
Vector Control of PMSM Using TD3 Reinforcement Learning Algorithm

Abstract
:1. Introduction
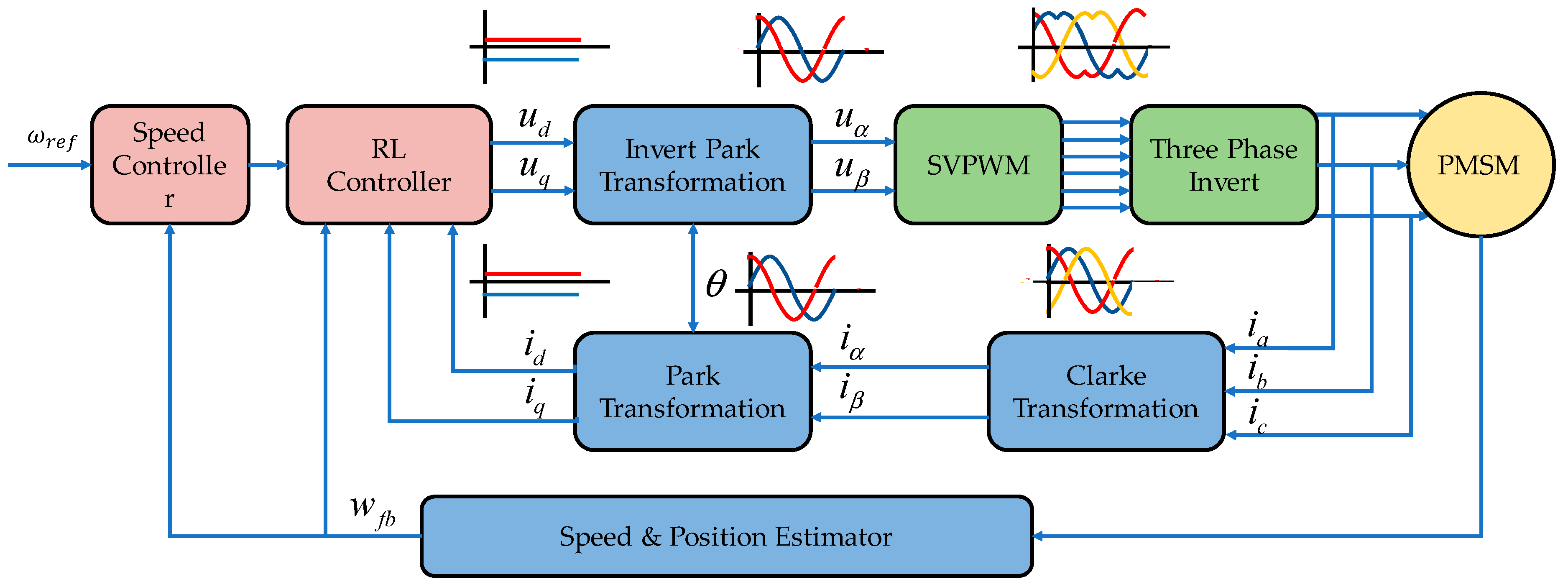
2. PMSM Model and RL
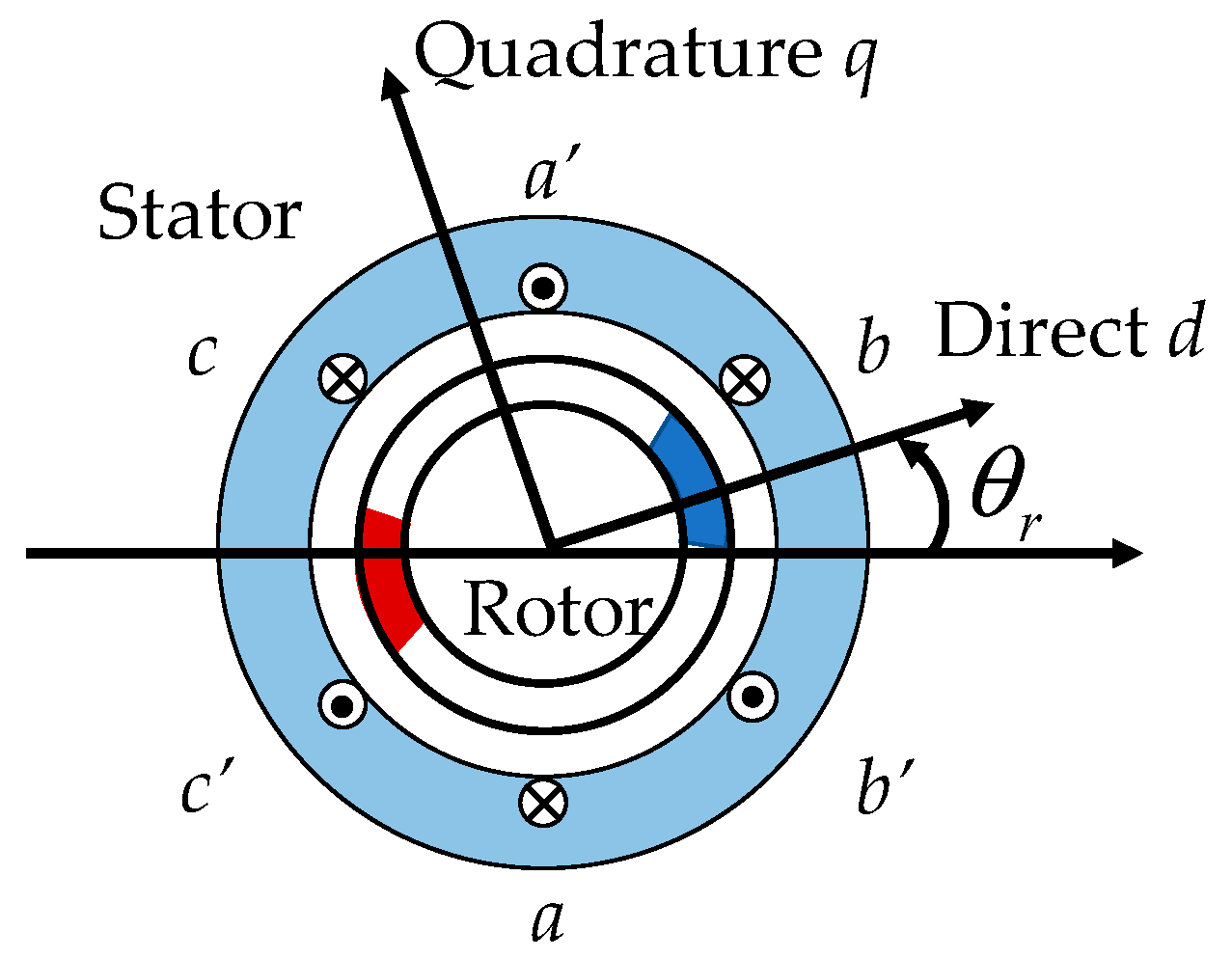
2.1. PMSM Model
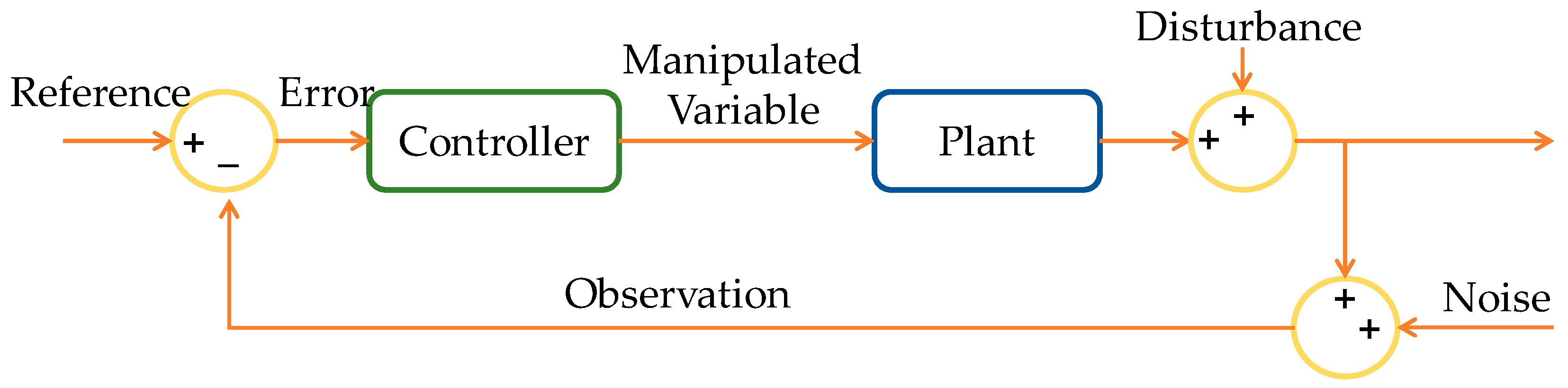
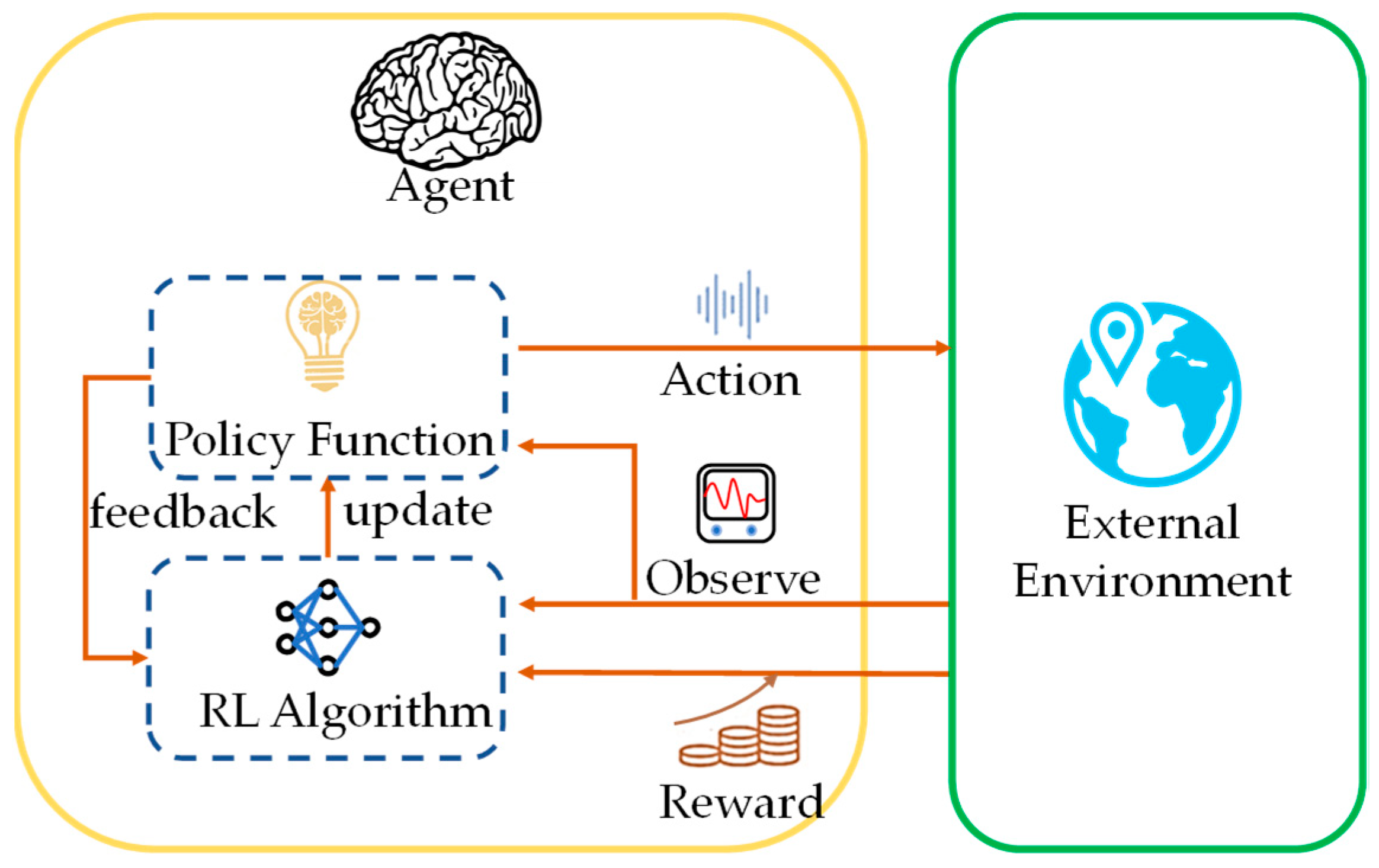
2.2. Reinforcement Learning
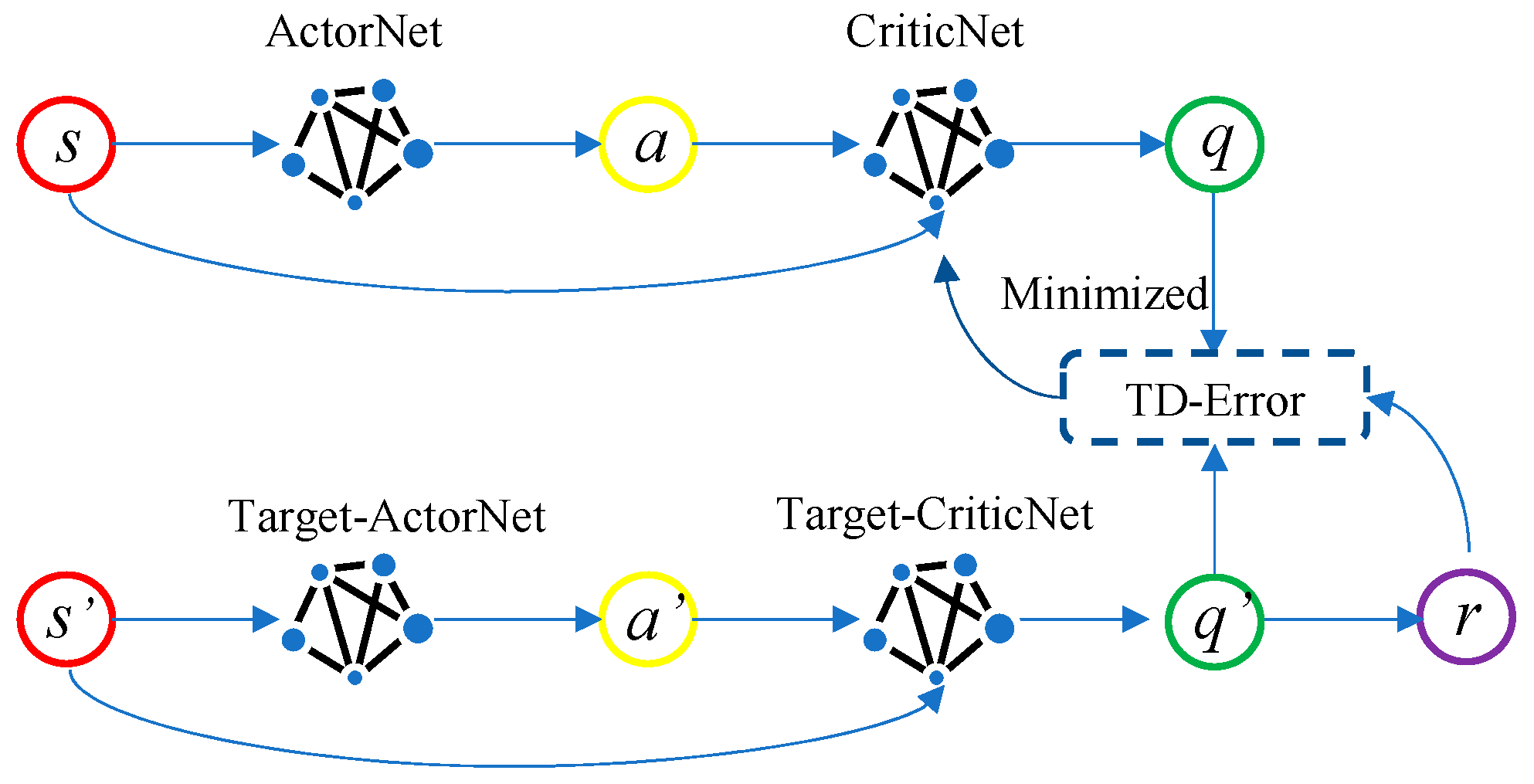
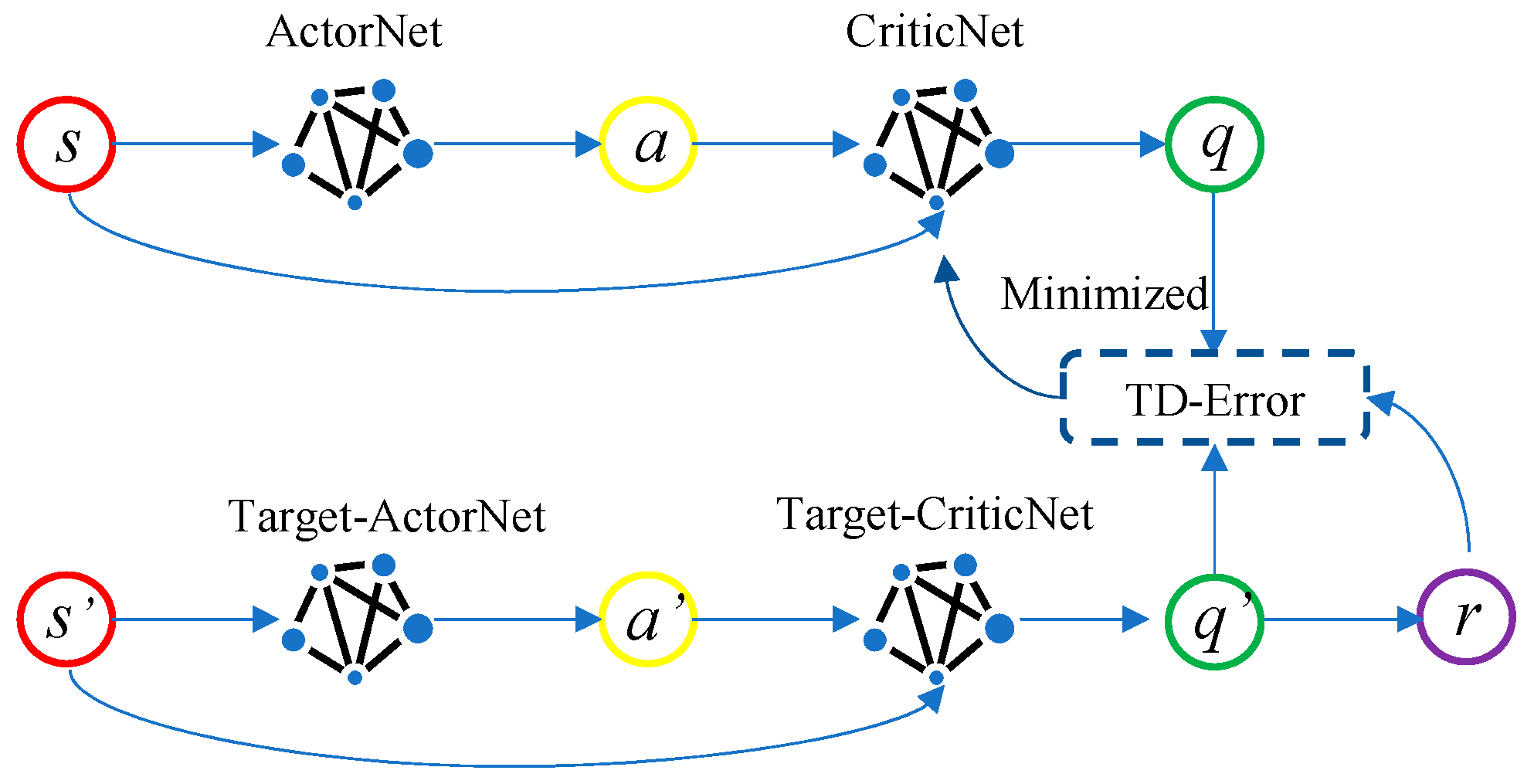
2.2.1. DDPG Algorithm
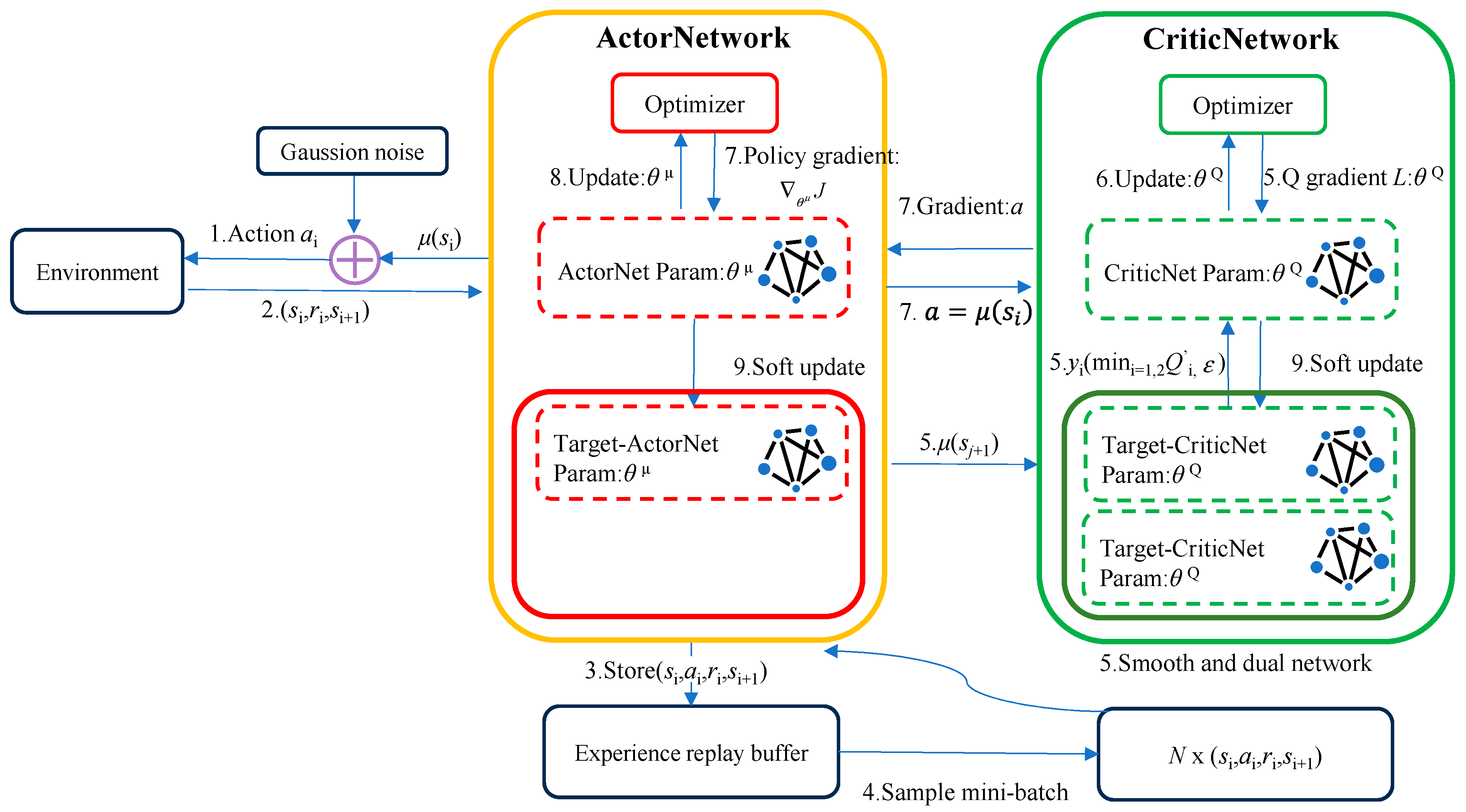
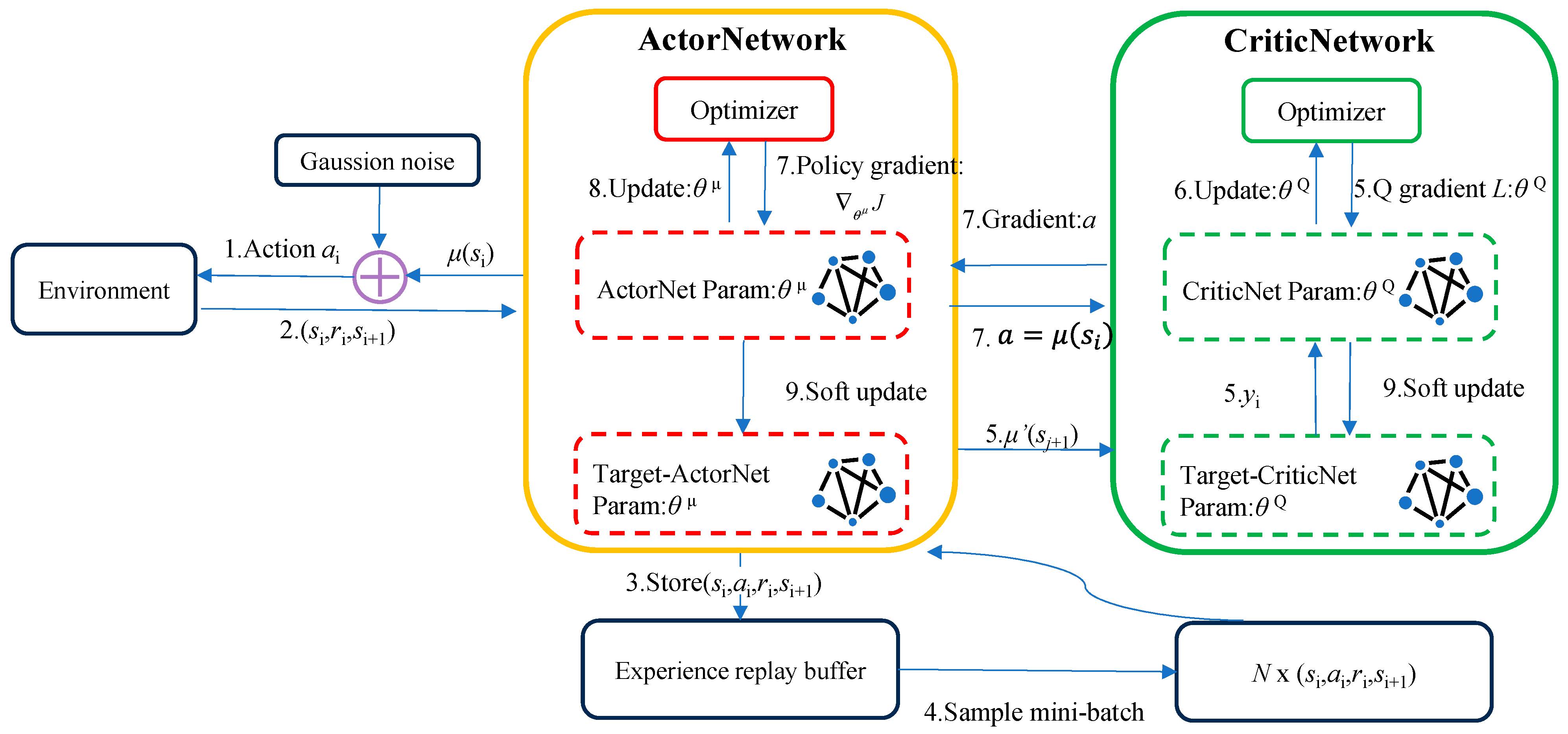
