

Model and Training Method of the Resilient Image Classifier Considering Faults, Concept Drift, and Adversarial Attacks


Abstract
1. Introduction
1.1. Motivation
1.2. Objectives and Contribution
- -
- To develop a new resource-efficient model and a training method, which simultaneously implement components of resilience such as robustness, graceful degradation, recovery, and improvement;
- -
- To test the model’s and training method’s ability to provide robustness, graceful degradation, recovery, and improvement.
2. The State-of-the-Art
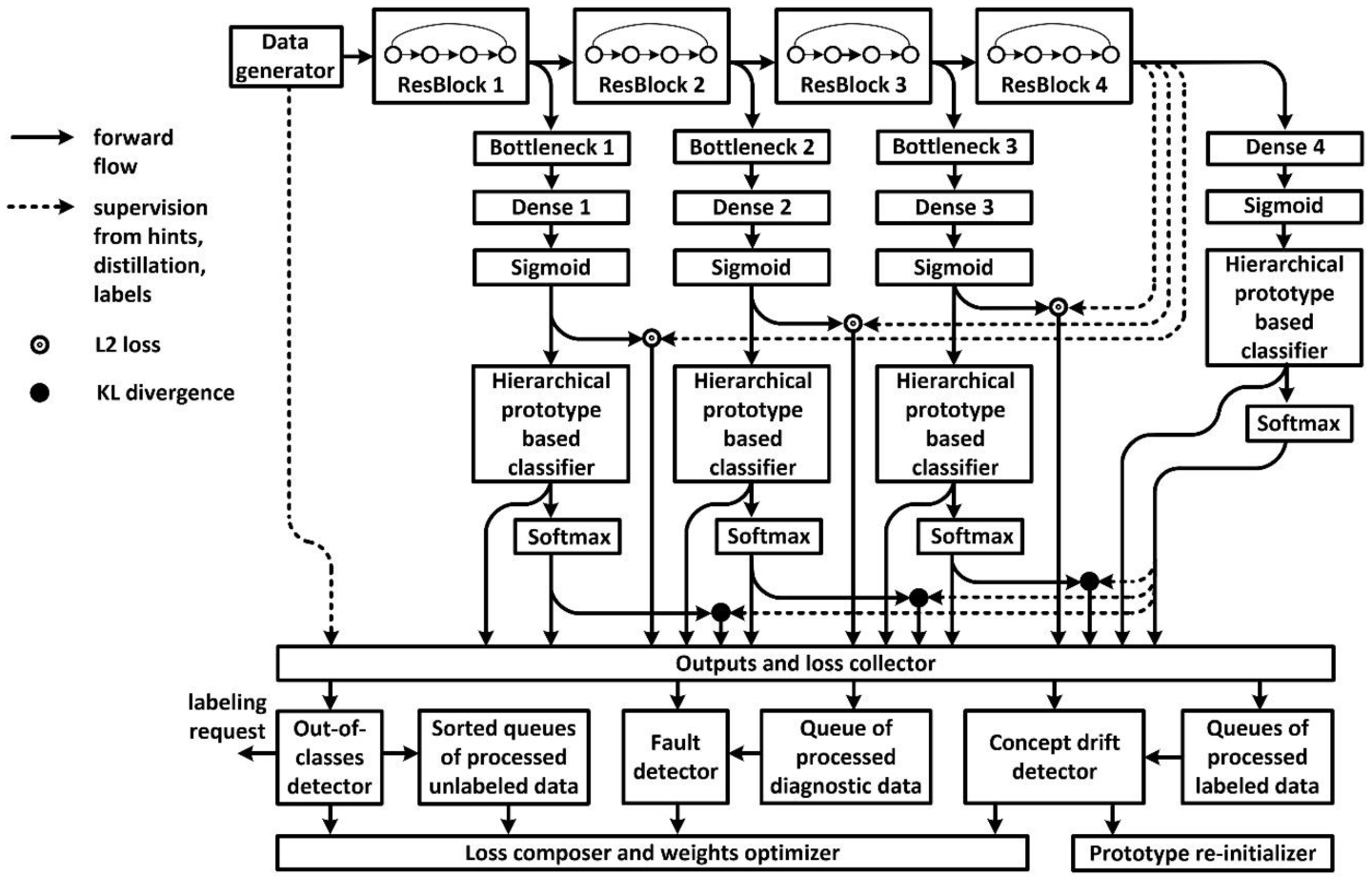
3. Classification Model Design
3.1. Principles
- -
- hierarchical labeling and hierarchical classification to implement the principle of graceful degradation by coarsening the prediction with a more abstract class and with reasonable confidence when classes at the bottom of the hierarchy are recognized with a low confidence level;
- -
- combining the mechanisms of self-knowledge distillation and nested learning to increase the robustness of the model by increasing the informativeness of the feedback for the lower layers at the training stage and accelerate inference by skipping high-level layers for simple samples at the inference stage;
- -
- prototype and compact spherical container formation for each class to simplify the detection of out-of-distribution samples and concept drifts;
- -
- using memory FIFO queues with a limited size to store labeled and unlabeled data with corresponding values of loss function obtained by inference for implementation diagnostic and recovery mechanism.
3.2. Architecture
- -
- neural network calculations are performed sequentially, section by section;
- -
- high-level sections can be skipped if the maximal value of the membership function in the output of the current section, with regards to a particular class of the lower hierarchical level, exceeds the confidence threshold ;
- -
- if the maximal value of the membership function of any of the hierarchical levels of the classifier at the output of the current section has not increased compared to the previous section, the subsequent calculations can be omitted;
- -
- where any of the conditions of omission of the subsequent sections are fulfilled or the classifier in question is the last classifier in the model and the maximal value of the membership function of the lower hierarchical level does not exceed the confidence threshold, a higher level in the hierarchy is checked;
- -
- where a class with a sufficient confidence level has not been identified, a decision is refused, a request for a manual labeling is generated, and the corresponding sample is designated as suitable for semi-supervised tuning.
