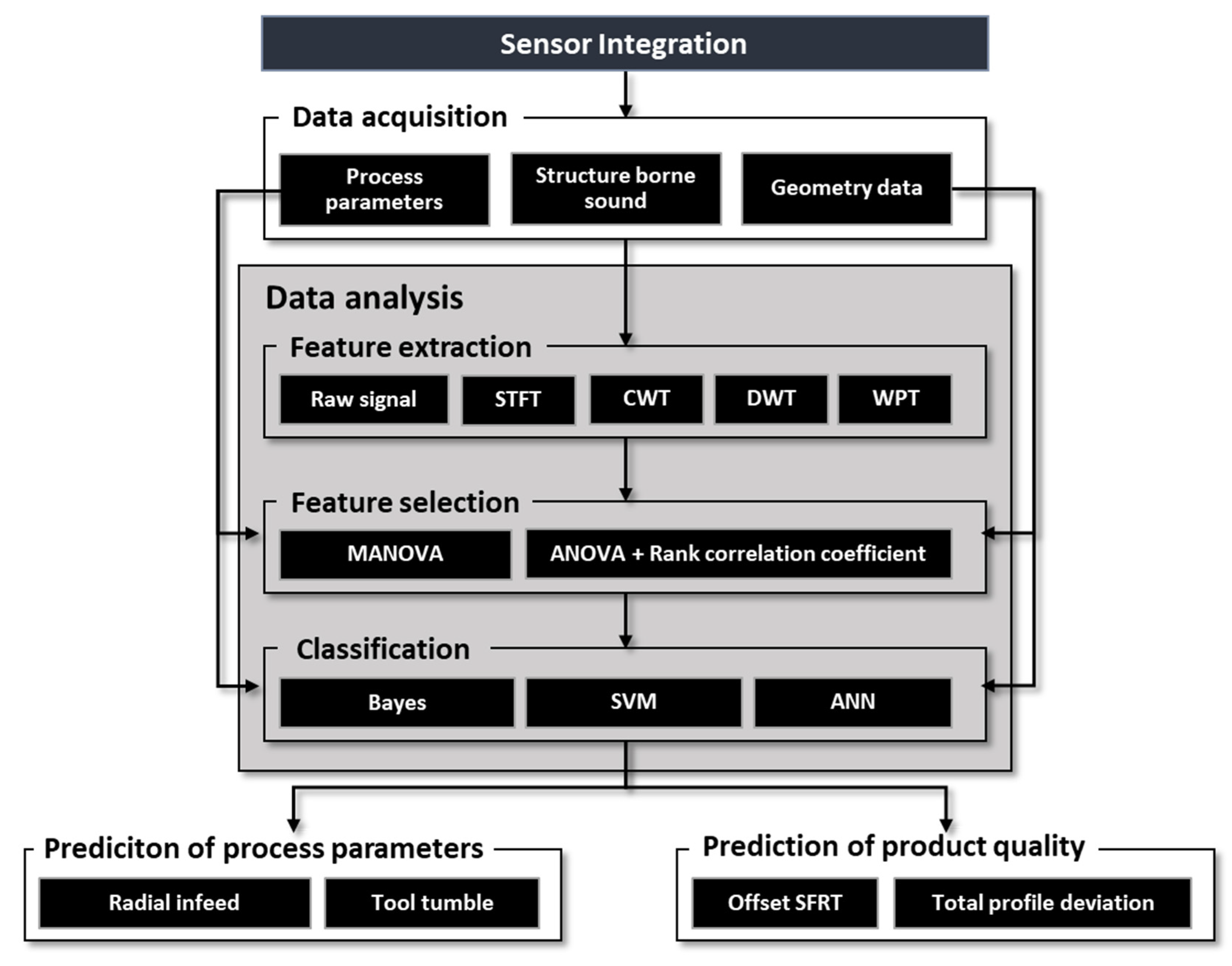
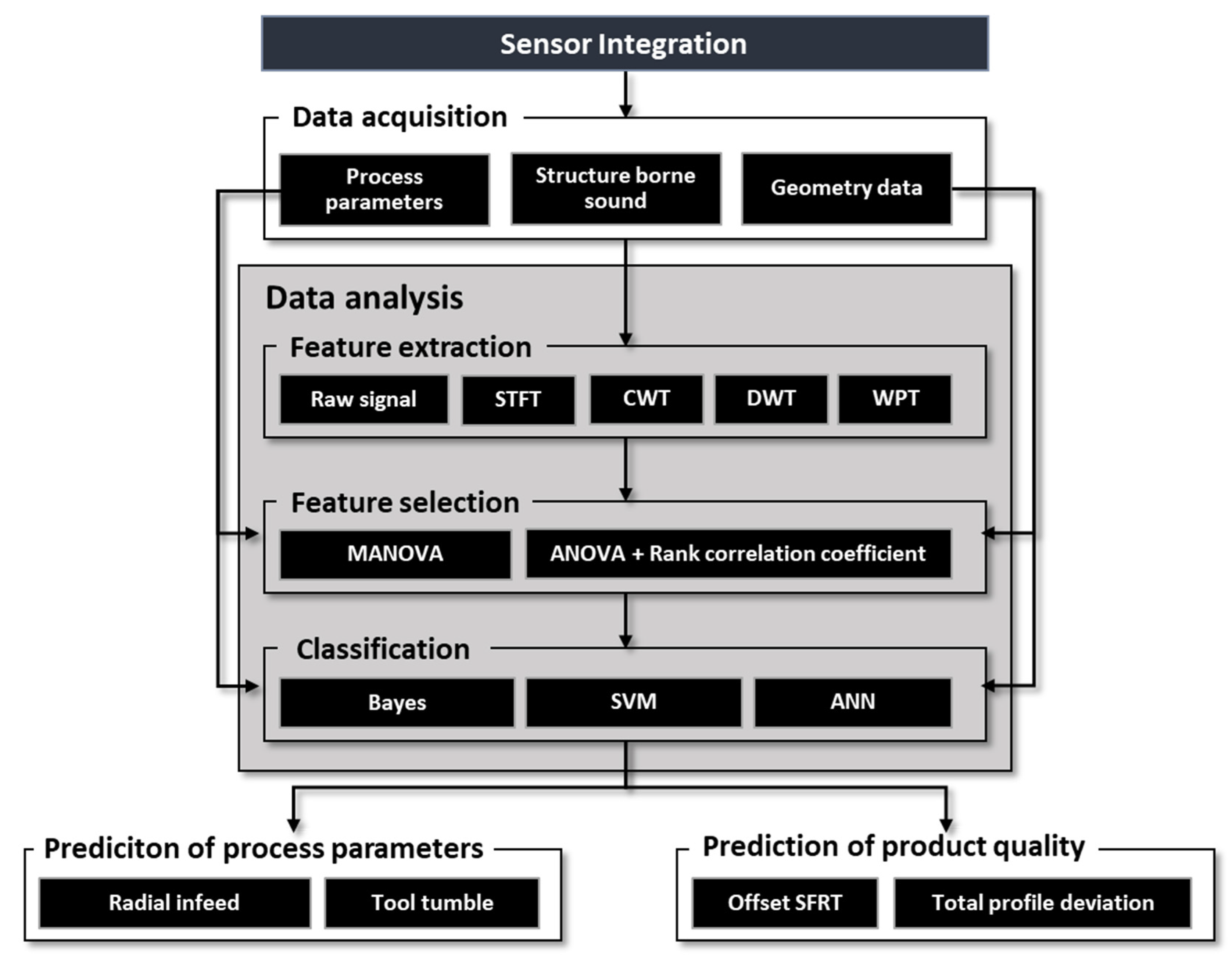
4.2.1. Feature Extraction
The reliability of the prediction of output variables such as tool wear, process parameters, or component quality depends on the quality of the extracted features [
8]. The vast majority of research already conducted extracts features using spectral analysis [
16,
25,
27]. Extraction from time signals is also used [
8,
25,
34,
35]. An overview of the features used in the aforementioned works can be seen in
Table 2.
Wantzen [
25] extracted features from both the time and frequency domains using the short-time Fourier transform (STFT) and the wavelet transform (WT). Since the features extracted using STFT and from the time domain carry more relevant information, they are selected more frequently than the WT features in the feature selection discussed below. Meng-Kun Liu et al. [
34] also extracted statistical features such as the RMS value, mean, standard deviation, and maximum values from the spectrum using the wavelet packet transform (WPT).
