1. Introduction
Let
be a non-singular matrix whose eigenvalues are found in
]. A logarithm of
A is defined as any matrix
such that
where
is the matrix exponential of
X. Although any non-singular matrix
A has infinite logarithms, we will only consider the principal logarithm represented by
, which is the only one whose eigenvalues all belong to the set
[
1].
The principal matrix logarithm is widely employed in numerous disciplines in science and engineering, such as sociology [
2], optics [
3], biomolecular dynamics [
4], quantum chemistry [
5], quantum mechanics [
6], mechanics [
7], buckling simulation [
8], the study of viscoelastic fluids [
9,
10], control theory [
11], computer graphics [
12], computer-aided design (CAD) [
13], neural networks [
14], machine learning [
15,
16,
17,
18,
19], brain-machine interfaces [
20], the study of Markov chains [
21], graph theory [
22], optimization [
23], topological distances between networks [
24], statistics and data processing [
25], and so on. The following is a more detailed description of the aforementioned fields in which the matrix logarithm has direct applicability.
Embeddability and identification issues, which are especially pertinent to modeling social phenomena using continuous-time Markov structures, when only fragmentary data are available or when the observations contain errors, are considered in [
2]. The logarithm function is required for estimating the intensity matrix.
A procedure based on using a linear differential equation expansion, for the extraction of elementary properties of a homogeneous depolarizing medium from the Mueller matrix logarithm is provided in [
3]. In a polarimetric measurement, the differential matrix and, consequently, the elementary polarization properties of the medium are obtained using the matrix logarithm of the experimental Mueller matrix.
In [
4], the method for identifying the most important metastable states of a system with complicated dynamical behavior from time series information was extended to handle arbitrary dimensions and to enlarge the diffusion classes considered. This approach represents the effective dynamics of the full system through a Markov jump process between metastable states and the dynamics within each of these metastable states with diffusions. In this method, the logarithm of the correlation matrix must be computed.
In [
5], the random phase approximation (RPA) correlation energy was expressed in terms of the exact local Kohn-Sham (KS) exchange potential and the corresponding adiabatic and non-adiabatic exchange kernels for density-functional reference determinants. This approach extends the RPA method and yields correlation energies that are more accurate than the traditional RPA technique. The logarithm matrix function is required in coupling strength integration.
A classical upper bound for quantum entropy is identified and illustrated in [
6], involving the matrix logarithm of the variance in phase space of the classical limit distribution of a given system.
In [
7], micro-dilatation theory or void elasticity was extended to both large displacement and large dilatation using thermodynamic principles. The deformation gradient tensor was defined by means of the matrix exponential function. The relationship of the displacement gradient and deformation gradient tensor was implemented using the matrix logarithm function.
A finite-element-based computational framework for modeling the buckling distortion of overlap joints due to gas metal arc welding was presented in [
8]. The total strain tensor was obtained thanks to logarithm computation of the displacement tensor.
In [
9], the matrix logarithm conformation representation of a viscoelastic fluid flow was implemented within a finite element method (FEM) context. A different derivation of the log-based evolution equation was also presented. An extension of the matrix logarithm formulation of the conformation tensor, to remove instabilities in the simulation of unsteady viscoelastic fluid flows using the spectral element method, was described in [
10].
In the context of the identification of linear continuous-time multivariable systems, a new series for the computation of the logarithm of a matrix with improved convergence properties was given in [
11].
To facilitate the design of pleasing inbetweening motions that interpolate between an initial and a final pose (affine transformation), steady affine morph (SAM) was proposed in [
12]. For that purpose, the extraction of affinity roots (EAR) algorithm was designed, which is based on closed-form expressions in two or three dimensions, using matrix logarithm computation. SAM applications to pattern design and animation and to key-frame interpolation were also discussed.
The problem of synthesizing a smooth motion for rigid bodies that interpolates a set of configurations in space was addressed in [
13] by means of the De Casteljau algorithm, whose classical form was used to generate interpolating polynomials. Lie groups are the most simple symmetric spaces, and for them expressions for the first- and second-order derivatives of generalized polynomial curves of arbitrary order, defined using the mentioned generalized algorithm, were developed. The behavior of the algorithm on
m-dimensional spheres was also analyzed. The algorithm implementation depended on the ability to compute matrix exponentials and logarithms.
Neural networks are commonly used to model conditional probability distributions. The idea is to represent the distribution parameters as functions of conditioning events, where the function is determined by the architecture and weights of the network. In [
14], the matrix logarithm parametrization of covariance matrices for multivariate normal distributions was explored.
Deep learning methods are popular in many image and video processing applications, where symmetric positive definite (SPD) matrices appear and their logarithms are required. In [
15], a deep neural network for non-linear learning was devised. It was composed of different layers, such as a matrix eigenvalue logarithm layer to perform Riemannian calculations on SPD matrices.
