Energy-Aware Machine Learning Models—A Review of Recent Techniques and Perspectives


Abstract
1. Introduction
- To review and analyze the existing literature on energy consumption in machine learning, identifying key areas where improvements can be made.
- To evaluate various techniques, such as model compression, pruning, and quantization, focusing on their potential to reduce energy usage without compromising model performance.
- To investigate the impact of different hardware and infrastructure choices on the energy efficiency of ML models, including the use of specialized hardware like GPUs and TPUs.
- To assess the environmental impact of ML models throughout the entire ML process pipeline.
- To explore the application of ML in optimizing energy use in other sectors, such as industrial processes and transportation, thereby comparing the positive and the negative impact of AI technologies.
- To provide practical recommendations for ML practitioners and policymakers on implementing more sustainable practices within the AI pipeline.
2. Theoretical Basics
2.1. Global Energy Consumption
- The Industrial Sector: This sector is the largest consumer of energy, accounting for approximately 37% of the world’s total delivered energy [8]. It includes various industries, such as chemicals, metals, cement, and paper and pulp.
- The Transport Sector: The transport sector consumes about 25–30% of global energy. This includes energy used for all forms of transportation, such as road, rail, air, and maritime [9].
- The Commercial Sector: This sector, which includes energy used by businesses and public services, accounts for about 8% of global energy consumption.
- Agriculture, Forestry, and Fishing: This sector consumes around 3% of global energy, primarily for activities related to food production and resource extraction [12].
2.2. Foundations of Machine Learning
2.3. Performance Metrics and Evaluation Techniques
- Cross-Validation: This technique involves partitioning the dataset into multiple subsets and performing training and validation iteratively on different partitions. Common methods include k-fold cross-validation, stratified k-fold cross-validation, and leave-one-out cross-validation. This approach mitigates overfitting and provides a more generalized assessment of model performance.
- Holdout Method: The dataset is divided into separate training and testing subsets. The model is trained on the training subset and evaluated on the testing subset, providing a straightforward yet less robust performance evaluation compared to cross-validation.
- Bootstrapping: This resampling technique involves generating multiple subsets from the original dataset through replacement. Models are trained and evaluated on these subsets to estimate the accuracy and stability of predictions.
2.4. Computational Efficiency and Resource Utilization
- Time complexity: This metric evaluates the duration an algorithm requires to complete its execution as a function of the size of its input. It provides an upper bound on the running time, thereby facilitating performance prediction as input sizes escalate.
- Space complexity: This metric assesses the amount of memory an algorithm utilizes relative to the size of its input.
- CPU vs. GPU vs. TPU:
- –
- CPU (Central Processing Unit): Versatile and suitable for general-purpose tasks, though often slower for parallelizable operations typical in machine learning.
- –
- GPU (Graphics Processing Unit): Highly parallel and efficient for tasks involving large-scale matrix and vector operations, making it ideal for training deep neural networks.
- –
- TPU (Tensor Processing Unit): Specialized hardware designed by Google specifically for accelerating machine learning workloads, providing significant speed-ups for tensor operations.
- Memory Usage:
- –
- Efficient memory usage is critical to handle large datasets and models. Techniques like memory swapping, gradient checkpointing, and efficient data pipelines can effectively manage memory usage.
- Energy Consumption:
- –
- Training and deploying machine learning models can be energy-intensive. Estimating and optimizing energy consumption are essential for sustainable AI practices. Techniques like model pruning, quantization, and the use of energy-efficient hardware can mitigate energy usage.
- Algorithmic Optimization:
- –
- Gradient Descent Variants: Techniques like Stochastic Gradient Descent (SGD), Momentum, RMSprop, and Adam optimize the convergence speed and stability of training.
- –
- Hyperparameter Tuning: Systematic approaches, such as grid search, random search, and Bayesian optimization, aid in identifying the optimal hyperparameters for the model.
- Model Optimization:
- –
- Pruning: Removing redundant parameters in neural networks to reduce model size and enhance inference speed without significantly affecting accuracy.
- –
- Quantization: Reducing the precision of model parameters (e.g., from 32-bit to 8-bit) to decrease memory usage and increase computational speed.
- –
- Knowledge Distillation: Training a smaller model (student) to replicate the performance of a larger model (teacher), thereby achieving a balance between efficiency and performance.
- Hardware-Level Optimization:
- –
- Parallel and Distributed Computing: Leveraging multiple processors or distributed systems to manage large-scale computations more efficiently.
