
Distributed Fuzzy Cognitive Maps for Feature Selection in Big Data Classification

 , , ,
, , ,  and
and 
Abstract
1. Introduction
- A novel fuzzy cognitive map based technique to extract the most significant features in a dataset that contribute to decision making was introduced.
- The proposed model was implemented in a distributed manner, thus enabling the scalability of the feature selection algorithm.
- Comparison of the performance of the proposed distributed fuzzy cognitive map feature selection algorithm with other best-performing algorithms was carried out.
2. Literature Review
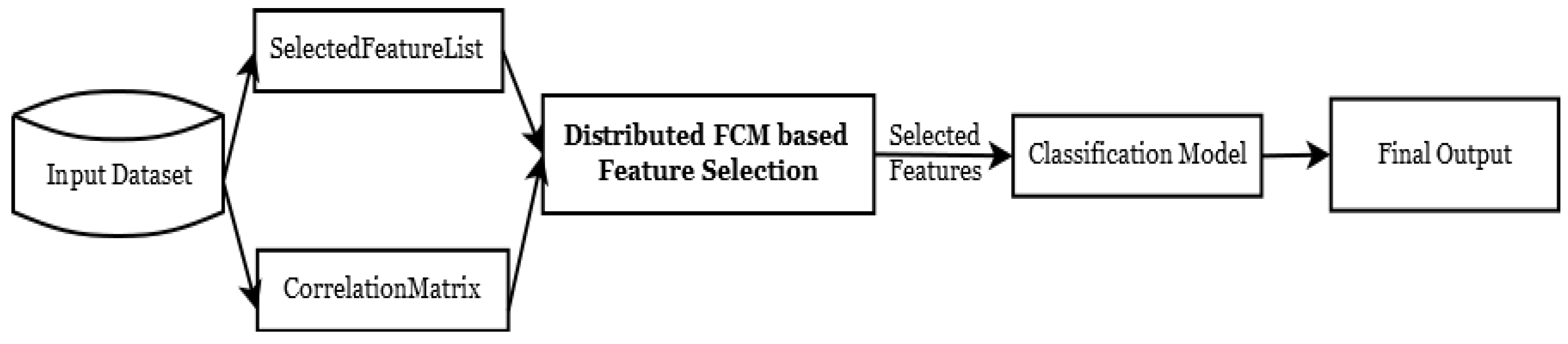
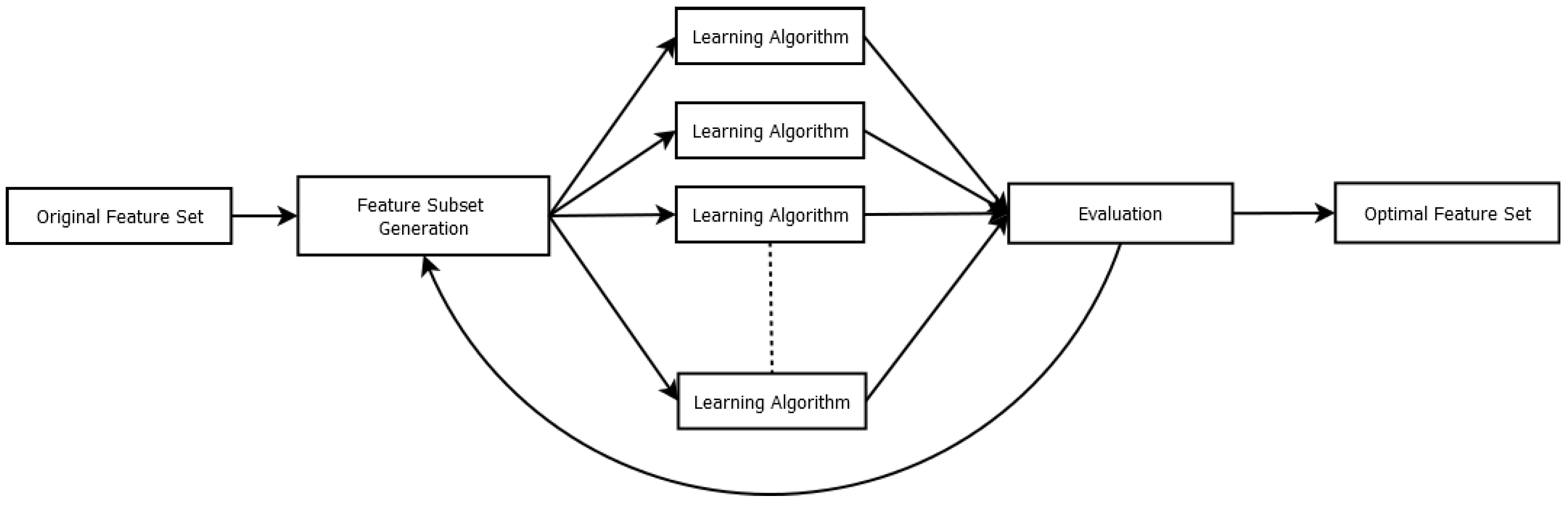
3. Materials and Methods
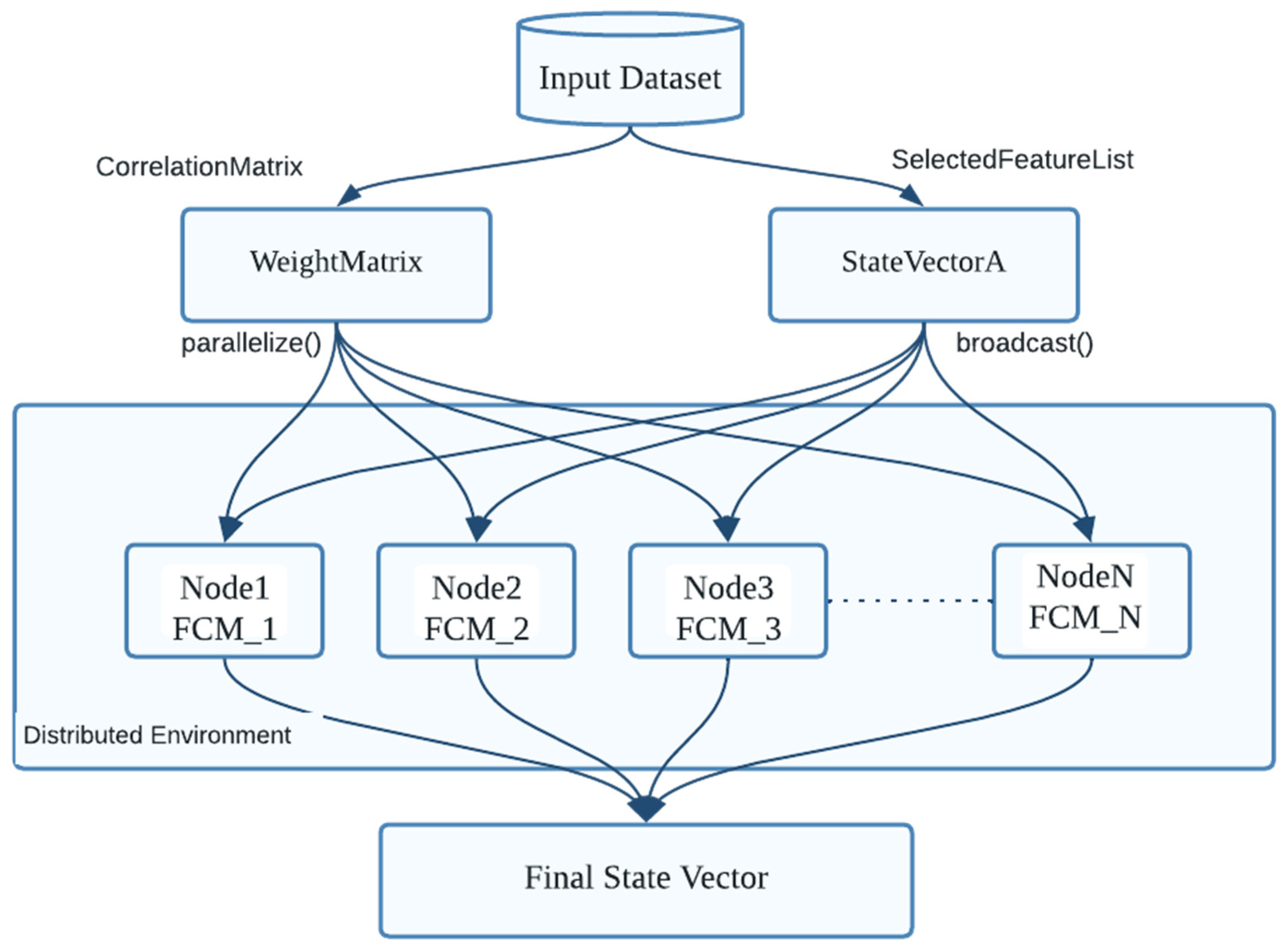
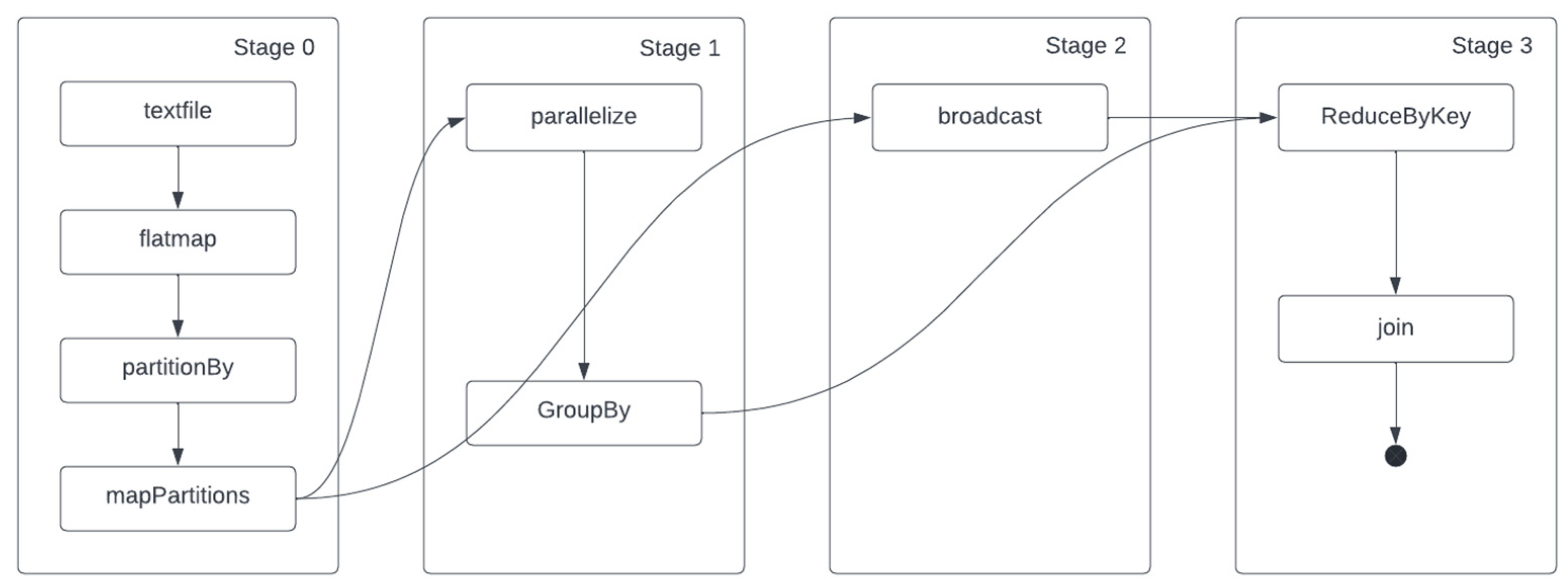
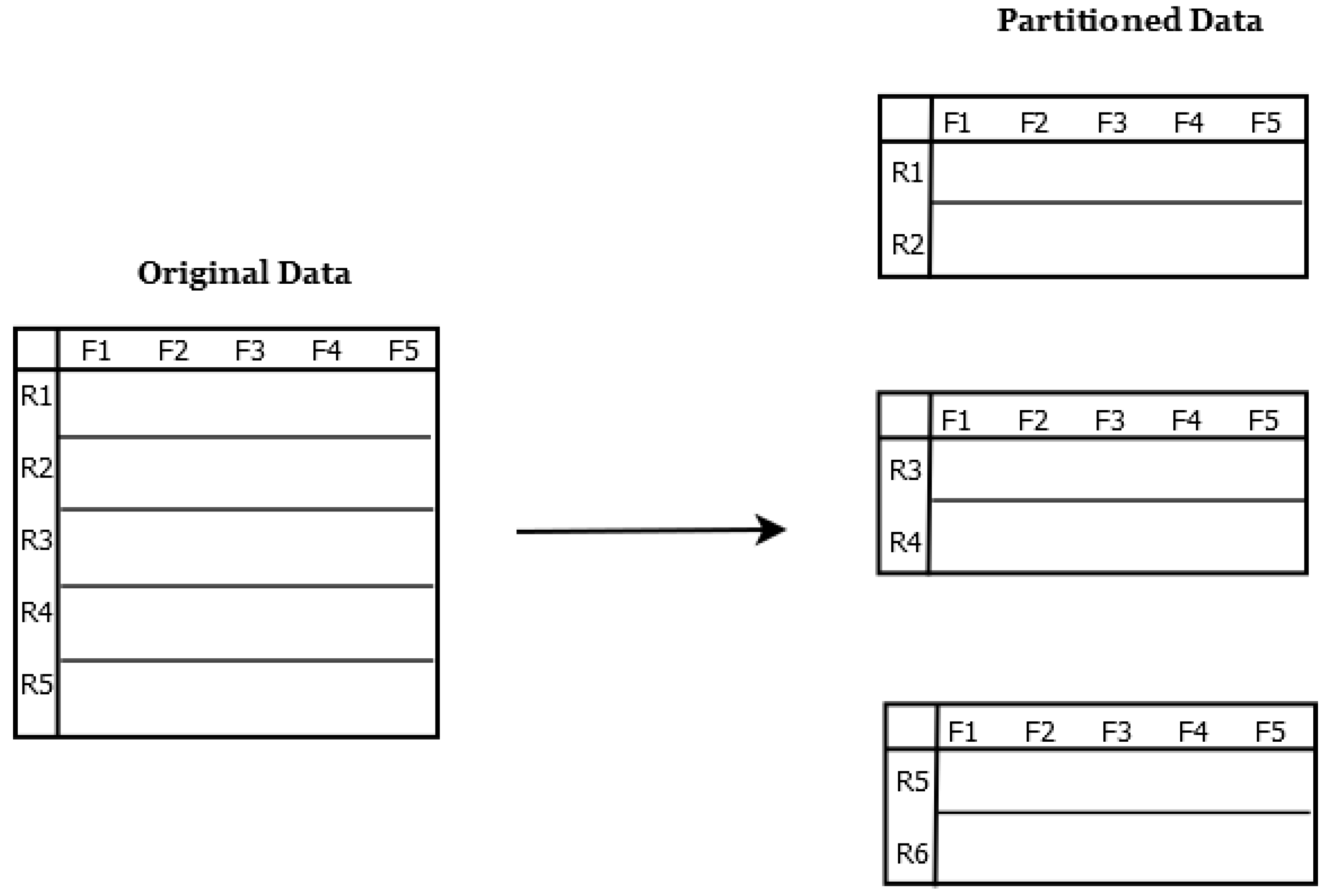
3.1. Distributed Fuzzy Cognitive Maps
3.2. FCM-Based Feature Selection
3.3. Classification Model
| Algorithm 1. Distributed Fuzzy Cognitive Map (FCM) algorithm for feature selection in big data | |
| 1 | Initialize global variable FeatureVector to 0 |
| 2 | procedure FCM() |
| 3 | { |
| 4 | Read the features in the dataset to a features variable |
| 5 | Compute the correlation matrix for the features and assign it to weight matrix |
| 6 | For all features[i] in features do |
| 7 | Initialize the StateVector with 1 for selected features and 0 otherwise |
| 8 | While(true) |
| 9 | Parallelize the WeightMatrix |
| 10 | Broadcast the StateVectorA |
| 11 | Update VectorA as weightMatrix * StateVectorA |
| 12 | Assign StateVectorA = updatedVectorA |
| 13 | Compute the classification Accuracy of updated StateVectorA |
| 14 | If(accuracy > accuracyThreshold) |
| 15 | Add the features in StateVectorA to FeatureVector |
