1. Introduction
Forecasting is essential for supporting decisions at strategic, tactical, and operational levels. Accurate forecasts can assist companies and organizations in reducing costs, avoid risks, and exploit opportunities, thus finding application in a variety of settings. Nevertheless, univariate forecasting is a challenging task that usually requires identifying patterns in time series data and selecting the most appropriate model for extrapolating them in time. As a result, numerous approaches have been proposed to perform model selection [
1]. Still, this selection process involves significant uncertainty, especially when the patterns of the series are complex or the data are noisy [
2]. To deal with model uncertainty, forecasters have been combining (ensembling) forecasts of multiple models, each making different assumptions about the distribution and correlation of the data [
3]. The practice of combining has been proved particularly effective in various forecasting studies and competitions [
4] and many ensemble strategies have been suggested to exploit its full potential.
From the combination methods found in the literature, those that build on data manipulation and transformation are probably the most promising. Instead of training different models on the examined series and combining their forecasts, these methods transform the series to create new ones, each highlighting particular characteristics (typically called time series features) of the original data. Then, the same or different models can be used to forecast the transformed series. More often than not, combining these forecasts (typically called base forecasts) results in better forecasting accuracy. Petropoulos and Spiliotis [
5] discuss how the “wisdom of the data” can be used to extract useful information from series and review various approaches that exploit its benefits in univariate forecasting settings.
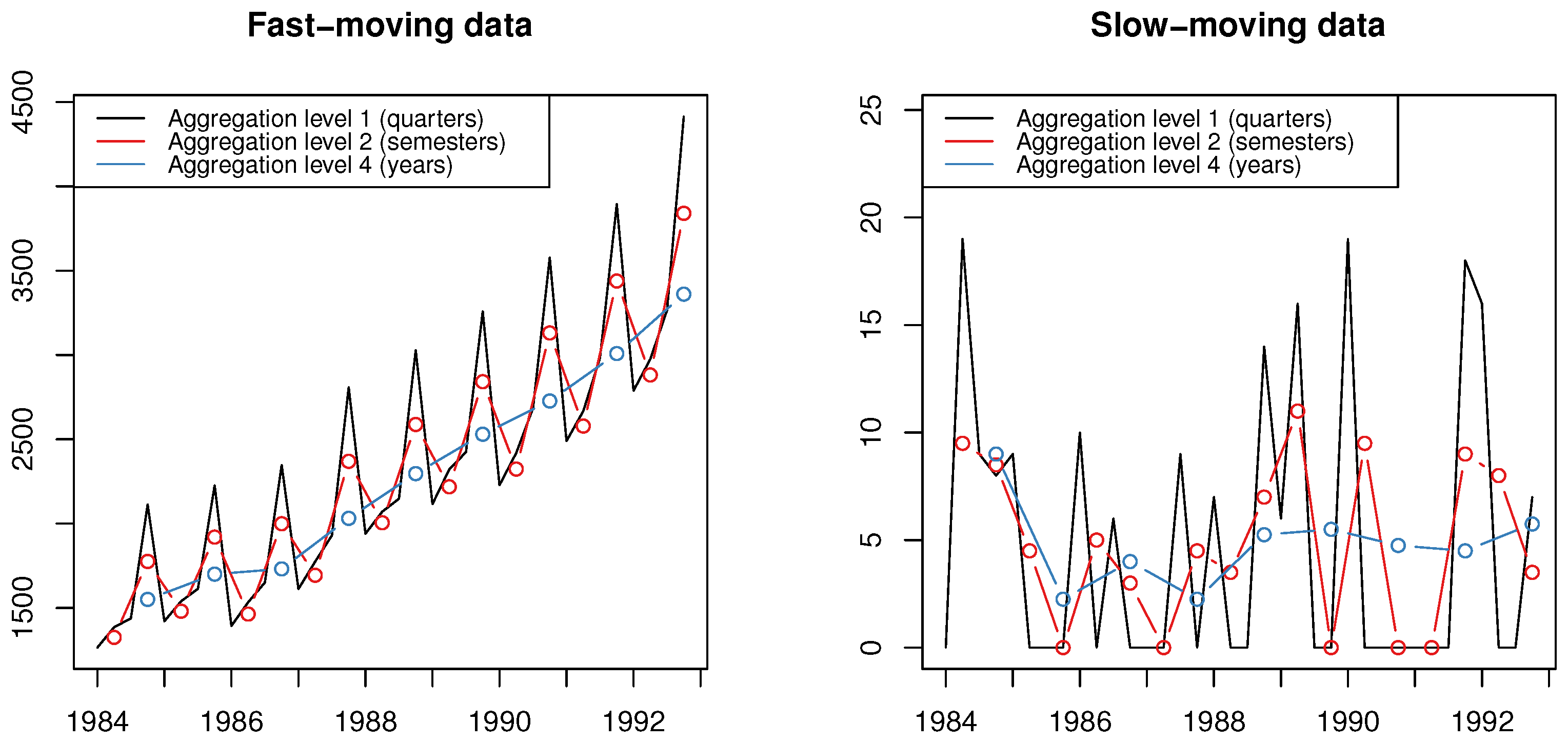
Temporal aggregation is one of the transformations that utilize the “wisdom of the data” concept to identify patterns that may be difficult to capture when analyzing the original series directly [
6]. Specifically, temporal aggregation is the transformation of a time series from one frequency to another, lower frequency. For instance, a quarterly time series of length
n can be transformed to a semi-yearly series of length
by using equally sized time buckets of two periods each or a yearly series of length
by aggregating (summing) the observations by four, as shown in
Figure 1. By changing the original frequency of the data, the apparent series characteristics also change and, as a result, different patterns can be observed and modeled to produce more accurate forecasts [
7]. Thus, temporal aggregation becomes relevant for predicting both slow- [
8,
9,
10,
11] and fast-moving [
12,
13] series. In the first case, where the data typically display intermittency or erraticness [
14], the aggregation filters out randomness and reveals the underlying signal of the series. In the second case, the transformation uncovers the trend patterns of the series, while allowing seasonality and level to be modeled at different levels.
