
A Hybrid Simulation and Reinforcement Learning Algorithm for Enhancing Efficiency in Warehouse Operations

 , , ,
, , ,  ,
,  and
and 
Abstract
1. Introduction
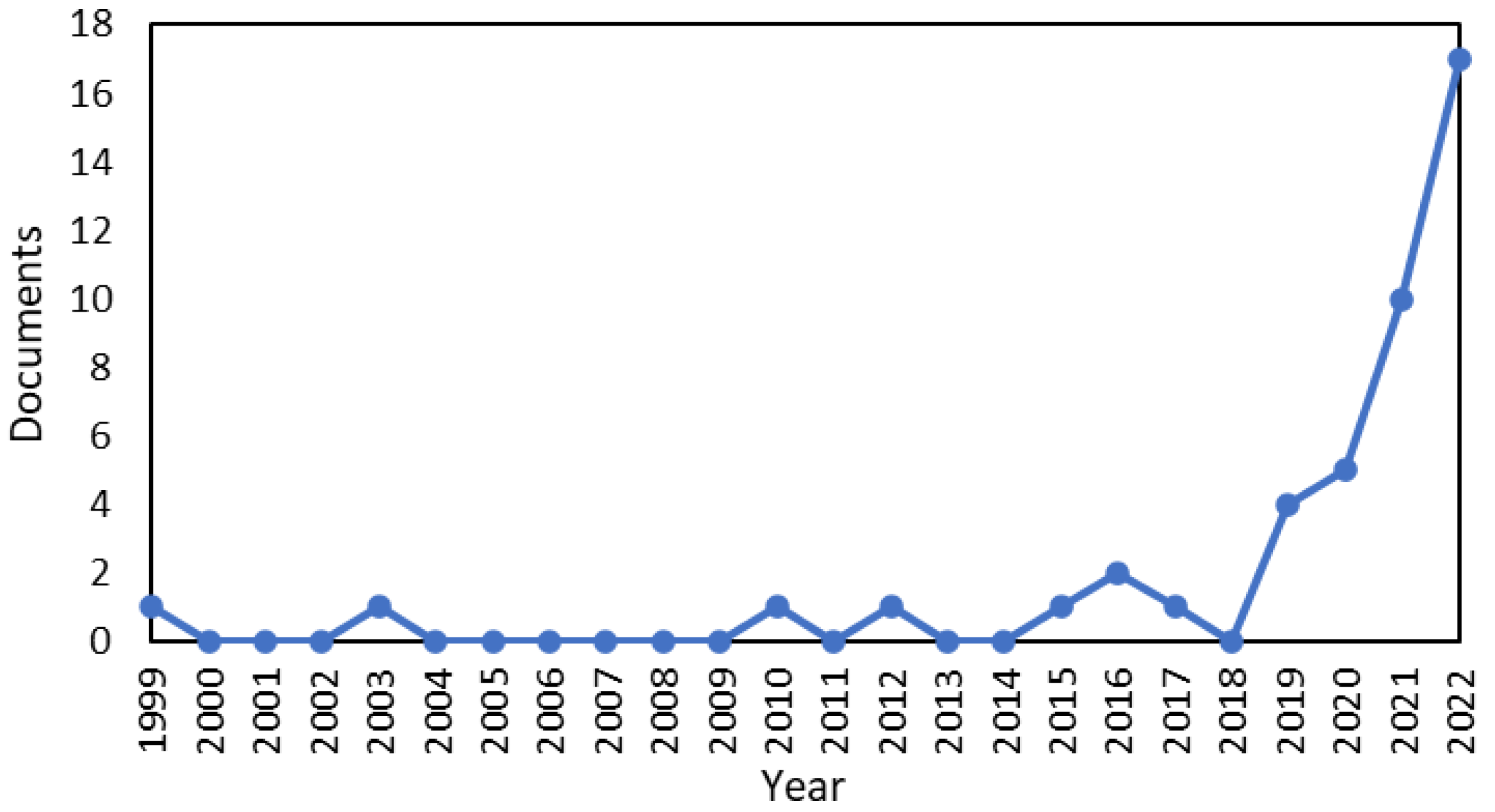
2. Related Work
2.1. Early Work on RL with Simulation for Warehouse Operations
2.2. Applications of RL with Simulation in Warehouse Operations
2.3. Advancements in RL with Simulation for Warehouse Operations

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Warehouse /Supply Chain Management | AGV /Robot Motion | Use DNN | Dedicated Simulation Software |
|---|---|---|---|---|
| Kinoshita et al. [9] | ✓ | |||
| Rao et al. [10] | ✓ | Arena | ||
| Yan et al. [11] | ✓ | |||
| Estanjini et al. [12] | ✓ | |||
| Dou et al. [13] | ✓ | |||
| Rabe and Dross [14] | ✓ | SimChain | ||
| Wang et al. [15] | ✓ | |||
| Drakaki and Tzionas [16] | ✓ | ✓ | ||
| Kono et al. [17] | ✓ | |||
| Li et al. [18] | ✓ | ✓ | ||
| Sartoretti et al. [19] | ✓ | |||
| Li et al. [20] | ✓ | ✓ | ||
| Barat et al. [21] | ✓ | |||
| Sun and Li [22] | ✓ | ✓ | ||
| Xiao et al. [23] | ✓ | ✓ | ||
| Yang et al. [24] | ✓ | ✓ | ||
| Ushida et al. [25] | ✓ | |||
| Shen et al. [26] | ✓ | ✓ | ||
| Newaz and Alam [27] | ✓ | ✓ | CoppeliaSim | |
| Peyas et al. [28] | ✓ | ✓ | ||
| Ha et al. [29] | ✓ | |||
| Liu et al. [30] | ✓ | |||
| Ushida et al. [31] | ✓ | ✓ | ||
| Lee and Jeong [32] | ✓ | |||