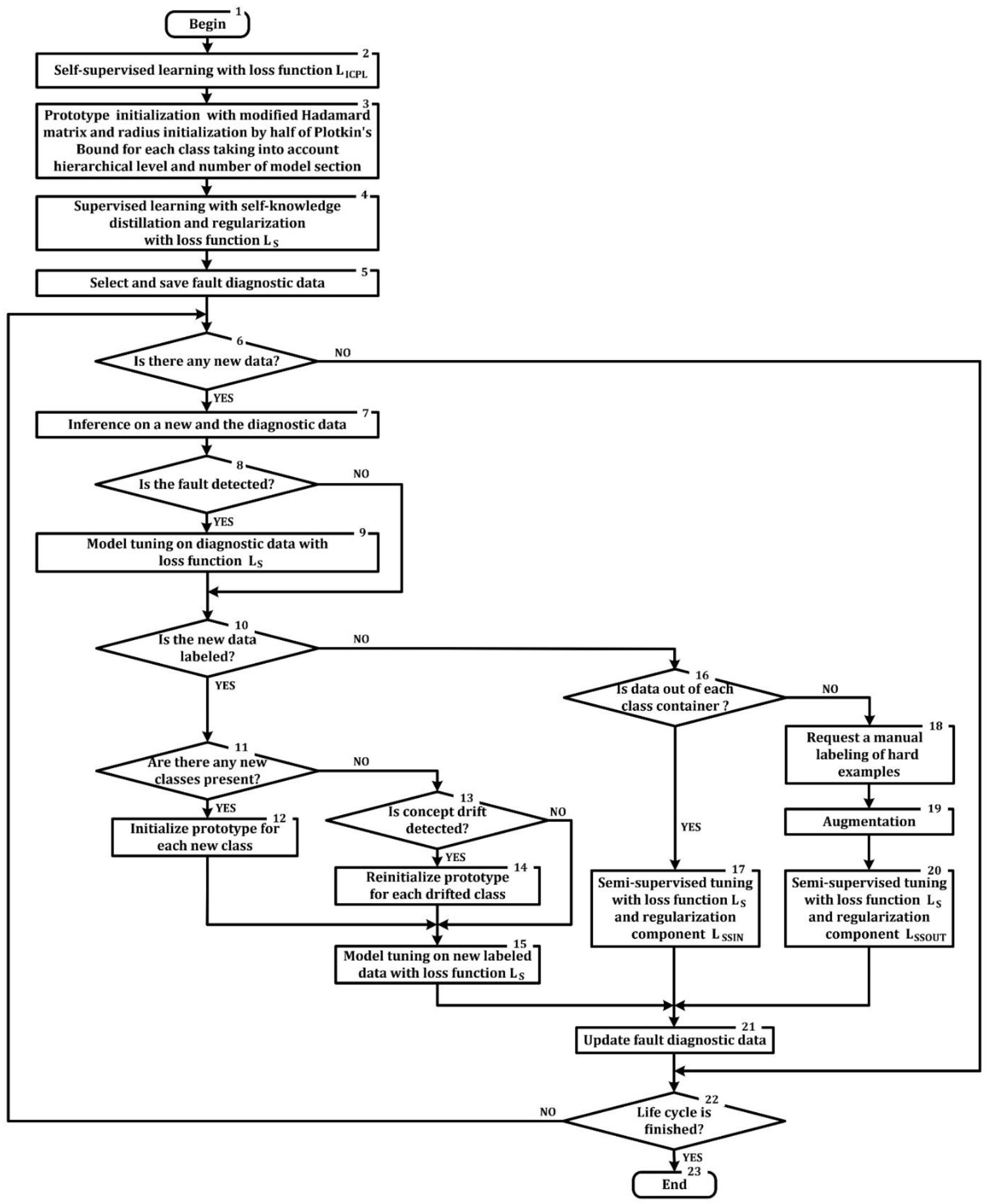
4. Training Method Design
4.1. Principles
- -
- accounting for the hierarchy of data labeling and hierarchy class prototypes by calculating the loss function separately for each level of the hierarchy to provide graceful degradation at the inference;
- -
- the implementation of self-knowledge distillation, i.e., distillation of knowledge from the high-level layer (section) of the model down to lower layers (sections) as additional regularization components to increase robustness and provide adaptive calculations in inference mode;
- -
- increasing the compactness of the distribution of classes and the buffer zone between classes to increase resistance to noise, outliers, and adversarial attacks in turn as an additional distance-based regularization component;
- -
- the discretization of feature representation in order to implement the information bottleneck and increase the robustness of the feature representation as an additional regularization component;
- -
- the ability to effectively use both labeled and unlabeled data samples to speed up adaptation with a limited quantity of labeled data, which usually comes with a time lag;
- -
- the avoidance of catastrophic forgetting when adapting to change and adversarial attacks without full retraining by implementing a reminding mechanism which utilizes the data buffers and distillation feedback of the upper layers.
4.2. Stages
- -
- self-supervision pre-training of the model with instance-prototype contrastive loss ;
- -
- prototype and radius initialization for each class;
- -
- supervised learning with loss function , which includes conventional cross-entropy and additional components for self-knowledge distillation and regularization;
- -
- selecting fault diagnostic data (selected randomly or with respect to the value of the loss function);
- -
- inference on a new and diagnostic data;
- -
- requesting manual labeling of hard examples;
- -
- supervised learning with loss function , taking into account manual labeling responses or semi-supervised fine-tuning (adaptation) with additional component or depends on the result of inference;
- -
- updating diagnostic data.
