1. Introduction
Among the available privacy-preserving techniques for network-based data, degree anonymization proves to be a practical tool in terms of conserving data utility and resisting re-identification attacks. It works by altering the set of edges of a graph so that nodes are indistinguishable in terms of their degrees. Formally, a graph
G is
k-degree anonymous if, for every vertex
v, there are at least
other vertices with the same degree as
v [
1]. This particular type of “hiding in the crowd” guarantees privacy, because an attacker can identify an individual with a probability of at most
, where
k is the anonymity/security level desired by the data publisher.
Unfortunately, the above classical definition of degree anonymity is too restrictive. Requiring at least k vertices to have the same degree, for each possible vertex degree, could have a very high edge-modification cost in large networks. An alternative multi-objective optimization approach is proposed in this paper. Our model sets restrictions on the number of added and deleted edges per vertex and relaxes the same-degree restriction by setting a range parameter on the resulting degrees, so they would be required to be close enough, while not affecting the privacy level. Thus, it extends the real applicability of this type of network data anonymization. We formally define degree anonymization as a multi-objective optimization (or multi-parameterized) problem, as follows.
Given: An undirected graph , positive constraint parameters , a range parameter t, and an anonymization parameter k.
Question: Can we obtain an anonymous graph by adding at most a and deleting at most d edges per single vertex, so that, for each vertex v, we have at least other vertices whose degrees fall into the interval ?
The anonymization parameter k is assumed to be pre-defined by the user based on the desired anonymization level and the type of the given data.
The parameters
a,
d, and
t are computed by the algorithm, as we propose in this paper, to deliver the least cost target solution. It is worth noting that adding local parameters or constraints, typically in graph modification problems, is known to have a notable positive effect on the problem’s complexity, while improving the practicality of the model. This was noted in [
2] in the context of (multi-parameterized) Cluster Editing, which inspired the above formulation and the work we present in this paper.
The above-proposed model is a generalization of the k-degree anonymization problem, which corresponds to the case where and . We formulate the resulting graph realization problem as an Integer Linear Programming (ILP) problem. We test the utility of our approach by applying clustering on the initial graph and the modified one after performing our anonymization procedure. The comparison is based on measuring the symmetric difference between clusters. In addition, we compare some graph metrics before and after perturbation.
2. Preliminaries
We assume familiarity with basic graph theory terminology such as adjacency, vertex degree, and neighborhood, among others. Networks, or graphs, are often subject to attacks that are based upon some prior or presumed knowledge about the degrees of some targeted nodes. This is assumed to be one of the most significant types of attacks [
3], since it could threaten individuals’ privacy by inferring knowledge about the links to a node and the topology of the graph. Other types of attacks that rely on a priori knowledge of the neighborhood of a targeted node, or the corresponding induced subgraph, can be reduced down to knowledge about the degree of that targeted node.
To cope with the above threats, several methods for network data anonymization have been introduced based on the “hiding in the crowd“ approach. Popular methods include clustering-based anonymization (see [
4,
5,
6]) and degree-based anonymization, which we address in this paper. In general, the
k-anonymity model aims at altering the structure of a given graph by adding and/or deleting edges or nodes such that each node in the resulting graph is similar to at least
other nodes, in terms of a specific property [
7,
8]. The
k-degree-anonymity approach specifies that nodes are indistinguishable by their degrees.
Each graph G can be represented by a sorted (often decreasing) sequence of the degrees of its vertices. We refer to this sequence by , being unique for G. The notion of the k-degree anonymity of a graph can, thus, be reduced to a transformation of its degree sequence into an anonymized one. We seek a minimal number of edge-editing operations.
Definition 1. Generally, a degree sequence is k-anonymous if every value in is repeated at least times. Then, a graph G is k-degree anonymous if its degree sequence is k-anonymous.
Our approach is divided into two parts. In the first, the descending degree sequence is computed and anonymized to produce a degree sequence . In the second part, is constructed so that . This latter procedure is known as graph realization, which we formulate as an ILP problem.
Previous Edge-Editing Methods
The first degree-based anonymization approach seems to be due to Liu and Terzi [
9], who proposed a technique that modifies a given graph/network by adding/deleting a certain number of edges to generate a
k-degree anonymous graph. While the work of Liu and Terzi is motivated by logical intuitions, they admit that additional work needs to be carried out to develop theoretically and practically sound privacy models for graphs.