- –
- Hardware Acceleration: Utilizing specialized hardware, such as GPUs and TPUs, to accelerate specific machine learning operations.
- Software Optimization:
- –
- Efficient Libraries and Frameworks: Employing optimized libraries and frameworks (e.g., TensorFlow, PyTorch) designed to maximize the underlying hardware.
- –
- Compiler Optimizations: Utilizing advanced compilers and settings that optimize the code for performance on specific hardware architectures.
3. Literature Review
3.1. AI Energy Consumption and CO2 Emission
3.2. Estimation of Energy Consumption in Machine Learning
3.3. Dynamic GPU Energy Optimization for Machine Learning Training Workloads
3.4. Intelligent AI on the Edge
3.5. Energy-Efficient Practices in Deep Learning Training
3.6. Parallelizing Deep Neural Networks: Data and Model Parallelism
- Hogwild! SGD [32]: This method removes locks on shared parameters, enabling multiple threads to update the global model parameters concurrently. Despite potential conflicts during updates, it has been shown to converge under certain conditions.
- Elastic Averaging SGD (EASGD) [33]: EASGD is designed for distributed systems and balances local updates with global model synchronization. It allows each worker to compute gradients independently, and it periodically synchronizes with a central server using a round-robin strategy, ensuring convergence and scalability.
3.7. Machine Learning for Reducing CO2 Emissions in Other Sectors
3.8. Quantifying the Carbon Emissions of Machine Learning
- Choose Energy-Efficient Hardware: Selecting hardware with higher computing efficiency is crucial for reducing energy consumption. For instance, Jouppi et al. [39] suggest that TPUs, with their higher performance per watt, are a more sustainable choice compared to traditional GPUs, especially for large-scale deep learning tasks.
- Optimize Training Procedures: Utilizing pre-trained models and efficient hyperparameter search methods can greatly reduce the computational resources required for training. Bergstra and Bengio [44] highlight the effectiveness of random search over grid search in hyperparameter optimization, significantly lowering the computation needed. Falkner et al. [45] further propose BOHB (Bayesian Optimization with HyperBand), which balances exploration and exploitation, providing a more efficient hyperparameter search mechanism.
- Select Low-Carbon Data Centers: The choice of data center is another critical factor. Researchers should consider cloud providers with a strong commitment to renewable energy. Google’s [42] and Microsoft’s [43] data centers, for example, offer lower carbon options due to their investments in sustainable energy infrastructure.
