
Mining Domain-Specific Design Patterns: A Case Study †


Abstract
:1. Introduction
2. Related Work
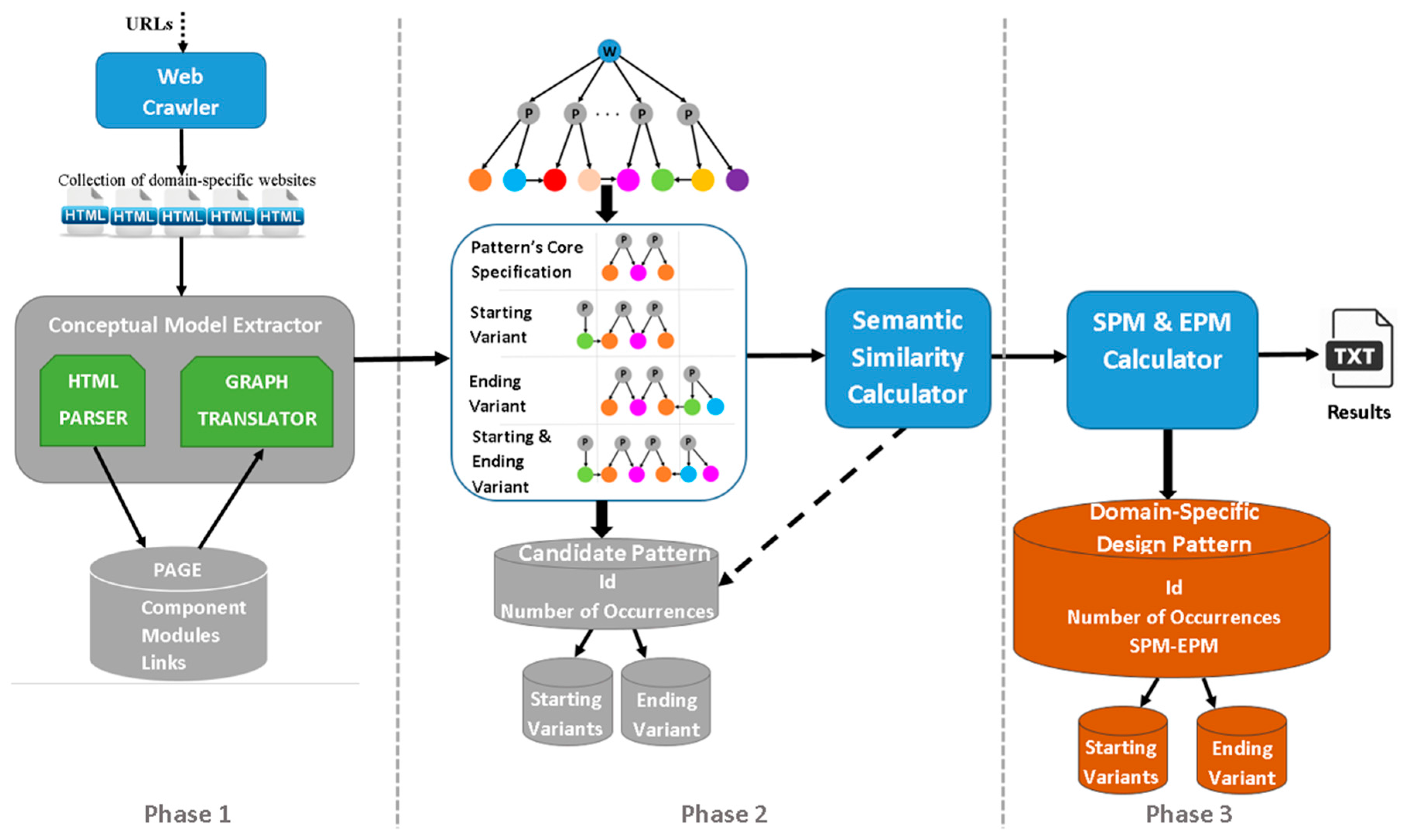
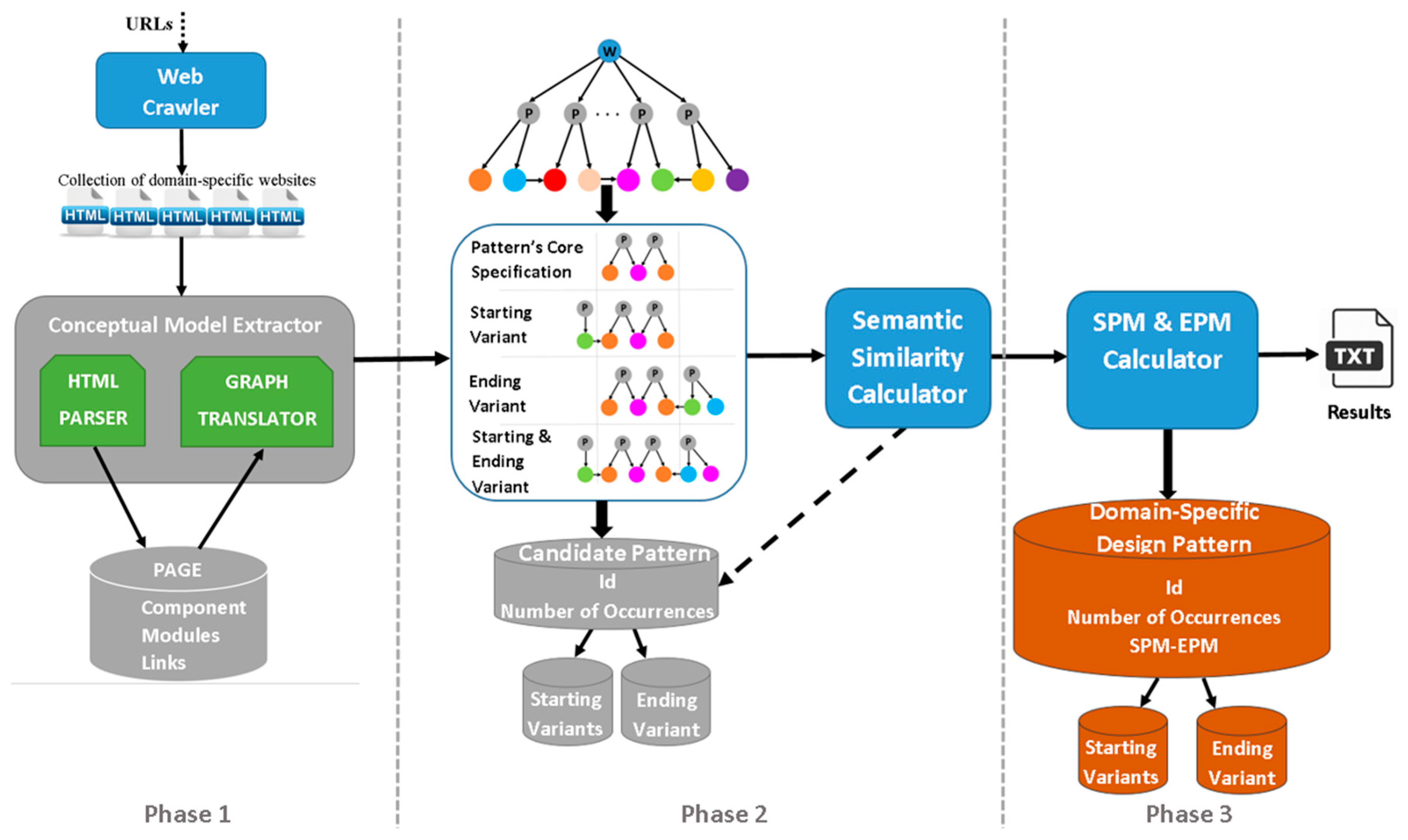
3. The Methodology
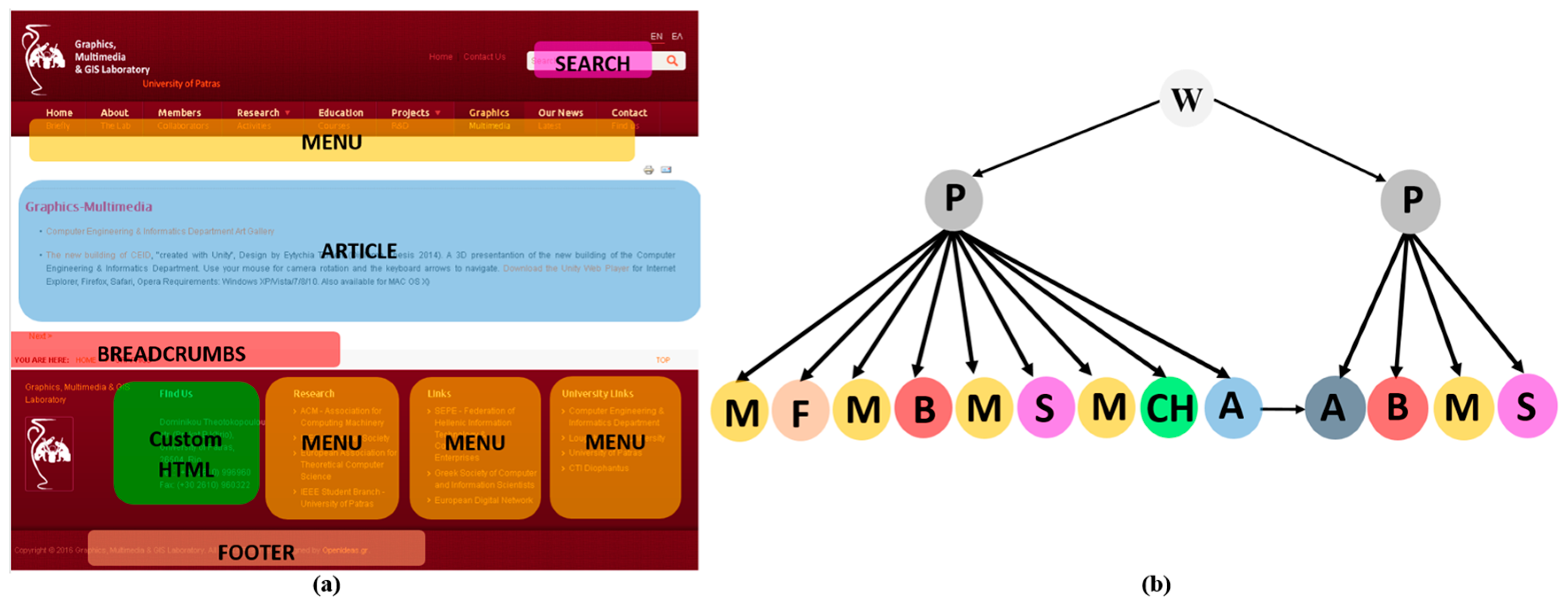
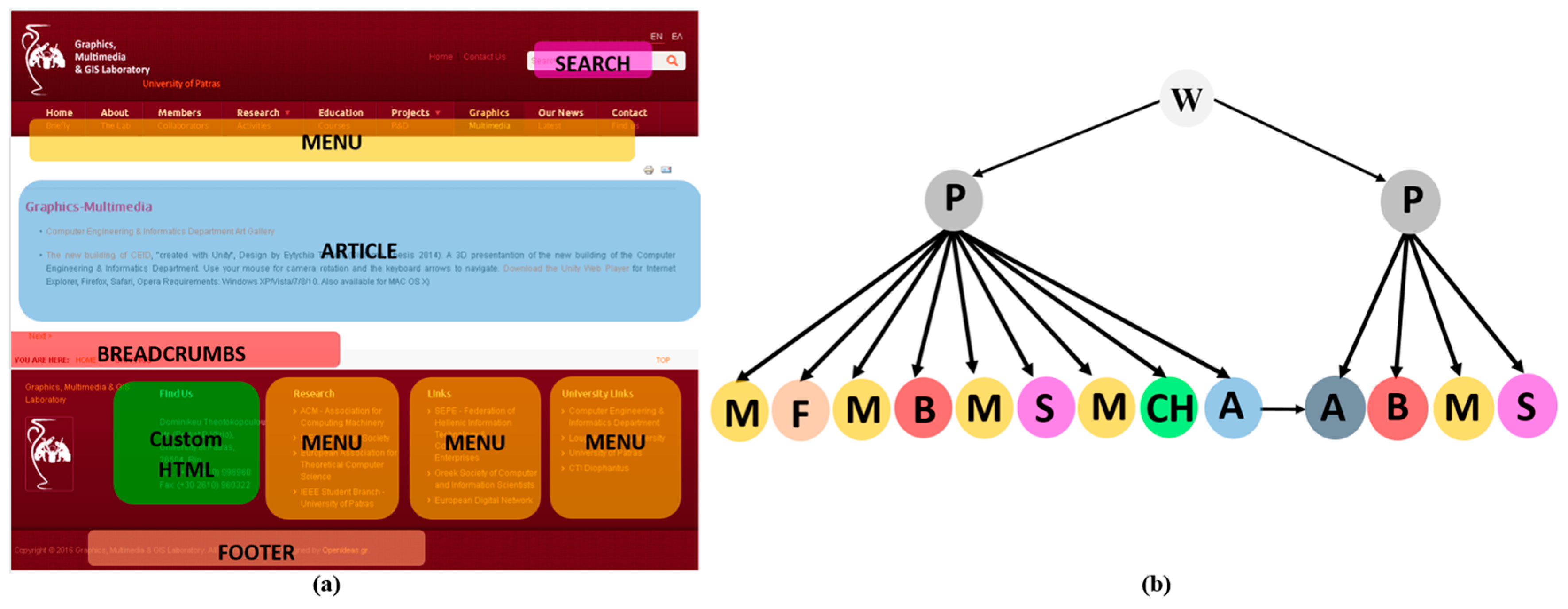
3.1. Phase 1: Extracting the Conceptual Models of the Websites
3.2. Phase 2: Mining the Candidate Domain-Specific Design Patterns
