Swarm Evol. Comput. 2018, 43, 284–311. [Google Scholar] [CrossRef]
- Liu, J.; Lampinen, J. A fuzzy adaptive differential evolution algorithm. Soft Comput. 2005, 9, 448–462. [Google Scholar] [CrossRef]
- Leon, M.; Xiong, N. Greedy adaptation of control parameters in differential evolution for global optimization problems. In Proceedings of the 2015 IEEE Congress on Evolutionary Computation (CEC), Sendai, Japan, 25–28 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 385–392. [Google Scholar]
- Barron, A.R. Approximation and estimation bounds for artificial neural networks. Mach. Learn. 1994, 14, 115–133. [Google Scholar] [CrossRef]
- Seeger, M. PAC-Bayesian generalisation error bounds for Gaussian process classification. J. Mach. Learn. Res. 2002, 3, 233–269. [Google Scholar]
- Vapnik, V.; Chapelle, O. Bounds on error expectation for support vector machines. Neural Comput. 2000, 12, 2013–2036. [Google Scholar] [CrossRef]
- Hoeffding, W. Probability inequalities for sums of bounded random variables. In The Collected Works of Wassily Hoeffding; Fisher, N.I., Sen, P.K., Eds.; Springer: New York, NY, USA, 1994; pp. 409–426. [Google Scholar]
- Zeng, Q.; Xie, Y.; Lu, Z.; Xia, Y. Pefat: Boosting semi-supervised medical image classification via pseudo-loss estimation and feature adversarial training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 15671–15680. [Google Scholar]
- Oord, A.V.D.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Zhu, X.; Xindong, W. Class noise vs. attribute noise: A quantitative study. Artif. Intell. Rev. 2004, 22, 177–210. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Adebayo, J.; Gilmer, J.; Muelly, M.; Goodfellow, I.; Hardt, M.; Kim, B. Sanity checks for saliency maps. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montreal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Nauta, M.; Trienes, J.; Pathak, S.; Nguyen, E.; Peters, M.; Schmitt, Y.; Schlötterer, J.; van Keulen, M.; Seifert, C. From Anecdotal Evidence to Quantitative Evaluation Methods: A Systematic Review on Evaluating Explainable AI. ACM Comput. Surv. 2022, 55, 295. [Google Scholar] [CrossRef]
- Rosenfeld, A. Better metrics for evaluating explainable artificial intelligence. In Proceedings of the 20th International Conference on Autonomous Agents and Multiagent Systems, Virtual, 3–7 May 2021; pp. 45–50. [Google Scholar]
- Skellefteå Kraft, Sweden. Energy Consumption Dataset. 2023. Available online: https://www.skekraft.se/privat/fjarrvarme/ (accessed on 6 February 2024).
- Xu, W.; Tang, J.; Xia, H. A review of semi-supervised learning for industrial process regression modeling. In Proceedings of the 40th IEEE Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; pp. 1359–1364. [Google Scholar]
- Ankenbrand, M.J.; Shainberg, L.; Hock, M.; Lohr, D.; Schreiber, L.M. Sensitivity analysis for interpretation of machine learning based segmentation models in cardiac MRI. BMC Med. Imaging 2021, 21, 27. [Google Scholar] [CrossRef] [PubMed]