| 16 | weightMatrix = updateWeights(weightMatrix) |
| 17 | epsilon = compute Epsilon() |
| 18 | if epsilon < threshold |
| 19 | break; |
| 20 | } |
4. Results
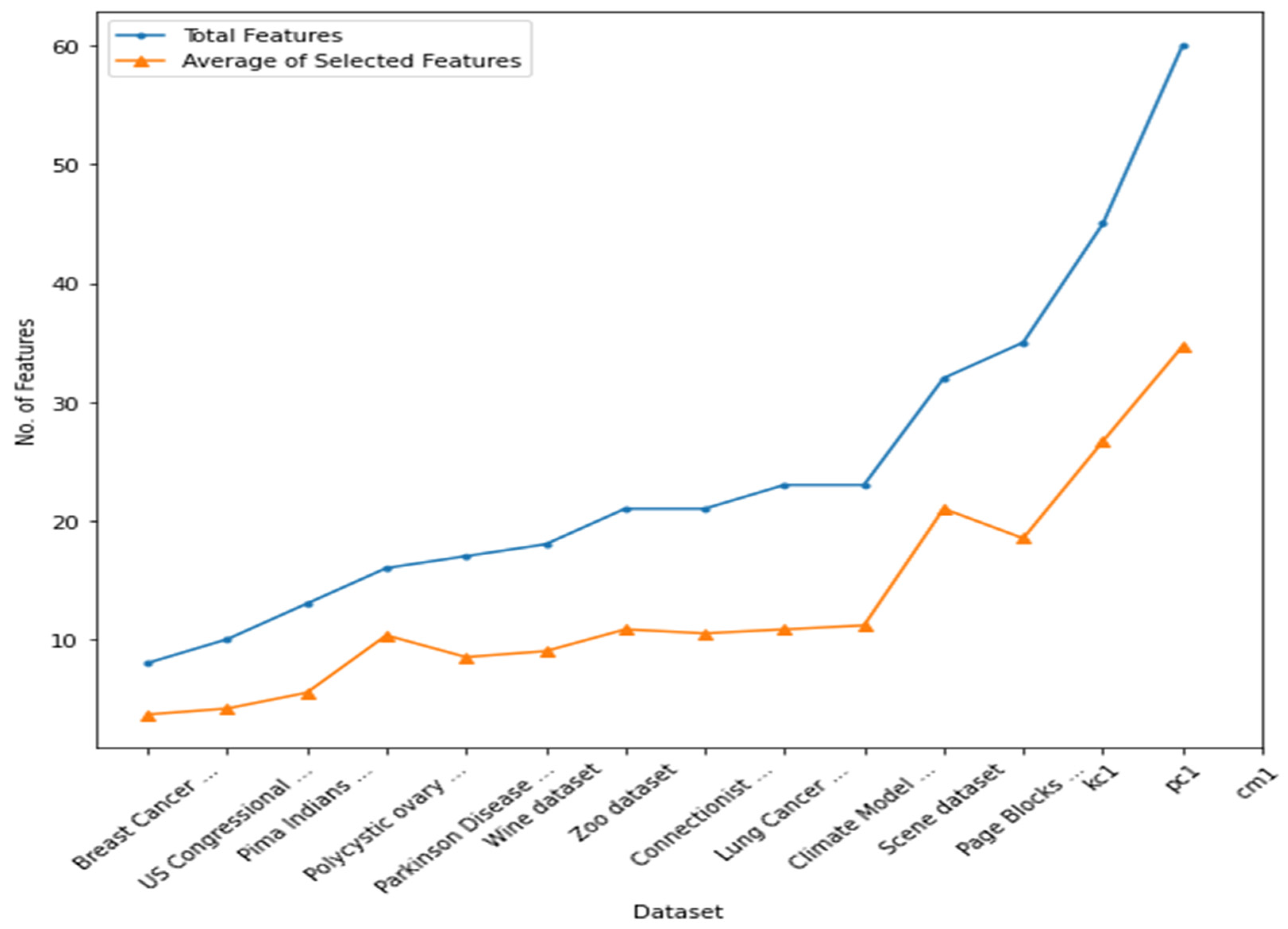
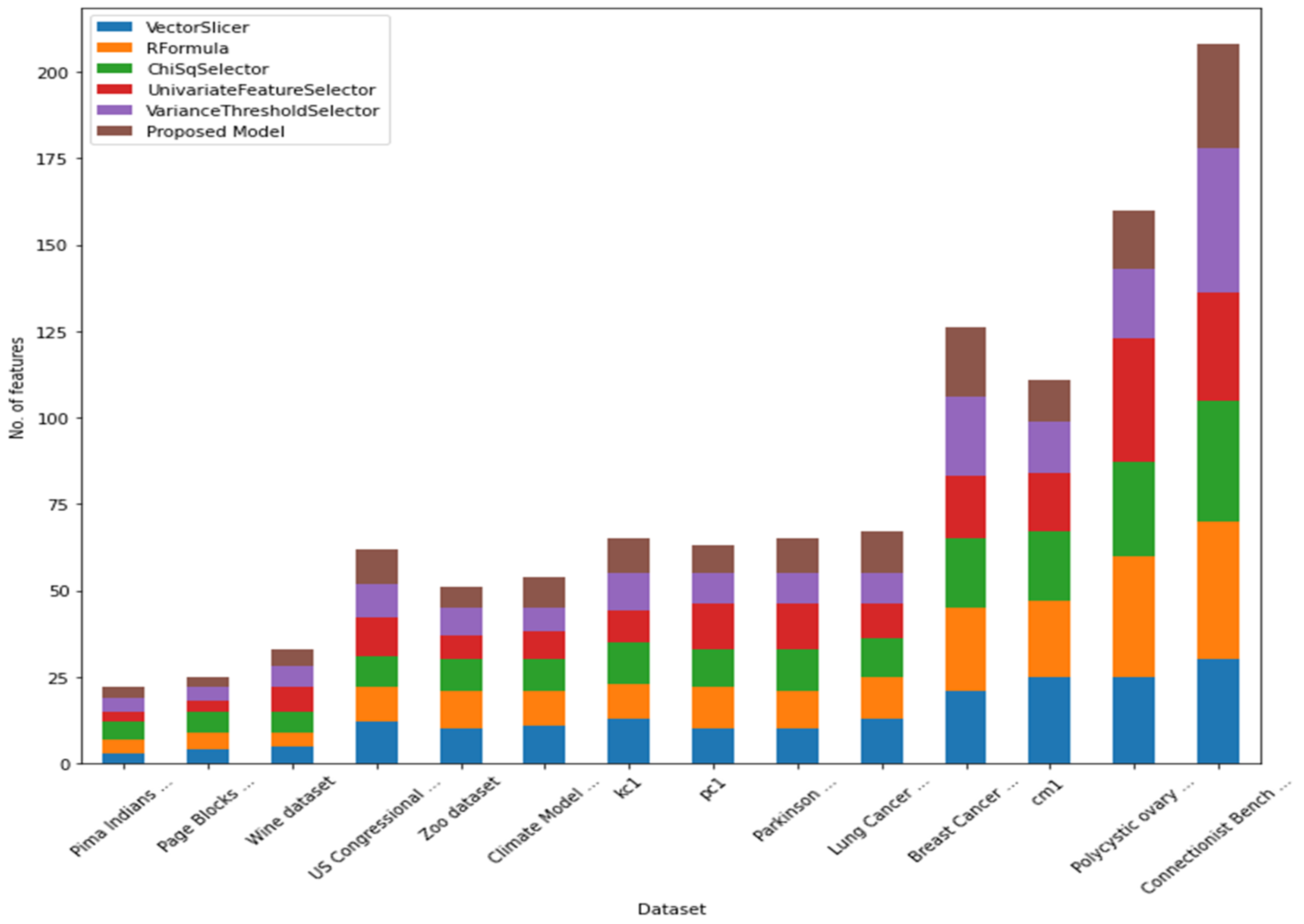
4.1. Total Number of Features vs. Average Number of Features
4.2. Proposed Feature Selection vs. Existing Feature Selection
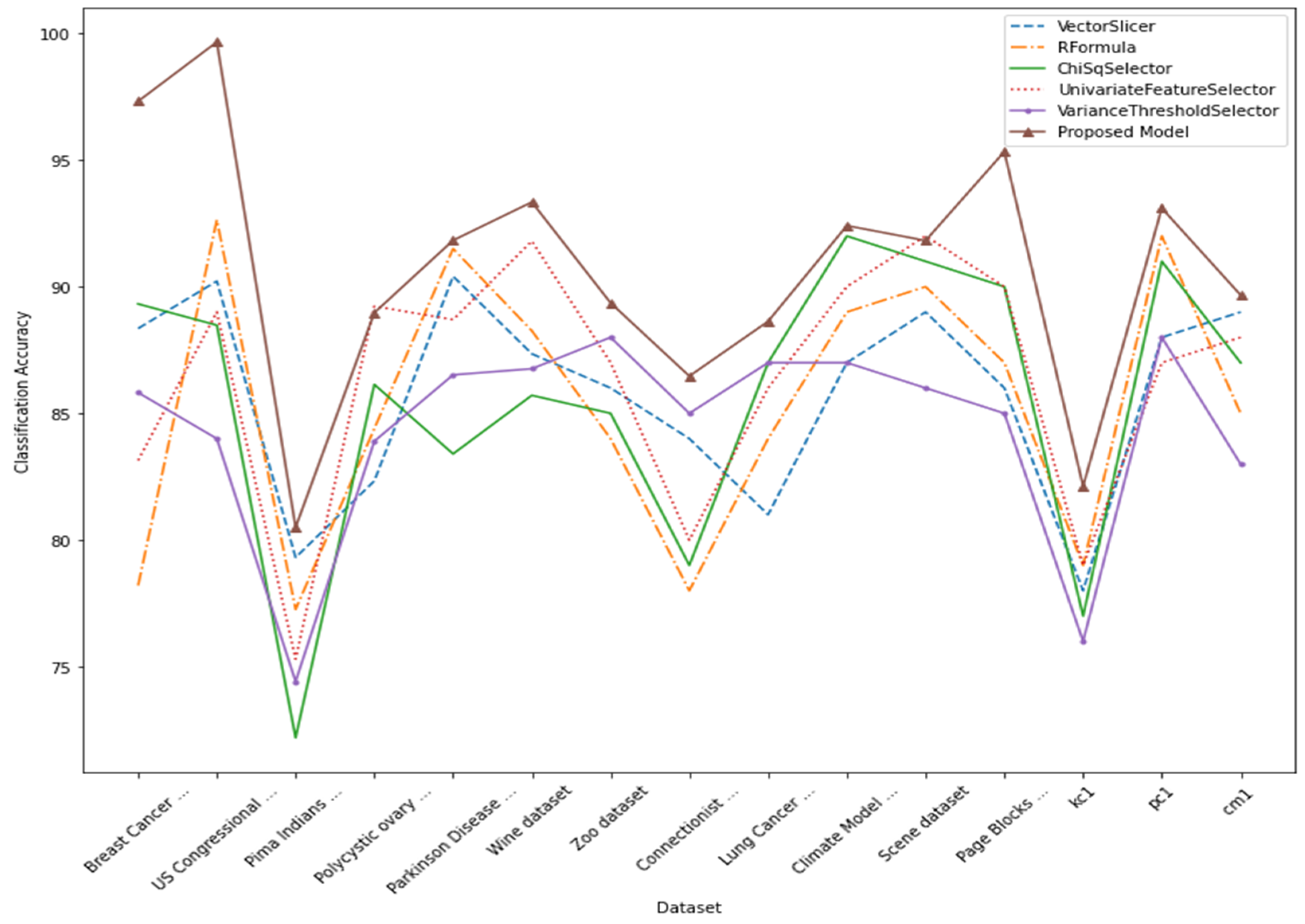
4.3. Performance Evaluation of the Proposed Feature Selection
4.4. Performance Comparison with Existing Feature Selection Methods
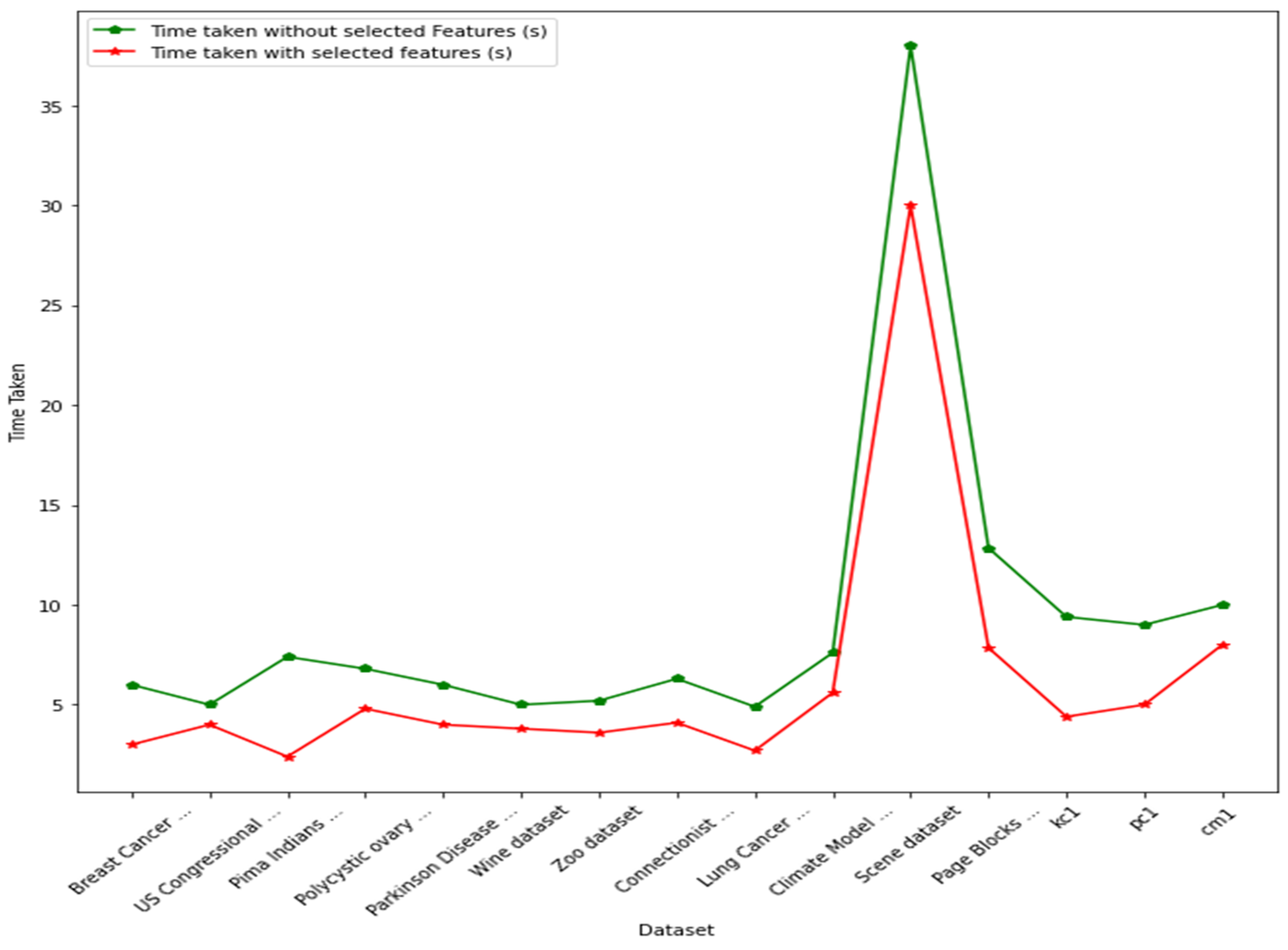
4.5. Comparison of Computational Time for Classification with and without Feature Selection
5. Performance Analysis and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A. Recent advances and emerging challenges of feature selection in the context of big data. Knowl.-Based Syst. 2015, 86, 33–45. [Google Scholar] [CrossRef]
- Kosko, B. Cognitive fuzzy maps. Int. J. Man-Mach. Stud. 1986, 24, 65–75. [Google Scholar] [CrossRef]
- Kohavi, G.H.J.R. Wrapper for Feature Subset Selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A. A review of feature selection methods on synthetic data. Knowl. Inf. Syst. 2013, 34, 483–519. [Google Scholar] [CrossRef]
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A. An ensemble of filters and classifiers for microarray data classification. Pattern Recognit. 2012, 45, 531–539. [Google Scholar] [CrossRef]
- Saeys, Y.; Abeel, T.; van de Peer, Y. Robust Feature Selection Using Ensemble Feature Selection Techniques. In Lecture Notes in Computer Science Book Series (LNAI); Springer Science: Berlin, Germany, 2008; Volume 5212. [Google Scholar]