In some other attempts, the set of vertices is changed instead of the set of edges. For example, Chester et al. proposed an approach that generates new edges between auxiliary and real nodes or between auxiliary nodes [
10]. For unlabeled graphs, experimental results demonstrated that perturbing the set of vertices changes some important properties of a graph (such as how the nodes cluster) and weakens the “data accuracy” because of the information loss. In [
11], Casas-Roma et al. presented an algorithm for graph anonymization based on the univariate micro-aggregation. It works by modifying the set of edges, based on the univariate micro-aggregation method for data protection.
Another approach by Alavi et al., named the “GAGA Graph Anonymizer”, was published in 2019 [
12]. Their “Genetic Algorithm for Graph Anonymization” is claimed to be the best solution for networks’ protection because it overcomes all of the limitations of other available solutions. Another genetic algorithm was presented in [
13]. Genetic algorithms, however, are known for their limitation in guaranteeing an optimal (or near-optimal) solution. Moreover, with the increase in problem size, especially with real large networks, a genetic algorithm tends to slowly converge to a local minimum. In our work, we can achieve optimum solutions, modulo the various parameters, by employing an ILP formulation of the problem.
Finally, Bazgan et al. [
14] proved that the problem of degree anonymization via edge rotation is NP-Hard. In this problem, instead of deleting or adding edges and vertices, the objective is to find a minimum amount of “edge rotations” that make the graph
k-degree anonymous.
3. Generating k-Anonymous Degree Sequences
We present an algorithm (namely Algorithm 1, below) that takes an original graph G and a privacy level k as input and starts by generating the descending ordered degree sequence and copying it into the target degree sequence , where the degree-modifications are performed. We assume that the privacy level k is given. Otherwise, we compute a privacy level that is most suitable for G, based on the deviation of the degrees in D. We leave a detailed description of this latter approach for future work. We apply a vector-based approach that divides into chunks, or segments, of at least k nodes each. For every segment, we define the constraint parameters a and d, which correspond to the maximum number of edge additions and deletions per single vertex, respectively.
We set a as the absolute value of the difference between the first degree in each segment and the last one minus , and we set as a default value. The average degree in each part is calculated, and the node’s degree that is the closest to the average will be set as the degree of the first node in that chunk in .
If the degree of the next node does not fall into the interval , then we add, for that node, the required number of edges for its degree to belong to the above interval. If the number of edges that have to be added exceeds the limit a, then we delete edges from the previous node and add edges to the second node within the allowed range. The algorithm will repeat the same process until is all covered.
| Algorithm 1: Multi-parameterized k-degree anonymizat |
![Algorithms 16 00436 i001]() |
3.1. Choosing k
As mentioned before, the anonymity value
k is chosen based on the purpose of publishing the data and the desired privacy level. The larger the value of
k, the more resistant to attacks the data will be, but the more perturbation to the data set which will be performed. Hence, the challenge in deciding on the value of
k is to keep the balance between maintaining privacy and utility simultaneously. The literature does not suggest any formula to set the value of
k, other than by experimenting. In this paper, we suggest and apply a statistical formula to decide on the privacy level that is the most convenient for each data set, based on the distribution of the degrees of nodes. The formula is centered around the standard deviation of degrees of nodes. The standard deviation tells how the values in the degree sequence vector are spread out from the average.
k is proportional to the standard deviation of degrees, which will have a good impact on data utility preservation. Formally:
where
is the standard deviation of the values in D. To assure that the final value is a natural whole number, we take the ceiling of the calculated number. If the degrees are relatively close to each other, i.e., the difference between them is small, then our formula would suggest a small value for
k, because the standard deviation is insignificant in this case. Working with a small
k can guarantee the best solution in terms of utility because the data set does not need major alterations to be anonymized. However, if there is a vast difference between the degrees, i.e., their standard deviation is remarkable, then k would be too large to guarantee a good privacy level.