- Mitruț, O.; Moise, G.; Moldoveanu, A.; Moldoveanu, F.; Leordeanu, M.; Petrescu, L. Clarity in Complexity: How Aggregating Explanations Resolves the Disagreement Problem. Artif. Intell. Rev. 2024, 57, 338. [Google Scholar] [CrossRef]
- Suwa, M.; Scott, A.C.; Shortliffe, E.H. An Approach to Verifying Completeness and Consistency in a Rule-Based Expert System. AI Mag. 1982, 3, 16–21. [Google Scholar]
- Cochran, W.G. Sampling Techniques, 3rd ed.; Wiley: New York, NY, USA, 1977. [Google Scholar]
- Lipton, Z.C. The Mythos of Model Interpretability. arXiv 2016, arXiv:1606.03490. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards a Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Rudin, C. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef]
- Gzar, D.A.; Mahmood, A.M.; Abbas, M.K. A Comparative Study of Regression Machine Learning Algorithms: Tradeoff Between Accuracy and Computational Complexity. Math. Model. Eng. Probl. 2022, 9, 2022. [Google Scholar] [CrossRef]
- Sze, V.; Chen, Y.-H.; Yang, T.-J.; Emer, J.S. Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Outline | Technique | Drawback |
|---|---|---|---|
| [11] | SSL is employed to classify COVID-19 from images. | COVIDCon algorithm, consisting of data augmentation, consistency regularization, and multi-contrastive learning. | COVIDCon does not consider domain knowledge nor perform regression and explain the output. |
| [12] | SSL algorithm is proposed to classify drug function from images of drug chemical structure. | “MultiCon” algorithm, consisting of data augmentation, consistency regularization, and multi-contrastive learning. | Domain knowledge, regression, and output explanation are not taken into account. |
| [53] | SSL method is proposed to address imbalanced data problem in tabular security datasets. | “MCoM” method, consisting of triplet mixup data augmentation, contrastive and feature reconstruction loss, pseudo-labeling, and downstream task. | Cyber security domain knowledge, regression, and classification output explanation are left unaddressed. |
| [54] | Labels are attributed to the unlabeled data using semi-supervised training. | SPEA2 was employed for semi-supervised training of LSSVM. | LSSVM is a data-driven approach without any domain knowledge. Regression and output explanation are also left unaddressed. |
| [55] | Synthetic, labeled data generation method was proposed with focus on accuracy and density. | Accuracy and density of generated data are dealt with by NSGA-II. KNN is employed to classify the synthetic data. | KNN does not contain any domain knowledge. Classification output is not explained by the proposed method. |
| [56] | Pseudo-labeling of the unlabeled data is taken as an optimization problem of the Genetic Algorithm. | GPR is used as base learner to assign the pseudo-labels to unlabeled data. | GPR has no domain knowledge. Diversity of the unlabeled data and output explanation are not taken into account by this method. |
