1. Introduction
The continuous development of mathematical knowledge, together with a constantly renewed and growing need to study, represent and analyze ever more complex physical phenomena and systems, are at the origin of new mathematical objects and models. In particular, the notion of matrices introduced by Gauss in 1810 to solve systems of linear algebraic equations, with the foundations of matrix computation developed during the 19th century by Sylvester (1814–1897) and Cayley (1821–1895), among several other mathematicians, has later given rise to the notion of tensors. Tensors of order higher than two, i.e., mathematical objects indexed by more than two indices, are multidimensional generalizations of vectors and matrices which are tensors of orders one and two, respectively. Such objects are well suited to represent and process multidimensional and multimodal signals and data, like in computer vision [
1], pattern recognition [
2], array processing [
3], machine learning [
4], recommender systems [
5], ECG applications [
6], bioinformatics [
7], and wireless communications [
8], among many other fields of application. Today, with ever constantly growing big data (texts, images, audio, and videos) to manage in multimedia applications and social networks, tensor tools are well adapted to fuse, classify, analyze and process digital information [
9].
The purpose of this paper is to present an overview of tensor-based methods for modeling and identifying nonlinear and multilinear systems using input–output data, as encountered in signal processing applications, with a focus on truncated Volterra models and block-oriented nonlinear ones and an introduction to memoryless input–output tensor systems. With a detailed reminder of the tensor tools useful to make the presentation as self-contained as possible and a review of main nonlinear models and their applications, this paper should be of interest to researchers and engineers concerned with signal processing applications.
First of all, developed as computational and representation tools in physics and geometry, tensors were the subject of mathematical developments related to polyadic decomposition [
10], aiming to generalize dyadic decompositions, i.e., matrix decompositions such as the singular value decomposition (SVD), discovered independently by Beltrami (1835–1900) and Jordan (1838–1922) in 1873 and 1874, respectively. Then, tensors were used for the analysis of three-dimensional data generalizing matrix analysis to sets of matrices, seen as arrays of data characterized by three indices, in the fields of psychometrics and chemometrics [
11,
12,
13,
14]. This explains the other name given to tensors as multiway arrays in the context of data analysis and data mining [
15].
Matrix decompositions, such as the SVD, have thus been generalized into tensor decompositions, such as the PARAFAC decomposition [
13], also called canonical polyadic decomposition (CPD), and the Tucker decomposition (TD) [
12]. Tensor decompositions consist in representing a high-order tensor by means of factor matrices and lower-order tensors, called core tensors. In the context of data analysis, such decompositions make it possible to highlight hidden structures of the data while preserving their multilinear structure, which is not the case when stacking the data in the form of vectors or matrices. Tensor decompositions can be used to reduce data dimensionality [
16], merge coupled data tensors [
17], handle missing data through the application of tensor completion methods [
18,
19], and design semi-blind receivers for tensor-based wireless communication systems [
8].
In
Table 1, we present basic and very useful matrix and third-order tensor decompositions, namely the reduced SVD, also known as the compact SVD, PARAFAC/CPD and TD, in a comparative way. A detailed presentation of PARAFAC and Tucker decompositions is given in
Section 4.2. Note that the matrix factors
and
which are column-orthonormal, contain the left and right singular vectors, respectively, whereas the diagonal matrix
contains the nonzero singular values, and
R denotes the rank of the matrix.
A historical review of the theory of matrices and tensors, with basic decompositions and applications, can be found in [
20].
Similarly, from the system modeling point of view, linear models of dynamic systems in the form of input–output relationships or state space equations have given rise to nonlinear and multilinear models to take into account nonlinearities inherent in physical systems. This explains why nonlinear models are appropriate in many engineering applications. Consequently, standard parameter estimation and filtering methods for linear systems, such as the least-squares (LS) algorithm and the Kalman filter (KF), first proposed by Legendre in 1805 [
21] and Kalman in 1960 [
22], respectively, were extended for parameter and state estimation of nonlinear systems. Thus, the alternating least-squares (ALS) algorithm [
13] and the extended Kalman filter (EKF) [
23] were developed, respectively, for estimating the parameters of a PARAFAC decomposition and applying the KF to nonlinear systems.
In
Table 2, we present two examples of standard linear models, namely the single-input single-output (SISO) finite impulse response (FIR) model and the memoryless multi-input multi-output (MIMO) model, often used for modeling a communication channel between
transmit antennas and
receive antennas, where
is the fading coefficient between the
jth transmit antenna and the
ith receiver antenna. The FIR model is one of the most used for modeling linear time-invariant (LTI) systems, i.e., systems which satisfy the constraints of linearity and time-invariance, which means that the system output
can be obtained from the input via a convolution
, where
is the system’s impulse response (IR), and ★ denotes the convolution operator.
The notion of linear dynamical system has been generalized to multilinear dynamical systems in [
24] to model tensor time series data, i.e., time series in which input and output data are tensors. In this paper, the multilinear operator is chosen in the form of a Kronecker product of matrices, and the parameters are estimated by means of an expectation-maximization algorithm, with application to various real datasets. Then, the notion of LTI system has been extended to multilinear LTI (MLTI) systems by [
25] using the Einstein product of even-order paired tensors, with an extension of the classical stability, reachability, and observability criteria to the case of MLTI systems. In
Table 2, four examples of nonlinear (NL) and multilinear (ML) models are introduced, namely the polynomial, truncated Volterra, tensor-input tensor-output (TITO), and multilinear tensor-input single-output (TISO) models, which will be studied in more detail in
Section 5 and
Section 6, as mentioned in
Table 2.
