
A Scenario-Based Model Comparison for Short-Term Day-Ahead Electricity Prices in Times of Economic and Political Tension
 , , , and
, , , and
Abstract
1. Introduction
1.1. Related Work
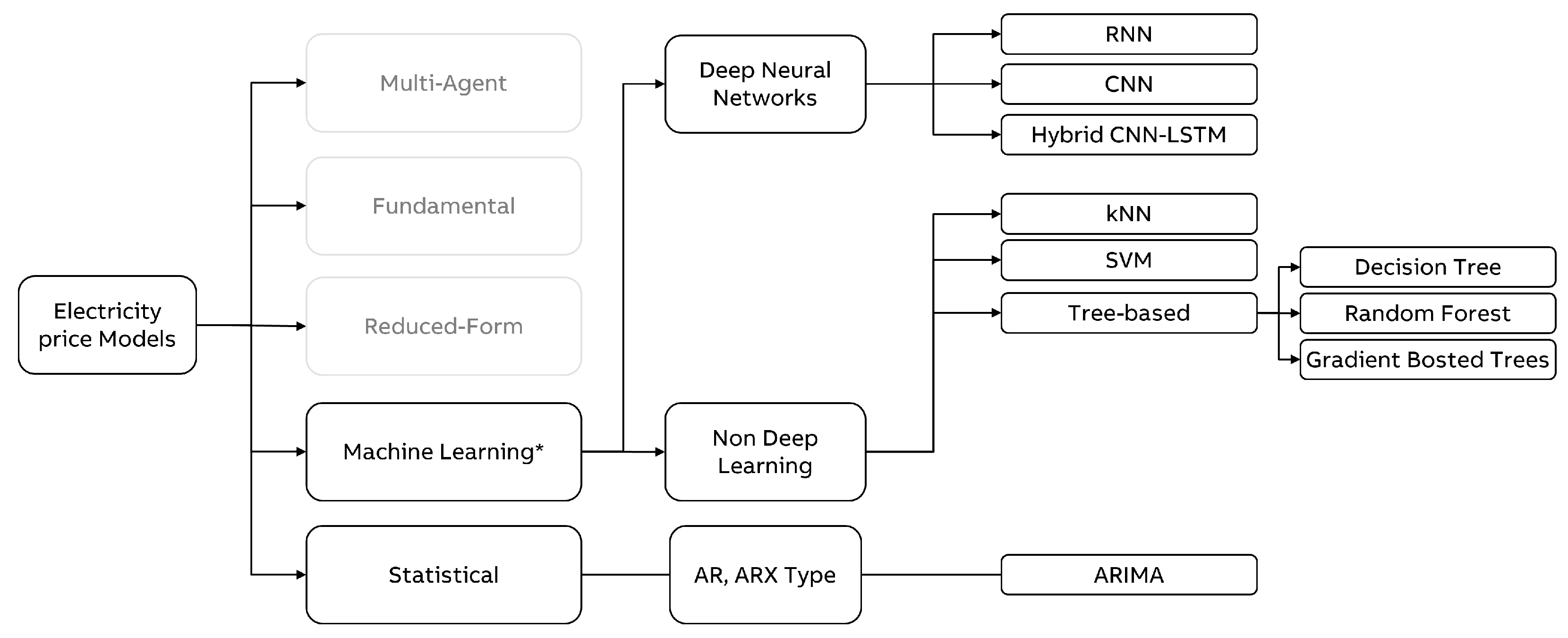
1.2. Techniques for Energy Market Prediction
- Multi-Agent ApproachesModel the behavior of different actors on the market by algebraic or differential equations and solve the equation systems to find the market equilibrium, such as the Nash Cournet Framework or Supply function equilibrium. Borenstein, Bushnell, and Knittel [24] or Cabero et al. [25] are worth mentioning for a sample application of the former and, e.g., Baldick et al. [26] of the latter one, respectively. An alternative approach is to simulate the market with the help of agent-based simulation models. This modeling approach is very flexible but requires many assumptions. Here, e.g., Guerci, Rastegar and Cincotti [27] can be referred to for further details.
- Fundamental or structural modelsThese models explicitly incorporate fundamental physical and economic relationships in energy production and trading and predict prices with the help of the resulting overall model. These models require detailed information about plant and transmission capacities and demand patterns. They also require assumptions about the physical and economic relationships in the market. See, e.g., Kanamura and Ohashi [28], Coulon and Howison [29], or Aïd, Canou, and Langrene [30] as illustrative examples.
- Reduced-form modelsThis class of models is inspired by financial models of price dynamics, where the intention is usually not to provide a precise hourly forecast. Instead, they aim to capture the characteristics of daily electricity prices, mainly as an input to risk analysis. Jump diffusion models (see Carea and Figueroa [31]) and Markov regime-switching models (see Hamilton [32]) can be considered as typical examples.
- Statistical modelsStatistical forecast of the current price by a mathematical combination of previous prices and/or previous or current values of exogenous factors. Among others, exponential smoothing (see Cruz, Muñoz, Zamora, and Espinola [33]), regression models (e.g., Kim, Yu and Song [34]) or AR-type time series models (see Cuaresma, Hlouskova, Kossmeier, and Obersteiner [35]) are typical approaches in that regard.
- Computational intelligence modelsThey are supposed to be nature-inspired computational techniques. Weron et al. [10] names here neural networks and support vector machines. See Chen, Dong, Meng, Xu, Wong, and Nagan [36], Garcia-Ascanio and Mate [37], Gareta et al. [38], or Mandal et al. [39] for the usage of neural networks, and Sansom, Downs, and Saha [40], among others, for SVM usage related to Energy Price Forecasting. To reflect the change in the perception of these methods in recent years, we decided to refer to this model type as a machine learning model.
2. Models
2.1. Statistical
- ARIMA Autoregressive integrated moving average (ARIMA) is a statistical time-series forecasting method combining an auto-regressive part [41], differentiating, and a moving average process. In this model, the future value is assumed to be a linear function of past observations and random errors. ARIMA models are widely used due to advantages such as simple structure and low computational complexity, as well as stable forecasting performance and capability to incorporate the seasonality factor prevailing in electricity price developments. In the presence of spikes, however, statistical methods perform relatively poorly. In addition, they struggle to capture the nonlinear fluctuation of market prices [10,42,43,44].
2.2. Machine Learning
2.2.1. Non Deep Learning
- kNNK-nearest-neighbors (kNN) is a training-free method that makes predictions by averaging observations with features closest to the input sample. The method of k-nearest neighbors is conceptually simple and explainable. They do not make assumptions about the data and work well with non-linear relationships, often producing accurate predictions. However, the method becomes unfeasible with large data sets or numerous features. kNNs are unable to extrapolate beyond the range of the training data and are sensitive to noisy and irrelevant features. Another limitation is sensitivity to the number of neighbors k to be compared with, and the chosen neighbor distance metric [53].
- SVMSupport vector machines (SVMs) work by detecting a hyperplane in a higher dimensional space with minimal distance to the fitted observations [54]. SVMs can solve linear and non-linear problems due to the ‘kernel trick’, implicitly mapping their inputs into high-dimensional feature spaces and then using simple linear functions to create linear decision boundaries in the new space. SVMs have become a common energy price forecasting method due to a variety of strengths, such as good approximating accuracy and generalization ability to unseen data, superior performance for small-scale training data, tolerance to redundant and highly interdependent features, as well as the capacity mentioned above to solve both linear and non-linear problems. The main challenges associated with SVM models are the computational costs of training, selection of a kernel function and parameters, sensitivity to noise and missing values, overfitting, and lack of explainability [10,42,44,46].
- Decision Trees, Random Forests and Gradient Boosted TreesOther popular methods are decision trees, random forests (making predictions by averaging a set of decorrelated trees built in parallel [55]), and gradient-boosted trees (which build an ensemble of trees iteratively by fitting a new tree on the residuals of the previous tree [56]). Decision trees are fast and interpretable: by retrieving the decision path for a given sample, one can see which feature values are used as criteria for the prediction. They can combine numerical and categorical features and capture non-linear relationships between features and the dependent variables. Trees are invariant under monotone transformations of individual features, robust concerning overfitting, and tolerant to outliers and missing values. Since feature selection implicitly occurs during training, decision trees are insensitive to irrelevant or interdependent features [53,55]. A relatively low accuracy limits them. The low accuracy, however, is alleviated by ensembling methods, for instance, random forests or gradient-boosted trees, which help increase prediction accuracy while maintaining all the benefits of decision trees, except for the loss of interpretability [46].