Temporal aggregation can be applied both in an non-overlapping and an overlapping manner. However, the former approach has become more popular since its results are easier to interpret and avoids introducing autocorrelations [
15]. Moreover, non-overlapping aggregation allows the series created to be organized in temporal hierarchies [
13] and, as a result, forecasts can be produced using methods that have been proved successful when predicting cross-sectional hierarchies. Apart for improving accuracy, forecasting with temporal hierarchies also has the advantage that it generates reconciled predictions that support aligned decisions at different planning horizons [
16]. In addition, it provides a structured framework for combining forecasts from multiple temporal levels, an approach called multiple temporal aggregation.
Multiple temporal aggregation, which is effectively a forecast combination subject to linear constraints [
17], has several advantages over focusing on a single aggregation level [
18]. Similar to standard ensemble strategies, widely used in the literature to blend forecasts produced by different models or variants of them, it avoids selecting a single “best” aggregation level, which is challenging to do in practice [
19], and mitigates model and parameter uncertainty by exploiting the merits of combining [for a non-systematic review on temporal aggregation, please refer to [
6]. In practice, the main difference between standard forecast combination and multiple temporal aggregation is that in the former case, the forecasts to be ensembled are reported just at the original frequency of the series, while in the latter, they are reported at various data frequencies, thus exploiting the potential benefits of temporal aggregation in addition to those of forecast combination.
Nevertheless, multiple temporal aggregation also comes with some challenges. First, when the series is characterized by seasonality, combining seasonal base forecasts (typically produced at lower aggregation levels) with non-seasonal base forecasts (typically produced at higher aggregation levels) may lead to an unnecessary seasonal shrinkage that deteriorates accuracy. Spiliotis et al. [
16] and Spiliotis et al. [
20] elaborate on this issue and propose some pre-processing techniques and heuristic rules to mitigate its effect. Second, some multiple temporal aggregation methods suggest that all levels should contribute equally to the final forecasts [
9], an approach that may be proved sub-optimal in practice. Simply put, the information available at some of the levels may be more critical for improving forecasting accuracy, meaning that more weight should be assigned to the respective base forecasts. Athanasopoulos et al. [
13] and Wickramasuriya et al. [
21] suggest accounting for error variances contributing to the forecast error at some or multiple aggregation levels to weight base forecasts more appropriately. However, these estimates still rely on in-sample one-step-ahead forecast errors (residual errors), which may neither represent post-sample performance precisely nor be correlated with the objective function ultimately used to assess forecasting performance. More importantly, these approaches will still combine the base forecasts linearly, thus possibly failing to account for complex data relationships. To tackle these issues, Jeon et al. [
22] suggested using cross-validation to estimate the forecast errors and weight the base forecasts accordingly, while Spiliotis et al. [
23] employed machine learning (ML) models to nonlinearly combine cross-sectional hierarchical forecasts using weights that explicitly focus on post-sample accuracy, thus allowing for more flexible and selective ensembling.
In this paper, we offer a dynamic perspective to the problem of (multiple) temporal aggregation to address the aforementioned challenges, i.e., to avoid seasonal shrinkage, dynamically compute combination weights, and adjust said weights using post-sample accuracy records. Inspired by the recent advances in the field of ML, we propose the use of a classification model to either select the most appropriate temporal aggregation level or to derive the weights that properly combine the base forecasts computed at various levels. To do so, we extract several time series features at multiple temporal aggregation levels [
24] and use the features as leading indicators to estimate the importance of each level in improving forecasting accuracy. Effectively, the proposed classifier serves as a meta-learner that directly links time series features with post-sample forecasting performance. Such feature-based meta-learners have been successfully employed in the literature to combine the forecasts of multiple models [
25] or predict their performance [
26], but not in temporal aggregation settings.
We focus on a variant of classification trees, called LightGBM [
27], that exploits the power of gradient boosting and has shown excellent performance in similar tasks [
28], including time series forecasting [
29]. Gradient-boosted trees are preferred over other classification models as they selectively capture nonlinear relationships across the explanatory variables (features) used for prediction, are faster to compute, have more reasonable memory requirements, are simpler to optimize in terms of hyperparameters, require less data to be sufficiently trained (e.g., compared to neural networks), and are widely used in the literature for developing meta-learners that are tasked to select or to combine forecasts from a pool of alternatives [
26,
30]. The contributions of this paper are threefold:
We propose a nonlinear approach for employing (multiple) temporal aggregation and deciding either on the selection of the most suitable aggregation level for producing forecasts or on the weights to be used for combining the base forecasts of multiple levels. Compared to existing alternatives, this method is more general, relying neither on heuristic rules [
8,
31] nor on pre-defined weights [
13,
25].
