1. Introduction
The past decade has seen a considerable surge in the integration of artificial intelligence into medicine [
1,
2], driven by the dramatic growth in deep machine learning methods [
3]. Medicine has emerged as a critical field for applying these advanced technologies, with deep learning primarily targeting clinical decision support and data analysis. These systems, adept at examining medical data to discover patterns and relationships, span a diverse range of applications. They have demonstrated significant progress in predicting patient outcomes [
4,
5,
6], as well as enhancing diagnostics and disease classification [
7,
8,
9,
10,
11,
12]. Beyond analysis and classification, deep learning has proven effective in data segmentation [
13,
14] and has made strides in the generation [
15,
16,
17,
18,
19] and anonymization of medical data [
20,
21,
22,
23,
24].
OA, particularly knee joint osteoarthritis (KOA) [
25,
26,
27], is a leading global cause of disability [
28], with estimated expenditures reaching up to 2.5% of the Gross National Product in western countries [
29]. Its early detection is often impeded by subtle radiographic markers and the variability in disease progression [
25,
28]. Leveraging deep learning for classifying KOA [
30,
31,
32,
33,
34] depends heavily on the availability of diverse and extensive datasets. However, obtaining such datasets is challenging, constrained by patient privacy considerations [
35,
36], data collection restrictions, and the inherent nature of OA. Various studies have utilized data augmentation techniques as a workaround, creating artificial data variability. For KOA, two primary data augmentation methods are employed: affine and online, where random transformations occur during training, and additive and offline, manipulating the base (original) data before training to generate more data points. These techniques, often used in tandem, have been successful in enhancing performance and mitigating overfitting. However, there has been no systematic exploration to determine which technique is most effective for the task at hand, nor which might be less beneficial.
There has been a notable gap in research regarding the impact of augmentation on medical data, especially in the context of knee joint osteoarthritis (KOA). While existing studies [
37,
38] in other medical imaging areas have identified both beneficial and detrimental effects of specific augmentations. Existing KOA studies have employed various approaches [
31,
39,
40], but without focusing on base data augmentation as the research objective. To the best of our knowledge, our study is the first to investigate both positive and adversarial augmentations in the context of knee joint osteoarthritis and first to explore adversarial augmentation beyond noise injection seen in prior medical imaging work.
Positive augmentations, a subset of offline base data augmentations, involve modifications that supportively enhance the dataset. These include variations of the original images and mild transformations that preserve the data’s core characteristics. Adversarial augmentations, on the other hand, introduce substantial alterations, such as noise and complex distortions, to challenge the model under difficult conditions. These augmentations are crucial for evaluating the model’s sensitivity and robustness, exposing its performance limitations and areas needing improvement. They can play a significant role in helping to identify confounds within images, clarifying which aspects of the data the model might rely on. One example can be seen in Goceri’s study [
37], where the author included an investigation of pixel noise, however to the best of our knowledge our study is the first to introduce adversarial augmentations beyond noise injection. Broadly, the scope is also differentiated from targeted adversarial attacks [
41,
42,
43,
44], where the objective is to change the predictions of specific cases. Instead, our approach introduces challenging conditions, without specific optimization for adversarial outcomes.
In this study, we address these research gaps. Our focus is on discerning the most suitable base augmentation technique for the task at hand and pinpointing potential confounding regions within the radiographs (using adversarial augmentation).
The following sections of this paper are organized as follows: In the Methods section, we provide a detailed description of our experimental pipeline, including data acquisition, selection of augmentation techniques, neural network architecture and configuration, our approach to interpretability, and the chosen figures of merit. Subsequently, in the Results section, we present a comprehensive analysis of the confusion matrices derived from various augmentation modalities, as well as a thorough examination of evaluation metrics. Lastly, in the Discussion section, we delve into the broader implications of our findings and discuss specific details of our study’s impact and significance.
2. Materials and Methods
In this study, we present a comprehensive augmentation methodology for the classification of knee joint X-ray images sourced from the Osteoarthritis Initiative [
45]. Our approach is threefold: data collection and preprocessing, image augmentation, and the application of a convolutional neural network (CNN) for classification. We utilized a dataset of 8260 images, graded via the Kellgren and Lawrence [
46] system, and subjected them to both positive/supportive and negative/adversarial augmentations. This was done to explore the benefits of image-based artificial diversity (Image-based artificial diversity refers to the application of image augmentation techniques in deep learning, This approach includes modifying images through various methods such as rotating, scaling, cropping, or changing color intensity, to generate a more diverse set of training data.) during training and to challenge the classifier’s resilience. The CNN model of choice was the EfficientNetV2-M [
47], which was trained over 15 epochs with a dataset split into training, validation, and testing sets. To enhance the interpretability of our CNN model, we employed the Grad-CAM [
48] algorithm, which offered visual insights into the network’s decision-making focus. These insights were generated offline and after the training phase. Our evaluation metrics included accuracy, precision, recall, and the F1 score, providing a comprehensive view of the model’s performance.
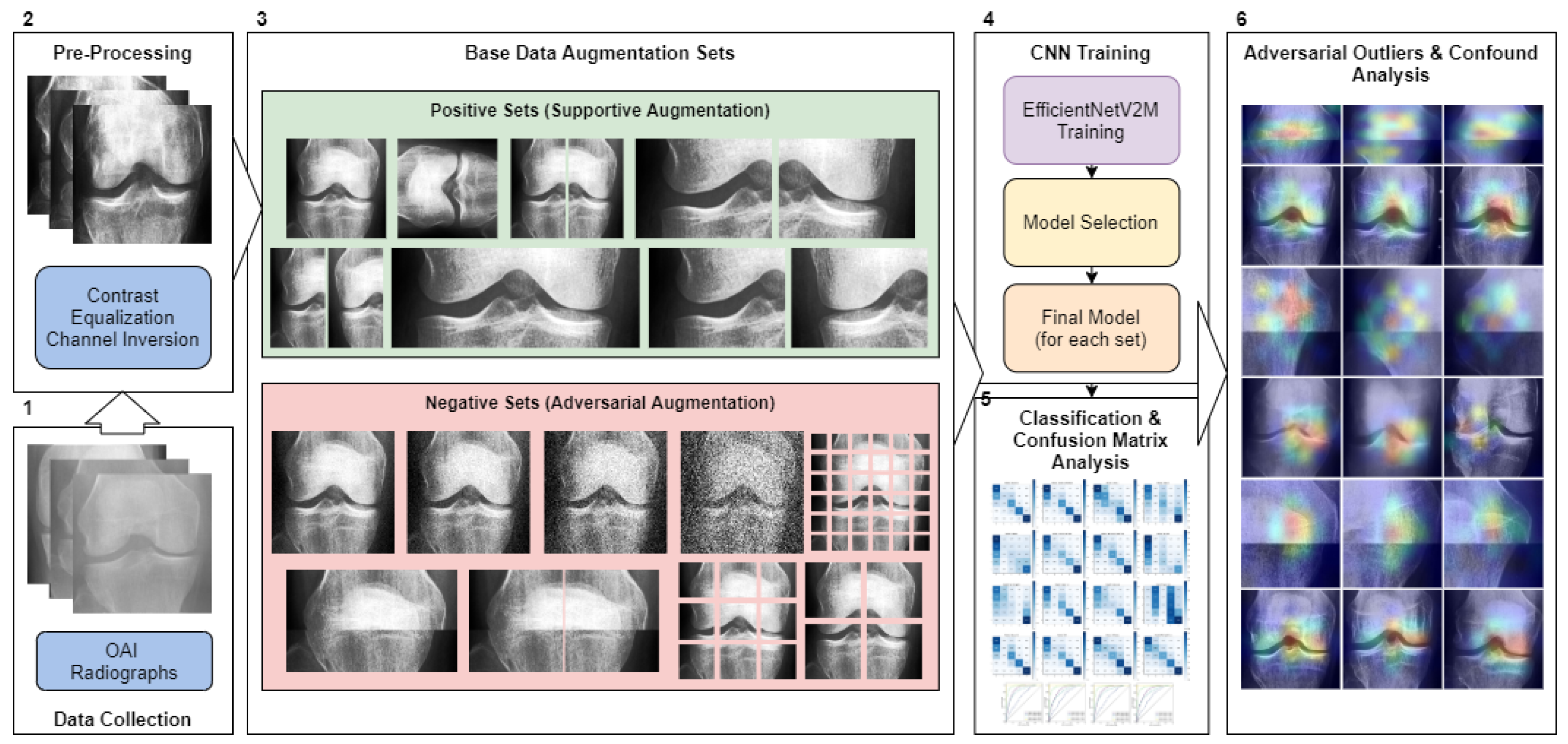
Figure 1 illustrates the study’s operational sequence using numeric markers. This section elaborates on each step in the order indicated by the numeric markers in the figure.
