

Time-Dependent Unavailability Exploration of Interconnected Urban Power Grid and Communication Network

 , , ,
, , ,  , , and
, , and
Abstract
:1. Introduction
2. State of the Art
- OpenFTA (Open-source): OpenFTA, an FTA tool, aids in comprehending and applying FTA, a method in safety engineering for qualitative and quantitative evaluation of CI system reliability and safety. However, having not been updated for over a decade, its relevance in contemporary applications might be questionable.
- OpenAltaRica (Restricted free access): OpenAltaRica focuses on risk analysis of intricate systems using the AltaRica language, a high-tier language crafted for the RAMS analysis of systems. Catering to vast models, it encompasses both qualitative and quantitative examination instruments.
- Fault Tree Analyser (Demo version available): A segment of ALD’s suite tailored for reliability engineering and risk evaluation, this tool offers a visual interface for constructing and scrutinizing FT. It is engineered to deduce the likelihood of a principal event from the probabilities of foundational events.
- Isograph FaultTree+ (7-day trial): Crafted by Isograph, FaultTree+ is a leading application for creating FT and executing qualitative and quantitative FTA. Its user-friendly interface is equipped to manage a range of logic gates and incidents. Industries such as defense, aerospace, nuclear, and rail have integrated Isograph’s software suite into their operations.
- Item Toolkit (30-day trial): This suite offers tools essential for reliability predictions—Failure Modes and Effects Analysis (FMEA), FTA, and other reliability engineering undertakings. Designed for analyzing both rudimentary and advanced systems, it aids engineers across domains, from electronics to mechanics, to gauge their designs’ reliability.
- DFTCalc (Open-source): Essentially a “DFT Calculator”, DFTCalc specializes in DFT analysis. Differing from conventional FT that employs just AND and OR gates, DFT encapsulates event sequences and intricate interdependencies. Scripted in C++, DFTCalc yields metrics for reliability and availability for such trees.
