
Improved Object Detection Method Utilizing YOLOv7-Tiny for Unmanned Aerial Vehicle Photographic Imagery




Abstract
:1. Introduction
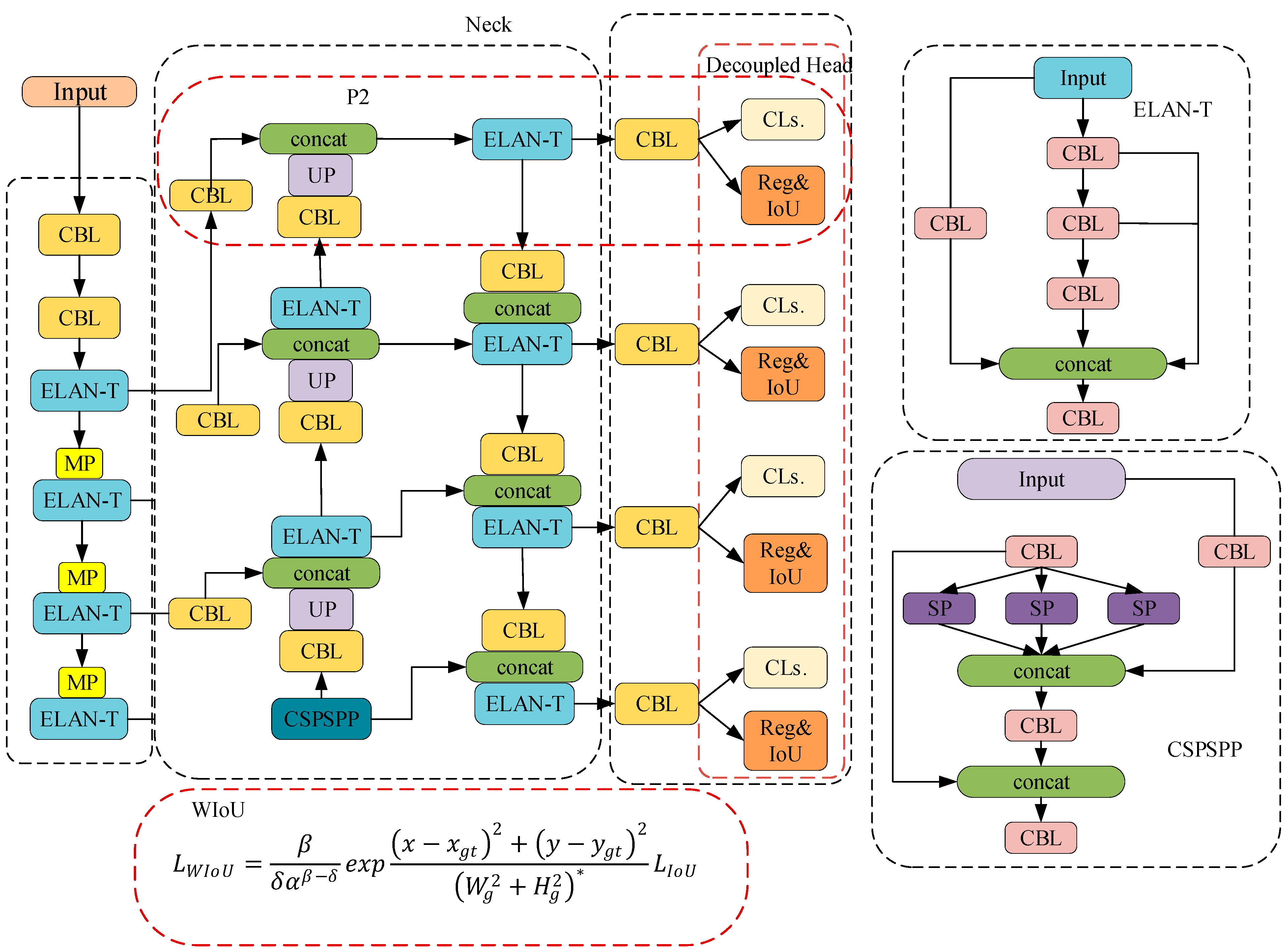
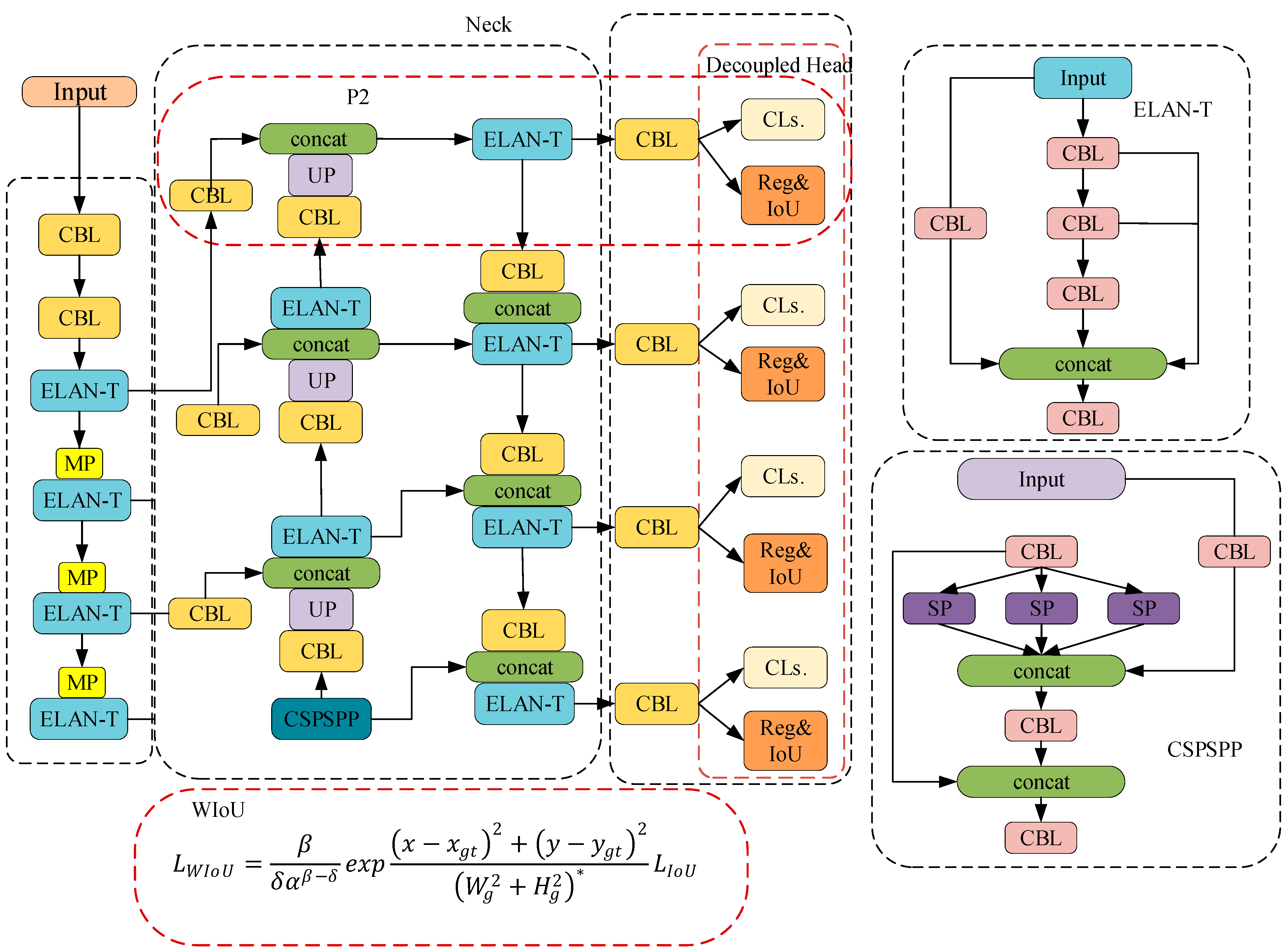
- A small-object detection layer was added that used a 160 × 160 resolution feature map to detect small objects. This adjustment enhanced the detection performance for small objects.