| [57] | Semi-supervised classification method is proposed with both labeled and unlabeled data. | SVM with modified Z-score based on fuzzy logic and cluster assumption. | SVM does not deal with domain knowledge. BRBES is superior to fuzzy logic in terms of uncertainties due to ignorance. Regression and output explanation are also left unadressed by this method. |
| [58] | SSL-aided evolutionary approach is presented to classify workers based on their risk perception. | MLP is used as classifier, with NSGA-II as evolutionary algorithm. | MLP is a data-driven approach with no domain knowledge. This method neither performs regression nor provides explanation for classification output. |
| Independent Variables | Outcome | |
|---|---|---|
| Period | Time | Solar Illumination (%) |
| January | 9:00 a.m. to 2:00 p.m. 2:01 p.m. to 4:00 p.m. 7:00 a.m. to 8:59 a.m. rest of the day | 100 50 50 0 |
| February | 8:00 a.m. to 4:00 p.m. 4:01 p.m. to 6:00 p.m. 6:00 a.m. to 7:59 a.m. rest of the day | 100 50 50 0 |
| March | 6:00 a.m. to 5:00 p.m. 5:01 p.m. to 7:00 p.m. 4:00 a.m. to 5:59 a.m. rest of the day | 100 50 50 0 |
| April | 4:00 a.m. to 7:00 p.m. 7:01 p.m. to 9:00 p.m. 2:00 a.m. to 3:59 a.m. rest of the day | 100 50 50 0 |
| May | 2:00 a.m. to 9:00 p.m. 9:01 p.m. to 11:00 p.m. 00:00 to 1:59 a.m. rest of the day | 100 50 50 0 |
| June | 1:00 a.m. to 10:00 p.m. rest of the day | 100 50 |
| July | 2:00 a.m. to 10:00 p.m. rest of the day | 100 50 |
| August | 4:00 a.m. to 8:00 p.m. 8:01 p.m. to 10:00 p.m. 2:00 a.m. to 3:59 a.m. rest of the day | 100 50 50 0 |
| September | 5:00 a.m. to 6:00 p.m. 6:01 p.m. to 8:00 p.m. 3:00 a.m. to 4:59 a.m. rest of the day | 100 50 50 0 |
| October | 7:00 a.m. to 4:00 p.m. 4:01 p.m. to 6:00 p.m. 5:00 a.m. to 6:59 a.m. rest of the day | 100 50 50 0 |
| November | 8:00 a.m. to 2:00 p.m. 2:01 p.m. to 4:00 p.m. 6:00 a.m. to 7:59 a.m. rest of the day | 100 50 50 0 |
| December | 10:00 a.m. to 1:00 p.m. 1:01 p.m. to 3:00 p.m. 8:00 a.m. to 9:59 a.m. rest of the day | 100 50 50 0 |
| Days | Period | Time | Interior Inhabitance (%) |
|---|---|---|---|
| Monday to Friday | September to May | 8:00 a.m. to 7:00 p.m. | 50 |
| 7:01 p.m. to 10:00 p.m. (Friday) | 50 | ||
| 7:01 p.m. to 10:00 p.m. (Monday–Thursday) | 80 | ||
| rest of the day | 100 | ||
| June to August | 8:00 a.m. to 7:00 p.m. | 30 | |
| 7:01 p.m. to 11:00 p.m. (Friday) | 50 | ||
| 7:01 p.m. to 11:00 p.m. (Monday–Thursday) | 70 | ||
| rest of the day | 80 |
| Days | Period | Time | Interior Inhabitance (%) |
|---|---|---|---|
| Saturday–Sunday | September to May | 9:00 a.m. to 7:00 p.m. | 40 |
| 7:01 p.m. to 10:00 p.m. (Sun) | 80 | ||
| 7:01 p.m. to 10:00 p.m. (Sat) | 50 | ||
| rest of the day | 80 | ||
| June to August | 9:00 a.m. to 7:00 p.m. | 10 | |
| 7:01 p.m. to 11:00 p.m. (Sun) | 50 | ||
| 7:01 p.m. to 11:00 p.m. (Sat) | 30 | ||
| rest of the day | 50 |
| Antecedent Part | Consequent Part | Activation Weight | |||||
|---|---|---|---|---|---|---|---|
| Rule No. | Interior Space | Solar Illumination | Interior Inhabitance | Energy Consumption | |||
