A cooperative learning framework is developed to analyze the spread of epidemic diseases and to leverage diverse data sources, such as social media and traditional public health data. Our approach is based on the use of multi-agent reinforcement learning, where each agent represents a geographical location and makes decisions based on its own observations and the observations of its neighbors. The agents collaborate to determine the optimal policies that minimize the spread of disease while maximizing social welfare. To implement this framework, we collected two types of data: social media data from Twitter and traditional public health data from the John Hopkins Coronavirus Resource Center. Social media data were used to understand the public’s sentiment towards the disease, as well as to identify potential outbreaks and hotspots. The public health data provide information on the number of confirmed cases, deaths, and recoveries, as well as the geographic distribution of these cases. To illustrate our methodology, we provided an example of a tweet that we collected during our data collection phase, namely “Feeling sick today. Staying home to avoid spreading the flu”. Our feature extraction process extracted the location of the tweet, which was used to determine the geographic spread of the disease. The time of the tweet was used to track the spread over time, and the sentiment of the tweet was used to determine the severity of the disease in that location. Our cooperative learning approach used this information to make decisions about how to prevent the spread of disease in that location.
We preprocessed the data by cleaning and filtering out irrelevant information, such as non-English tweets and duplicate entries. We then use NLP techniques to analyze the sentiment of the tweets and identify keywords related to the disease. Next, we used game theory to define the cooperative strategies that the agents could use to make decisions. We formulated the problem as a stochastic game with a common reward function that encouraged cooperation and minimized the spread of disease. The agents used reinforcement learning algorithms to learn the optimal policies, which were updated iteratively based on the observations of their neighbors.
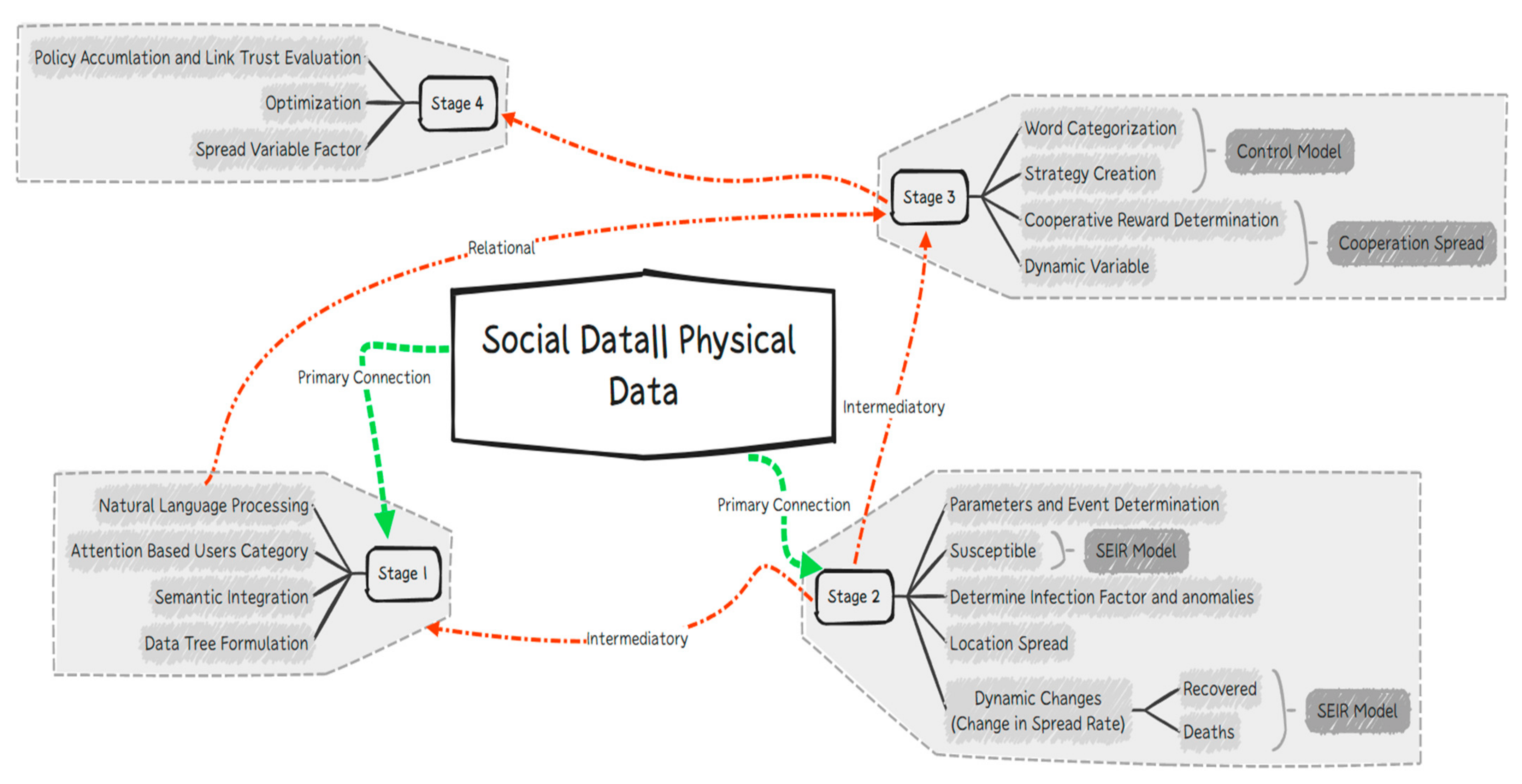
To evaluate the effectiveness of our approach, we use a spread-based analysis that measured the correlation between the spread of disease and the spread of information on social media. We also determined the dynamic variable of the spread rate and optimized the decision model using a control algorithm with complexity of order .