2.2.2. Deep Learning
- RNNWhile simple neural networks, such as fully connected feed-forward neural networks (FNN), are limited regarding sequential data, more sophisticated approaches have evolved [62]. So-called recurrent neural networks (RNN) are developed precisely for capturing sequential patterns and, thus, time series data. Instead of processing each timestamp independently and the entire sequence simultaneously, these models pursue a more dynamic approach: They process information incrementally and sequentially while creating an internal memory state on the fly—based on the previously provided content [63]. A particular performant kind of RNN is Long Short-Term Memory (LSTM), which can learn to recognize and store input and decide which information to preserve and which to forget. The key idea is to prevent older signals from gradually vanishing as the sequence elements get passed through the network [64]. This behavior is achieved by a memory block consisting of one or more memory cells and additional gates. The gates are an input gate, a forget gate, and an output gate. They control the information flows process [65].
- CNNAnother architecture to solve machine learning applications are convolutional neural networks (CNN) [66]. Originally designed to handle image data efficiently, this type of network shows its strengths when automatically extracting the most relevant features of grid-like data, such as images, text, or even time series. Whereas FNNs aim to learn global pattern given the entire input at once, CNNs focuses on spatially close or local patterns by applying kernels (a.k.a. filters or convolutions) over a subsection of input data. For image data, one or more kernels get sliced across an image, stopping at each subsection (a patch or chunk of the image, e.g., a few pixels) and applying the same transformation (called “convolution”) on it. The output of each transformation is a feature map that encodes specific aspects representative of each subsection [62]. Analogous to capturing relevant features across two dimensions in an image (along the height and width axes), this operation is also applied to time series data in that the sequence is treated like a one-dimensional image. The convolution operates over a 1D sequence in this regard, returning a 1D feature map for each subsection (e.g., a few timestamps) [67]. Because a CNN in its traditional structure does not consider the temporal dependence between past and future data, its isolated, plain application on time series data is not considered part of this comparison.
- Hybrid CNN-LSTMHowever, to potentially improve the learning process of LSTMs even further, some authors suggested combining the benefits of LSTMs and CNNs—notably, feature extraction and forecasting [57]. Accordingly, the idea contains two steps: The first step comprises a CNN part to extract the time-domain characteristics prevalent in different periods (e.g., days or weeks) to reduce frequency variation. The CNN is followed by an LSTM part, which—provided with the salient time series features—ought to efficiently capture the temporal dependencies within the previously constructed feature maps. Given an input of multivariate time series, the CNN applies a 1D convolution on each time series by sliding a 1D kernel (Instead of applying 1D filters on multiple time series simultaneously, an informative reader might also come up with the idea to stack the multivariate time series horizontally and use a single 2D-CNN with a two-dimensional kernel, that processes the input horizontally and vertically. The results turned out to be the same) vertically to the right (as time passes) to create corresponding time-domain feature maps. The output (feature maps with a specified width and a height of 1) gets transmitted to the LSTM layer(s). Two final dense layers deliver the prediction for a desired forecasting horizon.
2.2.3. Baseline
3. Materials and Methods
3.1. Data Set
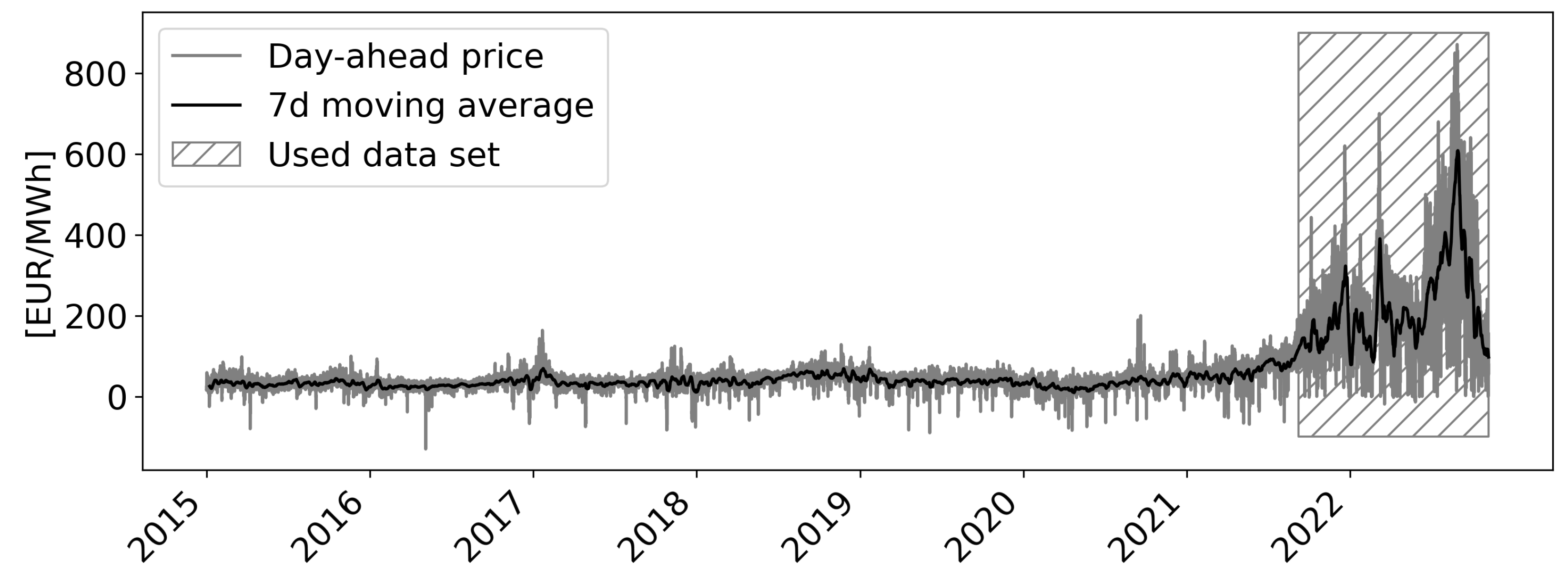
- Raw dataThe data set in this study consists of various publicly available weather data of the German Weather Service DWD [68] as well as market data from ENTSO-E [8]. The weather data set comprises measurements of several geographically distributed German weather stations, such as solar radiation, air pressure, wind speed, air temperature, and dew point temperature. The market data includes the traded spot market prices on the EEX in Leipzig and prices for energy sources such as Anthracite (hard coal) and natural gas. Overall, the complete data set contains more than 100 input variables. Although decades of historical data are available, this study focuses on data from recent years only, as a substantial shift in the data can be observed over the years (see Figure 1). Precisely, the data set starts on 9 September 2021 and covers the period until 1 November 2022—collected in hourly frequency.
- Feature Engineering and PreprocessingThe collected raw data undergoes a comprehensive pre-processing pipeline, including the following steps:At first, date-related features, such as an hour, day of the week, and day of the year, are transferred to a geometric representation with sine and cosine to prevent jumping transitions between two days, months, or years. Also, because the natural gas price is the only variable published daily instead of hourly, this variable must be forward-filled without any interpolation until the next available value to get an hourly resolution. Missing values in the weather data set are imputed by a k-Nearest-Neighbor (kNN) algorithm.A principal component analysis (PCA) on the weather data is performed To speed up the training process and improve the quality of the analysis, as they have shown to be highly correlated. The number of components depends on the explained variance; over 90% of the underlying information persists. Consequently, the weather data is reduced from 90 variables to 10.Since some algorithms cannot deal with time series with the trend or seasonal effects, a standard transformation of the target value in time series problems is to make them stationary. The data eventually approaches a stationary state by removing the daily and weekly periodicity and the removal of the inclining trend, verified by the Augmented Dickey-Fuller (ADFuller) and Kwiatkowski–Phillips–Schmidt–Shin (KPSS) test. Another step in the pre-processing pipeline is scaling input variables, notably by subtracting the mean and dividing by the standard deviation afterward; having all input variables in the same scale results in an improved model learning process. The same approach is applied to the target value as the final step.
