
Forecasting the Remaining Useful Life of Lithium-Ion Batteries Using Machine Learning Models—A Web-Based Application



Abstract

1. Introduction
2. Related Works
2.1. Data-Driven Methods for RUL Forecasting and Its Benefits
2.2. Web-Based Applications in Predictive Analytics
2.3. Advanced Technologies Driving Web-Based Predictive Analytics
2.4. Gaps in Current Research, Research Opportunities, and Challenges
3. Proposed Work
3.1. Data Collection and Preprocessing




3.2. Data Preprocessing
- Mean Squared Error (MSE): MSE quantifies how far predicted values deviate from actual values by averaging the squared differences between them, with lower values indicating better predictive performance. Formula: MSE = Σ(yi − ŷi)2/n, where yi is the actual value, ŷi is the predicted value, and n is the number of samples.
- Mean Absolute Error (MAE): MAE represents the average absolute differences between predicted and actual values. It evaluates how much, on average, the predictions deviate from the actual values. A lower MAE indicates a more precise model. Formula: MAE = Σ|yi − ŷi|/n.
- Root Mean Squared Error (RMSE): RMSE is calculated as the square root of the mean of the squared differences between predicted and actual values. It quantifies the model’s prediction error by assessing the standard deviation between predicted and true values, with lower RMSE indicating higher accuracy. Formula: RMSE = √(Σ(yi − ŷi)2/n).
- R-squared (R2): R-squared is defined as a statistical measure that shows the proportion of the variance in the dependent variable (RUL) that is explained by the independent variables (features) in the model. We have a range of values that is from 0 to 1, where 1 means a perfect fit and 0 shows no linear relationship between the independent and dependent variables. Given as: R2 = 1 − (Σ(yi − ŷi)2/Σ(yi − ȳ)2), where yi is the actual value, ŷi is the predicted value, and ȳ is the mean of the actual values.
3.3. Model Development and Training
3.3.1. Linear Regression
- is the target variable (dependent variable).
- are the predictor variables (independent variables).
- … are the coefficients (parameters) of the linear model.
- is the error term that shows the difference between the observed and predicted values.
3.3.2. Random Forest with Extra Trees Regressor
3.3.3. Artificial Neural Network
- represents the input features.
- represents the weights assigned to each input.
- is the bias term.
- σ(z) is the activation function (ReLU or sigmoid) which introduces non-linearity into the model.
3.3.4. Long Short-Term Memory (LSTM)
- 1.
- Forget Gate: Determines which information to discard from the cell state.
- 2.
- Input Gate: Decides which new information to store in the cell state.
- 3.
- Cell state update: Combine the forget and input operations to update the cell state.
- 4.
- Output Gate: Determines the output of the LSTM cell.
