
Large Scale Implementations for Twitter Sentiment Classification




Abstract
:1. Introduction
2. Related Work
2.1. Sentiment Analysis and Classification Models
2.2. Machine Learning Techniques
3. Cloud Computing Preliminaries
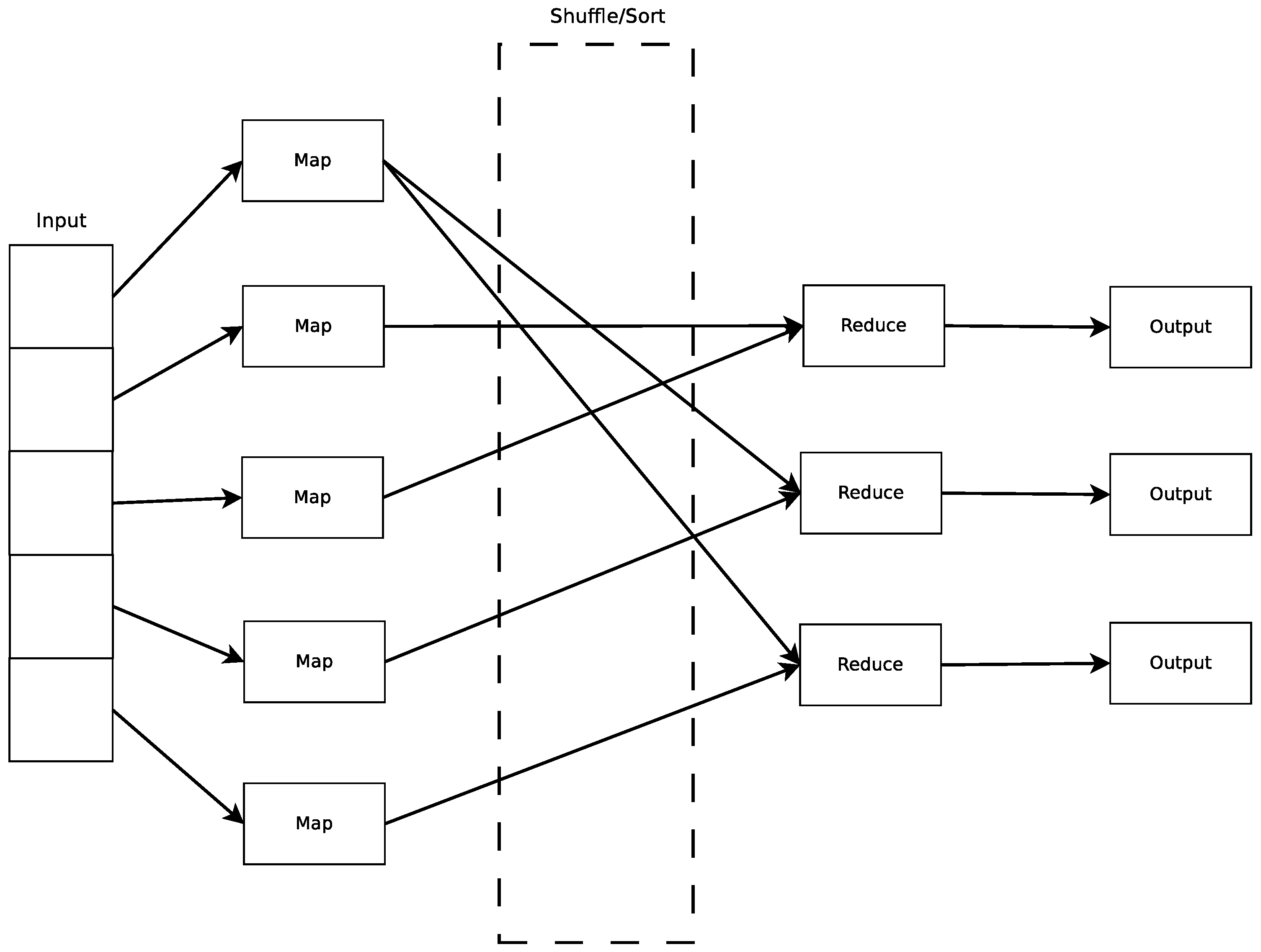
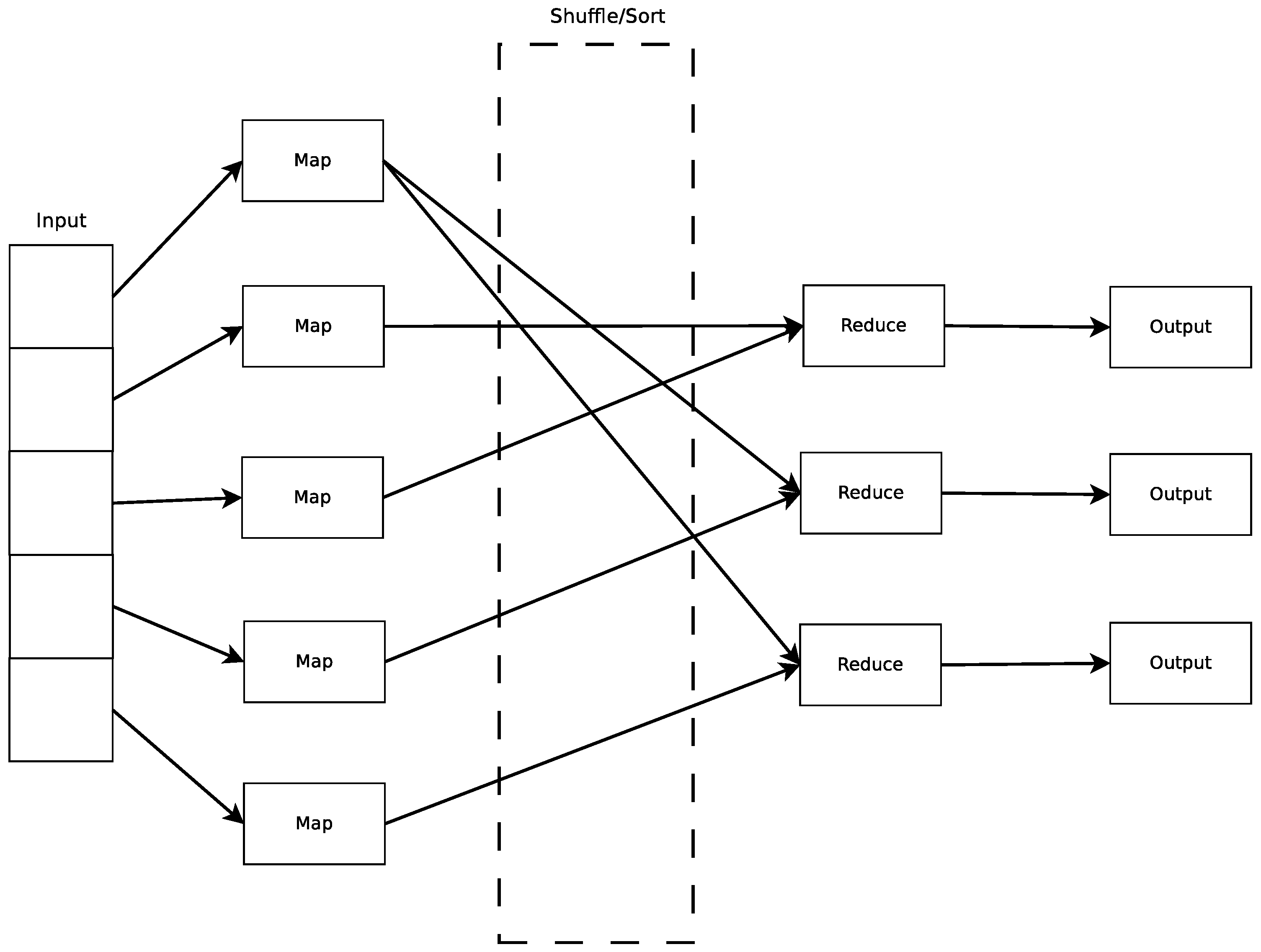
3.1. MapReduce Model
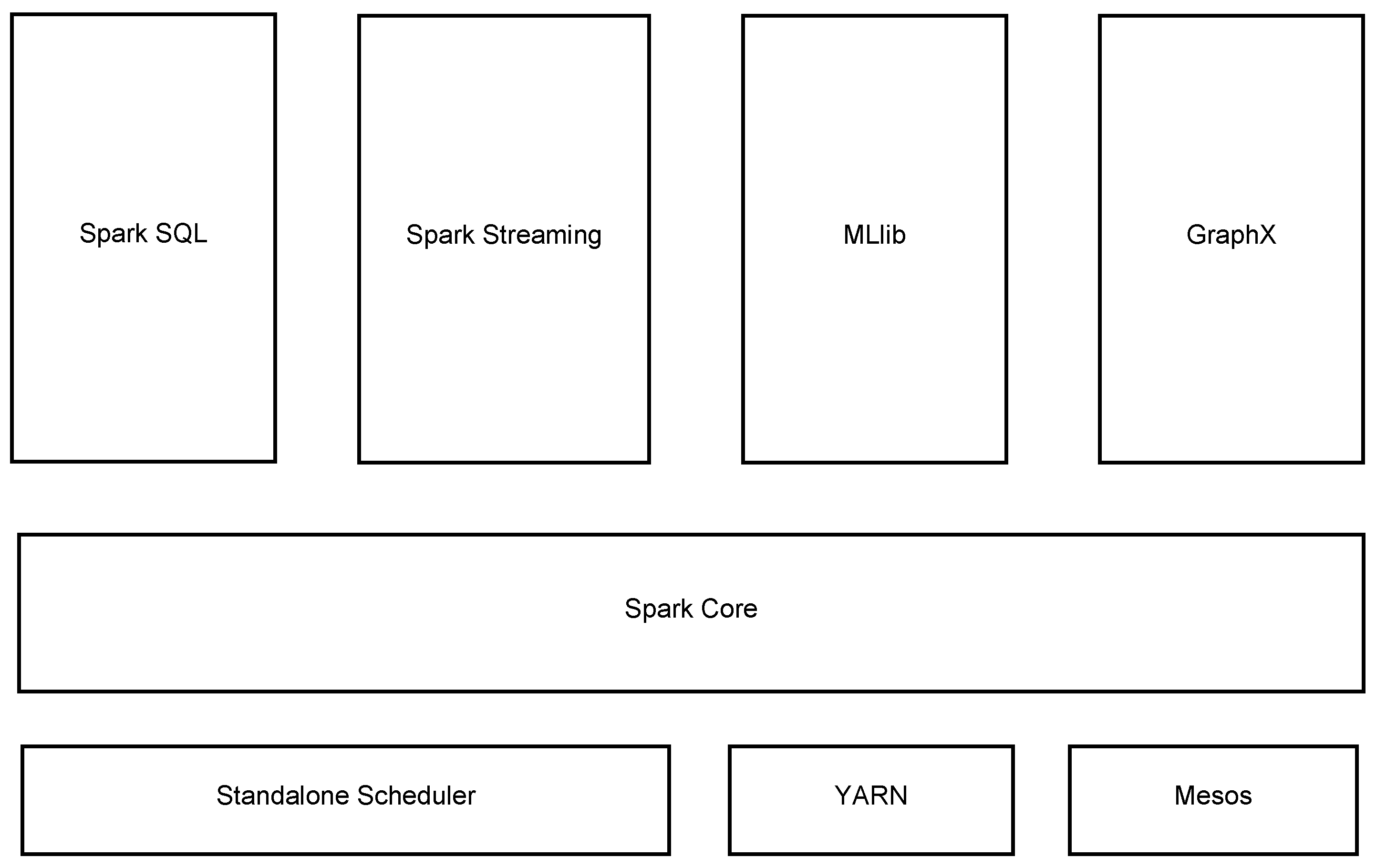
3.2. Spark Framework
3.3. MLlib
4. Sentiment Analysis Classification Framework
4.1. Feature Description
4.1.1. Word and N-Gram Features
4.1.2. Pattern Features
4.1.3. Punctuation Features
4.2. Bloom Filter Integration
4.3. kNN Classification Algorithm
4.4. Algorithmic Description