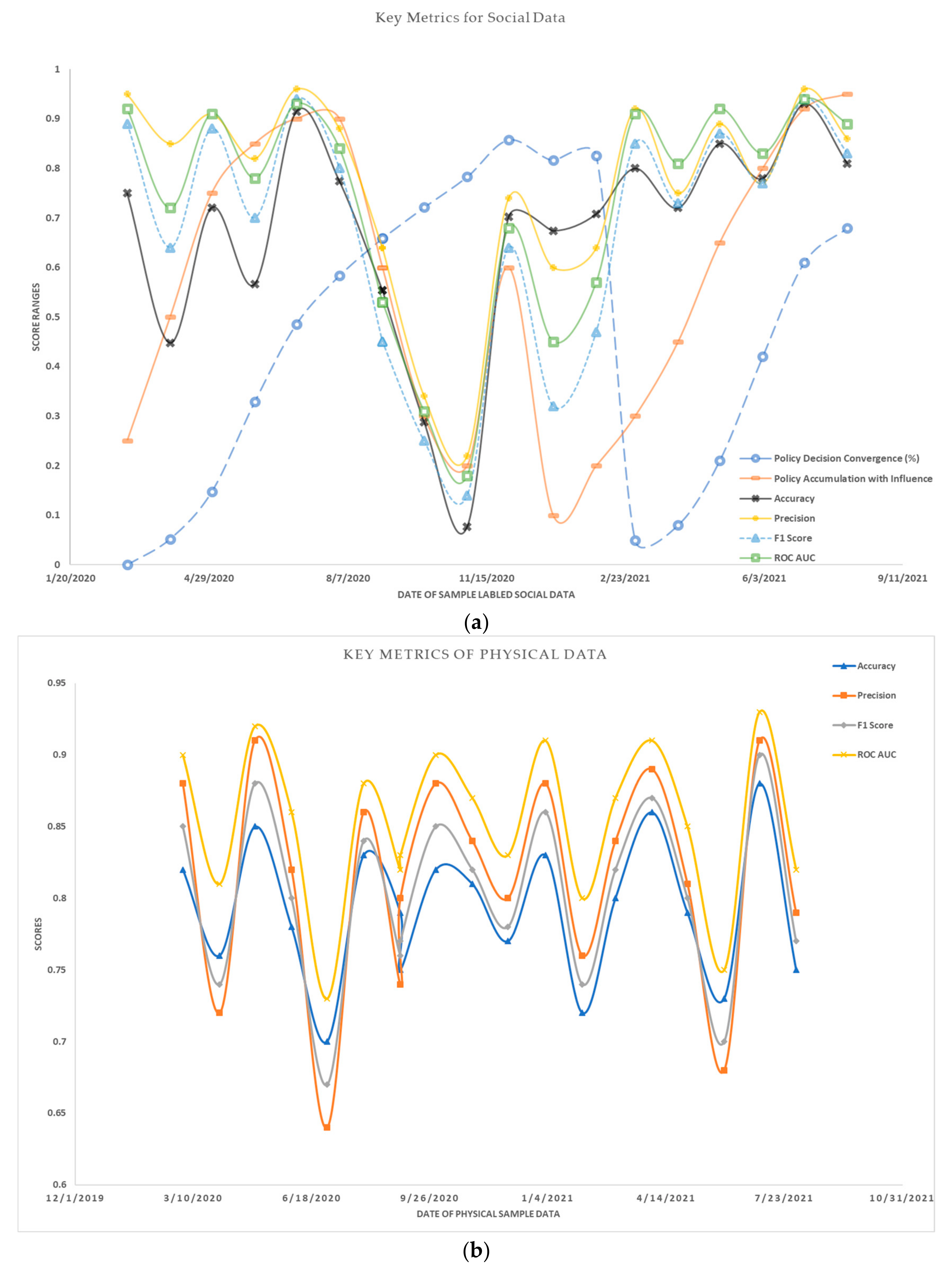
As an example, we wanted to understand the relationship between Twitter activity and the spread of COVID-19 in a particular state. Thus, we first collected Twitter data related to COVID-19 for that state, including hashtags, keywords, and geolocation data. We also collected physical data, such as the number of confirmed cases, deaths, and recoveries, from the John Hopkins University COVID-19 dashboard. We then integrated the data and pre-processed it to form a comprehensive dataset. The proposed model was then used to determine the optimal cooperative strategy for analyzing the spread of COVID-19 in that state. A spread-based analysis was carried out by defining the spread variable and using cooperative learning to determine the disease spread rate decision score. The spread dynamic variable was determined through the use of a stochastic game with a common reward, and the results were analyzed to understand the relationship between Twitter activity and the spread of COVID-19 in that state.
4.1. Learning-Based Multi-Agent Cooperation
Learning-based multi-agent cooperation is a framework that enables multiple agents to learn and act together to achieve a common goal. In this framework, agents interact with their environment and other agents to learn and develop strategies that maximize a common reward. The approach is particularly useful in complex scenarios where multiple agents must work together to solve a problem, such as in disease spread analysis. By leveraging learning-based multi-agent cooperation, we can enhance our understanding of the dynamics of disease spread and improve the effectiveness of disease control and prevention strategies. The complete interactions and dependability formulate collective functionalities in a complex network. It was observed that the full cooperation depends on the topological structure of a network with temporal constraints on information links, which constitute the dynamics of the network. The information links are reaction information, which evolve with time, and series of activated events at discrete time. The linked sequence of information dissemination is a state of causal flow, which affects the characteristics of a social network. These characteristics redefine the network structure, which includes clustering, node, controllability, and link length. These show static and irregular patterns of the inter-burst of temporal links. Thus, the systematic encapsulation of these inter-burst temporal links resolves the cooperative decision-making problem in the multi-agent network and require multiagent cooperation for optimized long-term cooperation [
18,
33].