3. Methodology
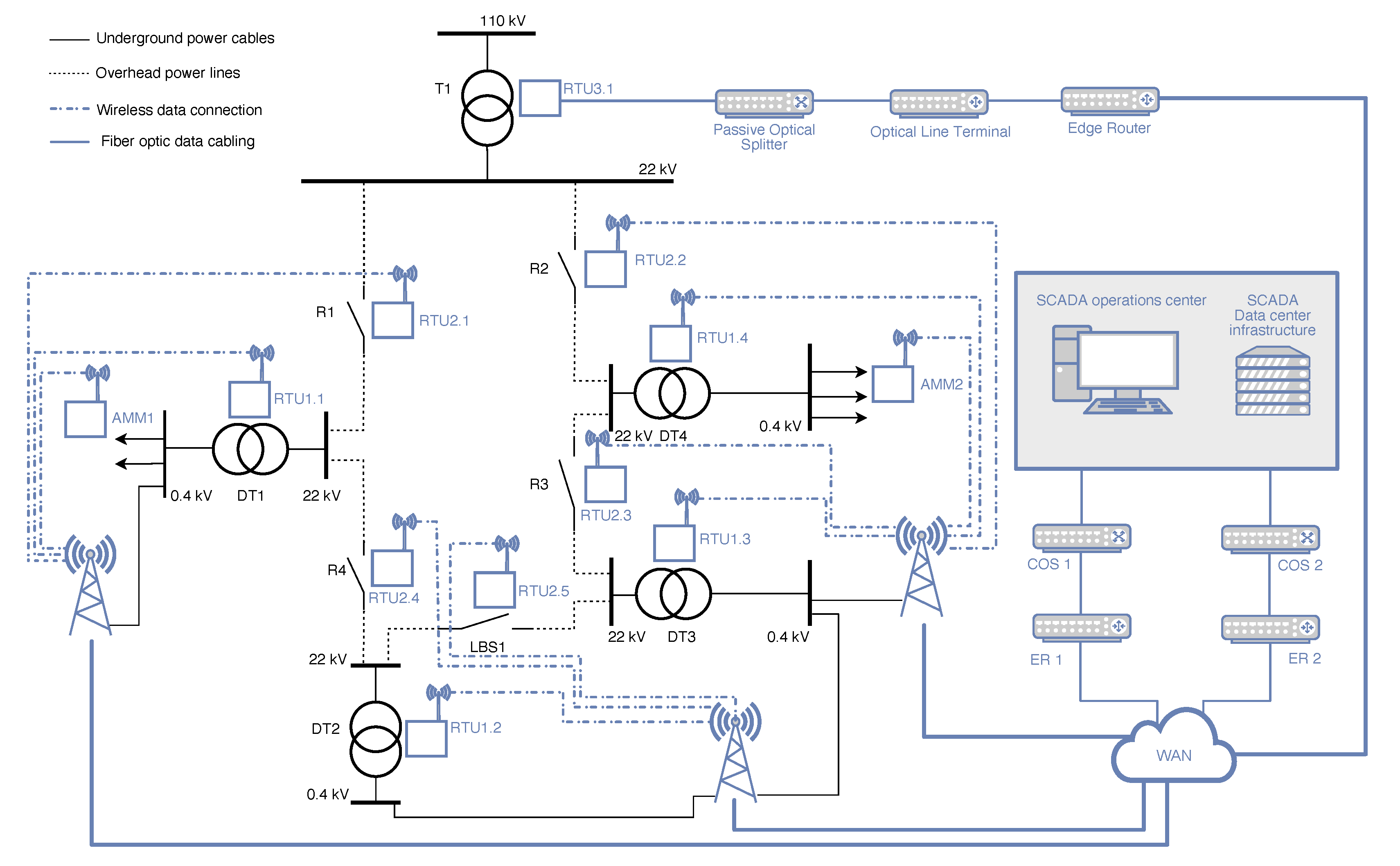
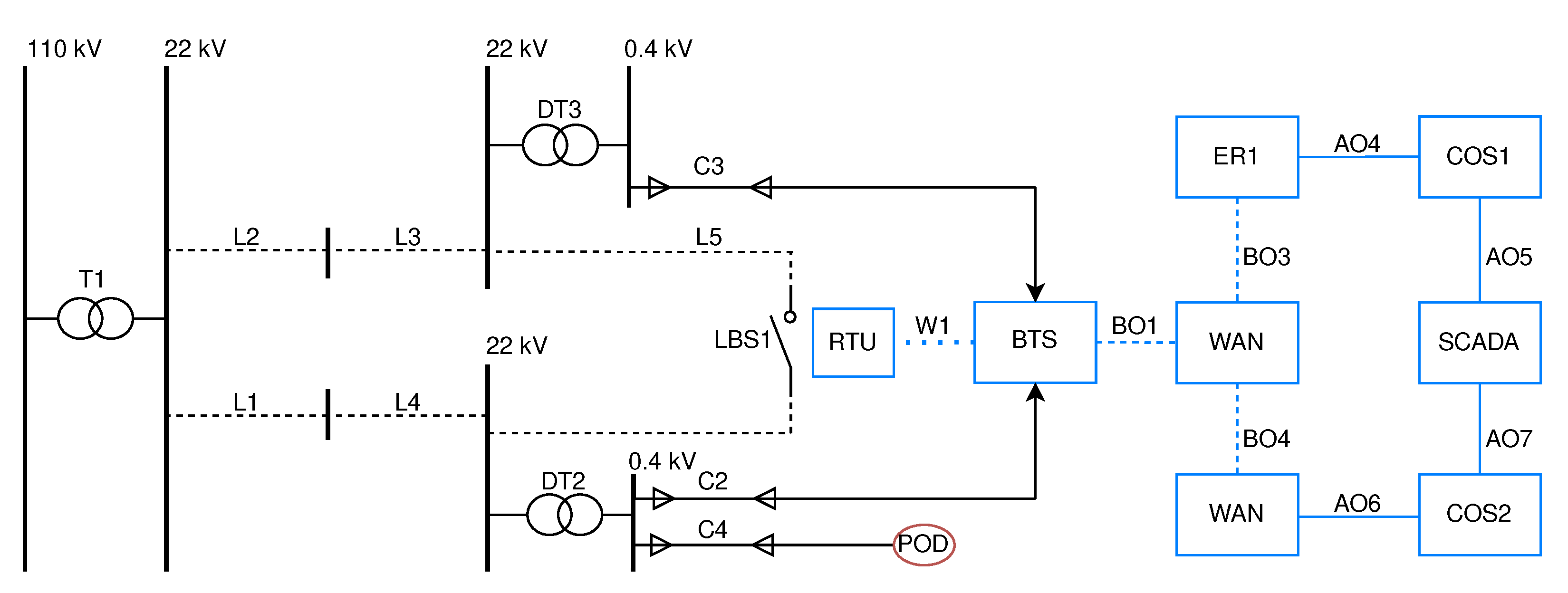
3.1. Description of Representative Infrastructure
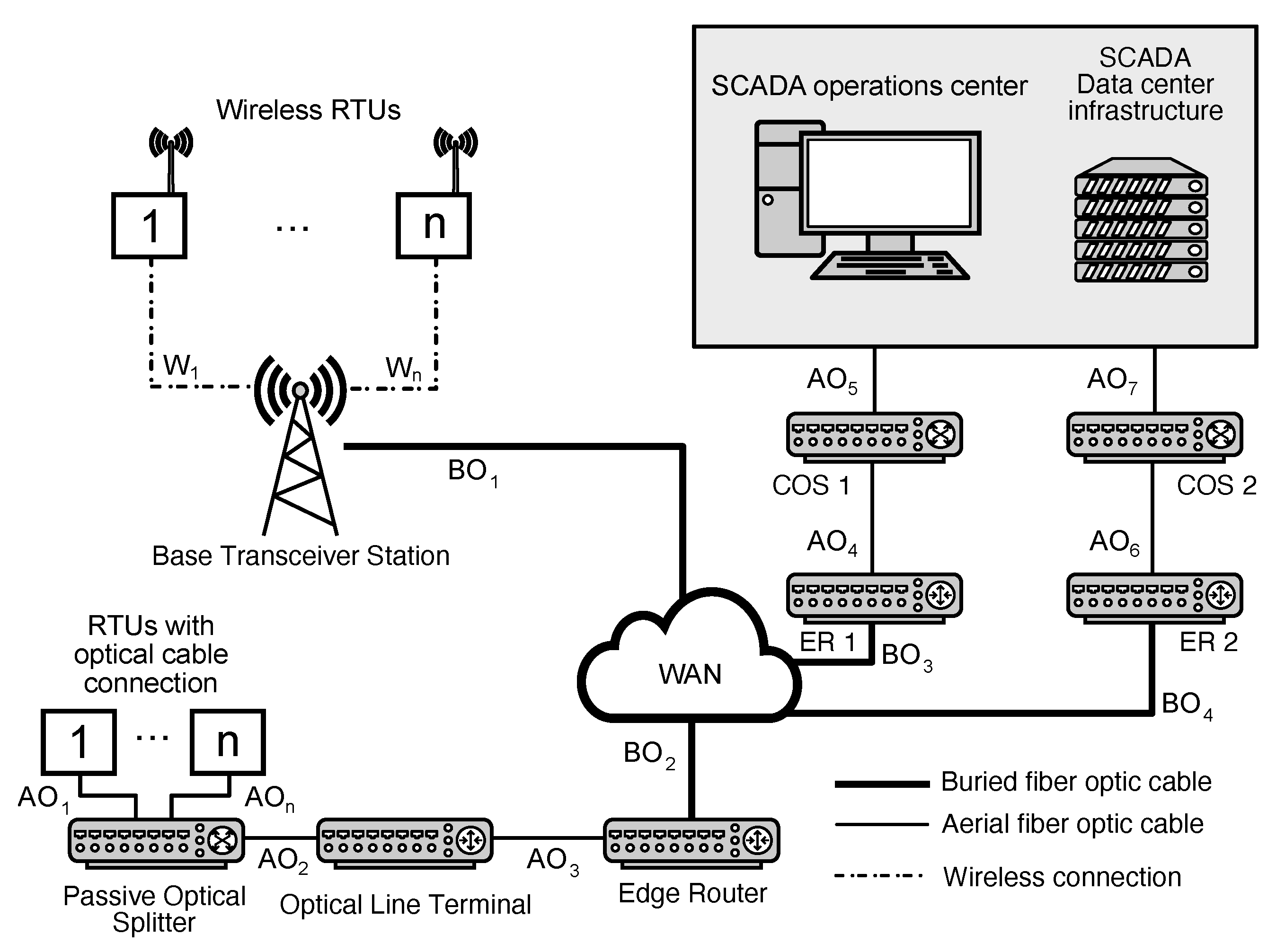
- The reliance of the communication infrastructure on the consistent performance of the distribution network. This is due to the wireless transmitters that source their power from the Low Voltage (LV) level of the distribution system. Specifically, they derive power from LV busbars of the Distribution Transformer (DT) labeled DT1, DT2, and DT3.
- The second dependency emerges from the integration of specific RTU and AMM devices within the distribution network. When these devices malfunction, they can disrupt the distribution system’s operations in two potential ways: (i) directly (by hindering the ability to control switching devices), and (ii) indirectly (through failures of metering devices). It is crucial to note that the influence of AMM devices on the distribution network’s operation is not taken into account for the purposes of this paper because they are exclusively utilized for metering objectives (non-direct impact).
- RTU installed in Medium Voltage (MV) switchboards at Distribution Transformer Stations (DTS), referenced as RTU1.1–4 in Figure 1.
- RTU serving as the control mechanism for reclosers on MV lines, denoted as RTU2.1–4.
- RTU positioned within the High Voltage (HV)/MV substations, labeled as RTU3.1.
- RTU functioning as the monitoring and command unit for section load break switches, identified as RTU2.5.
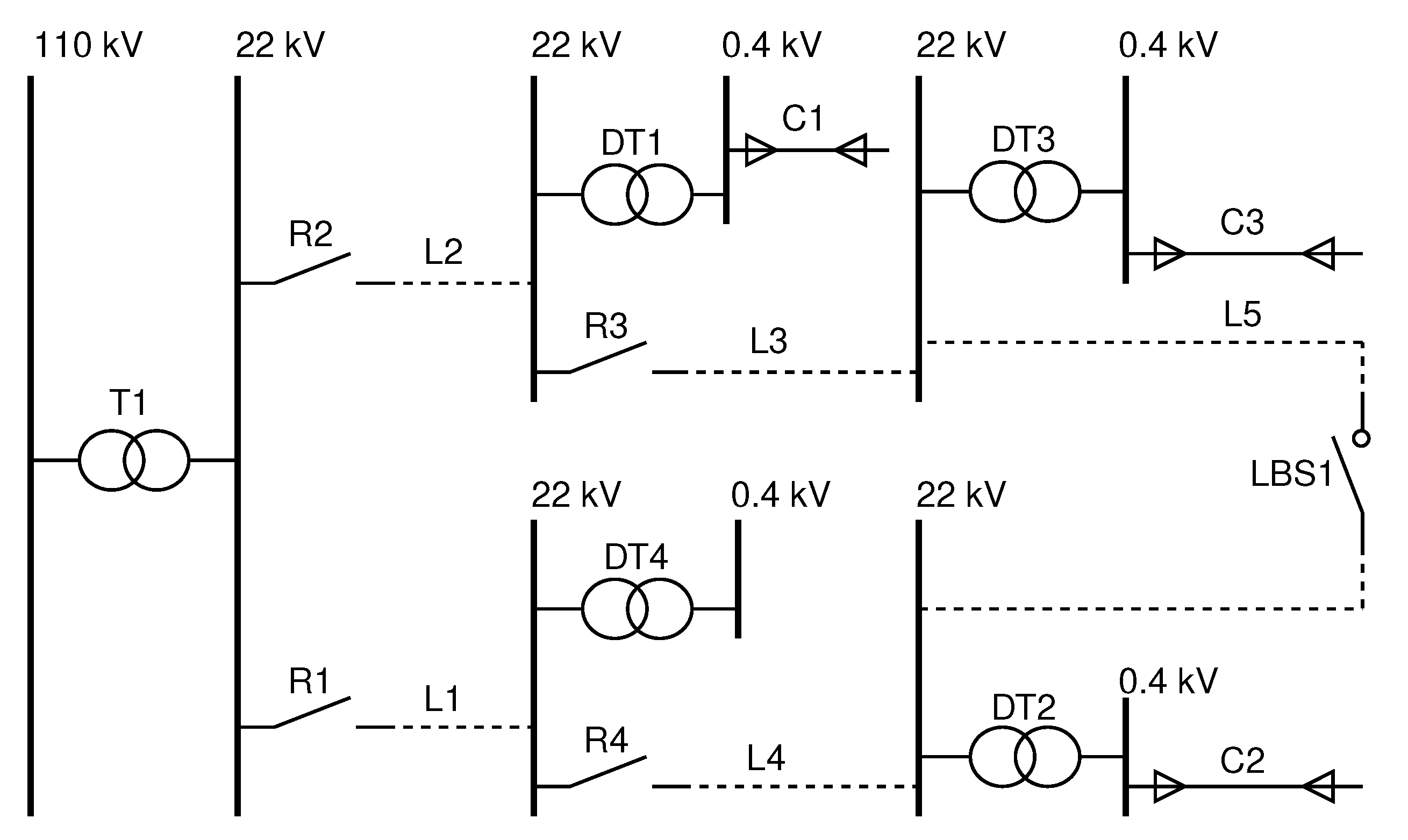
3.1.1. Power Grid Topology
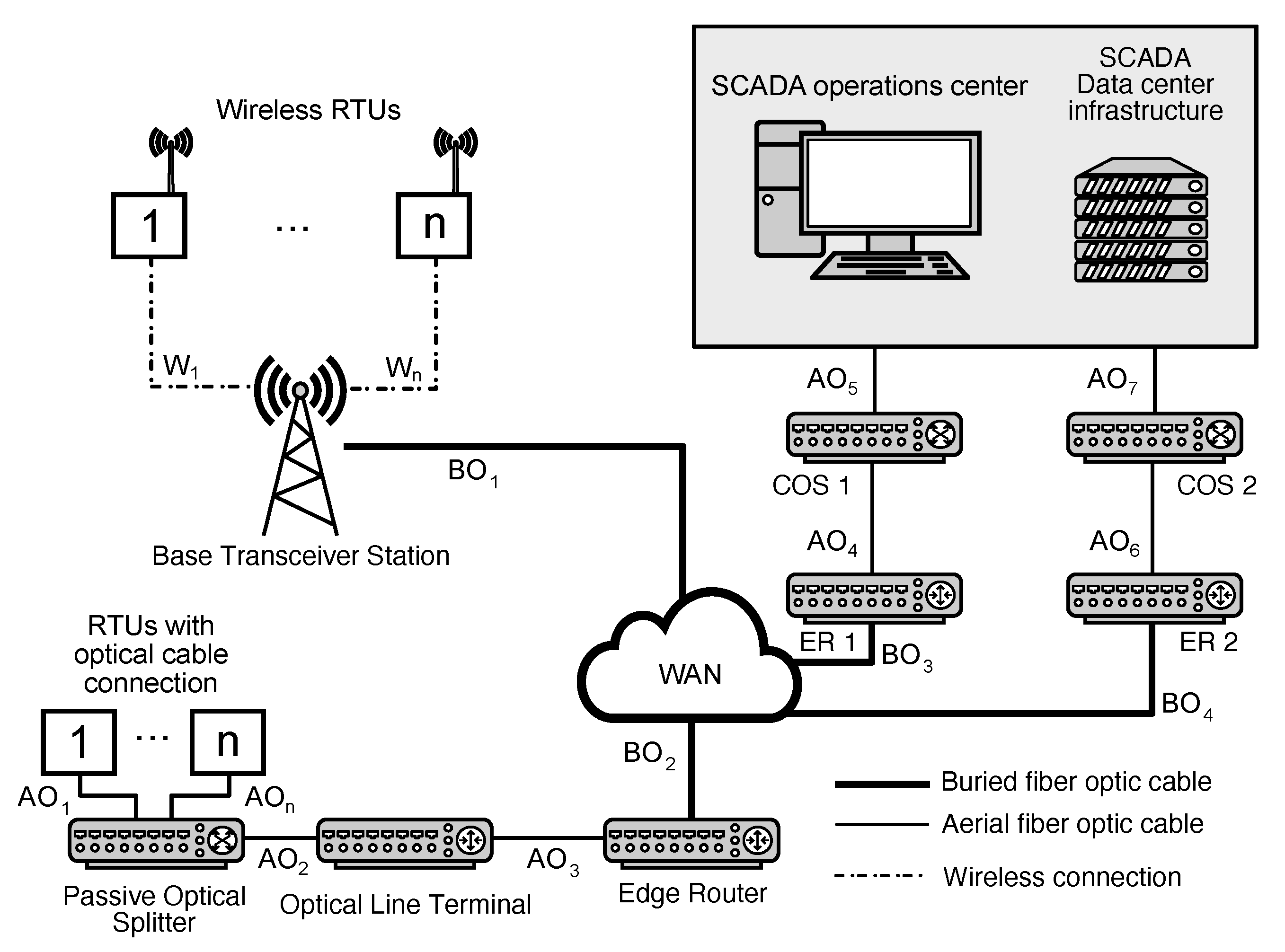
3.1.2. Communication Network Topology
3.2. Description of Network Functionality and Network Contingency Quantification
