
Nomological Deductive Reasoning for Trustworthy, Human-Readable, and Actionable AI Outputs



Abstract

1. Introduction
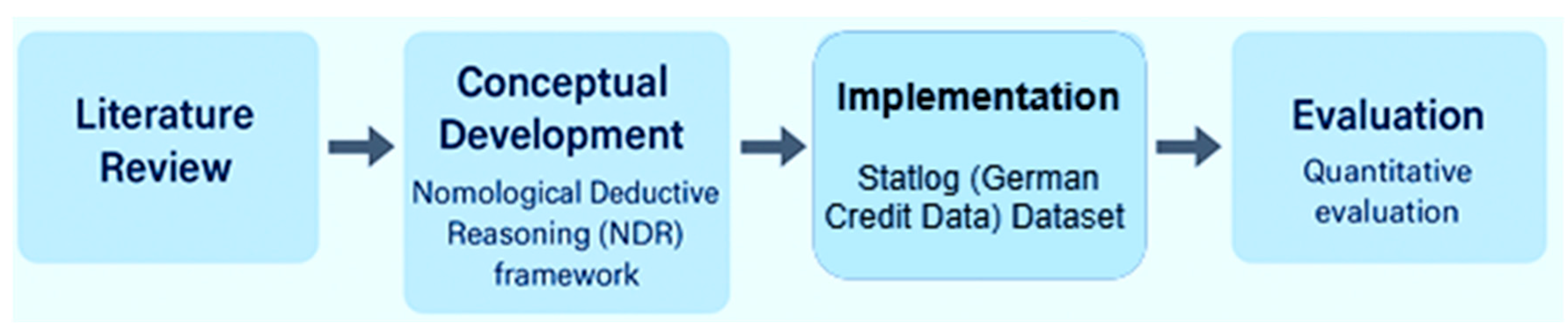
2. Methodology
2.1. Conceptual Framework Development
2.2. Architecture and Workflow
2.3. Experimental Setup
2.4. Deductive Validation and Explanation Generation
2.5. Evaluation Metrics
- Accuracy: Classification correctness of the machine learning model.
- Rule Consistency: Agreement of predictions with symbolic knowledge.
- Rule Coverage: Percentage of predictions for which valid rule-based explanations were generated.
- Mismatch Penalty: Count of predictions inconsistent with the knowledge base.
2.6. Reproducibility and Future Work
3. Current XAI State of the Art
3.1. Explanator Formats
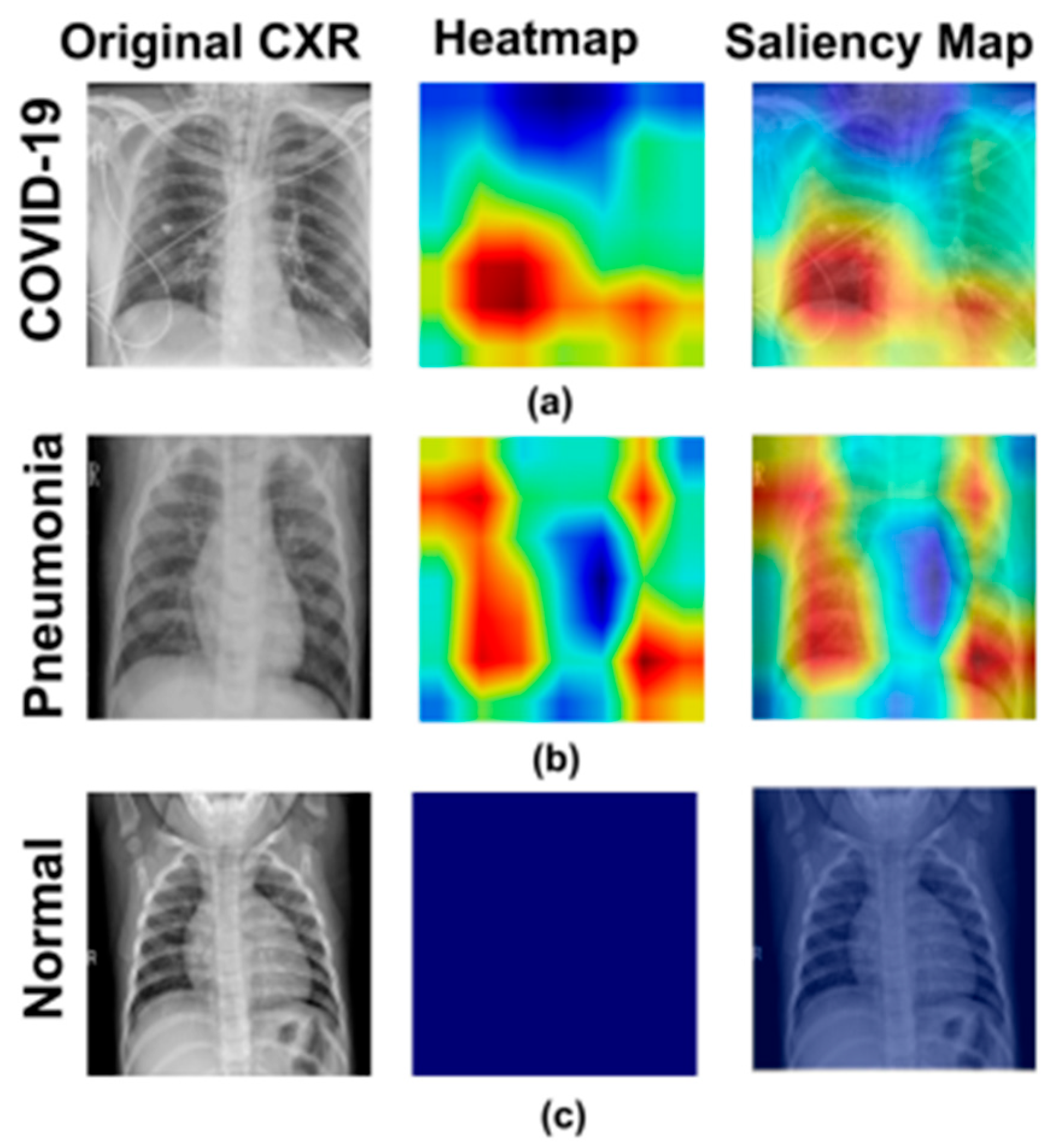
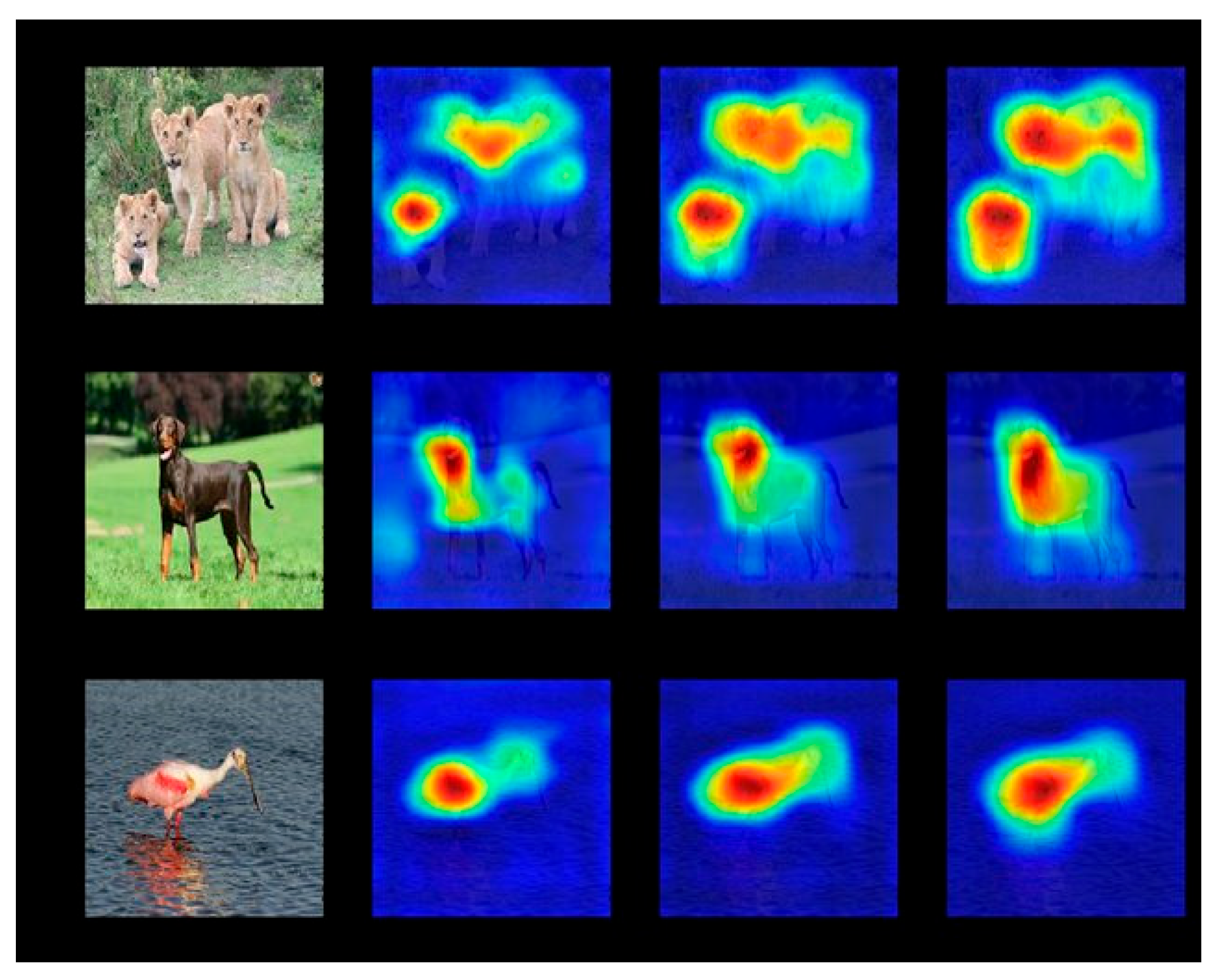
3.1.1. Visual Explanations
3.1.2. Textual Explanations
3.1.3. Rule-Based Explanations
3.1.4. Numerical/Graphical Explanations
3.1.5. Mixed (Multiformat) Explanations
3.2. Shortfall in Conveying Structured Human-Readable Explanations That Make Transparent the Reasoning Process
3.2.1. Lack of Contextual Relevance in Visual Explanations
3.2.2. Ambiguity and Imprecision in Textual Explanations
3.2.3. Limitations of Rule-Based Explanations
3.2.4. Overload from Numerical and Graphical Explanations
3.2.5. Mixed-Explanation Methods and Cognitive Overload
3.2.6. Confabulation and Lack of a Formal Logical Structure in LLM-Based Explanations
4. Twofold Need for Improvement in XAI Research
4.1. The Need for Enhanced Knowledge Representation
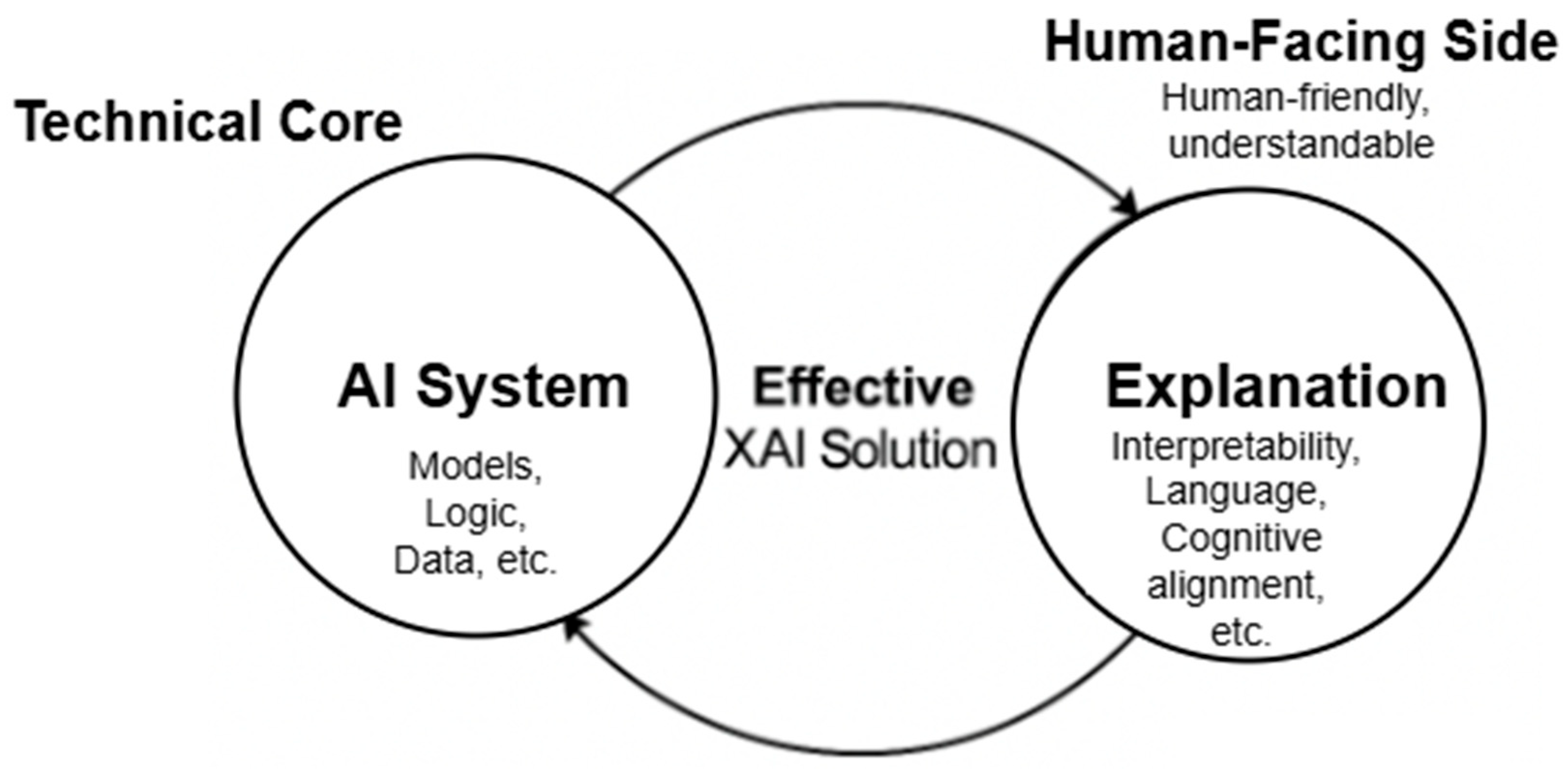
4.2. The Need for Effective and Efficient Integration of Explanation Theory into Explainability Design
5. Nomological Deductive Reasoning (NDR): A Proposed Solution
5.1. Mathematical Model of the NDR Framework
- Laws ()Let represent the set of laws or rules governing a certain real-world domain (healthcare diagnosis, bank credit score, traffic code for mobility applications, criminal justice, etc.). These laws are formalized as logical statements or principles that provide the foundation for reasoning in the system.Each law corresponds to a specific rule or law within the system.Example (in credit assessment settings):
- : “If an applicant has multiple financial obligations and a credit purpose that are considered risky, then they are at high risk of default”.