Assuming nodes
are choosing actions
after observing the system link states
simultaneously to distribute the reward
(Refer to
Table A1 in
Appendix A for the notations used throughout the paper). Thus, the agents can make decisions and accumulate rewards, as shown in
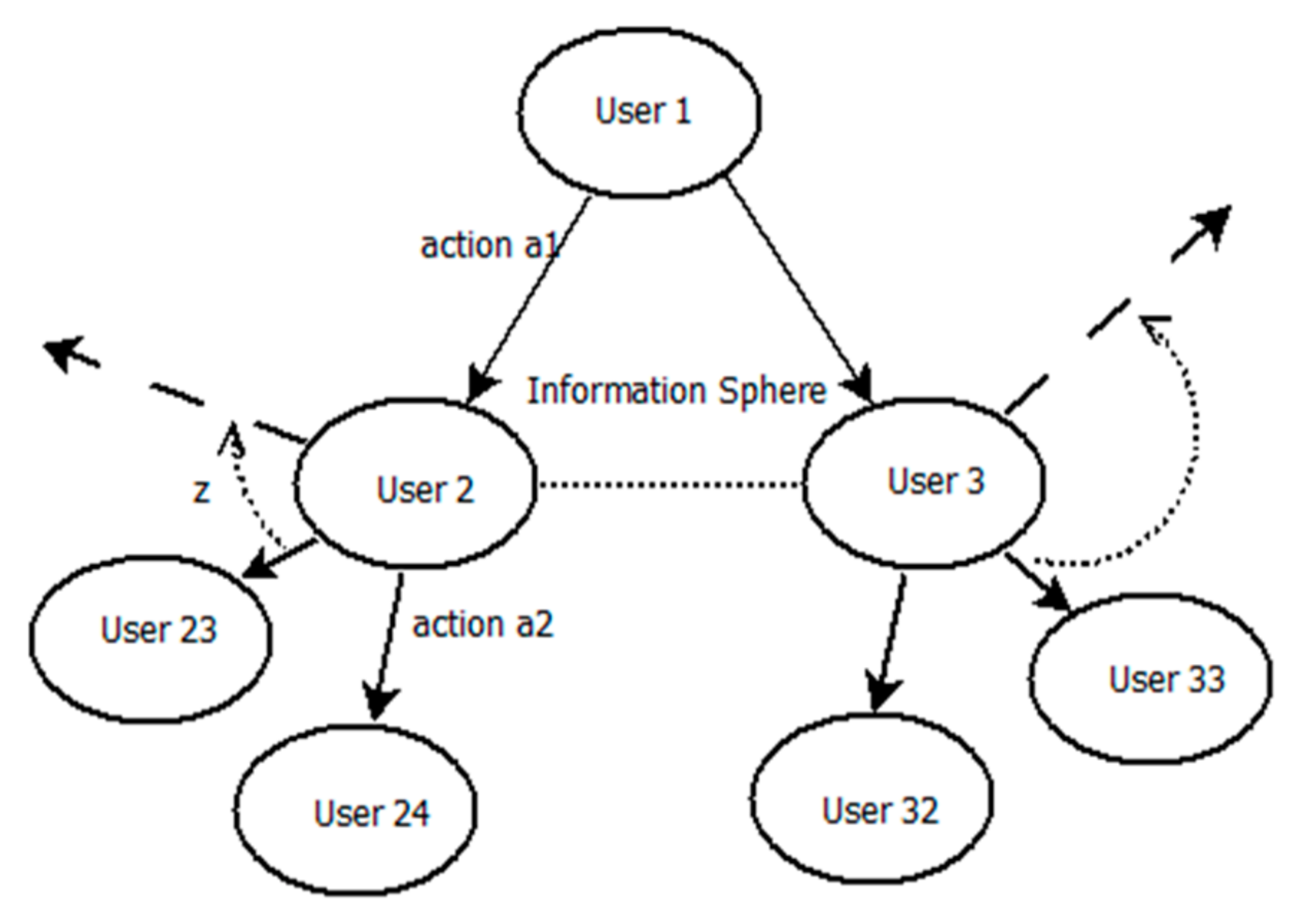
Figure 2. This tree-like diagram illustrates how the agents can make decisions and accumulate rewards based on their actions and the state of the system. It is a visual representation of the relationships between actions and rewards in a cooperative setting, and helps to understand how the agents can work together to achieve the best possible outcome. It displays the information sphere for cooperation, which includes the choices that agents can make and the rewards they can expect to receive based on their actions.
In this figure, the root node represents the initial state of the system, and the branches represent different possible actions that can be taken by the agents. Each branch leads to a different sub-tree that represents the consequences of taking that particular action. The leaves of the tree represent the terminal states, where the agents have completed their actions and received their rewards.
Lemma 1.
Given a multi-agent system, the cooperative algorithm ensures that agents adapt their policies based on local observations, leading to an improved overall system performance.
Proof. Assume agents can learn and adapt their policies based on the information available to them. The cooperative algorithm utilizes reinforcement learning to update agents’ policies, resulting in an iterative process where agents make decisions and receive rewards. As agents update their policies, their decision-making process converges towards optimal actions, leading to an improved overall system performance. □
Assuming a variable space containing
states as
with
actions as
; hence, the probable transitions in respect of a
are stated with reward (
) as
;
. Thus, each time
the user chooses action
which causes
to accumulate reward as
; therefore, the function can be defined for n nodes with a trade-off factor of
. Suppose we have a state
that represents a person’s health status, and the possible actions are to take a medicine or not. The reward function
could represent the improvement or worsening of the person’s health depending on the action taken. The trade-off factor
could represent the importance of immediate relief versus potential long-term side effects.
Hence, for multiple nodes,
Now, to have an optimal reward distribution policy in a cooperative setting
and to obtain global optima, Nash equilibrium is utilized by averaging the reward,
. Thus, a proper distribution and link formation policy is created by applying a competitive setting
to define the link reaction policy (
). Suppose we have a multi-agent system where each node represents a different person, and state
represents the current weather conditions. The possible actions could be to go outside or stay indoors. The joint policy function
would then represent the probability of each person going outside or staying indoors based on the current weather conditions. The probabilities
would represent the likelihood of each pair of people
going outside or staying indoors together based on the weather conditions.
where
i and
j are node links and
is the neighborhood bond. Hence, the optimal reward link is,
Now optimal joint cooperative policy
for
i,
j will be dependent on actions history
,
where,
is the probability of an action user node takes for a policy
.