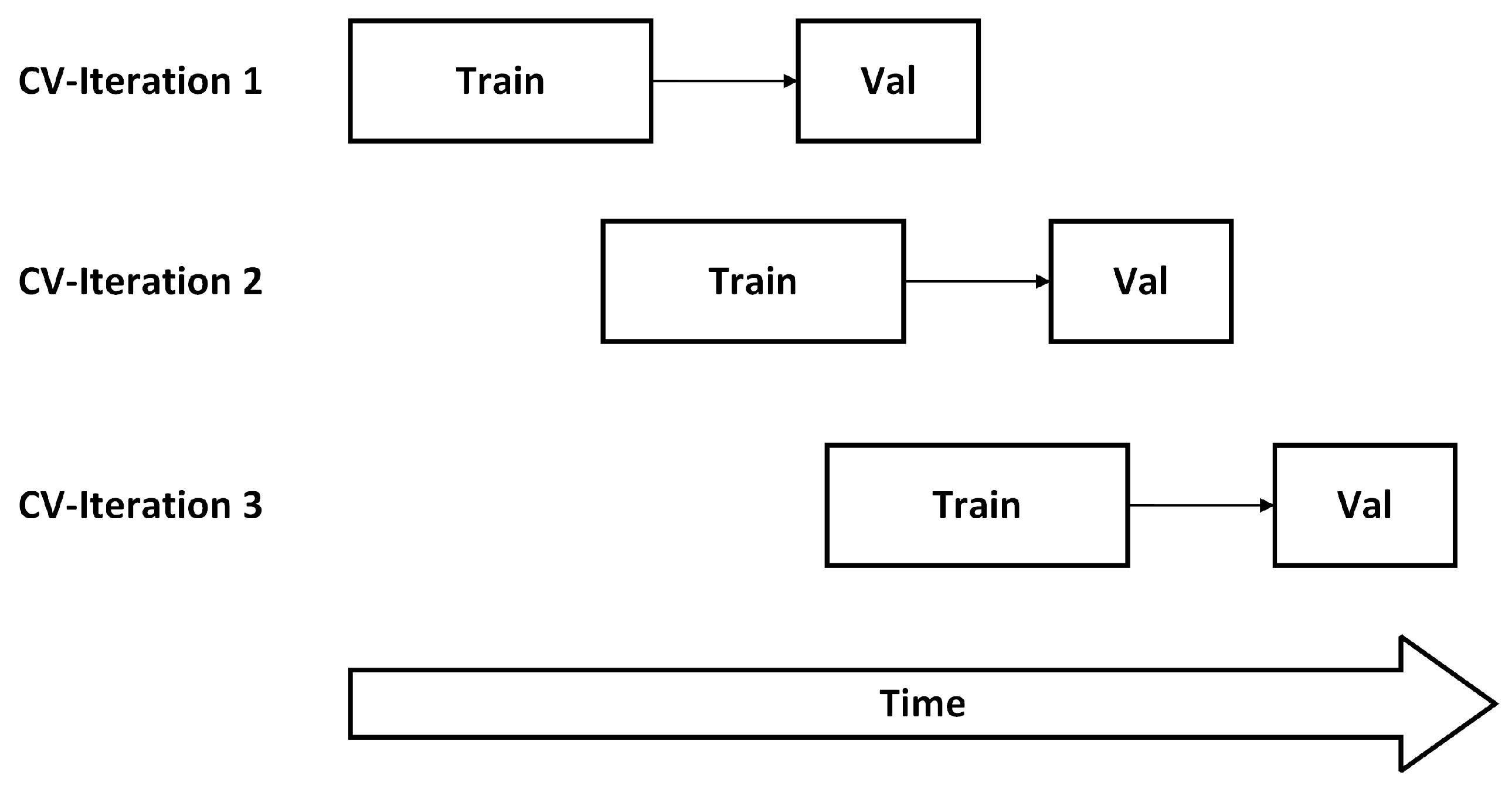
- Data splitFinally, the processed data set is split into training, validation, and test set. The training set consists of 8760 samples of window size 168 (equal to 168 h), resulting in one year. A subsequent time series with identical length is held out for validation and testing. Further details will be part of Section 3.4.
3.2. Scenario Selection
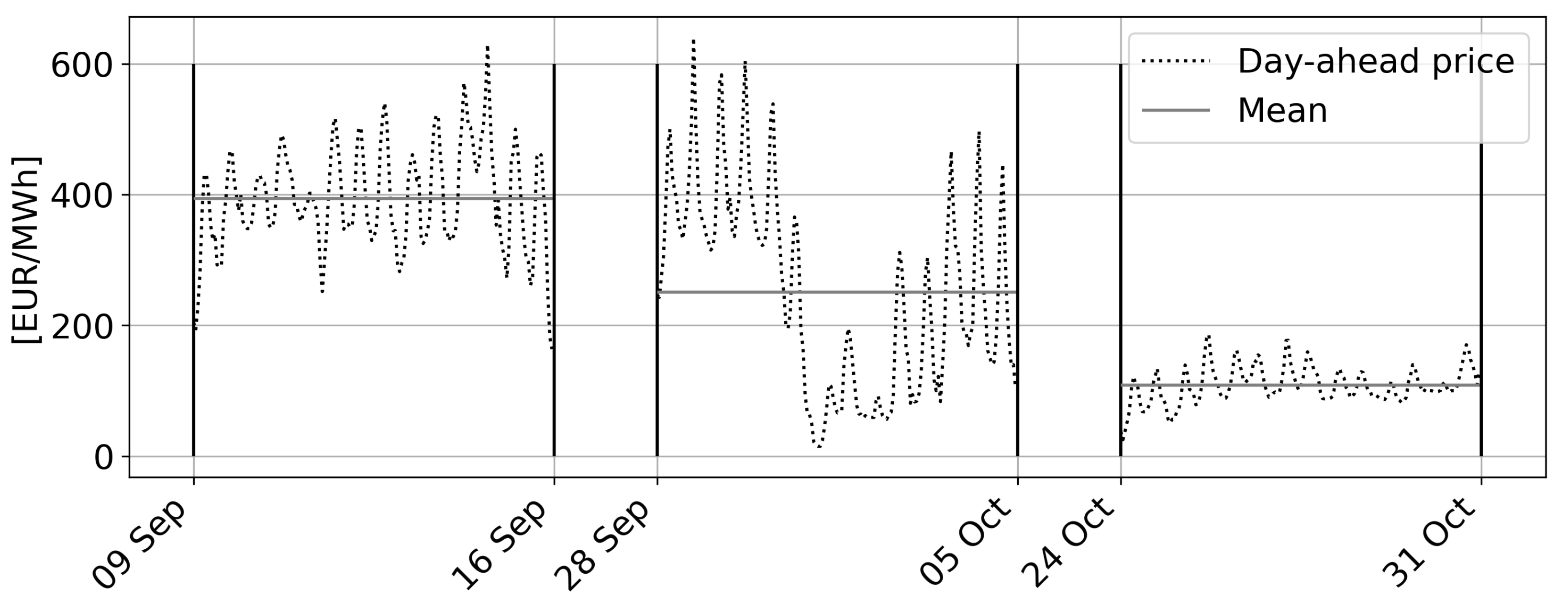
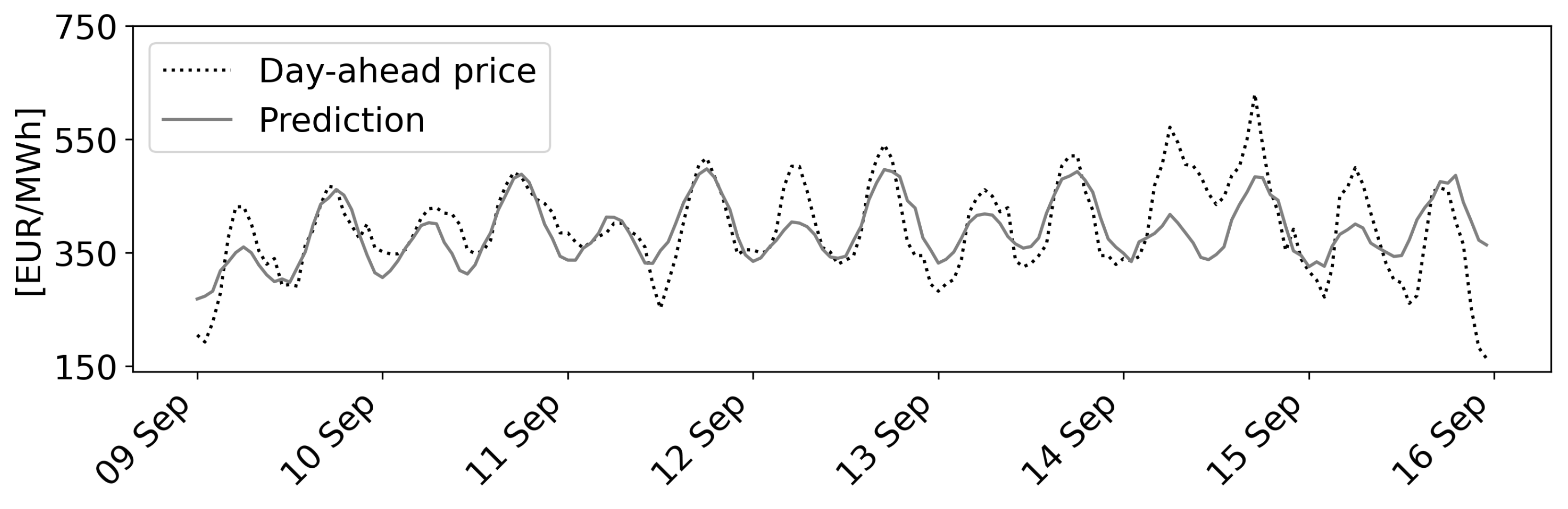
- Scenario 1 comprises the period from Friday, 9 September–Friday, 16 September 2022. This shows a day-dependent, cyclical behavior with normal price volatility.
