
Decision-Maker’s Preference-Driven Dynamic Multi-Objective Optimization

Abstract
:1. Introduction
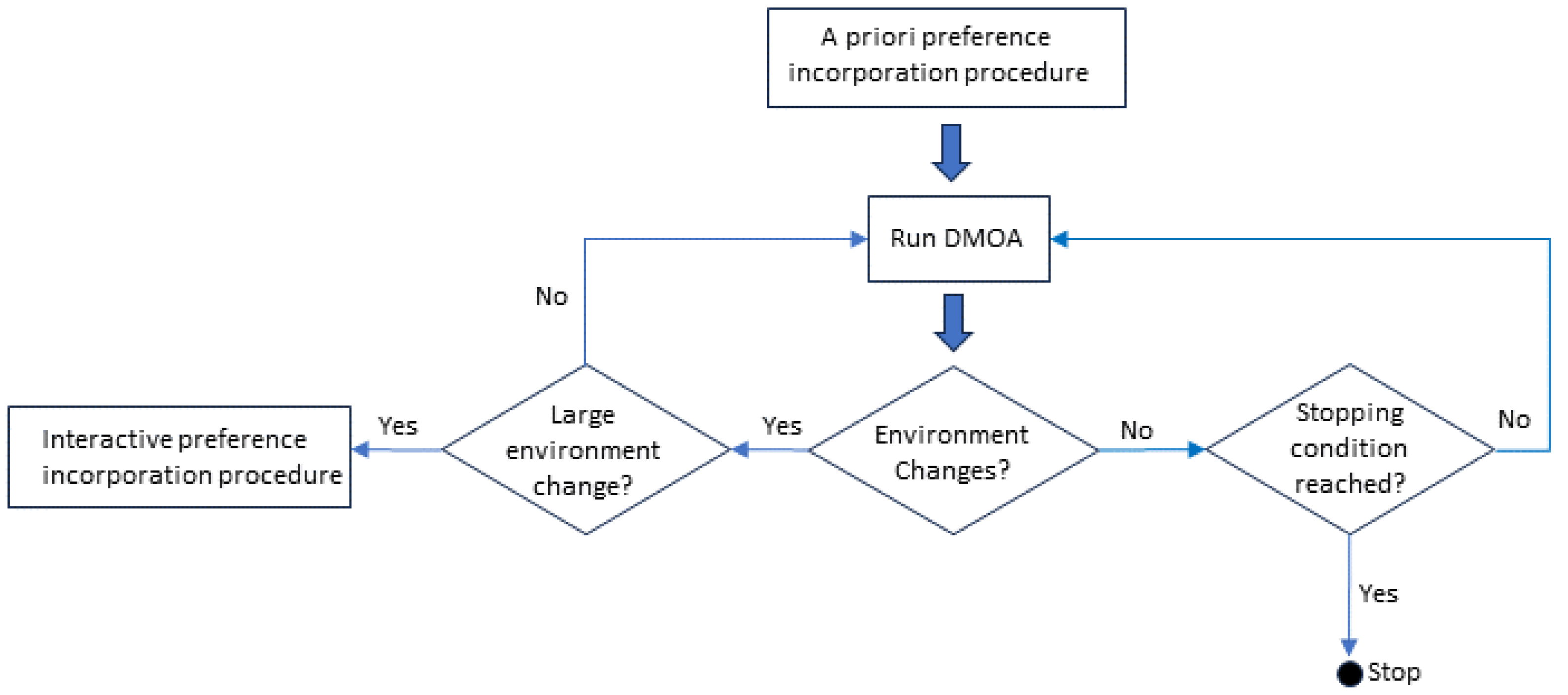
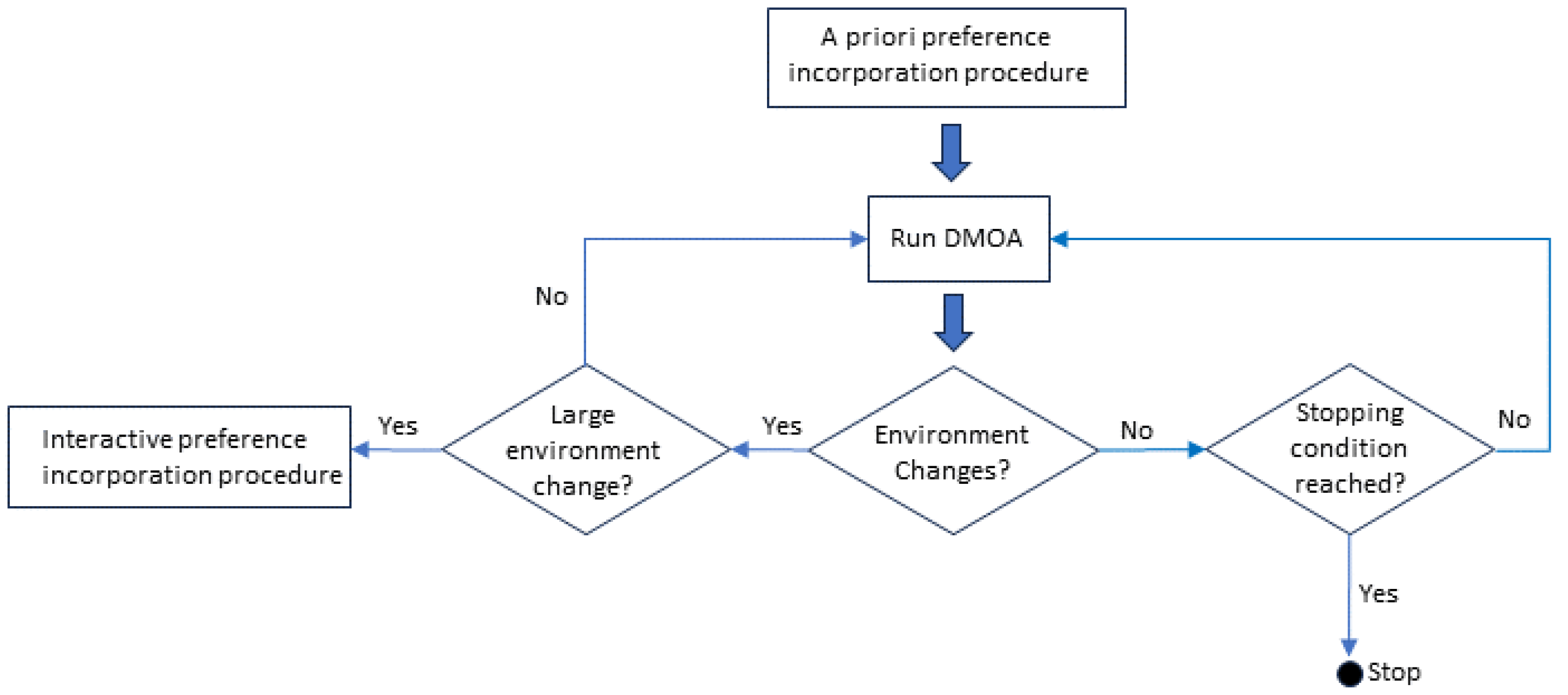
- A preference incorporation method adapted for DMOPs that is partly a priori and partly interactive and enables a DM to specify their preferences. The a priori incorporation of DM preferences occurs through a procedure, named bootstrap. The interactive incorporation of preferences is employed whenever a change occurs in the dynamic environment such that the DM preference set may be significantly affected.
- New approaches that can drive a DMOA’s search constrained by the DM’s preferences, as well as a comparative analysis of the constraint managing approaches incorporated into a DMOA. The proposed constraint managing approaches are fundamentally different from one another in terms of how they penalize solutions that violate a DM’s preferences.
- New performance measures that measure how well a found solution adheres to the preferences of a DM. In this article, a solution will henceforth be referred to as a decision.
2. Background
2.1. Bounding Box Mathematics
2.2. Mathematics for Newly Proposed Performance Measures
2.2.1. Deviation of Violating Decisions
2.2.2. Spread of Non-Violating Decisions
| Algorithm 1 Spread of Non-violating decisions | |
| 1: procedure SpreadEstimator(outcomes) ▹ outcomes: objective vectors preferred by DM | |
| 2: Get count of outcomes, N | |
| 3: if then | |
| 4: return 0 | ▹ 1 or zero outcomes, spread is zero |
| 5: if then | ▹ 2 outcomes |
| 6: return norm | ▹ return spread between 2 values |
| 7: dtot | ▹ more than 2 outcomes, calculation required - initialize total spread, |
| 8: firstNode ← outcomes(1) | ▹ get a node |
| 9: currentNode ← firstNode | ▹ set current node |
| 10: while do | ▹ process each outcome |
| 11: MarkNodeAsProcessed(currentNode) | ▹ mark outcome as processed |
| 12: nearestNode=getNearestNode(currentNode,outcomes) | ▹ find nearest node to outcome being processed |
| 13: dist = | ▹ calcuated distance between these two solutions |
| 14: dtot ← dtot + dist | ▹ add their distance to total distance |
| 15: currentNode ← nearestNode | |
| 16: dist = | ▹ finally calculate distance to first solution |
| 17: dtot ← dtot + dist | ▹ add last distance to total distance |
| 18: return dtot | ▹ return total distance |
2.3. Core Dynamic Multi-Objective Optimization Algorithm
| Algorithm 2 Dynamic Multi-objective Optimization Algorithm | |
| 1: procedure DMOA(freq, severity, maxiteration, dMOP) | |
| 2: Set population size, N | |
| 3: Set archive max size, SizeArchive | |
| 4: Initialize the iteration counter, | |
| 5: Initialize time, | |
| 6: Initialize() | ▹ initialize population of solutions, |
| 7: AssignNonDominatedToArchive(P, dMOP, t) | ▹ initialize archive |
| 8: while iteration ≤ maxiteration do | ▹ check if stopping condition has been reached |
| 9: t | ▹ calculate the current time |
| 10: Optimizer(P, dMOP, t) | ▹ perform the search optimization |
| 11: Pick sentry solutions | ▹ select sentry solutions to check for change |
| 12: if ENV changes(P, dMOP, t) then | ▹ check for change in environment |
| 13: ProcessChange(P, freq, severity, dMOP, t) | ▹ respond to change |
| 14: iteration ← iteration | ▹ increase iteration count |
3. Experimental Setup
3.1. Algorithm Setup
3.1.1. Decision-Maker’s Preference Incorporation
| Algorithm 3 Bootstrap Procedure | |
| 1: procedure BootStrap(freq, severity, iteration, F) | |
| 2: Call DMOA(freq, severity, iteration, F) ▹ DMOA returns ▹ where k is the kth environment change | |
| 3: | ▹ DM indicates their preferred POS |
| 4: | ▹ DM indicates their preferred solution |
| 5: | ▹ DM’s preference is formulated |
| 6: DM Choose box radius, r ← random() | ▹ DM indicates their preferred boundary box size |
| 7: return (x : p : r) | |
| Algorithm 4 Interactive Incorporation of Preferences | |
| 1: procedure RepositionBoundingBox(F, x, p, r, t) ▹ F: multi-objective function to be evaluated ▹ x: DM preferred decision vector ▹ p: DM preferred outcome as defined in Equation (2), page 3 ▹ r: DM preferred box radius ▹ Archive: | |
| 2: | ▹ POF is corresponding objective values of POS |
| 3: if p then | ▹ DM preferred outcome still lies on POF |
| 4: return (x:p:r) | |
| 5: if F(x,t) ∈ POF then | ▹ DM’s preferred decision lies on POF, preferred outcome does not |
| 6: Reposition center of box, p ← F(x, t) | ▹ Automatically reposition center of box |
| 7: return (x:p:r) | |
| 8: | ▹ DM selects a new position for and p |
| 9: Reposition center of box, | ▹ Reposition center of box based on DM’s input |
| 10: return () | |
3.1.2. Algorithms
- Proportionate Penalty: With this approach, the penalty is proportional to the violation, and violating decisions are penalized during function evaluation. Algorithm 5 presents this approach, referred to as PPA for the rest of the article.