The optimal joint cooperative policy for nodes and , is dependent on the actions history For example, suppose node represents a hospital and node represents a government health department. The actions history might include information on the number of COVID-19 patients being treated at the hospital, the availability of medical supplies, and the current policies being implemented by the health department. Based on this information, the joint policy can be determined to optimize the reward distribution for both nodes and . To calculate the optimal reward distribution, Equation (5) is utilized, where represents the probability of a user node taking a certain action for policy , and represents the expected reward for nodes and . For example, suppose the joint policy results in the hospital (node ) receiving more medical supplies from the health department (node ) and the health department receiving more data on COVID-19 patients being treated at the hospital. This joint policy can be optimized by calculating the expected reward for both nodes based on the actions taken and the resulting transitions in state .
The learning-based multi-agent cooperation algorithm is shown in
Appendix B.1 to define reward from a single to multimode and policy function for optimal reward distribution.
4.2. Cooperative Learning and Strategy Creation
Cooperative learning refers to the process of agents learning and improving their decision-making strategies through collaboration with other agents. Cooperative learning states the variability in network with the help of reciprocity to maintain the dynamics of the information for unbiased reward distribution by creating a strategy tie for consensus in any two states. This learning strategy constitutes the continuous communication dissemination in a network with continuous and discrete data sources. For example, consider the problem of a cluster of users that are randomly interacting to another cluster of users at any instant. Additionally, the length of the action link and time are not capped (time limitation for each links). However, the reaction can change according to the reciprocity of the user node reactions, thus the user link needs to reach into consensus for reward distribution.
Lemma 2.
Cooperative learning results in the creation of strategies that maximize the collective reward of the multi-agent system.
Proof. Assume agents in a multi-agent system can cooperate and learn from each other’s actions. Through cooperative learning, agents update their policies based on the rewards received from the environment and the actions of other agents. This iterative process converges towards strategies that maximize the collective reward of the system. □
Hence, to do this, assume that each user node has an information link of
where
represents the
th information of reward reciprocity, each user determine the length of time the communication occurs and sets as
and communicate through a directed graph and undirected graph
[
25], where
user nodes and
is an edge set of ordered pair of nodes. Assuming the edge
denotes the user node
which obtains information from
(not vice versa!) (directed) and undirected vice versa works.
Therefore, the amount of information flow is proportional to an accumulated amount of reward link formation. This link accumulation constitutes reactions, actions, and neighbor bond. The dynamics of accumulation of this is a dependent on a consensus breaking factor (CBF) and is designed by having direct messenger link with proportional consensus breaking factor. CBF is defined here as an information bonding link after the node decision. Here, we refer CBF as factors that are depended on influencing information, which can be gathered by other linking constraints to influences as and are which are rate of constants of influence and de-influence respectively.
Hence, the establishment of links depends on the rate of reactions with the dependence of neighbor bond. The explanation of the cooperative learning and strategy creation is shown in
Appendix B.2. The algorithm states a multi-agent cooperation with class and the constructor as agents, states, actions, reward, and trade-off factors. Here, the reward is used to compute from state and actions, whereas the joint policy and strategy is achieved by computing optimal joint policy [
18,
29,
30,
31,
32,
33]. This is formulated from the below formulation and with respect to a neighbor bond, when given as,
where
is a Laplacian communication flow [
24]
and
= [
] is an information at any state.
The activation state of bond represents the amount of influence that a node has on other nodes in the network, and the communication flow rate represents the rate at which information is exchanged between nodes. For example, in the context of the COVID-19 pandemic, the activation state of bond represents the level of trust or authority that a person or organization has in providing accurate and trustworthy information about the pandemic. The communication flow rate represents the speed at which information is shared or disseminated among different groups or communities.
We developed a social network formation model with large number of parameters and latent variables. We first allocated values to the unknown variables before testing the model’s validity. We learned the legacy vectors using real-world network observations, assuming the real-world networks were at or near pairwise symmetry, to equip our model with the capacity to match real-world networks. Thus, to construct the latent influence strategy, we defined Equation (9) to establish the optimal accumulated strategy, incorporating the communication link topology. This topology represents the organization and configuration of nodes and their connections within a network, denoted
where
covex and
concave as joint event evaluation.
Hence, the optimal accumulated strategy is be defined as,
where
defines the communication link topology.
4.3. Spread-Based Analysis for Cooperative Learning
In the context of spread-based analysis, “spread” refers to the dissemination or propagation of a phenomenon, such as the transmission of infectious diseases within a population. Spread-based analysis focuses on understanding and predicting the patterns of this propagation, considering various factors and data sources that may influence the spread. Here, we introduce a spread-based analysis approach for cooperative learning, designed to evaluate the potential of social data in forecasting the spread of disease with the help of the susceptible, exposed, infectious, and recovered (SEIR) model.
The SEIR model is a popular epidemiological model for the spread of diseases. To predict the development of infectious diseases in a community, the SEIR model reflects the progression of individuals through several stages of infection, namely from susceptible to infected to recovered. Individuals are divided into four stages according to the SEIR model [
12,
31,
32,
33,
34]. Susceptible (S): People in this stage are at risk of contracting the disease, but have not been exposed to it yet. Exposed (E): People in this stage have been exposed to the infection but are not yet contagious. They may not have symptoms just yet because they are still in the incubation stage. Infected (I): People who are in this stage can spread the illness to others. Recovered (R): Those in this stage have made a full recovery from the illness and have developed immunity.