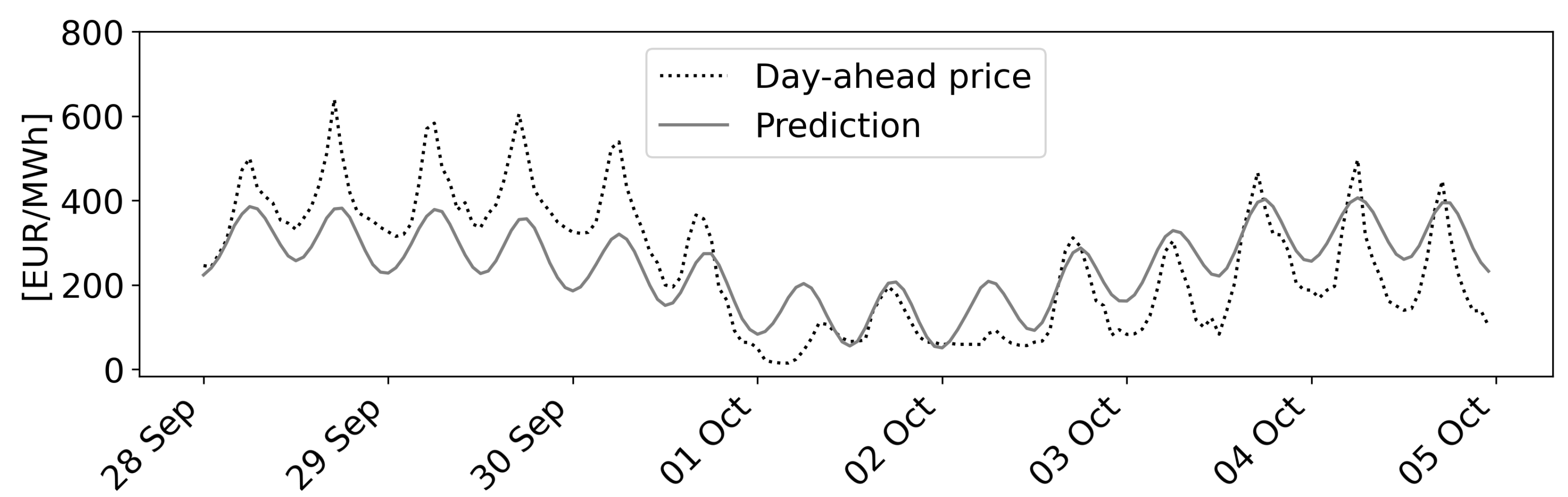
- Scenario 2 ranges from Wednesday, 28 September–Wednesday, 5 October 2022. It is characterized by high volatility and an acyclical price fall towards 0€/MWh.
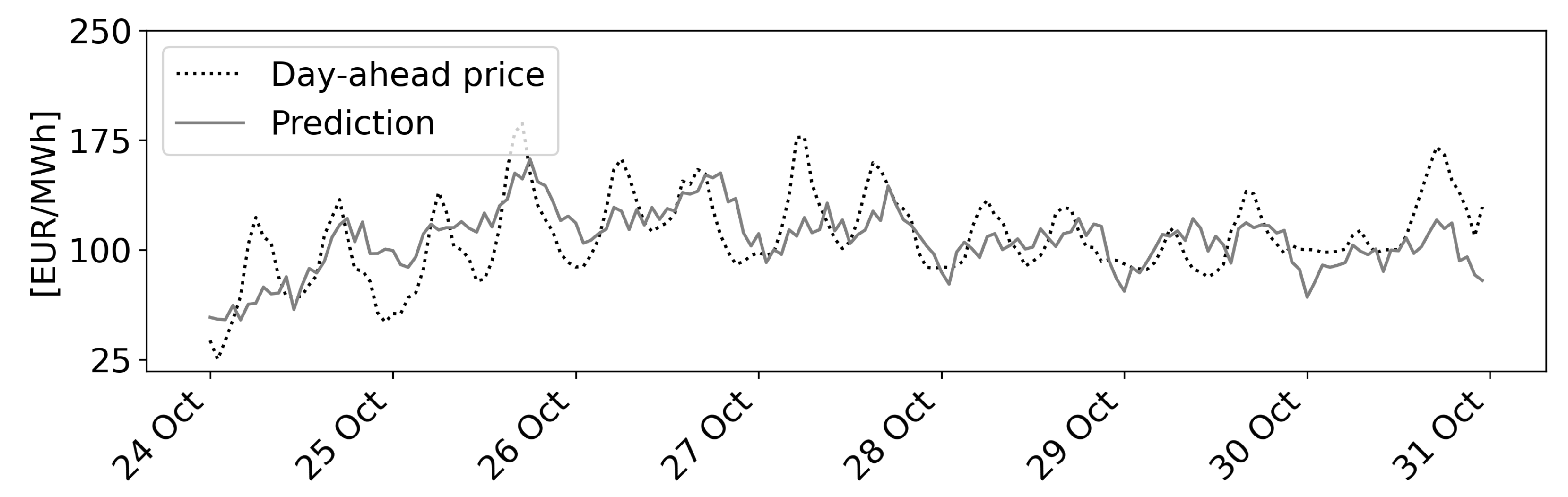
- Scenario 3 covers the period from Monday, 24 October–Monday, 31 October 2022 and shows low volatility and periodic prices with an offset of around −250€/MWh.
3.3. Model Fitting
3.4. Evaluation Criteria for the Algorithms
- is the predicted value for the ith observation in the dataset
- is the observed value for the ith observation in the dataset
- n is the sample size.