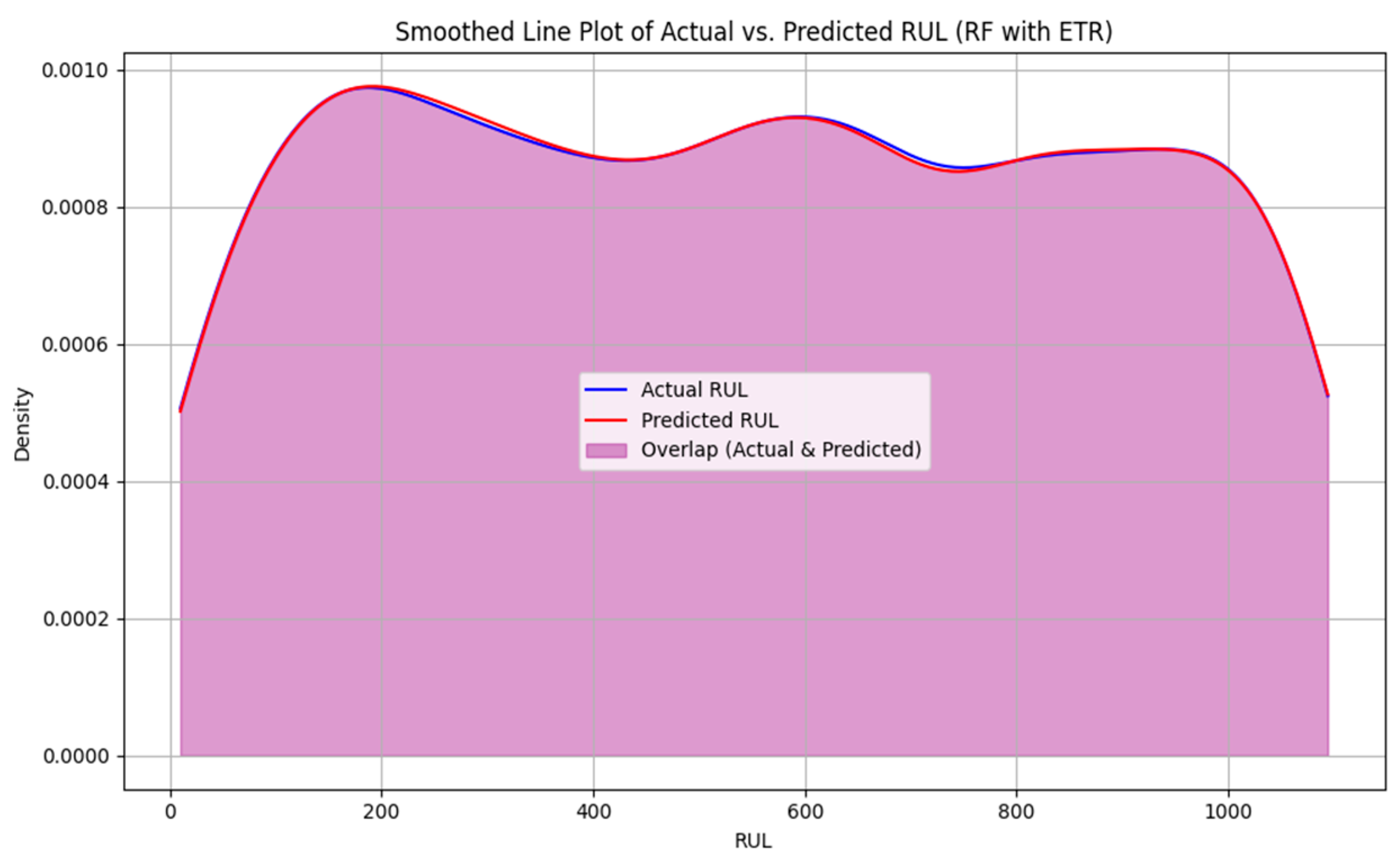
4. Results and Discussion
4.1. Analyzing the Role of Cycle Count and Key Features in Reducing MSE for Lithium-Ion Battery RUL Prediction
4.1.1. Accuracy
4.1.2. Interpretability
4.1.3. Time and Computational Efficiency
4.1.4. Cross Validation
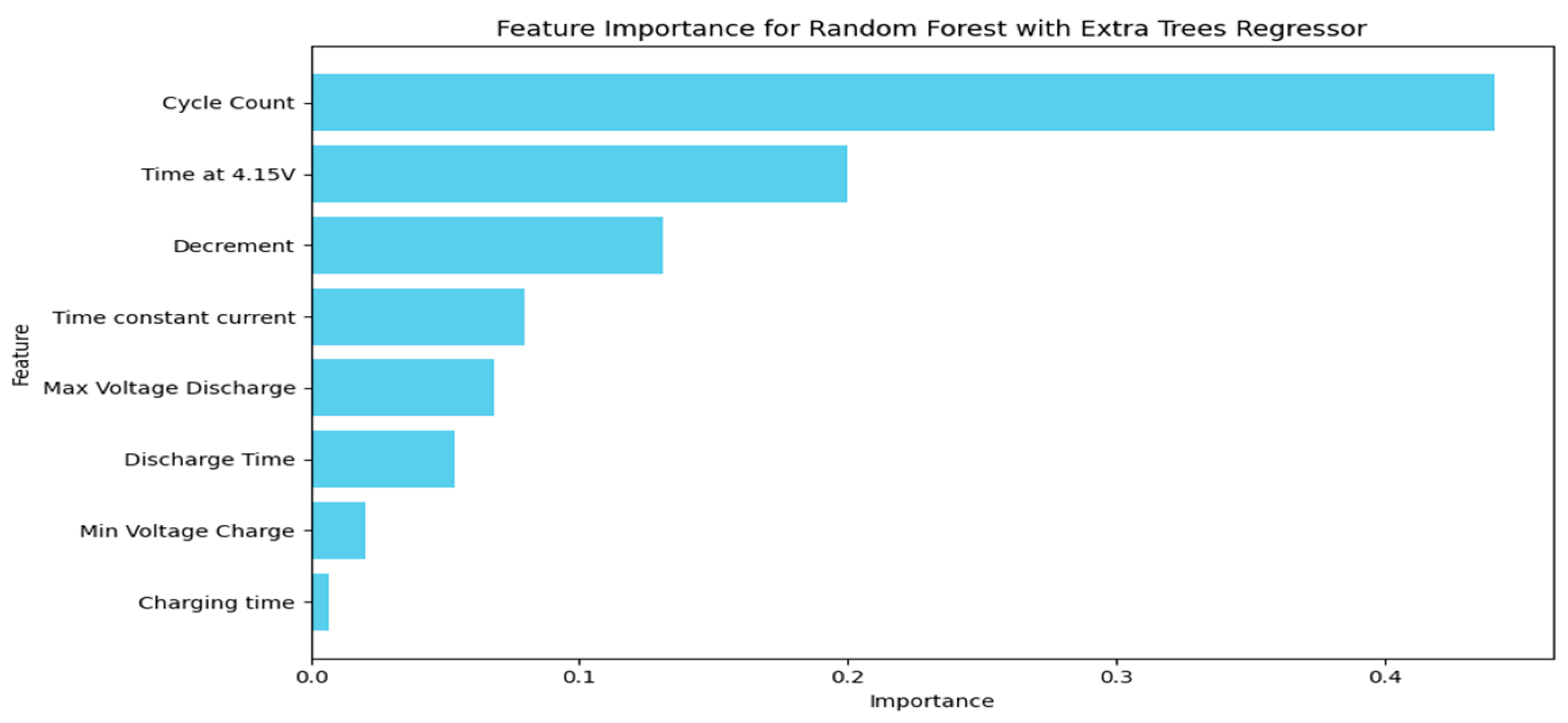
4.2. Feature Importance
4.3. Web Application Development
- Framework: The web application is developed using Streamlit, a Python-based framework known for its simplicity and interactive capabilities. Streamlit allows for rapid prototyping and the creation of visually appealing dashboards and applications. It provides built-in support for integrating machine learning models and simplifies the process of creating forms, charts, and dynamic outputs.
- Backend: The backend of the application is powered by Python, implementing trained machine learning models. These models are algorithms like LSTM, ANN, Random Forest etc., which have been pre-trained on a dataset of lithium-ion battery degradation patterns. Google Colab is utilized for model training and validation due to its cloud-based GPU acceleration, which speeds up computation-intensive tasks. The trained models are exported and integrated into the application for real-time prediction functionality.
- Frontend: The front end is designed with a user-friendly interface to ensure intuitive user experience. Users can input key battery parameters such as charge cycles, temperature ranges, and voltage levels through the application as shown in Figure 19 below. The frontend then displays the predicted RUL alongside visualizations like charts and graphs to provide insights into battery health and degradation trends. Streamlit’s interactive widgets and charts facilitate this process, enhancing usability.
