

Deep Q-Network Algorithm-Based Cyclic Air Braking Strategy for Heavy-Haul Trains

Abstract
1. Introduction
2. Model Construction for Heavy-Haul Trains
2.1. Dynamic Model
2.2. Running Constraints
2.3. Performance Indicators
3. DQN Control Algorithm
3.1. Markov Decision Process
3.2. DQN Algorithm Model
3.2.1. Policy Design
3.2.2. Reward Design
3.2.3. Prioritized Experience Replay Design
3.2.4. Action Value Function Design
| Algorithm 1 DQN-Based Intelligent Control Strategy for Circulating Air Brake of the Heavy-Haul Train |
| ///Initialization/// |
| 1: Use weight θ to randomly initialize the Q-network. |
| 2: Use weight = θ to initialize target network . |
|
| ///Process of training/// |
| 4: for episode = 1,…M do |
| 5: initialize the state of train through Equation (13) |
| 6: for k = 0,1,…,N−1 do |
| 7: choose action based on strategy π |
|
|
|
| 11: If done = True, set =; otherwise, |
| 12: calculate the of gradient with respect to weight θ |
| 13: update the weight θ by SGD method |
| 14: update the weight of the target network according to every J perods |
| 15: end for |
| 16: end for |
4. Algorithm Simulation and Analysis
4.1. Experimental Parameter Settings
4.2. Simulation Experiment Verification
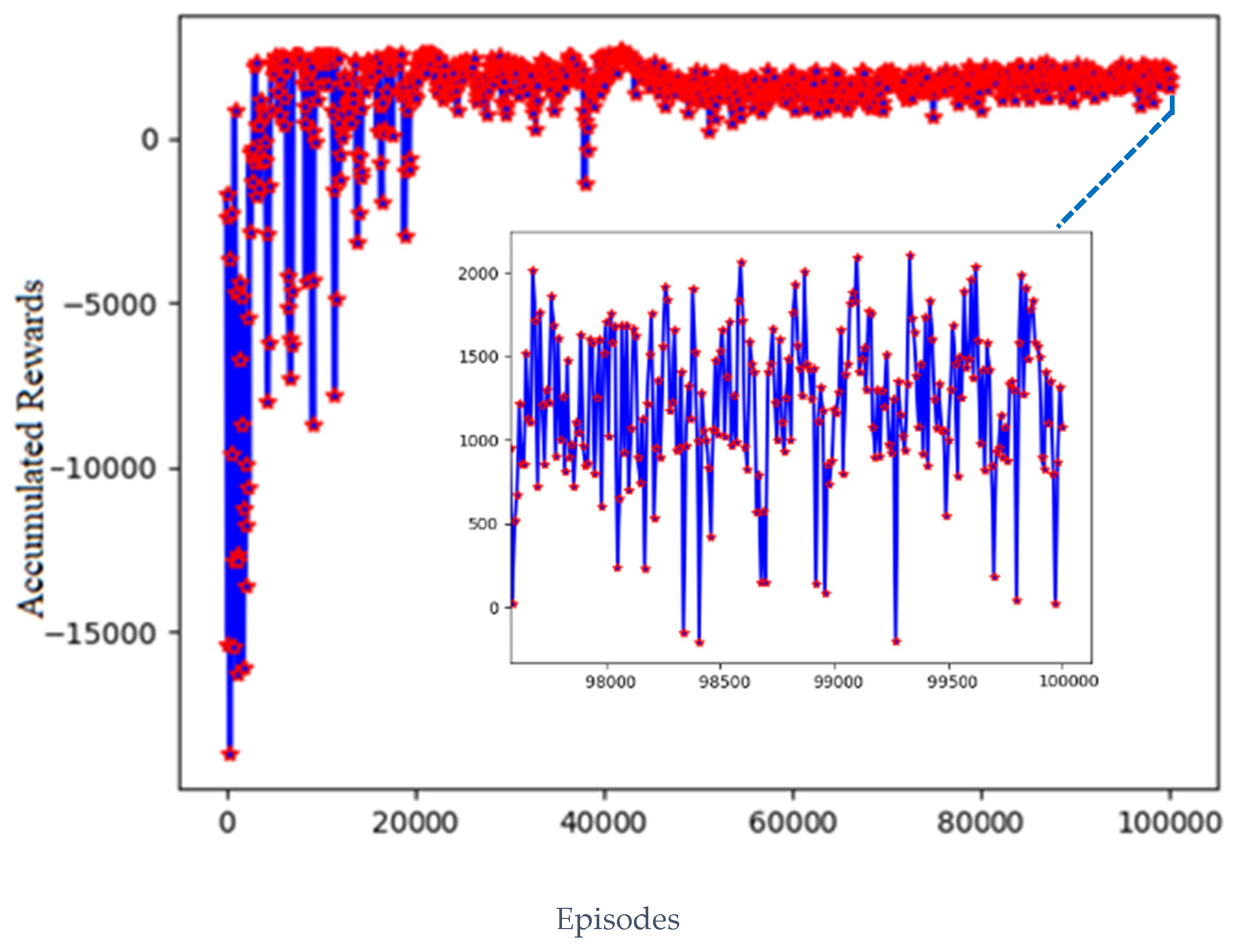
4.2.1. Model Training Process
4.2.2. Practical Application Performance Test
4.2.3. Comparison of Algorithm Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| M | Sum of the masses of all carriages | Acceleration of heavy-haul train | |
| F | Locomotive traction force | Running speed of train | |
| Output electric braking force | Output air brake force | ||
| Maximum electric brake force | Maximum traction force | ||
| Resistance of train | g | Gravity acceleration | |
| Upper limit of train running speed | Minimum release speed of air braking | ||
| Relative output ratio of traction force | Relative output ratio of the electric braking force | ||
| Equivalent emergency brake ratio of air braking | Equivalent friction coefficient of air braking | ||
| R | Curve radius | Tunnel length | |
| Service brake coefficient of air braking | i | Gradient of the line section | |
| Running resistance constant | Air brake distance | ||
| Time point of engaging air brake in the (j + 1)th cycle | Time point of releasing air brake in the jth cycle |
References
- Zhang, Z. Optimization Analysis of Smooth Operation for Ten-Thousand Ton Trains of Shuohuang Railway; Southwest Publishing House: Chengdu, China, 2017. [Google Scholar]