In applications related to machine learning, such as Bayesian neural networks, determinantal point processes, generalized Markov random fields, elliptical graphical models, or kernel learning for Gaussian processes, a log determinant of a positive definite matrix and its derivatives must be computed. However, the cost of such a function could be computationally prohibitive for large matrices, where Cholesky factorization is involved. Many approaches exploit the fact that the log determinant of a matrix is equal to the trace of the logarithm of that matrix, and thus this trace must be computed. In this way, this trace was worked out in [
16] using stochastic trace estimators, based on Chebyshev or Lanczos expansions, which use fast matrix vector multiplications. Alternatively, the trace of the logarithm of the matrix was approximated under the framework of maximum entropy, given information in the form of moment constraints from stochastic trace estimation [
17], from Chebyshev series approximations [
18], or using a stochastic Lanczos quadrature [
19].
Motor-imagery brain–machine interfaces use electroencephalography signals recorded from the brain to decode a movement imagined by the subject. The decoded information can be used to control an external device, and this is especially useful for individuals with physical disabilities. Brain signals must be classified, using machine learning models, usually embedded in microcontroller units. In [
20], a multispectral Riemannian classifier (MRC)-based model was proposed and incorporated in a low-power microcontroller with parallel processing units. The MRC was composed of multiple stages, such as the one in charge of calculating the logarithm of the so-called whitened covariance matrix. The matrix logarithm was computed via the eigenvalue decomposition by means of the QR algorithm with a implicit Wilkinson shift.
In [
21], it was shown how to obtain the most appropriate true or approximate generator matrix
Q for an empirically observed Markov transition matrix
P, with particular application to credit ratings. Credit rating transition matrices
P are traditionally considered in credit risk modeling and in the financial industry. Given that empirically estimated matrices
P are mostly for a one year period, there is a need to recover a matrix generator
Q, such as
, so that a transition matrix
can be obtained for any arbitrary period of time
t, e.g., with the purpose of assessing a possible default.
Systems involving transient interactions arise naturally in many areas, including telecommunications, online social networking, and neuroscience. A new mathematical framework where network evolution is handled continuously over time was presented in [
22], providing a representation of dynamical systems for the concept of node centrality. The novel differential equations approach, where the logarithm function of a matrix resulting from the subtraction of the identity and the continuous-time adjacency matrix appears, is convenient for modeling and analyzing network evolution. This new setting is suitable for many digital applications, such as ranking nodes, detecting virality, and making time-sensitive strategic decisions.
Two algorithms to solve the frequency-limited Riemannian optimization model order reduction problems of linear and bilinear systems were proposed in [
23]. For this purpose, a new Riemannian conjugate gradient scheme based on the Riemannian geometry notions on a product manifold was designed, and a new search direction was then generated. The algorithms are also suitable for generating reduced systems over a frequency interval in band-pass form. Both algorithms involved the computation of matrix logarithms and Fréchet derivatives.
Various distance measures for networks and graphs in persistent homology were surveyed in [
24]. The paper was especially focused on brain networks, but the methods could be adapted to any weighted graph in other fields. Among these metrics, the log-Euclidean distance can be found, which provides the shortest distance between two edge weights matrices and where the logarithm of both matrices must be computed.
Population covariance matrix estimation is an important component of many statistical methods and applications, such as the optimization and classification of human tumors from genomic data, among many others. In [
25], a method of estimating the covariance matrix by maximizing the penalized matrix logarithm transformed likelihood function was introduced. In this function, the matrix logarithm of the covariance matrix appears.
The matrix logarithm can also be used to retrieve the coefficient matrix of a system driven by the linear differential equation
from observations of the vector
y, and to calculate the time-invariant element of the state transition matrix in ODEs with periodic time-varying coefficients [
26].
The applicability of the matrix logarithm in so many distinct areas has encouraged the development of different approaches to its evaluation. The traditionally proposed methods incorporate algorithms based on the inverse scaling and squaring technique [
27], the Schur-Fréchet procedure [
28], the Padé approximants [
29,
30,
31,
32,
33,
34,
35,
36], arithmetic-geometric mean iteration [
37], numerical spectral and Jordan decomposition [
38], contour integrals [
39], or different quadrature formulas [
40,
41,
42,
43]. MATLAB incorporates
logm as a built-in function that uses the algorithms described in [
33,
34] to compute the principal matrix logarithm. Recently, an implementation that used matrix polynomial formulas to efficiently evaluate the Taylor approximation of the matrix logarithm was described in [
44].
The inverse scaling and squaring procedure, initially proposed in [
27], is an extension to the matrix domain of the technique used by Briggs to compute his table of logarithms, collected in [
45]. This method takes advantage of the matrix identity
and evaluates
by combining argument reduction and approximation. By taking a certain number of square roots of
A, the problem is reduced to the computation of the logarithm of a matrix with eigenvalues close to 1. Indeed, the approximation of the matrix logarithm is performed in three different stages, as explained in [
27]:
Find an integer s, so that matrix is close to the identity matrix I. For that purpose, an algorithm that computes matrix square roots must be employed;
Approximate by , where is the diagonal Padé approximant of degree m to the function ;
Compute the approximation .
