
Nonsmooth Optimization-Based Hyperparameter-Free Neural Networks for Large-Scale Regression
 ,
,  ,
, 
Abstract
:1. Introduction
- It takes full advantage of nonsmooth models and nonsmooth optimization in solving NNR problems (no need for smoothing etc.);
- It is hyperparameter-free due to the automated determination of the proper number of nodes;
- It is applicable to large-scale regression problems;
- It is an efficient and accurate predictive tool.
2. Related Work
3. Theoretical Background and Notations
3.1. Nonsmooth Optimization
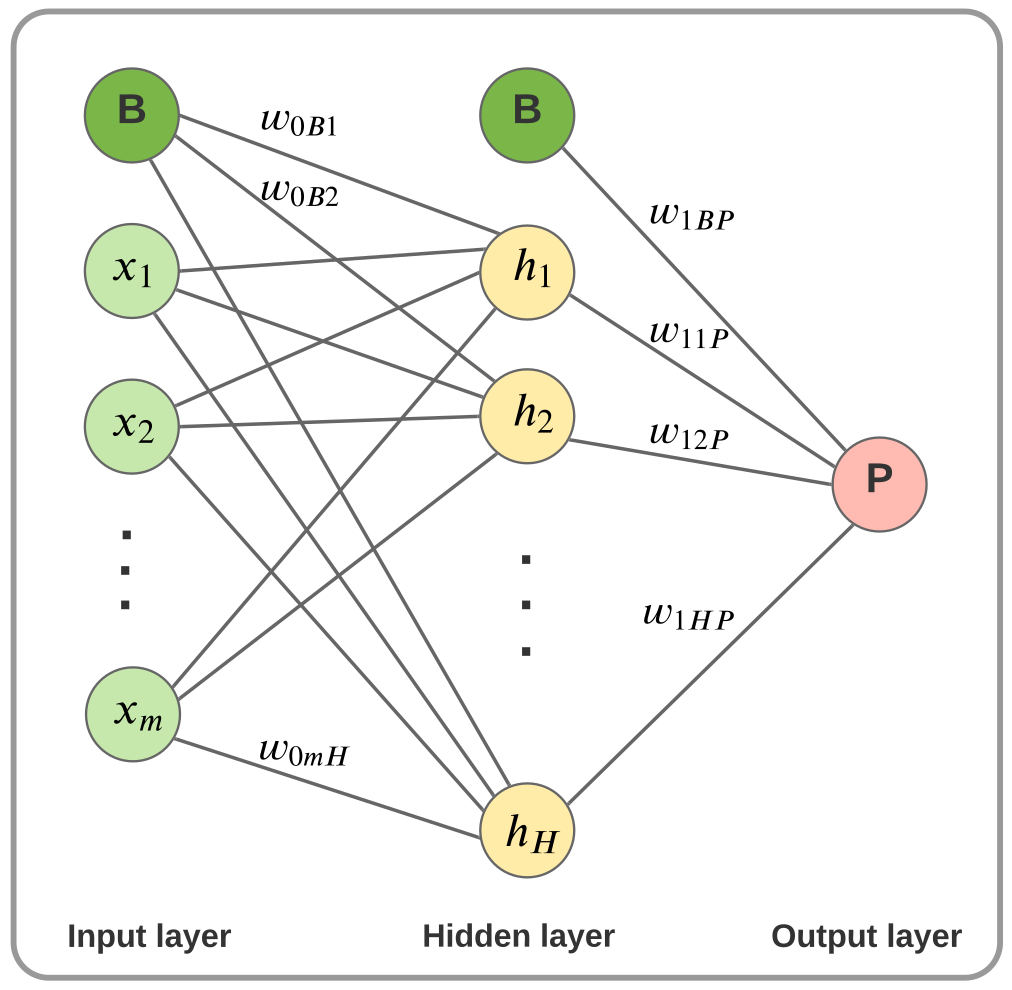
3.2. Neural Networks for Regression
4. Nonsmooth Optimization Model of ReLU-NNR
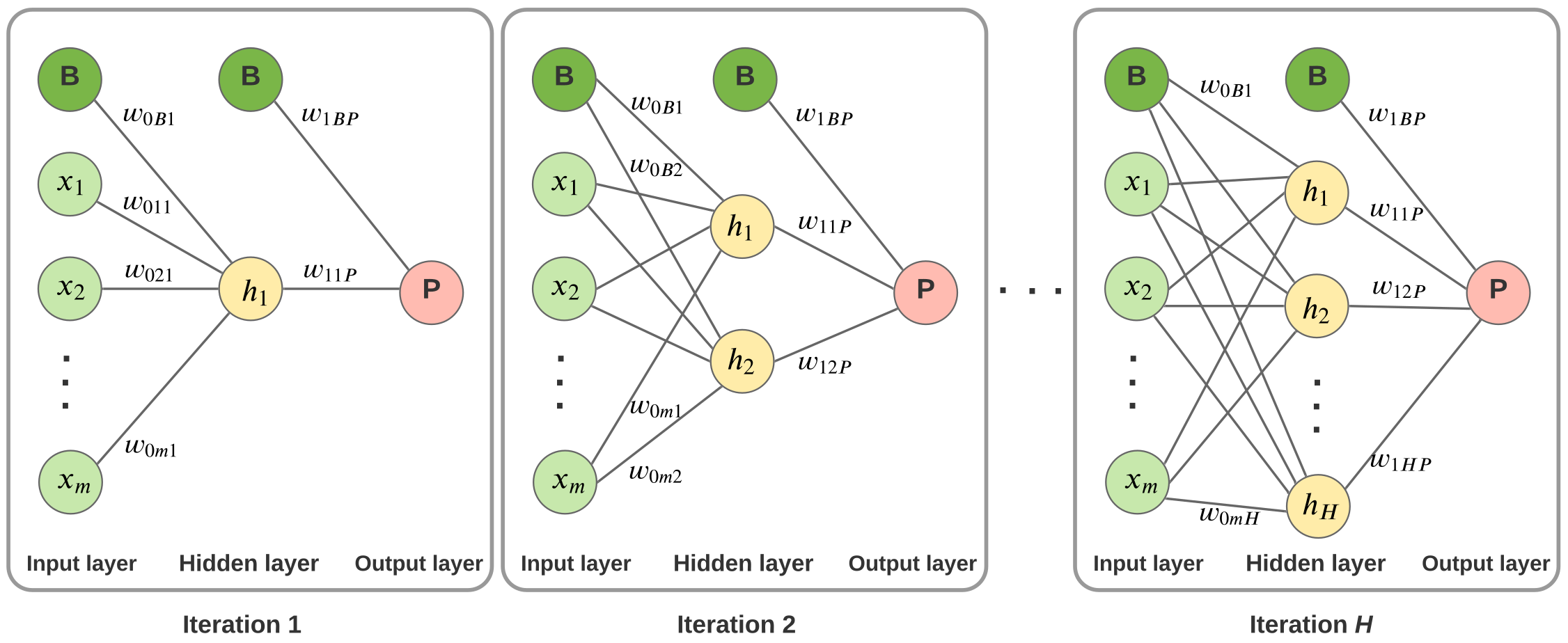
5. LMBNNR Algorithm
| Algorithm 1: LMBNNR |
 |
| Algorithm 2: LMBM for ReLU-NNR problems |
 |
6. Numerical Experiments
6.1. Data Sets and Performance Measures
6.2. Implementation of Algorithms
- Mini-Batch Gradient Descent (MBGD): batch size and number of epochs These are the default values for the BPN algorithm;
- Batch Gradient Descent (BGD): batch size = size of the training data and number of epochs . These choices mimic the proposed LMBNNR algorithm;
- Stochastic Gradient Descent (SGD): batch size and number of epochs for data sets with less than 100,000 samples and number of epochs for larger data. We reduce the number of epochs in the latter case due to very long computational times and the fact that the larger number of epochs often leads to NaN loss function values. SGD aims to be as a stochastic version of the BPN algorithm as possible.
6.3. Results and Discussion
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Malte, J. Artificial neural network regression models in a panel setting: Predicting economic growth. Econ. Model. 2020, 91, 148–154. [Google Scholar]
- Pepelyshev, A.; Zhigljavsky, A.; Žilinskas, A. Performance of global random search algorithms for large dimensions. J. Glob. Optim. 2018, 71, 57–71. [Google Scholar] [CrossRef]
- Haarala, N.; Miettinen, K.; Mäkelä, M.M. Globally Convergent Limited Memory Bundle Method for Large-Scale Nonsmooth Optimization. Math. Program. 2007, 109, 181–205. [Google Scholar] [CrossRef]