The feature types used here can be seen in
Table 3. These are chosen due to their good results in the literature. Features of the recorded structure-borne sound signals are extracted both from the raw signal itself and from the time-frequency spectra of various spectral analyses.
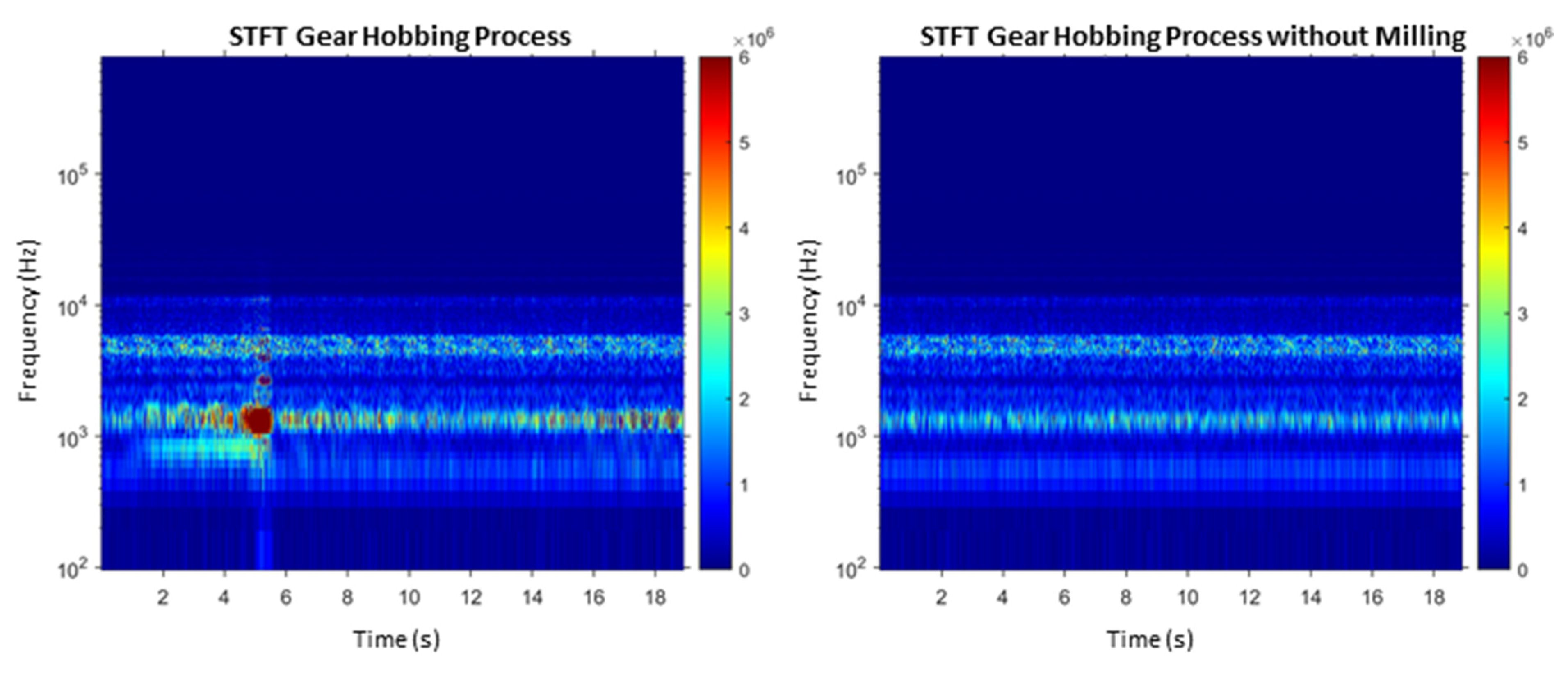
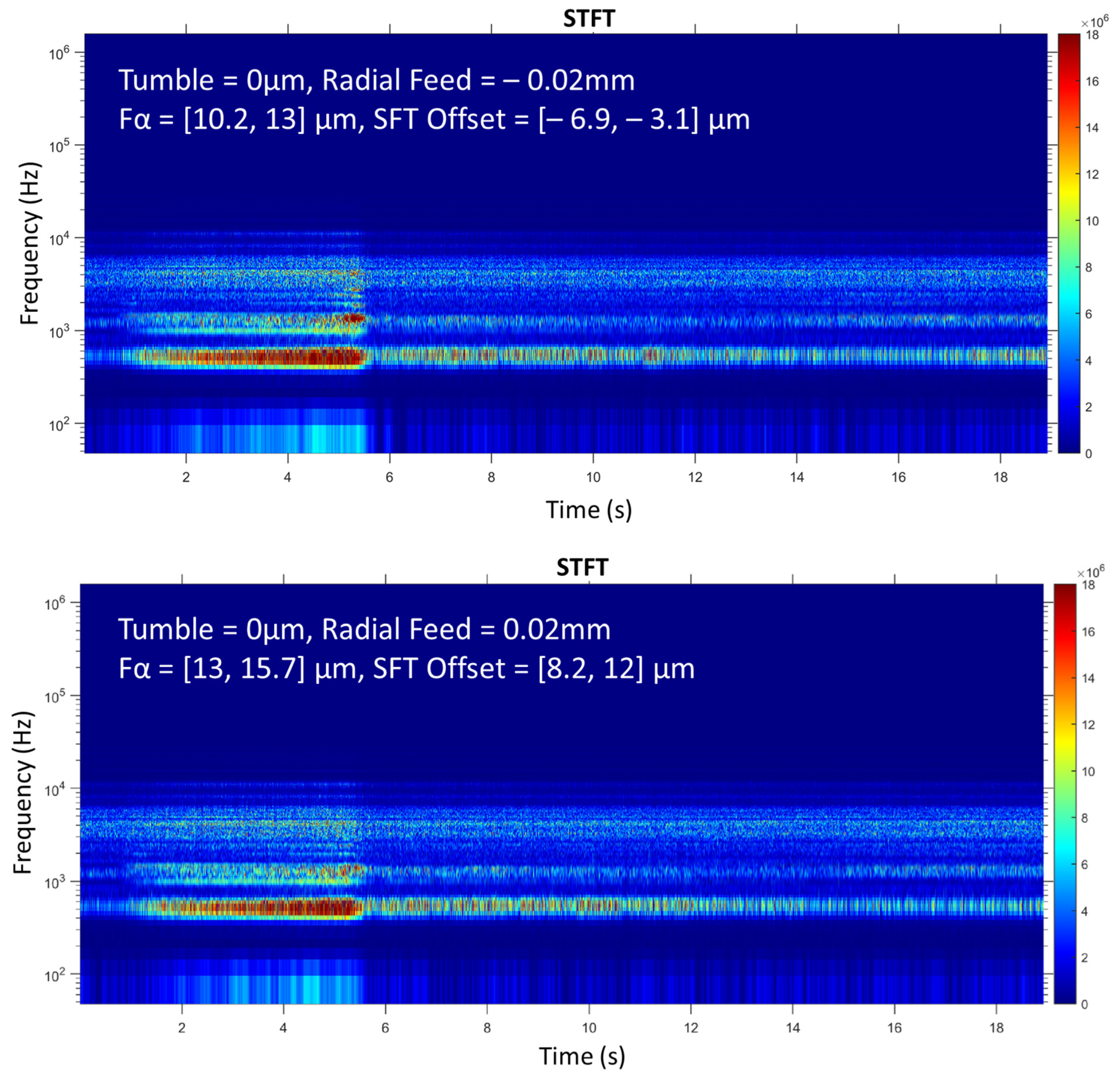
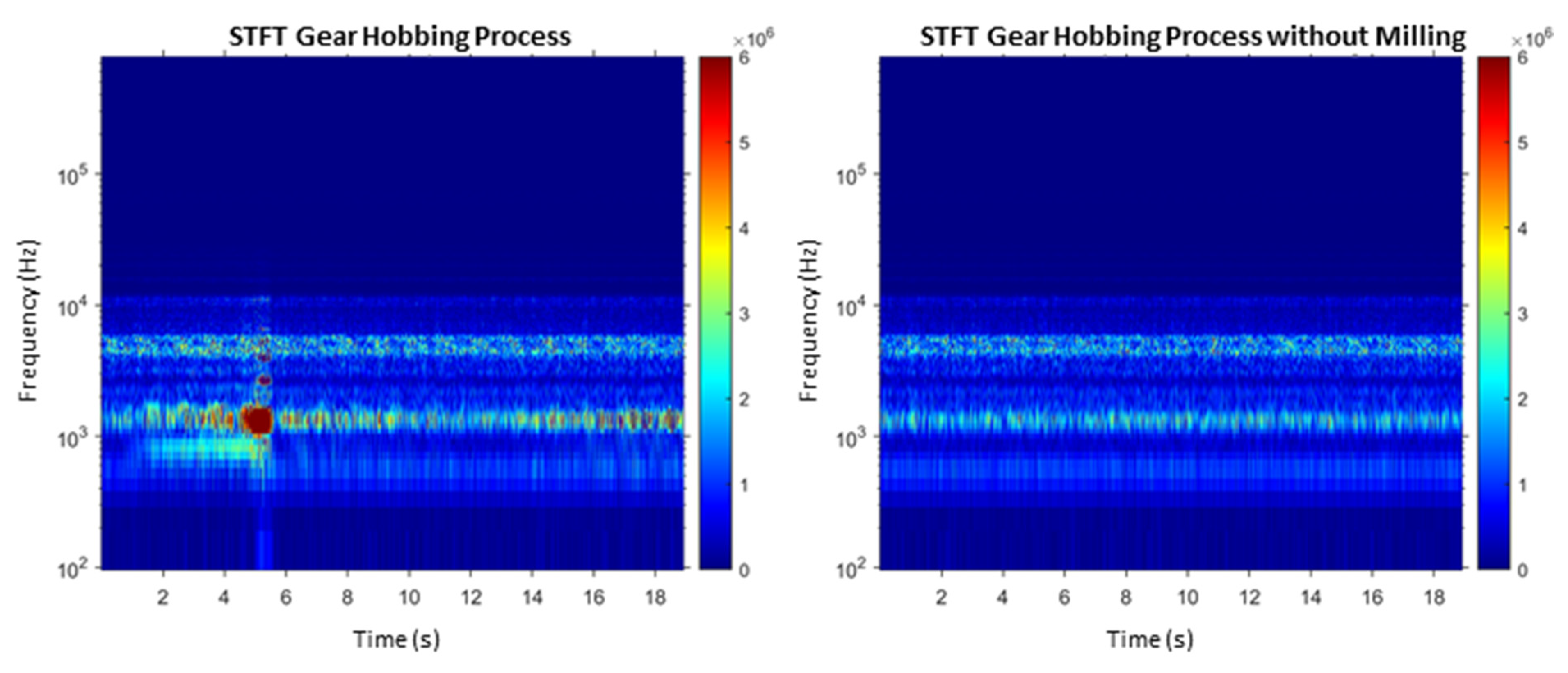
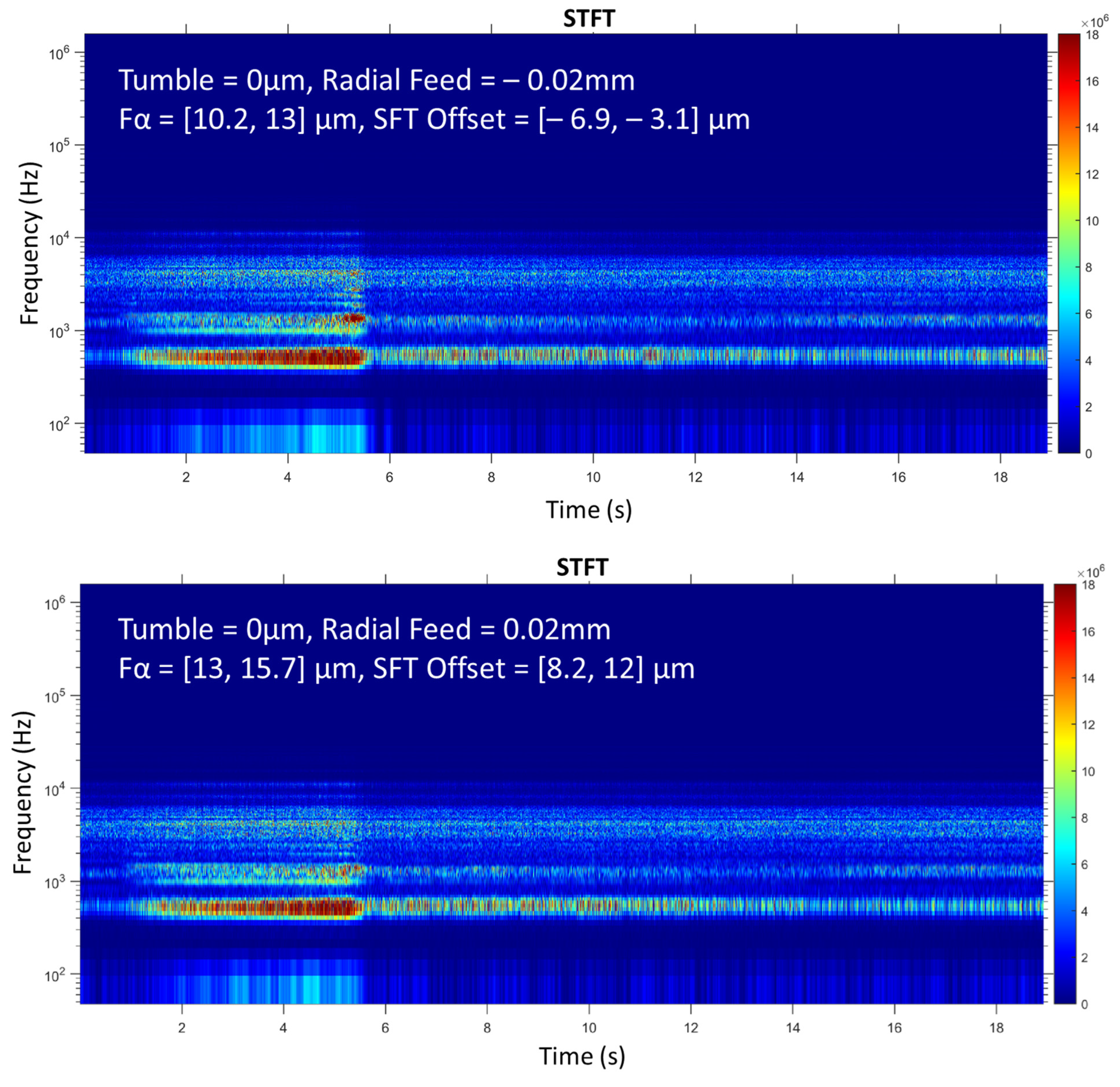
In addition to the short-time Fourier transform, the best-known spectral transform, various types of wavelet transforms are used here for feature extraction. Compared to STFT, these have the advantage that the resolution is not constant in the time-frequency domain. This results in a fine-frequency resolution at low frequencies, which becomes coarser as the frequency increases. With the wavelet packet transform (WPT) the resolution can even be adapted to the signal under consideration. For theoretical background, the reader is referred to Puente León 2019 [
36]. For feature extraction, the time-frequency spectra STFT, a continuous wavelet transform (CWT), a discrete wavelet transform (DWT), and the WPT with two different resolutions (15 and 128 coefficients), are used here.
Features can be extracted from the complete time series as well as from single intervals. Marinescu and Axinte [
16] analyze the spectrum of effective cutting times at which the tooth of the tool is engaged. As a result, less data has to be transformed into the time-frequency domain, which increases the efficiency of feature extraction.