- Lu, Q.; He, B.; Wu, M.; Zhang, Z.; Luo, J.; Zhang, Y.; He, R.; Wang, K. Establishment and analysis of energy consumption model of heavy-haul train on large long slope. Energies 2018, 11, 965. [Google Scholar] [CrossRef]
- Dong, S.; Yang, S.; Yang, C.; Ni, W. Analysis of Braking Methods for Express Freight Train on Long Ramp. Mod. Mach. 2022, 2, 28–34. [Google Scholar]
- Kuefler, A.; Morton, J.; Wheeler, T.; Kochenderfer, M. Imitating Driver Behavior with Generative Adversarial Networks. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; IEEE: New York, NY, USA, 2017. [Google Scholar]
- Yang, H.; Wang, Y.; Li, Z.; Fu, Y.; Tan, C. Expert supervised SAC reinforcement learning for optimizing the operation of heavy-duty trains. Control Theory Appl. 2022, 39, 799–808. [Google Scholar]
- Howlett, P. An optimal strategy for the control of a train. Anziam J. 1990, 31, 454–471. [Google Scholar] [CrossRef]
- Huang, Y.; Su, S.; Liu, W. optimization on the Driving Curve of Heavy Haul Trains Based on Artificial Bee Colony Algorithm. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; IEEE: New York, NY, USA, 2020. [Google Scholar]
- Du, L. Model Based Security Reinforcement Learning. Master’s Thesis, Harbin Institute of Technology, Harbin, China, 2021. [Google Scholar]
- Wang, Y.; De Schutter, B.; van den Boom, T.J.; Ning, B. Optimal trajectory planning for trains—A pseudo spectral method and a mixed integer linear programming approach. Transp. Res. Part C Emerg. Technol. 2013, 29, 97–114. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, Q.; Zhang, Z. A Study on Energy-Saving Optimization for High Speed Railways Based on Q-learning Algorithm. Railw. Transp. Econ. 2019, 41, 111–117. [Google Scholar]
- Zhang, M.; Zhang, Q.; Liu, W.; Zhou, B. A Policy-Based Reinforcement Learning Algorithm for Intelligent Train Control. J. China Railw. Soc. 2020, 42, 69–75. [Google Scholar]
- Zhang, W.; Sun, X.; Liu, Z.; Yang, L. Research on Energy-Saving Speed Curve of Heavy Haul Train Based on Reinforcement Learning. In Proceedings of the 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC), Bilbao, Bizkaia, 24–28 September 2023; IEEE: New York, NY, USA, 2023; pp. 2523–2528. [Google Scholar]
- Sandidzadeh, M.A.; Havaei, P. A comprehensive study on reinforcement learning application for train speed profile optimization. Multimed. Tools Appl. 2023, 82, 37351–37386. [Google Scholar] [CrossRef]
