
Placement of IoT Microservices in Fog Computing Systems: A Comparison of Heuristics


Abstract
:1. Introduction
2. Background and Problem Definition
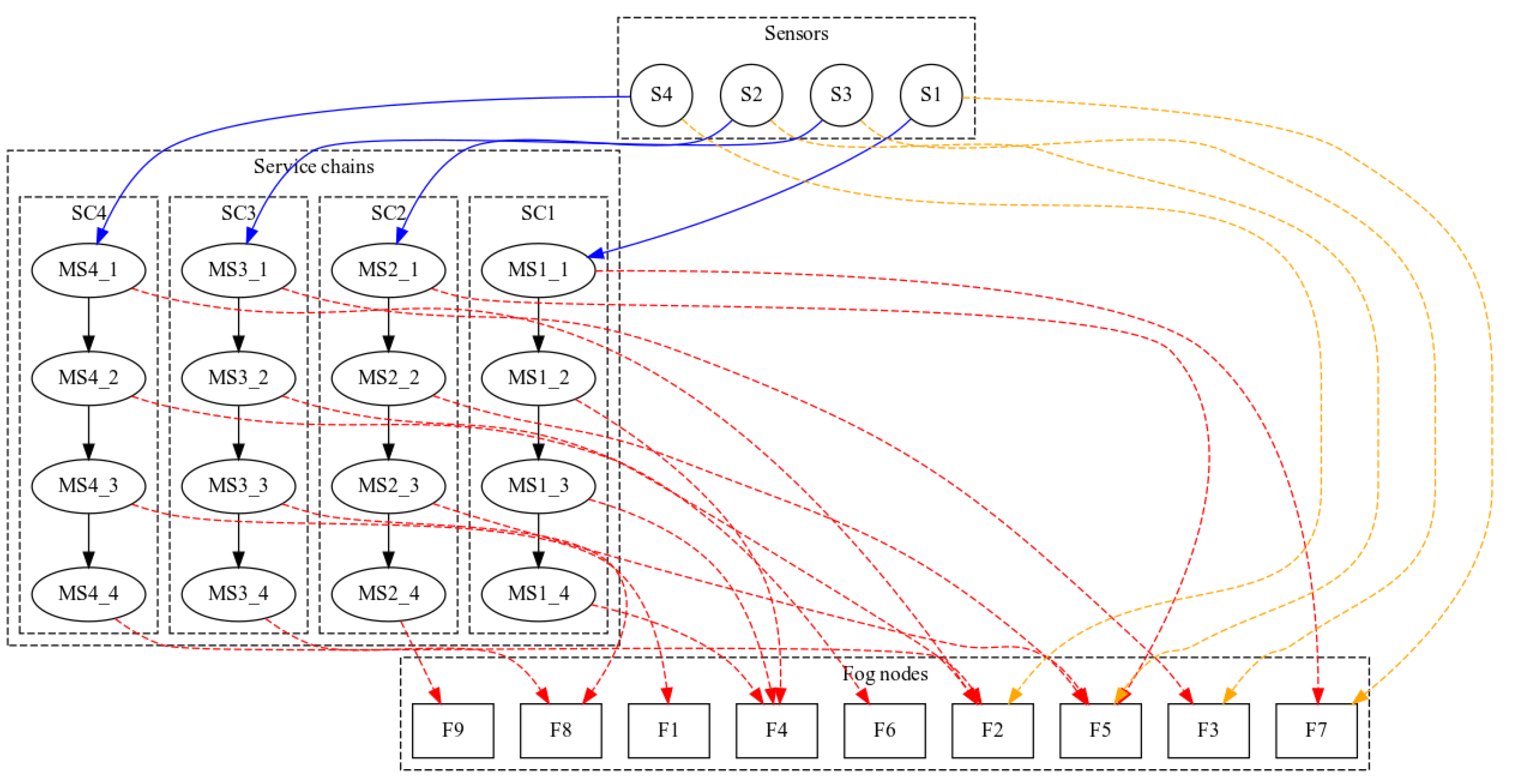
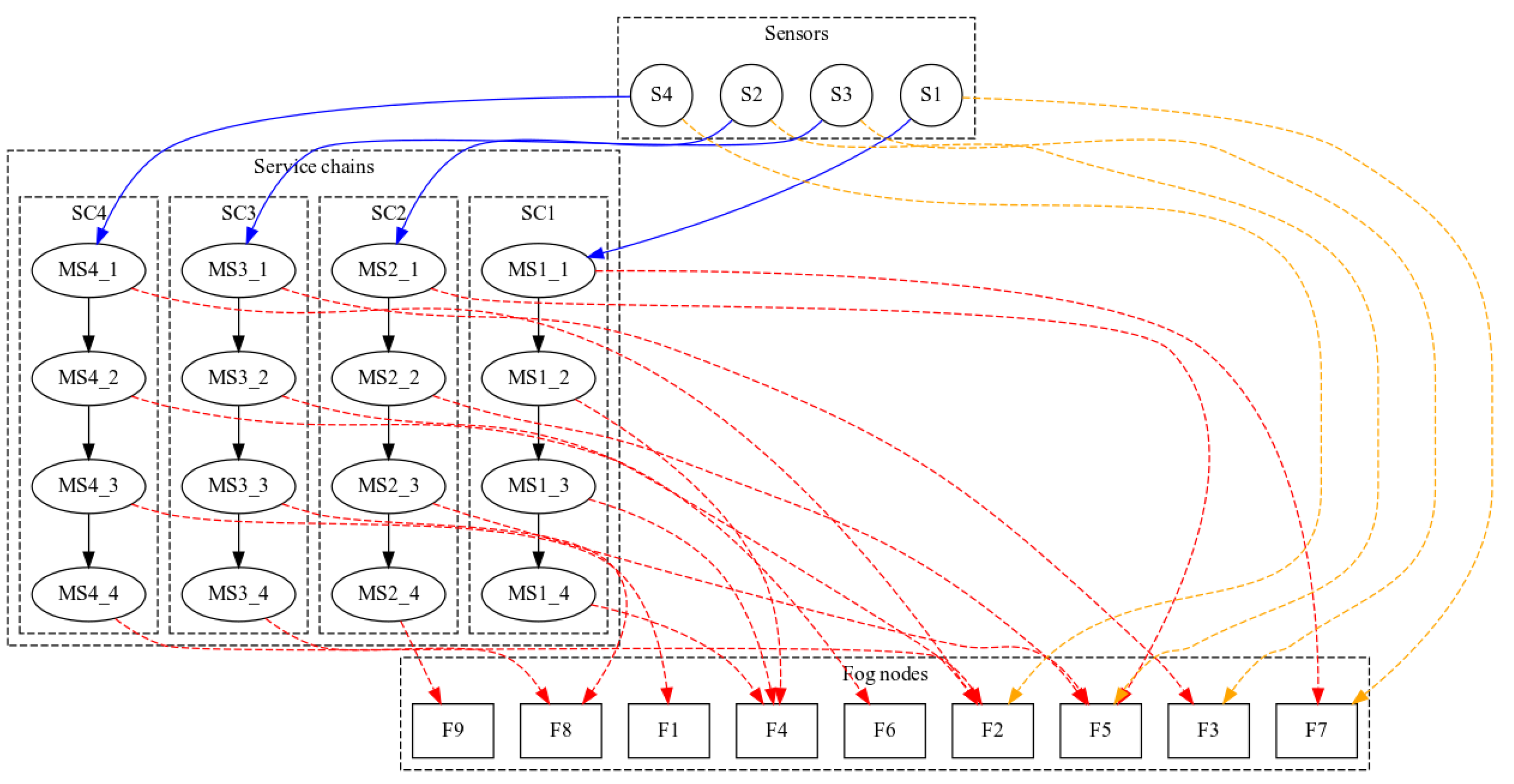
2.1. Reference Scenario
- A list of applications with related SLAs;
- A set of fog nodes, along with their computational capacity;
- A demand for applications with short-to-mid term expected load that is known a priori.