- The WIoU loss function [28] that expedites network convergence and enhances the regression accuracy was used instead of CIoU thus presenting a balanced regression approach for both high- and low-quality samples. Compared with CIoU [29], WIoU emphasizes anchor boxes of average quality, resulting in an overall performance enhancement for the detector. This function is suited to handling small object boxes and overlapping occluded object boxes, making it beneficial for small-object detection.
2. Related Work
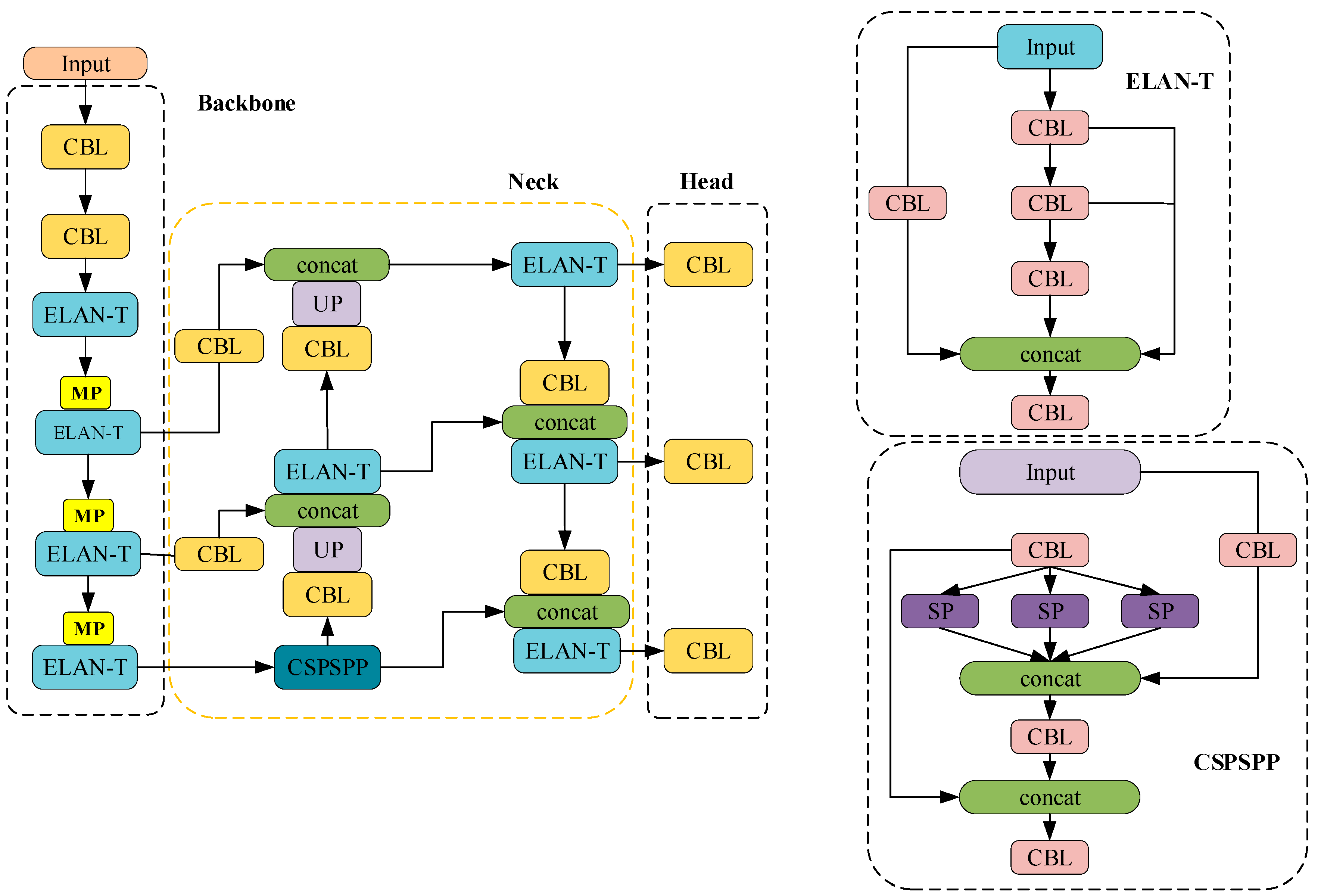