3.2. Time Complexity
From a time-complexity standpoint, the worst-case scenario happens when there is a high standard deviation between the degrees of nodes, or when all nodes have different degrees. In this case, many edges will be affected to reach the anonymity level of k. For each node, we may have at most operations of edge addition and/or deletion. Therefore, the time complexity is . In the best case, on the other hand, there would be no significant divergence between the degrees of nodes, or the graph is nearly regular (all nodes have almost the same degree), and then the time complexity would be .
4. A Graph Realization Approach
In the second phase of the anonymization procedure, the output graph
is constructed based on the target degree sequence
. Recall that we aim to produce a graph that is
k-anonymous by performing the least amount of perturbation to the topology and structure of
G. The common practice is to remove edges incident on vertices that have to decrease their degrees, and add new edges to vertices that have to increase their degrees, without taking into consideration the major effect of graph re-construction on the topology of the network. With this limitation in mind, we formally define “the realization” [
15] as an optimization problem as follows:
Weighted Graph Realization
Given: A graph G and a function .
Question: Is there a sequence of edge-editing operations that results in , such that ?
The realization procedure we propose begins by copying G into , on which edge edits are performed. Then, it computes the vector of changes between and D, i.e., . This vector is used to detect which nodes have to introduce or remove incident edges. It can also be used to compute the anonymization cost. To further explicate, if is negative, then incident edges on v should be removed. However, if is positive, then edges should be added to v. Each vertex will be labeled by its corresponding weight in .
We formulate this particular graph realization problem as an Integer Linear Programming problem (ILP). For this purpose we use a binary variable
for every pair of vertices
i and
j. The interpretation is that
if
was added or deleted, otherwise
. This gives the following ILP formulation:
In other words, if the ILP solution assigns a value of 1 to and is not an edge (initially), then we add the edge . On the other hand, if was an edge and , then we remove the edge. Here, w is the weight of the vertex representing the number of edges that should be added or deleted.
5. Experimental Analysis
We implemented our multi-objective degree anonymization algorithm and ran multiple tests using different graphs to assess its efficiency and, most importantly, its ability in preserving data utility. It was implemented in , and we used for the realization algorithm. The tests were performed on an Intel(R) Core(TM) i7-7600U CPU @ 2.80 GHz machine. Various values of k were tested while t was set to 2.
We compared our results with the ones presented in [
16] for the algorithm of Liu and Terzi (
k-Degree Anonymization:
k-
). We also compared our algorithm to the vertex addition approach by Chester et al. [
10], in which the anonymization process takes place by adding fake vertices to the network and fake edges between these vertices, and between fake vertices and real ones, to attain the required
k-anonymity level. Finally, we compared our results with Jordi-Casas et al.’s results in [
11]. Their algorithm is based on the univariate micro-aggregation. It is available in two versions. The first, dubbed “NC”, is based on the notion of neighborhood centrality, to decide which edges to delete. It tries to preserve the edges that are more relevant to the connectivity of the whole network than others. The second approach (“Rand”) randomly selects edges to be removed. We used the authors’ published results for comparison.
Real data sets were used for testing. The selected networks were obtained from the KONECT Project [
17]. They are different in terms of topological, structural, and attribute properties. However, all of the graphs used are simple, unweighted, and undirected. The following were chosen:
US politics book data (Polbooks-2004) [
18] is a network of US politics’ books where vertices represent books and an edge between two vertices implies that they are co-purchased frequently by the same buyers.
Polblogs [
19], which stands for political blog-sphere data, is a network that compiles data about links between US political blogs.
GrQc [
20] is a collaboration network that displays collaborations between authors and scientific papers in the field of General Relativity and Quantum Cosmology.
American college football [
21] is a network of American football games during Fall 2000. A vertex represents a playing team, and an edge between two teams means that they have played together.
Erdos [
17] network is a graph that shows a list of mathematician Paul Erdos’ co-authors along with their respective co-authors.
The Enron [
22] email network covers all email communications within a dataset of around half a million emails.
The notion of data utility is not well-defined yet, so different authors have different approaches in quantifying data loss in a graph. In our work, we use the following graph structural measures to quantify and analyze information loss induced by the anonymization process:
The largest eigenvalue of the adjacency matrix implies information about the diameter of a network and its cycles.
The second smallest eigenvalue of the Laplacian matrix implies information about the tree structure of the graph. It shows if the communities separate efficiently or not.