| H (%) | M (%) | L (%) | |||||
| 1 | High | High | High | 60 | 40 | 0 | 0 |
| 2 | High | High | Medium | 40 | 60 | 0 | 0 |
| 3 | High | High | Low | 0 | 80 | 20 | 0.49 |
| 4 | High | Medium | High | 80 | 20 | 0 | 0 |
| 5 | High | Medium | Medium | 60 | 40 | 0 | 0 |
| 6 | High | Medium | Low | 40 | 60 | 0 | 0 |
| 7 | High | Low | High | 100 | 0 | 0 | 0 |
| 8 | High | Low | Medium | 80 | 20 | 0 | 0 |
| 9 | High | Low | Low | 60 | 40 | 0 | 0 |
| 10 | Medium | High | High | 20 | 80 | 0 | 0 |
| 11 | Medium | High | Medium | 0 | 20 | 80 | 0 |
| 12 | Medium | High | Low | 0 | 60 | 40 | 0.51 |
| 13 | Medium | Medium | High | 20 | 80 | 0 | 0 |
| 14 | Medium | Medium | Medium | 0 | 100 | 0 | 0 |
| 15 | Medium | Medium | Low | 0 | 80 | 20 | 0 |
| 16 | Medium | Low | High | 80 | 20 | 0 | 0 |
| 17 | Medium | Low | Medium | 60 | 40 | 0 | 0 |
| 18 | Medium | Low | Low | 40 | 60 | 0 | 0 |
| 19 | Low | High | High | 0 | 20 | 80 | 0 |
| 20 | Low | High | Medium | 0 | 10 | 90 | 0 |
| 21 | Low | High | Low | 0 | 0 | 100 | 0 |
| 22 | Low | Medium | High | 0 | 60 | 40 | 0 |
| 23 | Low | Medium | Medium | 0 | 30 | 70 | 0 |
| 24 | Low | Medium | Low | 0 | 20 | 80 | 0 |
| 25 | Low | Low | High | 0 | 60 | 40 | 0 |
| 26 | Low | Low | Medium | 0 | 40 | 60 | 0 |
| 27 | Low | Low | Low | 0 | 20 | 80 | 0 |
| Belief Degrees of Consequent Attribute | Consumed Energy (District Heating) | Consumed Energy (Electric Heating) |
|---|---|---|
| H is the highest | (H × 2.40) + (M × 0.80) | (H × 4) + (M)/2 |
| L is the highest | ((1 − L) × 0.65) + (M × 0.15) | ((1 − L) × 2) + (M × 2)/3 |
| M is 100% | M × 0.40 | M × 3 |
| M is the highest, next is H | (M × 0.40) + (H × 2.40)/5 | (M × 3) + H |
| M is the highest, next is L | (M × 0.40) − (L × 0.20)/5 | (M × 2) − (L)/5 |
| Similarity | InfoNCE Loss Value |
|---|---|
| 100% 90% 80% 70% 60% 50% 40% 30% 20% 10% 0% | 1 0.80 0.60 0.40 0.20 0 −0.19 −0.39 −0.59 −0.79 −1 |
| Preconditions | Outcome | |
|---|---|---|
| Consequent Attribute’s Highest Belief Degree | Period | Counterfactual |
| H | Summer | However, fewer people indoors could have resulted in decreased energy use. Furthermore, if the apartment had been heated using the district or electric approach, it might have consumed (lesser/more) energy. |
| Other seasons | However, if it had been summer, when people would have been enjoying more activities outside in the solar illumination, energy consumption might have been lower. Furthermore, if the apartment had been heated using the district or electric approach, it might have consumed (lesser/more) energy. | |
| L | Winter | However, more people indoors might have resulted in increased energy consumption. Furthermore, if the apartment had been heated using the district or electric approach, it might have consumed (lesser/more) energy. |
| Other seasons | However, if it had been winter, when people would have stayed inside more often owing to the cold and lack of solar illumination, energy consumption might have been higher. Furthermore, if the apartment had been heated using the district or electric approach, it might have consumed (lesser/more) energy. | |
