1. Introduction
Next-generation wireless communications are geared towards versatility and adaptability to different radio environments and channel dynamics. CR is an enabling technology that extends the functionality of SDR by providing the mechanism to adapt intelligently to its environment [
1].
One of the critical features of CR is DSA, which allows radios to access and use the unused spectrum dynamically [
2]. DSA involves several tasks that a radio should execute to improve its performance automatically. Among these tasks, AMR is one of the most studied in the literature [
1,
3,
4]. One of the main challenges in AMR is to classify a received signal into a modulation type without (or with limited) prior information about the transmitted signal under dynamic channel conditions [
5].
Traditionally, AMR has been mainly tackled via LB and expert FB methods combined with pattern recognition methods [
6]. While LB methods find optimal solutions by minimizing the probability of false classification at the cost of high computational complexity, FB methods have lower complexity, and their performance is (near-)optimal when appropriately designed. However, these features are usually chosen by an expert and are based on a specific set of assumptions that are typically unrealistic [
5]. In recent years, some limitations of such techniques have been solved by applying DL techniques such as DNN, which allow both automatically extracting the relevant features from raw time-series data and performing the classification task [
7] on the extracted features.
More recently, several approaches based on DL have been proposed to solve the AMR task using raw time, frequency, and time-frequency data, outperforming traditional methods [
5,
7,
8,
9]. However, the primary assumption when using such models is the availability to train and run such models on high-end computational devices with hardware accelerators [
10,
11]. While this can be acceptable on traditional deployments where the radio is co-allocated with dedicated high-end servers, this is not the case for new approaches such as the desegregated RAN [
12] for private deployments in dense environments. In such cases, DL models trained in the cloud/core network will not be able to run on the DU or RU of such desegregated RAN, since such components are intended to run at the edge or far edge, where computational resources are constrained and shared. Therefore, there is a clear need to adapt models trained in high-end devices such that they can run on constrained ones by trading performance (e.g., classification accuracy) against model complexity (e.g., model size) [
13].
Recently, several frameworks and tools have been proposed to decrease the computational complexity of DNN using techniques such as quantization. Quantization reduces the models’ size by truncating the value of parameters such as inputs, activations, and weights. This truncation is achieved by moving from floating-point precision (e.g., 32 or 64 bits) representation of such parameters to a more straightforward and reduced representation using fewer bits as integers (e.g., 2, 4, and 8 bits). The main computational argument for quantization is that quantized weights and activations occupy much less memory space while trading-off model performance. The resulting quantized model can be housed entirely in the FPGA of the SDR device, allowing signal processing tasks, including DL-based ones, to be performed close to the radio. In addition, power consumption is reduced due to the simplification of the process by not having to work with floating-point modules [
14].
The available literature on how to design, implement, and evaluate the performance of quantized DL for AMR is very limited [
13,
15]. Most of these works focus on the performance of the proposed DL model when all layers are quantized with the same quantization value. As a result, there are no methodologies or guidelines to design quantized DL models where the designer can trade-off both main optimization objectives, the models’ performance (e.g., accuracy) against the model complexity (e.g., model size). This trade-off is fundamental since different computational environments will provide different computing capabilities, and it is up to the designer to find a balance between both objectives.
In this paper, we propose a methodology based on statistical analysis and its related algorithms to determine the degree of quantization that is required to achieve a given trade-off between model performance and model complexity and, without loss of generality, we validate the proposed approach in a well-known DNN architecture that has been used for AMR. To the best of the authors’ knowledge, this is the first work that proposes a methodology that allows the design of quantized DL models for AMR with a given trade-off between accuracy and model complexity. The main contributions of this paper are twofold:
We determine the strength of the relationship between the trainable parameters of a DNN architecture and objectives such as model performance (i.e., accuracy) and inference cost (related to model size).
We provide a method of analysis to determine the degree of quantification that is required in each layer to achieve the desired trade-off between both objectives.
The rest of the paper is organized as follows.
Section 2 introduces some terminology and background related to quantization in DNN.
Section 3 presents the related work on quantized and non-quantized DNN for AMR.
Section 4 shows the experimental methodology used to determine the relationship between the parameters quantified in the DL model and the optimization objectives to trade-off.
Section 5 presents the experimental analysis of the effect of inputs, activation, and quantified weights on the performance and size of a well-known DL model (VGG10 1D-CNN) that has been used for AMR using the methodology proposed in the previous section. In addition, we present the related algorithms that support the methodology and can find model architectures that trade-off the optimization objectives. Finally,
Section 6 concludes the paper and outlines future work in this research.
4. Design Methodology for Quantization Selection
As seen in previous sections, robust DL models are typically used.Nevertheless, due to the size/complexity of such models, signal processing must be performed in machines with high computational power, which is not the characteristic of the devices composing the radio access, edge, or far-edge networks. In
Section 2, we saw how quantization helps to reduce the computational cost of implementing a robust DL model; however, in
Section 3, we showed that only few works focus on quantization of DL models for radio signals. Moreover, we could verify that there is no general approach or methodology that guides researchers and radio practitioners in selecting the degree of quantization of a model DL to achieve a desired trade-off level between performance and the model’s complexity.
To start the description of the proposed methodology, let us consider an experiment with three design factors, where each element has three possible levels. Then, using a complete factorial design, we would need to run the same experiment times to determine which design factor impacts the response variable (i.e., the outcome) the most. Translating this small example to the field of DL model quantization, if we have three quantifiable parameters (e.g., the input, the activation layers, and the weights), each in the range of 1 to 32 bits, it gives possible combinations. Evaluating the impact of each parameter’s quantization level regarding the accuracy and inference cost is prohibitively time- and resource-consuming.
Based on a fractional factorial design [
34], our methodology allows reducing the number of experiments concerning quantifiable parameters. We divide the methodology into four stages. After each stage, we measure the trade-off between the model’s performance metric (e.g., accuracy) and its inference cost (e.g., space in memory, number of operations) regarding the unquantized model. It is worth mentioning that it is possible to include a preprocessing of the input signals to reduce their size before applying this methodology, such as dimensionality-reduction methods or averaged filters.