2.2. Problem Definition
- Heuristic execution time;
- Service chain response time;
- Number of hops normalized against the length of the service chain;
- Jain index.
3. Heuristics for Microservice Placement
3.1. Modified Best Fit Decreasing
| Algorithm 1 Modified Best Fit Decreasing |
| INPUT: : list of microservices, : list of fog nodes OUTPUT: : mapping of micro service over fog nodes
|
- Resources are used in a proper way: as an example, the remaining capacity of the fog nodes in a solution should not be less than zero.
- The objective function in (1) in is better than the older one in ; as network delays are considered, MBFD can balance the placement using awareness of the delay between nodes.
| Algorithm 2 compute_obj_function |
| INPUT: : mapping of microservices on fog nodes OUTPUT: Objective function for a given solution for each do for each do if != 0 then calculate , and else , and all equals to 0 for each do calculate based on the m’s mapping calculate object function |
3.2. Genetic Algorithms
3.3. Variable Neighborhood Search
- Algorithm 3: randomly select a leaf node , the farthest microservice allocated to , the nearest fog node to , and the sensor allocated to nearest to . If this new solution is feasible, swap and from their respective fog nodes.
- Algorithm 4: denote as the set of active fog nodes; calculate the load of each fog node as , then the average load of the active fog nodes as . Randomly select with load . Next, select the farthest microservice allocated to , then choose the node with the lowest load that is close to . Now, if feasible, remove from and place it on .
| Algorithm 3 Group Close Sensors |
| Function Bring_Near(x) Random choose a fog node from the solution. Get the farthest microservice allocated in F1. Select the closest fog node to the selected microservice. Select the closest microservice from F1. if then return else return x |
| Algorithm 4 Load-Based Microservice Migration |
| Function Reduce_Load(x) for to do Select fog node with load Get the farthest microservice allocated in F1. Select the node with lowest and near if then Remove from and allocate it on . return |
- : perform every possible microservice exchange on the fog nodes.
- : perform every possible allocation of microservices on the fog nodes.
4. Experimental Results
4.1. Experimental Setup
- Service chain length , that is, the number of microservices composing a chain;
- The service time of a service chain ;
- The average network delay between two fog nodes;
- Overall infrastructure load ;
- The problem size, that is, the number of fog nodes and service chains considered.
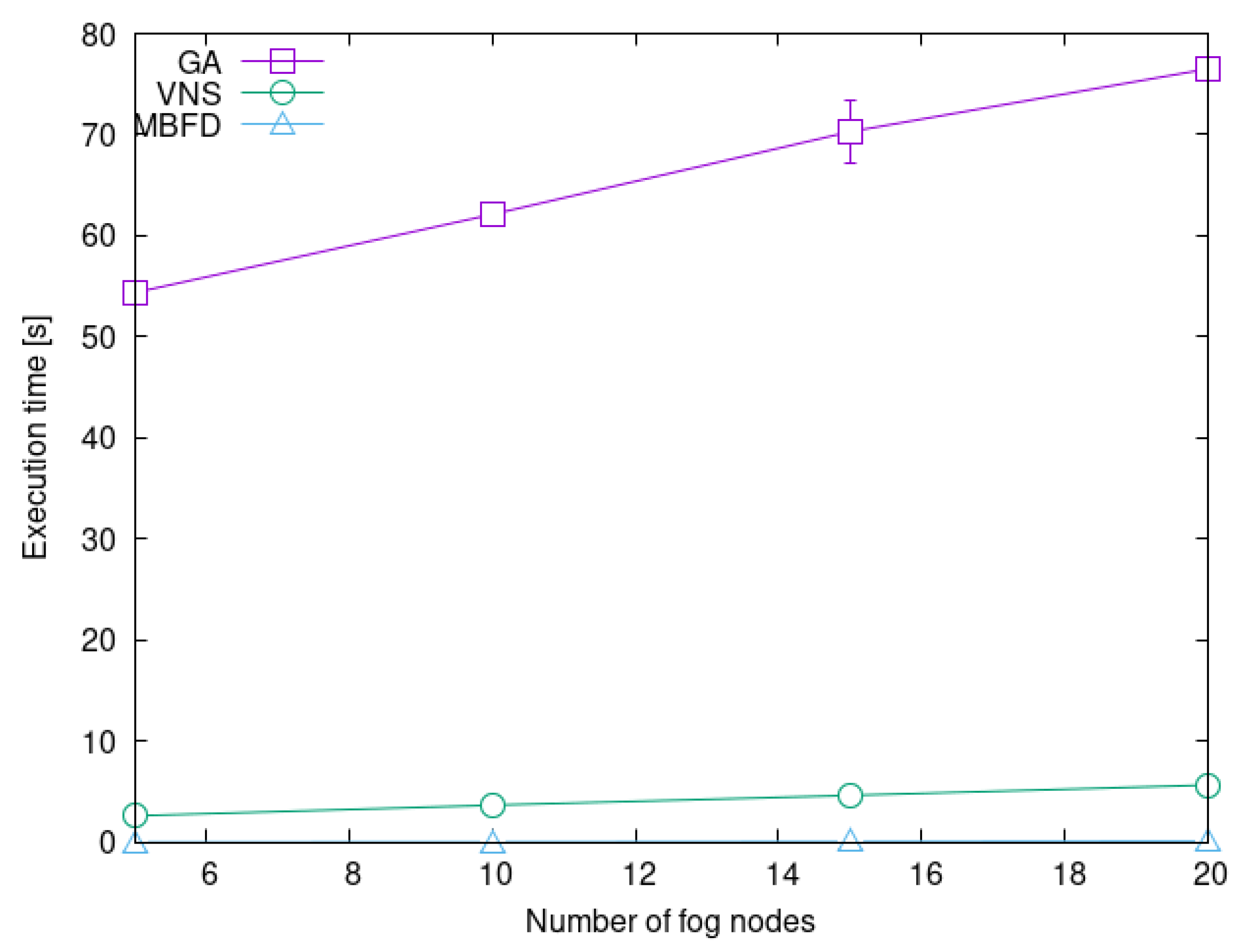
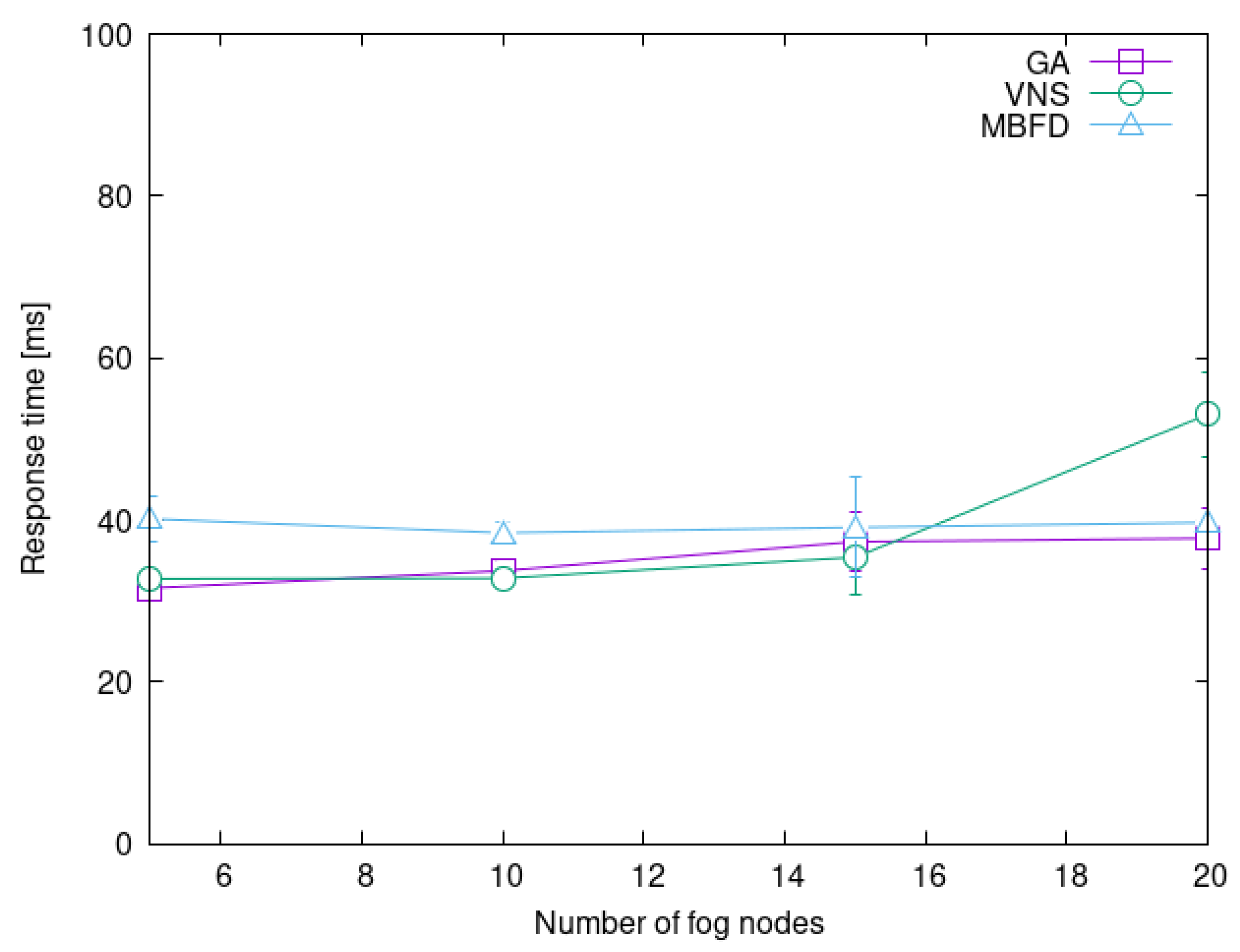
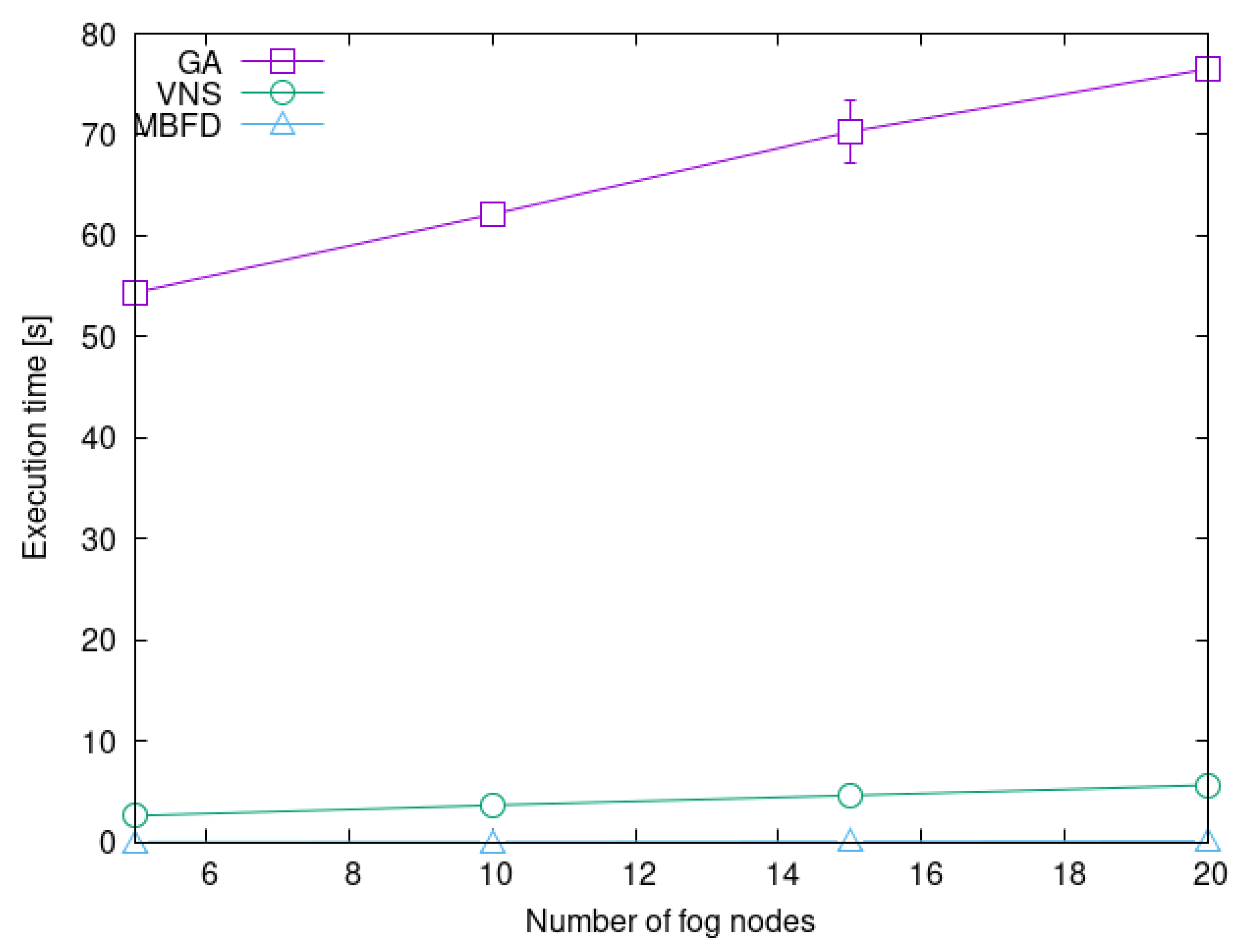
4.2. Heuristic Scalability
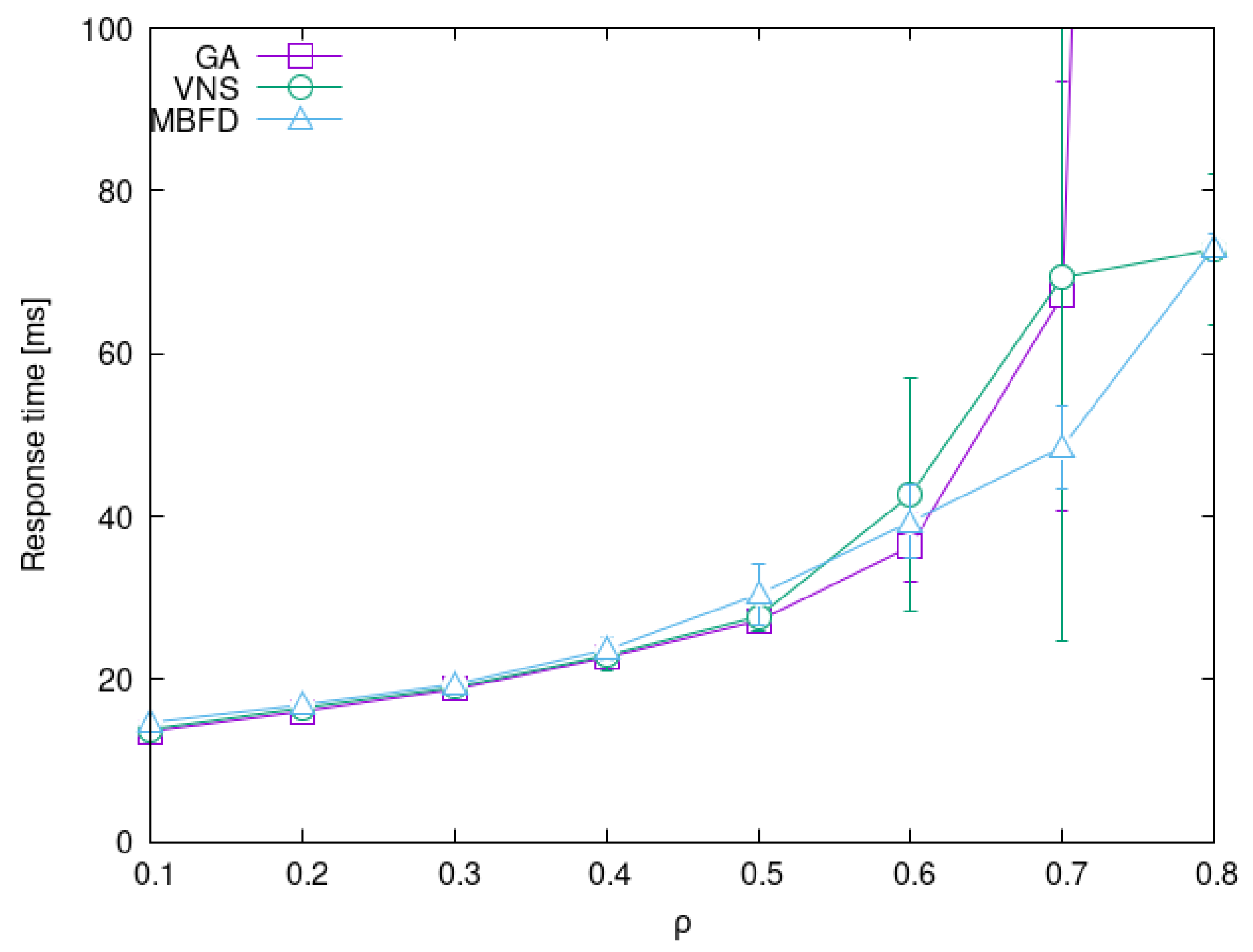
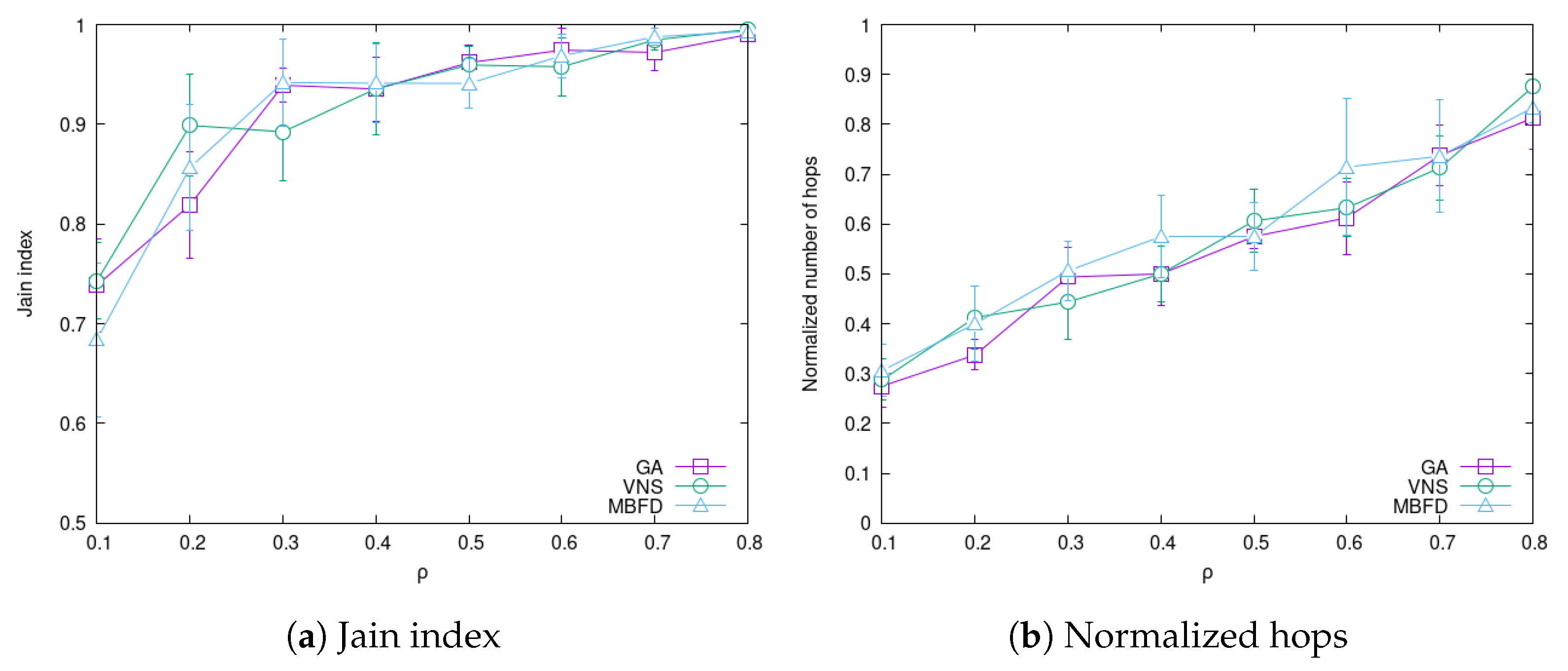
