
Evaluation of Diversification Techniques for Legal Information Retrieval †



Abstract
:1. Introduction
2. Legal Document Ranking Using Diversification
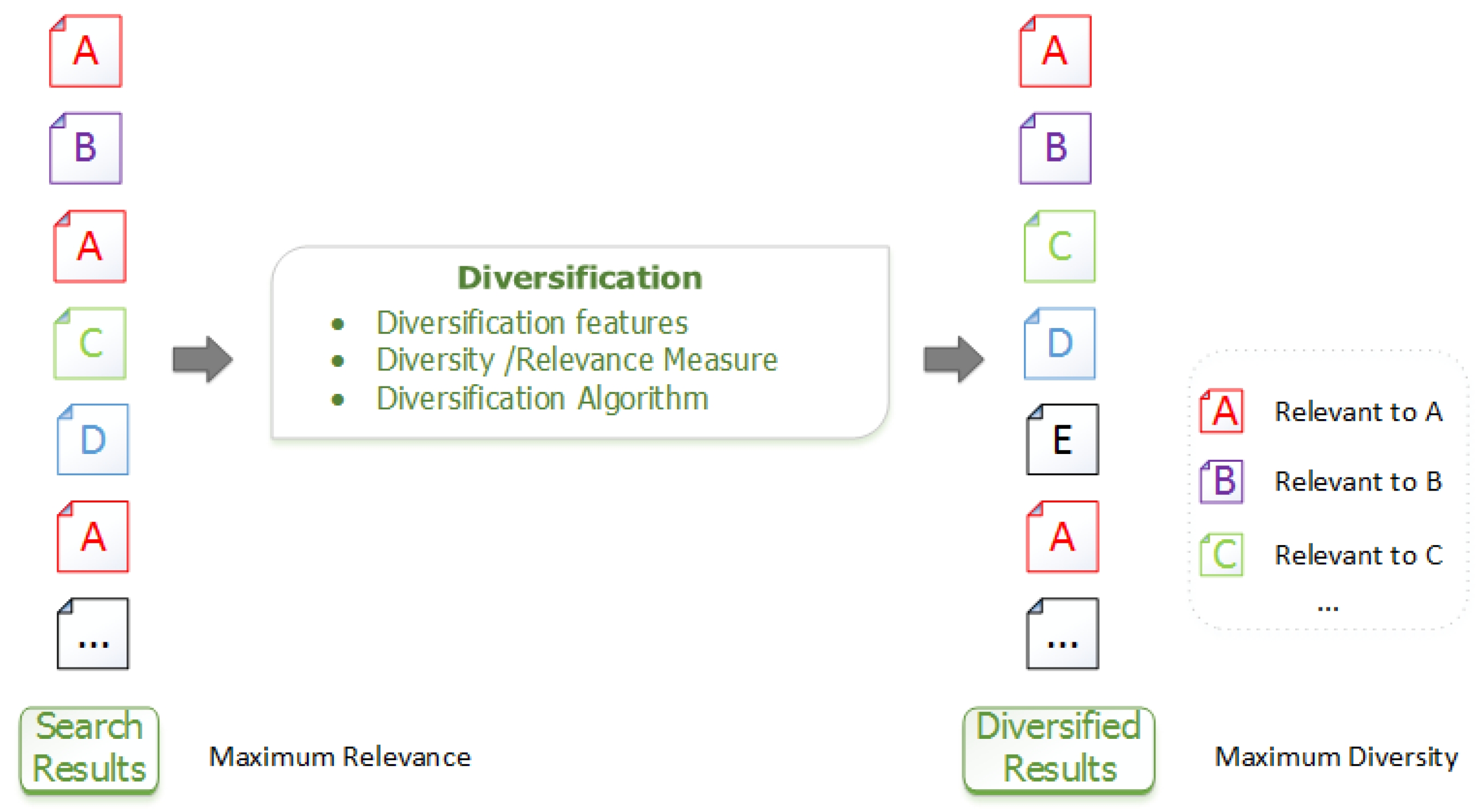
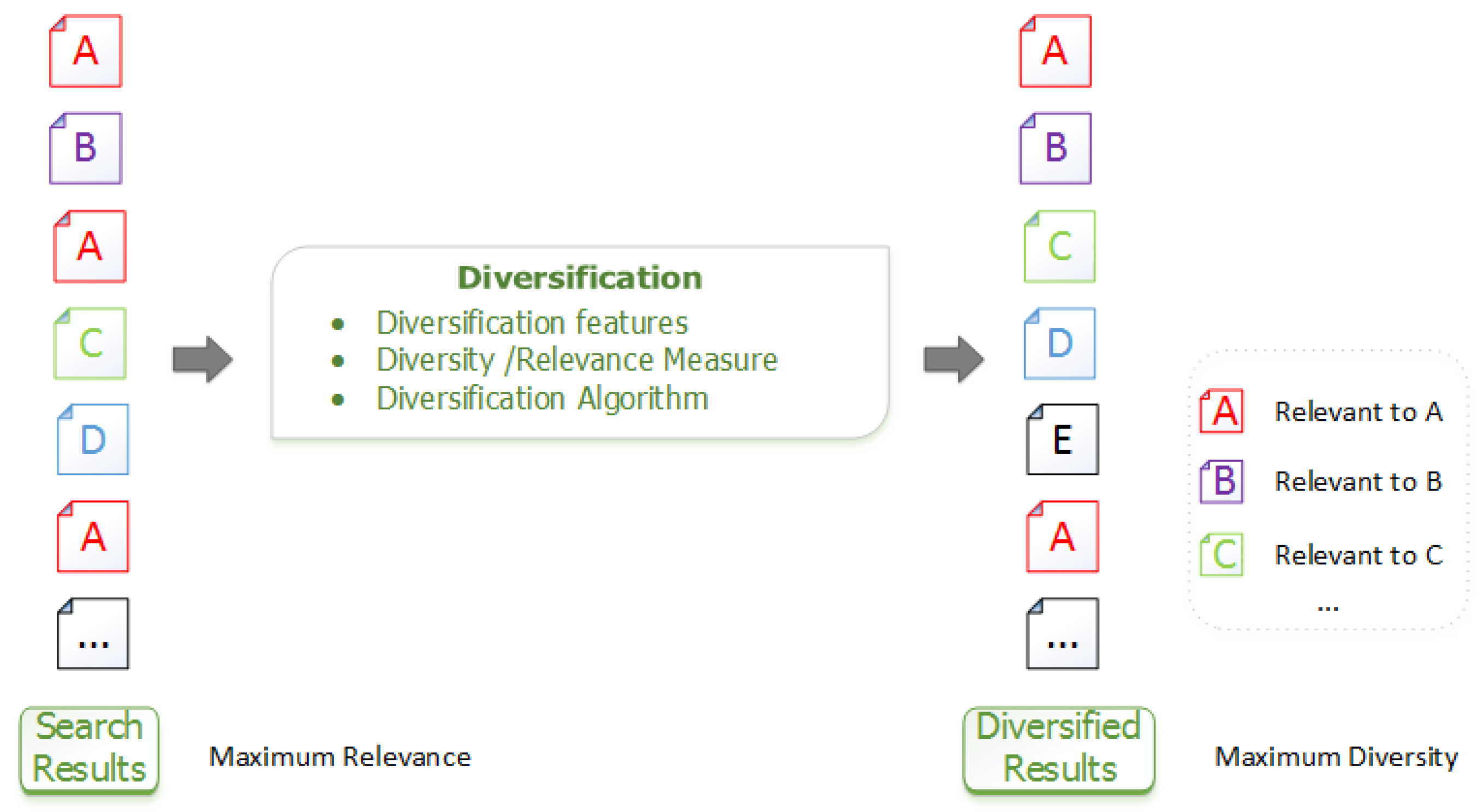
2.1. Diversification Overview
- Ranking features, features of legal documents that will be used in the ranking process.
- Distance measures, functions to measure the similarity between two legal documents and the relevance of a query to a given document. We note that in this work, as in information retrieval in general [9], the term “distance” is used informally to refer to a dissimilarity measure derived from the characteristics describing the objects.
- Diversification heuristics, heuristics to produce a subset of diverse results.
2.2. Ranking Features/Distance Measures
- Document similarity: Various well-known functions from the literature (e.g., Jaccard, cosine similarity, etc.) can be employed for computing the similarity of legal documents. In this work, we choose cosine similarity as a similarity measure; thus, the similarity between documents u and v, with term vectors U and V is:
- Document distance: The distance of two documents is:
- Query document similarity. The relevance of a query q to a given document u can be assigned as the initial ranking score obtained from the IR system, or calculated using the similarity measure, e.g., cosine similarity of the corresponding term vectors:
2.3. Diversification Heuristics
- MMR: Maximal marginal relevance [3], a greedy method to combine query relevance and information novelty, iteratively constructs the result set S by selecting documents that maximize the following objective function:MMR incrementally computes the standard relevance-ranked list when the parameter and computes a maximal diversity ranking among the documents in N when . For intermediate values of , a linear combination of both criteria is optimized. In MMR Algorithm 1, the set S is initialized with the document that has the highest relevance to the query. Since the selection of the first element has a high impact on the quality of the result, MMR often fails to achieve optimum results.
Algorithm 1 Produce diverse set of results with MMR. Input: Set of candidate results N , size of diverse set k Output: Set of diverse results ▹ Initialize with the highest relevant to the query document Set Set while do Find ▹ Iteratively select document that maximize Equation (5) Set Set end while - Max-sum: The Max-sum diversification objective function [4] aims at maximizing the sum of the relevance and diversity in the final result set. This is achieved by a greedy approximation, Algorithm 2, that selects a pair of documents that maximizes Equation (6) in each iteration.where is a pair of documents, since this objective considers document pairs for insertion. When is odd, in the final phase of the algorithm, an arbitrary element in N is chosen to be inserted in the result set S.Max-sum Algorithm 2, at each step, examines the pairwise distances of the candidate items N and selects the pair with the maximum pairwise distance, to insert into the set of diverse items S.