The average distance is the average of the shortest paths between all nodes in a network.
The harmonic mean of the shortest distance is similar to the average distance; it is used to evaluate the connectivity of a network.
Modularity measures the strength of the division of a network into clusters. High modularity values imply dense connections between the nodes of a graph.
Transitivity is similar to the clustering coefficient; it detects the presence of loops near a vertex.
Subgraph centrality measures the number of subgraphs a vertex takes part in, weighting them according to their size.
5.1. Empirical Results
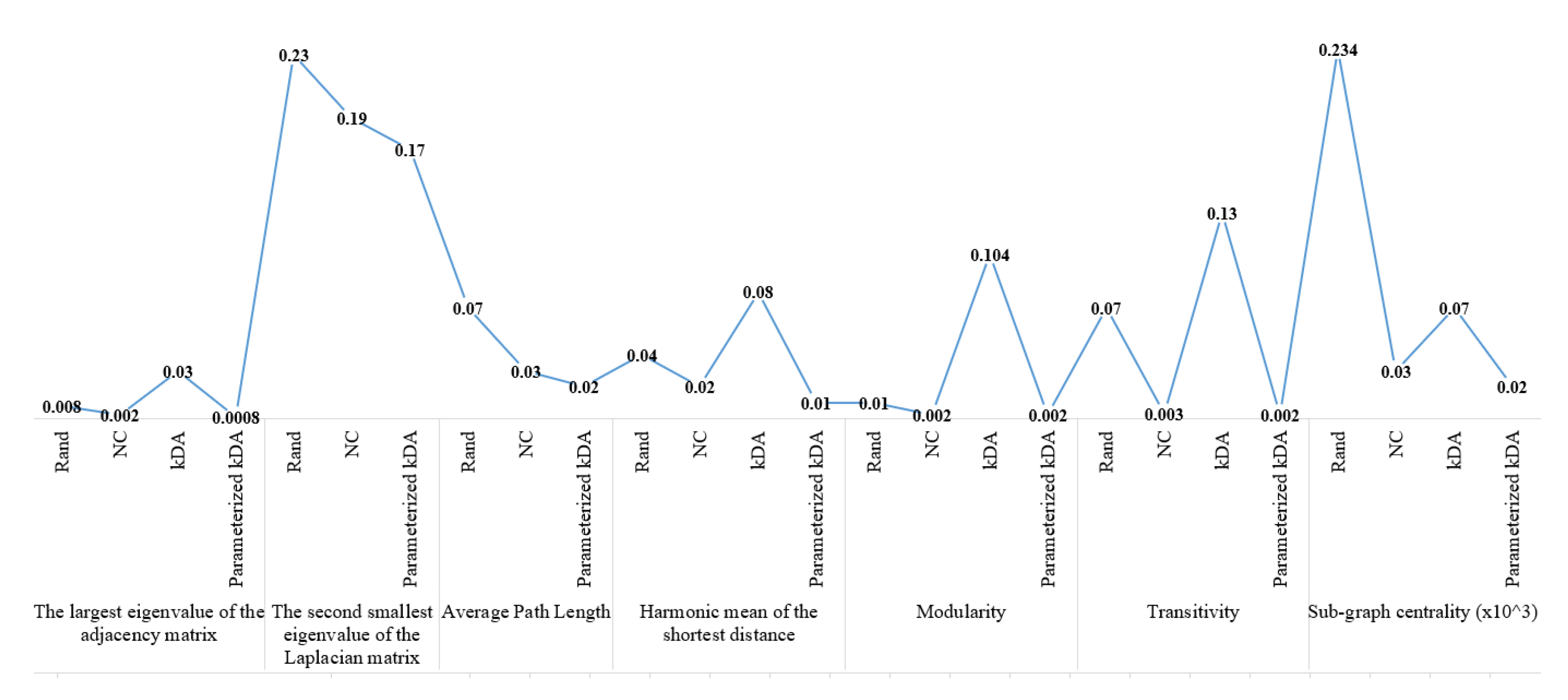
We tested each dataset using the above-described algorithms in addition to our multi-parameterized model. We used the “Polbooks” network; it was not used to test the vertex addition algorithm, so we compared our multi-objective approach with Rand, NC, and kDA. We recorded the error induced by each algorithm on different utility measures. As shown in
Figure 1, the Rand and NC algorithms surpass kDA, which induces a marginally less average error on the value of the transitivity measure. In general, NC outperforms Rand because it keeps essential edges in the network, which preserves the values of the measures to some extent. By comparing the average error produced by each algorithm, it is noticeable that our algorithm induces less noise and keeps the measures very close to their original values. Our results are shown for
.