| M | Winter | However, if it had been summer, when people would have been enjoying more outside activities in the solar illumination, energy consumption might have been lower. Furthermore, if the apartment had been heated using the district or electric approach, it might have consumed (lesser/more) energy. |
| Other seasons | However, if it had been winter, when people would have stayed inside more often owing to the cold and lack of solar illumination, energy consumption might have been higher. Furthermore, if the apartment had been heated using the district or electric approach, it might have consumed (lesser/more) energy. | |
| Dataset | Training | Testing |
|---|---|---|
| Labeled (preprocessed) | (10 × 3 × 7) = 210 rows | (3 × 3 × 7) = 63 rows |
| Weakly augmented pseudo-labeled data | (191 × 3 × 7) = 4011 rows | — |
| Strongly augmented pseudo-labeled data | (760 × 3 × 7) = 15,960 rows | — |
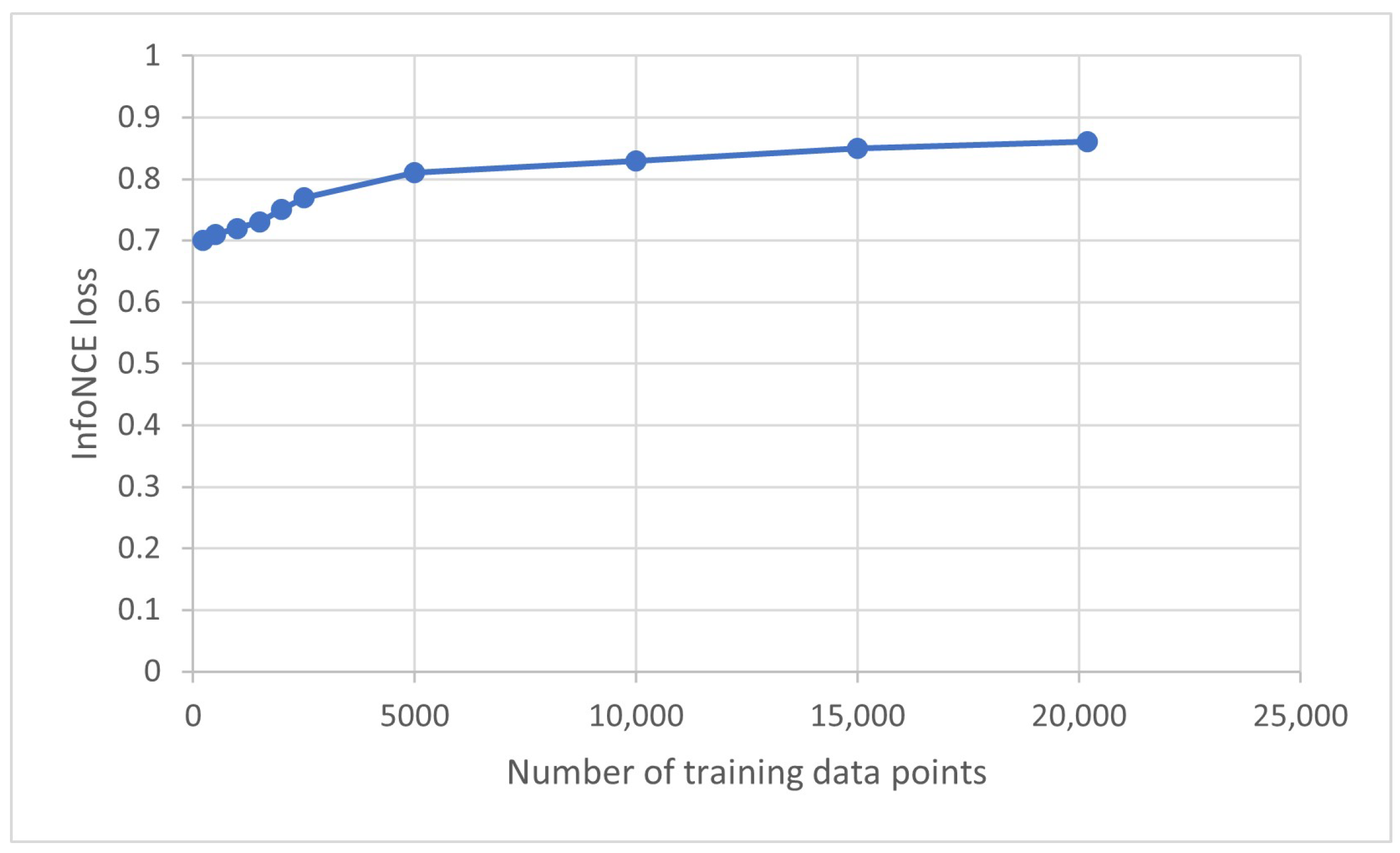
| Extended dataset (labeled + pseudo-labeled) | (210 + 4011 + 15,960) = 20,181 rows | — |
| Model | InfoNCE Loss | MAE | |
|---|---|---|---|
| Initial BRBES | 0.16 | 0.24 | 0.58 |
| Supervised BRBES | 0.70 | 0.08 | 0.87 |
| Confident BRBES | 0.70 | 0.08 | 0.87 |
| Weakly Semi-Supervised BRBES | 0.76 | 0.05 | 0.89 |
| Semi-Supervised BRBES | 0.86 | 0.04 | 0.93 |
| Support Vector Regressor (SVR) (Semi-Supervised) | 0.48 | 0.10 | 0.74 |
| Linear Regressor (LR) (Semi-Supervised) | 0.32 | 0.18 | 0.66 |
| MLP Regressor (Semi-Supervised) | 0.64 | 0.07 | 0.82 |
| Deep Neural Network (DNN) (Semi-Supervised) | 0.38 | 0.16 | 0.69 |
| Type | Optimization | InfoNCE Loss |
|---|---|---|
| Parameters | P1 | 0.38 |
| P2 | 0.39 | |
| P3 | 0.60 | |
| Structure of rule base | S1 | 0.39 |
| S2 | 0.56 | |
| S3 | 0.45 | |
| Parameters and Structure | P1 + P2 + P3 + S2 | 0.70 |
| Antecedent Part | Consequent Part | |||||
|---|---|---|---|---|---|---|
| Rule No. | Interior Space | Solar Illumination | Interior Inhabitance | Energy Consumption | ||
| H (%) | M (%) | L (%) | ||||
| 1 | High | High | High | 65 | 31 | 4 |
| 2 | High | High | Medium | 35 | 59 | 6 |
| 3 | High | High | Low | 9 | 80 | 11 |
| 4 | High | Medium | High | 53 | 26 | 21 |
| 5 | High | Medium | Medium | 71 | 26 | 3 |
| 6 | High | Medium | Low | 33 | 61 | 6 |
| 7 | High | Low | High | 69 | 16 | 15 |
| 8 | High | Low | Medium | 73 | 19 | 8 |
| 9 | High | Low | Low | 62 | 34 | 4 |
| 10 | Medium | High | High | 19 | 74 | 7 |
| 11 | Medium | High | Medium | 20 | 24 | 56 |
| 12 | Medium | High | Low | 3 | 74 | 23 |
| 13 | Medium | Medium | High | 11 | 84 | 5 |
| 14 | Medium | Medium | Medium | 9 | 86 | 5 |
| 15 | Medium | Medium | Low | 6 | 82 | 12 |
| 16 | Medium | Low | High | 61 | 31 | 8 |
| 17 | Medium | Low | Medium | 69 | 28 | 3 |
| 18 | Medium | Low | Low | 16 | 73 | 11 |
| 19 | Low | High | High | 21 | 28 | 51 |