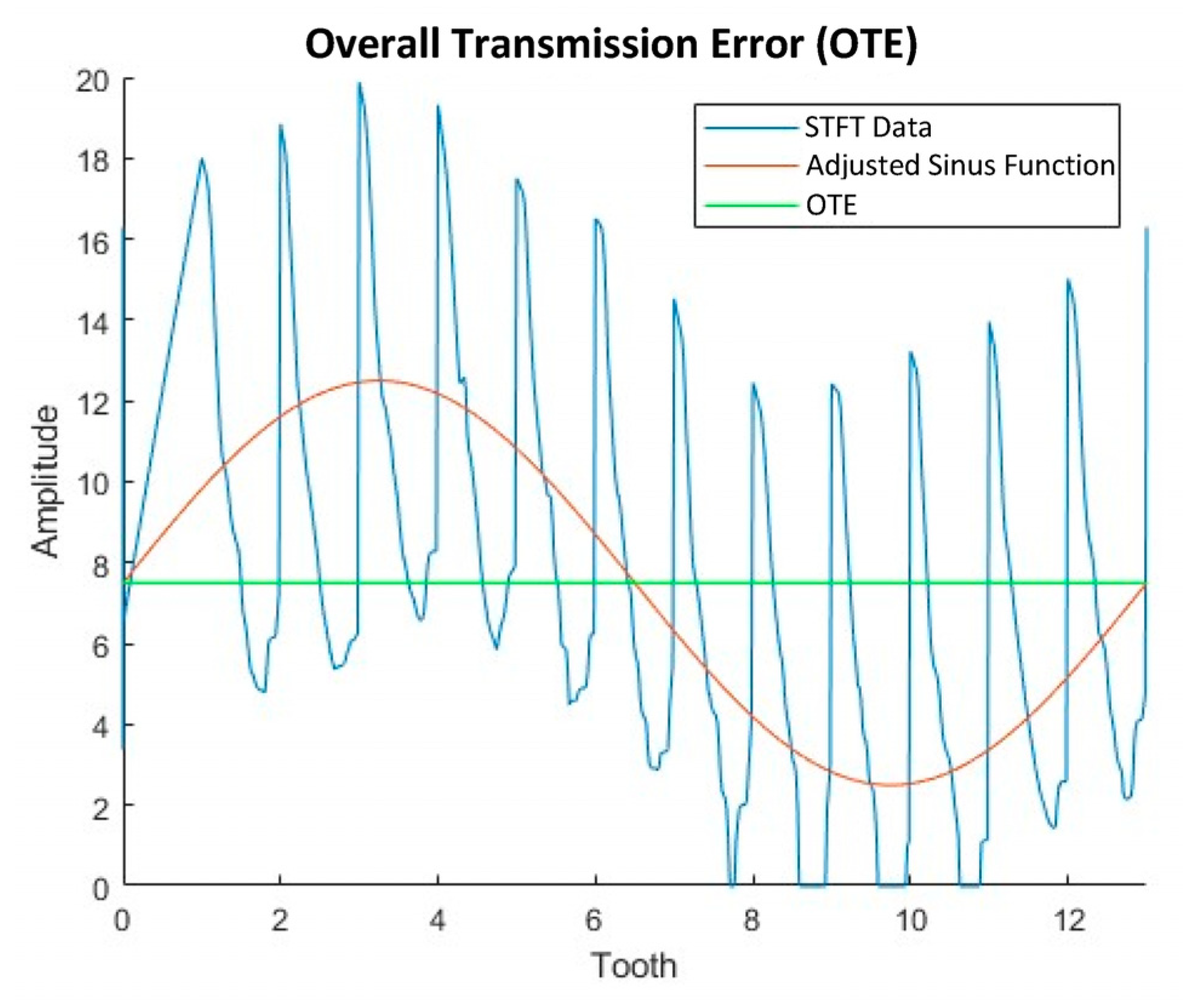
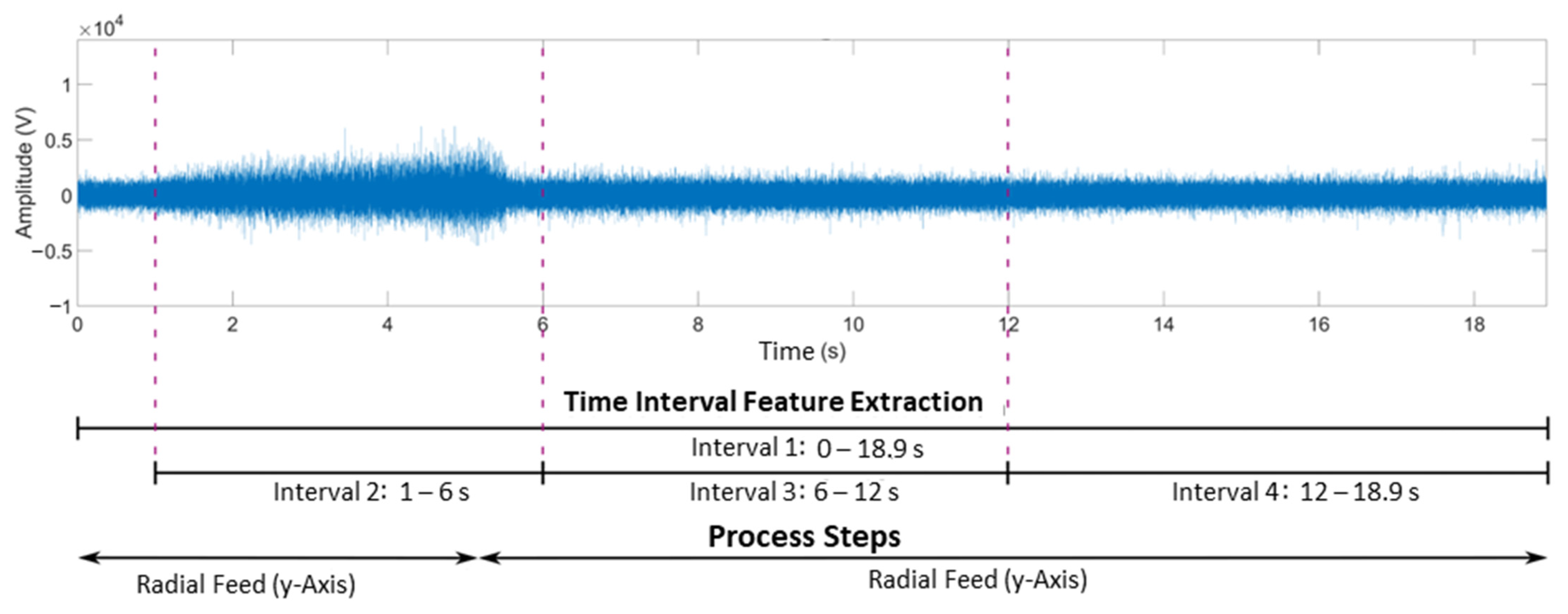
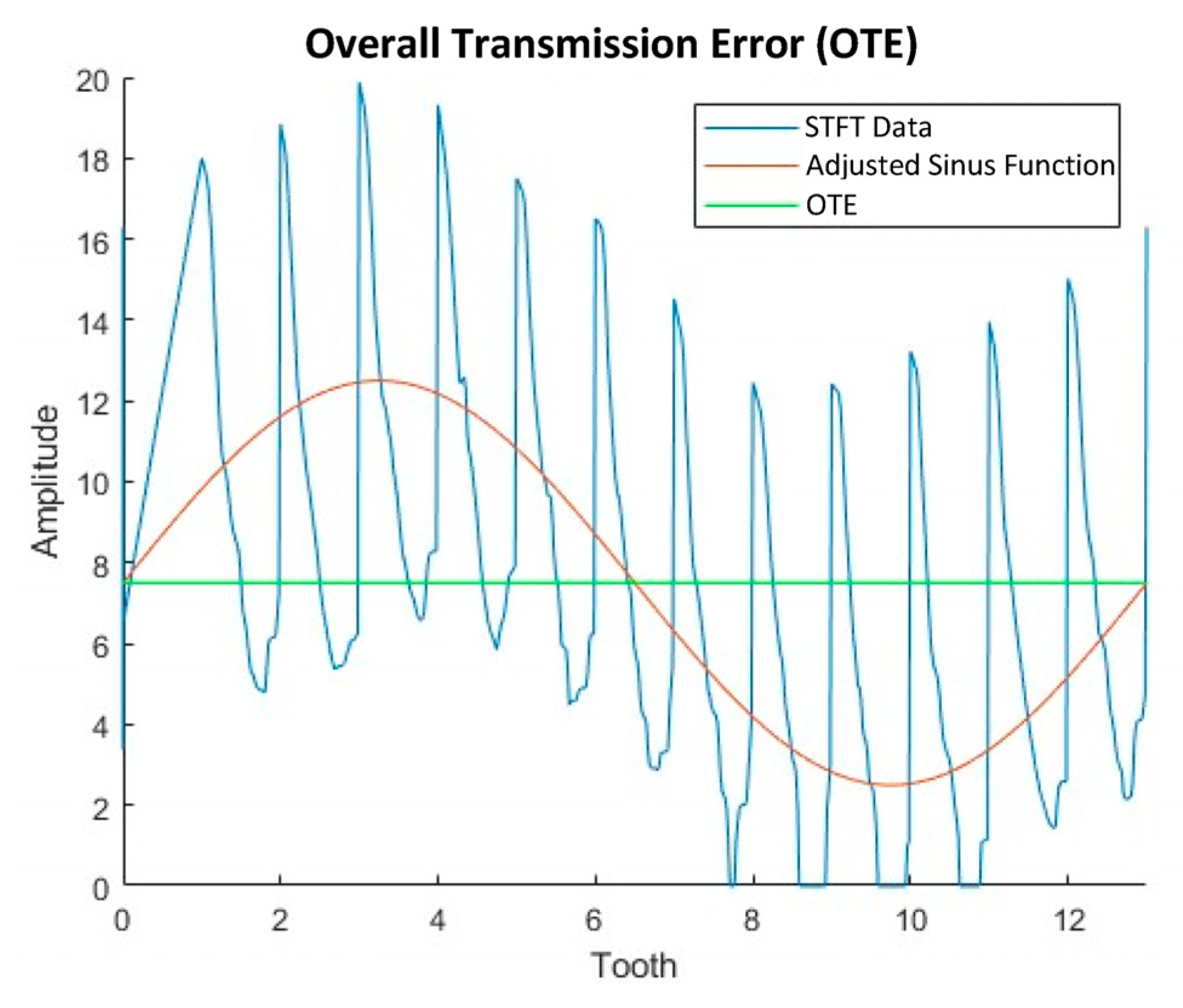
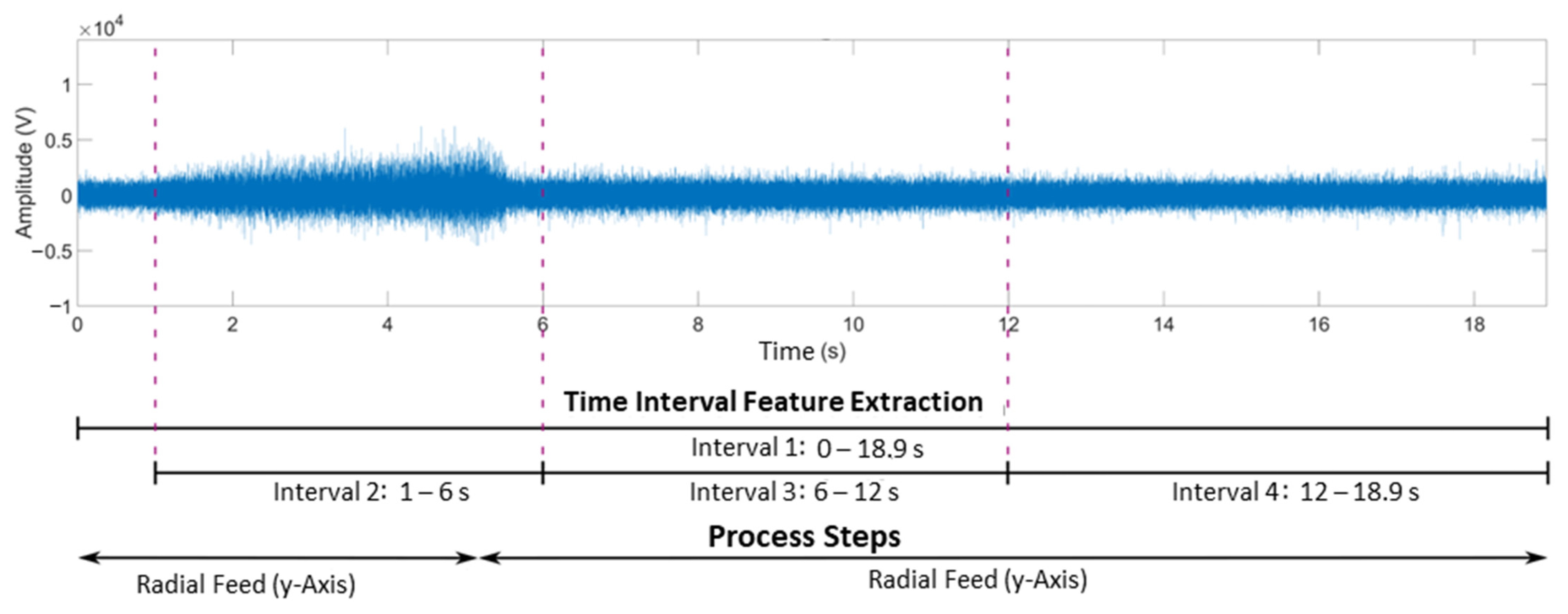
A time interval of either the raw signal or a spectrum is used here to determine a feature. Four time intervals are defined for feature extraction. Time interval one covers the entire hobbing process, while time intervals two to four cover only partial sections. The division into different time intervals allows the individual phases of the process to be considered separately and their characteristics to be examined individually. In this way, characteristics that only occur in one of the process steps become visible. The extracted feature is named based on the underlying data form (raw signal or spectral transform), its type, and the time interval used.
A raw signal acquired at 0 µm tumble and a radial feed of 0 mm and the time intervals used can be seen in
Figure 8.
4.2.2. Feature Selection
Since a large number of features would negatively influence the computation time and would not improve the classification result due to redundant information, a feature selection is performed.
There are many different approaches to feature selection in the literature. Wantzen [
25] and Yum et al. [
19] selected suitable features for classification using an analysis of variance. Here, features are either evaluated individually based on their suitability for classification (ANOVA), or the best feature combination is searched for iteratively (MANOVA) (see [
32]). To further reduce the number of features and redundancy, Yum et al. [
19] combined correlated features and thereby achieve a 4.2% increase in tool wear prediction accuracy. Li et al. [
8], on the other hand, fused the extracted features using principal component analysis. The features selected in this way achieved significantly better classification results than using all extracted features.
All extracted features of the raw signal and one spectral transform each are used as input for feature selection. Since the raw signal, which is the basis of the spectral transformations, is always recorded, raw signal features are always used. For reasons of efficiency, only one spectral transformation is to be calculated in the application and its features are to be used. Two alternative methods of feature selection, MANOVA and a combination of ANOVA and rank correlation coefficient rs, are used to select information-bearing features from the input variables, which allow a good separability of the output variables into their classes. For the four output variables of radial feed, tool tumble, OTE, and total profile deviation, suitable feature combinations are selected separately in each case.
The first feature selection method investigated selects the best feature combination for classification using MANOVA. Depending on the considered output variable, different numbers of features are selected by the MANOVA.
In the second feature selection procedure investigated, the features evaluated in the ANOVA are sorted according to their suitability for classification, and redundant features are removed. Only features with a rank correlation coefficient of less than 0.5 are retained. Thus, the highest-ranked 60 least redundant features per combination of raw signal features and features of a spectral transformation were selected.