Algorithm 2 Produce diverse set of results with Max-sum. Input: Set of candidate results N, size of diverse set k Output: Set of diverse results for do Find ▹ Select pair of docs that maximize Equation (6) Set Set end for if k is odd then ▹ If k is odd add an arbitrary document to S end if - Max-min: The Max-min diversification objective function [4] aims at maximizing the minimum relevance and dissimilarity of the selected set. This is achieved by a greedy approximation, Algorithm 3, that initially selects a pair of documents that maximize Equation (7) and then in each iteration selects the document that maximizes Equation (8):Max-min Algorithm 3, at each step, it finds, for each candidate document, its closest document belonging to S and calculates their pairwise distance . The candidate document that has the maximum distance is inserted into S.
Algorithm 3 Produce diverse set of results with Max-min. Input: Set of candidate results N, size of diverse set k Output: Set of diverse results Find ▹ Initially selects documents that maximize Equation (7) Set while do Find ▹ Select document that maximize Equation (8) Set end while - Mono-objective: Mono-objective [4] combines the relevance and the similarity values into a single value for each document. It is defined as:Algorithm 4 approximates the Mono-objective. The algorithm, at the initialization step, calculates a distance score for each candidate document. The objective function weights each document’s similarity to the query with the average distance of the document with the rest of the documents. After the initialization step, where scores are calculated, they are not updated after each iteration of the algorithm. Therefore, each step consists of selecting the document from the remaining candidates set with the maximum score and inserting it into S.
Algorithm 4 Produce diverse set of results with Mono-objective. Input: Set of candidate results N, size of diverse set k Output: Set of diverse results for do ▹ Calculate scores based on Equation (9) end for while do Find ▹ Sort and select documents Set Set end while - LexRank: LexRank [5] is a stochastic graph-based method for computing the relative importance of textual units. A document is represented as a network of inter-related sentences, and a connectivity matrix based on intra-sentence similarity is used as the adjacency matrix of the graph representation of sentences.In our setting, instead of sentences, we use documents that are in the initial retrieval set N for a given query. In this way, instead of building a graph using the similarity relationships among the sentences based on an input document, we utilize document similarity on the result set. If we consider documents as nodes, the result set document collection can be modeled as a graph by generating links between documents based on their similarity score as in Equation (2). Typically, low values in this matrix can be eliminated by defining a threshold so that only significantly similar documents are connected to each other. However, as in all discretization operations, this means information loss. Instead, we choose to utilize the strength of the similarity links. This way we use the cosine values directly to construct the similarity graph, obtaining a much denser, but weighted graph. Furthermore, we normalize our adjacency matrix B, so as to make the sum of each row equal to one.Thus, in LexRank scoring formula Equation (10), Matrix B captures pairwise similarities of the documents, and square matrix A, which represents the probability of jumping to a random node in the graph, has all elements set to , where is the number of documents.LexRank Algorithm 5 applies a variation of PageRank [11] over a document graph. A random walker on this Markov chain chooses one of the adjacent states of the current state with probability or jumps to any state in the graph, including the current state, with probability λ.