- Feature Extraction: Extract the features from all tweets in T and ,
- Feature Vector Construction: Build the feature vectors and , respectively,
- Distance Computation: For each vector find the matching vectors (if any exist) in ,
- Sentiment Classification: Assign a sentiment label .
4.4.1. Feature Extraction
| Algorithm 1: MapReduce Job 1 |
|
4.4.2. Feature Vector Construction
| Algorithm 2: MapReduce Job 2 |
|
4.4.3. Distance Computation
| Algorithm 3: MapReduce Job 3 |
|
4.4.4. Sentiment Classification
| Algorithm 4: MapReduce Job 4 |
|
4.5. Preprocessing and Features
- Unigrams, which are frequencies of words occurring in the tweets.
- Bigrams, which are frequencies of sequences of two words occurring in the tweets.
- Trigrams, which are frequencies of sequences of three words occurring in the tweets.
- Username, which is a binary flag that represents the existence of a user mention in the tweet.
- Hashtag, which is a binary flag that represents the existence of a hashtag in the tweet.
- URL, which is a binary flag that represents the existence of a URL in the tweet.
- POS Tags, where we used the Stanford NLT MaxEnt Tagger [50] to tag the tokenized tweets and the following are counted:
- Number of Adjectives,
- Number of Verbs,
- Number of Nouns,
- Number of Adverbs,
- Number of Interjections.