2.1. YOLOv7-Tiny Network Structure
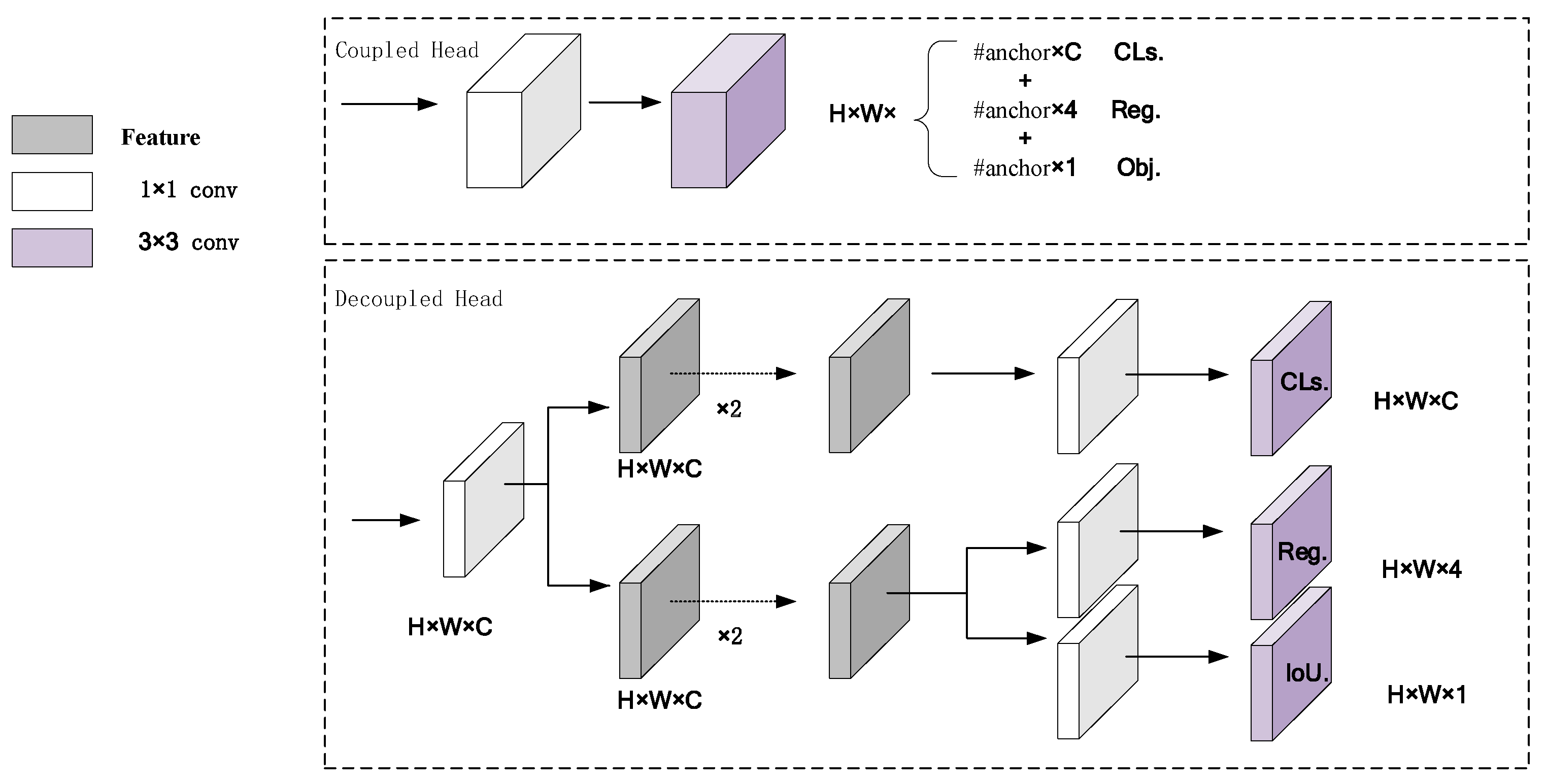
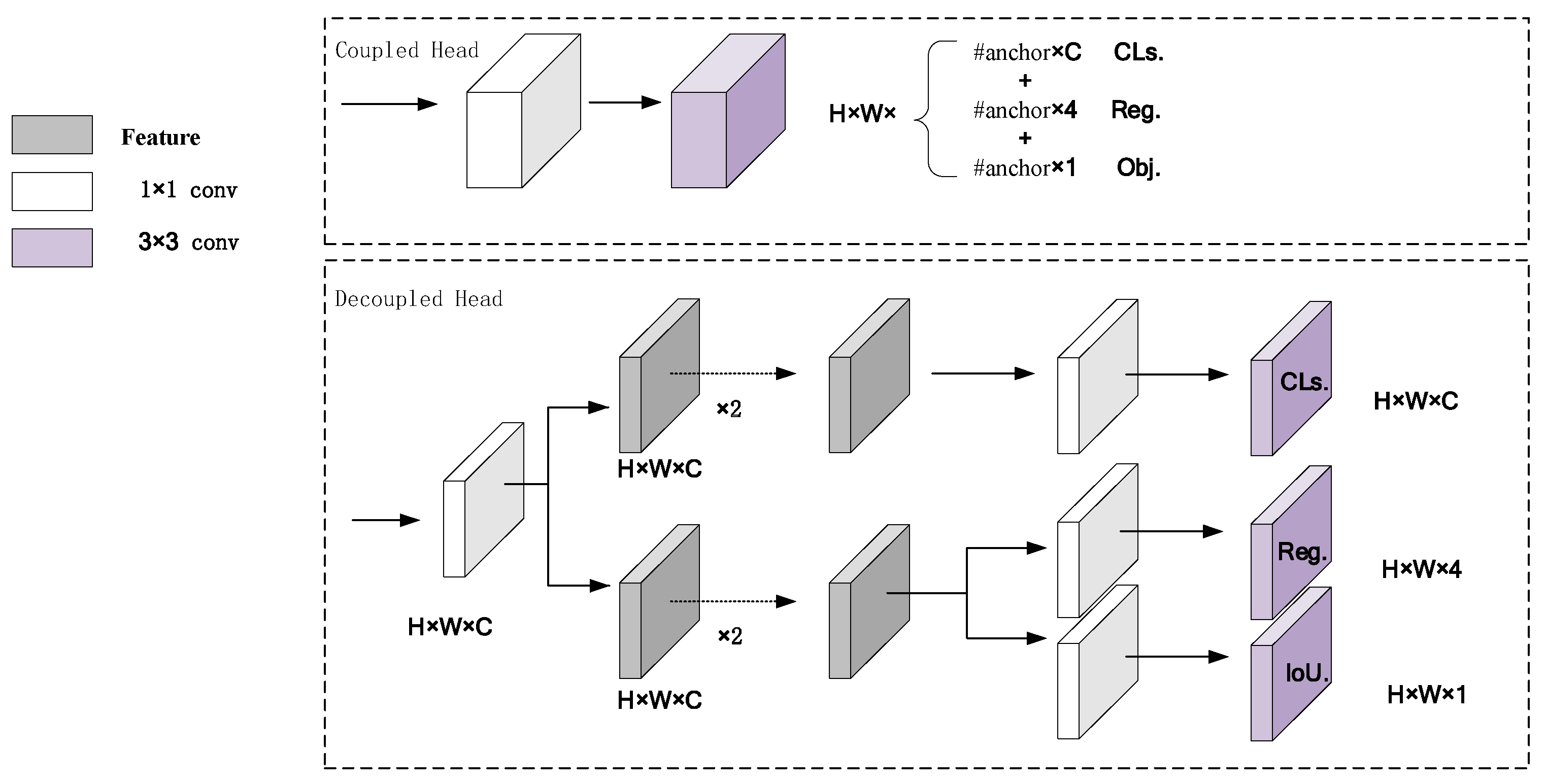
2.2. Detection Head
2.3. IoU
3. Methodology
3.1. Small-Object Detection Layer
3.2. Decoupled Head
3.3. WIoU
4. Experiments