4. Results
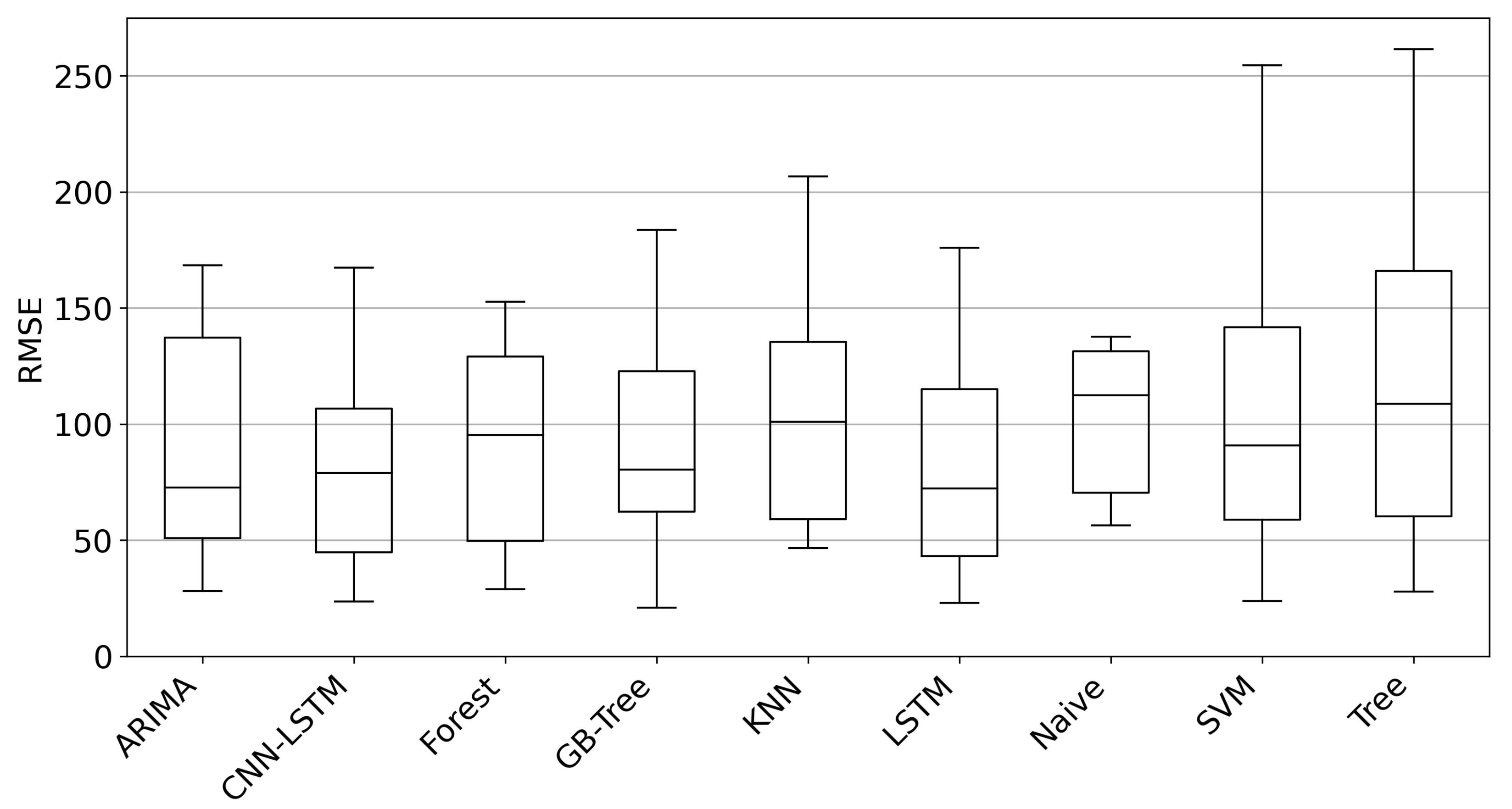
4.1. Model Robustness
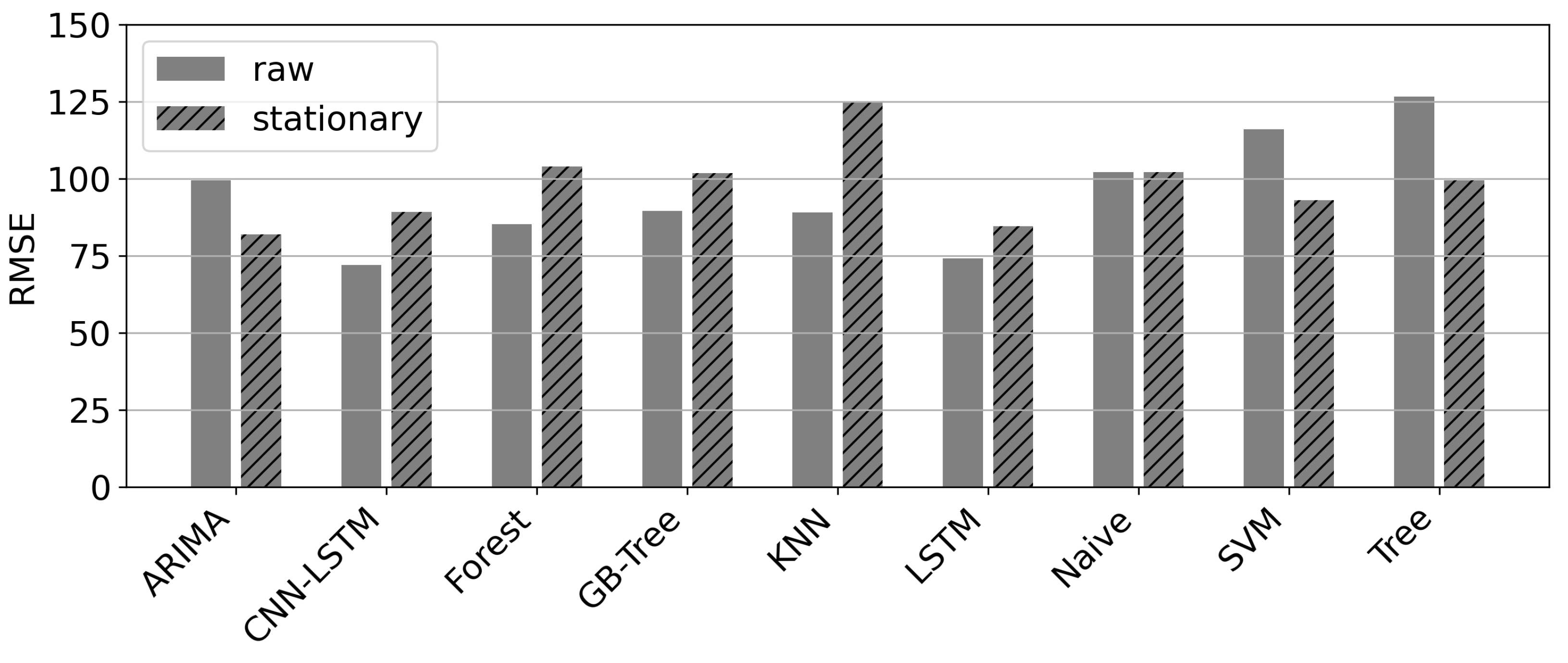
4.2. Data Set
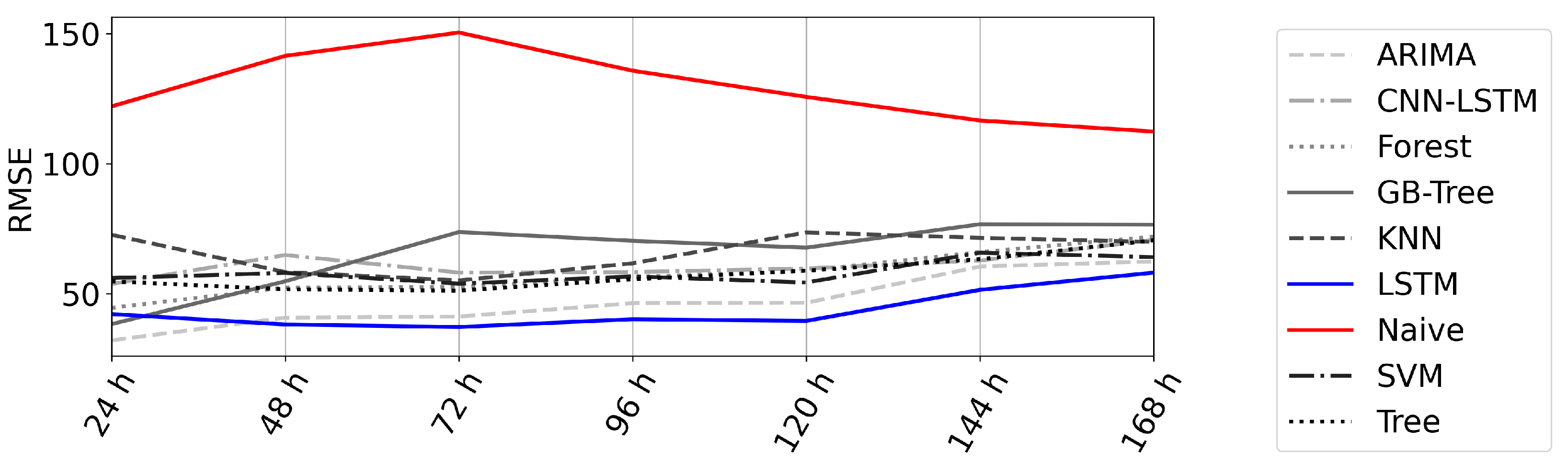
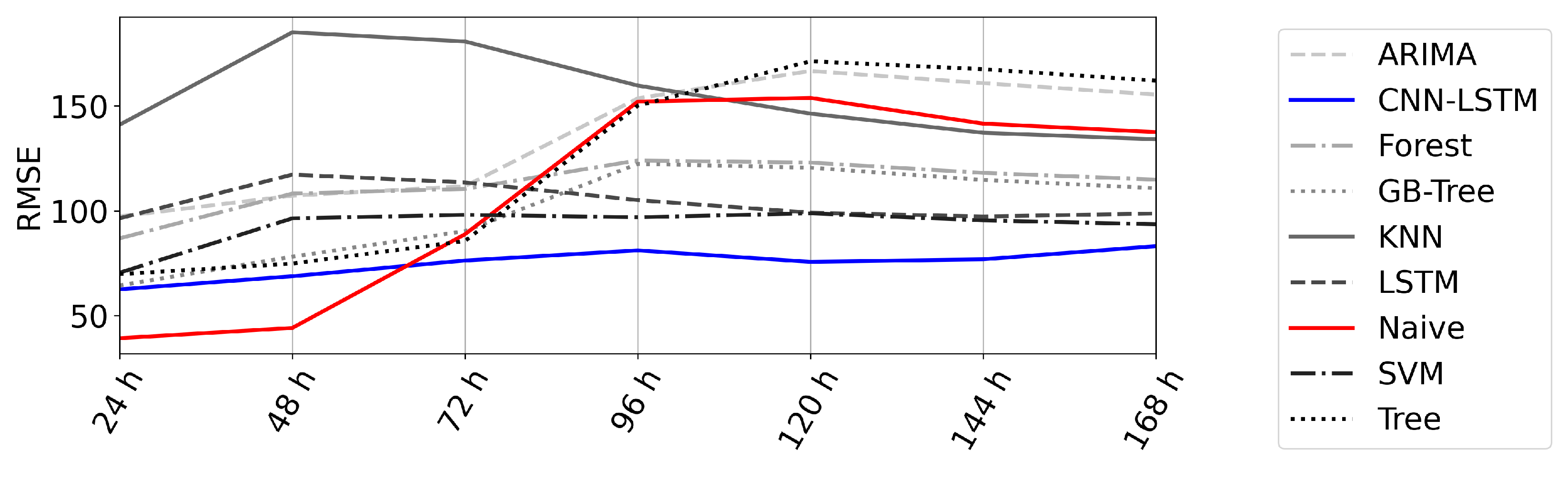
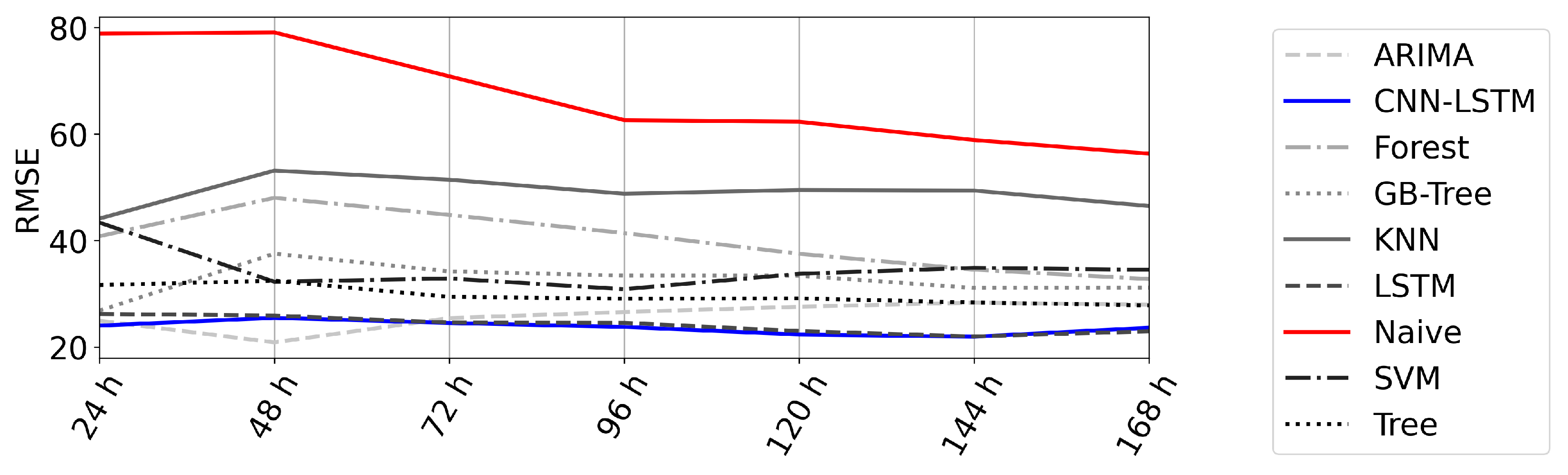
4.3. Error over Time
4.4. Predictions
5. Discussion
6. Conclusions
- Deep learning models are well suited for the prediction of time series in the interval of 168h in times of economic and political tension.
- The use of raw data has a positive influence on the error for best models/all deep learning models (RMSE decreases by approx. 10).
- Models based on CNN are best able to reproduce extreme values (fly up/down).
- Hyperparameter optimization can reduce the RSME by 20.
- The forecast error did not significantly rise with the forecast horizon.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADFuller | Augmented Dickey-Fuller |
| AR | Autoregressive Model |
| ARX | Autoregressive-exogenous Model |
| AI | Artificial Intelligence |
| ARMA | Autoregressive with Moving Average Model |
| ARIMA | Autoregressive Integrated Moving Average Model |
| CNN | Convolutional Neural Network |
| COVID-19 | Coronavirus disease 2019 |
| CV | Cross Validation |
| Decision Tree | Tree |
| DL | Deep Learning |
| DWD | Deutscher Wetter Dienst (German weather service) |
| EEX | European Energy Exchange |
| ENTSO-E | European association for the cooperation of transmission |
| system operators for electricity | |
| FNN | Feed-forward Neural Network |
| Forest | Random Forest |
| GB-Tree | Gradient Boosting Tree |
| KPSS | Kwiatkowski–Phillips–Schmidt–Shin |
| kNN | k-Nearest-Neighbors |
| LSTM | Long Short Term Memory |
| MAE | Mean Absolute Error |
| ML | Machine Learning |
| MLOps | Machine Learning Operations |
| MSE | Mean Square Error |