- : “If the loan duration is 12 months and the applicant has stable employment, then the credit is classified as ‘Good’”.
- Conditions (C)Let denote the set of antecedents or conditions that must hold true in order for a law to be applicable to a particular data instance. This means that each condition is a prerequisite or condition that must be satisfied for the corresponding law to be activated or relevant.Example (in medical settings):
- : “Applicant has stable employment”.
- : “The loan duration is 12 months”.
- Data instances (D)Let represent the set of input data fed into the AI system. Each represents a specific instance or data sample.Example (in credit assessment):
- : A data sample where the applicant has stable employment and is applying for a loan payable in more than 12 months.
- : A data sample where the applicant does not have any job and is asking for a loan payable in 3 months.
- Hypothesis or Prediction (H)Let represent the set of predictions or outcomes generated by the AI model. Each corresponds to a specific prediction or outcome generated for the instance .Example (in credit assessment):
- : “The applicant is at high risk for loan payment default”
- : “The applicant is not at high risk for loan payment default”.
- Formalized Deductive InferenceThe key goal of the NDR framework is to use deductive reasoning to formalize the process of how the AI model generates a prediction based on the combination of conditions C and laws L applied to the input data .The formalized deductive inference is represented aswhere
- is an input data instance;
- are the conditions (e.g., characteristics of the applicant);
- are banking principles or laws (e.g., rules about how conditions relate to prediction like good or bad credit);
- denotes the deductive reasoning process, where the combination of applicant conditions and banking laws leads to the prediction for the given instance .
- Formalized Explanation GenerationOnce we have the laws, conditions and input data, the explanation for the prediction can be expressed aswhere
- is the explanation for the prediction ;
- is the function that describes how the laws , conditions , and data combine to generate the outcome ;
- indicates the reasoning flow from the combination of laws and conditions to the prediction.