2.1. Data Collection
Our research utilized knee joint X-ray images from the Chen 2019 study [
49], originally sourced from the Osteoarthritis Initiative (OAI) [
45]. The OAI, a multi-center study focused on biomarkers for knee osteoarthritis, and included 4796 participants aged 45 to 79. We employed the pre-processed primary cohort data from Chen 2019 [
49], which had undergone automatic knee joint detection, bounding, and zoom standardization to 0.14 mm/pixel. This process yielded 8260 images (
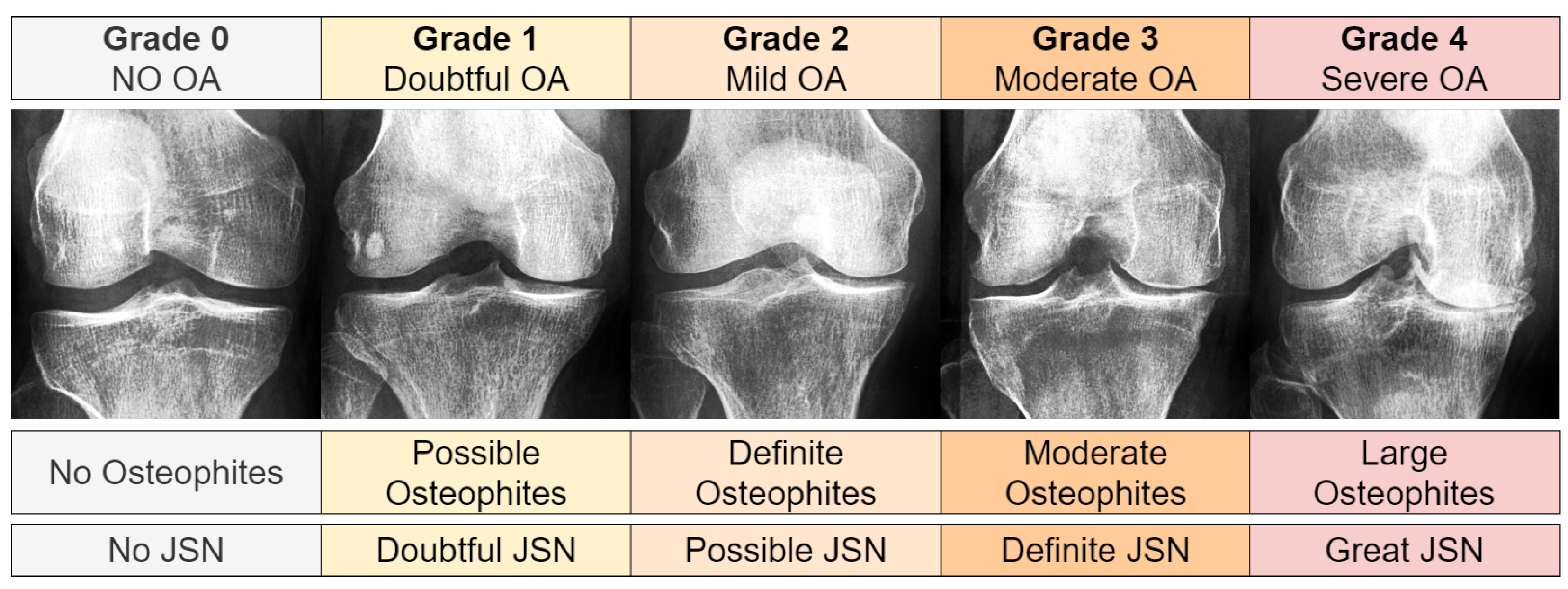
pixels) derived from 4130 X-rays, each containing both knee joints. The images were graded using the Kellgren and Lawrence (KL) system [
46], as shown in
Figure 2. The KL grade distribution was as follows: 3253 images for Grade 0, 1495 for Grade 1, 2175 for Grade 2, 1086 for Grade 3, and 251 for Grade 4.
2.2. Image Pre-Processing
We flipped each right knee joint image to mirror a left knee orientation. Then, we identified and inverted any negative channel images, resulting in 189 such alterations for KL01 and 77 for KL234. We then equalized the image histograms’ contrast using Equation (
1). In this equation, for a given grayscale image
with dimensions of
, we used the cumulative distribution function (cdf) and pixel value
v to obtain an equalized value
in the range
. Here,
represents a non-zero minimum value of the image’s cumulative distribution, while
signifies the total number of pixels.
2.3. Base Data Augmentation Sets
In our research, we divided our dataset into distinct splits and applied base data augmentations to each of these splits. We created two sets of base data augmentations. The term ‘base data’ refers to permanent modifications made to all the data (‘offline’) before introducing any ‘online’ affine augmentations during the training phase (
Table 1). The first set of augmentations focused on positive or supportive modifications, exploring the potential benefits of incorporating image-based artificial diversity during training. The second set, conversely, involved negative/adversarial augmentations, intended to challenge the classifier. This approach aimed to help identify potential confounds in the classification task and test the model’s resilience.
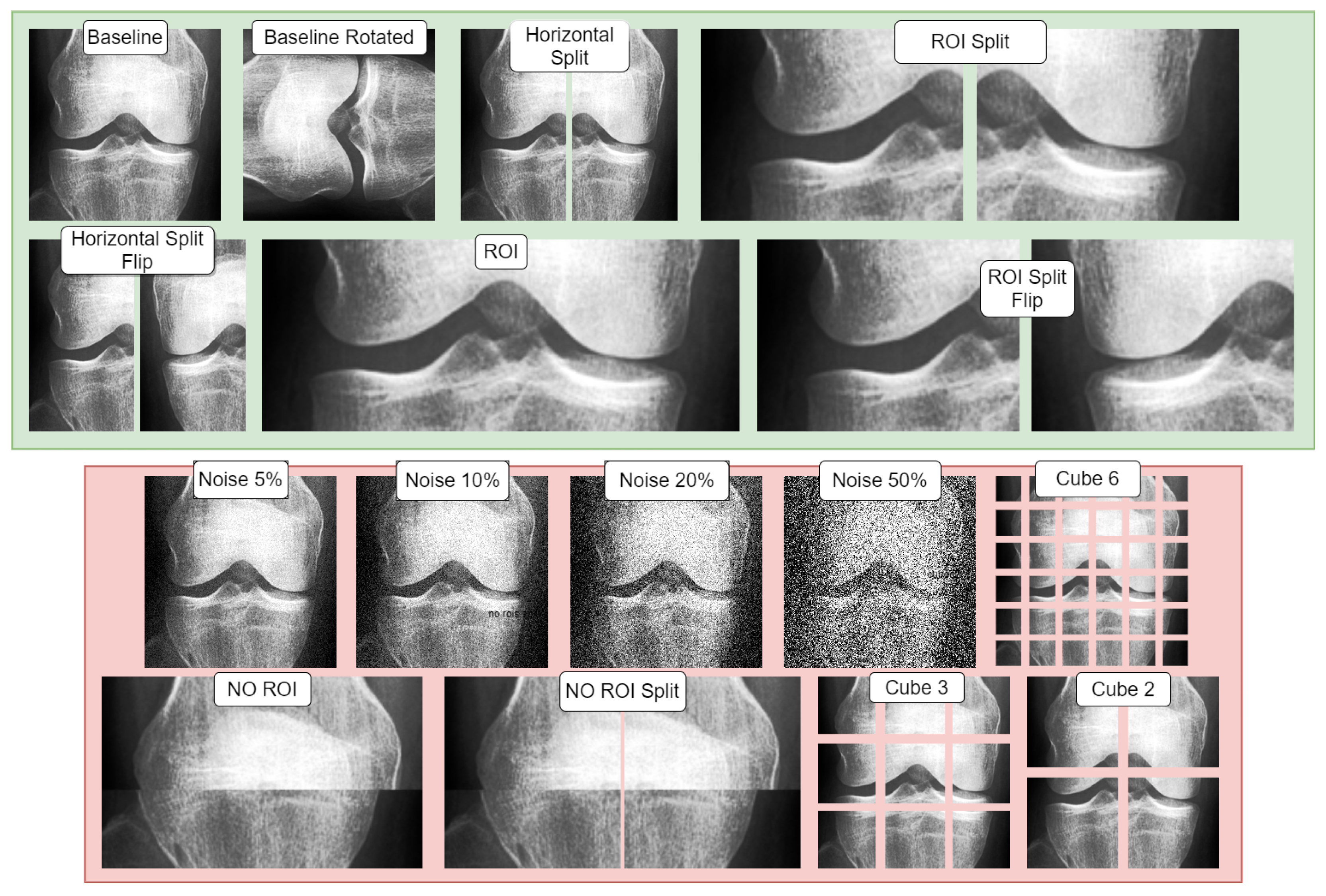
Table 2 showcases all the conditions used, while
Figure 3 visualizes the base augmentations made. The specifics of each type of augmentation are further elaborated in the following section.
2.4. Affine (Online) Augmentation
Affine augmentations typically involve geometric transformations, such as scaling, translation, rotation, and shearing, applied in real-time during model training. These online augmentations introduce a diverse range of geometric variations to training images, essential for enhancing model generalization. By exposing the model to different orientations and scales, affine transformations help to improve pattern recognition robustness to such variations, a critical aspect in tasks like image classification and object detection. These transforms are typical for almost every RGB-based image classification task.
2.5. Offline Base Data Augmentations
Offline base data augmentations involve pre-applied, static modifications to the entire dataset before training commences. These augmentations, ranging from simple image alterations to complex transformations, are crucial for introducing initial diversity to the training set (before online augmentation). They play a significant role in expanding the dataset’s variability, particularly beneficial in limited or less diverse datasets, and aid in reducing overfitting and enhancing the model’s performance.
2.5.1. Positive/Supportive Data Augmentations
Positive augmentations, a subset of offline base data augmentations, involve modifications that supportively enhance the dataset. These include variations of the original images and mild transformations that maintain the data’s core characteristics. Such augmentations are vital for enriching the dataset with beneficial variability, aiding in more nuanced feature extraction and understanding of data variations, ultimately leading to improved model accuracy and reliability.
2.5.2. Adversarial/Negative Augmentations
Adversarial augmentations are crucial in assessing model performance under challenging conditions. By introducing substantial alterations such as noise and complex distortions to the dataset, these augmentations provide insights into the model’s sensitivity and robustness. They are instrumental in revealing how the model’s performance degrades in difficult circumstances, highlighting its limitations and areas for improvement. Additionally, adversarial augmentations help in identifying confounds within images, clarifying which aspects of the data the model might erroneously rely on. This process is vital for ensuring that the model’s predictive capabilities are not only based on genuine features relevant to the task but are also resilient to misleading or irrelevant data variations.