Algorithm 5 Proportionate Penalty Algorithm 1: procedure FuncEvaluate(F, x, t)
▹ F: multi-objective function to be evaluated
▹ x: decision vector
▹ p: as defined in Equation (2), page 3
▹ r: as defined in Equation (2), page 3
▹: as defined in Equation (2), page 3
▹: a random number between 100 and 1000
▹: as defined in Equation (2), page 32: z ← F(x,t) ▹ calculate objective value of x 3: d (z-p) − r ▹ calculate violation of z 4: if d ≤ 0 then 5: return z ▹ x is a non-violating decision, no penalty applied ▹ x is a preference violating decision, proceed to penalize it for violation 6: penalty d ▹ calculate penalty 7: penalty ← I penalty ▹ vectorize penalty 8: z ← z + penalty ▹ impose proportionate penalty to objective value of x 9: return z ▹ return new penalized objective value of x - Death Penalty: Maximum/death penalty is imposed on violating decisions during function evaluation. Some penalty, which is death, is administered on a decision irrespective of the magnitude of the violation of that decision. With maximum penalty, it becomes very unlikely that violating decisions will find their way into the archive, because they will be dominated by non-violating decisions. Violating decisions are computationally eliminated during the search process, and the optimization process is driven towards a region of the search space dominated by non-violating decisions. The Death Penalty Algorithm, referred to as DPA in the rest of the article, is presented in Algorithm 6.
Algorithm 6 Death Penalty 1: procedure FuncEvaluate(F, x, t)
▹ F: multi-objective function to be evaluated
▹ x: decision vector
▹ p: as defined in Equation (2), page 3
▹ r: as defined in Equation (2), page 3
▹: as defined in Equation (2), page 3
▹ realmax: maximum real value on a machine2: z ← F(x,t) ▹ calculate objective value of x 3: d (z-p) − r ▹ calculate violation of z 4: if d ≤ 0 then 5: return z ▹ x is a non-violating decision, no penalty applied ▹ x is a preference violating decision, proceed to penalize it for violation 6: penalty ← realmax ▹ calculate penalty 7: penalty ← I penalty ▹ vectorize penalty 8: z ← penalty ▹ impose death/max penalty 9: return z ▹ return new penalized objective value of x - Restrict Search To Feasible Region: Feasibility is preserved by starting the search within the preferred bounding box and employing the death penalty to prevent preference violating decisions from entering the archive. This approach restricts the search to the feasible region, unlike [40], and it improves the exploring capability of this algorithm. Preferred decisions start the search during initialization of the population of decisions. A pool of preferred decisions is aggregated with the DM preference and the current decisions in the archive. Then, a loop is performed where nearly identical clones of the pool of preferred decisions are created using polynomial mutation [41]. These new clones constitute a new population from where the search will start. Some of the non-dominated decisions in the new population are added to the archive. Algorithm 7 presents the Restrict Search To Feasible Region Algorithm, referred to as RSTFRA in the rest of the article.
Algorithm 7 Restrict Search to Feasible Region 1: procedure Initialize()
▹ x: DM preferred decision vector)
▹ archive: POS
▹ F: multi-objective function to be evaluated
▹ N: population size, fixed for this study2: pool ← [x ; archive] ▹ pooled preferences 3: i ← 1 ▹ initialize counter 4: while i ≤ N do 5: iNumberAttempts ← 1 6: while (iNumberAttempts ≤ 100) && (!isPreferredDecision(solution, F, t) ) do ▹ searching for prefered decision 7: solution ← randomlyChooseIn(pool) ▹ randomly select solution from pool 8: solution ← polynomial_mutate(solution) ▹ apply mutation to solution 9: iNumberAttempts ← iNumberAttempts + 1 ▹ increment number of attempts 10: addSolutionToPopulation(P, solution) ▹ add mutated solution to the population 11: i ← i + 1 12: AssignNonDominatedToArchive(P, F, t ) ▹ add non-dominated decisions to archive
3.1.3. Differential Evolution Algorithm Control Parameters
- The base algorithm (refer to Algorithm 8) is characterized as DE/best/1/bin.
- To generate a trial vector from a parent vector during the mutation phase of the algorithm, the best vector in the adjacent hypercube or sub-population of the parent vector is selected as the target vector. The number of hypercubes employed by the algorithm is the same as the number of objective functions in the underlying DMOP.
- Two randomly selected vectors from the parent vector’s hypercube are used to form a difference vector.
- Binary crossover [42] is used due to its viability as a crossover method in DE algorithms.
- The scaling factor, , amplifies the effects of the difference vector. It has been shown that a larger increases the probably of escaping local minima, but can lead to premature convergence. On the other hand, a smaller value results in smaller mutation step sizes slowing down convergence, but facilitating better exploitation of the search space [43,44]. This leads to a typical choice for in the range [43,44]. Therefore, in this study, the algorithm randomly chooses . The recombination probability is , since DE convergence is insensitive to the control parameters [42,45] and a large value of speeds up convergence [43,45,46].
| Algorithm 8 Differential Evolution Algorithm | |
| 1: procedure Optimizer(P, F, t) ▹: scaling factor set per algorithm ▹ p: recombination prob set per algorithm ▹ maxgen(: number of function evaluations set per algorithm ▹ P: current population of vectors ▹ F: multi-objective function to be optimized ▹ t: current time | |
| 2: gen = 1 | ▹ set the generation counter |
| 3: P P | ▹ initialize current population |
| 4: V ←Ø | ▹ initialize set of vectors |
| 5: while gen ≤ maxgen do | ▹ check if stopping condition has been reached |
| 6: while moreUnprocessed(v ∈ P) do | ▹ process all individuals of population |
| 7: v getTrialVector(, v, P, F, t) | ▹ calculate trial vector |
| 8: v getChildVector(p, v, v, F, t) | ▹ produce child vector |
| 9: V ← V ∪ {v, v} | ▹ add trial and child vectors to set of vectors |
| 10: markAsProcessed(v ∈ P) | |
| 11: P getNextGenerationVectors(V) | ▹ produce next generation |
| 12: gen ← gen+1 | ▹ increment counter |
| 13: V ←Ø | ▹ reset set of vectors |
| 14: AssignNonDominatedToArchive(P, F, t ) | ▹ add non-dominated solutions to archive |
3.2. Decision-Maker’s Preferences
3.3. Benchmark Functions
3.4. Performance Measures
- Number of Non-Violating Decisions (nNVD) measures the number of decisions that fall within the DM’s preference set. The higher the value of this measure, the better a DMOA’s performance.
- Spread of Non-Violating Decisions (sNVD) measures the spread of decisions within the preference set. A high value indicates a good DMOA performance.
- Number of Violating Decisions (nVD) measures the number of violating decisions in the archive. These are decisions that do not lie within the preference set. The lower the value of this measure, the better the performance of the DMOA.
