To assess the proposed system’s ability to track the optimal network route under non-stationary settings, an evaluation setup based on simulated and emulated data was designed and a set of experimental results were collected. The evaluation setup, the collected results, and their analysis are presented below.
4.1. Datasets and Evaluation Setup
In order to facilitate the integration of the developed system with other tools and libraries commonly used in networks and multi-armed bandit research, React-UCB was implemented in the programming language Python. The KL-UCB component included in React-UCB is based on a well-known Python implementation from [
28].
To evaluate React-UCB’s performance with its default parametrisation, as specified in Algorithm 1, a set of experiments were run on two different evaluation setups: emulation setup and simulation setup. In the emulation setup, the agent is tasked to find the lowest-delay path in an emulated network topology. Conversely, in the simulation setup, the agent is challenged to find the arm with highest reward in a generic simulation of stochastic bandits. Both setups assume that the agent needs to handle paths (arms), whose normally distributed delays are piecewise-stationary, with reward distribution change-points occurring every time steps, up to the time horizon and in the emulation and simulation setups, respectively. The larger time horizon used for the simulation setup aims to cope with the higher diversity of distribution changes that occur in this setup.
The two evaluation setups were used due to their complementary characteristics. A network emulator is adequate for testing the system against highly likely reward distributions, enabling an analysis focused on expected events. However, it is also important to assess the system’s behaviour when facing uncommon distribution changes, which are hard to find with a network emulator without engaging with extensive topology manipulations. On the other hand, a generic simulation setup is adequate for testing the system against arbitrary network delay distribution changes, enabling an analysis that is independent of the network topologies specifically designed for the evaluation process.
The emulation setup is based on the open-source network emulator Mininet [
29]. Mininet was selected as it is a well-established solution for the creation of realistic virtual networks capable of running real, that is, deployable code. Moreover, Mininet is particularly suited to studying SDN-based systems. By relying on Mininet, the emulated network operation is highly accurate because it runs in real-time and the programmed delays and jitters operate as if they were emerging from real hardware.
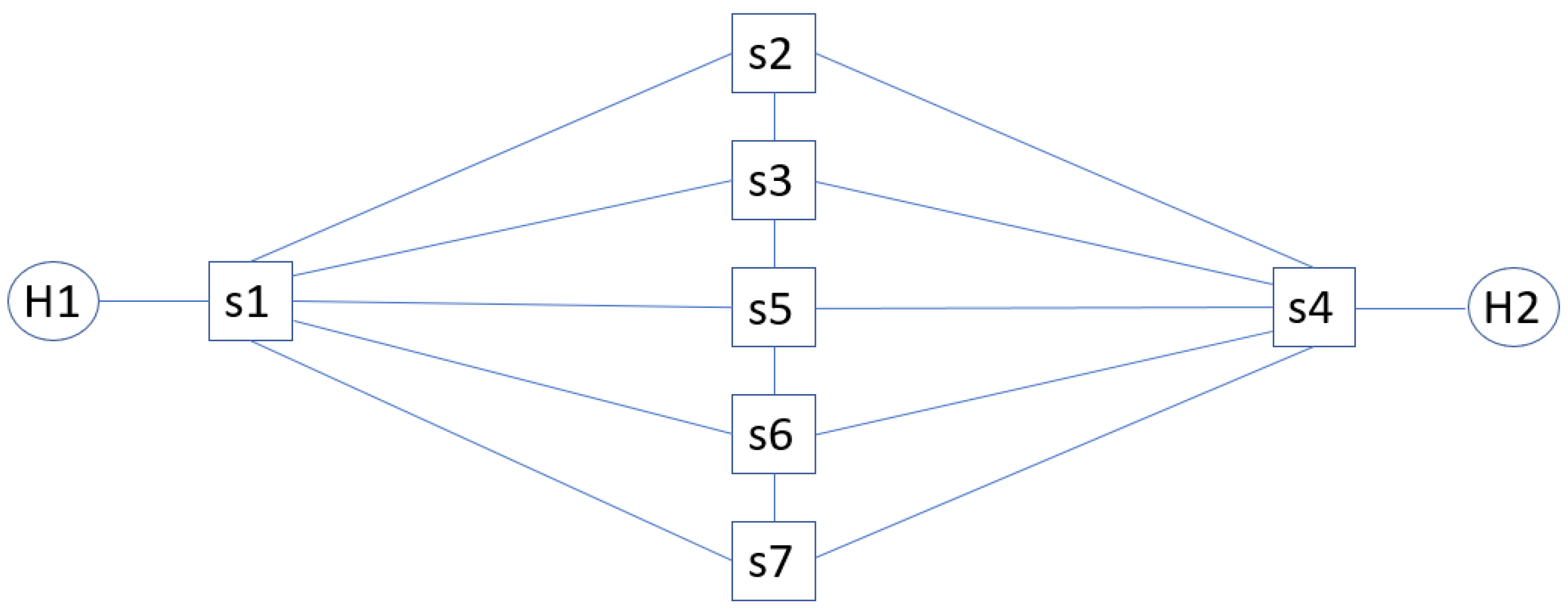
Figure 2 depicts the emulated network for this study, whose topology, composed of seven OpenvSwitches, results in 25 end-to-end paths between end-hosts H1 and H2. The seven switches are controlled via OpenFlow v1.3 by a Ryu [
30] SDN controller. In the emulation setup, React-UCB is tasked to select each time slot which one of the 25 end-to-end paths is selected for data transmission (an arm per path).
During the emulation runs, and as any used path can be decomposed in several hops, each hop’s delay contribution to the end-to-end single direction path delay is the sum of the processing delay at the hop source switch (influenced by the congestion level at the hop source switch), the link transmission delay between the hop source switch and the hop destination switch (influenced by the sum of the link transmission delay and the link propagation delay). The bidirectional delay in each end-to-end path changes according to a set of three distributions