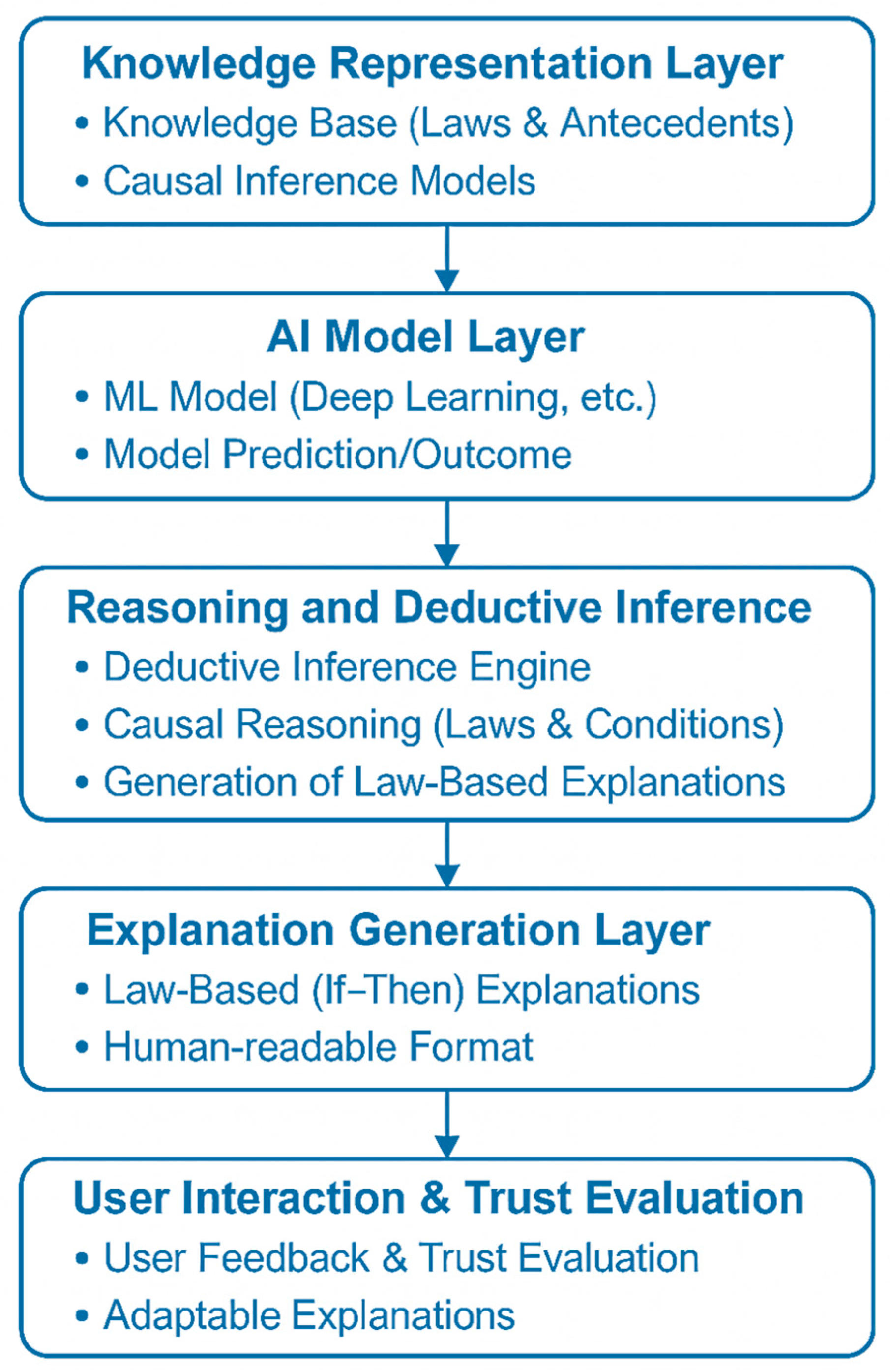
5.2. NDR Framework Architecture and Operational Integration with Machine Learning
5.2.1. System Architecture Overview
5.2.2. Knowledge Encoding: Symbolic Rule Definition
- IF checking_account = None AND savings < 100 THEN LiquidityRisk = TRUE;
- IF employment_duration < 1 year AND age < 30 THEN IncomeInstability = TRUE;
- IF LiquidityRisk = TRUE AND IncomeInstability = TRUE THEN CreditRisk = High.
5.2.3. Integration of Machine Learning and Deductive Reasoning
- Stage 1—ML Model Prediction: A supervised ML model (e.g., deep neural network, random forest, or any other model) generates a prediction for input .
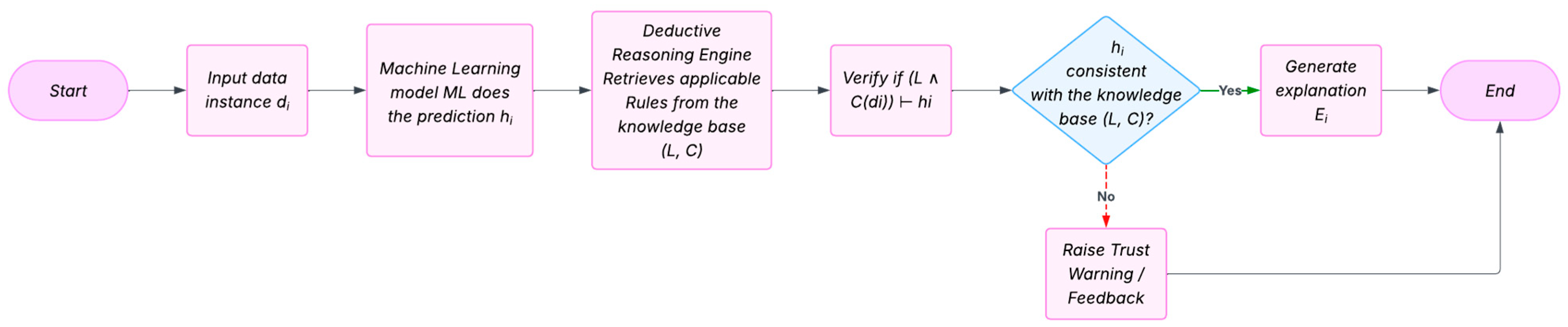
- Stage 2—Deductive Reasoning Engine: The reasoning module takes the input instance , the prediction and the knowledge base and and then verifies whether the prediction can be deduced from the knowledge base, such as byIf the deduction is consistent, the prediction is validated, and a logical explanation is generated. If not, the system raises a trust warning or requests further input.
5.2.4. Inference Flow and Operationalization
- Input: For example, in a bank loan application scenario, applicant data are provided as structured records and constitute the system input.
- ML Feature Extraction: A trained model (e.g., Random Forest) identifies the most influential features. These features are passed as symbolic assertions onto the knowledge layer.
- Symbolic Assertion Mapping: Features are translated into logical predicates (e.g., SavingsLow(Applicant123)).
- Deductive Inference: The reasoning engine applies the rules using forward chaining (modus ponens) to derive intermediate-risk indicators and final recommendations.
- Explanation Generation: Activated rules are converted into natural-language templates.
- Output: A classification decision (e.g., “High Credit Risk”) with justification is presented to the user.
5.3. Use-Case Implementation of the NDR-Based Explanations
5.3.1. Knowledge Base and Ontology Construction in NDR
Ontology Design
- Young(x) ≡ hasAge(x) < 25;
- HighLoan(x) ≡ hasLoanAmount(x) > 10,000;
- StableEmployment(x) ≡ hasEmploymentDuration(x) > 1;
- OwnsProperty(x) ≡ ownsProperty(x) = true.
Domain-Specific Laws (L)
Antecedent Conditions (C)
- -
- Age: 22;
- -
- Checking Account Status: None;
- -
- Employment duration: 0.5;
- -
- Credit history: critical;
- -
- Number of existing loans: 3;
- -
- Savings: less than 100.
- Young(A123), HighLoan(A123), NoCheckingAccount(A123), UnstableEmployment(A123), NumExistingLoans(A123) > 2.
Logical Reasoning and Inference
5.3.2. Data Processing and Model Training
- Number of trees: n_estimators = 100;
- Criterion: default Gini impurity;
- Random seed for reproducibility: random_state = 42;
- Other hyper parameters retained their default Scikit-learn values.