- Total Deviation of Violating Decisions (dVD) measures the total deviation from the preference set for all violating decisions in the archive. It is calculated based on the steps that are highlighted in Section 2.2.1. The lower the value of this measure, the better the DMOA’s performance.
3.5. Statistical Analysis
| Algorithm 9 wins-losses algorithm for wins and losses calculation [52] | |
| |
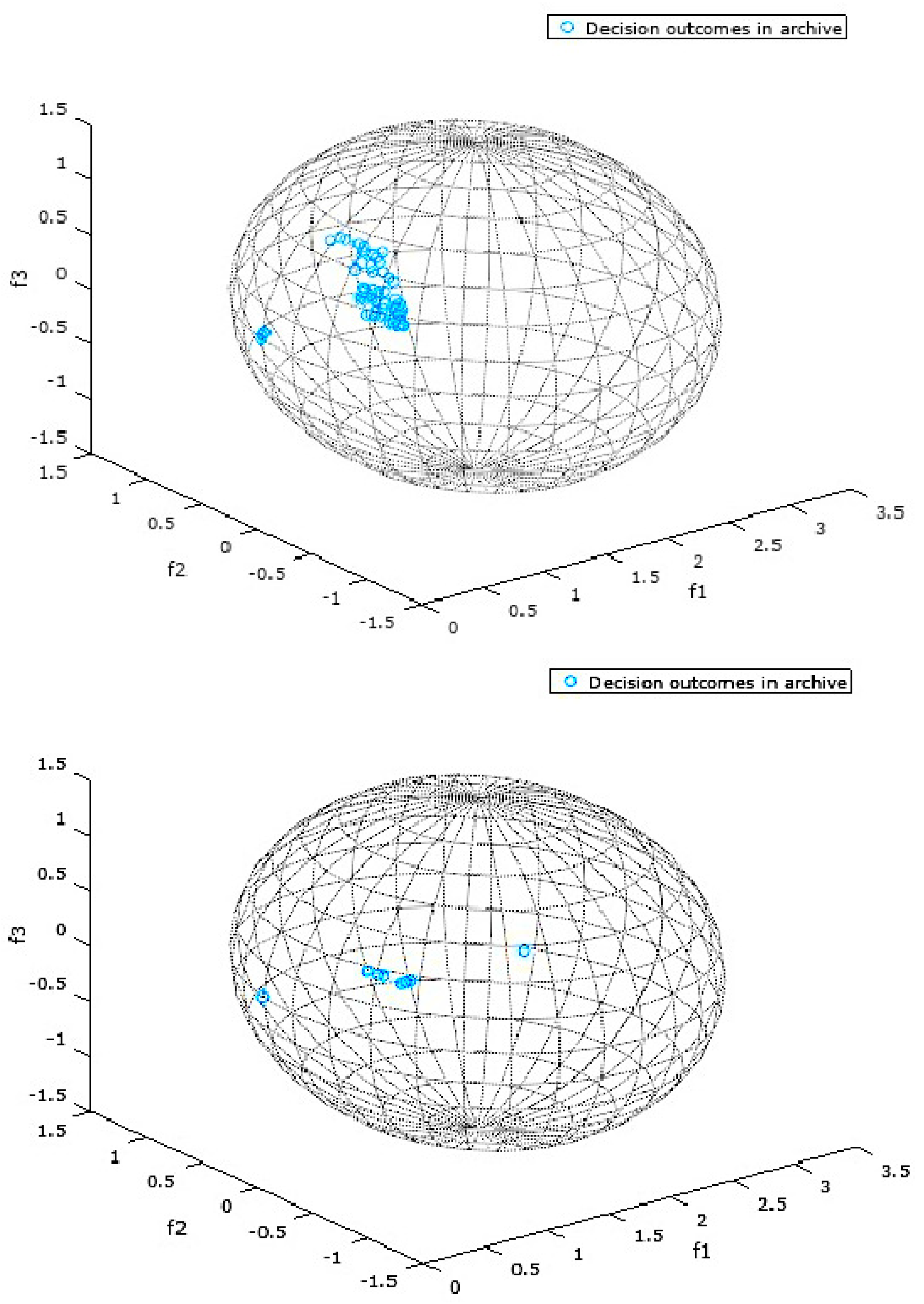
4. Results
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Detailed Results

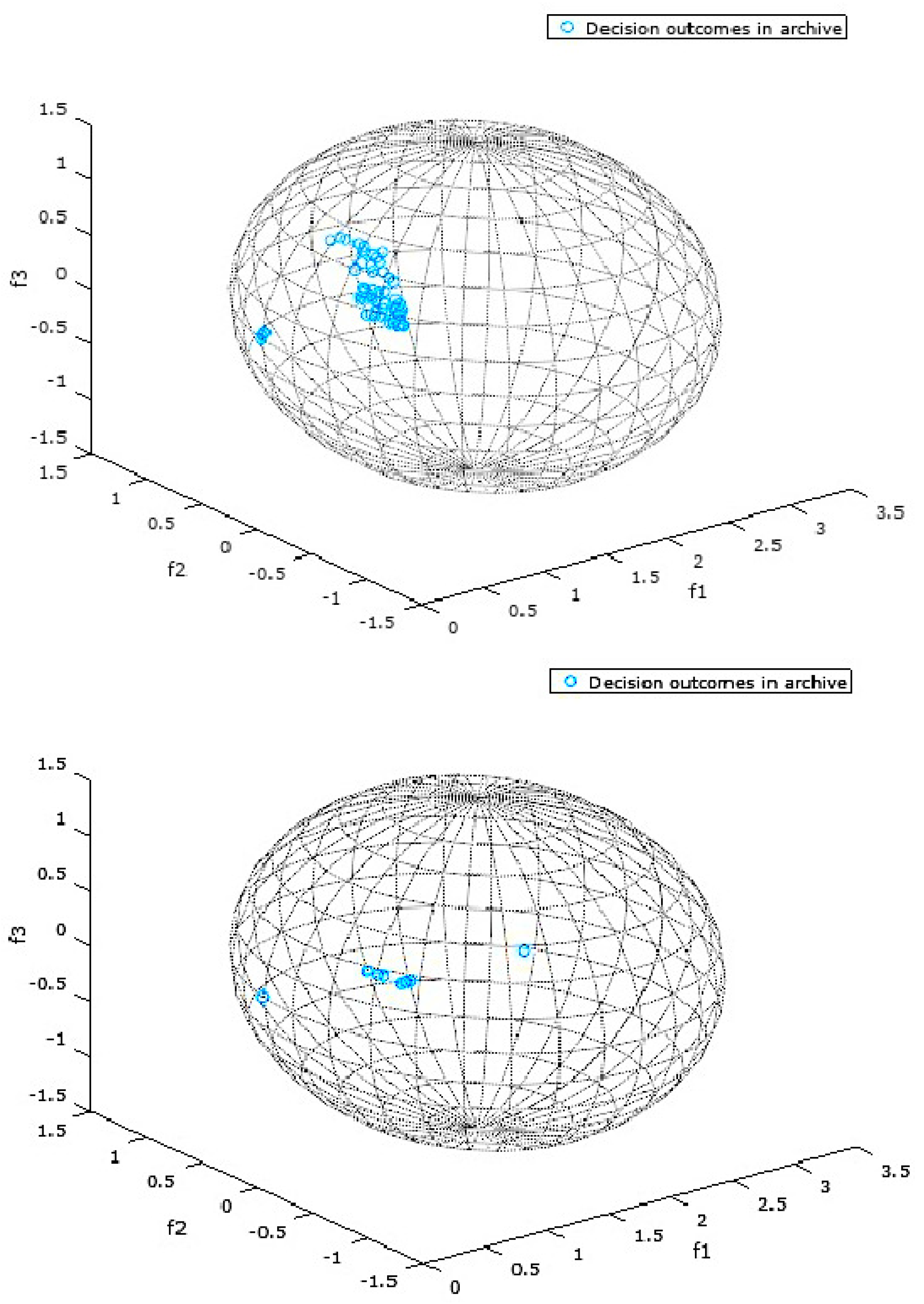
{kind=link}
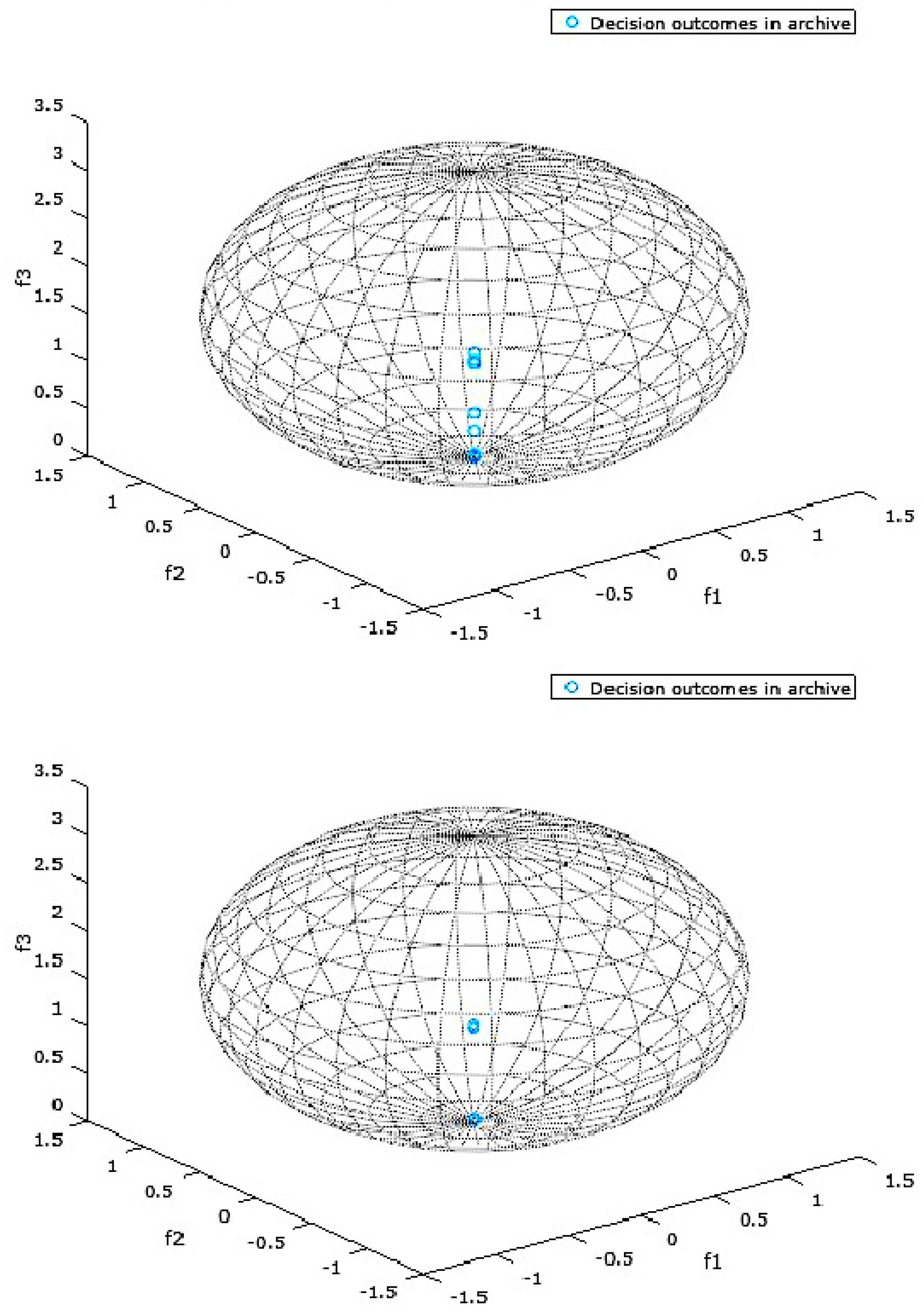
{kind=link}
{kind=link}
| DMOOP | PM | PPA | DPA | RSTFRA | PM | PPA | DPA | RSTFRA | ||
|---|---|---|---|---|---|---|---|---|---|---|
| fda1 | 10 | 4 | acc | 0.7100 | 0.7360 | 0.6633 | stab | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 10 | 4 | acc | 0.5959 | 0.6533 | 0.7089 | stab | 0.1913 | 0.2382 | 0.2055 |
| fda1 | 10 | 4 | acc | 0.6236 | 0.6581 | 0.6701 | stab | 0.1583 | 0.1845 | 0.1725 |
| fda1 | 10 | 4 | acc | 0.6355 | 0.5756 | 0.6087 | stab | 0.2044 | 0.1675 | 0.1932 |
| fda1 | 10 | 5 | acc | 0.6645 | 0.6721 | 0.7355 | stab | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 10 | 5 | acc | 0.6443 | 0.6303 | 0.6217 | stab | 0.1826 | 0.1801 | 0.1188 |
| fda1 | 10 | 5 | acc | 0.6204 | 0.6630 | 0.6485 | stab | 0.2073 | 0.2242 | 0.1906 |
| fda1 | 10 | 5 | acc | 0.5634 | 0.5295 | 0.5401 | stab | 0.2073 | 0.2242 | 0.1906 |
| fda1 | 10 | 2 | acc | 0.6993 | 0.5643 | 0.6647 | stab | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 10 | 2 | acc | 0.5952 | 0.6773 | 0.6496 | stab | 0.1347 | 0.1697 | 0.1500 |
| fda1 | 10 | 2 | acc | 0.6311 | 0.6796 | 0.6332 | stab | 0.1091 | 0.1621 | 0.1531 |
| fda1 | 10 | 2 | acc | 0.5669 | 0.5971 | 0.5843 | stab | 0.2105 | 0.1919 | 0.1923 |
| fda1 | 1 | 4 | acc | 0.9975 | 0.9936 | 0.9823 | stab | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 1 | 4 | acc | 0.7261 | 0.6684 | 0.7465 | stab | 0.0000 | 0.0002 | 0.0000 |
| fda1 | 1 | 4 | acc | 0.9671 | 0.9961 | 0.9836 | stab | 0.0329 | 0.0039 | 0.0164 |
| fda1 | 1 | 4 | acc | 0.6606 | 0.6645 | 0.7412 | stab | 0.0004 | 0.0000 | 0.0000 |
| fda1 | 1 | 5 | acc | 0.9644 | 0.7128 | 0.7965 | stab | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 1 | 5 | acc | 0.7928 | 0.8884 | 0.8250 | stab | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 1 | 5 | acc | 0.9139 | 0.6744 | 0.8290 | stab | 0.0845 | 0.278 | 0.1030 |
| fda1 | 1 | 5 | acc | 0.7700 | 0.8612 | 0.7521 | stab | 0.0000 | 0.0000 | 0.0012 |
| fda1 | 1 | 2 | acc | 0.9580 | 0.9370 | 0.8967 | stab | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 1 | 2 | acc | 0.8832 | 0.9017 | 0.8840 | stab | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 1 | 2 | acc | 0.9587 | 0.9519 | 0.8972 | stab | 0.0410 | 0.0252 | 0.0882 |
| fda1 | 1 | 2 | acc | 0.8834 | 0.7915 | 0.8299 | stab | 0.0000 | 0.0000 | 0.0000 |
| DMOOP | PM | PPA | DPA | RSTFRA | PM | PPA | DPA | RSTFRA | ||
|---|---|---|---|---|---|---|---|---|---|---|
| fda1 | 10 | 4 | hvr | 1.7400 | 1.7865 | 1.8379 | react | 13.0000 | 13.0000 | 13.0000 |
| fda1 | 10 | 4 | hvr | 1.5609 | 1.7001 | 1.9762 | react | 9.0000 | 9.0000 | 9.0000 |
| fda1 | 10 | 4 | hvr | 1.7016 | 1.6661 | 1.5562 | react | 5.0000 | 5.0000 | 5.0000 |
| fda1 | 10 | 4 | hvr | 1.7977 | 2.0063 | 1.5598 | react | 1.0000 | 1.0000 | 1.0000 |
| fda1 | 10 | 5 | hvr | 1.6588 | 1.592 | 1.9064 | react | 16.0000 | 16.0000 | 16.0000 |
| fda1 | 10 | 5 | hvr | 1.7341 | 1.7048 | 1.5894 | react | 11.0000 | 11.0000 | 11.0000 |
| fda1 | 10 | 5 | hvr | 1.6116 | 1.7846 | 1.7651 | react | 6.0000 | 6.0000 | 6.0000 |
| fda1 | 10 | 5 | hvr | 1.4383 | 1.733 | 1.624 | react | 1.0000 | 1.0000 | 1.0000 |
| fda1 | 10 | 2 | hvr | 1.7493 | 1.5363 | 1.7156 | react | 7.0000 | 7.0000 | 7.0000 |
| fda1 | 10 | 2 | hvr | 1.6243 | 1.5522 | 1.5465 | react | 5.0000 | 5.0000 | 5.0000 |
| fda1 | 10 | 2 | hvr | 1.5960 | 1.5437 | 1.4597 | react | 3.0000 | 3.0000 | 3.0000 |
| fda1 | 10 | 2 | hvr | 1.6373 | 1.5162 | 1.4294 | react | 1.0000 | 1.0000 | 1.0000 |
| fda1 | 1 | 4 | hvr | 1.4955 | 1.5851 | 1.7424 | react | 13.0000 | 13.0000 | 13.0000 |
| fda1 | 1 | 4 | hvr | 2.9606 | 2.7286 | 2.9838 | react | 8.3000 | 8.0667 | 8.4000 |
| fda1 | 1 | 4 | hvr | 1.4713 | 1.6797 | 1.7775 | react | 5.0000 | 5.0000 | 5.0000 |
| fda1 | 1 | 4 | hvr | 2.7961 | 2.7168 | 2.8980 | react | 1.0000 | 1.0000 | 1.0000 |
| fda1 | 1 | 5 | hvr | 2.0055 | 1.4014 | 1.4275 | react | 12.5000 | 7.5000 | 9.5000 |
| fda1 | 1 | 5 | hvr | 3.7040 | 4.3578 | 3.6041 | react | 10.4000 | 10.6333 | 10.3667 |
| fda1 | 1 | 5 | hvr | 1.8095 | 1.2873 | 1.2637 | react | 4.8333 | 3.0000 | 3.1667 |
| fda1 | 1 | 5 | hvr | 3.6045 | 4.2051 | 3.5012 | react | 1.0000 | 1.0000 | 1.0000 |
| fda1 | 1 | 2 | hvr | 2.0333 | 1.7847 | 2.0553 | react | 4.2000 | 3.5000 | 2.8000 |
| fda1 | 1 | 2 | hvr | 4.2680 | 4.2409 | 4.0464 | react | 4.6333 | 4.5667 | 4.5667 |
| fda1 | 1 | 2 | hvr | 1.9415 | 1.7069 | 2.4759 | react | 2.8000 | 2.6000 | 2.3333 |
| fda1 | 1 | 2 | hvr | 3.9993 | 3.5754 | 3.7061 | react | 1.0000 | 1.0000 | 1.0000 |
| DMOOP | PM | PPA | DPA | RSTFRA | PM | PPA | DPA | RSTFRA | ||
|---|---|---|---|---|---|---|---|---|---|---|
| fda1 | 10 | 4 | nNVD | 99.4333 | 98.1333 | 99.8000 | sNVD | 0.0297 | 0.0301 | 0.0296 |
| fda1 | 10 | 4 | nNVD | 99.5000 | 96.1667 | 96.0667 | sNVD | 0.0298 | 0.0308 | 0.0308 |
| fda1 | 10 | 4 | nNVD | 99.5000 | 94.3667 | 95.6000 | sNVD | 0.0298 | 0.0314 | 0.0310 |
| fda1 | 10 | 4 | nNVD | 99.0333 | 96.3000 | 96.8333 | sNVD | 0.0299 | 0.0308 | 0.0306 |
| fda1 | 10 | 5 | nNVD | 100.0000 | 100.0000 | 100.0000 | sNVD | 0.0295 | 0.0295 | 0.0295 |
| fda1 | 10 | 5 | nNVD | 100.0000 | 100.0000 | 100.0000 | sNVD | 0.0295 | 0.0295 | 0.0295 |
| fda1 | 10 | 5 | nNVD | 100.0000 | 99.9667 | 100.0000 | sNVD | 0.0295 | 0.0295 | 0.0296 |
| fda1 | 10 | 5 | nNVD | 100.0000 | 100.0000 | 100.0000 | sNVD | 0.0295 | 0.0295 | 0.0295 |
| fda1 | 10 | 2 | nNVD | 64.9667 | 64.9000 | 67.1333 | sNVD | 0.0457 | 0.0458 | 0.0441 |
| fda1 | 10 | 2 | nNVD | 67.4333 | 58.6667 | 57.6667 | sNVD | 0.0442 | 0.0506 | 0.0514 |
| fda1 | 10 | 2 | nNVD | 67.5667 | 58.7000 | 56.0000 | sNVD | 0.044 | 0.0505 | 0.0532 |
| fda1 | 10 | 2 | nNVD | 67.7000 | 57.4667 | 57.7333 | sNVD | 0.0438 | 0.0518 | 0.0512 |
| fda1 | 1 | 4 | nNVD | 26.2667 | 27.6333 | 25.6333 | sNVD | 0.0671 | 0.0648 | 0.0686 |
| fda1 | 1 | 4 | nNVD | 26.2333 | 26.5667 | 21.6333 | sNVD | 0.0719 | 0.0777 | 0.0853 |
| fda1 | 1 | 4 | nNVD | 26.1667 | 23.1333 | 22.7000 | sNVD | 0.0675 | 0.0773 | 0.0784 |
| fda1 | 1 | 4 | nNVD | 25.0000 | 25.3667 | 25.6000 | sNVD | 0.0735 | 0.0756 | 0.0769 |
| fda1 | 1 | 5 | nNVD | 100.0000 | 100.0000 | 100.0000 | sNVD | 0.0296 | 0.0295 | 0.0295 |
| fda1 | 1 | 5 | nNVD | 71.4333 | 99.0333 | 100.0000 | sNVD | 0.0422 | 0.0301 | 0.0296 |
| fda1 | 1 | 5 | nNVD | 100.0000 | 98.9333 | 99.3000 | sNVD | 0.0296 | 0.0299 | 0.0298 |
| fda1 | 1 | 5 | nNVD | 76.2667 | 98.1667 | 95.7667 | sNVD | 0.0394 | 0.0303 | 0.0291 |
| fda1 | 1 | 2 | nNVD | 66.0333 | 65.7000 | 66.2000 | sNVD | 0.0448 | 0.0453 | 0.0449 |