In order to analyze the complex data relationships between forecasting accuracy and time series features, we consider an ML process that involves the preparation of the data (estimation of time series features and conduction of forecasting simulations), the tuning of the meta-learner in terms of hyperparameters, and its training.
We suggest that once the meta-learner has been trained, it can directly be used to derive the combination weights of the base forecasts for any time series at hand in a robust and fast fashion using the features of said series as input.
Note that the proposed classification model is explicitly trained with the objective of producing results that minimize the forecast error, as defined by the forecaster. More importantly, training is performed by assessing the post-sample accuracy of each forecast being combined, measured through validation. Therefore, the suggestions of the meta-learner are expected to be more representative and better match the objectives of the forecasting task at hand. In addition, given that the classifier learns from multiple time series simultaneously (cross-learning), the meta-learner generalizes better, thus avoiding biases that may occur when the forecast errors computed for deriving the combination weights are estimated for each series separately. Moreover, its results are directly linked with the characteristics of the examined series, facilitating their interpretation.
We benchmark the performance of the meta-learner against standard methods used for applying (multiple) temporal aggregation considering two large data sets that contain both fast- and slow-moving series. The benchmarks include conventional forecasting (no temporal aggregation is applied), an equally weighted combination of base forecasts [
10], forecasting with temporal hierarchies [
13], as well as popular time series forecasting methods that have achieved good performance in well-known forecasting competitions. The results, which include tests for significance, suggest that the proposed approach can improve forecasting accuracy, especially for the case of the fast-moving data. These improvements reach 4% when compared to conventional forecasting and about 6% when compared to popular time series forecasting methods used in the field.
The remainder of the paper is organized as follows.
Section 2 describes popular methods found in the literature for applying (multiple) temporal aggregation.
Section 3 presents the proposed meta-learner and explains how it can be used in practice to select or combine the base forecasts generated at various temporal aggregation levels.
Section 4 presents the two data sets used for the empirical evaluation of the meta-learner and describes the experimental design.
Section 5 presents our results and discusses our findings. Finally,
Section 6 concludes the paper.
3. Proposed Method
As discussed in
Section 2, various approaches can be used to combine or to select forecasts (selection can be considered as an extreme combination case where the total weight is assigned to a single forecast and, as a result, the rest of the forecasts are discarded by receiving a weight of zero). A simple yet effective approach is to average all base forecasts available, since, due to the uncertainty present, there is often no guarantee that the “optimal” forecast combination will outperform the equal-weighted one [
3]. Similarly, one may decide to combine the base forecasts using other standard operators, such as the median [
41] or the mode [
42], as they are less sensitive to outliers and asymmetric distributions. Nevertheless, when there is strong evidence that some forecasts are more accurate than others, forecasters usually prefer to weight the base forecasts using either linear (e.g., optimal combining and variable weighting methods) or nonlinear combination (e.g., neural network methods and self-organizing algorithms) schemes [
38]. In such cases, the weights of combining are typically determined by evaluating the in-sample accuracy of the base forecasts [
39,
40], but cross-validation techniques [
43] can also be used to better simulate their post-sample performance [
1]. As a result, forecasts that are regarded as more accurate are weighted more in the combination compared to less accurate ones.
An interesting alternative to combine or to select forecasts involves the examination of the characteristics of the time series being predicted. The key idea behind this approach is that, depending on the characteristics of the series, different types of forecasts may be more relevant. Shah [
44] and Meade [
45] used linear regression and discriminant analysis methods to predict the performance of various forecasts, thus providing some early selection rules. Similarly, Collopy and Armstrong [
46], Goodrich [
47], Adya et al. [
48], and Adya et al. [
49] employed rule-based forecasting and expert systems to combine or to select forecasts depending on the data conditions. Petropoulos et al. [
25] considered a set of time series features and the forecasting horizon to select the most appropriate forecast concluding that there are useful feature cases both for fast- and slow-moving data. More recently, Kang et al. [
50] and Spiliotis et al. [
51] explored the characteristics of the time series used in popular forecasting competitions, including the M3 and M4 [
4], confirming that the relative performance of different forecasting methods depends on the particularities of the data.
Building on this concept, Montero-Manso et al. [
30] used the M4 data set to train a meta-learner that assigned combination weights to nine different forecasting methods by linking their performance, measured through cross-validation, with the features of the series. The meta-learner, which was an extreme gradient boosted tree, was proved very successful, winning the second place in the M4 competition. Similarly, Talagala et al. [
26] used a Bayesian multivariate regression method to construct a feature-based meta-leaner that predicts the performance of each forecasting method, thus providing evidence about which base forecast(s) should be selected or combined. In cross-sectional hierarchical forecasting settings, Abolghasemi et al. [
28] used ML classification methods to determine, based on the characteristics of the series involved in the hierarchy, which reconciliation method (e.g., bottom-up, top-down, and optimal) should be preferred.
There are many advantages of using ML meta-learners to combine or to select forecasts over utilizing other approaches [
23]. First, in contrast to expert systems and heuristic rule-based forecasting methods, the rules of the meta-learners are explicitly derived by the available data instead of being defined by experts, whose insights may be biased or focused on particular applications and data sets. Second, since ML models are nonlinear in nature, they can account for more complex relationships observed in the data compared to linear methods, also having a higher learning capacity. Third, meta-learners build their rules by directly linking time series features with post-sample performance, as defined by the forecaster, instead of considering the in-sample performance of the forecasts or accuracy measures that may differ to those actually used for the final evaluation of the forecasts, a practice that may lead to sub-optimal results [
52]. Fourth, meta-learners can define the rules by observing data relationships across multiple series. As a result, the models are sufficiently generalized, avoiding biases that may occur when modeling takes place for each series separately.
