1. Introduction
Optimization involves a series of tasks that employ mathematical or analytical methods to enhance the parameters of a given system or process at reduced cost. This process follows a trajectory that enables the problem to attain a global optimum [
1]. To date, optimization has been applied to real-world problems represented by mathematical models to address challenges in engineering, finance, and science [
2,
3]. The development of optimization algorithms has garnered significant interest in addressing optimization issues across various domains, including engineering, science, economics, and business [
4,
5,
6]. A real-world optimization problem can be resolved if it is mathematically expressed. When addressing real-world challenges, it is crucial to optimally derive the desired variables. Consequently, intelligent algorithms have been acknowledged as vital tools for solving these problems. These algorithms are categorized into deterministic and stochastic types [
7]. However, deterministic algorithms present several limitations, such as the necessity for complex mathematical computations, implementation challenges, and tendency to become trapped in local optima [
2,
8]. Stochastic algorithms that employ non-deterministic derivative-free methods have been utilized to mitigate these limitations. In this regard, metaheuristic optimization techniques, classified as stochastic algorithms, provide promising solutions to fulfil this requirement.
Such algorithms are based on theorems derived from scientific laws and mathematical modelling with specific constraints, as well as theorems that mimic the behavior of swarms with shared intelligence [
2]. The goal of metaheuristics is to identify search or optimization methods that are superior when applied to instances of a given class of problems. In all swarm-based optimization algorithms, the problem is optimized using a set of random solutions. Each time the algorithm is executed, this set of random solutions is evaluated and improved by using a fitness function. The probability of obtaining an overall optimal solution was increased through enough random solutions and iterations.
Metaheuristic algorithms are characterized by two primary phases: exploration and exploitation. The efficacy of the balance between these phases indicated the overall quality of the algorithm. Exploration pertains to the algorithm’s capacity to survey the entire search space, whereas exploitation involves each search agent’s ability to identify the optimal solution within its local vicinity. The effectiveness of an algorithm in addressing a specific problem set may not necessarily translate to optimization problems of a different nature or type [
9]. It is acknowledged that no single optimization algorithm is universally applicable to all problems. Metaheuristic algorithms can be designed to efficiently navigate the search space and deliver optimal solutions within a reasonable time frame.
The Genetic Algorithm (GA) [
10] is among the earliest swarm-based algorithms. The particle swarm optimization (PSO) algorithm [
11] has been extensively examined and has drawn inspiration from various algorithms, including the Grey Wolf Algorithm (GWO) [
12] and Harris Hawks Optimizer (HHO) [
8], among others, in terms of their operational principles [
11]. The hunger game search algorithm (HGS) [
13] was inspired by the hunger drive of animals, a common theme in swarm-based algorithms. Over the past two decades, numerous algorithms have been developed and implemented in this domain [
14,
15,
16].
The No-Free Lunch (NFL) theorem underscores the importance of leveraging problem-specific knowledge to enhance performance, thereby providing an opportunity to develop various strategies for fine-tuning a metaheuristic algorithm as desired [
17]. Hybridization techniques can be employed to obtain superior solutions [
18,
19]. Hybridization offers three significant advantages: it capitalizes on the flexibility of metaheuristics to tackle large-scale problems that individual metaheuristics alone cannot manage by integrating different strategies or algorithms, and it improves the problem-solving performance, resulting in more robust algorithms [
20].
Some examples of hybridization were examined in this study.
The authors of one paper highlight that hybrid metaheuristic algorithms improve the effectiveness of individual algorithms by combining their unique advantages. Many hybrid algorithms have been created for feature selection, with the goal of identifying the best feature subsets from datasets. These methods avoid getting stuck in local optima and prevent early convergence while thoroughly examining the search space. The algorithms strike a balance between exploration and exploitation. The improved algorithms produce results that are nearly optimal. By integrating multiple methods, hybrid metaheuristics enhance both convergence and the quality of solutions [
21].
The seminal study on hybridization explores hybrid meta-heuristic algorithms for optimizing the dimensions of hybrid renewable energy systems (HRES). HRES enhances energy sustainability in remote areas; however, optimization is complex due to multiple factors. Hybrid meta-heuristic algorithms yield more precise results than traditional methods for HRES optimization. The paper reviews these algorithms for both single-objective and multi-objective design optimization. In single-objective optimization, algorithms such as GA-TS, PSO-HS, and the GA-Markov model are employed to minimize costs and enhance reliability. For multi-objective optimization, algorithms like FPA-SA, MOPSO-NSGA-II, and ACO-ABC are utilized to optimize cost, emissions, and reliability simultaneously. Low-level co-evolutionary hybridization is most commonly employed to balance algorithm exploration and exploitation. The authors note an increased use of hybrid algorithms for multi-objective HRES optimization [
22]. The study evaluates an autonomous green energy system using hybrid metaheuristic methods. It presents a hybrid renewable energy system (HRES) with wind turbines, solar photovoltaic panels, biomass gasifier, and fuel cells with hydrogen storage for an off-grid university campus in Turkey. The research examines electricity production and optimization algorithms to minimize annual system cost while ensuring reliable supply. Using a Hybrid Firefly Genetic Algorithm (HFGA), which outperforms other algorithms, the optimal sizing is determined. The standalone system proves most cost-effective, achieving 100% renewable energy fraction [
23].
Recently, metaheuristic algorithms have been widely employed to address real-world problems, with applications spanning engineering challenges [
24,
25], efficient use of air conditioning technology [
25], and training of artificial neural networks [
2]. Furthermore, a substantial body of literature exists on the integration of metaheuristics into machine learning algorithms [
26,
27].
For instance, in one study, the authors examined the HVAC system [
28]. In paper, introduces a hybrid model that combines physical system modeling with symbolic regression, noted for its effectiveness with limited data and physical expressiveness. This model has been tested on air conditioning systems to forecast energy performance. IWHO develops optimization algorithms for machine learning (MLP) training. The algorithm’s optimization effectiveness and its impact on MLP training are evaluated, with applications to standard optimization tests and MLP training using the UCI Energy Efficiency dataset. IWHO excels in optimization and training stability. Enhanced with a Random Walk strategy, IWHO addresses premature convergence issues and delivers superior results compared to classical WHO and meta-heuristic algorithms, as validated by the Wilcoxon test. As an MLP training consultant, IWHO achieves lower error rates and higher explanatory power (R
2: 0.98) than classical WHO, providing precise outcomes in energy efficiency and HVAC systems. Box plots and convergence curves demonstrate that IWHO yields more stable results near the global optimum. Although it is slower by 23%, its accuracy makes this acceptable. IWHO’s adaptable nature suits various optimization problems and machine learning applications, ranging from energy efficiency to engineering design. The algorithm’s primary advantages are its novel optimization approach, integration with machine learning, and successful application to energy efficiency, with statistically significant results and stable performance.
In this study, the IWHO algorithm was utilized as an advisor for an artificial neural network, a machine-learning algorithm, thereby contributing to this field. The wild horse optimization algorithm considered in this study is a swarm-based algorithm [
27]. The group hierarchy in a swarm of wild horses is inspired by common swarm behaviors such as the satisfaction of motives. Several studies have addressed the WHO algorithm. It is pertinent to provide examples of previous studies. In 2022, the Wild Horse Optimizer (WHO) algorithm was developed based on swarm characteristics and the hierarchy of wild horses. For instance, to augment the exploitation capacity of the WHO algorithm and prevent it from becoming trapped in local optima, a random running strategy (RRS) was employed to ensure a balance between exploration and exploitation, and to strengthen competition with the waterhole mechanism (CWHM). In addition, the dynamic inertia weight strategy (DIWS) was used to achieve a global optimal result [
29]. To address the limitations of the WHO algorithm, such as its inadequate search accuracy and slow convergence speed, a Hybrid Multi-Strategy Improved Wild Horse Optimizer (HMSWHO) is proposed. The Halton sequence is utilized to increase the diversity of the swarm, the adaptive parameter TDR is employed for exploration-exploitation balance, and the simplex method is applied to improve the worst position of the swarm [
30]. In another study aimed at enhancing the WHO algorithm, a new algorithm was developed by implementing two strategies to increase the global search efficiency and avoid local optima. The first strategy is the quantum acceleration strategy, which enhances the individual abilities of each horse, and the chaotic mapping strategy, which prevents entrapment in the local optima [
31].