Algorithm 5 Produce diverse set of results with LexRank. Input: Set of candidate results N, size of diverse set k Output: Set of diverse results for do ▹ Calculate connectivity matrix based on document similarity Equation (2) end for ▹ Calculate stationary distribution of Equation (10). (Omitted for clarity) while do Find ▹ Sort and select documents Set Set end while - Biased LexRank: Biased LexRank [6] provides for a LexRank extension that takes into account a prior document probability distribution, e.g., the relevance of documents to a given query. The Biased LexRank scoring formula is analogous to LexRank scoring formula Equation (10), with matrix A, which represents the probability of jumping to a random node in the graph, proportional to the query document relevance.Algorithm 5 is also used to produce a diversity-oriented ranking of results with the Biased LexRank method. In Biased LexRank scoring formula Equation (10), we set matrix B as the connectivity matrix based on document similarity for all documents that are in the initial retrieval set N for a given query and matrix A elements proportional to the query document relevance.
- DivRank: DivRank [7] balances popularity and diversity in ranking, based on a time-variant random walk. In contrast to PageRank [11], which is based on stationary probabilities, DivRank assumes that transition probabilities change over time; they are reinforced by the number of previous visits to the target vertex. If is the transition probability from any vertex u to vertex v at time T, is the prior distribution that determines the preference of visiting vertex and is the transition probability from u to v prior to any reinforcement, then,where is the number of times the walk has visited up to time T and,DivRank was originally proposed in a query independent context; thus, it is not directly applicable to the diversification of search results. We introduce a query dependent prior and thus utilize DivRank as a query-dependent ranking schema. In our setting, we use documents that are in the initial retrieval set N for a given query q, create the citation network between those documents and apply the DivRank Algorithm 6 to select divers’ documents in S.
Algorithm 6 Produce diverse set of results with DivRank. Input: Set of candidate results N, size of diverse set k Output: Set of diverse results for do ▹ Connectivity matrix is based on citation network adjacency matrix end for ▹ Calculate stationary distribution of Equation (11). (Omitted for clarity) while do Find ▹ Sort and select documents Set Set end while - Grasshopper: Similar to the DivRank ranking algorithm, it is described in [8]. This model starts with a regular time-homogeneous random walk, and in each step, the vertex with the highest weight is set as an absorbing state.where is the number of times the walk has visited up to time T and,Since Grasshopper and DivRank utilize a similar approach and will ultimately present rather similar results, we utilized Grasshopper distinctively from DivRank. In particularly, instead of creating the citation network of documents belonging to the initial result set, we form the adjacency matrix based on document similarity, as previously explained in LexRank Algorithm 5.
3. Experimental Setup
3.1. Legal Corpus
3.2. Evaluation Metrics
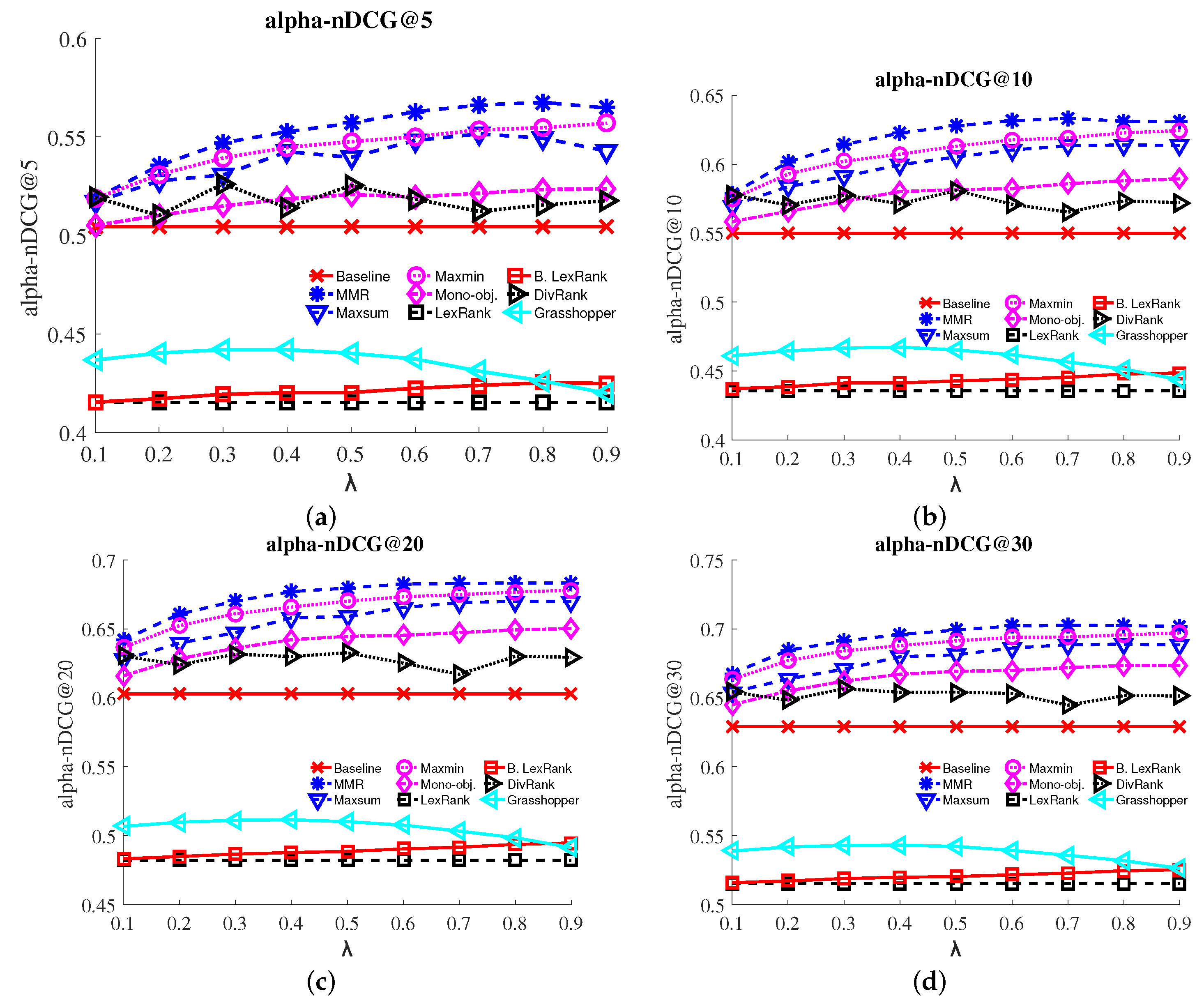
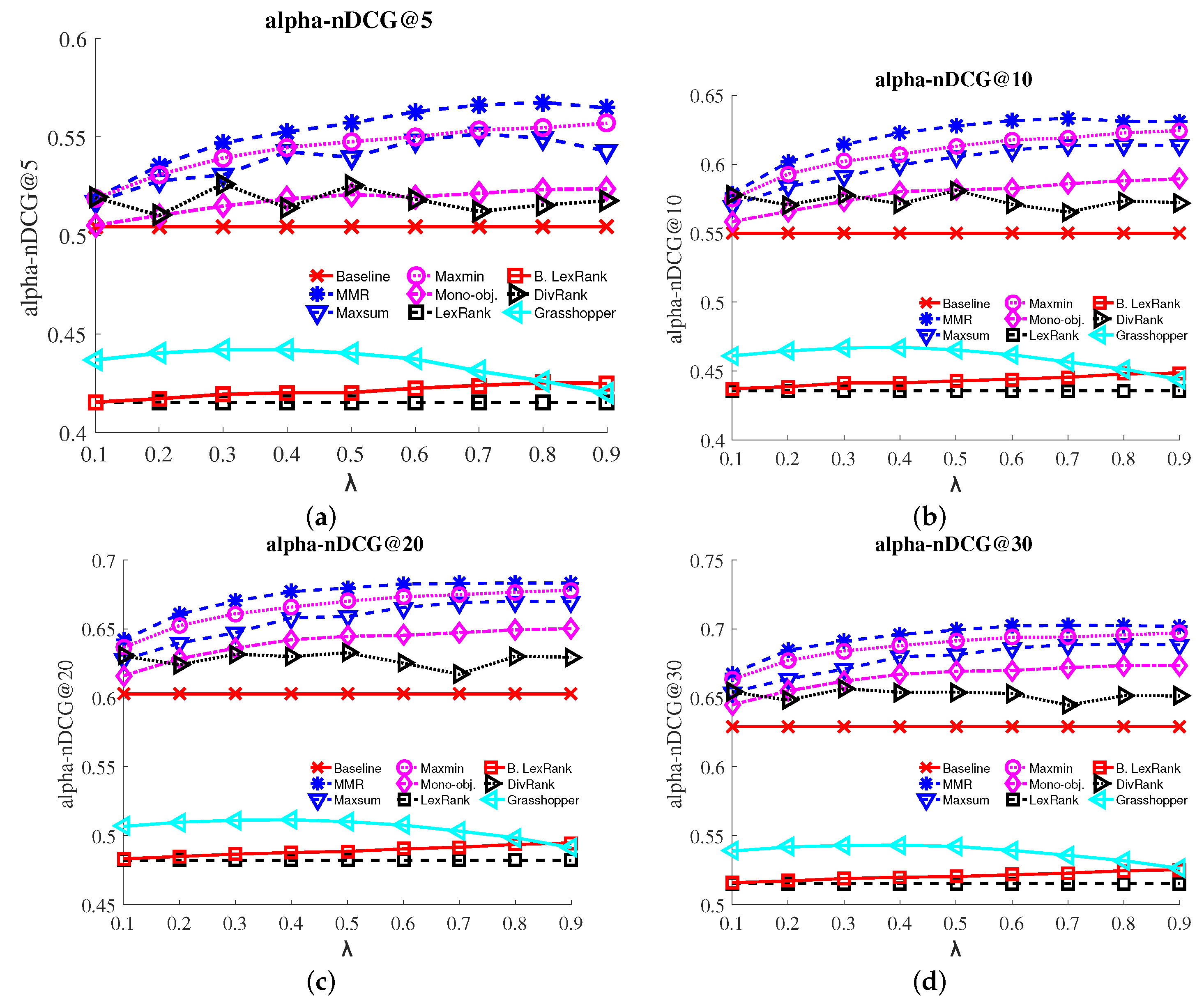
- a-nDCG: The a-normalized discounted cumulative gain [15] metric quantifies the amount of unique aspects of the query q that are covered by the ranked documents. We use , as typical in TREC evaluation.
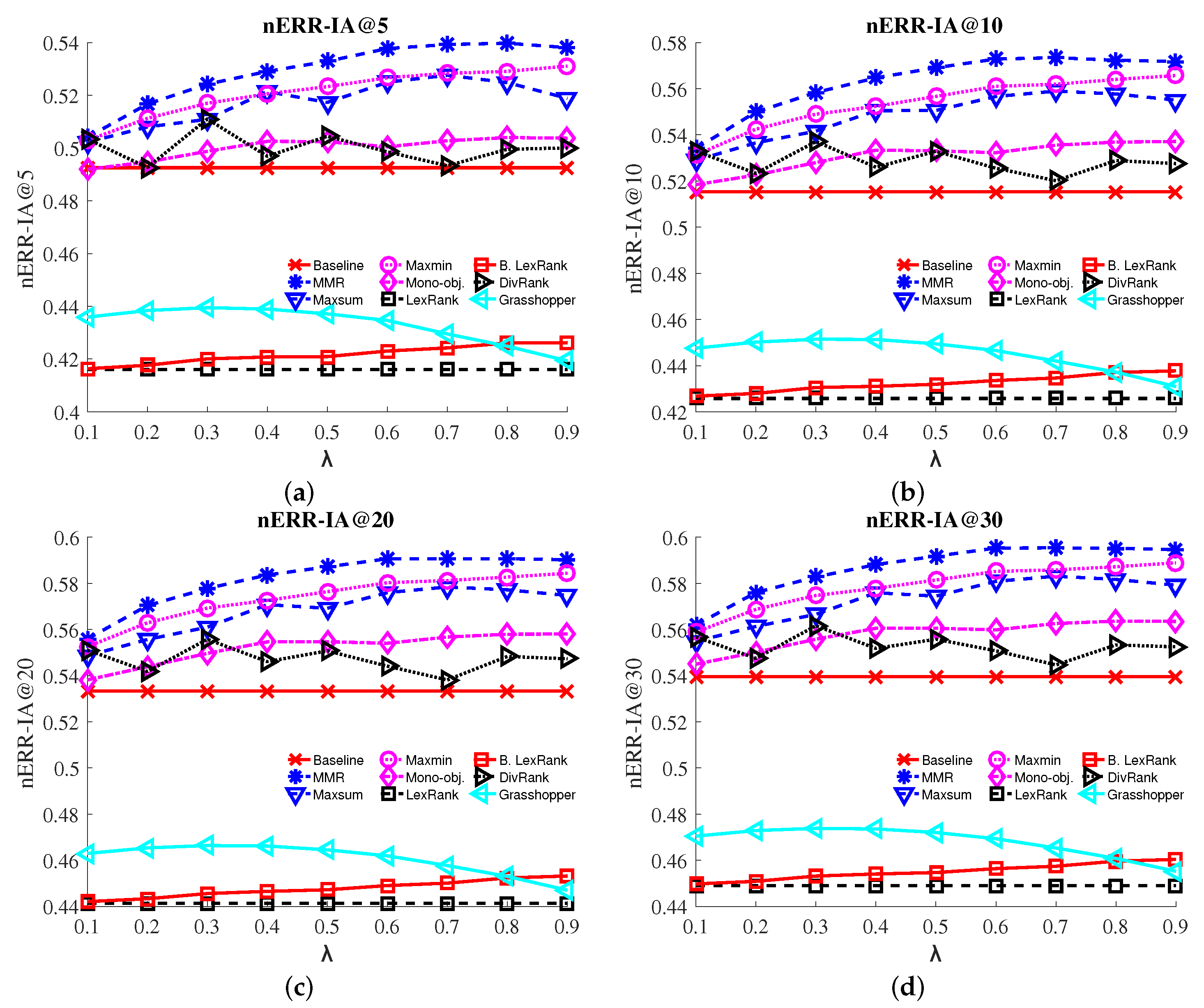
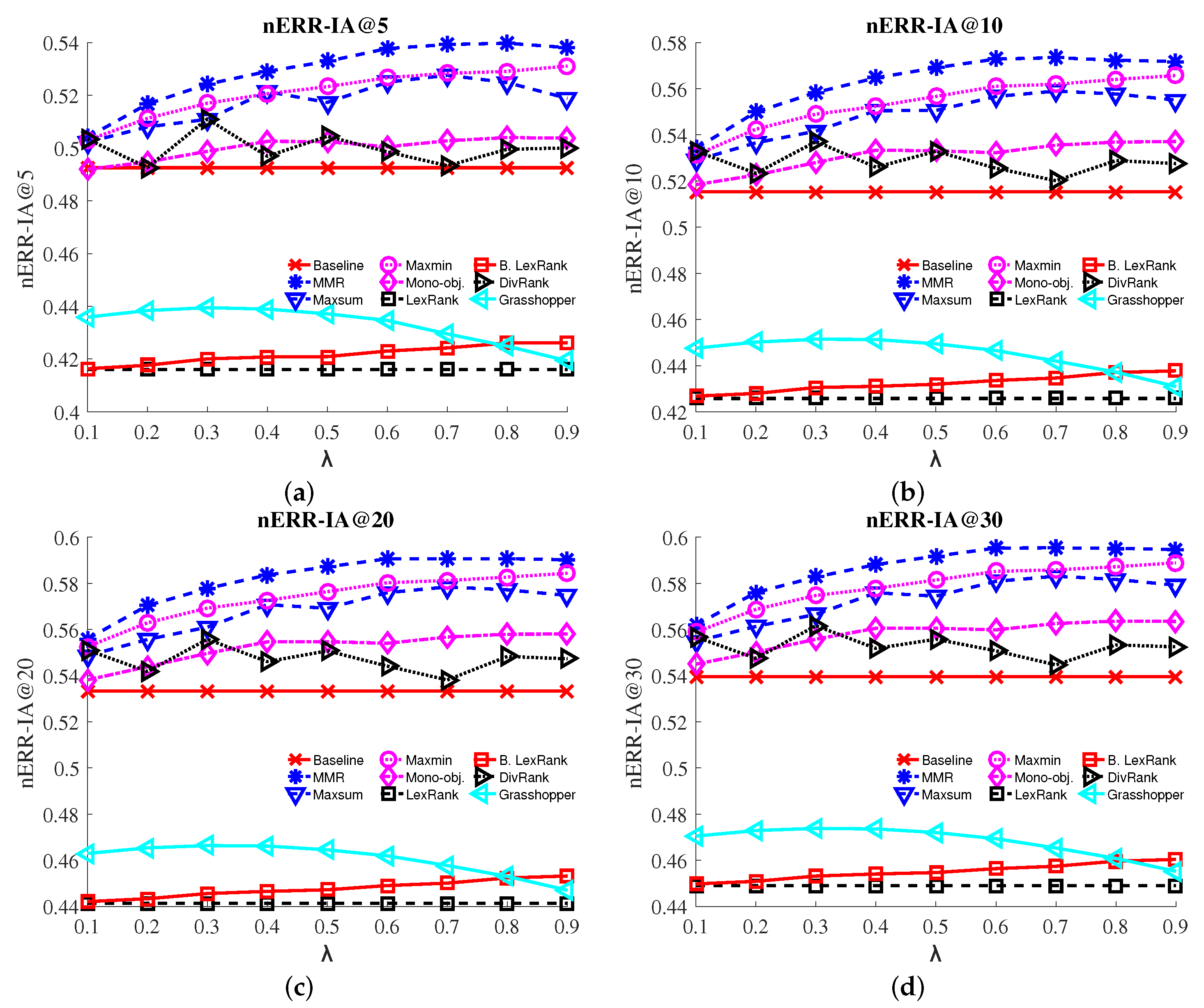
- ERR-IA: Expected reciprocal rank-intent aware [16] is based on inter-dependent ranking. The contribution of each document is based on the relevance of documents ranked above it. The discount function is therefore not just dependent on the rank, but also on the relevance of previously ranked documents.