Drawing from the above, we propose using a feature-based meta-learner to dynamically employ (multiple) temporal aggregation. The proposed meta-learner is a decision-tree-based classification model that can be used to either select the most appropriate temporal aggregation level or derive the weights that appropriately combine the base forecasts computed at the various levels. Below, we describe our methodological approach, including the time series features used as input by the classification model, as well as the training and forecasting process.
3.1. Feature Selection
There is a significiant range of features that can be used to describe a time series and its characteristics. When it comes to fast-moving data, a widely used set of time series features can be retrieved from the
tsfeatures package for R [
53]. Another interesting set of features has been introduced by Lemke and Gabrys [
54], emphasizing statistics, frequency, autocorrelation, and diversity. Considering slow-moving data, Nasiri Pour et al. [
55] proposed a set of features aiming to sufficiently describe lumpy series. Nevertheless, there is no objective way of determining the optimal number or set of features to be used for describing a data set, nor it is guaranteed that using the maximum amount of possible extracted features will result in better results. Therefore, in our study, we use a variety of features that, in our opinion, can sufficiently describe the essential components of the time series at hand.
Specifically, for slow-moving data, we consider two essential features that are widely used for categorizing demand patterns [
56]: the average inter-demand interval (ADI), which measures the frequency of zero instances in the data set, and the coefficient of variation (
), which measures the variation of non-zero demand occurrences. In addition, we use some of the features proposed by Nasiri Pour et al. [
55]. Note that the aforementioned features are calculated both for the original time series and the time series of lower frequencies derived when employing temporal aggregation. This process results in a richer set of features that not only describes the original data set, but also provides useful information for the temporally aggregated series.
With regard to the fast-moving data, we exploit the wide variety of features provided by the
tsfeatures package. The features capture time series characteristics such as trend, seasonality, and stability, as well as statistical measures over the time series data, such as autocorrelation. In resemblance to the approach used for the slow-moving data, we extract the selected features at all temporal aggregation levels. The features used, along with the levels on which they are calculated for both the slow- and fast-moving data sets, are presented in
Table A1 and
Table A2 of
Appendix A.
3.2. Classifier (Meta-Learner)
In the attempt to develop a meta-learner, we utilize a ML classification model. Classification consists a supervised ML problem, focusing on the accurate assignment of observations (in our case, time series) into certain classes (in our case, temporal aggregation levels). The problem can be either binary, meaning that there are only two possible classes, or multi-class.
To perform classification, a set of selected features (inputs) is extracted for each observation included in the data set used for training the ML method, along with their respective class (output or label). Then, the method is tasked to identify patterns so that the classes are precisely predicted based on the features available. Ultimately, once the relationships between the classes and the features have been learned, the method can be used to classify observations that were not originally included in the train set. Note that most classifiers do not predict the label per se, but estimate the probability of a class to be the “right” one. Therefore, the output of the classifier can be realized as a probabilistic prediction that can be used to identify the class that is presumably “correct”.
In the settings of our study, the probabilities will refer to how likely it is for a certain temporal aggregation level to result in the most accurate forecasts. Consequently, selecting the level of the highest probability will suggest forecasting through temporal aggregation, while combing the forecasts produced at all levels with weights that are driven by said probabilities will suggest forecasting through multiple temporal aggregation. Note that, if the lowest temporal aggregation level is identified as “best”, the classifier will effectively suggest conventional forecasting, i.e., forecasting at the original frequency of the series.
Although the classifier can be implemented using any ML model of preference, we chose a gradient boosting model due to its high accuracy and low computational cost. Specifically, we employed the Booster model from the LightGBM library for Python, an ML algorithm built on gradient boosting trees that generates multiple independent trees, one at a time, aiming to decrease each time the errors made by the former trained tree.
LightGBM involves several hyperparameters that can significantly affect its performance. In order to tune them, we apply grid search, an automated method that explores a set of different hyperparameter values and computes the forecasting performance on a validation set to find the most appropriate ones, as defined by an accuracy measure. We focus on the most critical hyperparameters, i.e., the number of boosting iterations (), which determines the number of trees to be created (the model generates ( × ) trees), the maximum number of leaves in each tree (), the learning rate, the percentage of features sampled (feature fraction), the percentage of data sampled from the data set without re-sampling (bagging fraction), and the frequency in which the data are being sampled during the iterations (sampling frequency).
The ranges from which the hyperparameter values were randomly sampled in our experiments are presented in
Table 1. In our case, the validation set consisted of the last
h observations of the time series train set, with
h being the forecasting horizon. However, once the hyperparameters were identified, the classifier was re-trained using the complete train set.