, which are summarized in
Table 1. The table only presents paths that are optimal for at least one of the distributions. For every
P steps, the active distribution changes. Concretely, assuming
to be the currently active distribution, the next active distribution is randomly sampled from
.
The distributions in D were carefully crafted to challenge React-UCB’s ability to detect and react to sudden and abrupt reward distributions. This is attained by ensuring that the path with minimum delays is different in each distribution and that it is not always possible for React-UCB to detect distribution changes by simply sensing a reward drop in the current optimal path (this reward may remain the same across distribution change-points), thus requiring a proper handling of the exploration–exploitation trade-off.
In the simulation setup, each of the 25 arms returns a stochastic reward according to a normal distribution, whose parameters are randomly selected in every reward distribution change-point. Hence, in this setup, React-UCB faces challenging scenarios, in which reward distributions change in unpredictable and diverse ways.
Concretely, in each simulation time step t, the delay expectation of every path (arm) , , and standard deviation , are either updated or maintained. Formally, if or t is a multiple of P, then and ; otherwise and . The delay observed by the agent when selecting path (pulling arm) is obtained by sampling a normal distribution parameterized with the randomly selected expected delays and their standard deviations, .
4.2. Results
This section presents the set of results that were collected with both emulation and simulation setups with four different tested React-UCB configurations. Testing with different configurations aims to assess the contribution of each React-UCB’s feature (e.g., arms correlation, reset functionality) to the overall algorithm’s performance.
The baseline configuration, referred to as B, represents the implemented discounted KL-UCB (Equation (
24)) augmented with
-greedy for coverage guarantees in non-stationary reward distributions. This configuration, composed of standard components, serves as a benchmark for the remaining configurations.
The second configuration, hereafter referred to BR, extends configuration B by including the reset functionality. Hence, a performance improvement in configuration BR over configuration B should be an indication that the reset functionality provides added value to the overall solution.
The third configuration, hereafter referred to BRC, builds upon configuration BR by including arms’ correlation information in the decision-making process. The goal of this configuration is to assess whether the correlation between arms, that is, knowledge regarding how many links are shared across paths, can make a valuable contribution to the provision of pseudo-rewards.
Finally, the fourth configuration, referred to as BRCT, extends configuration BRC by including the mechanism that allows for the algorithm (Lines 7–8 in Algorithm 1) to cancel exploration when rewards rise above a given satisfactory threshold, that is, the rewards are good enough for the task at hand.