- Deployment: The machine learning models are available on Github Repository, furthermore, to ensure accessibility and scalability, the application is hosted on a cloud platform. Google Colab is used in conjunction with Streamlit and Django for model deployment. By linking our Algorithm on Google Colab notebooks directly to the Streamlit application, real-time predictions can be achieved without requiring extensive local computational resources. The cloud-hosted nature of the application ensures that users can access it from any device with internet connectivity, enabling widespread adoption and utility.
4.4. Benefits and Features
5. Conclusions and Future Enhancements
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- U.S. Department of Energy. Battery Life and Performance Testing Methodology: PEV Battery Test Manual, Revision 3, INL/EXT-13-30323; Idaho National Laboratory: Idaho Falls, ID, USA, 2015.
- IEC 61960-3; Secondary Lithium Cells and Batteries for Portable Applications—Part 3: Prismatic and Cylindrical Lithium Secondary Cells and Batteries Made from Them. International Electrotechnical Commission (IEC): Geneva, Switzerland, 2017.
- Li, J.; Gu, Y.; Wang, L.; Wu, X. A Review of State-of-Health Estimation for Lithium-Ion Batteries. J. Power Sources 2018, 391, 54–60. [Google Scholar] [CrossRef]
- Jardine, A.K.S.; Lin, D.; Banjevic, D. A Review on Machinery Diagnostics and Prognostics Implementing Condition-Based Maintenance. Mech. Syst. Signal Process. 2006, 20, 1483–1510. [Google Scholar] [CrossRef]
- Ecker, M.; Tran, T.K.D.; Dechent, P.; Käbitz, S.; Warnecke, A.; Sauer, D.U. Parameterization of a Physico-Chemical Model for Lithium-Ion Batteries Based on Electrochemical Impedance Spectroscopy. J. Power Sources 2012, 215, 248–257. [Google Scholar] [CrossRef]
- Wang, D.; Wang, Y.; Zhang, J.; Li, H.; Chen, M.; Liu, Q.; Zhao, L.; Huang, X.; Yang, F.; Zhou, Y.; et al. Hybrid Models for Lithium-Ion Battery RUL Prediction. Appl. Energy 2020, 259, 114151. [Google Scholar]
- Yang, N.; Hofmann, H.; Sun, J.; Song, Z. Remaining Useful Life Prediction of Lithium-ion Batteries with Limited Degradation History Using Random Forest. IEEE Trans. Transp. Electrif. 2023, 10, 5049–5060. [Google Scholar] [CrossRef]
- Li, J.; Wang, Q.; Du, Z.; Chen, M.; Sun, J. Thermal Runaway Mechanism of Lithium Ion Battery for Electric Vehicles: A Review. Energy Storage Mater. 2018, 10, 246–267. [Google Scholar] [CrossRef]
- Fei, Z.; Yang, F.; Tsui, K.-L.; Li, L.; Zhang, Z. Early Prediction of Battery Lifetime via a Machine Learning-Based Framework. Battery Res. Adv. 2021, 19, 102–115. [Google Scholar] [CrossRef]
- Jafari, S.; Byun, Y.-C. Optimizing Battery RUL Prediction of Lithium-Ion Batteries Based on Harris Hawk Optimization Approach Using Random Forest and LightGBM. IEEE Access 2023, 11, 114047–114059. [Google Scholar] [CrossRef]
- Sekhar, J.N.C.; Domathoti, B.; Gonzalez, E.D.R.S. Prediction of Battery Remaining Useful Life Using Machine Learning Algorithms. Sustainability 2023, 15, 15283. [Google Scholar] [CrossRef]
- Kumarapp, S.; M, M.H. Machine Learning-Based Prediction of Lithium-Ion Battery Life Cycle for Capacity Degradation Modelling. World J. Adv. Res. Rev. 2024, 21, 1299–1309. [Google Scholar] [CrossRef]