| Tang et al. [33] | ✓ | ✓ | ||
| Li et al. [34] | ✓ | CloudSim | ||
| Ren and Huang [35] | ✓ | ✓ | ||
| Balachandran et al. [36] | ✓ | ✓ | Gazebo | |
| Arslan and Ekren [37] | ✓ | ✓ | ||
| Lewis et al. [38] | ✓ | ✓ | NVIDIA Isaac Sim | |
| Ho et al. [39] | ✓ | ✓ | ||
| Zhou et al. [40] | ✓ | |||
| Cestero et al. [41] | ✓ | ✓ | ||
| Choi et al. [42] | ✓ | ✓ | ||
| Elkunchwar et al. [43] | ✓ | |||
| Wang et al. [44] | ✓ | |||
| Y. Ekren and Arslan [45] | ✓ | Arena | ||
| Yu [46] | ✓ | ✓ | ||
| Sun et al. [47] | ✓ | ✓ | ||
| Ushida et al. [48] | ✓ | |||
| Lee et al. [49] | ✓ | ✓ | ||
| Liang et al. [50] | ✓ | ✓ | ||
| Guo and Li [51] | ✓ | ✓ | Unity | |
| Yan et al. [52] | ✓ | ✓ | SUMO |
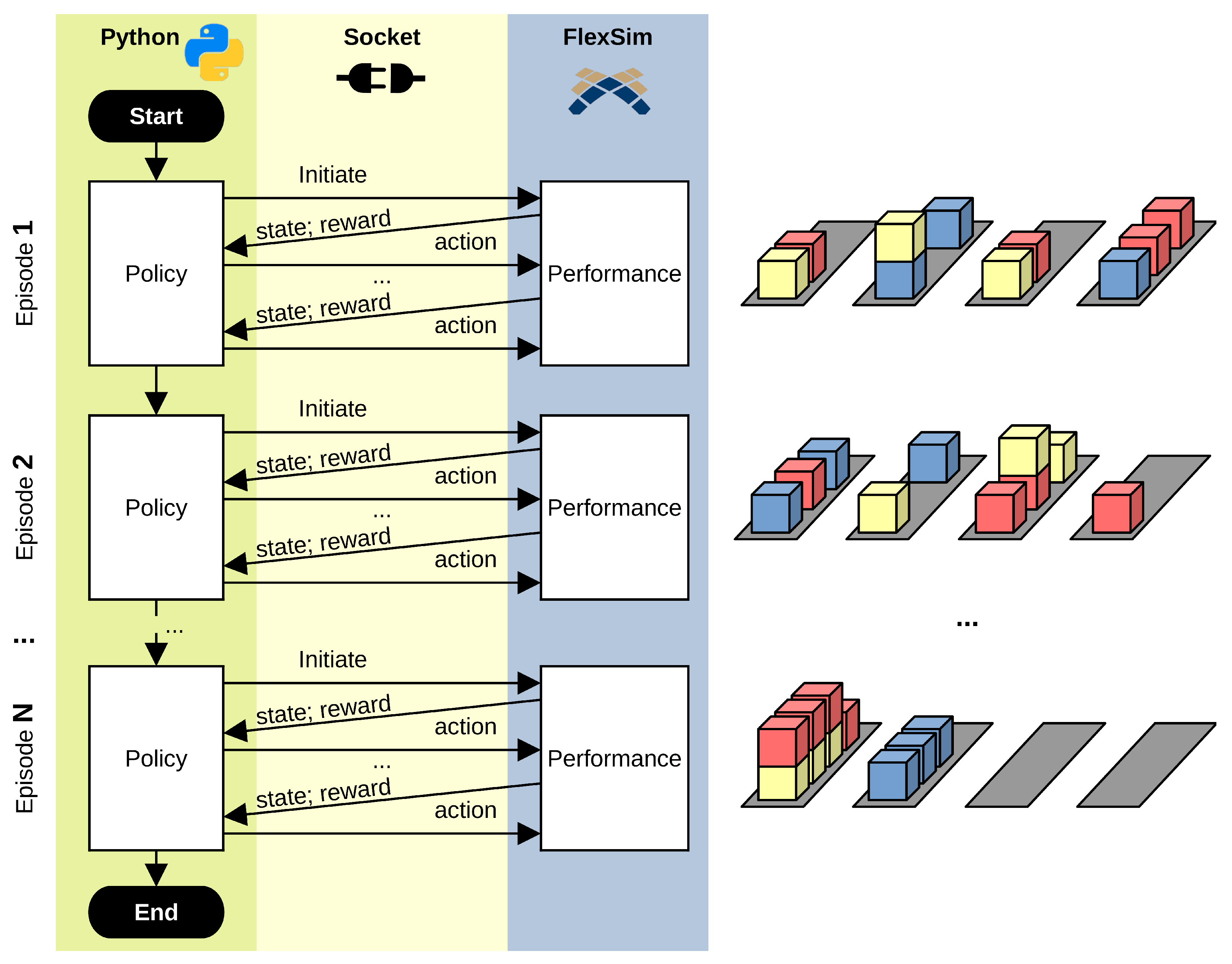
3. Reinforcement Learning in FlexSim
| Algorithm 1 Reinforcement learning framework. | |
| Input: Environment, Agent | |
| Output: Agent | ▹ The trained Agent with the learned Policy |
| 1: initialize | |
| 2: while do | ▹ Equivalent to running Episodes |
| 3: initialize | ▹ Start a new Episode = instance of FlexSim |
| 4: while isFinished do | |
| 5: updatePolicy() | ▹ Learning from current state and reward |
| 6: chooseAction() | ▹ Using the best available Policy |
| 7: step | |
| 8: observe | |
| 9: | |
| 10: | |
| 11: close | |
| 12: return Agent | |
| 13: | |
4. Case Study
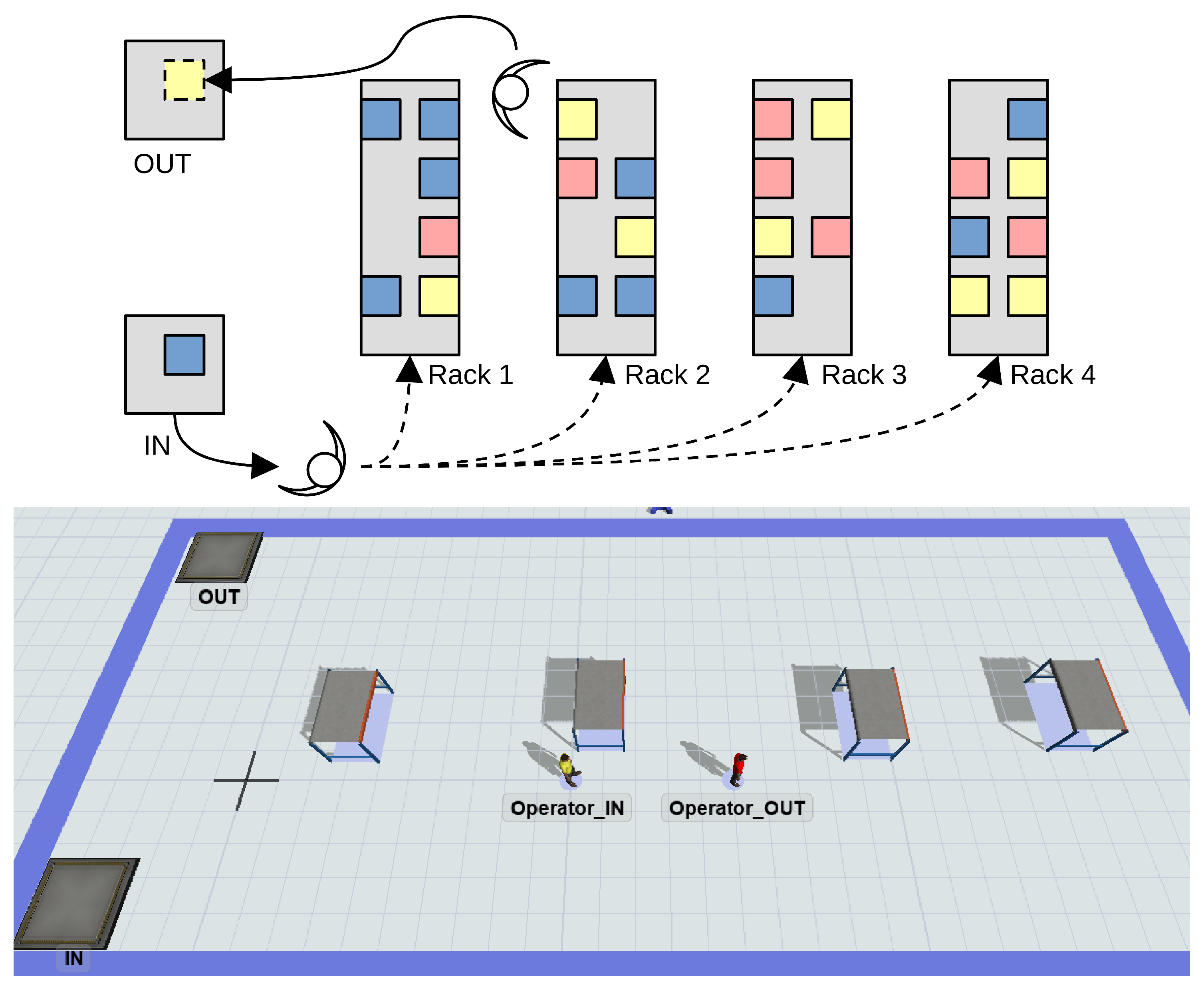
