
Shelved–Retrieved Method for Weakly Balanced Constrained Clustering Problems

Abstract
:1. Introduction
2. Related Work
2.1. Conventional Methods on Size-Constrained Clustering
2.2. Clustering Methods Induced by Diagrams
2.3. Analysis of Related Work
3. Methodology
3.1. Mathematical Formulation
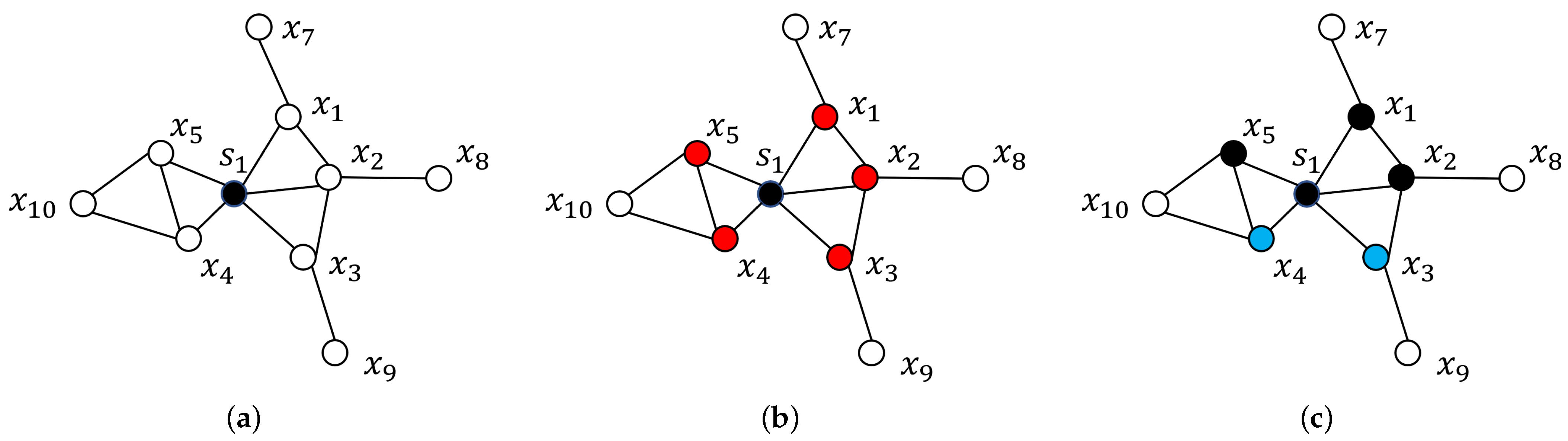
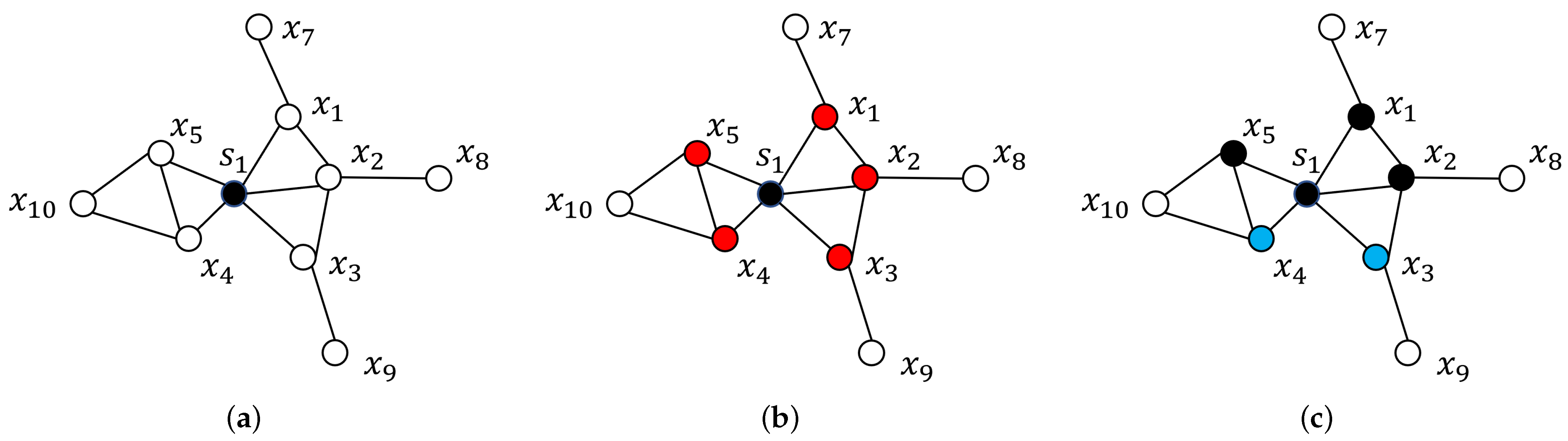
3.2. Shelved–Retrieved Method
| Algorithm 1 Clustering by power diagrams based on connectivity |
