In this section, we present the mathematical models representing our three problems.
4.1. LPM
Our LPM deterministic model is formulated as a MIP, aiming to maximize the project value while considering duration and cost constraints. We now provide an overview of our notation, model, and explanations of its objectives and constraints.
We consider a project consisting of
J activities, where each activity
j can be executed in one of
modes and is preceded by a set of immediate predecessors
. Executing activity
j in mode
m requires a duration
and incurs a fixed cost
. Additionally, there are
K renewable resources available, each with a unit cost
per period. Resource
k is consumed by activity
j in mode
m at a rate of
units. The project is constrained by a due date
D and a budget
C. We assume that if the project adheres to the budget constraint, the required resources can be readily acquired. Similar assumptions regarding resource availability can be found in studies on time-cost tradeoff problems and recent project scheduling research [
73,
74,
75,
76,
77].
The project encompasses V different value attributes, denoted by the parameter which represents the value of attribute v for activity j executed in mode m. Decision variable corresponds to the value of attribute v for activity j when executed in its selected mode. To determine the project value for each attribute v, we define the function which takes into account the individual attribute values and the function , which calculates the project value based on the attribute values.
Within our model, the binary decision variable indicates whether activity j is performed in mode m. Additionally, decision variable denotes the starting time of activity j, where j ranges from 0 to . In this context, denotes a project milestone that has only one mode and does not have any duration, cost, resources, or value. It functions as the starting point of the project. Conversely, represents another milestone signifying the project’s end.
The model itself is:
subject to:
Objective (1) aims to maximize the project value, which is a specific function of the chosen modes. Constraints (2) are responsible for determining the value attributes based on the selected modes. Constraints (3) introduce the binary decision variable that indicates the chosen mode for each activity. These constraints ensure that exactly one mode is selected for each activity. Constraint (4) sets the beginning of the project as the starting time for milestone 0. Constraint (5) ensures that the project is completed within the specified due date. Constraints (6) ensure that an activity cannot start before its immediate predecessor is finished. Constraint (7) restricts the fixed and resource costs to be within the project budget. Lastly, constraints (8) and (9) are integrality and nonnegativity constraints.
In the case of a model with stochastic activity durations, constraints (5) and (7) cannot be guaranteed with certainty. Hence, we need to model them as chance constraints. A common approach to solving such stochastic programs is using a scenario approach (SA), which was introduced by [
78] and applied in several project scheduling papers [
79,
80,
81]. The idea behind SA is to generate
S samples or scenarios representing the possible outcomes of the random variables in the constraints, such as the activity durations. These samples replace the deterministic scenario. If our objective function is linear, the resulting SA program becomes a MILP, which can be solved using commercial solvers. We employ this method as a benchmark in the computational experiments presented in
Section 7 (a discussion of SA falls outside the scope of this paper; more details on this topic can be found in [
78]).
To continue our presentation of the LPM model, we must now introduce additional notation and constraints and provide an explanation for the SA formulation of our problem. We can define parameters
S and
to represent the number of scenarios sampled and the duration of activity
j in mode
m for scenario
s, respectively. Parameters
and
are established as the desired probabilities of the project finishing within the due date and on budget, while parameters
and
serve as upper limits for the project’s delay and budget overrun. Let decision variable
represent the starting time of activity
j in scenario
and let binary decision variables
and
indicate whether the project finishes within the due date and on budget, respectively, in scenario
s. In the SA model, the objective function (1) and constraints (2) and (3) remain unchanged while
replace
in constraints (9). Constraints (10) through (15) provided below replace constraints (4) to (7).
Constraints (10) define the project’s starting time as the beginning of milestone 0 across all scenarios. Constraints (11) maintain the project’s completion within the due date () or within the specified upper bound (). To meet the desired probability, constraint (12) guarantees that the proportion of scenarios completing within the due date aligns accordingly. In each scenario, constraints (13) ensure that no activity can commence before its immediate predecessor concludes. Constraints (14) enforce the project’s adherence to the budget () or the specified upper limit (). Constraint (15) ensures that the fraction of scenarios completed within the budget aligns with the desired probability. Lastly, constraints (16) and (17) represent the integrality and nonnegativity conditions, respectively.
Our LPM model is highly relevant and applicable to project management in several ways. Firstly, the objective function and the chance constraints aim to maximize project value while meeting the deadline and staying within budget—a key objective for project managers. Secondly, the LPM model considers uncertainties in activity durations, which is a common challenge in project management. By incorporating stochastic duration parameters, the model provides a more realistic representation of project timelines and allows project managers to make more informed decisions. Thirdly, the model adopts a multimode approach that considers the impact of mode selection on project cost, duration, and value. This allows project managers to optimize project outcomes by selecting the most appropriate mode for each activity. Finally, the LPM model provides a framework for decision-making that can help project managers balance project schedule, cost, and value.