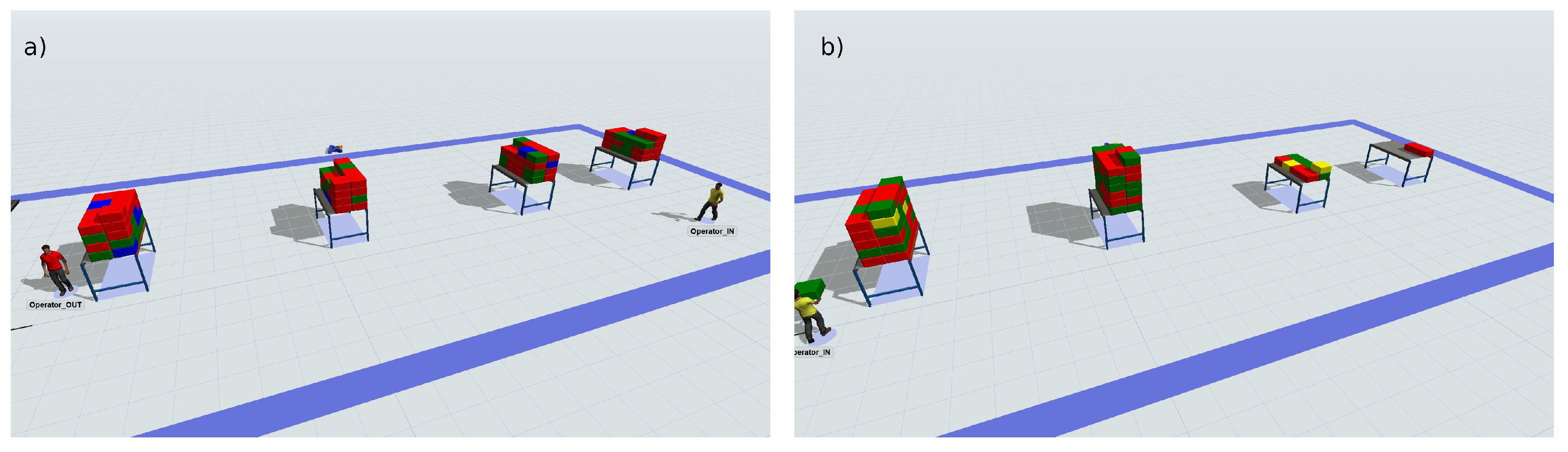
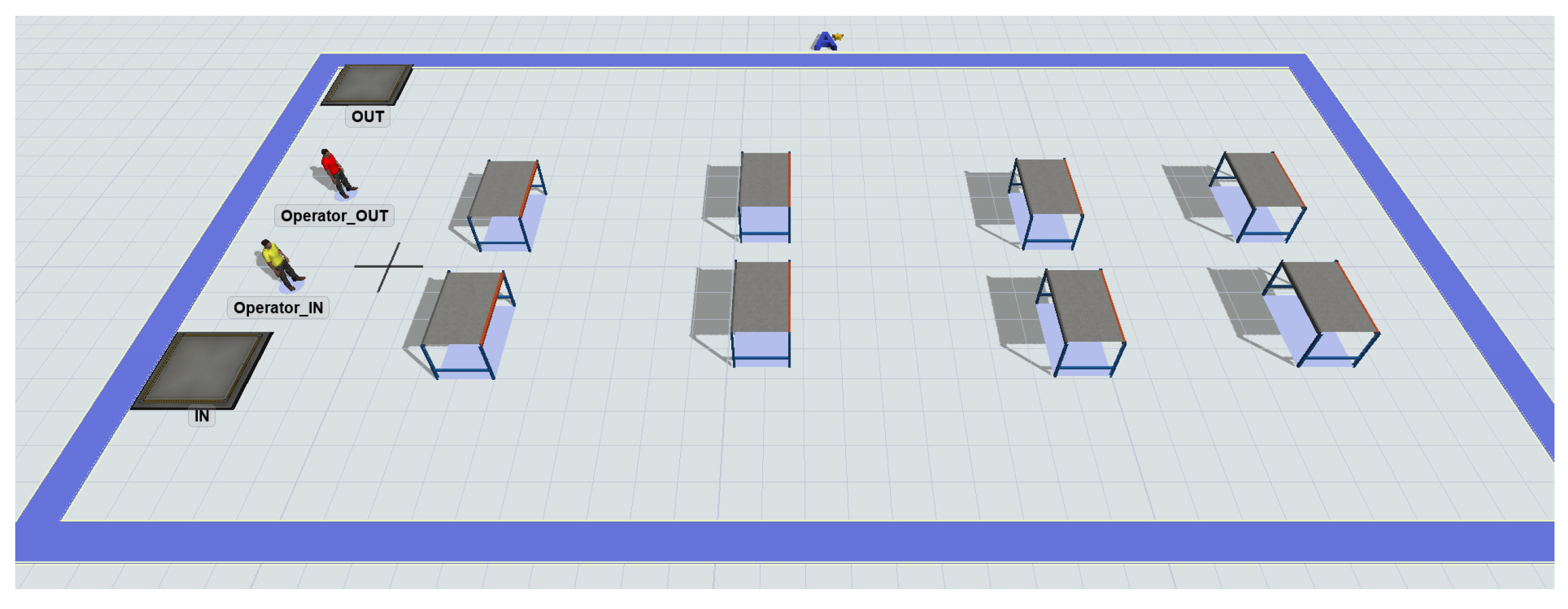
4.1. Use Case Description
| Algorithm 2 Random policy. |
Input: Item, Locations Output: Location ▹ Location ∈ Locations to which the Item is assigned
|
| Algorithm 3 Greedy policy. |
Input: Item, Locations Output: Location
|
4.2. Simulation Environment
4.3. Reinforcement Learning Implementations
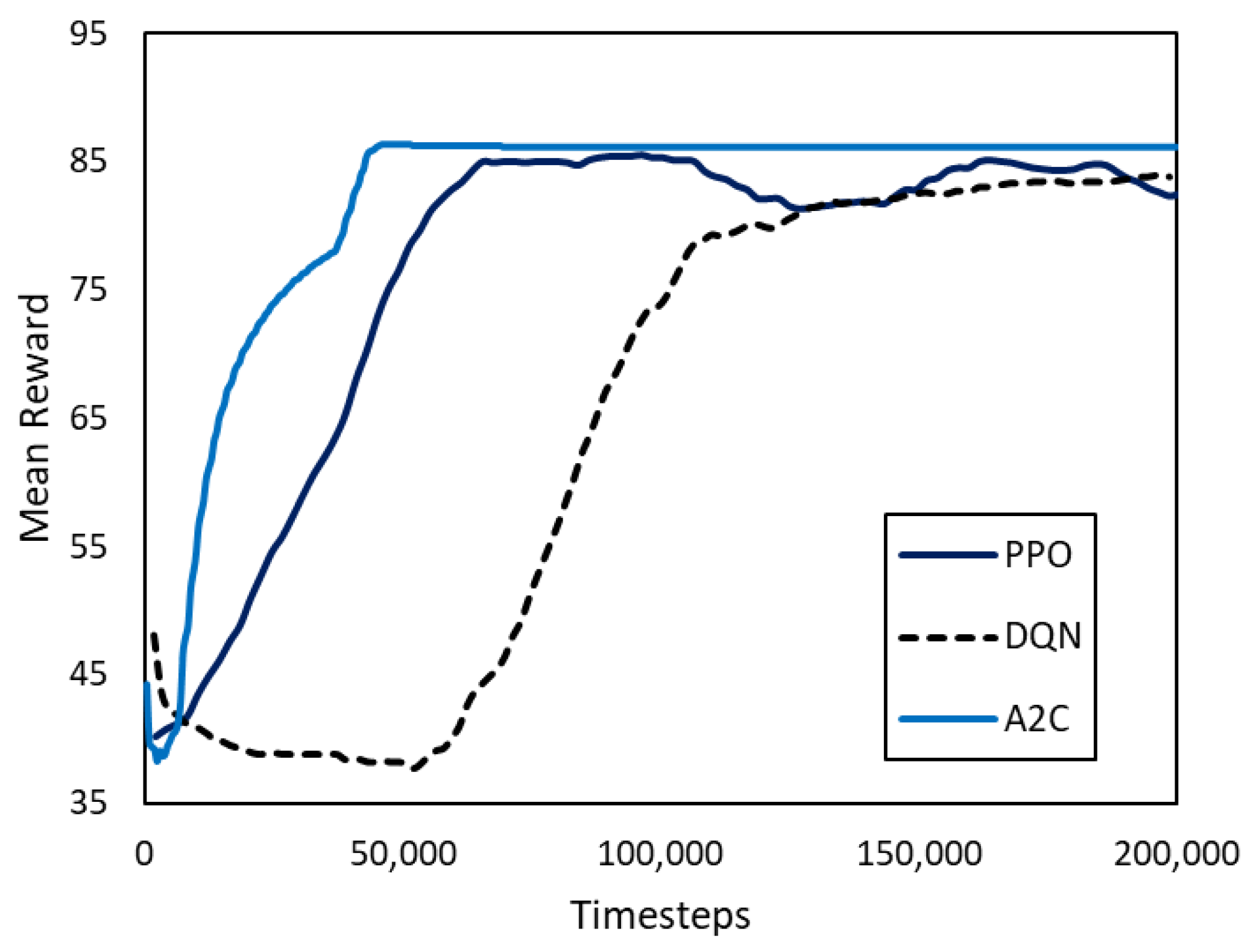
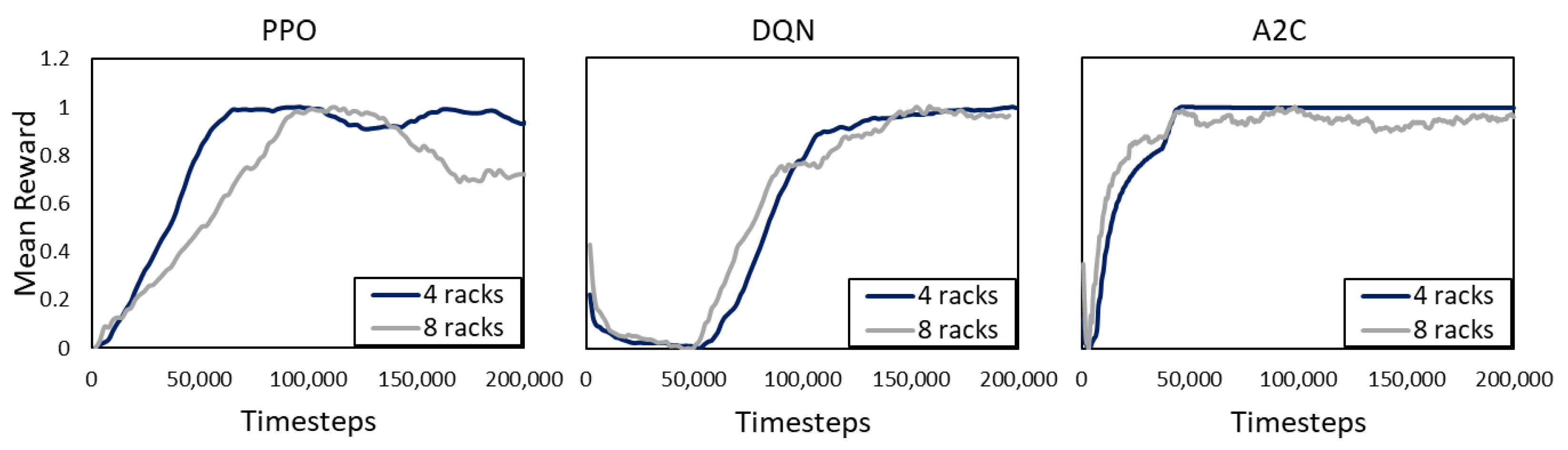
4.4. Training Results
4.5. Validation Results
4.6. Performance Discussion
5. Key Applications and Open Research Lines
- Process Optimization: analyze and optimize various processes, such as receiving, put-away, picking, packing, and shipping. Managers can identify bottlenecks, test process changes, etc.;
- Layout and Design: design and optimize the layout, including the placement of racks, shelves, etc.;
- Resource Allocation: optimize the allocation of resources, such as labor, equipment, and space;
- Inventory Management: analyze and optimize inventory management strategies, such as reorder points, safety stock levels, and order quantities;
- Demand Forecasting: simulate demand patterns and forecast inventory requirements;
- Labor Planning and Scheduling: optimize labor planning and scheduling;