System modeling and identification is a fundamental problem in engineering applications. Real-life systems being often nonlinear in nature, NL models are very useful for various application areas. Parameter estimation using measurements of input and output (I/O) signals is at the heart of identification methods. In this paper, two main families of NL models are considered: (i) discrete-time Volterra models, also called truncated Volterra series expansions; (ii) block-oriented (Wiener, Hammerstein, Wiener–Hammerstein) models. In the sequel, we assume that the systems to be modeled are time invariant, i.e., their properties and consequently the parameters of their model do not depend on time.
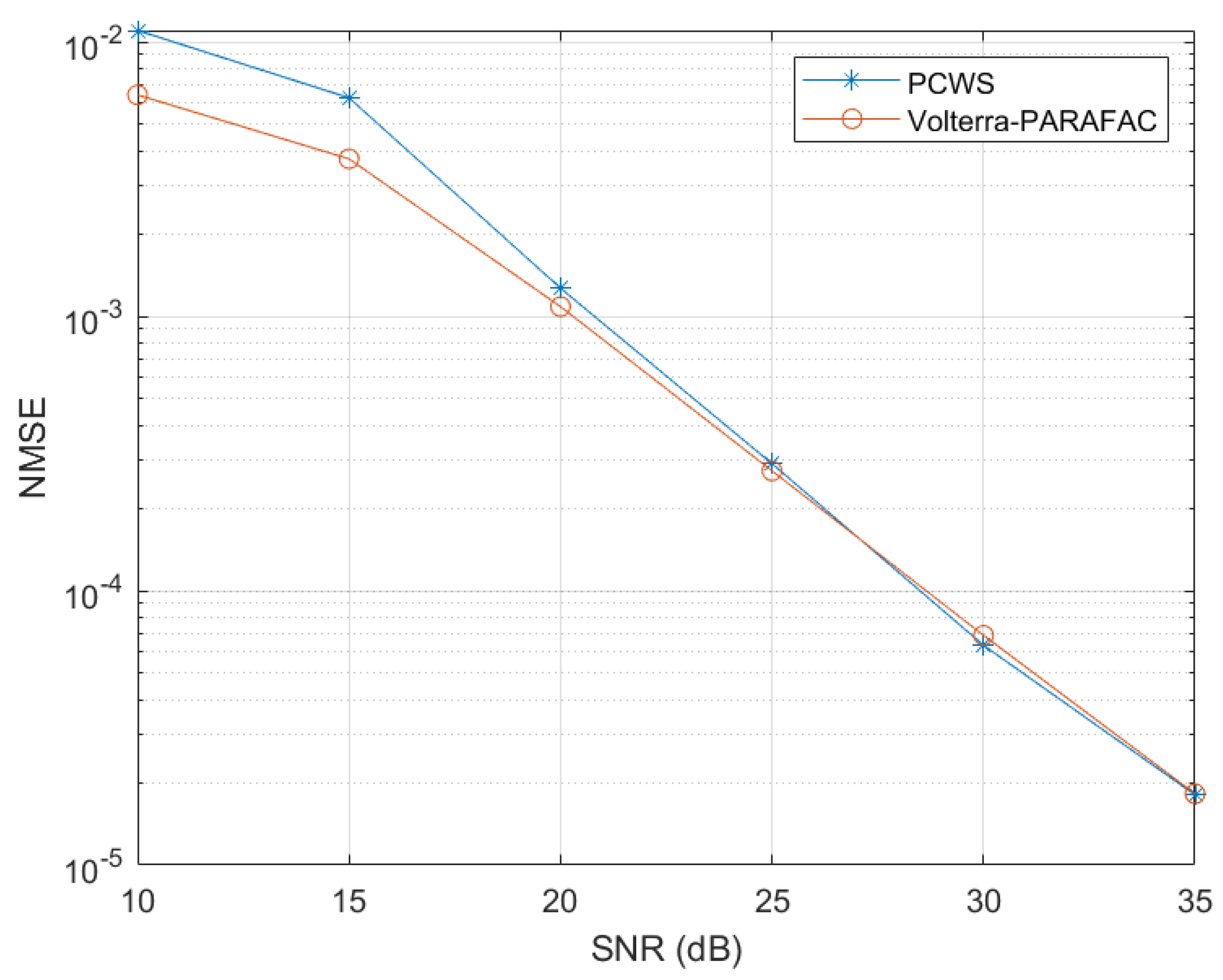
Volterra models are frequently used due to the fact that they allow approximating any fading memory nonlinear systems with an arbitrary precision, as shown in [
26]. They represent a direct nonlinear extension of the very popular FIR linear model, with guaranteed stability in the bounded-input bounded-output (BIBO) sense, and they have the advantage to be linear in their parameters, the kernel coefficients [
27]. The nonlinearity of a
Pth-order truncated Volterra model is due to products of up to
P samples of delayed inputs. Moreover, they are interpretable in terms of multidimensional convolutions which makes the derivation of their z-transform and Fourier transform representations easy[
28].