Numerous studies have applied the WHO algorithm to various engineering challenges. In one study, the WHO algorithm was employed as a controller in a wind turbine system to standardize the wind speed through a specific controller and to avert potential failures [
32]. Another study hybridized the WHO algorithm with the dwarf mongoose optimization (DMO) algorithm to assess its efficacy as a controller to reduce electricity costs in a small-grid system model [
33]. Within the domain of energy engineering, the WHO algorithm has demonstrated its effectiveness as an optimization controller [
34]. It has also been used for attribute selection [
35]. In the context of scheduling problems, the WHO algorithm has been successfully applied to the planning of work processes in workshops by hybridizing it with various strategies [
36]. The stability of the WHO algorithm served as a key motivation for this study. The quality of the algorithm was evaluated using the CEC 2019 [
37] benchmark functions and hybridized with the Random Walking (RW) strategy to enhance outcomes. The RW strategy augments the potential of metaheuristic algorithms by introducing randomness into local search processes and generating alternative solutions [
38,
39]. The findings of this study indicated a significant improvement in the performance of the WHO algorithm across most functions. Previously, Eker et al. conducted a similar investigation using the RW-ARO algorithm, which resulted from the hybridization of the artificial rabbit optimization (ARO) algorithm and RW strategy, achieving successful results in Control Engineering [
40]. In this study, the proposed IWHO hybrid algorithm was employed to train the CL and HL for HVAC systems in buildings via MLP, with the IWHO designated as the trainer. The WHO algorithm was selected as an alternative. This study utilized the Energy Efficiency dataset from the UCI, which addresses the energy efficiency problem [
41]. Previous studies have explored related topics. One study assessed the predictive capabilities of Artificial Neural Networks (ANN) and XGBoost surrogate models for heating, cooling, lighting loads, and equivalent primary energy requirements, using EnergyPlus (Matlab2024) simulation data across various office cell model versions. The XGBoost models exhibited superior accuracy in predicting these loads. The mc-intersite-proj-th sampling method slightly enhanced prediction accuracy compared to maximin Latin hypercube sampling for both models. XGBoost models, which consist of collections of piecewise constant functions, perform optimally when the simulated loads show minimal variation or smaller gradients across the design space. This implies that fewer regression trees may suffice for precise predictions, or the same number could yield more accurate results. In this case study, XGBoost models demonstrated greater accuracy for lighting loads and primary energy needs than for heating and cooling loads, which have simpler slanted shapes with higher gradients not approaching zero [
42]. In another study on the increasing prevalence of electric vehicles, accurately predicting energy consumption is essential for effective power grid management. This research evaluated eleven machine learning models, including Ridge Regression, Lasso Regression, K-Nearest Neighbors, Gradient Boosting, Support Vector Regression, Multi-Layer Perceptron, XGBoost, CatBoost, LightGBM, Gaussian Process Regression (GPR), and Extra Trees Regressor, using data from Colorado. The models were assessed using metrics such as Mean Absolute Error (MAE), Mean Squared Error (MSE), R
2, Root Mean Squared Error (RMSE), and Normalized RMSE (NRMSE). Both Gradient Boosting and K-Nearest Neighbors (KNN) also demonstrated strong performance, while non-linear and linear regression models faced challenges in predicting extreme energy levels. The Extra Trees Regressor emerged as the most precise in forecasting energy consumption. A limitation of this study is its exclusive reliance on data from Colorado. Although accurate, the computational demands of the Extra Trees Regressor may affect its scalability for real-time applications. Future research should consider exploring deep learning models, expanding datasets, and employing time-series analysis to enhance forecasting precision [
43]. Khishe and Mohammadi trained a passive sonar dataset using the SSA-MLP hybrid system, achieving high classification accuracy [
44]. He et al. proposed a metaheuristic-based algorithm model for designing underwater wireless sensor networks to enhance energy efficiency and extend network lifetime, suggesting a hybrid hierarchical chimpanzee optimization algorithm to efficiently manage clustering and multihop routing procedures [
45].
Building on these advancements, our research introduces the IWHO-MLP framework, which utilizes the Improved Wild Horse Optimizer for training Multi-Layer Perceptrons (MLPs). Comparative analyses using boxplots and convergence curves reveal that IWHO-MLP consistently outperforms both traditional and hybrid methods, achieving lower MSE, RMSE, and higher R2 values on the energy efficiency dataset and CEC 2019 benchmark functions. These findings not only confirm but also advance the current state-of-the-art, highlighting the efficacy of metaheuristic-driven optimization in neural network training.
In the existing literature, there are studies on artificial neural networks that incorporate the WHO algorithm. A comprehensive study of face recognition systems in the banking sector employed methods such as artificial neural networks, decision trees, and adaptive neural fuzzy inference systems, with the WHO algorithm contributing to the optimization of these methods [
44]. Additionally, the WHO algorithm has been utilized as an optimizer in artificial neural networks for the classification of long-term storage of medical images in the healthcare domain [
45].
The proposed approach offers several key strengths and advantages, including enhanced performance. The IWHO algorithm demonstrated superior results compared with the original WHO algorithm and other alternatives across most benchmark functions.
Stability and consistency: boxplot analysis indicated that the IWHO algorithm consistently exhibited stable performance.
Improved exploration-exploitation balance: the Random Walk strategy mitigates early convergence and prevents entrapment in local optima.
Competitive performance: the IWHO surpasses other algorithms when addressing the challenging test sets of CEC 2019.
Statistical significance: the Wilcoxon signed-rank test confirmed the distinctiveness and efficacy of the IWHO algorithm.
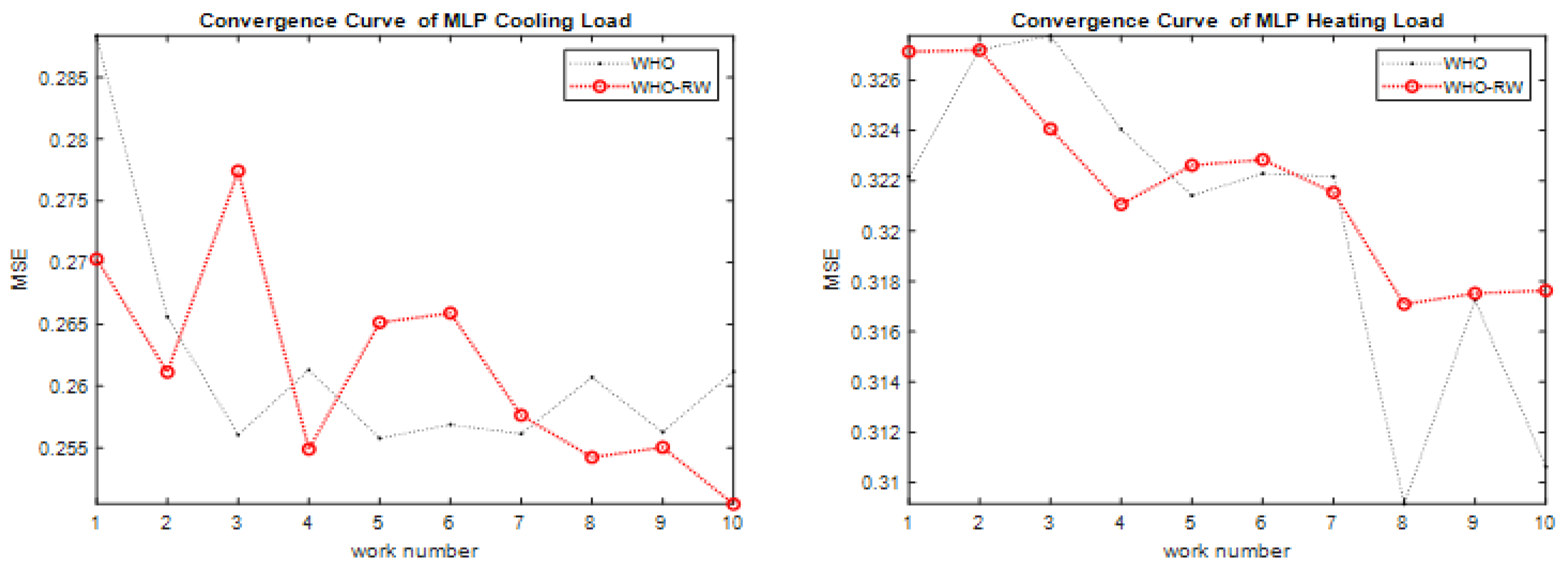
Efficient MLP training: the IWHO excels in training a Multi-Layer Perceptron for the energy efficiency problem, achieving lower MSE values and more reliable outcomes.