- Karmitsa, N. Limited Memory Bundle Method and Its Variations for Large-Scale Nonsmooth Optimization. In Numerical Nonsmooth Optimization: State of the Art Algorithms; Bagirov, A.M., Gaudioso, M., Karmitsa, N., Mäkelä, M.M., Taheri, S., Eds.; Springer: Cham, Switzerland, 2020; pp. 167–200. [Google Scholar]
- Bagirov, A.M.; Karmitsa, N.; Taheri, S. Partitional Clustering via Nonsmooth Optimization: Clustering via Optimization; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Halkola, A.; Joki, K.; Mirtti, T.; Mäkelä, M.M.; Aittokallio, T.; Laajala, T. OSCAR: Optimal subset cardinality regression using the L0-pseudonorm with applications to prognostic modelling of prostate cancer. PLoS Comput. Biol. 2023, 19, e1010333. [Google Scholar] [CrossRef] [PubMed]
- Karmitsa, N.; Bagirov, A.M.; Taheri, S.; Joki, K. Limited Memory Bundle Method for Clusterwise Linear Regression. In Computational Sciences and Artificial Intelligence in Industry; Tuovinen, T., Periaux, J., Neittaanmäki, P., Eds.; Springer: Cham, Switzerland, 2022; pp. 109–122. [Google Scholar]
- Karmitsa, N.; Taheri, S.; Bagirov, A.M.; Mäkinen, P. Missing value imputation via clusterwise linear regression. IEEE Trans. Knowl. Data Eng. 2022, 34, 1889–1901. [Google Scholar] [CrossRef]
- Airola, A.; Pahikkala, T. Fast Kronecker product kernel methods via generalized vec trick. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3374–3387. [Google Scholar]
- Bian, W.; Chen, X. Neural network for nonsmooth, nonconvex constrained minimization via smooth approximation. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 545–556. [Google Scholar] [CrossRef] [PubMed]
- JunRu, L.; Hong, Q.; Bo, Z. Learning with smooth Hinge losses. Neurocomputing 2021, 463, 379–387. [Google Scholar]
- Griewank, A.; Rojas, A. Treating Artificial Neural Net Training as a Nonsmooth Global Optimization Problem. In Machine Learning, Optimization, and Data Science. LOD 2019; Nicosia, G., Pardalos, P., Umeton, R., Giuffrida, G., Sciacca, V., Eds.; Springer: Cham, Switzerland, 2019; Volume 11943. [Google Scholar]
- Griewank, A.; Rojas, A. Generalized Abs-Linear Learning by Mixed Binary Quadratic Optimization. In Proceedings of African Conference on Research in Computer Science CARI 2020, Thes, Senegal, 14–17 October 2020; Available online: https://hal.science/hal-02945038 (accessed on 10 September 2023).