In order to explain how people move between various stages based on variables such as the transmission rate, recovery rate, and incubation duration, the SEIR model uses differential equations. By utilizing these equations, the SEIR model can forecast the progression of the disease over time and assist decision-makers in comprehending the effects of various control methods. In this study, the spread analysis model is defined through reward optimization of a social network with the help of physical network data. The model represents basic stages of susceptible, exposed, infectious, and recovered, in which the probable infections are defined with respect to an event, situation, or state.
Lemma 3.
Cooperative learning enables the multi-agent system to adapt to the spread of a disease, minimizing its impact on the network.
Proof. Assume agents in the multi-agent system can cooperate and learn from the spread of the disease. Agents utilize spread-based analysis to update their policies based on the current state of the disease and its impact on the network. As the disease spreads, agents adapt their strategies to minimize its impact, leading to a reduction in the rate of infection and an overall improvement in the network health. □
Here, we propose using cooperative strategy learning, which has a low reward with respect to reward accumulation dynamics. However, to create a consensus in reward distribution, CBF is selected for any unmatched micro events in case of any macro event. The micro and macro events refer to different levels of analysis or granularity when examining events within a system, such as a network or a social setting. Hence, the reward spread is defined as the exponential of the learning-based cooperation, cumulative infection rate, and environment. The spread process is then defined as the maximization of reward spread, which is to maximize the spread estimation
by considering the exponential of the transmission rate between individuals
, and is formulated as shown below,
This is considered in order to understand the spread and reward processes considering granularity. The social data bank analysis provides a building block to identify susceptible nodes by monitoring the activities of friends and relatives. The algorithm achieves this by scrutinizing word clusters and identifying hidden outbreaks within the network. These rewards and allocations help track the progression of disease and offer insight into its impact on different individuals and communities. The SEIR model serves to simulate the dissemination of infectious diseases, providing information on parameters such as event occurrence, infection rate, geographical spread, and alterations in the spread rate. The SEIR model is supplemented by data from physical sources, contributing to a more accurate representation of the disease’s propagation.
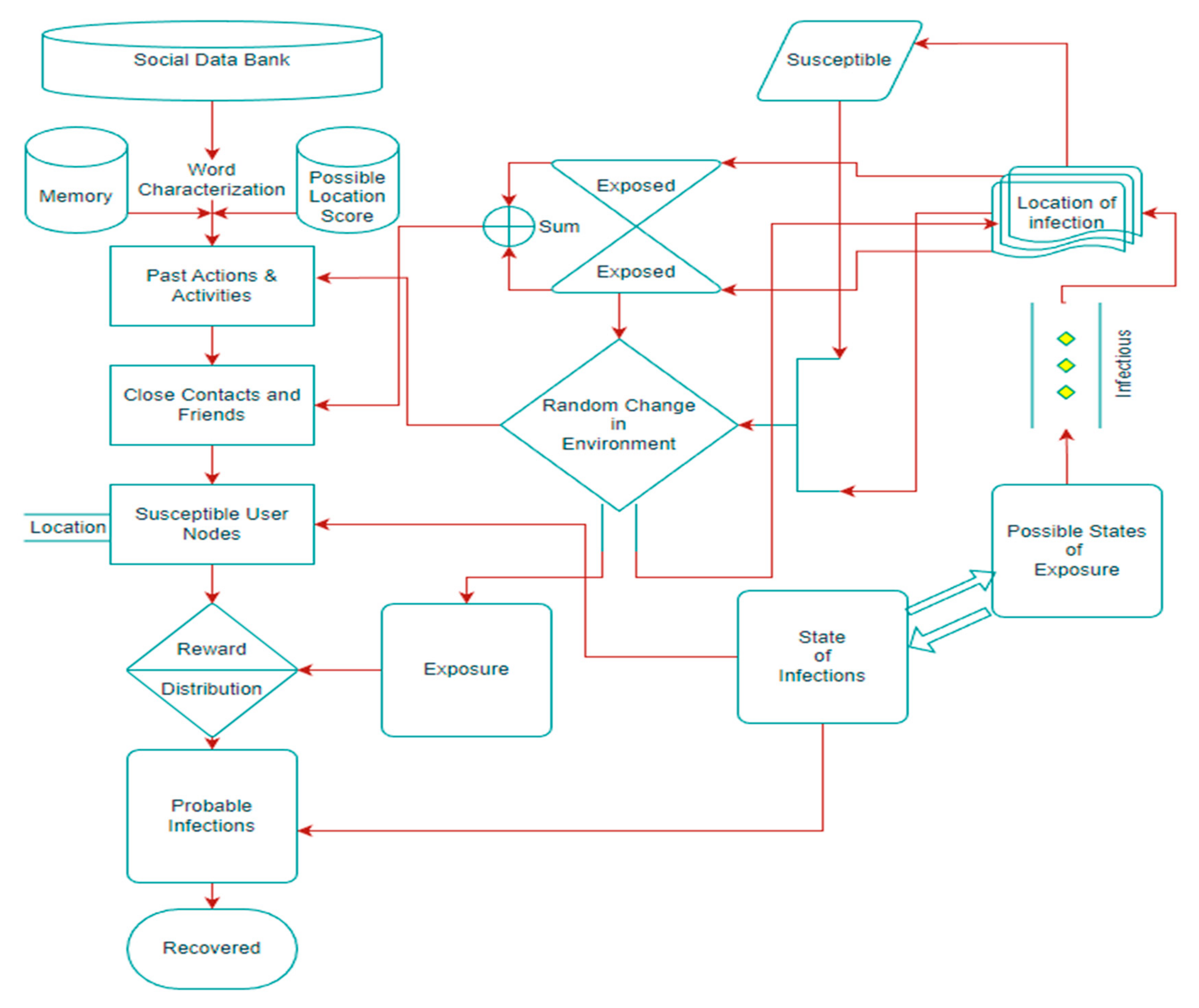
The method shown in
Figure 3 incorporates microenvironment and random change exposure effects, along with social data bank analysis. This increasing complexity represents the diverse factors affecting disease transmission, such as climate change, population mobility, and public health initiatives. Random change exposure effects reveal the disease’s impact on various individuals and communities, influenced by factors such as behavior, socio-economic conditions, and public health measures. The algorithm includes a block for past actions, assisting in tracking the progression of disease and understanding its influencing factors. This block uses data from the SEIR model and social data bank analysis to determine optimal measures and policies for preventing and slowing the spread of disease.