- Tuv, E.; Borisov, A.; Runger, G.; Torkkola, K. Feature selection with ensembles, artificial variables, and redundancy elimination. J. Mach. Learn. Res. 2009, 10, 1341–1366. [Google Scholar]
- Vainer, I.; Kraus, S.; Kaminka, G.A.; Slovin, H. Obtaining scalable and accurate classification in large-scale spatio-temporal domains. Knowl. Inf. Syst. 2011, 29, 527–564. [Google Scholar] [CrossRef]
- Zhang, Y.; Ding, C.; Li, T. Gene selection algorithm by combining reliefF and mRMR. BMC Genom. 2008, 9, S27. [Google Scholar] [CrossRef] [PubMed]
- el Akadi, A.; Amine, A.; el Ouardighi, A.; Aboutajdine, D. A two-stage gene selection scheme utilizing MRMR filter and GA wrapper. Knowl. Inf. Syst. 2011, 26, 487–500. [Google Scholar] [CrossRef]
- Jiang, Y.; Yin, S.; Dong, J.; Kaynak, O. A Review on Soft Sensors for Monitoring, Control, and Optimization of Industrial Processes. IEEE Sens. J. 2021, 21, 12868–12881. [Google Scholar] [CrossRef]
- Karthik, S.; Bhadoria, R.S.; Lee, J.G.; Sivaraman, A.K.; Samanta, S.; Balasundaram, A.; Chaurasia, B.K.; Ashokkumar, S. Prognostic Kalman Filter Based Bayesian Learning Model for Data Accuracy Prediction. Comput. Mater. Contin. 2022, 72, 243–259. [Google Scholar] [CrossRef]
- Bhadoria, R.S.; Samanta, S.; Pathak, Y.; Shukla, P.K.; Zubi, A.A.; Kaur, M. Bunch graph based dimensionality reduction using auto-encoder for character recognition. Multimed. Tools Appl. 2022, 81, 32093–32115. [Google Scholar] [CrossRef]
- Hashemi, A.; Dowlatshahi, M.B.; Nezamabadi-pour, H. Ensemble of feature selection algorithms: A multi-criteria decision-making approach. Int. J. Mach. Learn. Cybern. 2022, 13, 49–69. [Google Scholar] [CrossRef]
- Kusy, M.; Zajdel, R. A weighted wrapper approach to feature selection. Int. J. Appl. Math. Comput. Sci. 2021, 31, 685–696. [Google Scholar]