4.2. CCBM
Traditionally, the CCBM scheduling approach begins by creating a baseline schedule that minimizes the project duration based on deterministic estimates of activity durations such as the median or mean values [
82]. This involves solving the resource-constrained project scheduling problem (RCPSP) or its multimode extension. Due to the NP-hard nature of the problem [
83], heuristic methods are commonly used, especially for larger projects.
Once a baseline schedule is established, the PBs and FBs are inserted using a buffer-sizing technique such as the methods discussed in
Section 2.2. The aim is to create a stable schedule that can be evaluated using robustness measures described in relevant literature, such as the standard deviation of project length, stability cost, and timely project completion probability [
44].
The on-time probability not only serves as an indicator of schedule robustness but also plays a role in buffer calculation. Hoel and Taylor [
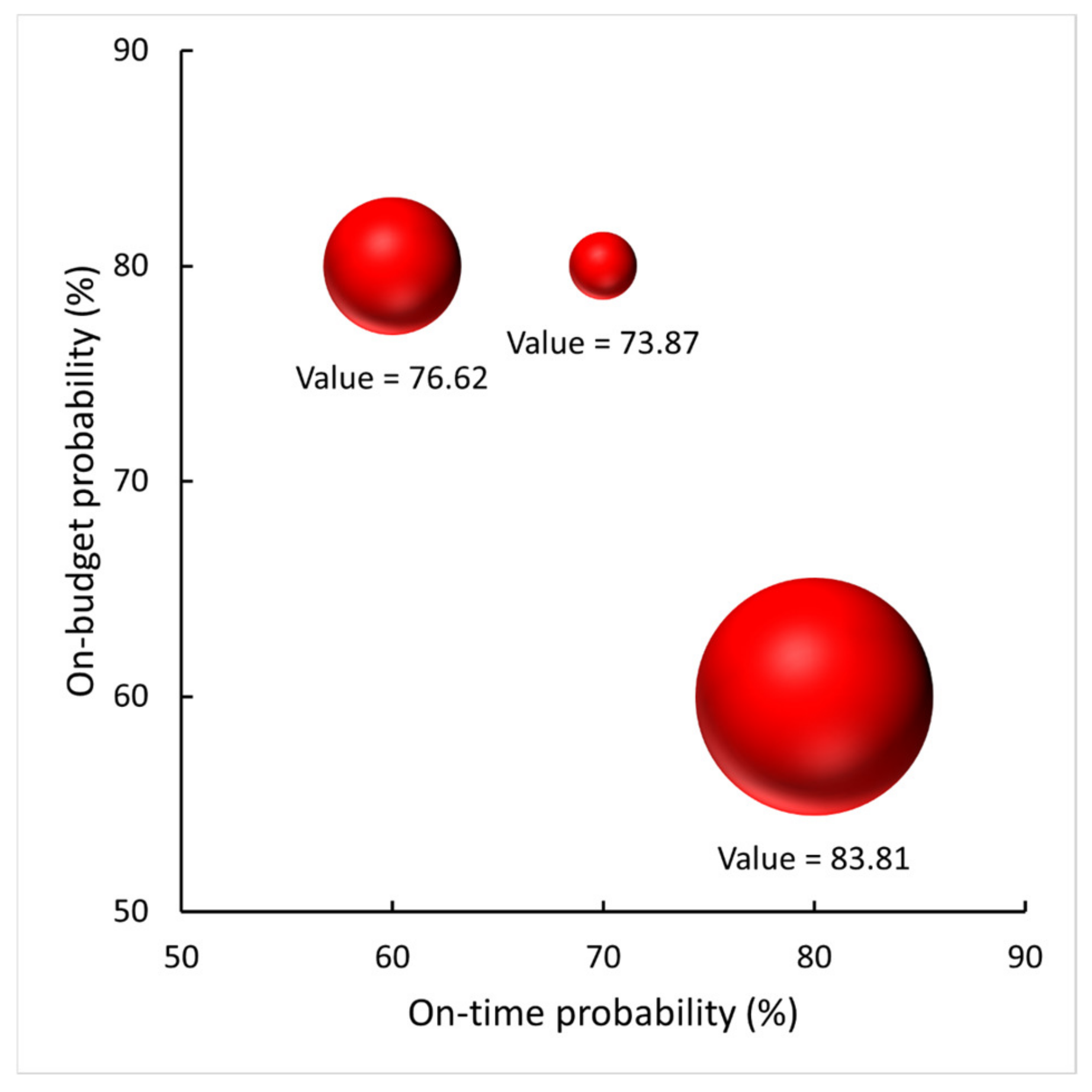
26] proposed the use of Monte Carlo simulation to determine the cumulative distribution function (CDF) for project completion time, thereby determining the size of the PB. For example, if we aim for a 95% probability of completing the project on schedule, the PB would be the difference between the project duration at the 95th percentile and the duration of the baseline schedule.