Our proposed technique merges attention-based cooperative learning with a partially observable setting, allowing for the efficient utilization of diverse data sources to predict disease dissemination. The spread-based analysis offers comprehensive insight into the reliability of social data for predicting the spread of disease, while the cooperative learning algorithm uses the SEIR model to predict the spread in specific locations, as demonstrated in
Appendix B.3. The model algorithm takes into account various factors, namely transmission, recovery, and the incubation period, concerning social data to forecast the spread. The algorithm calculates the disease spread by considering the combined effect of these factors in a cooperative manner, exponentially emphasizing the importance of each factor’s contribution and accounting for the cumulative effect of these factors over time in a dynamic environment.
4.4. Determination of Spread Dynamic Variable
Determining the spread dynamic variable is a critical aspect of understanding disease transmission. In the current pandemic situation, developing effective methods to gauge disease spread has become increasingly vital. The spread dynamic variable represents the rate at which a disease is transmitted from one person to another, influenced by factors such as infection rate, location, and time. The selection of dynamic variables is best suited for statistical tests or criteria that employ automatic variable selection techniques to optimally fit the sample based on statistical information criteria, including stepwise regression and shrinkage methods. When selecting a variable, the pros and cons are always considered as potential factors for defining and selecting a model in order to justify the global optimal criteria, where the variance of outcomes changes over time and increases the number of computations. It is known that as variables increase, the model’s complexity grows exponentially. Consequently, when time series data incorporate dynamic variables, the correlation may generate nonsensical relationships that affect accuracy and precision [
30,
33,
34,
35].
In a dynamic social network, the data source consists of discrete timestamps for a specific period, where interconnected nodes have a high likelihood of forming strong reciprocal links, creating a dynamic cluster. However, this dynamic cluster poses a challenge, as it can cause long-term bias in the social network. Smaller perturbations can lead to significant changes in relationships and bonds within the network, which can be identified as variances from the current state. As a result, small changes can lead to increased variances in link reciprocity due to alterations in the network and the presence of unnecessary links (noise). Furthermore, a cooperative strategy is employed to detect these temporal links and achieve optimal information dissemination.
Lemma 4.
The spread dynamic variable (SDV) quantifies the relationship between the spread of the disease and the actions taken by the multi-agent system.
Proof. Assume the spread dynamic variable is a function of the disease spread and the actions taken by the multi-agent system. As the system adapts its policies to minimize the impact of the disease, SDV reflects the effectiveness of these actions. SDV converges as the multi-agent system learns to optimally respond to the spread of the disease, quantifying the relationship between the system’s actions and the disease spread. □
To maximize the objectivity of this strategy, we optimize the function by compositing two or more variables, which results in better network topography by defining the cost difference of the objective function. Assuming the linear objective function is given by the changes in nodes evolution
over the period of t,
. If the variable environment is stationary for a given time interval, the parameter
and
will result in the following constraints,
where a steady state
and
, and the dynamic variable will be defined as,
Hence, the optimal cooperative spread will be defined as,
, is a critical state for determining action.
Here, Equation (12), represents the changes in the evolution of nodes over a period. Here, is the value of the node at time is the steady state value, is the initial value, and is the parameter that determines the rate of change of the node. The equation shows that the value of the node approaches the steady state value exponentially over time. Equation (13) calculates the spread dynamic variable (SDV), which measures the relationship between the spread of a disease and the actions taken by the multi-agent system. Here, is the SDV between nodes and at time is the number of connections from node i to node at time t in the cluster is the number of connections from node to node at time t in the cluster , and is a normalization factor. It calculates SDV as the difference between the number of connections to node and the number of connections to node i, normalized by the maximum and minimum value of SDV. Hence, Equation (14) determines the optimal cooperative spread in the network, given the SDV and a critical state of action determination, . The equation calculates the probability that a susceptible node will transition from cooperation to defection or from defection to cooperation, based on the determined SDV and the critical state of action. The equation involves multiple parameters such as , which is the cluster at time where is the probability of a node h to take an action in cluster , and is the probability of a node to take a specific action at time .
The method determines the network configuration at any given time by utilizing clusters extracted from the previous time step. This approach introduces a two-stage event-based adaptive algorithm, illustrated in
Figure 3, which employs an event-tracking system. For each time step, the associated components of the spread collected from the last timestamp serve as the initial information for the state. The distribution surrounding the seeds is established by optimizing the ratio of the average internal and external degree of information of the local cluster. The bursty nature of social networks contributes to the complexities of various social and economic phenomena. This event-based spread implicitly acknowledges that network links change over specific time periods. This spread analysis highlights the bursty character of social networks [
37,
39,
41,
42,
43], where the dynamics of social and economic impact are compared for spread analysis.
Social network analysis offers a method for examining communications and relationships within groups, providing various measures for understanding and quantifying the spread of information, influence, or other characteristics within a network. To ascertain situational spread, it is essential to have a clear understanding of the cumulative infection location rate
. To achieve this, information fusion is employed to identify the relationships between objects. In such contexts, one approach to reduce the knowledge presented to the user involves classifying objects based on their capacities or properties [
18]. However, in some instances, it may be more beneficial to recognize the observed entities solely according to their relationships with other entities. This relationship is measured through a similarity computation using the Cosine model for a CF model [
25,
35].
where
represents a location rating for the spread corresponding to each action. The location rate calculates the cumulative infection location rate
by considering the similarity between users
and their relationship with other entities. It takes into account the observed entities and their relationships, providing a metric to measure the spread of influence or information within the network. This analysis is conducted using Twitter data related to COVID-19 and physical data obtained from the Johns Hopkins website [
40].