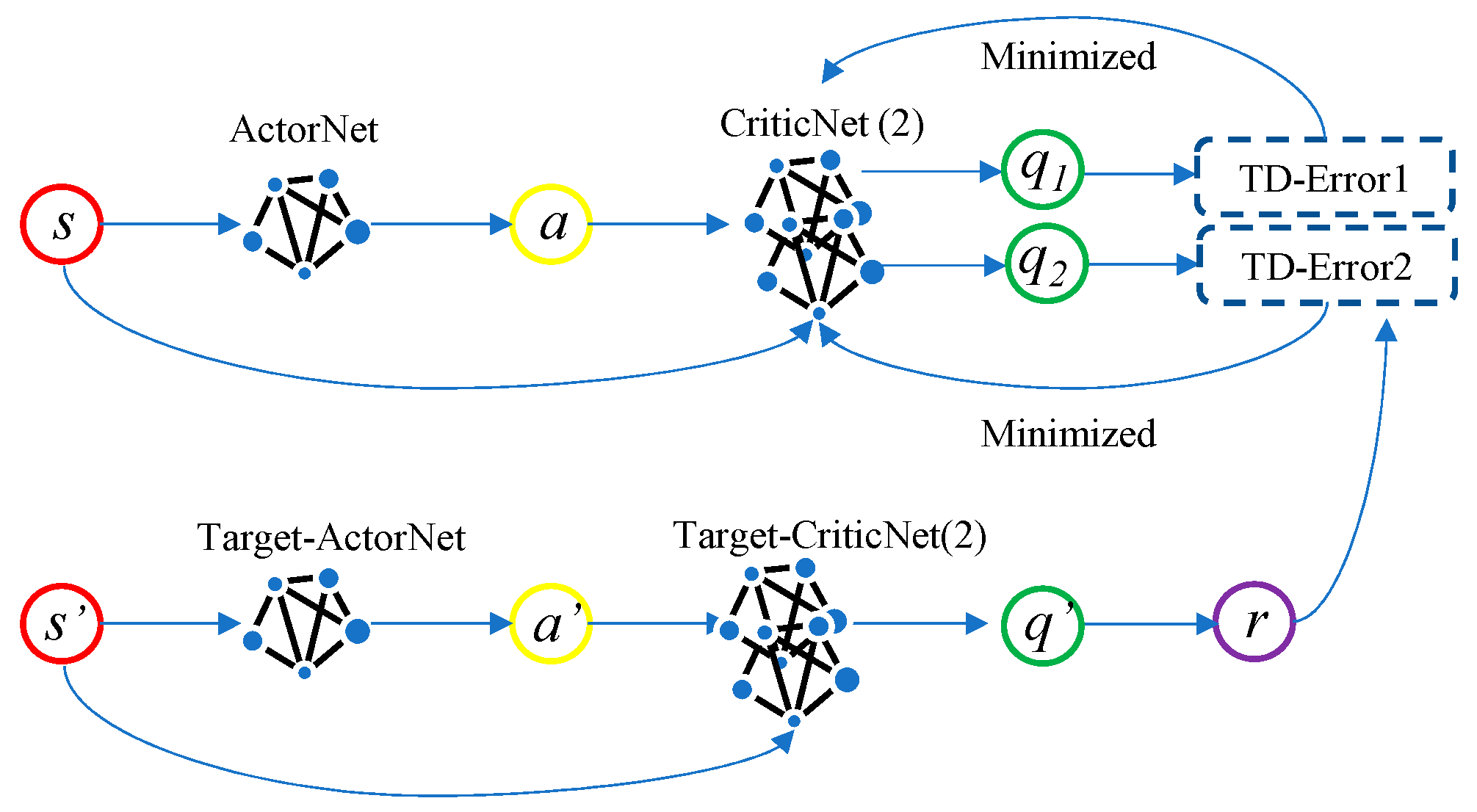
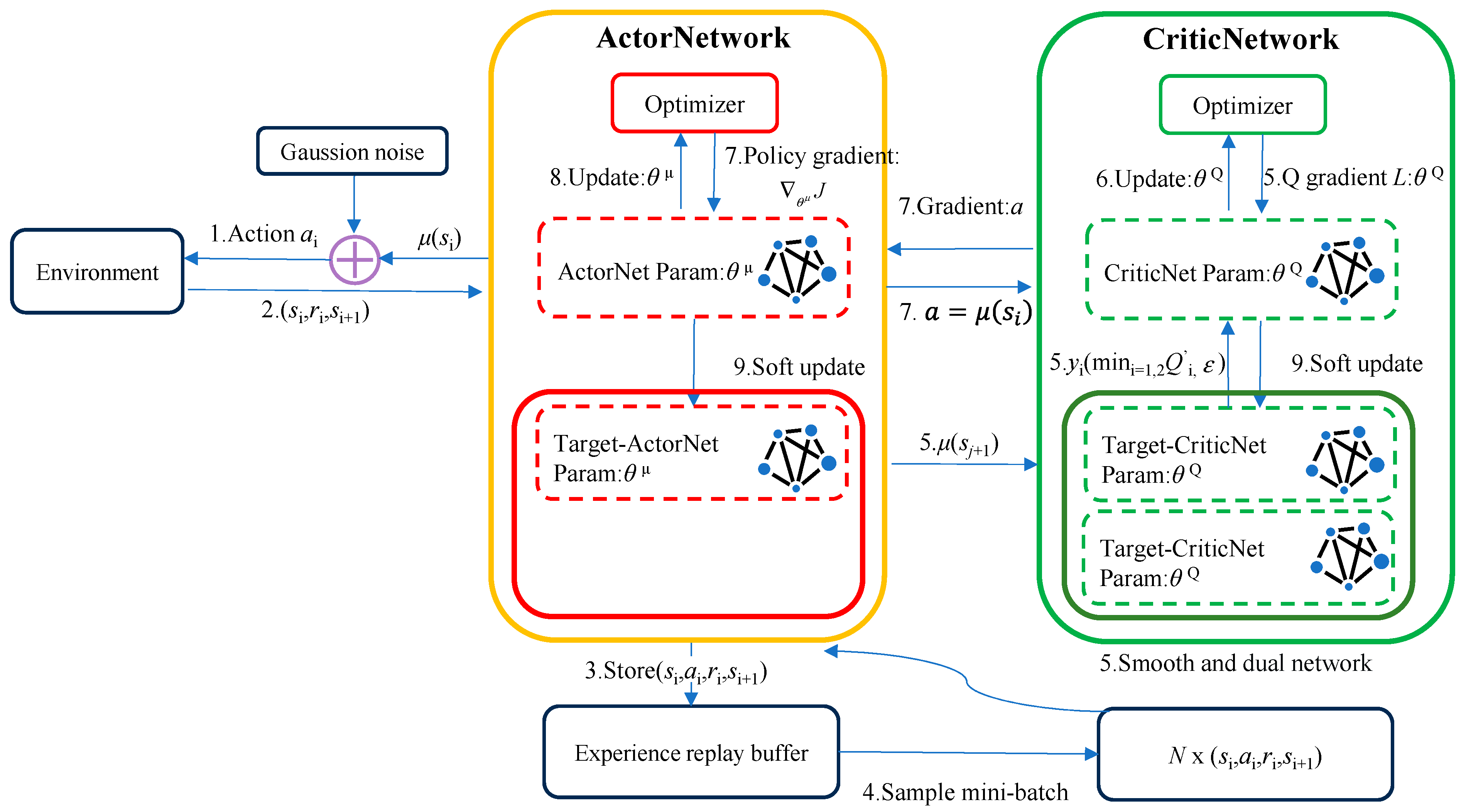
2.2.2. TD3 Algorithm
- Double network: Two sets of Critic networks are adopted, and the smaller value of the two is taken when calculating the target value, to suppress the overestimation problem of the network. According to Equation (3), the update mode of the target value Q′ can be known. The following Equation (7) represents the overestimation between the target value Q′ and the actual value Q*, when Q′ is close to y:
