
Problem-Driven Scenario Generation for Stochastic Programming Problems: A Survey

Abstract
1. Introduction
2. Problem Definition
2.1. A Two-Stage Stochastic Programming Problem
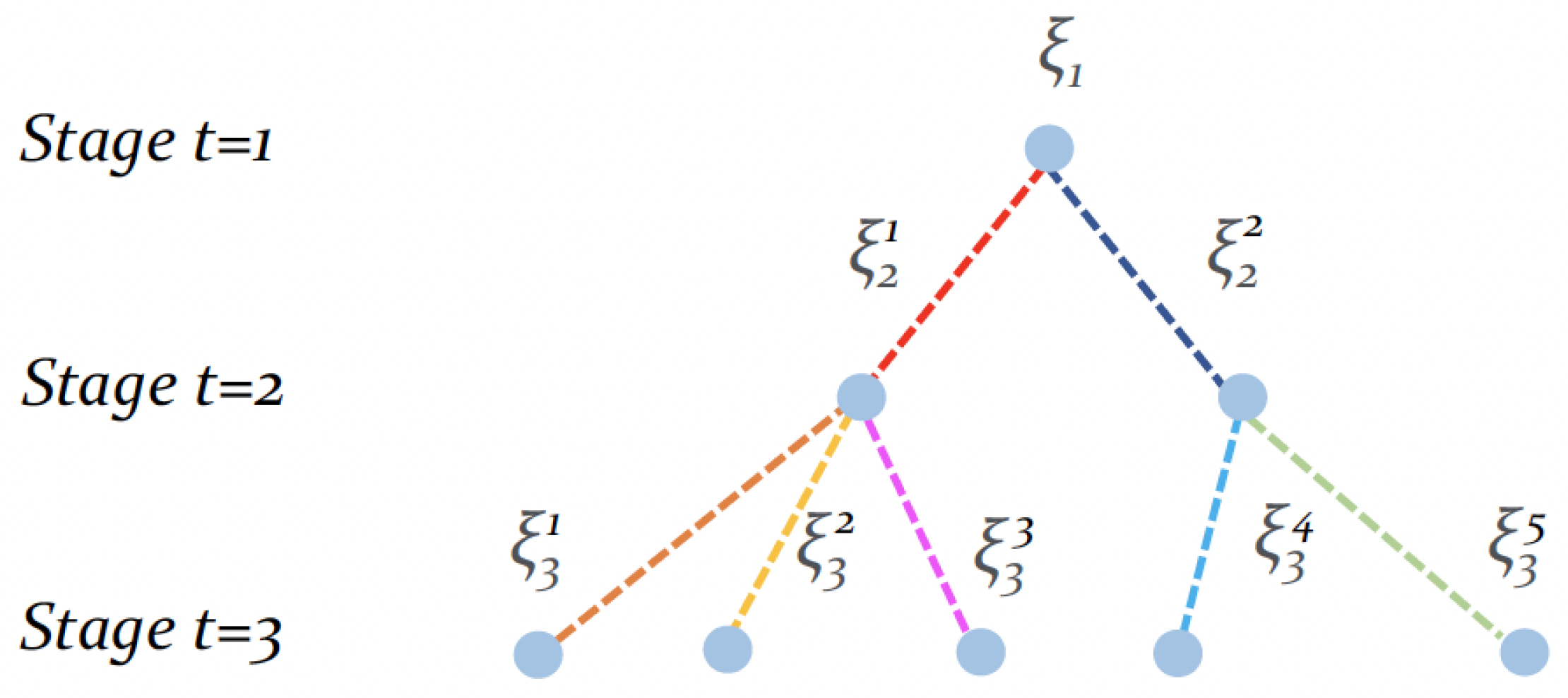
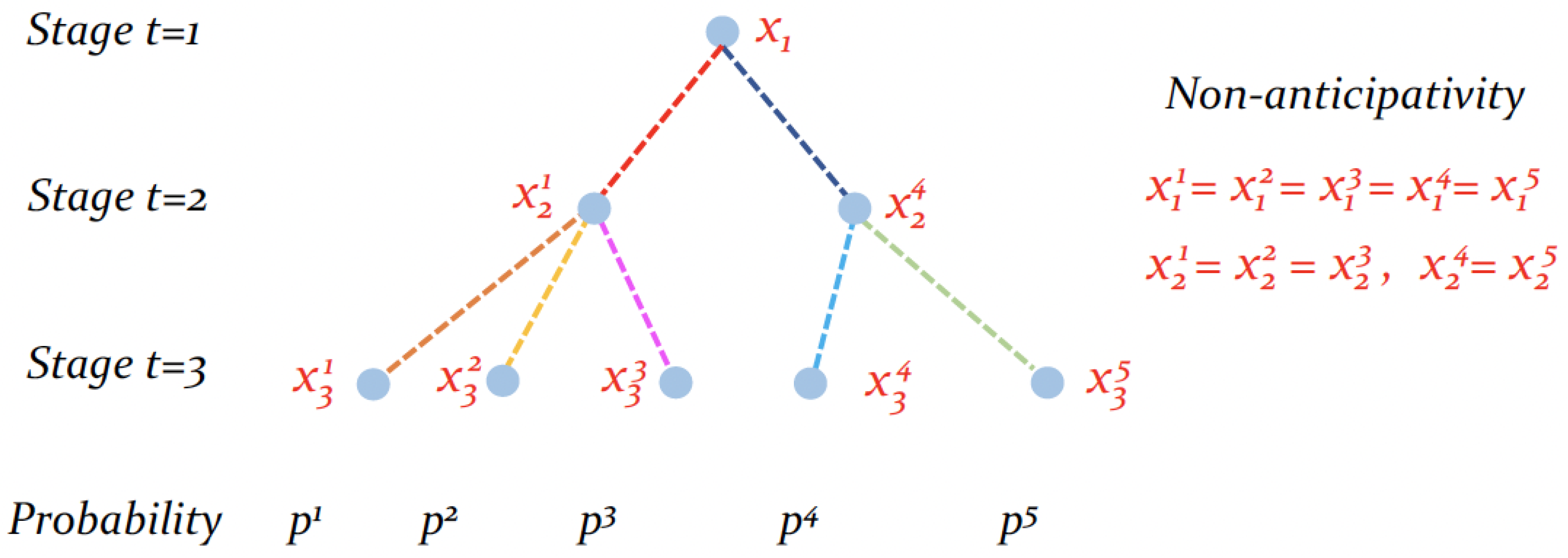
2.2. A Multi-Stage Stochastic Programming Problem
2.3. Scenario-Tree and Solving Techniques
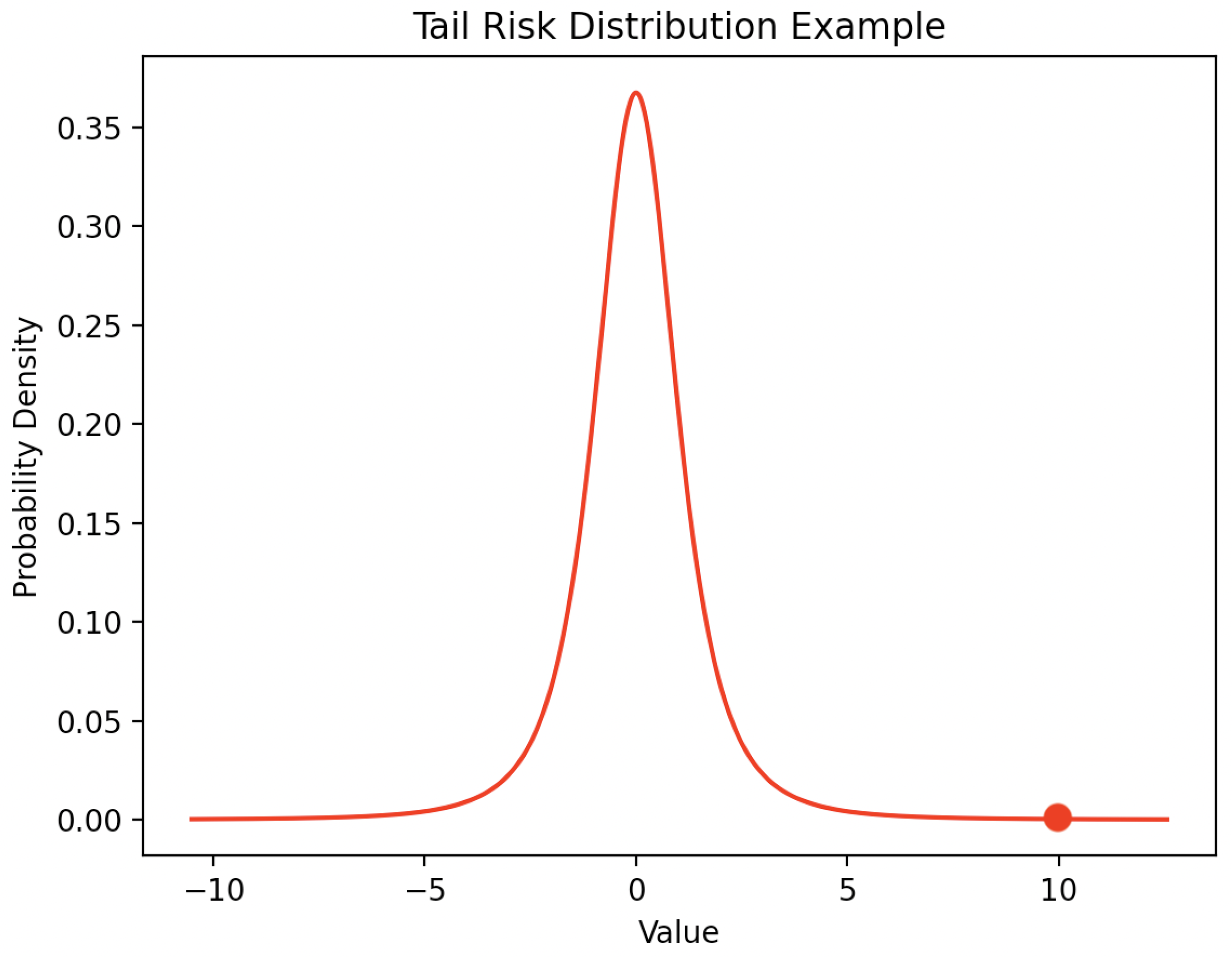
3. Quality Evaluation of a Scenario-Tree and a Solution
3.1. In-Sample and Out-of-Sample Performance
- The ranking of the solutions is preserved: if solution outperforms when evaluated out-of-sample, it should be highly probable that will also outperform when evaluated in-sample.
- Overconfident outliers should be excluded. An outlier is defined as the inconsistency between the out-of-sample and in-sample values . For example, for a solution better than in a maximizing problem:
- –
- If , while , it is an acceptable outlier.
- –
- If , , it is a non-acceptable outlier.
- The in-sample values approximate well the out-of-sample values: .
- Initiating with an empty scenario-tree, scenarios are gradually added until stability is achieved. This iterative process continues until the desired level of stability is attained.
- Beginning with a large stable scenario-tree containing numerous scenarios, scenarios are successively removed to observe the loss of stability during the reduction process.
3.2. Generalization of a Solution Obtained from a Scenario-Tree
4. Problem-Driven Scenario Generation
4.1. Difference between Distribution-Oriented and Problem-Oriented Scenario Generation
4.2. Literature Overview
- Feature-based filtering of outcomes (FFO);
- Guided scenario generation with problem-specific knowledge (GSG);
- Stability arguments of the scenario-trees (SA).
- Scenario reduction and clustering (SRC).