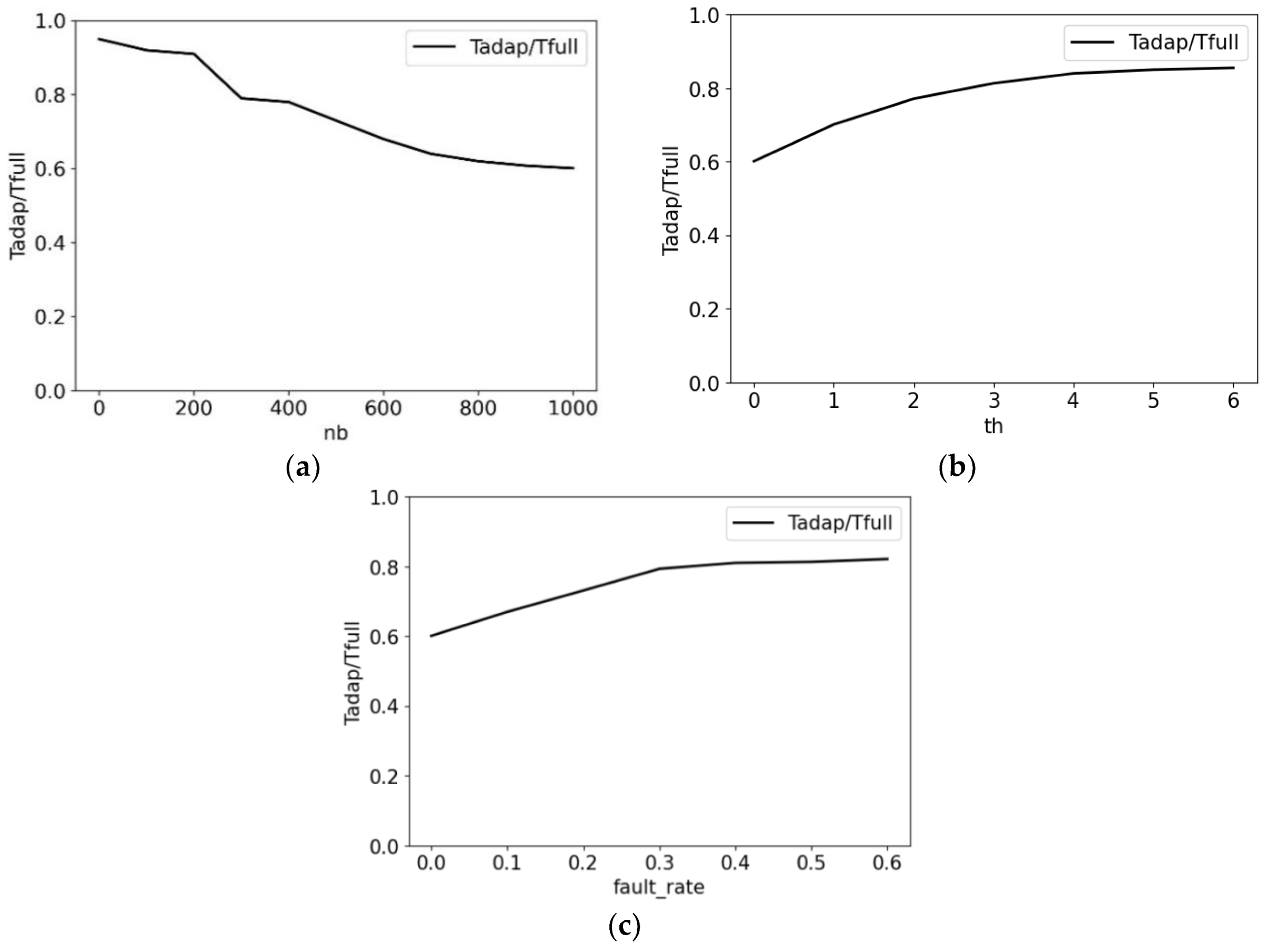
5. Experiments
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Eigner, O.; Eresheim, S.; Kieseberg, P.; Klausner, L.; Pirker, M.; Priebe, T.; Tjoa, S.; Marulli, F.; Mercaldo, F. Towards Resilient Artificial Intelligence: Survey and Research Issues. In Proceedings of the IEEE International Conference on Cyber Security and Resilience (CSR), Rhodes, Greece, 26–28 July 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Olowononi, F.; Rawat, D.; Liu, C. Resilient Machine Learning for Networked Cyber Physical Systems: A Survey for Machine Learning Security to Securing Machine Learning for CPS. IEEE Commun. Surv. Tutor. 2021, 23, 524–552. [Google Scholar] [CrossRef]
- Dymond, J. Graceful Degradation and Related Fields. A Review for Applied Research Centre at the Alan Turing Institute. Available online: https://eprints.soton.ac.uk/455349/ (accessed on 22 June 2021).