- Chellappan, S.; Ganesan, D. Practical Apache Spark; Apress: Berkeley, CA, USA, 2018. [Google Scholar]
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A. Feature selection and classification in multiple class datasets: An application to KDD Cup 99 dataset. Expert Syst. Appl. 2011, 38, 5947–5957. [Google Scholar] [CrossRef]
- Forman, G. An Extensive Empirical Study of Feature Selection Metrics for Text Classification. J. Mach. Learn. Res. 2000, 1, 1289–1305. [Google Scholar]
- Gomez, J.C.; Boiy, E.; Moens, M.F. Highly discriminative statistical features for email classification. Knowl. Inf. Syst. 2012, 31, 23–53. [Google Scholar] [CrossRef]
- Yu, L.; Liu, H. Redundancy based feature selection for microarray data. In Proceedings of the KDD-2004—Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 737–742. [Google Scholar]
- Saari, P.; Eerola, T.; Lartillot, O. Generalizability and Simplicity as Criteria in Feature Selection: Application to Mood Classification in Music. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 1802–1812. [Google Scholar] [CrossRef]
- Axelrod, R. Structure of Decisions: The Cognitive Maps of Political Elites; Princeton University Press: Princeton, NJ, USA, 1976. [Google Scholar]
- Giles, B.G.; Findlay, C.S.; Haas, G.; LaFrance, B.; Laughing, W.; Pembleton, S. Integrating conventional science and aboriginal perspectives on diabetes using fuzzy cognitive maps. Soc. Sci. Med. 2007, 64, 562–576. [Google Scholar] [CrossRef]
- Giabbanelli, P.J.; Torsney-Weir, T.; Mago, V.K. A fuzzy cognitive map of the psychosocial determinants of obesity. Appl. Soft Comput. J. 2012, 12, 3711–3724. [Google Scholar] [CrossRef]