| fda1 | 1 | 2 | nNVD | 31.7000 | 30.2333 | 40.3000 | sNVD | 0.0973 | 0.1029 | 0.0726 |
| fda1 | 1 | 2 | nNVD | 62.6000 | 43.2333 | 43.4333 | sNVD | 0.04708 | 0.0690 | 0.0670 |
| fda1 | 1 | 2 | nNVD | 31.4667 | 31.3667 | 28.8667 | sNVD | 0.0981 | 0.1001 | 0.1089 |
| DMOOP | PM | PPA | DPA | RSTFRA | PM | PPA | DPA | RSTFRA | ||
|---|---|---|---|---|---|---|---|---|---|---|
| fda1 | 10 | 4 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 10 | 4 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 10 | 4 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 10 | 4 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 10 | 5 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 10 | 5 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 10 | 5 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 10 | 5 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 10 | 2 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 10 | 2 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 10 | 2 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 10 | 2 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 1 | 4 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 1 | 4 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 1 | 4 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 1 | 4 | nVD | 0.0667 | 0.0000 | 0.0000 | dVD | 0.0667 | 0.0000 | 0.0000 |
| fda1 | 1 | 5 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 1 | 5 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 1 | 5 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 1 | 5 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 1 | 2 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 1 | 2 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 1 | 2 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda1 | 1 | 2 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| DMOOP | PM | PPA | DPA | RSTFRA | PM | PPA | DPA | RSTFRA | ||
|---|---|---|---|---|---|---|---|---|---|---|
| fda5 | 10 | 4 | acc | 0.6404 | 0.5962 | 0.5380 | stab | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 10 | 4 | acc | 0.6751 | 0.7731 | 0.7557 | stab | 0.1793 | 0.1457 | 0.0884 |
| fda5 | 10 | 4 | acc | 0.4445 | 0.4619 | 0.6266 | stab | 0.4251 | 0.4261 | 0.2747 |
| fda5 | 10 | 4 | acc | 0.2282 | 0.2270 | 0.1946 | stab | 0.4743 | 0.5300 | 0.4098 |
| fda5 | 10 | 5 | acc | 0.2683 | 0.4080 | 0.8316 | stab | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 10 | 5 | acc | 0.4298 | 0.6803 | 0.8570 | stab | 0.1992 | 0.1543 | 0.0168 |
| fda5 | 10 | 5 | acc | 0.5140 | 0.6998 | 0.8183 | stab | 0.2266 | 0.1100 | 0.0883 |
| fda5 | 10 | 5 | acc | 0.5382 | 0.6913 | 0.7904 | stab | 0.2461 | 0.1599 | 0.1331 |
| fda5 | 10 | 2 | acc | 0.6239 | 0.6727 | 0.9835 | stab | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 10 | 2 | acc | 0.8799 | 0.8925 | 0.9526 | stab | 0.0985 | 0.0860 | 0.0000 |
| fda5 | 10 | 2 | acc | 0.6285 | 0.6549 | 0.9234 | stab | 0.3367 | 0.2923 | 0.0277 |
| fda5 | 10 | 2 | acc | 0.4285 | 0.4320 | 0.9186 | stab | 0.4402 | 0.4291 | 0.0455 |
| fda5 | 1 | 4 | acc | 0.9984 | 1.0000 | 1.0000 | stab | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 1 | 4 | acc | 0.9986 | 0.9955 | 0.9970 | stab | 0.0014 | 0.0045 | 0.0030 |
| fda5 | 1 | 4 | acc | 1.0000 | 0.9991 | 0.9991 | stab | 0.0000 | 0.0009 | 0.0009 |
| fda5 | 1 | 4 | acc | 0.9996 | 0.9945 | 0.9956 | stab | 0.0004 | 0.0055 | 0.0044 |
| fda5 | 1 | 5 | acc | 1.0000 | 0.9993 | 0.9958 | stab | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 1 | 5 | acc | 0.9953 | 0.9915 | 0.9746 | stab | 0.0047 | 0.0085 | 0.0254 |
| fda5 | 1 | 5 | acc | 1.0000 | 0.9971 | 0.9976 | stab | 0.0000 | 0.0029 | 0.0024 |
| fda5 | 1 | 5 | acc | 0.9963 | 0.9962 | 0.9793 | stab | 0.0037 | 0.0038 | 0.0207 |
| fda5 | 1 | 2 | acc | 1.0000 | 0.9993 | 0.9948 | stab | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 1 | 2 | acc | 0.9963 | 0.9990 | 0.9781 | stab | 0.0037 | 0.0010 | 0.0219 |
| fda5 | 1 | 2 | acc | 1.0000 | 0.9993 | 0.9980 | stab | 0.0000 | 0.0007 | 0.0020 |
| fda5 | 1 | 2 | acc | 1.0000 | 0.9987 | 0.9853 | stab | 0.0000 | 0.0013 | 0.0147 |
| DMOOP | PM | PPA | DPA | RSTFRA | PM | PPA | DPA | RSTFRA | ||
|---|---|---|---|---|---|---|---|---|---|---|
| fda5 | 10 | 4 | hvr | 1.6654 | 1.3814 | 1.2592 | react | 12.9667 | 12.9667 | 12.5000 |
| fda5 | 10 | 4 | hvr | 2.4693 | 1.7110 | 1.5734 | react | 8.9333 | 8.8333 | 8.8333 |
| fda5 | 10 | 4 | hvr | 3.2302 | 1.8911 | 1.6400 | react | 5.0000 | 4.9667 | 5.0000 |
| fda5 | 10 | 4 | hvr | 2.0206 | 2.0017 | 1.7762 | react | 1.0000 | 1.0000 | 1.0000 |
| fda5 | 10 | 5 | hvr | 2.1537 | 2.7315 | 2.4955 | react | 16.0000 | 16.0000 | 15.9333 |
| fda5 | 10 | 5 | hvr | 2.2018 | 2.6023 | 1.9044 | react | 11.0000 | 10.8000 | 10.9333 |
| fda5 | 10 | 5 | hvr | 2.267 | 2.3623 | 2.0773 | react | 6.0000 | 6.0000 | 6.0000 |
| fda5 | 10 | 5 | hvr | 2.1636 | 2.4252 | 1.8647 | react | 1.0000 | 1.0000 | 1.0000 |
| fda5 | 10 | 2 | hvr | 1.5414 | 1.6826 | 1.2248 | react | 6.9000 | 7.0000 | 7.0000 |
| fda5 | 10 | 2 | hvr | 3.3034 | 3.2674 | 1.4156 | react | 5.0000 | 4.9667 | 5.0000 |
| fda5 | 10 | 2 | hvr | 4.9233 | 5.1433 | 1.1358 | react | 3.0000 | 3.0000 | 3.0000 |
| fda5 | 10 | 2 | hvr | 3.5145 | 4.0314 | 1.2700 | react | 1.0000 | 1.0000 | 1.0000 |
| fda5 | 1 | 4 | hvr | 4.4565 | 4.0032 | 3.8261 | react | 12.6000 | 13.0000 | 13.0000 |
| fda5 | 1 | 4 | hvr | 2.4313 | 2.5719 | 2.2178 | react | 7.7667 | 7.3000 | 7.5333 |
| fda5 | 1 | 4 | hvr | 4.7446 | 3.4347 | 3.5272 | react | 5.0000 | 4.8667 | 4.8667 |
| fda5 | 1 | 4 | hvr | 2.1979 | 2.7897 | 2.2656 | react | 1.0000 | 1.0000 | 1.0000 |
| fda5 | 1 | 5 | hvr | 2.9987 | 2.6455 | 1.9198 | react | 16.0000 | 15.0000 | 11.5000 |
| fda5 | 1 | 5 | hvr | 2.6475 | 2.1308 | 1.0979 | react | 8.2000 | 7.3000 | 2.8000 |
| fda5 | 1 | 5 | hvr | 3.088 | 2.8665 | 2.5523 | react | 6.0000 | 5.3333 | 5.5000 |
| fda5 | 1 | 5 | hvr | 2.5349 | 2.3717 | 1.3460 | react | 1.0000 | 1.0000 | 1.0000 |
| fda5 | 1 | 2 | hvr | 3.0785 | 3.5184 | 1.8674 | react | 4.0000 | 3.9000 | 3.0000 |
| fda5 | 1 | 2 | hvr | 2.2679 | 3.1541 | 1.0209 | react | 3.3000 | 3.7000 | 1.2000 |
| fda5 | 1 | 2 | hvr | 2.9413 | 3.3106 | 3.2396 | react | 3.0000 | 2.9333 | 2.6667 |
| fda5 | 1 | 2 | hvr | 3.2166 | 3.2704 | 2.2137 | react | 1.0000 | 1.0000 | 1.0000 |
| DMOOP | PM | PPA | DPA | RSTFRA | PM | PPA | DPA | RSTFRA | ||
|---|---|---|---|---|---|---|---|---|---|---|
| fda5 | 10 | 4 | nNVD | 39.5000 | 50.0333 | 45.3000 | sNVD | 0.1175 | 0.0966 | 0.1008 |
| fda5 | 10 | 4 | nNVD | 57.1667 | 67.3333 | 68.4333 | sNVD | 0.0906 | 0.0791 | 0.0726 |
| fda5 | 10 | 4 | nNVD | 63.5000 | 74.6333 | 63.1333 | sNVD | 0.1100 | 0.0915 | 0.0962 |
| fda5 | 10 | 4 | nNVD | 71.9000 | 72.9333 | 58.8667 | sNVD | 0.1237 | 0.1122 | 0.1245 |
| fda5 | 10 | 5 | nNVD | 42.0000 | 49.9667 | 27.4000 | sNVD | 0.1652 | 0.1327 | 0.1010 |
| fda5 | 10 | 5 | nNVD | 72.0667 | 70.2000 | 35.0667 | sNVD | 0.1105 | 0.1015 | 0.0915 |
| fda5 | 10 | 5 | nNVD | 74.4333 | 65.4667 | 36.4000 | sNVD | 0.1089 | 0.1005 | 0.0940 |