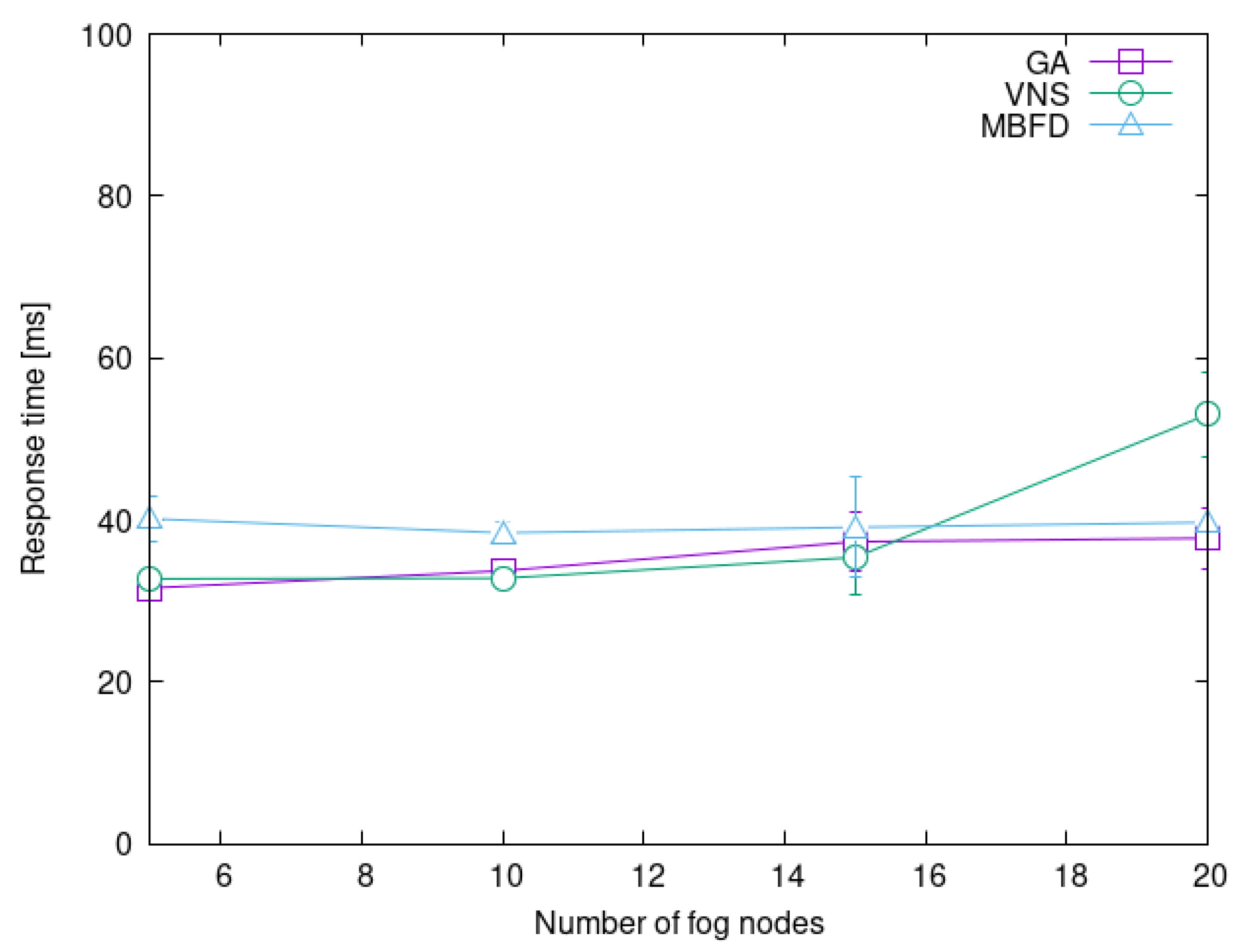
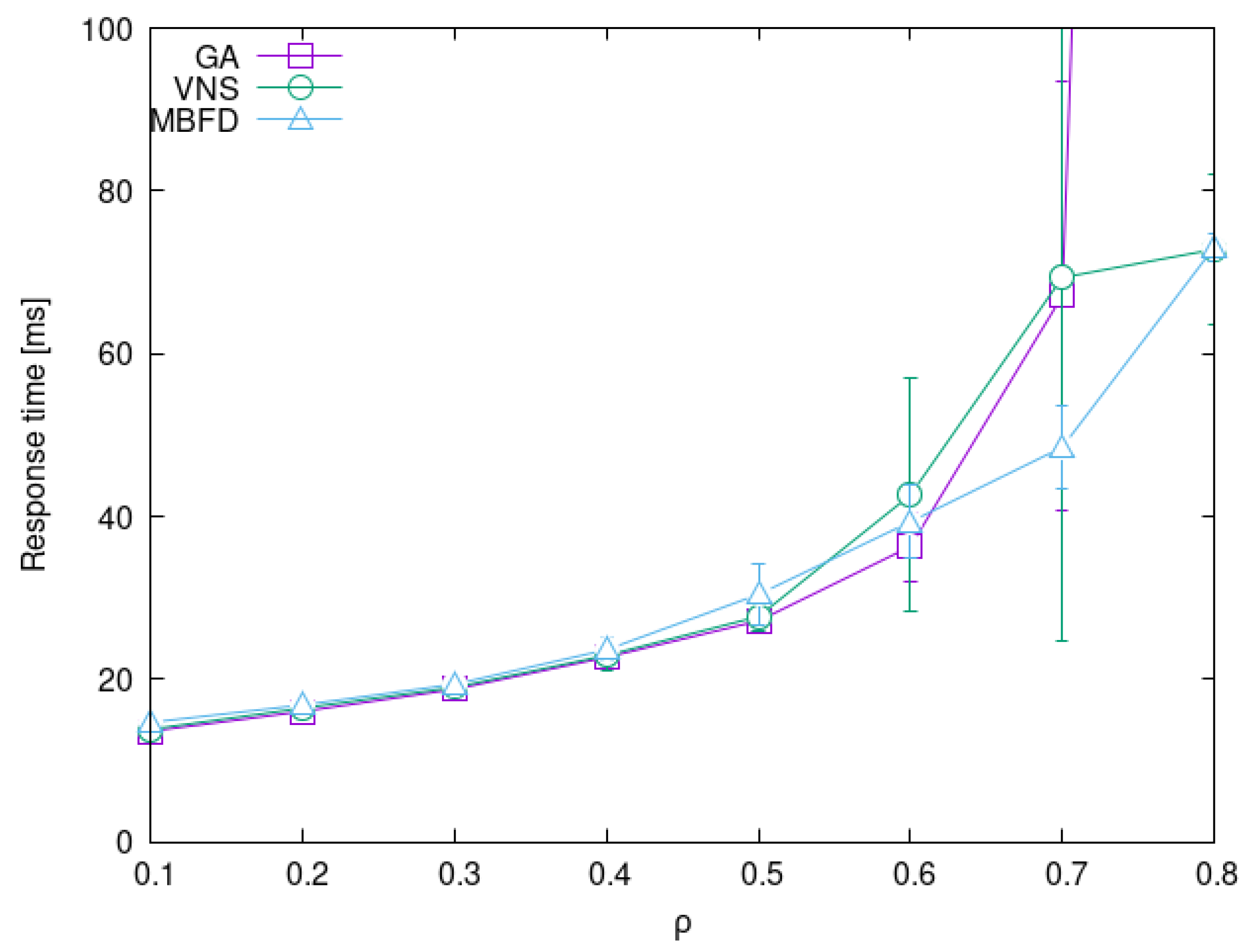
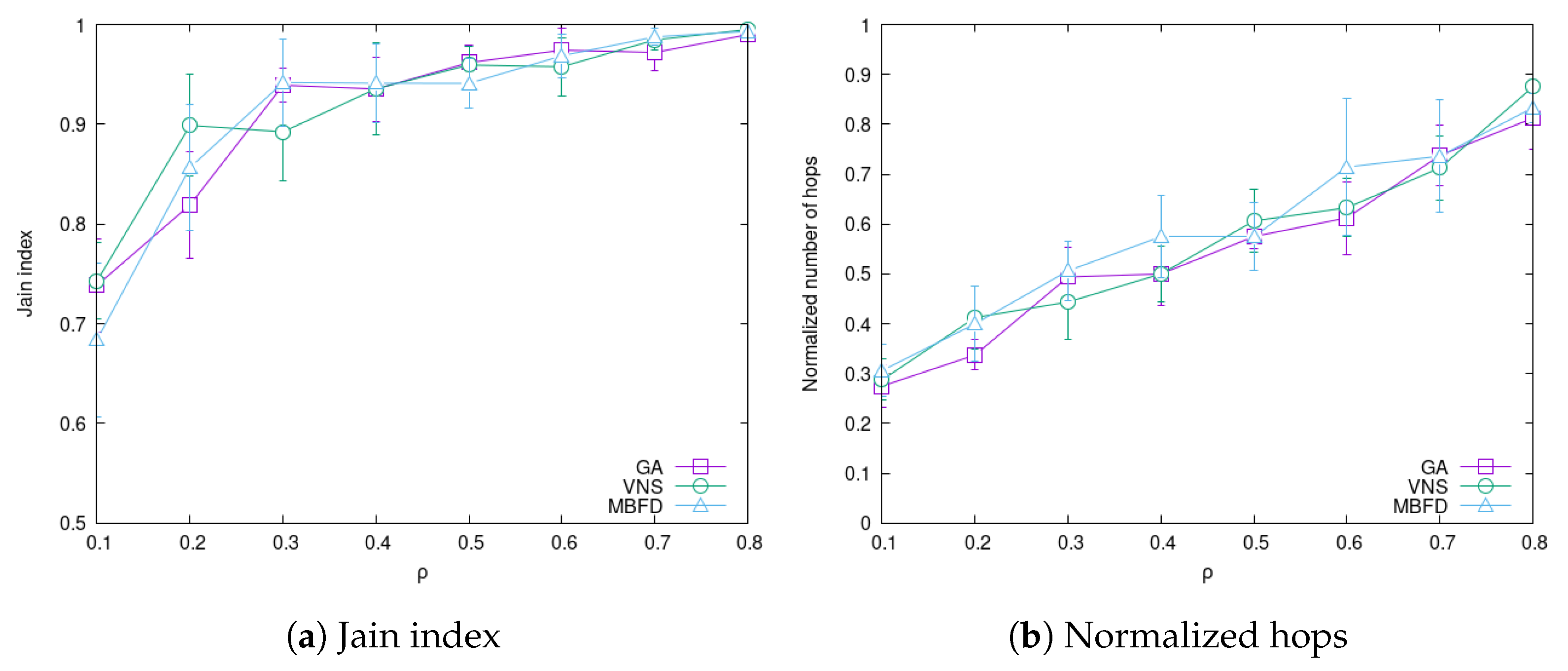
4.3. Impact of System Load
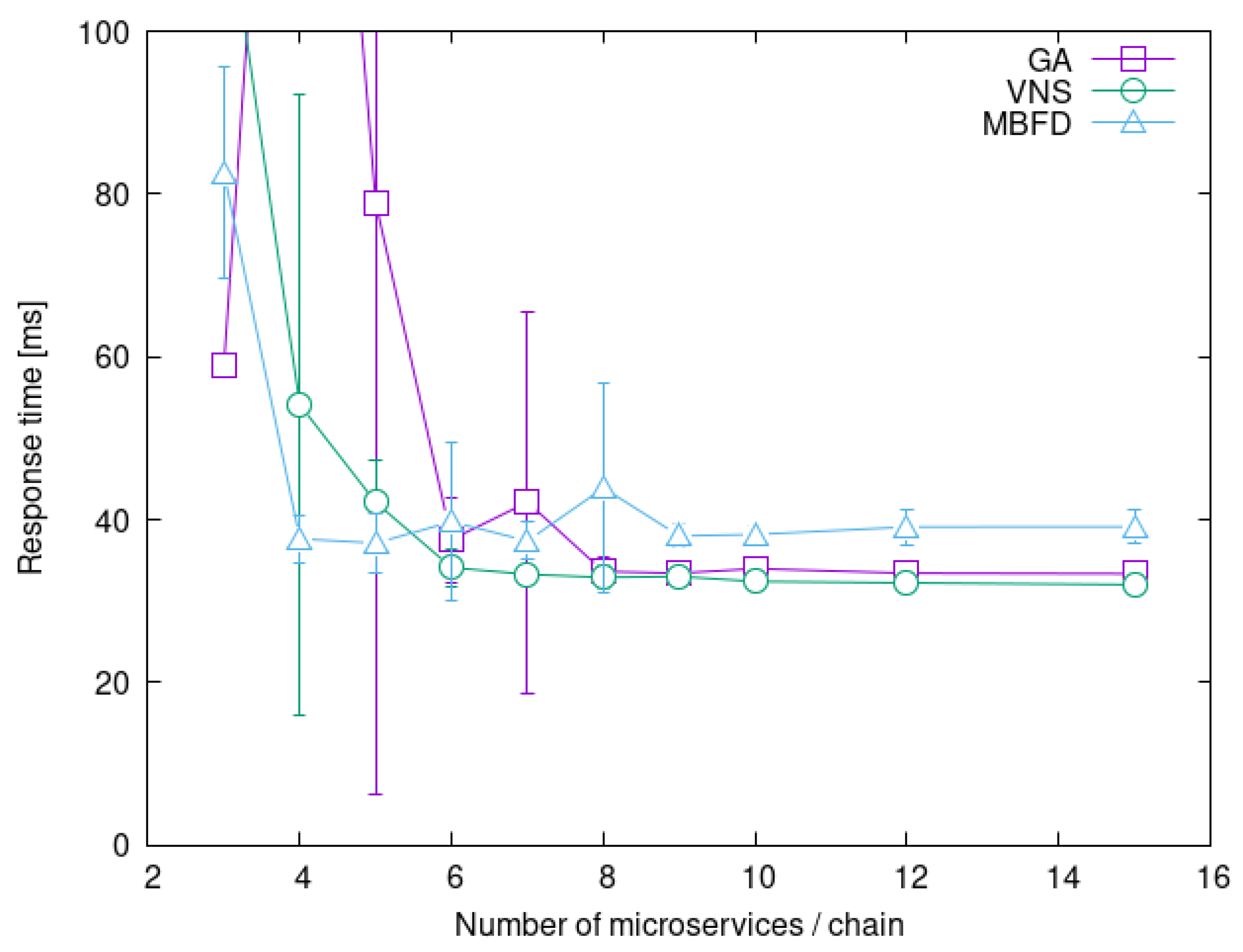
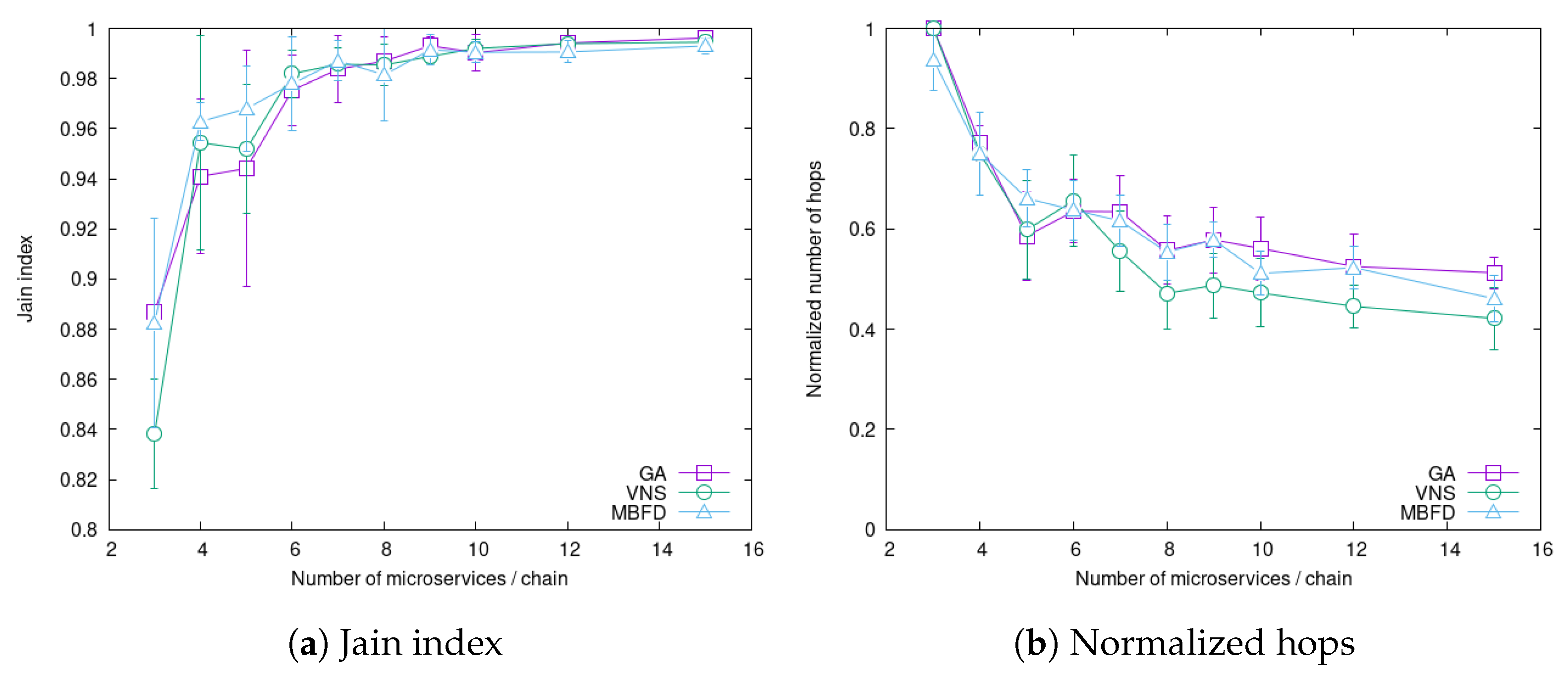
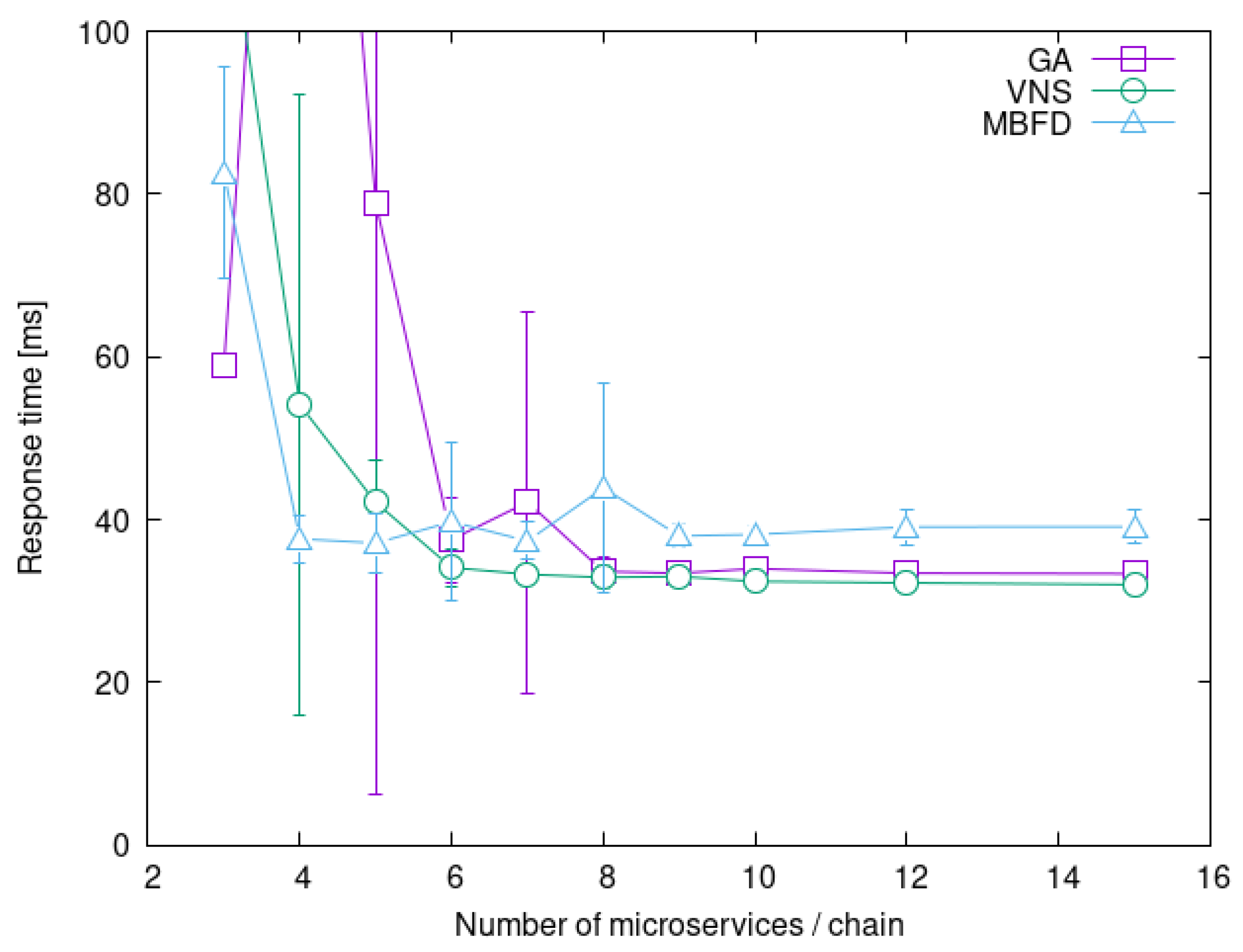
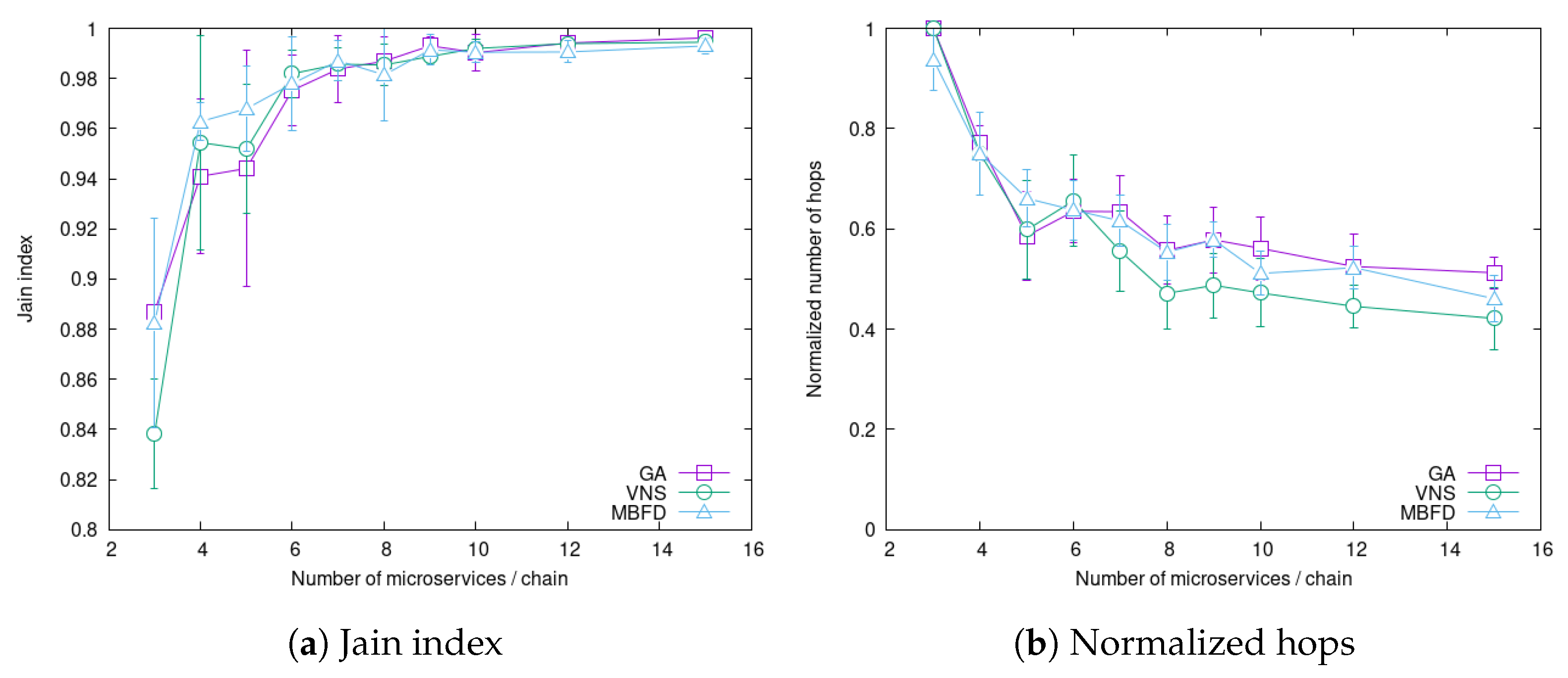
4.4. Impact of Service Chain Length
4.5. Summary of Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bugshan, N.; Khalil, I.; Moustafa, N.; Rahman, M.S. Privacy-Preserving Microservices in Industrial Internet-of-Things-Driven Smart Applications. IEEE Internet Things J. 2023, 10, 2821–2831. [Google Scholar] [CrossRef]
- De Iasio, A.; Furno, A.; Goglia, L.; Zimeo, E. A Microservices Platform for Monitoring and Analysis of IoT Traffic Data in Smart Cities. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 5223–5232. [Google Scholar] [CrossRef]
- Al-Dhuraibi, Y.; Paraiso, F.; Djarallah, N.; Merle, P. Elasticity in Cloud Computing: State of the Art and Research Challenges. IEEE Trans. Serv. Comput. 2018, 11, 430–447. [Google Scholar] [CrossRef]
- Abdullah, M.; Iqbal, W.; Berral, J.L.; Polo, J.; Carrera, D. Burst-Aware Predictive Autoscaling for Containerized Microservices. IEEE Trans. Serv. Comput. 2022, 15, 1448–1460. [Google Scholar] [CrossRef]
- Canali, C.; Di Modica, G.; Lancellotti, R.; Scotece, D. Optimal placement of micro-services chains in a Fog infrastructure. In Proceedings of the 12nd International Conference on Cloud Computing and Services Science, CLOSER 2022, Tuzla, Bosnia and Herzegovina, 6–9 April 2022. [Google Scholar]