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-Learning in Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5149–5169. [Google Scholar] [CrossRef] [PubMed]
- Parisi, G.; Kemker, R.; Part, J.; Kanan, C.; Wermter, S. Continual lifelong learning with neural networks: A review. Neural Netw. 2019, 113, 54–71. [Google Scholar] [CrossRef] [PubMed]
- Fraccascia, L.; Giannoccaro, I.; Albino, V. Resilience of Complex Systems: State of the Art and Directions for Future Research. Complexity 2018, 2018, 3421529. [Google Scholar] [CrossRef]
- Madni, A. Affordable Resilience. Transdiscipl. Syst. Eng. 2017, 133–159. [Google Scholar] [CrossRef]
- Zhang, L.; Bao, C.; Ma, K. Self-Distillation: Towards Efficient and Compact Neural Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4388–4403. [Google Scholar] [CrossRef] [PubMed]
- Marquez, E.; Hare, J.; Niranjan, M. Deep Cascade Learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5475–5485. [Google Scholar] [CrossRef] [PubMed]
- Leslie, N.S. A useful taxonomy for adversarial robustness of Neural Networks. Trends Comput. Sci. Inf. Technol. 2020, 5, 37–41. [Google Scholar] [CrossRef]
- Xie, C.; Wang, J.; Zhang, Z.; Ren, Z.; Yuille, A. Mitigating Adversarial Effects Through Randomization. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–16. [Google Scholar] [CrossRef]
- Makarichev, V.; Lukin, V.; Illiashenko, O.; Kharchenko, V. Digital Image Representation by Atomic Functions: The Compression and Protection of Data for Edge Computing in IoT Systems. Sensors 2022, 22, 3751. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a Defense to Adversarial Perturbations Against Deep Neural Networks. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2016; pp. 582–597. [Google Scholar] [CrossRef]
- Srisakaokul, S.; Zhong, Z.; Zhang, Y.; Yang, W.; Xie, T.; Ti, B. MULDEF: Multi-model-based Defense Against Adversarial Examples for Neural Networks. arXiv 2018, arXiv:1809.00065. [Google Scholar]
- Song, Y.; Kim, T.; Nowozin, S.; Ermon, S.; Kushman, N. PixelDefend: Leveraging Generative Models to Understand and Defend against Advers arial Examples. In Proceedings of the International Conference on Learning Representations, Vancouver, QC, Canada, 30 April–3 May 2018; pp. 1–20. [Google Scholar] [CrossRef]
- Samangouei, P.; Kabkab, M.; Chellappa, R. Defense-GAN: Protecting Classifiers Against Adversarial Attacks Using Generative Models. arXiv 2018, arXiv:1805.06605. [Google Scholar]
- Athalye, A.; Carlini, N.; Wagner, D. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples. arXiv 2018, arXiv:1802.00420. [Google Scholar]
- Kwon, H.; Lee, J. Diversity Adversarial Training against Adversarial Attack on Deep Neural Networks. Symmetry 2021, 13, 428. [Google Scholar] [CrossRef]
- Laermann, J.; Samek, W.; Strodthoff, N. Achieving Generalizable Robustness of Deep Neural Networks by Stability Training. In Proceedings of the 41st DAGM German Conference, Dortmund, Germany, 10–13 September 2019; pp. 360–373. [Google Scholar] [CrossRef]
- Jakubovitz, D.; Giryes, R. Improving DNN Robustness to Adversarial Attacks using Jacobian Regularization. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 1–16. [Google Scholar] [CrossRef]
- Xu, J.; Li, Z.; Du, B.; Zhang, M.; Liu, J. Reluplex made more practical: Leaky ReLU. In Proceedings of the IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Shu, X.; Tang, J.; Qi, G.-J.; Li, Z.; Jiang, Y.-G.; Yan, S. Image Classification with Tailored Fine-Grained Dictionaries. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 454–467. [Google Scholar] [CrossRef]
- Deng, Z.; Yang, X.; Xu, S.; Su, H.; Zhu, J. LiBRe: A Practical Bayesian Approach to Adversarial Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 972–982. [Google Scholar] [CrossRef]
- Abusnaina, A.; Wu, Y.; Arora, S.; Wang, Y.; Wang, F.; Yang, H.; Mohaisen, D. Adversarial Example Detection Using Latent Neighborhood Graph. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar] [CrossRef]
- Carrara, F.; Becarelli, R.; Caldelli, R.; Falchi, F.; Amato, G. Adversarial Examples Detection in Features Distance Spaces. In Physics of Solid Surfaces; Springer: Berlin/Heidelberg, Germany, 2019; pp. 313–327. [Google Scholar] [CrossRef]
- Carlini, N.; Wagner, D. Adversarial Examples Are Not Easily Detected. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 3–14. [Google Scholar] [CrossRef]
- Yang, S.; Luo, P.; Change Loy, C.; Shum, K.W.; Tang, X. Deep representation learning with target coding. In Proceedings of the AAAI15: Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January2015; pp. 3848–3854. [Google Scholar]
- Moskalenko, V.; Zaretskyi, M.; Moskalenko, A.; Korobov, A.; Kovalsky, Y. Multi-stage deep learning method with self-supervised pretraining for sewer pipe defects classification. Radioelectron. Comput. Syst. 2021, 71–81. [Google Scholar] [CrossRef]