| Algorithm 1. NDR Framework: SP Algorithm with Formal Inference |
|
1: Input: I (input data), KB (Knowledge Base), M (Model), F (Feature Extraction function), R (Reasoning function), E (Explanation Generation function) 2: Output: Explanation Ei for each prediction set of predictions 3: Step 1: Preprocess the input data 4: I′ ← Preprocess(I) {Clean and format input data} 5: Step 2: Model prediction ~ Extract features from the preprocessed input 6: F ← ExtractFeatures (I′) {Feature extraction using ML model} 7: Step 3: Retrieve relevant laws from the Knowledge Base 8: L ← GetLaws(KB) {Retrieve laws from Knowledge Base} 9: Step 4: Retrieve the conditions or antecedents for the relevant laws 10: C ← GetConditions(KB) {Retrieve conditions that must hold true for laws} 11: Step 5: Perform reasoning based on the extracted features and laws 12: C′ ← Reason(F, L, C) {Reason using features, laws and conditions} 13: Step 6: Perform prediction based on reasoning and extracted features 14: ← Predict(M, C′) {Model prediction based on reasoning output and features} 15: Step 7: Generate the explanation based on reasoning, features, and prediction 16: Ei ← E(L′, C′, I′, ) {Explanation generation based on laws, conditions, data, and prediction} 17: Step 8: Output the generated explanation 18: Return Ei |
5.3.3. Experimental Results
Prediction Accuracy
Rule-Based Explanation Generation
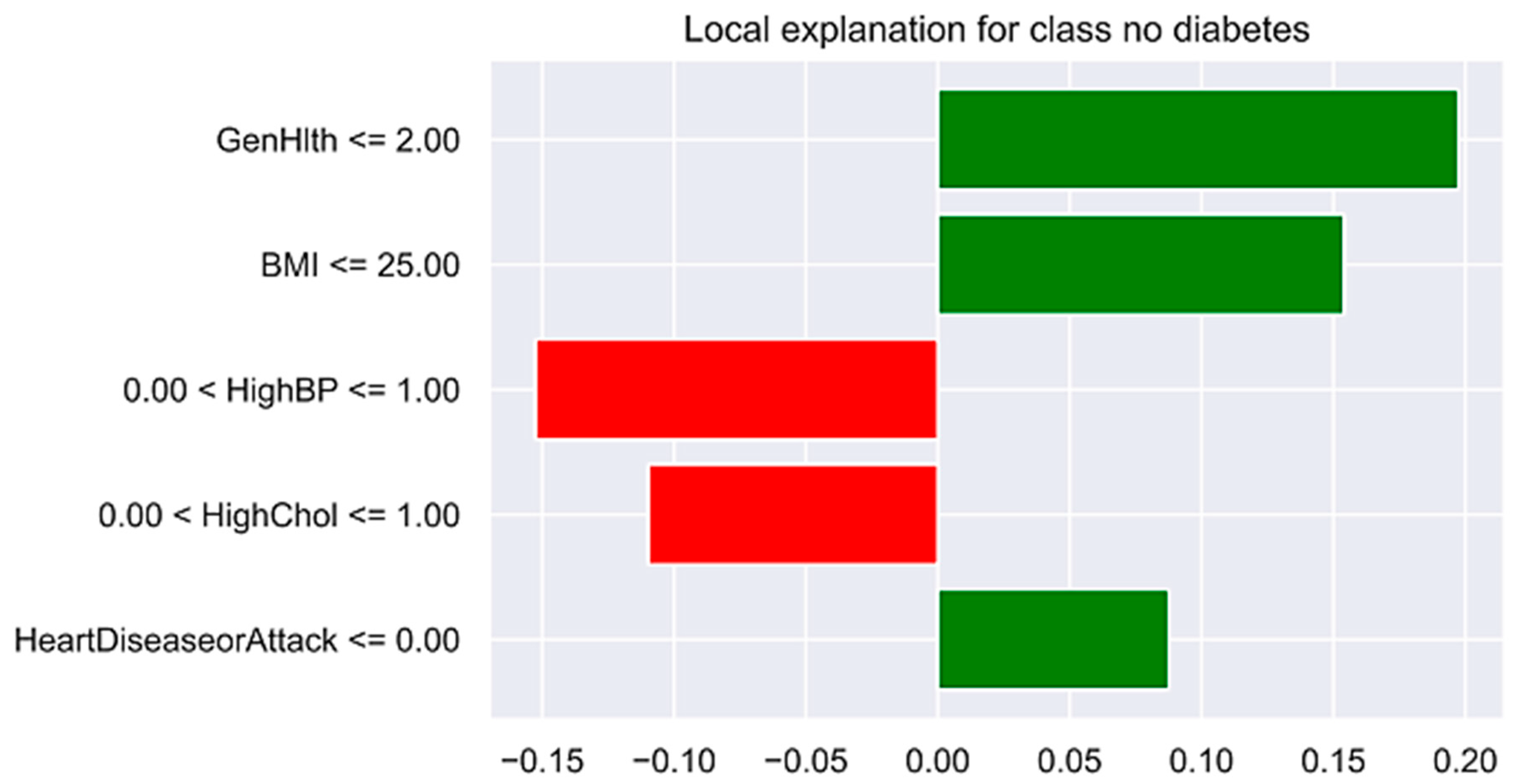
- Example (see Figure 9):
- Prediction Case 1: “Good Credit”
- Explanation: “The model predicts a ‘Good credit’ because based on banking laws, the applicant has a stable family or marital status, which is positive for creditworthiness; manageable installment rates, which indicate financial stability; and the loan duration is for more than 12 months, which indicates a positive sign of credit”.
- Model Reasoning: (i) Personal Status: Stable marital/family status → positively influences creditworthiness, (ii) Installment Rate: Manageable installment amount → indicates financial responsibility, and (iii) Duration: Loan duration > 12 months → considered favorable under domain rules.
- Prediction Case 2: “Bad Credit”.
- Explanation: “The model predicts a bad credit because based on banking laws, the person has multiple financial obligations which increases financial risk, and the credit purpose is considered risky, contributing to a negative credit prediction”.
- Model Reasoning: (i) Other Debtors: Multiple financial obligations → higher perceived risk and (ii) Purpose: Loan purpose considered high-risk → contributes to a negative classification.
Alignment with Domain Knowledge
- Rule Consistency: All 300 predictions were logically consistent with the rules defined in the Knowledge Base.
- Rule Coverage: Every prediction was fully accounted for by one or more symbolic rules, resulting in a Rule Coverage = 1.00, meaning 100% of rule coverage before decision-making.
- Mismatch Penalty: There were no mismatches between the model’s explanations and the rule base, indicating a Mismatch Penalty of 0, reflecting 100% loyalty to the rule base.
Summary of Results
5.3.4. Evaluation of the Explanatory Quality of the NDR Framework
- “The model predicts a ‘Good Credit’ because, based on banking laws, the duration of the loan is longer than 12 months, which indicates a positive sign for credit, and the installment rate is manageable, which suggests financial stability”.which is the more human-friendly form adapted by NDR explanation layer from:
- “If the duration of the loan is longer than 12 months, which indicates a positive sign for credit, and if the installment rate is manageable, suggesting financial stability, then the model predicts a ‘Good Credit’ based on banking laws”.
6. Discussion and Future Work
- Scalability and Automation: Developing methods for automated rule induction from structured data and text, as well as mechanisms for dynamic rule updates, will be crucial for broadening the applicability of the NDR framework in real-time and large-scale systems.
- Handling Uncertainty: Integrating probabilistic reasoning or fuzzy logic into the NDR architecture could improve its robustness in domains where knowledge is imprecise, incomplete, or uncertain.
- Hybrid Integration with LLMs: A promising direction for enhancing the NDR framework lies in its integration with Large Language Models (LLMs), such as GPT-3 and GPT-4. These models have shown substantial potential in explainable AI (XAI) by generating coherent, human-readable explanations [144,145,146,147,148,149]. Their ability to articulate complex model behavior in natural language makes them valuable for broadening accessibility and personalizing explanations for diverse user groups [148,150]. However, LLMs often lack transparency in their internal reasoning, functioning as black boxes without a structured, verifiable logic chain behind their outputs [151]. This opaqueness, combined with tendencies toward hallucinations [24], biases [152], and occasionally vague or overly generic responses, limits their trustworthiness in high-stakes settings. To address this, future work will explore how LLMs can be coupled with the rule-based rigor of NDR—where LLMs serve as natural-language interfaces that translate formal rule-based deductions into user-friendly narratives. Such a hybrid approach aims to preserve the logical integrity of NDR while enhancing user engagement and interpretability through the expressive capabilities of LLMs.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Explanation Theory | Author(s) | Main Idea of the Model | Common Element (with All Other Theories) |
|---|---|---|---|
| Deductive Model of Explanation | Carl G. Hempel and Paul Oppenheim [134] | Explanation involves showing that the phenomenon to be explained follows deductively from general laws or premises. It emphasizes logical reasoning and general laws. | Logical structure and relationships: Like other theories, it connects a phenomenon to its cause/effect, focusing on structure and relationships (causal, statistical, etc.). |
| Statistical Relevance (SR Model) | Wesley Salmon [153] | Explanations are based on showing the statistical relevance of factors. A phenomenon is explained by demonstrating how certain statistical factors increase the probability of the event. | Cause–effect relationships: Emphasizes how statistical relevance or probability connects events, similar to the focus on causal mechanisms in other theories. |
| Causal Mechanical Model | Wesley Salmon [154] | Explanations are based on identifying and describing the causal mechanisms that lead to the phenomenon. It focuses on the underlying processes or mechanisms. | Causal relationships and mechanisms: Like the deductive model, it aims to logically link causes to effects while focusing on mechanisms, as seen in other theories. |
| Unificationist Model | Michael Friedman and Philip Kitcher [155,156] | Explanations aim to unify a range of phenomena under a common principle or theory. The goal is to reduce complexity by explaining multiple phenomena in terms of a single framework. | Simplification and coherence: Like other theories, it seeks to organize complex phenomena, reducing complexity while maintaining causal or statistical relationships. |
| Pragmatic Model of Explanation | Bas van Fraassen [157] | Explanations are context-dependent, and their effectiveness is judged by their utility in a given context. They are considered good if they meet practical needs and goals | Contextual and practical utility: Shares with other theories the need for the explanation to be useful and relevant for understanding or predictions, with a focus on practical applications. |
References
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Pasquale, F. The Black Box Society: The Secret Algorithms That Control Money and Information; Harvard University Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Zednik, C. Solving the Black Box Problem: A Normative Framework for Explainable Artificial Intelligence. Philos. Technol. 2021, 34, 265–288. [Google Scholar] [CrossRef]
- Hassija, V.; Chamola, V.; Mahapatra, A.; Singal, A.; Goel, D.; Huang, K.; Scardapane, S.; Spinelli, I.; Mahmud, M.; Hussain, A. Interpreting Black Box Models: A Review on Explainable Artificial Intelligence. Cogn. Comput. 2024, 16, 45–74. [Google Scholar] [CrossRef]
- Peters, U. Explainable AI Lacks Regulative Reasons: Why AI and Human Decision-Making Are Not Equally Opaque. AI Ethics 2023, 3, 963–974. [Google Scholar] [CrossRef]
- Minh, D.; Wang, H.X.; Li, Y.F.; Nguyen, T.N. Explainable Artificial Intelligence: A Comprehensive Review. Artif. Intell. Rev. 2022, 55, 3503–3568. [Google Scholar] [CrossRef]
- Evans, T.; Retzlaff, C.O.; Geißler, C.; Kargl, M.; Plass, M.; Müller, H.; Kiehl, T.-R.; Zerbe, N.; Holzinger, A. The Explainability Paradox: Challenges for xAI in Digital Pathology. Fut. Genet. Comput. Syst. 2022, 133, 281–296. [Google Scholar] [CrossRef]
- Černevičienė, J.; Kabašinskas, A. Explainable Artificial Intelligence (XAI) in Finance: A Systematic Literature Review. Artif. Intell. Rev. 2024, 57, 216. [Google Scholar] [CrossRef]
- Weber, P.; Carl, K.V.; Hinz, O. Applications of Explainable Artificial Intelligence in Finance—A Systematic Review of Finance, Information Systems, and Computer Science Literature. Manag. Rev. Q. 2024, 74, 867–907. [Google Scholar] [CrossRef]
- Atakishiyev, S.; Salameh, M.; Yao, H.; Goebel, R. Explainable artificial intelligence for autonomous driving: A comprehensive overview and field guide for future research directions. IEEE Access 2024, 12, 101603–101625. [Google Scholar] [CrossRef]
- European Union. General Data Protection Regulation (GDPR). 2016. Available online: https://gdpr.eu/ (accessed on 25 January 2025).