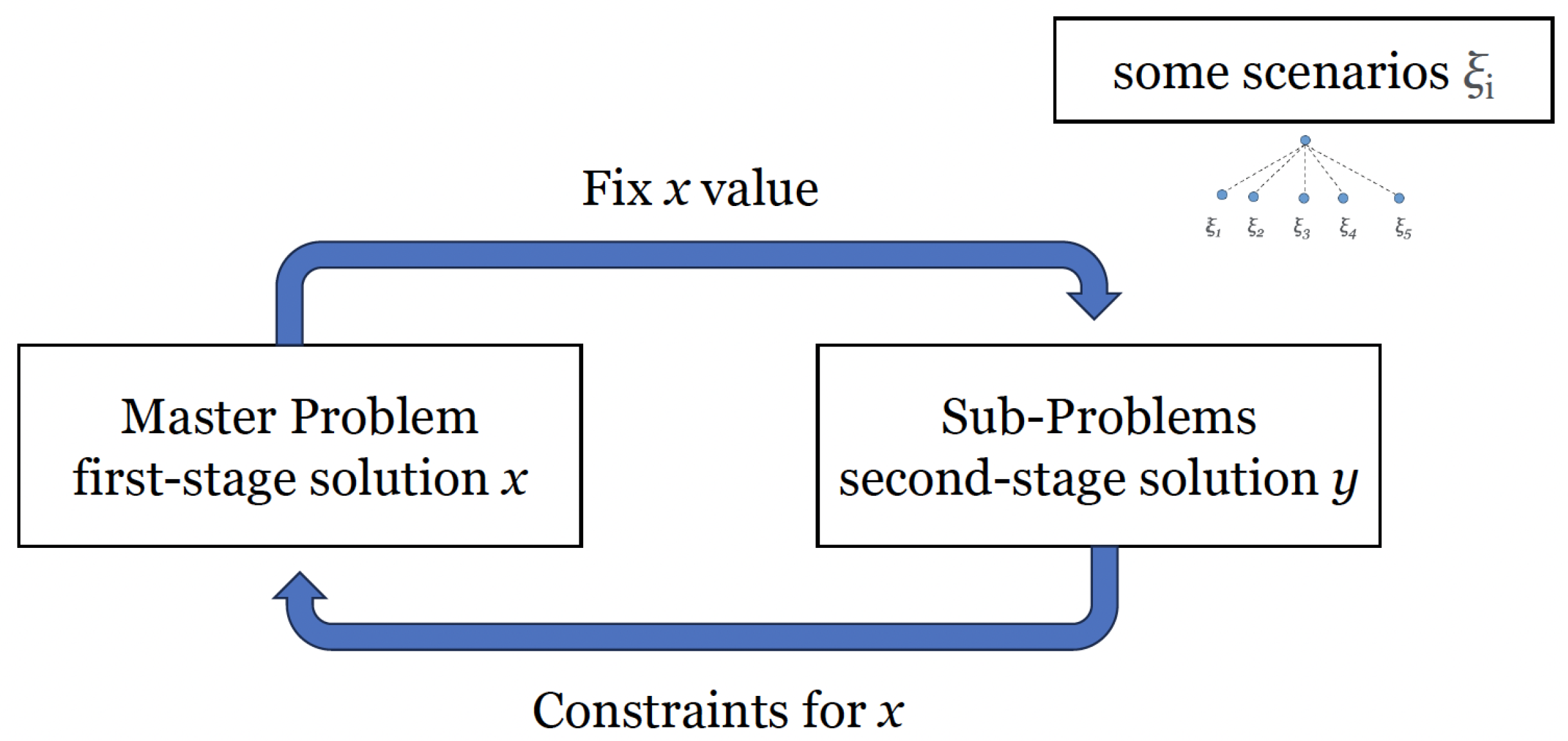
4.3. Methodologies
- Initiate the process by generating a pool of solutions with , using a heuristic approach that strikes an appropriate balance between speed and accuracy. It is unnecessary for the solutions to be optimal or feasible in scenario-related constraints.
- Proceed to evaluate the performance of the solutions by out-of-sample evaluation, denoted as .
- Formulate a loss function that quantifies the discrepancy between the in-sample performance of the solutions on a given scenario-tree and the out-of-sample performances of the solutions, i.e., versus .
- Undertake a search to identify the scenario-tree that minimizes the loss function, considering all possible scenario-trees with , defined by a predetermined number of scenarios s.
4.4. Advantages and Disadvantages
- A more accurate scenario sets in terms of solving the problem: with scenarios generated based on the problem structure and features, they are more likely to provide more accurate solutions.
- More efficient use of computational resources: Several works have proven that problem-driven scenario generation can reduce the number of scenarios needed to achieve a certain level of accuracy, thereby decreasing the computational burden of the optimization problem.
- Requirements of problem-specific subroutines that could be difficult to identify.
- Limited generalizability: often there is no direct comparison with other problem-driven scenario generation methodologies.
- Risk of over-fitting: a common issue when a stochastic problem is solved within a small number of scenarios.
- Time-consuming for complex problems.
5. Potential Applications
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shapiro, A.; Philpott, A.B. A Tutorial on Stochastic Programming. 2007. Available online: https://stoprog.org/sites/default/files/SPTutorial/TutorialSP.pdf (accessed on 15 September 2023).