| Require: Domain , sites , parameters , adjacent set Ensure: Clustering solution
|
| Algorithm 2 Shelved-retrieved method |
| Require: Domain , weight set , set , weight matrix , adjacent set for each point , and maximum number of iterations M. Ensure: Clustering solution
|
4. Results
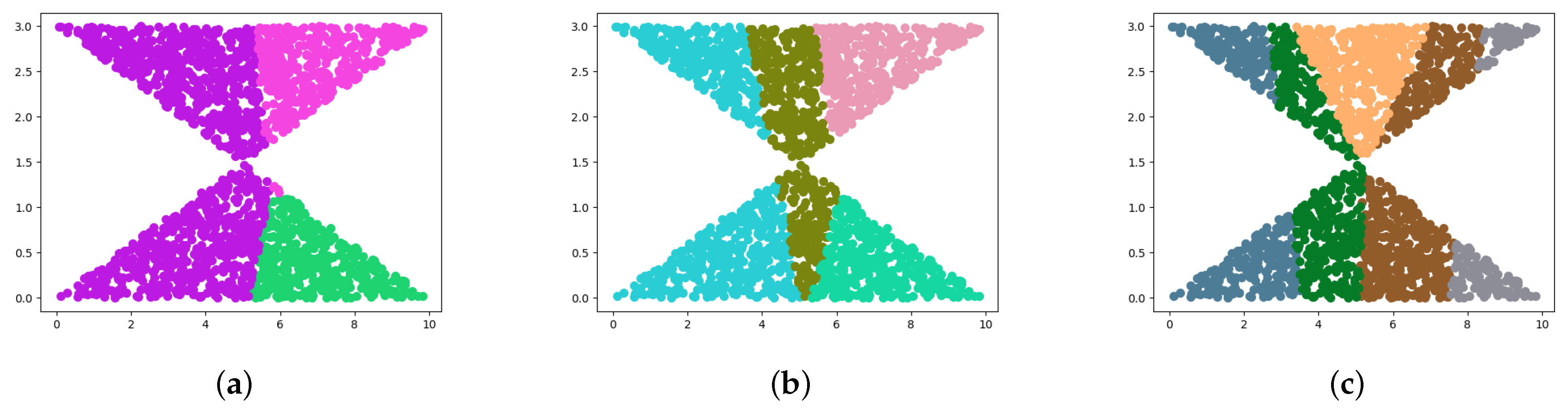
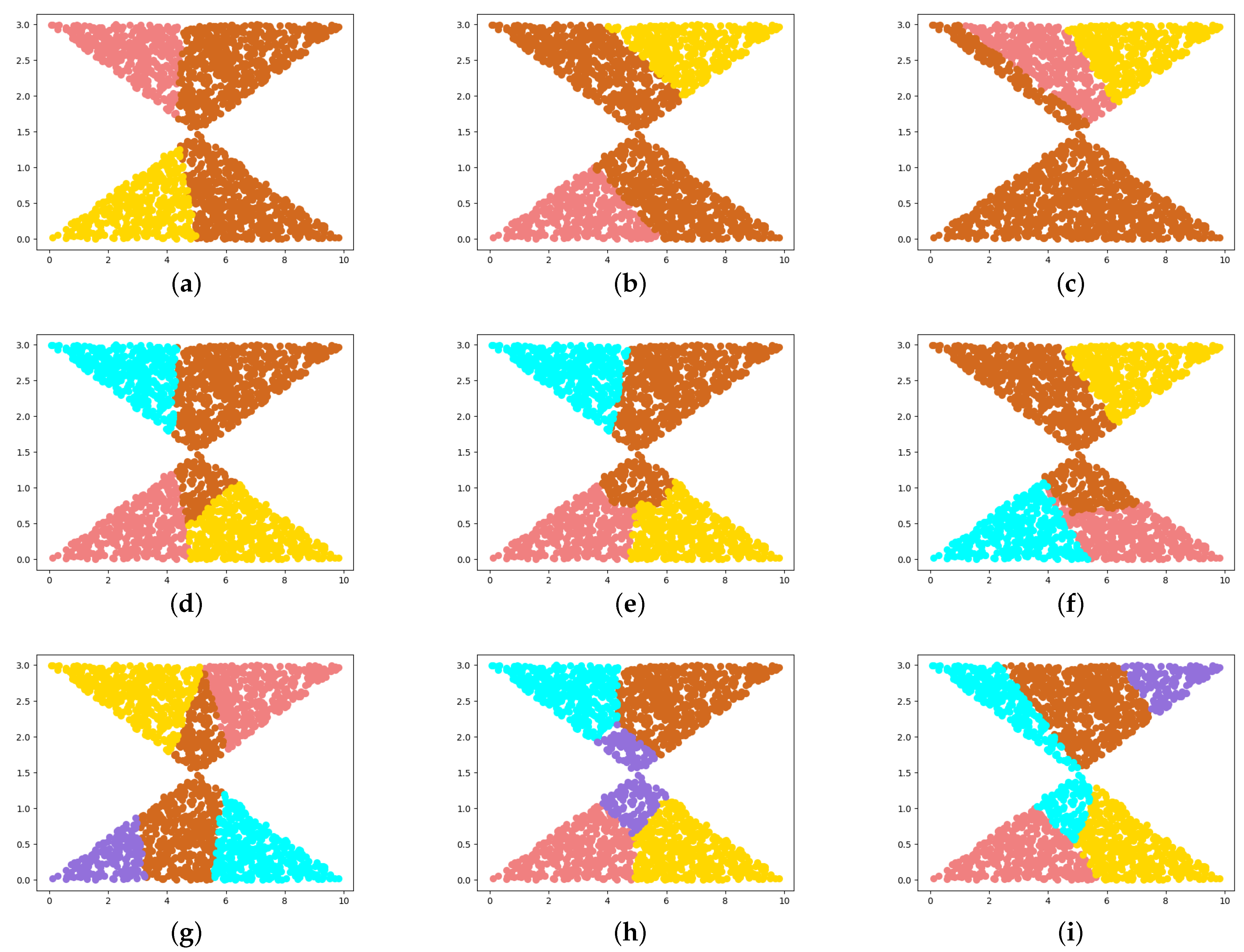
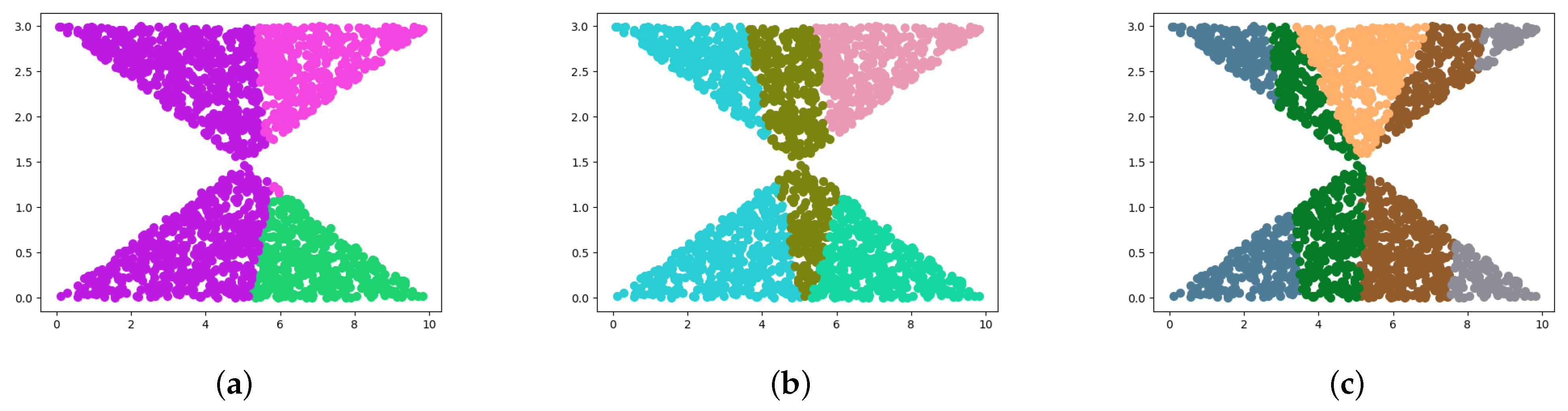
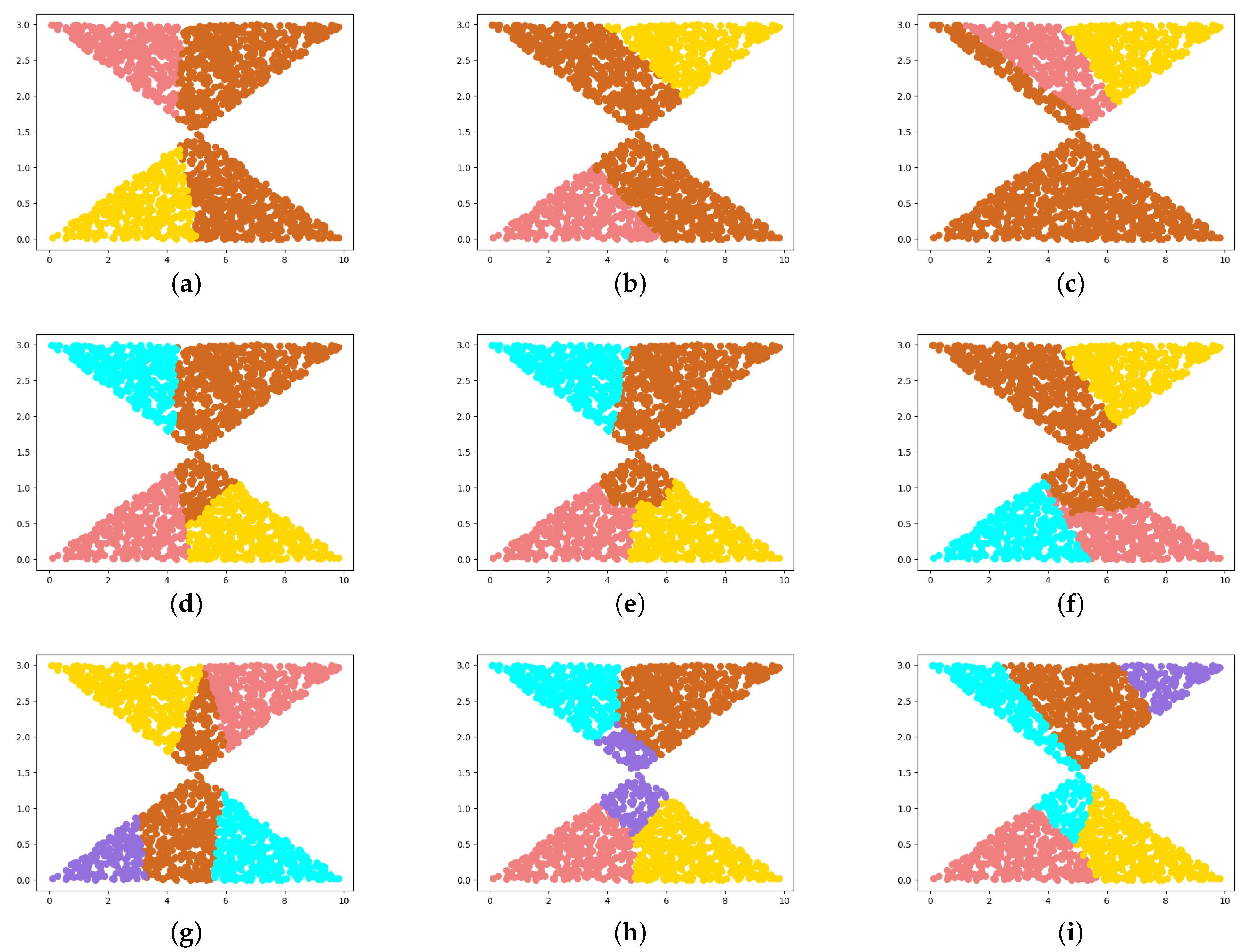
4.1. Synthetic Datasets
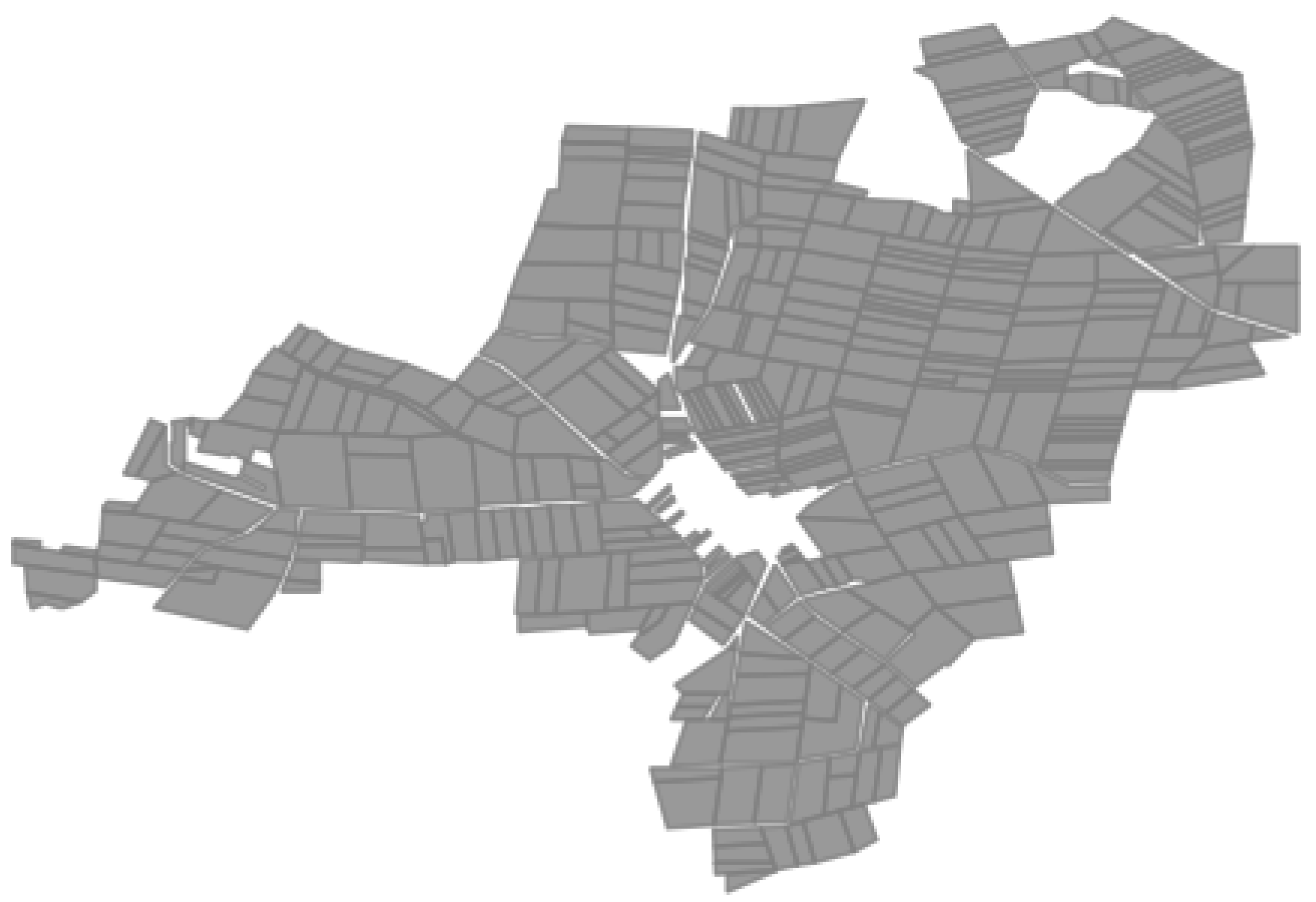
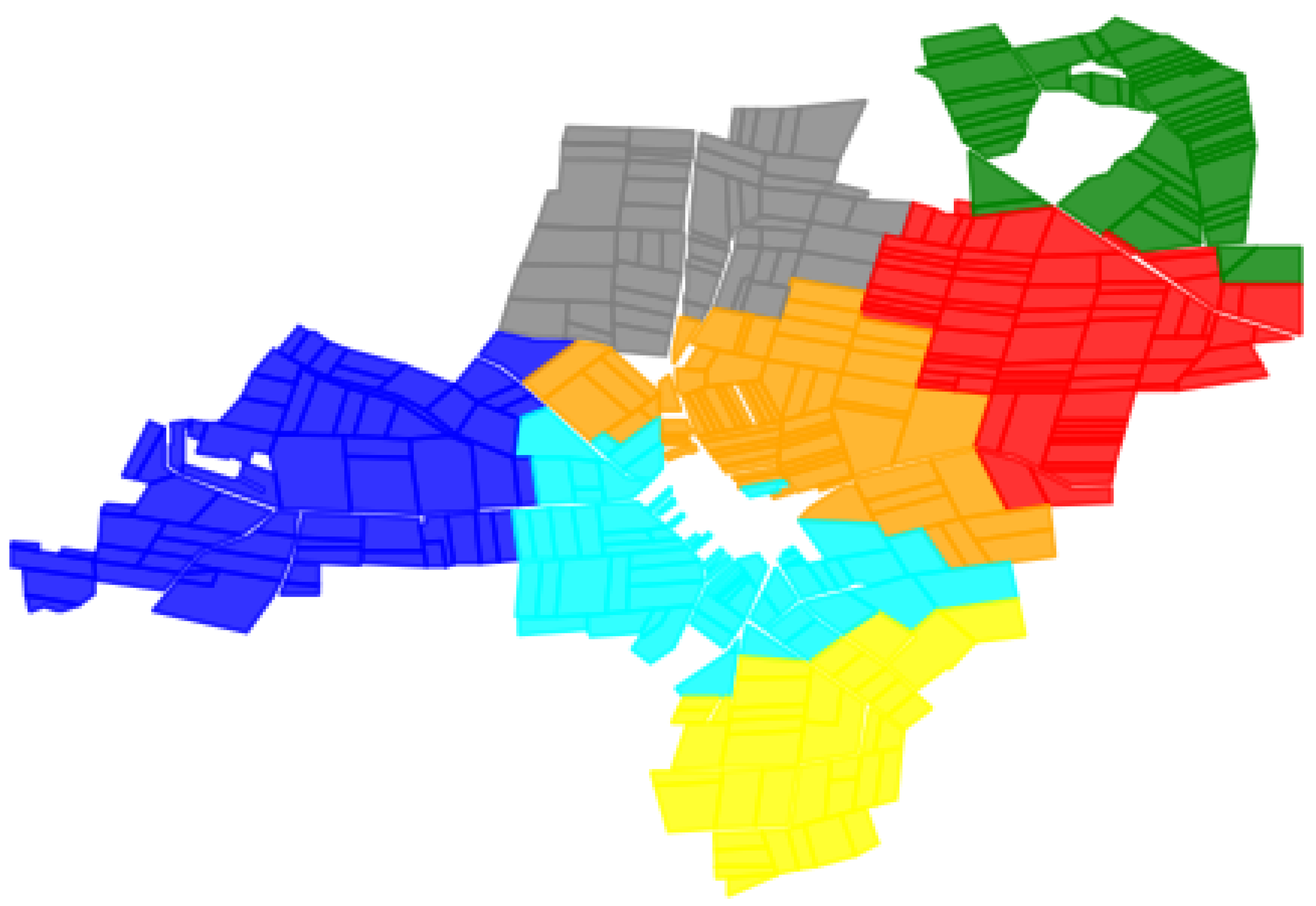