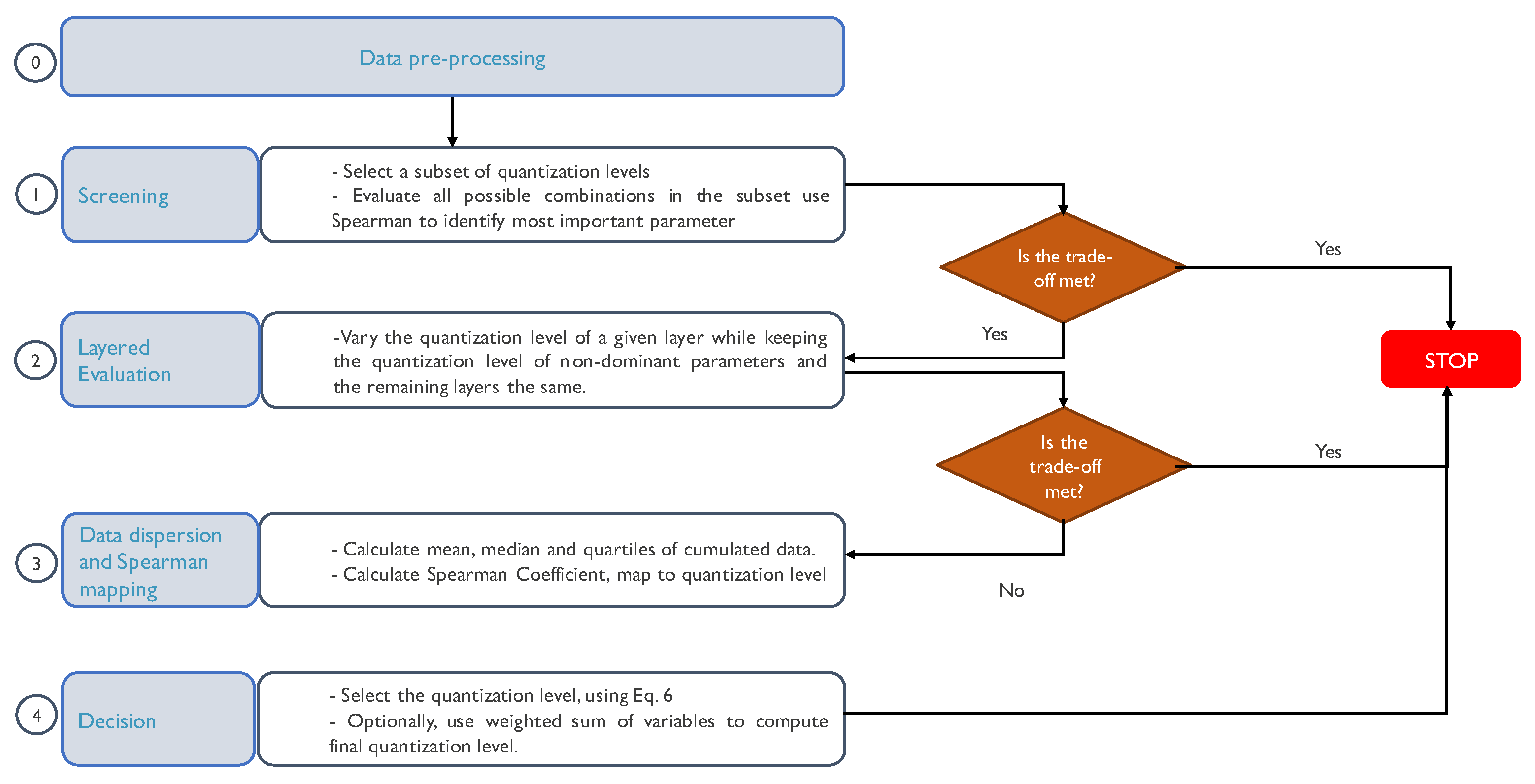
Figure 3 illustrates a detailed block diagram of the developed methodology.
During the first stage, we identify the dominant parameter in the quantization. To perform this, we select a subset of representative levels and evaluate all the possible combinations over that subset (i.e., screening). That evaluation is made regarding the model accuracy and the NICS (i.e., the outputs). Accuracy is the ratio between the number of correct and the total number of predictions in all classes. The NICS calculation is obtained by comparing the weight bits, total activation bits, and BOPS against the reference model, as described in Equation (
5).
where
and
are the BOPS of the evaluated (quantized) and the reference (non-quantized) model, respectively. Similarly,
and
are the total bits used by the weights in the evaluated and the reference models, respectively.
Note that previous information can help refine the selection of subsets. For instance, [
35,
36] showed that an 8-bit quantized CNN model achieves an accuracy close to that of an unquantized model for AMR. Then, a reduced subset of quantization levels can be used (i.e., from 1- to 8-bit quantization).
Once we obtain the performance and the inference cost for each combination of the subset, we apply Spearman’s correlation coefficient (see Equation (
6)) to identify which quantized parameter (i.e., input, activations, and weights) has the highest impact on the output, i.e., the dominant parameter. We use Spearman’s correlation, where
n is the number of observations and
D is the variable of interest, since it allows for correlation variables that bear a nonlinear relationship. If, during the screening, a combination that meets the expected trade-off is found, e.g., by creating the Pareto front using the resulting accuracy and NICS metrics from the quantized models, then we can conclude our search. Otherwise, we can move to the second stage. Algorithm 1 shows the pseudocode of the first stage. Notice that the resulting accuracy and NICS metrics from the quantized models are returned in variable
E in Algorithm 1.
| Algorithm 1 Screening: Detection of relevant parameters. |
| Require: I/Q samples data set . |
| Require: DNN model M. |
| Require: Set I with different number of bits to quantize the input parameter. |
| Require: Set a with different number of bits to quantize the activation function parameter on all layers. |
| Require: Set W with different number of bits to quantize the weight parameter on all layers. |
| 1: Initialize set E of experiments |
| 2: for do |
| 3: Quantize M’s input with i bits |
| 4: for do |
| 5: Quantize M’s activation functions with a bits |
| 6: for do |
| 7: Quantize M’s weights with w bits |
| 8: Apply quantize-aware training to M and use dataset |
| 9: Calculate accuracy of M |
| 10: Calculate NICS of M |
| 11: [, ] |
| 12: |
| 13: end for |
| 14: end for |
| 15: end for |
| 16: Calculate Spearman’s correlation analysis on E |
| 17: Return E and the parameter with higher correlation with respect to accuracy and NICS |
Since modern DL models are composed of several layers, if the dominant parameters are activation or weights, we can evaluate in a layered way which layer has the highest effect on the trade-off (stage 2). Notice that the weights are more likely to significantly impact the accuracy and inference cost outputs compared to activations and inputs since there are more hidden units and connections among them than layers.