5. Implementation
5.1. Our Datasets for Evaluating MapReduce versus Spark Framework
5.2. Open Datasets for Evaluating Machine Learning Techniques in Spark Framework
5.2.1. Binary Classification
5.2.2. Ternary Classification
6. Results and Evaluation
6.1. Our Datasets for Evaluating MapReduce versus Spark Framework
6.1.1. Classification Performance
6.1.2. Effect of k
6.1.3. Space Compression
6.1.4. Running Time
6.1.5. Scalability and Speedup
6.2. Open Datasets for Evaluating Machine Learning Techniques in Spark Framework
7. Conclusions
Author Contributions
Conflicts of Interest
References
- Sentiment. Available online: http://www.thefreedictionary.com/sentiment (accessed on 2 March 2017).
- Wang, X.; Wei, F.; Liu, X.; Zhou, M.; Zhang, M. Topic Sentiment Analysis in Twitter: A Graph-based Hashtag Sentiment Classification Approach. In Proceedings of the ACM International Conference on Information and Knowledge Management (CIKM), Glasgow, UK, 24–28 October 2011; pp. 1031–1040.
- Emoticon. Available online: http://dictionary.reference.com/browse/emoticon (accessed on 2 March 2017).
- Lin, J.; Dyer, C. Data-Intensive Text Processing with MapReduce; Morgan and Claypool Publishers: San Rafael, CA, USA, 2010. [Google Scholar]
- van Banerveld, M.; Le-Khac, N.; Kechadi, M.T. Performance Evaluation of a Natural Language Processing Approach Applied in White Collar Crime Investigation. In Proceedings of the Future Data and Security Engineering (FDSE), Ho Chi Minh City, Vietnam, 19–21 November 2014; pp. 29–43.
- Agarwal, A.; Xie, B.; Vovsha, I.; Rambow, O.; Passonneau, R. Sentiment Analysis of Twitter Data. In Workshop on Languages in Social Media; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 30–38. [Google Scholar]
- Davidov, D.; Tsur, O.; Rappoport, A. Enhanced Sentiment Learning Using Twitter Hashtags and Smileys. In Proceedings of the International Conference on Computational Linguistics, Posters, Beijing, China, 23–27 August 2010; pp. 241–249.
- Jiang, L.; Yu, M.; Zhou, M.; Liu, X.; Zhao, T. Target-dependent Twitter Sentiment Classification. In Proceedings of the Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Volume 1, pp. 151–160.
- Dean, J.; Ghemawat, S. MapReduce: Simplified Data Processing on Large Clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- White, T. Hadoop: The Definitive Guide, 3rd ed.; O’Reilly Media/Yahoo Press: Sebastopol, CA, USA, 2012. [Google Scholar]
- Karau, H.; Konwinski, A.; Wendell, P.; Zaharia, M. Learning Spark: Lightning-Fast Big Data Analysis; O’Reilly Media: Sebastopol, CA, USA, 2015. [Google Scholar]
- Pang, B.; Lee, L. Opinion Mining and Sentiment Analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef]
- Hu, M.; Liu, B. Mining and Summarizing Customer Reviews. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177.
- Zhuang, L.; Jing, F.; Zhu, X.Y. Movie Review Mining and Summarization. In Proceedings of the ACM International Conference on Information and Knowledge Management (CIKM), Arlington, VA, USA, 5–11 November 2006; pp. 43–50.
- Zhang, W.; Yu, C.; Meng, W. Opinion Retrieval from Blogs. In Proceedings of the ACM Conference on Conference on Information and Knowledge Management (CIKM), Lisbon, Portugal, 6–10 November 2007; pp. 831–840.
- Turney, P.D. Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Philadephia, PA, USA, 6–12 July 2002; pp. 417–424.
- Wilson, T.; Wiebe, J.; Hoffmann, P. Recognizing Contextual Polarity in Phrase-Level Sentiment Analysis. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing (HLT/EMNLP), Vancouver, BC, Canada, 6–8 October 2005; pp. 347–354.
- Wilson, T.; Wiebe, J.; Hoffmann, P. Recognizing Contextual Polarity: An Exploration of Features for Phrase-level Sentiment Analysis. Comput. Linguist. 2009, 35, 399–433. [Google Scholar] [CrossRef]
- Yu, H.; Hatzivassiloglou, V. Towards Answering Opinion Questions: Separating Facts from Opinions and Identifying the Polarity of Opinion Sentences. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 11–12 July 2003; pp. 129–136.
- Lin, C.; He, Y. Joint Sentiment/Topic Model for Sentiment Analysis. In Proceedings of the ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; pp. 375–384.
- Mei, Q.; Ling, X.; Wondra, M.; Su, H.; Zhai, C. Topic Sentiment Mixture: Modeling Facets and Opinions in Weblogs. In Proceedings of the International Conference on World Wide Web (WWW), Banff, AB, Canada, 8–12 May 2007; pp. 171–180.