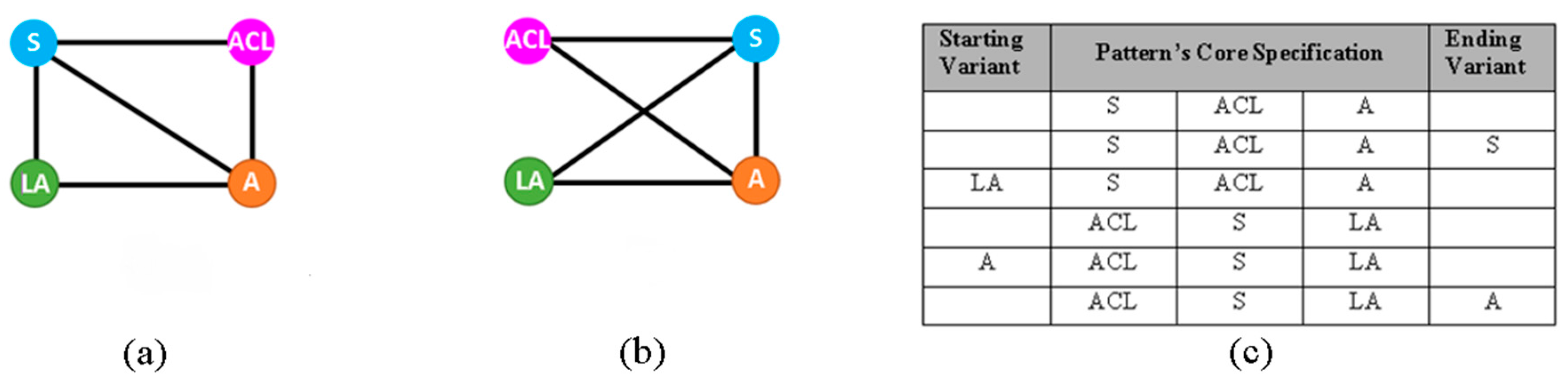
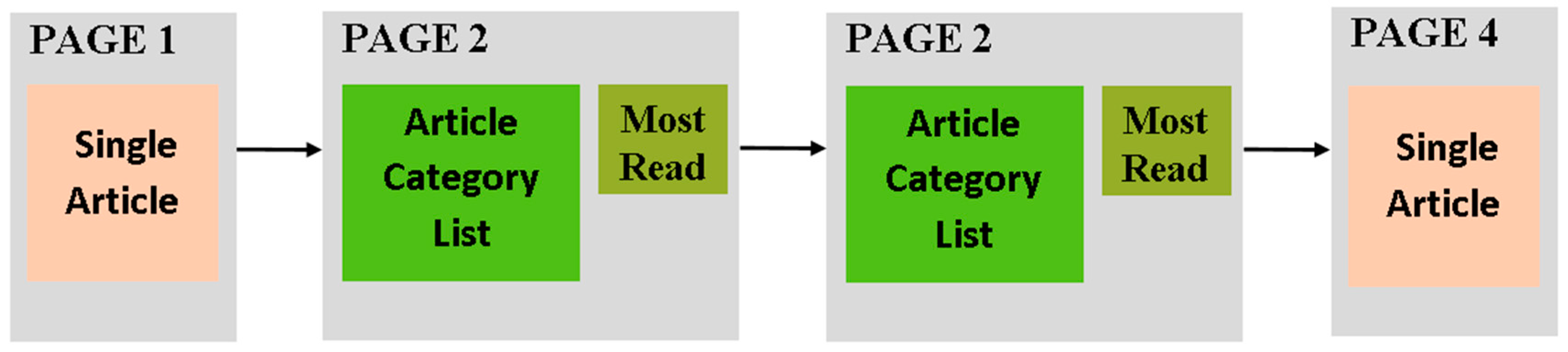
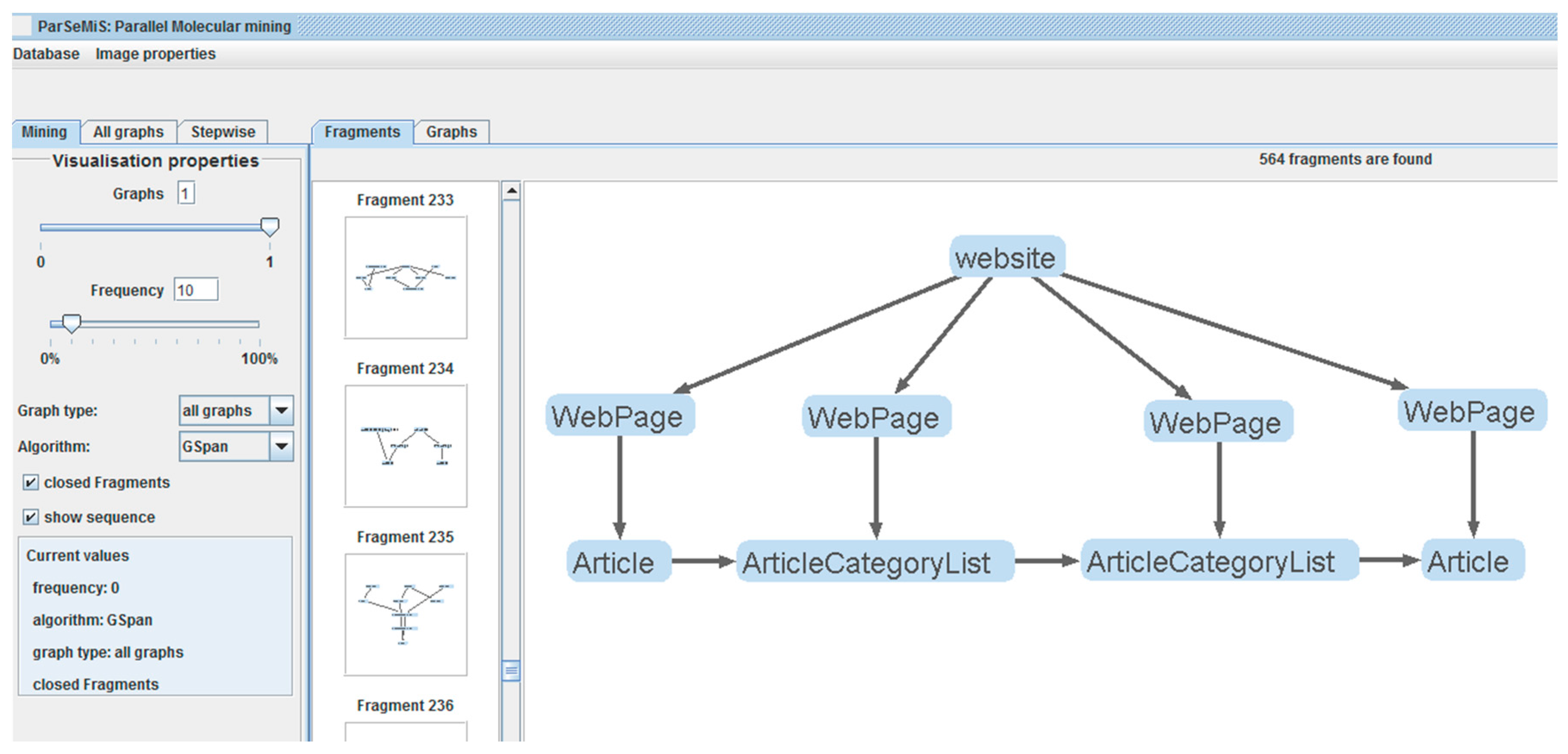
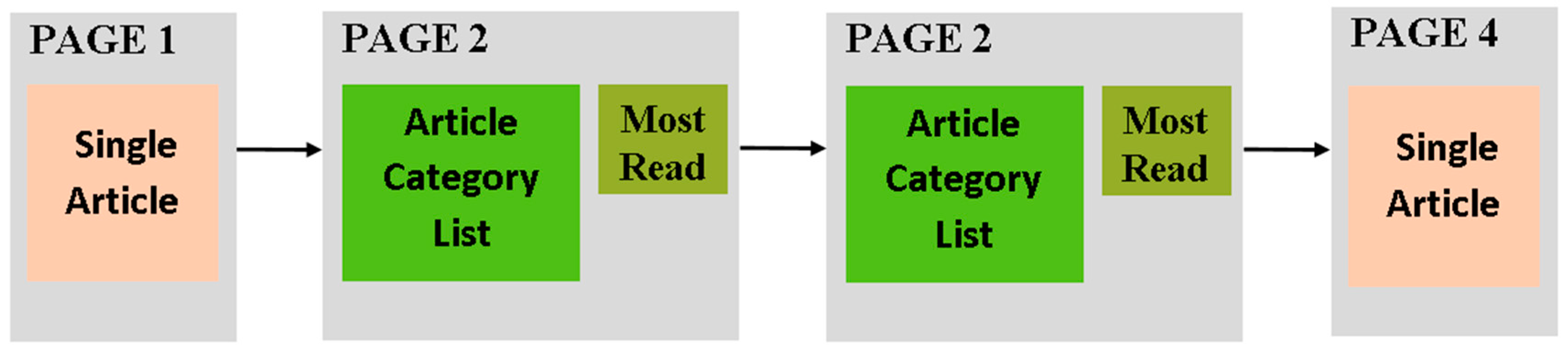
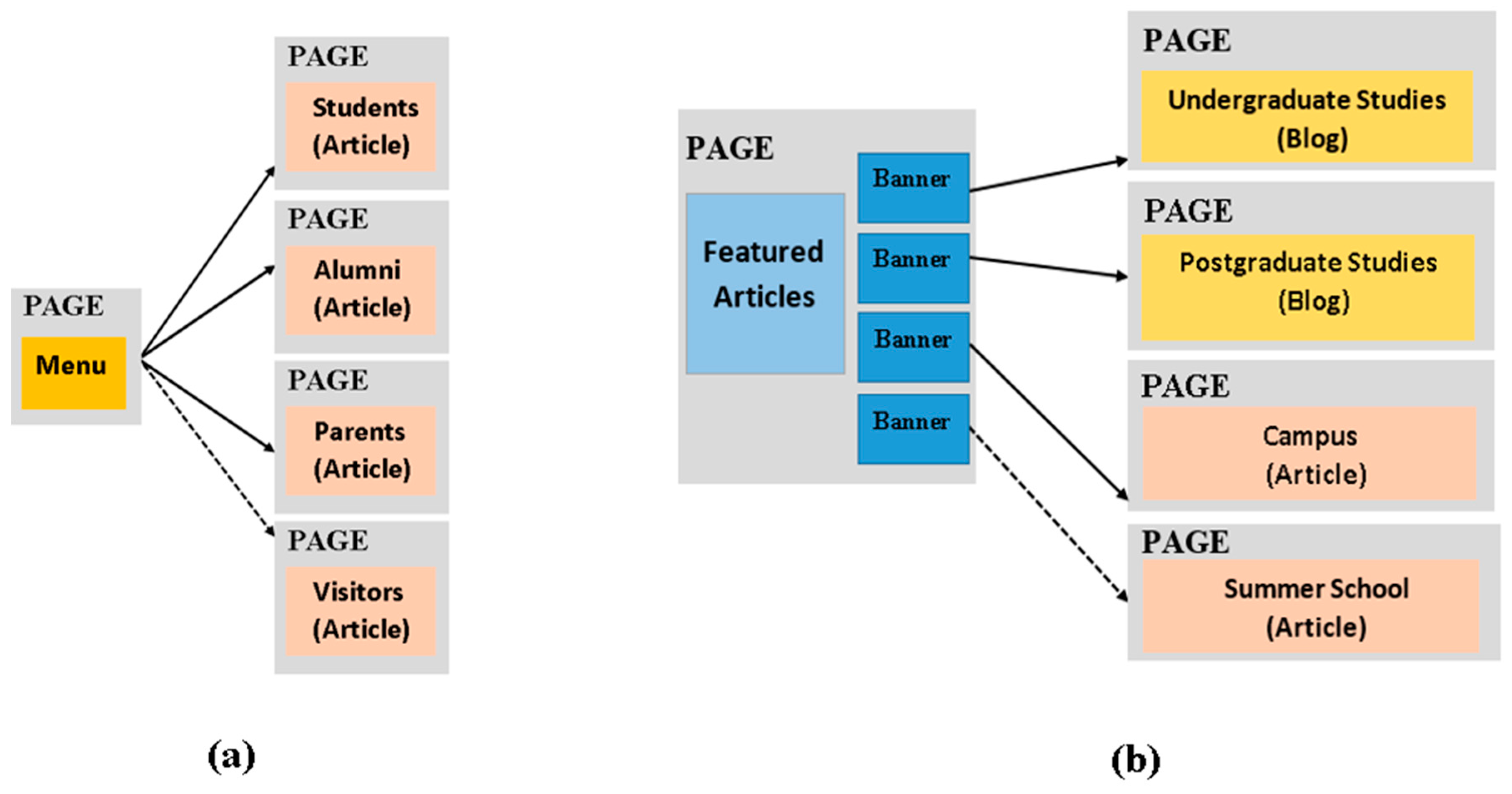
3.2.1. Mining the Recurrent Patterns at Hypertext Level
3.2.2. Inspecting Data Level: Identifying Patterns Supporting Common Functionality
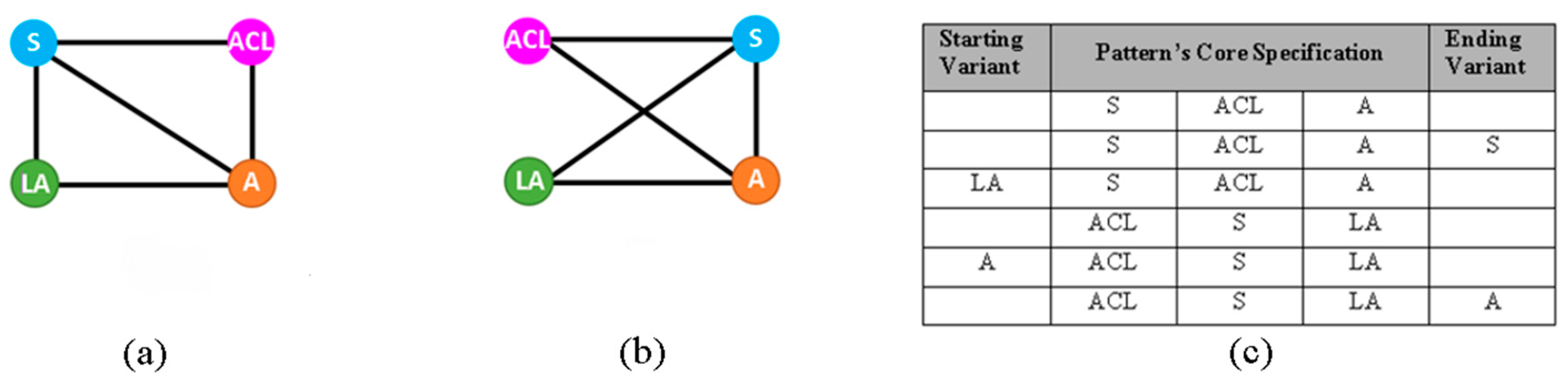