- Hu, X.; Jiang, J.; Cao, D. Battery health prognosis for electric vehicles using data-driven approaches. Renew. Sustain. Energy Rev. 2017, 75, 301–315. [Google Scholar]
- He, W.; Chen, H. Cost analysis of predictive maintenance in lithium-ion batteries. Energy Storage Mater. 2019, 18, 420–430. [Google Scholar]
- Kim, T.; Lim, H.; Cho, B.H. Advances in battery safety through RUL prediction: A review. Prog. Energy Combust. Sci. 2021, 85, 100905. [Google Scholar]
- Zhang, X.; Wang, L.; Li, J. Sustainability-driven battery management systems: Benefits and challenges. J. Clean. Prod. 2022, 331, 129870. [Google Scholar]
- Smith, J.; Brown, K. Democratizing Predictive Analytics: The Role of Web Applications. J. Anal. Technol. 2020, 12, 45–62. [Google Scholar]
- White, A. Centralized Data Management for Predictive Analytics; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Amazon Web Services. Predictive Maintenance with Amazon Monitron. 2022. Available online: https://aws.amazon.com/solutions/guidance/predictive-maintenance-with-amazon-monitron/ (accessed on 18 March 2025).
- Li, X.; Zhao, Y. Real-Time Monitoring and Predictive Analytics in IoT Systems. IoT Anal. Rev. 2021, 8, 210–227. [Google Scholar]
- Khan, M.; Singh, R. Smart Grids: Real-Time Optimization through Predictive Tools. IEEE Trans. Energy Syst. 2021, 15, 300–315. [Google Scholar]
- Johnson, T. Frameworks for Developing Interactive Dashboards. Int. J. Data Vis. 2022, 14, 50–64. [Google Scholar]
- Patel, R. User-Centered Design in Predictive Analytics Applications. ACM Comput. Surv. 2021, 53, 120–142. [Google Scholar]
- Williams, D. Enhancing User Experience with Data Visualization. Data Sci. J. 2020, 10, 67–80. [Google Scholar]
- Martinez, L.; Carter, P. Enterprise Integration with Predictive Systems. Int. J. Syst. Archit. 2022, 19, 90–102. [Google Scholar]
- Zhou, H.; Lee, C. Machine Learning Algorithms for Predictive Maintenance Applications; Elsevier: Amsterdam, The Netherlands, 2020. [Google Scholar]
- Baker, F.; Nguyen, T. Improving Decision-Making with Web-Based Analytics. Harv. Bus. Rev. 2021, 99, 48–54. [Google Scholar]
- Stevens, G. Standardizing Integration Frameworks for Predictive Analytics. Softw. Eng. Q. 2022, 31, 88–104. [Google Scholar]
- Hosseini, M. Optimizing Energy Storage Systems with Predictive Maintenance. Arshon Technology Blog. 2024. Available online: https://arshon.com/blog/optimizing-energy-storage-systems-with-predictive-maintenance/ (accessed on 18 March 2025).
- Bandi, M.; Masimukku, A.K.; Vemula, R.; Vallu, S. Predictive Analytics in Healthcare: Enhancing Patient Outcomes through Data-Driven Forecasting and Decision-Making. J. Mach. Learn. Robot. 2024, 8, 1–20. Available online: https://injmr.com/index.php/fewfewf/article/view/144 (accessed on 11 May 2025).
- Lee, H.L.; Padmanabhan, V.; Whang, S. Information Distortion in a Supply Chain: The Bullwhip Effect. Manag. Sci. 1997, 43, 546–558. [Google Scholar] [CrossRef]
- GDPR Advisor. GDPR and Cloud Computing: Safeguarding Data in the Digital Cloud. 2022. Available online: https://www.gdpr-advisor.com/gdpr-and-cloud-computing-safeguarding-data-in-the-digital-cloud/ (accessed on 18 March 2025).