During the second stage, we measure the degree of quantization per layer required to meet a given trade-off. Notice that if the input is the parameter that most impacts the outputs, then the second stage is the same, but the only layer to alter is the input one. A good starting point is to take the same quantization subset as in stage one. In this stage, we vary the quantization level of a given layer while keeping the quantization level of the non-dominant parameters and the remaining layers the same.
Compared to previous works such as [
13,
15], our second stage differs from them since they typically apply the same quantization level to all the model’s layers. Suppose the trade-off between the model performance metric and the inference cost is met, then we conclude our search by obtaining an architecture in which we have identified which layer of the model has the highest impact. Otherwise, we can continue with the third stage. Algorithm 2 summarizes the procedure to analyze the effect of the quantization level in each layer of a DNN independently, assuming the weight parameter has the most impact in the output (from Algorithm 1).
| Algorithm 2 Stage 2: Layered evaluation for weights. |
| Require: I/Q samples data set . |
| Require: DNN model M. |
| Require: Set L with the layers of M to be quantized. |
| Require: Fixed number of bits i to quantize the input parameter. |
| Require: Fixed number of bits a to quantize the activation function parameter on all layers. |
| Require: Set W with different number of bits to quantize the weight parameter. |
| 1: Initialize set E of experiments |
| 2: for do |
| 3: Quantize M’s input with i bits |
| 4: Quantize M’s activation functions with a bits |
| 5: for do |
| 6: for do |
| 7: Quantize layer p of model M with max [W] bits |
| 8: end for |
| 9: Quantize layer l of model M with w bits |
| 10: Apply quantize-aware training to M and use dataset |
| 11: Calculate accuracy of M |
| 12: Calculate NICS of M |
| 13: [, ] |
| 14: |
| 15: end for |
| 16: end for |
| 17: Return E |
So far, we have analyzed the impact of only one layer in the trade-off. However, we may obtain a better model’s configuration by quantizing different layers using different quantization levels. Using the results from the previous stage, we analyze the data dispersion using the mean, the median, and the main quartiles per layer, per variable of interest (i.e., model performance metric and inference cost). At this point, the layer with higher dispersion is the layer that influences the trade-off the most. This allows us to analyze the behavior of each layer, but we still need to determine its level of quantization. To answer this question, we must correlate the information using Spearman. Since the Spearman’s correlation ranges from 1 to , we can obtain an equivalent scale for the quantization level. During the search, we identify the quantization level that, in general terms, offers a better trade-off. This quantization level is regarded as the highest Spearman’s correlation coefficient. Then, it is possible to obtain the quantization level and the direction, e.g., a 1 as correlation coefficient means that the layer must be quantized at the highest quantization level possible. In contrast, a as correlation coefficient means that the layer must be quantized with the lowest level possible.
In the last stage (stage four), we can select the level of quantization that every model layer should have. Thus, having the Spearman’s correlation results per layer, we map the correlation coefficient with the quantization level as described above and following Equation (
7), where
M is the median, and
D is the variable of interest. If there is more than one variable of interest, Equation (
7) should be applied per variable, and the quantization level of each model layer can be selected as a weighted sum of the quantization levels per variable of interest. In this way, the experimenter can choose which variable of interest to care for the most. In
Section 5, we derive a detailed procedure to realize stages 3 and 4 with a concrete set of experimental results on a well-known DNN architecture for AMR.
5. Analysis and Results
In this section, we apply the methodology proposed in
Section 4 to a model for solving the AMR problem. In AMR, a model tries to automatically detect the type of modulation used by a received radio signal. One of the most prominent DL models for solving AMR is proposed by O’Shea et al. in [
37], where they adopt the well-known VGG10 1D-CNN model [
38] from classifying images to classifying modulations. This DL model is composed of 18 layers (one input layer, seven convolutional layers, seven pooling layers, and three fully connected layers) and was trained using the RadioML 2018.01A dataset, also proposed by O’Shea et al. [
37]. The dataset includes synthetic, simulated channel effects and over-the-air recordings of twenty-four analog and digital modulation types.
By default, the VGG10 1D-CNN model is not quantized. By applying the proposed methodology, we expect to maintain the accuracy achieved by the unquantized model but at a much lower computation cost. For completion purposes, we also quantized the original model’s layers at 8 bits. All models described here (quantized and not quantized) were trained and tested using only 10% of the dataset. Notice that although depicted in the methodology (see
Figure 3), we did not preprocess the dataset. The evaluation of all the resulting models was made in terms of accuracy and the NICS. In the following, we show the results obtained at each stage of the methodology.
5.1. Stage 1: Screening, Analyzing the Effect of Quantizing Inputs, Activations, and Weights Reference Model
The first step in the methodology is to select the subset of quantization levels to be considered for the screening. From the literature review, we noticed that an 8-bit quantized CNN model achieves an accuracy close to that of an unquantized model. Therefore, our subset of quantization levels starts at eight. Moreover, instead of considering the full range of quantized values, which is from 1 to 8, we use a subset of that range. As a result, we consider only quantization at {2, 3, 4, 5, 6, and 8} bits. Secondly, we quantized the input layer (i), the layers that include an activation (a), and the layers that include weights (w), using each of the defined quantization levels.