4.2.3. Classification
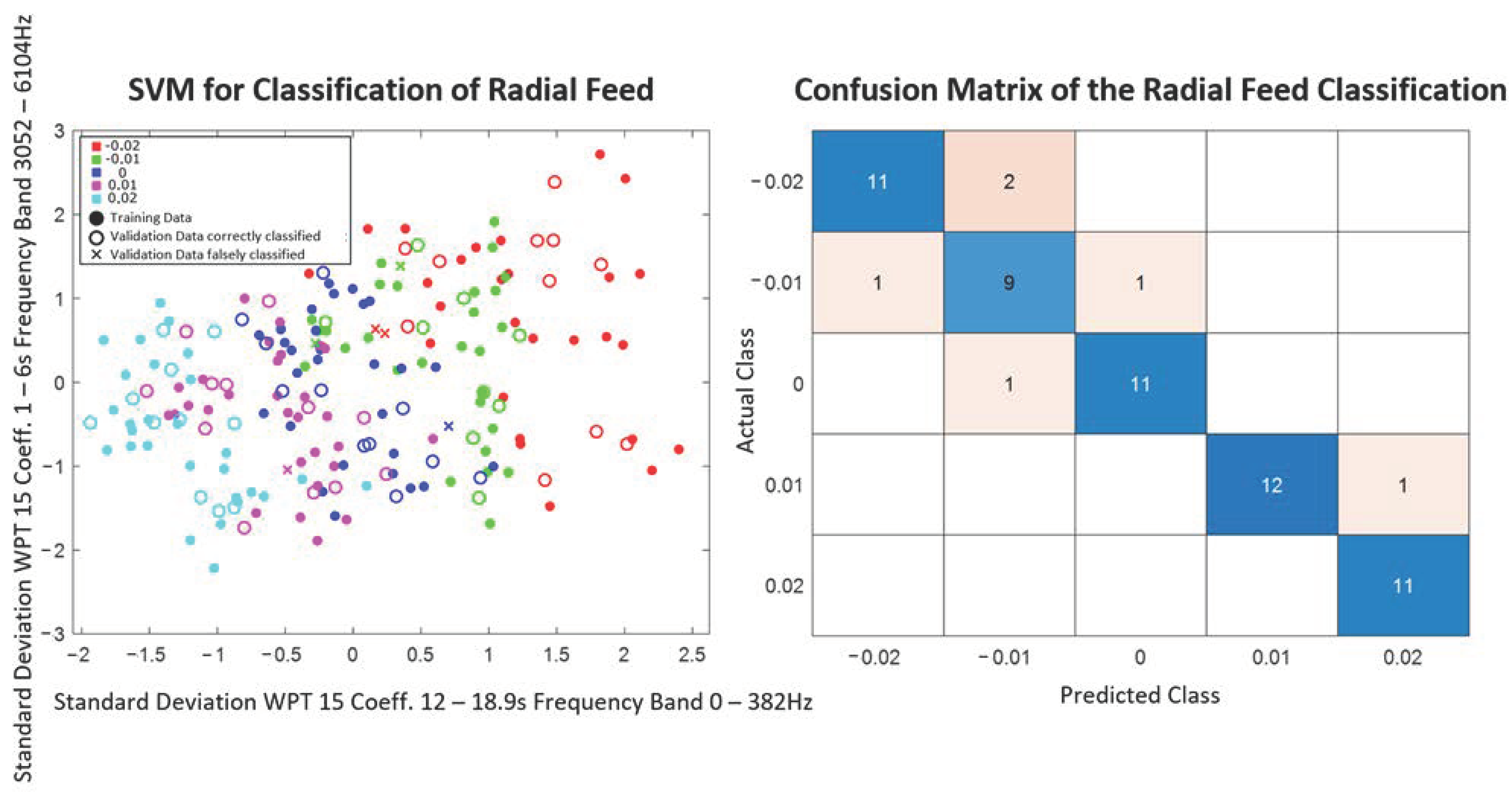
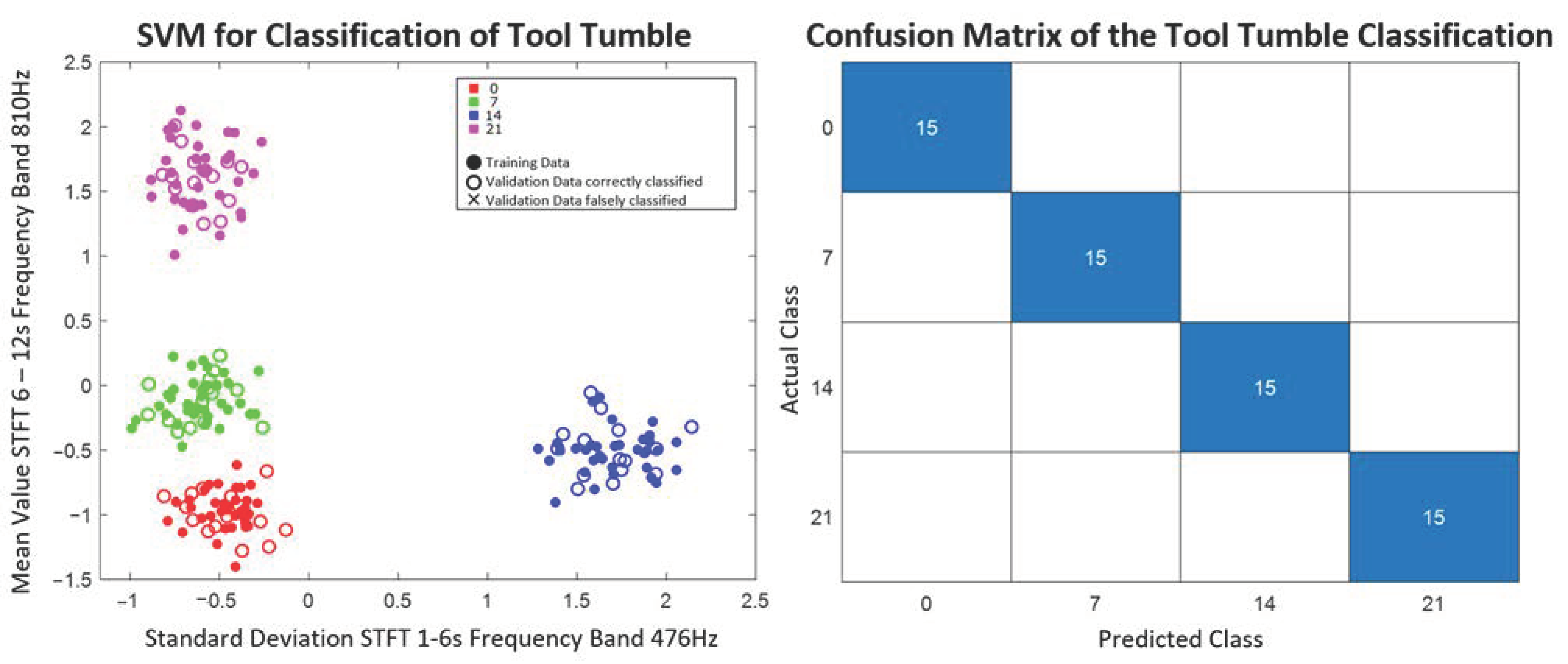
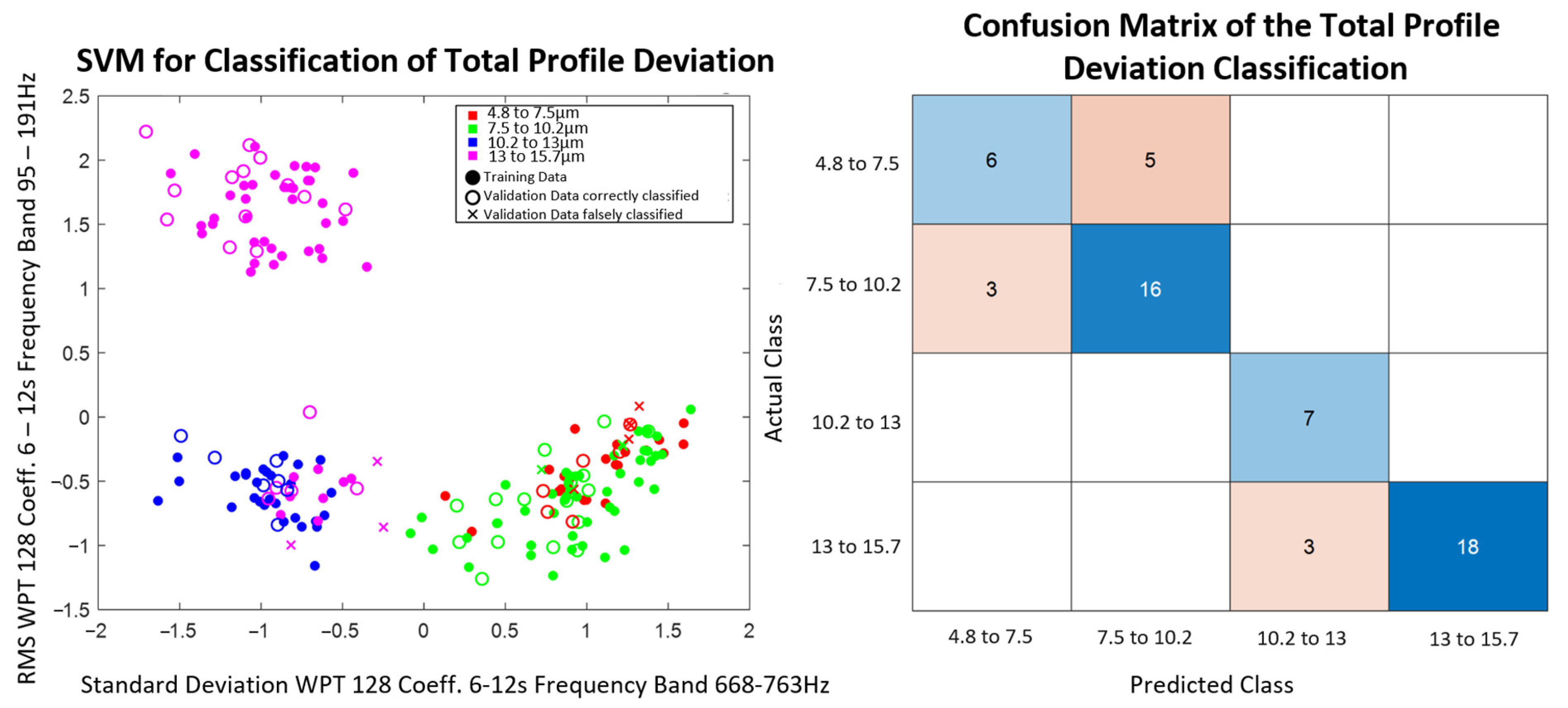
The whole data set contains 200 structure-borne sound signals at 20 different combinations of radial feed and tool tumble. Seven structure-borne sound signals of each of the ten repetitions per parameter setting are used as labeled learning data sets for the model training (140 structure-borne sound signals). Three signals per parameter setting (60 structure-borne sound signals) are randomly selected, excluded from model training, and later classified with the trained model in order to validate the models found. All data are also variance normalized.