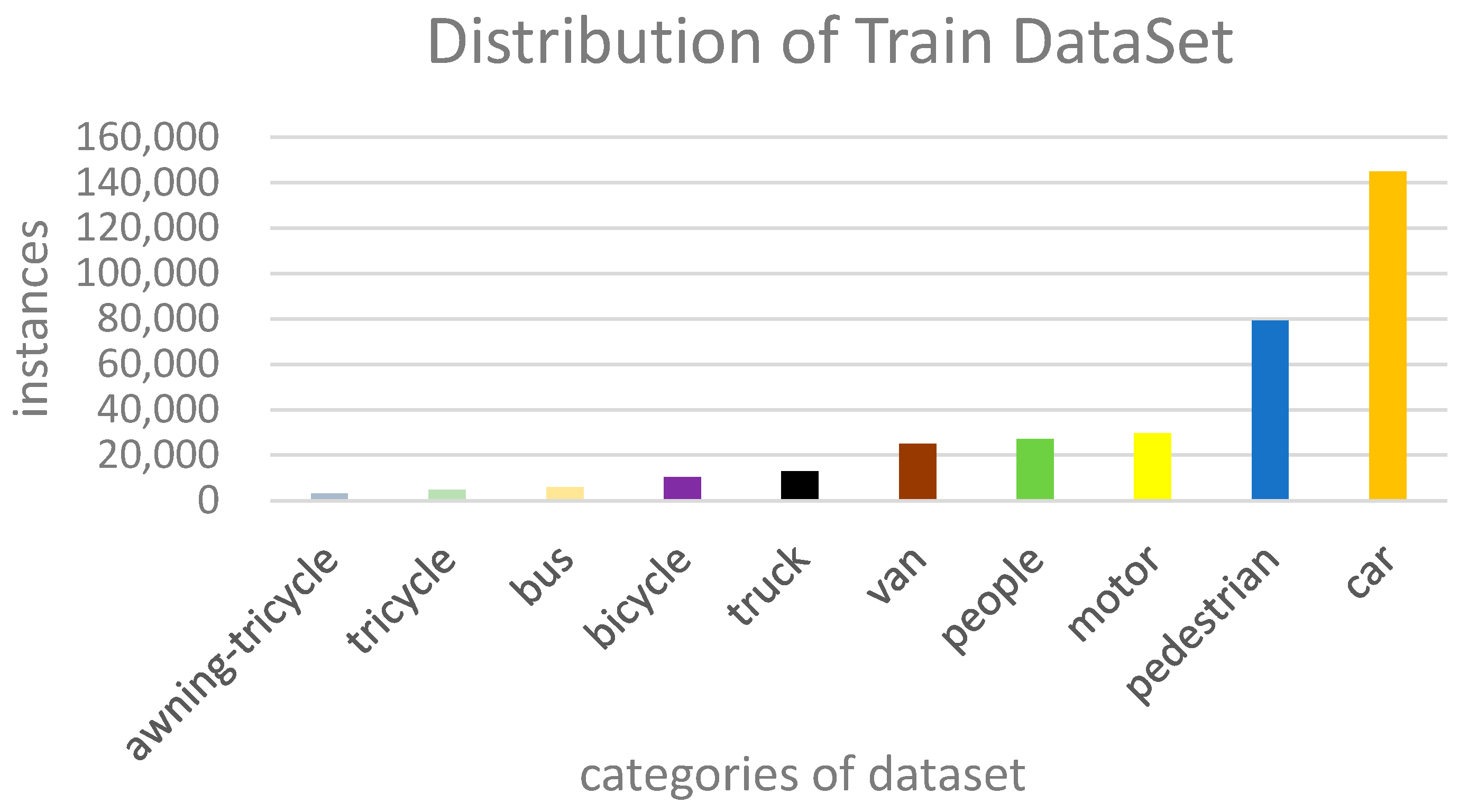
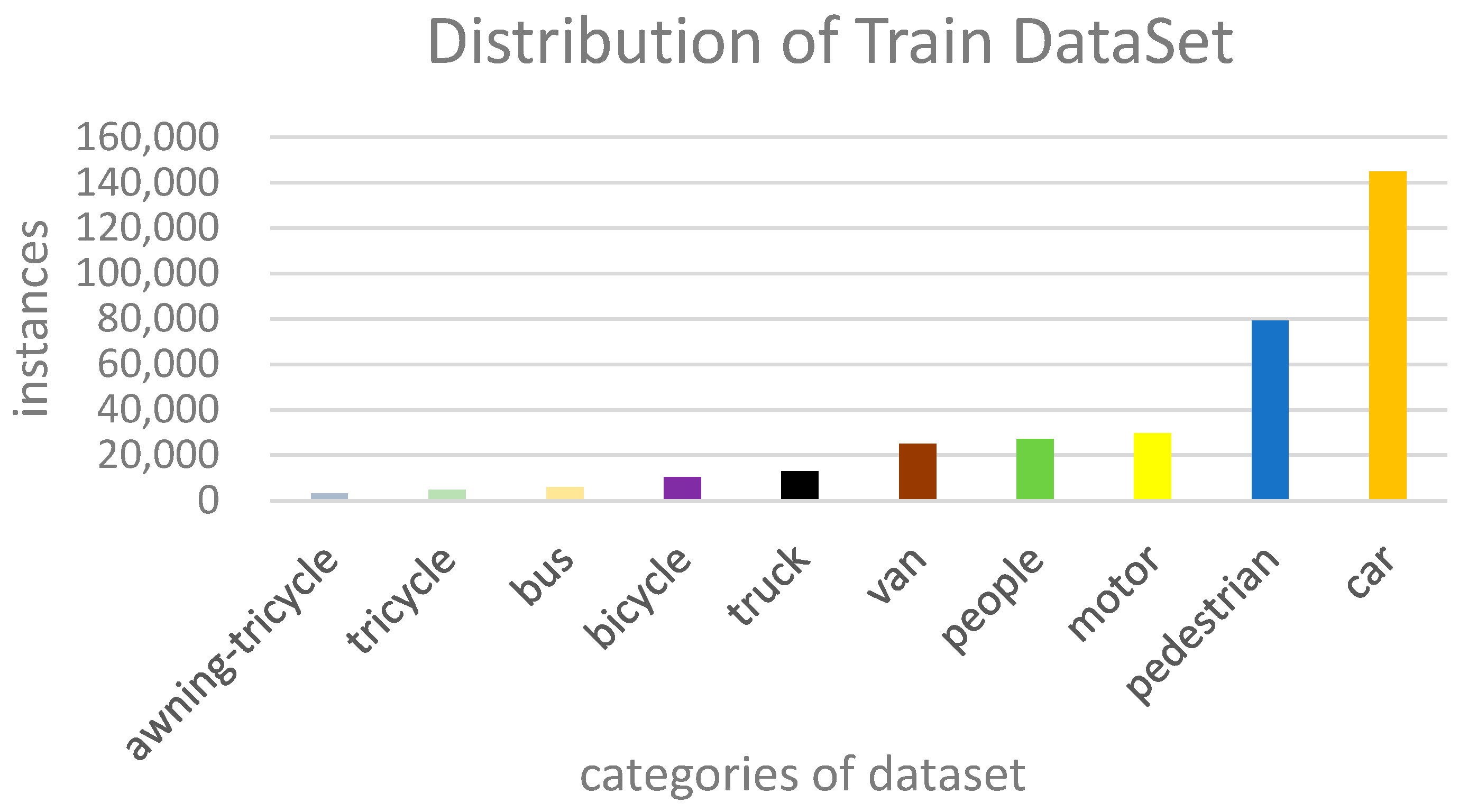
4.1. Dataset
4.2. Experimental Platform
4.3. Evaluation Criteria
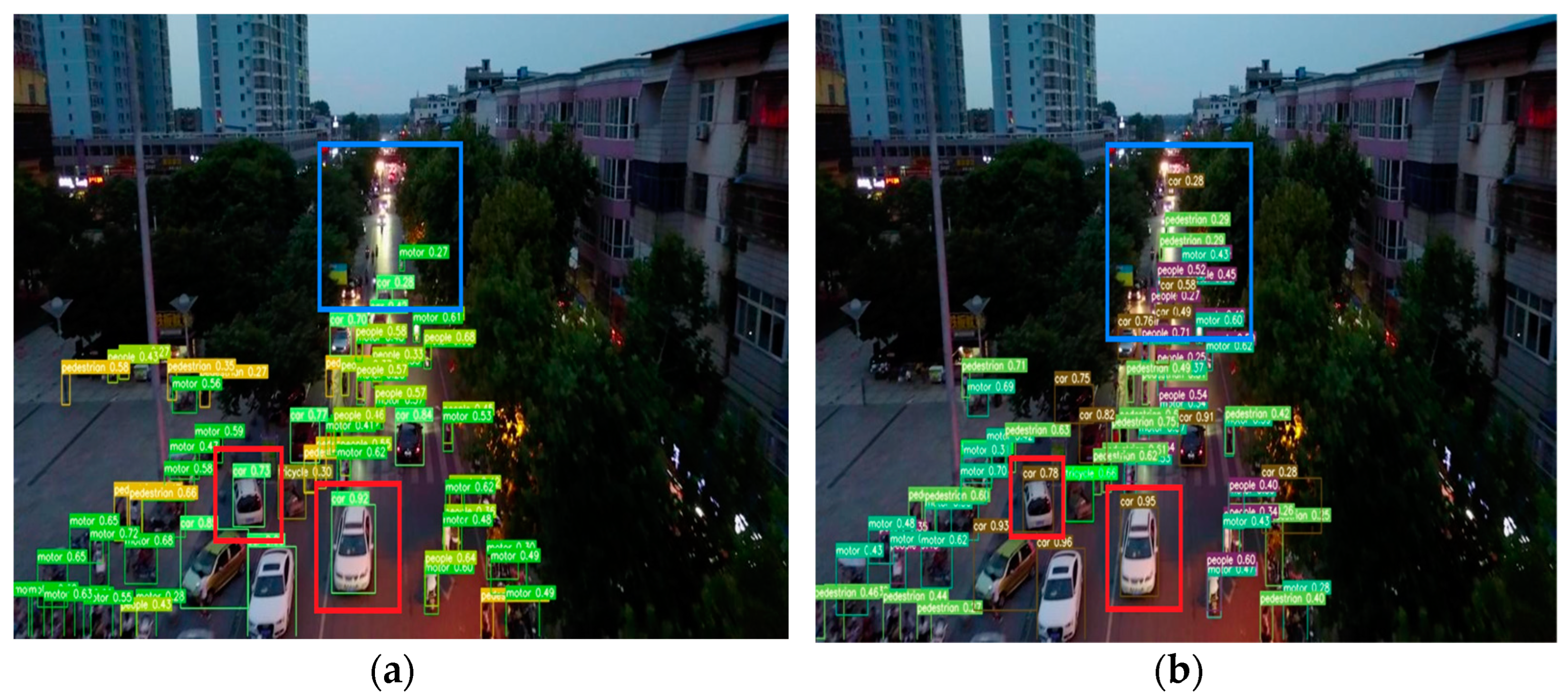
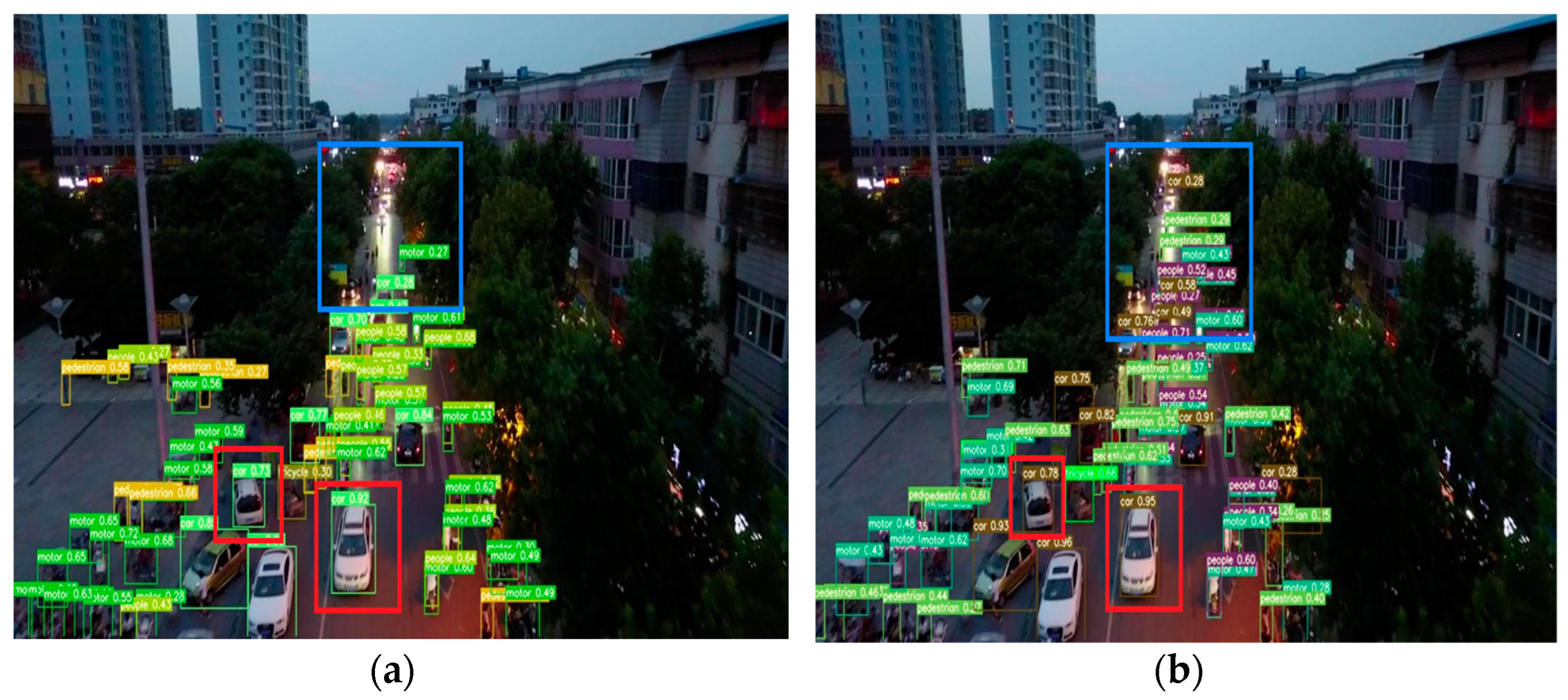
4.4. Experimental Results
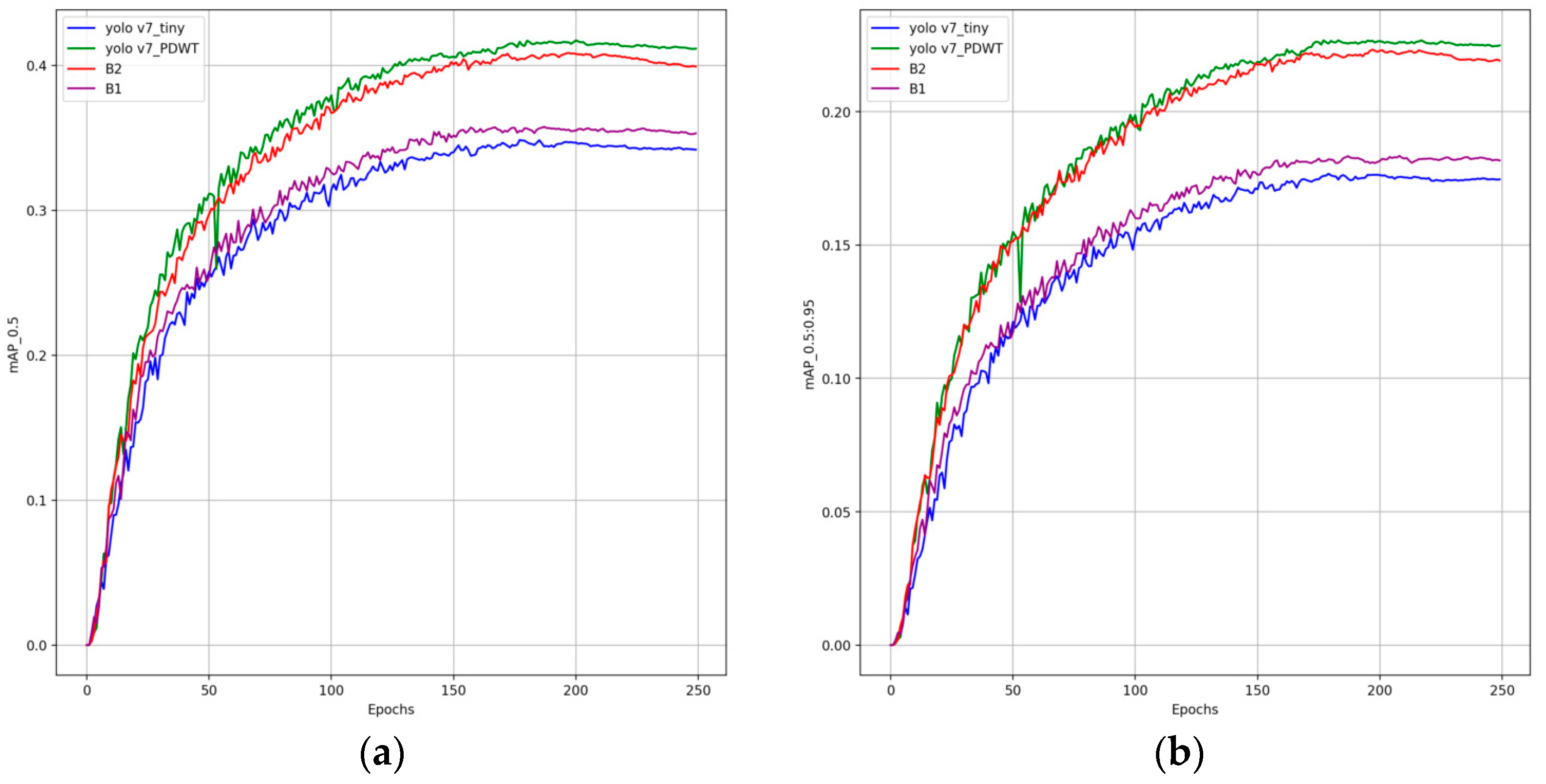
4.5. Ablation Experiment
4.6. IoU Contrast Experiment
4.7. Extended Experiment
5. Discussion
6. Conclusions
- To enhance the detection performance for small objects in drone images, a small-object detection layer was incorporated into the algorithm.