Taking into account the previous three-stage procedure and the following integral expression for the logarithm [
40]
our proposal in this work is to compute the matrix logarithm in three phases somewhat similar to those described above. Notwithstanding,
is approximated in the second stage by means of the expression (
2) and using the well-known Romberg method [
46]. In addition, the matrix square roots in the first phase are worked out thanks to the scaled Denman–Beavers iteration explained in [
1]. The importance of the method used for matrix square root computation must be emphasized.Working with one method or another has a direct impact, not only on the accuracy of the result, but also on the associated execution time.
Romberg’s method employs the trapezoidal rule to approximate numerically the definite integral
. It reduces the integration step
h by half at each iteration and applies the Richardson extrapolation formula to the previous results. This quadrature method generates the so-called Romberg tableau, in the form of a lower triangular matrix
R, whose elements are numerical estimates of the definite integral to be calculated. If we take
as the integration step to be applied in the successive iterations, we define the calculation of each term
as
Below is a diagram depicting how the triangular matrix elements are filled after
m iterations, where the arrows indicate the order in which each term is generated from the previous ones:
The last diagonal term
of the matrix is always the most accurate estimate of the integral. In addition, according to ([
46] p. 342), it is known that if function
f has
continuous derivatives, then the asymptotic error is
Moreover, if
m is sufficiently large, then
Therefore, the previous process must be continued until the difference between two successive diagonal elements becomes sufficiently small.
In this paper, we represent as
(or
I) the matrix identity of order
n. The matrix norm
addresses any subordinate matrix.In particular,
is the traditional 1-norm. If
, its 2-norm denoted by
complies with that in [
47]
This work is structured as follows:
Section 2 presents a theoretical analysis of the error incurred when computing the matrix logarithm using the Romberg integration technique, together with the inverse scaling and squaring Romberg numerical method proposed and the suggested corresponding algorithms.
Section 3 includes the results of the experiments carried out to exhibit the numerical and computational performance of this method under a state-of-the-art and heterogeneous test battery and with respect to three third-party codes. Finally,
Section 4 provides the conclusions.
3. Numerical Tests
This section collects the results corresponding to the different numerical experiments carried out using the following four MATLAB codes, to comparatively determine the accuracy and efficiency of the proposed algorithms:
logm_romberg: This computes the principal matrix logarithm using the inverse scaling and squaring procedure and the Romberg integration method, as described above in Algorithms 1 and 2. The code is available at
http://personales.upv.es/joalab/software/logm_romberg.m (accessed on 2 August 2023). Input parameters
max_sqrts,
m, and
tol were set to 10, 7, and
, respectively, for all the tests;
logm_iss_full: This consists of Algorithm 5.2 detailed in [
33], designated as the
iss_new code. It uses the transformation-free form of the inverse scaling and squaring technique with Padé approximation to compute the matrix logarithm. Matrix square roots are calculated by means of the product form of the Denman–Beavers iteration, as detailed in [
1] (Equation (6.29));
logm_new: This is Algorithm 4.1, denoted as the
iss_schur_new function, as detailed in [
33]. This code initially performs the transformation to the Schur triangular form
of the input matrix
A. Then, the logarithm of the upper triangular matrix
T is computed by applying the inverse scaling and squaring technique and Padé approximation. The Björck and Hammarling algorithm, detailed in [
1] (Algorithm 6.3) and [
51], is applied to work out the square roots of matrix
T;
logm: This is a MATLAB built-in function that calculates the matrix logarithm from the algorithms included in [
33,
34]. Its algorithmic structure is very similar to that of
logm_new, but the square roots of
T are calculated using a recursive blocking version of de Björck and Hammarling method [
52]. Matrix multiplications and the Sylvester equation solution are the main computational problems involved.
Three types of matrices, with very different characteristics from each other, were generated to build a heterogeneous test battery, which allowed comparing the numerical and computational performance of these codes. The MATLAB Symbolic Math Toolbox with 256 digits of precision was employed to compute
“exactly” the matrix logarithm function using the
vpa (variable-precision floating-point arithmetic) function. The battery featured the following three matrix sets, which are practically the same as the ones used and described in [
44]:
- (a)
Set 1: One hundred diagonalizable complex matrices. For each of them, an orthogonal matrix was first generated from a Hadamard matrix H. In addition, from a diagonal matrix D whose eigenvalues were all complex, a matrix was computed. Their 2-norm ranged from to 300. The “exact” logarithm was calculated as ;
- (b)
Set 2: One hundred non-diagonalizable complex matrices. For each of them, an orthogonal matrix V was obtained first. Elements of V belonged to intervals getting longer and longer, from for the first matrix to for the last one. Next, a Jordan matrix J whose complex eigenvalues had an algebraic multiplicity from 1 to 3 was computed. Then, a test matrix was generated. The 2-norm of these matrices took values from to . As in the previous set, the matrix logarithm was exactly calculated as ;
- (c)
Set 3: Fifty-two matrices from the matrix computation toolbox (MCT) [
53] and twenty from the Eigtool MATLAB Package (EMP) [
54]. The size of these was
. The matrix logarithm of each matrix was computed
“exactly” according to this protocol, as described in [
44]:
Compute the eigenvalues of each matrix A by means of the MATLAB functions vpa and eig. Consequently, matrices V and D will be provided, such that . Each element of matrix D that is not strictly greater than 0 is substituted by the sum of its absolute value and a random positive number less than 1, giving place to a new matrix . If not, is equivalent to D. Lastly, matrices and are generated;
Approximate the matrix logarithm via functions vpa and logm, i.e., ;
Take into consideration matrix
, and consequently, its
“exact” logarithm, only if it is satisfied that
For the numerical tests, forty-seven matrices, forty from the MCT and seven from the EMP, were taken into account. The reasons for not considering the rest were as follows:
Matrices 17, 18, and 40 belonging to the MCT, and Matrices 7, 9, and 14 contained in the EMP did not successfully pass the above algorithm;
Due to their ill-conditioning for the matrix logarithm function, the error committed by some of the codes was equal to or greater than 1 for Matrices 2, 4, 6, 9, 35, and 38 of the MCT, and Matrices 1, 4, and 20 of the EMP;
The code logm_iss_full failed at runtime for Matrices 12, 16, and 26 included in the MCT, and Matrices 10, 15, and 18 incorporated in the EMP. The explanation for this is that the function sqrtm_dbp exceeded the maximum number of iterations allowed in the product form of the Denman–Beavers iteration code, in charge of approximating the matrix square roots;
Matrices 8, 11, 13, and 16 from the EMP are also incorporated in the MCT.