- Yang, T.; Mahdavi, M.; Jin, R.; Zhu, S. An efficient primal dual prox method for non-smooth optimization. Mach. Learn. 2015, 98, 369–406. [Google Scholar] [CrossRef]
- Astorino, A.; Gaudioso, M. Ellipsoidal separation for classification problems. Optim. Methods Softw. 2005, 20, 267–276. [Google Scholar] [CrossRef]
- Bagirov, A.M.; Taheri, S.; Karmitsa, N.; Sultanova, N.; Asadi, S. Robust piecewise linear L1-regression via nonsmooth DC optimization. Optim. Methods Softw. 2022, 37, 1289–1309. [Google Scholar] [CrossRef]
- Gaudioso, M.; Giallombardo, G.; Miglionico, G.; Vocaturo, E. Classification in the multiple instance learning framework via spherical separation. Soft Comput. 2020, 24, 5071–5077. [Google Scholar] [CrossRef]
- Astorino, A.; Fuduli, A. Support vector machine polyhedral separability in semisupervised learning. J. Optim. Theory Appl. 2015, 164, 1039–1050. [Google Scholar] [CrossRef]
- Astorino, A.; Fuduli, A. The proximal trajectory algorithm in SVM cross validation. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 966–977. [Google Scholar] [CrossRef] [PubMed]
- Joki, K.; Bagirov, A.M.; Karmitsa, N.; Mäkelä, M.M.; Taheri, S. Clusterwise support vector linear regression. Eur. J. Oper. Res. 2020, 287, 19–35. [Google Scholar] [CrossRef]
- Selmic, R.R.; Lewis, F.L. Neural-network approximation of piecewise continuous functions: Application to friction compensation. IEEE Trans. Neural Netw. 2002, 13, 745–751. [Google Scholar] [CrossRef] [PubMed]
- Imaizumi, M.; Fukumizu, K. Deep Neural Networks Learn Non-Smooth Functions Effectively. In Proceedings of the Machine Learning Research, Naha, Okinawa, Japan, 16–18 April 2019; Volume 89, pp. 869–878. [Google Scholar]
- Davies, D.; Drusvyatskiy, D.; Kakade, S.; Lee, J. Stochastic subgradient method converges on tame functions. Found. Comput. Math. 2020, 20, 119–154. [Google Scholar] [CrossRef]
- Aggarwal, C. Neural Networks and Deep Learning; Springer: Berlin, Germany, 2018. [Google Scholar]
- Rumelhart, D.; Hinton, G.; Williams, R. Learning representations by back-propagating errors. Nature 1988, 323, 533–536. [Google Scholar] [CrossRef]
- Huang, G.B. Learning capability and storage capacity of two-hidden-layer feedforward networks. IEEE Trans. Neural Netw. 2003, 14, 274–281. [Google Scholar] [CrossRef]
- Reed, R.; Marks, R.J. Neural Smithing: Supervised Learning in Feedforward Artificial Neural Networks; The MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Vicoveanu, P.; Vasilache, I.; Scripcariu, I.; Nemescu, D.; Carauleanu, A.; Vicoveanu, D.; Covali, A.; Filip, C.; Socolov, D. Use of a feed-forward back propagation network for the prediction of small for gestational age newborns in a cohort of pregnant patients with thrombophilia. Diagnostics 2022, 12, 1009. [Google Scholar] [CrossRef]
- Broomhead, D.; Lowe, D. Radial Basis Functions, Multi-Variable Functional Interpolation and Adaptive Networks; Royals Signals and Radar Establishment: Great Malvern, UK, 1988. [Google Scholar]
- Olusola, A.O.; Ashiribo, S.W.; Mazzara, M. A machine learning prediction of academic performance of secondary school students using radial basis function neural network. Trends Neurosci. Educ. 2022, 22, 100190. [Google Scholar]
- Zhang, D.; Zhang, N.; Ye, N.; Fang, J.; Han, X. Hybrid learning algorithm of radial basis function networks for reliability analysis. IEEE Trans. Reliab. 2021, 70, 887–900. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
- Faris, H.; Mirjalili, S.; Aljarah, I. Automatic selection of hidden neurons and weights in neural networks using grey wolf optimizer based on a hybrid encoding scheme. Int. J. Mach. Learn. Cybern. 2019, 10, 2901–2920. [Google Scholar] [CrossRef]
- Huang, D.S.; Du, J.X. A constructive hybrid structure optimization methodology for radial basis probabilistic neural networks. IEEE Trans. Neural Netw. 2008, 19, 2099–2115. [Google Scholar] [CrossRef] [PubMed]
- Odikwa, H.; Ifeanyi-Reuben, N.; Thom-Manuel, O.M. An improved approach for hidden nodes selection in artificial neural network. Int. J. Appl. Inf. Syst. 2020, 12, 7–14. [Google Scholar]
- Leung, F.F.; Lam, H.K.; Ling, S.H.; Tam, P.S. Tuning of the structure and parameters of a neural network using an improved genetic algorithm. IEEE Trans. Neural Netw. 2003, 11, 79–88. [Google Scholar] [CrossRef] [PubMed]