- Park, E. Model Interpretability in Machine Learning for Non-Experts. Artif. Intell. J. 2020, 17, 210–229. [Google Scholar]
- Zhang, Y.; Richardson, R.R.; Liu, K.; Howey, D.A. Battery Prognostics under Uncertainty: A Comparative Study and New Prediction Horizon Metric. J. Power Sources 2020, 479, 228806. [Google Scholar] [CrossRef]
- Kim, H.; Lee, S. A Review of RUL Prediction Models for Variable Operational Environments. Int. J. Progn. Health Manag. 2021, 10, 78–92. [Google Scholar]
- Li, F.; Zhang, Q. Integrating Predictive Analytics with Practical Systems: Barriers and Opportunities. IEEE Trans. Ind. Inform. 2020, 16, 1234–1243. [Google Scholar]
- Williams, R. Autonomous Fleet Management Enabled by Predictive Maintenance. Fleet Insights 2023, 8, 34–47. [Google Scholar]
- Luh, M.; Blank, T. Comprehensive Battery Aging Dataset: Capacity and Impedance Fade Measurements of a Lithium-Ion NMC/C-SiO Cell. Sci. Data 2024, 11, 1004. [Google Scholar] [CrossRef] [PubMed]
- Gupta, A.; Shukla, D. Developing Open-Access Battery Datasets for Predictive Modeling. Renew. Energy Syst. J. 2022, 9, 89–98. [Google Scholar]
- Thomas, P.; White, E. Simplifying Predictive Analytics Tools for Non-Experts. J. Hum.-Comput. Interact. 2020, 12, 150–162. [Google Scholar]
- Johnson, K.; Tran, V. Intuitive Dashboards for RUL Prediction: Design and Implementation. Predict. Insights Q. 2023, 7, 44–59. [Google Scholar]
- Sun, J.; Zhou, W. Improving Interpretability in Deep Learning Models for Predictive Analytics. AI Ethics 2022, 5, 100–120. [Google Scholar]
- Paneru, B.; Thapa, B.; Mainali, D.P.; Paneru, B.; Shah, K.B. Remaining Useful Life Prediction for Batteries Utilizing an Explainable AI Approach with a Predictive Application for Decision-Making. arXiv 2024, arXiv:2409.17931. Available online: https://arxiv.org/abs/2409.17931 (accessed on 18 March 2025).
- Martin, D.; Lopez, M. Data Security in IoT-Based Predictive Systems: A Review. Cybersecur. Priv. J. 2023, 11, 134–148. [Google Scholar]
- Kumar, N. Balancing Accessibility and Security in Predictive Analytics Platforms. Cloud Comput. Insights 2020, 8, 67–79. [Google Scholar]
- Stevens, C.; Patel, N. RUL Prediction for Emerging Battery Chemistries. Adv. Battery Technol. 2021, 15, 90–103. [Google Scholar]
- Wang, Y.; Li, X. Next-Generation Batteries: Challenges in Prognostics and RUL Prediction. Energy Storage Futures 2023, 13, 320–335. [Google Scholar]
- Rodríguez-Pérez, N.; Domingo, J.M.; López, G.L. ICT Scalability and Replicability Analysis for Smart Grids: Methodology and Application. Energies 2024, 17, 574. [Google Scholar] [CrossRef]
- Taylor, B. Big Data Processing in Cloud Computing Environments; Wiley: Hoboken, NJ, USA, 2019. [Google Scholar]
- Doe, J.; Smith, A. Advancements in AI for Energy Management. Energy Technol. J. 2023, 15, 100–115. [Google Scholar]
- Lacy, F.; Ruiz-Reyes, A.; Brescia, A. Machine learning for low signal-to-noise ratio detection. Pattern Recognit. Lett. 2024, 179, 115–122. [Google Scholar] [CrossRef]
