A Study on Sensitive Bands of EEG Data under Different Mental Workloads




Abstract
1. Introduction
2. EEG Dataset
2.1. Experimental Subject
2.2. Experimental Platform
2.3. Experimental Procedure
2.4. Data Acquisition
2.4.1. Subjective Rating Scale
2.4.2. The Operational Performance Measurement System
2.4.3. Physiological Acquisition System
3. Data Analysis Method
3.1. Data Preprocessing Method
Independent Component Analysis
3.2. Feature Extraction Method
3.3. Feature Selection Method
Gini Impurity
3.4. SVM Classifier
3.4.1. Description
3.4.2. Kernel Function
4. Significance Analysis of Mental Workload and Feature Based on SVM Classifier
4.1. Data Preprocessing
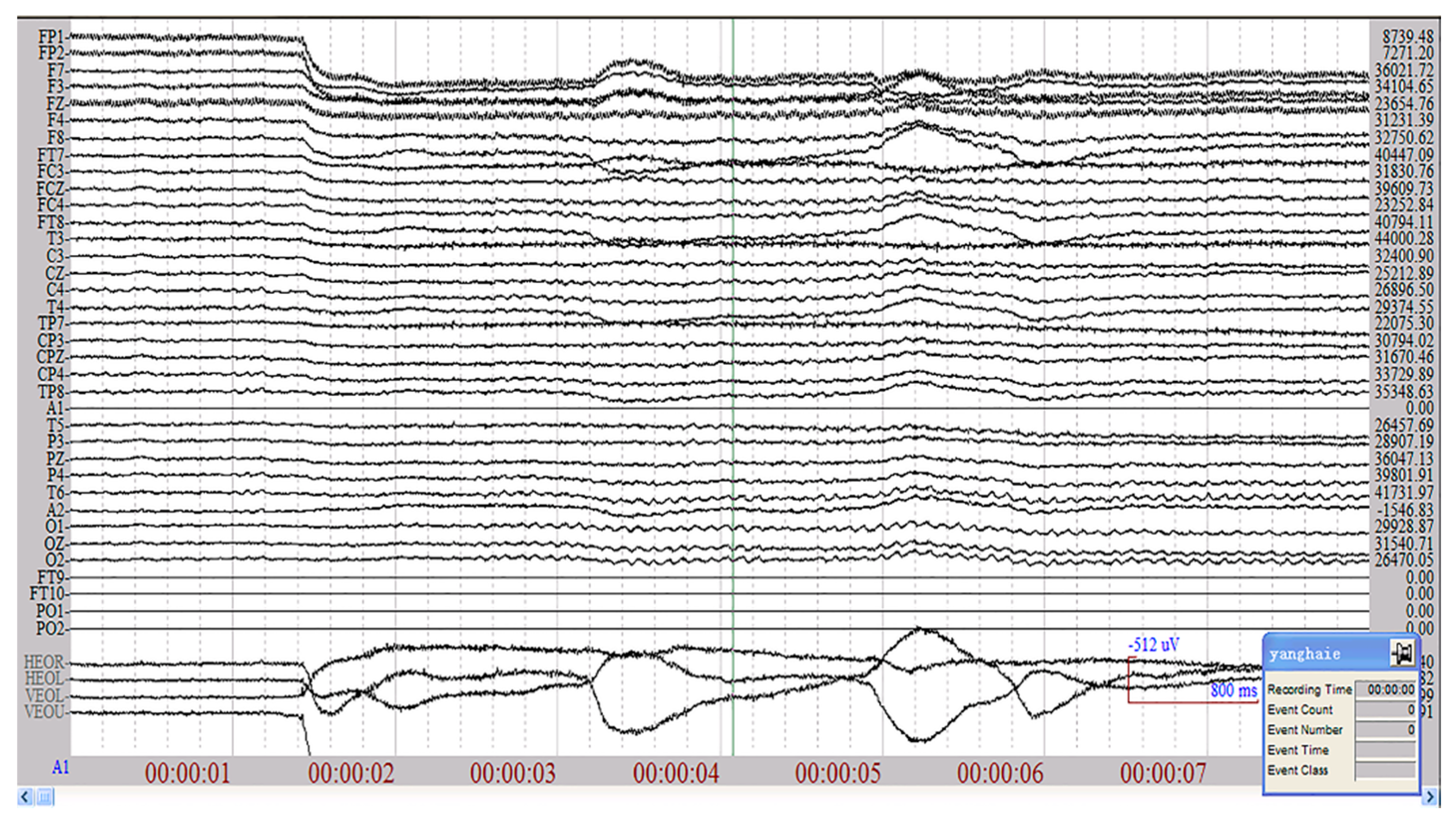
ICA-Based EEG Signal EOG Elimination
4.2. Feature Extraction
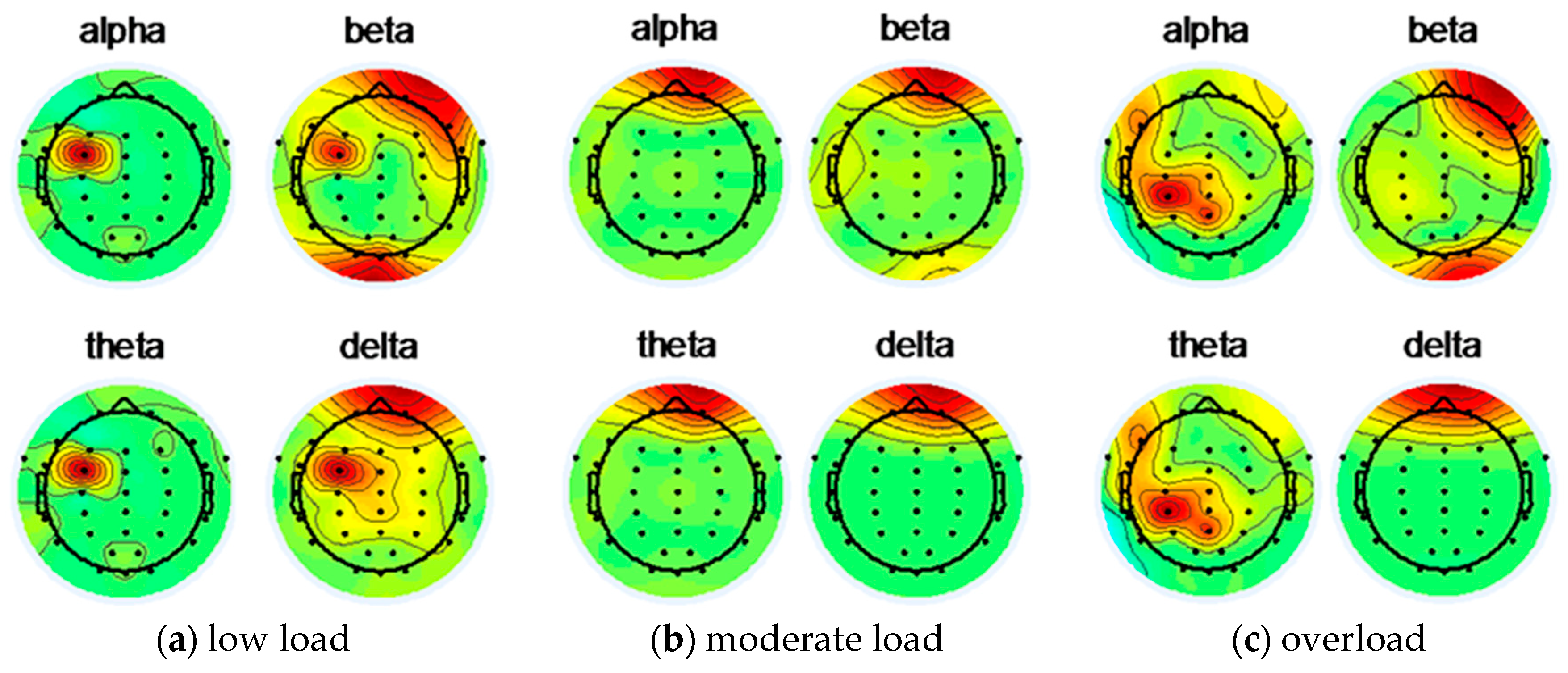
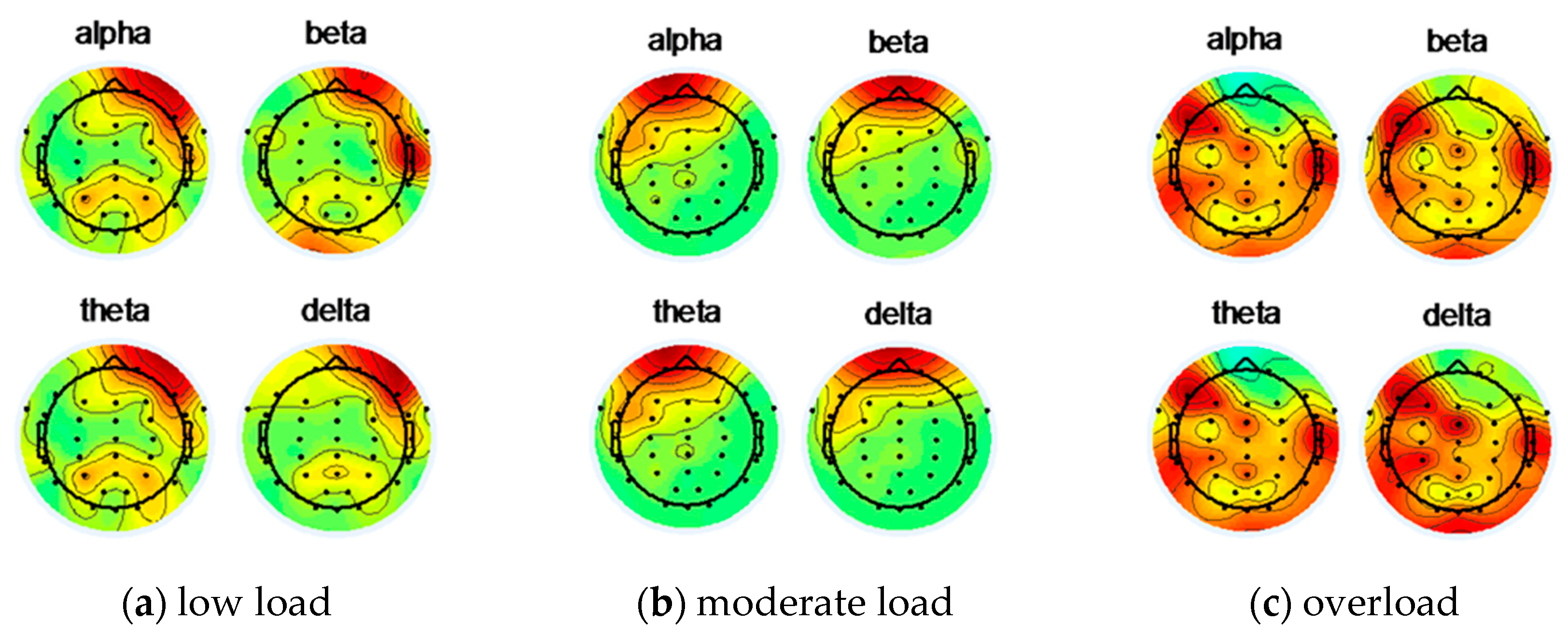
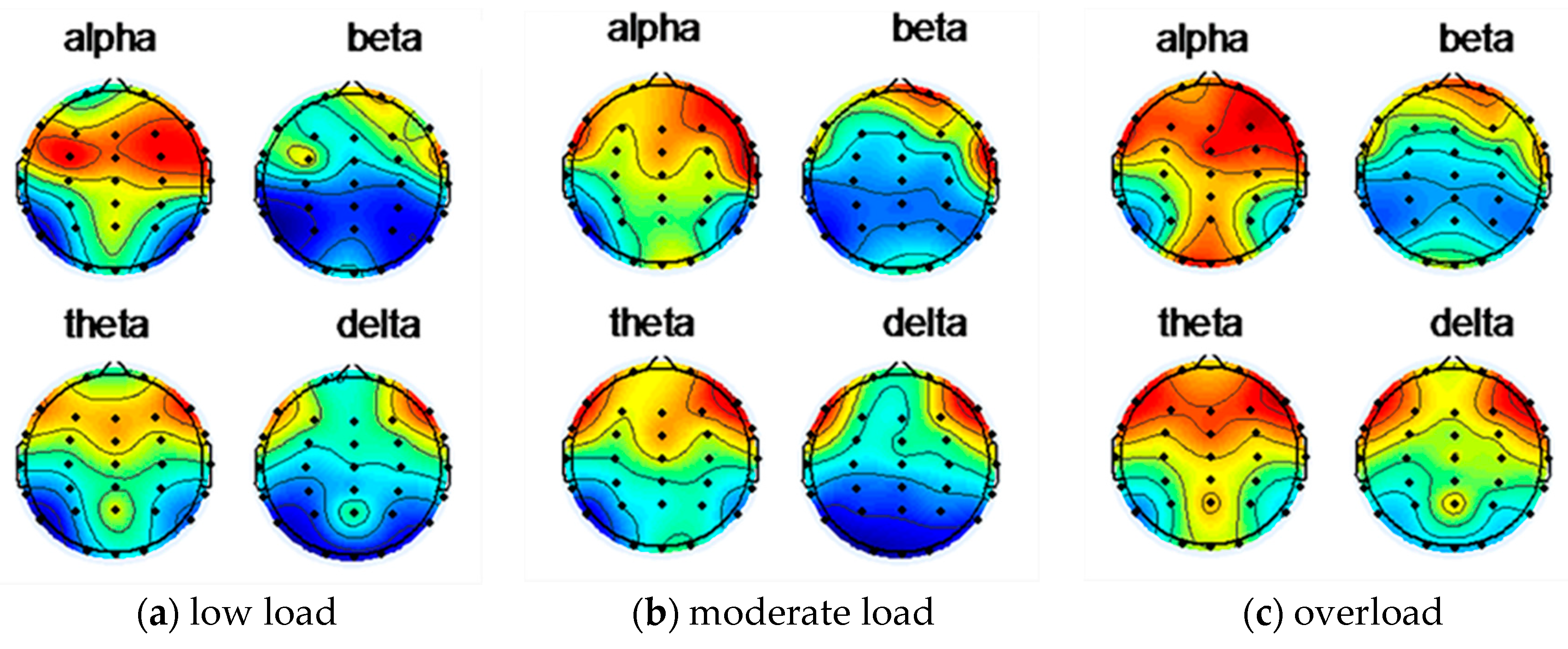
4.2.1. Four Bands of EEG Data
4.2.2. Feature Extraction Based on Power Spectral Density and Energy
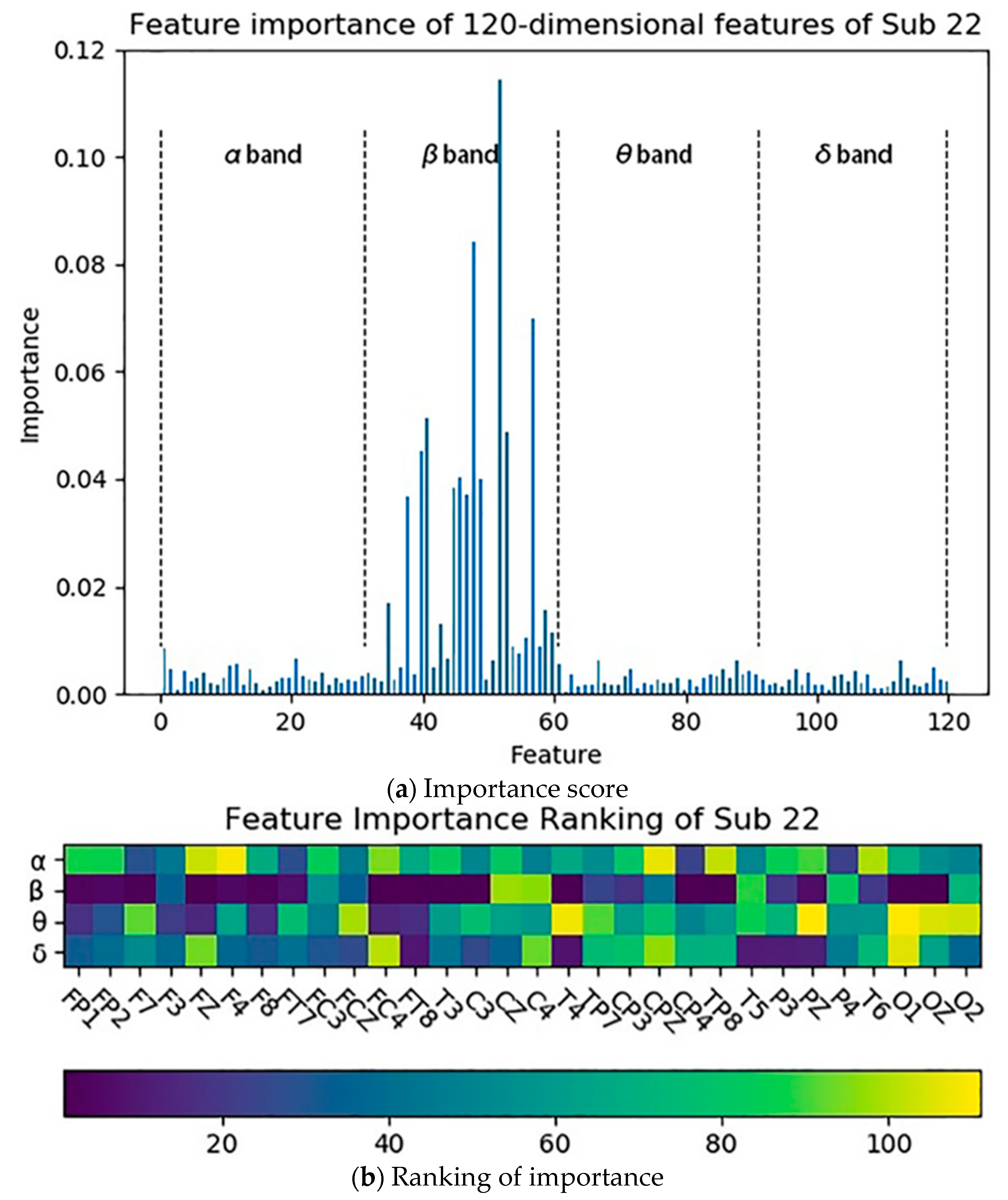
4.3. Feature Selection Based on Gini Impurity
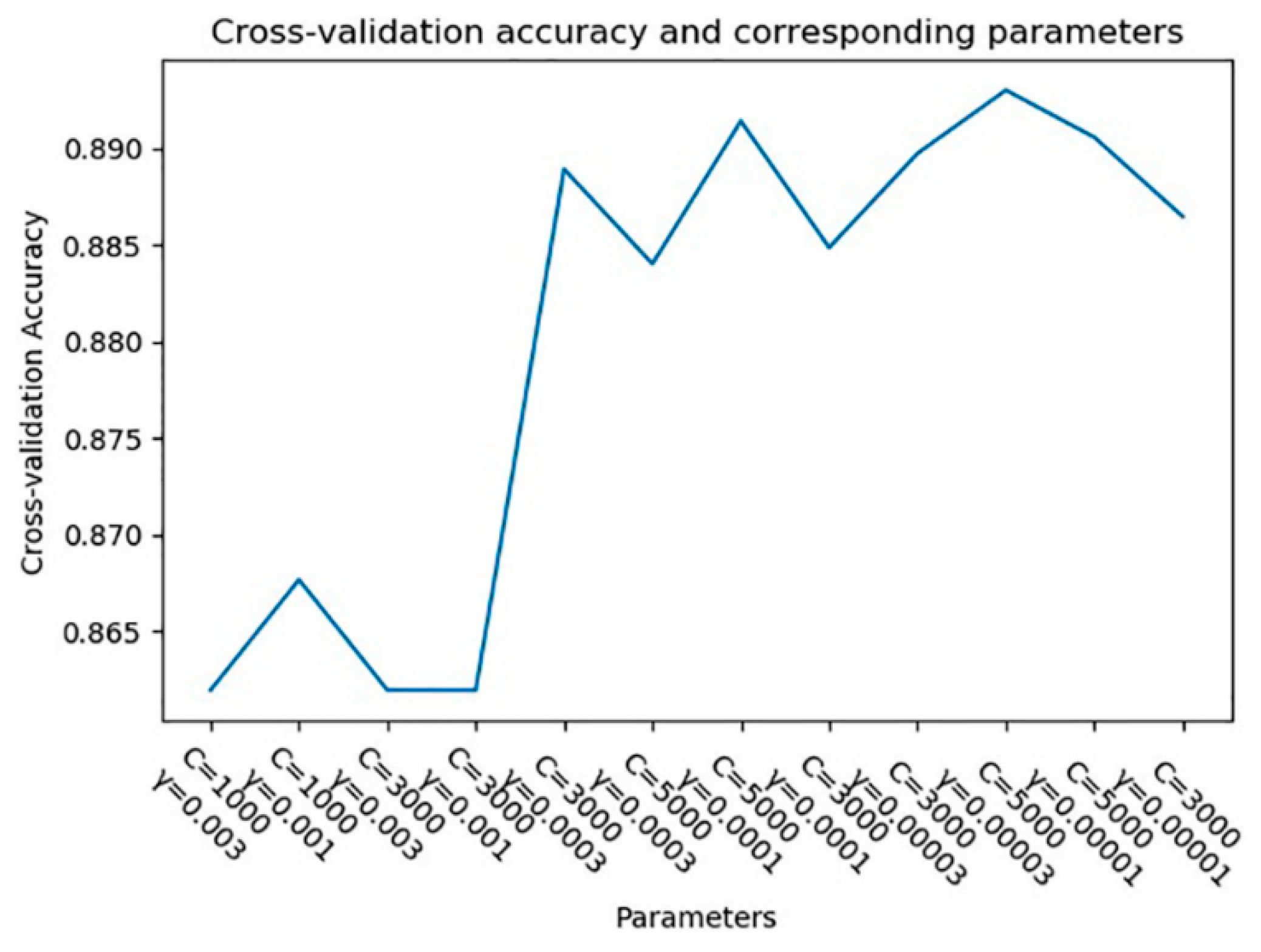
4.4. Application of SVM Classifier to EEG Signals
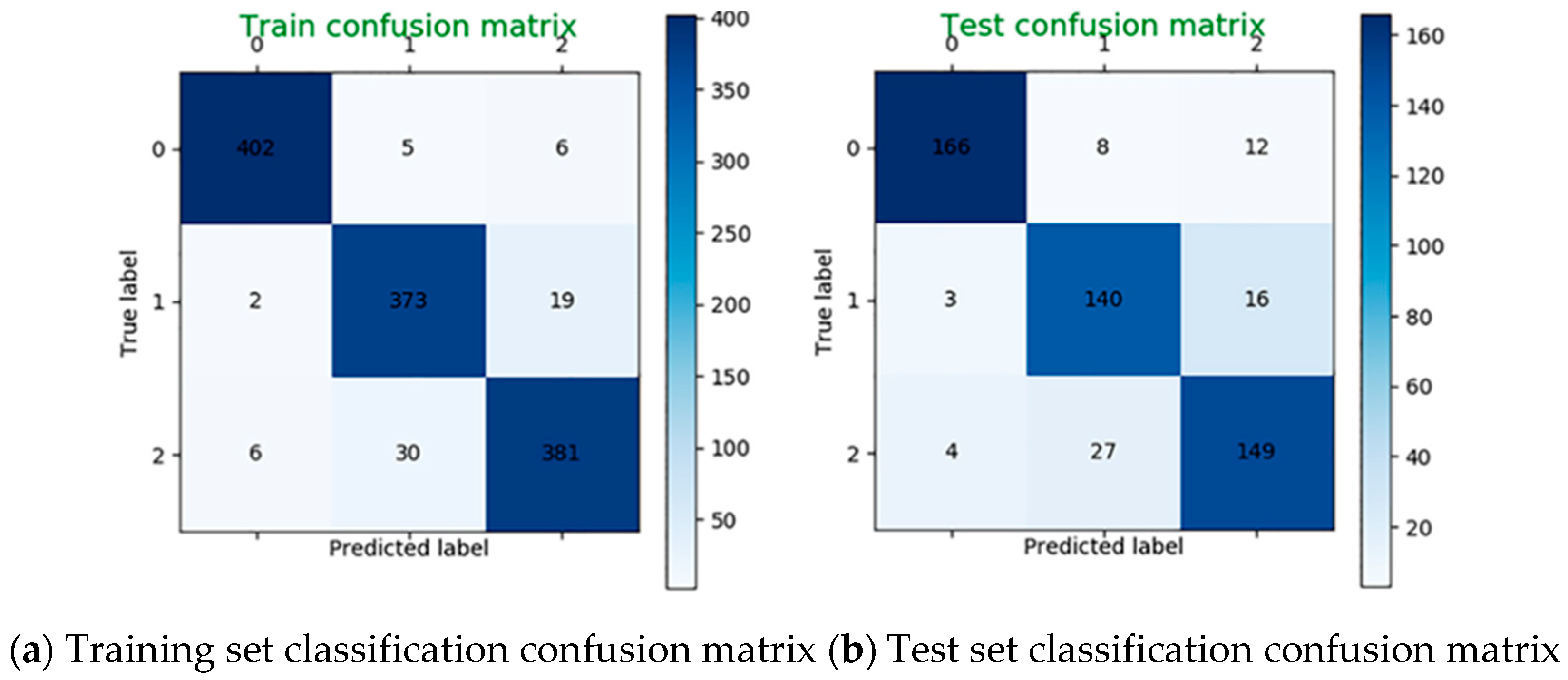
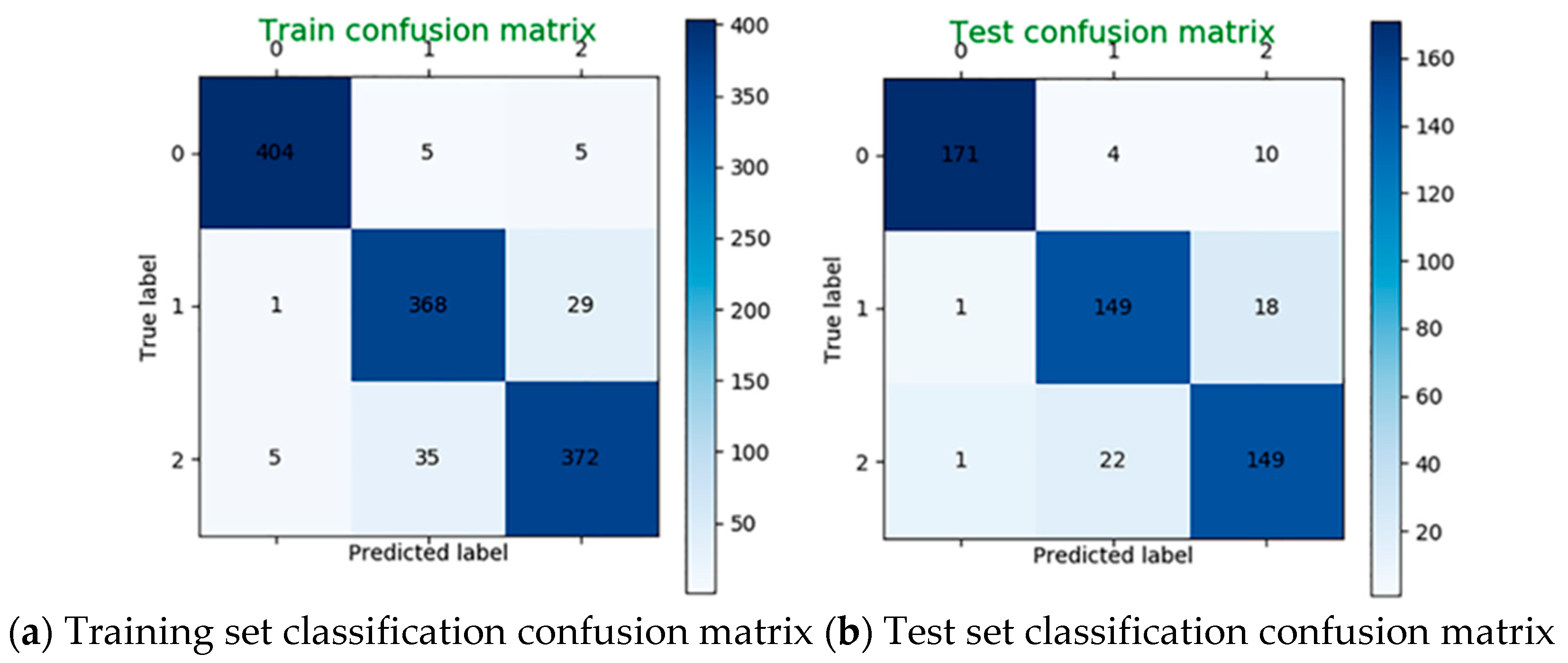
4.5. Classification Result of All Feature Data
4.6. Classification Result of β Band Feature Data