- Equipment and Automation: evaluate the impact of equipment and automation technologies, such as conveyor systems, automated guided vehicles, and robots.
- Warehouse Management: optimize tasks such as inventory management, order picking, and routing;
- Autonomous Robots: train autonomous robots for tasks such as automated material handling, order fulfillment, and package sorting. Robots can learn how to navigate in complex warehouse environments, handle different types of items, and interact with other equipment and personnel;
- Resource Allocation: optimize the allocation of resources such as labor, equipment, and space;
- Energy Management: optimize energy consumption, which can have a significant impact on operational costs. For example, an agent can learn to control the usage of lighting, heating, and ventilation, based on occupancy, time of day, and other environmental factors;
- Safety and Security: for example, an agent can learn to detect and respond to safety hazards, such as obstacles in pathways, spills, or damaged equipment.
- Wider range of applications in warehouse operations. As manufacturing and logistics systems grow more complex and businesses seek to remain both competitive and sustainable, the increasing availability of data as well as new technologies through Industry 4.0 is expected to open up a wider range of applications in warehouse operations. This will give rise to a greater number of decision variables, objective functions, and restrictions.
- Emergence of DRL. DRL holds significant potential over traditional RL due to its ability to handle high-dimensional and complex state spaces through deep neural networks. DRL allows for more efficient and automated feature extraction, enabling the model to learn directly from raw data.
- Distributed and parallel techniques. Distributed and parallel RL can accelerate the learning process by allowing multiple agents to learn concurrently. Moreover, this approach can improve scalability, as it enables RL algorithms to handle larger and more complex state spaces. Finally, distributed and parallel RL can provide robustness and fault tolerance, as multiple agents can work in parallel, and failures or perturbations in one agent do not necessarily disrupt the entire learning process.
- Explicability. Explicability is important for building trust and acceptance of RL systems, as users may be hesitant to adopt decision-making systems that lack transparency and understanding. In addition, it can aid in understanding and diagnosing model behaviour, facilitating debugging, troubleshooting, and identifying potential biases or ethical concerns. Lastly, explicability can be crucial for compliance with regulatory requirements in domains where transparency and accountability are essential.