2.5.3. Adversarial (Negative) and Supportive (Positive) Augmentations Visualization
Figure 3 illustrates both adversarial and supportive/positive augmentations. In the green window, the supportive augmentations are displayed as variants of the provided baseline image. Likewise, in the red window, one can observe the adversarial variants and their visual form, all applied on the same unaltered baseline image shown in the green window.
2.6. Convolutional Neural Networks
Convolutional neural networks (CNNs) [
50] are foundational in the recent deep learning revolution [
3]. CNNs are a type of neural network often used for computer vision. These neural networks employ the convolution operation between input and a filter-kernel. Filters slide across inputs to highlight features in a response known as a feature map. Various feature maps are combined to produce higher-level feature maps corresponding to higher-level concepts. Formally [
51], for an image
of
dimensions and filter-kernel
of
dimensions, we can obtain feature map
by convolution across the two axes with kernel
as:
Typically, the feature map values are filtered with an activation function. The role of the activation function is to re-map the values across a given function.
2.7. Convolutional Neural Network Architecture
The EfficientNet architecture, as introduced by Tan and Le in their 2019 paper [
52], stands as a significant milestone in the evolution of deep learning architectures. It is based on the principle of compound scaling, a novel approach that meticulously balances three fundamental dimensions of a neural network: depth, width, and resolution. Depth refers to the number of layers in the network, width to the size of each layer, and resolution to the size of the input image that the network processes. This balance is crucial, as it allows EfficientNet to scale up in a more structured and efficient manner compared to previous architectures.
The scaling process itself can be underpinned formaly in Equation (
3):
In this formula, and are constants that determine how each dimension scales, while is a user-defined coefficient that dictates the overall scaling of the model. The base values represent the depth, width, and resolution of the base model, respectively. This formulation allows for a systematic and controlled scaling of the network dimensions, leading to improvements in model performance.
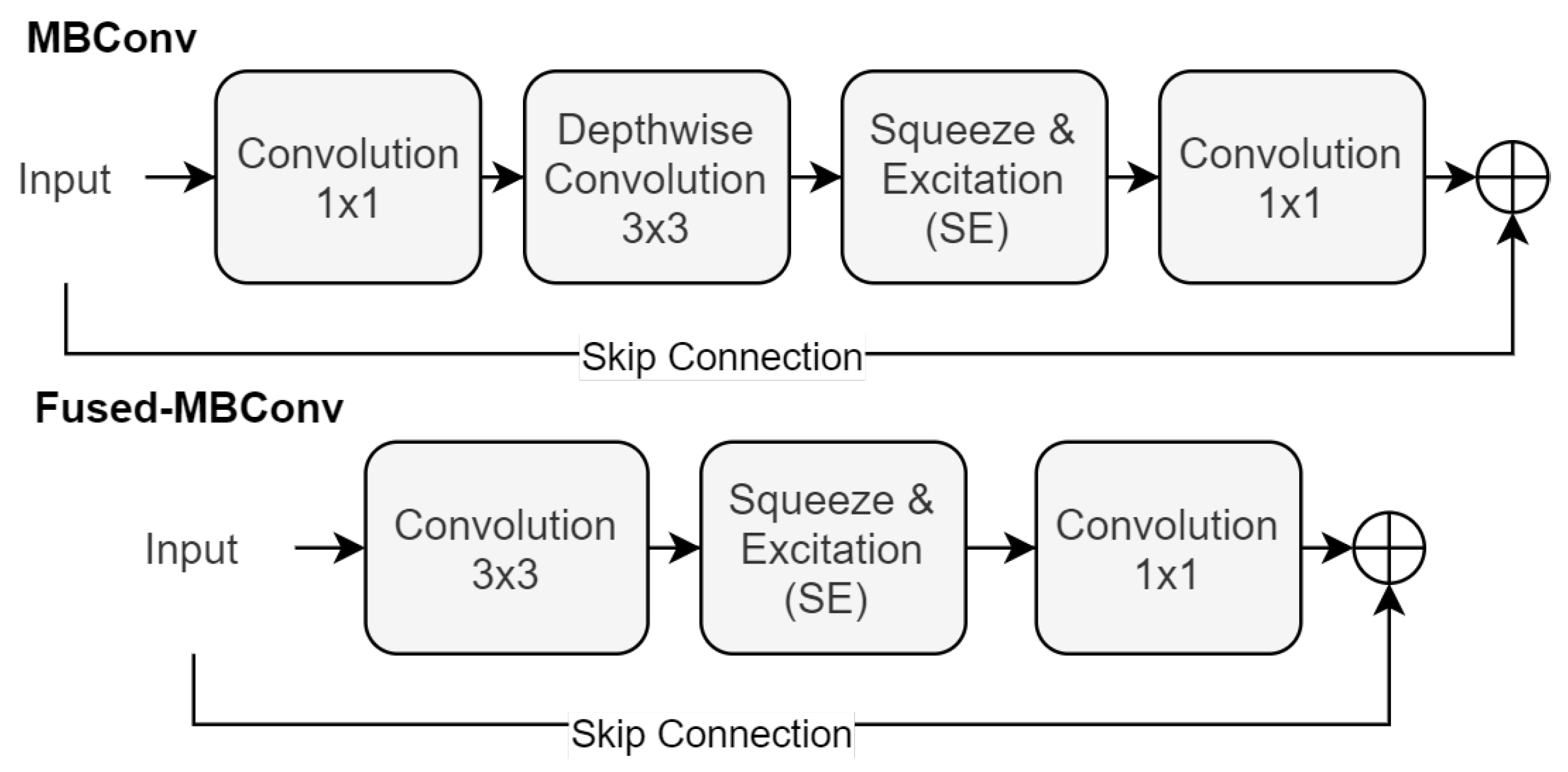
At the heart of EfficientNet’s design is the MBConv block, a series of transformations that are crucial for its effectiveness. This block sequences a
convolution, a depth-wise convolution, a Squeeze-and-Excitation (SE) operation [
53], and concludes with another
convolution, as shown in Equation (
4):
Here, and represent the convolutional filters, is the depth-wise convolutional filter, and denotes the Squeeze-and-Excitation operation. This arrangement of operations is pivotal in enhancing the network’s ability to focus on the most informative features of the input.
Building upon the foundations laid by EfficientNet, the EfficientNetV2 [
47] introduces an evolution in the form of the Fused-MBConv block. This new block design streamlines the architecture by combining the initial
and depth-wise convolutions into a single
convolution. This is then followed by an SE operation and a final
convolution, as detailed in Equation (
5):
In this configuration,
refers to the
convolutional filter that merges the initial
and depth-wise convolutions.
represents the final
convolutional filter. Each convolution in this sequence is followed by an activation function, and the architecture may include skip connections to facilitate effective training and convergence.
Figure 4 showcases both the MBConv and Fused-MBConv Block.
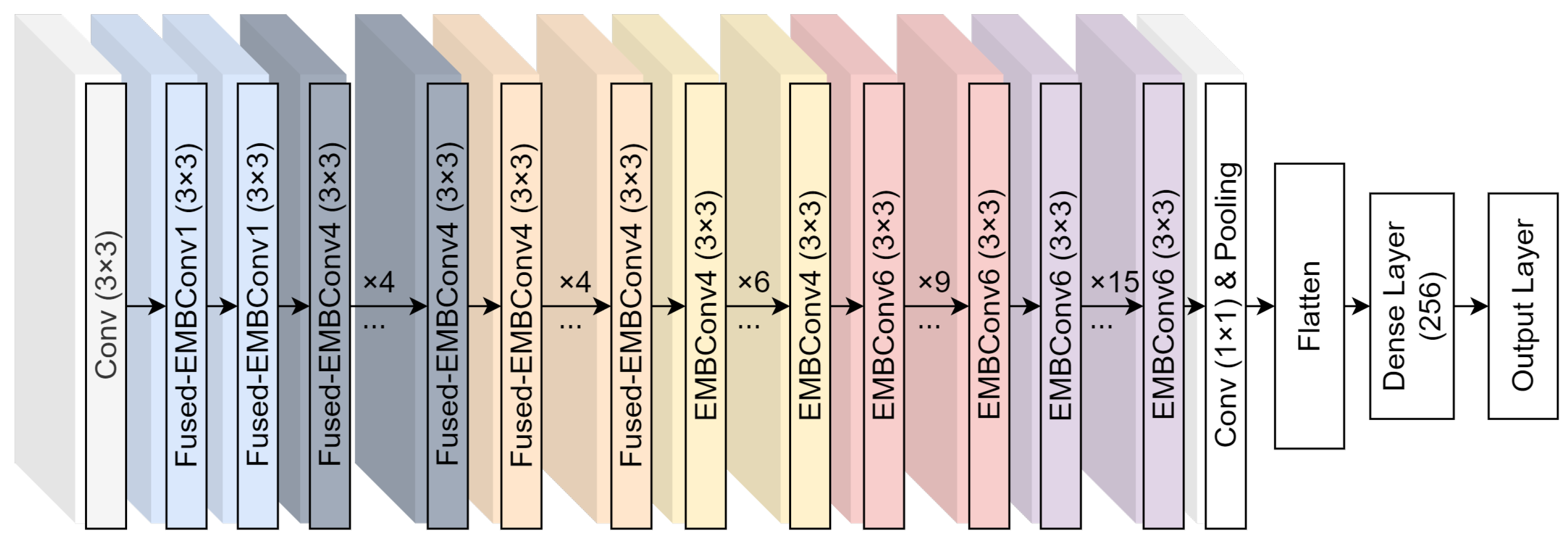
Figure 5 provides a visual representation of the base EfficientNetV2 model (B0) and the modifications we have implemented. These modifications are aimed at enhancing the network’s performance in specific applications, demonstrating the adaptability and scalability of the EfficientNet architecture.