Among the numerous application areas of Volterra models, we can mention chemical and biochemical processes [
29], radio-over-fiber (RoF) wireless communication systems (due to optical/electrical (O/E) conversion) [
30,
31], high-power amplifiers (HPA) in satellite communications [
32,
33], physiological systems [
34], vibrating structures and more generally mechatronic systems like robots [
35], and acoustic echo cancellation [
36].
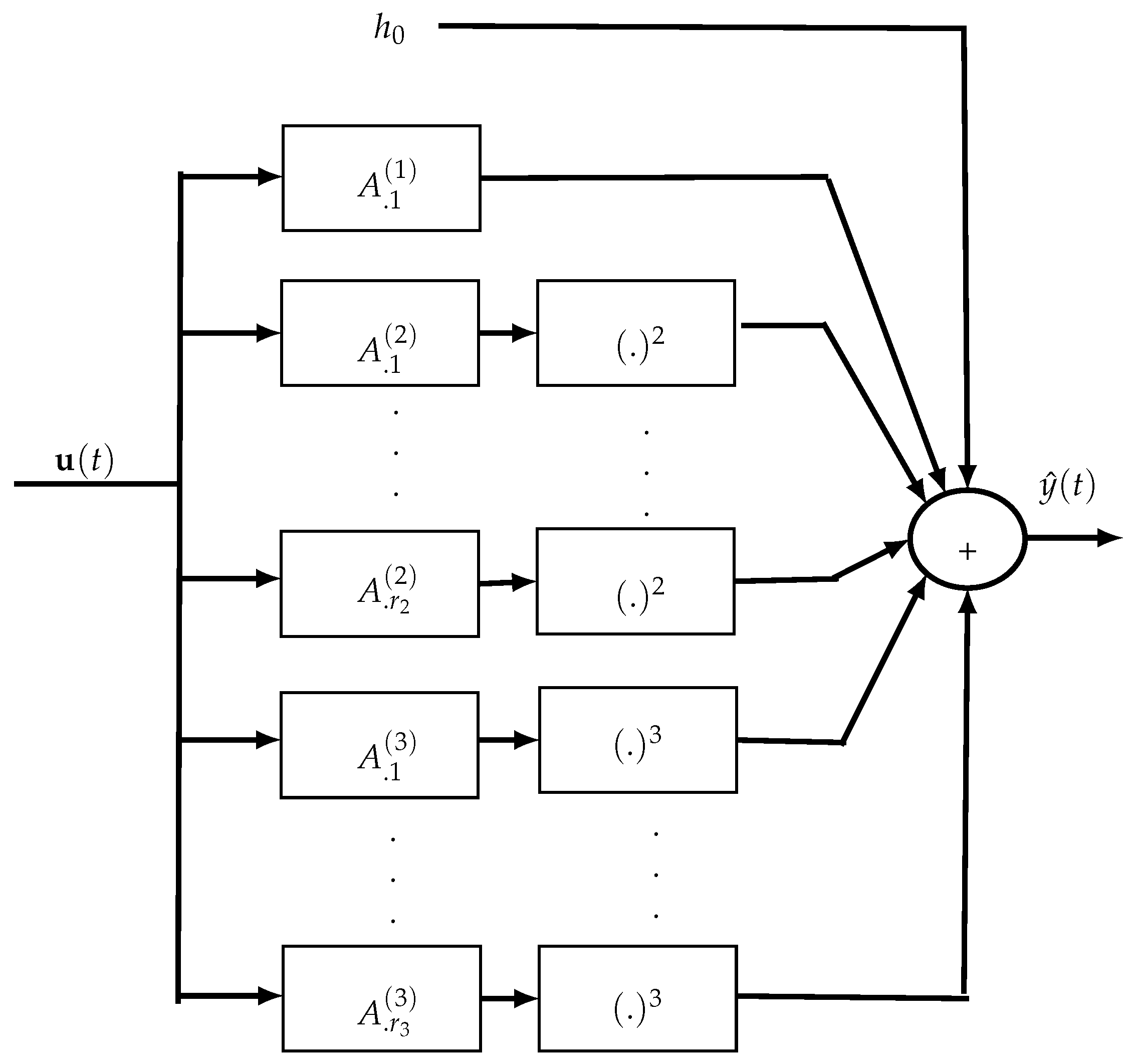
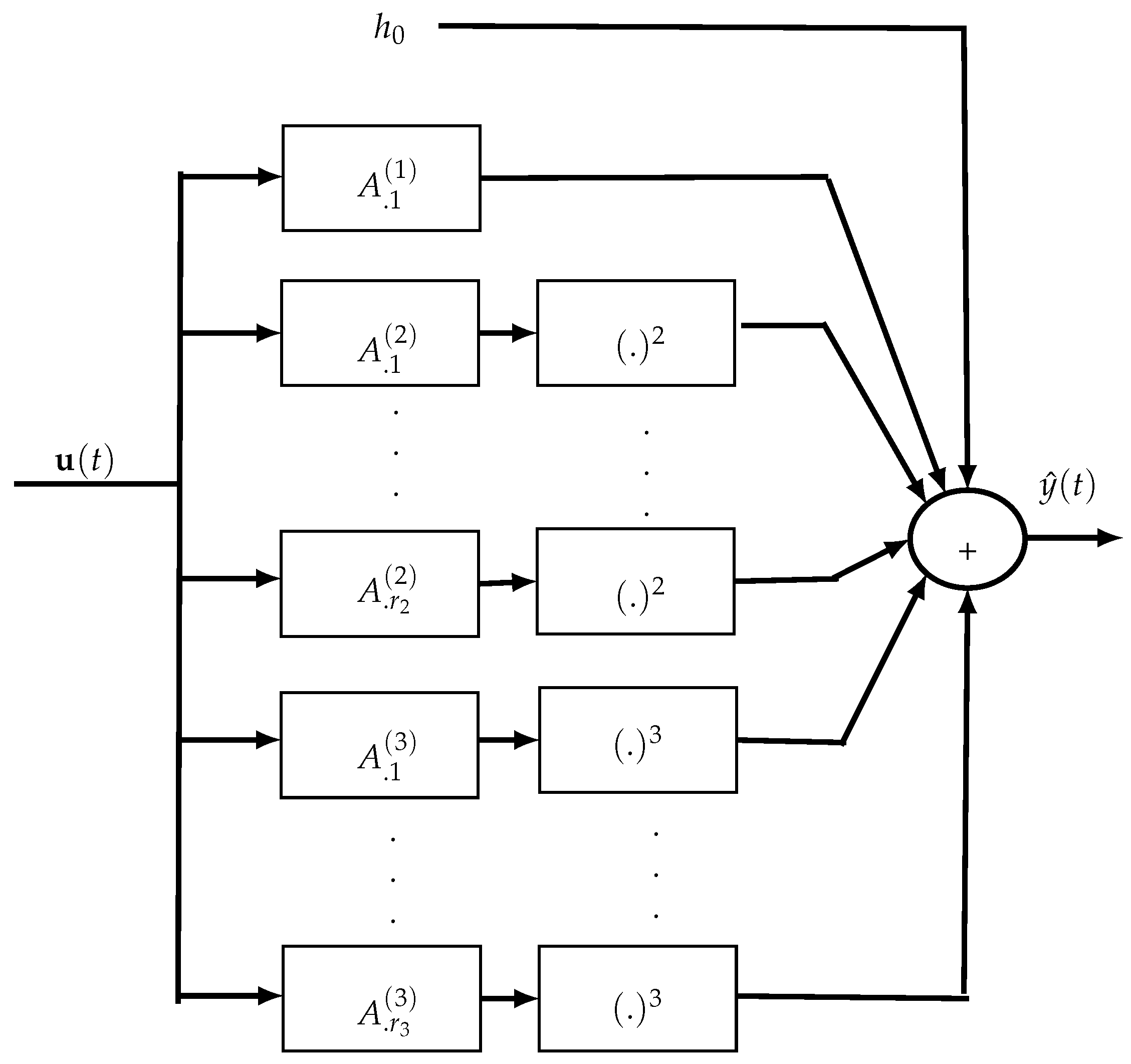
The main drawback of Volterra models is their parametric complexity implying the need to estimate a huge number of parameters which exponentially grows with the order and memory of the kernels. So, several complexity reduction approaches for Volterra models have been developed using symmetrization or triangularization of Volterra kernels, or their expansion on orthogonal bases like Laguerre and Kautz ones, or generalized orthogonal bases (GOB). Considering Volterra kernels as tensors, they can also be decomposed using a PARAFAC decomposition or a tensor train (TT). These approaches lead to the so-called Volterra–Laguerre, Volterra–GOB–Tucker, Volterra–PARAFAC and Volterra–TT models [
37,
38,
39,
40,
41,
42]. In
Section 5.3 and
Section 5.4, we review the Volterra–PARAFAC and Volterra–GOB–Tucker models. Note that a model-pruning approach can also be employed to adjust the complexity reduction in considering only nearly diagonal coefficients of the kernels and removing the other ones which correspond to more delayed input values whose influence decreases when the delay increases [
43].