- Power Flow Analysis: Here, AGs act as a representation of the power flow in a grid. The nodes within these graphs stand for substations, while the edges denote power transmission lines. By using AGs, engineers and researchers can determine the most efficient power flow routes and detect potential bottlenecks within the grid. For a deeper dive into this application, readers can refer to [29,30].
- Maintenance Optimization: Maintenance within the power grid often requires intricate scheduling to account for dependencies and constraints. AGs assist in this endeavor by helping to prioritize tasks. With the help of these graphs, it becomes easier to determine which tasks need immediate attention and ensure a systematic and efficient completion sequence. More on this can be explored in [26,31,32].
- Power and Data Outage Modeling: AGs also find their application in modeling power and data outages. In such models, nodes signify the various components of the grid, and edges represent the inter-relationships between them. Through these AG-based models, it is possible to swiftly identify the primary causes of an outage. Furthermore, they provide a roadmap for an effective response strategy to restore either power grids, as discussed in [33], or data networks, as highlighted in [34].
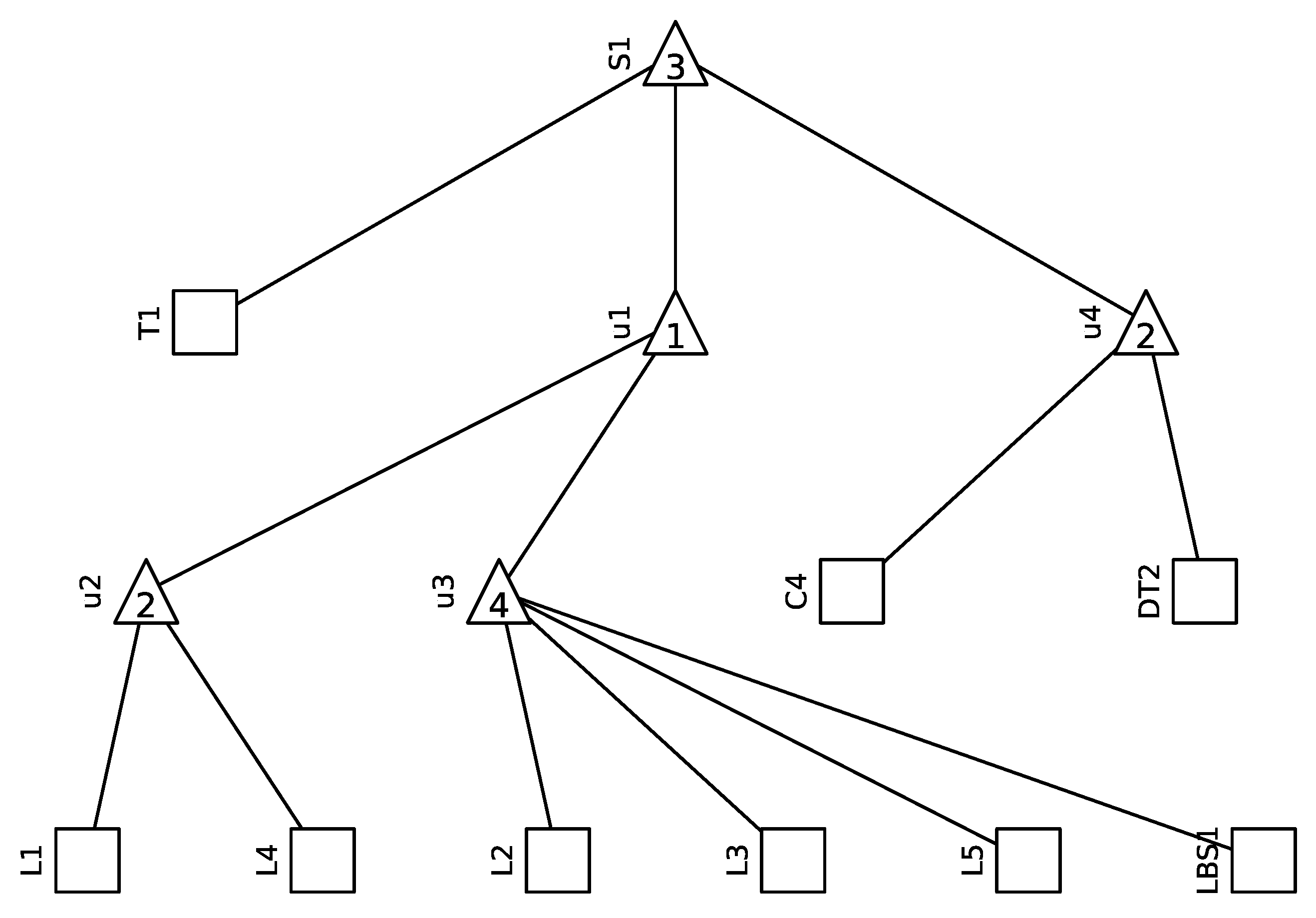
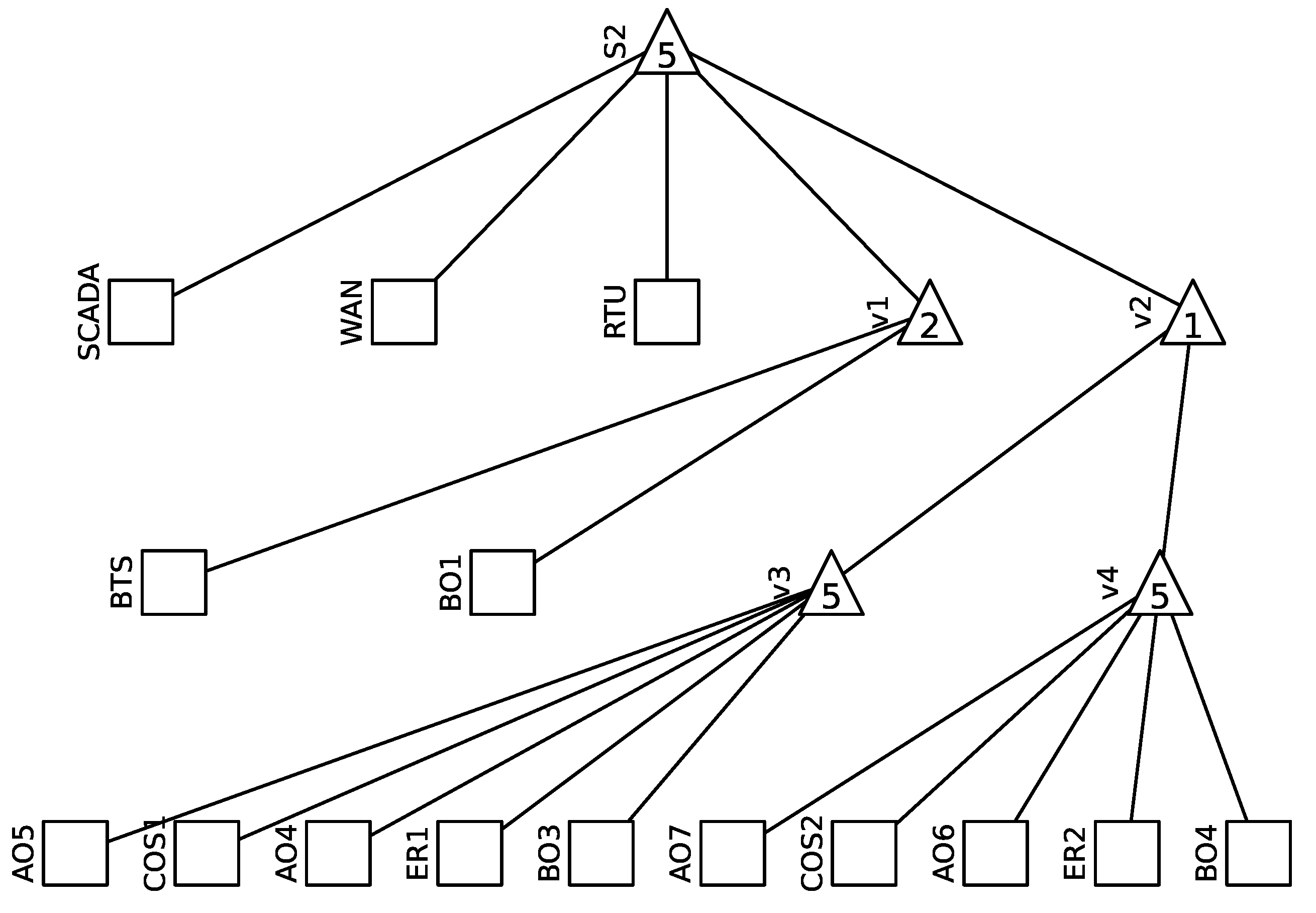
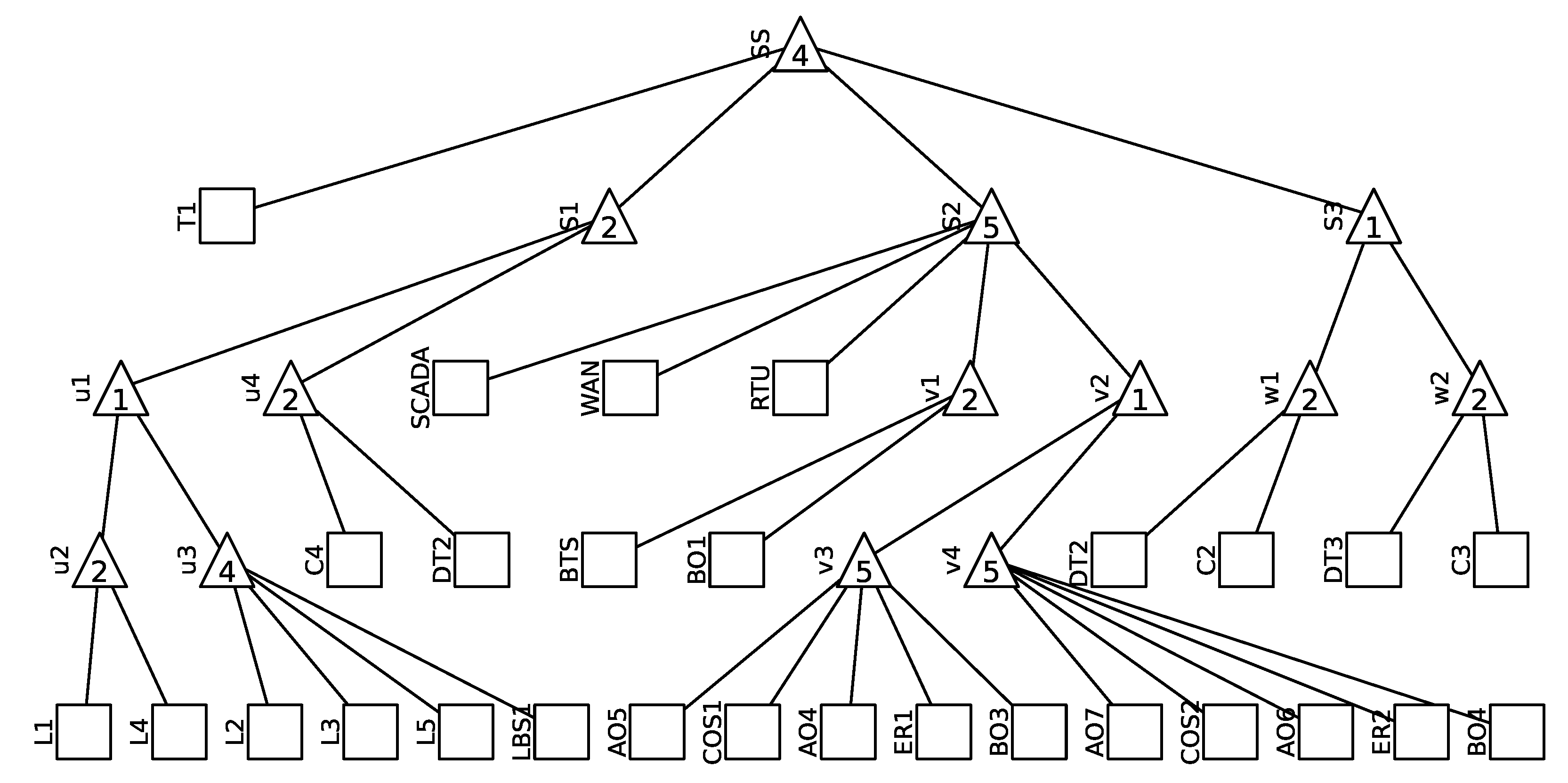
- First, the graph is inherently acyclic, ensuring that two directly connected nodes share a singular edge.
- At the top of the AG is a solitary SS node. This unique node symbolizes the overall system’s functionality, illustrating correct operation against system failure.
- An inherent directionality exists between the nodes of the AG, establishing the relationship of subordination between them, delineated as a slave node in relation to a master node.
- An internal node, also referred to as a non-terminal node, typifies the stochastic behavior inherent within a subsystem. This subsystem is perceived to be in a state of correct functionality only when a minimum of m subordinate nodes (which can either be terminal or non-terminal) concurrently display correct functionality. This stipulation requires the integer m to reside within a specific interval. Specifically:
- −
- The total number of input edges is marked n.
- −
- For a situation where m equals 1, the internal node effectively emulates a logical OR function.
- −
- Conversely, when m matches n, the internal node resonates with a logical AND function.
- The role of terminal nodes is pivotal as they symbolize the operational status of the diverse components integrated within the system. To be precise, these components are subject to events which can either be stochastic in nature or deterministic. For those events characterized by stochasticity, they need to be articulated via distinct probability distributions, specifically catering to the occurrence of faults. Additionally, events tethered to maintenance, either preventive or corrective, necessitate clear and unambiguous specifications.
- Function (i): Ensuring that the HV level supplies the MV level, as signified by transformer T1 in the system.
- Function (ii): Guaranteeing a consistent voltage to the MV busbar prior to the Distribution Transformers, as well as ensuring the supply to the critical POD, denoted as u1 in the network.
- Function (iii): Establishing and safeguarding the data communication link between the SCADA operation center and the RTU which oversees the LBS operations in the distribution network. This is represented by subsystem S2 in the system’s configuration.
- Function (iv): Ensuring a stable power supply to the BTS from the MV level. This is facilitated by subsystem S3 through transformers DT2 or DT3 and via cables C2 or C3 in the system architecture.
3.3. Theory for Analyzing Incident Key Performance Indicators
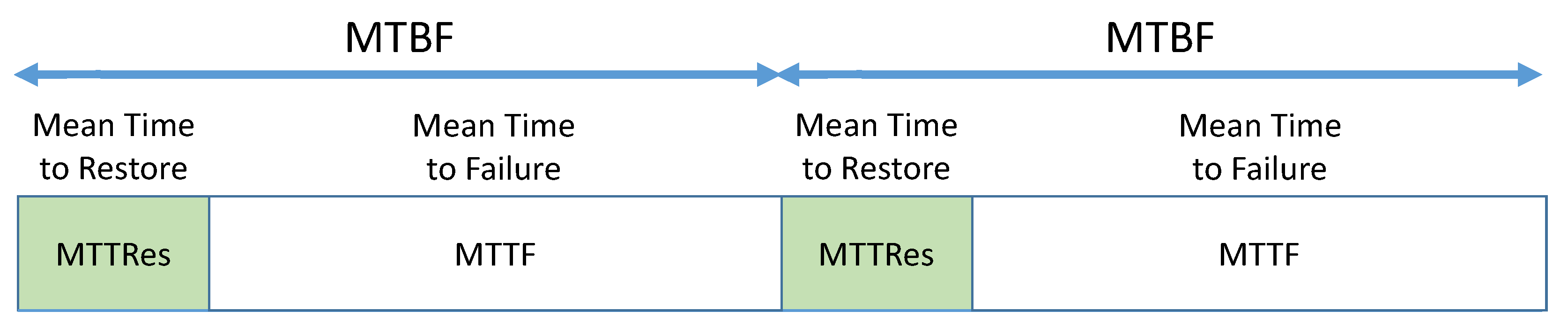
- Mean Time To Failure (MTTF),
- Mean Time Between Failures (MTBF),
- Mean Time To Repair (MTTRep),
- Mean Time To Restore service (MTTRes).