- Beyer, H.G.; Sendhoff, B. Robust optimization—A comprehensive survey. Comput. Methods Appl. Mech. Eng. 2007, 196, 3190–3218. [Google Scholar] [CrossRef]
- Ruszczyński, A. Decomposition methods in stochastic programming. Math. Program. 1997, 79, 333–353. [Google Scholar] [CrossRef]
- Ravi, R.; Sinha, A. Hedging Uncertainty: Approximation Algorithms for Stochastic Optimization Problems. Math. Program. 2006, 108, 97–114. [Google Scholar] [CrossRef]
- Rahmaniani, R.; Crainic, T.G.; Gendreau, M.; Rei, W. The Benders decomposition algorithm: A literature review. Eur. J. Oper. Res. 2017, 259, 801–817. [Google Scholar] [CrossRef]
- Mitra, S. A White Paper on Scenario Generation for Stochastic Programming. In Optirisk Systems: White Paper Series; Ref. No. OPT004; OptiRisk Systems: Uxbridge, UK, 2006. [Google Scholar]
- Li, C.; Grossmann, I.E. A Review of Stochastic Programming Methods for Optimization of Process Systems Under Uncertainty. Front. Chem. Eng. Sec. Comput. Methods Chem. Eng. 2021, 2, 34. [Google Scholar] [CrossRef]
- Shapiro, A. Monte Carlo sampling approach to stochastic programming. Proc. MODE-SMAI Conf. 2003, 13, 65–73. [Google Scholar] [CrossRef]
- Chou, X.; Gambardella, L.M.; Montemanni, R. Monte Carlo Sampling for the Probabilistic Orienteering Problem. In New Trends in Emerging Complex Real Life Problems; AIRO Springer Series; Daniele, P., Scrimali, L., Eds.; Springer: Cham, Switzerland, 2018; Volume 1, pp. 169–177. [Google Scholar]
- Chou, X.; Gambardella, L.M.; Montemanni, R. A tabu search algorithm for the probabilistic orienteering problem. Comput. Oper. Res. 2021, 126, 105107. [Google Scholar] [CrossRef]
- Leövey, H.; Römisch, W. Quasi-Monte Carlo methods for linear two-stage stochastic programming problems. Math. Program. 2015, 151, 315–345. [Google Scholar] [CrossRef]
- Messina, E.; Toscani, D. Hidden Markov models for scenario generation. IMA J. Manag. Math. 2008, 19, 379–401. [Google Scholar] [CrossRef]
- Pflug, G.C.; Pichler, A. Dynamic generation of scenario trees. Comput. Optim. Appl. 2015, 62, 641–668. [Google Scholar] [CrossRef]
- Høyland, K.; Kaut, M.; Wallace, S.W. A heuristic for moment-matching scenario generation. Comput. Optim. Appl. 2003, 24, 169–185. [Google Scholar] [CrossRef]
- Lidestam, H.; Rönnqvist, M. Use of Lagrangian decomposition in supply chain planning. Math. Comput. Model. 2011, 54, 2428–2442. [Google Scholar] [CrossRef][Green Version]
- Escudero, L.F.; Garín, M.A.; Unzueta, A. Cluster Lagrangean decomposition in multistage stochastic optimization. Comput. Oper. Res. 2016, 67, 48–62. [Google Scholar] [CrossRef]
- Murphy, J. Benders, Nested Benders and Stochastic Programming: An Intuitive Introduction. arXiv 2013, arXiv:1312.3158. [Google Scholar]
- Hart, W.E.; Watson, J.P.; Woodruff, D.L. Pyomo: Modeling and solving mathematical programs in Python. Math. Program. Comput. 2011, 3, 219–260. [Google Scholar] [CrossRef]
- Bynum, M.L.; Hackebeil, G.A.; Hart, W.E.; Laird, C.D.; Nicholson, B.L.; Siirola, J.D.; Watson, J.P.; Woodruff, D.L. Pyomo–Optimization Modeling in Python, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 2021; Volume 67. [Google Scholar]
- Python Programming Language. Available online: https://www.python.org/ (accessed on 12 October 2023).
- JuMP. Available online: https://jump.dev/ (accessed on 12 October 2023).
- The Julia Programming language. Available online: https://julialang.org/ (accessed on 12 October 2023).
- Gay, D.M. Update on AMPL Extensions for Stochastic Programming. Available online: https://ampl.com/wp-content/uploads/2010_08_Halifax_RC4.pdf (accessed on 12 October 2023).
- AMPL. Available online: https://ampl.com/ (accessed on 12 October 2023).