The normwise relative error used to test the accuracy of the four codes previously described, hereinafter referred to as
, was computed for each matrix
A in our test bed as
where
stands for the
“exact” matrix algorithm and
represents the approximate one. All the executions were run on a Microsoft Windows 11 × 64 PC equipped with an Intel Core i7-12700H processor and 32 GB of RAM, using MATLAB R2023a.
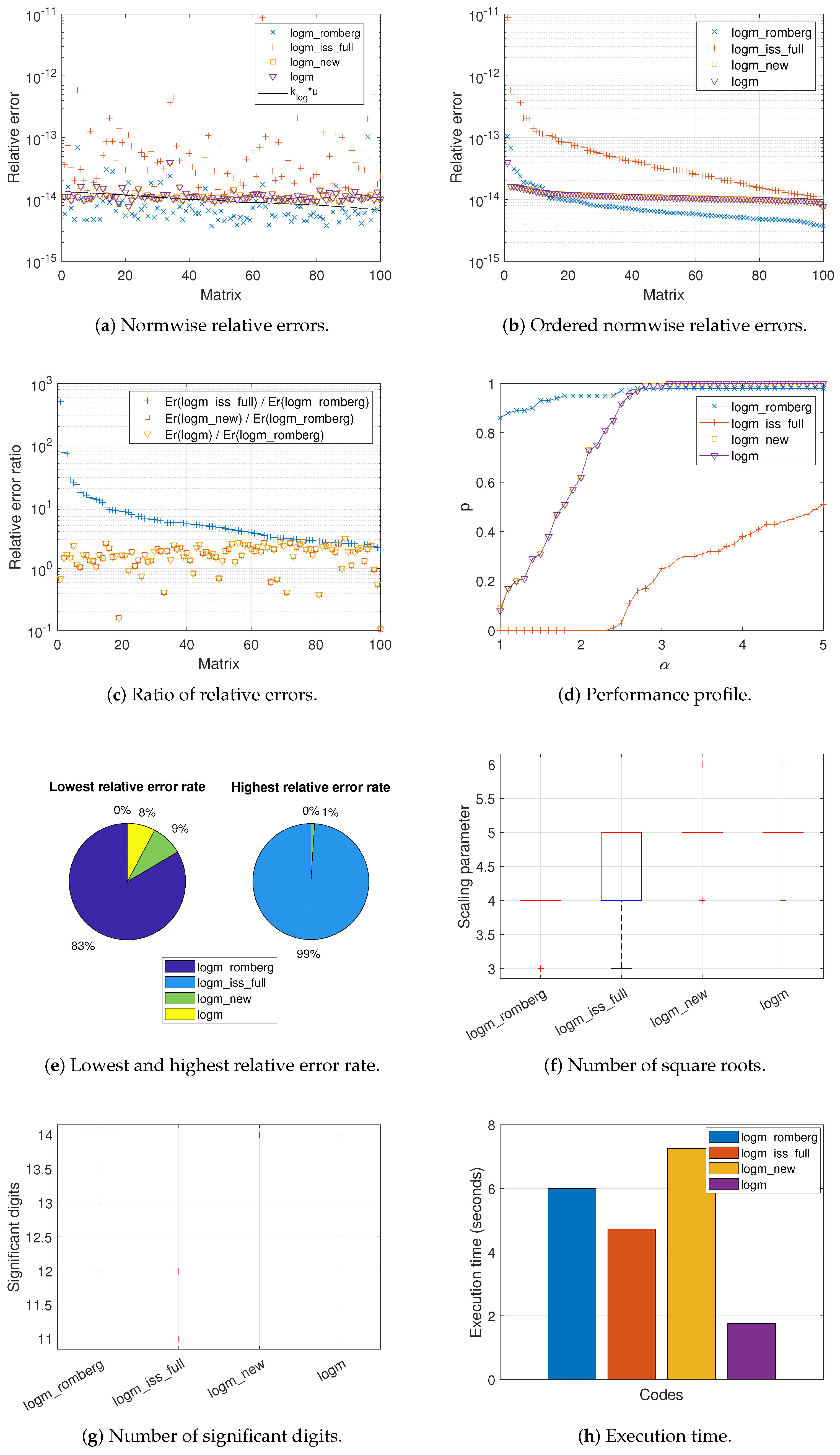
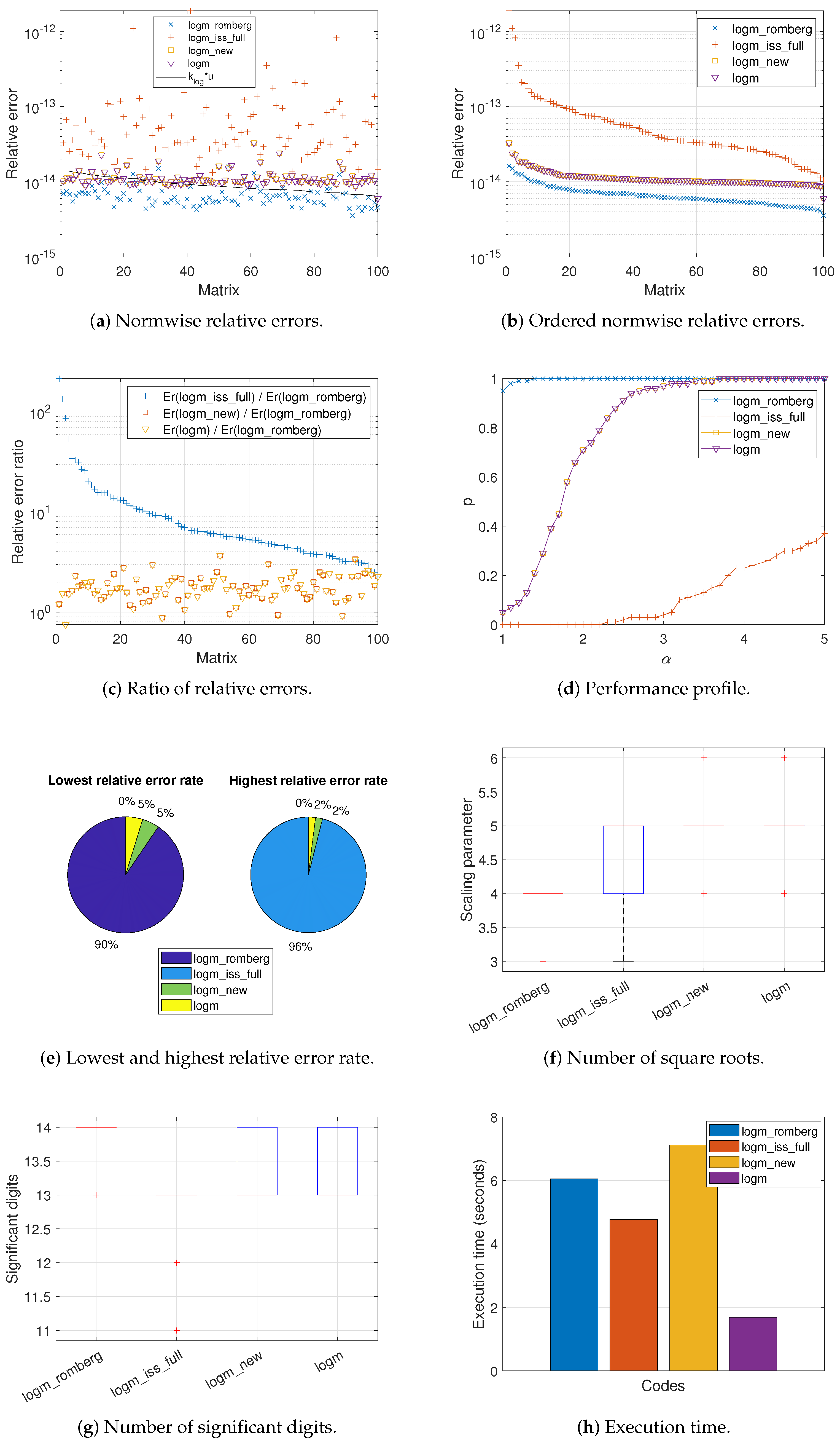
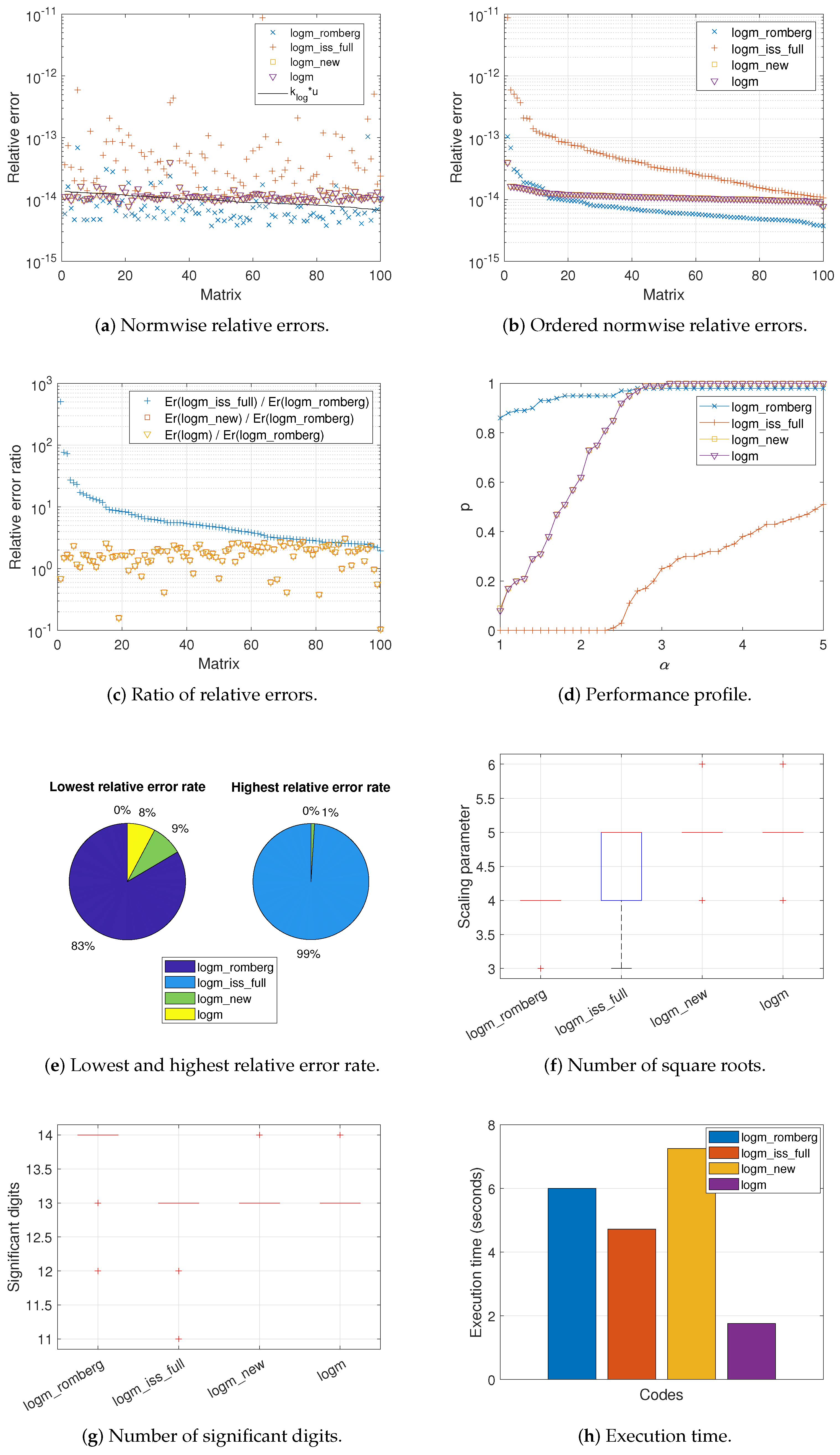
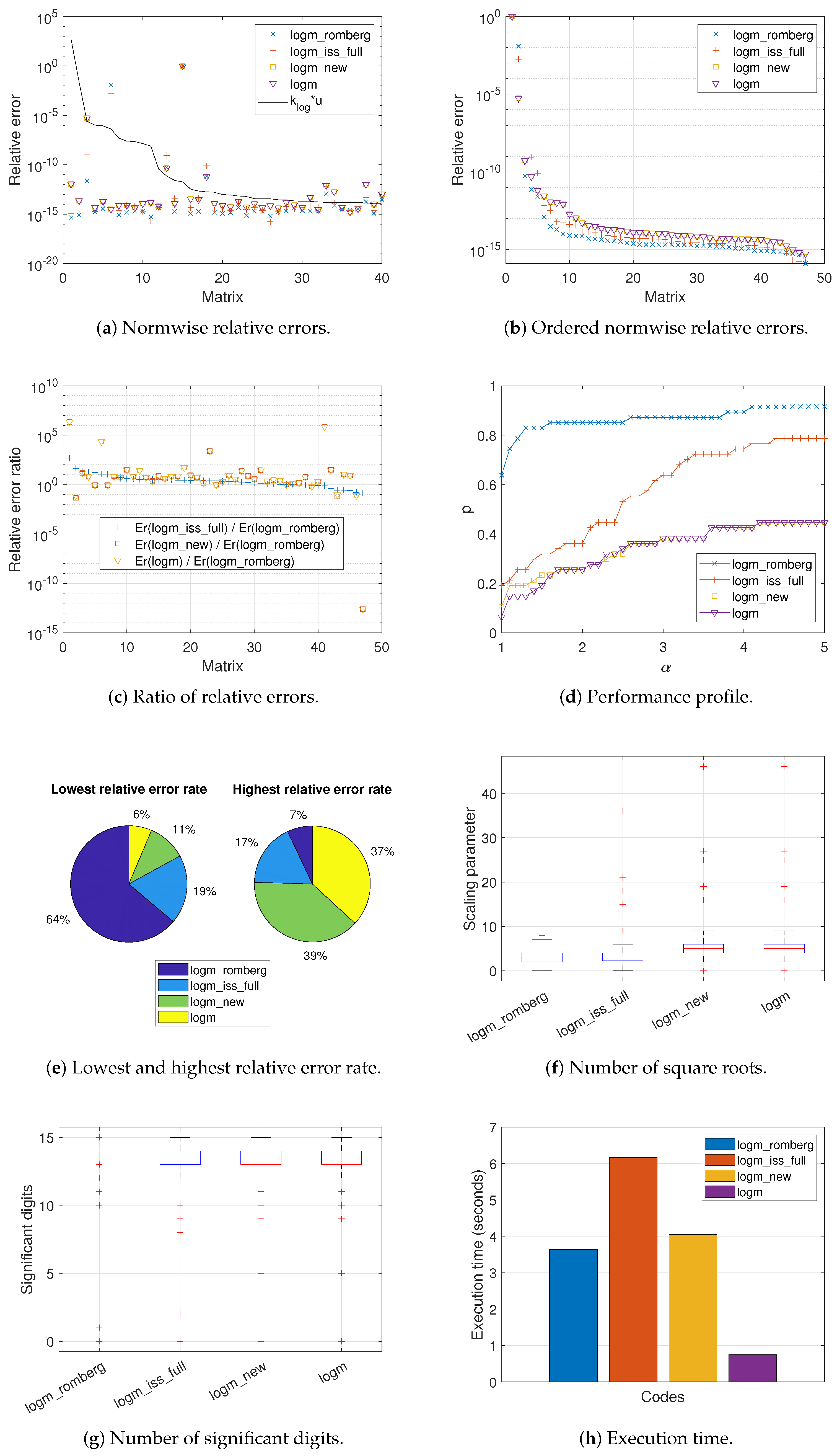
Figure 1,
Figure 2 and
Figure 3 show graphically the behavior of the different methods with respect to the matrices that composed each test set, respectively. In fact,
Figure 1a,
Figure 2a and
Figure 3a depict the normwise relative error
committed by all the codes when computing the logarithm of each matrix. The black solid line appearing in these graphs corresponds to function
, where
is the condition number of the logarithm function for each matrix and
u is the unit roundoff. Approximately, the value of the function