- Ding, T.; Xiang, D.; Sun, T.; Qi, Y.; Zhao, Z. AI-Driven Prognostics for State of Health Prediction in Li-ion Batteries: A Comprehensive Analysis with Validation. arXiv 2025, arXiv:2504.05728. [Google Scholar]
- Ren, L.; Zhao, L.; Hong, S.; Zhao, S.; Wang, H.; Zhang, L. Remaining useful life prediction for lithium-ion battery: A deep learning approach. IEEE Access 2018, 6, 50587–50598. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiong, R.; He, H.; Pecht, M.G. Long short-term memory recurrent neural network for remaining useful life prediction of lithium-ion batteries. IEEE Trans. Veh. Technol. 2018, 67, 5695–5705. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ML Model | MSE | RMSE | MAE | R2 | Training Time (s) | Prediction Time (s) |
|---|---|---|---|---|---|---|
| LSTM | 12,291.69 | 110.87 | 65.39 | 0.89 | 954.72 | 5.62 |
| LR | 3363.206 | 57.995 | 44.55 | 0.90 | 5.97 | 0.16 |
| ANN | 2456.65 | 49.56 | 37.21 | 0.94 | 593.54 | 3.03 |
| RF with ETR | 384.27 | 19.85 | 8.86 | 0.98 | 15.87 | 0.51 |
| ML Model | MSE | RMSE | MAE | R2 | Training Time (s) | Prediction Time (s) |
|---|---|---|---|---|---|---|
| ANN | 1858.31 | 43.11 | 36.06 | 0.96 | 276.80 | 1.61 |
| LSTM | 824.15 | 28.71 | 12.04 | 0.97 | 532.63 | 2.37 |
| LR | 51.86 | 7.20 | 4.54 | 0.98 | 2.35 | 0.01 |
| RF with ETR | 10.23 | 3.66 | 1.99 | 0.99 | 7.34 | 0.05 |
| References | ML Model | MSE | RMSE | MAE | R2 | Training Time | Prediction Time |
|---|---|---|---|---|---|---|---|
| [9] | Support Vector Machine (SVM) | _ | 115 | _ | 0.90 | _ | _ |
| [10] | Random Forest Optimization with HHO | 2148.865 | 46.35 | 36.88 | 0.97 | _ | _ |
| [53] | Adaptive Deep Neural Network (ADNN) | _ | 6.66 | _ | 0.93 | _ | _ |
| [11] | Random Forest | 14.11 | 3.75 | 2.09 | 0.99 | _ | 0.06 |
| Proposed | Random Forest with Extra Trees Regressor | 10.23 | 3.66 | 1.99 | 0.99 | 7.34 | 0.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Onyenagubo, C.; Ismail, Y.; Belu, R.; Lacy, F. Forecasting the Remaining Useful Life of Lithium-Ion Batteries Using Machine Learning Models—A Web-Based Application. Algorithms 2025, 18, 303. https://doi.org/10.3390/a18060303
Onyenagubo C, Ismail Y, Belu R, Lacy F. Forecasting the Remaining Useful Life of Lithium-Ion Batteries Using Machine Learning Models—A Web-Based Application. Algorithms. 2025; 18(6):303. https://doi.org/10.3390/a18060303
Chicago/Turabian StyleOnyenagubo, Chisom, Yasser Ismail, Radian Belu, and Fred Lacy. 2025. "Forecasting the Remaining Useful Life of Lithium-Ion Batteries Using Machine Learning Models—A Web-Based Application" Algorithms 18, no. 6: 303. https://doi.org/10.3390/a18060303
APA StyleOnyenagubo, C., Ismail, Y., Belu, R., & Lacy, F. (2025). Forecasting the Remaining Useful Life of Lithium-Ion Batteries Using Machine Learning Models—A Web-Based Application. Algorithms, 18(6), 303. https://doi.org/10.3390/a18060303