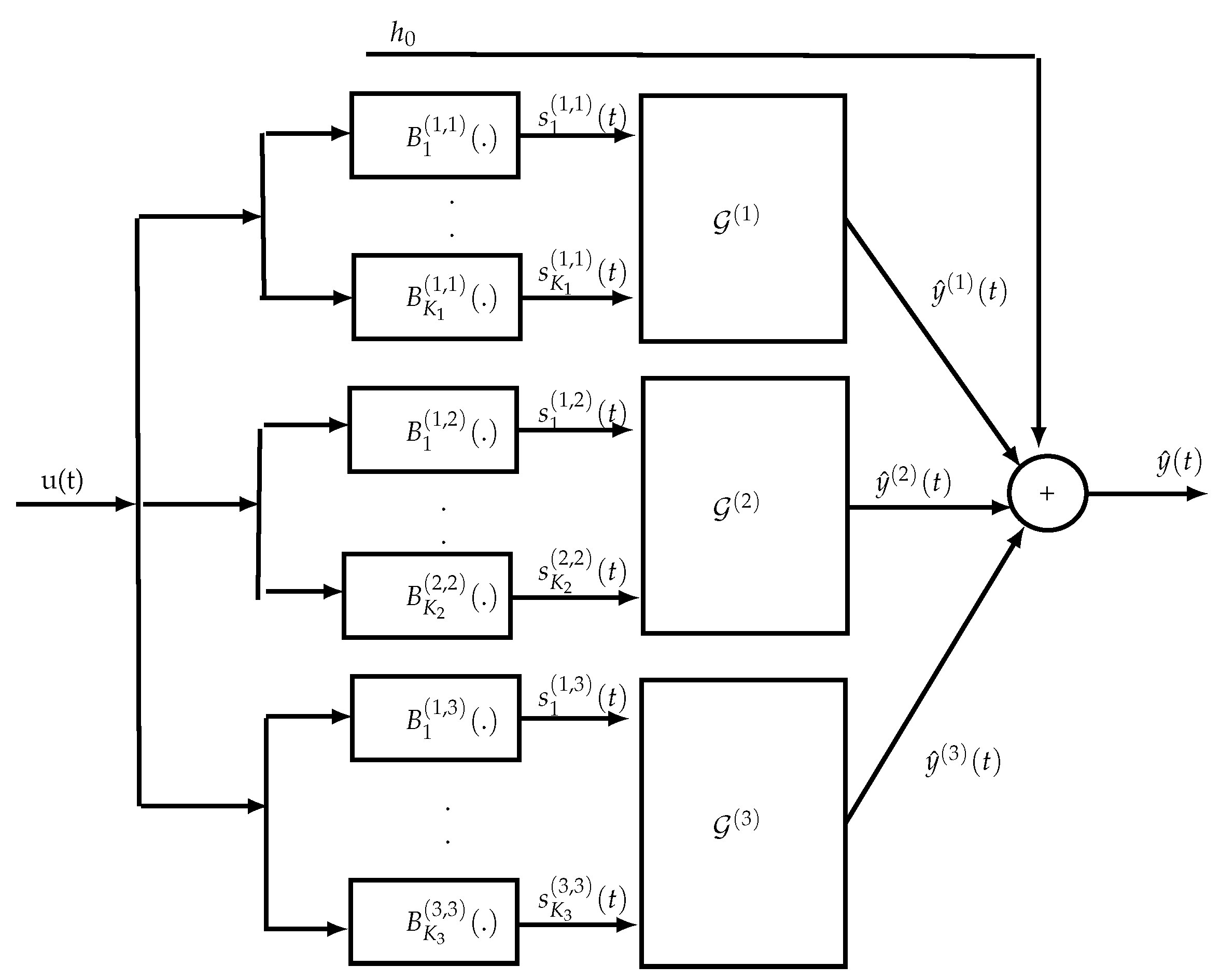
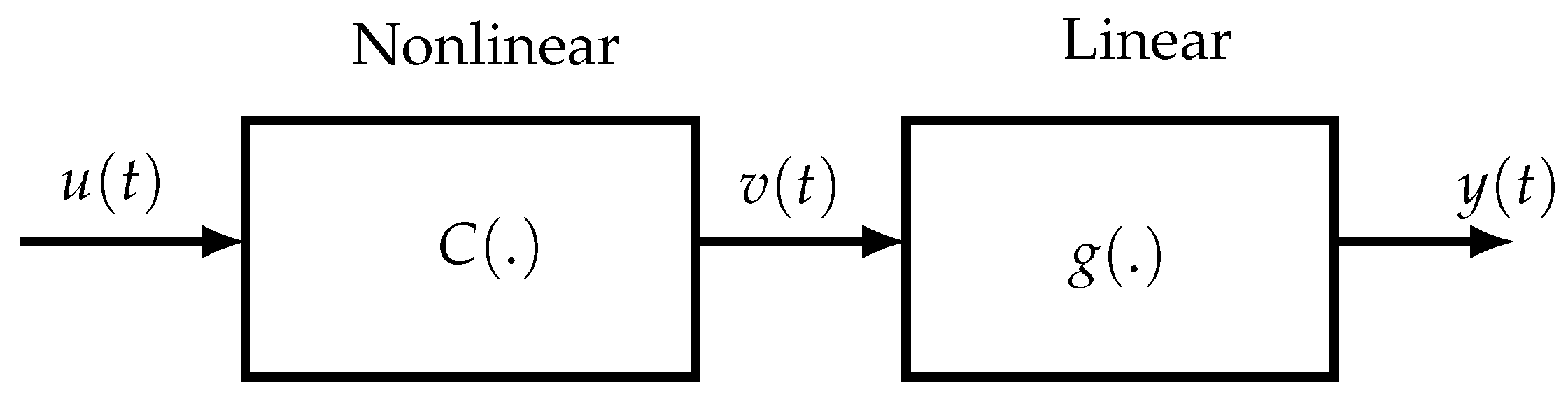
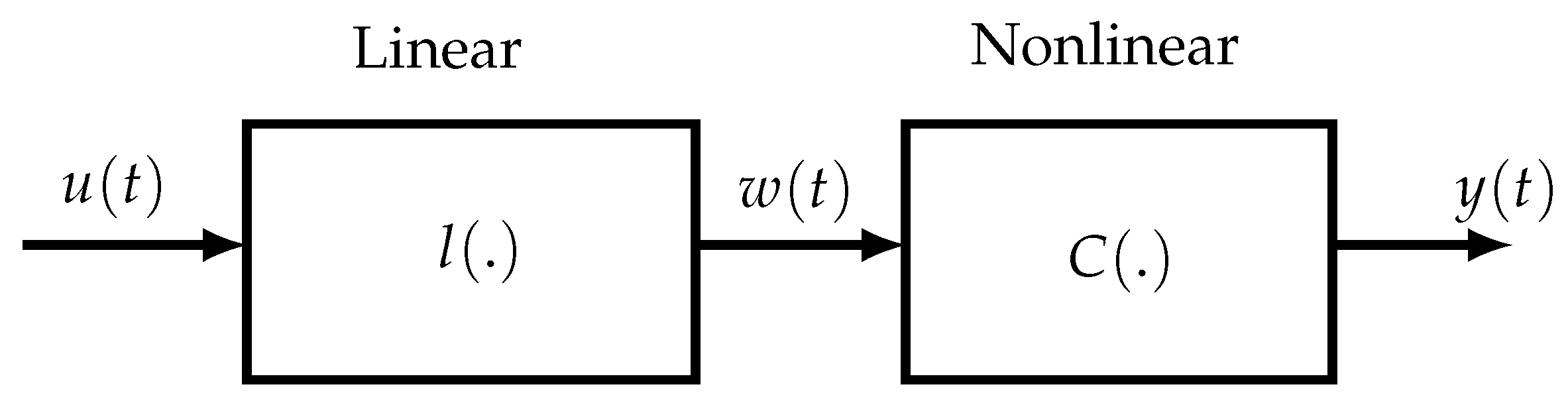
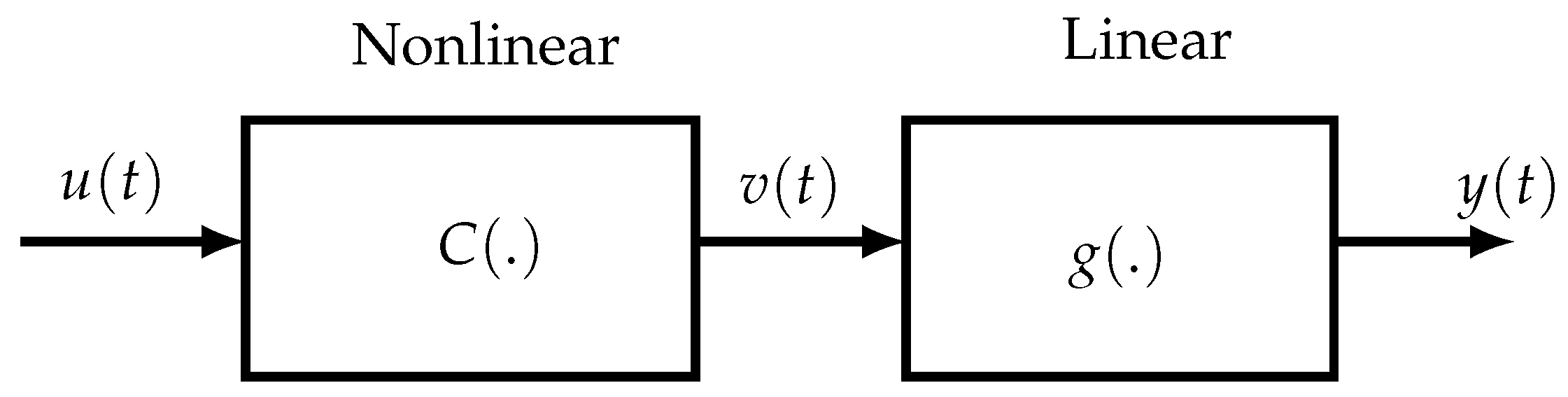
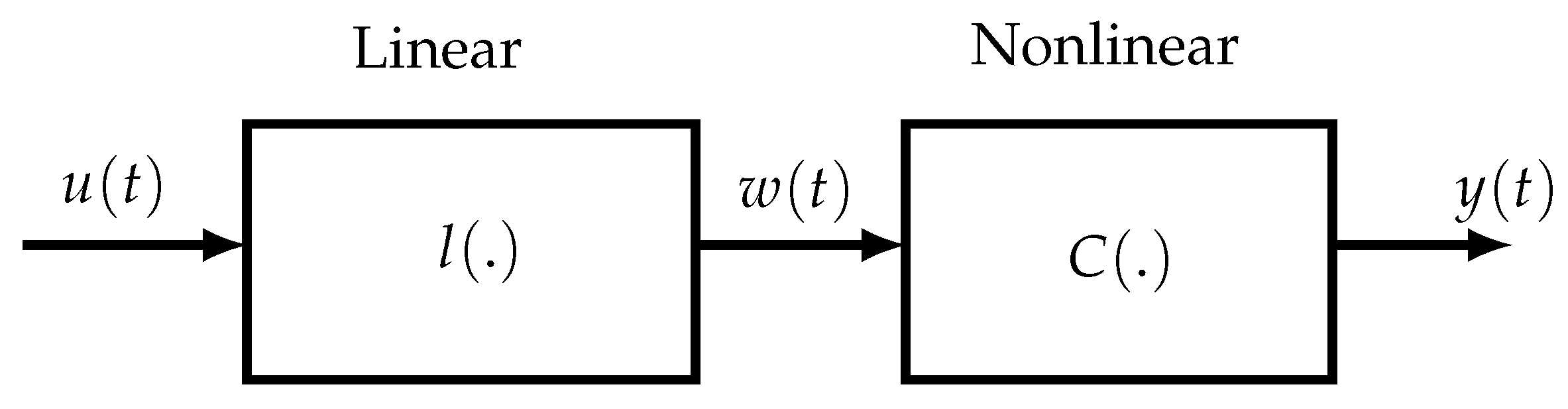
Another approach for ensuring a reduced parametric complexity consists in considering block-oriented NL models, composed of two types of blocks: linear time-invariant (LTI) dynamic blocks and static NL blocks. The linear blocks may be parametric (transfer functions, FIR models, state-space representations) or nonparametric (impulse responses), whereas the NL blocks may be with memory or memoryless. The different blocks are concatenated in series leading to the so-called Hammerstein (NL-LTI) and Wiener (LTI-NL) models, extended to the Wiener–Hammerstein (LTI-NL-LTI) and Hammerstein–Wiener (NL-LTI-NL) models, abbreviated W-H and H-W, respectively. To extend the modeling potential of block-oriented models, several W-H and H-W models can also be interconnected in parallel. Although such models are simpler but less general than Volterra models, they allow us to represent numerous nonlinear systems. One of the first applications of block-oriented NL models was for modeling biological systems [
44]. A lot of papers have been devoted to the identification of block-oriented models and their applications. For more details, the reader is referred to the book [
45] and the survey papers [
46,
47].
In
Section 5.5, we show that the Wiener, Hammerstein and W-H models are equivalent to structured Volterra models. This equivalence is at the origin of the structure identification method for block-oriented systems, which will be presented in
Section 5.5.4. Tensor-based methods using this equivalence have been developed to estimate the parameters of block-oriented nonlinear systems [
48,
49,
50,