- Target policy smoothing regularization: when the target value is calculated, the perturbation is added to the action of the next state, so that the value evaluation is more accurate:
- Soft update: After the Critic network is updated for several times, the Actor network is updated, to ensure that the Actor network training is more stable. A learning rate τ is introduced, the old target network parameters and the new corresponding network parameters are weighted averaged, and then assigned to the target network:
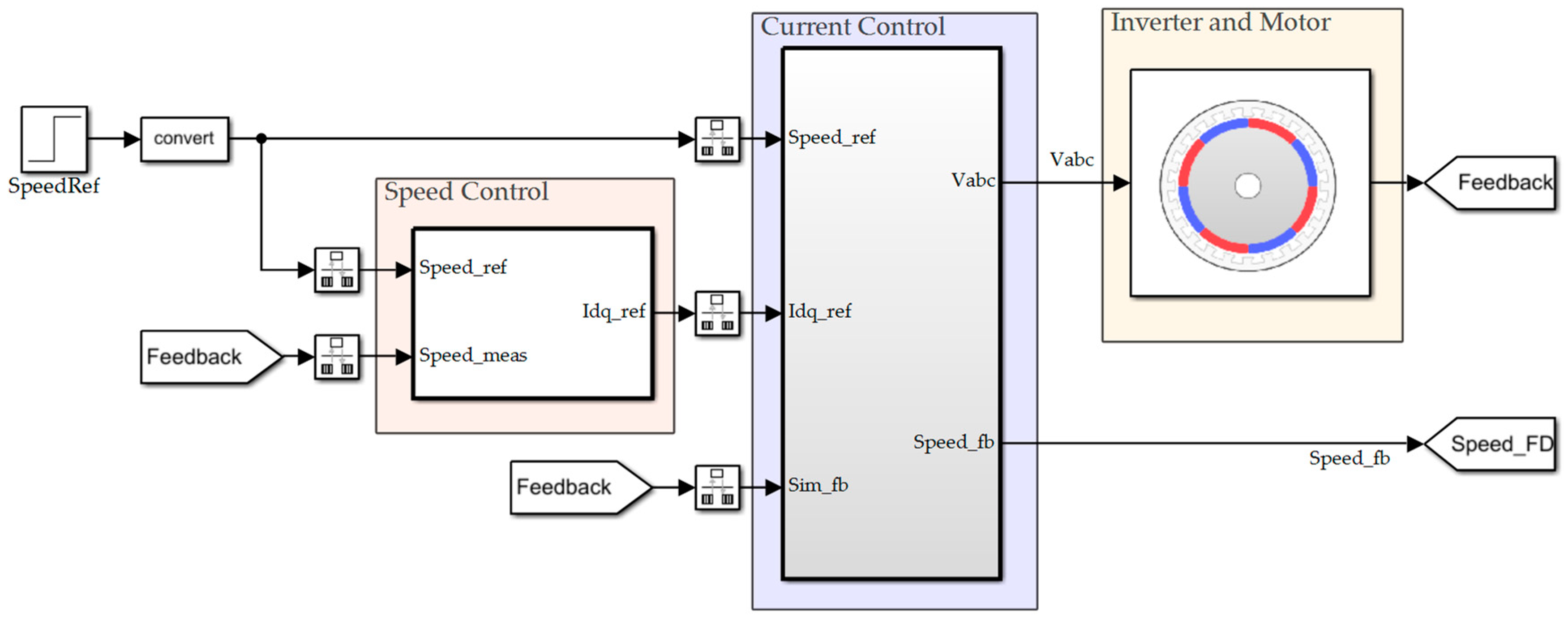