- Moskalenko, V.; Moskalenko, A. Neural network based image classifier resilient to destructive perturbation influences—Architecture and training method. Radioelectron. Comput. Systems. 2022, 3, 95–109. [Google Scholar] [CrossRef]
- Silva, S.; Najafirad, P. Opportunities and Challenges in Deep Learning Adversarial Robustness: A Survey. arXiv 2020, arXiv:2007.00753. [Google Scholar]
- Huang, K.; Siegel, P.H.; Jiang, A. Functional Error Correction for Robust Neural Networks. IEEE J. Sel. Areas Inf. Theory 2020, 267–276. [Google Scholar] [CrossRef]
- Jang, M.; Hong, J. MATE: Memory- and Retraining- Free Error Correction for Convolutional Neural Network Weights. J. Lnf. Commun. Converg. Eng. 2021, 19, 22–28. [Google Scholar] [CrossRef]
- Hoang, L.-H.; Hanif, M.A.; Shafique, M. TRe-Map: Towards Reducing the Overheads of Fault-Aware Retraining of Deep Neural Networks by Merging Fault Maps. In Proceedings of the 24th Euromicro Conference on Digital System Design (DSD), Palermo, Italy, 1–3 September 2021; pp. 434–441. [Google Scholar] [CrossRef]
- Li, W.; Ning, X.; Ge, G.; Chen, X.; Wang, Y.; Yang, H. FTT-NAS: Discovering Fault-Tolerant Neural Architecture. In Proceedings of the 25th Asia and South Pacific Design Automation Conference (ASP-DAC), Beijing, China, 13–16 January 2020; pp. 211–216. [Google Scholar] [CrossRef]
- Valtchev, S.Z.; Wu, J. Domain randomization for neural network classification. J. Big Data 2021, 8, 1–12. [Google Scholar] [CrossRef]
- Volpi, R.; Namkoong, H.; Sener, O.; Duchi, J.; Murino, V.; Savarese, S. Generalizing to unseen domains via adversarial data augmentation. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 2–8 December 2018; pp. 1–11. [Google Scholar] [CrossRef]
- Xu, Q.; Yao, L.; Jiang, Z.; Jiang, G.; Chu, W.; Han, W.; Zhang, W.; Wang, C.; Tai, Y. DIRL: Domain-Invariant Representation Learning for Generalizable Semantic Segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 22 February–3 March 2022; pp. 2884–2892. [Google Scholar] [CrossRef]
- Museba, T.; Nelwamondo, F.; Ouahada, K. ADES: A New Ensemble Diversity-Based Approach for Handling Concept Drift. Mob. Inf. Syst. 2021, 2021, 5549300. [Google Scholar] [CrossRef]
- Tang, J.; Shu, X.; Li, Z.; Qi, G.-J.; Wang, J. Generalized Deep Transfer Networks for Knowledge Propagation in Heterogeneous Domains. ACM Trans. Multimedia Comput. Commun. Appl. 2016, 12, 1–22. [Google Scholar] [CrossRef]
- Shu, X.; Qi, G.-J.; Tang, J.; Wang, J. Weakly-Shared Deep Transfer Networks for Heterogeneous-Domain Knowledge Propagation. In Proceedings of the 23rd ACM International Conference on Multimedia–MM ’15, Brisbane Australia, 26–30 October 2015; pp. 35–44. [Google Scholar] [CrossRef]
- Achddou, R.; Di Martino, J.; Sapiro, G. Nested Learning for Multi-Level Classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2815–2819. [Google Scholar] [CrossRef]
- Castellani, A.; Schmitt, S.; Hammer, B. Task-Sensitive Concept Drift Detector with Constraint Embedding. In Proceedings of the IEEE Symposium Series on Computational Intelligence (SSCI), Orlando, FL, USA, 4–7 December 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Yu, H.; Zhang, Q.; Liu, T.; Lu, J.; Wen, Y.; Zhang, G. Meta-ADD: A meta-learning based pre-trained model for concept drift active detection. Inf. Sci. 2022, 608, 996–1009. [Google Scholar] [CrossRef]
- Javaheripi, M.; Koushanfar, F. HASHTAG: Hash Signatures for Online Detection of Fault-Injection Attacks on Deep Neural Networks. In Proceedings of the IEEE/ACM International Conference on Computer Aided Design (ICCAD), Munich, Germany, 1–4 November 2021; pp. 1–9. [Google Scholar] [CrossRef]
- Li, J.; Rakin, A.S.; He, Z.; Fan, D.; Chakrabarti, C. RADAR: Run-time Adversarial Weight Attack Detection and Accuracy Recovery. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 1–5 February 2021; pp. 790–795. [Google Scholar] [CrossRef]
- Wang, C.; Zhao, P.; Wang, S.; Lin, X. Detection and recovery against deep neural network fault injection attacks based on contrastive learning. In Proceedings of the 3rd Workshop on Adversarial Learning Methods for Machine Learning and Data Mining at KDD, Singapore, 14 August 2021; pp. 1–5. [Google Scholar]
- Girau, B.; Torres-Huitzil, C. Fault tolerance of self-organizing maps. Neural Comput. Appl. 2020, 32, 17977–17993. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, Y.; Zhao, C.; Lin, Y.; Zhao, X.; Tao, H.; Wang, Y.; Khan, L. CLEAR: Contrastive-Prototype Learning with Drift Estimation for Resource Constrained Stream Mining. In Proceedings of the Web Conference, Ljubljana, Slovenia, 19–23 April 2021; pp. 1351–1362. [Google Scholar] [CrossRef]
- Margatina, K.; Vernikos, G.; Barrault, L.; Aletras, N. Active Learning by Acquiring Contrastive Examples. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 1–14. [Google Scholar] [CrossRef]