- Wu, T.; Dong, W.; Ye, H.; Sun, X.; Ji, Y. A Deep Reinforcement Learning Approach for Optimal Scheduling of Heavy-haul Railway. IFAC-PapersOnLine 2023, 56, 3491–3497. [Google Scholar] [CrossRef]
- Lin, X.; Liang, Z.; Shen, L.; Zhao, F.; Liu, X.; Sun, P.; Cao, T. Reinforcement learning method for the multi-objective speed trajectory optimization of a freight train. Control Eng. Pract. 2023, 138, 105605. [Google Scholar] [CrossRef]
- Tang, H.; Wang, Y.; Liu, X.; Feng, X. Reinforcement learning approach for optimal control of multiple electric locomotives in a heavy-haul freight train: A Double-Switch-Q-network architecture. Knowl.-Based Syst. 2020, 190, 105173. [Google Scholar]
- Wang, M.Y.; Kou, B.Q.; Zhao, X.K. Analysis of Energy Consumption Characteristics Based on Simulation and Traction Calculation Model for the CRH Electric Motor Train Units. In Proceedings of the 2018 21st International Conference on Electrical Machines and Systems (ICEMS), Jeju, Republic of Korea, 7–10 October 2018; IEEE: New York, NY, USA, 2018; pp. 2738–2743. [Google Scholar]
- Yu, H.; Huang, Y.; Wang, M. Research on operating strategy based on particle swarm optimization for heavy haul train on long down-slope. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; IEEE: New York, NY, USA, 2018; pp. 2735–2740. [Google Scholar]
- Huang, Y.; Bai, S.; Meng, X.; Yu, H.; Wang, M. Research on the driving strategy of heavy-haul train based on improved genetic algorithm. Adv. Mech. Eng. 2018, 10, 1687814018791016. [Google Scholar] [CrossRef]
- Su, S.; Tang, T.; Li, X. Driving strategy optimization for trains in subway systems. Proc. Inst. Mech. Eng. Part F J. Rail Rapid Transit 2018, 232, 369–383. [Google Scholar] [CrossRef]
- Niu, H.; Hou, T.; Chen, Y. Research on Energy-saving Operation of High-speed Trains Based on Improved Genetic Algorithm. J. Appl. Sci. Eng. 2022, 26, 663–673. [Google Scholar]
- Zhang, Z. Train Traction Calculation; China Railway Press: Beijing, China, 2013. [Google Scholar]
- Su, S.; Wang, X.; Cao, Y.; Yin, J. An energy-efficient train operation approach by integrating the metro timetabling and eco-driving. IEEE Trans. Intell. Transp. Syst. 2019, 21, 4252–4268. [Google Scholar] [CrossRef]
- Ma, H. Research on Optimization Control of Long Downhill Braking Process for Heavy Haul Trains. Master’s Thesis, East China Jiaotong University, Nanchang, China, 2019. [Google Scholar]
- Wu, J. Train Traction Calculation; Southwest Jiaotong University Press: Chengdu, China, 2013; pp. 50–141. [Google Scholar]