- Engage in Responsible Computing Practices: Awareness of the environmental implications of computing tasks is essential. Schwartz et al. [46] advocate for “Green AI”, encouraging the community to prioritize energy-efficient algorithms and reduce unnecessary computations. This includes adopting practices like thorough literature reviews to avoid redundant experiments, efficient code debugging, and leveraging optimized algorithms.
3.9. Sustainable AI
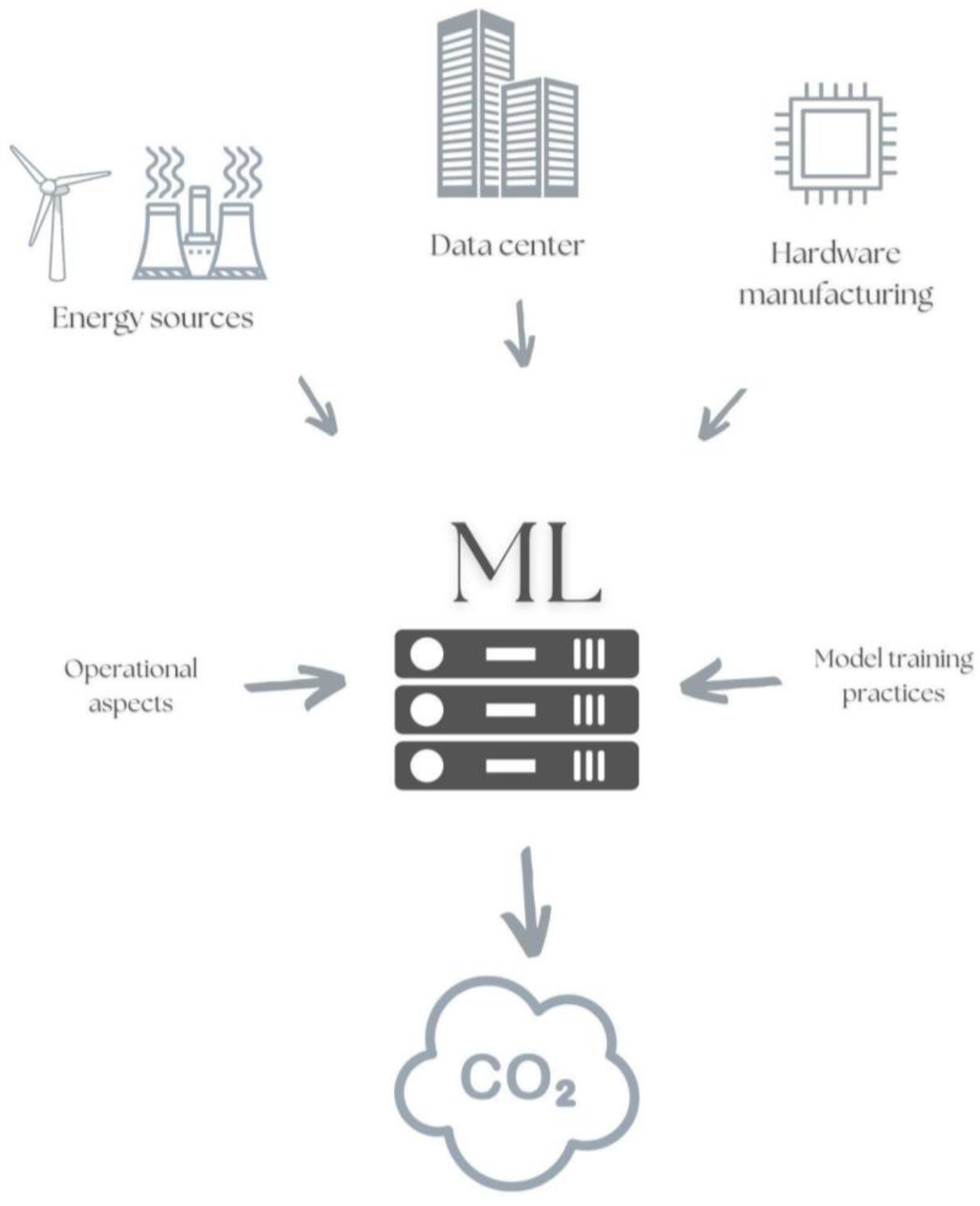
3.9.1. Operational vs. Embodied Carbon Footprint and the Environmental Impact of AI Model Training
3.9.2. Challenges and Opportunities for Sustainable AI
- Development of Resource-Efficient Algorithms: There is a need for the AI community to prioritize the development of algorithms that are both computationally efficient and environmentally friendly. Techniques like model compression, knowledge distillation, and low-rank approximation can reduce the computational demands of AI models without compromising performance [51].
- Lifecycle Assessments of AI Systems: Conducting comprehensive lifecycle assessments (LCAs) of AI systems can help identify the most significant sources of carbon emissions throughout the AI lifecycle, from hardware production to deployment and end-of-life disposal. This approach can guide the development of more sustainable AI systems by highlighting areas where carbon reductions are most feasible.
- Optimizing AI Pipelines: Implementing best practices in AI pipeline management, such as avoiding redundant computations, optimizing data transfer, and utilizing energy-efficient hardware, can lead to substantial reductions in carbon emissions. Techniques like hyperparameter tuning and early stopping can also help minimize the computational resources required for model training.
- Shift to Renewable Energy Sources: Encouraging the use of data centers powered by renewable energy sources is critical for reducing the operational carbon footprint of AI. Wu et al. [20] highlight the importance of geographical location in this regard, suggesting that AI workloads should be shifted to regions with a higher proportion of renewable energy in their power grids.
- Collaboration Across Stakeholders: Addressing the environmental challenges of AI requires collaboration between AI developers, policymakers, and industry stakeholders. Wu et al. [20] call for a collective effort to establish industry-wide standards and policies that promote the development and deployment of sustainable AI technologies.
3.10. Integrating Green AI Principles into Automated Machine Learning Systems
4. Key Findings
4.1. Comprehensive View
- Lifecycle consideration—the longer the component is able to serve its purpose, the smaller the carbon footprint (assuming equal energy efficiency of components).
- Material sourcing—material extraction, transportation, etc.
- The center’s energy sources—renewable or of high environmental impact.
- –
- Possibility of onsite power generation.