- OECD. OECD Principles on Artificial Intelligence. 2019. Available online: https://www.oecd.org/going-digital/ai/principles/ (accessed on 25 January 2025).
- European Commission. Artificial Intelligence Act. 2021. Available online: https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai (accessed on 25 January 2025).
- State Council of China. Ethical Guidelines for Artificial Intelligence. 2022. Available online: https://www.gov.cn/zhengce/2022-01-01/ (accessed on 25 January 2025).
- Ministry of Internal Affairs and Communications of Japan. AI R&D Guidelines. 2020. Available online: https://www.soumu.go.jp/main_content/000730466.pdf (accessed on 25 January 2025).
- Australian Government. AI Ethics Framework. 2020. Available online: https://www.industry.gov.au/data-and-publications/australias-artificial-intelligence-ethics-framework (accessed on 25 January 2025).
- South African Government. South Africa’s Artificial Intelligence Policy. 2023. Available online: https://www.dcdt.gov.za/sa-national-ai-policy-framework/file/338-sa-national-ai-policy-framework.html (accessed on 25 January 2025).
- Nigerian Government. Nigeria’s Artificial Intelligence Policy. 2023. Available online: https://www.nitda.gov.ng (accessed on 25 January 2025).
- Rwanda Government. Rwanda’s AI Policy. 2023. Available online: https://www.minict.gov.rw/index.php?eID=dumpFile&t=f&f=67550&token=6195a53203e197efa47592f40ff4aaf24579640e (accessed on 25 January 2025).
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. In Proceedings of the 32nd International Conference on Neural Information Processing Systems (NeurIPS 2018); pp. 1525–1535. Available online: https://arxiv.org/abs/1802.07681 (accessed on 18 December 2024).
- Chen, J.; Song, L.; Wang, S.; Xie, L.; Wang, X.; Zhang, M. Towards Prototype-Based Explanations of Deep Neural Networks. In Proceedings of the 36th International Conference on Machine Learning (ICML 2019), 2019. Available online: https://arxiv.org/abs/1905.11742 (accessed on 14 November 2024).
- Ehsan, U.; Riedl, M. Explainable AI Reloaded: Challenging the XAI Status Quo in the Era of Large Language Models. In Proceedings of the Halfway to the Future Symposium, Santa Cruz, CA, USA, 21–23 October 2024; pp. 1–8. [Google Scholar]
- Giudici, P.; Raffinetti, E. Shapley-Lorenz Explainable Artificial Intelligence. Expert Syst. Appl. 2021, 167, 114104. [Google Scholar] [CrossRef]
- Moradi, M.; Samwald, M. Post-Hoc Explanation of Black-Box Classifiers Using Confident Itemsets. Expert Syst. Appl. 2021, 165, 113941. [Google Scholar] [CrossRef]
- Vilone, G.; Longo, L. Explainable Artificial Intelligence: A Systematic Review. arXiv 2020, arXiv:2006.00093. Available online: https://arxiv.org/abs/2006.00093 (accessed on 25 January 2025).
- Miller, T. Explanation in Artificial Intelligence: Insights from the Social Sciences. arXiv 2018, arXiv:1706.07222. Available online: https://arxiv.org/abs/1706.07222 (accessed on 25 January 2025).
- Longo, L.; Brcic, M.; Cabitza, F.; Choi, J.; Confalonieri, R.; Del Ser, J.; Guidotti, R.; Hayashi, Y.; Herrera, F.; Holzinger, A.; et al. Explainable Artificial Intelligence (XAI) 2.0: A Manifesto of Open Challenges and Interdisciplinary Research Directions. Inf. Fusion 2024, 106, 102301. [Google Scholar] [CrossRef]
- Lipton, Z.C. The Mythos of Model Interpretability. Commun. ACM 2018, 61, 36–43. [Google Scholar] [CrossRef]
- Rago, A.; Palfi, B.; Sukpanichnant, P.; Nabli, H.; Vivek, K.; Kostopoulou, O.; Kinross, J.; Toni, F. Exploring the Effect of Explanation Content and Format on User Comprehension and Trust. arXiv 2024, arXiv:2408.17401. Available online: https://arxiv.org/abs/2408.17401 (accessed on 25 January 2025).
- Ali, S.; Abuhmed, T.; El-Sappagh, S.; Muhammad, K.; Alonso-Moral, J.M.; Confalonieri, R.; Guidotti, R.; Del Ser, J.; Díaz-Rodríguez, N.; Herrera, F. Explainable Artificial Intelligence (XAI): What We Know and What Is Left to Attain Trustworthy Artificial Intelligence. Inf. Fusion 2023, 99, 101805. [Google Scholar] [CrossRef]
- Hofmann, H. Statlog (German Credit Data). UCI Machine Learning Repository. 1994. Available online: https://archive.ics.uci.edu/dataset/144/statlog+german+credit+data (accessed on 10 February 2025).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- De Graaf, M.M.; Malle, B.F. How People Explain Action (and Autonomous Intelligent Systems Should Too). In Proceedings of the 2017 AAAI Fall Symposium Series, Arlington, VA, USA, 9–11 November 2017. [Google Scholar]
- Harbers, M.; van den Bosch, K.; Meyer, J.-J. A Study into Preferred Explanations of Virtual Agent Behavior. In Intelligent Virtual Agents, Proceedings of the 9th International Workshop, Amsterdam, The Netherlands, 14–16 September 2009; Nijholt, A., Reidsma, D., Hondorp, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 132–145. [Google Scholar]
- Vilone, G.; Longo, L. Notions of Explainability and Evaluation Approaches for Explainable Artificial Intelligence. Inf. Fusion 2021, 76, 89–106. [Google Scholar] [CrossRef]
- Vilone, G.; Longo, L. Classification of Explainable Artificial Intelligence Methods through Their Output Formats. Mach. Learn. Knowl. Extr. 2021, 3, 615–661. [Google Scholar] [CrossRef]
- Love, P.; Fang, W.; Matthews, J.; Porter, S.; Luo, H.; Ding, L. Explainable Artificial Intelligence (XAI): Precepts, Methods, and Opportunities for Research in Construction. arXiv 2022, arXiv:2211.06579. [Google Scholar] [CrossRef]
- Malaviya, C.; Lee, S.; Roth, D.; Yatskar, M. What If You Said That Differently? How Explanation Formats Affect Human Feedback Efficacy and User Perception. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Mexico City, Mexico, 16–21 June 2024; pp. 3046–3065. [Google Scholar]
- Morrison, K.; Shin, D.; Holstein, K.; Perer, A. Evaluating the Impact of Human Explanation Strategies on Human-AI Visual Decision-Making. Proc. ACM Hum.—Comput. Interact. 2023, 7, 1–37. [Google Scholar] [CrossRef]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 839–847. [Google Scholar]
- Bhowal, P.; Sen, S.; Yoon, J.H.; Geem, Z.W.; Sarkar, R. Choquet Integral and Coalition Game-Based Ensemble of Deep Learning Models for COVID-19 Screening From Chest X-Ray Images. IEEE J. Biomed. Health Inform. 2021, 25, 4328–4339. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv 2014, arXiv:1312.6034. [Google Scholar]
- Erhan, D.; Bengio, Y.; Courville, A.; Vincent, P. Visualizing Higher-Layer Features of a Deep Network. Univ. Montr. 2009, 1341, 1. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning Important Features Through Propagating Activation Differences. arXiv 2017, arXiv:1704.02685v2. [Google Scholar] [CrossRef]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic Attribution for Deep Networks. In Proceedings of the 34th International Conference on Machine Learning (ICML 2017), Sydney, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; PMLR: Cambridge, MA, USA, 2017; pp. 3319–3328. [Google Scholar]
- Mostafa, S.; Mondal, D.; Beck, M.A.; Bidinosti, C.P.; Henry, C.J.; Stavness, I. Leveraging Guided Backpropagation to Select Convolutional Neural Networks for Plant Classification. Front. Artif. Intell. 2022, 5, 871162. [Google Scholar] [CrossRef]
- Petsiuk, V.; Das, A.; Saenko, K. RISE: Randomized Input Sampling for Explanation of Black-Box Models. arXiv 2018, arXiv:1806.07421. [Google Scholar]
- Kumar, D.; Wong, A.; Taylor, G.W. Explaining the Unexplained: A Class-Enhanced Attentive Response (CLEAR) Approach to Understanding Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 36–44. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Poli, J.-P.; Ouerdane, W.; Pierrard, R. Generation of Textual Explanations in XAI: The Case of Semantic Annotation. In Proceedings of the 2021 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Luxembourg, 11–14 July 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Chattopadhyay, P.; Elhoseiny, M.; Sharma, T.; Batra, D.; Parikh, D.; Lee, S. Choose Your Neuron: Incorporating Domain Knowledge through Neuron-Importance. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 526–541. [Google Scholar]