- MV/LV transformer (22/0.4 kV) labeled as DT2–DT3 is determined by study [17], where the study introduces MTBF 43,800.361 h and MTTRes 0.361 h for MV/LV transformers.
- Load break switch (LBS1) on 22 kV overhead line is determined from study [17], where all power switches are generalized under one category. The study introduces MTBF 224,621.087 h and MTTRes 5.702 h for 22 kV switches.
- ER is determined from study [19], which introduces the values MTTF and MTTR for the edge and core router. However, the representative architecture introduced in this paper’s case brings together the ER and the Core Router (CR), so it is more accurate to obtain the numbers for the “core” router. The authors use the same methodology and provide clear values for MTTF and MTTRes (as “MTTR”). Therefore, Equation 4 is used to determine the MTBF.
- Indicators for Optical Line Terminal, Passive Optical Splitter, and Core Optical Switch are all determined from study survey [20]. The study introduces the Failure In Time (FIT) values and MTTRes (as “MTTR”) and the relationship between FIT and “MTBF” (or as defined in the proposed methodology, MTTF in hours):
- The optic fiber communication link is divided into a buried link labeled BO1-BO3 and an aerial link labeled AO1-AOn. The indicators are obtained from [22], where the authors published three values for various scenarios: optimistic, nominal, and conservative. Nominal values are used, considered per km for their study.
3.4. Theory for Computing Unavailability of the Investigated Infrastructure
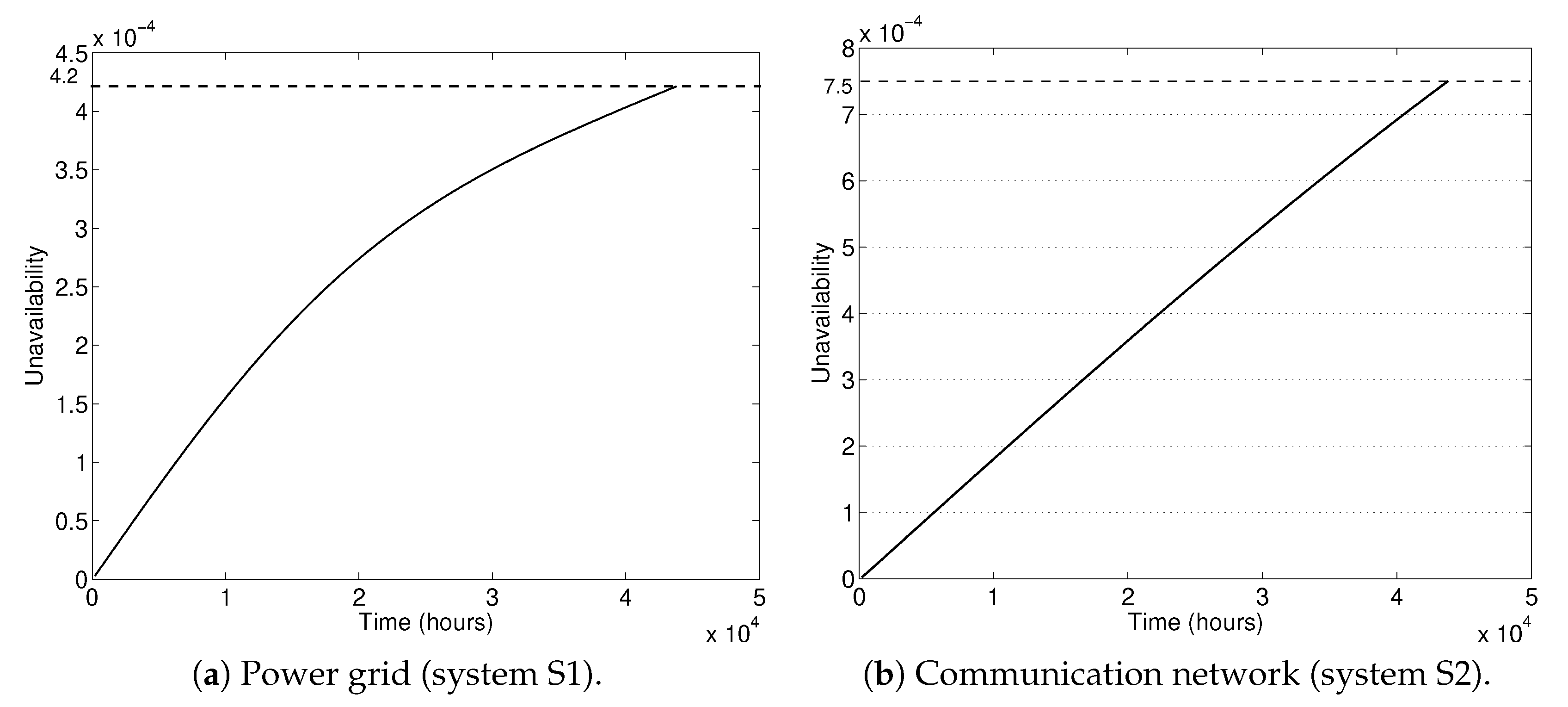
4. Results
5. Conclusions
- Description of the novel real critical energy infrastructure use case, which consists of interconnected urban power grid and communication network, was presented. Parameters of reliability and maintenance models of components were estimated from the literature review and expert knowledge.
- The developed computational model assumes the ageing of components, which is simulated by the Weibull distribution. The use of the Weibull distribution is consistent with real failure datasets of power distribution components. Moreover, the interconnected model also exploits the observation that the time to repair of these components can be modeled by an exponential distribution.
- Time-dependent reliability assessment of the interconnected use case was performed. The identification of the critical components of the interconnected network and their interdependencies was provided by the general directed AG. Highly reliable components and interconnected networks were properly modeled. The software tool leveraged exact reliability quantification of highly reliable events.