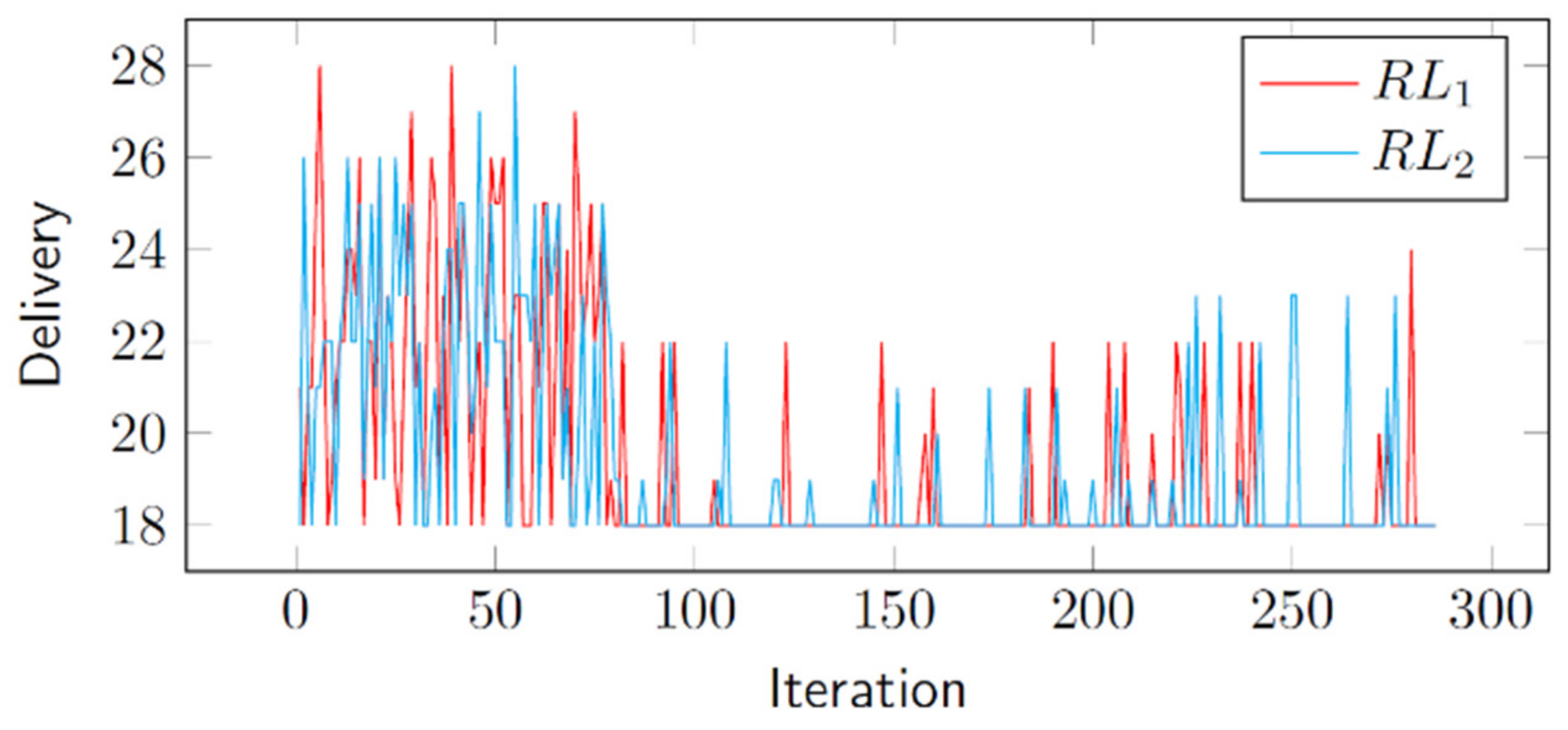
Let us go one step further. If we directly search for the shortest time-buffered schedule that meets the desired on-time probability, we can identify a schedule with the same probability but a shorter duration. This leads us to the chance-constrained CCBM problem, where we consider multimode projects. In this problem formulation, we not only search for the schedule but also determine the activity modes that result in the shortest project duration while meeting the desired on-time probability. This duration encompasses the baseline schedule, nominal (deterministic) activity durations, and the PB. In this paper, we define project delivery as this time-buffered project duration, which represents the deadline we can meet (i.e., deliver the project) with the desired on-time probability.