Improved prediction accuracy: the IWHO algorithm delivers higher prediction rates for Cooling Load (CL) factors than the original WHO algorithm.
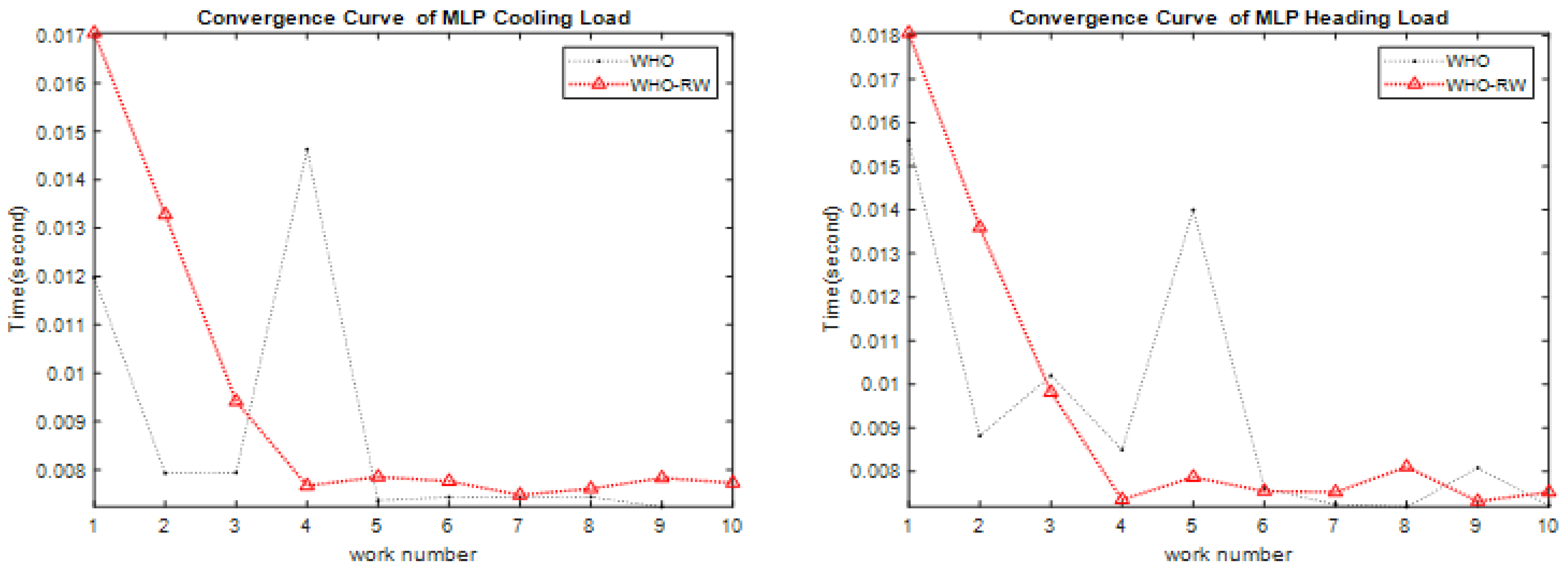
Time efficiency: despite its increased complexity, the IWHO completes the optimization process within a reasonable timeframe.
Flexibility and hybridization potential: the success of the IWHO suggests that the WHO algorithm possesses a flexible structure that is amenable to integration with other strategies.
Real-world applicability: the IWHO algorithm demonstrates potential for addressing practical issues such as optimizing HVAC systems in smart buildings for energy efficiency.
The remainder of the paper is organized as follows:
Section 2 discusses the WHO algorithm, RW search strategy, and proposed IWHO hybridization structure.
Section 3 presents the testing of the IWHO algorithm using the CEC 2019.
Section 4 covers MLP training, and
Section 5 presents the results.
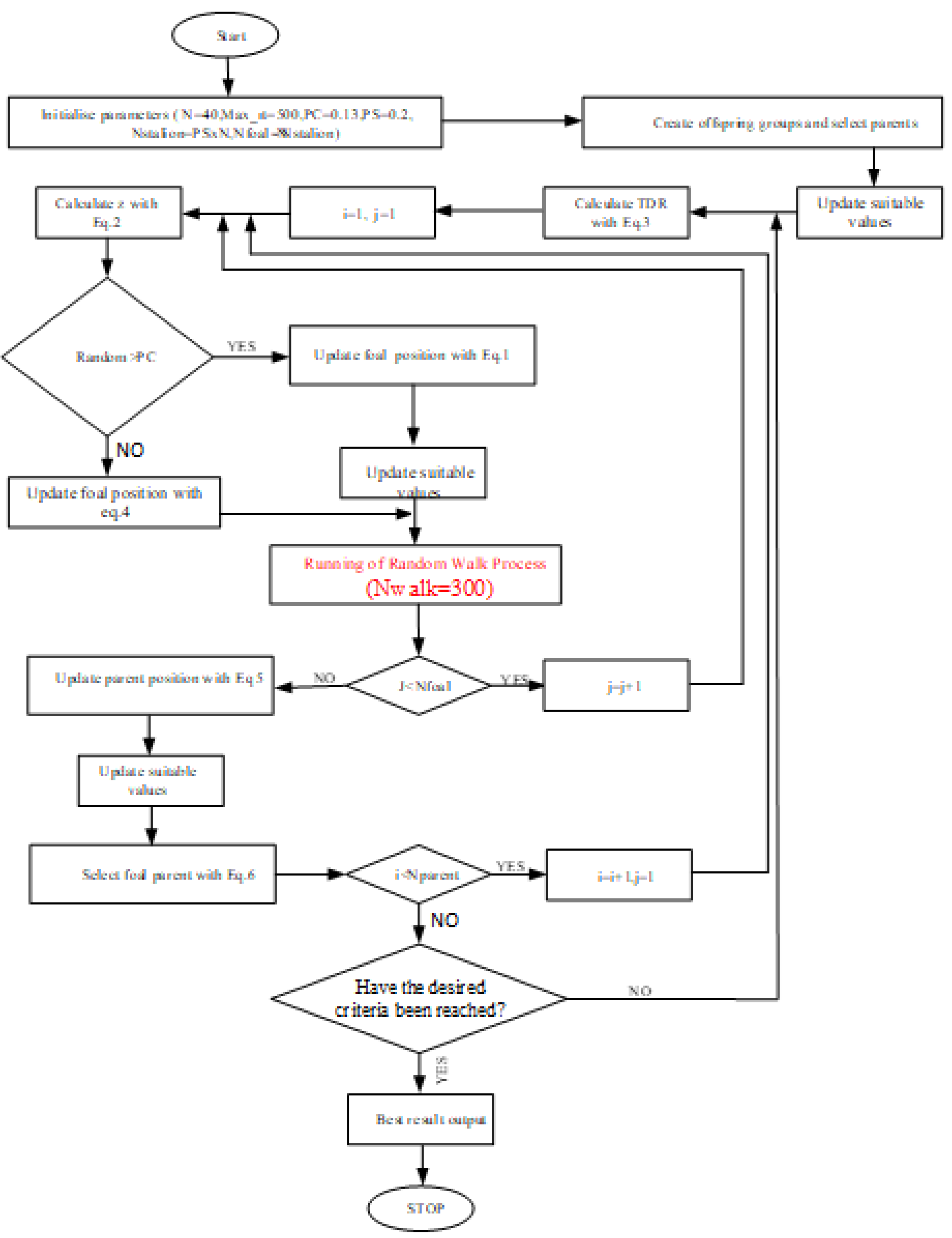
The proposed hybrid IWHO and the optimization process with alternative algorithms are given in
Figure 1 below.