- Metaheuristics. Metaheuristics hold potential for various applications in RL. Firstly, they can be used for hyperparameter tuning in RL algorithms to optimize the performance of agents. Secondly, metaheuristics can be employed for policy search, where they can explore the policy space to find promising policies for RL agents. Lastly, they can aid in solving complex problems in RL with high-dimensional state and action spaces, where traditional RL algorithms may struggle, by providing effective search strategies for discovering good policies. The combination of RL with metaheuristics and simheuristics [59] is also an open challenge.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, L.; Zhou, L.; Ren, L.; Laili, Y. Modeling and Simulation in Intelligent Manufacturing. Comput. Ind. 2019, 112, 103123. [Google Scholar] [CrossRef]
- Leon, J.F.; Li, Y.; Peyman, M.; Calvet, L.; Juan, A.A. A Discrete-Event Simheuristic for Solving a Realistic Storage Location Assignment Problem. Mathematics 2023, 11, 1577. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Yan, Y.; Chow, A.H.; Ho, C.P.; Kuo, Y.H.; Wu, Q.; Ying, C. Reinforcement Learning for Logistics and Supply Chain Management: Methodologies, State of the Art, and Future Opportunities. Transp. Res. Part E Logist. Transp. Rev. 2022, 162, 102712. [Google Scholar] [CrossRef]
- Nordgren, W.B. FlexSim Simulation Environment. In Proceedings of the Winter Simulation Conference, San Diego, CA, USA, 8–11 December 2002; Chick, S., Sánchez, P.J., Ferrin, D., Morrice, D.J., Eds.; Institute of Electrical and Electronics Engineers, Inc.: Orem, UT, USA, 2002; pp. 250–252. [Google Scholar]
- Van Rossum, G.; Drake, F.L. Python 3 Reference Manual; CreateSpace: Scotts Valley, CA, USA, 2009. [Google Scholar]
- Leon, J.F.; Marone, P.; Peyman, M.; Li, Y.; Calvet, L.; Dehghanimohammadabadi, M.; Juan, A.A. A Tutorial on Combining Flexsim With Python for Developing Discrete-Event Simheuristics. In Proceedings of the 2022 Winter Simulation Conference (WSC), Singapore, 11–14 December 2022; Institute of Electrical and Electronics Engineers, Inc.: Singapore, 2022; pp. 1386–1400. [Google Scholar]
- Reyes, J.; Solano-Charris, E.; Montoya-Torres, J. The Storage Location Assignment Problem: A Literature Review. Int. J. Ind. Eng. Comput. 2019, 10, 199–224. [Google Scholar] [CrossRef]
- Kinoshita, M.; Watanabe, M.; Kawakami, T.; Kakazu, Y. Emergence of field intelligence for autonomous block agents in the automatic warehouse. Intell. Eng. Syst. Through Artif. Neural Netw. 1999, 9, 1129–1134. [Google Scholar]
- Rao, J.J.; Ravulapati, K.K.; Das, T.K. A simulation-based approach to study stochastic inventory-planning games. Int. J. Syst. Sci. 2003, 34, 717–730. [Google Scholar] [CrossRef]
- Yan, W.; Lin, C.; Pang, S. The Optimized Reinforcement Learning Approach to Run-Time Scheduling in Data Center. In Proceedings of the 2010 Ninth International Conference on Grid and Cloud Computing, Nanjing, China, 1–5 November 2010; pp. 46–51. [Google Scholar]
- Estanjini, R.M.; Li, K.; Paschalidis, I.C. A least squares temporal difference actor-critic algorithm with applications to warehouse management. Nav. Res. Logist. 2012, 59, 197–211. [Google Scholar] [CrossRef]
- Dou, J.; Chen, C.; Yang, P. Genetic Scheduling and Reinforcement Learning in Multirobot Systems for Intelligent Warehouses. Math. Probl. Eng. 2015, 2015. [Google Scholar] [CrossRef]
- Rabe, M.; Dross, F. A reinforcement learning approach for a decision support system for logistics networks. In Proceedings of the 2015 Winter Simulation Conference (WSC), Huntington Beach, CA, USA, 6–9 December 2015; pp. 2020–2032. [Google Scholar]
- Wang, Z.; Chen, C.; Li, H.X.; Dong, D.; Tarn, T.J. A novel incremental learning scheme for reinforcement learning in dynamic environments. In Proceedings of the 2016 12th World Congress on Intelligent Control and Automation (WCICA), Guilin, China, 12–15 June 2016; pp. 2426–2431. [Google Scholar]
- Drakaki, M.; Tzionas, P. Manufacturing scheduling using Colored Petri Nets and reinforcement learning. Appl. Sci. 2017, 7, 136. [Google Scholar] [CrossRef]
- Kono, H.; Katayama, R.; Takakuwa, Y.; Wen, W.; Suzuki, T. Activation and spreading sequence for spreading activation policy selection method in transfer reinforcement learning. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 7–16. [Google Scholar] [CrossRef]
- Li, M.P.; Sankaran, P.; Kuhl, M.E.; Ganguly, A.; Kwasinski, A.; Ptucha, R. Simulation analysis of a deep reinforcement learning approach for task selection by autonomous material handling vehicles. In Proceedings of the 2018 Winter Simulation Conference (WSC), Gothenburg, Sweden, 9–12 December 2018; pp. 1073–1083. [Google Scholar]
- Sartoretti, G.; Kerr, J.; Shi, Y.; Wagner, G.; Satish Kumar, T.; Koenig, S.; Choset, H. PRIMAL: Pathfinding via Reinforcement and Imitation Multi-Agent Learning. IEEE Robot. Autom. Lett. 2019, 4, 2378–2385. [Google Scholar] [CrossRef]
- Li, M.P.; Sankaran, P.; Kuhl, M.E.; Ptucha, R.; Ganguly, A.; Kwasinski, A. Task Selection by Autonomous Mobile Robots in a Warehouse Using Deep Reinforcement Learning. In Proceedings of the 2019 Winter Simulation Conference, National Harbor, MD, USA, 8–11 December 2019; Institute of Electrical and Electronics Engineers, Inc.: National Harbor, MD, USA, 2019; pp. 680–689. [Google Scholar]