Our study employed EfficientNetV2-M, enhancing it with flattening and 256-neuron dense layers. The training process was executed over 15 epochs using the Adam optimizer [
54], with the dataset divided into Training (75%), Validation (15%), and Testing (15%) sets (patient aware splits). The minimum validation loss determined early stopping. All CNN training and online affine augmentations were implemented with the open-source library Deep Fast Vision [
55]. All offline affine augmentations are consistently applied to each image, but the degree to which they are applied is randomized within the specified ranges of each technique. These augmentations are directly incorporated and executed using the Keras library [
56].
We chose the EfficientNetV2-M for our study due to its high performance on ImageNet [
57] and it’s maximal compatibility with our NVIDIA Tesla P100 GPU, which allowed us to fully leverage its computational capabilities. This choice was further supported by EfficientNet’s efficient training times and its advanced architecture enabled us to achieve competitive scores while efficiently utilizing our entire computational resources. The experiments were carried out on the computation servers at the University of Jyväskylä in Finland.
2.8. CNN Interpretability
While the complexity of neural networks increases their capabilities, it also complicates the interpretation of their predictions. Due to this complexity, these systems are often considered ‘black boxes’. However, the Grad-CAM [
48] algorithm, based on the CAM [
58] framework, helps reduce this ‘black box’ effect. At a high level, Grad-CAM is an algorithm that visualizes how a convolutional neural network makes its decisions. It creates what are known as “heat maps” or “activation maps” that highlight the areas in an input image that the model considers important for making its prediction. The Grad-CAM spatial activation map
can be calculated using the
activation function on the sum of neuron importance weights
multiplied by feature maps
as shown below:
In this equation, are the neuron importance weights of feature map k for class p, represents the partial derivative of the final layer prediction for class p () with respect to the last convolutional layer’s kth feature map . Z is the total pixels, and are the indexes for each element within feature map k. is the feature map k given by the last convolutional layer, spatially averaged. In our study, we extracted Grad-CAM activations from the layer immediately preceding the flattening operation.
2.9. Figures of Merit
In evaluating the results of our experiment, we employ several key figures of merit to quantify the performance.
Accuracy is the proportion of true results (both true positives and true negatives) among the total number of cases examined. It can be calculated using the following equation:
Precision (also called positive predictive value) is the fraction of relevant instances among the retrieved instances. It is calculated as follows:
Recall (also known as sensitivity, hit rate, or true positive rate) is the fraction of the total amount of relevant instances that were actually retrieved. The equation for recall is:
The F1 score is the harmonic mean of precision and recall. It aims to find the balance between precision and recall. The F1 score can be calculated as follows:
In these formulas, TP stands for True Positives, TN for True Negatives, FP for False Positives, and FN for False Negatives.
2.10. Confusion Matrix
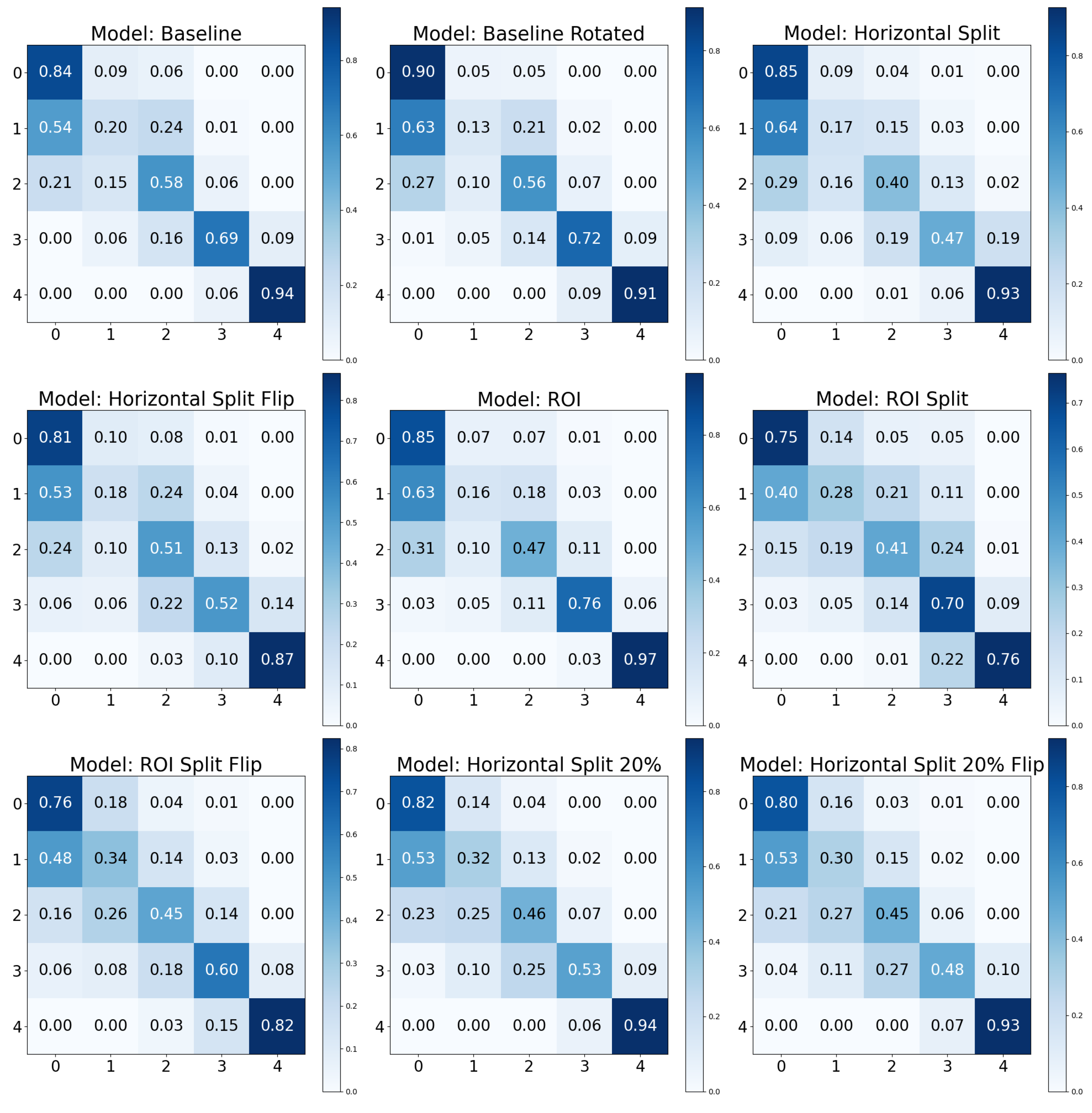
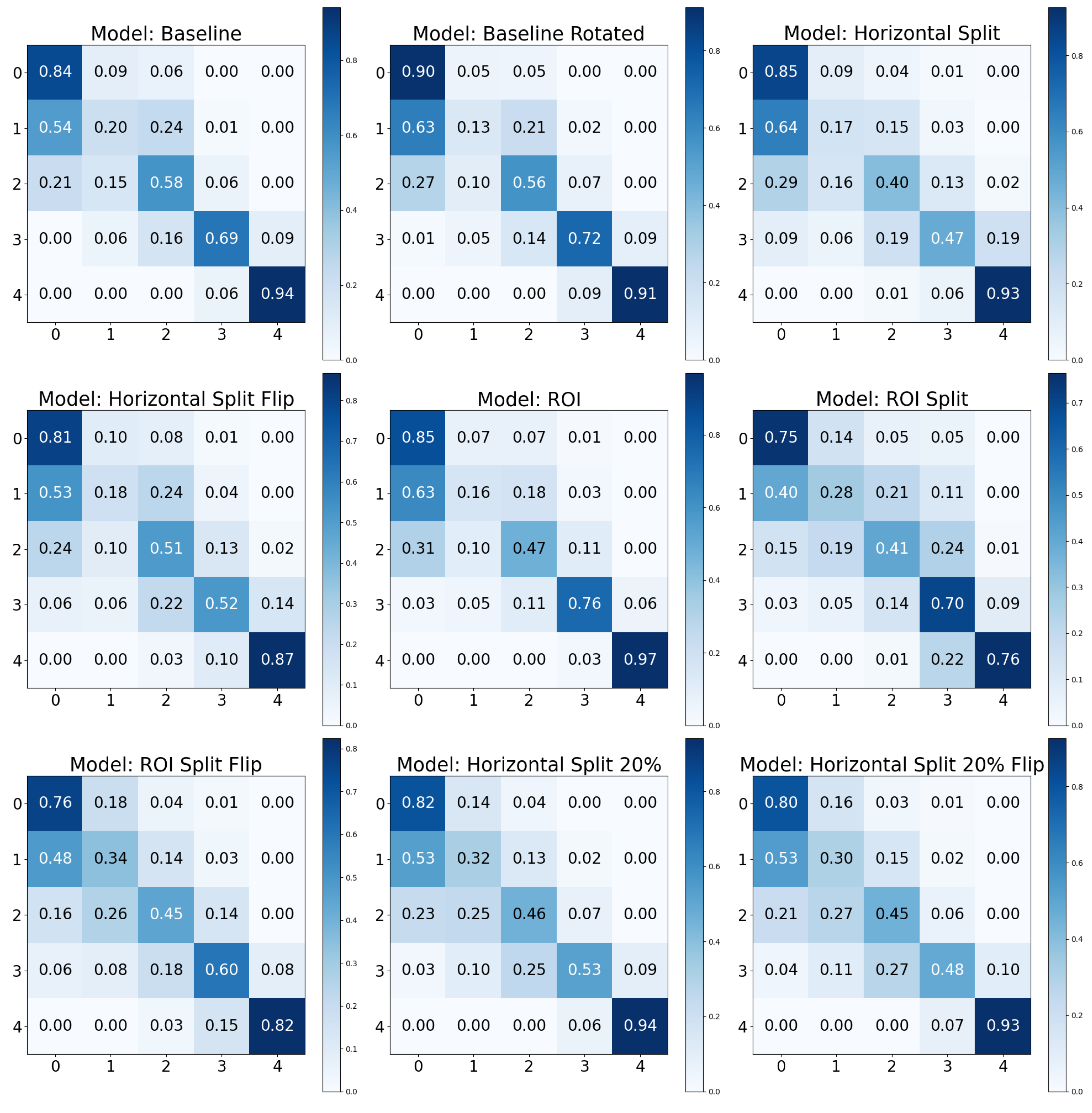
To further elucidate the model’s performance, especially in a multi-class setting, the confusion matrix is an essential tool. A confusion matrix is a tabular representation that allows for the visualization of a model’s performance. Each row of the matrix represents the instances in an actual class, while each column represents the instances in a predicted class. The diagonal cells represent the number of correct classifications for each class, while the off-diagonal cells indicate errors.