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment Classification using Machine Learning Techniques. In Proceedings of the ACL Conference on Empirical methods in Natural Language Processing, Philadelphia, PA, USA, 6–7 July 2002; pp. 79–86.
- Boiy, E.; Moens, M. A Machine Learning Approach to Sentiment Analysis in Multilingual Web Texts. Inf. Retr. 2009, 12, 526–558. [Google Scholar] [CrossRef]
- Nasukawa, T.; Yi, J. Sentiment Analysis: Capturing Favorability Using Natural Language Processing. In Proceedings of the International Conference on Knowledge Capture, Sanibel Island, FL, USA, 23–25 October 2003; pp. 70–77.
- Ding, X.; Liu, B. The Utility of Linguistic Rules in Opinion Mining. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 811–812.
- Xavier, U.H.R. Sentiment Analysis of Hollywood Movies on Twitter. In Proceedings of the IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Paris, France, 25–28 August 2013; pp. 1401–1404.
- Yamamoto, Y.; Kumamoto, T.; Nadamoto, A. Role of Emoticons for Multidimensional Sentiment Analysis of Twitter. In Proceedings of the International Conference on Information Integration and Web-based Applications Services (iiWAS), Hanoi, Vietnam, 4–6 December 2014; pp. 107–115.
- Waghode Poonam, B.; Kinikar, M. Twitter Sentiment Analysis with Emoticons. Int. J. Eng. Comput. Sci. 2015, 4, 11315–11321. [Google Scholar]
- Chikersal, P.; Poria, S.; Cambria, E. SeNTU: Sentiment Analysis of Tweets by Combining a Rule-based Classifier with Supervised Learning. In Proceedings of the International Workshop on Semantic Evaluation (SemEval), Denver, CO, USA, 4–5 June 2015; pp. 647–651.
- Barbosa, L.; Feng, J. Robust Sentiment Detection on Twitter from Biased and Noisy Data. In Proceedings of the International Conference on Computational Linguistics: Posters, Beijing, China, 23–27 August 2010; pp. 36–44.
- Naveed, N.; Gottron, T.; Kunegis, J.; Alhadi, A.C. Bad News Travel Fast: A Content-based Analysis of Interestingness on Twitter. In Proceedings of the 3rd International Web Science Conference (WebSci’11), Koblenz, Germany, 15–17 June 2011; pp. 8:1–8:7.
- Nakov, P.; Rosenthal, S.; Kozareva, Z.; Stoyanov, V.; Ritter, A.; Wilson, T. SemEval-2013 Task 2: Sentiment Analysis in Twitter. In Proceedings of the 7th International Workshop on Semantic Evaluation (SemEval@NAACL-HLT), Atlanta, GA, USA, 14–15 June 2013; pp. 312–320.
- Rosenthal, S.; Ritter, A.; Nakov, P.; Stoyanov, V. SemEval-2014 Task 9: Sentiment Analysis in Twitter. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval@COLING), Dublin, Ireland, 23–24 August 2014; pp. 73–80.
- Rosenthal, S.; Nakov, P.; Kiritchenko, S.; Mohammad, S.; Ritter, A.; Stoyanov, V. SemEval-2015 Task 10: Sentiment Analysis in Twitter. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval@NAACL-HLT), Denver, CO, USA, 4–5 June 2015; pp. 451–463.
- Nakov, P.; Ritter, A.; Rosenthal, S.; Sebastiani, F.; Stoyanov, V. SemEval-2016 Task 4: Sentiment Analysis in Twitter. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval@NAACL-HLT), San Diego, CA, USA, 16–17 June 2016; pp. 1–18.
- Lee, C.; Roth, D. Distributed Box-Constrained Quadratic Optimization for Dual Linear SVM. In Proceedings of the 32nd International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 987–996.
- Zhuang, Y.; Chin, W.; Juan, Y.; Lin, C. Distributed Newton Methods for Regularized Logistic Regression. In Proceedings of the 19th Pacific-Asia Conference, Advances in Knowledge Discovery and Data Mining (PAKDD), Ho Chi Minh City, Vietnam, 19–22 May 2015; pp. 690–703.
- Sahni, T.; Chandak, C.; Chedeti, N.R.; Singh, M. Efficient Twitter Sentiment Classification using Subjective Distant Supervision. arXiv, 2017; arXiv:1701.03051. [Google Scholar]
- Kanavos, A.; Perikos, I.; Vikatos, P.; Hatzilygeroudis, I.; Makris, C.; Tsakalidis, A. Conversation Emotional Modeling in Social Networks. In Proceedings of the IEEE International Conference on Tools with Artificial Intelligence (ICTAI), Limassol, Cyprus, 10–12 November 2014; pp. 478–484.