3.3. Evaluation of Pattern Variants Consistent Use
4. The Case Study
4.1. Domain Description
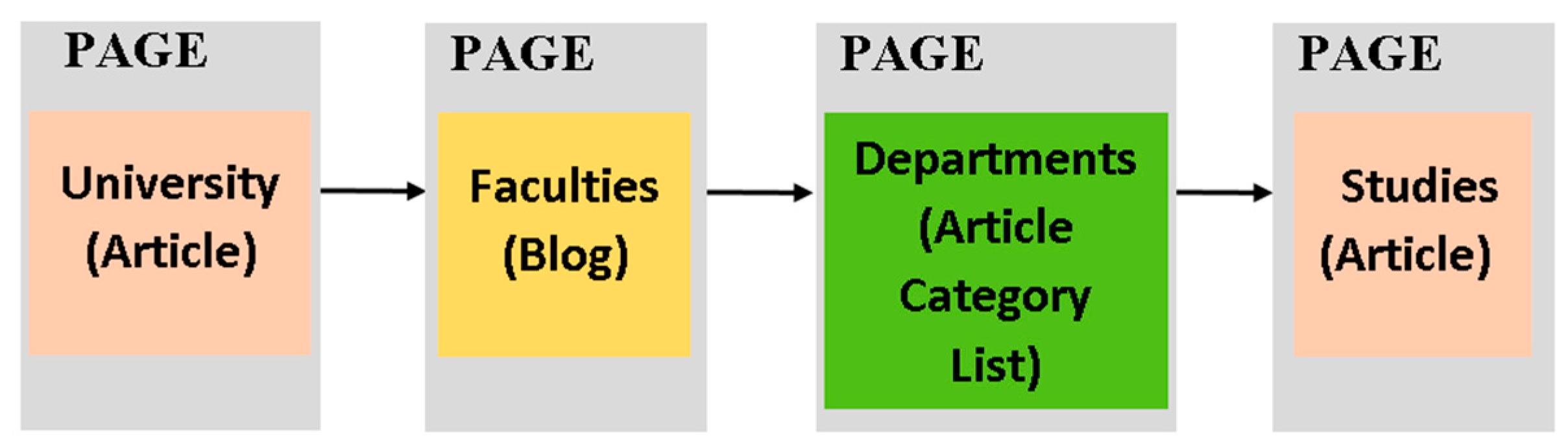
4.2. Domain-Specific Design Patterns for Educational Websites
5. Conclusions and Future Work
Author Contributions
Conflicts of Interest
References
- Gamma, E.; Helm, R.; Johnson, R.; Vlissides, J. Design Patterns: Elements of Reusable Object-Oriented Software; Addison-Wesley: Reading, MA, USA, 1995. [Google Scholar]