To model our chance-constrained CCBM problem, we adopt a MILP approach using the flow-based formulation described in [
84], extending it to accommodate multimode projects. We handle the chance constraints using SA as in the LPM model but require additional parameters and decision variables that were not present there.
There are K distinct renewable resources available, each having a total availability of units. When activity j is executed in mode m, it requires units of resource k. For a given scenario s, the earliest start time for activity j is denoted as , while represents the latest start time.
The project delivery is represented by decision variable . Project milestones 0 and have a singular mode, zero duration, and no resource requirements. Binary decision variable is employed to indicate if activity j commences after the completion of activity i, taking a value of 1 in such cases. The flow variable models the amount of resource k transferred from activity i to activity j.
Our chance-constrained CCBM model incorporates constraints (3), (8), (12), and (16) from the LPM model. Moving forward, we will present the model, followed by an explanation of the objective function and the remaining constraints.
subject to:
The objective function (18) is designed to minimize the project’s delivery time. Constraints (19) indicate whether a scenario is completed within the desired timeframe. Constraints (20) and (21), derived from previous works [
84,
85], prevent cycles of 2 or 3 or more activities. Constraints (22) enforce the precedence relationships between activities. Constraints (23) establish the relationship between continuous activity start time variables and binary sequencing variables. Constraints (24) define upper and lower bounds for activity start times. Constraints (25), drawing from [
85], establish a connection between the continuous resource flow variables, binary sequencing variables, and mode variables.
Outflow constraints (26) guarantee that all activities, except for milestone transfer their resources (when finished with them) to other activities. Inflow constraints (27) ensure that all activities, except for milestone 0, receive their resources from other activities. Constraints (28) set bounds on the flow variables based on the maximum resource consumption modes.
It is important to note that the general constraints (25) and (28) can be reformulated as MIP constraints using linear and special-ordered set constraints, along with auxiliary variables [
86]. Commercial solvers such as Gurobi automatically handle the equivalent formulation (in [
85], these constraints are also handled by the solver).
Once the MILP is solved, constructing a schedule follows a straightforward approach. The project is represented as an activity-on-node (AON) network, with arcs connecting activities
j to their immediate predecessors
. If resources flow from activity
i to
j,
j cannot start before
i finishes, making
i an immediate predecessor of
j. Hence, we add arcs between activities wherever