- Kanavos, A.; Perikos, I.; Hatzilygeroudis, I.; Tsakalidis, A. Integrating User’s Emotional Behavior for Community Detection in Social Networks. In Proceedings of the International Conference on Web Information Systems and Technologies (WEBIST), Rome, Italy, 8–10 November 2016; pp. 355–362.
- Baltas, A.; Kanavos, A.; Tsakalidis, A. An Apache Spark Implementation for Sentiment Analysis on Twitter Data. In Proceedings of the International Workshop on Algorithmic Aspects of Cloud Computing (ALGOCLOUD), Aarhus, Denmark, 22–26 August 2016.
- Nodarakis, N.; Sioutas, S.; Tsakalidis, A.; Tzimas, G. Large Scale Sentiment Analysis on Twitter with Spark. In Proceedings of the EDBT/ICDT Workshops, Bordeaux, France, 15–18 March 2016.
- Khuc, V.N.; Shivade, C.; Ramnath, R.; Ramanathan, J. Towards Building Large-Scale Distributed Systems for Twitter Sentiment Analysis. In Proceedings of the Annual ACM Symposium on Applied Computing, Gyeongju, Korea, 24–28 March 2012; pp. 459–464.
- Apache Spark. Available online: http://spark.apache.org/ (accessed on 2 March 2017).
- MLlib. Available online: http://spark.apache.org/mllib/ (accessed on 2 March 2017).
- Nodarakis, N.; Pitoura, E.; Sioutas, S.; Tsakalidis, A.; Tsoumakos, D.; Tzimas, G. kdANN+: A Rapid AkNN Classifier for Big Data. Trans. Large Scale Data Knowl. Cent. Syst. 2016, 23, 139–168. [Google Scholar]
- Davidov, D.; Rappoport, A. Efficient Unsupervised Discovery of Word Categories Using Symmetric Patterns and High Frequency Words. In Proceedings of the International Conference on Computational Linguistics, Sydney, Australia, 17–21 July 2006; pp. 297–304.
- Bloom, B.H. Space/Time Trade-offs in Hash Coding with Allowable Errors. Commun. ACM 1970, 13, 422–426. [Google Scholar] [CrossRef]
- Using Hadoop for Large Scale Analysis on Twitter: A Technical Report. Available online: http://arxiv.org/abs/1602.01248 (accessed on 2 March 2017).
- Toutanova, K.; Klein, D.; Manning, C.D.; Singer, Y. Feature-Rich Part-of-Speech Tagging with a Cyclic Dependency Network. In Proceedings of the HLT-NAACL, Edmonton, AB, Canada, 31 May–1 June 2003; pp. 252–259.
- Twitter Developer Documentation. Available online: https://dev.Twitter.com/rest/public/search (accessed on 2 March 2017).
- Go, A.; Bhayani, R.; Huang, L. Twitter Sentiment Classification Using Distant Supervision; CS224N Project Report; Stanford University: Stanford, CA, USA, 2009; pp. 1–6. [Google Scholar]
- Sentiment140 API. Available online: http://help.sentiment140.com/api (accessed on 2 March 2017).
- Cheng, Z.; Caverlee, J.; Lee, K. You Are Where You Tweet: A Content-based Approach to Geo-locating Twitter Users. In Proceedings of the ACM International Conference on Information and Knowledge Management (CIKM), Washington, DC, USA, 25–28 July 2010; pp. 759–768.
- Twitter Cikm 2010. Available online: https://archive.org/details/Twitter_cikm_2010 (accessed on 2 March 2017).
- Twitter Sentiment Analysis Training Corpus (Dataset). Available online: http://thinknook.com/Twitter-sentiment-analysis-training-corpus-dataset-2012-09-22/ (accessed on 2 March 2017).
- Ternary Classification. Available online: https://www.crowdflower.com/data-for-everyone/ (accessed on 2 March 2017).
- Barbieri, F.; Saggion, H. Modelling Irony in Twitter: Feature Analysis and Evaluation. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC), Reykjavik, Iceland, 26–31 May 2014; pp. 4258–4264.
- Bosco, C.; Patti, V.; Bolioli, A. Developing Corpora for Sentiment Analysis: The Case of Irony and Senti-TUT. IEEE Intell. Syst. 2013, 28, 55–63. [Google Scholar] [CrossRef]
- González-Ibáñez, R.I.; Muresan, S.; Wacholder, N. Identifying Sarcasm in Twitter: A Closer Look. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL), Portland, OR, USA, 19–24 June 2011; pp. 581–586.