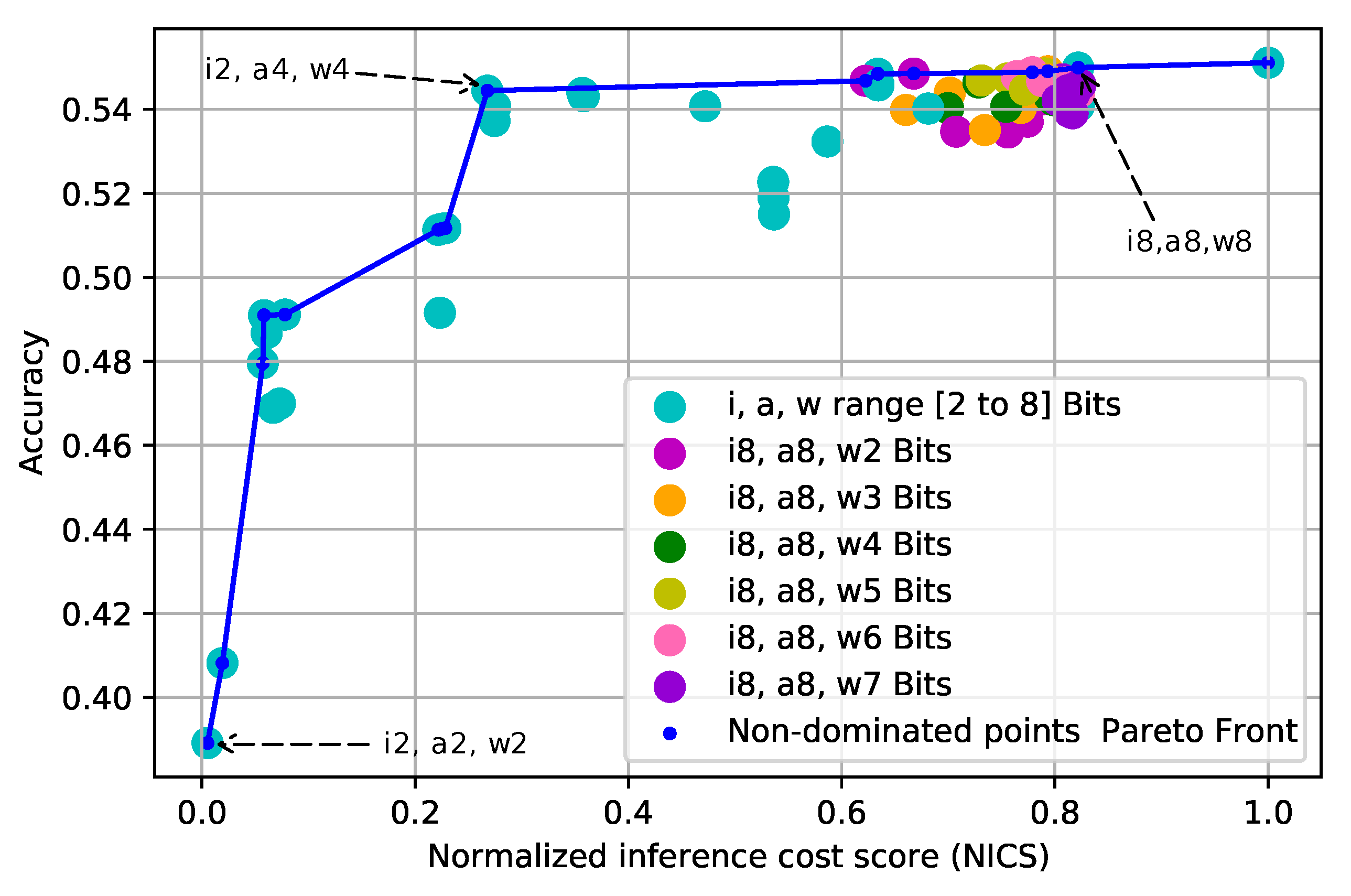
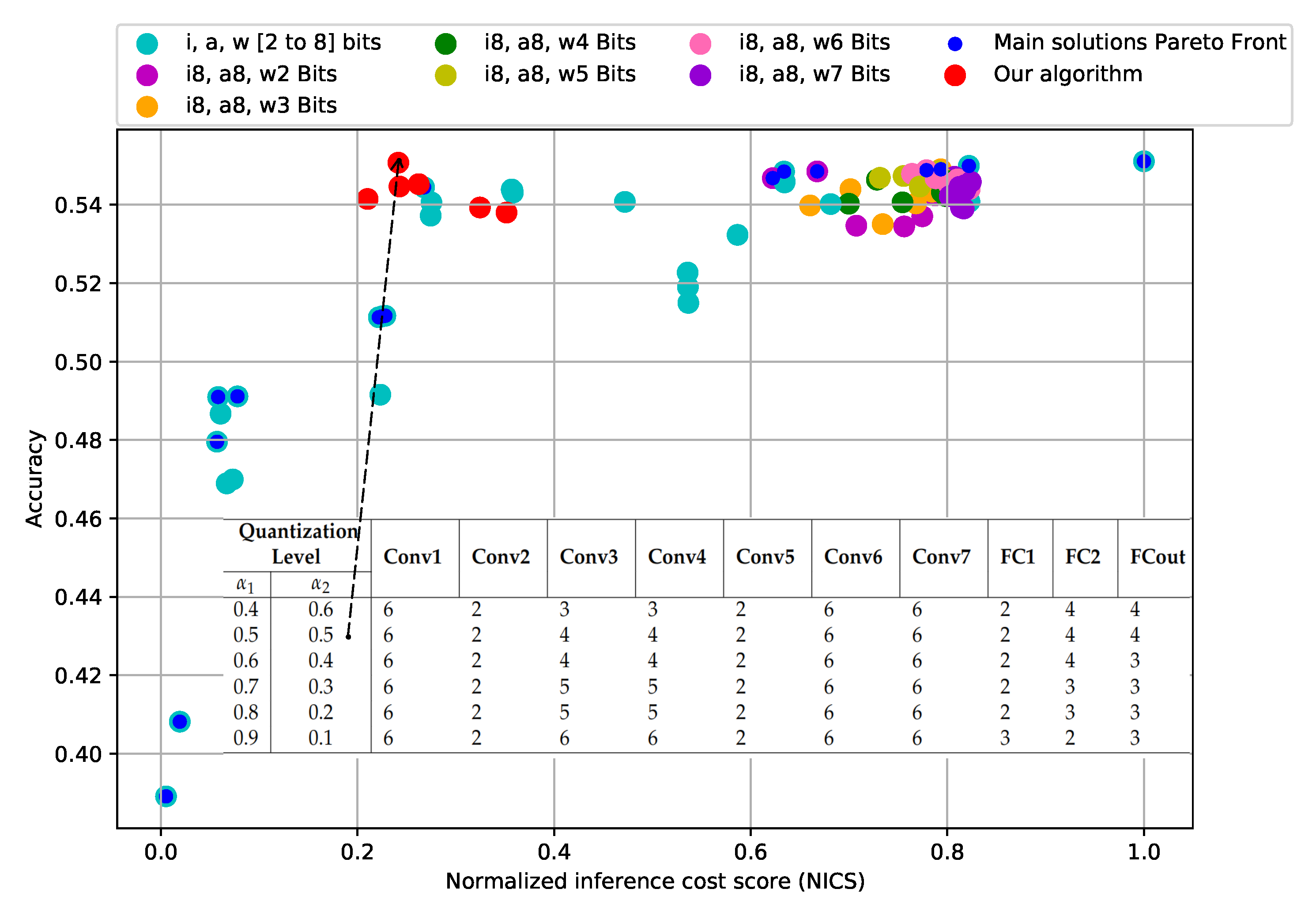
Figure 4 shows the solutions represented by their degree of quantization in aquamarine color. Notice that we intentionally do not discriminate between the quantization levels. Following this figure, it is possible to select one of the quantization options quickly; the choice will depend on how much accuracy we are willing to sacrifice in search of a lower inference cost. In this case, performing a Pareto optimal analysis can identify the quantizations with the best solutions so far. For example, the configuration (
), the one located at the bottom-left corner in which all layers (input, activations, and weights) are quantized at 2 bits, shows the lowest inference cost equivalent to a 99.4% reduction. Nevertheless, this solution also offers the lowest classification accuracy with a drop in accuracy to 29.3%. On the contrary, the benchmark quantization (
), in the upper right corner, shows the highest accuracy, which is similar to that of the unquantized model, but with a higher inference cost. However, it is possible to find a middle ground that allows for a sound inference cost reduction and acceptable accuracy.
For instance, when applying the configuration (), the accuracy drop is only about 1.2% regarding the highest. Moreover, the inference cost is reduced by 73.2%. Besides the good results regarding the quantization objective (i.e., good accuracy at lower inference cost), this last configuration also shows us that each quantized parameter (input, activations, and weights) has an independent effect on the accuracy and the inference cost. Therefore, we can analyze the impact of each layer in the second stage of the process.
Using the results, we compute Spearman’s correlation coefficient to identify the parameter that most influences the trade-off.