- Stathakis, D. How many hidden layers and nodes? Int. J. Remote Sens. 2009, 30, 2133–2147. [Google Scholar] [CrossRef]
- Tsai, J.T.; Chou, J.H.; Liu, T.K. Tuning the structure and parameters of a neural network by using hybrid Taguchi-genetic algorithm. IEEE Trans. Neural Netw. 2006, 17, 69–80. [Google Scholar] [CrossRef]
- Bagirov, A.M.; Karmitsa, N.; Mäkelä, M.M. Introduction to Nonsmooth Optimization: Theory, Practice and Software; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Clarke, F.H. Optimization and Nonsmooth Analysis; Wiley-Interscience: New York, NY, USA, 1983. [Google Scholar]
- Wilamowski, B.M. Neural Network Architectures. In The Industrial Electronics Handbook; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Kärkkäinen, T.; Heikkola, E. Robust formulations for training multilayer perceptrons. Neural Comput. 2004, 16, 837–862. [Google Scholar] [CrossRef]
- Karmitsa, N.; Taheri, S.; Joki, K.; Mäkinen, P.; Bagirov, A.; Mäkelä, M.M. Hyperparameter-Free NN Algorithm for Large-Scale Regression Problems; TUCS Technical Report, No. 1213; Turku Centre for Computer Science: Turku, Finland, 2020; Available online: https://napsu.karmitsa.fi/publications/lmbnnr_tucs.pdf (accessed on 10 September 2023).
- Zhang, H.; Hager, W. A nonmonotone line search technique and its application to unconstrained optimization. SIAM J. Optim. 2004, 14, 1043–1056. [Google Scholar] [CrossRef]
- Byrd, R.H.; Nocedal, J.; Schnabel, R.B. Representations of quasi-Newton matrices and their use in limited memory methods. Math. Program. 1994, 63, 129–156. [Google Scholar] [CrossRef]
- Kiwiel, K.C. Methods of Descent for Nondifferentiable Optimization; Lecture Notes in Mathematics 1133; Springer: Berlin, Germany, 1985. [Google Scholar]
- Bihain, A. Optimization of upper semidifferentiable functions. J. Optim. Theory Appl. 1984, 4, 545–568. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. 2011, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- Lang, B. Monotonic Multi-Layer Perceptron Networks as Universal Approximators. In Artificial Neural Networks: Formal Models and Their Applications—ICANN 2005; Duch, W., Kacprzyk, J., Oja, E., Zadroźny, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3697. [Google Scholar]
- Tüfekci, P. Prediction of full load electrical power output of a base load operated combined cycle power plant using machine learning methods. Int. J. Electr. Power Energy Syst. 2014, 60, 126–140. [Google Scholar] [CrossRef]
- Kaya, H.; Tüfekci, P.; Gürgen, S.F. Local and Global Learning Methods for Predicting Power of a Combined Gas & Steam Turbine. In Proceedings of the International Conference on Emerging Trends in Computer and Electronics Engineering ICETCEE 2012, Dubai, United Arab Emirates, 24–25 March 2012; pp. 13–18. [Google Scholar]
- Dua, D.; Karra Taniskidou, E. UCI Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 25 November 2020).
- Yeh, I. Modeling of strength of high performance concrete using artificial neural networks. Cem. Concr. Res. 1998, 28, 1797–1808. [Google Scholar] [CrossRef]
- Harrison, D.; Rubinfeld, D. Hedonic prices and the demand for clean air. J. Environ. Econ. Manag. 1978, 5, 81–102. [Google Scholar] [CrossRef]
- Paredes, E.; Ballester-Ripoll, R. SGEMM GPU kernel performance (2018). In UCI Machine Learning Repository. Available online: https://doi.org/10.24432/C5MK70 (accessed on 10 September 2023).
- Nugteren, C.; Codreanu, V. CLTune: A Generic Auto-Tuner for OpenCL Kernels. In Proceedings of the MCSoC: 9th International Symposium on Embedded Multicore/Many-core Systems-on-Chip, Turin, Italy, 23–25 September 2015. [Google Scholar]
- Fernandes, K.; Vinagre, P.; Cortez, P. A Proactive Intelligent Decision Support System for Predicting the Popularity of Online News. In Proceedings of the 17th EPIA 2015—Portuguese Conference on Artificial Intelligence, Coimbra, Portugal, 8–11 September 2015. [Google Scholar]
- Rafiei, M.; Adeli, H. A novel machine learning model for estimation of sale prices of real estate units. ASCE J. Constr. Eng. Manag. 2015, 142, 04015066. [Google Scholar] [CrossRef]
- Buza, K. Feedback Prediction for Blogs. In Data Analysis, Machine Learning and Knowledge Discovery; Springer International Publishing: Cham, Switzerland, 2014; pp. 145–152. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 14 November 2021).