- Sarkar, S.; Chatterjee, S.; Misra, S. Assessment of the Suitability of Fog Computing in the Context of Internet of Things. IEEE Trans. Cloud Comput. 2018, 6, 46–59. [Google Scholar] [CrossRef]
- Yousefpour, A.; Ishigaki, G.; Jue, J.P. Fog Computing: Towards Minimizing Delay in the Internet of Things. In Proceedings of the 2017 IEEE International Conference on Edge Computing (EDGE), Honolulu, HI, USA, 25–30 June 2017; pp. 17–24. [Google Scholar] [CrossRef]
- Songhorabadi, M.; Rahimi, M.; MoghadamFarid, A.; Haghi Kashani, M. Fog computing approaches in IoT-enabled smart cities. J. Netw. Comput. Appl. 2023, 211, 103557. [Google Scholar] [CrossRef]
- Bonomi, F.; Milito, R.; Zhu, J.; Addepalli, S. Fog Computing and Its Role in the Internet of Things. In Proceedings of the First Edition of the MCC Workshop on Mobile Cloud Computing, MCC ’12, New York, NY, USA, 17 August 2012; pp. 13–16. [Google Scholar]
- Salaht, F.A.; Desprez, F.; Lebre, A. An Overview of Service Placement Problem in Fog and Edge Computing. ACM Comput. Surv. 2020, 53, 1–35. [Google Scholar] [CrossRef]
- Beloglazov, A.; Abawajy, J.; Buyya, R. Energy-aware resource allocation heuristics for efficient management of data centers for cloud computing. Future Gener. Comput. Syst. 2012, 28, 755–768. [Google Scholar] [CrossRef]