Table 2 shows the dependency between quantized parameters and their effects on NICS and accuracy. Quantizing the input, which corresponds to the I/Q signal used to train the model, does not significantly affect accuracy. For instance, the correlation coefficient has values of 0.295 and 0.275, corresponding to NICS and accuracy, respectively, representing low dependency, where the highest correlation coefficient is one. Regarding activations, the correlation shows that they have a mid-strong relationship with accuracy, higher than NICS. This means that quantizing the activations impacts the accuracy (e.g., does not heavily reduce the accuracy) but barely affects the inference cost. On the contrary, quantizing the weights correlates strongly with NICS and, to a lesser extent, with accuracy. With a correlation of 0.955, it is clear that the parameters that, when quantified, have the most significant impact in reducing inference cost are the weights. Moreover, it can also be seen that the accuracy is barely affected, having a value of 0.790, which is considered to be high. This indicates that we can quantize the weights to obtain similar accuracy at a reduced inference cost regarding the reference model.
5.2. Stage 2: Layered Evaluation, Analyzing the Impact of Quantization per Layer
In this experiment, we independently quantized the weights of each layer over a range of 2 to 8 bits. Contrary to the previous stage, we used the full range in quantization bits. The quantization of inputs, activations, and non-considered layers was set to 8 bits. This was due to the results observed in the previous section, where it was shown that quantifying these two parameters does not strongly affect the inference cost and classification accuracy. An example of how this stage was carried out is shown in
Table 3, where a particular layer is quantized at 2 bits, keeping the remaining layers quantized at 8 bits. As can be inferred, for the VGG10 1D-CNN, we executed ten runs per quantization level.
5.3. Stage 3: Data Dispersion and Spearman Mapping, Distribution of the Results by Layer
We obtained the accuracy and the inference cost for each configuration (
) in which the quantized value for the weights in a given layer were varied. Then, we analyzed the data distribution of those results, i.e., whether it was possible to define a specific behavior that would shed light on possible alternatives for quantification by layer discrimination.