To identify vulnerable nodes, word categories were grouped into positive feelings regarding COVID-19. The study created a sampling space with homogeneous spread and actions, but did not fully represent influencing locations. Positivity rates in specific cities were calculated using physical data and similarity scores to map exposed users.
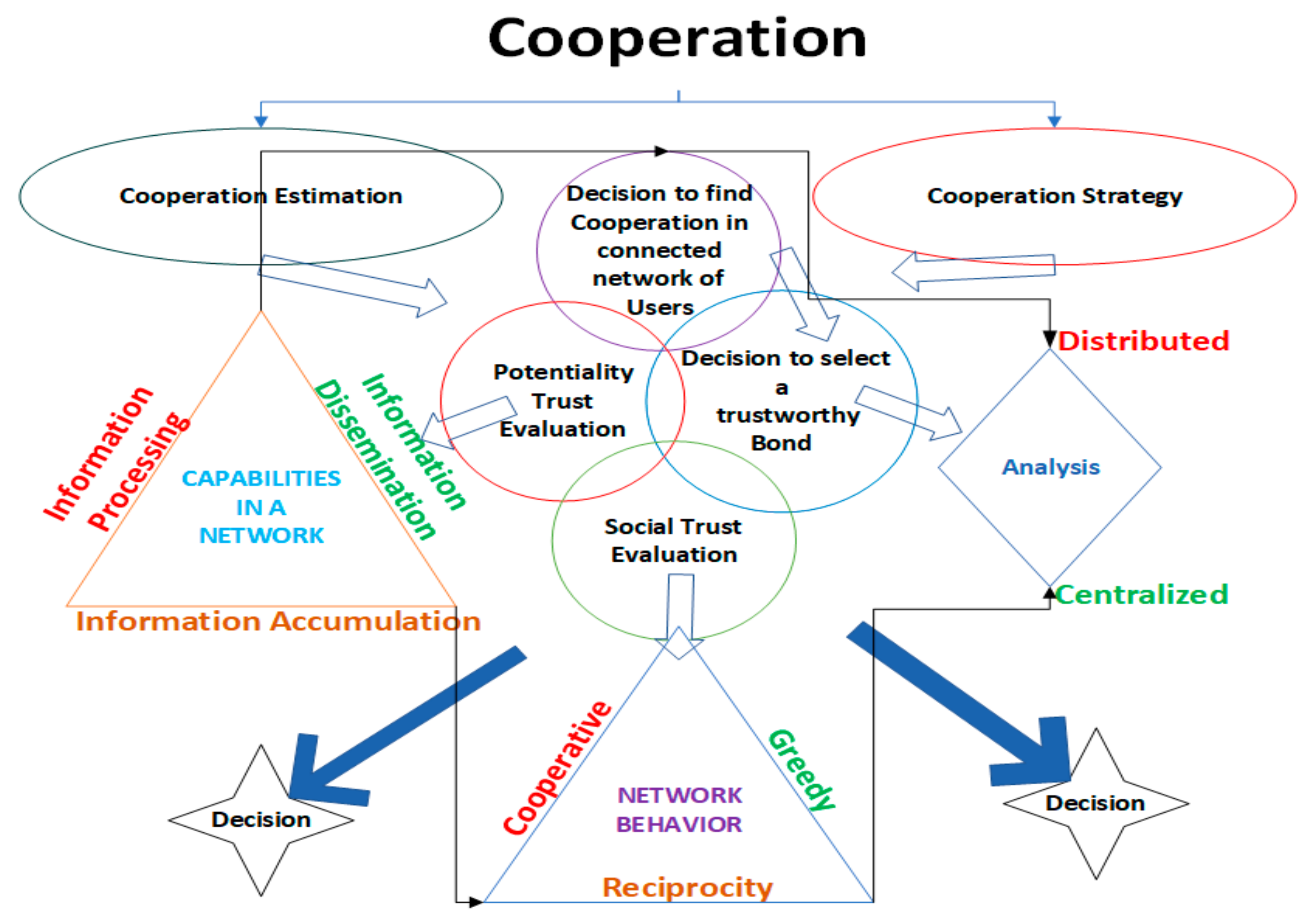
Figure 4 shows that a cooperation estimation and strategy are key components, involving information processing and network distribution. A triangular agenda visually represents this, and the data assess social trust, trust likelihood, and reciprocity-based network actions. Distributed analysis, decision-making, and reliable network ties form the cooperation strategy to foster social trust and effective cooperative spread.
As we know, the social and physical network establishes a multiagent system that is based on decentralized cooperation. It represents the nodes that forward critical information about events or situations in possible conditions. The situations are filtered from the data gathered from physical locations that are behaving abnormally from the threshold values at that time interval, corresponding to the social data. This leads to categorizing the words from the social data in ascending order. The first level is physical data, as per Twitter user-based importance. This data directly relates to user updates copied or correlated with agencies’ reports. This is the raw critical information categorized from real-time data using physical data. Assuming each user network node
where
is a set of all of the network nodes, with the capability to perceive a local and global directed and direct path for link reciprocity. Each node
receives observation as
via a noisy observation link
, such that the node
observes a random variable
for the environment state
. Thus, the collective information links is defined as [
5],
Therefore, utilizing the control algorithm [
5],
As time passes, the size of information increases, leading to memory utilization challenges. To address this issue, the latent space is defined using weight sharing and an attention mechanism that incorporates a policy adapted to the multi-agent environment.