- Chen, Y.; Wei, C.; Wang, D.; Ji, C.; Li, B. Semi-Supervised Contrastive Learning for Few-Shot Segmentation of Remote Sensing Images. Remote Sens. 2022, 14, 4254. [Google Scholar] [CrossRef]
- Caccia, M.; Rodríguez, P.; Ostapenko, O.; Normandin, F.; Lin, M.; Caccia, L.; Laradji, I.; Rish, I.; Lacoste, A.; Vazquez, D.; et al. Online fast adaptation and knowledge accumulation (OSAKA): A new approach to continual learning. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; pp. 16532–16545. [Google Scholar]
- Dovbysh, A.; Shelechov, I.; Khibovska, J.; Matiash, O. Information and analytical system for assessing the compliance of educational content specialties cyber security with modern requirements. Radioelectron. Comput. Syst. 2021, 1, 70–80. [Google Scholar] [CrossRef]
- Konkle, T.; Alvarez, G. A self-supervised domain-general learning framework for human ventral stream representation. Nat. Commun. 2020, 13, 491. [Google Scholar] [CrossRef]
- Verma, G.; Swami, A. Error correcting output codes improve probability estimation and adversarial robustness of deep neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, QC, Canada, 8–14 December 2019; pp. 8646–8656. [Google Scholar]
- Wu, J.; Tian, X.; Zhong, G. Supervised Contrastive Representation Embedding Based on Transformer for Few-Shot Classification. J. Phys. Conf. Ser. 2022, 2278, 012022. [Google Scholar] [CrossRef]
- Doon, R.; Rawat, T.K.; Gautam, S. Cifar-10 Classification using Deep Convolutional Neural Network. In Proceedings of the IEEE Punecon, Pune, India, 30 November–3 December 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Li, G.; Pattabiraman, K.; DeBardeleben, N. TensorFI: A Configurable Fault Injector for TensorFlow Applications. In Proceedings of the IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW), Charlotte, NC, USA, 15–18 October 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Kotyan, S.; Vargas, D. Adversarial robustness assessment: Why in evaluation both L0 and L∞ attacks are necessary. PLoS ONE 2022, 17, e0265723. [Google Scholar] [CrossRef]
- Sun, Y.; Fesenko, H.; Kharchenko, V.; Zhong, L.; Kliushnikov, I.; Illiashenko, O.; Morozova, O.; Sachenko, A. UAV and IoT-Based Systems for the Monitoring of Industrial Facilities Using Digital Twins: Methodology, Reliability Models, and Application. Sensors 2022, 22, 6444. [Google Scholar] [CrossRef]
- Kharchenko, V.; Kliushnikov, I.; Rucinski, A.; Fesenko, H.; Illiashenko, O. UAV Fleet as a Dependable Service for Smart Cities: Model-Based Assessment and Application. Smart Cities 2022, 5, 1151–1178. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Goal | Approach | Capability | Weakness | Algorithm | Authors |
|---|---|---|---|---|---|
| Adversarial resilience | Gradient masking | Perturbation absorption | Vulnerability to attacks based on gradient approximation or black-box optimization with evolution strategies | Non-differentiable input transformation [11,12] | Xie, C.; Wang, J.; Zhang, Z.; Ren, Z.; Yuille, L. [11] Makarichev, V.; Lukin, V.; Illiashenko, O.; Kharchenko V. [12] |
| Defensive distillation [13] | Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. [13] | ||||
| Random model selection from a family of models [14] | Srisakaokul, S.; Zhong, Z.; Zhang, Y.; Yang, W.; Xie, T. [14] | ||||
| Generative model PixelDefend or Defense-GAN [15,16] | Song, Y.; Kim, T.; Nowozin, S.; Ermon, S.; Kushman [15] Samangouei, P.; Kabkab, M.; Chellappa, R. [16] | ||||
| Robust- ness optimization | Perturbation absorption and performance recovery | Significant computational resource consumption to obtain a good result | Adversarial retraining [18] | Kwon, H.; Lee, J. [18] | |
| Stability training [19] | Laermann, J.; Samek, W.; Strodthoff, N. [19] | ||||
| Jacobian regularization [20] | Jakubovitz, D.; Giryes, R. [20] | ||||
| Sparse coding-based representation [22] | Shu, X.; Tang, J.; Qi, G.-J.; Li, Z.; Jiang Y.-G.; Yan, S. [22] | ||||
| Intra- concentration and inter- separability regularization [27,28,29] | Yang, S.; Luo, P.; Change Loy, C.; Shum, K. W.; Tang. X. [27] Moskalenko, V.; Zaretskyi, M.; Moskalenko, A.; Korobov, A.; Kovalsky, Y. [28] Moskalenko, V.; Moskalenko, A. [29] | ||||
| Provable defenses with the Reluplex algorithm [21] | Xu, J.; Li, Z.; Du, B.; Zhang, M.; Liu, J. [21] | ||||
| Detecting adversarial examples | Graceful degradation | Not reliable enough | Light-weight Bayesian refinement [23] | Deng, Z.; Yang, X.; Xu, S.; Su, H.; Zhu, J. [23] | |
| Adversarial example detection using latent neighborhood graph [24] | Abusnaina, A.; Wu, Y.; Arora, S.; Wang, Y.; Wang, F.; Yang, H.; Mohaisen, D. [24] | ||||
| Feature distance space analysis [25] | Carrara, F.; Becarelli, R.; Caldelli, R.; Falchi, F.; Amato, G. [25] | ||||
| Fault resilience | Redundancy and fault masking | Perturbation absorption | Computational intensive model synthesis and inference redundancy overhead | Explicit redundancy [31] | Huang, K.; Siegel, P. H.; Jiang, A. [31] |