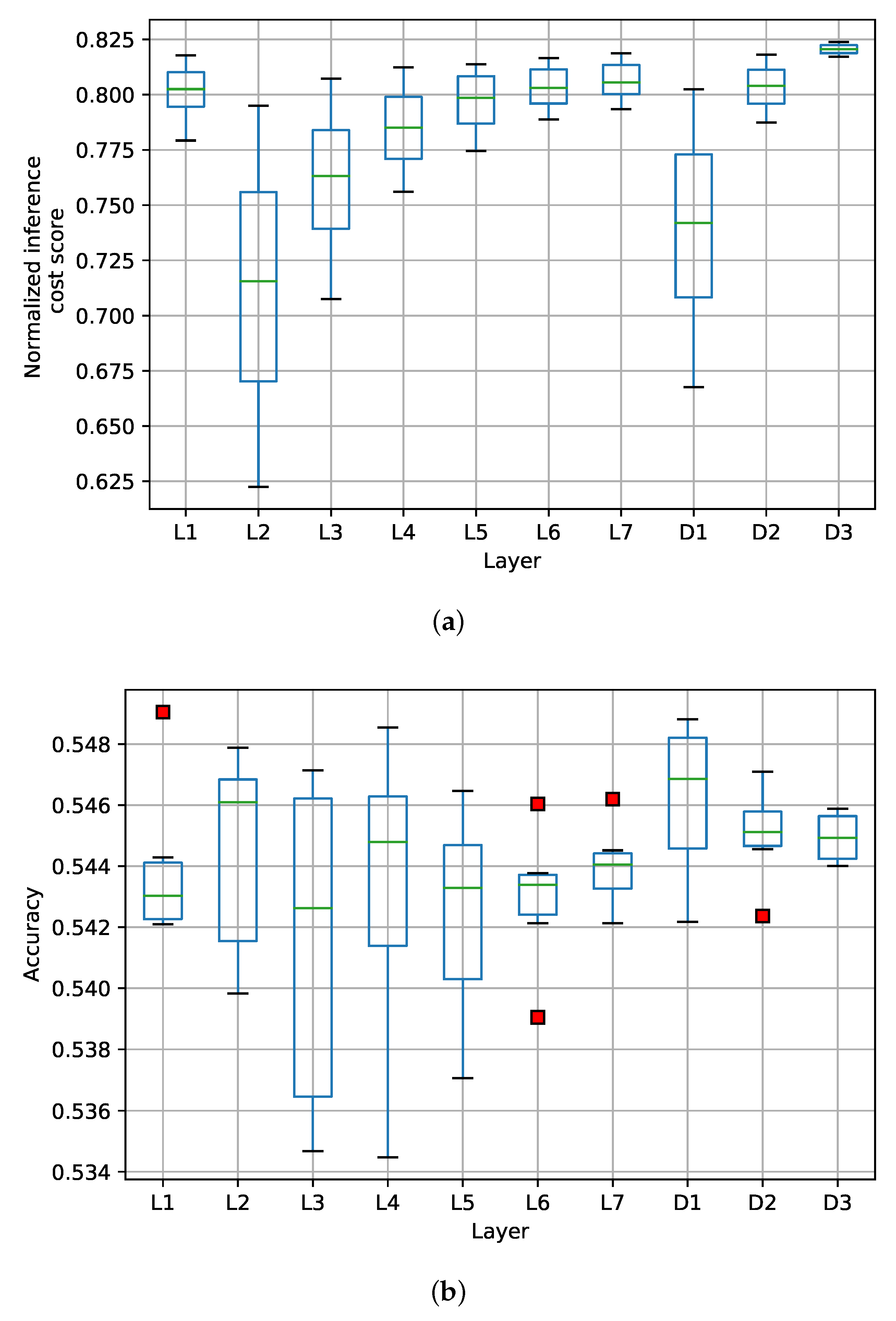
Figure 5a shows the box plot of the mean, median, and quartiles of the results obtained in the previous stage per layer and their impact on the inference cost. The figure shows that NICS is symmetric in the bit range used in the experiments. In this sense, it is observed that layer two (CNN L2) has the most significant impact on the reduction of the NICS, and to a lesser extent, layers three (CNN L3) and four (CNN L4). However, the input layer (CNN L1) does not significantly impact the computational cost reduction when quantified in the range of 2 to 8 bits. As for the FC layers, it is observed that the first dense layer (D1) significantly reduces the computational cost when quantized, but the output layer (D3) does not.
Furthermore,
Figure 5a shows that each quantized layer has an exponential effect on the computational cost reduction; this behavior is due to the max pooling filter applied to the output of the convolutional layers. Similarly,
Figure 5b shows the box plot of the results obtained and their impact on accuracy. From the figure, we can see that the quantization of each layer does not have a clear effect or general behavior regarding accuracy. This indicates that each layer could be quantized independently to achieve good accuracy with a lower computational cost. Nevertheless, we still need to determine the recommended quantization level for each model layer.
To determine the recommended quantization level per layer, we calculated the Spearman’s correlation coefficient with the results obtained from the previous stage.
Figure 6 shows a box plot with Spearman’s correlation. As can be observed, it is possible to measure how strong the relationship is between each layer and the accuracy (see
Figure 6a) and the inference cost (see
Figure 6b) is. Concerning the accuracy, we observe that the results are dispersed. However, in most cases, the median of the data is above or below
, indicating a possible direction at the quantization level; that is, the quantization level should be increased (
) or decreased (
). In the case of the inference cost, we observe that there is no dispersion in the results. Only layers one, six, and fully connected layer two showed minimal dispersion. However, a similar approach can be followed to define the direction at the quantization level.
5.4. Stage 4: Selection of the Quantization Level per Layer
In the last stage of the methodology, we propose using the Spearman’s correlation coefficient as an indicator for the degree and direction of the relationship of each layer regarding the accuracy and inference cost. Then, since the Spearman’s correlation ranges from 1 to −1, we map the bit quantization levels from 4 to −4 to have an equivalent scale. This way, the highest possible quantization level (8 bits) is never exceeded. Since there are two variables we want to control (accuracy and inference cost), we applied Equation (
7) to each of them. As a result, Equations (
8) and (
9) show how we define the scale to map the quantization bits according to the sign of the ratio. Using these equations, it is possible to determine a configuration that achieves the best compromise between accuracy and cost of inference. In the Equations,
is the bit selection from the accuracy perspective, while
is the bit selection from the inference cost perspective.
and
are the medians of the Spearman coefficient for a given layer, regarding accuracy and inference cost, respectively (see
Figure 6).
Then, we can select a layer-discriminated quantization level for the model using Equation (
10), which is a weighted sum that takes into account the contribution of each variable of interest.
Q is the quantization level to be applied to a given layer, while
and
represent the importance given to accuracy or inference cost, with
. The result is a quantization level that considers both accuracy and inference cost.