- Papageorgiou, E.; Subramanian, J.; Karmegam, A.; Papandrianos, N. A risk management model for familial breast cancer: A new application using Fuzzy Cognitive Map method. Comput. Methods Programs Biomed. 2015, 122, 123–135. [Google Scholar] [CrossRef] [PubMed]
- Andreou, A.S.; Mateou, N.H.; Zombanakis, G.A. Soft computing for crisis management and political decision making: The use of genetically evolved fuzzy cognitive maps. Soft Comput. 2005, 9, 194–210. [Google Scholar] [CrossRef][Green Version]
- Zhai, D.S.; Chang, Y.N.; Zhang, J. An application of fuzzy cognitive map based on active hebbian learning algorithm in credit risk evaluation of listed companies. In Proceedings of the 2009 International Conference on Artificial Intelligence and Computational Intelligence, AICI 2009, Washington, DC, USA, 7–8 November 2009. [Google Scholar]
- Carvalho, J.P.; Tome, J.A.B. Rule based fuzzy cognitive maps expressing time in qualitative system dynamics. In Proceedings of the 10th IEEE International Conference on Fuzzy Systems (Cat. No.01CH37297), Melbourne, VIC, Australia, 2–5 December 2001. [Google Scholar]
- Salmeron, J.L. Modelling grey uncertainty with fuzzy grey cognitive maps. Expert Syst. Appl. 2010, 37, 7581–7588. [Google Scholar] [CrossRef]
- Iakovidis, D.K.; Papageorgiou, E. Intuitionistic fuzzy cognitive maps for medical decision making. IEEE Trans. Inf. Technol. Biomed. 2011, 15, 100–107. [Google Scholar] [CrossRef]
- Aguilar, J. Dynamic Random Fuzzy Cognitive Maps. Comput. Sist. 2004, 7, 260–271. [Google Scholar]
- Kottas, T.L.; Boutalis, Y.S.; Christodoulou, M.A. Fuzzy cognitive network: A general framework. Intell. Decis. Technol. 2007, 1, 183–196. [Google Scholar] [CrossRef]