- Location (climate and cooling needs, water availability, vulnerability to natural hazards).
- The cooling system’s efficiency—more efficient in a naturally colder climate.
- –
- Variable-speed fans—adjusting energy consumption to demand.
- Monitoring and Management: Implementing Data Center Infrastructure Management (DCIM) software allows for real-time monitoring of energy consumption. These data help identify inefficiencies and opportunities for improvement, such as detecting underutilized servers or optimizing cooling systems.
- Energy-Efficient Hardware: Upgrading to modern servers that use advanced chip architectures and smart power management can decrease energy consumption. Virtualization also allows for multiple workloads to run on fewer physical servers, improving overall resource utilization.
- –
- Raising the ambient temperature of data centers can lead to immediate energy savings in cooling without negatively impacting server performance. Modern equipment can operate efficiently at higher temperatures.
- Dynamic Power Management: Implementing advanced scheduling algorithms and dynamic power management techniques can optimize resource allocation and reduce energy waste by adjusting power usage based on workload demands.
- Operational aspects
- –
- Deployment and inference: Using optimizing inference runtime systems can significantly improve efficiency.
- –
- Model shadowing: Often times, when an upgraded or updated model comes into production, they work in parallel for some time to ensure that the new model is correct. This doubles the energy consumption of that period, so it is important to ensure that those periods are as short as possible.
- Model training
- –
- Computational complexity of the model: It is important to not over-complicate a model and to delete unnecessary layers. Another aspect is choosing an adequate pre-trained model.
- –
- Training time: Practices like early stopping for underperforming models can help reduce unnecessary resource and time use.
- –
- Hyperparameter tuning: Traditional methods like grid search for hyperparameter tuning can lead to excessive computational demands. More efficient tuning methods can help minimize energy use and emissions during the training phase.
4.2. Environmental Impact of Machine Learning Methods
4.2.1. Overview of Methods
- Knowledge Distillation: This involves training a smaller model, often referred to as the “student”, to replicate the behavior of a larger, more complex model, known as the “teacher”. The process of transferring knowledge from the teacher to the student allows the student model to achieve similar performance with significantly fewer computational resources. This technique enables the deployment of smaller, more efficient models that maintain high accuracy while consuming less energy. Studies have shown that it can reduce energy use and CO2 equivalent by a factor of 19 [58].
- Quantization: This reduces the precision of the model’s parameters, such as converting 32-bit floating-point numbers to 8-bit integers. This reduction decreases both memory usage and computational demand, making it particularly useful for deploying models on edge devices with limited resources. This method can lead to savings in energy consumption and memory usage [59], with up to 16 times reduction in memory footprint [60], making it an effective strategy for reducing the environmental impact of machine learning models.
- Early Stopping: This is a technique used during model training to halt the process once the model’s performance stabilizes or reaches a pre-defined threshold. By stopping training early, unnecessary computations are avoided, which not only reduces energy consumption but also prevents overfitting. Additionally, this method helps extend the lifespan of hardware by lowering computational demands (up to 80% reduction in energy consumption for model training) [61].
- Data Parallelization: This method distributes data across multiple processors or computing nodes, enabling parallel computation during the training process. This method accelerates training by processing multiple data batches simultaneously, which in turn reduces training time and leads to proportional reductions in energy use and emissions. Effective parallelization also improves the utilization of computational resources by minimizing idle times, thereby enhancing overall energy efficiency [62,63].
- Renewable Energy-Powered Data Centers: These centers utilize energy from renewable sources, such as solar, wind, or hydropower, to power data centers. By transitioning to renewable energy, these data centers can achieve carbon reductions up to 40% compared to those that rely on conventional fossil fuels [64]. This significant reduction is due to the elimination of carbon emissions from energy generation, making it a highly effective strategy for sustainable computing [65].
- Optimizing Data Transfer: This focuses on reducing the volume of data transferred between nodes or stages in a machine learning pipeline. By minimizing data movement and optimizing communication protocols, energy consumption associated with data transfer can be significantly reduced. In addition to energy savings, this method reduces processing overhead and enhances overall system performance, making it a valuable operational optimization technique [20,66].
- Lifecycle Assessment: This is a comprehensive evaluation method that assesses the environmental impact of a machine learning system throughout its entire lifecycle—from development and training to deployment and eventual decommissioning. By identifying the major sources of energy consumption and emissions at each stage, it helps in developing targeted strategies to reduce overall environmental impact.