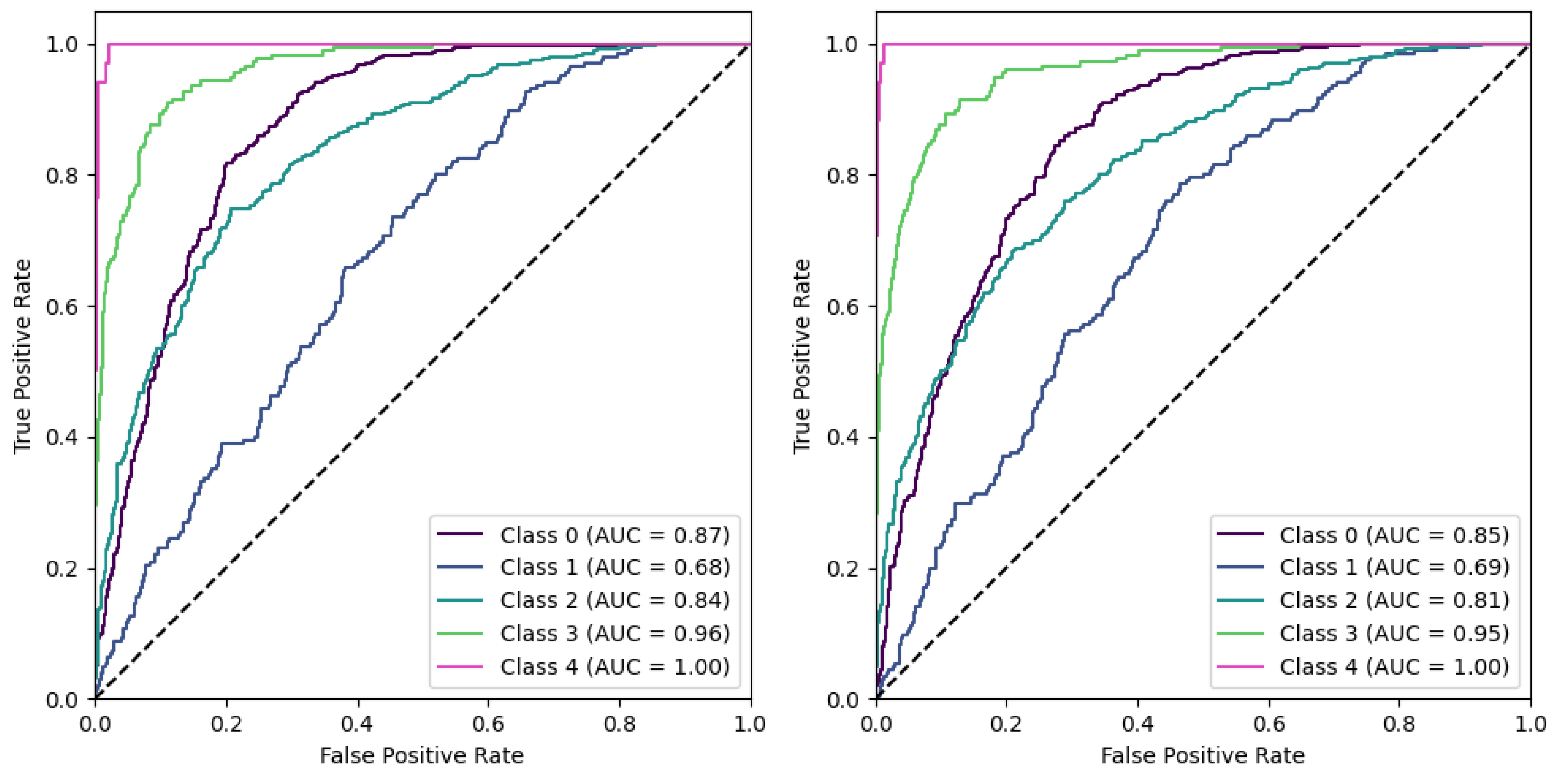
The confusion matrix not only provides a clear visual of the performance but also showcases the calculation of various performance metrics, including recall for each class (normalized matrix diagonal). This is particularly important in multi-class classification problems, where understanding the model’s performance for each class is critical. While accuracy gives a general overview of the model’s performance, recall provides essential insight into the model’s ability to correctly identify each class. This is crucial in scenarios where certain classes are more significant or have greater consequences associated with misclassification.
In our study, we normalized the confusion matrices for each class so that the sum of values in each row equals 1. This normalization ensures that the diagonal elements of the matrix represent the recall for each class. By adopting this approach, the matrix not only indicates how well the model classifies each category but also allows for a direct and clear comparison of class-specific performance. The row-wise normalization simplifies the understanding of the matrix, making it more intuitive to evaluate the recall, as the values directly reflect the proportion of correctly identified instances for each class.
4. Discussion
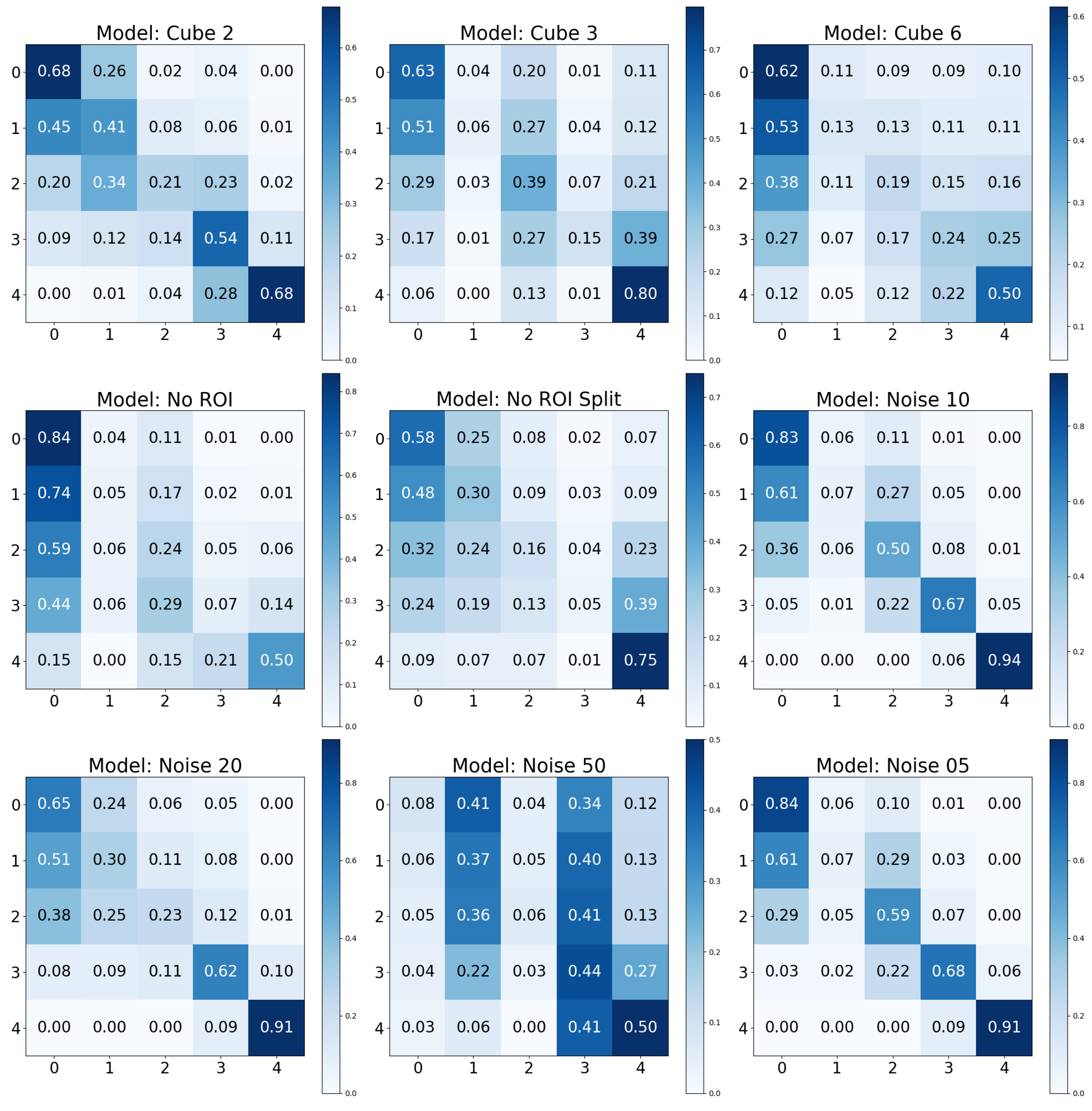
Our analysis has highlighted the marked effectiveness of certain positive data augmentations in improving model performance. Specifically, the ‘Baseline Rotated’ model showed the highest accuracy but second-best recall. Incorporating rotation into our baseline model could have increased its robustness to orientation changes in the images, contributing to its superior accuracy. Furthermore, the confusion matrix analysis demonstrated excellent recall for the KL0 and KL4 grades, a result that may be associated with the distinct radiographic features of these classes. Conversely, the ‘Horizontal Split’ model, which divided the image into two parts along the horizontal axis, performed the worst across all considered metrics. This could be because this approach might eliminate or distort crucial radiographic features, thereby reducing the model’s ability to classify the images accurately. Notably, the results contradicted our initial expectation that the ROI models would outperform the baseline models, given the assumption that focusing on specific regions containing more relevant information would increase performance. However, the results indicated that models utilizing the entire image data might have a slight edge in performance over those focusing on a particular ROI, suggesting that potentially important information outside the ROI might be missed, or that confounds are integrated, inflating the performance.