| Weight representation with error-correcting codes [32] | Jang, M.; Hong, J. [32] | ||||
| Fault-tolerant training based on fault injection during training [33] | Hoang, L.-H.; Hanif, M. A.; Shafique, M. [33] | ||||
| Neural architecture search [34] | Li, W.; Ning, X.; Ge, G.; Chen, X.; Wang, Y.; Yang, H. [34] | ||||
| Error detection | Graceful degradation and recovery by downloading a clean copy of weights | The model does not improve itself and information from vulnerable weights is not spread among other neurons | Encoding the most vulnerable model weights using a low-collision hash-function [44] | Javaheripi, M.; Koushanfar, F. [44] | |
| Checksum- based algorithm that computes low- dimensional binary signature for each weight group [45] | Li, J.; Rakin, A. S.; He, Z.; Fan, D.; Chakrabarti, C. [45] | ||||
| Active recovery | Performance recovery | Not reliable recovery | Contrastive fine-tuning on diagnostic sample [46] | Wang, C.; Zhao, P.; Wang, S.; Lin, X. [46] | |
| Weight-shifting mechanism in self-organizing map [47] | Girau, B.; Torres-Huitzil, C. [47] | ||||
| Concept drift resilience | Out-of- domain generalization | Perturbation absorption | Applicable only to counteract virtual concept drift and useless in case of real concept drift | Domain randomization [35] | Valtchev, S. Z.; Wu, J. [35] |
| Adversarial data augmentation [36] | Volpi, R.; Namkoong, H.; Sener, O.; Duchi, J.; Murino, V.; Savarese, S. [36] | ||||
| Domain- invariant representation [37] | Xu, Q.; Yao, L.; Jiang, Z.; Jiang, G.; Chu, W.; Han, W.; Zhang, W.; Wang, C.; Tai, Y. [37] | ||||
| Heterogeneous-domain knowledge propagation [39,40] | Tang, J.; Shu, X.; Li, Z.; Qi, G.-J.; Wang, J. [39,40] | ||||
| Drift detection | Graceful degradation | Increasing the ability to detect concept drift at the expense of fast adaptation abilities | Constraint embedding [43] | Castellani, A.; Schmitt, S.; Hammer, B. [43] | |
| Meta-learning to detect concept drift [43] | Yu, H.; Zhang, Q.; Liu, T.; Lu, J.; Wen, Y.; Zhang, G. [43] | ||||
| Continual adaptation | Performance recovery and improvement | The need to implement complex mechanisms to prevent catastrophic forgetting and speedup of adaptation | Adaptive diversified ensemble selection [38] | Museba, T.; Nelwamondo, F.; Ouahada, K. [38] | |
| Continual learning [48] | Wang, Z.; Chen, Y.; Zhao, C.; Lin, Y.; Zhao, X.; Tao, H.; Wang, Y.; Khan, L. [48] | ||||
| Active learning [49] | Margatina, K.; Vernikos, G.; Barrault, L.; Aletras, N. [49] | ||||
| Semi- supervised learning [50] | Chen, Y.; Wei, C.; Wang, D.; Ji, C.; Li, B. [50] | ||||
| Continual meta-learning [51] | Caccia, M.; Rodríguez, P.; Ostapenko, O.; Normandin, F.; Lin, M., Caccia, L.; Laradji, I.; Rish, I.; Lacoste, A.; Vazquez, D.; Charlin, L. [51] |
| Dataset | Fault Rate | MED (Acc) Under Fault Injection | MED (Acc) After Recovery | MED (Acc) for Superclass Level Under Fault Injection | MED (Acc) for Superclass Level After Recovery | MED (Rec_Steps) | MED (Rec_Steps) for Superclass Level |
|---|---|---|---|---|---|---|---|
| CIFAR-10 | 0.0 | 0.993 | - | 0.980 | - | - | - |
| CIFAR-10 | 0.1 | 0.985 | 0.991 | 0.975 | 0.979 | 12 | 12 |
| CIFAR-10 | 0.2 | 0.932 | 0.976 | 0.930 | 0.961 | 29 | 21 |
| CIFAR-10 | 0.3 | 0.852 | 0.971 | 0.870 | 0.932 | 32 | 32 |
| CIFAR-10 | 0.4 | 0.801 | 0.921 | 0.790 | 0.914 | 49 | 54 |
| CIFAR-10 | 0.5 | 0.713 | 0.882 | 0.730 | 0.893 | 63 | 71 |
| CIFAR-10 | 0.6 | 0.532 | 0.851 | 0.721 | 0.881 | 81 | 80 |
| CIFAR-100 | 0.0 | 0.890 | - | 0.970 | - | - | - |
| CIFAR-100 | 0.1 | 0.879 | 0.889 | 0.962 | 0.970 | 35 | 25 |
| CIFAR-100 | 0.2 | 0.871 | 0.881 | 0.961 | 0.970 | 55 | 51 |
| CIFAR-100 | 0.3 | 0.790 | 0.880 | 0.926 | 0.961 | 59 | 50 |
| CIFAR-100 | 0.4 | 0.600 | 0.870 | 0.910 | 0.958 | 62 | 64 |
| CIFAR-100 | 0.5 | 0.551 | 0.851 | 0.890 | 0.929 | 70 | 71 |
| CIFAR-100 | 0.6 | 0.357 | 0.758 | 0.665 | 0.910 | 80 | 77 |
| Dataset | Threshold for Perturbation Level | MED (Acc) on Perturbed Test Data | MED (Acc) for Superclass Level on Perturbed Test Data | MED (Prec) on Perturbed Test Data | MED (Prec) for Superclass Level on Perturbed Test Data | ||||
|---|---|---|---|---|---|---|---|---|---|
| - Attack | - Attack | - Attack | Linf- Attack | - Attack | Linf- Attack | - Attack | Linf- Attack | ||
| CIFAR-10 | 0 | 0.981 | 0.981 | 0.995 | 0.995 | 0.981 | 0.981 | 0.995 | 0.995 |
| CIFAR-10 | 1 | 0.975 | 0.967 | 0.980 | 0.970 | 0.979 | 0.978 | 0.991 | 0.991 |
| CIFAR-10 | 2 | 0.941 | 0.853 | 0.965 | 0.881 | 0.978 | 0.977 | 0.991 | 0.990 |
| CIFAR-10 | 3 | 0.851 | 0.762 | 0.880 | 0.811 | 0.977 | 0.975 | 0.989 | 0.984 |
| CIFAR-10 | 4 | 0.831 | 0.744 | 0.875 | 0.771 | 0.977 | 0.974 | 0.985 | 0.980 |
| CIFAR-10 | 5 | 0.801 | 0.711 | 0.871 | 0.741 | 0.963 | 0.955 | 0.985 | 0.979 |