For the classification of the process parameters and quality parameters, three different classification methods are tested with the selected features. The chosen methods, the Bayes classifier, the support vector machine, and the nearest-k-neighbor classifier, are selected since they are commonly used in literature and based on different principles. While in the Bayes classifier, the decision is made probability based and in the SVM the best separation plane to separate the different classes is searched in an optimization problem. In the KNN classifier, unknown data points are compared with similar (small-distance or large-correlation coefficient) training objects.
The models of the classification methods are trained using the learning data set in fivefold cross validation. The standard hyperparameters of the different models (see
Table 4) are varied in 30 iterations. In an automatic optimization, the classification model with the minimum classification error is searched for.
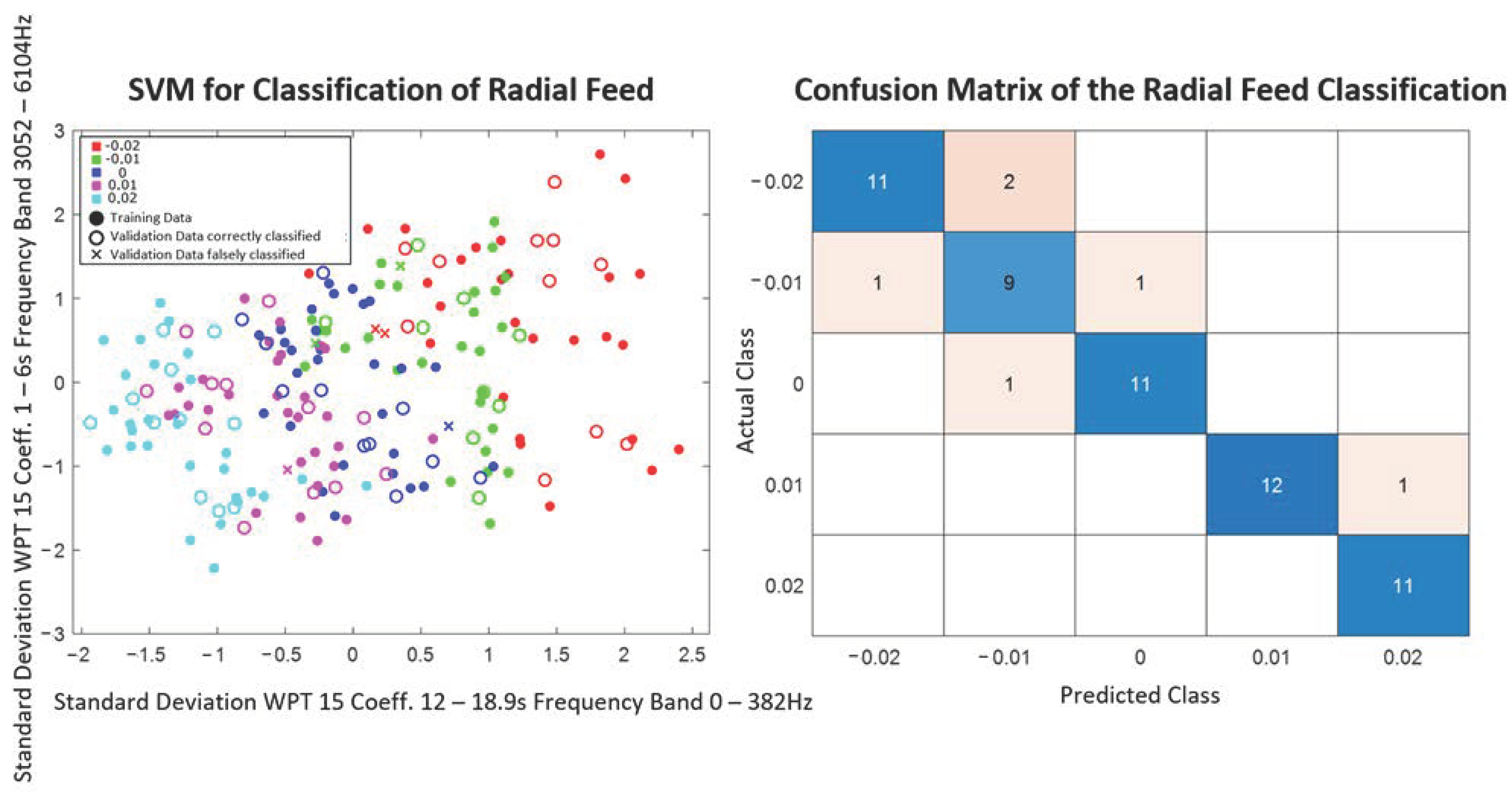
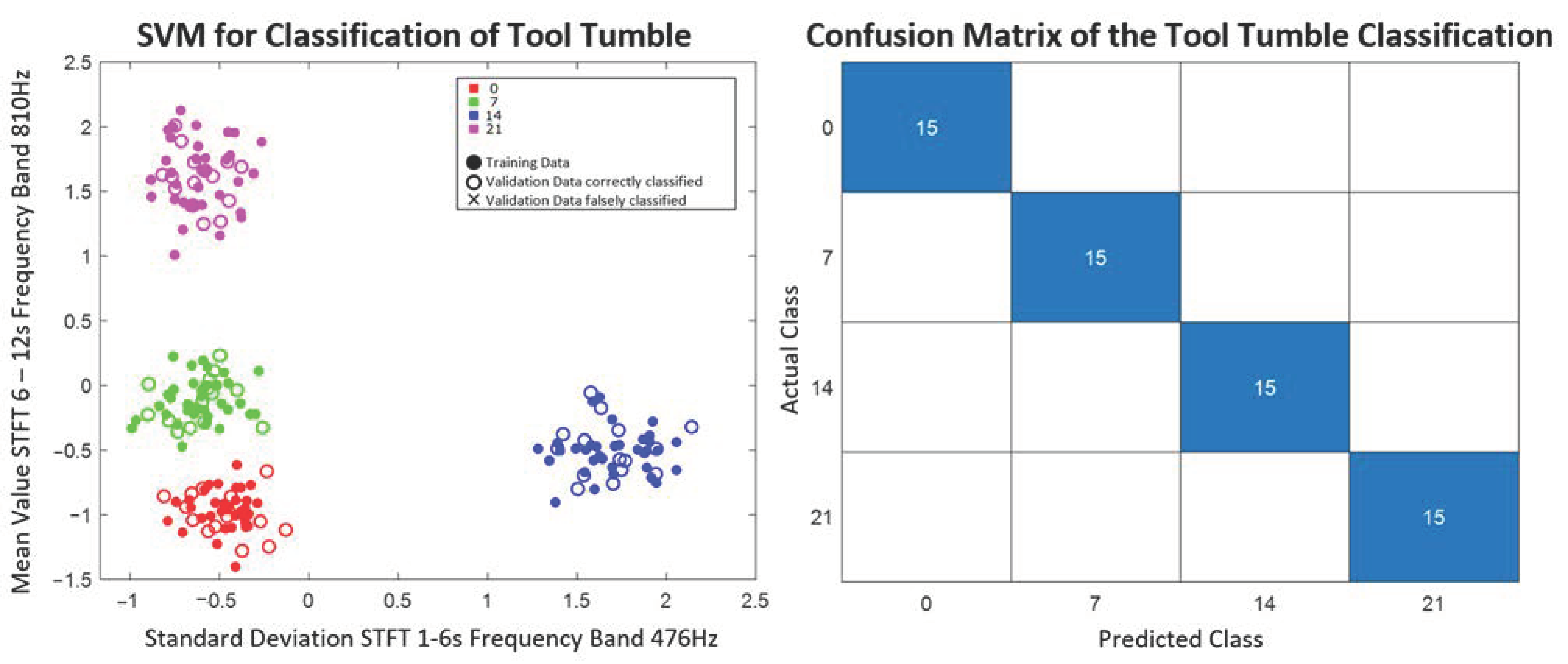
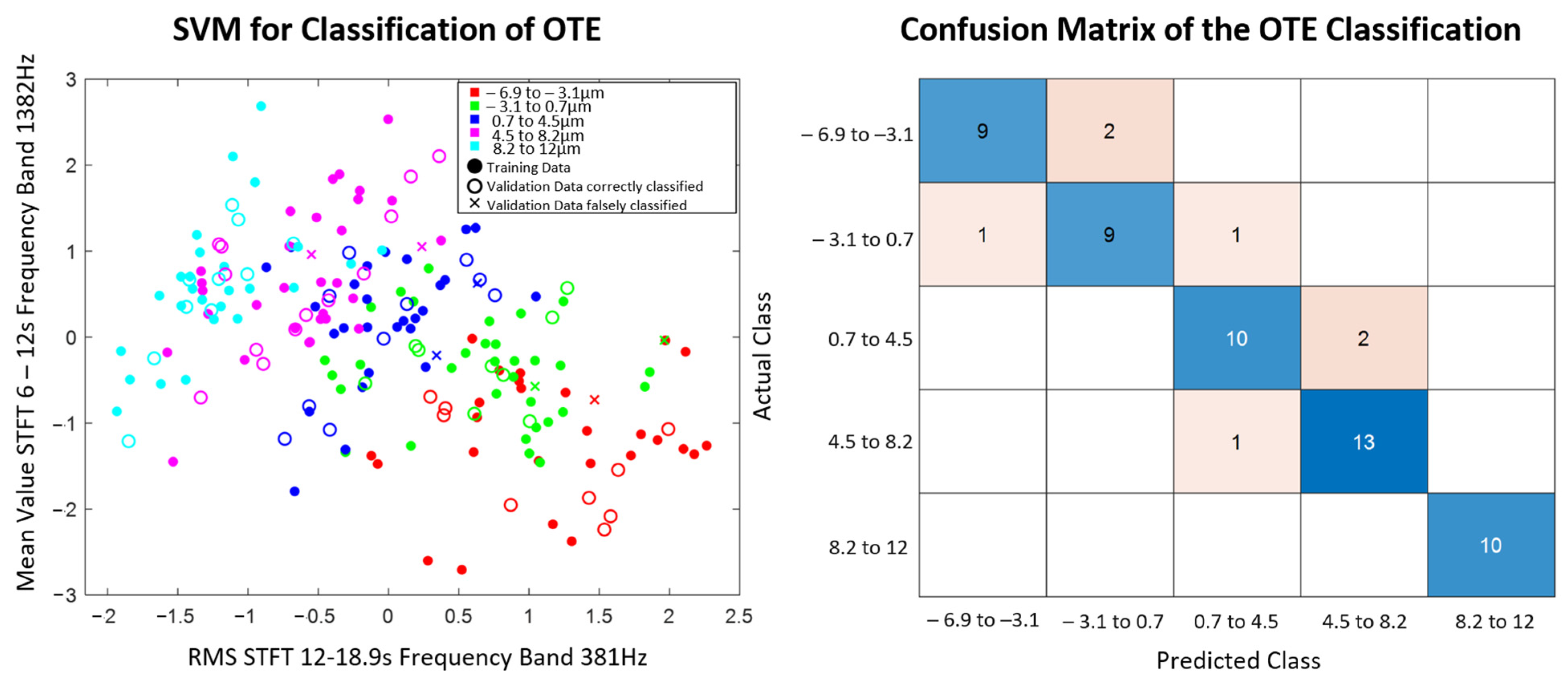
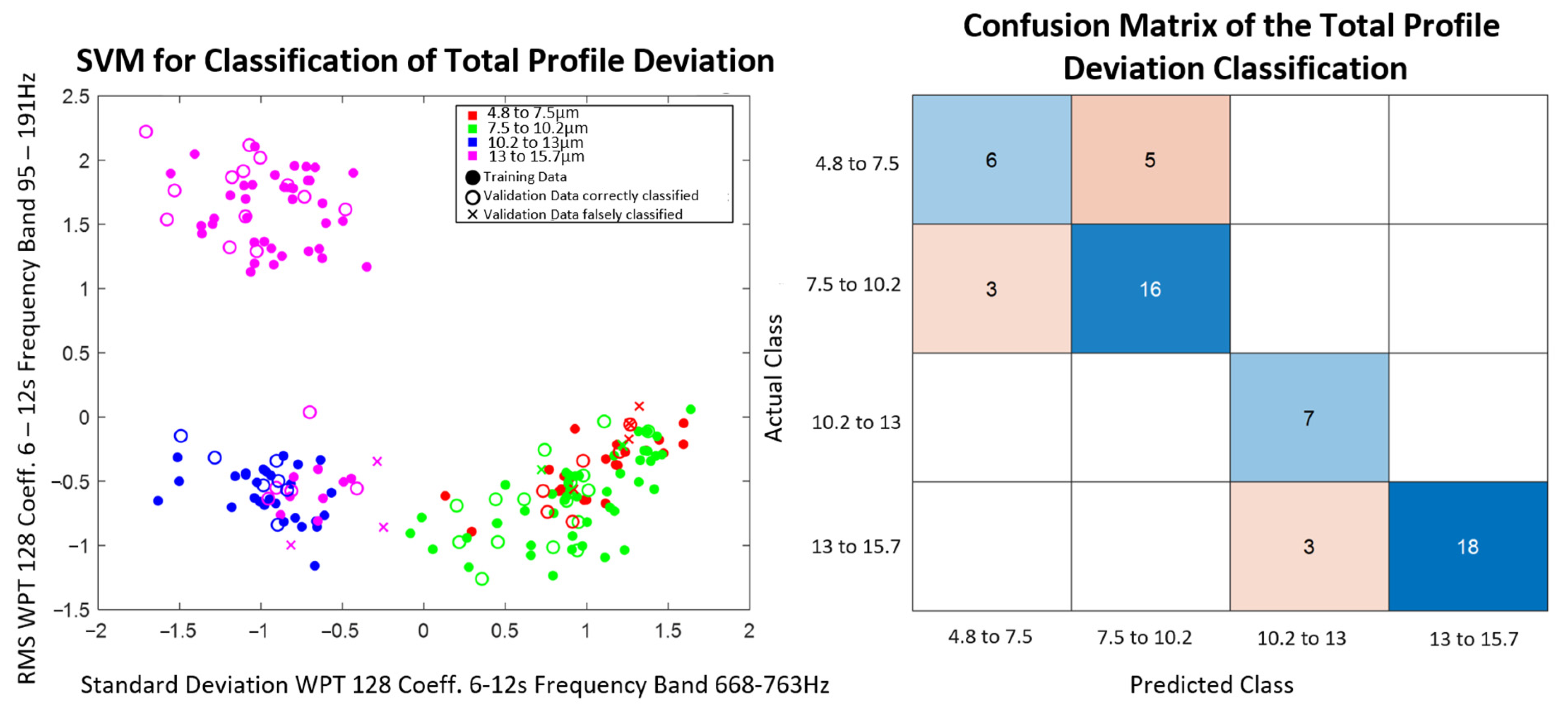
The model found is then used to predict the output variables of the validation data set. With the evaluation measure, accuracy, the models trained per feature combination and classification method are evaluated with respect to their suitability for the prediction of the respective output variable. The calculation of the accuracy can be seen in Equation (1). The evaluation allows statements about which combination of feature extraction and selection, as well as classification methods for the prediction of process parameters and quality variables, are potentially promising in the practical application.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}