Finally, complementing the analysis methodology with Equations (
8)–(
10), we select the quantization levels discriminated on each layer in the DNN. Algorithm 3 shows the procedure’s pseudocode to perform stages three and four. We call this the LDQ algorithm. In LDQ, we define the necessary steps to determine the degree of quantization of each layer of a DNN for AMR. Note that the first part of the algorithm obtains the resulting accuracy and NICS metrics from the quantized models when varying the quantized values on each layer in Algorithm 2. Between lines 4 and 7, the solutions are mapped, grouping them by layers, and then analyzed with Spearman’s correlation (lines 8 and 9). In lines 10 and 11, using Equations (
8) and (
9), the decision threshold for each layer of the DNN is obtained. Finally, the quantification values are obtained between lines 13 and 17. Note that in this part, the alpha parameters allow different quantification configurations to be obtained depending on the importance assigned to them following Equation (
10).
| Algorithm 3 Stage 3 and 4: Layered Discriminated Quantization LDQ. |
| Require: Set E from Algorithm 2 |
| Require: Set L with the layers of M to be quantized |
| Require: and , where |
| 1: for do |
| 2: |
| 3: |
| 4: for do |
| 5: |
| 6: |
| 7: end for |
| 8: Calculate Spearman’s correlation analysis on |
| 9: Calculate Spearman’s correlation analysis on |
| 10: Apply Equation (8) using |
| 11: Apply Equation (9) using |
| 12: end for |
| 13: for do |
| 14: for do |
| 15: Apply Equation (10) with parameters |
| 16: , , and |
| 17: end for |
| 18: end for |
| 19: Return E |
5.5. Classification Evaluation
This section evaluates the configurations obtained from the layer discrimination analysis. This exercise aims to determine a suitable model configuration with a low bit size but that simultaneously does not compromise accuracy.
Figure 7 shows, in red, the configurations obtained following the methodology described in the previous section. The solutions obtained with the quantizations used in the screening stage are also shown. The figure shows the two best results when the CNN model is quantized following the configuration
and
. Configuration
has an accuracy of 0.541 and an inference cost of 0.210, while configuration
has an accuracy of 0.550 and an inference cost of 0.241, equivalent to 78.9% and 75.8% lower computational inference cost with respect to the non-quantized model. However, the reduction in accuracy is only 1.74% in the former case and 0.06% in the latter compared to the reference model. Therefore, we have shown that by independently quantizing every layer of the model, we can achieve similar performance to the reference model but at much lower computational cost.
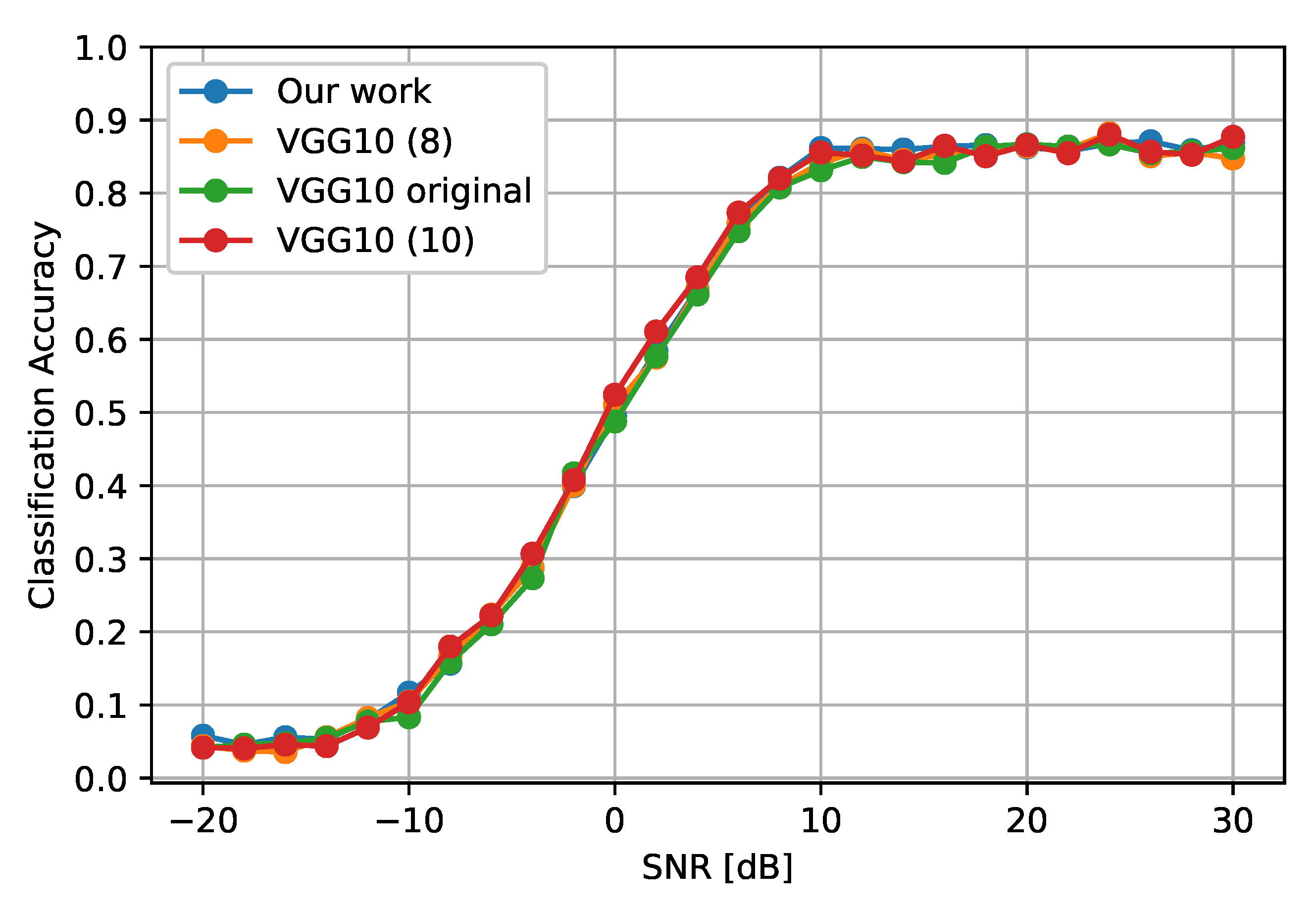
To verify this result, we compare the modulation classification accuracy of a configuration given by the methodology against the 8- and 10-bit quantized reference model. Since 8-bit quantization values were used as the basis for experimental quantization, we defined a reference model whose values were above any other test settings and could be used as a benchmark.