3. Multilayer Perceptron Architecture
The Multi-Layer Perceptron (MLP) is an artificial neural network architecture that serves as a nonparametric estimator, applicable for both classification, prediction, and regression tasks. The brain is an information processing device with extraordinary capabilities, surpassing current technological products in various fields such as vision, speech recognition, and learning. These applications have clear economic advantages when implemented on machines. By understanding how the brain accomplishes these functions, we can develop formal algorithms to solve these tasks and implement them on computers. The human brain is fundamentally different from a computer. While a computer typically has a single processor, the brain consists of an enormous number of processing units, approximately
neurons, which operate in parallel. Although the precise details are not fully understood, these processing units are thought to be much simpler and slower than a computer processor. Another distinguishing feature of the brain, which is believed to contribute to its computational power, is its extensive connectivity. Neurons in the brain have connections, called synapses, to around
other neurons, also functioning in parallel. In a computer, the processor is active and the memory is separate and passive; however, in the brain, it is believed that processing and memory are distributed throughout the network. Processing is carried out by the neurons, while memory resides in the synapses between neurons. The information processing system in the brain requires a fundamental theory, algorithm, and hardware. This includes data input for the desired operation, an algorithm to perform the function, and the capability to execute commands using a specific hardware implementation. The training of neural networks, which involves a mathematical function, is made possible through statistical techniques. One of the architectures designed for this training is the MLP structure [
48].
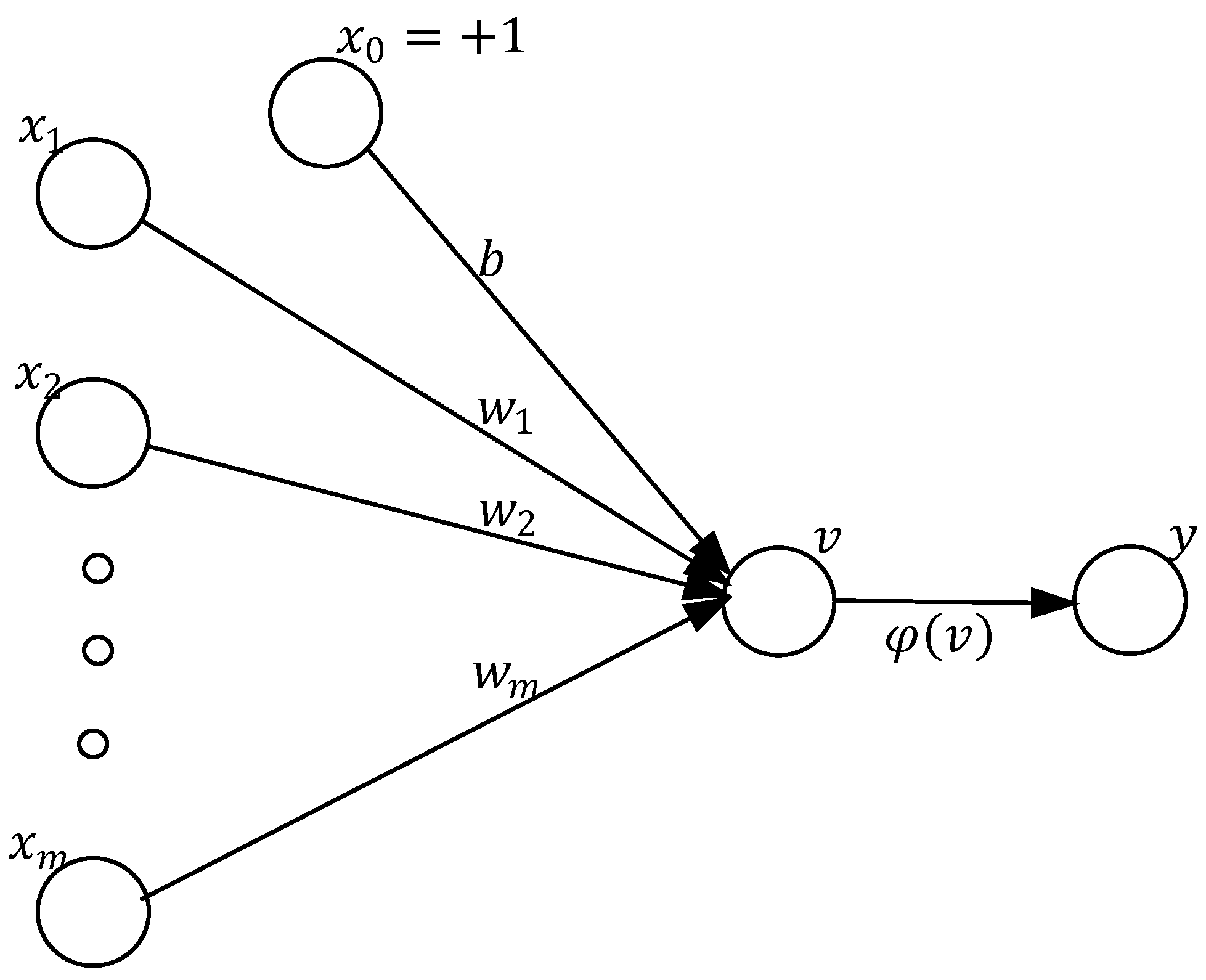
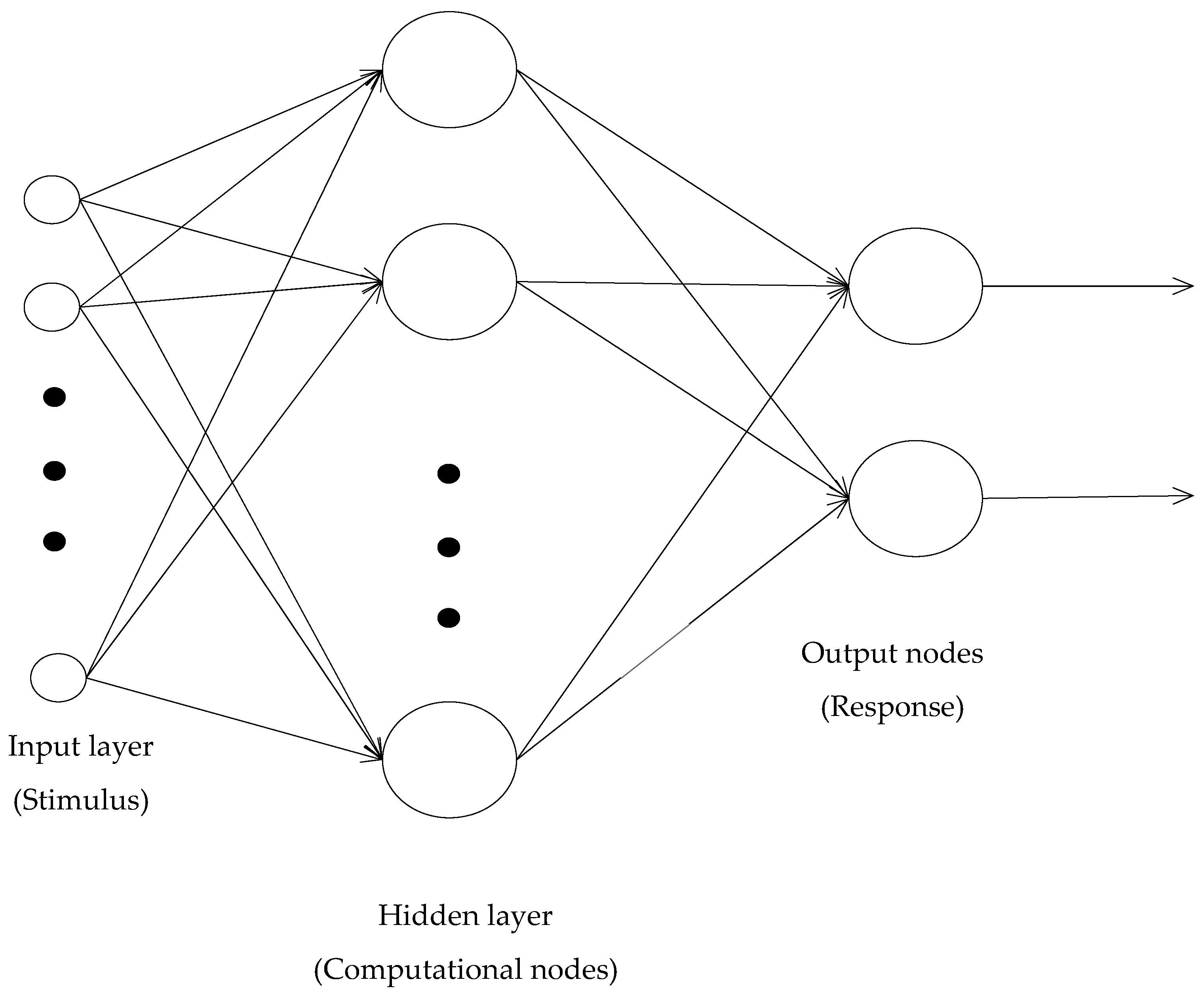
The aim of perceptron is to correctly classify the set of externally applied stimuli
into one of two classes. In
Figure 4 bias denoted by
b,
inputs value,
connection or synaptic weight, v induced local field of the neuron, and
transfer function. Given
can also be defined as a hyperplane.