4.7. Comparative Analysis of Classification Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Schalk, G.; McFarland, D.J.; Hinterberger, T.; Birbaumer, N.; Wolpaw, J.R. BCI2000: A General-Purpose Brain-Computer Interface (BCI) System. IEEE Trans. Biomed. Eng. 2004, 51, 1034–1043. [Google Scholar] [CrossRef] [PubMed]
- Cavazza, M. A Motivational Model of BCI-Controlled Heuristic Search. Brain Sci. 2018, 8, 166. [Google Scholar] [CrossRef] [PubMed]
- Hosseini, M.-P.; Pompili, D.; Elisevich, K.; Soltanian-Zadeh, H. Optimized Deep Learning for EEG Big Data and Seizure Prediction BCI via Internet of Things. IEEE Trans. Big Data 2017, 3, 392–404. [Google Scholar] [CrossRef]
- Heilinger, A.; Guger, C. EEG-Trockenelektroden und ihre Anwendungen bei BCI-Systemen. Das Neurophysiol.-Labor 2019. [Google Scholar] [CrossRef]
- Lin, C.-J.; Hsieh, M.-H. Classification of mental task from EEG data using neural networks based on particle swarm optimization. Neurocomputing 2009, 72, 1121–1130. [Google Scholar] [CrossRef]
- De Haan, W.; Pijnenburg, Y.A.; Strijers, R.L.; van der Made, Y.; van der Flier, W.M.; Scheltens, P.; Stam, C.J. Functional neural network analysis in frontotemporal dementia and Alzheimer’s disease using EEG and graph theory. BMC Neurosci. 2009, 10, 101. [Google Scholar] [CrossRef]
- Radüntz, T.; Scouten, J.; Hochmuth, O.; Meffert, B. Automated EEG artifact elimination by applying machine learning algorithms to ICA-based features. J. Neural Eng. 2017, 14, 046004. [Google Scholar] [CrossRef]