- Lucas, D.; Yver Kwok, C.; Cameron-Smith, P.; Graven, H.; Bergmann, D.; Guilderson, T.; Weiss, R.; Keeling, R. Designing optimal greenhouse gas observing networks that consider performance and cost. Geosci. Instrum. Methods Data Syst. 2015, 4, 121–137. [Google Scholar] [CrossRef]
- Diaz, M.; Grimmer, B. Optimal convergence rates for the proximal bundle method. SIAM J. Optim. 2023, 33, 424–454. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Data Set | No. of Samples | No. of Features | Reference |
|---|---|---|---|
| Combined cycle power plant | 9568 | 5 | [50,51] |
| Airfoil self-noise | 1503 | 6 | [52] |
| Concrete compressive strength | 1030 | 9 | [53] |
| Physicochemical properties | |||
| of protein tertiary structure | 45,730 | 10 | [52] |
| Boston housing data | 506 | 14 | [54] |
| SGEMM GPU kernel performance 1 | 241,600 | 15 | [55,56] |
| Online news popularity | 39,644 | 59 | [57] |
| Residential building data set 1 | 372 | 108 | [58] |
| BlogFeedback 2 | 52,397 | 281 | [59] |
| ISOLET | 7797 | 618 | [52] |
| CIFAR-10 | 60,000 | 3073 | [60] |
| Greenhouse gas observing network | 2921 | 5232 | [61] |
| LMBNNR | MBGD | BGD | SGD | ELM | MONMLP | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | CPU | RMSE | CPU | RMSE | CPU | RMSE | CPU | RMSE | CPU | RMSE | CPU | |
| Combined cycle power plant | ||||||||||||
| 2 | 4.433 | 0.14 | 8.472 | 1.45 | 19.061 | 0.51 | 4.582 | 1036.42 | 18.987 | 0.00 | 6.811 | 17.10 |
| 5 | 4.267 | 0.61 | 6.091 | 0.97 | 20.547 | 0.58 | 4.415 | 790.27 | 5.192 | 0.00 | 6.692 | 40.72 |
| 10 | 4.216 | 2.02 | 5.784 | 0.78 | 17.809 | 0.47 | 4.278 | 650.95 | 5.192 | 0.02 | 6.667 | 97.91 |
| 50 | 4.140 | 12.72 | 4.712 | 1.04 | 18.790 | 0.66 | 4.215 | 679.02 | 5.192 | 0.17 | 9.424 | 1347.99 |
| 100 | 4.139 | 17.70 | 4.612 | 0.65 | 17.213 | 0.38 | 4.167 | 639.65 | 5.192 | 0.49 | 17.007 | 1154.44 |
| 200 | 4.139 | 31.92 | 4.566 | 0.66 | 17.649 | 0.69 | 4.190 | 691.76 | 5.192 | 2.34 | t-lim | – |
| 500 | 4.534 | 1.00 | 16.514 | 0.63 | 4.168 | 761.36 | 5.192 | 8.03 | t-lim | – | ||
| 5000 | 4.533 | 1.81 | 16.710 | 1.53 | 4.205 | 897.52 | 5.192 | 1347.99 | t-lim | – | ||
| Best: | 4.138 | 8.14 | ||||||||||
| ASP: | 4.139 | 13.73 | ||||||||||
| Airfoil self-noise | ||||||||||||
| 2 | 4.907 | 0.02 | 6.756 | 0.36 | 10.129 | 0.29 | 4.387 | 102.65 | 87.622 | 0.00 | 5.709 | 4.98 |
| 5 | 4.407 | 0.10 | 6.580 | 0.35 | 9.465 | 0.30 | 3.688 | 102.13 | 30.274 | 0.00 | 5.634 | 9.05 |
| 10 | 4.410 | 0.30 | 5.888 | 0.35 | 8.950 | 0.33 | 2.804 | 101.01 | 30.274 | 0.00 | 5.648 | 19.72 |
| 50 | 4.344 | 7.05 | 5.595 | 0.34 | 7.114 | 0.30 | 2.386 | 100.87 | 30.274 | 0.00 | 6.308 | 231.75 |
| 100 | 1.897 | 19.80 | 5.516 | 0.40 | 6.840 | 0.33 | 2.018 | 102.91 | 30.274 | 0.05 | 6.727 | 224.88 |
| 200 | 1.897 | 29.04 | 5.346 | 0.38 | 6.967 | 0.32 | 2.044 | 108.73 | 30.274 | 0.17 | 6.723 | 890.39 |
| 500 | 5.319 | 0.35 | 6.743 | 0.30 | 2.194 | 116.60 | 30.274 | 1.27 | t-lim | – | ||
| 5000 | 5.299 | 0.42 | 6.689 | 0.37 | 2.035 | 133.00 | 30.274 | 46.66 | t-lim | – | ||
| Best: | 1.897 | 17.29 | ||||||||||
| ASP: | 1.897 | 20.15 | ||||||||||
| Concrete compressive strength | ||||||||||||
| 2 | 11.657 | 0.02 | 17.554 | 0.37 | 30.305 | 0.33 | 7.659 | 70.00 | 16.511 | 0.00 | 6.339 | 5.43 |
| 5 | 6.808 | 0.10 | 15.736 | 0.37 | 23.220 | 0.32 | 6.372 | 74.19 | 14.173 | 0.00 | 5.026 | 15.21 |