3.3. Forecasting Framework
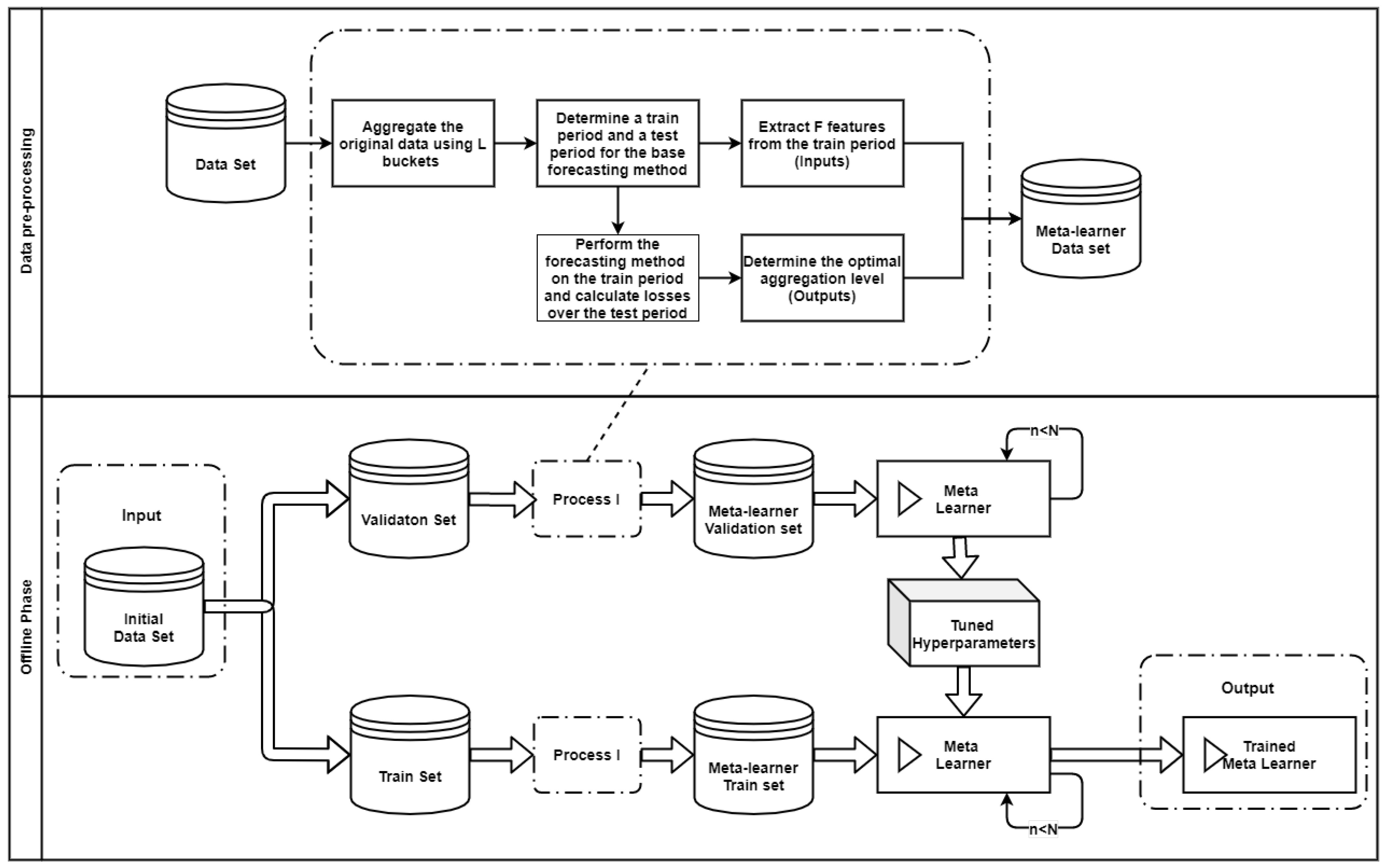
The proposed framework, summarized in Algorithm 1, is implemented into two phases; the offline and the online phase. The offline phase involves the preparation of the data, the tuning of the meta-learner, and the training process, while the online phase puts in actual use the trained classifier to generate forecasts. The pipeline for implementing the framework is also visualized in
Appendix B.
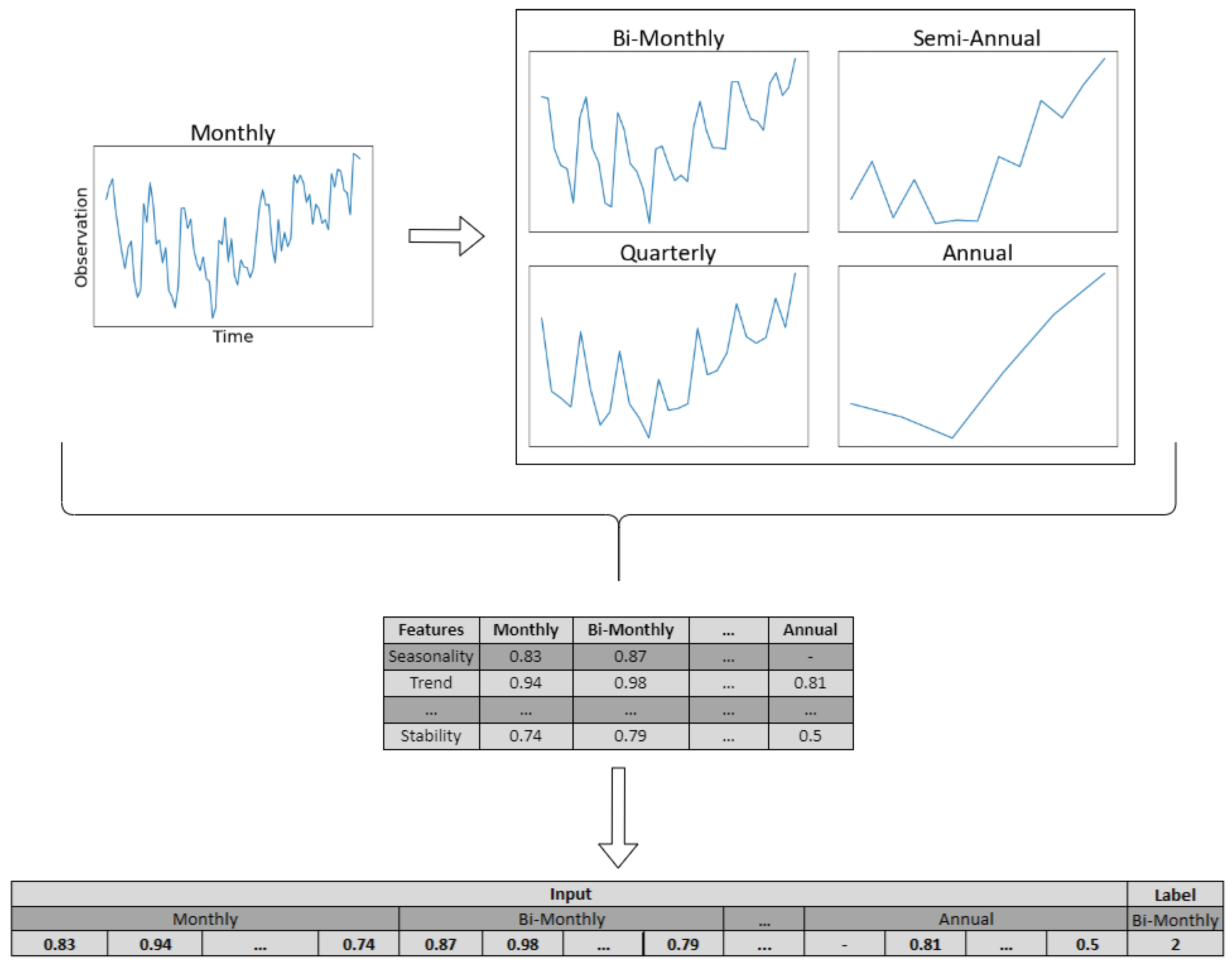
The first objective of the framework is to select for each time series of a given data set the most suitable level of temporal aggregation, i.e., the level that maximizes forecasting accuracy. Given a time series of certain frequency, we employ non-overlapping temporal aggregation to transform the data into lower frequencies. From the constructed time series, and depending on whether the data are slow- or fast-moving, we extract the time series features presented in