- Croce, P.; Zappasodi, F.; Marzetti, L.; Merla, A.; Pizzella, V.; Chiarelli, A.M. Deep Convolutional Neural Networks for feature-less automatic classification of Independent Components in multi-channel electrophysiological brain recordings. IEEE Trans. Biomed. Eng. 2019. [Google Scholar] [CrossRef]
- Hasasneh, A.; Kampel, N.; Sripad, P.; Shah, N.J.; Dammers, J. Deep Learning Approach for Automatic Classification of Ocular and Cardiac Artifacts in MEG Data. J. Eng. 2018, 2018, 1350692. [Google Scholar] [CrossRef]
- Dharwarkar, G.S.; Basir, O. Enhancing Temporal Classification of AAR Parameters in EEG single-trial analysis for Brain-Computer Interfacing. In Proceedings of the 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference, Shanghai, China, 1–4 September 2005; pp. 5358–5361. [Google Scholar]
- Zhang, A.; Yang, B.; Huang, L. Feature Extraction of EEG Signals Using Power Spectral Entropy. In Proceedings of the 2008 International Conference on BioMedical Engineering and Informatics, Sanya, China, 28–30 May 2008; pp. 435–439. [Google Scholar]
- Kottaimalai, R.; Rajasekaran, M.P.; Selvam, V.; Kannapiran, B. EEG signal classification using Principal Component Analysis with Neural Network in Brain Computer Interface applications. In Proceedings of the 2013 IEEE International Conference ON Emerging Trends in Computing, Communication and Nanotechnology (ICECCN), Tirunelveli, India, 25–26 March 2013; pp. 227–231. [Google Scholar]
- Subasi, A. EEG signal classification using wavelet feature extraction and a mixture of expert model. Expert Syst. Appl. 2007, 32, 1084–1093. [Google Scholar] [CrossRef]