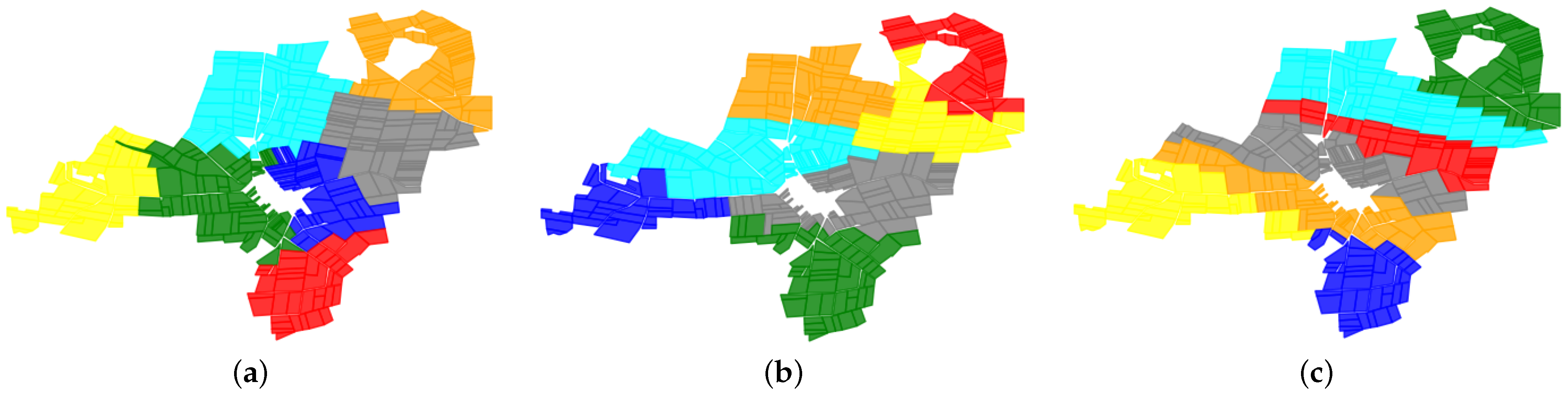
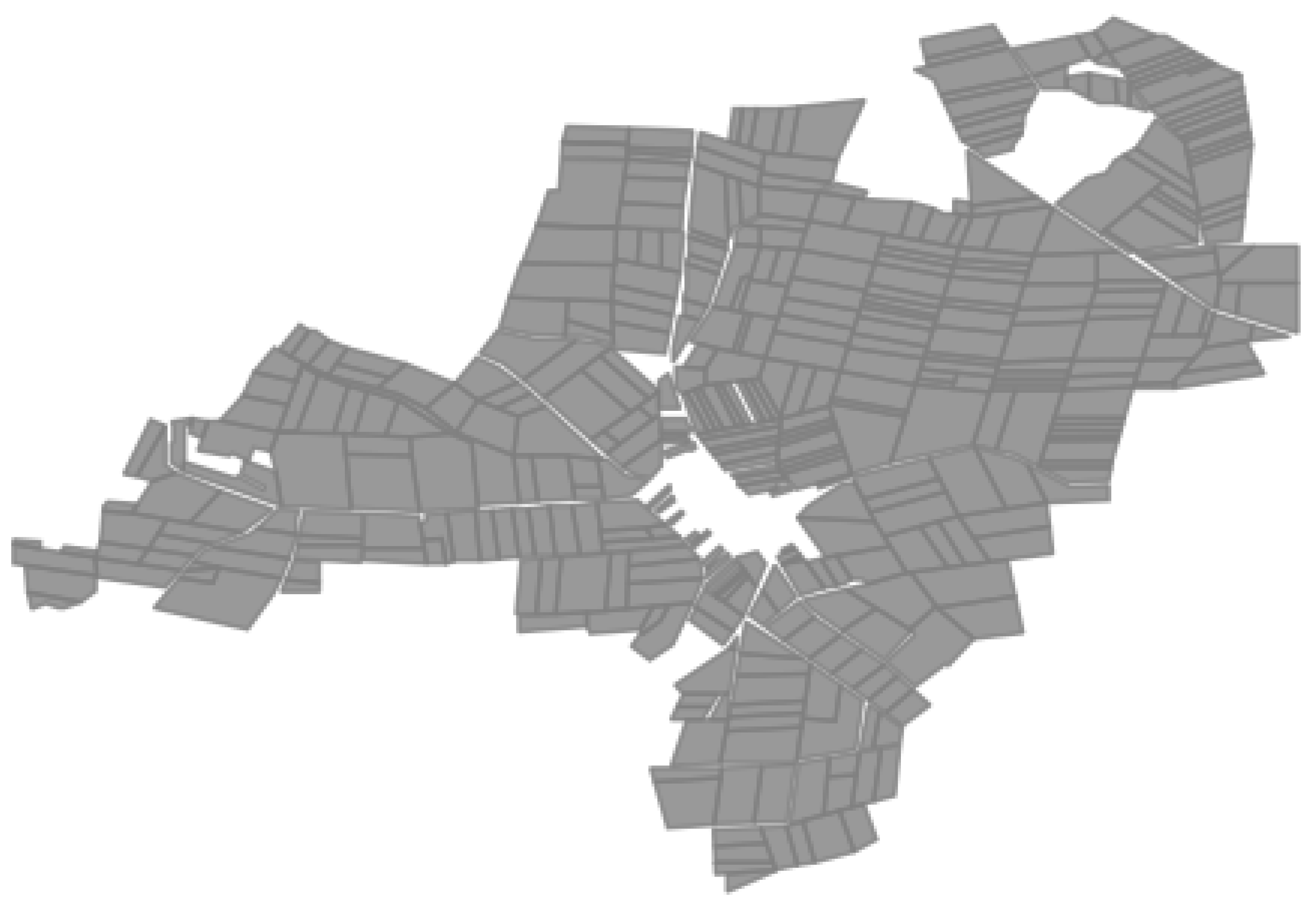
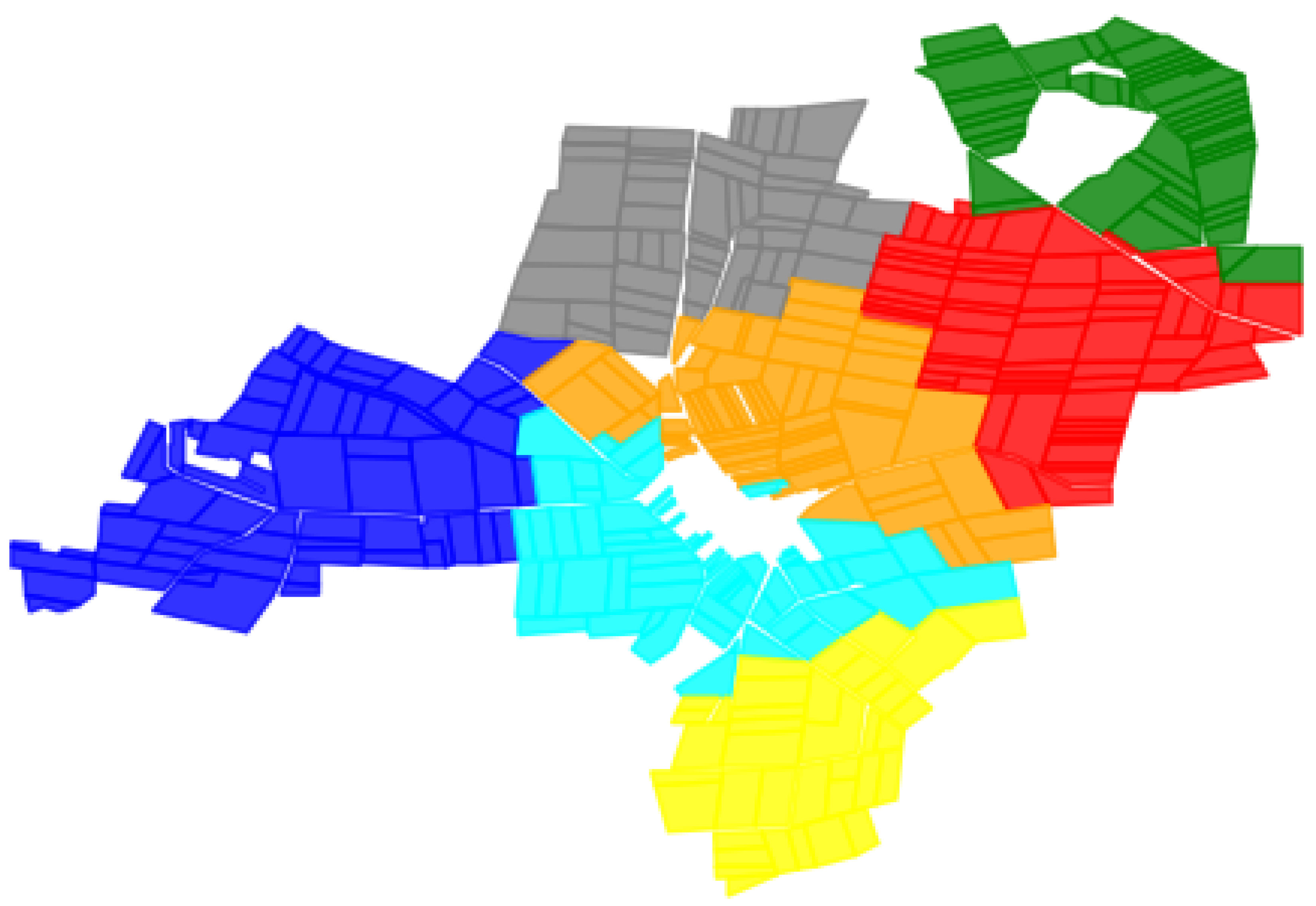
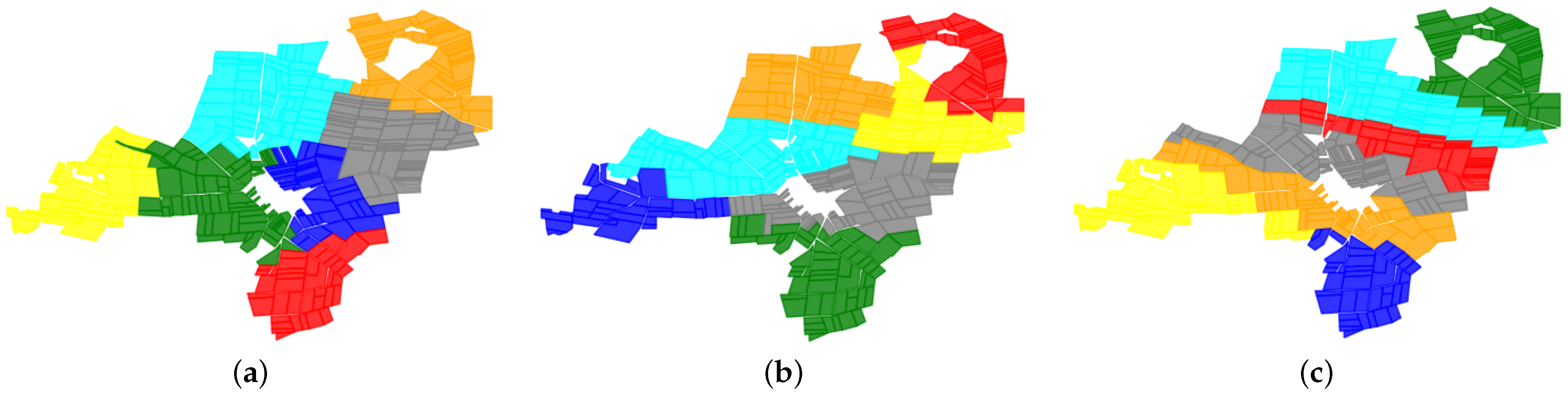
4.2. Farmland Consolidation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| WBCC | Weakly Balanced Constrained Clustering |
| RMSSTD | Root-Mean-Square Standard Deviation |
Appendix A. D-CPD Method
| Algorithm A1 D-CPD method |
| Require: Domain , weight set , capacity sets , . Ensure: Clustering solution
|
References