51]. These methods are generally composed of two steps. In the first one, the Volterra kernel associated with a particular block-oriented system is used to estimate the LTI component(s). Note that there exist closed-form solutions for estimating only the Volterra kernel of interest. Such a solution is proposed in [
52,
53] for a third-order and fifth-order kernel, respectively. Then, in a second step, the nonlinear block is estimated using the LS method. An example of a tensor-based method for identifying a nonlinear communication channel represented by means of a W-H model was proposed in [
54] using the associated third-order Volterra kernel.
On the other hand, multilinear models are useful for modeling coupled dynamical systems in engineering, biology, and physics. Tensor-based approaches have been proposed for solving and identifying multilinear systems [
24,
55,
56]. Using the Einstein product of tensors, we first introduce a new class of systems, the so-called memoryless tensor-input tensor-output (TITO) systems, in which the multidimensional input and output signals define two tensors. The LS method is applied to estimate the tensor transfer of such a system. Then the case of a tensor-input single-output (TISO) system is considered assuming the system transfer is a rank-one
Nth-order tensor, which leads to a multilinear system with respect to the impulse responses (IR) of the
N subsystems associated with the
N modes of the input tensor.
The non-recursive weighted least-squares (WLS) method is used to estimate the multilinear impulse response (MIR) under a vectorized form. A closed-form method is also proposed to estimate the IR of each subsystem from the estimated MIR.
The rest of the paper is structured as follows. In
Section 2, we present the notations with the index convention used throughout the paper. In