- Jahankhani, P.; Kodogiannis, V.; Revett, K. EEG Signal Classification Using Wavelet Feature Extraction and Neural Networks. In Proceedings of the IEEE John Vincent Atanasoff 2006 International Symposium on Modern Computing (JVA’06), Sofia, Bulgaria, 3–6 October 2006; pp. 120–124. [Google Scholar]
- Srinivasan, V.; Eswaran, C.; Sriraam, N. Approximate Entropy-Based Epileptic EEG Detection Using Artificial Neural Networks. IEEE Trans. Inform. Technol. Biomed. 2007, 11, 288–295. [Google Scholar] [CrossRef]
- Hyekyung, L.; Seungjin, C. PCA+HMM+SVM for EEG pattern classification. In Proceedings of the Seventh International Symposium on Signal Processing and Its Applications 2003, Paris, France, 1–4 July 2003; Volume 1, pp. 541–544. [Google Scholar]
- Orhan, U.; Hekim, M.; Ozer, M. EEG signals classification using the K-means clustering and a multilayer perceptron neural network model. Expert Syst. Appl. 2011, 38, 13475–13481. [Google Scholar] [CrossRef]
- Trujillo-Barreto, N.J.; Aubert-Vázquez, E.; Valdés-Sosa, P.A. Bayesian model averaging in EEG/MEG imaging. NeuroImage 2004, 21, 1300–1319. [Google Scholar] [CrossRef]
- Baldwin, C.L.; Penaranda, B.N. Adaptive training using an artificial neural network and EEG metrics for within- and cross-task workload classification. NeuroImage 2012, 59, 48–56. [Google Scholar] [CrossRef] [PubMed]