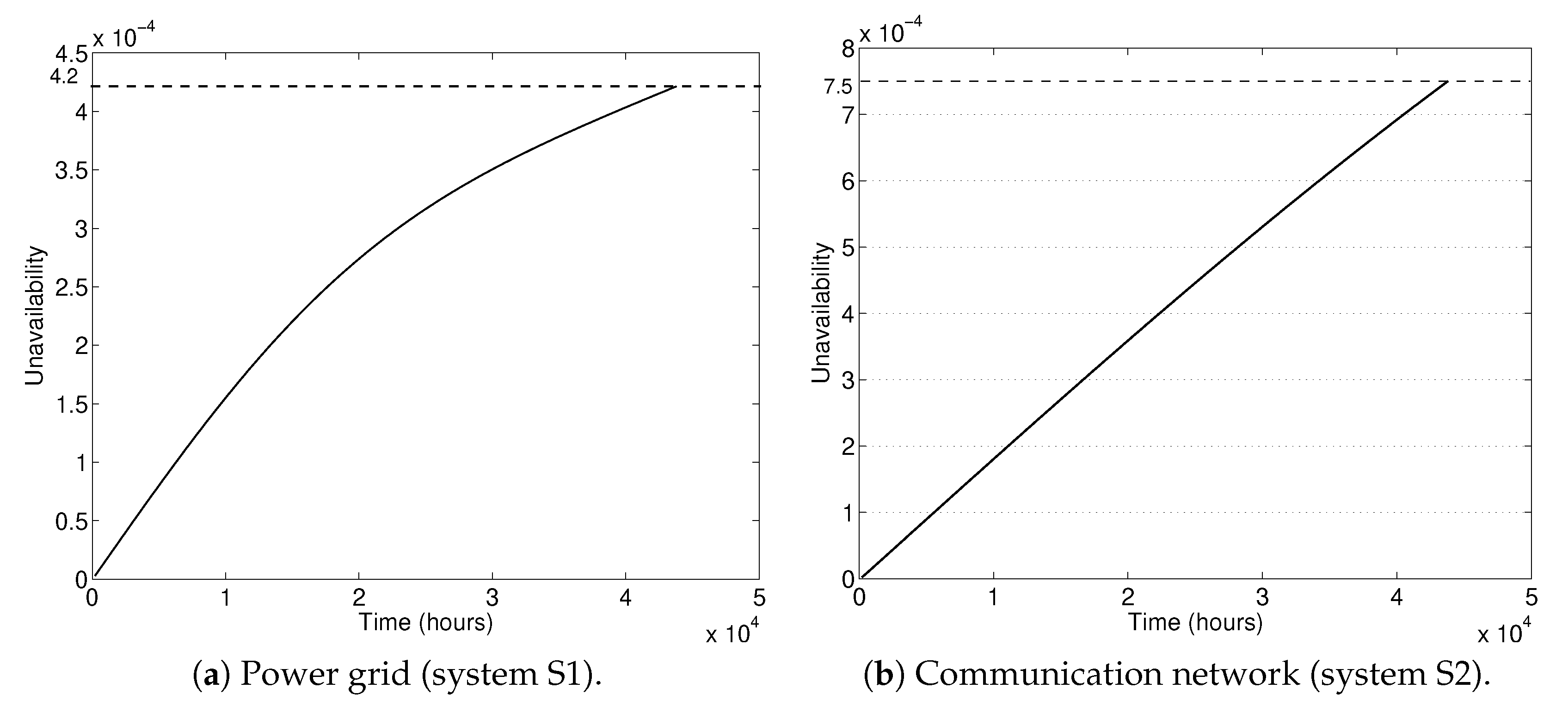
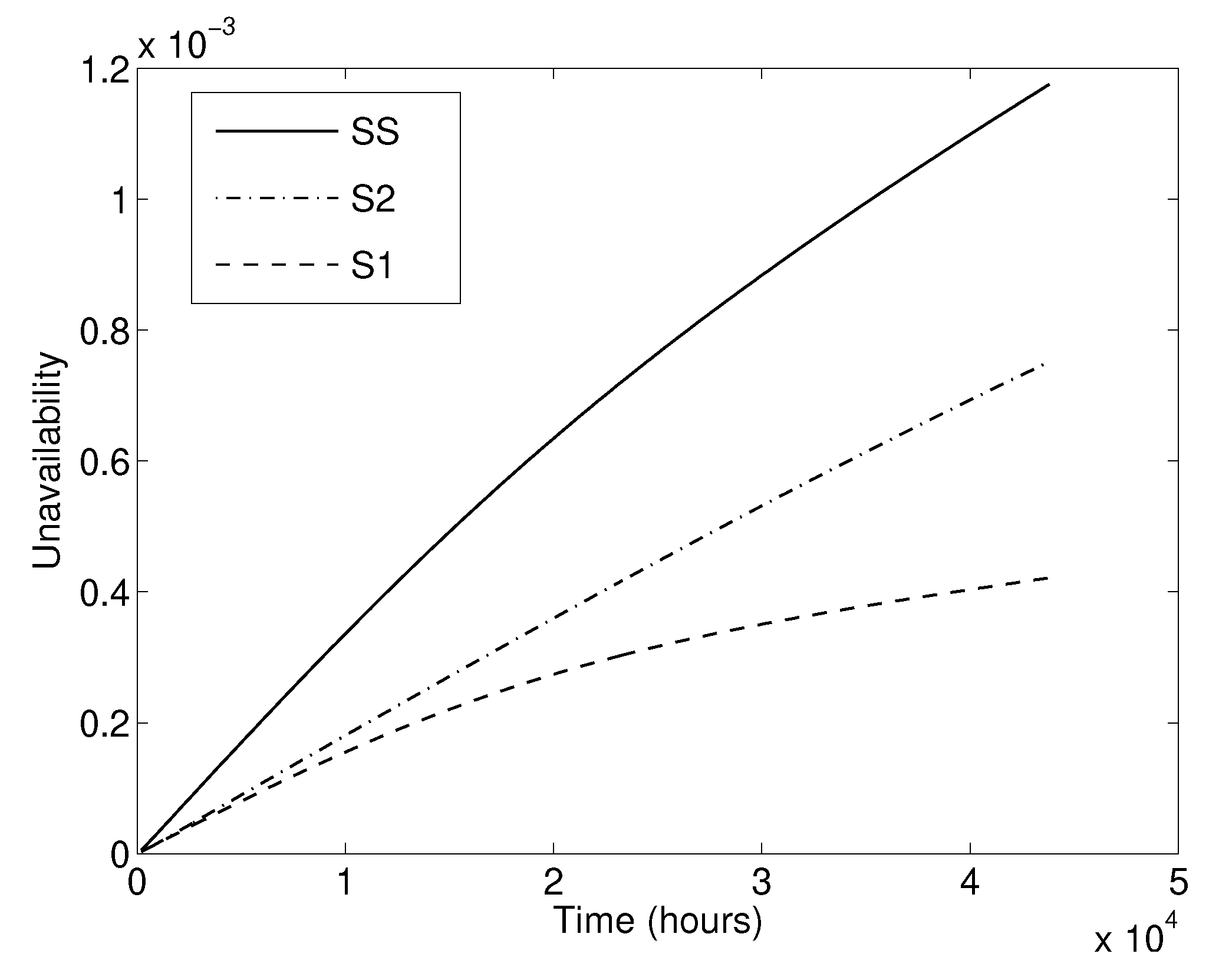
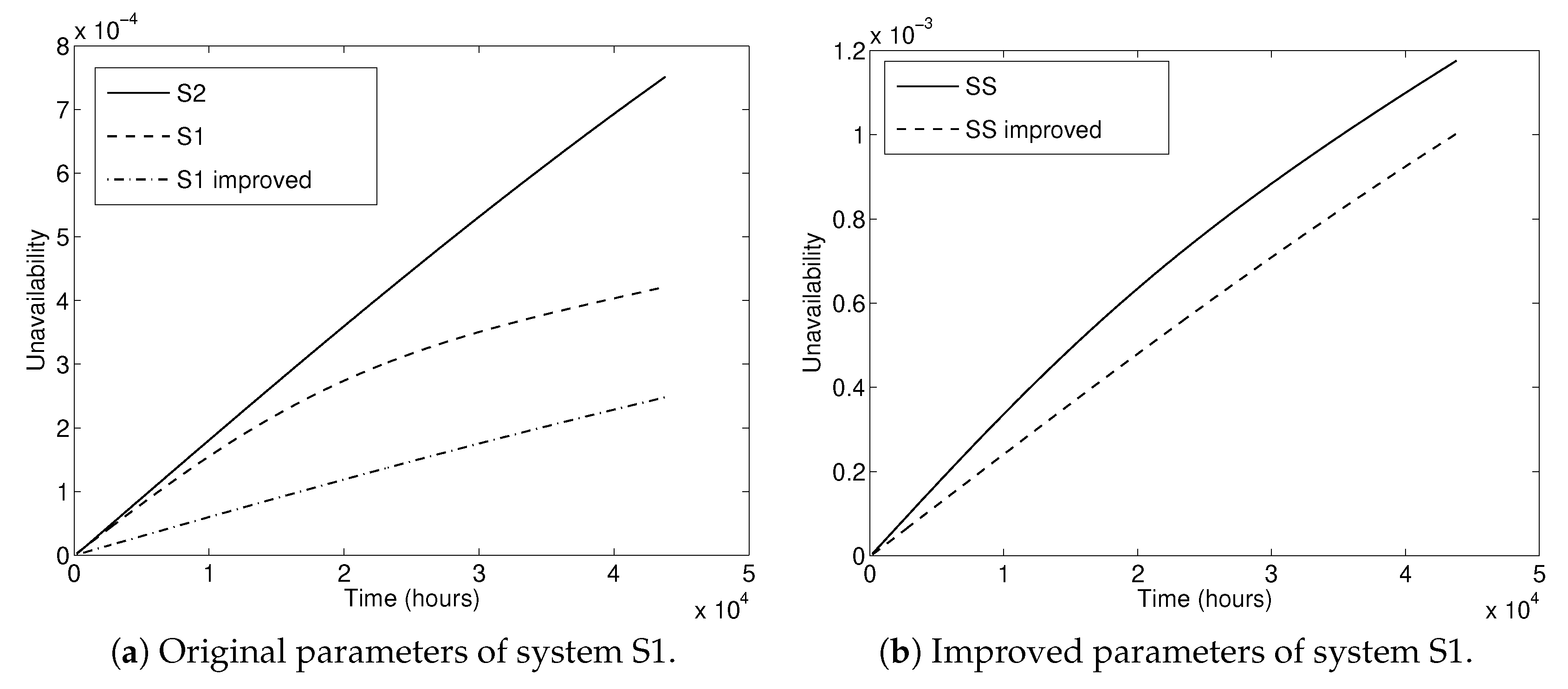
- Results indicated that the original design has an unacceptable large unavailability S1.
- Slightly modified design to improve the reliability of the interconnected system was proposed, in which only a limited number of components in the system were modified to keep the additional costs of the improved design limited.
- Numerical results indicated reduction in the unavailability of the improved interconnected system in comparison with the initial reliability design.