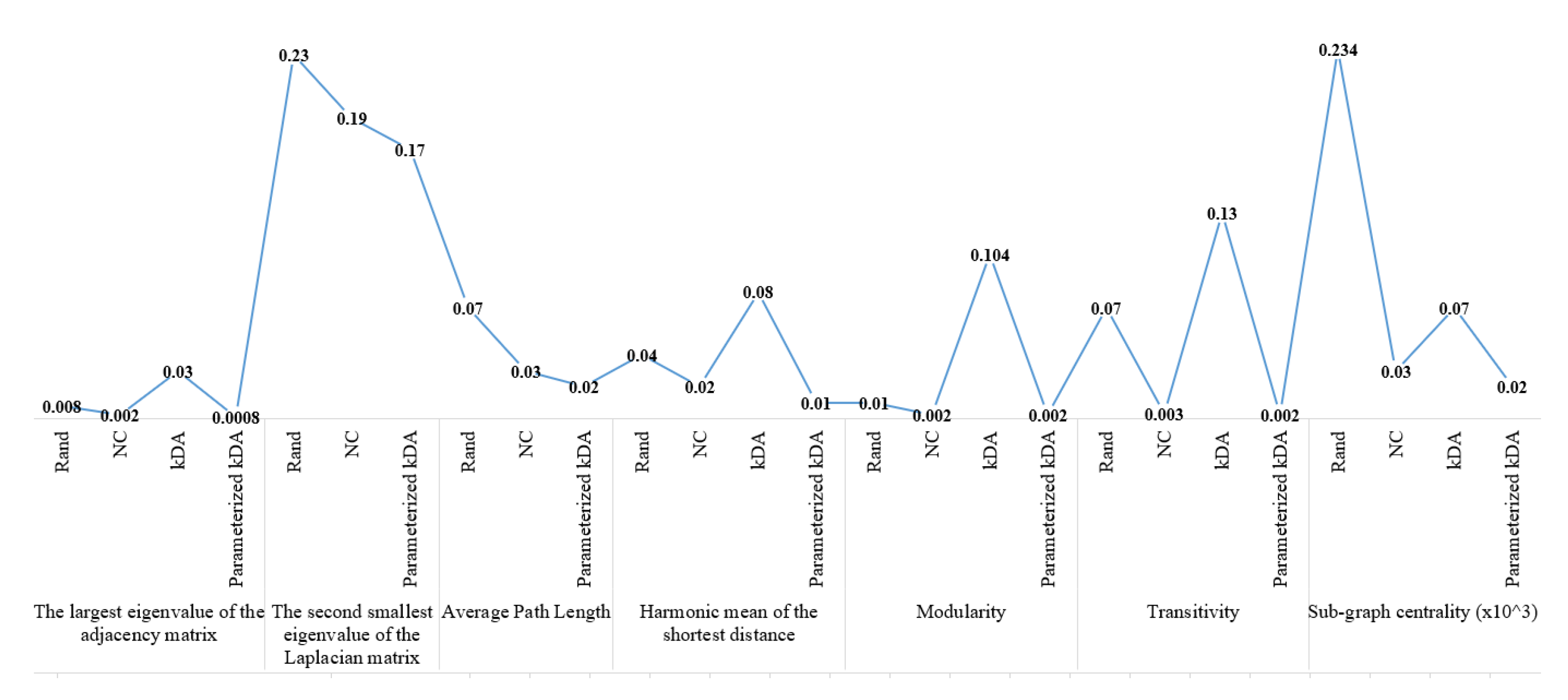
We tested a larger network which is “Polblogs”. According to
Figure 2, Rand and NC produced an average error that is less than that produced by vertex addition or kDA on all measures. kDA produced a remarkable deviation from the originally measured values. The average error is 0.286 for NC and 0.291 for Rand, while it is 1.953 for kDA on the largest eigenvalue of the adjacency matrix. Keeping eigenvalues close to their original values implies preserving cycles and the diameter of the network. Our approach outperformed Rand and NC by producing a smaller average error of around 0.213. Likewise, the vertex addition algorithm produces a 0.043 average error on the harmonic mean of the shortest distance, while it is 0.0037 using our algorithm. Preserving the value of the harmonic mean of the shortest distance implies preserving connectivity and path lengths. The same analysis applies to other measures. Our results are shown for
.