- Nápoles, G.; Grau, I.; Papageorgiou, E.; Bello, R.; Vanhoof, K. Rough Cognitive Networks. Knowl.-Based Syst. 2016, 91, 46–61. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2017; Available online: http://archive.ics.uci.edu/ml (accessed on 3 April 2022).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sl.no. | Dataset | Instances | Features | Class |
|---|---|---|---|---|
| 1 | Breast Cancer Wisconsin (Diagnostic) Data Set | 569 | 32 | 2 |
| 2 | US Congressional Voting Records dataset | 435 | 16 | 2 |
| 3 | Pima Indians Diabetes dataset | 768 | 8 | 2 |
| 4 | Polycystic ovary syndrome (PCOS) dataset | 541 | 45 | 2 |
| 5 | Parkinson Disease Detection dataset | 197 | 23 | 2 |
| 6 | Wine dataset | 178 | 13 | 3 |
| 7 | Zoo dataset | 101 | 17 | 7 |
| 8 | Connectionist Bench (Sonar, Mines vs. Rocks) Data Set | 208 | 60 | 2 |
| 9 | Lung Cancer Data Set | 226 | 23 | 3 |
| 10 | Climate Model Simulation Crashes Data Set | 540 | 18 | 2 |
| 11 | Scene dataset | 2407 | 294 | 2 |
| 12 | Page Blocks Classification Data Set | 5473 | 10 | 5 |
| 13 | kc1 | 2110 | 21 | 2 |
| 14 | pc1 | 1109 | 21 | 2 |
| 15 | cm1 | 345 | 35 | 2 |
| Dataset | Vector Slicer | RFormula | ChiSq Selector | Univariate Feature Selector | Variance Threshold Selector | Proposed Model |
|---|---|---|---|---|---|---|
| Pima Indians Diabetes dataset | 3 | 4 | 5 | 3 | 4 | 3 |
| Page Blocks Classification Data Set | 4 | 5 | 6 | 3 | 4 | 3 |
| Wine dataset | 5 | 4 | 6 | 7 | 6 | 5 |
| US Congressional Voting Records dataset | 12 | 10 | 9 | 11 | 10 | 10 |
| Zoo dataset | 10 | 11 | 9 | 7 | 8 | 6 |
| Climate Model Simulation Crashes Data Set | 11 | 10 | 9 | 8 | 7 | 9 |
| kc1 | 13 | 10 | 12 | 9 | 11 | 10 |
| pc1 | 10 | 12 | 11 | 13 | 9 | 8 |
| Parkinson Disease Detection dataset | 10 | 11 | 12 | 13 | 9 | 10 |