. This construction, referred to as a resource flow network [
87], can be achieved by simply adding
i to
. Finally, we schedule all activities using the “early start” approach, where each activity commences when its immediate predecessor concludes.
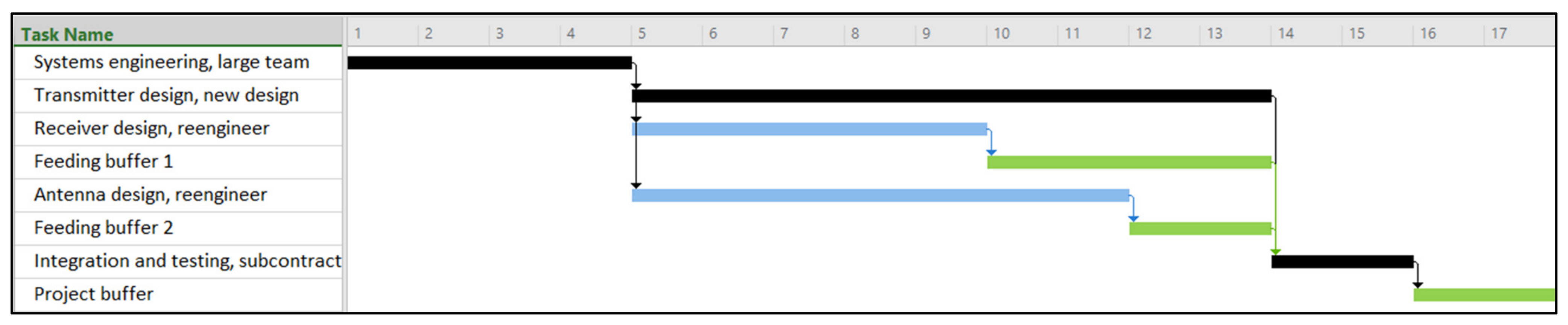
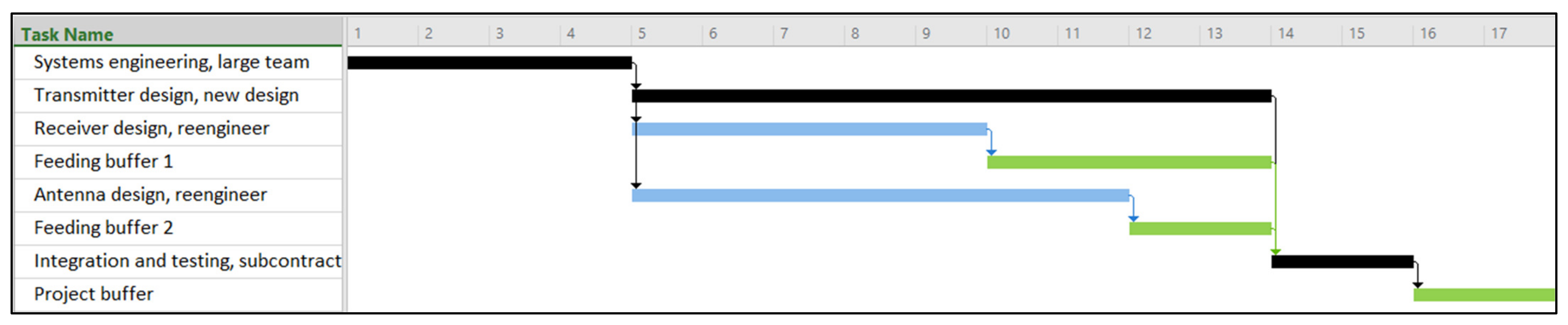
For the baseline schedule, the activity duration used is typically the most likely duration based on a three-point estimate. After the completion of the last activity, the PB is inserted, calculated as the difference between the project delivery time and the baseline duration. An example illustrating this approach can be found in
Section 6.
To insert FBs, we adopt the method proposed by [
26] and applied in subsequent works, e.g., [
88,
89] (the latter employing the method as an upper bound for the buffers). In this approach, activities are scheduled using an “early start” strategy, and the FB is determined based on the free float of the activity that merges into the critical chain, ensuring that no new resource conflicts arise from the insertion of FBs. Thus, since we initiate all activities as early as possible, we can disregard the size of FBs in our problem.
Our CCBM model is extremely significant for project management applications, especially for addressing uncertainties and risks in project scheduling. The objective function and chance constraints allow the project manager to produce time-buffered project plans that minimize the project delivery date while staying within the stakeholders’ risk threshold. In the Introduction, we discussed the importance of this topic, and in
Section 2.2, we discussed the limitations of existing scheduling methods. In
Section 8, we demonstrate the effectiveness of the proposed CCBM model in producing shorter project durations compared with established benchmarks.
4.3. TVNPV
In line with
Section 4.2, we utilize the flow-based formulation introduced by [
84] and extend it to encompass multimode projects, NPV, value functions, and chance constraints. The primary objective of the TVNPV model is to maximize the robust project NPV and the project value. To address the chance constraints, we employ SA. We now describe additional parameters and decision variables that are not present in the LPM and CCBM models.
Within the problem context, we have
K distinct renewable resources, each associated with a unit cost
per period. Additionally, activity
j executed in mode
m incurs a fixed cash inflow or outflow
consisting of fixed costs and payments received. For convenience, we assume that payments are received or made at the end of each activity. To avoid gaps between activities and prevent indefinitely postponing activities with negative cash flows, two main approaches exist in the literature: (1) utilizing a deadline [
57] and (2) assuming a sufficiently large payout at the end of the project to offset the gains from postponing activities impacting project completion [
66]. In this paper, we adopt the latter approach.