| 20 | Low | High | Medium | 7 | 16 | 77 |
| 21 | Low | High | Low | 9 | 12 | 79 |
| 22 | Low | Medium | High | 4 | 69 | 27 |
| 23 | Low | Medium | Medium | 21 | 27 | 52 |
| 24 | Low | Medium | Low | 13 | 21 | 66 |
| 25 | Low | Low | High | 3 | 76 | 21 |
| 26 | Low | Low | Medium | 4 | 18 | 78 |
| 27 | Low | Low | Low | 3 | 6 | 91 |
| Model | Feature Coverage | Relevance | Test-Retest Reliability | Coherence | Difference |
|---|---|---|---|---|---|
| Supervised BRBES (Nonoptimized) | 1 | 12.01, 3.79, 5.87 | 146.68 | 87.04% | 0% |
| Supervised BRBES (JOPS-optimized) | 1 | 18.56, 5.15, 8.04 | 202.73 | 95.51% | 0% |
| Weakly Semi-Supervised BRBES (JOPS-optimized) | 1 | 19.39, 5.36, 8.36 | 210.86 | 97.03% | 0% |
| Semi-Supervised BRBES (JOPS-optimized) | 1 | 20.41, 5.62, 8.76 | 219.02 | 98.83% | 0% |
| Support Vector Regressor (SVR) (Semi-Supervised) | 1 | 17.85, 4.94, 7.66 | 5.23 | 55.16% | 44.18% |
| Linear Regressor (LR) (Semi-Supervised) | 1 | 16.65, 4.33, 6.57 | 4.44 | 36.77% | 62.79% |
| MLP Regressor (Semi-Supervised) | 1 | 17.78, 4.91, 7.57 | 13.28 | 73.55% | 25.58% |
| Deep Neural Network (DNN) (Semi-Supervised) | 1 | 17.42, 4.44, 6.66 | 3.46 | 43.67% | 55.81% |
| Model | Pragmatism | Connectedness |
|---|---|---|
| Supervised BRBES (Non-optimized) | 87.50% | 100% |
| Supervised BRBES (JOPS-optimized) | 87.50% | 100% |
| Weakly Semi-Supervised BRBES (JOPS-optimized) | 87.50% | 100% |
| Semi-Supervised BRBES (JOPS-optimized) | 87.50% | 100% |
| Support Vector Regressor (SVR) (Semi-Supervised) | ||
| Linear Regressor (LR) (Semi-Supervised) | Not applicable | |
| MLP Regressor (Semi-Supervised) | ||
| Deep Neural Network (DNN) (Semi-Supervised) | ||
| Model Remarks | Runtime Complexity | Memory Requirement |
|---|---|---|
| Semi-supervised BRBES | ||
| Support Vector Regressor (SVR) * (Semi-Supervised) | to | |
| Linear Regressor (LR) * (Semi-Supervised) | ||
| MLP Regressor * (Semi-Supervised) | ||
| Deep Neural Network (DNN) * (Semi-Supervised) | (sum over layers) | + h · nout + L · h) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kabir, S.; Hossain, M.S.; Andersson, K. A Semi-Supervised-Learning-Aided Explainable Belief Rule-Based Approach to Predict the Energy Consumption of Buildings. Algorithms 2025, 18, 305. https://doi.org/10.3390/a18060305
Kabir S, Hossain MS, Andersson K. A Semi-Supervised-Learning-Aided Explainable Belief Rule-Based Approach to Predict the Energy Consumption of Buildings. Algorithms. 2025; 18(6):305. https://doi.org/10.3390/a18060305
Chicago/Turabian StyleKabir, Sami, Mohammad Shahadat Hossain, and Karl Andersson. 2025. "A Semi-Supervised-Learning-Aided Explainable Belief Rule-Based Approach to Predict the Energy Consumption of Buildings" Algorithms 18, no. 6: 305. https://doi.org/10.3390/a18060305
APA StyleKabir, S., Hossain, M. S., & Andersson, K. (2025). A Semi-Supervised-Learning-Aided Explainable Belief Rule-Based Approach to Predict the Energy Consumption of Buildings. Algorithms, 18(6), 305. https://doi.org/10.3390/a18060305