- The proposed unavailability exploration strategy is general and can bring a valuable reliability improvement in interconnected systems including the energy and communication sectors.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Notations
| Abbreviations | |
| 5G | Fifth-Generation Broadband Cellular Networks |
| AG | Acyclic Graph |
| AMM | Advanced Metering Monitor |
| AO | Aerial Optical Pathways |
| API | Application Programming Interface |
| AT | Attack Trees |
| BE | Basic Event |
| BDD | Binary Decision Diagram |
| BO | Subterranean Optical Counterpart |
| BTS | Base Transceiver Station |
| CI | Critical Infrastructure |
| CM | Corrective Maintenance |
| COS | Core Optical Switch |
| CPS | Cyber-Physical System |
| CFT | Conventional Fault Tree |
| DER | Distributed Energy Resources |
| DFT | Dynamic Fault Tree |
| DSO | Distribution System Operator |
| DT | Distribution Transformer |
| DTS | Distribution Transformer Station |
| EFT | Extended Fault Tree |
| ER | Edge Router |
| ET | Event Trees |
| FTA | Fault Tree Analysis |
| FT | Fault Tree |
| GSM | Global System for Mobile Communications |
| HV | High Voltage |
| I/O | Input/Output |
| KPI | Key Performance Indicator |
| LBS | Load Break Switch |
| LTE | Long-Term Evolution |
| LV | Low Voltage |
| MM | Markov Modeling |
| MDE | Model-Driven Engineering |
| MTBF | Mean Time Between Failures |
| MTTF | Mean Time To Failure |
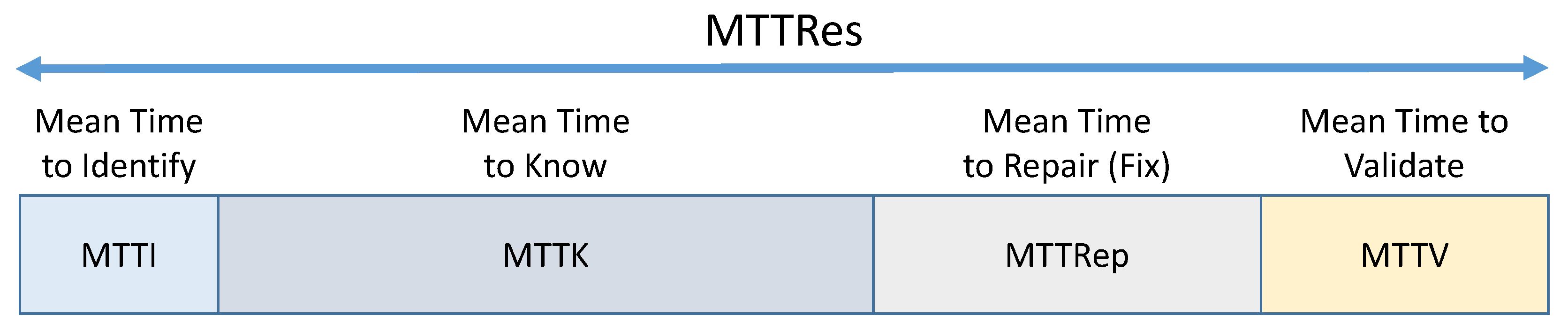
| MTTI | Mean Time To Incident |
| MTTK | Mean Time To Known issue |
| MTTRep | Mean Time To Replicate |
| MTTRes | Mean Time To Repairable event |
| MTTV | Mean Time To Validate |
| MV | Medium Voltage |
| OLT | Optical Line Terminal |
| PDMP | Piecewise Deterministic Markov Process |
| PN | Petri Nets |
| POD | Point of Delivery |
| POS | Passive Optical Splitter |
| Probability Density Function | |
| RFT | Repairable Fault Tree |
| RAMS | Reliability, Availability, Maintainability, and Safety/Security |
| RTU | Remote Terminal Unit |
| SAIDI | System Average Interruption Duration Index |
| SAIFI | System Average Interruption Frequency Index |
| SCADA | Supervisory Control And Data Acquisition |
| VPN | Virtual Private Network |
| W | Wireless Linkage |
| WAN | Wide Area Network |
| Variables | |
| X | time to failure (the lifetime) |
| Y | repair (recovery) time after a failure occurs |
| cumulative time allocated for repairs | |
| cumulative time allocated to restore | |
| Indices | |
| F(t) | distribution function of a random variable X |
| f(t) | probability density function of a random variable X |
| U(t) | instantaneous time-dependent unavailability function |
| A(t) = 1 − U(t) | instantaneous availability function |
| h(x) | renewal density |
| Parameters | |
| shape parameter | |
| scale parameter |
References
- Briš, R.; Byczanski, P. On innovative stochastic renewal process models for exact unavailability quantification of highly reliable systems. Proc. Inst. Mech. Eng. Part J. Risk Reliab. 2017, 231, 617–627. [Google Scholar] [CrossRef]
- Ruijters, E.; Stoelinga, M. Fault tree analysis: A survey of the state-of-the-art in modeling, analysis and tools. Comput. Sci. Rev. 2015, 15, 29–62. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, N.; Yan, J.; Zhu, G.; Min, G. Optimization of maintenance personnel dispatching strategy in smart grid. World Wide Web 2023, 26, 139–162. [Google Scholar] [CrossRef]
- Nagaraju, V.; Fiondella, L.; Wandji, T. A survey of fault and attack tree modeling and analysis for cyber risk management. In Proceedings of the 2017 IEEE International Symposium on Technologies for Homeland Security (HST), Boston, MA, USA, 25–26 April 2017; pp. 1–6. [Google Scholar]
- Garg, H.; Ram, M. Reliability Management and Engineering: Challenges and Future Trends; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Pirbhulal, S.; Gkioulos, V.; Katsikas, S. A Systematic Literature Review on RAMS analysis for critical infrastructures protection. Int. J. Crit. Infrastruct. Prot. 2021, 33, 100427. [Google Scholar] [CrossRef]
- Budde, C.E.; Stoelinga, M. Efficient algorithms for quantitative attack tree analysis. In Proceedings of the 2021 IEEE 34th Computer Security Foundations Symposium (CSF), Dubrovnik, Croatia, 21–24 June 2021; pp. 1–15. [Google Scholar]
- Lazarova-Molnar, S.; Mohamed, N.; Shaker, H.R. Reliability modeling of cyber-physical systems: A holistic overview and challenges. In Proceedings of the 2017 Workshop on Modeling and Simulation of Cyber-Physical Energy Systems (MSCPES), Pittsburgh, PA, USA, 18–21 April 2017; pp. 1–6. [Google Scholar]
- Niloofar, P.; Lazarova-Molnar, S. Data-driven extraction and analysis of repairable fault trees from time series data. Expert Syst. Appl. 2023, 215, 119345. [Google Scholar] [CrossRef]
- Rehioui, H.; Idrissi, A. New clustering algorithms for twitter sentiment analysis. IEEE Syst. J. 2019, 14, 530–537. [Google Scholar] [CrossRef]
- Baklouti, A.; Nguyen, N.; Choley, J.Y.; Mhenni, F.; Mlika, A. Free and open source fault tree analysis tools survey. In Proceedings of the 2017 Annual IEEE International Systems Conference (SysCon), Montreal, QU, Canada, 24–27 April 2017; pp. 1–8. [Google Scholar]
- Rodrigues, M. Network Availability: How Much Do You Need? How Do You Get It? (Logic Monitor). 2023. Available online: https://www.cisco.com/site/au/en/solutions/full-stack-observability/index.html?team=digital_marketing&medium=paid_search&campaign=reimagine_applications&ccid=cc002659&dtid=psexsp001647&gad_source=1&gclid=EAIaIQobChMIlMTEjuyDgwMVmKpmAh0GNwabEAAYASAAEgLwn_D_BwE&gclsrc=aw.ds (accessed on 14 June 2023).
- Zhang, R.; Zhao, Z.; Chen, X. An overall reliability and security assessment architecture for electric power communication network in smart grid. In Proceedings of the 2010 International Conference on Power System Technology, Hangzhou, China, 24–28 October 2010; pp. 1–6. [Google Scholar]
- Cisco. Cisco Crosswork Cloud Trust Insights Data Sheet. 2021. (Data-Sheet). Available online: https://www.cisco.com/c/en/us/products/collateral/cloud-systems-management/crosswork-network-automation/datasheet-c78-741972.html (accessed on 6 July 2023).
- Cisco. Network Availability: How Much Do You Need? How Do You Get It? (White Paper). 2004. Available online: https://www.cisco.com/web/IT/unified_channels/area_partner/cisco_powered_network/net_availability.pdf (accessed on 23 June 2023).
- Xu, S.; Qian, Y.; Hu, R.Q. On reliability of smart grid neighborhood area networks. IEEE Access 2015, 3, 2352–2365. [Google Scholar] [CrossRef]
- Drholec, J.; Gono, R. Reliability database of industrial local distribution system. In Proceedings of the First International Scientific Conference “Intelligent Information Technologies for Industry” (IITI’16); Springer: Berlin/Heidelberg, Germany, 2016; Volume 2, pp. 481–489. [Google Scholar]
- Muhammad Ridzuan, M.I.; Djokic, S.Z. Energy regulator supply restoration time. Energies 2019, 12, 1051. [Google Scholar] [CrossRef]
- Santos, G.L.; Endo, P.T.; Gonçalves, G.; Rosendo, D.; Gomes, D.; Kelner, J.; Sadok, D.; Mahloo, M. Analyzing the it subsystem failure impact on availability of cloud services. In Proceedings of the 2017 IEEE Symposium on Computers and Communications (ISCC), Heraklion, Greece, 3–6 July 2017; pp. 717–723. [Google Scholar]
- Union, I.T. Series G: Transmission Systems and Media, Digital Systems and Networks. Passive Optical Network Protection Considerations (ITU-T, Series G—Supplement 51, 02/2016). 2016. Available online: https://www.itu.int/rec/dologin_pub.asp?lang=f&id=T-REC-G.Sup51-201602-S!!PDF-E&type=items (accessed on 16 July 2023).