- Acharya, U.R.; Oh, S.L.; Hagiwara, Y.; Tan, J.H.; Adeli, H. Deep convolutional neural network for the automated detection and diagnosis of seizure using EEG signals. Comput. Biol. Med. 2018, 100, 270–278. [Google Scholar] [CrossRef] [PubMed]
- Richhariya, B.; Tanveer, M. EEG signal classification using universum support vector machine. Expert Syst. Appl. 2018, 106, 169–182. [Google Scholar] [CrossRef]
- Saccá, V.; Campolo, M.; Mirarchi, D.; Gambardella, A.; Veltri, P.; Morabito, F.C. On the Classification of EEG Signal by Using an SVM Based Algorithm. In Multidisciplinary Approaches to Neural Computing; Esposito, A., Faudez-Zanuy, M., Morabito, F.C., Pasero, E., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 69, pp. 271–278. [Google Scholar]
- Clark, I.; Biscay, R.; Echeverría, M.; Virués, T. Multiresolution decomposition of non-stationary eeg signals: A preliminary study. Comput. Biol. Med. 1995, 25, 373–382. [Google Scholar] [CrossRef]
- Moretti, D.V.; Babiloni, C.; Binetti, G.; Cassetta, E.; Dal Forno, G.; Ferreric, F.; Ferri, R.; Lanuzza, B.; Miniussi, C.; Nobili, F.; et al. Individual analysis of EEG frequency and band power in mild Alzheimer’s disease. Clin. Neurophysiol. 2004, 115, 299–308. [Google Scholar] [CrossRef]
- Liao, X.; Yao, D.; Wu, D.; Li, C. Combining Spatial Filters for the Classification of Single-Trial EEG in a Finger Movement Task. IEEE Trans. Biomed. Eng. 2007, 54, 821–831. [Google Scholar] [CrossRef]
- Saby, J.N.; Marshall, P.J. The Utility of EEG Band Power Analysis in the Study of Infancy and Early Childhood. Dev. Neuropsychol. 2012, 37, 253–273. [Google Scholar] [CrossRef]