- Bellini, V.; Schiavone, A.; Di Noia, T.; Ragone, A.; Di Sciascio, E. Knowledge-Aware Autoencoders for Explainable Recommender Systems. In Proceedings of the 3rd Workshop on Deep Learning for Recommender Systems, Vancouver, BC, Canada, 6 October 2018; pp. 24–31. [Google Scholar]
- Zhang, W.; Paudel, B.; Zhang, W.; Bernstein, A.; Chen, H. Interaction Embeddings for Prediction and Explanation in Knowledge Graphs. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 January 2019; pp. 96–104. [Google Scholar]
- Lei, T.; Barzilay, R.; Jaakkola, T. Rationalizing Neural Predictions. arXiv 2016, arXiv:1606.04155. [Google Scholar]
- Barratt, S. InterpNet: Neural Introspection for Interpretable Deep Learning. arXiv 2017, arXiv:1710.09511. [Google Scholar]
- Hendricks, L.A.; Akata, Z.; Rohrbach, M.; Donahue, J.; Schiele, B.; Darrell, T. Generating Visual Explanations. In Computer Vision–ECCV 2016: Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016, Proceedings, Part IV; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; Volume 14, pp. 3–19. [Google Scholar]
- Garcia-Magarino, I.; Muttukrishnan, R.; Lloret, J. Human-Centric AI for Trustworthy IoT Systems with Explainable Multilayer Perceptrons. IEEE Access 2019, 7, 125562–125574. [Google Scholar] [CrossRef]
- Bennetot, A.; Laurent, J.L.; Chatila, R.; Díaz-Rodríguez, N. Towards Explainable Neural-Symbolic Visual Reasoning. arXiv 2019, arXiv:1909.09065. [Google Scholar]
- Letham, B.; Rudin, C.; McCormick, T.H.; Madigan, D. Interpretable Classifiers Using Rules and Bayesian Analysis: Building a Better Stroke Prediction Model. J. Am. Stat. Assoc. 2015, 110, 1350–1371. [Google Scholar] [CrossRef]
- Fürnkranz, J. Rule-Based Methods. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013; pp. 1703–1706. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, the Thirtieth Innovative Applications of Artificial Intelligence Conference, and the Eighth AAAI Symposium on Educational Advances in Artificial Intelligence (AAAI’18/IAAI’18/EAAI’18), New Orleans, LA, USA, 2–7 February 2018; AAAI Press: Palo Alto, CA, USA, 2018; pp. 1527–1535. [Google Scholar]
- Yang, H.; Rudin, C.; Seltzer, M. Scalable Bayesian Rule Lists. In Proceedings of the 34th International Conference on Machine Learning (ICML 2017), Sydney, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; PMLR: Cambridge, MA, USA, 2017; pp. 3921–3930. [Google Scholar]
- Almutairi, M.; Stahl, F.; Bramer, M. Reg-Rules: An Explainable Rule-Based Ensemble Learner for Classification. IEEE Access 2021, 9, 52015–52035. [Google Scholar] [CrossRef]
- Lakkaraju, H.; Bach, S.H.; Leskovec, J. Interpretable Decision Sets: A Joint Framework for Description and Prediction. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1675–1684. [Google Scholar]
- Gao, J.; Liu, N.; Lawley, M.; Hu, X. An Interpretable Classification Framework for Information Extraction from Online Healthcare Forums. J. Healthc. Eng. 2017, 2017, 9275318. [Google Scholar] [CrossRef]
- Shortliffe, E.H.; Davis, R.; Axline, S.G.; Buchanan, B.G.; Green, C.C.; Cohen, S.N. Computer-Based Consultations in Clinical Therapeutics: Explanation and Rule Acquisition Capabilities of the MYCIN System. Comput. Biomed. Res. 1975, 8, 303–320. [Google Scholar] [CrossRef]
- Keneni, B.M.; Kaur, D.; Al Bataineh, A.; Devabhaktuni, V.K.; Javaid, A.Y.; Zaientz, J.D.; Marinier, R.P. Evolving Rule-Based Explainable Artificial Intelligence for Unmanned Aerial Vehicles. IEEE Access 2019, 7, 17001–17016. [Google Scholar] [CrossRef]
- Bride, H.; Dong, J.; Dong, J.S.; Hóu, Z. Towards Dependable and Explainable Machine Learning Using Automated Reasoning. In Proceedings of the Formal Methods and Software Engineering: 20th International Conference on Formal Engineering Methods, ICFEM 2018, Gold Coast, QLD, Australia, 12–16 November 2018; Proceedings 20. Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 412–416. [Google Scholar]
- Johansson, U.; Niklasson, L.; König, R. Accuracy vs. Comprehensibility in Data Mining Models. In Proceedings of the Seventh International Conference on Information Fusion, Stockholm, Sweden, 28 June–1 July 2004; Elsevier: Amsterdam, The Netherlands, 2004; Volume 1, pp. 295–300. [Google Scholar]
- Setzu, M.; Guidotti, R.; Monreale, A.; Turini, F.; Pedreschi, D.; Giannotti, F. GlocalX—From Local to Global Explanations of Black Box AI Models. Artif. Intell. 2021, 294, 103457. [Google Scholar] [CrossRef]
- Asano, K.; Chun, J. Post-Hoc Explanation Using a Mimic Rule for Numerical Data. In Proceedings of the ICAART (2), Virtual, Online, 4–6 February 2021; pp. 768–774. [Google Scholar]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2001. [Google Scholar]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation Importance: A Corrected Feature Importance Measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef]
- Marcílio, W.E.; Eler, D.M. From Explanations to Feature Selection: Assessing SHAP Values as Feature Selection Mechanism. In Proceedings of the 2020 33rd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Recife/Porto de Galinhas, Brazil, 7–10 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 340–347. [Google Scholar] [CrossRef]
- Goldstein, A.; Kapelner, A.; Bleich, J.; Pitkin, E. Peeking Inside the Black Box: Visualizing Statistical Learning with Plots of Individual Conditional Expectation. J. Comput. Graph. Stat. 2015, 24, 44–65. [Google Scholar] [CrossRef]
- Kim, B.; Wattenberg, M.; Gilmer, J.; Cai, C.; Wexler, J.; Viegas, F. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). In Proceedings of the 35th International Conference on Machine Learning (ICML 2018), Stockholm, Sweden, 10–15 July 2018; Caruana, R., Lou, Y., Eds.; PMLR: Cambridge, MA, USA, 2018; pp. 2668–2677. [Google Scholar]
- Tan, S.; Caruana, R.; Hooker, G.; Lou, Y. Distill-and-Compare: Auditing Black-Box Models Using Transparent Model Distillation. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, New Orleans, LA, USA, 2–7 February 2018; pp. 303–310. [Google Scholar]
- Strumbelj, E.; Kononenko, I. An Efficient Explanation of Individual Classifications Using Game Theory. J. Mach. Learn. Res. 2010, 11, 1–18. [Google Scholar]
- Štrumbelj, E.; Kononenko, I. Towards a Model Independent Method for Explaining Classification for Individual Instances. In Proceedings of the Data Warehousing and Knowledge Discovery: 10th International Conference, DaWaK 2008, Turin, Italy, 2–5 September 2008; Proceedings 10. Springer: Berlin/Heidelberg, Germany, 2008; pp. 273–282. [Google Scholar]
- Adler, P.; Falk, C.; Friedler, S.A.; Nix, T.; Rybeck, G.; Scheidegger, C.; Smith, B.; Venkatasubramanian, S. Auditing Black-Box Models for Indirect Influence. Knowl. Inf. Syst. 2018, 54, 95–122. [Google Scholar] [CrossRef]
- Alain, G.; Bengio, Y. Understanding Intermediate Layers Using Linear Classifier Probes. arXiv 2016, arXiv:1610.01644. [Google Scholar] [CrossRef]
- Främling, K. Explaining Results of Neural Networks by Contextual Importance and Utility. In Proceedings of the AISB, Brighton, UK, 1–2 April 1996; Volume 96. [Google Scholar]
- Juscafresa, A.N. An Introduction to Explainable Artificial Intelligence with LIME and SHAP. Bachelor’s Thesis, Degree in Computer Engineering, Universitat de Barcelona, Barcelona, Spain, 29 June 2022. Supervised by Dr. Albert Clapés and Dr. Sergio Escalera. Available online: https://www.google.com/url?sa=t&source=web&rct=j&opi=89978449&url=https://sergioescalera.com/wp-content/uploads/2022/06/presentacio_tfg_nieto_juscafresa_aleix.pdf&ved=2ahUKEwjni4PW4sCNAxXF7TgGHbtUAJsQFnoECBkQAQ&usg=AOvVaw35mUA85cyJvPfQ2SaFsHTS (accessed on 27 January 2025).