- Optimizing Java Code: This involves fine-tuning Java code for machine learning applications to improve runtime efficiency and memory management. Energy consumption can be reduced by 6.2% to 80% (in extreme cases) through optimized code execution. This optimization not only enhances resource utilization but also prolongs the lifespan of hardware by reducing the computational load required to run machine learning models [67,68].
- Optimizing GPU Operations: This focuses on improving the efficiency of GPU operations, such as parallel execution and memory management. By ensuring that GPUs are used more efficiently, power consumption and emissions can be reduced by up to 75%. The GPU Accelerator can reduce a company’s carbon footprint by as much as 80% while delivering 5× average speedups and 4× reductions in computing costs. This method is particularly beneficial for energy-intensive tasks like training deep learning models, where the energy savings can be substantial [69].
- Carbon-Friendly Inference Techniques: These techniques optimize runtime systems for inference with an emphasis on reducing carbon emissions. By prioritizing the use of energy-efficient hardware, rightsizing the hardware, restructuring code for maximizing the existing CPUs’ usage (reuse), and leveraging renewable energy sources, these techniques and individual design strategies save around 29%, 25%, 34%, and 41% carbon for reusing, rightsizing, reducing, and recycling, respectively [70].
- Energy-Efficient Hardware: This includes specialized devices, such as low-power GPUs or Tensor Processing Units (TPUs), designed to operate with reduced energy consumption. These devices can reduce energy use by up to 50% compared to traditional hardware. They often incorporate advanced power management features and are optimized for specific computational tasks, resulting in further reductions in energy consumption and heat generation during machine learning operations [71].
- Reducing Redundant Computations: This aims to minimize unnecessary or duplicate computations within machine learning pipelines. By streamlining the process and eliminating redundancy, a 4.40× decrease in energy consumption can be observed while training CNNs [72]. Reducing redundant computations not only saves energy but also enhances the overall efficiency and speed of data processing and model training, contributing to a lower environmental footprint.
- Bayesian Hyperparameter Tuning: This uses probabilistic models to explore hyperparameter spaces more efficiently than traditional methods, such as grid search or random search. By focusing on the most promising regions of the hyperparameter space, this method reduces the number of evaluations needed to find optimal parameters. This approach is particularly effective for large-scale models where hyperparameter tuning is computationally expensive [73,74].
- Deleting Unnecessary Layers: This involves identifying and removing layers from neural networks that do not contribute significantly to the model’s performance. Simplifying the model in this way reduces computational complexity, leading to decreased energy usage and emissions [75]. In addition to energy savings, simplified models require less training and inference time, making them more efficient in deployment scenarios.
- Model Parallelization: This divides a model into segments that can be processed concurrently across multiple processors. This technique is especially useful for managing large models that exceed the computational capacity of a single processor. By distributing the computational load, energy consumption can be reduced by up to 26×, resulting in significant energy savings [76]. Additionally, it optimizes the use of high-performance computing resources, further reducing the overall environmental impact.
4.2.2. Description of Parameters Utilized for Environmental Impact Evaluation
- Environmental Impact: Quantifies the overall effect of a method on the environment, including reductions in energy consumption and carbon emissions. A high environmental impact means that the method significantly lowers energy use and emissions, contributing to greener AI practices.
- Energy Efficiency Ratio: Measures the ratio of performance improvement (e.g., accuracy, speed) to the energy consumed. It helps assess how effectively a method balances performance with energy consumption.
- Scalability Impact: Measures how the environmental impact scales with increasing data size, model complexity, or deployment scenarios. It indicates how changes in scale affect energy consumption and emissions.
- Lifecycle Emissions: Evaluates the total emissions produced over the entire lifecycle of the method, including development, training, deployment, and maintenance phases. It provides a comprehensive view of the total environmental footprint.
- Training Time Impact: Measures how the method influences the duration of training processes. Methods with a low training time impact reduce the time needed for training, thereby enhancing efficiency.
4.2.3. Optimization Techniques in Machine Learning for Minimizing Energy Consumption
4.3. Methodology for Energy Consumption Estimation
- Basic Binary Classification: Spam detection in emails using a small set of features.
- Simple Regression: Predicting house prices based on a few key attributes.
- Intermediate Classification: Sentiment analysis of text reviews to determine if a review is positive or negative.
- Moderate Regression: Predicting sales figures based on various market indicators.