- Canali, C.; Lancellotti, R. Exploiting Classes of Virtual Machines for Scalable IaaS Cloud Management. In Proceedings of the 4th Symposium on Network Cloud Computing and Applications (NCCA), Munich, Germany, 11–12 June 2015. [Google Scholar]
- Shojafar, M.; Canali, C.; Lancellotti, R.; Abolfazli, S. An Energy-aware Scheduling Algorithm in DVFS-enabled Networked Data Centers. In Proceedings of the 6th International Conference on Cloud Computing and Services Science (CLOSER), Rome, Italy, 23–25 April 2016. [Google Scholar]
- Binitha, S.; Sathya, S.S. A survey of bio inspired optimization algorithms. Int. J. Soft Comput. Eng. 2012, 2, 137–151. [Google Scholar]
- Yusoh, Z.I.M.; Tang, M. A penalty-based genetic algorithm for the composite SaaS placement problem in the Cloud. In Proceedings of the IEEE Congress on Evolutionary Computation, Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar] [CrossRef]
- Hansen, P.; Mladenović, N.; Moreno Pérez, J.A. Variable neighbourhood search: Methods and applications. Ann. Oper. Res. 2010, 175, 367–407. [Google Scholar] [CrossRef]
- Yu, R.; Xue, G.; Zhang, X. Application Provisioning in FOG Computing-enabled Internet-of-Things: A Network Perspective. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 783–791. [Google Scholar] [CrossRef]
- Skarlat, O.; Nardelli, M.; Schulte, S.; Dustdar, S. Towards QoS-Aware Fog Service Placement. In Proceedings of the 2017 IEEE 1st International Conference on Fog and Edge Computing (ICFEC), Madrid, Spain, 14–15 May 2017; pp. 89–96. [Google Scholar] [CrossRef]