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data clustering: A review. ACM Comput. Surv. (CSUR) 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Omran, M.G.H.; Engelbrecht, A.P.; Salman, A. An overview of clustering methods. Intell. Data Anal. 2007, 11, 583–605. [Google Scholar] [CrossRef]
- Stillwell, M.; Schanzenbach, D.; Vivien, F.; Casanova, H. Resource allocation using virtual clusters. In Proceedings of the 2009 9th IEEE/ACM International Symposium on Cluster Computing and the Grid, Shanghai, China, 18–21 May 2009; pp. 260–267. [Google Scholar]
- Fischer, D.T.; Church, R.L. Clustering and compactness in reserve site selection: An extension of the biodiversity management area selection model. For. Sci. 2003, 49, 555–565. [Google Scholar]
- Yang, K.; Shekhar, A.H.; Oliver, D.; Shekhar, S. Capacity-constrained network-voronoi diagram. IEEE Trans. Knowl. Data Eng. 2015, 27, 2919–2932. [Google Scholar] [CrossRef]
- Chopra, S.; Rao, M.R. The partition problem. Math. Program. 1993, 59, 87–115. [Google Scholar] [CrossRef]
- Baranwal, M.; Salapaka, S.M. Clustering with capacity and size constraints: A deterministic approach. In Proceedings of the 2017 Indian Control Conference (ICC), Guwahati, India, 4–6 January 2017; pp. 251–256. [Google Scholar]
- Brieden, A.; Gritzmann, P.; Klemm, F. Constrained clustering via diagrams: A unified theory and its application to electoral district design. Eur. J. Oper. Res. 2017, 263, 18–34. [Google Scholar] [CrossRef]
- Brieden, A.; Gritzmann, P. On optimal weighted balanced clusterings: Gravity bodies and power diagrams. SIAM J. Discret. Math. 2012, 26, 415–434. [Google Scholar] [CrossRef]
- Borgwardt, S.; Brieden, A.; Gritzmann, P. Geometric clustering for the consolidation of farmland and woodland. Math. Intell. 2014, 36, 37–44. [Google Scholar] [CrossRef]
- Bradley, P.S.; Bennett, K.P.; Demiriz, A. Constrained k-means clustering. Microsoft Res. Redmond 2000, 20. Available online: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-2000-65.pdf (accessed on 15 October 2023).