- Stochastic Programming in GAMS Documentation. Available online: https://www.gams.com/latest/docs/UG_EMP_SP.html (accessed on 12 October 2023).
- IBM ILOG CPLEX Optimization Studio. Available online: https://www.ibm.com/products/ilog-cplex-optimization-studio (accessed on 12 October 2023).
- Gurobi Optimization. Available online: https://www.gurobi.com/ (accessed on 12 October 2023).
- Gupta, S.D. Using Julia + JuMP for Optimization—Benders Decomposition. Available online: https://www.juliaopt.org/notebooks/Shuvomoy%20-%20Benders%20decomposition.html (accessed on 15 September 2023).
- Biel, M.; Johansson, M. Efficient stochastic programming in Julia. INFORMS J. Comput. 2022, 34, 1885–1902. [Google Scholar] [CrossRef]
- Prochazka, V.; Wallace, S.W. Scenario tree construction driven by heuristic solutions of the optimization problem. Comput. Manag. Sci. 2020, 17, 277–307. [Google Scholar] [CrossRef]
- Römisch, W. Scenario Generation in Stochastic Programming. 2009. Available online: https://opus4.kobv.de/opus4-matheon/files/665/6733_wileyRoem.pdf (accessed on 15 September 2023).
- Dupačová, J. Stability and sensitivity-analysis for stochastic programming. Ann. Oper. Res. 1990, 27, 115–142. [Google Scholar] [CrossRef]
- Keutchayan, J.; Munger, D.; Gendreau, M. On the Scenario-Tree Optimal-Value Error for Stochastic Programming Problems. Math. Oper. Res. 2020, 45, 1193–1620. [Google Scholar] [CrossRef]
- Heitsch, H.; Römisch, W. A note on scenario reduction for two-stage stochastic programs. Oper. Res. Lett. 2007, 35, 731–738. [Google Scholar] [CrossRef]
- Defourny, B.; Ernst, D.; Wehenkel, L. Scenario trees and policy selection for multistage stochastic programming using machine learning. NFORMS J. Comput. 2013, 25, 395–598. [Google Scholar] [CrossRef]
- Keutchayan, J.; Gendreau, M.; Saucier, A. Quality evaluation of scenario-tree generation methods for solving stochastic programming problems. Comput. Manag. Sci. 2017, 14, 333–365. [Google Scholar] [CrossRef]
- Galuzzi, B.G.; Messina, E.; Candelieri, A.; Archetti, F. Optimal Scenario-Tree Selection for Multistage Stochastic Programming. In Proceedings of the Machine Learning, Optimization, and Data Science: 6th International Conference, LOD 2020, Siena, Italy, 19–23 July 2020; pp. 335–346. [Google Scholar]
- Rasmussen, C.E.; Nickisch, H. Gaussian Processes for Machine Learning (GPML) Toolbox. J. Mach. Learn. Res. 2010, 11, 3011–3015. [Google Scholar]
- Altman, N. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 17–185. [Google Scholar]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; de Freitas, N. Taking the Human Out of the Loop: A Review of Bayesian Optimization. Proc. IEEE 2016, 104, 148–175. [Google Scholar] [CrossRef]
- Zaffalon, M.; Antonucci, A.; Nas, R.C. Structural Causal Models Are (Solvable by) Credal Networks. arXiv 2020, arXiv:2008.00463. [Google Scholar]
- Candelieri, A.; Chou, X.; Archetti, F.; Messina, E. Generating Informative Scenarios via Active Learning. In Proceedings of the International Conference on Optimization and Decision Science, ODS2023, Ischia, Italy, 4–7 September 2023. [Google Scholar]
- Shapiro, A. Quantitative stability in stochastic programming. Math. Program. 1994, 67, 99–108. [Google Scholar] [CrossRef]
- Kirui, K.B.; Pichler, A.; Pflug, G.C. ScenTrees.jl: A Julia Package for Generating Scenario Trees and Scenario Lattices for Multistage Stochastic Programming. J. Open Source Softw. 2020, 5, 1912. [Google Scholar] [CrossRef]
- Kaut, M.; Wallace, S.W. Evaluation of Scenario-Generation Methods for Stochastic Programming. Pac. J. Optim. 2007, 3, 257–271. [Google Scholar]
- Narum, B.S. Problem-Based Scenario Generation in Stochastic Programming with Binary Distributions—Case Study in Air Traffic Flow Management. 2020. Available online: https://ntnuopen.ntnu.no/ntnu-xmlui/handle/11250/2777017 (accessed on 15 September 2023).