Figure 8 shows the accuracy of the original model (not quantized), the 8- and 10-bit quantized model, and configuration
. Notice that all the layers are quantized at 8 and 10 bits in their respective versions. As we can see, the accuracy of all models is similar across different SNR values. As expected, the inference cost in
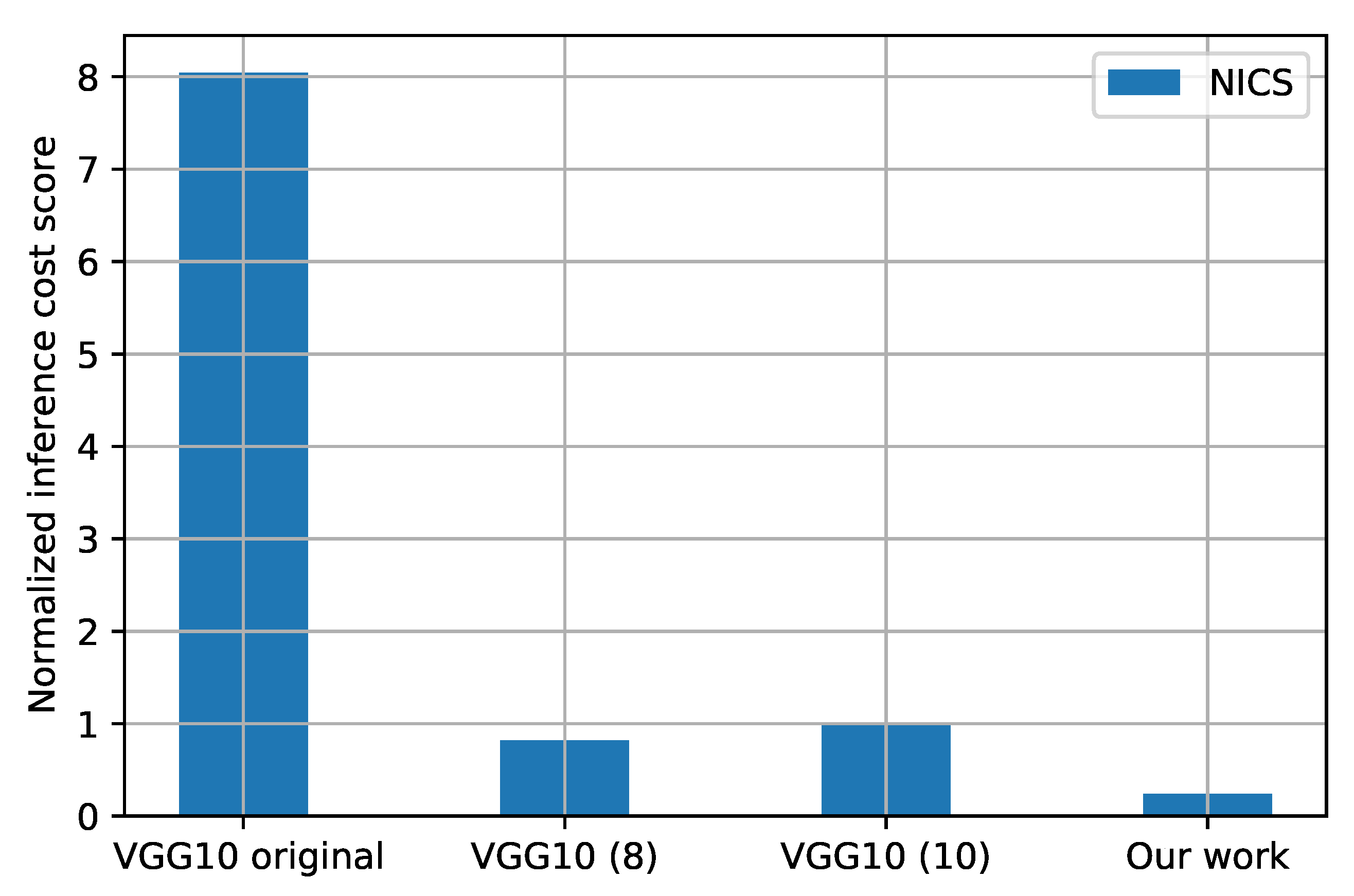
Figure 9 is much lower in the quantized models than in the original model. In addition, a significant difference is observed in the solution found by using the methodology proposed in this paper.
6. Conclusions and Future Work
New-generation communications are geared toward coverage, service quality, and greater bandwidth with better use of available resources. In this sense, AI and parallel processing are tools that are called to support this type of task in modern radio systems. However, implementing DL algorithms in hardware is a non-trivial task due to the reduced ability to support large models. This has created a gap between research on intelligent communication algorithms and the implementation of such algorithms in radios. To close this gap, quantization is a technique that reduces the computational cost (e.g., model size in memory, number of operations, among others) of DL models, so that they can be deployed in devices with limited computational resources such as FPGA.
However, most of the proposed quantization methods for DL models apply the same quantization level to all the trainable parameters in the model, including inputs, activations, and weights. On the contrary, this article proposes a methodology to analyze the impact on accuracy against the inference cost of a quantized DNN model. Then, depending on the quantization level, a similar accuracy to the non-quantized model can be achieved at a much-reduced inference cost. Furthermore, our findings show that it is convenient to quantize the layers independently, as each layer has a different effect on inference cost and accuracy. In this sense, we showed that by independently quantizing the model layers according to the level of compromise in the model’s performance, an accuracy close to that obtained with the same model without quantization could be obtained.
In future work, we want to use our methodology to find the appropriate quantization level using other DNN architectures for AMR. In addition, the combination of our method with other quantization techniques or in combination with pruning remains to be addressed, which could provide an even more significant reduction in the inference cost and validation to the generality of the proposed approach. We will also validate our methodology with other DL architectures solving the same problem and DL architectures used to solve other related problems at the radio receiver side that will benefit from obtaining low-computational-cost models. Finally, we will complement our experimental results with performance evaluations of some of the resulting models as a part of a wireless communication system running on an FPGA. This is fundamental to provide further quantitative results of the trade-off between model accuracy and other metrics related to the model size, such as energy consumption and processing speed.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}