When aiming to minimize project duration, a common measure of robustness is the timely project completion probability [
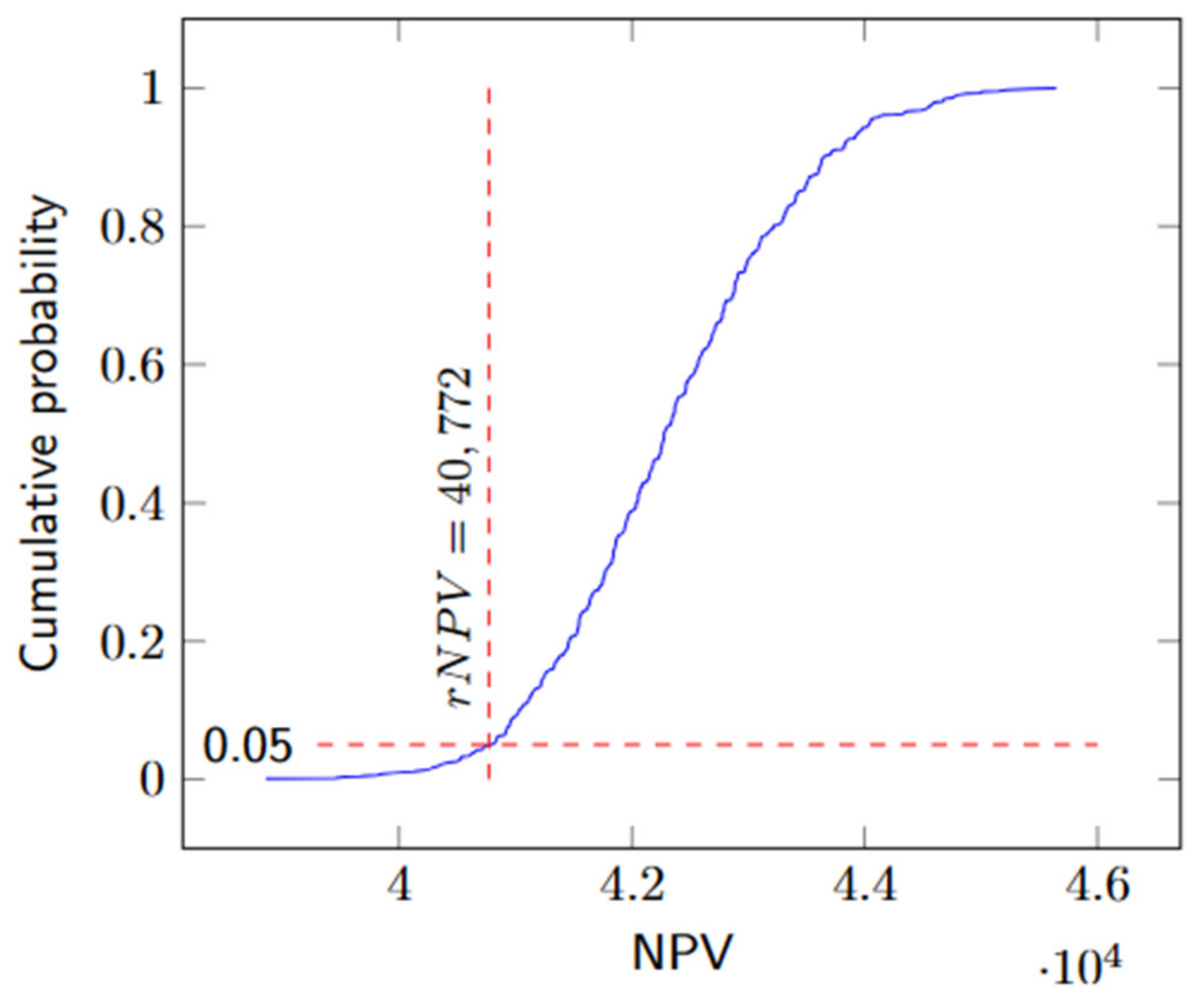
44]. In our problem, we adapt this concept and introduce the decision variable rNPV to represent the robust NPV. It signifies the project NPV achieved with a probability of at least
γ. Thus, instead of evaluating the robustness of a given schedule, we search directly for a schedule with the desired level of robustness.
Several parameters are defined within the model. serves as an upper bound for rNPV. denotes the discount rate, while and represent the earliest and latest finish times for activity j in scenario s, respectively. Additionally, acts as an upper bound for the project’s duration.
To represent the finish time of activity j in scenario s, we introduce the decision variable . Binary variable takes the value 1 if the scenario NPV is greater than rNPV. Moreover, decision variable represents the discount factor for activity j in scenario s, and serves as an upper bound for the discount factor.