- Trejo, L.J.; Kochavi, R.; Kubitz, K.; Montgomery, L.D.; Rosipal, R.; Matthews, B. Measures and Models for Predicting Cognitive Fatigue. In Proceedings of the Defense and Security, Orlando, FL, USA, 23 May 2005; p. 105. [Google Scholar]
- Raileanu, L.E.; Stoffel, K. Theoretical Comparison between the Gini Index and Information Gain Criteria. Ann. Math. Artif. Intell. 2004, 41, 77–93. [Google Scholar] [CrossRef]
- Strobl, C.; Boulesteix, A.-L.; Augustin, T. Unbiased split selection for classification trees based on the Gini Index. Comput. Stat. Data Anal. 2007, 52, 483–501. [Google Scholar] [CrossRef]
- Vigario, R.; Sarela, J.; Jousmiki, V.; Hamalainen, M.; Oja, E. Independent component approach to the analysis of EEG and MEG recordings. IEEE Trans. Biomed. Eng. 2000, 47, 589–593. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
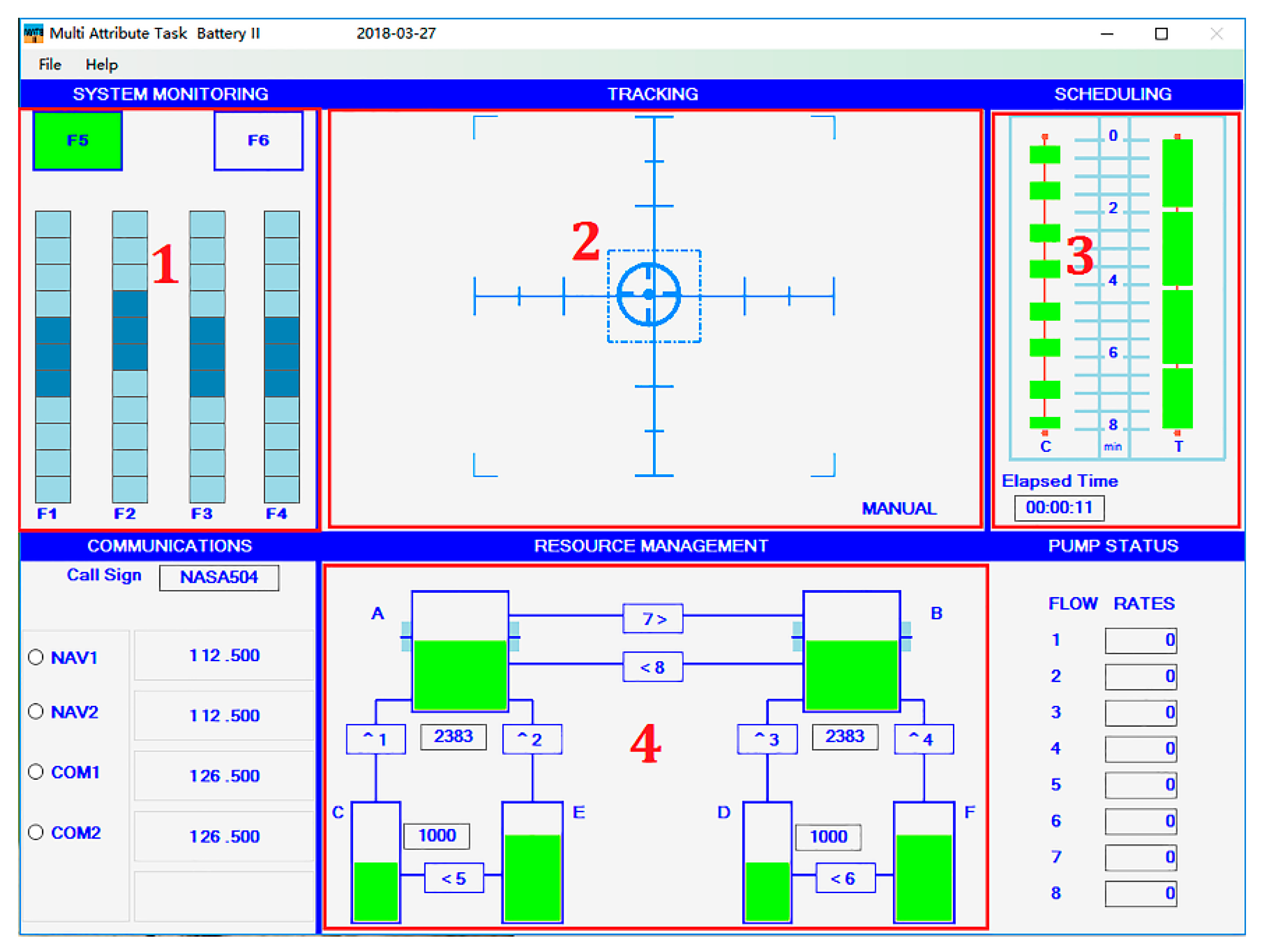
| Task | Description | Presentation Frequency (Number Of Operations Required within 5 Min) | ||
|---|---|---|---|---|
| Low Load | Moderate Load | High Load | ||
| System monitoring task | Monitor the status of the upper left system monitoring task, and click the corresponding position with the mouse to respond. | 1 | 12 | 24 |
| Tracking monitoring tasks | Monitor the upper and middle tracking monitoring task status and position information, press the button to respond, control the joystick. | 1 | 12 | 24 |