- Reyes, A.; Rosso, P.; Veale, T. A Multidimensional Approach for Detecting Irony in Twitter. Lang. Resour. Eval. 2013, 47, 239–268. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Symbol | Meaning |
|---|---|
| H | set of hashtags |
| E | set of emoticons |
| T | training set |
| test set | |
| L | set of sentiment labels of T |
| p | set of sentiment polarities of |
| C | AkNN classifier |
| weight of feature f | |
| number of times feature f appears in a tweet | |
| count of feature f in corpus | |
| frequency of feature f in corpus | |
| upper bound for content words | |
| lower bound for high frequency words | |
| maximal observed value of feature f in corpus | |
| i-th hash function | |
| feature vector of T | |
| feature vector of | |
| V | set of matching vectors |
| Framework | MapReduce | Spark | ||||
|---|---|---|---|---|---|---|
| Setup | BF | NBF | Random Baseline | BF | NBF | Random Baseline |
| Binary Emoticons | 0.77 | 0.69 | 0.5 | 0.77 | 0.76 | 0.5 |
| Binary Hashtags | 0.74 | 0.53 | 0.5 | 0.73 | 0.71 | 0.5 |
| Multi-class Emoticons | 0.55 | 0.56 | 0.25 | 0.59 | 0.56 | 0.25 |
| Multi-class Hashtags | 0.32 | 0.33 | 0.08 | 0.37 | 0.35 | 0.08 |
| Setup | BF | NBF |
|---|---|---|
| Binary Emoticons | 0.08 | 0.06 |
| Binary Hashtags | 0.05 | 0.03 |
| Multi-class Emoticons | 0.05 | 0.02 |
| Multi-class Hashtags | 0.05 | 0.01 |
| Framework | MapReduce | Spark | ||||||
|---|---|---|---|---|---|---|---|---|
| Setup | ||||||||
| Binary Emoticons BF | 0.77 | 0.77 | 0.78 | 0.78 | 0.77 | 0.77 | 0.77 | 0.78 |
| Binary Emoticons NBF | 0.69 | 0.75 | 0.78 | 0.79 | 0.76 | 0.77 | 0.78 | 0.78 |
| Binary Hashtags BF | 0.74 | 0.75 | 0.75 | 0.75 | 0.73 | 0.73 | 0.73 | 0.74 |
| Binary Hashtags NBF | 0.53 | 0.62 | 0.68 | 0.72 | 0.71 | 0.72 | 0.73 | 0.74 |
| Multi-class Emoticons BF | 0.55 | 0.55 | 0.55 | 0.55 | 0.59 | 0.59 | 0.59 | 0.59 |
| Multi-class Emoticons NBF | 0.56 | 0.58 | 0.6 | 0.6 | 0.56 | 0.58 | 0.58 | 0.59 |
| Multi-class Hashtags BF | 0.32 | 0.32 | 0.32 | 0.32 | 0.37 | 0.37 | 0.37 | 0.38 |
| Multi-class Hashtags NBF | 0.33 | 0.35 | 0.37 | 0.37 | 0.35 | 0.36 | 0.37 | 0.38 |
| Framework | MapReduce | Spark | ||
|---|---|---|---|---|
| Setup | BF | NBF | BF | NBF |
| Binary Emoticons | 98 | 116.76 | 1605.8 | 1651.4 |
| Binary Hashtags | 98 | 116.78 | 403.3 | 404 |
| Multi-class Emoticons | 776.45 | 913.62 | 3027.7 | 3028 |
| Multi-class Hashtags | 510.83 | 620.1 | 2338.8 | 2553 |
| Framework | MapReduce | Spark | ||
|---|---|---|---|---|
| Setup | BF | NBF | BF | NBF |
| Binary Emoticons | 1312 | 1413 | 445 | 536 |
| Binary Hashtags | 521 | 538 | 113 | 123 |
| Multi-class Emoticons | 1737 | 1727 | 747 | 777 |
| Multi-class Hashtags | 1240 | 1336 | 546 | 663 |
| Framework | MapReduce | Spark | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1-1 Fraction F | 0.2 | 0.4 | 0.6 | 0.8 | 1 | 0.2 | 0.4 | 0.6 | 0.8 | 1 |
| Multi-class Emoticons BF | 636 | 958 | 1268 | 1421 | 1737 | 178 | 305 | 490 | 605 | 747 |
| Multi-class Emoticons NBF | 632 | 1009 | 1323 | 1628 | 1727 | 173 | 326 | 453 | 590 | 777 |
| Multi-class Hashtags BF | 537 | 684 | 880 | 1058 | 1240 | 151 | 242 | 324 | 449 | 546 |