is equivalent to the expected relative error for each matrix calculation. In this sense, it is well known that a code is more stable the closer its results are to these function values, and even more so if they are located below it, which is highly desirable. In view of these results, it seems clear that
logm_romberg was the most stable code, generally providing the smallest relative errors. In the case of Set 3, the results of only forty matrices are represented in
Figure 3a. The others (Matrices 19, 21, 23, 27, 51, and 52 of the MCT, and Matrix 17 of the EMP) were not considered due to the large condition number of our objective matrix function.
These results are consistent with those reported in
Table 2, which displays the percentages of matrices in which the relative error incurred by
logm_romberg was lower or higher than those of the other codes. As indicated,
logm_romberg outperformed all of the other codes in at least 72% of the cases, even reaching 100% against
logm_iss_full in Sets 1 and 2.
More in depth,
Table 3 distributes these percentages of improvement into four different error ranges, in an attempt to quantify how much better or worse
logm_romberg was in comparison with the others. For Sets 1 and 2, the highest percentages of improvement for
logm_romberg occurred in the intervals 2 to 4 against
logm_iss_full or in the first and second ranges against
logm_new and
logm. Instead, the percentages were spread over the four intervals, regardless of the code considered for Set 3.
Furthermore, and for the sake of completeness,
Table 4 contains a variety of statistical data concerning the relative error of each code, such as the maximum, minimum, mean, and standard deviation. In addition,
Table 4 incorporates the 25th, 50th, and 75th percentiles (
,
, or median, and
, respectively), and the number of outliers, i.e., those values outside of the interval
. Overall, the smallest values for these parameters were provided by
logm_romberg. The maximum error value attained by the codes for the matrices of Set 3 was remarkable, owing to its ill-conditioning.
While
Figure 1a,
Figure 2a and
Figure 3a show the relative errors in descending order for each matrix according to its value in the solid line function,
Figure 1b,
Figure 2b and
Figure 3b plot the same relative errors for each code but independently of each other, sorted from highest to lowest. There is not, therefore, a direct correspondence between a matrix on the X-axis and the errors obtained for the four codes analyzed and collected on the Y-axis. As can be seen,
logm_romberg occupied the bottom of these illustrations for most of the matrices in our test bed, with the exception of a group of more than a dozen matrices in Set 2 and a few isolated cases in Set 3. In this sense, the first column of
Table 5 gives, for the codes under comparison, the result of the integral of the discrete function corresponding to the relative error committed for each matrix. In other words,
Table 5 provides the value of the area delimited between function
, the X axis, and the lines
and
, for Sets 1 and 2, or
, for Set 3. Smaller values of this integral are expected to be associated with more accurate codes. The most reduced area was achieved by
logm_romberg in the case of Sets 1 and 2. For Set 3, the area was very similar and too high for the three codes under analysis, due to the excessively large errors in calculating the logarithm for some matrices.