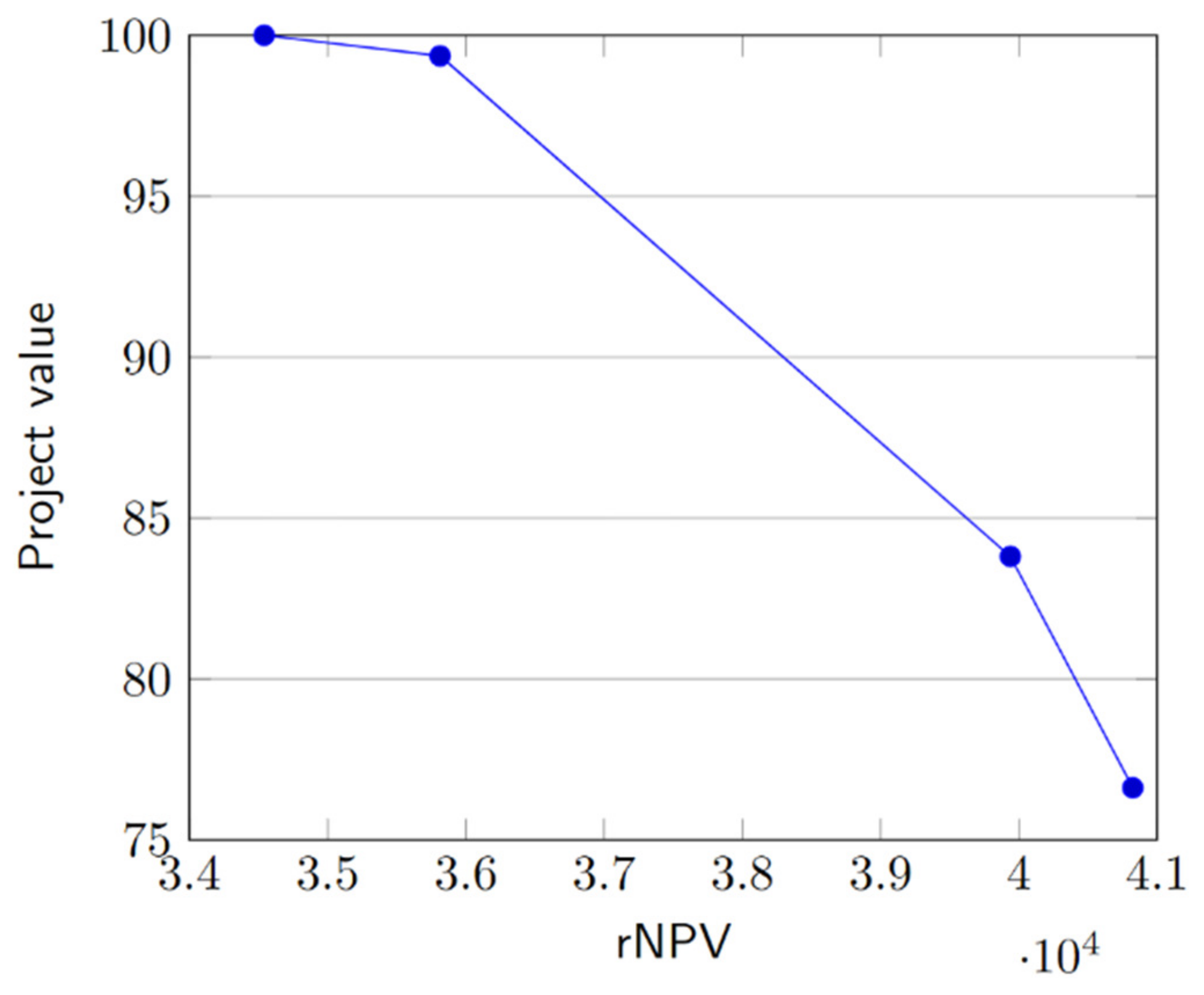
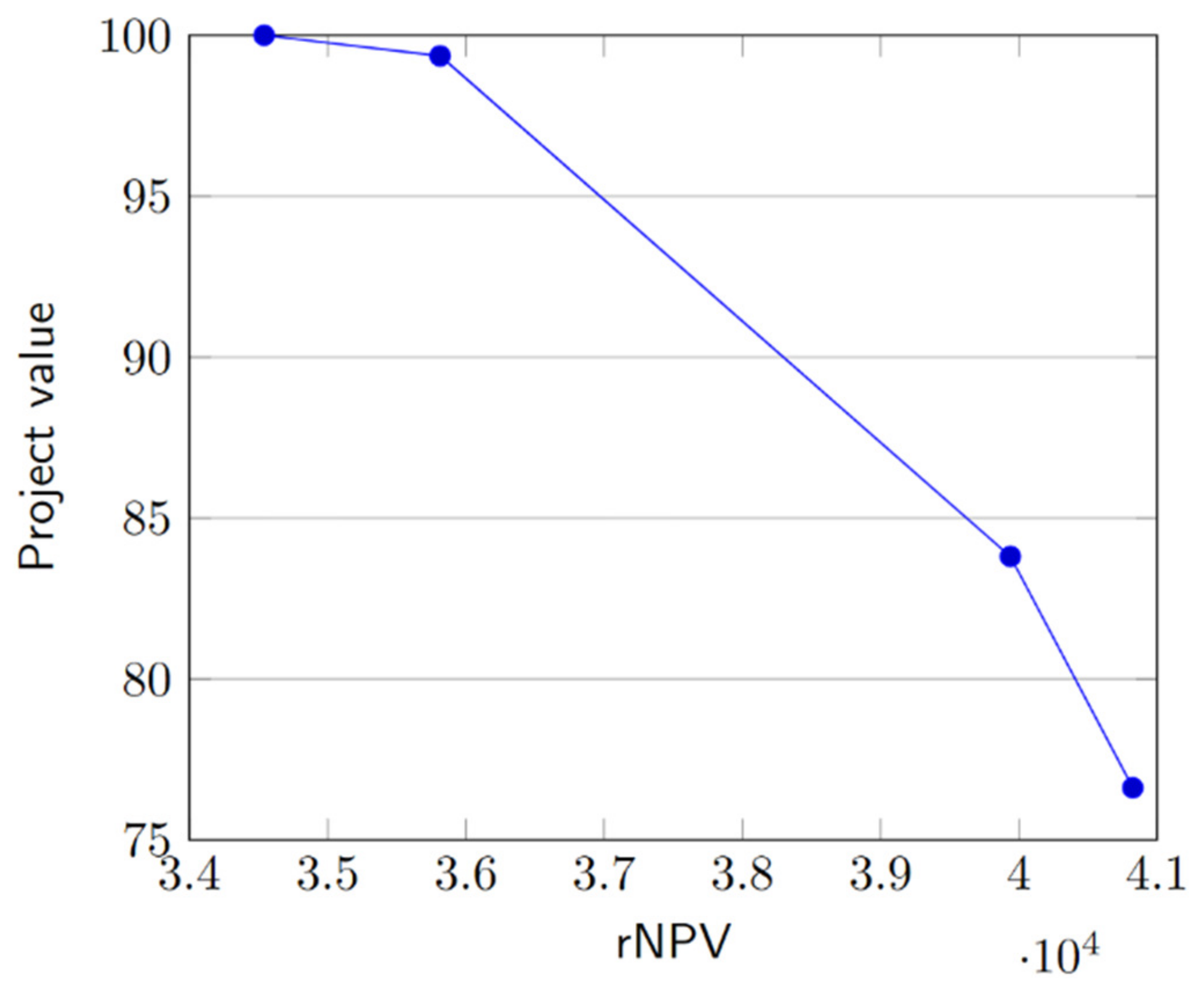
Objective function weights and are included to determine the tradeoff between rNPV and the project value. By solving the MIP for different values of and we can identify the efficient frontier that balances these objectives.
To linearize two sets of constraints, we introduce additional variables. Binary variables are assigned a value of 0 for all and 1 for all . Variables replace the products . The model incorporates constraints (2), (3), (8), (20)–(22), and (25)–(28) from the LPM and CCBM models.
We now present the model, providing an explanation of the objective function, followed by an overview of the remaining constraints. Subsequently, we will discuss the linearization of the nonlinear constraints.
subject to:
The primary objective of the model, captured in the objective function (29), is to maximize a weighted sum of the project’s rNPV and its overall value. This approach, known as the weighted-sum method, is widely employed in multi-objective optimization [
90] and has been utilized in various project scheduling studies, e.g., [
72,
91,
92].
To ensure the robustness of the project’s NPV, constraints (30) are introduced, which evaluate whether a scenario’s NPV surpasses the project’s rNPV. Inspired by [
93], we adopt a discrete discount factor in constraints (31). Constraint (32) is employed to monitor the fraction of scenarios that yield the desired rNPV, enforcing this fraction to remain above a predetermined threshold.
The interdependence between the continuous activity finish time variables and the binary sequencing variables is established through constraints (33). Additionally, constraints (34) provide necessary bounds for the activity’s finish times.