| Communication monitoring task | Monitor the right communication monitoring taskbar and upcoming communication tasks, and press the button to respond. | 1 | 12 | 24 |
| Resource management task | Monitor the middle and lower resource management tanks A, B, C, D oil status and oil pump failure information. | 1 | 12 | 24 |
| Experimental Stage | Experimental Operation | Time-Consuming (Minutes) |
|---|---|---|
| 1. Experimental training | Read the lab guide, flight simulation mission training | 20 |
| 2. Debugging physiological equipment | Debug EEG acquisition system and experimental preparation | 30 |
| 3. Resting task | Rest 3min task (blinking, closed eye activity) | 5 |
| 4. Formal experiment 1 | Carry out the first load level experiment | 25 |
| 5. Fill in the form and rest | Fill in the 3D-SART scale, NASA-TLX scale, rest | 15 |
| 6. Formal experiment 2 | Carry out the second load level experiment | 25 |
| 7. Fill in the form and rest | Fill in the 3D-SART scale, NASA-TLX scale, rest | 10 |
| 8. Formal experiment 3 | Carry out the third load level experiment | 25 |
| 9. Fill in the form | Fill in the 3D-SART scale, NASA-TLX scale | 5 |
| 10. Fill in the form | NASA-TLX weight check, task attribute comparison score | 10 |
| Data | Low Load | Moderate Load | High Load | Training Set | Cross-Validation Set | Test Set | |
|---|---|---|---|---|---|---|---|
| After Feature Extraction | number | 583 | 583 | 583 | 1224 | 122 | 525 |