- Barat, S.; Kumar, P.; Gajrani, M.; Khadilkar, H.; Meisheri, H.; Baniwal, V.; Kulkarni, V. Reinforcement Learning of Supply Chain Control Policy Using Closed Loop Multi-agent Simulation. In International Workshop on Multi-Agent Systems and Agent-Based Simulation; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer International Publishing: Cham, Switzerland, 2020; Volume 12025 LNAI, pp. 26–38. [Google Scholar]
- Sun, Y.; Li, H. An end-to-end reinforcement learning method for automated guided vehicle path planning. In Proceedings of the International Symposium on Artificial Intelligence and Robotics 2020, Kitakyushu, Japan, 1–10 August 2020; Volume 11574, pp. 296–310. [Google Scholar]
- Xiao, Y.; Hoffman, J.; Xia, T.; Amato, C. Learning multi-robot decentralized macro-action-based policies via a centralized q-net. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 10695–10701. [Google Scholar]
- Yang, Y.; Juntao, L.; Lingling, P. Multi-robot path planning based on a deep reinforcement learning DQN algorithm. CAAI Trans. Intell. Technol. 2020, 5, 177–183. [Google Scholar] [CrossRef]
- Ushida, Y.; Razan, H.; Sakuma, T.; Kato, S. Policy Transfer from Simulation to Real World for Autonomous Control of an Omni Wheel Robot. In Proceedings of the 2020 IEEE 9th Global Conference on Consumer Electronics (GCCE), Kobe, Japan, 13–16 October 2020; pp. 952–953. [Google Scholar]
- Shen, G.; Ma, R.; Tang, Z.; Chang, L. A deep reinforcement learning algorithm for warehousing multi-agv path planning. In Proceedings of the 2021 International Conference on Networking, Communications and Information Technology (NetCIT), Manchester, UK, 26–27 December 2021; pp. 421–429. [Google Scholar]
- Newaz, A.A.R.; Alam, T. Hierarchical Task and Motion Planning through Deep Reinforcement Learning. In Proceedings of the 2021 Fifth IEEE International Conference on Robotic Computing (IRC), Taichung, Taiwan, 5–17 November 2021; pp. 100–105. [Google Scholar]
- Peyas, I.S.; Hasan, Z.; Tushar, M.R.R.; Musabbir, A.; Azni, R.M.; Siddique, S. Autonomous Warehouse Robot using Deep Q-Learning. In Proceedings of the TENCON 2021–2021 IEEE Region 10 Conference (TENCON), Auckland, New Zealand, 7–10 December 2021; pp. 857–862. [Google Scholar]
- Ha, W.Y.; Cui, L.; Jiang, Z.P. A Warehouse Scheduling Using Genetic Algorithm and Collision Index. In Proceedings of the 2021 20th International Conference on Advanced Robotics (ICAR), Ljubljana, Slovenia, 6–10 December 2021; pp. 318–323. [Google Scholar]
- Liu, S.; Wen, L.; Cui, J.; Yang, X.; Cao, J.; Liu, Y. Moving Forward in Formation: A Decentralized Hierarchical Learning Approach to Multi-Agent Moving Together. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 4777–4784. [Google Scholar]
- Ushida, Y.; Razan, H.; Sakuma, T.; Kato, S. Omnidirectional Mobile Robot Path Finding Using Deep Deterministic Policy Gradient for Real Robot Control. In Proceedings of the 2021 IEEE 10th Global Conference on Consumer Electronics (GCCE), Kyoto, Japan, 12–15 October 2021; pp. 555–556. [Google Scholar]
- Lee, H.; Jeong, J. Mobile Robot Path Optimization Technique Based on Reinforcement Learning Algorithm in Warehouse Environment. Appl. Sci. 2021, 11, 1209. [Google Scholar] [CrossRef]
- Tang, H.; Wang, A.; Xue, F.; Yang, J.; Cao, Y. A Novel Hierarchical Soft Actor-Critic Algorithm for Multi-Logistics Robots Task Allocation. IEEE Access 2021, 9, 42568–42582. [Google Scholar] [CrossRef]
- Li, H.; Li, D.; Wong, W.E.; Zeng, D.; Zhao, M. Kubernetes virtual warehouse placement based on reinforcement learning. Int. J. Perform. Eng. 2021, 17, 579–588. [Google Scholar]
- Ren, J.; Huang, X. Potential Fields Guided Deep Reinforcement Learning for Optimal Path Planning in a Warehouse. In Proceedings of the 2021 IEEE 7th International Conference on Control Science and Systems Engineering (ICCSSE), Qingdao, China, 30 July–1 August 2021; pp. 257–261. [Google Scholar]
- Balachandran, A.; Lal, A.; Sreedharan, P. Autonomous Navigation of an AMR using Deep Reinforcement Learning in a Warehouse Environment. In Proceedings of the 2022 IEEE 2nd Mysore Sub Section International Conference (MysuruCon), Mysuru, India, 16–17 October 2022; pp. 1–5. [Google Scholar]
- Arslan, B.; Ekren, B.Y. Transaction selection policy in tier-to-tier SBSRS by using Deep Q-Learning. Int. J. Prod. Res. 2022. [Google Scholar] [CrossRef]
- Lewis, T.; Ibarra, A.; Jamshidi, M. Object Detection-Based Reinforcement Learning for Autonomous Point-to-Point Navigation. In Proceedings of the 2022 World Automation Congress (WAC), San Antonio, TX, USA, 11–15 October 2022; pp. 394–399. [Google Scholar]
- Ho, T.M.; Nguyen, K.K.; Cheriet, M. Federated Deep Reinforcement Learning for Task Scheduling in Heterogeneous Autonomous Robotic System. IEEE Trans. Autom. Sci. Eng. 2022, 1–13. [Google Scholar] [CrossRef]
- Zhou, L.; Lin, C.; Ma, Q.; Cao, Z. A Learning-based Iterated Local Search Algorithm for Order Batching and Sequencing Problems. In Proceedings of the 2022 IEEE 18th International Conference on Automation Science and Engineering (CASE), Mexico City, Mexico, 20–24 August 2022; pp. 1741–1746. [Google Scholar]