Furthermore, when evaluating performance, the recall metric offered an additional layer of insight. For instance, despite a slight drop in accuracy, the ‘Baseline’ model showed a higher recall than the ‘Baseline Rotated’ model, underscoring its capability to comprehensively identify relevant cases. This can be a critical consideration in fields like medical diagnostics, where certain classes might have greater consequences associated with misclassification. This observation revealed that when dealing with significantly skewed class distributions, utilizing the baseline modality may lead to more evenly distributed performance across the relevant classes.
While data augmentation techniques have been widely adopted in deep learning, studies specifically investigating their effects in the medical imaging domain remain sparse. Often, the choice of augmentation techniques relies heavily on informal recommendations or generic best practices that aren’t always tailored to the unique challenges and characteristics of medical images [
37]. This lack of systematic exploration can lead to suboptimal model performance or even introduce biases. In this context, the studies by Goceri [
37] and Hussain et al. [
38] stand out as notable exceptions that delve into the intricacies of various additive augmentation methods and their impact on model performance in medical imaging tasks.
The study by Goceri [
37], spanning different medical imaging domains such as lung CT, mammography, and brain MR images, observed distinct patterns in the effectiveness of additive augmentation. For lung CT images, translating and shearing produced the highest accuracy of 0.857, whereas mere translation yielded the lowest at 0.610. In mammography images, the combination of translation, shearing, and clockwise rotation was most effective, achieving an accuracy of 0.833, while adding ‘salt-and-pepper’ noise and shearing underperformed, achieving only 0.667. For brain MR images, the same combination of translation, shearing, and clockwise rotation outperformed other methods with an accuracy of 0.882, while adding ‘salt-and-pepper’ noise and shearing showed the lowest accuracy at 0.624. Another investigation by Hussain et al. [
38] explored different mammography additive augmentation techniques, producing varied results. Notably, the Shear augmentation achieved the highest training accuracy of 0.891 and a validation accuracy of 0.879. Conversely, Noise augmentation was the least effective, with training and validation accuracies of 0.625 and 0.660, respectively. Augmentations such as Gaussian Filter, Rotate, and Scale also demonstrated high accuracy in training and validation phases. Comparing our results, those of Goceri, and the findings from Hussain et al., it becomes evident that while some augmentation methods consistently show effectiveness across studies, their efficacy can vary based on domain specificity and dataset nuances. Our results, especially those pertaining to the ‘Baseline Rotated’ model, suggest that certain augmentations, such as rotation, might have unique advantages in the context of KOA.
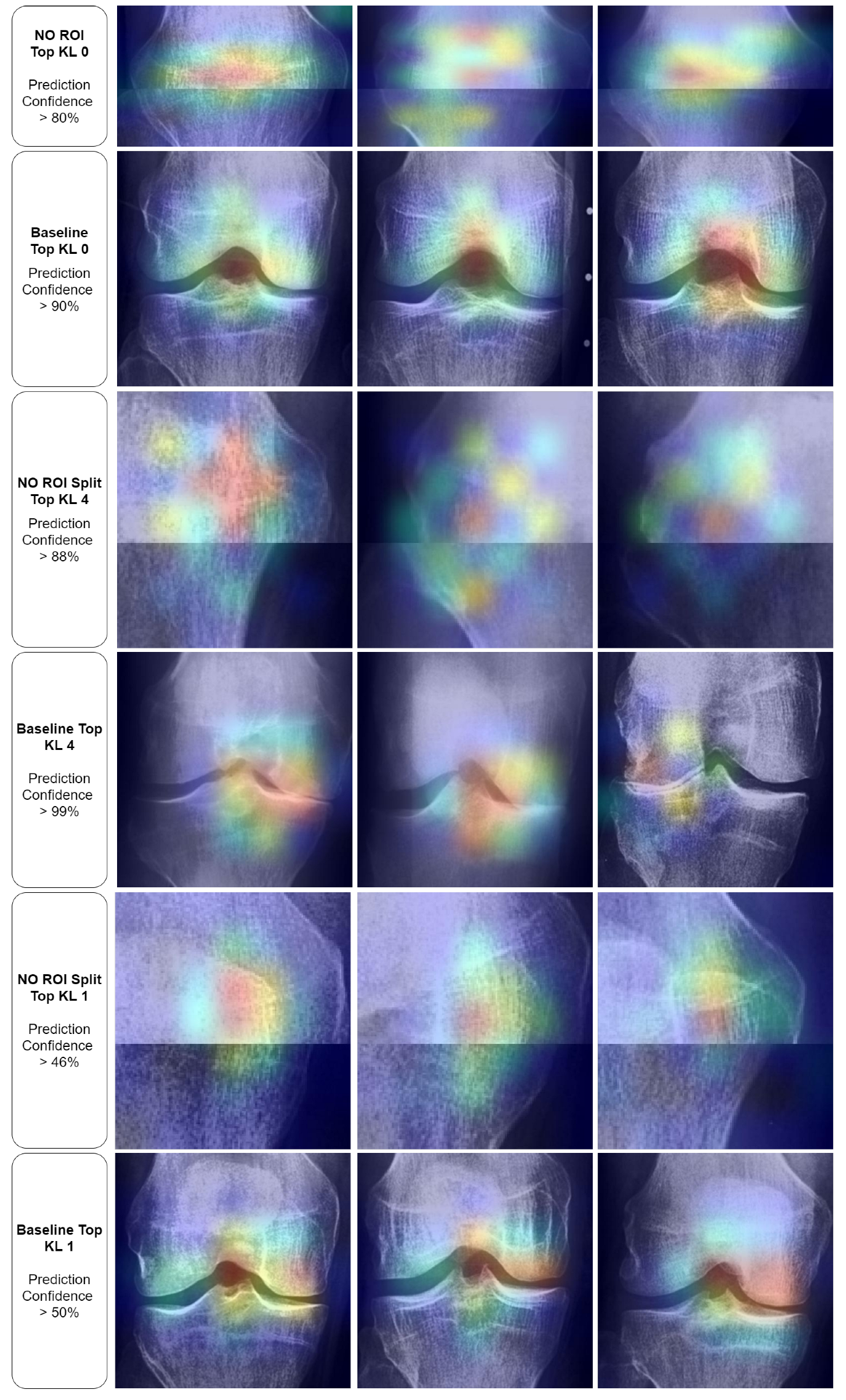