| 10 | 6.104 | 0.34 | 15.156 | 0.38 | 23.949 | 0.36 | 5.577 | 71.78 | 9.861 | 0.00 | 4.338 | 33.68 |
| 50 | 5.235 | 6.94 | 13.729 | 0.39 | 17.824 | 0.35 | 4.918 | 74.42 | 9.861 | 0.02 | 15.042 | 139.85 |
| 100 | 5.224 | 15.60 | 13.277 | 0.39 | 18.069 | 0.31 | 5.019 | 72.87 | 9.861 | 0.05 | 15.899 | 472.58 |
| 200 | 5.224 | 22.42 | 12.472 | 0.36 | 17.365 | 0.31 | 4.807 | 76.91 | 9.861 | 0.25 | 15.895 | 1573.22 |
| 500 | 12.379 | 0.40 | 16.515 | 0.42 | 4.771 | 79.92 | 9.861 | 0.57 | t-lim | – | ||
| 5000 | 12.362 | 0.45 | 16.496 | 0.41 | 4.468 | 94.33 | 9.861 | 9.89 | t-lim | – | ||
| Best: | 5.224 | 15.06 | ||||||||||
| ASP: | 5.225 | 13.22 | ||||||||||
| Physicochemical properties of protein | ||||||||||||
| 2 | 5.304 | 1.06 | 5.223 | 2.29 | 7.838 | 0.71 | 5.127 | 3368.54 | 6.703 | 0.00 | 4.962 | 111.60 |
| 5 | 5.095 | 4.89 | 5.122 | 2.14 | 8.366 | 0.72 | NaN | – | 6.457 | 0.03 | 4.798 | 296.25 |
| 10 | 5.062 | 17.76 | 5.082 | 2.09 | 8.168 | 0.73 | 4.856 | 3356.05 | 5.215 | 0.08 | 4.947 | 771.12 |
| 50 | 4.794 | 109.34 | 4.975 | 2.05 | 6.784 | 0.73 | NaN | – | 5.215 | 0.72 | t-lim | – |
| 100 | 4.793 | 151.02 | 4.952 | 1.86 | 6.466 | 0.69 | NaN | – | 5.215 | 2.56 | t-lim | – |
| 200 | 4.793 | 259.12 | 4.941 | 2.31 | 6.155 | 0.77 | NaN | – | 5.215 | 10.80 | t-lim | – |
| 500 | 4.972 | 3.06 | 6.130 | 1.07 | NaN | – | 5.215 | 26.48 | t-lim | – | ||
| 5000 | 4.942 | 5.79 | 6.043 | 4.68 | NaN | – | 5.215 | 2761.84 | t-lim | – | ||
| Best: | 4.793 | 114.31 | ||||||||||
| ASP: | 4.793 | 131.93 | ||||||||||
| 2/10 runs led to NaN loss function value. | ||||||||||||
| 8/10 runs led to NaN loss function value. | ||||||||||||
| Boston housing | ||||||||||||
| 2 | 5.539 | 0.01 | 10.983 | 0.47 | 13.335 | 0.33 | 4.675 | 40.02 | 9.883 | 0.01 | 2.773 | 4.72 |
| 5 | 5.534 | 0.04 | 9.345 | 0.49 | 12.203 | 0.33 | 4.019 | 33.65 | 8.922 | 0.00 | 2.432 | 7.90 |
| 10 | 4.551 | 0.22 | 8.753 | 0.51 | 12.663 | 0.32 | 3.936 | 34.16 | 6.433 | 0.00 | 2.591 | 17.06 |
| 50 | 4.228 | 4.03 | 8.061 | 0.49 | 10.831 | 0.33 | 3.784 | 35.72 | 4.786 | 0.00 | 3.967 | 80.14 |
| 100 | 4.228 | 7.75 | 7.702 | 0.54 | 10.636 | 0.29 | 3.794 | 37.22 | 4.786 | 0.05 | 5.842 | 275.42 |
| 200 | 4.228 | 12.37 | 7.498 | 0.33 | 10.516 | 0.55 | 3.609 | 38.10 | 4.786 | 0.19 | 7.588 | 967.62 |
| 500 | 7.699 | 0.47 | 10.410 | 0.32 | 3.656 | 38.44 | 4.786 | 0.22 | t-lim | – | ||
| 5000 | 7.625 | 0.50 | 9.956 | 0.37 | 3.669 | 47.45 | 4.786 | 2.31 | t-lim | – | ||
| Best: | 4.228 | 1.87 | ||||||||||
| ASP: | 4.228 | 2.97 | ||||||||||
| SGEMM GPU kernel performance | ||||||||||||
| 2 | 223.258 | 1.37 | 168.971 | 8.11 | 515.647 | 2.15 | 148.531 | 1536.53 | 327.404 | 0.05 | 91.07 | 970.11 |
| 5 | 118.697 | 5.87 | 128.186 | 7.98 | 549.201 | 2.18 | 105.851 | 1812.15 | 310.172 | 0.15 | 68.93 | 2551.58 |
| 10 | 94.826 | 19.60 | 116.195 | 8.02 | 502.793 | 2.14 | 78.309 | 1839.19 | 289.019 | 0.36 | 81.37 | 6779.13 |
| 50 | 93.362 | 75.16 | 108.867 | 8.09 | 429.332 | 2.32 | 43.959 | 1669.78 | 285.953 | 4.56 | t-lim | – |
| 100 | 93.362 | 234.57 | 106.440 | 8.09 | 402.935 | 2.31 | 41.323 | 1809.20 | 285.953 | 15.92 | t-lim | – |
| 200 | 93.362 | 887.41 | 104.307 | 8.44 | 385.360 | 2.52 | 37.311 | 1835.75 | 285.953 | 60.72 | t-lim | – |