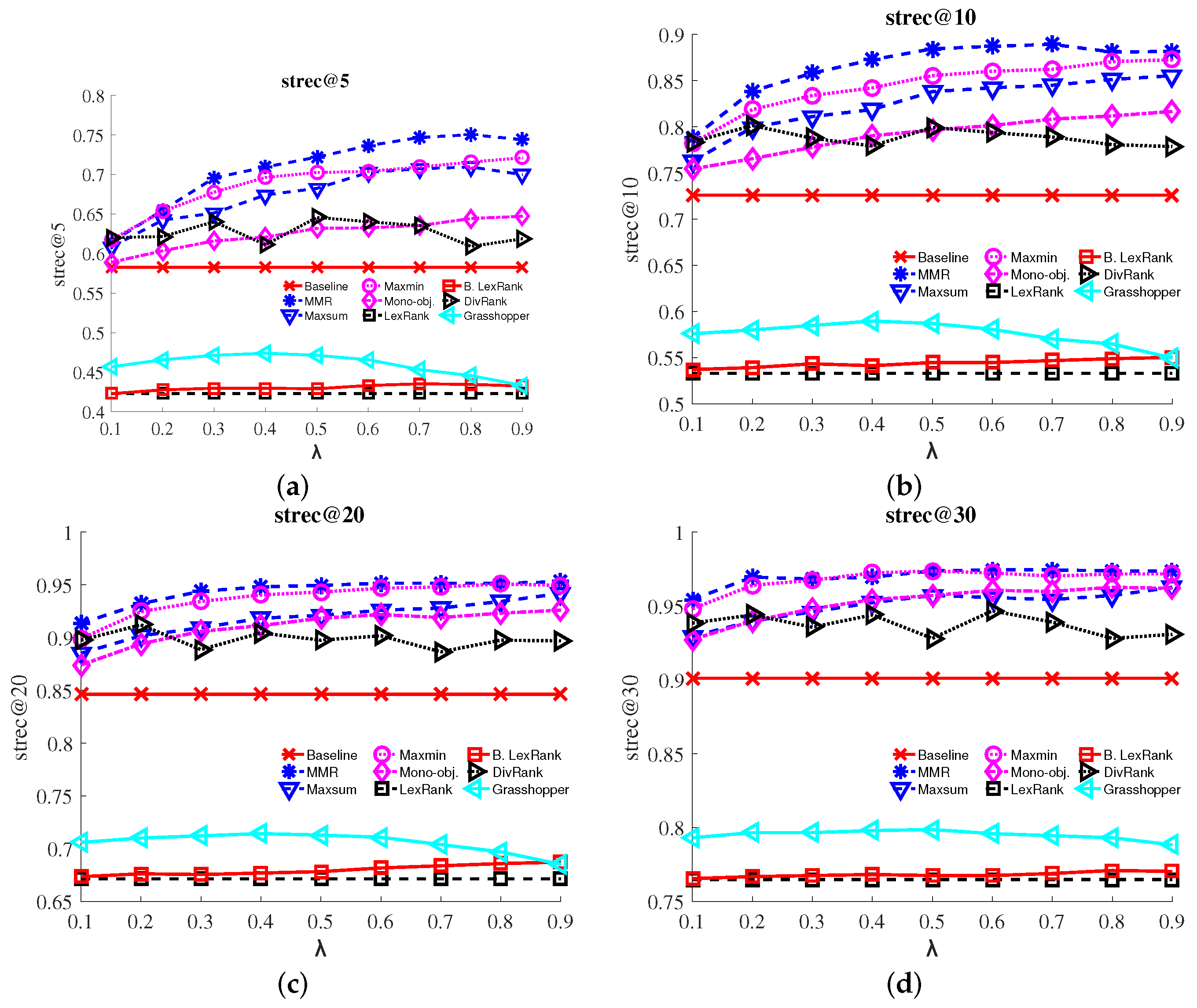
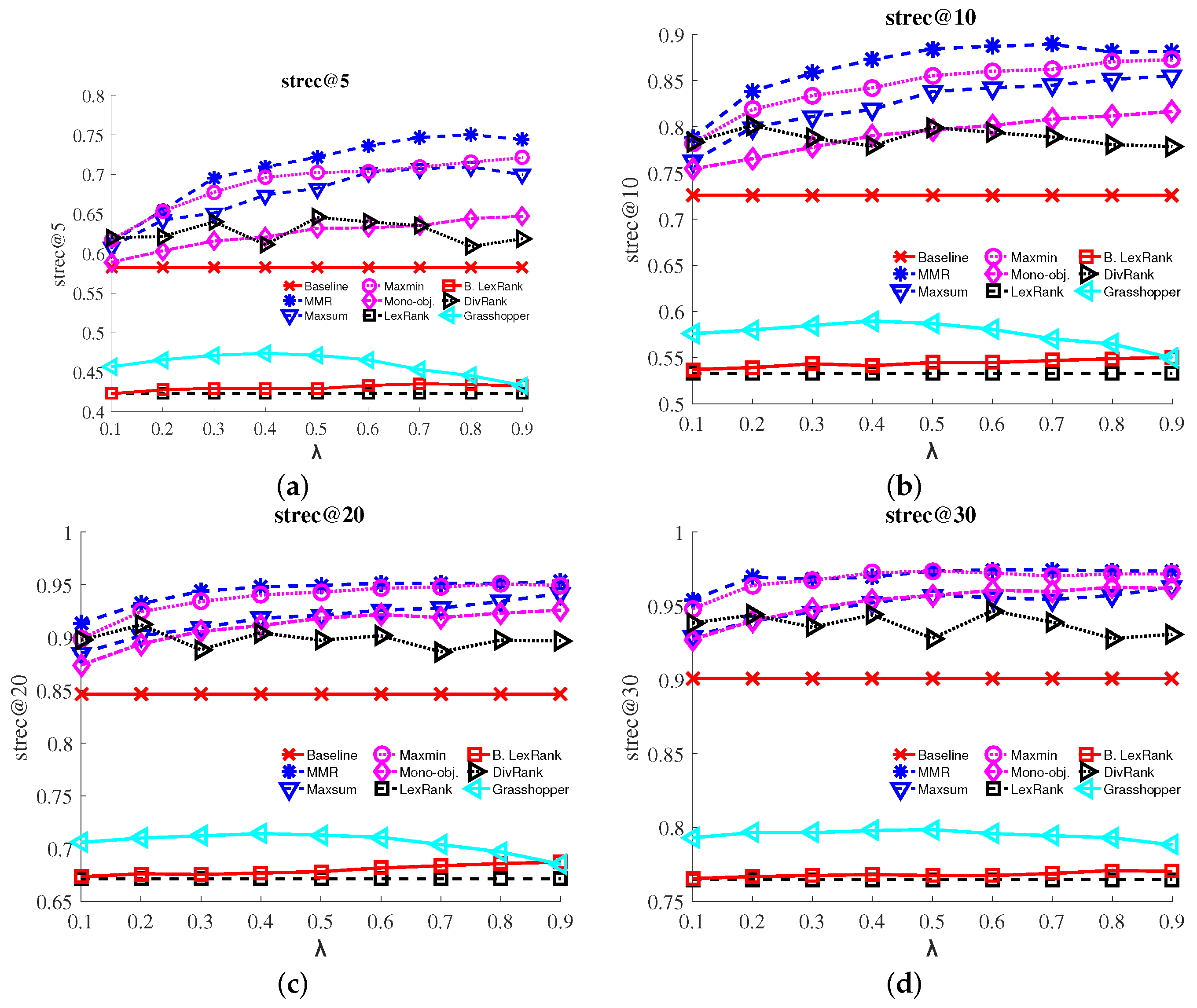
- S-recall: Subtopic-recall [17] is the number of unique aspects covered by the results, divided by the total number of aspects. It measures the aspect coverage for a given result list at depth k.
3.3. Relevance Judgments
3.4. Results
4. Related Work
4.1. Query Result Diversification
4.2. Diversified Ranking on Graphs
4.3. Legal Text Retrieval
5. Conclusions
Author Contributions
Conflicts of Interest
References
- Alces, K.A. Legal diversification. Columbia Law Rev. 2013, 113, 1977–2038. [Google Scholar]
- Koniaris, M.; Anagnostopoulos, I.; Vassiliou, Y. Diversifying the Legal Order. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Thessaloniki, Greece, 16–18 September 2016; pp. 499–509.
- Carbonell, J.; Goldstein, J. The use of MMR, diversity-based reranking for reordering documents and producing summaries. In Proceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval, Melbourne, Australia, 24–28 August 1988; pp. 335–336.
- Gollapudi, S.; Sharma, A. An Axiomatic Approach for Result Diversification. In Proceedings of the 18th International Conference on World Wide Web, Madrid, Spain, 20–24 April 2009; pp. 381–390.
- Erkan, G.; Radev, D.R. LexRank: Graph-based lexical centrality as salience in text summarization. J. Artif. Intell. Res. 2004, 22, 457–479. [Google Scholar]
- Otterbacher, J.; Erkan, G.; Radev, D.R. Biased LexRank: Passage retrieval using random walks with question-based priors. Inf. Process. Manag. 2009, 45, 42–54. [Google Scholar] [CrossRef]
- Mei, Q.; Guo, J.; Radev, D. Divrank: The interplay of prestige and diversity in information networks. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25–28 July 2010; pp. 1009–1018.