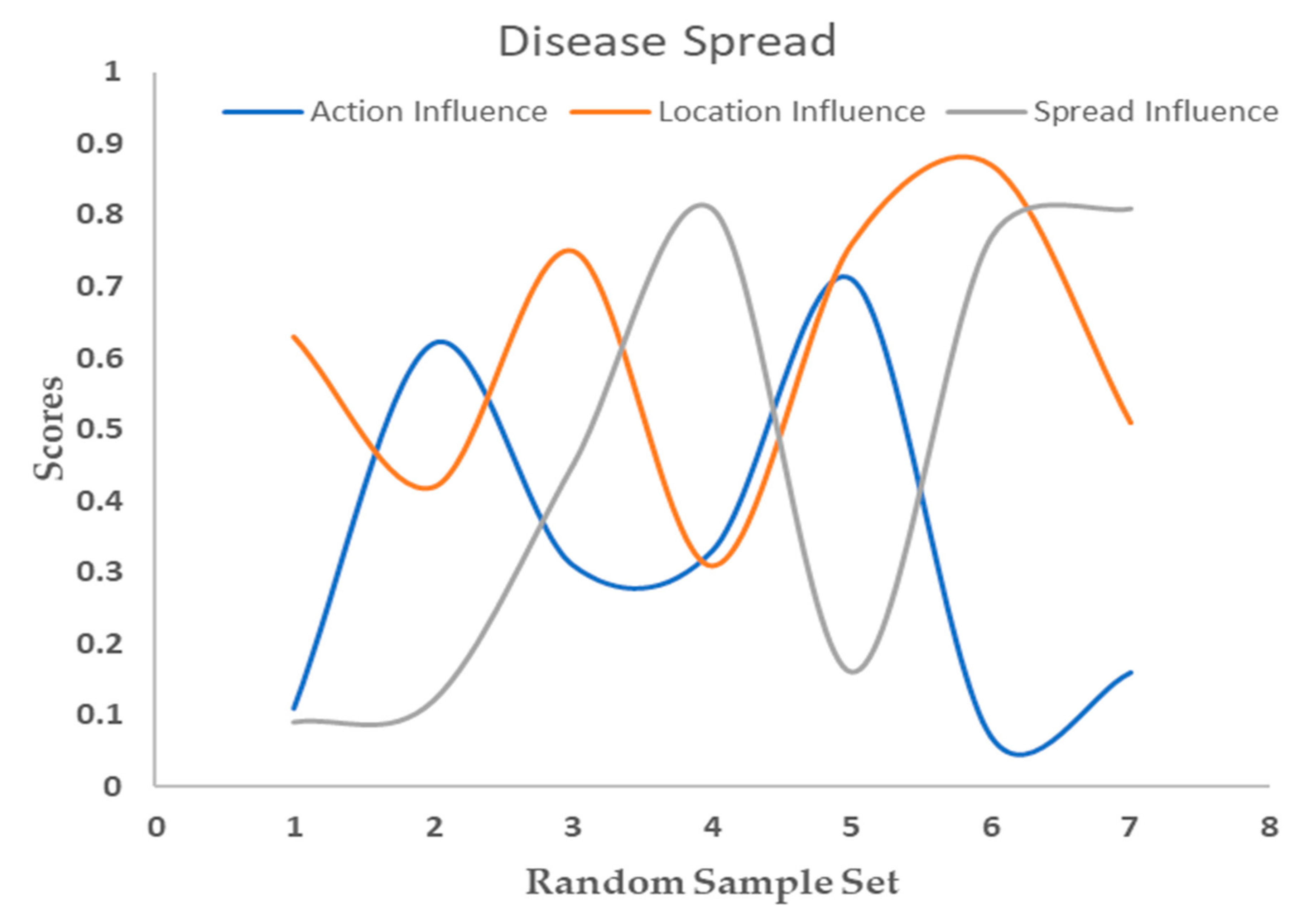
Figure 5 presents the effects of various factors on the spread for decision-making policies within a network. The figure demonstrates the analysis results obtained through a control algorithm for sampled space, action influence, location influence, and spread influence. Furthermore, social spread is observed by measuring behavior changes over time using location-based COVID-19 datasets from the US. This approach, adapted from previous work, focuses on data source changes rather than behavior frequencies.
Figure 5 reveals a relationship between spread and action influence, as well as their cumulative effect. Influence spread is examined using influence space scores, and action space helps assess network cooperation and trust. It presents the adaptive algorithm results for a 49,999-node sample space, showing the influence scores, policy accumulation, and spread decision rates for seven nodes. Influence scores (0–1) indicate node impact, policy accumulation (0–2.56) refers to decision-making policy buildup, and spread decision rates (0.05–0.32) represent policy dissemination rates.
Nodes with higher influence scores have higher policy accumulation and spread decision rates, implying greater effectiveness in decision-making and policy dissemination. Higher spread decision rates correlate with higher policy accumulation, indicating that effective policy dissemination leads to greater policy accumulation. This information can identify key nodes and optimize the spread of policy decision-making. This knowledge can be applied to improve network resilience, particularly in situations where cooperative behavior is essential. By understanding the dynamics of social spread and focusing on influential nodes, it is possible to promote cooperation and trust within the network, leading to better decision-making and more effective policy implementation.
The sampled space represents the number of individuals in the network capable of making decisions and influencing others. Action influence measures the impact an individual’s actions have on the dissemination of decision-making policies within the network. As shown in
Figure 5, the highest action influence value was 0.71, while the lowest was 0.07. Location influence quantifies the effect an individual’s location has on the propagation of decision-making policies throughout the network. In
Figure 5, the highest location influence value is 0.87, and the lowest is 0.31.
The spread influence measures the collective impact of the network on the propagation of decision-making policies. This information reveals that the dissemination of decision-making policies within a network is affected by individual actions, location, and the overall influence of the network. Upon examining this data, it becomes evident that the spread of decision-making policies in a network is not exclusively reliant on a single factor; rather, it is shaped by a combination of various factors. This underscores the significance of taking into account both individual actions and network influences when assessing the distribution of decision-making policies in a network.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