| 500 | 102.033 | 10.12 | 383.167 | 3.25 | 34.283 | 1679.94 | 285.953 | 147.90 | t-lim | – | ||
| 5000 | 101.886 | 23.86 | 367.074 | 23.83 | 28.524 | 2243.39 | t-lim | – | t-lim | – | ||
| Best: | 93.362 | 26.94 | ||||||||||
| ASP: | 94.270 | 25.78 | ||||||||||
| LMBNNR | MBGD | BGD | SGD | ELM | MONMLP | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | CPU | RMSE | CPU | RMSE | CPU | RMSE | CPU | RMSE | CPU | RMSE | CPU | |
| Online news popularity | ||||||||||||
| 2 | 12,387.46 | 0.75 | 12,301.20 | 1.68 | 15,701.63 | 0.63 | 12,475.79 | 2664.11 | 11,228.42 | 0.03 | 10,626.67 | 692.14 |
| 5 | 12,377.17 | 3.78 | 12,304.05 | 1.65 | 18,562.27 | 0.65 | NaN | – | 11,189.21 | 0.05 | 9500.96 | 2310.14 |
| 10 | 12,365.38 | 13.27 | 12,351.97 | 1.62 | 18,095.87 | 0.69 | NaN | – | 11,098.65 | 0.09 | 9548.60 | 2554.58 |
| 50 | 12,365.19 | 52.38 | 12,670.86 | 1.77 | 16,461.91 | 0.67 | NaN | – | 11,046.39 | 0.94 | t-lim | – |
| 100 | 12,365.19 | 202.50 | 12,714.96 | 1.78 | 14,731.39 | 0.68 | NaN | – | 11,043.69 | 3.07 | t-lim | – |
| 200 | 12,365.19 | 782.59 | 12,937.68 | 1.80 | 13,977.35 | 0.74 | NaN | – | 11,043.69 | 10.28 | t-lim | – |
| 500 | 12,519.33 | 2.10 | 13,089.17 | 0.91 | NaN | – | 11,043.69 | 23.44 | t-lim | – | ||
| 5000 | 12,322.53 | 6.27 | 12,364.06 | 3.52 | NaN | – | t-lim | – | t-lim | – | ||
| Best: | 12,365.19 | 16.49 | ||||||||||
| ASP: | 12,365.19 | 16.49 | ||||||||||
| 7/10 runs led to NaN loss function value. | ||||||||||||
| Residential building | ||||||||||||
| 2 | 239.14 | 0.09 | 1163.96 | 0.54 | 1635.84 | 0.32 | 236.87 | 25.92 | 1838.86 | 0.00 | 60.93 | 22.39 |
| 5 | 240.63 | 0.37 | 1048.95 | 0.35 | 1350.82 | 0.33 | 192.68 | 25.93 | 1832.78 | 0.00 | 399.07 | 25.40 |
| 10 | 183.46 | 1.40 | 1046.23 | 0.36 | 1524.37 | 0.31 | 155.14 | 26.91 | 976.84 | 0.00 | 1200.13 | 49.06 |
| 50 | 183.11 | 8.34 | 1014.72 | 0.35 | 1217.39 | 0.32 | 148.19 | 27.61 | 170.17 | 0.00 | 1200.32 | 966.99 |
| 100 | 183.11 | 12.93 | 998.60 | 0.36 | 1119.60 | 0.33 | NaN | – | 128.27 | 0.03 | t-lim | – |
| 200 | 183.11 | 23.77 | 956.51 | 0.35 | 1018.66 | 0.31 | NaN | – | 128.27 | 0.06 | t-lim | – |
| 500 | 972.95 | 0.35 | 998.18 | 0.33 | NaN | – | 128.27 | 0.14 | t-lim | – | ||
| 5000 | 775.80 | 0.45 | 916.63 | 0.40 | NaN | – | 128.27 | 1.38 | t-lim | – | ||
| Best: | 182.94 | 1.69 | ||||||||||
| ASP: | 183.12 | 6.18 | ||||||||||
| 2/10 runs led to NaN loss function value. | ||||||||||||
| 1/10 runs led to NaN loss function value. | ||||||||||||
| 4/10 runs led to NaN loss function value. | ||||||||||||
| BlogFeedback | ||||||||||||
| 2 | 29.14 | 3.83 | NaN | – | NaN | – | NaN | – | 32.51 | 0.07 | 28.61 | 5877.94 |
| 5 | 29.14 | 17.59 | NaN | – | NaN | – | NaN | – | 32.03 | 0.13 | t-lim | – |
| 10 | 27.02 | 68.04 | NaN | – | NaN | – | NaN | – | 28.26 | 0.17 | t-lim | – |
| 50 | 27.02 | 405.20 | NaN | – | NaN | – | NaN | – | 27.53 | 1.08 | t-lim | – |
| 100 | 27.02 | 1449.46 | NaN | – | NaN | – | NaN | – | 27.50 | 3.45 | t-lim | – |
| 200 | 27.02 | 5598.74 | NaN | – | NaN | – | NaN | – | 27.37 | 18.83 | t-lim | – |
| 500 | NaN | – | NaN | – | NaN | – | 27.37 | 96.81 | t-lim | – | ||
| 5000 | NaN | – | NaN | – | NaN | – | 27.37 | 4178.65 | t-lim | – | ||
| Best: | 27.02 | 68.04 | ||||||||||
| ASP: | 27.02 | 75.07 | ||||||||||
| ISOLET | ||||||||||||