| Lung Cancer Data Set | 13 | 12 | 11 | 10 | 9 | 12 |
| Breast Cancer Wisconsin (Diagnostic) Data Set | 21 | 24 | 20 | 18 | 23 | 20 |
| cm1 | 25 | 22 | 20 | 17 | 15 | 12 |
| Polycystic ovary syndrome (PCOS) dataset | 25 | 35 | 27 | 36 | 20 | 17 |
| Connectionist Bench (Sonar, Mines vs. Rocks) Data Set | 30 | 40 | 35 | 31 | 42 | 30 |
| Dataset | Naïve Bayes | Decision Tree | Random Forest | Multi-layer Perceptron | Logistic Regression |
|---|---|---|---|---|---|
| Breast Cancer Wisconsin (Diagnostic) Data Set | 78.3 | 85.14 | 97.32 | 74.55 | 88.57 |
| US Congressional Voting Records dataset | 80.65 | 83.231 | 99.66 | 90.86 | 84.3 |
| Pima Indians Diabetes dataset | 64.84 | 72.72 | 80.5 | 66.06 | 75.36 |
| Polycystic ovary syndrome (PCOS) dataset | 66.38 | 77.8 | 88.97 | 85.14 | 90.65 |
| Parkinson Disease Detection dataset | 76.2 | 86.71 | 91.83 | 82.901 | 87.025 |
| Wine dataset | 80.97 | 79.7 | 93.34 | 87.26 | 82.36 |
| Zoo dataset | 67.55 | 72.53 | 89.36 | 84.321 | 79.015 |
| Connectionist Bench (Sonar, Mines vs. Rocks) Data Set | 61.23 | 76.66 | 86.47 | 69.8 | 80.704 |
| Lung Cancer Data Set | 70.4 | 80.5 | 88.63 | 76.04 | 83.9 |
| Climate Model Simulation Crashes Data Set | 72.84 | 80.97 | 92.41 | 86.32 | 89.01 |
| Scene dataset | 68.19 | 74.85 | 91.82 | 93.74 | 85.44 |
| Page Blocks Classification Data Set | 73.85 | 83.5 | 95.33 | 90.88 | 89.56 |
| kc1 | 69.73 | 72.3 | 82.125 | 85.67 | 77.46 |
| pc1 | 74.96 | 76.72 | 93.1 | 87.58 | 90.11 |
| cm1 | 68.432 | 70.658 | 89.67 | 85.4 | 92.85 |
| Dataset | Accuracy | Accuracy after Feature Selection | Total Features | Selected Features |
|---|---|---|---|---|
| Breast Cancer Wisconsin (Diagnostic) Data Set | 96.25 | 97.32 | 32 | 14 |