- Zhu, X.; Goldberg, A.B.; Van Gael, J.; Andrzejewski, D. Improving Diversity in Ranking using Absorbing Random Walks. In Proceedings of the Human Language Technologies: The Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT), 2007, Rochester, NY, USA, 22–27 April 2007; pp. 97–104.
- Hand, D.J.; Mannila, H.; Smyth, P. Principles of Data Mining; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Wong, S.M.; Raghavan, V.V. Vector space model of information retrieval: A reevaluation. In Proceedings of the 7th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Cambridge, UK, 2–6 July 1984; pp. 167–185.
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Technical Report for Stanford InfoLab: Stanford University, Stanford, CA, USA, 1999. [Google Scholar]
- Galgani, F.; Compton, P.; Hoffmann, A. Combining different summarization techniques for legal text. In Proceedings of the Workshop on Innovative Hybrid Approaches to the Processing of Textual Data, Avignon, France, 22 April 2012; pp. 115–123.
- Sanderson, M. Test Collection Based Evaluation of Information Retrieval Systems. Found. Trends® Inf. Retr. 2010, 4, 247–375. [Google Scholar] [CrossRef]
- Radlinski, F.; Bennett, P.N.; Carterette, B.; Joachims, T. Redundancy, diversity and interdependent document relevance. In ACM SIGIR Forum; Association for Computing Machinery (ACM): New York, NY, USA, 2009; Volume 43, pp. 46–52. [Google Scholar]
- Clarke, C.L.A.; Kolla, M.; Cormack, G.V.; Vechtomova, O.; Ashkan, A.; Büttcher, S.; MacKinnon, I. Novelty and diversity in information retrieval evaluation. In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Singapore, 20–24 July 2008; pp. 659–666.
- Chapelle, O.; Metlzer, D.; Zhang, Y.; Grinspan, P. Expected reciprocal rank for graded relevance. In Proceedings of the 18th ACM conference on Information and Knowledge Management—CIKM ’09, Hong Kong, China, 2–6 November 2009; pp. 621–630.
- Zhai, C.X.; Cohen, W.W.; Lafferty, J. Beyond independent relevance. In Proceedings of the 26th annual international ACM SIGIR conference on Research and development in information retrieval, Toronto, ON, Canada, 28 July–1 August 2003; pp. 10–17.
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Singh, J.; Nejdl, W.; Anand, A. History by Diversity: Helping Historians Search News Archives. In Proceedings of the 2016 ACM on Conference on Human Information Interaction and Retrieval, Carrboro, NC, USA, 13–17 March 2016; pp. 183–192.
- Giannopoulos, G.; Koniaris, M.; Weber, I.; Jaimes, A.; Sellis, T. Algorithms and criteria for diversification of news article comments. J. Intell. Inf. Syst. 2015, 44, 1–47. [Google Scholar] [CrossRef]
- Cheng, S.; Arvanitis, A.; Chrobak, M.; Hristidis, V. Multi-Query Diversification in Microblogging Posts. In Proceedings of the 17th International Conference on Extending Database Technology (EDBT), Athens, Greece, 24–28 March 2014; pp. 133–144.
- Koniaris, M.; Giannopoulos, G.; Sellis, T.; Vasileiou, Y. Diversifying microblog posts. In Proceedings of the International Conference on Web Information Systems Engineering, Thessaloniki, Greece, 12–14 October 2014; pp. 189–198.
- Song, K.; Tian, Y.; Gao, W.; Huang, T. Diversifying the image retrieval results. In Proceedings of the 14th ACM International Conference on Multimedia, Santa Barbara, CA, USA, 23–27 October 2006; pp. 707–710.
- Ziegler, C.N.; McNee, S.M.; Konstan, J.A.; Lausen, G. Improving recommendation lists through topic diversification. In Proceedings of the 14th International Conference on World Wide Web, Chiba, Japan, 10–14 May 2005; pp. 22–32.
- Raman, K.; Shivaswamy, P.; Joachims, T. Online learning to diversify from implicit feedback. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 705–713.
- Makris, C.; Plegas, Y.; Stamatiou, Y.C.; Stavropoulos, E.C.; Tsakalidis, A.K. Reducing Redundant Information in Search Results Employing Approximation Algorithms. In Proceedings of the International Conference on Database and Expert Systems Applications, Munich, Germany, 1–4 September 2014; pp. 240–247.
- Zhang, B.; Li, H.; Liu, Y.; Ji, L.; Xi, W.; Fan, W.; Chen, Z.; Ma, W.Y. Improving web search results using affinity graph. In Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Salvador, Brazil, 15–19 August 2005; pp. 504–511.
- Chen, H.; Karger, D.R. Less is more: probabilistic models for retrieving fewer relevant documents. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, WA, USA, 6–10 August 2006; pp. 429–436.
- Cronen-Townsend, S.; Croft, W.B. Quantifying Query Ambiguity. In Proceedings of the Second International Conference on Human Language Technology Research, San Diego, CA, USA, 24–27 March 2002; pp. 104–109.
- Santos, R.L.T.; Macdonald, C.; Ounis, I. Search Result Diversification. Found. Trends® Inf. Retr. 2015, 9, 1–90. [Google Scholar] [CrossRef]
- Drosou, M.; Pitoura, E. Search result diversification. ACM SIGMOD Rec. 2010, 39, 41. [Google Scholar] [CrossRef]
- Santos, R.L.; Macdonald, C.; Ounis, I. Exploiting query reformulations for web search result diversification. In Proceedings of the 19th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2010; pp. 881–890.
- Agrawal, R.; Gollapudi, S.; Halverson, A.; Ieong, S. Diversifying search results. In Proceedings of the second ACM international conference on web search and data mining, Barcelona, Spain, 9–11 February 2009; pp. 5–14.
- Hu, S.; Dou, Z.; Wang, X.; Sakai, T.; Wen, J.R. Search Result Diversification Based on Hierarchical Intents. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; pp. 63–72.
- Langville, A.N.; Meyer, C.D. A survey of eigenvector methods for web information retrieval. SIAM Rev. 2005, 47, 135–161. [Google Scholar] [CrossRef]
- Moens, M. Innovative techniques for legal text retrieval. Artif. Intell. Law 2001, 9, 29–57. [Google Scholar] [CrossRef]
- Biagioli, C.; Francesconi, E.; Passerini, A.; Montemagni, S.; Soria, C. Automatic semantics extraction in law documents. In Proceedings of the 10th international conference on Artificial intelligence and law, Bologna, Italy, 6–11 June 2005.
- Mencia, E.L.; Fürnkranz, J. Efficient pairwise multilabel classification for large-scale problems in the legal domain. In Machine Learning and Knowledge Discovery in Databases; Springer: Berlin, Germany, 2008; pp. 50–65. [Google Scholar]
- Grabmair, M.; Ashley, K.D.; Chen, R.; Sureshkumar, P.; Wang, C.; Nyberg, E.; Walker, V.R. Introducing LUIMA: an experiment in legal conceptual retrieval of vaccine injury decisions using a UIMA type system and tools. In Proceedings of the 15th International Conference on Artificial Intelligence and Law, San Diego, CA, USA, 8–12 June 2015; pp. 69–78.
- Saravanan, M.; Ravindran, B.; Raman, S. Improving legal information retrieval using an ontological framework. Artif. Intelli. Law 2009, 17, 101–124. [Google Scholar] [CrossRef]
- Schweighofer, E.; Liebwald, D. Advanced lexical ontologies and hybrid knowledge based systems: First steps to a dynamic legal electronic commentary. Artif. Intell. Law 2007, 15, 103–115. [Google Scholar] [CrossRef]
- Sagri, M.T.; Tiscornia, D. Metadata for content description in legal information. In Proceedings of the 14th International Workshop on Database and Expert Systems Applications, Prague, Czech Republic, 1–5 September 2003; pp. 745–749.
- Klein, M.C.; Van Steenbergen, W.; Uijttenbroek, E.M.; Lodder, A.R.; van Harmelen, F. Thesaurus-based Retrieval of Case Law. In Proceedings of the 2006 conference on Legal Knowledge and Information Systems: JURIX 2006: The Nineteenth Annual Conference, Paris, France, 8 December 2006; Volume 152, p. 61.
- Hoekstra, R.; Breuker, J.; di Bello, M.; Boer, A. The LKIF Core ontology of basic legal concepts. In Proceedings of the 2nd Workshop on Legal Ontologies and Artificial Intelligence Techniques (LOAIT 2007), Stanford, CA, USA, 4 June 2007.
- Farzindar, A.; Lapalme, G. Legal text summarization by exploration of the thematic structures and argumentative roles. In Text Summarization Branches Out Workshop Held in Conjunction with ACL; Association for Computational Linguistics (ACL): Barcelona, Spain, 25–26 July 2004; pp. 27–34. [Google Scholar]
- Farzindar, A.; Lapalme, G. Letsum, an automatic legal text summarizing system. In Proceedings of the Legal Knowledge and Information Systems. JURIX 2004: The Seventeenth Annual Conference, Berlin, Germany, 8–10 December 2004; pp. 11–18.
- Moens, M.F. Summarizing court decisions. Inf. Process. Manag. 2007, 43, 1748–1764. [Google Scholar] [CrossRef]
- Aktolga, E.; Ros, I.; Assogba, Y. Detecting outlier sections in us congressional legislation. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval—SIGIR ’11, Beijing, China, 24–28 July 2011; pp. 235–244.
- Marx, S.M. Citation networks in the law. Jurimetr. J. 1970, 10, 121–137. [Google Scholar]
- Van Opijnen, M. Citation Analysis and Beyond: In Search of Indicators Measuring Case Law Importance. In Proceedings of the Legal Knowledge and Information Systems-JURIX 2012: The Twenty-Fifth Annual Conference, Amsterdam, The Netherlands, 17–19 December 2012; pp. 95–104.
- Fowler, J.H.; Jeon, S. The Authority of Supreme Court precedent. Soc. Netw. 2008, 30, 16–30. [Google Scholar] [CrossRef]
- Fowler, J.H.; Johnson, T.R.; Spriggs, J.F.; Jeon, S.; Wahlbeck, P.J. Network Analysis and the Law: Measuring the Legal Importance of Precedents at the U.S. Supreme Court. Political Anal. 2006, 15, 324–346. [Google Scholar] [CrossRef]
- Galgani, F.; Compton, P.; Hoffmann, A. Citation based summarisation of legal texts. In Proceedings of the PRICAI 2012: Trends in Artificial Intelligence, Kuching, Malaysia, 3–7 September 2012; pp. 40–52.