The normwise relative error ratio between the other three codes and
logm_romberg is provided in
Figure 1c,
Figure 2c and
Figure 3c. Logically, most of these quotients were greater than 1. Matrices were arranged according to the rate of the error caused by
logm_iss_full and
logm_romberg.
Figure 1d,
Figure 2d and
Figure 3d present the performance profile. For an
from 1 to 5, this graph gives the percentage of matrices in terms of one (
p), for which the error of a code is less than or equal to
times the smallest error achieved by any of them. As
increases, the probability of the codes desirably tends toward 1. Therefore, those codes with the highest values in most of the plots are more reliable and accurate. To reduce the influence of relative errors smaller than the unit roundoff in the performance profile pictures, these errors were modified according to the transformation described in [
55]. Clearly,
logm_romberg was the code generally placed at the top for most test cases, followed in Sets 1 and 2 by
logm_new and
logm, with identical values to each other, or by
logm_iss_full in Set 3. Nonetheless,
logm_romberg was slightly surpassed by
logm_new and
logm for an
close to 3 in the second set of matrices.
Table 5 also lists, in its second column, the value of the integral of the performance profile function, i.e., the area enclosed between the X-axis, the value of
p, and the lines
and
. Once again, the largest area values provided by
logm_romberg revealed that it was, broadly speaking and as previously mentioned, more accurate and reliable than its competitors.
By means of pie charts,
Figure 1e,
Figure 2e and
Figure 3e represent the matrix percentage for which each code delivered the smallest or largest relative error. It is noticeable how
logm_romberg always corresponds to the largest sector of the left-hand pies (90%, 83%, and 64%, respectively, for each matrix group) and the smallest part of the right-hand ones (0% for Sets 1 and 2, and 7% for Set 3).
Table 6 collects the minima, maxima, means, and medians achieved for the parameters
m and
s. In the case of
logm_romberg,
m stands for the number of rows actually required in the Romberg tableau for the logarithm computation of the matrices that compose each set; that is, the value of the variable
i in Algorithm 2. The needed values of
m ranged from 6 to 7 for Sets 1 and 2, and from 5 to 7 for Set 3. However, the most frequently used value was 6. Recall that the maximum allowed value of
m was 7 in all our runs. For the rest of the codes,
m represents the Padé approximant degree. Clearly, this means that the values of
m should not be compared between
logm_romberg and the others.
On the other hand,
s denotes the number of square roots that executed by the codes. These numerical values of
s, included in
Table 6, have been also visualized in the form of box plots in
Figure 1f,
Figure 2f and
Figure 3f, with the objective of representing them graphically through their quartiles. Thus, for each box, its bottom, central, and top marks signify the 25th (
), the 50th (
or median), and the 75th (
) percentiles. Outliers, individually represented by symbol ‘+’, are the values outside the interval
, as stated above. The whiskers extend to the most extreme datapoints in the cited range. It is obvious from these data that
logm_romberg performed a smaller number of roots than the other codes. Except for
logm_romberg, the high values of
s achieved by the rest of the codes for some matrices in Set 3 are remarkable.
Different statistical data corresponding to the number of significant digits achieved in the computed solution by each code are compiled at numerical level in
Table 7 and as a box plot in
Figure 1g,
Figure 2g and
Figure 3g. On average,
logm_romberg provided the largest number of valid digits. In detail, this code guarantees that its solutions have, in the worst case, at least 13 significant digits for the matrices in Set 1, and 12 digits for Set 2. For this latter set, this value was improved by
logm_new and
logm, guaranteeing at least 13 digits. In one way or another, the values of
,
, and
were favorable for
logm_romberg. The same can be stated for Set 3 regarding
,
, and
, although unfortunately no significant digit was guaranteed by any code in the particular case of one of its matrices. The interquartile range, which measures the distribution of values and is calculated as
, was always 0 in the case of
logm_romberg for all three types of matrix. This indicates the high reliability of the code, as it guaranteed at least 14 correct digits in the vast majority of the matrices addressed.
To conclude this comparative study,
Table 8 shows the execution times invested by the four different codes in calculating the logarithm of the matrices that constituted our test battery. For Sets 1 and 2,
logm_romberg required an intermediate amount of time, between that of
logm_iss_full and
logm_new. Even for Set 3,
logm_romberg consumed less time than the abovementioned codes. Clearly, the most cost-effective code was
logm. Notwithstanding, it should be clarified that
logm was the only one composed of MATLAB built-in functions. Let us recall that the code for these functions is not interpreted as for any other written in MATLAB, but they have already been compiled to machine language and are part of executable files. Thus, from the point of view of the execution time, the comparison of
logm with the rest of the implementations is far from fair. Moreover, these time results are graphically illustrated in
Figure 1h,
Figure 2h and
Figure 3h, in the form of bar graphs.







{kind=link}
{kind=link}
{kind=link}