- Wei, W.; Jiang, Y.; Zhang, Y.; Zhao, X.; Zhang, J. Study on a Segmented Electro-Pneumatic Braking System for Heavy-Haul Trains. Transp. Saf. Environ. 2020, 2, 216–225. [Google Scholar] [CrossRef]
- Su, S.; Tang, T.; Xun, J.; Cao, F.; Wang, Y. Design of Running Grades for Energy-Efficient Train Regulation: A Case Study for Beijing Yizhuang Line. IEEE Intell. Transp. Syst. Mag. 2019, 13, 189–200. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Locomotive Parameters | Freight Car Parameters | ||
|---|---|---|---|
| Parameter Name | Value | Parameter Name | Value |
| Model | HXD1 | Model | C80 |
| Mass | 200 t | Mass | 100 t |
| Length | 35.2 m | Length | 13.2 m |
| Distance (m) | Gradient (-‰) | Distance (m) | Gradient (-‰) |
|---|---|---|---|
| 0–1000 | 1.5 | 12,430–14,080 | 10.5 |
| 1000–1400 | 7.5 | 14,080–16,330 | 11.4 |
| 1400–6200 | 10.9 | 16,330–19,130 | 10.6 |
| 6200–6750 | 9 | 19,130–22,260 | 10.9 |
| 6750–12,430 | 11.3 | 22,260–23,800 | 3.3 |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Maximum training episode M | 100,000 | Minimum air-refilling time | 100 |
| Update period of target network | 300 | Batch size of sampling | 32 |
| Discount rate γ | 0.94 | Learning rate λ | 0.001 |
| Initial value of ε | 0.98 | Final value of ε | 0.1 |
| Capacity of memory buffer D | 5000 | Planned operation time T | 1500 s |
| Positive reward | 5 | Negative reward | −20 |
| Minimum braking speed | 40 km/h | Maximum braking speed | 80 km/h |
| Algorithm | Target | ||||
|---|---|---|---|---|---|
| Safety Indicator Y | Air Braking Distance/m | Planned Running Time/s | Actual Running Time/s | Average Speed/(km/h) | |
| Q learning | 1 | 7576.9 | 1500 | 1360 | 63 |
| DQN | 1 | 7417.6 | 1500 | 1260 | 68 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Zhou, S.; He, J.; Jia, L. Deep Q-Network Algorithm-Based Cyclic Air Braking Strategy for Heavy-Haul Trains. Algorithms 2024, 17, 190. https://doi.org/10.3390/a17050190
Zhang C, Zhou S, He J, Jia L. Deep Q-Network Algorithm-Based Cyclic Air Braking Strategy for Heavy-Haul Trains. Algorithms. 2024; 17(5):190. https://doi.org/10.3390/a17050190
Chicago/Turabian StyleZhang, Changfan, Shuo Zhou, Jing He, and Lin Jia. 2024. "Deep Q-Network Algorithm-Based Cyclic Air Braking Strategy for Heavy-Haul Trains" Algorithms 17, no. 5: 190. https://doi.org/10.3390/a17050190
APA StyleZhang, C., Zhou, S., He, J., & Jia, L. (2024). Deep Q-Network Algorithm-Based Cyclic Air Braking Strategy for Heavy-Haul Trains. Algorithms, 17(5), 190. https://doi.org/10.3390/a17050190