| Multi-class Hashtags NBF | 520 | 698 | 905 | 1135 | 1336 | 135 | 242 | 334 | 470 | 663 |
| Number of Slave Nodes | 1 | 2 | 3 |
|---|---|---|---|
| Multi-class Emoticons BF | 1513 | 972 | 747 |
| Multi-class Emoticons NBF | 1459 | 894 | 777 |
| Dataset Size | Decision Trees | Logistic Regression | Naive Bayes |
|---|---|---|---|
| 1.000 | 0.597 | 0.662 | 0.572 |
| 5.000 | 0.556 | 0.665 | 0.684 |
| 10.000 | 0.568 | 0.649 | 0.7 |
| 15.000 | 0.575 | 0.665 | 0.71 |
| 20.000 | 0.59 | 0.651 | 0.728 |
| 25.000 | 0.56 | 0.655 | 0.725 |
| Classifier | Positive | Negative | Neutral | Total |
|---|---|---|---|---|
| Decision Trees | 0.646 | 0.727 | 0.557 | 0.643 |
| Logistic Regression | 0.628 | 0.592 | 0.542 | 0.591 |
| Naive Bayes | 0.717 | 0.75 | 0.617 | 0.696 |
| Features | Positive | Negative | Neutral | Total |
|---|---|---|---|---|
| Complete Feature Vector | 0.646 | 0.727 | 0.557 | 0.643 |
| w/o Unigrams | 0.57 | 0.681 | 0.549 | 0.597 |
| w/o Bigrams | 0.647 | 0.729 | 0.557 | 0.644 |
| w/o Trigrams | 0.646 | 0.728 | 0.557 | 0.644 |
| w/o User | 0.646 | 0.727 | 0.557 | 0.643 |
| w/o Hashtag | 0.639 | 0.601 | 0.529 | 0.594 |
| w/o URL | 0.64 | 0.615 | 0.554 | 0.606 |
| w/o POS Tags | 0.659 | 0.729 | 0.56 | 0.65 |
| Features | Positive | Negative | Neutral | Total |
|---|---|---|---|---|
| Complete Feature Vector | 0.628 | 0.592 | 0.542 | 0.591 |
| w/o Unigrams | 0.596 | 0.457 | 0.451 | 0.51 |
| w/o Bigrams | 0.616 | 0.6 | 0.546 | 0.59 |
| w/o Trigrams | 0.649 | 0.623 | 0.572 | 0.618 |
| w/o User | 0.625 | 0.6 | 0.54 | 0.592 |
| w/o Hashtag | 0.612 | 0.591 | 0.526 | 0.58 |
| w/o URL | 0.613 | 0.598 | 0.537 | 0.585 |
| w/o POS Tags | 0.646 | 0.585 | 0.512 | 0.587 |
| Features | Positive | Negative | Neutral | Total |
|---|---|---|---|---|
| Complete Feature Vector | 0.717 | 0.75 | 0.617 | 0.696 |
| w/o Unigrams | 0.628 | 0.602 | 0.537 | 0.592 |
| w/o Bigrams | 0.714 | 0.769 | 0.629 | 0.705 |
| w/o Trigrams | 0.732 | 0.77 | 0.643 | 0.716 |
| w/o User | 0.718 | 0.751 | 0.618 | 0.698 |
| w/o Hashtag | 0.721 | 0.739 | 0.608 | 0.692 |
| w/o URL | 0.72 | 0.748 | 0.619 | 0.697 |
| w/o POS Tags | 0.716 | 0.748 | 0.617 | 0.695 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kanavos, A.; Nodarakis, N.; Sioutas, S.; Tsakalidis, A.; Tsolis, D.; Tzimas, G. Large Scale Implementations for Twitter Sentiment Classification. Algorithms 2017, 10, 33. https://doi.org/10.3390/a10010033
Kanavos A, Nodarakis N, Sioutas S, Tsakalidis A, Tsolis D, Tzimas G. Large Scale Implementations for Twitter Sentiment Classification. Algorithms. 2017; 10(1):33. https://doi.org/10.3390/a10010033
Chicago/Turabian StyleKanavos, Andreas, Nikolaos Nodarakis, Spyros Sioutas, Athanasios Tsakalidis, Dimitrios Tsolis, and Giannis Tzimas. 2017. "Large Scale Implementations for Twitter Sentiment Classification" Algorithms 10, no. 1: 33. https://doi.org/10.3390/a10010033
APA StyleKanavos, A., Nodarakis, N., Sioutas, S., Tsakalidis, A., Tsolis, D., & Tzimas, G. (2017). Large Scale Implementations for Twitter Sentiment Classification. Algorithms, 10(1), 33. https://doi.org/10.3390/a10010033