- Canali, C.; Lancellotti, R. A Fog Computing Service Placement for Smart Cities based on Genetic Algorithms. In Proceedings of the International Conference on Cloud Computing and Services Science (CLOSER 2019), Heraklion, Greece, 2–4 May 2019. [Google Scholar]
- Kayal, P.; Liebeherr, J. Distributed Service Placement in Fog Computing: An Iterative Combinatorial Auction Approach. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–9 July 2019; pp. 2145–2156. [Google Scholar] [CrossRef]
- Xiao, Y.; Krunz, M. QoE and power efficiency tradeoff for fog computing networks with fog node cooperation. In Proceedings of the IEEE INFOCOM 2017—IEEE Conference on Computer Communications, Atlanta, GR, USA, 1–4 May 2017; pp. 1–9. [Google Scholar] [CrossRef]
- Zeng, D.; Gu, L.; Guo, S.; Cheng, Z.; Yu, S. Joint Optimization of Task Scheduling and Image Placement in Fog Computing Supported Software-Defined Embedded System. IEEE Trans. Comput. 2016, 65, 3702–3712. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Parameters | |
|---|---|
| Set of microservices | |
| Set of fog nodes | |
| Set of service chains | |
| Incoming rEquation rate to microservice m | |
| Incoming rEquation rate to fog node f | |
| Incoming rEquation rate to service chain c | |
| Incoming global request rate | |
| Avg. service time for microservice m | |