- Image Classification: Recognizing objects in images using CNNs.
- Complex Pattern Recognition: Predicting stock market trends based on multiple economic indicators.
- Large-Scale Natural Language Processing: Using transformer models like BERT or GPT for language understanding across vast corpora.
- High-Dimensional Data Processing: Processing and analyzing video data with DNNs or CNNs.
- CPU Power Consumption: A typical CPU used for machine learning tasks consumes around 100 watts (0.1 kW) [79]. A CPU is suitable for non-complex and moderate tasks.
5. Summary and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Carbonell, J.G.; Michalski, R.S.; Mitchel, T.M. An overview of machine learning. In Machine Learning: An Artificial Intelligence Approach, 1st ed.; Carbonell, J.G., Michalski, R.S., Mitchel, T.M., Eds.; Springer: Berlin Heidelberg, Germany, 1983; pp. 3–23. [Google Scholar]
- Kessides, I.N.; Toman, M. World Bank Blogs. The Global Energy Challenge. Available online: https://blogs.worldbank.org/en/developmenttalk/the-global-energy-challenge/ (accessed on 13 January 2025).
- Energy Alliance. The Global Challenge. Available online: https://energyalliance.org/powering-people-planet-2023/the-global-challenge/ (accessed on 13 January 2025).
- NS Energy. Profiling the World’s Top Five Countries in Electricity Consumption. Available online: https://www.nsenergybusiness.com/analysis/electricity-consuming-countries/ (accessed on 13 January 2025).
- IEA Executive Summary. Available online: https://www.iea.org/reports/electricity-2024/executive-summary (accessed on 1 May 2025).
- World Energy & Climate Statistics. Available online: https://yearbook.enerdata.net/total-energy/world-consumption-statistics.html (accessed on 1 May 2025).
- Electric Energy Consumption. Available online: https://en.wikipedia.org/wiki/Electric_energy_consumption (accessed on 1 May 2025).
- IEA. Energy Sytem/Industry. Available online: https://www.iea.org/energy-system/industry (accessed on 1 May 2025).
- EBSCO, Energy-Efficient Modes of Transportation. Available online: https://www.ebsco.com/research-starters/power-and-energy/energy-efficient-modes-transportation (accessed on 1 May 2025).
- González-Torres, M.; Pérez-Lombard, L.; Coronel, J.F.; Maestre, I.R.; Bertoldi, P. Activity and efficiency trends for the residential sector across countries. Energy Build. 2022, 273, 112428. [Google Scholar] [CrossRef]
- IEA. Energy Efficiency 2023. Available online: https://iea.blob.core.windows.net/assets/dfd9134f-12eb-4045-9789-9d6ab8d9fbf4/EnergyEfficiency2023.pdf (accessed on 1 May 2025).
- REN21, Renewables Global Status Report (GSR) Collection 2023. Available online: https://www.ren21.net/wp-content/uploads/2019/05/GSR2023_Fact_Sheet_Agriculture.pdf (accessed on 1 May 2025).
- Frontier Group. Fact File: Computing Is Using More Energy than Ever. Available online: https://frontiergroup.org/resources/fact-file-computing-is-using-more-energy-than-ever/ (accessed on 13 January 2025).
- Hardesty, L. MIT News. Explained: Neural Networks. Available online: https://news.mit.edu/2017/explained-neural-networks-deep-learning-0414/ (accessed on 13 January 2025).
- Genetic Science Learning Center. Neurons Transmit Messages in the Brain. Available online: https://learn.genetics.utah.edu/content/neuroscience/neurons/ (accessed on 13 January 2025).
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv 2015. [Google Scholar] [CrossRef]
- Dupond, S. A thorough review on the current advance of neural network structures. Annu. Rev. Control. 2019, 14, 200–230. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. OpenAI. 2019. Available online: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf (accessed on 17 January 2025).
- Wu, C.J.; Raghavendra, R.; Gupta, U.; Acun, B.; Ardalani, N.; Maeng, K.; Hazelwood, K. Sustainable AI: Environmental implications, challenges and opportunities. Proc. Mach. Learn. Syst. 2022, 4, 795–813. [Google Scholar]
- Lacoste, A.; Luccioni, A.; Schmidt, V.; Dandres, T. Quantifying the Carbon Emissions of Machine Learning. arXiv 2019. [Google Scholar] [CrossRef]
- AI Is An Energy Hog. This Is What It Means for Climate Change. Available online: https://www.technologyreview.com/2024/05/23/1092777/ai-is-an-energy-hog-this-is-what-it-means-for-climate-change/ (accessed on 13 January 2025).