- Høyland, K.; Wallace, S.W. Generating Scenario Trees for Multistage Decision Problems. Manag. Sci. 2001, 47, 295–307. [Google Scholar] [CrossRef]
- Feng, Y.; Ryan, S.M. Solution sensitivity-based scenario reduction for stochastic unit commitment. Comput. Manag. Sci. 2016, 13, 29–62. [Google Scholar] [CrossRef]
- Zhao, Y.; Wallace, S.W. Appraising redundancy in facility layout. Int. J. Prod. Res. 2016, 54, 665–679. [Google Scholar] [CrossRef]
- Sun, M.; Teng, F.; Konstantelos, I.; Strbac, G. An objective-based scenario selection method for transmission network expansion planning with multivariate stochasticity in load and renewable energy sources. Energy 2018, 145, 871–885. [Google Scholar] [CrossRef]
- Prochazka, V.; Wallace, S.W. Stochastic programs with binary distributions: Structural properties of scenario trees and algorithm. Comput. Manag. Sci. 2018, 15, 397–410. [Google Scholar] [CrossRef]
- Fairbrother, J.; Turner, A.; Wallace, S. Scenario generation for single-period portfolio selection problems with tail risk measures: Coping with high dimensions and integer variables. INFORMS J. Comput. 2018, 30, 472–491. [Google Scholar] [CrossRef]
- Fairbrother, J.; Turner, A.; Wallace, S.W. Problem-driven scenario generation: An analytical approach for stochastic programs with tail risk measure. Math. Program. 2019, 191, 141–182. [Google Scholar] [CrossRef]
- Guo, Z.; Wallace, S.W.; Kaut, M. Vehicle Routing with Space- and Time-Correlated Stochastic Travel Times: Evaluating the Objective Function. INFORMS J. Comput. 2019, 31, 654–670. [Google Scholar] [CrossRef]
- Keutchayan, J.; Ortmann, J.; Rei, W. Problem-Driven Scenario Clustering in Stochastic Optimization. arXiv 2021, arXiv:2106.11717. [Google Scholar] [CrossRef]
- Henrion, R.; Römisch, W. Problem-based optimal scenario generation and reduction in stochastic programming. Math. Program. 2022, 191, 183–205. [Google Scholar] [CrossRef]
- Hewitt, M.; Ortmann, J.; Rei, W. Decision-based scenario clustering for decision-making under uncertainty. Ann. Oper. Res. 2022, 315, 747–771. [Google Scholar] [CrossRef]
- Bertsimas, D.; Mundru, N. Optimization-Based Scenario Reduction for Data-Driven Two-Stage Stochastic Optimization. Oper. Res. 2022, 71, 1343–1361. [Google Scholar] [CrossRef]
- Narum, B.S.; Fairbrother, J.; Wallace, S.W. Problem-Based Scenario Generation by Decomposing Output Distribution. 2022. Available online: https://www.researchgate.net/publication/361651159_Problem-based_scenario_generation_by_decomposing_output_distributions (accessed on 15 September 2023).
- Fairbrother, J. Problem-Driven Scenario Generation for Stochastic Programs. 2015. Available online: https://eprints.lancs.ac.uk/id/document/46997 (accessed on 15 September 2023).
- Kaut, M.; Lium, A.G. Scenario Generation: Property Matching with Distribution Functions. 2007. Available online: https://www.researchgate.net/publication/228424333_Scenario_generation_Property_matching_with_distribution_functions (accessed on 15 September 2023).