| Standard deviation of | |
| Computational power of fog node f | |
| Avg. waiting time on fog node f | |
| Avg. service time on fog node f | |
| Standard deviation of | |
| Avg. response time for fog f | |
| Avg. response time for service chain c | |
| SLA of service chain c | |
| Services order of execution in a chain | |
| Network delay between nodes and | |
| Model indices | |
| f | Fog node |
| c | Service chain |
| m | Microservice |
| Decision variables | |
| Allocation of microservice m to fog node f | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Canali, C.; Gazzotti, C.; Lancellotti, R.; Schena, F. Placement of IoT Microservices in Fog Computing Systems: A Comparison of Heuristics. Algorithms 2023, 16, 441. https://doi.org/10.3390/a16090441
Canali C, Gazzotti C, Lancellotti R, Schena F. Placement of IoT Microservices in Fog Computing Systems: A Comparison of Heuristics. Algorithms. 2023; 16(9):441. https://doi.org/10.3390/a16090441
Chicago/Turabian StyleCanali, Claudia, Caterina Gazzotti, Riccardo Lancellotti, and Felice Schena. 2023. "Placement of IoT Microservices in Fog Computing Systems: A Comparison of Heuristics" Algorithms 16, no. 9: 441. https://doi.org/10.3390/a16090441
APA StyleCanali, C., Gazzotti, C., Lancellotti, R., & Schena, F. (2023). Placement of IoT Microservices in Fog Computing Systems: A Comparison of Heuristics. Algorithms, 16(9), 441. https://doi.org/10.3390/a16090441