3. Establish Simulation Model
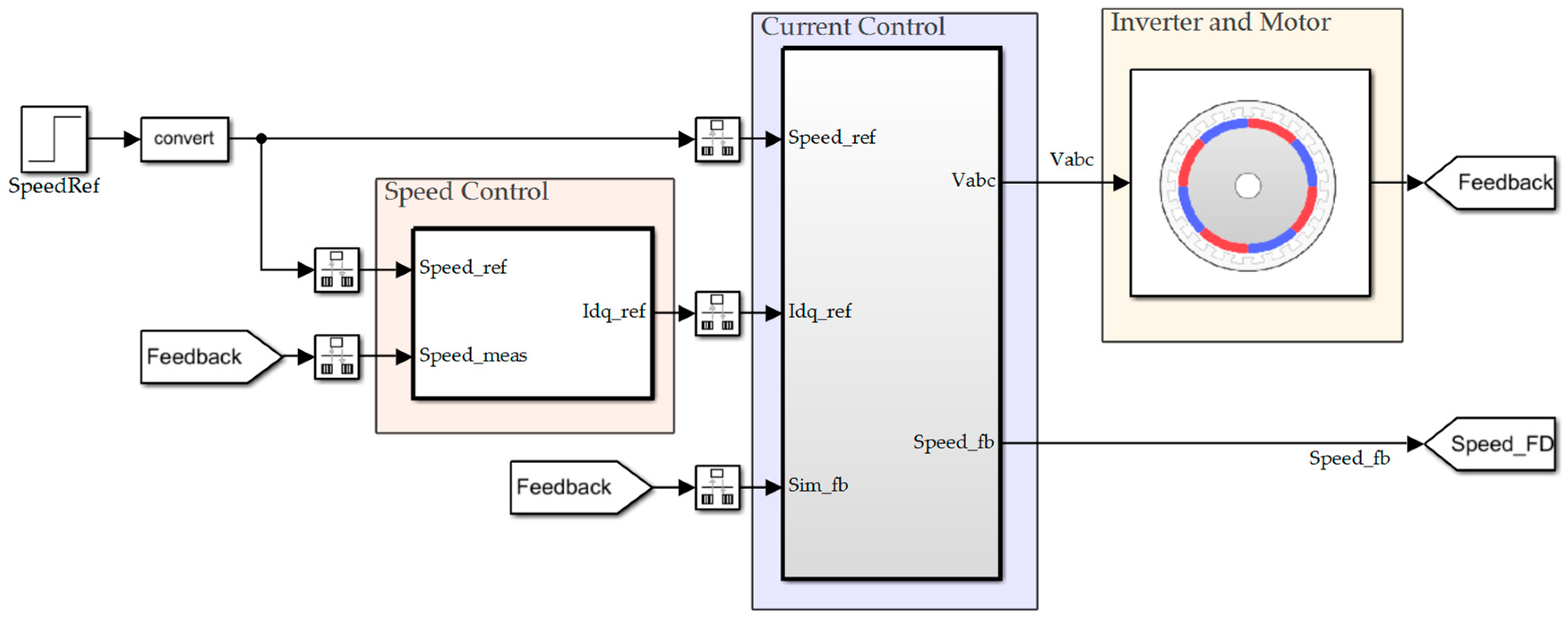
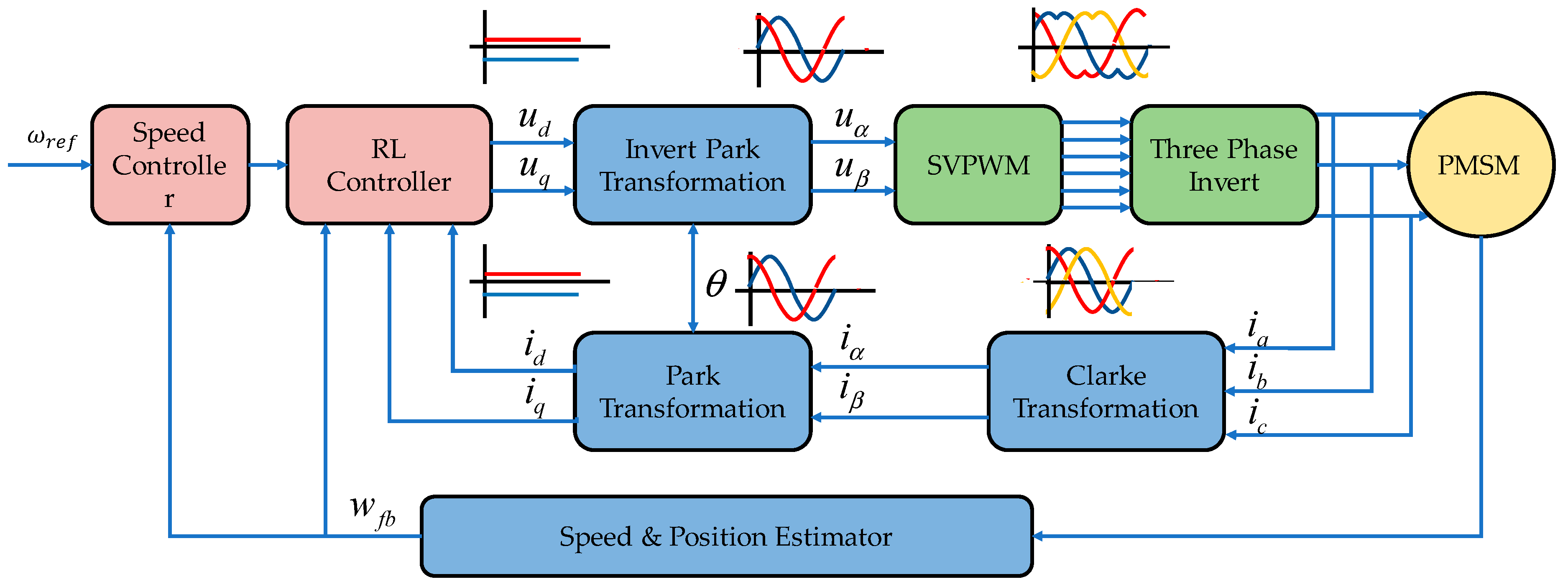
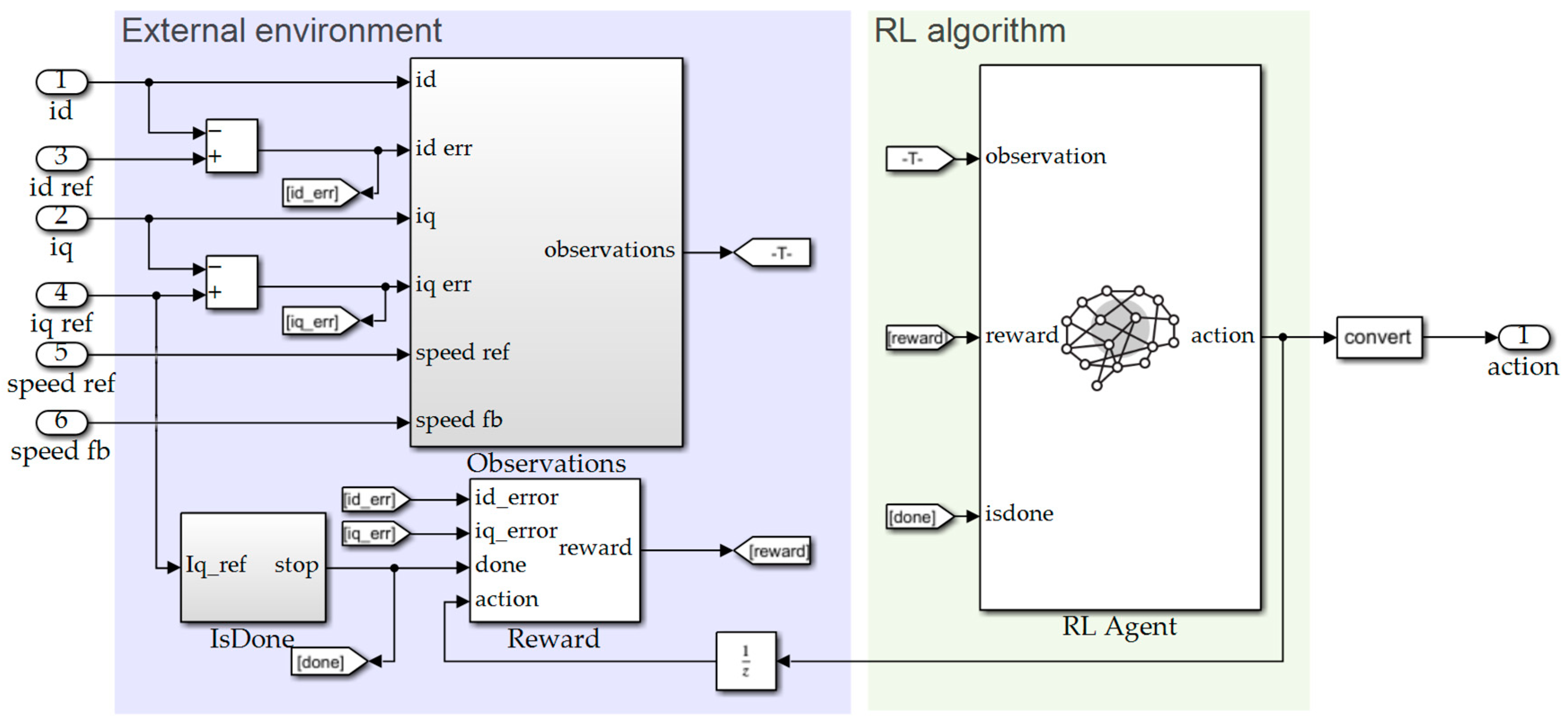
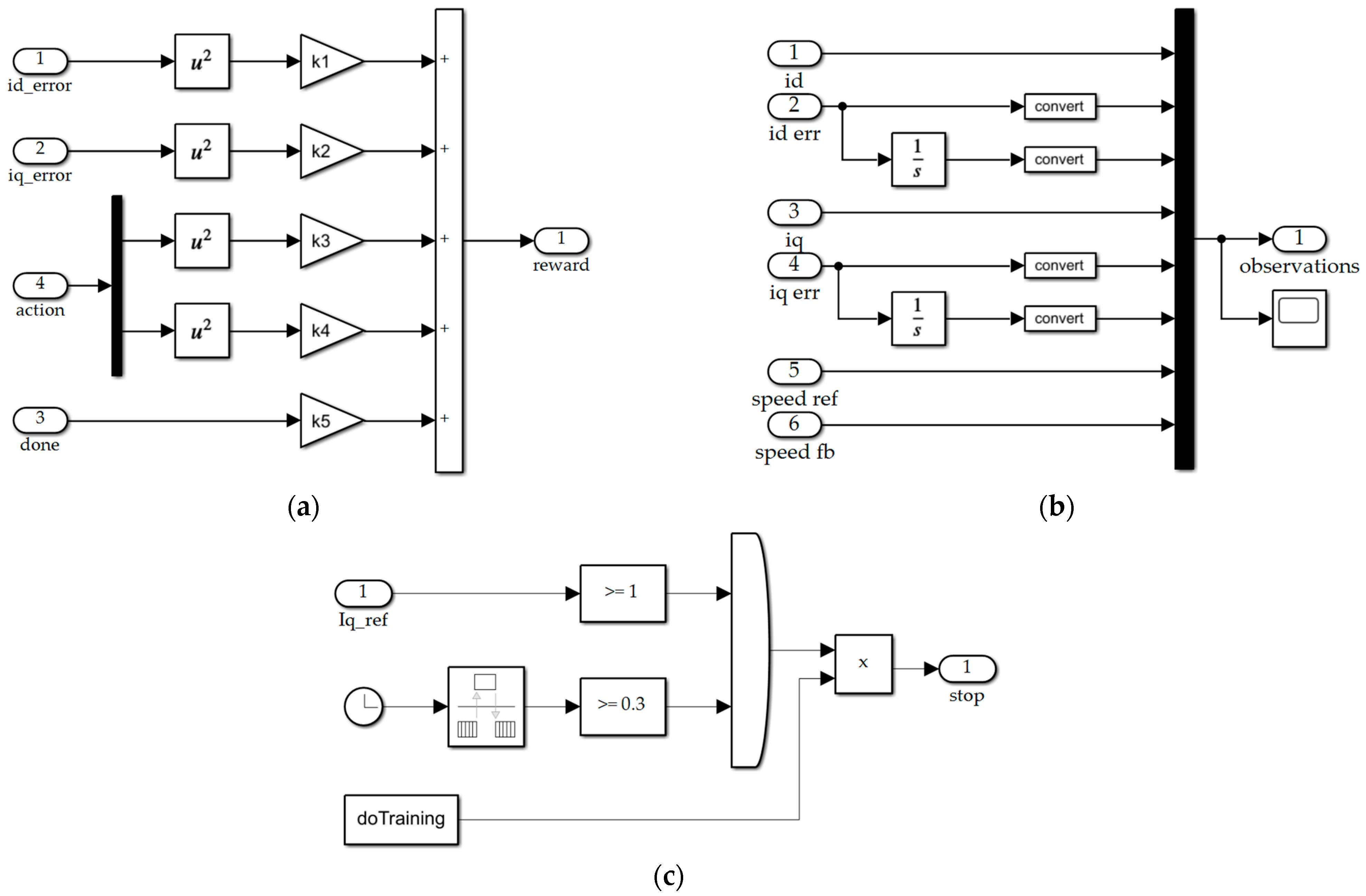
3.1. Create Environment
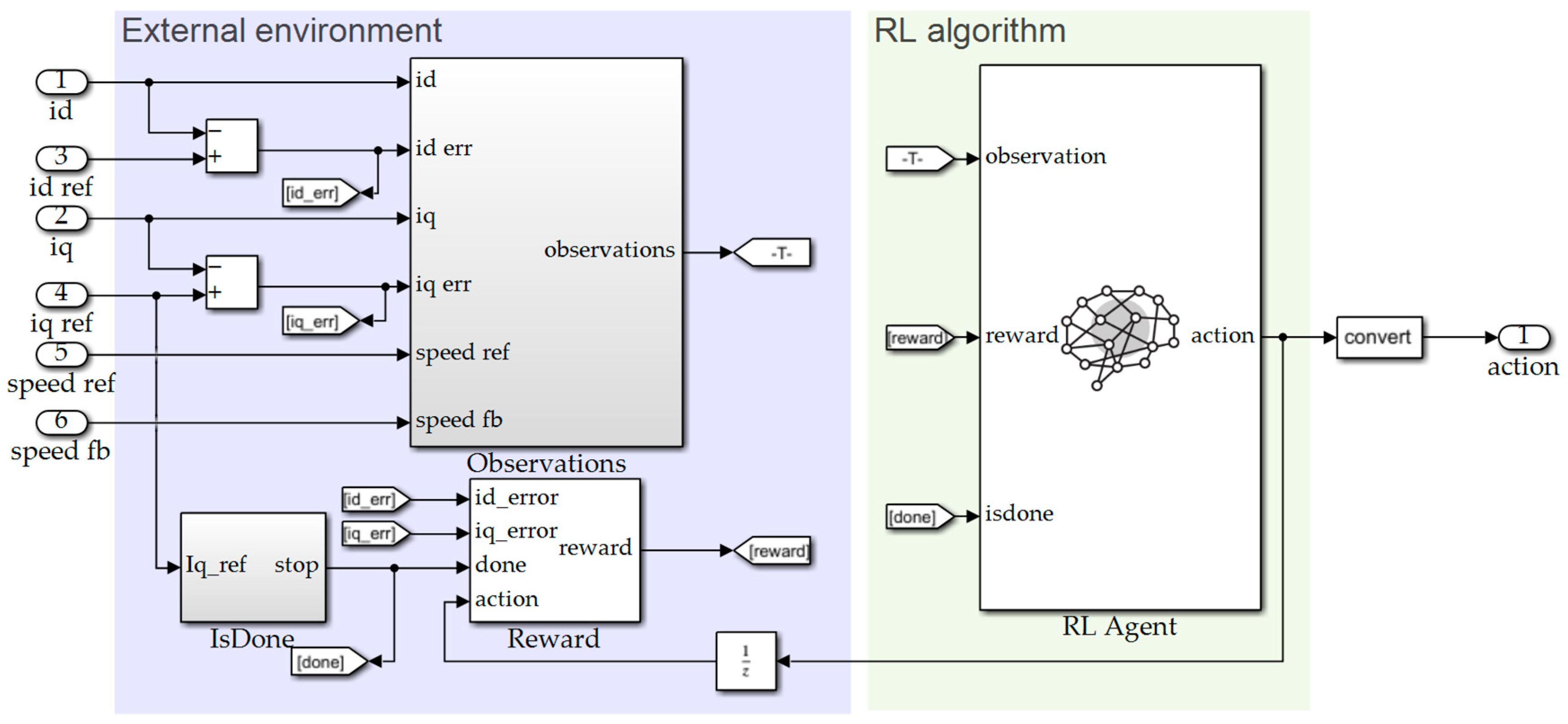
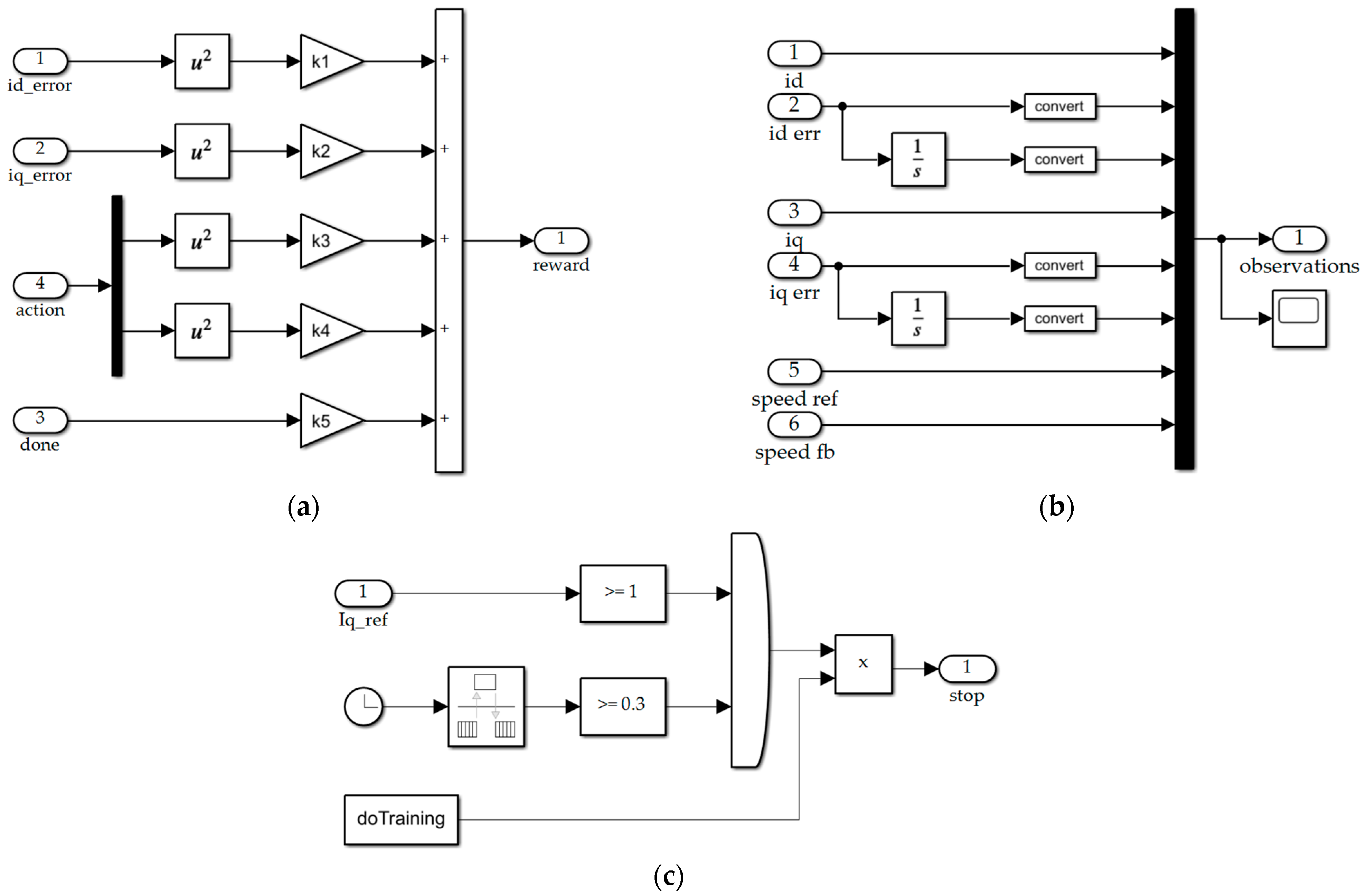
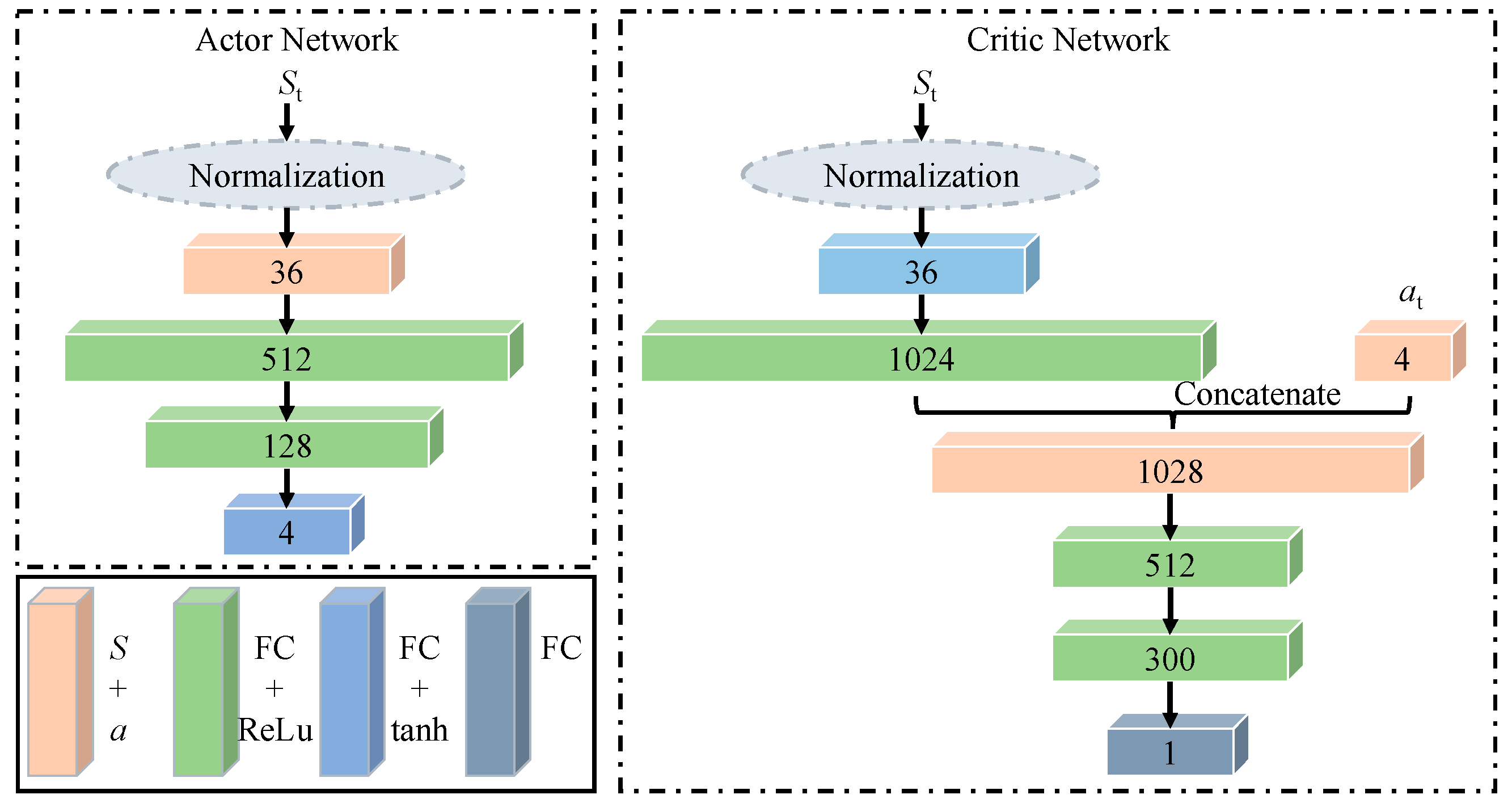
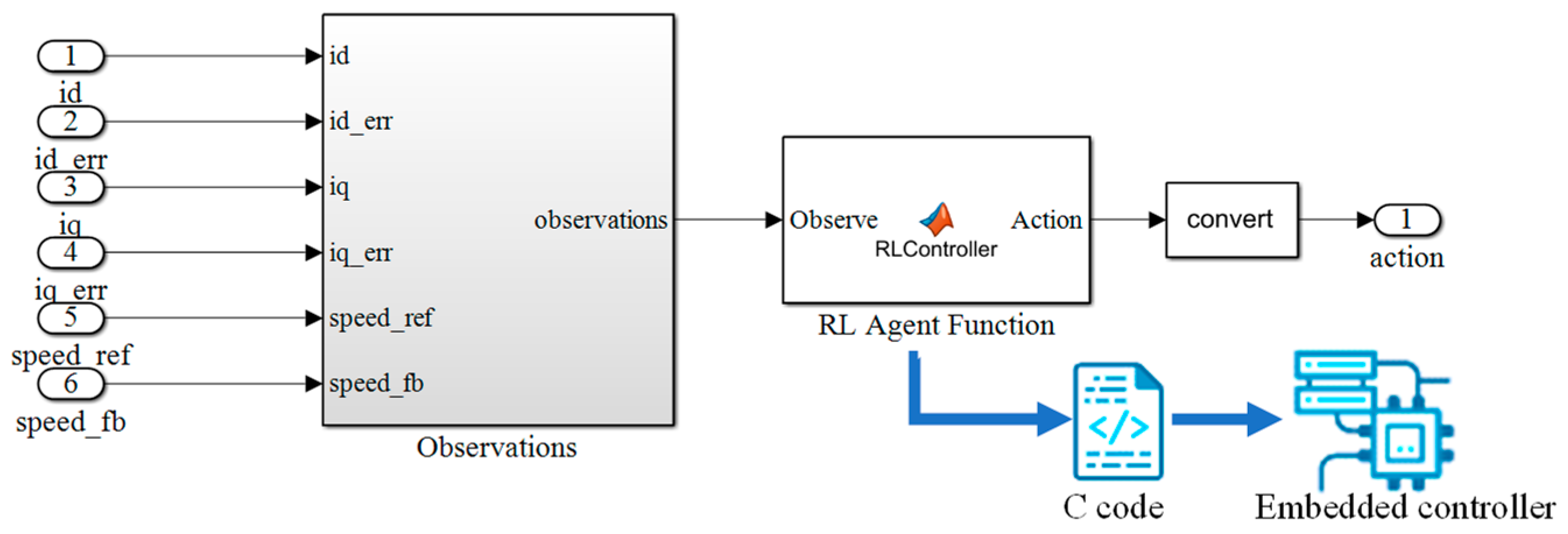
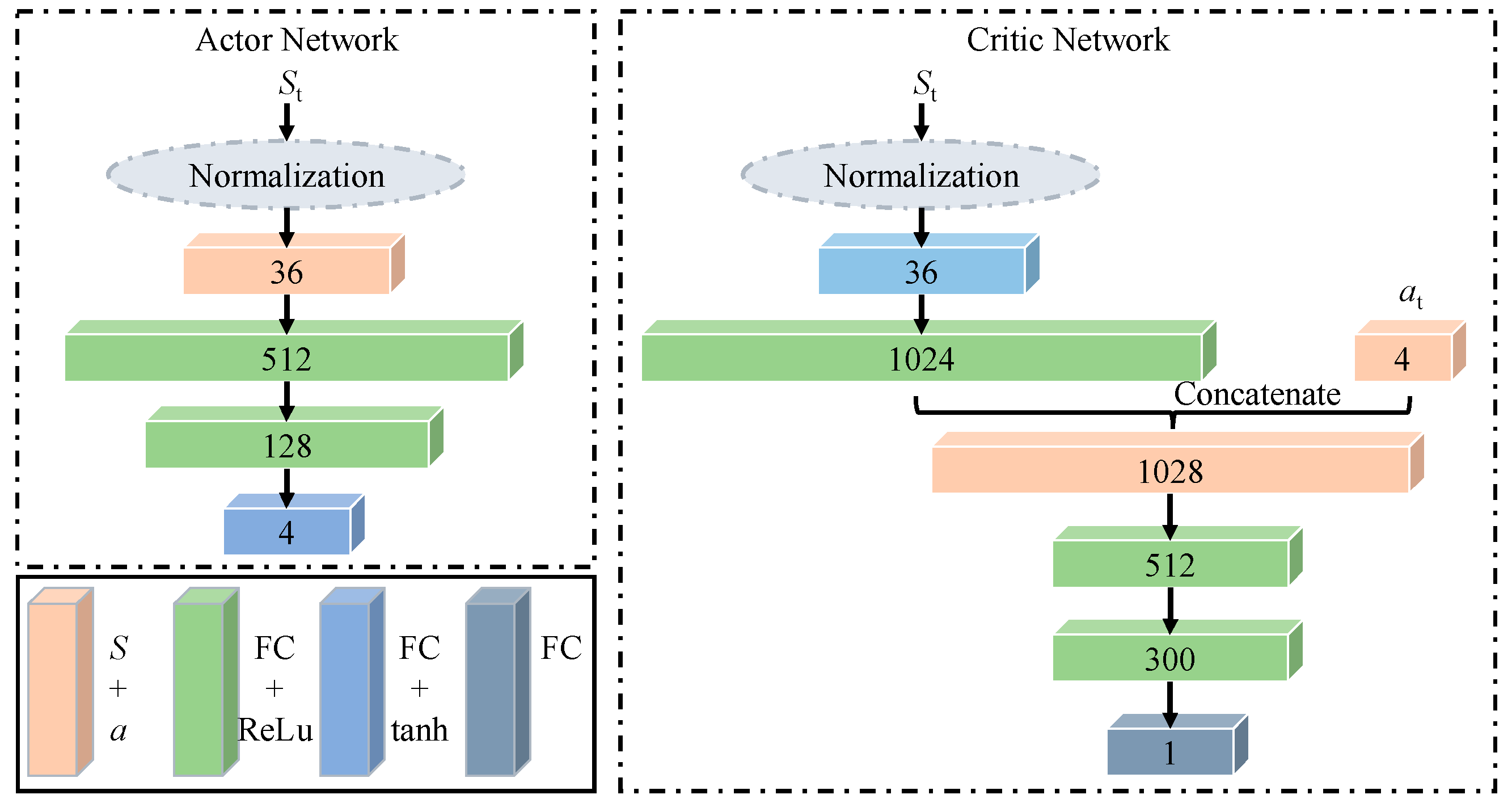
3.2. Create RL Module
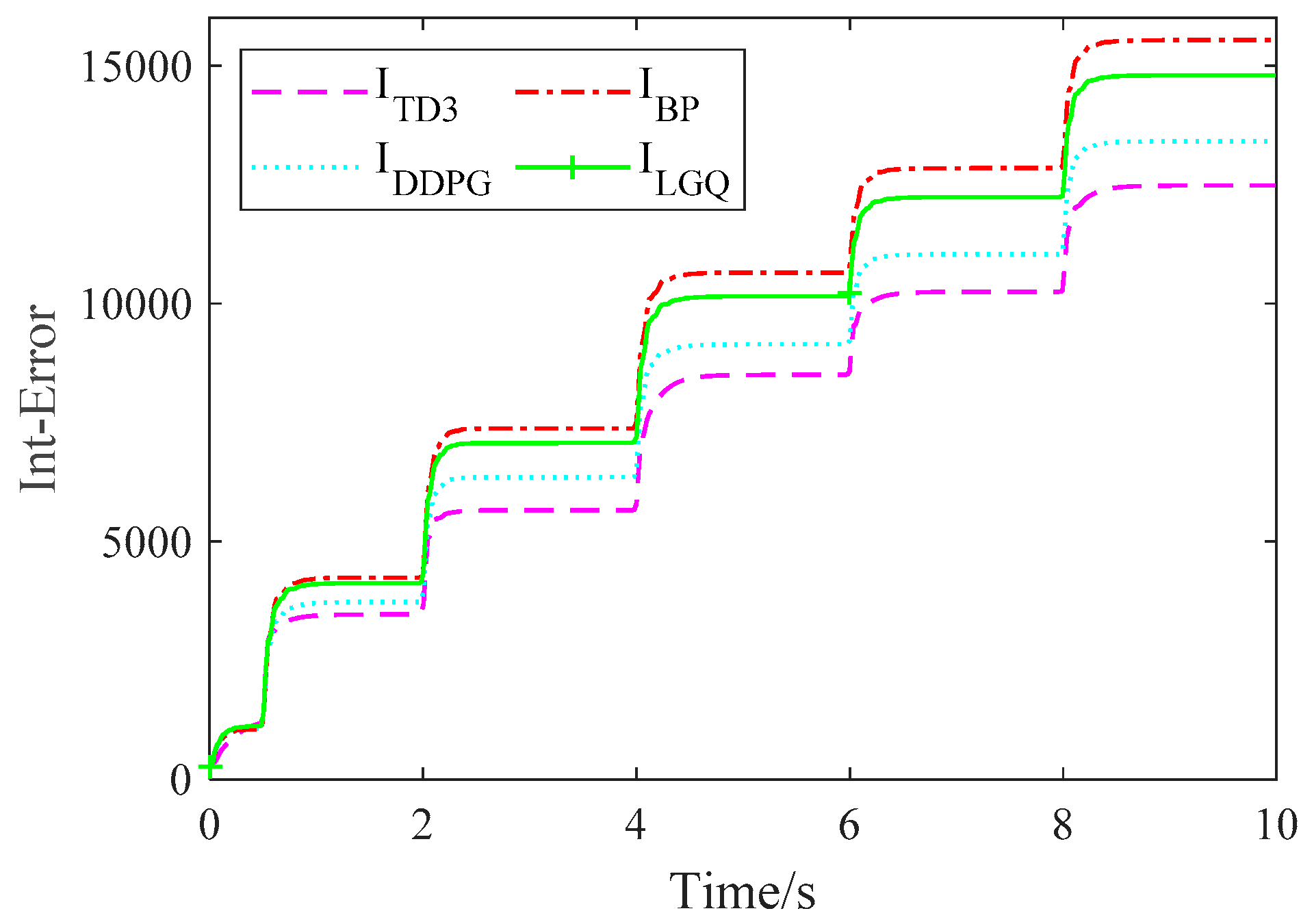
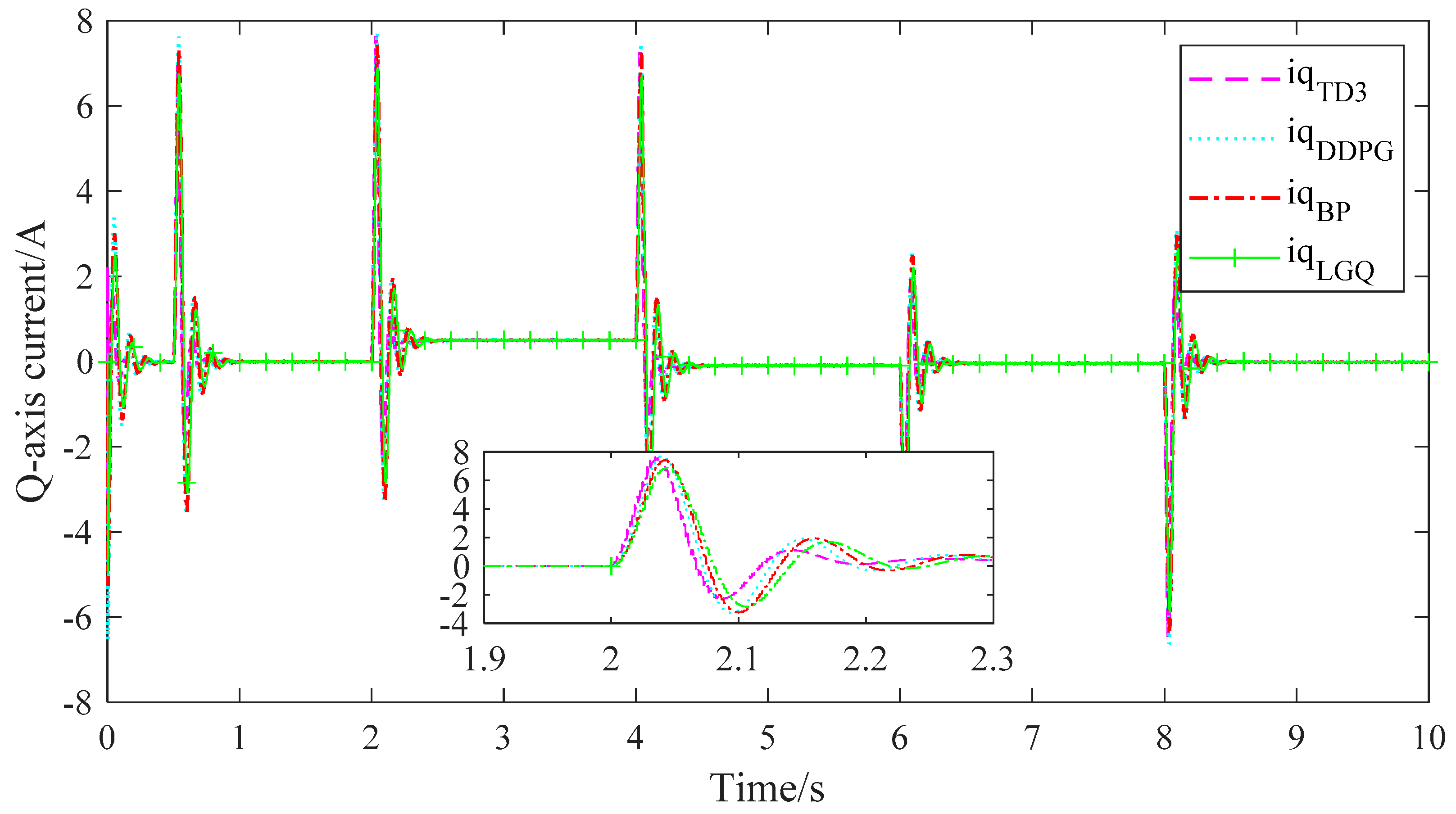