- Chen, J.; Song, L.; Wainwright, M.; Jordan, M. Learning to Explain: An Information-Theoretic Perspective on Model Interpretation. In Proceedings of the 35th International Conference on Machine Learning 2018, Stockholm, Sweden, 10–15 July 2018; pp. 883–892. [Google Scholar]
- Verma, S.; Boonsanong, V.; Hoang, M.; Hines, K.E.; Dickerson, J.P.; Shah, C. Counterfactual Explanations and Algorithmic Recourses for Machine Learning: A Review. arXiv 2020, arXiv:2010.10596. [Google Scholar] [CrossRef]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the 32nd International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015; Bach, F., Blei, D., Eds.; PMLR: Cambridge, MA, USA, 2015; pp. 2048–2057. [Google Scholar]
- Yang, S.C.H.; Shafto, P. Explainable Artificial Intelligence via Bayesian Teaching. In Proceedings of the NIPS 2017 Workshop on Teaching Machines, Robots, and Humans, Long Beach, CA, USA, 9 December 2017; Volume 2. [Google Scholar]
- Caruana, R.; Kangarloo, H.; Dionisio, J.D.; Sinha, U.; Johnson, D. Case-Based Explanation of Non-Case-Based Learning Methods. In Proceedings of the AMIA Symposium; American Medical Informatics Association: Bethesda, MD, USA, 1999; pp. 212–215. [Google Scholar] [PubMed] [PubMed Central]
- Spinner, T.; Schlegel, U.; Schäfer, H.; El-Assady, M. explAIner: A Visual Analytics Framework for Interactive and Explainable Machine Learning. IEEE Trans. Vis. Comput. Graph. 2019, 26, 1064–1074. [Google Scholar] [CrossRef]
- Khanna, R.; Kim, B.; Ghosh, J.; Koyejo, S. Interpreting Black Box Predictions Using Fisher Kernels. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics (AISTATS 2019), Naha, Okinawa, Japan, 16–18 April 2019; Chaudhuri, K., Sugiyama, M., Eds.; PMLR: Cambridge, MA, USA, 2019; pp. 3382–3390. [Google Scholar]
- Dhurandhar, A.; Chen, P.-Y.; Luss, R.; Tu, C.-C.; Ting, P.; Shanmugam, K.; Das, P. Explanations Based on the Missing: Towards Contrastive Explanations with Pertinent Negatives. In Advances in Neural Information Processing Systems 31 (NeurIPS 2018); Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 592–603. [Google Scholar]
- Agostinho, C.; Dikopoulou, Z.; Lavasa, E.; Perakis, K.; Pitsios, S.; Branco, R.; Reji, S.; Hetterich, J.; Biliri, E.; Lampathaki, F.; et al. Explainability as the Key Ingredient for AI Adoption in Industry 5.0 Settings. Front. Artif. Intell. 2023, 6, 1264372. [Google Scholar] [CrossRef] [PubMed]
- Hanif, A.; Zhang, F.; Wang, H.; Barhamgi, M.; Chen, L.; Zhou, R. A Comprehensive Survey of Explainable Artificial Intelligence (XAI) Methods: Exploring Transparency and Interpretability. In Web Information Systems Engineering—WISE 2023; Zhang, F., Wang, H., Barhamgi, M., Chen, L., Zhou, R., Eds.; Lecture Notes in Computer Science; Springer: Singapore, 2023; Volume 14306, pp. 1–13. [Google Scholar] [CrossRef]
- Dvorak, J.; Kopp, T.; Kinkel, S.; Lanza, G. Explainable AI: A Key Driver for AI Adoption, a Mistaken Concept, or a Practically Irrelevant Feature? In Proceedings of the 4th UR-AI Symposium, Villingen-Schwenningen, Germany, 14–16 September 2022; pp. 88–101. [Google Scholar]
- Adebayo, J.; Gilmer, J.; Muelly, M.; Goodfellow, I.; Hardt, M.; Kim, B. Sanity Checks for Saliency Maps. arXiv 2018, arXiv:1810.03292. [Google Scholar] [CrossRef]
- Kim, B.; Seo, J.; Jeon, S.; Koo, J.; Choe, J.; Jeon, T. Why Are Saliency Maps Noisy? Cause of and Solution to Noisy Saliency Maps. arXiv 2019, arXiv:1902.04893. [Google Scholar] [CrossRef]
- Slack, D.; Song, L.; Koyejo, S.O.; Padhye, J.; Dhurandhar, A.; Zhang, Y.; Sattigeri, P.; Hughes, T.; Mojsilović, A.; Varshney, K.R.; et al. Fooling LIME and SHAP: Adversarial Attacks on Post-Hoc Explanation Methods. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency (FAccT), Barcelona, Spain, 27–30 January 2020; ACM: New York, NY, USA, 2020; pp. 1–12. [Google Scholar] [CrossRef]
- Ghorbani, A.; Abid, A.; Zou, J. Interpretation of Neural Networks is Fragile. In Proceedings of the 36th International Conference on Machine Learning (ICML 2019), Long Beach, CA, USA, 9–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; PMLR: Cambridge, MA, USA, 2019; Volume 97, pp. 2242–2251. Available online: http://proceedings.mlr.press/v97/ghorbani19c.html (accessed on 27 January 2025).
- Caruana, R.; Lou, Y.; Gehrke, J.; Koch, P.; Sturm, M.; Elhadad, N. Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission. In Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1721–1730. [Google Scholar]
- Carter, S.; Kim, B.; Brown, R.; Doshi-Velez, F. Visualizing and Understanding High-Dimensional Models in Machine Learning. In Proceedings of the 2019 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Washington, DC, USA, 5–8 October 2019; pp. 230–239. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable; Springer: Berlin/Heidelberg, Germany, 2020; pp. 173–174. [Google Scholar]
- Van der Laan, M.J.; Woutersen, D. Ethics of Explainability: The Social and Psychological Implications of Algorithmic Decisions. J. Ethics 2021, 25, 121–146. [Google Scholar]
- Dave, P.; Dastin, J. Money, Mimicry, and Mind Control: Big Tech Slams Ethics Brakes on AI. Reuters. 2021. Available online: https://news.trust.org/item/20210908095953-jtdiz (accessed on 20 March 2025).
- Hoffman, R.R.; Mueller, S.T.; Klein, G. Explaining Explanations: A Taxonomy of AI Interpretability and Its Implications for Trust and User Behavior. ACM Trans. Interact. Intell. Syst. 2018, 8, 25–34. [Google Scholar]
- Anderson, J.R. Cognitive Psychology and Its Implications, 6th ed.; W.H. Freeman: New York, NY, USA, 2005. [Google Scholar]
- Newell, A.; Simon, H.A. Human Problem Solving; Prentice-Hall: Englewood Cliffs, NJ, USA, 1972. [Google Scholar]
- Plato; Jowett, B. The Republic; Dover Publications: Mineola, NY, USA, 1999. [Google Scholar]
- Descartes, R. Meditations on First Philosophy; Cottingham, J., Translator; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Piaget, J. The Psychology of the Child; Basic Books: New York, NY, USA, 1972. [Google Scholar]
- Vygotsky, L.S. Mind in Society: The Development of Higher Psychological Processes; Cole, M., John-Steiner, V., Scribner, S., Souberman, E., Eds.; Harvard University Press: Cambridge, MA, USA, 1978. [Google Scholar]
- Minsky, M. A Framework for Representing Knowledge; Technical Report; Massachusetts Institute of Technology: Cambridge, MA, USA, 1974. [Google Scholar]
- McCarthy, J.J.; Minsky, M.L.; Rochester, N. Artificial Intelligence; Research Laboratory of Electronics (RLE), Massachusetts Institute of Technology (MIT): Cambridge, MA, USA, 1959; Available online: https://dspace.mit.edu/bitstream/handle/1721.1/52263/RLE_QPR_053_XIII.pdf (accessed on 17 February 2025).
- McCarthy, J. Programs with Common Sense. In Mechanization of Thought Processes; Brain, M., Ed.; Her Majesty’s Stationery Office: London, UK, 1959; Volume I, Available online: https://stacks.stanford.edu/file/druid:yt623dt2417/yt623dt2417.pdf (accessed on 15 February 2025).
- Goldstein, I.; Papert, S. Artificial Intelligence, Language, and the Study of Knowledge. Cogn. Sci. 1977, 1, 84–123. [Google Scholar]
- Sowa, J.F. Knowledge Representation: Logical, Philosophical, and Computational Foundations; Brooks/Cole: Pacific Grove, CA, USA, 2000; Volume 13. [Google Scholar]
- Di Maio, M. Mindful Technology. Buddhist Door, Online Article, Hong Kong, 2019. Available online: https://www.buddhistdoor.net/features/knowledge-representation-in-the-nalanda-buddhist-tradition (accessed on 17 February 2025).