Section 3.1. Then, base forecasts are computed for each aggregation level using a forecasting method of preference. Finally, given a validation set, the forecasts are evaluated using an error measure of choice and the aggregation level that reports the highest accuracy is labeled as the “right” class. The aforementioned process is repeated for all the series included in the data set, resulting in a rich set of time series features and their corresponding “best” level of temporal aggregation. An illustrative example of the data set preparation stage is presented in
Figure 3 for a monthly time series. Having the train set of the meta-learner constructed, we tune the hyperparameters of the classifier as described in
Section 3.2 and then train the model using the complete train set. These steps complete the offline phase of the framework.
| Algorithm 1: Forecasting with conditional (multiple) temporal aggregation |
 |
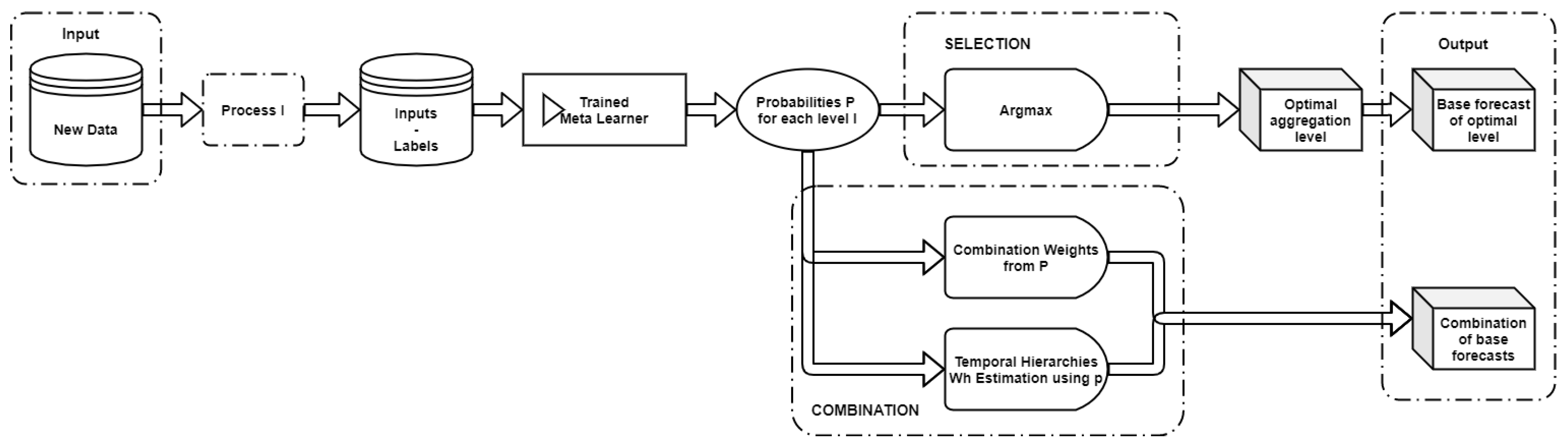
After training the meta-learner, we move on to the online phase of the framework in which the meta-learner predicts the “best” aggregation level(s) of a given time series. To do so, we introduce two methods for combining the base forecasts, using as input the probabilities generated by the classifier for each level.