| 2 | 4.82 | 1.71 | 5.32 | 0.71 | 9.25 | 0.42 | NaN | – | 13.01 | 0.06 | 2.83 | 3190.22 |
| 5 | 4.20 | 8.53 | 4.91 | 0.68 | 11.01 | 0.43 | NaN | – | 10.53 | 0.09 | t-lim | – |
| 10 | 3.88 | 31.19 | 4.76 | 0.68 | 9.90 | 0.42 | NaN | – | 9.08 | 0.07 | t-lim | – |
| 50 | 3.89 | 128.68 | 4.69 | 0.74 | 9.75 | 0.45 | NaN | – | 6.55 | 0.54 | t-lim | – |
| 100 | 3.89 | 409.63 | 4.66 | 0.78 | 9.65 | 0.46 | NaN | – | 6.00 | 1.33 | t-lim | – |
| 200 | 3.89 | 1953.21 | 4.66 | 0.87 | 9.04 | 0.50 | NaN | – | 4.95 | 3.54 | t-lim | – |
| 500 | 4.83 | 1.20 | 9.23 | 0.66 | NaN | – | 4.34 | 6.97 | t-lim | – | ||
| 5000 | NaN | – | 8.22 | 2.90 | NaN | – | 4.09 | 467.00 | t-lim | – | ||
| Best: | 3.88 | 31.19 | ||||||||||
| ASP: | 3.89 | 35.48 | ||||||||||
| CIFAR-10 | ||||||||||||
| 2 | 2.83 | 74.22 | NaN | – | NaN | – | NaN | – | 5.05 | 4.89 | t-lim | – |
| 5 | 2.80 | 345.60 | NaN | – | NaN | – | NaN | – | 3.18 | 5.10 | t-lim | – |
| 10 | 2.78 | 683.83 | NaN | – | NaN | – | NaN | – | 3.18 | 7.06 | t-lim | – |
| 50 | 2.77 | 4845.04 | NaN | – | NaN | – | NaN | – | 2.98 | 25.42 | t-lim | – |
| 100 | t-lim | – | NaN | – | NaN | – | NaN | – | 2.96 | 45.22 | t-lim | – |
| 200 | t-lim | – | NaN | – | NaN | – | NaN | – | 2.93 | 88.11 | t-lim | – |
| 500 | NaN | – | NaN | – | NaN | – | 2.92 | 250.08 | t-lim | – | ||
| 5000 | NaN | – | NaN | – | NaN | – | t-lim | – | t-lim | – | ||
| Best: | 2.77 | 755.45 | ||||||||||
| ASP: | 2.77 | 968.08 | ||||||||||
| Greenhouse gas observing network | ||||||||||||
| 2 | 25.07 | 5.09 | 67.65 | 0.70 | 362.12 | 0.58 | NaN | – | 75.04 | 0.18 | t-lim | – |
| 5 | 23.51 | 25.60 | NaN | – | 315.62 | 0.54 | NaN | – | 52.22 | 0.34 | t-lim | – |
| 10 | 23.18 | 94.54 | NaN | – | 506.36 | 0.59 | NaN | – | 47.97 | 0.50 | t-lim | – |
| 50 | 23.18 | 404.90 | NaN | – | 488.83 | 0.84 | NaN | – | 27.91 | 1.73 | t-lim | – |
| 100 | 23.18 | 1338.38 | NaN | – | 455.62 | 0.68 | NaN | – | 23.88 | 3.55 | t-lim | – |
| 200 | 23.18 | 6084.58 | NaN | – | 493.25 | 0.80 | NaN | – | 20.65 | 6.75 | t-lim | – |
| 500 | NaN | – | 576.69 | 1.55 | NaN | – | 17.39 | 7.30 | t-lim | – | ||
| 5000 | NaN | – | 1189.71 | 10.83 | NaN | – | fail | – | t-lim | – | ||
| Best: | 23.18 | 94.54 | ||||||||||
| ASP: | 23.18 | 100.38 | ||||||||||
| 4/10 runs led to NaN loss function value. | ||||||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karmitsa, N.; Taheri, S.; Joki, K.; Paasivirta, P.; Bagirov, A.M.; Mäkelä, M.M. Nonsmooth Optimization-Based Hyperparameter-Free Neural Networks for Large-Scale Regression. Algorithms 2023, 16, 444. https://doi.org/10.3390/a16090444
Karmitsa N, Taheri S, Joki K, Paasivirta P, Bagirov AM, Mäkelä MM. Nonsmooth Optimization-Based Hyperparameter-Free Neural Networks for Large-Scale Regression. Algorithms. 2023; 16(9):444. https://doi.org/10.3390/a16090444
Chicago/Turabian StyleKarmitsa, Napsu, Sona Taheri, Kaisa Joki, Pauliina Paasivirta, Adil M. Bagirov, and Marko M. Mäkelä. 2023. "Nonsmooth Optimization-Based Hyperparameter-Free Neural Networks for Large-Scale Regression" Algorithms 16, no. 9: 444. https://doi.org/10.3390/a16090444
APA StyleKarmitsa, N., Taheri, S., Joki, K., Paasivirta, P., Bagirov, A. M., & Mäkelä, M. M. (2023). Nonsmooth Optimization-Based Hyperparameter-Free Neural Networks for Large-Scale Regression. Algorithms, 16(9), 444. https://doi.org/10.3390/a16090444