| PCA | Principle Component Analysis |
| RMSE | Root Mean Square Error |
| RNN | Recurrent Neural Network |
| SVM | Support Vector Machine |
References
- Lu, H.; Ma, X.; Ma, M.; Zhu, S. Energy price prediction using data-driven models: A decade review. Comput. Sci. Rev. 2021, 39, 100356. [Google Scholar] [CrossRef]
- Bento, P.; Mariano, S.; Calado, M.; Pombo, J. Impacts of the COVID-19 pandemic on electric energy load and pricing in the Iberian electricity market. Energy Rep. 2021, 7, 4833–4849. [Google Scholar] [CrossRef]
- Pradhan, A.K.; Rout, S.; Khan, I.A. Does market concentration affect wholesale electricity prices? An analysis of the Indian electricity sector in the COVID-19 pandemic context. Util. Policy 2021, 73, 101305. [Google Scholar] [CrossRef]
- Lazo, J.; Aguirre, G.; Watts, D. An impact study of COVID-19 on the electricity sector: A comprehensive literature review and Ibero-American survey. Renew. Sustain. Energy Rev. 2022, 158, 112135. [Google Scholar] [CrossRef] [PubMed]
- Şahin, U.; Ballı, S.; Chen, Y. Forecasting seasonal electricity generation in European countries under COVID-19-induced lockdown using fractional grey prediction models and machine learning methods. Appl. Energy 2021, 302, 117540. [Google Scholar] [CrossRef]
- Bigerna, S.; Bollino, C.A.; D’Errico, M.C.; Polinori, P. COVID-19 lockdown and market power in the Italian electricity market. Energy Policy 2022, 161, 112700. [Google Scholar] [CrossRef]
- Pizarro-Irizar, C. Is it all about supply? Demand-side effects on the Spanish electricity market following COVID-19 lockdown policies. Util. Policy 2023, 80, 101472. [Google Scholar] [CrossRef]
- European Network of Transmission System Operators for Electricity (ENTSO-E). Transparency Platform. 2022. Available online: https://transparency.entsoe.eu (accessed on 6 December 2022).