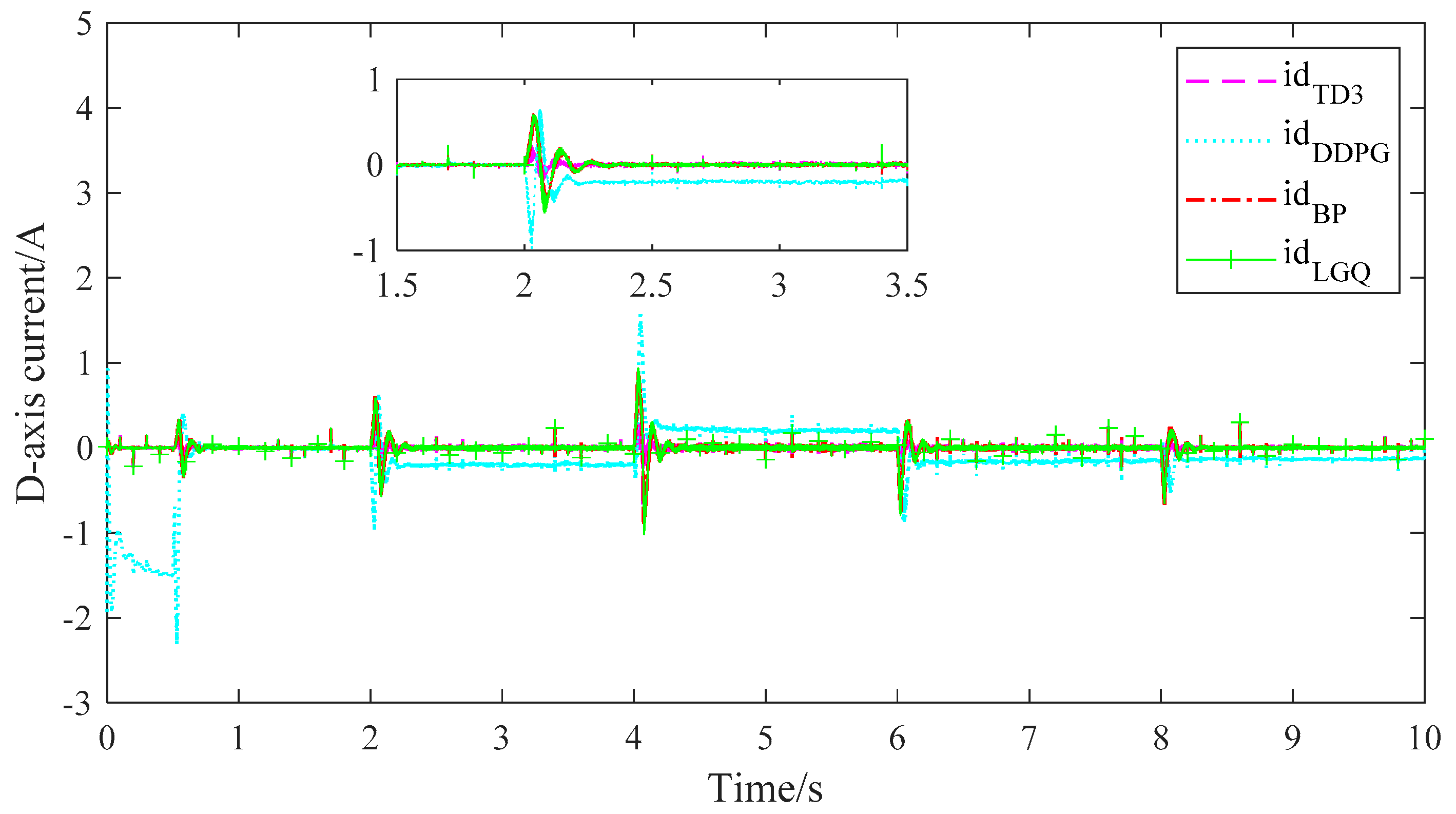
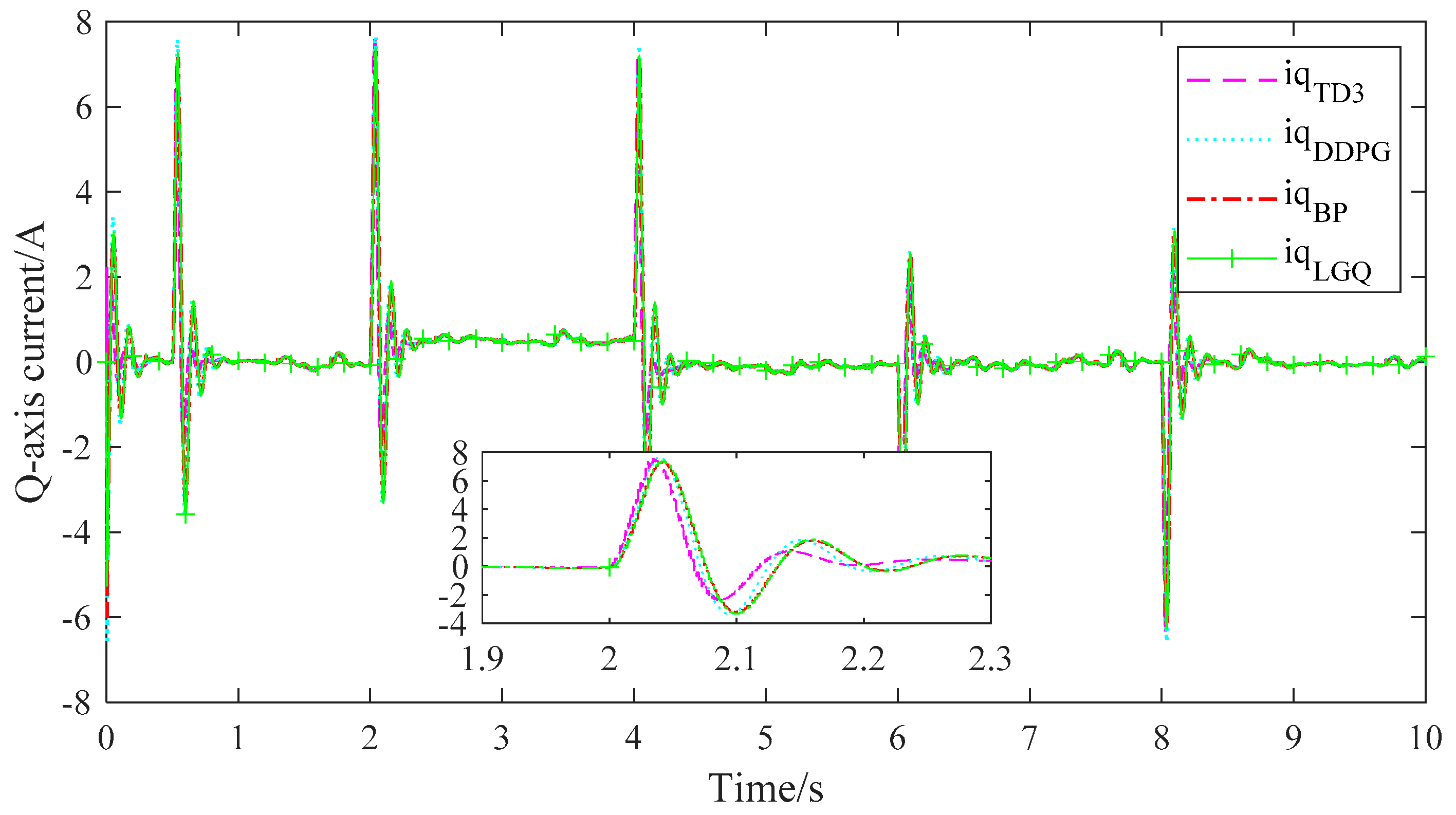
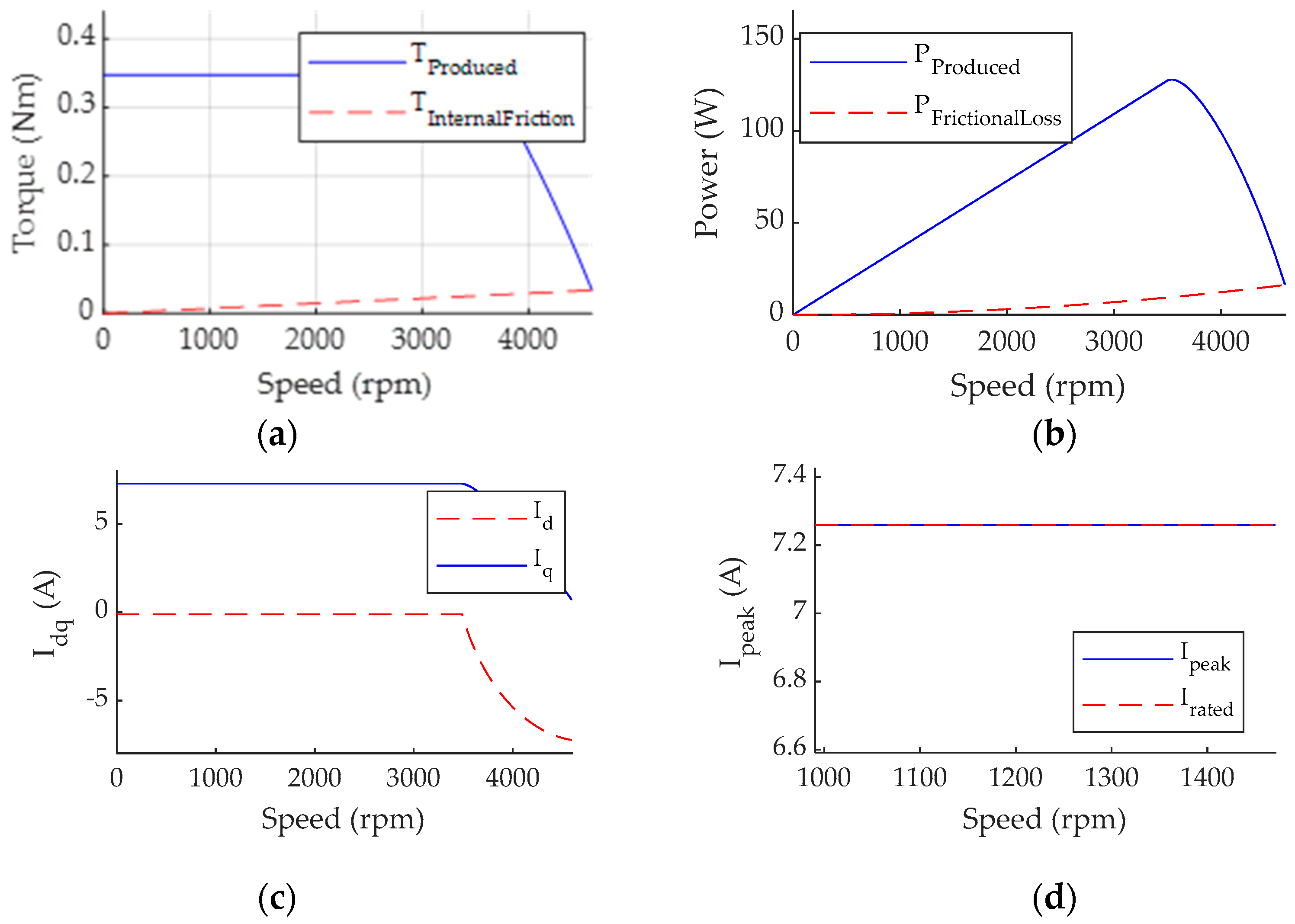
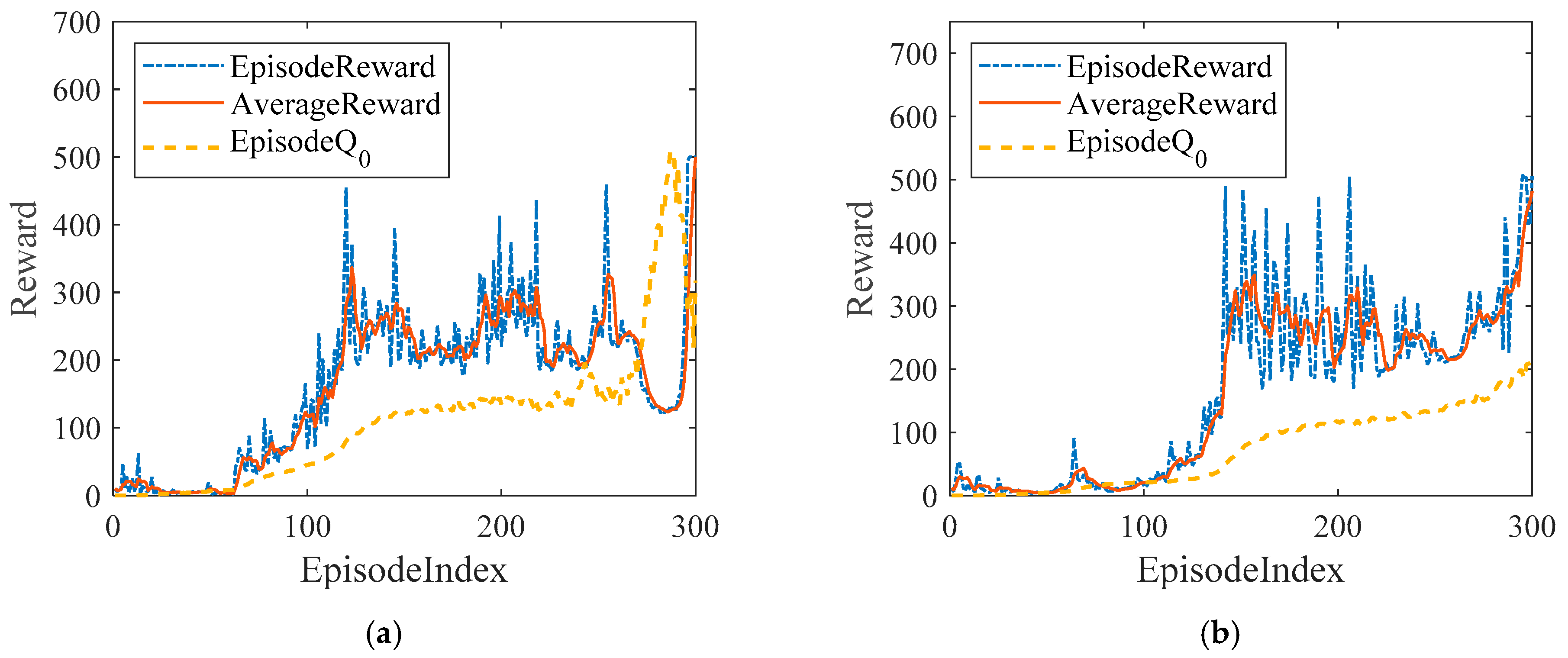
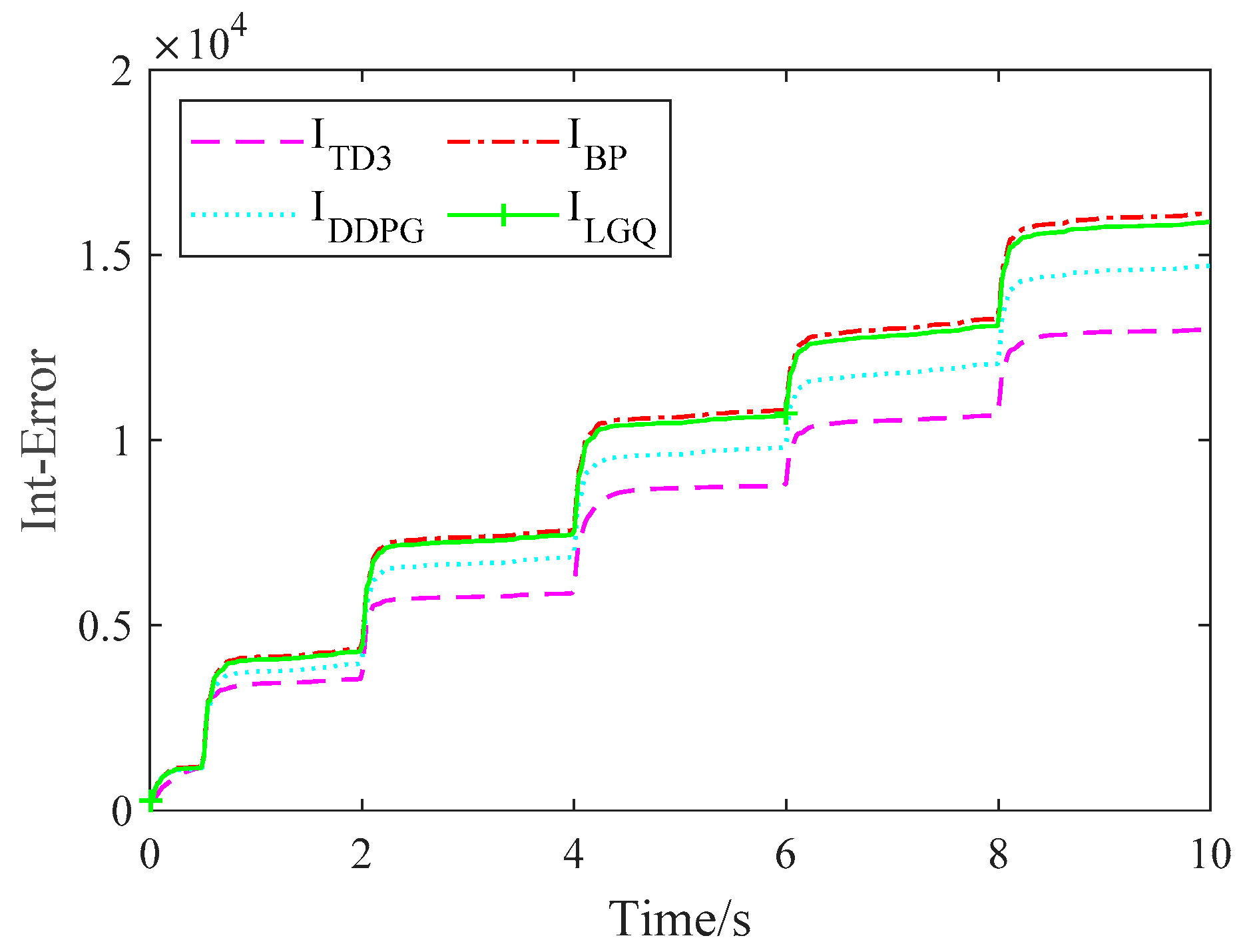
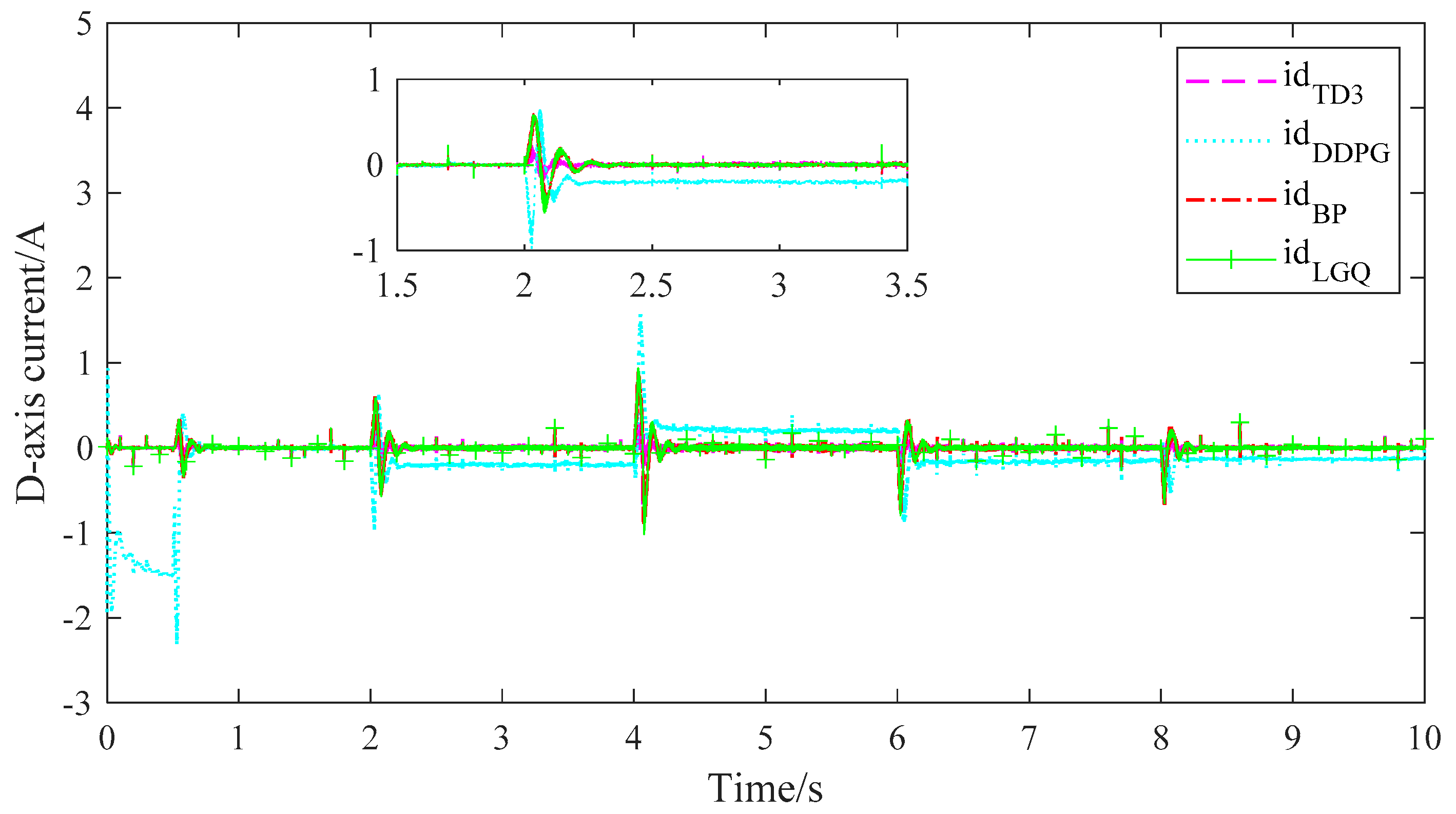
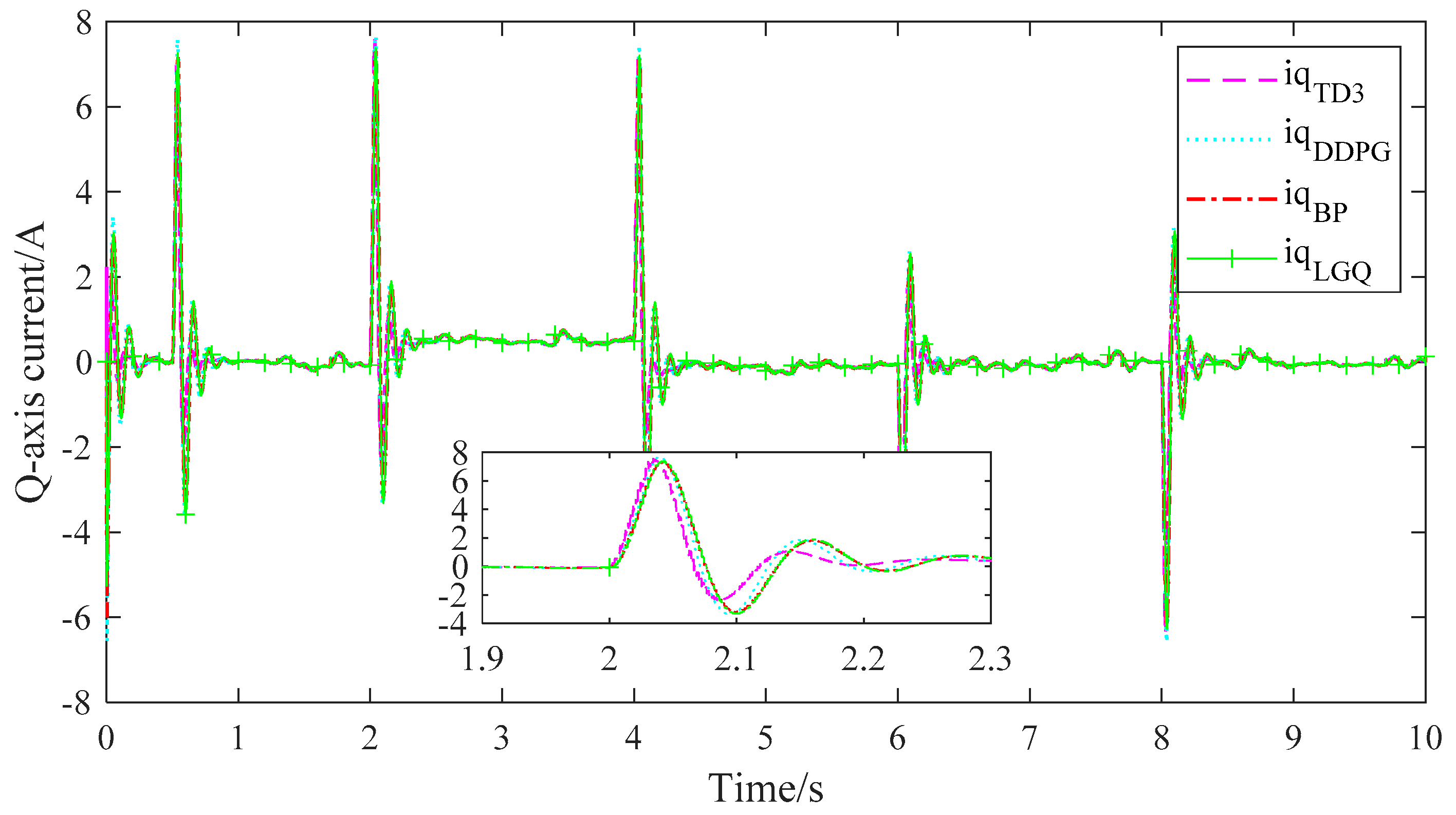
4. Comparison of Simulation Results
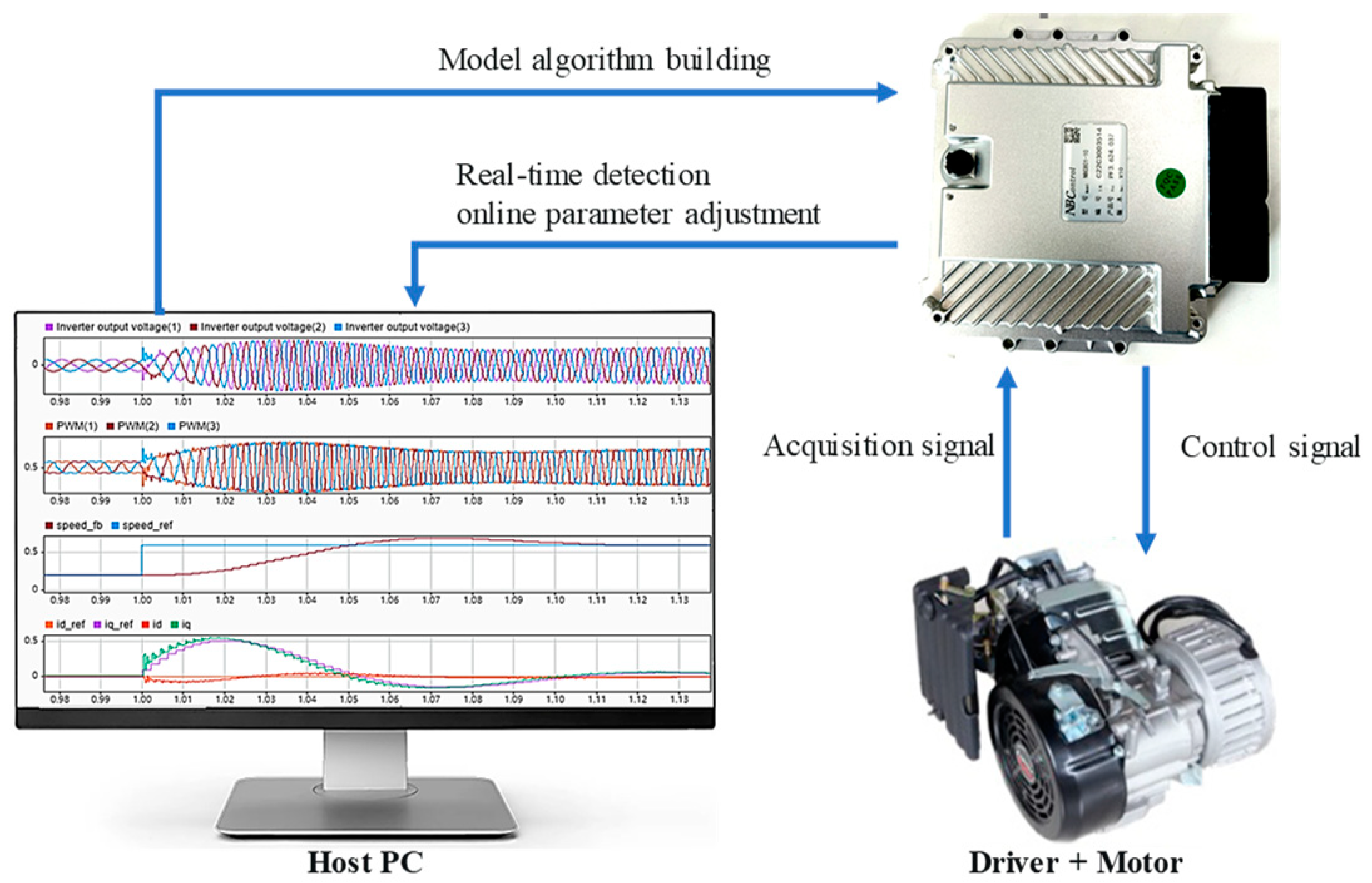
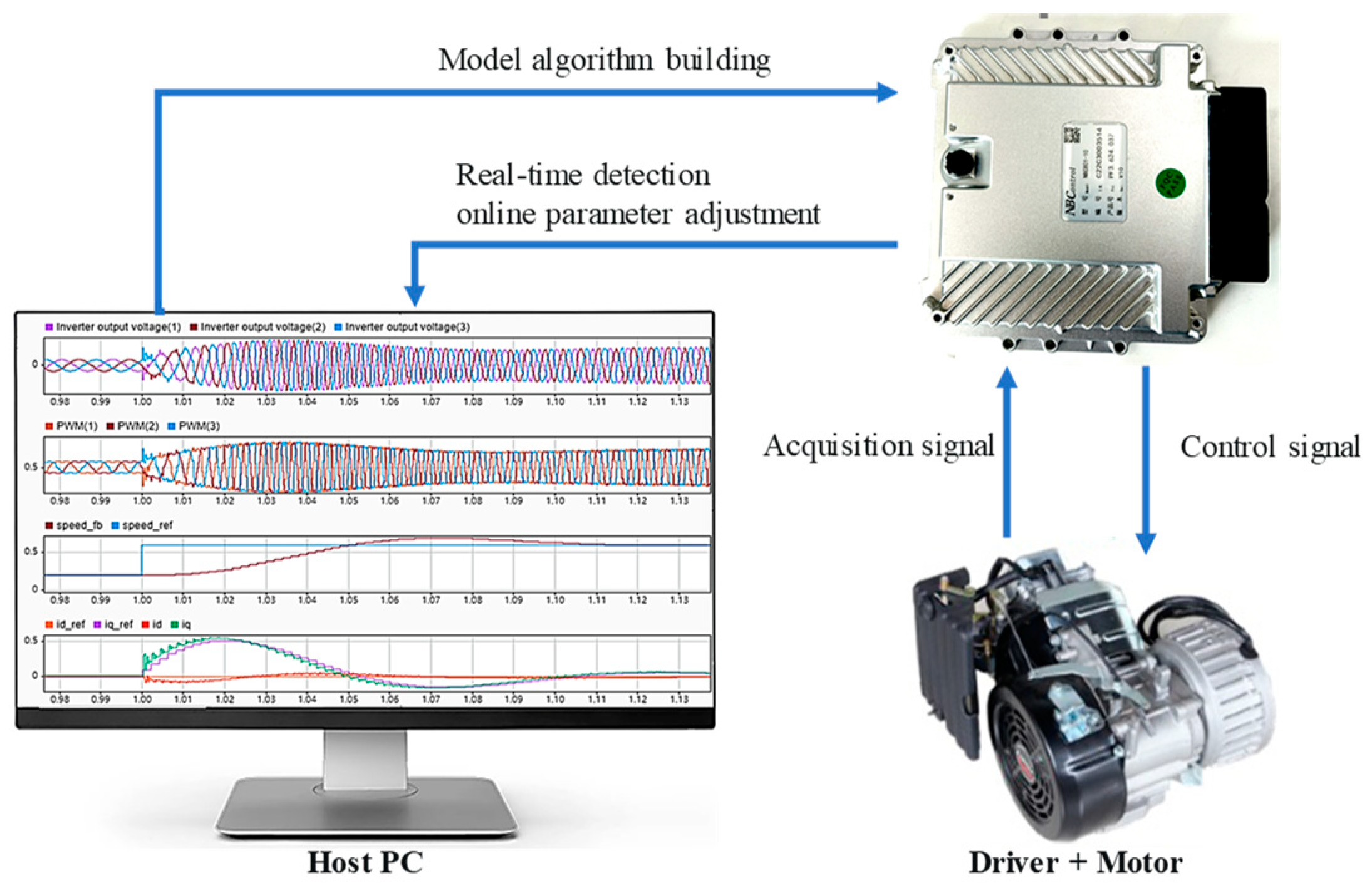
5. Experiment
5.1. Real-Time Simulation
5.2. Rapid Control Prototype
- (1)
- Easy deployment: quick and efficient deployment of control algorithms, which lessens the need for subsequent development.
- (2)
- Simple coordination: by connecting to the controlled object, any issues with the control technique can be rapidly identified. Offline digital simulation is performed before the algorithm model is downloaded to the control board in C for further debugging.
- (3)
- High degree of adaptability: the RCP simulation platform’s powerful performance and abundant resources can suit a variety of research and development objectives.