- Yahoo Design Pattern Library. Available online: https://developer.yahoo.com/ypatterns (accessed on 15 November 2016).
- Patterns Catalog. Available online: http://hillside.net/patterns/patterns-catalog (accessed on 15 November 2016).
- Hypermedia Design Patterns Repository. Available online: http://wiki.c2.com/?HypermediaDesignPatternsRepository (accessed on 15 November 2016).
- Patterns in Interaction Design, the Carrousel Pattern. Available online: http://welie.com/patterns/showPattern.php?patternID=carrousel (accessed on 23 January 2017).
- Arango, R.G. Prieto-Diaz, Introduction and overview: Domain analysis concepts and research directions. In Domain Analysis and Software Systems Modeling; Prieto-Diaz, R., Arango, G., Eds.; IEEE Press: New York, NY, USA, 1991; pp. 9–32. [Google Scholar]
- Gkantouna, V.; Tzimas, V.; Tampakas, B.; Tsaknakis, J. Mining Domain-Specific Design Patterns. In Proceedings of the AIAI, Thessaloniki, Greece, 16–18 September 2016.
- Domain-Specific Patterns for CMS. Available online: http://alkistis.ceid.upatras.gr/research/modeling/domainspecificpatterns (accessed on 15 November 2016).
- Joomla! CMS Website. Available online: http://community.joomla.org (accessed on 15 November 2016).
- Drupal CMS Website. Available online: https://www.drupal.org/ (accessed on 15 November 2016).
- A Pattern Library for Interaction Design. Available online: http://www.welie.com/patterns (accessed on 15 November 2016).
- UI Patterns. Available online: http://ui-patterns.com/patterns/miscellaneous/list (accessed on 15 November 2016).