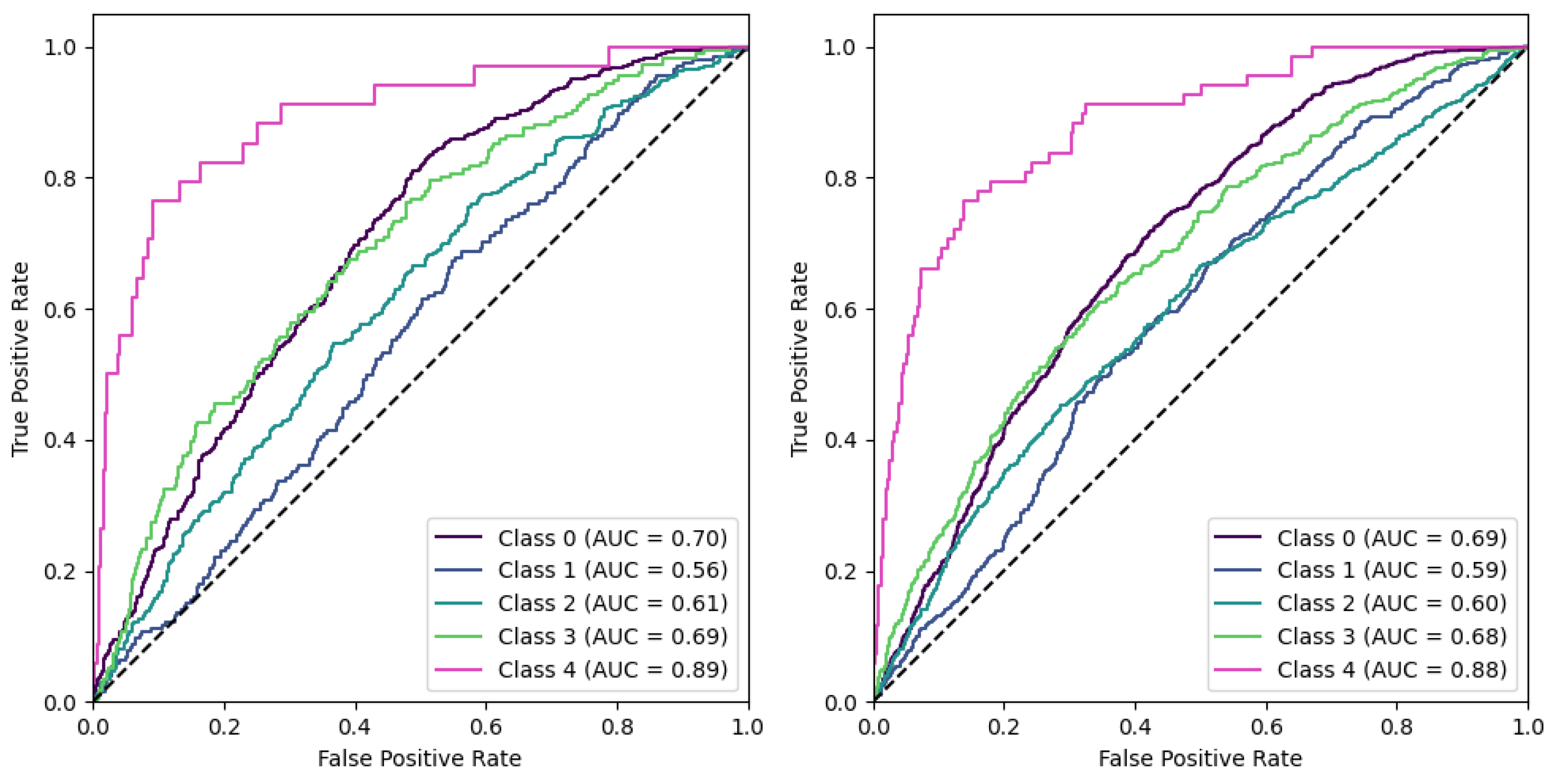
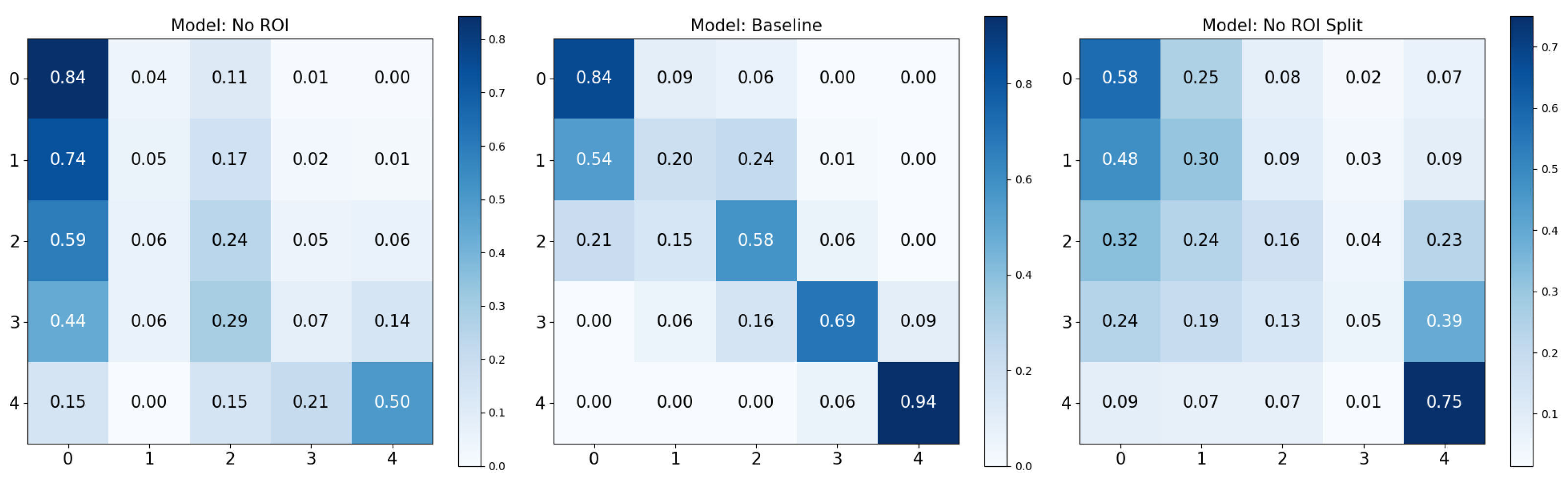
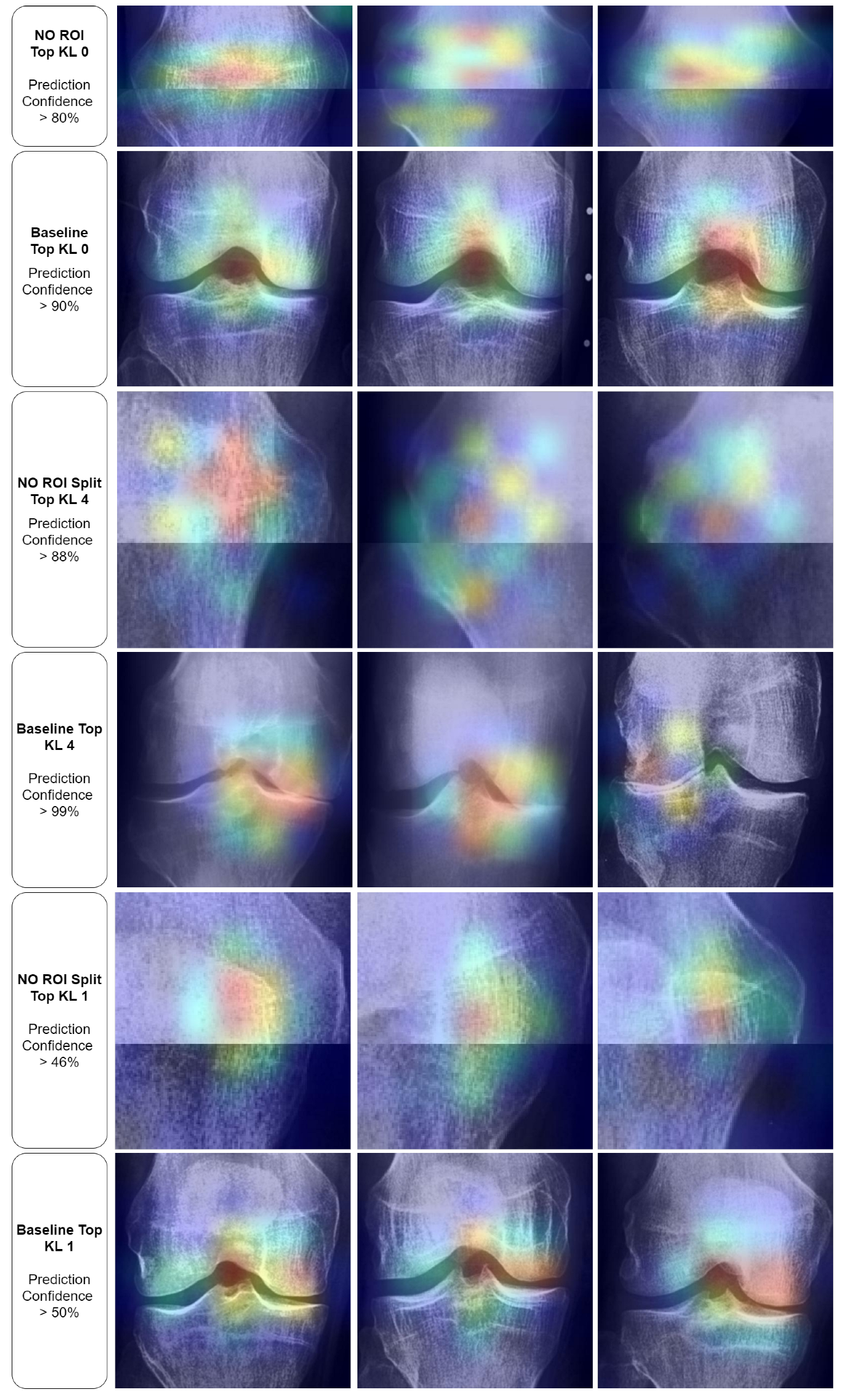
Adversarial (negative) augmentations, in the form of adversarial attacks, were explored in our study. It was observed that as the noise level increased, the models’ performance deteriorated, suggesting that the introduction of excessive noise could disrupt the discernment of relevant features within the images. Interestingly, the models lacking a Region of Interest (ROI) performed poorly overall. However, these models did exhibit exceptionally high performance for specific KL grades, such as KL0 and KL4, which may indicate the presence of confounding variables that the model leverages to make its predictions. The results for the “No ROI” and “No ROI Split” models were particularly intriguing. Despite the absence of a region of interest, the high-performance scores achieved by these models for specific KL grades suggest that they might be identifying other image features unrelated directly to knee joint osteoarthritis for classification decisions. In the case of KL0, the identical scores from the ‘Baseline’ and ‘No ROI’ models suggest either that the absence of an ROI may not affect KL0 classification or that true class confounds are visible. For KL4, the ‘No ROI Split’ model demonstrated performance remarkably similar to the ‘Baseline’ model, hinting at similar influences. The most notable result, however, was the clear performance boost for KL1 in the ‘No ROI Split’ model. This class is historically challenging to classify in Knee-Osteoarthritis studies, making this finding particularly interesting.
Regarding adversarial attacks and augmentation within the broad spectrum of medical domain literature, we identify three main categories. The first category encompasses studies focused on adversarial attacks with a specific objective [
41,
42,
43,
44] (e.g., to alter the prediction for a single instance or a set of instances towards a target or model behaviour). The second category involves adversarial augmentation without an explicit optimization pipeline (e.g., noise injection) dedicated to a clearly defined adversarial objective [
37]. This category primarily includes adversarial augmentations. It appears that the distinction lies in the experimental approach; adversarial augmentation studies are exploratory, seeking to detect issues through analysis, in contrast to the first category, where the aim is to induce a specific issue or effect. The third category includes research that examines specific known or hypothesized biases, such as hospital identification bias [
59], and thus the experimental design is constructed towards investigating the bias. To our knowledge, our method of cropping based adversarial augmentation, which unveiled potential confounds upon analysis, is novel. This is especially pertinent as adversarial augmentations in the medical field predominantly focused on noise injection. To the best of our knowledge, and throughout our review, we found no similar studies that identified potential confounds in medical images by eliminating regions of interest.