Table 2 summarizes the average (AVG) and the standard deviation (STD), per time step, of the regret obtained with each of the four tested configurations. These statistics were computed by considering the total regret accumulated over 30 independent runs, divided by the number of time steps in each run (a run lasts
T time steps, with
T varying according to the evaluation setup, as described earlier). A total of 30 independent runs was selected to increase the power of the statistical tests to compare several configurations; that is, to minimise the impact that the randomness in both agent and reward systems may have on the variance in the results. The independence between runs was enforced by using a different random seed in the beginning of each run.
As expected,
Table 2 shows that including each React-UCB’s component results in a gradual decrease in terms of regret. These results are confirmed in both simulation and emulation setups, meaning that these results apply to both network and generic application scenarios. Hence, the devised solutions reset the MAB when a reward distribution change is detected, exploit the arms correlation to build pseudo-rewards, and stop exploration when task-dependent, good-enough rewards are reached. These all positively contribute to the algorithm’s performance. In fact, the fourth configuration, BRCT, exhibits only
of the regret suffered by the baseline (benchmark) configuration, B, across both setups. Hence, this result indicates an overall important reduction in terms of agent regret.
Considering the emulation setup,
Table 3 shows that the increase in the agent’s average reward per iteration is well-aligned with the previously discussed decrease in the agent’s regret in the
Table 2.
Table 3 also shows that enhancements on the agent’s average reward per iteration make an important positive contribution to the network throughput, mainly after the last component (T, which inhibits the agent’s exploration after a good reward has been discovered) is activated in the MAB’s algorithm.
Table 4 shows that the regret differences observed between the four configurations (
Table 2) are all statistically significant for a
confidence level (
), according to the Student’s two-sample unequal variance
t-test, considering a two-tailed distribution. Hence, it is very unlikely that the observed performance differences associated with the diverse agent components are due to chance.
Table 4 also shows that the observed regret differences have practical significance; that is, they are likely to have practical benefits. Here, practical significance is defined in terms of effect size, measured with Cohen’s
d metric. All configuration comparisons indicated in
Table 4 exhibit a large effect size [
26] (
), except for the difference between configurations BRC and BRCT, which presents a medium effect size [
26] (
). Resets occur with a median delay from the reward distribution change-points of 11 time steps and 23 time steps in the emulation and simulation setups, respectively. Hence, assuming a plausible median period of
between time steps, resets are expected to occur with a median delay of approximately
and
in scenarios with similar reward distributions to those present in the emulation and simulation setups, respectively. This shows the algorithm’s ability to adequately react to sudden and abrupt reward distribution changes, explaining its low empirical regret.
In summary, the results show that the several React-UCB’s components provide added value to the whole algorithm and that this conclusion is supported by strong statistical and practical significance validation tests, which were performed on the evaluation results of our proposal.
4.3. Comparison to Standard SDN
The previous section analysed the benefits of the elements that comprise the devised MAB agent for end-to-end path delay minimisation, avoiding the negative impact of congested network devices in the quality of top system applications or services. This section compares the benefits of using an MAB agent for this purpose compared to a standard SDN solution without the support of any intelligent agent.
In a standard SDN solution, all links need to be periodically probed to determine their current delay. Without this periodic and global probing process, the SDN controller is unable to determine the optimal path for packet exchange. The periodic and global nature of the traffic imposed by these probing messages results in a considerable overhead on the network.