- Infanger, G. Monte carlo (importance) sampling within a benders decomposition algorithm for stochastic linear programs. Ann. Oper. Res. 1992, 39, 69–95. [Google Scholar] [CrossRef]
- Li, Z.; Floudas, C.A. Optimal scenario reduction framework based on distance of uncertainty distribution and output performance: I. Single reduction via mixed integer linear optimization. Comput. Chem. Eng. 2014, 70, 50–66. [Google Scholar] [CrossRef]
- Rockafellar, R.T.; Uryasev, S. Conditional value-at-risk for general loss distributions. J. Bank. Financ. 2002, 26, 1443–1471. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Y.; Zhou, X.; Kong, X.; Luo, J. Curb-GAN: Conditional Urban Traffic Estimation through Spatio-Temporal Generative Adversarial Networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 15–17 July 2020; pp. 842–852. [Google Scholar]
- Li, J.; Zhou, J.; Chen, B. Review of wind power scenario generation methods for optimal operation of renewable energy systems. Appl. Energy 2020, 280, 115992. [Google Scholar] [CrossRef]
- Bengio, Y.; Frejinger, E.; Lodi, A.; Patel, R.; Sankaranarayanan, S. A learning-based algorithm to quickly compute good primal solutions for stochastic integer programs. In Integration of Constraint Programming, Artificial Intelligence, and Operations Research; CPAIOR 2020. Lecture Notes in Computer Science; Hebrard, E., Musliu, N., Eds.; Springer: Cham, Switzerland, 2020; Volume 12296, pp. 99–111. [Google Scholar]
- Wu, Y.; Song, W.; Cao, Z.; Zhang, J. Learning Scenario Pepresentation for Solving Two-Stage Stochastic Interger Programs. Available online: https://openreview.net/forum?id=06Wy2BtxXrz (accessed on 15 September 2023).
- Dumouchelle, J.; Patel, R.; Khalil, E.B.; Bodur, M. Neur2SP: Neural Two-Stage Stochastic Programming. arXiv 2022, arXiv:2205.12006. [Google Scholar]
- Dai, H.; Xue, Y.; Syed, Z.; Dai, D.S.B. Neural Stochastic Dual Dynamic Programming. 2022. Available online: https://openreview.net/forum?id=aisKPsMM3fg (accessed on 15 September 2023).
- Larsen, E.; Frejinger, E.; Gendron, B.; Lodi, A. Fast continuous and integer L-shaped heuristics through supervised learning. arXiv 2022, arXiv:2205.00897. [Google Scholar] [CrossRef]
- Nair, V.; Dvijotham, D.; Dunning, I.; Vinyals, O. Learning Fast Optimizers for Contextual Stochastic Integer Programs. In Proceedings of the Conference on Uncertainty in Artifical Intelligence, UAI 2018, Montrery, CA, USA, 6–10 August 2018; pp. 591–600. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Cat. | Example Problem |
|---|---|---|
| Høyland and Wallace [47] | SA | Asset allocation |
| Feng and Ryan [48] | GSG | Stochastic unit commitment |
| Zhao and Wallace [49] | GSG | Facility layout problem |
| Sun et al. [50] | GSG | Transmission network expansion planning |
| Prochazka and Wallace [51] | FFO | Stochastic knapsack problem |
| Fairbrother et al. [52] | FFO | Portfolio selection with tail risk measures |
| Fairbrother et al. [53] | FFO | Portfolio selection with tail risk measures |
| Guo et al. [54] | GSG | Stochastic vehicle routing problem |
| Prochazka and Wallace [30] | SA | Stochastic knapsack problem |
| Narum [46] | SA | Air traffic flow management |
| Keutchayan et al. [55] | SRC | Network design/Facility location |
| Henrion and Römisch [56] | SRC | The news-vendor problem |
| Hewitt et al. [57] | SRC | Biweekly fleet planning/Network design |
| Bertsimas and Mundru [58] | SRC | Portofolio optimization/Aircraft allocation/ |
| Narum et al. [59] | SRC | Electric power extension planning Network design/Multidimensional news-vendor/Air- lift operations scheduling/Storage layout and routing |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chou, X.; Messina, E. Problem-Driven Scenario Generation for Stochastic Programming Problems: A Survey. Algorithms 2023, 16, 479. https://doi.org/10.3390/a16100479
Chou X, Messina E. Problem-Driven Scenario Generation for Stochastic Programming Problems: A Survey. Algorithms. 2023; 16(10):479. https://doi.org/10.3390/a16100479
Chicago/Turabian StyleChou, Xiaochen, and Enza Messina. 2023. "Problem-Driven Scenario Generation for Stochastic Programming Problems: A Survey" Algorithms 16, no. 10: 479. https://doi.org/10.3390/a16100479
APA StyleChou, X., & Messina, E. (2023). Problem-Driven Scenario Generation for Stochastic Programming Problems: A Survey. Algorithms, 16(10), 479. https://doi.org/10.3390/a16100479