- Guarino, N. The Ontological Level: Revisiting 30 Years of Knowledge Representation. In Conceptual Modeling: Foundations and Applications; Springer: Berlin/Heidelberg, Germany, 2009; pp. 52–67. [Google Scholar]
- Di Maio, P. Neurosymbolic Knowledge Representation for Explainable and Trustworthy AI. Preprints 2020, 2020010163. [Google Scholar] [CrossRef]
- Besold, T.R.; d’Avila Garcez, A.; Bader, S.; Bowman, H.; Domingos, P.; Hitzler, P.; Kühnberger, K.-U.; Lamb, L.C.; Lowd, D.; Moura, J.M.F.; et al. Neural-Symbolic Learning and Reasoning: A Survey and Interpretation 1. In Neuro-Symbolic Artificial Intelligence: The State of the Art; IOS Press: Amsterdam, The Netherlands, 2021; pp. 1–51. [Google Scholar]
- Tiddi, I.; Schlobach, S. Knowledge Graphs as Tools for Explainable Machine Learning: A Survey. Artif. Intell. 2022, 302, 103627. [Google Scholar] [CrossRef]
- Pearl, J. The Seven Tools of Causal Inference, with Reflections on Machine Learning. Commun. ACM 2019, 62, 54–60. [Google Scholar] [CrossRef]
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference; Morgan Kaufmann: San Mateo, CA, USA, 1988. [Google Scholar]
- Granger, C.W.J. Investigating Causal Relations by Econometric Models and Cross-Spectral Methods. Econometrica 1969, 37, 424–438. [Google Scholar] [CrossRef]
- Spirtes, P.; Glymour, C.; Scheines, R. Causation, Prediction, and Search, 2nd ed.; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar] [CrossRef]
- Pearl, J. Causality: Models, Reasoning, and Inference, 2nd ed.; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar] [CrossRef]
- Merton, R.K. The Sociology of Science: Theoretical and Empirical Investigations; University of Chicago Press: Chicago, IL, USA, 1967. [Google Scholar]
- Popper, K. The Logic of Scientific Discovery; Routledge: London, UK, 2002. [Google Scholar]
- Hempel, C.G.; Oppenheim, P. Studies in the Logic of Explanation. Philos. Sci. 1948, 15, 135–175. [Google Scholar] [CrossRef]
- Yang, S.-H.C.; Folke, N.E.T.; Shafto, P. A Psychological Theory of Explainability. In Proceedings of the 39th International Conference on Machine Learning (ICML 2022); Chaudhuri, K., Salakhutdinov, R., Eds.; PMLR: Cambridge, MA, USA, 2022; Volume 162, pp. 25007–25021. [Google Scholar]
- Johnson-Laird, P.N. Mental Models: Towards a Cognitive Science of Language and Reasoning; Cambridge University Press: Cambridge, UK, 1983. [Google Scholar]
- Chater, N.; Oaksford, M. The Rational Analysis of Deductive Reasoning. Psychol. Rev. 1999, 106, 443–467. [Google Scholar]
- Baron, J. Thinking and Deciding, 4th ed.; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Newton, I. Philosophiæ Naturalis Principia Mathematica (Mathematical Principles of Natural Philosophy); Royal Society: London, UK, 1687. [Google Scholar]
- Hume, D. An Enquiry Concerning Human Understanding; A. Millar: London, UK, 1748. [Google Scholar]
- Hempel, C.G. Aspects of Scientific Explanation and Other Essays in the Philosophy of Science; Free Press: New York, NY, USA, 1965. [Google Scholar]
- Mitchell, T.M. Machine Learning; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: https://www.deeplearningbook.org (accessed on 20 February 2025).
- Bhattacharjee, A.; Moraffah, R.; Garland, J.; Liu, H. Towards LLM-Guided Causal Explainability for Black-Box Text Classifiers. arXiv 2024, arXiv:2309.13340. [Google Scholar]
- Kroeger, N.; Ley, D.; Krishna, S.; Agarwal, C.; Lakkaraju, H. In-context explainers: Harnessing LLMs for explaining black box models. arXiv 2023, arXiv:2310.05797. [Google Scholar]
- Nguyen, V.B.; Schlötterer, J.; Seifert, C. From Black Boxes to Conversations: Incorporating XAI in a Conversational Agent. In Proceedings of the World Conference on Explainable Artificial Intelligence, Lisboa, Portugal, 26–28 July 2023; pp. 71–96. [Google Scholar]
- Slack, D.; Krishna, S.; Lakkaraju, H.; Singh, S. Explaining machine learning models with interactive natural language conversations using TalkToModel. Nat. Mach. Intell. 2023, 5, 873–883. [Google Scholar] [CrossRef]
- Zytek, A.; Pidò, S.; Veeramachaneni, K. LLMs for XAI: Future directions for explaining explanations. arXiv 2024, arXiv:2405.06064. [Google Scholar]
- Burton, J.; Al Moubayed, N.; Enshaei, A. Natural Language Explanations for Machine Learning Classification Decisions. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Queensland, Australia, 18–23 June 2023; pp. 1–9. [Google Scholar]
- Mavrepis, P.; Makridis, G.; Fatouros, G.; Koukos, V.; Separdani, M.M.; Kyriazis, D. XAI for all: Can large language models simplify explainable AI? arXiv 2024, arXiv:2401.13110. [Google Scholar]
- Cambria, E.; Malandri, L.; Mercorio, F.; Nobani, N.; Seveso, A. XAI meets LLMs: A survey of the relation between explainable AI and large language models. arXiv 2024, arXiv:2407.15248. [Google Scholar]
- Lareo, X. Large Language Models (LLM). European Data Protection Supervisor. 2023. Available online: https://edps.europa.eu (accessed on 2 March 2025).
- Salmon, W.C. Statistical Explanation and Statistical Relevance; University of Pittsburgh Press: Pittsburgh, PA, USA, 1971; Volume 69. [Google Scholar]
- Salmon, W.C. Scientific Explanation and the Causal Structure of the World; Princeton University Press: Princeton, NJ, USA, 1984. [Google Scholar]
- Friedman, M. Explanation and scientific understanding. J. Philos. 1974, 71, 5–19. [Google Scholar] [CrossRef]
- Kitcher, P. Explanatory unification. Philos. Sci. 1981, 48, 507–531. [Google Scholar] [CrossRef]
- Van Fraassen, B.C. The pragmatics of explanation. Am. Philos. Q. 1977, 14, 143–150. [Google Scholar]



| Learning Task | Explanation Example | Reference |
|---|---|---|
Animal’s image classification Prediction: Yellow-headed blackbird | has_eye_color = black has_underparts_color = white has_belly_color = white has_breast_color = white has_breast_pattern = solid | [55] |
| Movie Recommendation Prediction: Terminator 2 | We guess you would like to watch Terminator 2: Judgement Day (1991) more than Transformers: Revenge of the Fallen (2009) because you may prefer:
| [56] |
| Knowledge graph completion (link prediction) | Prediction: World War I—entity involved—German empire Explanation: World War I—commanders—Erich Ludendorff Erich Ludendorff—commands—German Empire Supported by: Falkland Wars—entities involved—United Kingdom Falkland Wars—commanders—Margaret Thatcher Margaret Thatcher—commands—United Kingdom | [57] |
| Explanation Constituents | Description | Example |
|---|---|---|
| Explanandum | Sentence describing the phenomenon to be explained (not the phenomenon itself) | The leaves of the tea plant are yellowing. |
| Explanans | Class of those sentences which are adduced to account for the phenomenon. These sentences fall into two subclasses: Certain sentences , which state specific antecedent conditions, and a set of sentences , which represent general laws in the domain of the problem at hand. | While the weather and soil conditions seem to be normal, the leaves of tea plant are yellowing Nitrogen deficiency leads to the yellowing of leaves (chlorosis) in tea plants |
| Metric | Value | Description |
|---|---|---|
| Accuracy | 97% | Correct classification of creditworthiness. |
| Rule Coverage | 1.00 | Fraction of predictions supported by domain rules in the KB. |
| Rule-consistent Predictions | 300/300 | Number of predictions fully explainable by symbolic logic. |
| Mismatch Penalty | 0 | Instances where statistical outputs conflicted with KB rules. |
| Dimension | Design Mechanism in NDR | Justification |
|---|---|---|
| Trustworthy | Deductive reasoning; causal law constraints; rule-consistency check | Ensures epistemic soundness; aligns predictions with domain knowledge |
| Human-readable | Plain-language “if–then” format; feature-based explanations | Clear, structured, and easy to interpret by non-expert users. |
| Actionable | Highlights modifiable inputs; grounded in formal policies/laws | Enables users to take informed actions; supports operational decision-making. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hakizimana, G.; Ledezma Espino, A. Nomological Deductive Reasoning for Trustworthy, Human-Readable, and Actionable AI Outputs. Algorithms 2025, 18, 306. https://doi.org/10.3390/a18060306
Hakizimana G, Ledezma Espino A. Nomological Deductive Reasoning for Trustworthy, Human-Readable, and Actionable AI Outputs. Algorithms. 2025; 18(6):306. https://doi.org/10.3390/a18060306
Chicago/Turabian StyleHakizimana, Gedeon, and Agapito Ledezma Espino. 2025. "Nomological Deductive Reasoning for Trustworthy, Human-Readable, and Actionable AI Outputs" Algorithms 18, no. 6: 306. https://doi.org/10.3390/a18060306
APA StyleHakizimana, G., & Ledezma Espino, A. (2025). Nomological Deductive Reasoning for Trustworthy, Human-Readable, and Actionable AI Outputs. Algorithms, 18(6), 306. https://doi.org/10.3390/a18060306