- Prat, J. Next-Generation FTTH Passive Optical Networks: Research towards Unlimited Bandwidth Access; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Verbrugge, S.; Colle, D.; Demeester, P.; Huelsermann, R.; Jaeger, M. General availability model for multilayer transport networks. In Proceedings of the 5th International Workshop on Design of Reliable Communication Networks, Ischia, Italy, 16–19 October 2005; p. 8. [Google Scholar]
- Scheer, G.W. Answering substation automation questions through fault tree analysis. In Proceedings of the Fourth Annual Texas A&M Substation Automation Conference, College Station, TX, USA, 8–9 April 1998. [Google Scholar]
- Dolezilek, D.J. Choosing between Communications Processors, RTUS, and PLCS as Substation Automation Controllers; White Paper; Schweitzer Engineering Laboratories, Inc.: Pullman, WD, USA, 2000. [Google Scholar]
- Scholl, M.; Jain, R. Availability and Sensitivity Analysis of Smart Grid Components. 2011. Available online: https://www.cse.wustl.edu/~jain/cse567-11/ftp/grid/index.html (accessed on 26 June 2023).
- Briš, R.; Byczanski, P.; Goňo, R.; Rusek, S. Discrete maintenance optimization of complex multi-component systems. Reliab. Eng. Syst. Saf. 2017, 168, 80–89. [Google Scholar] [CrossRef]
- Vrtal, M.; Fujdiak, R.; Benedikt, J.; Topolanek, D.; Ptacek, M.; Toman, P.; Misurec, J.; Beloch, M.; Praks, P. Determination of Critical Parameters and Interdependencies of Infrastructure Elements in Smart Grids. In Proceedings of the 2023 23rd International Scientific Conference on Electric Power Engineering (EPE), Aalborg, Denmark, 4–8 September 2023; pp. 1–6. [Google Scholar]
- Vrtal, M.; Benedikt, J.; Fujdiak, R.; Topolanek, D.; Toman, P.; Misurec, J. Investigating the Possibilities for Simulation of the Interconnected Electric Power and Communication Infrastructures. Processes 2022, 10, 2504. [Google Scholar] [CrossRef]
- Bose, S.; Gayme, D.F.; Chandy, K.M.; Low, S.H. Quadratically constrained quadratic programs on acyclic graphs with application to power flow. IEEE Trans. Control Netw. Syst. 2015, 2, 278–287. [Google Scholar] [CrossRef]
- Wang, D.; Zhou, F.; Li, J. Cloud-based parallel power flow calculation using resilient distributed datasets and directed acyclic graph. J. Mod. Power Syst. Clean Energy 2019, 7, 65–77. [Google Scholar] [CrossRef]
- Jha, N.K. Low power system scheduling and synthesis. In Proceedings of the IEEE/ACM International Conference on Computer Aided Design (ICCAD 2001), IEEE/ACM Digest of Technical Papers (Cat. No. 01CH37281), San Jose, CA, USA, 4–8 November 2001; IEEE: Piscataway, NJ, USA, 2001; pp. 259–263. [Google Scholar]
- Ding, S.; Cao, Y.; Vosoogh, M.; Sheikh, M.; Almagrabi, A. A directed acyclic graph based architecture for optimal operation and management of reconfigurable distribution systems with PEVs. IEEE Trans. Ind. Appl. 2020. [Google Scholar] [CrossRef]
- Maharana, M.K.; Swarup, K.S. Particle swarm optimization based corrective strategy to alleviate overloads in power system. In Proceedings of the 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009; pp. 37–42. [Google Scholar]
- Lohith, Y.; Narasimman, T.S.; Anand, S.; Hedge, M. Link peek: A link outage resilient ip packet forwarding mechanism for 6lowpan/rpl based low-power and lossy networks (llns). In Proceedings of the 2015 IEEE International Conference on Mobile Services, New York, NY, USA, 27 June–2 July 2015; pp. 65–72. [Google Scholar]
- Allan, R.; De Oliveira, M.; Kozlowski, A.; Williams, G. Evaluating the reliability of electrical auxiliary systems in multi-unit generating stations. IEE Proc. (Gener. Transm. Distrib.) 1980, 127, 65–71. [Google Scholar] [CrossRef]
- Stanek, E.K.; Venkata, S. Mine power system reliability. IEEE Trans. Ind. Appl. 1988, 24, 827–838. [Google Scholar] [CrossRef]
- Farag, A.; Wang, C.; Cheng, T.; Zheng, G.; Du, Y.; Hu, L.; Palk, B.; Moon, M. Failure analysis of composite dielectric of power capacitors in distribution systems. IEEE Trans. Dielectr. Electr. Insul. 1998, 5, 583–588. [Google Scholar] [CrossRef]
- Roos, F.; Lindah, S. Distribution system component failure rates and repair times—An overview. In Proceedings of the Nordic Distribution and Asset Management Conference, Espoo, Finland, 23 August–24 August 2004; pp. 23–24. [Google Scholar]
- Anders, G.J.; Maciejewski, H.; Jesus, B.; Remtulla, F. A comprehensive study of outage rates of air blast breakers. IEEE Trans. Power Syst. 2006, 21, 202–210. [Google Scholar] [CrossRef]
- He, Y. Study and Analysis of Distribution Equipment Reliability Data (Datastudier och Analys av Tillförlitlighetsdata på Komponentnivå för Eldistributionsnät). Elforsk Rapport 10:3, ELFORSK. 2010. Available online: https://docplayer.net/39290413-Study-and-analysis-of-distribution-equipment-reliability-data.html (accessed on 15 July 2023).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | MTBF (h) | MTTRes (h) | (-) |
|---|---|---|---|
| Transformer T1 (110/22 kV) | 26,310.709 | 4.403 | 2 |
| Distribution transformer DT2 (22/0.4 kV) | 43,800.361 | 0.361 | 2 |
| Distribution transformer DT3 (22/0.4 kV) | 43,800.361 | 0.361 | 2 |
| Load break switch LBS1 (22 kV) | 224,621.087 | 5.702 | 2 |
| Overhead line L1 (22 kV) | 54,750.000 | 11.417 | 2 |
| Overhead line L2 (22 kV) | 41,714.286 | 11.417 | 2 |
| Overhead line L3 (22 kV) | 62,571.429 | 11.417 | 2 |
| Overhead line L4 (22 kV) | 48,666.666 | 11.417 | 2 |
| Overhead line L5 (22 kV) | 43,800.000 | 11.417 | 2 |
| Underground cable C2 (0.4 kV) | 57,737.828 | 85.000 | 2 |
| Underground cable C3 (0.4 kV) | 38,491.886 | 85.000 | 2 |
| Underground cable C4 (0.4 kV) | 153,967.543 | 85.000 | 2 |
| Component | MTBF (h) | MTTRes (h) | (-) |
|---|---|---|---|
| Edge Router ER1 | 16,246.780 | 0.780 | 2 |
| Edge Router ER2 | 16,246.780 | 0.780 | 2 |
| Core Optical Switch COS1 | 5,000,014.000 | 14.000 | 2 |
| Core Optical Switch COS2 | 5,000,014.000 | 14.000 | 2 |
| Aerial Optic fiber AO4 | 500,000.000 | 6.000 | 2 |
| Aerial Optic fiber AO5 | 1,093,750.000 | 6.000 | 2 |
| Aerial Optic fiber AO6 | 500,000.000 | 6.000 | 2 |
| Aerial Optic fiber AO7 | 1,093,750.000 | 6.000 | 2 |
| Buried Optic fiber BO1 | 821,875.000 | 12.000 | 2 |
| Buried Optic fiber BO3 | 1,753,333.333 | 12.000 | 2 |
| Buried Optic fiber BO4 | 1,753,333.333 | 12.000 | 2 |
| Remote Terminal Unit RTU | 100,048.000 | 48.000 | 2 |
| SCADA operation and data center | 175,200.000 | 184.600 | 2 |
| Base Transceiver Station BTS | 100,000.000 | 4.000 | 2 |
| Wide Area Network WAN | 100,000.000 | 4.000 | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vrtal, M.; Fujdiak, R.; Benedikt, J.; Praks, P.; Bris, R.; Ptacek, M.; Toman, P. Time-Dependent Unavailability Exploration of Interconnected Urban Power Grid and Communication Network. Algorithms 2023, 16, 561. https://doi.org/10.3390/a16120561
Vrtal M, Fujdiak R, Benedikt J, Praks P, Bris R, Ptacek M, Toman P. Time-Dependent Unavailability Exploration of Interconnected Urban Power Grid and Communication Network. Algorithms. 2023; 16(12):561. https://doi.org/10.3390/a16120561
Chicago/Turabian StyleVrtal, Matej, Radek Fujdiak, Jan Benedikt, Pavel Praks, Radim Bris, Michal Ptacek, and Petr Toman. 2023. "Time-Dependent Unavailability Exploration of Interconnected Urban Power Grid and Communication Network" Algorithms 16, no. 12: 561. https://doi.org/10.3390/a16120561
APA StyleVrtal, M., Fujdiak, R., Benedikt, J., Praks, P., Bris, R., Ptacek, M., & Toman, P. (2023). Time-Dependent Unavailability Exploration of Interconnected Urban Power Grid and Communication Network. Algorithms, 16(12), 561. https://doi.org/10.3390/a16120561