In our study, the primary goal was to evaluate base data augmentation within a naturalistic paradigm, where the use of affine augmentations is applied consistently across all datasets. This approach mirrors standard practices in neural network learning scenarios. By including affine augmentations in every set, we ensure a level playing field, allowing for an accurate comparison with the baseline set whose base data remained unmodified. This methodology is crucial because omitting affine augmentations from certain sets while only augmenting the base data could skew results. Affine approaches have consistently demonstrated effectiveness in enhancing model performance and mitigating overfitting. Therefore, to avoid giving an unfair advantage to these approaches, our study incorporates them uniformly across all datasets. This strategy ensures that our primary comparison point—the baseline set without base data modifications—remains a reliable standard for evaluating the effectiveness of base data augmentation within this naturalistic paradigm.
In the “No ROI” image, the upper portion of the patella is visible, along with the upper femur and the medial and lateral femoral condyles. The lower portions of the tibia and fibula are also evident. However, the entire medial and lateral tibial plateaus are missing. The Grad-CAM visualizations for these “No ROI” images show activations concentrated on peripheral regions of the knee joint, such as the edges of the femur and tibia that do not articulate directly. Consequently, the omission of the tibial plateaus means that the critical weight-bearing surfaces of the knee joint, essential for assessing osteoarthritis, are absent from the image. The joint space, crucial for evaluating the degree of cartilage loss and joint space narrowing, cannot be visualized either. The absence of the articulating surfaces largely prevents the assessment of osteophyte presence, subchondral bone sclerosis, and cyst formation, all key features used to grade the severity of osteoarthritis according to the Kellgren and Lawrence grading system.
Further insights from our Grad-CAM visualization analysis indicate potential confounding regions that might affect our models’ decision-making processes. Notably, in the absence of a designated region of interest (ROI) for KL0, the models tend to focus on the texture and contours of the patella. Interestingly, this pattern shifts with the baseline KL0 models, where the joint and its eminence are distinctly highlighted. However, the spread of activation that extends broadly across and above the knee joint suggests the model might be considering features beyond the knee joint for classification. In the No ROI Split KL4, the model appeared to be using general wear-and-tear texture indications for their classifications, which may not be directly related to disease progression but rather to the participant’s age. Finally, in the KL1 category, the models oscillate between specific and non-specific textures, further underscoring potential confounding regions.
Regarding Grad-CAM limitations, it is important to highlight that Grad-CAM has several limitations that can lead to misinterpretations. Firstly, it often highlights correlations rather than causations, meaning the regions it emphasizes may not be causally linked to the prediction. It is also limited to convolutional layers, providing no insight into how other types of layers contribute to the model’s decision. Grad-CAM can fail to localize multiple instances of the same class, and for single class examples, it may fail to localize the entire region of the class [
60]. Users might over-rely on these visual explanations for model validation, potentially overlooking other issues like biases in training data. Furthermore, Grad-CAM may also fall short in capturing complex, abstract reasoning that isn’t spatially localized. Its effectiveness is tied to model architectures, and different architectures may yield varying results, limiting generalizability. Additionally, if a model is overfitted, Grad-CAM might highlight non-generalizable, idiosyncratic features. Lastly, it often misses the global context of the image, focusing only on local features, which may not always convey the complete picture necessary for accurate interpretation. These limitations underscore the importance of using Grad-CAM cautiously and in conjunction with other validation methods to ensure a comprehensive understanding of model behavior.
Incorporating findings from Saporta et al. [
61], the application of saliency methods like Grad-CAM in medical imaging appears to demand scrutiny, particularly in their role in diagnostic decision-making. The authors conducted a comprehensive evaluation of seven saliency methods, including Grad-CAM, across diverse neural network architectures. A notable aspect of their study was the establishment of the first human benchmark for chest X-ray segmentation in a multilabel classification context. The study’s results indicated that while Grad-CAM was generally more effective than its counterparts in highlighting pathologies, all the evaluated saliency methods were more prone to fail in localizing important pathologies compared to human experts. This gap in performance was particularly evident in cases of pathologies that were smaller and had more complex shapes. Additionally, the research highlighted a positive correlation between the confidence level of the model and the accuracy of Grad-CAM in localizing pathologies. These findings emphasize the need for caution and further research before considering the integration of saliency methods like Grad-CAM into real-world clinical settings.
From our results, one high-performing set involved rotation, which may be partly attributed to the rotated orientation of the knee joint along the vertical axis of the radiograph image. In this configuration, the convolution operation repeatedly encounters relevant features as it slides across the image, potentially leading to more condensed and effective feature maps. This is in contrast to a non-rotated radiograph image, where the knee joint occupies only a single vertical segment of the image. In this latter case, the convolution would likely traverse the entire joint just once or twice, depending on the receptive field, making feature extraction potentially slightly less effective. However, we previously discussed how the ‘baseline’ configuration enhanced recall values, which is a significant factor, especially in scenarios where missing true positives is costly. By utilizing the baseline modality, we may achieve a more evenly distributed performance across the relevant classes, ensuring that the system is not only accurate but also consistently reliable in identifying true instances across different categories.
Integrating adversarial augmentations into the study of various diseases offers considerable advantages. For instance, selectively omitting regions of interest (ROIs)—whether through dynamic clustering algorithms or predetermined for specific diseases—might reveal potential confounds, especially if the model’s key performance indicators remain stable despite these alterations. Adding pixel noise is another strategic augmentation that serves two critical functions: it underscores potential disruptions in the classification process and uncovers specific sensitivities of the employed architecture to noise. This insight is particularly valuable; for example, if a solution demonstrates extreme sensitivity to noise, it could inform the decision to incorporate affine blurring transformations during the training phase to mitigate this issue. Such strategies not only bolster the robustness of the models but also deepen our understanding of disease detection and classification, thereby enhancing the precision and reliability of medical imaging analyses.
In assessing the underperformance of certain methods, particularly the horizontal split approach, it becomes apparent that this technique may inherently dilute the informativeness of the image data. In knee radiography, pathological changes are often more pronounced on one side of the knee joint. When the image is split horizontally, one half may carry less informative features but is still labeled similarly to the more informative half. This dilution of label information could be a significant factor contributing to the reduced efficacy of this method. The horizontal split essentially divides the image into two halves that may not equally contribute to the accurate classification of the knee joint’s condition, leading to a skewed or incomplete understanding of the disease’s manifestation.
Furthermore, the underperformance of the Region of Interest (ROI) model can be contrastively elucidated by examining why the ‘No ROI’ model performed exceptionally well for the extreme classes. It has been recognized that patient age correlates with the progression and stage of osteoarthritis (OA). Interestingly, neural networks might still infer age-related information even when the knee joint is absent from the image. Indicators such as faint signs of sclerosis and the general condition of the remaining knee radiograph may inadvertently provide age-related clues. This is particularly relevant in the later stages of OA, where osteophytes can be exceptionally large and located further from the knee joint. Consequently, we suspect that age may be a confounding variable that the models are inadvertently leveraging. Such a hypothesis warrants further investigation that would help to explain both the ‘ROI’ underperformance and the ‘No ROI’ overperformance at the extremes.
To further investigate this hypothesis, future studies should consider directly targeting age as a classification (or regression) variable. Utilizing the ROI, Baseline, and Non-ROI model sets in this context could provide valuable insights into the extent to which age can be predicted from knee radiographs. Such an approach would not only help in understanding the potential confounding influence of age on OA automatic grading but also contribute to the broader discourse on the interpretability and reliability of neural network decisions in KOA medical imaging. This exploration into the intersection of age, disease markers, and AI model performance might be crucial for refining automatic tools and ensuring that they are as accurate and unbiased as possible. This setup, focusing on the relationship between age and OA manifestations in knee radiography and its impact on AI models, warrants further investigation and could potentially lead to more nuanced and accurate classification methods in the future. In this endeavor, we also consider the participation of medical experts mandatory for validation purposes, and broader discussions on the clinical implications of the outcomes.
Our findings regarding pixel noise underscore an essential consideration in raw radiograph data, which may contain parts of suboptimal quality with substantial pixel noise. These observations align with similar findings reported in other studies [
37,
38].The classifier sensitivity to noise was particularly acute in the no-OA to early grade classes (KL0-1), where even a minimal noise level of
, led to a decline in early grade performance. This decline in early grade performance might be explained by the point that noise may falsely trigger or mask faint osteophyte features or other similar features in the images which are characteristic of early stages OA, leading to misinterpretations by the deep learning model during training. Moreover, a critical issue in digitized X-rays is the severe aliasing problems that may occur. Aliasing can introduce what is known as aliasing-associated noise. Such noise may interfere by creating misleading artifacts. Overall noise artifacts raise questions about the inclusion of low-quality radiographs in classification systems. They also underscore the necessity for research aimed at establishing guidelines for acceptable levels of noise, including aliasing-associated noise. One possible intervention could involve incorporating blur effects in the image augmentation process. However, it’s important to note that the effectiveness of this method specifically addresses pixel noise, and its impact on aliasing issues remains unclear. On the other hand, the effect of aliasing and methods to mitigate it on the performance of these systems is an area that is not yet well understood and requires further investigation. We could consider that severe noise artifacts and aliasing might even interfere with medical expert analysis, as well as artificial neural networks. In pursuing this endeavor, we deem the involvement of medical professionals essential for validation purposes and for engaging in more extensive discussions about the clinical implications.
Further studies are needed to confirm the presence, and by extension the extent of confounding factors in non-adversarial images. If such factors might exist in non-adversarial contexts this is of particular concern. This could lead in systems augmented with non-adversarial images, where models could misinterpret non-disease related features, potentially leading to overdiagnosis or misdiagnosis if used as computer-assisted diagnostic aids. Clinicians must understand the reasoning behind a model’s decision to trust and use it effectively. Models that focus on non-specific features could result in decisions that are counterintuitive or misaligned with clinical knowledge. Therefore, models should undergo rigorous validation and evaluation before deployment. This process should involve not only statistical metrics but also feedback from medical professionals, ensuring that the model’s decision-making process aligns with clinical expertise.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}