We can express the output of the perceptron as a dot product, and augmenting the input vector
and weight vector
to include the bias weight and input, respectively.
During testing, the output y is calculated with the given weights w for input x. To implement a given task, it is necessary to learn the weights w, which are the parameters of the system, such that the correct outputs are produced given the inputs.
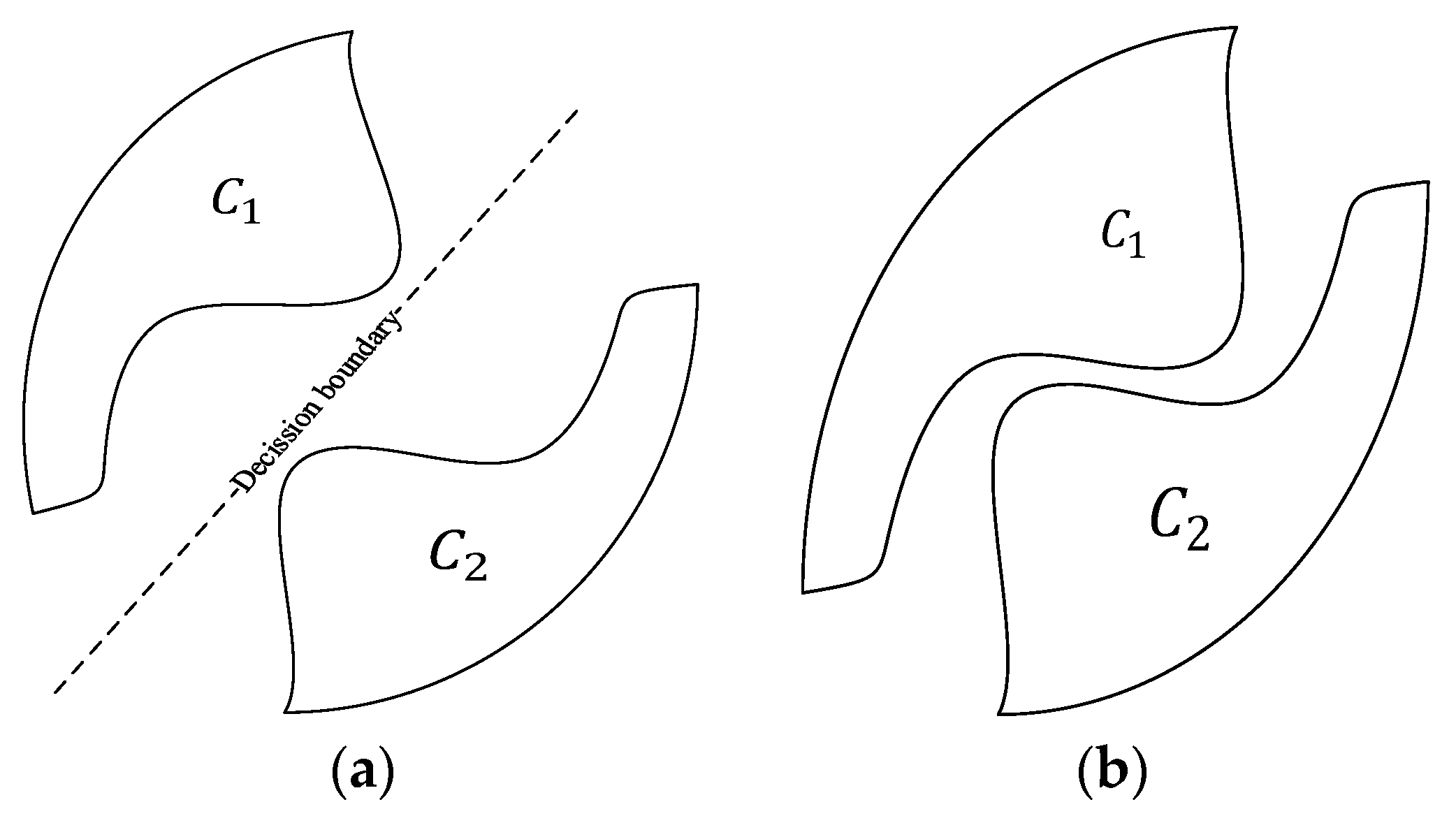
The hyperplane can be utilized to partition the input space into two regions: one where the values are positive and another where the values are negative. This concept is foundational in implementing a linear separation function. In
Figure 5, the detector can then classify the input into one of two classes by examining the sign of the output: if the output is positive, it belongs to one class
; if negative, it belongs to the other class
[
49].
If
belongs to
else
,
as a treshold function, We need to activation functon or output (y) for calculate risk. The transfer function is the mathematical function that defines the properties of the network and is chosen according to the problem that the network has to solve. The reason for choosing sigmoid as the transfer function in this paper is that it has continuous and differentiable values in the interval [0, 1]. Here the parameter a is the slope of the transfer function.