- Koniaris, M.; Anagnostopoulos, I.; Vassiliou, Y. Network Analysis in the Legal Domain: A complex model for European Union legal sources. arXiv, 2015; arXiv:1501.05237. [Google Scholar]
- Lettieri, N.; Altamura, A.; Faggiano, A.; Malandrino, D. A computational approach for the experimental study of EU case law: analysis and implementation. Soc. Netw. Anal. Min. 2016, 6. [Google Scholar] [CrossRef]
- Koniaris, M.; Anagnostopoulos, I.; Vassiliou, Y. Multi-dimension Diversification in Legal Information Retrieval. In Proceedings of the International Conference on Web Information Systems Engineering, Shanghai, China, 8–10 November 2016; pp. 174–189.
- Wittfoth, A.; Chung, P.; Greenleaf, G.; Mowbray, A. AustLII’s Point-in-Time Legislation System: A generic PiT system for presenting legislation. Available online: http://portsea.austlii.edu.au/pit/papers/PiT_background_2005.rtf (accessed on 25 January 2017).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Range |
|---|---|
| algorithms tested | MMR, Max-min, Max-sum, Mono-objective, LexRank, Biased LexRank, DivRank, Grasshopper |
| tradeoff l values | 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9 |
| candidate set size n = | 100 |
| result set size k = | 5, 10, 20, 30 |
| # of sample queries | 298 |
| 1: | Abandoned and Lost Property | 3: | Abortion and Birth Control |
| 24: | Aliens Immigration and Citizenship | 31: | Antitrust and Trade Regulation |
| 61: | Breach of Marriage Promise | 84: | Commodity Futures Trading Regulation |
| 88: | Compromise and Settlement | 199: | Implied and Constructive Contracts |
| 291: | Privileged Communications and Confidentiality | 363: | Threats Stalking and Harassment |
| Topic | Top Words |
|---|---|
| 1 | court applicant property respondent claim order costs company trustee trust |
| 2 | evidence agreement contract business drtime hamiltonrespondent applicant sales |
| 3 | tribunal rights land title native evidence area claim interests appellant |
| 4 | evidence agreement meeting conduct time tiltformsecond brand septemberaustralia |
| 5 | evidence professor university dr property gray patent uwaclaimnrc |
| Document | Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 |
|---|---|---|---|---|---|
| 08_711 | 0.731 | 0.267 | 0.00172 | 8.79 × 10 | 4 × 10 |
| 09_1395 | 0.467 | 2.25 × 10 | 0.459 | 0.0746 | 1.04 × 10 |
| 09_1383 | 0.99 | 2.85 × 10 | 0.00944 | 0.000298 | 1.31 × 10 |
| 06_1169 | 0.994 | 5.33 × 10 | 0.00559 | 5.41 × 10 | 2.46 × 10 |
| 07_924 | 0.237 | 4.83 × 10 | 4.64 × 10 | 4.9 × 10 | 0.763 |
| a-nDCG | nERR-IA | S-recall | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | @5 | @10 | @20 | @30 | @5 | @10 | @20 | @30 | @5 | @10 | @20 | @30 |
| baseline | 0.5044 | 0.5498 | 0.6028 | 0.6292 | 0.4925 | 0.5153 | 0.5333 | 0.5395 | 0.5827 | 0.7260 | 0.8464 | 0.9010 |
| MMR | 0.5187 | 0.5785 * | 0.642 * | 0.6676 * | 0.5041 | 0.5341 | 0.5559 ° | 0.562 ° | 0.6145 | 0.7875 * | 0.9135 * | 0.9543 * |
| Max-sum | 0.5170 | 0.5699 | 0.6276 | 0.6541 | 0.5022 | 0.5290 | 0.5486 | 0.5549 | 0.6083 | 0.7626 | 0.8851 | 0.9294 |
| Max-min | 0.5188 | 0.5749 | 0.6365 | 0.6633 | 0.5029 | 0.5313 | 0.5526 | 0.5589 | 0.6173 | 0.7820 | 0.8990 | 0.9481 |
| Mono-objective | 0.5052 | 0.5584 | 0.6160 | 0.6450 | 0.4919 | 0.5184 | 0.5382 | 0.5450 | 0.5889 | 0.7543 | 0.8740 | 0.9273 |
| LexRank | 0.4152 | 0.4357 | 0.4823 | 0.5154 | 0.4160 | 0.4258 | 0.4413 | 0.4491 | 0.4228 | 0.5329 | 0.6713 | 0.7647 |
| Biased LexRank | 0.4155 | 0.4373 | 0.4833 | 0.5160 | 0.4163 | 0.4268 | 0.4421 | 0.4498 | 0.4228 | 0.5370 | 0.6734 | 0.7654 |
| DivRank | 0.5195 | 0.5774 | 0.6304 | 0.6543 | 0.5035 | 0.5328 | 0.5511 | 0.5567 | 0.6208 | 0.7820 | 0.8976 | 0.9384 |
| Grasshopper | 0.4368 | 0.4611 | 0.5069 | 0.5389 | 0.4359 | 0.4476 | 0.4630 | 0.4705 | 0.4567 | 0.5758 | 0.7059 | 0.7931 |
| baseline | 0.5044 | 0.5498 | 0.6028 | 0.6292 | 0.4925 | 0.5153 | 0.5333 | 0.5395 | 0.5827 | 0.7260 | 0.8464 | 0.9010 |
| MMR | 0.5356 | 0.6015 | 0.6607 | 0.6845 | 0.5167 | 0.5499 | 0.5704 | 0.576 | 0.6547 | 0.8388 | 0.9322 | 0.9696 |
| Max-sum | 0.5277 | 0.5838 | 0.6397 | 0.6637 | 0.5080 | 0.5366 | 0.5557 | 0.5613 | 0.6422 | 0.7993 | 0.9017 | 0.9398 |
| Max-min | 0.5309 | 0.5929 | 0.6524 | 0.6771 | 0.5113 | 0.5425 | 0.5629 | 0.5687 | 0.6533 | 0.8187 | 0.9246 | 0.9640 |
| Mono-objective | 0.5102 | 0.5658 | 0.6284 | 0.6550 | 0.4947 | 0.5226 | 0.5439 | 0.5502 | 0.6035 | 0.7654 | 0.8941 | 0.9398 |
| LexRank | 0.4152 | 0.4357 | 0.4823 | 0.5154 | 0.4160 | 0.4258 | 0.4413 | 0.4491 | 0.4228 | 0.5329 | 0.6713 | 0.7647 |
| Biased LexRank | 0.4172 | 0.4387 | 0.4850 | 0.5173 | 0.4176 | 0.4280 | 0.4433 | 0.4509 | 0.4277 | 0.5391 | 0.6761 | 0.7668 |
| DivRank | 0.5077 | 0.5657 | 0.6209 | 0.6454 | 0.4902 | 0.5196 | 0.5386 | 0.5444 | 0.6159 | 0.7931 | 0.9100 | 0.9453 |
| Grasshopper | 0.4403 | 0.4647 | 0.5099 | 0.5419 | 0.4384 | 0.4502 | 0.4654 | 0.4729 | 0.4657 | 0.5799 | 0.7100 | 0.7965 |
| baseline | 0.5044 | 0.5498 | 0.6028 | 0.6292 | 0.4925 | 0.5153 | 0.5333 | 0.5395 | 0.5827 | 0.7260 | 0.8464 | 0.9010 |
| MMR | 0.547 | 0.6142 | 0.6702 | 0.6912 | 0.5242 | 0.5584 | 0.5778 | 0.5828 | 0.6955 | 0.8581 | 0.9439 | 0.9682 |
| Max-sum | 0.5308 | 0.5911 | 0.6473 | 0.6708 | 0.5109 | 0.5416 | 0.5610 | 0.5666 | 0.6512 | 0.8111 | 0.9093 | 0.9460 |
| Max-min | 0.5394 | 0.6022 | 0.6610 | 0.6840 | 0.5170 | 0.5490 | 0.5693 | 0.5748 | 0.6775 | 0.8339 | 0.9343 | 0.9675 |
| Mono-objective | 0.5150 | 0.5731 | 0.6361 | 0.6621 | 0.4988 | 0.5280 | 0.5497 | 0.5558 | 0.6159 | 0.7779 | 0.9059 | 0.9481 |
| LexRank | 0.4152 | 0.4357 | 0.4823 | 0.5154 | 0.4160 | 0.4258 | 0.4413 | 0.4491 | 0.4228 | 0.5329 | 0.6713 | 0.7647 |
| Biased LexRank | 0.4194 | 0.4414 | 0.4867 | 0.5190 | 0.4201 | 0.4305 | 0.4456 | 0.4532 | 0.4298 | 0.5433 | 0.6754 | 0.7675 |
| DivRank | 0.5261 | 0.5779 | 0.6316 | 0.6566 | 0.5109 | 0.5371 | 0.5557 | 0.5616 | 0.6394 | 0.7882 | 0.8886 | 0.9356 |
| Grasshopper | 0.4421 | 0.4667 | 0.5113 | 0.5430 | 0.4395 | 0.4514 | 0.4664 | 0.4738 | 0.4713 | 0.5848 | 0.7121 | 0.7965 |
| baseline | 0.5044 | 0.5498 | 0.6028 | 0.6292 | 0.4925 | 0.5153 | 0.5333 | 0.5395 | 0.5827 | 0.7260 | 0.8464 | 0.9010 |
| MMR | 0.5527 | 0.6226 | 0.677 | 0.696 | 0.5291 | 0.5647 | 0.5836 | 0.5881 | 0.7093 | 0.8727 | 0.9481 | 0.9696 |
| Max-sum | 0.5425 | 0.5996 | 0.6580 | 0.6798 | 0.5214 | 0.5505 | 0.5708 | 0.5759 | 0.6740 | 0.8187 | 0.9183 | 0.9522 |
| Max-min | 0.5447 | 0.6073 | 0.6659 | 0.6879 | 0.5206 | 0.5524 | 0.5726 | 0.5778 | 0.6962 | 0.8422 | 0.9405 | 0.9723 |
| Mono-objective | 0.5186 | 0.5802 | 0.6422 | 0.6671 | 0.5025 | 0.5334 | 0.5546 | 0.5605 | 0.6208 | 0.7903 | 0.9114 | 0.9543 |