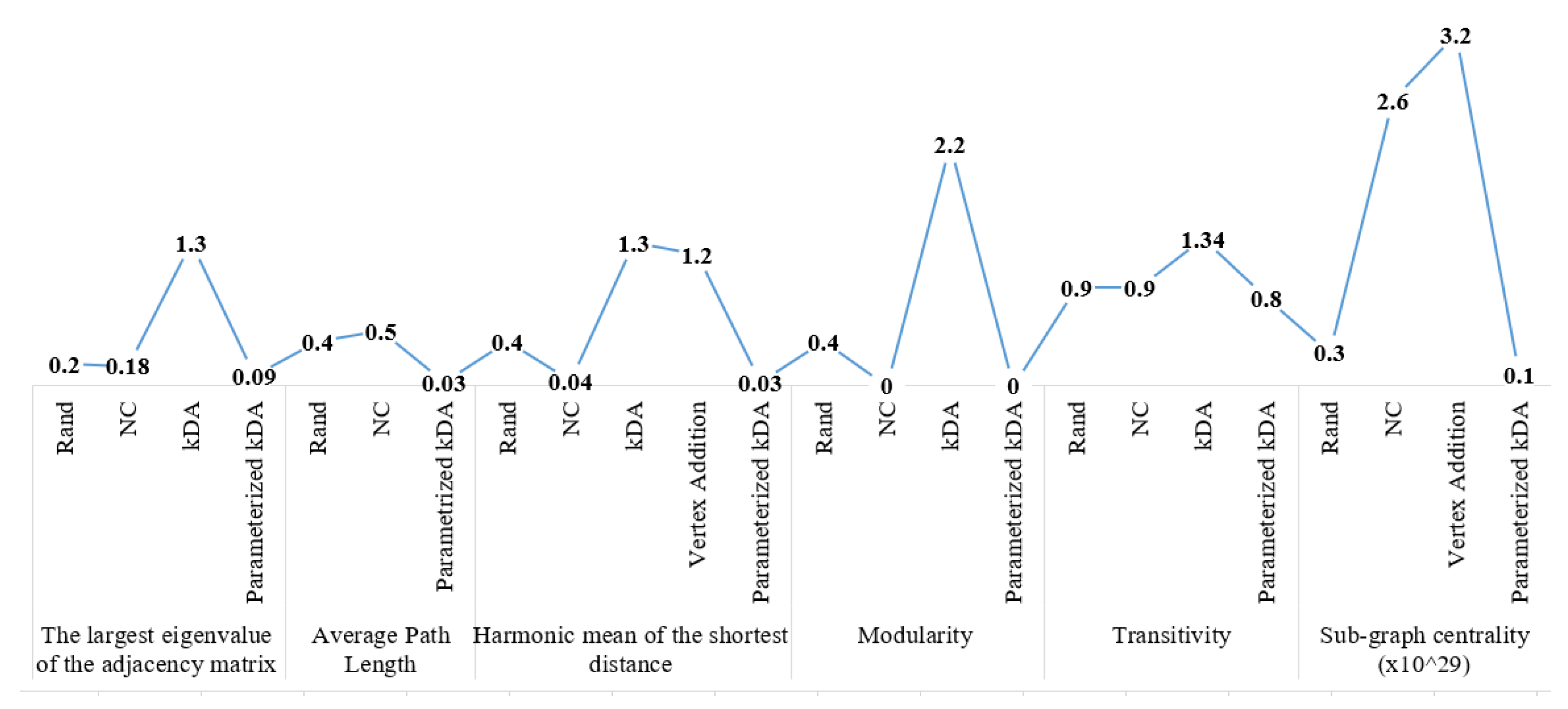
For the GrQc graph, we show results for the same values of
k as in [
11], but better results could be obtained when
.