- Cestero, J.; Quartulli, M.; Metelli, A.M.; Restelli, M. Storehouse: A reinforcement learning environment for optimizing warehouse management. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–9. [Google Scholar]
- Choi, H.B.; Kim, J.B.; Han, Y.H.; Oh, S.W.; Kim, K. MARL-Based Cooperative Multi-AGV Control in Warehouse Systems. IEEE Access 2022, 10, 100478–100488. [Google Scholar] [CrossRef]
- Elkunchwar, N.; Iyer, V.; Anderson, M.; Balasubramanian, K.; Noe, J.; Talwekar, Y.; Fuller, S. Bio-inspired source seeking and obstacle avoidance on a palm-sized drone. In Proceedings of the 2022 International Conference on Unmanned Aircraft Systems (ICUAS), Dubrovnik, Croatia, 21–24 June 2022; pp. 282–289. [Google Scholar]
- Wang, D.; Jiang, J.; Ma, R.; Shen, G. Research on Hybrid Real-Time Picking Routing Optimization Based on Multiple Picking Stations. Math. Probl. Eng. 2022, 2022, 5510749. [Google Scholar] [CrossRef]
- Ekren, B.Y.; Arslan, B. A reinforcement learning approach for transaction scheduling in a shuttle-based storage and retrieval system. Int. Trans. Oper. Res. 2022. [Google Scholar] [CrossRef]
- Yu, H. Research on Fresh Product Logistics Transportation Scheduling Based on Deep Reinforcement Learning. Sci. Program. 2022, 2022, 8750580. [Google Scholar] [CrossRef]
- Sun, S.; Zhou, J.; Wen, J.; Wei, Y.; Wang, X. A DQN-based cache strategy for mobile edge networks. Comput. Mater. Contin. 2022, 71, 3277–3291. [Google Scholar] [CrossRef]
- Ushida, Y.; Razan, H.; Ishizuya, S.; Sakuma, T.; Kato, S. Using sim-to-real transfer learning to close gaps between simulation and real environments through reinforcement learning. Artif. Life Robot. 2022, 27, 130–136. [Google Scholar] [CrossRef]
- Lee, H.; Hong, J.; Jeong, J. MARL-Based Dual Reward Model on Segmented Actions for Multiple Mobile Robots in Automated Warehouse Environment. Appl. Sci. 2022, 12, 4703. [Google Scholar] [CrossRef]
- Liang, F.; Yu, W.; Liu, X.; Griffith, D.; Golmie, N. Toward Deep Q-Network-Based Resource Allocation in Industrial Internet of Things. IEEE Internet Things J. 2022, 9, 9138–9150. [Google Scholar] [CrossRef]
- Guo, W.; Li, S. Intelligent Path Planning for AGV-UAV Transportation in 6G Smart Warehouse. Mob. Inf. Syst. 2023, 2023, 4916127. [Google Scholar] [CrossRef]
- Yan, Z.; Kreidieh, A.R.; Vinitsky, E.; Bayen, A.M.; Wu, C. Unified Automatic Control of Vehicular Systems with Reinforcement Learning. IEEE Trans. Autom. Sci. Eng. 2023, 20, 789–804. [Google Scholar] [CrossRef]
- Bayliss, C.; Juan, A.A.; Currie, C.S.; Panadero, J. A Learnheuristic Approach for the Team Orienteering Problem with Aerial Drone Motion Constraints. Appl. Soft Comput. 2020, 92, 106280. [Google Scholar] [CrossRef]
- Beysolow, T., II. Applied Reinforcement Learning with Python: With OpenAI Gym, Tensorflow, and Keras; Apress: New York, NY, USA, 2019. [Google Scholar]
- Raffin, A.; Hill, A.; Gleave, A.; Kanervisto, A.; Ernestus, M.; Dormann, N. Stable-Baselines3: Reliable Reinforcement Learning Implementations. J. Mach. Learn. Res. 2021, 22, 1–8. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the International Conference on Machine Learning. PMLR, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari With Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Rabe, M.; Deininger, M.; Juan, A.A. Speeding Up Computational Times in Simheuristics Combining Genetic Algorithms with Discrete-Event Simulation. Simul. Model. Pract. Theory 2020, 103, 102089. [Google Scholar] [CrossRef]







| Policy | Distance Traveled (m) | Items Processed | Throughput (Items/min) |
|---|---|---|---|
| Random | 7763 | 172 | 2.06 |
| Greedy | 6680 | 241 | 2.89 |
| PPO | 6801 | 241 | 2.89 |
| DQN | 6894 | 241 | 2.89 |
| A2C | 6676 | 241 | 2.89 |
| Policy | Distance Traveled (m) | Items Processed | Throughput (Items/min) |
|---|---|---|---|
| Random | 8813 | 172 | 2.06 |
| Greedy | 6663 | 241 | 2.89 |
| PPO | 8302 | 241 | 2.89 |
| DQN | 7084 | 241 | 2.89 |
| A2C | 8704 | 241 | 2.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leon, J.F.; Li, Y.; Martin, X.A.; Calvet, L.; Panadero, J.; Juan, A.A. A Hybrid Simulation and Reinforcement Learning Algorithm for Enhancing Efficiency in Warehouse Operations. Algorithms 2023, 16, 408. https://doi.org/10.3390/a16090408
Leon JF, Li Y, Martin XA, Calvet L, Panadero J, Juan AA. A Hybrid Simulation and Reinforcement Learning Algorithm for Enhancing Efficiency in Warehouse Operations. Algorithms. 2023; 16(9):408. https://doi.org/10.3390/a16090408
Chicago/Turabian StyleLeon, Jonas F., Yuda Li, Xabier A. Martin, Laura Calvet, Javier Panadero, and Angel A. Juan. 2023. "A Hybrid Simulation and Reinforcement Learning Algorithm for Enhancing Efficiency in Warehouse Operations" Algorithms 16, no. 9: 408. https://doi.org/10.3390/a16090408
APA StyleLeon, J. F., Li, Y., Martin, X. A., Calvet, L., Panadero, J., & Juan, A. A. (2023). A Hybrid Simulation and Reinforcement Learning Algorithm for Enhancing Efficiency in Warehouse Operations. Algorithms, 16(9), 408. https://doi.org/10.3390/a16090408