| US Congressional Voting Records dataset | 97.2 | 99.66 | 16 | 7 |
| Pima Indians Diabetes dataset | 78.9 | 80.5 | 8 | 3 |
| Polycystic ovary syndrome (PCOS) dataset | 86.02 | 88.97 | 45 | 17 |
| Parkinson Disease Detection dataset | 87.65 | 91.83 | 23 | 9 |
| Wine dataset | 92.6 | 93.34 | 13 | 5 |
| Zoo dataset | 88.15 | 89.36 | 17 | 6 |
| Connectionist Bench (Sonar, Mines vs. Rocks) Data Set | 75.3 | 86.47 | 60 | 26 |
| Lung Cancer Data Set | 83.5 | 88.63 | 23 | 10 |
| Climate Model Simulation Crashes Data Set | 88 | 92.41 | 18 | 9 |
| Scene dataset | 86.8 | 91.82 | 294 | 101 |
| Page Blocks Classification Data Set | 91 | 95.33 | 10 | 3 |
| kc1 | 81 | 82.125 | 21 | 10 |
| pc1 | 80 | 93.1 | 21 | 8 |
| cm1 | 83 | 89.67 | 35 | 12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haritha, K.; Judy, M.V.; Papageorgiou, K.; Georgiannis, V.C.; Papageorgiou, E. Distributed Fuzzy Cognitive Maps for Feature Selection in Big Data Classification. Algorithms 2022, 15, 383. https://doi.org/10.3390/a15100383
Haritha K, Judy MV, Papageorgiou K, Georgiannis VC, Papageorgiou E. Distributed Fuzzy Cognitive Maps for Feature Selection in Big Data Classification. Algorithms. 2022; 15(10):383. https://doi.org/10.3390/a15100383
Chicago/Turabian StyleHaritha, K., M. V. Judy, Konstantinos Papageorgiou, Vassilis C. Georgiannis, and Elpiniki Papageorgiou. 2022. "Distributed Fuzzy Cognitive Maps for Feature Selection in Big Data Classification" Algorithms 15, no. 10: 383. https://doi.org/10.3390/a15100383
APA StyleHaritha, K., Judy, M. V., Papageorgiou, K., Georgiannis, V. C., & Papageorgiou, E. (2022). Distributed Fuzzy Cognitive Maps for Feature Selection in Big Data Classification. Algorithms, 15(10), 383. https://doi.org/10.3390/a15100383