- Fraternali, P.; Matera, M.; Maurino, A. WQA: An XSL Framework for Analyzing the Quality of Web Applications. In Proceedings of the 2nd International Workshop on Web-Oriented Software Technologies—IWWOST’02, Malaga, Spain, 10–14 June 2002.
- Lucca, G.A.; Fasolino, A.R.; Tramontana, P. Recovering interaction design patterns in web applications. In Proceedings of the Ninth European Conference on Software Maintenance and Reengineering, Manchester, UK, 21–23 March 2005.
- Rekhisa, S.; Bouassidaa, N.; Bouaziza, R.; Duvalletb, C.; Sadegb, B. A new method for constructing and reusing domain specific design patterns: Application to RT domain. J. King Saud Univ. Comput. Inf. Sci. 2016. [Google Scholar] [CrossRef]
- Rekhis, S.; Bouassida, N.; Duvallet, C.; Bouaziz, R.; Sadeg, B. A Process to derive Domain-Specific Patterns: Application to the Real-Time Domain. In Proceedings of the Advances in Databases and Information Systems, Novi Sad, Serbia, 20–24 September 2010.
- Montero, S.; Dıaz, P.; Aedo, I. A semantic representation for domain-specific patterns. In Proceedings of the International Symposium on Metainformatics, Salzburg, Austria, 15–18 September 2004.
- Kim, D.; France, R.B.; Ghosh, S. A UML-based Language for Specifying Domain-Specific Patterns. J. Visual Lang. Comput. 2004, 15, 265–289. [Google Scholar] [CrossRef]
- MMLAB Educational Website. Available online: http://mmlab.ceid.upatras.gr/en/ (accessed on 15 November 2016).
- Yan, X.; Han, J. gSpan: Graph-based substructure pattern mining. In Proceedings of the ICDM’02, Washington, DC, USA, 9–12 December 2002.
- Philippsen, M. ParSeMiS—The Parallel and Sequential Mining Suite. Available online: https://www2.cs.fau.de/EN/research/zold/ParSeMiS/index.html (accessed on 15 November 2016).
- Simpson, T.; Dao, T. WordNet-Based Semantic Similarity Measurement. Available online: http://www.codeproject.com/Articles/11835/WordNet-based-semantic-similarity-measurement (accessed on 15 November 2016).
- The Graduate School of Arts and Sciences (GSAS) Website. Available online: https://gsas.harvard.edu/ (accessed on 15 November 2016).
- Wordpress CMS Website. Available online: https://wordpress.org/ (accessed on 23 January 2017).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PATTERN | MENU [Module] | ARTICLE [Component] | CATEGORY LIST [Component] | CATEGORY LIST [Component] | ARTICLE [Component] |
|---|---|---|---|---|---|
| Occ.1 | Top Menu | AUTH University | Departments in AUTH | Academic staff—Department of Informatics | Professor Mr. Papadopoulos |
| Occ.2 | Main Menu | Piraeus University | Undergraduate Studies—Departments | Academic Staff—Department of Electronics Engineering | Professor Mrs. Rammou |
| SemSimScore Occ.1–2 | 85% | 75% | 70% | 70% | |
| Common Semantic Concept | University | Departments | Staff | Professor | |
| AverageSemSimScore Occ1.–Occ.2 | 75% | ||||
| Occ.3 | Top Menu | AUTH University | Departments in AUTH | Undergraduate Studies | Databases—Course Description |
| SemSimScore Occ.1-3 | 100% | 100% | 10% | 23% | |
| Common Semantic Concept | University | Departments | Education | Course | |
| AverageSemSimScore Occ1.–Occ.3 | 58% | ||||
| EPM-SPM Range | Measurement Scale Value |
|---|---|
| 0 ≤ SPM < 0.2 | Insufficient |
| 0.2 ≤ SPM < 0.4 | Weak |
| 0.4 ≤ SPM < 0.6 | Discrete |
| 0.6 ≤ SPM < 0.8 | Good |
| 0.8 ≤ SPM ≤ 1 | Optimum |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gkantouna, V.; Tzimas, G. Mining Domain-Specific Design Patterns: A Case Study †. Algorithms 2017, 10, 28. https://doi.org/10.3390/a10010028
Gkantouna V, Tzimas G. Mining Domain-Specific Design Patterns: A Case Study †. Algorithms. 2017; 10(1):28. https://doi.org/10.3390/a10010028
Chicago/Turabian StyleGkantouna, Vassiliki, and Giannis Tzimas. 2017. "Mining Domain-Specific Design Patterns: A Case Study †" Algorithms 10, no. 1: 28. https://doi.org/10.3390/a10010028
APA StyleGkantouna, V., & Tzimas, G. (2017). Mining Domain-Specific Design Patterns: A Case Study †. Algorithms, 10(1), 28. https://doi.org/10.3390/a10010028