3.3.1. Probability-Based Weights
Let
p =
be a probability vector, where
L is the number of examined temporal aggregation levels and
the probability that the
i-th level will result to the most accurate forecasts. Then, the combination weight for the corresponding forecasts will be
If we denote the forecasts of the
i-th aggregation level as
, then the forecast of the ensemble
will be
Note that since in Equation (
4), the probabilities are squared, the weights assigned to temporal aggregation levels of relatively low probabilities will further decrease, while levels of relatively high probabilities will retain a significant impact on the final forecasts. As a result, the negative effect of presumably inaccurate forecasts is reduced.
3.3.2. Probability-Based Structural Scaling
This approach utilizes the structural scaling estimator of the temporal hierarchies, using, however, a modified version of the matrix so that, similarly to our previous approach, the contribution of the presumably inaccurate forecasts to the ensemble is shrinked.
We approximate the
W matrix as
, with
L being the number of aggregation levels (in the case of quarterly data,
). Each value of the diagonal of the
matrix is then calculated as
where
is the data frequency of the
i-th level,
is a
-dimensional identity matrix, and
is the probability appointed by the classifier to the
i-th level.
5. Results and Discussion
The forecasting performance of the meta-learner in the M4 and M5 data sets is summarized in
Table 3. CTA stands for conditional temporal aggregation, where a single “best” level is selected by the meta-learner, CMTA-PW for conditional multiple temporal aggregation with probability-based weights, and CMTA-PSTR for conditional multiple temporal aggregation with probability-based structural scaling. In all cases, ETS is used for producing the base forecasts.
To enable comparisons, we also consider several benchmarks. The first benchmark, CON, refers to conventional forecasting, i.e., producing forecasts only at the original frequency of the series using ETS. The second, MTA-EW, is a simple implementation of multiple temporal aggregation where the base ETS forecasts are combined using equal weights. The third benchmark, MTA-STR, involves forecasting with temporal hierarchies, using the ETS framework and the structural scaling matrix as estimator. In addition, to allow comparisons with popular time series forecasting methods, we include two more benchmarks per data set, namely the top performing approaches from the benchmarks considered by the organizers of the M4 and M5 competitions. For M4, this is the simple arithmetic average of SES, Holt, and Damped exponential smoothing (Comb) and the Theta method [
62], while for M5, this is the simple arithmetic mean of ETS and ARIMA (
) and the Syntetos–Boylan approximation (SBA; [
14]). Note that Comb,
, Theta, and SBA represent conventional forecasting approaches.
The results of
Table 3 suggest that, in both data sets, the meta-learner outperforms the rest of the forecasting approaches when used for applying multiple temporal aggregation. CMTA-PW is slightly more accurate than CMTA-PSTR, but the differences between the two combination methods are minor. Despite the uncertainty involved in the selection process, CTA also results in slightly more accurate forecasts than CON, being at the same time better than MTA-EW in the M4 data set. Moreover, we observe that the proposed meta-learners always outperform the Comb/
and Theta/SBA methods. This finding is encouraging, highlighting the potential benefits of the proposed method over traditional approaches where temporal aggregation is either neglected or implemented without investigating the contribution of each temporal aggregation level to the final forecasts.
Our results are in agreement with the literature, confirming that multiple temporal aggregation can improve the accuracy of conventional forecasting, also being more effective in general than simple temporal aggregation. This conclusion remains true when reviewing both the benchmarks and the variants of the proposed meta-learner.
Another important finding refers to the extent of the accuracy improvements depending on the particularities of the data set. As seen in
Table 3, multiple temporal aggregation is more effective in fast-moving data than in slow-moving series. This can be attributed to the variation and intermittency of the M5 data that render the extraction of time series patterns more challenging, even at high aggregation levels. In contrast, temporal aggregation manages to extract hidden patterns in the M4 data, where the series are less noisy and are characterized by trend and seasonality.