Section 3, we introduce some tensor sets in connection with multilinear forms. In
Section 4, we briefly recall basic tensor operations and decompositions.
Section 5 and
Section 6 are devoted to tensor-based approaches for nonlinear and multilinear systems modeling and identification, respectively. Finally,
Section 7 concludes the paper, with some perspectives for future work.
Many books and survey papers discuss estimation theory and system identification. In the field of engineering sciences, we can cite the fundamental contributions of [
57,
58,
59,
60,
61,
62,
63] for linear systems and [
27,
28,
29,
47,
64,
65,
66,
67,
68,
69] for nonlinear systems. In the case of multilinear systems, the reader is referred to [
55,
56] for more details.
2. Notation and Index Convention
Scalars, column vectors, matrices, and tensors are denoted by lower-case, boldface lower-case, boldface upper-case, and calligraphic letters, e.g., x, , X, , respectively. We denote by the element and by (resp. ) the rth column (resp. ith row) of . denotes the identity matrix of size .
The transpose, complex conjugate, transconjugate, and Moore–Penrose pseudo-inverse operators are represented by , , and , respectively.
The operator forms a diagonal matrix from its vector argument, while stands for a diagonal matrix holding the ith row of on the diagonal.
The operator forms a Toeplitz matrix from its vector argument , whose first column and row are, respectively, and .
Given , the vec and unvec operators are defined such that: , where the order of dimensions in the product is linked to the order of variation of the indices, with the column index j varying more slowly than the row index i.
The outer, Kronecker and Khatri–Rao products are denoted by ∘, ⊗ and ⋄, respectively.