| LexRank | 0.4152 | 0.4357 | 0.4823 | 0.5154 | 0.4160 | 0.4258 | 0.4413 | 0.4491 | 0.4228 | 0.5329 | 0.6713 | 0.7647 |
| Biased LexRank | 0.4202 | 0.4415 | 0.4879 | 0.5199 | 0.4208 | 0.4310 | 0.4465 | 0.4541 | 0.4298 | 0.5412 | 0.6768 | 0.7682 |
| DivRank | 0.5140 | 0.5710 | 0.6298 | 0.6540 | 0.4968 | 0.5258 | 0.5460 | 0.5517 | 0.6111 | 0.7785 | 0.9045 | 0.9439 |
| Grasshopper | 0.4421 | 0.4673 | 0.5117 | 0.5432 | 0.4389 | 0.4513 | 0.4662 | 0.4736 | 0.4740 | 0.5896 | 0.7142 | 0.7979 |
| baseline | 0.5044 | 0.5498 | 0.6028 | 0.6292 | 0.4925 | 0.5153 | 0.5333 | 0.5395 | 0.5827 | 0.7260 | 0.8464 | 0.9010 |
| MMR | 0.557 | 0.6278 | 0.6796 | 0.6991 | 0.5329 | 0.5691 | 0.5872 | 0.5918 | 0.7218 | 0.8844 | 0.9495 | 0.9737 |
| Max-sum | 0.5397 | 0.6052 | 0.6590 | 0.6812 | 0.5173 | 0.5506 | 0.5692 | 0.5744 | 0.6824 | 0.8381 | 0.9211 | 0.9571 |
| Max-min | 0.5477 | 0.6130 | 0.6701 | 0.6913 | 0.5233 | 0.5567 | 0.5764 | 0.5814 | 0.7024 | 0.8554 | 0.9433 | 0.9737 |
| Mono-objective | 0.5208 | 0.5816 | 0.6446 | 0.6693 | 0.5024 | 0.5331 | 0.5547 | 0.5605 | 0.6318 | 0.7965 | 0.9183 | 0.9571 |
| LexRank | 0.4152 | 0.4357 | 0.4823 | 0.5154 | 0.4160 | 0.4258 | 0.4413 | 0.4491 | 0.4228 | 0.5329 | 0.6713 | 0.7647 |
| Biased LexRank | 0.4203 | 0.4429 | 0.4887 | 0.5204 | 0.4209 | 0.4319 | 0.4472 | 0.4547 | 0.4291 | 0.5446 | 0.6782 | 0.7675 |
| DivRank | 0.5252 | 0.5810 | 0.6327 | 0.6542 | 0.5044 | 0.5329 | 0.5507 | 0.5558 | 0.6450 | 0.8000 | 0.8976 | 0.9280 |
| Grasshopper | 0.4402 | 0.4654 | 0.5103 | 0.5423 | 0.4371 | 0.4494 | 0.4645 | 0.4720 | 0.4713 | 0.5869 | 0.7128 | 0.7986 |
| baseline | 0.5044 | 0.5498 | 0.6028 | 0.6292 | 0.4925 | 0.5153 | 0.5333 | 0.5395 | 0.5827 | 0.7260 | 0.8464 | 0.9010 |
| MMR | 0.5628 | 0.6315 | 0.6825 | 0.7021 | 0.5377 | 0.5729 | 0.5906 | 0.5953 | 0.7363 | 0.8872 | 0.9516 | 0.9744 |
| Max-sum | 0.5482 | 0.6103 | 0.6656 | 0.6861 | 0.5250 | 0.5566 | 0.5760 | 0.5809 | 0.7024 | 0.8422 | 0.9260 | 0.9557 |
| Max-min | 0.5501 | 0.6176 | 0.6733 | 0.6939 | 0.5267 | 0.5610 | 0.5803 | 0.5852 | 0.7038 | 0.8602 | 0.9467 | 0.9723 |
| Mono-objective | 0.5196 | 0.5824 | 0.6454 | 0.6699 | 0.5005 | 0.5323 | 0.5540 | 0.5598 | 0.6325 | 0.8014 | 0.9218 | 0.9606 |
| LexRank | 0.4152 | 0.4357 | 0.4823 | 0.5154 | 0.4160 | 0.4258 | 0.4413 | 0.4491 | 0.4228 | 0.5329 | 0.6713 | 0.7647 |
| Biased LexRank | 0.4225 | 0.4442 | 0.4905 | 0.5217 | 0.4230 | 0.4336 | 0.4490 | 0.4564 | 0.4332 | 0.5446 | 0.6817 | 0.7675 |
| DivRank | 0.5185 | 0.5711 | 0.6253 | 0.6532 | 0.4986 | 0.5256 | 0.5442 | 0.5508 | 0.6401 | 0.7945 | 0.9017 | 0.9467 |
| Grasshopper | 0.4374 | 0.4619 | 0.5077 | 0.5394 | 0.4346 | 0.4465 | 0.4619 | 0.4693 | 0.4657 | 0.5806 | 0.7107 | 0.7958 |
| baseline | 0.5044 | 0.5498 | 0.6028 | 0.6292 | 0.4925 | 0.5153 | 0.5333 | 0.5395 | 0.5827 | 0.7260 | 0.8464 | 0.9010 |
| MMR | 0.5662 | 0.6333 | 0.6829 | 0.7026 | 0.5393 | 0.5734 | 0.5907 | 0.5954 | 0.7467 | 0.8893 | 0.9516 | 0.9744 |
| Max-sum | 0.5516 | 0.6134 | 0.6690 | 0.6886 | 0.5276 | 0.5590 | 0.5784 | 0.5831 | 0.7073 | 0.8450 | 0.9280 | 0.9543 |
| Max-min | 0.5536 | 0.6191 | 0.6749 | 0.6941 | 0.5283 | 0.5619 | 0.5812 | 0.5858 | 0.7093 | 0.8623 | 0.9481 | 0.9702 |
| Mono-objective | 0.5215 | 0.5859 | 0.6473 | 0.6720 | 0.5028 | 0.5355 | 0.5567 | 0.5626 | 0.6353 | 0.8083 | 0.9190 | 0.9599 |
| LexRank | 0.4152 | 0.4357 | 0.4823 | 0.5154 | 0.4160 | 0.4258 | 0.4413 | 0.4491 | 0.4228 | 0.5329 | 0.6713 | 0.7647 |
| Biased LexRank | 0.4239 | 0.4456 | 0.4917 | 0.5229 | 0.4242 | 0.4347 | 0.4501 | 0.4574 | 0.4353 | 0.5467 | 0.6837 | 0.7689 |
| DivRank | 0.5123 | 0.5654 | 0.6170 | 0.6446 | 0.4933 | 0.5202 | 0.5381 | 0.5446 | 0.6353 | 0.7896 | 0.8865 | 0.9391 |
| Grasshopper | 0.4312 | 0.4566 | 0.5034 | 0.5359 | 0.4295 | 0.4420 | 0.4577 | 0.4653 | 0.4533 | 0.5702 | 0.7038 | 0.7945 |
| baseline | 0.5044 | 0.5498 | 0.6028 | 0.6292 | 0.4925 | 0.5153 | 0.5333 | 0.5395 | 0.5827 | 0.7260 | 0.8464 | 0.9010 |
| MMR | 0.5676 | 0.6312 | 0.6834 | 0.7024 | 0.5397 | 0.5723 | 0.5906 | 0.5952 | 0.7502 | 0.881 | 0.9516 | 0.9737 |
| Max-sum | 0.5494 | 0.6140 | 0.6700 | 0.6889 | 0.5248 | 0.5577 | 0.5772 | 0.5817 | 0.7093 | 0.8512 | 0.9343 | 0.9571 |
| Max-min | 0.5547 | 0.6228 | 0.6767 | 0.6957 | 0.5291 | 0.5640 | 0.5827 | 0.5872 | 0.7156 | 0.8706 | 0.9509 | 0.9716 |
| Mono-objective | 0.5234 | 0.5880 | 0.6493 | 0.6735 | 0.5040 | 0.5369 | 0.5580 | 0.5636 | 0.6443 | 0.8118 | 0.9232 | 0.9626 |
| LexRank | 0.4152 | 0.4357 | 0.4823 | 0.5154 | 0.4160 | 0.4258 | 0.4413 | 0.4491 | 0.4228 | 0.5329 | 0.6713 | 0.7647 |
| Biased LexRank | 0.4252 | 0.4479 | 0.4937 | 0.5247 | 0.4261 | 0.4371 | 0.4524 | 0.4596 | 0.4346 | 0.5488 | 0.6858 | 0.7709 |
| DivRank | 0.5155 | 0.5735 | 0.6304 | 0.6517 | 0.4995 | 0.5289 | 0.5484 | 0.5534 | 0.6090 | 0.7806 | 0.8976 | 0.9280 |
| Grasshopper | 0.4262 | 0.4515 | 0.4986 | 0.5320 | 0.4249 | 0.4372 | 0.4530 | 0.4608 | 0.4457 | 0.5647 | 0.6969 | 0.7931 |
| baseline | 0.5044 | 0.5498 | 0.6028 | 0.6292 | 0.4925 | 0.5153 | 0.5333 | 0.5395 | 0.5827 | 0.7260 | 0.8464 | 0.9010 |
| MMR | 0.5647 | 0.6306 | 0.6834 | 0.7018 | 0.5381 | 0.5718 | 0.5902 | 0.5946 | 0.7439 | 0.8817 | 0.9529 | 0.9737 |
| Max-sum | 0.5429 | 0.6136 | 0.6699 | 0.6884 | 0.5188 | 0.5551 | 0.5748 | 0.5792 | 0.6997 | 0.8554 | 0.9419 | 0.9626 |
| Max-min | 0.5570 | 0.6244 | 0.6781 | 0.6971 | 0.5311 | 0.5657 | 0.5844 | 0.5889 | 0.7211 | 0.8727 | 0.9495 | 0.9716 |
| Mono-objective | 0.5238 | 0.5894 | 0.6502 | 0.6734 | 0.5037 | 0.5371 | 0.5580 | 0.5635 | 0.6471 | 0.8166 | 0.9260 | 0.9619 |
| LexRank | 0.4152 | 0.4357 | 0.4823 | 0.5154 | 0.4160 | 0.4258 | 0.4413 | 0.4491 | 0.4228 | 0.5329 | 0.6713 | 0.7647 |
| Biased LexRank | 0.4250 | 0.4486 | 0.4948 | 0.5254 | 0.4262 | 0.4377 | 0.4532 | 0.4604 | 0.4325 | 0.5502 | 0.6872 | 0.7702 |
| DivRank | 0.5177 | 0.5721 | 0.6295 | 0.6511 | 0.5001 | 0.5275 | 0.5473 | 0.5524 | 0.6187 | 0.7785 | 0.8969 | 0.9280 |
| Grasshopper | 0.4199 | 0.4438 | 0.4915 | 0.5264 | 0.4193 | 0.4309 | 0.4470 | 0.4552 | 0.4332 | 0.5495 | 0.6851 | 0.7882 |
| Baseline () | MMR: Light Diversity () | MMR: Moderate Diversity () | MMR: High Diversity () | |
|---|---|---|---|---|
| Query 24: Aliens Immigration and Citizenship | ||||
| 1 | Virgin Holdings SA v Commissioner of Taxation [2008] FCA 1503 (10 October 2008) | Virgin Holdings SA v Commissioner of Taxation [2008] FCA 1503 (10 October 2008) | Virgin Holdings SA v Commissioner of Taxation [2008] FCA 1503 (10 October 2008) | Virgin Holdings SA v Commissioner of Taxation [2008] FCA 1503 (10 October 2008) |