- Deutscher Wetterdienst. DWD Climate Data Center (CDC). 2022. Available online: https://www.dwd.de/DE/leistungen/opendata/opendata.html (accessed on 14 December 2022).
- Weron, R. Electricity Price Forecasting: A Review of the State-of-the-Art with a Look into the Future. Int. J. Forecast. 2014, 30, 1030–1081. [Google Scholar] [CrossRef]
- Lago, J.; Marcjasz, G.; De Schutter, B.; Weron, R. Forecasting day-ahead electricity prices: A review of state-of-the-art algorithms, best practices and an open-access benchmark. Appl. Energy 2021, 293, 116983. [Google Scholar] [CrossRef]
- Brusaferri, A.; Matteucci, M.; Portolani, P.; Vitali, A. Bayesian deep learning based method for probabilistic forecast of day-ahead electricity prices. Appl. Energy 2019, 250, 1158–1175. [Google Scholar] [CrossRef]
- Li, W.; Becker, D.M. Day-ahead electricity price prediction applying hybrid models of LSTM-based deep learning methods and feature selection algorithms under consideration of market coupling. Energy 2021, 237, 121543. [Google Scholar] [CrossRef]
- Tschora, L.; Pierre, E.; Plantevit, M.; Robardet, C. Electricity price forecasting on the day-ahead market using machine learning. Appl. Energy 2022, 313, 118752. [Google Scholar] [CrossRef]
- Lago, J.; De Ridder, F.; De Schutter, B. Forecasting spot electricity prices: Deep learning approaches and empirical comparison of traditional algorithms. Appl. Energy 2018, 221, 386–405. [Google Scholar] [CrossRef]
- Mujeeb, S.; Javaid, N.; Ilahi, M.; Wadud, Z.; Ishmanov, F.; Afzal, M.K. Deep Long Short-Term Memory: A New Price and Load Forecasting Scheme for Big Data in Smart Cities. Sustainability 2019, 11, 987. [Google Scholar] [CrossRef]
- Guo, X.; Zhao, Q.; Zheng, D.; Ning, Y.; Gao, Y. A short-term load forecasting model of multi-scale CNN-LSTM hybrid neural network considering the real-time electricity price. Energy Rep. 2020, 6, 1046–1053. [Google Scholar] [CrossRef]
- Memarzadeh, G.; Keynia, F. Short-term electricity load and price forecasting by a new optimal LSTM-NN based prediction algorithm. Electr. Power Syst. Res. 2021, 192, 106995. [Google Scholar] [CrossRef]
- Keles, D.; Scelle, J.; Paraschiv, F.; Fichtner, W. Extended forecast methods for day-ahead electricity spot prices applying artificial neural networks. Appl. Energy 2016, 162, 218–230. [Google Scholar] [CrossRef]
- Roeger, W.; Welfens, P.J. Gas price caps and electricity production effects in the context of the Russo-Ukrainian War: Modeling and new policy reforms. Int. Econ. Econ. Policy 2022, 19, 645–673. [Google Scholar] [CrossRef]
- Osička, J.; Černoch, F. European energy politics after Ukraine: The road ahead. Energy Res. Soc. Sci. 2022, 91, 102757. [Google Scholar] [CrossRef]
- Meng, A.; Wang, P.; Zhai, G.; Zeng, C.; Chen, S.; Yang, X.; Yin, H. Electricity price forecasting with high penetration of renewable energy using attention-based LSTM network trained by crisscross optimization. Energy 2022, 254, 124212. [Google Scholar] [CrossRef]
- Yang, H.; Schell, K.R. QCAE: A quadruple branch CNN autoencoder for real-time electricity price forecasting. Int. J. Electr. Power Energy Syst. 2022, 141, 108092. [Google Scholar] [CrossRef]
- Borenstein, S.; Bushnell, J.; Knittel, C.R. Market power in electricity markets: Beyond concentration measures. Energy J. 1999, 20. [Google Scholar] [CrossRef]
- Cabero, J.; Baillo, A.; Cerisola, S.; Ventosa, M.; Garcia-Alcalde, A.; Peran, F.; Relano, G. A medium-term integrated risk management model for a hydrothermal generation company. IEEE Trans. Power Syst. 2005, 20, 1379–1388. [Google Scholar] [CrossRef]
- Baldick, R.; Grant, R.; Kahn, E. Theory and application of linear supply function equilibrium in electricity markets. J. Regul. Econ. 2004, 25, 143–167. [Google Scholar] [CrossRef]
- Rastegar, M.A.; Guerci, E.; Cincotti, S. Forward Contract Effects in the Italian Whole-sale Electricity Market. In Handbook of Power Systems II; Rebennack, S., Pardalos, P.M., Pereira, M.V.F., Iliadis, N.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 241–286. [Google Scholar]
- Kanamura, T.; Ōhashi, K. On transition probabilities of regime switching in electricity prices. Energy Econ. 2008, 30, 1158–1172. [Google Scholar] [CrossRef]
- Howison, S.; Coulon, M. Stochastic behaviour of the electricity bid stack: From fundamental drivers to power prices. J. Energy Mark. 2009, 2, 29–69. [Google Scholar]
- Aïd, R.; Campi, L.; Langrené, N. A Structural Risk-Neutral Model for Pricing and Hedging Power Derivatives. Math. Financ. Int. J. Math. Stat. Financ. Econ. 2013, 23, 387–438. [Google Scholar] [CrossRef]
- Cartea, A.; Figueroa, M.G. Pricing in electricity markets: A mean reverting jump diffusion model with seasonality. Appl. Math. Financ. 2005, 12, 313–335. [Google Scholar] [CrossRef]
- Hamilton, J.D. Regime switching models. In Macroeconometrics and Time Series Analysis; Durlauf, S.N., Blume, L.E., Eds.; Palgrave Macmillan: London, UK, 2010; pp. 202–209. [Google Scholar]
- Cruz, A.; Muñoz, A.; Zamora, J.L.; Espínola, R. The effect of wind generation and weekday on Spanish electricity spot price forecasting. Electr. Power Syst. Res. 2011, 81, 1924–1935. [Google Scholar] [CrossRef]
- Kim, C.i.; Yu, I.K.; Song, Y. Prediction of system marginal price of electricity using wavelet transform analysis. Energy Convers. Manag. 2002, 43, 1839–1851. [Google Scholar] [CrossRef]
- Cuaresma, J.C.; Hlouskova, J.; Kossmeier, S.; Obersteiner, M. Forecasting electricity spot-prices using linear univariate time-series models. Appl. Energy 2004, 77, 87–106. [Google Scholar] [CrossRef]
- Chen, X.; Dong, Z.Y.; Meng, K.; Xu, Y.; Wong, K.P.; Ngan, H. Electricity price forecasting with extreme learning machine and bootstrapping. IEEE Trans. Power Syst. 2012, 27, 2055–2062. [Google Scholar] [CrossRef]
- Garcia-Ascanio, C.; Maté, C. Electric power demand forecasting using interval time series: A comparison between VAR and iMLP. Energy Policy 2010, 38, 715–725. [Google Scholar] [CrossRef]
- Gareta, R.; Romeo, L.M.; Gil, A. Forecasting of electricity prices with neural networks. Energy Convers. Manag. 2006, 47, 1770–1778. [Google Scholar] [CrossRef]
- Mandal, P.; Senjyu, T.; Funabashi, T. Neural networks approach to forecast several hour ahead electricity prices and loads in deregulated market. Energy Convers. Manag. 2006, 47, 2128–2142. [Google Scholar] [CrossRef]
- Sansom, D.C.; Downs, T.; Saha, T.K. Evaluation of support vector machine based forecasting tool in electricity price forecasting for Australian national electricity market participants. J. Electr. Electron. Eng. Aust. 2003, 22, 227–233. [Google Scholar]
- Box, G.E.; Jenkins, G.M.; Reinsel, G. Time Series Analysis: Forecasting and Control; Holden-Day, Inc.: San Francisco, CA, USA, 1970. [Google Scholar]
- Jiang, L.; Hu, G. A Review on Short-Term Electricity Price Forecasting Techniques for Energy Markets. In Proceedings of the 2018 15th International Conference on Control, Automation, Robotics and Vision (ICARCV), Singapore, 18–21 November 2018; pp. 937–944. [Google Scholar] [CrossRef]