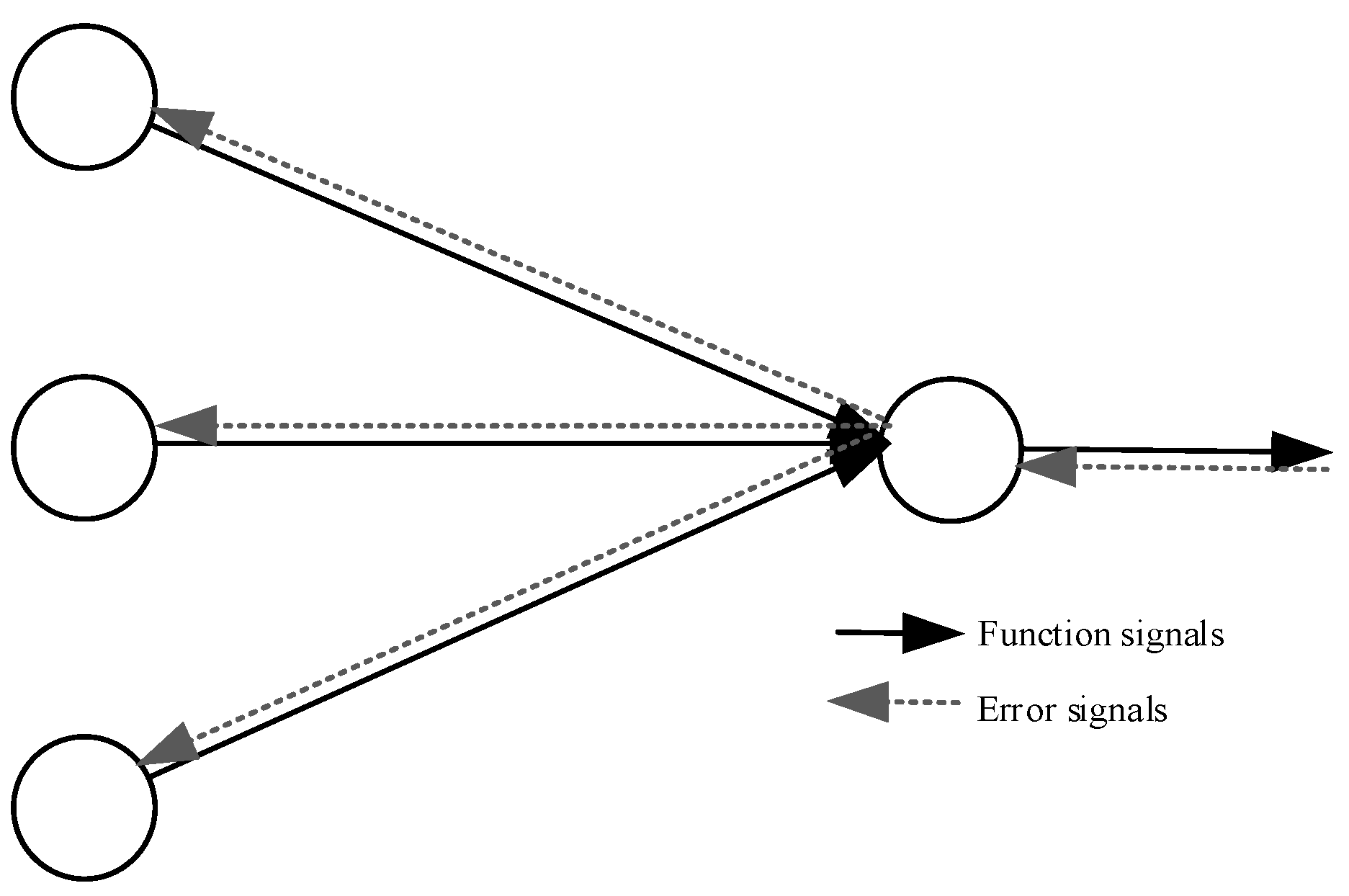
A perceptron with a single layer of weights can only approximate linear functions of the input and cannot solve problems like XOR, where the discriminant to be estimated is nonlinear. Similarly, a perceptron cannot be used for nonlinear regression. This limitation does not apply to feedforward networks with hidden layers between the input and output layers. When used for classification, such Multi-Layer Perceptrons can implement nonlinear discriminants, and when used for regression, they can approximate nonlinear functions of the input. Typically, the network consists of a set of source nodes that constitute the input layer, one or more hidden layers of computation nodes, and an output layer of computation nodes. These neural networks are called Multi-Layer Perceptrons (MLPs), representing a generalization of the single-layer perceptron. MLPs have been applied successfully to solve some difficult and diverse problems by training them in a supervised manner with a viral algorithm known as “backprop”. The learning process performed with this algorithm is called backpropagation learning. As seen
Figure 6 in an MLP, while function signals flow in the forward propagation direction, the error signal responds with the backpropagation flow and is corrected to minimize the error. An error signal begins at an output neuron of the network and travels backward through the network. Each neuron in the network computes using a function namely error that depends on the error in some way [
49,
50].
Learning is a process in which the free parameters of a neural network are adapted by the environment in which the network is embedded through a simulation process shown as
Figure 7. The type of learning is determined by the way parameter changes take place [
50].
Error metrics serve as a quantitative measure of the deviation between predicted outcomes and actual values. While a single result may not yield extensive insights, it facilitates the selection of the most appropriate regression model by providing a numerical basis for comparison with other model outcomes. The supervisor can provide the neural network with the desired response for a specific training vector, representing the optimal action the network should undertake. The network parameters are adjusted under the combined influence of the training vector and the error signal, defined as the difference between the desired and actual responses of the network. This tuning process is conducted iteratively and incrementally, with the objective of ensuring that the neural network eventually emulates the supervisor, which is presumed to be optimal in a statistical sense. Through this process, the environmental information available to the supervisor is transferred as comprehensively as possible to the neural network during training. Once this condition is achieved, the tutor can be dispensed with, allowing the neural network to independently interact with the environment. Error values can be calculated using metrics such as mean squared error (MSE), root mean square error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE), and the coefficient of determination (
).
In Equation (14) is the training samples, is the number of outputs value, is the desired output, and actual output.
4. Experimental Results
The main goal of this paper is to solve a global non-parametric standardized function set using the WHO algorithm (IWHO) hybridized with the Random Walk strategy and to compare the results with those of alternative competitive metaheuristic algorithms. A notation table summarizing all parameters of the algorithm has been added as
Table 1.
The analysis tools used include statistical tables, boxplots, and convergence curve. The CEC 2019 functions are among the most challenging non-linear function sets due to their structure, which delays reaching the global solution, and are widely accepted for evaluating algorithm quality. The primary rationale for selecting only 10 functions from the CEC 2019 set in our research is that these functions are internationally recognized as a challenging and diverse benchmark. The CEC 2019 functions are designed to evaluate the effectiveness of optimization algorithms, encompassing a wide range of problem types and complexities. This variety is sufficient for an objective assessment of both the algorithms’ convergence speed and their ability to identify the global optimum. As indicated in the manuscript (refer to
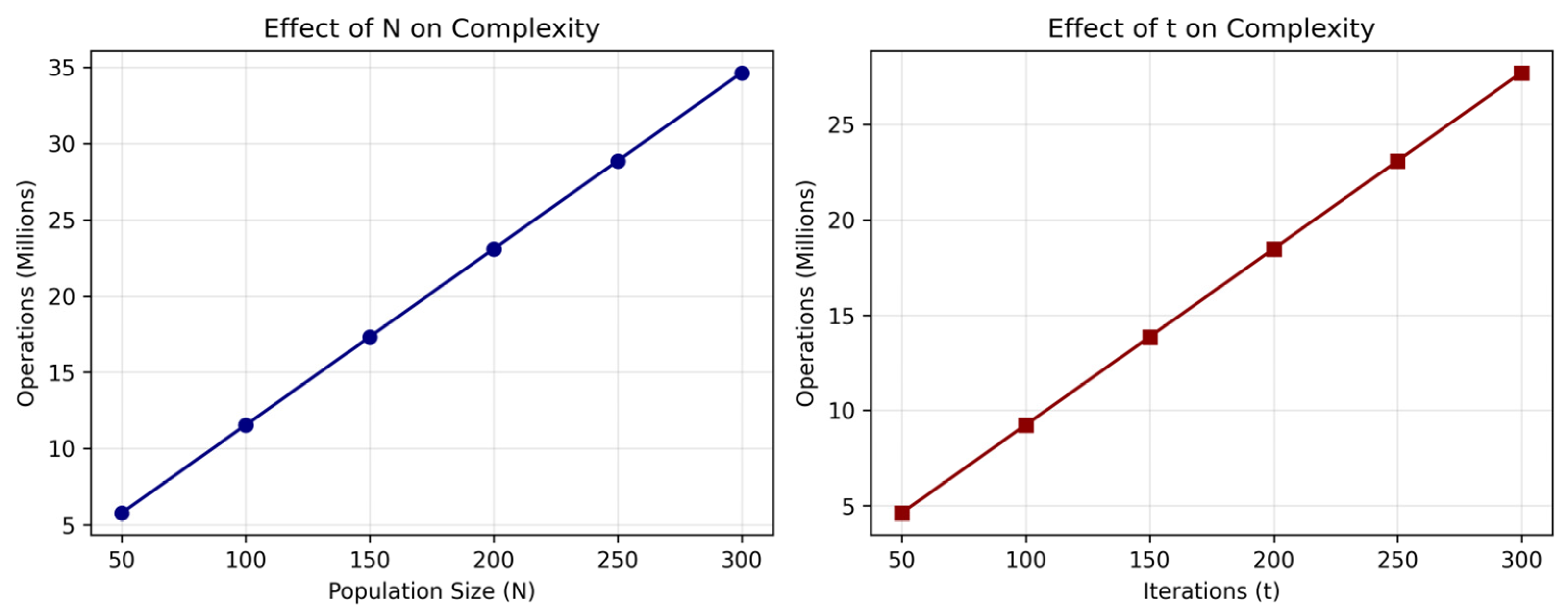
Table 2), the selected 10 functions vary in dimension, range, and problem type, providing adequate challenge and diversity to thoroughly evaluate the algorithms’ performance. These functions constitute the core and most frequently cited subset of the CEC 2019 benchmark. The specified the hardware used (Intel Core i7-10700K CPU, 32 GB RAM) and MATLAB settings (R2021a, parallel processing enabled). For IWHO, 40 search agents, 500 iterations, and 300 Random Walk steps were chosen. Each function was tested in 51 independent runs, a number that ensures the results are more objective and reliable.