| CIFAR-10 | 6 | 0.781 | 0.680 | 0.841 | 0.711 | 0.950 | 0.949 | 0.973 | 0.970 |
| CIFAR-100 | 0 | 0.890 | 0.890 | 0.970 | 0.970 | 0.930 | 0.930 | 0.980 | 0.980 |
| CIFAR-100 | 1 | 0.885 | 0.883 | 0.970 | 0.967 | 0.930 | 0.926 | 0.978 | 0.971 |
| CIFAR-100 | 2 | 0.881 | 0.880 | 0.942 | 0.941 | 0.910 | 0.910 | 0.972 | 0.968 |
| CIFAR-100 | 3 | 0.833 | 0.829 | 0.910 | 0.900 | 0.905 | 0.900 | 0.970 | 0.941 |
| CIFAR-100 | 4 | 0.741 | 0.745 | 0.902 | 0.871 | 0.898 | 0.889 | 0.960 | 0.941 |
| CIFAR-100 | 5 | 0.692 | 0.701 | 0.820 | 0.812 | 0.891 | 0.884 | 0.920 | 0.905 |
| CIFAR-100 | 6 | 0.642 | 0.603 | 0.780 | 0.750 | 0.890 | 0.883 | 0.820 | 0.831 |
| Dataset | Threshold for Perturbation Level | MED (Rec_Steps) | MED (Rec_Steps) for Superclass Level | IRQ (Rec_Steps) | IRQ (Rec_Steps) for Superclass Level | ||||
|---|---|---|---|---|---|---|---|---|---|
| - Attack | - Attack | - Attack | - Attack | - Attack | - Attack | - Attack | - Attack | ||
| CIFAR-10 | 1 | 12 | 18 | 10 | 13 | 1 | 2 | 2 | 2 |
| CIFAR-10 | 2 | 21 | 29 | 20 | 21 | 1 | 1 | 3 | 3 |
| CIFAR-10 | 3 | 32 | 45 | 31 | 35 | 2 | 3 | 2 | 5 |
| CIFAR-10 | 4 | 39 | 50 | 39 | 42 | 3 | 3 | 4 | 4 |
| CIFAR-10 | 5 | 50 | 68 | 41 | 44 | 2 | 6 | 3 | 7 |
| CIFAR-10 | 6 | 91 | 111 | 59 | 52 | 4 | 5 | 5 | 6 |
| CIFAR-100 | 1 | 34 | 37 | 20 | 22 | 3 | 3 | 4 | 4 |
| CIFAR-100 | 2 | 39 | 41 | 42 | 42 | 5 | 3 | 3 | 4 |
| CIFAR-100 | 3 | 45 | 45 | 44 | 45 | 4 | 5 | 5 | 5 |
| CIFAR-100 | 4 | 46 | 49 | 49 | 50 | 2 | 4 | 4 | 4 |
| CIFAR-100 | 5 | 68 | 71 | 70 | 70 | 6 | 5 | 5 | 6 |
| CIFAR-100 | 6 | 100 | 99 | 80 | 85 | 7 | 6 | 5 | 7 |
| Perturbation | Number of Steps for Training from Scratch | Number of Steps for Supervised Recovery (Maximum Value among Experiments) | ||
|---|---|---|---|---|
| CIFAR-10 | CIFAR-100 | CIFAR-10 | CIFAR-100 | |
| Add one new class | 2400 | 2800 | 33 | 38 |
| Add two new classes | 2400 | 3000 | 56 | 62 |
| Real concept drift between pair of classes | 2800 | 3000 | 73 | 75 |
| Real concept drift between three classes | 2800 | 3200 | 95 | 97 |
| Are the Outputs of Intermediate Sections Taken into Account? | Perturbation | MED (Acc) after Perturbation | |||
|---|---|---|---|---|---|
| Backbone Based on ResNet Blocks | Backbone Based on Swin Transformer Blocks | ||||
| Prototype-Based Classifier Head | Dense Layer-Based Classifier Head | Prototype-Based Classifier Head | Dense Layer-Based Classifier Head | ||
| True | Fault injection (fault_rate = 0.3) | 0.852 | 0.831 | 0.849 | 0.841 |
| False | Fault injection (fault_rate = 0.3) | 0.802 | 0.792 | 0.810 | 0.800 |
| True | Adversarial attack (threshold = 3) | 0.762 | 0.712 | 0.782 | 0.722 |
| False | Adversarial attack (threshold = 3) | 0.723 | 0.685 | 0.754 | 0.709 |
| Are the Outputs of Intermediate Sections Taken into Account? | Perturbation | MED (Rec_Steps) | |||
|---|---|---|---|---|---|
| Backbone Based on ResNet Blocks | Backbone based on Swin Transformer Blocks | ||||
| Prototype-Based Classifier Head | Dense Layer-Based Classifier Head | Prototype-Based Classifier Head | Dense Layer-Based Classifier Head | ||
| True | Fault injection (fault_rate = 0.3) | 25 | 45 | 55 | 95 |
| False | Fault injection (fault_rate = 0.3) | 151 | 277 | 240 | 297 |
| True | Adversarial attack (threshold = 3) | 41 | 83 | 95 | 173 |
| False | Adversarial attack (threshold = 3) | 270 | 450 | 403 | 489 |
| Perturbation | Number of Steps for Training from Scratch | Number of Steps for Supervised Recovery (Maximum Value among Experiments) | ||
|---|---|---|---|---|
| CIFAR-10 | CIFAR-100 | CIFAR-10 | CIFAR-100 | |
| Add one new class | 3600 | 5600 | 41 | 47 |
| Add two new classes | 2600 | 4600 | 68 | 72 |
| Real concept drift between pair of classes | 3600 | 4600 | 88 | 88 |
| Real concept drift between three classes | 3600 | 4800 | 130 | 145 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moskalenko, V.; Kharchenko, V.; Moskalenko, A.; Petrov, S. Model and Training Method of the Resilient Image Classifier Considering Faults, Concept Drift, and Adversarial Attacks. Algorithms 2022, 15, 384. https://doi.org/10.3390/a15100384
Moskalenko V, Kharchenko V, Moskalenko A, Petrov S. Model and Training Method of the Resilient Image Classifier Considering Faults, Concept Drift, and Adversarial Attacks. Algorithms. 2022; 15(10):384. https://doi.org/10.3390/a15100384
Chicago/Turabian StyleMoskalenko, Viacheslav, Vyacheslav Kharchenko, Alona Moskalenko, and Sergey Petrov. 2022. "Model and Training Method of the Resilient Image Classifier Considering Faults, Concept Drift, and Adversarial Attacks" Algorithms 15, no. 10: 384. https://doi.org/10.3390/a15100384
APA StyleMoskalenko, V., Kharchenko, V., Moskalenko, A., & Petrov, S. (2022). Model and Training Method of the Resilient Image Classifier Considering Faults, Concept Drift, and Adversarial Attacks. Algorithms, 15(10), 384. https://doi.org/10.3390/a15100384