| fda5 | 10 | 5 | nNVD | 79.0667 | 60.1667 | 34.0333 | sNVD | 0.1017 | 0.1079 | 0.1059 |
| fda5 | 10 | 2 | nNVD | 12.2667 | 11.8333 | 2.9333 | sNVD | 0.2712 | 0.2546 | 0.0040 |
| fda5 | 10 | 2 | nNVD | 13.1667 | 9.1000 | 1.5667 | sNVD | 0.1928 | 0.2910 | 0.0032 |
| fda5 | 10 | 2 | nNVD | 19.3000 | 9.8000 | 2.6333 | sNVD | 0.2200 | 0.3729 | 0.0005 |
| fda5 | 10 | 2 | nNVD | 41.5667 | 33.8000 | 2.6000 | sNVD | 0.1413 | 0.1716 | 0.0062 |
| fda5 | 1 | 4 | nNVD | 12.9667 | 12.7000 | 9.6333 | sNVD | 0.1967 | 0.2117 | 0.0279 |
| fda5 | 1 | 4 | nNVD | 32.4667 | 18.6667 | 12.3667 | sNVD | 0.2258 | 0.1087 | 0.0253 |
| fda5 | 1 | 4 | nNVD | 13.6667 | 12.9667 | 9.3667 | sNVD | 0.2683 | 0.2654 | 0.0122 |
| fda5 | 1 | 4 | nNVD | 29.2333 | 28.9000 | 16.5333 | sNVD | 0.2238 | 0.0853 | 0.0124 |
| fda5 | 1 | 5 | nNVD | 19.4000 | 23.2000 | 21.7333 | sNVD | 0.0897 | 0.0592 | 0.0568 |
| fda5 | 1 | 5 | nNVD | 35.8333 | 34.2000 | 67.6333 | sNVD | 0.0946 | 0.0687 | 0.0368 |
| fda5 | 1 | 5 | nNVD | 21.0333 | 23.4333 | 21.0333 | sNVD | 0.1374 | 0.1011 | 0.0651 |
| fda5 | 1 | 5 | nNVD | 39.1 | 33.6333 | 62.8333 | sNVD | 0.0757 | 0.0693 | 0.0407 |
| fda5 | 1 | 2 | nNVD | 22.1667 | 23.6333 | 26.4333 | sNVD | 0.1600 | 0.1365 | 0.0837 |
| fda5 | 1 | 2 | nNVD | 20.8667 | 17.8667 | 6.6000 | sNVD | 0.0726 | 0.0964 | 0.0577 |
| fda5 | 1 | 2 | nNVD | 18.8000 | 17.5000 | 17.4333 | sNVD | 0.2013 | 0.2357 | 0.1891 |
| fda5 | 1 | 2 | nNVD | 20.2667 | 18.0333 | 11.4667 | sNVD | 0.0617 | 0.0747 | 0.0391 |
| DMOOP | PM | PPA | DPA | RSTFRA | PM | PPA | DPA | RSTFRA | ||
|---|---|---|---|---|---|---|---|---|---|---|
| fda5 | 10 | 4 | nVD | 0.0333 | 0.0000 | 0.0000 | dVD | 0.0333 | 0.0000 | 0.0000 |
| fda5 | 10 | 4 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 10 | 4 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 10 | 4 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 10 | 5 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 10 | 5 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 10 | 5 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 10 | 5 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 10 | 2 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 10 | 2 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 10 | 2 | nVD | 0.0333 | 0.0000 | 0.0000 | dVD | 0.0333 | 0.0000 | 0.0000 |
| fda5 | 10 | 2 | nVD | 0.0333 | 0.0000 | 0.0000 | dVD | 0.0333 | 0.0000 | 0.0000 |
| fda5 | 1 | 4 | nVD | 0.0667 | 0.0000 | 0.0000 | dVD | 0.0667 | 0.0000 | 0.0000 |
| fda5 | 1 | 4 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 1 | 4 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 1 | 4 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 1 | 5 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 1 | 5 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 1 | 5 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 1 | 5 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 1 | 2 | nVD | 0.0333 | 0.0000 | 0.0000 | dVD | 0.0333 | 0.0000 | 0.0000 |
| fda5 | 1 | 2 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 1 | 2 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| fda5 | 1 | 2 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| DMOOP | PM | PPA | DPA | RSTFRA | PM | PPA | DPA | RSTFRA | ||
|---|---|---|---|---|---|---|---|---|---|---|
| dmop2 | 10 | 4 | acc | 0.8700 | 0.7811 | 0.8707 | stab | 0.0000 | 0.0000 | 0.0000 |
| dmop2 | 10 | 4 | acc | 0.8284 | 0.8287 | 0.8715 | stab | 0.0000 | 0.0164 | 0.0000 |
| dmop2 | 10 | 4 | acc | 0.8124 | 0.8805 | 0.8840 | stab | 0.0000 | 0.0110 | 0.0002 |
| dmop2 | 10 | 4 | acc | 0.9980 | 0.9717 | 0.9995 | stab | 0.0006 | 0.0165 | 0.0001 |
| dmop2 | 10 | 5 | acc | 0.7858 | 0.7680 | 0.9103 | stab | 0.0000 | 0.0000 | 0.0000 |
| dmop2 | 10 | 5 | acc | 0.6857 | 0.7187 | 0.9217 | stab | 0.0099 | 0.0261 | 0.0000 |
| dmop2 | 10 | 5 | acc | 0.8374 | 0.7731 | 0.9080 | stab | 0.0000 | 0.0159 | 0.0000 |
| dmop2 | 10 | 5 | acc | 0.9773 | 0.9755 | 0.9951 | stab | 0.0209 | 0.0226 | 0.0036 |
| dmop2 | 10 | 2 | acc | 0.8127 | 0.8490 | 0.8298 | stab | 0.0000 | 0.0000 | 0.0000 |
| dmop2 | 10 | 2 | acc | 0.8232 | 0.8581 | 0.7979 | stab | 0.0000 | 0.0000 | 0.0000 |
| dmop2 | 10 | 2 | acc | 0.9443 | 0.8277 | 0.8558 | stab | 0.0000 | 0.0000 | 0.0000 |
| dmop2 | 10 | 2 | acc | 0.9980 | 0.9975 | 0.9988 | stab | 0.0009 | 0.0003 | 0.0002 |
| dmop2 | 1 | 4 | acc | 0.9266 | 0.3449 | 0.3097 | stab | 0.0000 | 0.0000 | 0.0000 |
| dmop2 | 1 | 4 | acc | 0.9309 | 0.8833 | 0.5509 | stab | 0.0224 | 0.1167 | 0.4491 |
| dmop2 | 1 | 4 | acc | 1.0000 | 0.3802 | 0.6802 | stab | 0.0000 | 0.6198 | 0.3198 |
| dmop2 | 1 | 4 | acc | 0.5236 | 0.4389 | 0.4764 | stab | 0.0073 | 0.0045 | 0.0396 |
| dmop2 | 1 | 5 | acc | 0.9478 | 0.2882 | 0.9615 | stab | 0.0000 | 0.0000 | 0.0000 |
| dmop2 | 1 | 5 | acc | 0.9393 | 0.9508 | 0.9574 | stab | 0.0177 | 0.0492 | 0.0426 |
| dmop2 | 1 | 5 | acc | 0.9991 | 0.3737 | 0.9778 | stab | 0.0009 | 0.6263 | 0.0222 |
| dmop2 | 1 | 5 | acc | 0.4861 | 0.3884 | 0.7584 | stab | 0.0103 | 0.0710 | 0.2271 |
| dmop2 | 1 | 2 | acc | 0.9548 | 0.7587 | 0.9164 | stab | 0.0000 | 0.0000 | 0.0000 |
| dmop2 | 1 | 2 | acc | 0.9833 | 0.8949 | 0.9059 | stab | 0.0059 | 0.1051 | 0.0941 |
| dmop2 | 1 | 2 | acc | 0.9942 | 0.8278 | 0.9069 | stab | 0.0058 | 0.1722 | 0.0931 |
| dmop2 | 1 | 2 | acc | 0.4735 | 0.5391 | 0.7011 | stab | 0.0169 | 0.0625 | 0.2519 |
| DMOOP | PM | PPA | DPA | RSTFRA | PM | PPA | DPA | RSTFRA | ||
|---|---|---|---|---|---|---|---|---|---|---|
| dmop2 | 10 | 4 | hvr | 1.2872 | 1.2594 | 1.2577 | react | 12.8667 | 12.9667 | 12.3667 |
| dmop2 | 10 | 4 | hvr | 1.1982 | 1.2284 | 1.3295 | react | 8.0333 | 8.6333 | 8.6000 |
| dmop2 | 10 | 4 | hvr | 1.5950 | 1.5624 | 1.4643 | react | 4.9667 | 4.8333 | 4.8333 |
| dmop2 | 10 | 4 | hvr | 1.3038 | 1.4336 | 1.4014 | react | 1.0000 | 1.0000 | 1.0000 |
| dmop2 | 10 | 5 | hvr | 1.9143 | 1.8882 | 1.1107 | react | 16.0000 | 16.0000 | 16.0000 |
| dmop2 | 10 | 5 | hvr | 1.6730 | 1.7919 | 1.1055 | react | 11.0000 | 11.0000 | 11.0000 |
| dmop2 | 10 | 5 | hvr | 1.7423 | 1.6500 | 1.0242 | react | 6.0000 | 5.9333 | 5.9667 |
| dmop2 | 10 | 5 | hvr | 1.8847 | 2.0522 | 1.1175 | react | 1.0000 | 1.0000 | 1.0000 |
| dmop2 | 10 | 2 | hvr | 1.3575 | 1.5524 | 1.4858 | react | 6.8000 | 6.9000 | 6.8000 |
| dmop2 | 10 | 2 | hvr | 1.3303 | 1.4589 | 1.4937 | react | 4.8000 | 4.9333 | 4.8333 |
| dmop2 | 10 | 2 | hvr | 1.7886 | 1.3657 | 1.3977 | react | 2.9333 | 2.8000 | 2.9000 |
| dmop2 | 10 | 2 | hvr | 1.5989 | 1.5930 | 1.4986 | react | 1.0000 | 1.0000 | 1.0000 |
| dmop2 | 1 | 4 | hvr | 1.5361 | 2.0163 | 1.6181 | react | 8.6000 | 2.6000 | 1.4000 |
| dmop2 | 1 | 4 | hvr | 2.4648 | 9.2045 | 4.3700 | react | 7.8000 | 5.2667 | 2.3333 |
| dmop2 | 1 | 4 | hvr | 0.9826 | 6.7302 | 10.8249 | react | 5.0000 | 2.4667 | 4.6000 |
| dmop2 | 1 | 4 | hvr | 2.0165 | 5.4407 | 2.7435 | react | 1.0000 | 1.0000 | 1.0000 |
| dmop2 | 1 | 5 | hvr | 1.651 | 4.8469 | 0.9488 | react | 12.0000 | 2.5000 | 12.5000 |
| dmop2 | 1 | 5 | hvr | 2.1529 | 14.7819 | 0.9485 | react | 9.6333 | 8.3333 | 8.6667 |