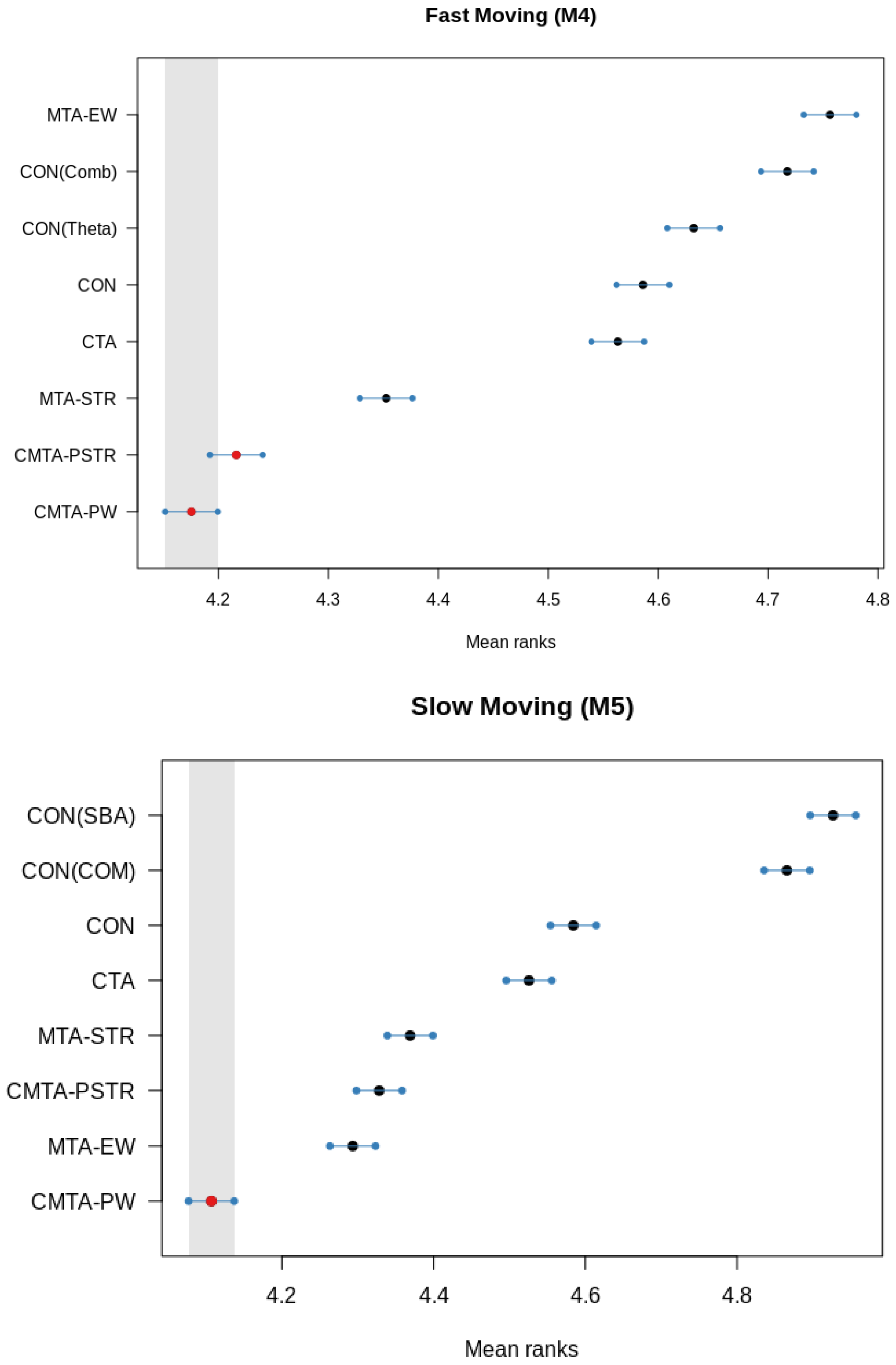
In order to obtain a better understanding of the differences of the examined forecasting approaches, we apply the multiple comparisons with the best (MCB) test that compares whether the average ranking of a forecasting method is significantly better or worse than the other methods [
63]. The results are shown in
Figure 4. If the intervals of two methods do not overlap, this indicates a statistically different performance. Thus, methods that do not overlap with the gray interval of the figures are considered significantly worse than the best method, and vice versa.
Focusing on the fast-moving series, it is confirmed that conditional multiple temporal aggregation significantly outperforms the rest of the methods, with CMTA-PW and CMTA-PSTR being, however, of similar accuracy. MTA-STR follows in terms of average rank, being significantly more accurate than CTA and CON. Interestingly, MTA-EW has the lowest performance, possibly due to the seasonal shrinkage it implies. Regarding the slow-moving data, CMTA-PW is again the top-ranked method and significantly better than the rest of the forecasting approaches. However, in this case it is followed by MTA-EW, which is reasonable given the lack of strong seasonal patterns in the M5 data set. Yet, MTA-EW is not significantly better than the approaches that build on structural scaling, being superior only to conventional forecasting and CTA. We also observe that in both data sets, CON has a better average rank than the Comb/ and Theta/SBA forecasting approaches. Therefore, we conclude that ETS has been correctly identified as the most accurate method for producing base forecasts, enhancing the performance of the methods considered for applying (multiple) temporal aggregation.
6. Conclusions
We have proposed a meta-learner that can be used to either select the most appropriate temporal aggregation level for producing forecasts or to derive weights that properly combine the forecasts generated at various levels. To do so, the meta-learner extracts a rich set of time series features and correlates them to post-sample forecasting accuracy, thus allowing for conditional forecast selection or combination.
Our results indicate that conditional (multiple) temporal aggregation can outperform both conventional forecasting and established methods used for applying temporal aggregation. The improvements are more significant for fast-moving data where patterns are easier to identify, but can be realized for slow-moving data as well. As expected, conditional multiple temporal aggregation performs better on average than conditional temporal aggregation. However, we find that in many cases, selecting the “best” aggregation level is feasible, leading to better forecasts than forecasting at the original data frequency.
Future work could focus on extending and improving the proposed approach. This could include the investigation of alternative classification methods (e.g., logistic regression, extreme gradient boosting, and neural networks) and the development of alternative schemes for transforming classification probabilities into combination weights. Moreover, since the potential benefits of (multiple) temporal aggregation seem to magnify for time series of relatively higher frequencies, the proposed meta-learner could be tested for data that are sampled on an hourly or even minute basis. To the best of our knowledge, the work performed in the field of temporal aggregation has insufficiently covered said applications, despite the fact that methods such as the one proposed in the present paper could improve forecasting accuracy through a conditional aggregation of time series patterns observed at different temporal aggregation levels.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