Table 3 summarizes the notation used for sets of indices and dimensions [
70].
We now introduce the index convention which allows eliminating the summation symbols in formulae involving multi-index variables. For example, is simply written as . Note there are two differences relative to Einstein’s summation convention:
The index convention can be interpreted in terms of two types of summation, the first associated with the row indices (superscripts) and the second associated with the column indices (subscripts), with the following rules [
70]:
In
Table 4, we give some examples of vector and matrix products using index convention, where
.
Using the index convention, the multiple sum over the indices of
will be abbreviated to
where
denotes a set of ones whose number is fixed by the index
P of the set
. The notation
and
allows us to simplify the expression of the multiple sum into a single sum over an index set, which is further simplified by using the index convention.
3. Tensors and Multilinear Forms
In signal processing applications, a tensor
of order
N and size
is typically viewed as an array of numbers
. The order corresponds to the number of indices
that characterize its elements
, also denoted
or
. Each index
, for
, is associated with a mode, also called a way, and
denotes the dimension of the
nth mode. The number of elements in
is equal to
. For instance, in a wireless communication system [
8], each index of a signal
corresponds to a different form of diversity (in time, space, frequency, code, etc., domains), and the dimensions
are the numbers of time samples, receive antennas, subcarriers, the code length, etc.
The tensor is said to be real (resp. complex) if its elements are real numbers (resp. complex numbers), which corresponds to (resp. ). It is said to have even order (resp. odd order) if N is even (resp. odd). The special cases and correspond to the sets of matrices and column vectors , respectively.
If , the Nth-order tensor is said to be hypercubic, of dimensions I, with , for . The number of elements in is then equal to . The set of (real or complex) hypercubic tensors of order N and dimensions I will be denoted .
A hypercubic tensor of order
N and dimensions
I is said to be symmetric if it is invariant under any permutation
of its modes, i.e.,
The identity tensor of order
N and dimensions
I is denoted
, with
, for
, or simply
. It is a hypercubic tensor whose elements are defined using the generalized Kronecker delta
It is a diagonal tensor whose diagonal elements are equal to 1 and other elements to zero, which can be written as the sum of
I outer products of
N canonical basis vectors
of the space
where the outer product operation is defined later in Table 9.
A diagonal tensor
of order
N, whose diagonal elements are the entries of vector
, will be written as
Different matricizations, also called matrix unfoldings, can be defined for a tensor
. Consider a partitioning of the set of modes
into two disjoint ordered subsets
and
, composed of
p and
modes, respectively, with
. A general matrix unfolding formula was given by [
71] as follows
where
is the
-th vector of the canonical basis of
, and
, for
. We say that
is a matrix unfolding of
along the modes of
for the rows and along the modes of
for the columns, with
and
.
For instance, in the case of a third-order tensor , we have six flat unfoldings and six tall unfoldings. For and , we have the following mode-1 flat unfolding , while for and we obtain the following mode-1 tall unfolding .
Vectorized forms of
are obtained by combining the modes in a given order. Thus, a lexicographical vectorization gives the vector
with element
at the position
in
, i.e.,
, with [
72]
By convention, the order of the dimensions in a product associated with the index combination follows the order of variation of the indices , with varying more slowly than , which in turn varies more slowly than , etc.
The Frobenius norm of
is the square root of the inner product of the tensor with itself, i.e.,
Table 5 presents various sets of tensors that will be considered in this paper, with the notation introduced in [
70].
We can make the following remarks about the sets of tensors defined in
Table 5:
- •
For , the set is the set of (real or complex) matrices of size .
- •
The set is also denoted or T by some authors.
- •
The set is called the set of even-order (or square) tensors of order and size . The name of square tensor comes from the fact that the index set is divided into two identical subsets of dimension .
- •
Analogously to matrices, tensors in the sets with and are said to be rectangular. The set is called the set of rectangular tensors with index blocks of dimensions and .
The various tensor sets introduced above can be associated with scalar real-valued multilinear forms in vector variables and with homogeneous polynomials. Like in the matrix case, we will distinguish between homogeneous polynomials of degree P that depend on the components of P vector variables and those that depend on just one vector variable.
A real-valued multilinear form, also called a
P-linear form, is a map
f such as
that is separately linear with respect to each vector variable
when the other variables
, for
, are fixed. Using the index convention, the multilinear form can be written for
,
, as
The tensor
is called the tensor associated with the multilinear form
f.
Two multilinear forms are presented in
Table 6, which also states the transformation corresponding to each of them, as well as the associated tensor.
Table 7 recalls the definitions of bilinear/quadratic forms using the index convention, then presents the multilinear forms defined in
Table 6, as well as the associated tensors from
Table 5 and the corresponding homogeneous polynomials.
We can make the following remarks:
In the same way that bilinear forms depend on two variables that do not necessarily belong to the same vector space, general real multilinear forms depend on P variables that may belong to different vector spaces: .
Analogously to quadratic forms obtained from bilinear forms by replacing the pair with the vector , real multilinear forms can be expressed using just one vector . In the same way symmetric quadratic forms lead to the notion of symmetric matrices, the symmetry of multilinear forms is directly linked to the symmetry of their associated tensors.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}