| dmop2 | 1 | 5 | hvr | 0.9861 | 6.5701 | 0.9669 | react | 6.0000 | 2.8333 | 6.0000 |
| dmop2 | 1 | 5 | hvr | 1.7927 | 6.4797 | 0.7462 | react | 1.0000 | 1.0000 | 1.0000 |
| dmop2 | 1 | 2 | hvr | 1.9387 | 7.6131 | 1.4606 | react | 3.3000 | 1.5000 | 2.9000 |
| dmop2 | 1 | 2 | hvr | 2.3369 | 5.3866 | 1.5312 | react | 4.7667 | 3.1333 | 2.8667 |
| dmop2 | 1 | 2 | hvr | 0.9523 | 10.4355 | 2.5348 | react | 3.0000 | 2.9333 | 3.0000 |
| dmop2 | 1 | 2 | hvr | 1.7974 | 1.3771 | 0.7159 | react | 1.0000 | 1.0000 | 1.0000 |
| DMOOP | PM | PPA | DPA | RSTFRA | PM | PPA | DPA | RSTFRA | ||
|---|---|---|---|---|---|---|---|---|---|---|
| dmop2 | 10 | 4 | nNVD | 5.3667 | 5.8333 | 6.4333 | sNVD | 0.0597 | 0.0511 | 0.0466 |
| dmop2 | 10 | 4 | nNVD | 4.0667 | 3.9333 | 3.6000 | sNVD | 0.0698 | 0.0835 | 0.0716 |
| dmop2 | 10 | 4 | nNVD | 3.1333 | 3.0000 | 3.1000 | sNVD | 0.0775 | 0.1051 | 0.0987 |
| dmop2 | 10 | 4 | nNVD | 4.3000 | 3.3333 | 3.0667 | sNVD | 0.0721 | 0.0806 | 0.0951 |
| dmop2 | 10 | 5 | nNVD | 12.6000 | 13.3333 | 3.8333 | sNVD | 0.1300 | 0.1264 | 0.0291 |
| dmop2 | 10 | 5 | nNVD | 10.4000 | 9.8667 | 3.0000 | sNVD | 0.1548 | 0.1585 | 0.0395 |
| dmop2 | 10 | 5 | nNVD | 11.0000 | 9.3333 | 2.9667 | sNVD | 0.1465 | 0.1710 | 0.0382 |
| dmop2 | 10 | 5 | nNVD | 9.6667 | 7.9333 | 2.5667 | sNVD | 0.1740 | 0.2079 | 0.0364 |
| dmop2 | 10 | 2 | nNVD | 5.8333 | 5.8667 | 6.5667 | sNVD | 0.1150 | 0.1180 | 0.1052 |
| dmop2 | 10 | 2 | nNVD | 3.9000 | 3.1333 | 2.8667 | sNVD | 0.1543 | 0.1751 | 0.2310 |
| dmop2 | 10 | 2 | nNVD | 3.7333 | 2.9333 | 2.8333 | sNVD | 0.1752 | 0.1745 | 0.2025 |
| dmop2 | 10 | 2 | nNVD | 4.6333 | 3.2000 | 3.0333 | sNVD | 0.1419 | 0.1825 | 0.2077 |
| dmop2 | 1 | 4 | nNVD | 68.1667 | 91.5667 | 94.4667 | sNVD | 0.0441 | 0.0326 | 0.0319 |
| dmop2 | 1 | 4 | nNVD | 49.3000 | 24.8000 | 60.7000 | sNVD | 0.0633 | 0.1534 | 0.1541 |
| dmop2 | 1 | 4 | nNVD | 50.8000 | 63.1667 | 30.2333 | sNVD | 0.0585 | 0.0660 | 0.1982 |
| dmop2 | 1 | 4 | nNVD | 0 | 0.0333 | 0 | sNVD | 0.0000 | 0.0000 | 0.0000 |
| dmop2 | 1 | 5 | nNVD | 81.0667 | 75.4333 | 0.9333 | sNVD | 0.0366 | 0.0596 | 0 |
| dmop2 | 1 | 5 | nNVD | 59.5333 | 3.4333 | 1.0000 | sNVD | 0.0519 | 0.0929 | 0 |
| dmop2 | 1 | 5 | nNVD | 60.6333 | 66.3333 | 0.9 | sNVD | 0.0492 | 0.0532 | 0 |
| dmop2 | 1 | 5 | nNVD | 0.0000 | 0.0000 | 0.0000 | sNVD | 0.0000 | 0.0000 | 0.0000 |
| dmop2 | 1 | 2 | nNVD | 31.4333 | 32.0333 | 5.8000 | sNVD | 0.1038 | 0.1133 | 0.0060 |
| dmop2 | 1 | 2 | nNVD | 13.4333 | 1.7000 | 2.1000 | sNVD | 0.2290 | 0.3570 | 0.0454 |
| dmop2 | 1 | 2 | nNVD | 19.9333 | 12.5333 | 0.6333 | sNVD | 0.1599 | 0.5381 | 0.0247 |
| dmop2 | 1 | 2 | nNVD | 0.0000 | 0.0000 | 0.0000 | sNVD | 0.0000 | 0.0000 | 0.0000 |
| DMOOP | PM | PPA | DPA | RSTFRA | PM | PPA | DPA | RSTFRA | ||
|---|---|---|---|---|---|---|---|---|---|---|
| dmop2 | 10 | 4 | nVD | 0.0667 | 0.0000 | 0.0000 | dVD | 0.0667 | 0.0000 | 0.0000 |
| dmop2 | 10 | 4 | nVD | 0.0333 | 0.0000 | 0.0000 | dVD | 0.0333 | 0.0000 | 0.0000 |
| dmop2 | 10 | 4 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| dmop2 | 10 | 4 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| dmop2 | 10 | 5 | nVD | 0.0333 | 0.0000 | 0.0000 | dVD | 0.0333 | 0.0000 | 0.0000 |
| dmop2 | 10 | 5 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| dmop2 | 10 | 5 | nVD | 0.1333 | 0.0000 | 0.0000 | dVD | 0.1333 | 0.0000 | 0.0000 |
| dmop2 | 10 | 5 | nVD | 0.0667 | 0.0000 | 0.0000 | dVD | 0.0667 | 0.0000 | 0.0000 |
| dmop2 | 10 | 2 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| dmop2 | 10 | 2 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| dmop2 | 10 | 2 | nVD | 0.0333 | 0.0000 | 0.0000 | dVD | 0.0333 | 0.0000 | 0.0000 |
| dmop2 | 10 | 2 | nVD | 0.0333 | 0.0000 | 0.0000 | dVD | 0.0333 | 0.0000 | 0.0000 |
| dmop2 | 1 | 4 | nVD | 0.0000 | 0.0000 | 0.0000 | dVD | 0.0000 | 0.0000 | 0.0000 |
| dmop2 | 1 | 4 | nVD | 0.0000 | 23.3333 | 0.0000 | dVD | 0.0000 | 8.0838 | 0.0000 |
| dmop2 | 1 | 4 | nVD | 0.0000 | 0.0000 | 3.3333 | dVD | 0.0000 | 0.0000 | 1.1525 |
| dmop2 | 1 | 4 | nVD | 1.0000 | 96.6667 | 100.0000 | dVD | 78.3002 | 64.215 | 85.5742 |
| dmop2 | 1 | 5 | nVD | 0.0000 | 6.6667 | 6.6667 | dVD | 0.0000 | 1.0863 | 1.0156 |
| dmop2 | 1 | 5 | nVD | 0.0000 | 66.6667 | 0.0000 | dVD | 0.0000 | 25.4565 | 0.0000 |
| dmop2 | 1 | 5 | nVD | 0.0000 | 13.3333 | 10.0000 | dVD | 0.0000 | 2.5970 | 1.7496 |
| dmop2 | 1 | 5 | nVD | 1.0000 | 100.0000 | 100.0000 | dVD | 83.0633 | 65.1873 | 93.9007 |
| dmop2 | 1 | 2 | nVD | 0.0000 | 0.0000 | 6.6667 | dVD | 0.0000 | 0.0000 | 1.1100 |
| dmop2 | 1 | 2 | nVD | 0.0000 | 26.7333 | 1.7000 | dVD | 0.0000 | 9.0173 | 0.4143 |
| dmop2 | 1 | 2 | nVD | 0.0000 | 0.0000 | 24.1667 | dVD | 0.0000 | 0.0000 | 7.6244 |
| dmop2 | 1 | 2 | nVD | 1.0000 | 62.4667 | 57.6333 | dVD | 85.1725 | 90.4603 | 93.0091 |
References
- Helbig, M.; Engelbrecht, A.P. Analysing the performance of dynamic multi-objective optimisation algorithms. In Proceedings of the IEEE Congress on Evolutionary Computation, Cancun, Mexico, 20–23 June 2013; pp. 1531–1539. [Google Scholar] [CrossRef]
- Jiang, S.; Yang, S. A benchmark generator for dynamic multi-objective optimization problems. In Proceedings of the UK Workshop on Computational Intelligence (UKCI), Bradford, UK, 8–10 September 2014; pp. 1–8. [Google Scholar] [CrossRef]
- Azzouz, R.; Bechikh, S.; Said, L.B. Recent Advances in Evolutionary Multi-objective Optimization; Springer: Berlin/Heidelberg, Germany, 2017; Volume 20. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Yang, S.; Branke, J. Evolutionary dynamic optimization: A survey of the state of the art. Swarm Evol. Comput. 2012, 6, 1–24. [Google Scholar] [CrossRef]
- Coello Coello, C.A.; Reyes-Sierra, M. Multi-Objective Particle Swarm Optimizers: A Survey of the State-of-the-Art. Int. J. Comput. Intell. Res. 2006, 2, 287–308. [Google Scholar] [CrossRef]
- Pareto, V. Cours D’Economie Politique; Librairie Droz: Geneva, Switzerland, 1964. [Google Scholar]
- Deb, K. Multi-Objective Optimization Using Evolutionary Algorithms; John Wiley & Sons, Inc.: New York, NY, USA, 2001. [Google Scholar]
- Bianco, N.; Fragnito, A.; Iasiello, M.; Mauro, G.M. A CFD multi-objective optimization framework to design a wall-type heat recovery and ventilation unit with phase change material. Appl. Energy 2023, 347, 121368. [Google Scholar] [CrossRef]
- Deb, K.; Bhaskara Rao, N.U.; Karthik, S. Dynamic Multi-objective Optimization and Decision-making Using Modified NSGA-II: A Case Study on Hydro-thermal Power Scheduling. In Proceedings of the International Conference on Evolutionary Multi-Criterion Optimization, EMO’07, Matsushima, Japan, 5–8 March 2007; pp. 803–817. [Google Scholar]
- Farina, M.; Deb, K.; Amato, P. Dynamic multiobjective optimization problem: Test cases, approximation, and applications. IEEE Trans. Evol. Comput. 2004, 8, 425–442. [Google Scholar]
- Hämäläinen, R.P.; Mäntysaari, J. A dynamic interval goal programming approach to the regulation of a lake–river system. J. Multi-Criteria Decis. Anal. 2001, 10, 75–86. [Google Scholar] [CrossRef]