- Additionally, a decoupled head was added in place of the detection head IDetect in YOLOv7-tiny, which mitigated conflicts between classification and regression and improved detection accuracy.
- Finally, WIoU was used instead of CIoU in the loss function to improve the network convergence speed and improve regression accuracy.
- The experimental results demonstrate that PDWT-YOLO outperforms YOLOv7-tiny in object detection accuracy and has good network convergence performance for multiscale targets, especially for small objects. It can be inferred that the PDWT-YOLO model excels at extracting targets from intricate backgrounds with greater precision when compared with the YOLOv7-tiny model.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AP | Average precision |
| APL | Average precision for large objects |
| APM | Average precision for medium objects |
| APS | Average precision for small objects |
| CIoU | Complete Intersection over Union |
| CSP DarkNet | Cross Stage Partial Networks |
| DIoU | Distance Intersection over Union |
| E-ELAN | Extended efficient layer aggregation network |
| EIoU | Efficient Intersection over Union |
| FN | False negative |
| FP | False positive |
| FPN | Feature pyramid network |
| GFLOPs | Giga floating-point operations per second |
| GIoU | Generalized Intersection over Union |
| GPU | Graphics processing unit |
| IOU | Intersection over Union |
| MPConv | Max-pooling convolution |
| PANet | Path Aggregation Network |
| R-CNN | Region-based convolutional neural network |
| ResNet | Residual Network |
| SIoU | Scylla Intersection over Union |
| SSD | Single Shot MultiBox Detector |
| SPP-Net | Spatial pyramid pooling network |
| TP | True positive |
| UAV | Unmanned aerial vehicle |
| VGG | Visual Geometry Group Network |
| WIoU | Wise Intersection over Union |
| YOLO | You Only Look Once |
References
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Kaur, J.; Singh, W. Tools, techniques, datasets and application areas for object detection in an image: A review. Multimed. Tools Appl. 2022, 81, 38297–38351. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Yu, J.-G.; Tan, Y.; Tian, J.; Ma, J. A Novel Spatio-Temporal Saliency Approach for Robust Dim Moving Target Detection from Airborne Infrared Image Sequences. Inf. Sci. 2016, 369, 548–563. [Google Scholar] [CrossRef]
- Ahmed, M.; Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. Survey and Performance Analysis of Deep Learning Based Object Detection in Challenging Environments. Sensors 2021, 21, 5116. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; Volume 28, pp. 91–99. [Google Scholar] [CrossRef]
- Zhao, W.; Huang, H.; Li, D.; Chen, F.; Cheng, W. Pointer Defect Detection Based on Transfer Learning and Improved Cascade-RCNN. Sensors 2020, 20, 4939. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-Captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar] [CrossRef]
- Ultralytics. Yolov5. [EB/OL]. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 November 2021).
- Chen, Z.; Zhang, F.; Liu, H.; Wang, L.; Zhang, Q.; Guo, L. Real-Time Detection Algorithm of Helmet and Reflective Vest Based on Improved YOLOv5. J. Real-Time Image Process 2023, 20, 4. [Google Scholar] [CrossRef]
- Wu, D.; Jiang, S.; Zhao, E.; Liu, Y.; Zhu, H.; Wang, W.; Wang, R. Detection of Camellia oleifera Fruit in Complex Scenes by Using YOLOv7 and Data Augmentation. Appl. Sci. 2022, 12, 11318. [Google Scholar] [CrossRef]
- Jiang, K.; Xie, T.; Yan, R.; Wen, X.; Li, D.; Jiang, H.; Jiang, N.; Feng, L.; Duan, X.; Wang, J. An Attention Mechanism-Improved YOLOv7 Object Detection Algorithm for Hemp Duck Count Estimation. Agriculture 2022, 12, 1659. [Google Scholar] [CrossRef]
- Li, B.; Chen, Y.; Xu, H.; Fei, Z. Fast Vehicle Detection Algorithm on Lightweight YOLOv7-Tiny. arXiv 2023, arXiv:2304.06002. [Google Scholar]
- Kulyukin, V.A.; Kulyukin, A.V. Accuracy vs. Energy: An Assessment of Bee Object Inference in Videos from On-Hive Video Loggers with YOLOv3, YOLOv4-Tiny, and YOLOv7-Tiny. Sensors 2023, 23, 6791. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. Automatic Ship Detection Based on RetinaNet Using Multi-Resolution Gaofen-3 Imagery. Remote Sens. 2019, 11, 531. [Google Scholar] [CrossRef]
- Zhang, X.; Fan, K.; Hou, H.; Liu, C. Real-Time Detection of Drones Using Channel and Layer Pruning, Based on the YOLOv3-SPP3 Deep Learning Algorithm. Micromachines 2022, 13, 2199. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Liao, J.; Xu, C. Vehicle Detection Based on Drone Images with the Improved Faster R-CNN. In Proceedings of the 2019 11th International Conference on Machine Learning and Computing (ICMLC’19), Zhuhai, China, 22–24 February 2019; pp. 466–471. [Google Scholar] [CrossRef]