5.2. Clustering Analysis
To test the impact of the anonymization process on the topology of graphs and knowledge extraction, we measure its effect on how data elements cluster. If the anonymization algorithm keeps almost the same clustered communities, then the topology of the original graph is not affected much and the released graph would be useful for data mining applications. To compare the clusters of the original graph
G and those of the anonymized graph
, we need a certain measure of divergence. We used a precision index defined in [
23], which has a value between 0 and 1. A higher value implies that the clusters of
G and
are closer. A value of 1 is obtained when the clusters of
G and
overlap completely. The corresponding experiments were implemented using R [
24] and the results can be found in
Table 1. The best algorithm is the one that has the highest precision index or the least precision error.
According to [
11], NC produces less precision error than Rand on most data sets. However, our multi-parameterized degree anonymization algorithm surpasses NC by notably minimizing the precision error. For the American college football network, our precision error is
less than that produced by NC. This is because, during the graph construction phase, we perform the minimum number of edge edits. As for Erdos, which is larger than the football network, our error is about
less than that of NC. Finally, we used the large network Enron to test the scalability of our algorithm. The corresponding average error produced is
less than that of NC.
6. Security Analysis
The essential features of our generalized multi-objective approach are the flexibility and practicality while applying the least modifications needed for a graph to be anonymous. Depending on the sensitivity of the data to be anonymized, the value of the parameter
t differs, as it can be set to balance between privacy and utility. If we want to anonymize very sensitive data, then setting
t to zero and applying our anonymization approach gives better results in terms of preserving data utility, compared to using traditional approaches. For each vertex, we are applying the minimum number of edge-editing operations. However, if the data are not critical enough, but the statistical information (for data mining purposes) is essential, we can assign a value for
t that keeps the data utility as we can see in
Table 2, where we present experimental results on the “GrQc” network when
, versus those that are found in [
11]. We measured the average error induced by each algorithm on the data utility measures for different
k values. When,
, parameterized kDA produced an average error that is 47% less than that produced by NC on the harmonic mean of the shortest path. For transitivity, our average error is 10% less than that of NC. Having this flexibility makes our approach a general umbrella for the existing algorithms, because we can preserve data utility and fine tune by setting the parameter
t. Of course, our approach focused on enhancing the preservation of data utility without affecting privacy.
To evaluate the robustness of our model in preserving privacy and security, we analyze and contradict the behavior of an intruder. If we consider the example of a medical data set where an intruder may have some information about a targeted individual like age, gender, or address, among other things collected from external resources, then the (potential) intruder tries to match this information with nodes in the released network. Using our constrained anonymization model to mask the data before releasing it has a better chance of hindering the intruder from identifying his/her target, because the given information will be matched with many more individuals. To illustrate, if an individual in a network has 500 links, and , then our approach can yield more vertices whose degrees fall in the interval . In practice, distinguishing between an individual with 500 links and another with 503 links is challenging. Furthermore, an intruder may try to link his/her a priori information with released nodes and estimate the probability of correct matching. In this context, a node is at risk if its identification probability exceeds a certain value. This probabilistic technique is particularly not helpful for identifying individuals in our case, since we guarantee that many nodes have the same identification probability, which obviously increases the intruder’s uncertainty.
7. Conclusions and Future Work
We presented a generalized degree anonymization problem by adding constraints and bounds on the number of edge modifications, thereby relaxing the problem definition, which can extend its practicality and use in real applications. When applying degree-based anonymization, we have to use graph realization to obtain the resulting graph. An ILP formulation has enabled us to compute the best possible solution by minimizing data loss caused by edge modification operations. The main objective was to show the utility of the proposed k-anonymization model.
We considered simple unweighted undirected graphs, but this work can be extended to other types of graphs. Future work includes testing our approach on dynamic graphs, like online social networks where degrees vary with time, which requires adjusting the degree-anonymization solution. A possible approach would be to use a parameterized dynamic variant of the problem (see [
25,
26,
27] for examples of studied parameterized dynamic problems). It would also be interesting to modify our notion of degree-based anonymity to apply to distributed networks like intranets or communication networks.






{kind=link}
{kind=link}