- Hämäläinen, R.P.; Mäntysaari, J. Dynamic multi-objective heating optimization. Eur. J. Oper. Res. 2002, 142, 1–15. [Google Scholar] [CrossRef]
- Huang, L.; Suh, I.H.; Abraham, A. Dynamic multi-objective optimization based on membrane computing for control of time-varying unstable plants. Inf. Sci. 2011, 181, 2370–2391. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, G.; Zhang, D.; Zhang, L.; Qian, F. Dynamic Multi-Objective Optimization in Brazier-Type Gasification and Carbonization Furnace. Materials 2023, 16, 1164. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, Y.; Huang, Z.; Yang, C.; Yen, G.G. Dynamic multi-objective optimization and fuzzy AHP for copper removal process of zinc hydrometallurgy. Appl. Soft Comput. 2022, 129, 109613. [Google Scholar] [CrossRef]
- Fang, Y.; Liu, F.; Li, M.; Cui, H. Domain Generalization-Based Dynamic Multiobjective Optimization: A Case Study on Disassembly Line Balancing. IEEE Trans. Evol. Comput. 2022, 1. [Google Scholar] [CrossRef]
- Iris, C.; Asan, S.S. Computational Intelligence Systems in Industrial Engineering. Comput. Intell. Syst. Ind. Eng. 2012, 6, 203–230. [Google Scholar] [CrossRef]
- Helbig, M. Challenges Applying Dynamic Multi-objective Optimisation Algorithms to Real-World Problems. In Women in Computational Intelligence: Key Advances and Perspectives on Emerging Topics; Smith, A.E., Ed.; Springer International Publishing: Cham, Switzerland, 2022; pp. 353–375. [Google Scholar] [CrossRef]
- Jaimes, A.L.; Montaño, A.A.; Coello Coello, C.A. Preference incorporation to solve many-objective airfoil design problems. In Proceedings of the IEEE Congress of Evolutionary Computation (CEC), New Orleans, LA, USA, 5–8 June 2011; pp. 1605–1612. [Google Scholar] [CrossRef]
- Coello, C.A.C.; Lamont, G.B.; Veldhuizen, D.A.V. Evolutionary Algorithms for Solving Multi-Objective Problems; Springer: New York, NY, USA, 2007. [Google Scholar] [CrossRef]
- Cruz-Reyes, L.; Fernandez, E.; Gomez, C.; Sanchez, P. Preference Incorporation into Evolutionary Multiobjective Optimization Using a Multi-Criteria Evaluation Method. In Recent Advances on Hybrid Approaches for Designing Intelligent Systems; Castillo, O., Melin, P., Pedrycz, W., Kacprzyk, J., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 533–542. [Google Scholar] [CrossRef]
- Cruz-Reyes, L.; Fernandez, E.; Sanchez, P.; Coello Coello, C.A.; Gomez, C. Incorporation of implicit decision-maker preferences in multi-objective evolutionary optimization using a multi-criteria classification method. Appl. Soft Comput. J. 2017, 50, 48–57. [Google Scholar] [CrossRef]
- Ferreira, T.N.; Vergilio, S.R.; de Souza, J.T. Incorporating user preferences in search-based software engineering: A systematic mapping study. Inf. Softw. Technol. 2017, 90, 55–69. [Google Scholar] [CrossRef]
- Rostami, S.; O’Reilly, D.; Shenfield, A.; Bowring, N. A novel preference articulation operator for the Evolutionary Multi-Objective Optimisation of classifiers in concealed weapons detection. Inf. Sci. 2015, 295, 494–520. [Google Scholar] [CrossRef]
- Goulart, F.; Campelo, F. Preference-guided evolutionary algorithms for many-objective optimization. Inf. Sci. 2016, 329, 236–255. [Google Scholar] [CrossRef]
- Sudenga, S.; Wattanapongsakornb, N. Incorporating decision maker preference in multiobjective evolutionary algorithm. In Proceedings of the IEEE Symposium on Computational Intelligence for Engineering Solutions (CIES), Orlando, FL, USA, 9–12 December 2014; pp. 22–29. [Google Scholar] [CrossRef]
- Thiele, L.; Thiele, L.; Miettinen, K.; Miettinen, K.; Korhonen, P.J.; Korhonen, P.J.; Molina, J.; Molina, J. A Preference-Based Evolutionary Algorithm for Multi-Objective Optimization. Evol. Comput. 2009, 17, 411–436. [Google Scholar] [CrossRef]
- Mezura-Montes, E.; Coello Coello, C.A. Constraint-handling in nature-inspired numerical optimization: Past, present and future. Swarm Evol. Comput. 2011, 1, 173–194. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. A discrete binary version of the particle swarm algorithm. In Proceedings of the 1997 IEEE International Conference on Systems, Man, and Cybernetics. Computational Cybernetics and Simulation, Orlando, FL, USA, 12–15 October 1997; Volume 5, pp. 4104–4108. [Google Scholar] [CrossRef]
- Jensen, P.A.; Bard, J.F. Operations Research Models and Methods; John Wiley & Sons: New York, NY, USA, 2003. [Google Scholar]
- Methods, C.; Michalewicz, Z. A Survey of Constraint Handling Techniques in Evolutionary Computation Methods. Evol. Program. 1995, 4, 135–155. [Google Scholar]
- Zhang, W.; Yen, G.G.; He, Z. Constrained Optimization Via Artificial Immune System. IEEE Trans. Cybern. 2014, 44, 185–198. [Google Scholar] [CrossRef]
- Azzouz, R.; Bechikh, S.; Said, L.B. Articulating Decision Maker’s Preference Information within Multiobjective Artificial Immune Systems. In Proceedings of the 2012 IEEE 24th International Conference on Tools with Artificial Intelligence, Athens, Greece, 7–9 November 2012; Volume 1, pp. 327–334. [Google Scholar] [CrossRef]
- Das, S.; Suganthan, P.N. Differential Evolution: A Survey of the State-of-the-Art. IEEE Trans. Evol. Comput. 2011, 15, 4–31. [Google Scholar] [CrossRef]
- Deb, K.; Agrawal, S.; Pratap, A.; Meyarivan, T. A Fast Elitist Non-dominated Sorting Genetic Algorithm for Multi-objective Optimization: NSGA-II. In Proceedings of the Parallel Problem Solving from Nature PPSN VI, Paris, France, 18–20 September 2020; Schoenauer, M., Deb, K., Rudolph, G., Yao, X., Lutton, E., Merelo, J.J., Schwefel, H.P., Eds.; Springer: Berlin/Heidelberg, Germany, 2000; pp. 849–858. [Google Scholar]
- Adekunle, R.A.; Helbig, M. A differential evolution algorithm for dynamic multi-objective optimization. In Proceedings of the IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–10. [Google Scholar] [CrossRef]
- Helbig, M.; Engelbrecht, A.P. Issues with performance measures for dynamic multi-objective optimisation. In Proceedings of the IEEE Symposium on Computational Intelligence in Dynamic and Uncertain Environments (CIDUE), Singapore, 16–19 April 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 17–24. [Google Scholar]
- Helbig, M. Solving Dynamic Multi-Objective Optimisation Problems Using Vector Evaluated Particle Swarm Optimisation. Ph.D. Thesis, University of Pretoria, Pretoria, South Africa, 2012. [Google Scholar]
- Goh, C.K.; Tan, K.C. A competitive-cooperative coevolutionary paradigm for dynamic multiobjective optimization. IEEE Trans. Evol. Comput. 2009, 13, 103–127. [Google Scholar] [CrossRef]
- Padhye, N.; Mittal, P.; Deb, K. Feasibility preserving constraint-handling strategies for real parameter evolutionary optimization. Comput. Optim. Appl. 2015, 62, 851–890. [Google Scholar] [CrossRef]
- Hamdan, M. On the disruption-level of polynomial mutation for evolutionary multi-objective optimisation algorithms. Comput. Inform. 2010, 29, 783–800. [Google Scholar]
- Engelbrecht, A.P. Computational Intelligence: An Introduction; John Wiley & Sons: New York, NY, USA, 2007. [Google Scholar]