| 2 | Undershaft (No 1) Limited v Commissioner of Taxation [2009] FCA 41 (3 February 2009) | Fowler v Commissioner of Taxation [2008] FCA 528 (21 April 2008) | Fowler v Commissioner of Taxation [2008] FCA 528 (21 April 2008) | Soh v Commonwealth of Australia [2008] FCA 520 (18 April 2008) |
| 3 | Fowler v Commissioner of Taxation [2008] FCA 528 (21 April 2008) | Wight v Honourable Chris Pearce, MP, Parliamentary Secretary to the Treasurer [2007] FCA 26 (29 January 2007) | Coleman v Minister for Immigration & Citizenship [2007] FCA 1500 (27 September 2007) | SZJDI v Minister for Immigration & Citizenship (No. 2) [2008] FCA 813 (16 May 2008) |
| 4 | Wight v Honourable Chris Pearce, MP, Parliamentary Secretary to the Treasurer [2007] FCA 26 (29 January 2007) | Undershaft (No 1) Limited v Commissioner of Taxation [2009] FCA 41 (3 February 2009) | Charlie v Minister for Immigration and Citizenship [2008] FCA 1025 (10 July 2008) | Charlie v Minister for Immigration and Citizenship [2008] FCA 1025 (10 July 2008) |
| 5 | Coleman v Minister for Immigration & Citizenship [2007] FCA 1500 (27 September 2007) | Coleman v Minister for Immigration & Citizenship [2007] FCA 1500 (27 September 2007) | VSAB v Minister for Immigration and Multicultural and Indigenous Affairs [2006] FCA 239 (17 March 2006) | VSAB v Minister for Immigration and Multicultural and Indigenous Affairs [2006] FCA 239 (17 March 2006) |
| Query 84: Commodity Futures Trading Regulation | ||||
| 1 | BHP Billiton Iron Ore Pty Ltd. v The National Competition Council [2006] FCA 1764 (18 December 2006) | BHP Billiton Iron Ore Pty Ltd. v The National Competition Council [2006] FCA 1764 (18 December 2006) | BHP Billiton Iron Ore Pty Ltd. v The National Competition Council [2006] FCA 1764 (18 December 2006) | BHP Billiton Iron Ore Pty Ltd. v The National Competition Council [2006] FCA 1764 (18 December 2006) |
| 2 | Australian Securities & Investments Commission v Lee [2007] FCA 918 (15 June 2007) | Australian Securities & Investments Commission v Lee [2007] FCA 918 (15 June 2007) | Australian Securities & Investments Commission v Lee [2007] FCA 918 (15 June 2007) | Australian Competition and Consumer Commission v Dally M Publishing and Research Pty Limited [2007] FCA 1220 (10 August 2007) |
| 3 | Woodside Energy Ltd. (ABN 63 005 482 986) v Commissioner of Taxation (No 2) [2007] FCA 1961 (10 December 2007) | Woodside Energy Ltd. (ABN 63 005 482 986) v Commissioner of Taxation (No 2) [2007] FCA 1961 (10 December 2007) | Woodside Energy Ltd. (ABN 63 005 482 986) v Commissioner of Taxation (No 2) [2007] FCA 1961 (10 December 2007) | Heritage Clothing Pty Ltd. trading as Peter Jackson Australia v Mens Suit Warehouse Direct Pty Ltd. trading as Walter Withers [2008] FCA 1775 (28 November 2008) |
| 4 | BHP Billiton Iron Ore Pty Ltd. v National Competition Council (No 2) [2007] FCA 557 (19 April 2007) | Keynes v Rural Directions Pty Ltd. (No 2) (includes Corrigendum dated 16 July 2009) [2009] FCA 567 (3 June 2009) | Keynes v Rural Directions Pty Ltd. (No 2) (includes Corrigendum dated 16 July 2009) [2009] FCA 567 (3 June 2009) | Travelex Limited v Commissioner of Taxation (Corrigendum dated 4 February 2009) [2008] FCA 1961 (19 December 2008) |
| 5 | Keynes v Rural Directions Pty Ltd. (No 2) (includes Corrigendum dated 16 July 2009) [2009] FCA 567 (3 June 2009) | Queanbeyan City Council v ACTEW Corporation Limited [2009] FCA 943 (24 August 2009) | Heritage Clothing Pty Ltd. trading as Peter Jackson Australia v Mens Suit Warehouse Direct Pty Ltd trading as Walter Withers [2008] FCA 1775 (28 November 2008) | Ashwick (Qld) No 127 Pty Ltd. (ACN 010 577 456) v Commissioner of Taxation [2009] FCA 1388 (26 November 2009) |
| Query 291:Privileged Communications and Confidentiality | ||||
| 1 | Siam Polyethylene Co Ltd. v Minister of State for Home Affairs (No 3) [2009] FCA 839 (7 August 2009) | Siam Polyethylene Co Ltd. v Minister of State for Home Affairs (No 3) [2009] FCA 839 (7 August 2009) | Siam Polyethylene Co Ltd. v Minister of State for Home Affairs (No 3) [2009] FCA 839 (7 August 2009) | Siam Polyethylene Co Ltd. v Minister of State for Home Affairs (No 3) [2009] FCA 839 (7 August 2009) |
| 2 | AWB Limited v Australian Securities and Investments Commission [2008] FCA 1877 (11 December 2008) | AWB Limited v Australian Securities and Investments Commission [2008] FCA 1877 (11 December 2008) | AWB Limited v Australian Securities and Investments Commission [2008] FCA 1877 (11 December 2008) | Krueger Transport Equipment Pty Ltd. v Glen Cameron Storage [2008] FCA 803 (30 May 2008) |
| 3 | Brookfield Multiplex Limited v International Litigation Funding Partners Pte Ltd. (No 2) [2009] FCA 449 (6 May 2009) | Brookfield Multiplex Limited v International Litigation Funding Partners Pte Ltd (No 2) [2009] FCA 449 (6 May 2009) | Autodata Limited v Boyce’s Automotive Data Pty Limited [2007] FCA 1517 (4 October 2007) | Futuretronics.com.au Pty Limited v Graphix Labels Pty Ltd. [2007] FCA 1621 (29 October 2007) |
| 4 | Cadbury Schweppes Pty Ltd. (ACN 004 551 473) v Amcor Limited (ACN 000 017 372) [2008] FCA 88 (19 February 2008) | Barrett Property Group Pty Ltd. v Carlisle Homes Pty Ltd (No 2) [2008] FCA 930 (17 June 2008) | Barrett Property Group Pty Ltd. v Carlisle Homes Pty Ltd (No 2) [2008] FCA 930 (17 June 2008) | Australian Competition & Consumer Commission v Visy Industries [2006] FCA 136 (23 February 2006) |
| 5 | Barrett Property Group Pty Ltd v Carlisle Homes Pty Ltd. (No 2) [2008] FCA 930 (17 June 2008) | Cadbury Schweppes Pty Ltd. (ACN 004 551 473) v Amcor Limited (ACN 000 017 372) [2008] FCA 88 (19 February 2008) | Optus Networks Ltd. v Telstra Corporation Ltd (No. 2) (includes Corrigendum dated 7 July 2009) [2009] FCA 422 (9 July 2009) | IO Group Inc v Prestige Club Australasia Pty Ltd. (No 2) [2008] FCA 1237 (11 August 2008) |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koniaris, M.; Anagnostopoulos, I.; Vassiliou, Y. Evaluation of Diversification Techniques for Legal Information Retrieval. Algorithms 2017, 10, 22. https://doi.org/10.3390/a10010022
Koniaris M, Anagnostopoulos I, Vassiliou Y. Evaluation of Diversification Techniques for Legal Information Retrieval. Algorithms. 2017; 10(1):22. https://doi.org/10.3390/a10010022
Chicago/Turabian StyleKoniaris, Marios, Ioannis Anagnostopoulos, and Yannis Vassiliou. 2017. "Evaluation of Diversification Techniques for Legal Information Retrieval" Algorithms 10, no. 1: 22. https://doi.org/10.3390/a10010022
APA StyleKoniaris, M., Anagnostopoulos, I., & Vassiliou, Y. (2017). Evaluation of Diversification Techniques for Legal Information Retrieval. Algorithms, 10(1), 22. https://doi.org/10.3390/a10010022