- Brieden, A.; Gritzmann, P. A quadratic optimization model for the consolidation of farmland by means of lend-lease agreements. In Operations Research Proceedings 2003; Springer: Berlin/Heidelberg, Germany, 2004; pp. 324–331. [Google Scholar]
- Borgwardt, S.; Brieden, A.; Gritzmann, P. Constrained minimum-k-star clustering and its application to the consolidation of farmland. Oper. Res. 2011, 11, 1–17. [Google Scholar] [CrossRef]
- Ganganath, N.; Cheng, C.; Chi, K.T. Data clustering with cluster size constraints using a modified k-means algorithm. In Proceedings of the 2014 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery, Shanghai, China, 13–15 October 2014; pp. 158–161. [Google Scholar]
- Höppner, F.; Klawonn, F. Clustering with size constraints. In Computational Intelligence Paradigms Innovative Applications; Springer: Berlin/Heidelberg, Germany, 2008; pp. 167–180. [Google Scholar]
- Zhu, S.; Wang, D.; Li, T. Data clustering with size constraints. Knowl.-Based Syst. 2010, 23, 883–889. [Google Scholar] [CrossRef]
- Rose, K. Deterministic Annealing, Clustering, and Optimization; California Institute of Technology: Pasadena, CA, USA, 1991. [Google Scholar]
- Hu, C.W.; Li, H.; Qutub, A.A. Shrinkage clustering: A fast and size-constrained clustering algorithm for biomedical applications. BMC Bioinform. 2018, 19, 19. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Horiguchi, Y.; Sawaragi, T. Cluster size-constrained fuzzy c-means with density center searching. Int. J. Fuzzy Log. Intell. Syst. 2020, 20, 346–357. [Google Scholar] [CrossRef]
- Tang, W.; Yang, Y.; Zeng, L.; Zhan, Y. Size constrained clustering with milp formulation. IEEE Access 2020, 8, 1587–1599. [Google Scholar] [CrossRef]
- Balzer, M. Capacity-constrained voronoi diagrams in continuous spaces. In Proceedings of the 2009 Sixth International Symposium on Voronoi Diagrams, Copenhagen, Denmark, 23–26 June 2009; pp. 79–88. [Google Scholar]
- Xin, S.; Lévy, B.; Chen, Z.; Chu, L.; Yu, Y.; Tu, C.; Wang, W. Centroidal power diagrams with capacity constraints: Computation, applications, and extension. ACM Trans. Graph. (TOG) 2016, 35, 1–12. [Google Scholar] [CrossRef]
- Galvao, L.C.; Novaes, A.G.; De Cursi, J.S.; Souza, J.C. A multiplicatively-weighted voronoi diagram approach to logistics districting. Comput. Oper. Res. 2006, 33, 93–114. [Google Scholar] [CrossRef]
- Aurenhammer, F.; Hoffmann, F.; Aronov, B. Minkowski-type theorems and least-squares clustering. Algorithmica 1998, 20, 61–76. [Google Scholar] [CrossRef]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Z.; Xiong, H.; Gao, X.; Wu, J. Understanding of internal clustering validation measures. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13 December 2010; pp. 911–916. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Method | Benefits | Limitations |
|---|---|---|---|
| Modified k-means method [14] | Escaping from local minima | High computational complexity | |
| Deterministic Annealing method [7] | Fast convergence | Low accuracy | |
| Heuristic method [16] | Fast convergence | Low accuracy | |
| Size-constrained | Shrinkage clustering method [18] | Ease of implementation | High computational complexity |
| Fuzzy C-means method [15,19] | High stability | High computational complexity | |
| Minimum Cost Flow method [11] | Escaping from local minima | Low efficiency | |
| Mixed integer programming method [20] | High accuracy | Low efficiency | |
| Diagram-induced | Network Voronoi diagrams method [5] | High accuracy | Low efficiency |
| Power diagrams method in discrete space [9,10,24] | High accuracy | High computational complexity |
| Case | Cost Kernel | Shelved–Retrieved Method | D-CPD Method | Reduction |
|---|---|---|---|---|
| 2614.56 | 2615.82 | 0.0482% | ||
| Case 1 | 3916.60 | / | / | |
| 3040.00 | / | / | ||
| 2615.81 | 3319.67 | 21.20% | ||
| Case 2 | 2635.42 | / | / | |
| 2345.04 | / | / | ||
| 1881.07 | 3506.45 | 46.35% | ||
| Case 3 | 2254.69 | / | / | |
| 2069.65 | / | / |
| Case | Cost Kernel | Shelved–Retrieved Method | D-CPD Method | Reduction |
|---|---|---|---|---|
| 0.809 | 0.813 | 0.492% | ||
| Case 1 | 0.99 | / | / | |
| 0.87 | / | / | ||
| 0.74 | 0.91 | 18.68% | ||
| Case 2 | 0.81 | / | / | |
| 0.77 | / | / | ||
| 0.69 | 0.94 | 26.60% | ||
| Case 3 | 0.75 | / | / | |
| 0.72 | / | / |
| Cost Kernel | Shelved–Retrieved Method | D-CPD Method |
|---|---|---|
| 8239.77 | 13,772.06 | |
| 9711.75 | / | |
| 10,538.33 | / |
| Cost Kernel | Shelved–Retrieved Method | D-CPD Method |
|---|---|---|
| 3.24 | 4.19 | |
| 3.46 | / | |
| 3.67 | / |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, X.; Qiu, A.; Yang, L.; Yang, Z. Shelved–Retrieved Method for Weakly Balanced Constrained Clustering Problems. Algorithms 2023, 16, 492. https://doi.org/10.3390/a16100492
Hou X, Qiu A, Yang L, Yang Z. Shelved–Retrieved Method for Weakly Balanced Constrained Clustering Problems. Algorithms. 2023; 16(10):492. https://doi.org/10.3390/a16100492
Chicago/Turabian StyleHou, Xinxiang, Andong Qiu, Lu Yang, and Zhouwang Yang. 2023. "Shelved–Retrieved Method for Weakly Balanced Constrained Clustering Problems" Algorithms 16, no. 10: 492. https://doi.org/10.3390/a16100492
APA StyleHou, X., Qiu, A., Yang, L., & Yang, Z. (2023). Shelved–Retrieved Method for Weakly Balanced Constrained Clustering Problems. Algorithms, 16(10), 492. https://doi.org/10.3390/a16100492