- Gaemperle, R.; Mueller, S.D.; Koumoutsakos, P. A Parameter Study for Differential Evolution. Adv. Intell. Syst. Fuzzy Syst. Evol. Comput. 2002, 10, 293–298. [Google Scholar]
- Ronkkonen, J.; Kukkonen, S.; Price, K. Real-parameter optimization with differential evolution. In Proceedings of the IEEE Congress on Evolutionary Computation, Scotland, UK, 2–5 September 2005; Volume 1, pp. 506–513. [Google Scholar] [CrossRef]
- Price, K.V. Differential Evolution. In Handbook of Optimization: From Classical to Modern Approach; Zelinka, I., Snášel, V., Abraham, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 187–214. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Cámara, M.; Ortega, J.; de Toro, F. A Single Front Genetic Algorithm for Parallel Multi-objective Optimization in Dynamic Environments. Neurocomputing 2009, 72, 3570–3579. [Google Scholar] [CrossRef]
- Van Veldhuizen, D. Multiobjective Evolutionary Algorithms: Classification, Analyses, and New Innovations. Ph.D. Thesis, Faculty of the Graduate School of Engineering, Air Force Institute of Technology, Air University, Wright-Patterson Air Force Base, OH, USA, 1999. [Google Scholar]
- Helbig, M.; Engelbrecht, A.P. Performance measures for dynamic multi-objective optimisation algorithms. Inf. Sci. 2013, 250, 61–81. [Google Scholar] [CrossRef]
- Sola, M.C. Parallel Processing for Dynamic Multi-Objective Optimization. Ph.D. Thesis, Universidad de Granada, Granada, Spain, 2010. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Helbig, M. Dynamic Multi-objective Optimization Using Computational Intelligence Algorithms. In Proceedings of the Computational Intelligence and Data Analytics; Buyya, R., Hernandez, S.M., Kovvur, R.M.R., Sarma, T.H., Eds.; Springer Nature: Singapore, 2023; pp. 41–62. [Google Scholar]

| S/N | ||||||
|---|---|---|---|---|---|---|
| 1 | 0.47600 | 0.53000 | 0.5877 | 0.59104 | 0.5324 | 0.4989 |
| 2 | 0.47700 | 0.33000 | 0.1630 | 0.42817 | 0.3250 | 0.2654 |
| 3 | 0.47600 | 0.19000 | 0.0912 | 0.17928 | 0.1616 | 0.2331 |
| 4 | 0.81600 | 0.95000 | 0.8768 | 0.86623 | 0.4892 | 0.7924 |
| 5 | 0.76100 | −0.10000 | 0.1513 | −0.17267 | 0.0387 | 0.1229 |
| 6 | 0.16700 | 0.18000 | 0.0032 | −0.00311 | 0.1462 | −0.0284 |
| 7 | 0.96400 | 3.5 × 10 | 0.5378 | 0.51880 | 0.3188 | 0.5433 |
| 8 | 0.00000 | 2.8 × 10 | 0.3660 | 0.28965 | 0.4592 | 0.3918 |
| 9 | 1.00000 | 0.00030 | 0.3992 | 0.39925 | 0.5292 | 0.4621 |
| 10 | 0.35700 | 1.00000 | 0.5083 | 0.74667 | 0.8383 | 0.7472 |
| 11 | 0.00000 | 0.00091 | 0.7330 | 0.49810 | 0.8207 | 0.6616 |
| 12 | 0.00000 | 0.08000 | 0.6419 | 0.87802 | 0.8485 | 0.8020 |
| 13 | 0.14600 | 0.31000 | 0.2970 | 0.30878 | 0.3052 | 0.3065 |
| 14 | 0.73400 | 0.16000 | 0.1657 | 0.13508 | 0.1101 | 0.1729 |
| 15 | 0.31700 | 0.31000 | 0.3230 | 0.32197 | 0.3290 | 0.2881 |
| 16 | 0.06100 | 0.00460 | 0.0027 | 0.00225 | 0.0032 | 0.0079 |
| 17 | 1.00000 | 0.04400 | 0.0391 | 0.10593 | 0.0204 | 0.0658 |
| 18 | 0.00000 | 0.00280 | 0.0015 | 0.00042 | 0.0016 | 0.0045 |
| S/N | |||
|---|---|---|---|
| 1 | 0.4800 | 0.3200 | N/A |
| 2 | 0.4800 | 0.6200 | N/A |
| 3 | 0.4800 | 0.9300 | N/A |
| 4 | 0.8200 | 2.4000 | N/A |
| 5 | 0.7600 | 0.1700 | N/A |
| 6 | 0.1700 | 0.6300 | N/A |
| 7 | 0.9300 | 4.5 × 10 | 1.3843 |
| 8 | 1.8000 | 2.9 × 10 | 0 |
| 9 | 1.0 × 10 | 4.5 × 10 | 1.6781 |
| 10 | 2.8 × 10 | 2.8 × 10 | 1.6354 |
| 11 | 2.9000 | 0.0041 | 0 |
| 12 | 3.5000 | 0.4400 | 0 |
| 13 | 0.1500 | 4.6000 | N/A |
| 14 | 0.7300 | 9.5000 | N/A |
| 15 | 0.3200 | 4.3000 | N/A |
| 16 | 0.0610 | 0.9700 | N/A |
| 17 | 1.0000 | 0.2100 | N/A |
| 18 | 0.0000 | 1.0000 | N/A |
| S/N | DMOP | Iterations | c(f(x)) | |||
|---|---|---|---|---|---|---|
| 1 | FDA1 | 4 | 10 | 16 | 20 | 30 |
| 2 | FDA1 | 5 | 10 | 20 | 20 | 30 |
| 3 | FDA1 | 2 | 10 | 8 | 20 | 30 |
| 4 | FDA1 | 4 | 1 | 16 | 20 | 30 |
| 5 | FDA1 | 5 | 1 | 20 | 20 | 30 |
| 6 | FDA1 | 2 | 1 | 8 | 20 | 30 |
| 7 | FDA5 | 4 | 10 | 16 | 20 | 30 |
| 8 | FDA5 | 5 | 10 | 20 | 20 | 30 |
| 9 | FDA5 | 2 | 10 | 8 | 20 | 30 |
| 10 | FDA5 | 4 | 1 | 16 | 20 | 30 |
| 11 | FDA5 | 5 | 1 | 20 | 20 | 30 |
| 12 | FDA5 | 2 | 1 | 8 | 20 | 30 |
| 13 | dMOP2 | 4 | 10 | 16 | 20 | 30 |
| 14 | dMOP2 | 5 | 10 | 20 | 20 | 30 |
| 15 | dMOP2 | 2 | 10 | 8 | 20 | 30 |
| 16 | dMOP2 | 4 | 1 | 16 | 20 | 30 |
| 17 | dMOP2 | 5 | 1 | 20 | 20 | 30 |
| 18 | dMOP2 | 2 | 1 | 8 | 20 | 30 |
| RESULTS | PPA | DPA | RSTFRA | ||
|---|---|---|---|---|---|
| 10 | 4 | Wins | 64 | 59 | 53 |
| 10 | 4 | Losses | 54 | 58 | 64 |
| 10 | 4 | Diff | 10 | 1 | −11 |
| 10 | 4 | Rank | 1 | 2 | 3 |
| 10 | 5 | Wins | 61 | 67 | 32 |
| 10 | 5 | Losses | 45 | 40 | 75 |
| 10 | 5 | Diff | 16 | 27 | −43 |
| 10 | 5 | Rank | 2 | 1 | 3 |
| 10 | 2 | Wins | 73 | 60 | 35 |
| 10 | 2 | Losses | 40 | 54 | 74 |
| 10 | 2 | Diff | 33 | 6 | −39 |
| 10 | 2 | Rank | 1 | 2 | 3 |
| 1 | 4 | Wins | 41 | 67 | 56 |
| 1 | 4 | Losses | 66 | 44 | 54 |
| 1 | 4 | Diff | −25 | 23 | 2 |
| 1 | 4 | Rank | 3 | 1 | 2 |
| 1 | 5 | Wins | 56 | 73 | 43 |
| 1 | 5 | Losses | 53 | 47 | 72 |
| 1 | 5 | Diff | 3 | 26 | −29 |
| 1 | 5 | Rank | 2 | 1 | 3 |
| 1 | 2 | Wins | 51 | 77 | 55 |
| 1 | 2 | Losses | 64 | 49 | 70 |
| 1 | 2 | Diff | −13 | 28 | −15 |
| 1 | 2 | Rank | 3 | 1 | 2 |
| PM | RESULTS | PPA | DPA | RSTFRA |
|---|---|---|---|---|
| acc | Wins | 69 | 83 | 63 |
| acc | Losses | 75 | 60 | 80 |
| acc | Diff | −6 | 23 | −17 |
| acc | Rank | 2 | 1 | 3 |
| stab | Wins | 23 | 23 | 32 |
| stab | Losses | 22 | 34 | 22 |
| stab | Diff | 1 | −11 | 10 |
| stab | Rank | 2 | 2 | 1 |
| hvr | Wins | 82 | 94 | 40 |
| hvr | Losses | 62 | 50 | 104 |
| hvr | Diff | 20 | 44 | −64 |
| hvr | Rank | 2 | 1 | 3 |
| react | Wins | 14 | 45 | 45 |
| react | Losses | 57 | 25 | 22 |
| react | Diff | −43 | 20 | 23 |
| react | Rank | 3 | 1 | 1 |
| nNVD | Wins | 91 | 65 | 39 |
| nNVD | Losses | 38 | 67 | 90 |
| nNVD | Diff | 53 | −2 | −51 |
| nNVD | Rank | 1 | 2 | 3 |
| sNVD | Wins | 67 | 87 | 47 |
| sNVD | Losses | 68 | 48 | 85 |
| sNVD | Diff | −1 | 39 | −38 |
| sNVD | Rank | 2 | 1 | 3 |
| nVD | Wins | 0 | 2 | 4 |
| nVD | Losses | 0 | 4 | 2 |
| nVD | Diff | 0 | −2 | 2 |
| nVD | Rank | 3 | 2 | 1 |
| dVD | Wins | 0 | 4 | 4 |
| dVD | Losses | 0 | 4 | 4 |
| dVD | Diff | 0 | 0 | 0 |
| dVD | Rank | 3 | 1 | 1 |
| RESULTS | PPA | DPA | RSTFRA |
|---|---|---|---|
| Wins | 346 | 403 | 274 |
| Losses | 322 | 292 | 409 |
| Diff | 24 | 111 | −135 |
| Rank | 2 | 1 | 3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adekoya, A.R.; Helbig, M. Decision-Maker’s Preference-Driven Dynamic Multi-Objective Optimization. Algorithms 2023, 16, 504. https://doi.org/10.3390/a16110504
Adekoya AR, Helbig M. Decision-Maker’s Preference-Driven Dynamic Multi-Objective Optimization. Algorithms. 2023; 16(11):504. https://doi.org/10.3390/a16110504
Chicago/Turabian StyleAdekoya, Adekunle Rotimi, and Mardé Helbig. 2023. "Decision-Maker’s Preference-Driven Dynamic Multi-Objective Optimization" Algorithms 16, no. 11: 504. https://doi.org/10.3390/a16110504
APA StyleAdekoya, A. R., & Helbig, M. (2023). Decision-Maker’s Preference-Driven Dynamic Multi-Objective Optimization. Algorithms, 16(11), 504. https://doi.org/10.3390/a16110504