- Huang, H.; Li, L.; Ma, H. An Improved Cascade R-CNN-Based Target Detection Algorithm for UAV Aerial Images. In Proceedings of the 2022 7th International Conference on Image, Vision and Computing (ICIVC), Xi’an, China, 26–28 July 2022; pp. 232–237. [Google Scholar] [CrossRef]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Ling, H.; Hu, Q.; Zheng, J.; Peng, T.; Wang, X.; Zhang, Y.; et al. VisDrone-SOT2019: The Vision Meets Drone Single Object Tracking Challenge Results. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 199–212. [Google Scholar]
- Liu, C.; Xie, N.; Yang, X.; Chen, R.; Chang, X.; Zhong, R.Y.; Peng, S.; Liu, X. A Domestic Trash Detection Model Based on Improved YOLOX. Sensors 2022, 22, 6974. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef]
- Shin, H.-C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef]
- Huang, X.; Wang, X.; Lv, W.; Bai, X.; Long, X.; Deng, K.; Dang, Q.; Han, S.; Liu, Q.; Hu, X.; et al. PP-YOLOv2: A Practical Object Detector. arXiv 2021, arXiv:2104.10419. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A.; Liu, W.; et al. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-style ConvNets Great Again. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13728–13737. [Google Scholar] [CrossRef]
- Sinaga, K.P.; Yang, M.-S. Unsupervised K-Means Clustering Algorithm. IEEE Access 2020, 8, 80716–80727. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Li, B.Y.; Liu, Y.; Wang, X.G. Gradient Harmonized Single-Stage Detector. Proc. AAAI Conf. Artif. Intell. 2019, 33, 8577–8584. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mAP@0.5:0.95 | mAP@0.5 | Params (M) | APS | APM | APL |
|---|---|---|---|---|---|---|
| Faster R-CNN | 21.9 | 37.1 | 137.1 | 13.1 | 33.6 | 37.1 |
| Cascade R-CNN | 24.5 | 39 | 673 | 15.2 | 36.7 | 39.2 |
| CenterNet | 18.7 | 33.6 | 104.8 | 9.8 | 29.3 | 38.7 |
| YOLOv3 | 16.4 | 31.4 | 59.13 | 8.3 | 26.7 | 36.5 |
| YOLOX | 22.4 | 39.1 | 8.9 | 13.7 | 33.1 | 41.3 |
| YOLOv5l | 20.5 | 36.2 | 46.1 | 12.4 | 29.9 | 36.4 |
| YOLOv7-tiny | 17.5 | 34.5 | 6.2 | 10.4 | 26.5 | 36.5 |
| PDWT-YOLO | 22.5 | 41.2 | 6.44 | 15.1 | 31.8 | 36.6 |
| Method | Pedestrian | People | Bicycle | Car | Van | Truck | Tricycle | Awning Tricycle | Bus | Motor | mAP@0.5 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv3 | 12.8 | 7.8 | 4.0 | 43.0 | 23.5 | 16.5 | 9.5 | 5.1 | 29.0 | 12.5 | 31.4 |
| YOLOv5l | 44.4 | 36.8 | 15.6 | 73.9 | 39.2 | 36.2 | 22.6 | 11.9 | 50.5 | 42.8 | 36.2 |
| YOLOv7-tiny | 37.7 | 35.9 | 11.0 | 74.5 | 35.2 | 27.6 | 22.4 | 8.3 | 48.5 | 43.6 | 34.5 |
| PDWT-YOLO | 48.7 | 41.6 | 14.7 | 82.0 | 43.2 | 35.4 | 26.8 | 14.2 | 56.4 | 49.3 | 41.2 |
| Method | Decoupled Head | P2 | WIoU | mAP@0.5 | mAP@ 0.5:0.95 | Inference Time (ms) | Params | GFLOPS | APS | APM | APL |
|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv7-tiny | 34.5 | 17.5 | 2.9 | 6.2 | 13.1 | 10.4 | 26.5 | 36.5 | |||
| B1 | √ | 35.5 | 18.2 | 3.2 | 5.8 | 18.9 | 11.3 | 27.2 | 34.2 | ||
| B2 | √ | √ | 40.2 | 22.2 | 4.3 | 6.44 | 24.2 | 14.7 | 31.4 | 38 | |
| PDWT-YOLO | √ | √ | √ | 41.2 | 22.5 | 4.4 | 6.44 | 24.2 | 15.1 | 31.8 | 36.6 |
| IoU | mAP@0.5:0.95 | mAP@0.5 |
|---|---|---|
| CIoU | 22.2 | 40.6 |
| GIoU | 22.0 | 40.2 |
| DIoU | 22.4 | 40.6 |
| WIoU | 22.5 | 41.2 |
| Method | Person | Car | Bicycle | Other Vehicle | Do Not Care | mAP@0.5 |
|---|---|---|---|---|---|---|
| YOLOv7-tiny | 89.1 | 97.1 | 88.3 | 67.1 | 52.1 | 78.8 |
| PDWT-YOLO | 92.7 | 96.6 | 89.5 | 67.2 | 65.7 | 82.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Xiong, N.; Pan, X.; Yue, X.; Wu, P.; Guo, C. Improved Object Detection Method Utilizing YOLOv7-Tiny for Unmanned Aerial Vehicle Photographic Imagery. Algorithms 2023, 16, 520. https://doi.org/10.3390/a16110520
Zhang L, Xiong N, Pan X, Yue X, Wu P, Guo C. Improved Object Detection Method Utilizing YOLOv7-Tiny for Unmanned Aerial Vehicle Photographic Imagery. Algorithms. 2023; 16(11):520. https://doi.org/10.3390/a16110520
Chicago/Turabian StyleZhang, Linhua, Ning Xiong, Xinghao Pan, Xiaodong Yue, Peng Wu, and Caiping Guo. 2023. "Improved Object Detection Method Utilizing YOLOv7-Tiny for Unmanned Aerial Vehicle Photographic Imagery" Algorithms 16, no. 11: 520. https://doi.org/10.3390/a16110520
APA StyleZhang, L., Xiong, N., Pan, X., Yue, X., Wu, P., & Guo, C. (2023). Improved Object Detection Method Utilizing YOLOv7-Tiny for Unmanned Aerial Vehicle Photographic Imagery. Algorithms, 16(11), 520. https://doi.org/10.3390/a16110520