| dimension | 120 | 120 | 120 | 120 | 120 | 120 | |
| After Feature Selection | number | 583 | 583 | 583 | 1224 | 122 | 525 |
| dimension | 30 | 30 | 30 | 30 | 30 | 30 |
| Target Class | M00 | M01 | M02 |
| M10 | M11 | M12 | |
| M20 | M21 | M22 | |
| Output Class | |||
| Subject Number | Acc(f) | Acc(β) | Acc(β) − Acc(f) |
|---|---|---|---|
| Subject 01 | 72 | 73 | +1 |
| Subject 02 | 72 | 74 | +2 |
| Subject 05 | 87 | 86 | −1 |
| Subject 06 | 90 | 93 | +3 |
| Subject 07 | 89 | 91 | +2 |
| Subject 08 | 77 | 77 | 0 |
| Subject 10 | 79 | 81 | +2 |
| Subject 12 | 96 | 96 | 0 |
| Subject 18 | 91 | 92 | +1 |
| Subject 22 | 87 | 89 | +2 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, H.; Fan, Z.; Cao, S.; Pang, L.; Wang, H.; Zhang, J. A Study on Sensitive Bands of EEG Data under Different Mental Workloads. Algorithms 2019, 12, 145. https://doi.org/10.3390/a12070145
Qu H, Fan Z, Cao S, Pang L, Wang H, Zhang J. A Study on Sensitive Bands of EEG Data under Different Mental Workloads. Algorithms. 2019; 12(7):145. https://doi.org/10.3390/a12070145
Chicago/Turabian StyleQu, Hongquan, Zhanli Fan, Shuqin Cao, Liping Pang, Hao Wang, and Jie Zhang. 2019. "A Study on Sensitive Bands of EEG Data under Different Mental Workloads" Algorithms 12, no. 7: 145. https://doi.org/10.3390/a12070145
APA StyleQu, H., Fan, Z., Cao, S., Pang, L., Wang, H., & Zhang, J. (2019). A Study on Sensitive Bands of EEG Data under Different Mental Workloads. Algorithms, 12(7), 145. https://doi.org/10.3390/a12070145