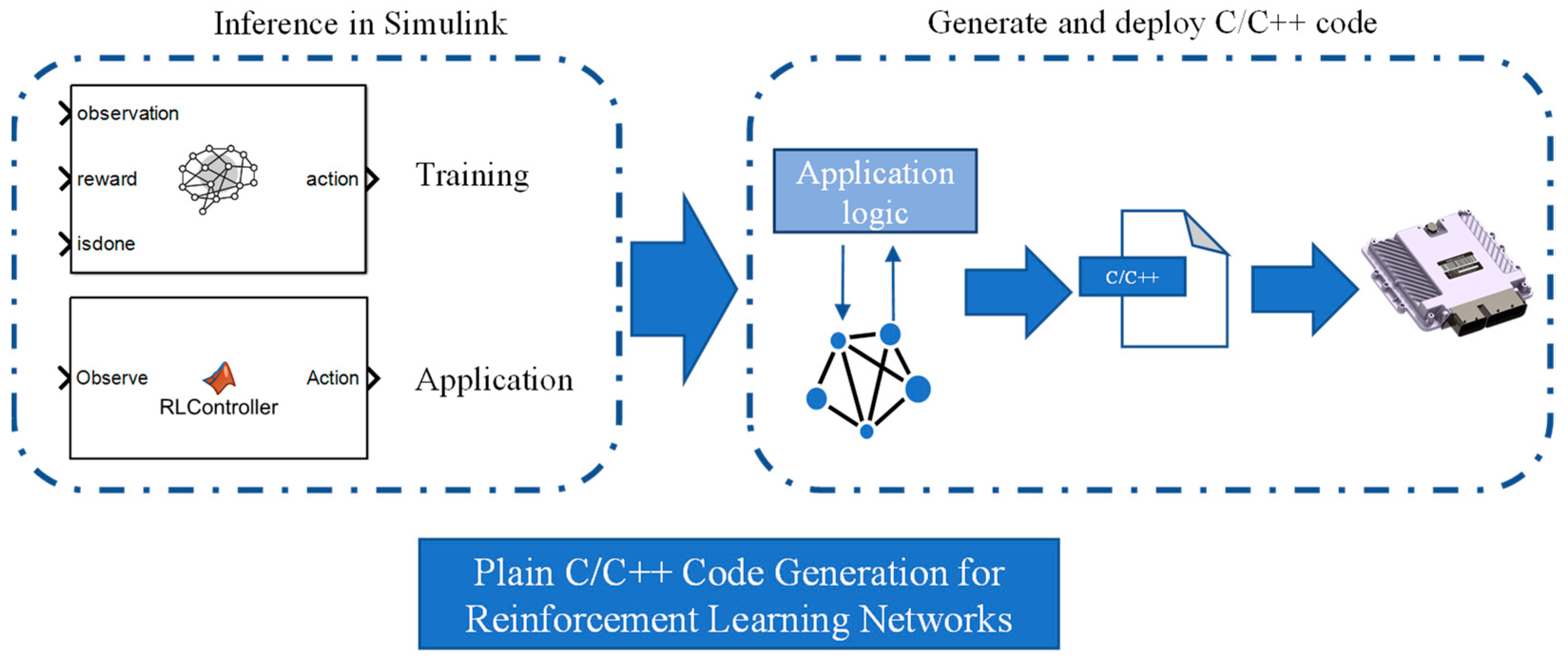
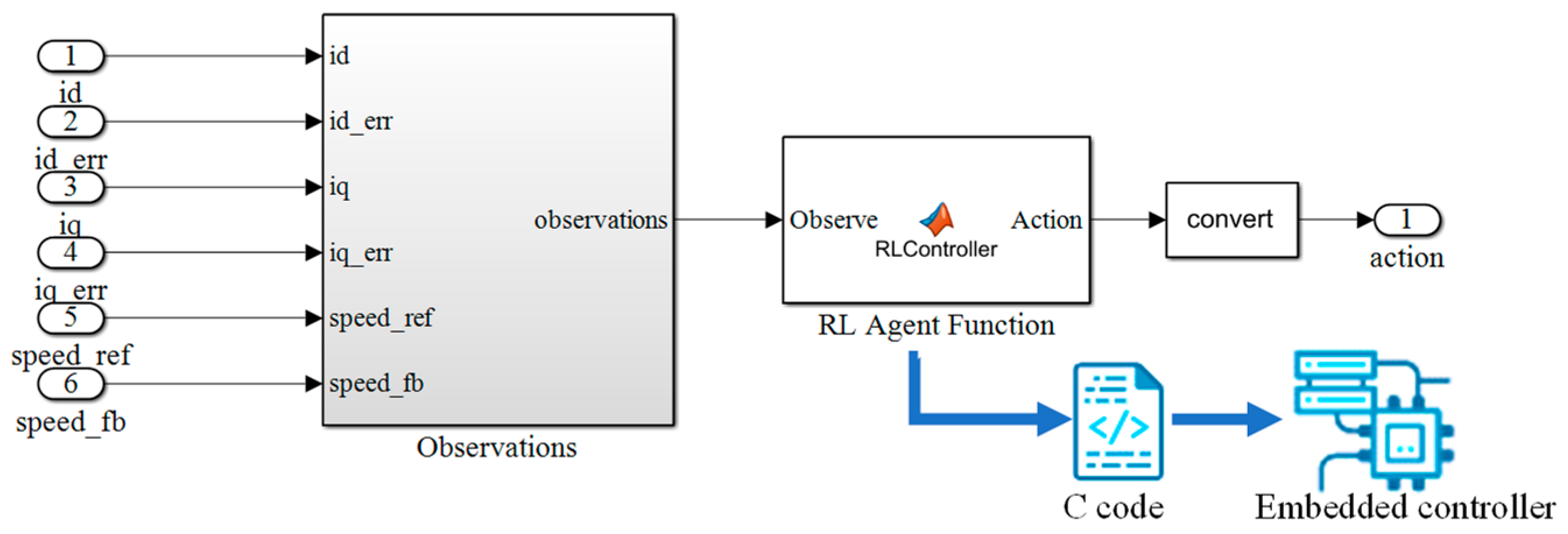
5.3. Code Generation
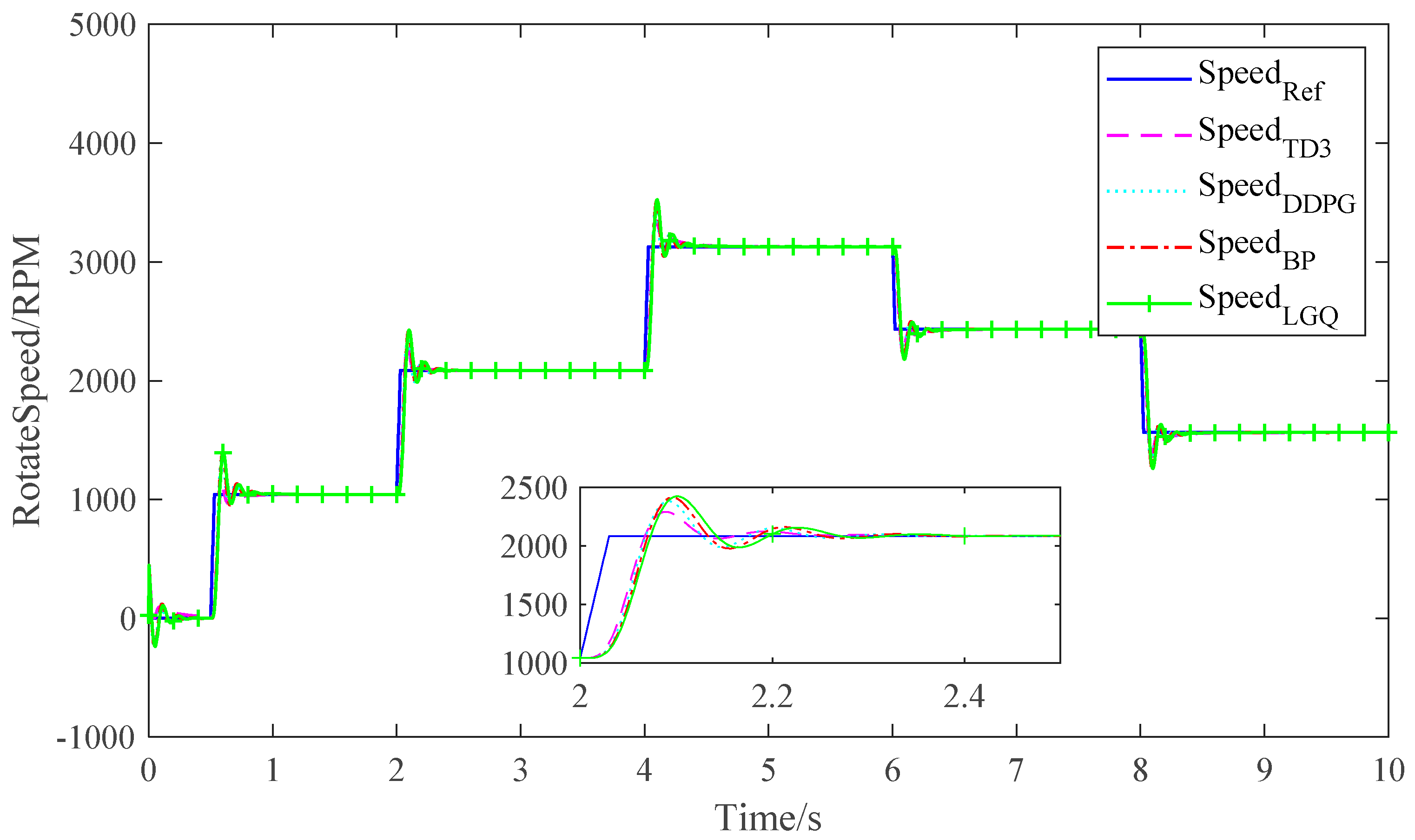
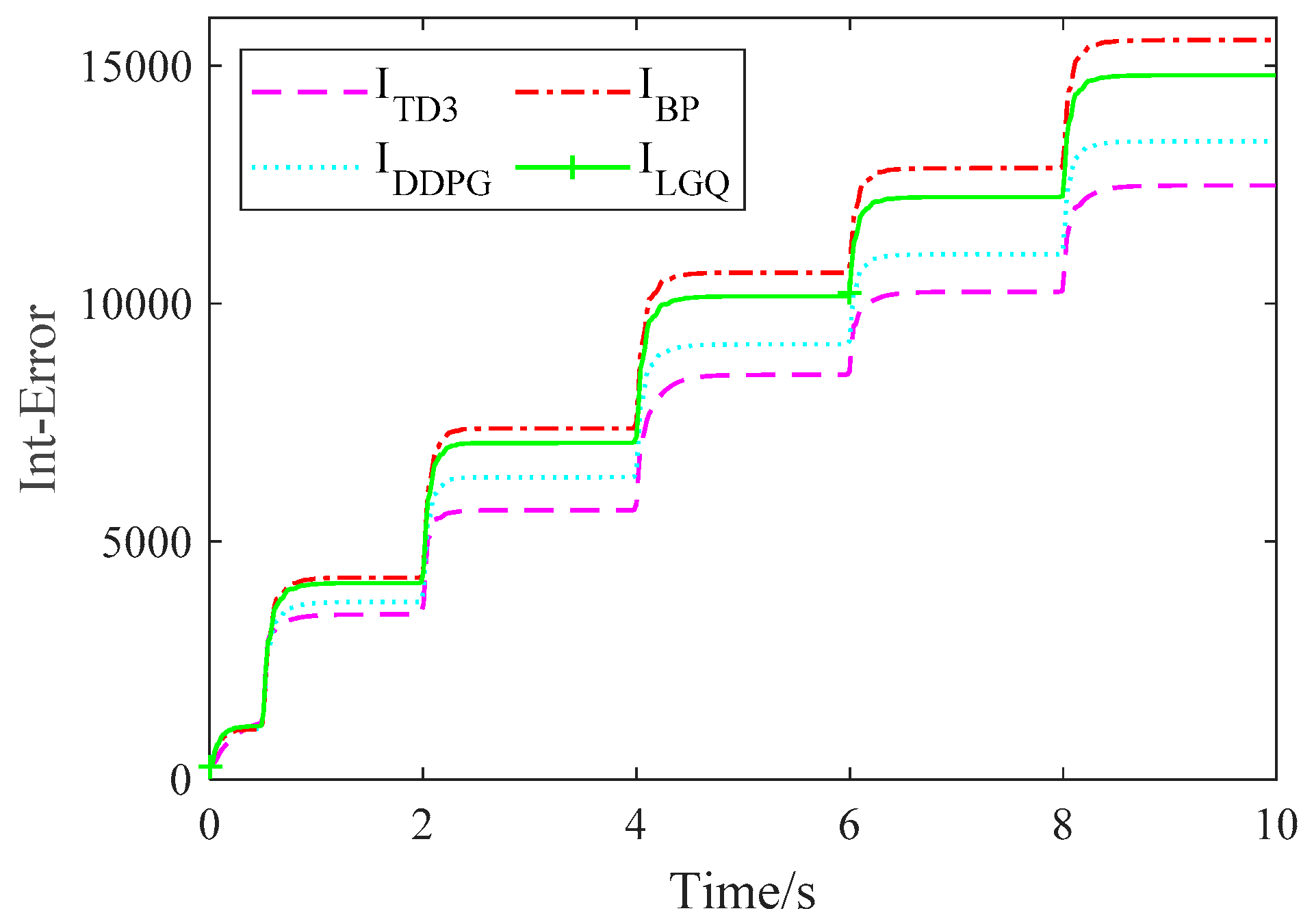
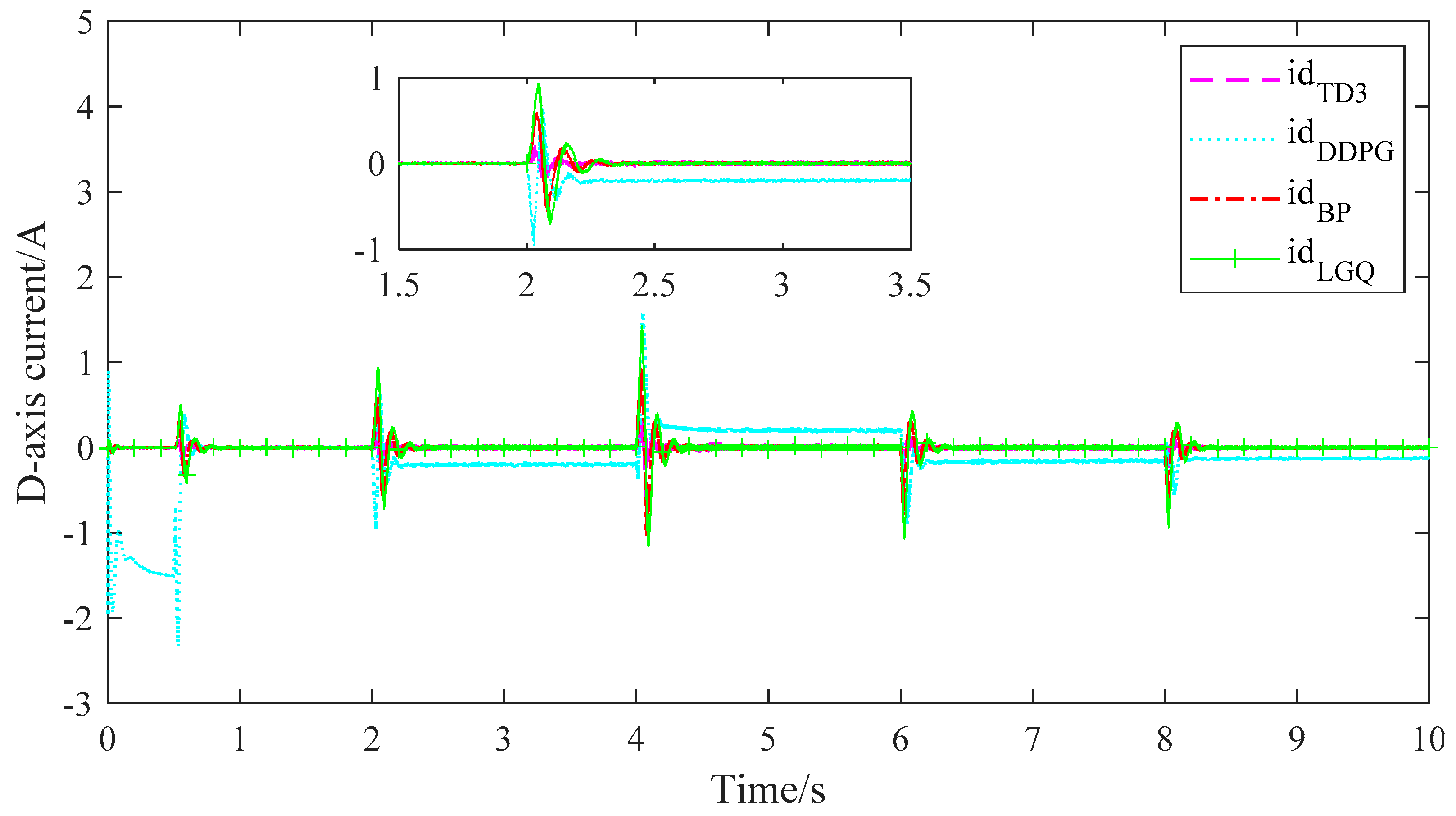
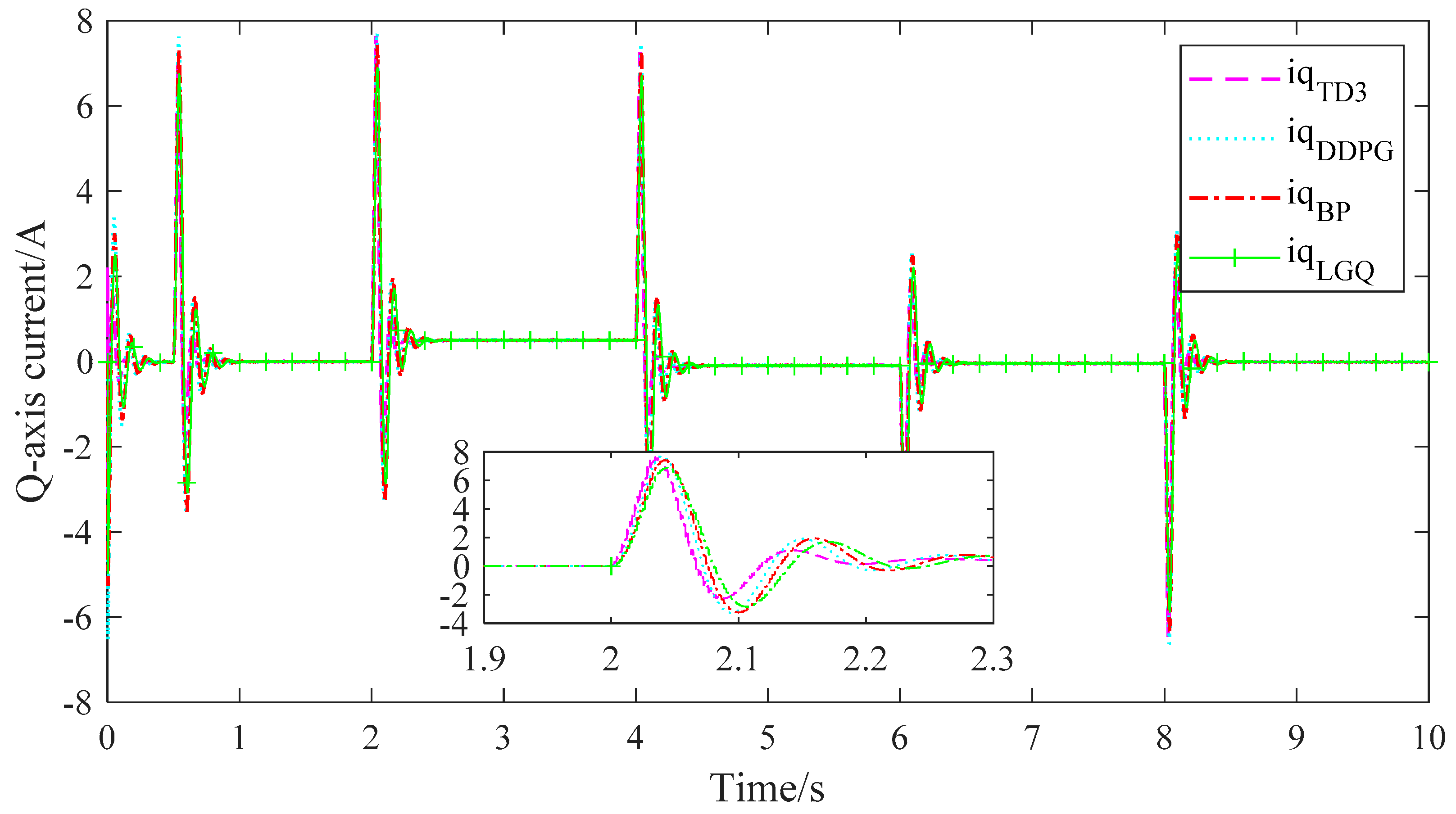
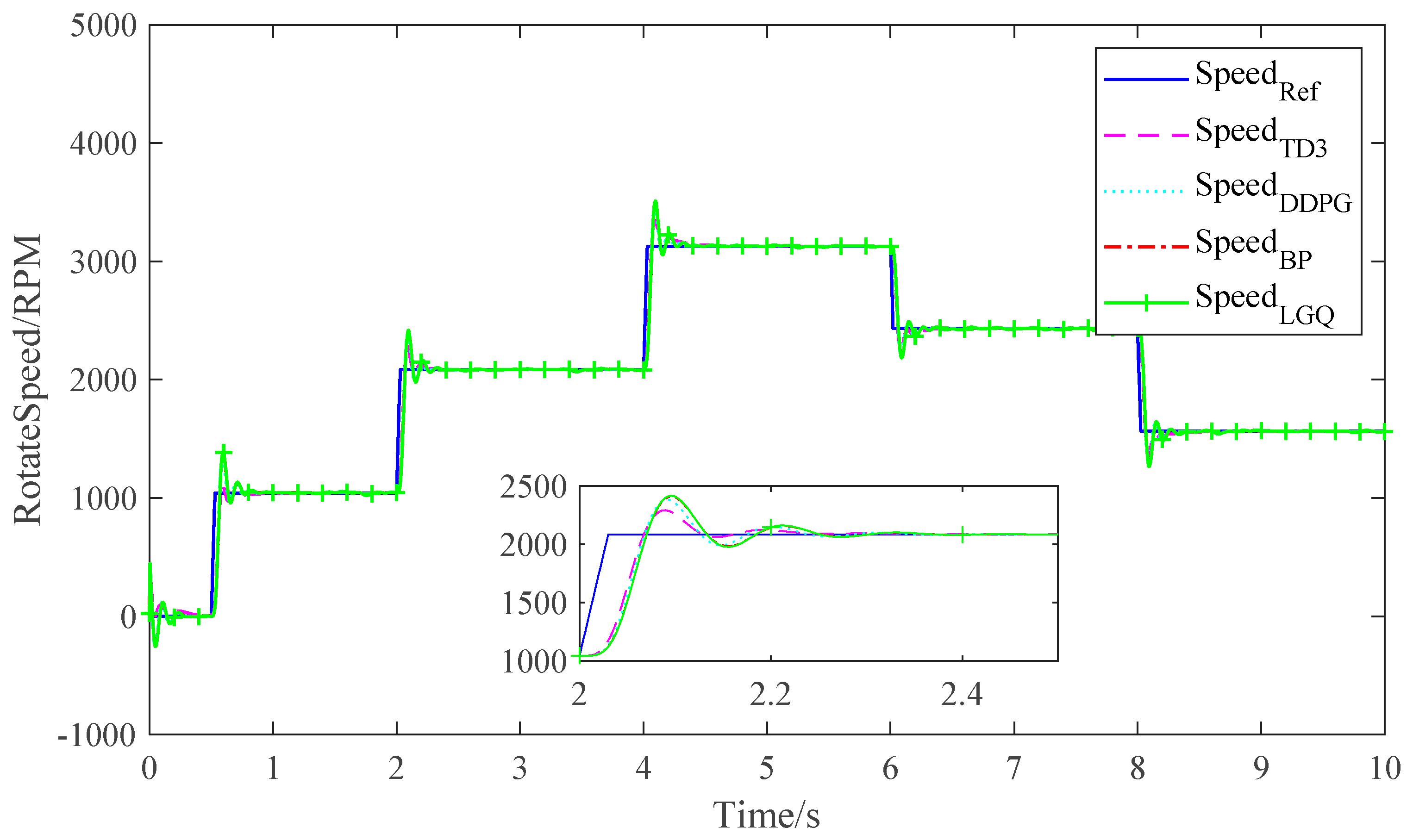
5.4. Result Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sarlioglu, B.; Morris, C.T. More Electric Aircraft: Review, challenges, and opportunities for commercial transport aircraft. IEEE Trans. Transp. Electron. 2015, 1, 54–64. [Google Scholar] [CrossRef]
- Zhang, M.; Mccarthy, Z.; Finn, C.; Levine, S.; Abbeel, P. Learning deep neural network policies with continuous memory states. In Proceedings of the International Conference on Robotics and Automation, Stockholm, Sweden, 16 May 2016; pp. 520–527. [Google Scholar]
- Lenz, I.; Knepper, R.; Saxena, A. DeepMPC: Learning deep latent features for model predictive control. In Proceedings of the Robotics Scienceand Systems, Rome, Italy, 13–17 July 2015; pp. 201–209. [Google Scholar]
- Bolognani, S.; Bolognani, S.; Peretti, L.; Zigliotto, M. Design and implementation of model predictive control for electrical motor drives. IEEE Trans. Ind. Electron. 2009, 56, 1925–1936. [Google Scholar] [CrossRef]
- Tiwari, A.; Singh, S.; Singh, S. PMSM Drives and its Application: An Overview. Recent Adv. Electr. Electron. Eng. 2023, 16, 4–16. [Google Scholar]
- Beaudoin, M.; Boulet, B. Improving gearshift controllers for electric vehicles with reinforcement learning. Mech. Mach. Theory 2022, 169, 104654. [Google Scholar] [CrossRef]
- Chang, X.; Liu, L.; Ding, W.; Liang, D.; Liu, C.; Wang, H.; Zhao, X. Novel nonsingular fast terminal sliding mode control for a PMSM chaotic system with extended state observer and tracking differentiator. J. Vib. Control 2017, 23, 2478–2493. [Google Scholar] [CrossRef]
- Chen, J.; Yao, W.; Ren, Y.; Wang, R.; Zhang, L.; Jiang, L. Nonlinear adaptive speed control of a permanent magnet synchronous motor: A perturbation estimation approach. Control Eng. Pract. 2019, 85, 163–175. [Google Scholar] [CrossRef]
- Dai, C.; Guo, T.; Yang, J.; Li, S. A disturbance observer-based current-constrained controller for speed regulation of PMSM systems subject to unmatched disturbances. IEEE Trans. Ind. Electron. 2021, 68, 767–775. [Google Scholar] [CrossRef]
- Guo, T.; Sun, Z.; Wang, X.; Li, S.; Zhang, K. A simple current-constrained controller for permanent-magnet synchronous motor. IEEE Trans. Ind. Inf. 2019, 15, 1486–1495. [Google Scholar] [CrossRef]
- Xu, Q.; Zhang, C.; Zhang, L.; Wang, C. Multi-objective Optimization of PID Controller of PMSM. Control Sci. Eng. 2014, 2014, 471609. [Google Scholar]
- Zhang, W.; Cao, B.; Nan, N.; Li, M.; Chen, Y. An adaptive PID-type sliding mode learning compensation of torque ripple in PMSM position servo systems towards energy efficiency. ISA Trans. 2020, 110, 258–270. [Google Scholar] [CrossRef] [PubMed]
- Lu, W.; Cheng, K.; Hu, M. Reinforcement Learning for Autonomous Underwater Vehicles via Data-Informed Domain Randomization. Appl. Sci. 2023, 13, 1723. [Google Scholar] [CrossRef]
- Zhang, L.; Li, D.; Xi, Y.; Jia, S. Reinforcement learning with actor-critic for knowledge graph reasoning. Sci. China Inf. Sci. 2020, 63, 1–3. [Google Scholar] [CrossRef]
- Zhao, B.; Liu, D.; Luo, C. Reinforcement learning-based optimal stabilization for unknown nonlinear systems subject to inputs with uncertain constraints. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4330–4340. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Li, Y.; Dong, Q. Autonomous navigation of UAV in multi-obstacle environments based on a Deep Reinforcement Learning approach. Appl. Soft. Comput. 2022, 115, 108194. [Google Scholar] [CrossRef]
- Nicola, M.; Nicola, C.; Selișteanu, D.; Ionete, C. Control of PMSM Based on Switched Systems and Field-Oriented Control Strategy. Automation 2022, 3, 646–673. [Google Scholar] [CrossRef]
- Hong, Z.; Xu, W.; Lv, C.; Ouyang, Q.; Wang, Z. Control Strategy of Deep reinforcement Learning-PI Air Rudder Servo System based on Genetic Algorithm optimization. J. Mech. Electron. Eng. 2019, 40, 1071–1078. [Google Scholar]
- Yang, C.; Wang, H.; Zhao, J. Model-free optimal coordinated control for rigidly coupled dual motor systems based on reinforcement learning. IEEE/ASME Trans. Mechatron. 2023, 16, 1–13. [Google Scholar]
- Pesce, E.; Montana, G. Learning multi-agent coordination through connectivity-driven communication. Mach. Learn. 2022, 112, 483–514. [Google Scholar] [CrossRef]
- Li, Y.; Wu, B. Software-Defined Heterogeneous Edge Computing Network Resource Scheduling Based on Reinforcement Learning. Appl. Sci. 2022, 13, 426. [Google Scholar] [CrossRef]
- Huo, L.; Tang, Y. Multi-Objective Deep Reinforcement Learning for Personalized Dose Optimization Based on Multi-Indicator Experience Replay. Appl. Sci. 2022, 13, 325. [Google Scholar] [CrossRef]
- Wu, C.; Pan, W.; Staa, R.; Liu, J.; Sun, G.; Wu, L. Deep reinforcement learning control approach to mitigating actuator attacks. Automatica 2023, 152, 110999. [Google Scholar] [CrossRef]