Constraints (30) pose a challenge due to the nonlinearity arising from the product of the discount factor and the indicator variable, . To address this nonlinearity, we replace constraints (30) with constraints (35) that involve auxiliary variables, denoted as . To ensure the equivalence of and , constraints (36)–(39) are introduced to maintain the relationship between these variables within the model.
To replace the exponential discount factor from constraints (31), we introduce linear constraints (40) into the model. Additionally, we incorporate the following constraints into the model:
Constraints (41) establish a connection between the binary variables and .
Constraints (42) ensure that an activity can only have a single finish time.
Constraints (43) impose bounds on as the predecessor will always have a value of 1 before its successor.
Constraints (44) and (45) fix the value of for finish times occurring before the early finish and after the late finish, respectively.
Finally, constraints (46) determine the fixed value for the initial milestone.
We can use a commercial solver to solve the MIP if the value function of the project is linear because the constraints are linearized, as explained before. This method is our benchmark for the computational experiments that we present in
Section 7.
Our TVNPV model is very useful and suitable for project management in various aspects. Firstly, the objective function and the chance constraints aim to maximize both project value and NPV. This is a new and useful tool for decision-making because it allows the generation of project plans on the efficient frontier with different optimal combinations of value and NPV. Secondly, the uncertainties in activity durations and the chance constraints enable the calculation of a robust NPV according to the stakeholders’ tolerance for risk. Additionally, the model employs a multimode approach that evaluates the impact of mode selection on project cost, duration, resources, and value.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}