In
Table 2, CEC 2019 featured demonstration. In
Table 3, mean, best value, worst value, and standard deviation are used as statistical measures to evaluate the suitability of the values obtained by the algorithms.
When examining
Table 3, the proposed IWHO algorithm achieves the best value in all functions except CEC03 and CEC04. For CEC03, all algorithms yield the same results with different standard deviations. In this case, WHO performs very well, and the proposed IWHO algorithm ranks second.
The IWHO algorithm proposed in this paper is compared with the WHOFWA and WHOW algorithms, which were previously proposed as variants of WHO. It is also compared with the RW-DO algorithm, which has been studied with the random walking strategy in the IWHO algorithm. As a result, as shown in
Table 4 the IWHO algorithm has a superior performance in seven functions.
In
Table 5, the nonparametric Wilcoxon test was used to evaluate whether the proposed IWHO algorithm differs from other algorithms when working with a different data set, assessing its originality. In this context,
W (Win) represents a victory,
T (Till) a draw, and
L (Low) a defeat. The confidence level was set at
p = 0.05. From the results, it can be concluded that the proposed IWHO algorithm is unique and original, as it produced significantly different results with 24 wins, 1 tills, and 5 losses out of 30 results.
Table 5 analyzed, The Wilcoxon signed-rank test was employed to assess if there was a statistically significant difference in the performance of the two algorithms.
Table 5: W/T/L: These letters stand for ‘Win’, ‘Tie’, and ‘Lose’, respectively, reflecting the status of the IWHO algorithm in comparison to other algorithms.
p-value: A value under 0.05 was deemed to indicate statistical significance. The IWHO algorithm demonstrated notable superiority (W) over the CAPSA and HHO algorithms for almost all functions. When compared to the WHO algorithm, it was superior in some functions and either matched or fell short in others. Remarkably, against CAPSA and HHO, the IWHO excelled in nine or all ten functions. The
p-values were mostly very small (e.g., 5.15 × 10
−10), indicating that the observed difference is unlikely to be by chance, but rather that the IWHO’s superiority is statistically sound. The results of the Wilcoxon signed-rank test reveal that the IWHO algorithm is statistically significantly superior in nearly all CEC 2019 functions, especially when compared to the CAPSA and HHO algorithms. Although it surpassed the WHO algorithm in certain functions, it showed similar or lower performance in others. These findings imply that the IWHO is generally a more effective and dependable optimization algorithm than its competitors.
Benferroni correction was used. Taking into account the evaluation, all elements of the h vector were 1. This result shows that the functions are significant according to the Benferroni test.
This paper performs a sensitivity analysis to determine the optimal beta parameter values within the RW-DO algorithm. For this purpose, the CEC 2019 benchmark, consisting of ten distinct functions, was chosen. The parameter C was tested at values of 0.12, 0.13, and 0.14, while the parameter ps remained constant at 0.2. The effects of these adjustments on the IWHO algorithm were evaluated. Although the results for CEC 06 did not produce the best standard deviation, the outcomes for all other functions were favorable. These results are detailed in the accompanying
Table 6 and
Table 7.
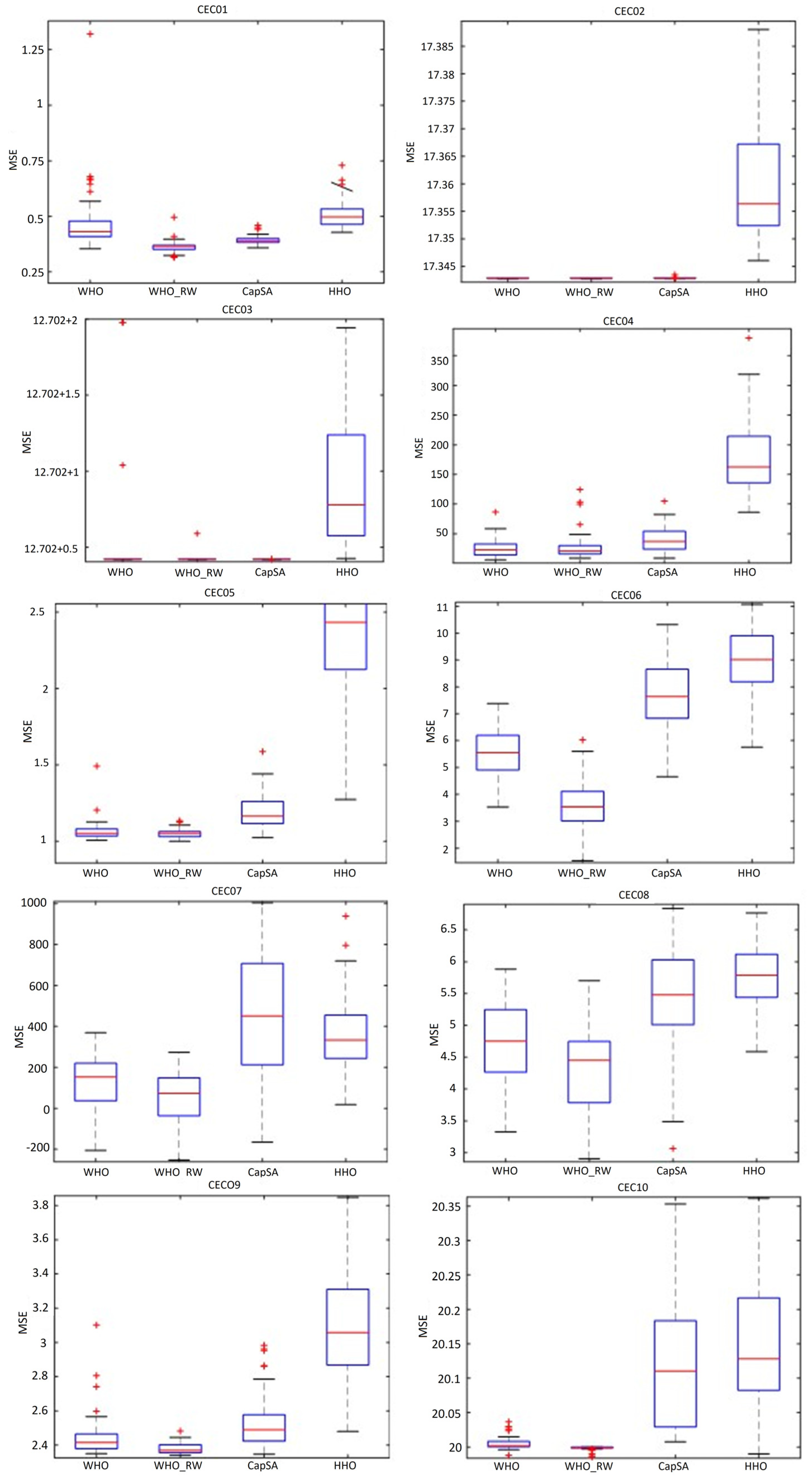
Upon reviewing
Figure 8, it becomes evident that the values produced by the proposed IWHO algorithm are more closely clustered across all functions, making it the algorithm nearest to the optimal point compared to others. The whiskers and boxes for the CEC01 function in both the WHO and IWHO algorithms are notably lower and shorter than those of HHO and CapSA. This indicates that WHO and IWHO achieve superior (lower MSE) and more consistent results. The lowest whisker point suggests that these algorithms may be closer to, or have reached, the global optimum. For the CEC02 function, WHO, IWHO, and CapSA show very short whiskers and low boxes, while HHO is significantly higher and more variable. It is likely that WHO and IWHO have reached the global optimum. Similarly, for the CEC03 function, the whiskers for WHO and IWHO are the lowest, whereas HHO is considerably higher, further indicating that WHO and IWHO are closer to the global optimum. Across functions in the range CEC04-CEC10, WHO and IWHO display the lowest whisker values, suggesting that these algorithms yield superior results (closer to the global optimum) compared to the others. Although a few outlier values are observed in the CEC01, CEC03, CEC04, and CEC10 functions, the consistency of results from fifty-one independent runs highlights the algorithm’s stable structure. Consequently, it can be concluded that the global solutions of this algorithm are within the best limits and closer to the optimal global solution.