- Jean, C.; Kyandoghere, K. Systems Science in Engineering for Advanced Modelling, Simulation, Control and Optimization; CRC Press: Boca Raton, FL, USA, 2019; pp. 34–50. [Google Scholar]
- Riazollah, F. Servo Motors and Industrial Control Theory; Springer: Berlin/Heidelberg, Germany, 2014; pp. 21–40. [Google Scholar]
- GonzálezRodríguez, A.; BarayArana, R.; RodríguezMata, A.; RobledoVega, I.; Acosta, C. Validation of a Classical Sliding Mode Control Applied to a Physical Robotic Arm with Six Degrees of Freedom. Processes 2022, 10, 2699. [Google Scholar] [CrossRef]
- Dhulipati, H.; Ghosh, E.; Mukundan, S.; Korta, P.; Tjong, J.; Kar, N. Advanced design optimization technique for torque profile improvement in six-phase PMSM using supervised machine learning for direct-drive EV. IEEE Trans. Energy Convers. 2019, 34, 2041–2051. [Google Scholar] [CrossRef]
- Zhao, X.; Ding, S. Research on deep rein-forcement learning. Comput. Sci. 2018, 45, 1–6. [Google Scholar]
- Wen, G.; Philip, C.C.L.; Sam, G.S.; Yang, H.; Liu, X. Optimized adaptive nonlinear tracking control using actor–critic rein-forcement learning policy. IEEE Trans. Ind. Inf. 2019, 15, 4969–4977. [Google Scholar] [CrossRef]
- Thuruthel, T.G.; Shih, B.; Laschi, C.; Tolley, M.T. Soft robot perception using embedded soft sensors and recurrent neural networks. Sci. Rob. 2019, 4, 1488–1497. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Li, J.; Li, Z. A TD3-based multi-agent deep reinforcement learning method in mixed cooperation-competition environment. Neurocomputing 2020, 411, 206–215. [Google Scholar] [CrossRef]
- Yao, J.; Ge, Z. Path-Tracking Control Strategy of Unmanned Vehicle Based on DDPG Algorithm. Sensors 2022, 22, 7881. [Google Scholar] [CrossRef]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic Policy Gradient Algorithms. OpenAI 2014, 12, 387–395. [Google Scholar]
- Vrabie, D.; Vamvoudakis, K.; Lewis, F. Optimal Adaptive Control and Differential Games by Reinforcement Learning Principles. IET Digit. Libr. 2012, 3, 1–47. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
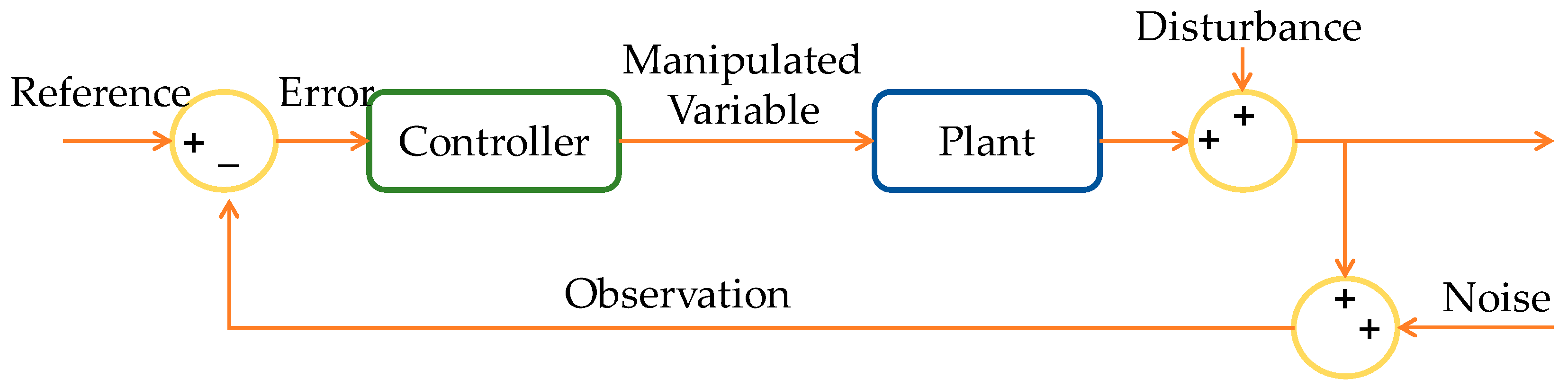
| RL | Control System |
|---|---|
| Policy | Controller |
| Environment | Everything except the controller—The environment in the figure above contains the plant, the reference signal, and the estimated error value. |
| Observation | Any quantifiable value visible to the agent from the environment |
| Action | Regulate or alter variables |
| Reward | A measurement, an error signal, or a function of another performance metric |
| Learning algorithm | Adaptive mechanism |
| Term Name | Symbol | Value |
|---|---|---|
| Pole pairs | p | 7 |
| Torque constant | Kt | 0.0583 N·m/A |
| Friction coefficient | B | 7.01 × 10−5 Kg·m2/s |
| Rate current | Ir | 7.26 A |
| Stator resistor | Rs | 0.293 Ω |
| D-Axis inductance value | Ld | 0.877 mH |
| Q-Axis inductance value | Lq | 0.777 mH |
| Inertia | J | 0.0083 Kg·m2 |
| Max speed | Vmax | 4300 RPM |
| Position offset | Po | 0.165 |
| QEP encoder slits | Qs | 4096 |
| Hyperparameter | Symbol | Value |
|---|---|---|
| Random seed | αr | 1 |
| Maximal set | M | 2000 |
| Maximum sub-step size per episode | T | 5000 |
| Sample Time | Ts | 2 × 10−4 |
| Time of simulation | Tf | 3 |
| Experience Buffer Length | Β | 2 × 106 |
| Quantity of batch | N | 250 |
| Threshold of gradient | ε | 1 |
| Learning rate of Actor network | La | 0.001 |
| Learning rate of Critic network | Lc | 0.0002 |
| Noise of exploration | e | 0.1 |
| Delayed updating | D | 2 |
| L2 Regularization Factor | L2 | 0.001 |
| Target Update Frequency | wt | 10 |
| Factor of discount | γ | 0.995 |
| Rate of soft renewal | τ | 0.01 |
| Performance Parameters | BP | LQG | DDPG | TD3 |
|---|---|---|---|---|
| Settling time | 0.98 s | 0.82 s | 0.89 s | 0.8 s |
| Risetime | 0.2 s | 0.19 s | 0.15 s | 0.1 s |
| Undershoot | 15.03% | 12.7% | 12.21% | 7.76% |
| Type | Technical Specifications |
|---|---|
| MCU | Mononuclear & 32 bit & 600 MHz |
| Current operating system | Simulink & CODESYS |
| Memory space | 512 KB × RAM Flash 16 MB |
| Interface | 1 × USB 3.0 & 2 × USB 2.0 |
| Computer interface | 4 × CAN, 1 × RS 232 |
| Power supply | +9–+32 V |
| Port channel number | 20 × AI(0–5 V/0–20 mA), 4 × AI(0–5 V/32 V), 2 × AI(0–2.2 kΩ) |
| 10 × PI | |
| 8 × DO | |
| 30 × PWM | |
| Dimension | 242 × 234 × 40 mm |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, F.; Yuan, X.; Ma, Z.; Xu, X. Vector Control of PMSM Using TD3 Reinforcement Learning Algorithm. Algorithms 2023, 16, 404. https://doi.org/10.3390/a16090404
Yin F, Yuan X, Ma Z, Xu X. Vector Control of PMSM Using TD3 Reinforcement Learning Algorithm. Algorithms. 2023; 16(9):404. https://doi.org/10.3390/a16090404
Chicago/Turabian StyleYin, Fengyuan, Xiaoming Yuan, Zhiao Ma, and Xinyu Xu. 2023. "Vector Control of PMSM Using TD3 Reinforcement Learning Algorithm" Algorithms 16, no. 9: 404. https://doi.org/10.3390/a16090404
APA StyleYin, F., Yuan, X., Ma, Z., & Xu, X. (2023). Vector Control of PMSM Using TD3 Reinforcement Learning Algorithm. Algorithms, 16(9), 404. https://doi.org/10.3390/a16090404