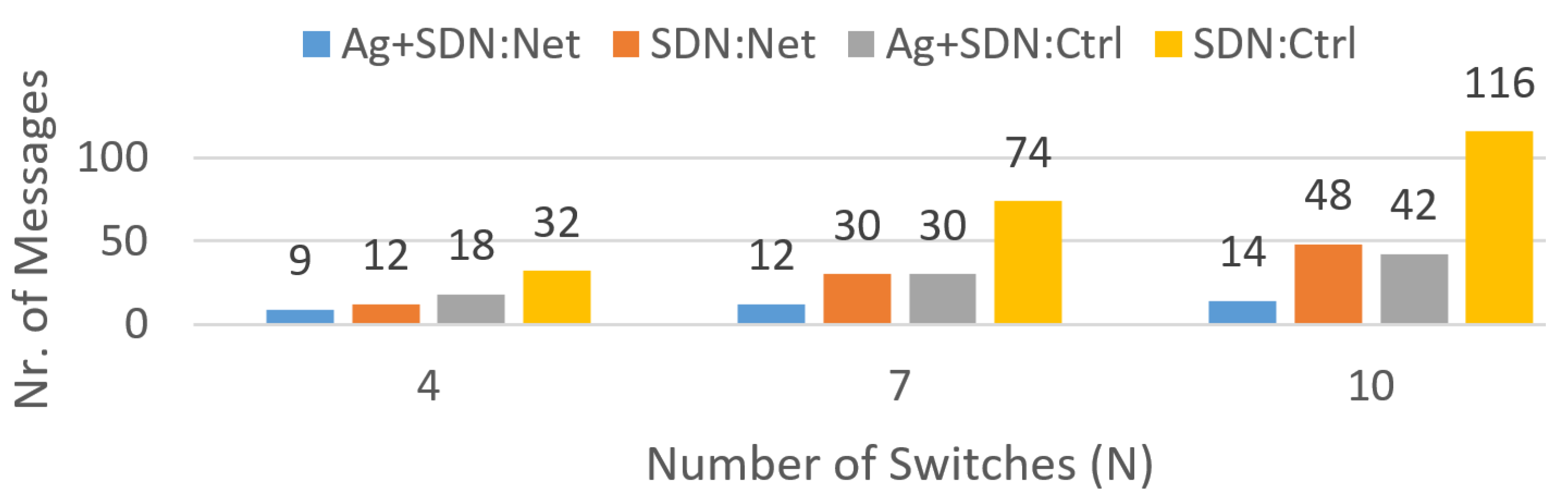
Figure 3 presents the number of messages that need to be exchanged by a classic SDN-based solution, when the network is composed of four, seven, and ten switches, at both network and control levels. Analyzing these results, it is clear that the higher the number of switches, the higher the number of probing messages that flow through the network.
The MAB-based solution for end-to-end path delay minimisation proposed in this article aims to reduce the number of probing messages by properly handling the exploration–exploitation trade-off.
Figure 3 shows that the number of messages exchanged at both the network and control levels of the MAB agent is systematically lower than the number of messages exchanged by a standard SDN solution. Interestingly, the growth rate in the number of messages, as a function of the number of switches, is lower with the MAB-based solution than with the standard SDN solution. Hence, the MAB-based solution offers higher scalability than the standard SDN solution as the network increases in size.
4.4. Computational Complexity Results
React-UCB’s complexity analysis, as presented in
Section 3.7, was verified with empirical results. These results were obtained on a MacBook Pro 2019, with 32 GB DDR4 and 2.3 GHz 8-Core Intel Core i9 (Apple Inc., United States), using the simulation setup with 25, 100, 200, 300, and 400 arms.
Figure 4 presents the obtained average CPU execution time per time-step
t (i.e., per React-UCB’s decision making) over a horizon of
time steps. Execution time was estimated with
time.process_time() Python function in a conservative manner, that is, by including the whole algorithm, simulation setup, and corresponding interactions.
A second-order polynomial curve was fit to the obtained execution timings to assess the theoretical algorithm’s asymptotic execution time of
(see
Section 3.7). The quadratic order of complexity was confirmed by the almost perfect coefficient of determination achieved by the regression process,
. It is also notorious that the quadratic coefficient (
) is several orders of magnitude smaller than the linear coefficient (
). This is due to the fact that the quadratic order of complexity was limited to the probabilistic inference step. The smaller quadratic coefficient results in a low execution time for a practical number of arms. For instance, considering 25 and 400 arms, the algorithm only takes, on average,
and
to output a decision per time step
t, respectively. These are adequate processing timings from a practical standpoint.









{kind=link}
{kind=link}
{kind=link}
{kind=link}