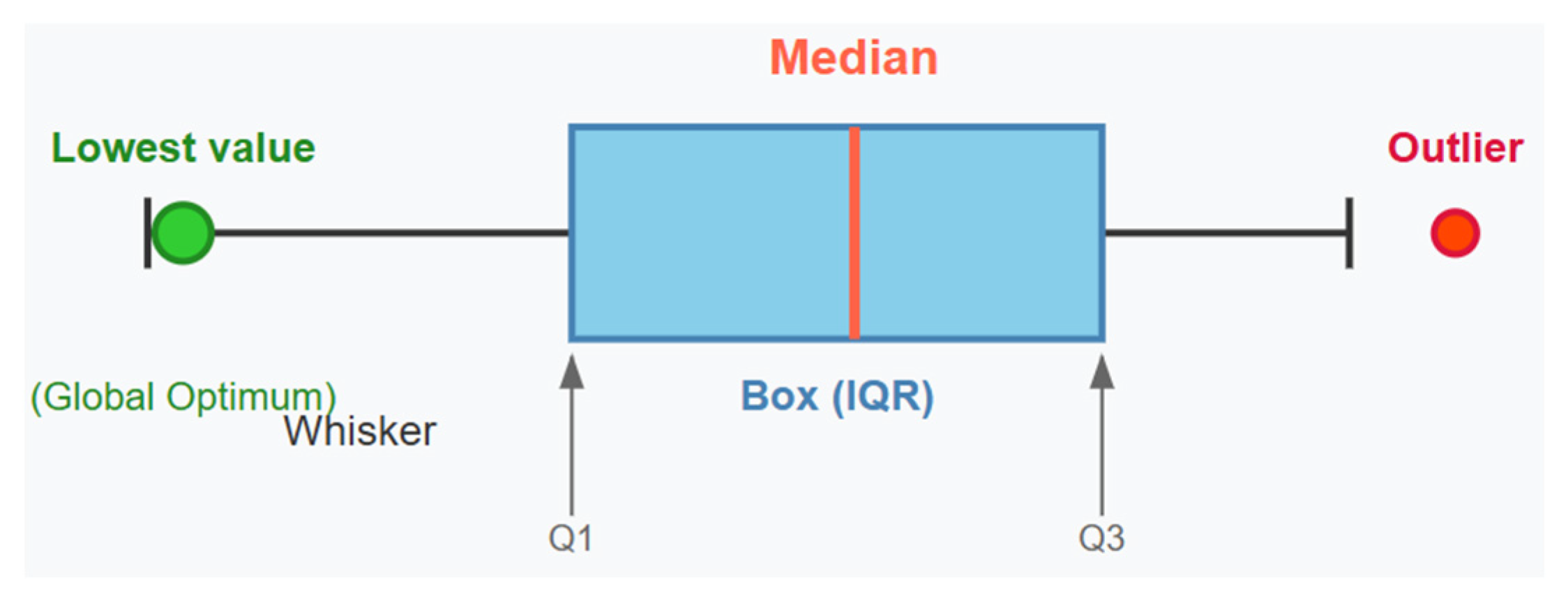
As seen in the box plot model in
Figure 9, box plots are displayed as lines with whiskers extending from the box to the minimum and maximum non-outlier values, revealing the spread of the data. The lowest point reached by the whisker, or the lowest outlier, might represent the optimal value (global optimum) identified by the algorithm, assuming it aligns with the true global optimum of the function. In a boxplot, the whiskers extend from the box to the minimum and maximum non-outlier values, indicating the spread of most of the data. The box itself represents the interquartile range (IQR), which encompasses the middle 50% of the data, from the first quartile (Q1) to the third quartile (Q3). The thick line within the box signifies the median, or the 50th percentile, of the data. Any data point outside the whiskers is considered an outlier and is depicted as a red dot. The lowest value reached by the left whisker, or the lowest outlier, might represent the optimal value (global optimum) identified by an optimization algorithm, provided it corresponds to the true minimum of the function.
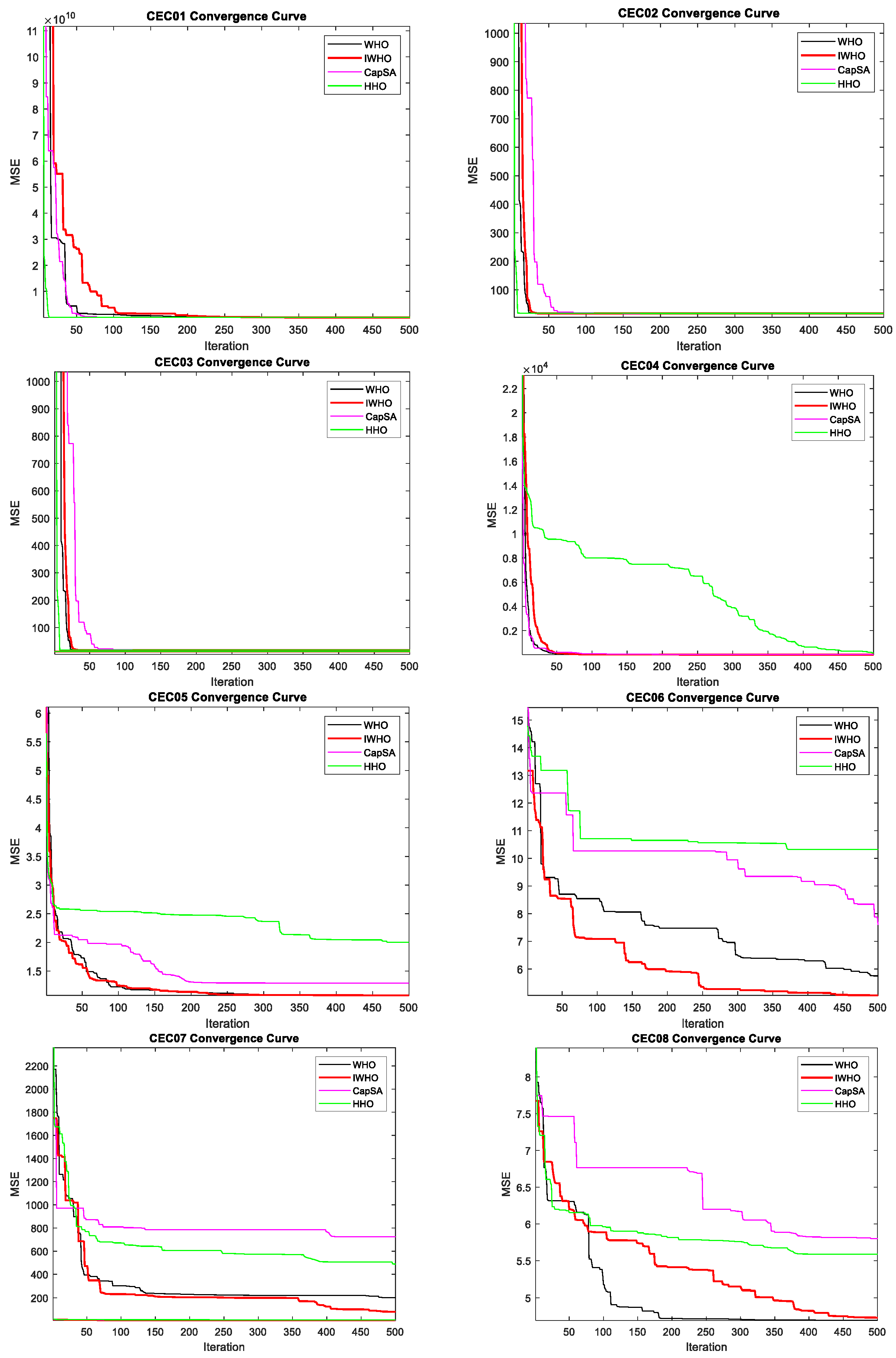
Convergence curves determine how the algorithms approach the optimal value over 500 iterations, whether they get stuck at local minimum points, and if they are subject to premature convergence. In this context,
Figure 10 shows that the proposed IWHO algorithm progresses gradually in all functions without early convergence. Observing that the IWHO algorithm does not show constant progress in a certain range of iterations, but instead continually moves towards better solutions, can be considered proof that the IWHO algorithm reaches the global solution without getting stuck at local optima. As a result, it can be observed that the IWHO algorithm converges towards the optimal point across the entire function set.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}