- Luo, X.; Zhu, X.; Gee Lim, E. A Hybrid Model for Short Term Real-Time Electricity Price Forecasting in Smart Grid. Big Data Anal. 2018, 3, 8. [Google Scholar] [CrossRef]
- Patel, H.; Shah, M. Energy Consumption and Price Forecasting Through Data-Driven Analysis Methods: A Review. SN Comput. Sci. 2021, 2, 315. [Google Scholar] [CrossRef]
- Zhang, R.; Li, G.; Ma, Z. A Deep Learning Based Hybrid Framework for Day-Ahead Electricity Price Forecasting. IEEE Access 2020, 8, 143423–143436. [Google Scholar] [CrossRef]
- Ghoddusi, H.; Creamer, G.G.; Rafizadeh, N. Machine Learning in Energy Economics and Finance: A Review. Energy Econ. 2019, 81, 709–727. [Google Scholar] [CrossRef]
- Stathakis, E.; Papadimitriou, T.; Gogas, P. Forecasting Electricity Price Spikes Using Support Vector Machines. SSRN Electron. J. 2017. [Google Scholar] [CrossRef]
- Papadimitriou, T.; Gogas, P.; Stathakis, E. Forecasting energy markets using support vector machines. Energy Econ. 2014, 44, 135–142. [Google Scholar] [CrossRef]
- Zhao, J.H.; Dong, Z.Y.; Xu, Z.; Wong, K.P. A statistical approach for interval forecasting of the electricity price. IEEE Trans. Power Syst. 2008, 23, 267–276. [Google Scholar] [CrossRef]
- Díaz, J.; Romero, Á.; Dorronsoro, J.R. Day-ahead price forecasting for the spanish electricity market. Int. J. Interact. Multimed. Artif. Intell. 2018, 5, 42–50. [Google Scholar]
- Mei, J.; He, D.; Harley, R.; Habetler, T.; Qu, G. A random forest method for real-time price forecasting in New York electricity market. In Proceedings of the 2014 IEEE PES General Meeting|Conference & Exposition, National Harbor, MD, USA, 27–31 July 2014; pp. 1–5. [Google Scholar]
- Al-Qahtani, F.H.; Crone, S.F. Multivariate k-nearest neighbour regression for time series data—A novel algorithm for forecasting UK electricity demand. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–8. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer Series in Statistics; Springer: New York, NY, USA, 2009. [Google Scholar]
- Awad, M.; Khanna, R. Support Vector Regression. In Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers; Apress: Berkeley, CA, USA, 2015; pp. 67–80. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Kuo, P.H.; Huang, C.J. An Electricity Price Forecasting Model by Hybrid Structured Deep Neural Networks. Sustainability 2018, 10, 1280. [Google Scholar] [CrossRef]
- Chang, Z.; Zhang, Y.; Chen, W. Electricity price prediction based on hybrid model of adam optimized LSTM neural network and wavelet transform. Energy 2019, 187, 115804. [Google Scholar] [CrossRef]
- Zhang, C.; Li, R.; Shi, H.; Li, F. Deep Learning for Day-ahead Electricity Price Forecasting. IET Smart Grid 2020, 3, 462–469. [Google Scholar] [CrossRef]
- Huang, C.J.; Shen, Y.; Chen, Y.H.; Chen, H.C. A novel hybrid deep neural network model for short-term electricity price forecasting. Int. J. Energy Res. 2021, 45, 2511–2532. [Google Scholar] [CrossRef]
- Heidarpanah, M.; Hooshyaripor, F.; Fazeli, M. Daily electricity price forecasting using artificial intelligence models in the Iranian electricity market. Energy 2023, 263, 126011. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 21 January 2023).
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to Forget: Continual Prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Chollet, F. Deep Learning with Python; Manning Publications: Shelter Island, NY, USA, 2021. [Google Scholar]
- European Energy Exchange AG. Basics of the Power Market. 2023. Available online: https://www.eex.com/en/ (accessed on 21 January 2023).
- SKTime. Sliding Window Schema. Available online: https://www.sktime.org/en/stable/api_reference/auto_generated/sktime.forecasting.model_selection.SlidingWindowSplitter.html (accessed on 17 January 2023).
- Löning, M.; Bagnall, A.; Ganesh, S.; Kazakov, V.; Lines, J.; Király, F.J. sktime: A unified interface for machine learning with time series. arXiv 2019, arXiv:1909.07872. [Google Scholar]
- Chai, T.; Draxler, R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Uniejewski, B.; Weron, R.; Ziel, F. Variance Stabilizing Transformations for Electricity Spot Price Forecasting. IEEE Trans. Power Syst. 2018, 33, 2219–2229. [Google Scholar] [CrossRef]
- Ziel, F.; Weron, R. Day-ahead electricity price forecasting with high-dimensional structures: Univariate vs. multivariate modeling frameworks. Energy Econ. 2018, 70, 396–420. [Google Scholar] [CrossRef]
- Sculley, D.; Holt, G.; Golovin, D.; Davydov, E.; Phillips, T.; Ebner, D.; Chaudhary, V.; Young, M.; Crespo, J.F.; Dennison, D. Hidden Technical Debt in Machine Learning Systems. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://papers.nips.cc/paper/2015/hash/86df7dcfd896fcaf2674f757a2463eba-Abstract.html (accessed on 1 January 2023).
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Abdar, M.; Pourpanah, F.; Hussain, S.; Rezazadegan, D.; Liu, L.; Ghavamzadeh, M.; Fieguth, P.; Cao, X.; Khosravi, A.; Acharya, U.R.; et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Inf. Fusion 2021, 76, 243–297. [Google Scholar] [CrossRef]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1050–1059. [Google Scholar]
- Angelopoulos, A.N.; Bates, S. A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification. arXiv 2021, arXiv:2107.07511. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Average | Best | |||
|---|---|---|---|---|
| Model | RMSE | MAE | RMSE | MAE |
| LSTM | 79.33 | 64.52 | 59.92 | 48.45 |
| CNN-LSTM | 80.52 | 65.16 | 59.15 | 46.18 |
| ARIMA | 90.67 | 75.80 | 81.93 | 68.21 |
| Random Forests | 94.54 | 81.24 | 73.20 | 59.73 |
| Gradient Boosted Trees | 95.65 | 80.70 | 72.83 | 61.10 |
| Naive | 102.07 | 79.90 | 102.07 | 79.90 |
| SVM | 104.45 | 90.42 | 64.06 | 52.41 |
| KNN | 106.97 | 88.82 | 83.50 | 68.98 |
| Decision Trees | 113.01 | 98.60 | 86.80 | 70.47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baskan, D.E.; Meyer, D.; Mieck, S.; Faubel, L.; Klöpper, B.; Strem, N.; Wagner, J.A.; Koltermann, J.J. A Scenario-Based Model Comparison for Short-Term Day-Ahead Electricity Prices in Times of Economic and Political Tension. Algorithms 2023, 16, 177. https://doi.org/10.3390/a16040177
Baskan DE, Meyer D, Mieck S, Faubel L, Klöpper B, Strem N, Wagner JA, Koltermann JJ. A Scenario-Based Model Comparison for Short-Term Day-Ahead Electricity Prices in Times of Economic and Political Tension. Algorithms. 2023; 16(4):177. https://doi.org/10.3390/a16040177
Chicago/Turabian StyleBaskan, Denis E., Daniel Meyer, Sebastian Mieck, Leonhard Faubel, Benjamin Klöpper, Nika Strem, Johannes A. Wagner, and Jan J. Koltermann. 2023. "A Scenario-Based Model Comparison for Short-Term Day-Ahead Electricity Prices in Times of Economic and Political Tension" Algorithms 16, no. 4: 177. https://doi.org/10.3390/a16040177
APA StyleBaskan, D. E., Meyer, D., Mieck, S., Faubel, L., Klöpper, B., Strem, N., Wagner, J. A., & Koltermann, J. J. (2023). A Scenario-Based Model Comparison for Short-Term Day-Ahead Electricity Prices in Times of Economic and Political Tension. Algorithms, 16(4), 177. https://doi.org/10.3390/a16040177