- How AI Can Optimize Energy Efficiency and Reduce Carbon Emissions. 2023. Available online: https://energycentral.com/c/pip/how-ai-can-optimize-energy-efficiency-and-reduce-carbon-emissions/ (accessed on 13 January 2025).
- Garcıa-Martın, E.; Rodrigues, C.F.; Riley, G.; Grahn, H. Estimation of energy consumption in machine learning. J. Parallel Distrib. Comput. 2019, 134, 75–88. [Google Scholar] [CrossRef]
- Shahid, A. Towards Reliable and Accurate Energy Predictive Modelling Using Performance Events on Modern Computing Platforms. Ph.D. Thesis, University College Dublin, Dublin, Ireland, 2020. Available online: https://hcl.ucd.ie/system/files/%5B%5BFinal%5D%5D%20Towards%20Reliable%20and%20Accurate%20Energy%20Predictive%20Modelling%20using%20Performance%20Events%20on%20Modern%20Computing%20Platforms.pdf (accessed on 13 January 2025).
- Wu, X.; Taylor, V.; Lan, Z. Performance and Power Modeling and Prediction Using MuMMI and Ten Machine Learning Methods. arXiv 2020. [Google Scholar] [CrossRef]
- Awan, M.R.; Rojas, H.A.G.; Hameed, S.; Riaz, F.; Hamid, S.; Hussain, A. Machine Learning-Based Prediction of Specific Energy Consumption for Cut-Off Grinding. Sensors 2022, 22, 7152. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, W.; Lai, S.; Hao, M.; Wang, Z. Dynamic GPU energy optimization for machine learning training workloads. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 2943–2954. [Google Scholar] [CrossRef]
- Pengfei, Z.; Li, A.; Barker, K.; Ge, R. Indicator-directed dynamic power management for iterative workloads on GPU-accelerated systems. In Proceedings of the 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID), Melbourne, Australia, 11–14 May 2020; Available online: https://www.researchgate.net/publication/342929972_Indicator-Directed_Dynamic_Power_Management_for_Iterative_Workloads_on_GPU-Accelerated_Systems (accessed on 13 January 2025).
- Kumar, M.; Zhang, X.; Liu, L.; Wang, Y.; Shi, W. Energy-efficient machine learning on the edges. In Proceedings of the IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), New Orleans, LA, USA, 18–22 May 2020; Available online: https://weisongshi.org/papers/kumar20-EEML.pdf (accessed on 13 January 2025).
- Yarally, T.; Cruz, L.; Feitosa, D.; Sallou, J.; van Deursen, A. Uncovering Energy-Efficient Practices in Deep Learning Training: Preliminary Steps Towards Green AI. arXiv 2023. [Google Scholar] [CrossRef]
- Niu, F.; Recht, B.; Re, C.; Wright, S.J. Hogwild!: A lock-free approach to parallelizing stochastic gradient descent. Advances in neural information processing systems 24. In Proceedings of the 25th Annual Conference on Neural Information Processing Systems (NIPS), Granada, Spain, 12–17 December 2011; Available online: https://proceedings.neurips.cc/paper/2011/file/218a0aefd1d1a4be65601cc6ddc1520e-Paper.pdf (accessed on 13 January 2025).
- Sixin, Z.; Choromanska, A.E.; LeCun, Y. Deep learning with elastic averaging SGD. In Proceedings of the 29th International Conference on Neural Information Processing Systems—Volume 1, Montreal, QC, Canada, 7–12 December 2015; MIT Press: Cambridge, MA, USA, 2015; pp. 685–693. [Google Scholar]
- Wongpanich, A. Efficient Parallel Computing for Machine Learning at Scale. Technical Report of Univ. of California Berkeley. Available online: https://www2.eecs.berkeley.edu/Pubs/TechRpts/2020/EECS-2020-225.pdf (accessed on 18 December 2020).
- Ghoroghi, A.; Rezgui, Y.; Petri, I.; Beach, T. Advances in application of machine learning to life cycle assessment: A literature review. Int. J. Life Cycle Assess. 2022, 27, 433–456. [Google Scholar] [CrossRef]
- Sayyah, A.; Ahangari, M.; Mostafaei, J.; Nabavi, S.R.; Niaei, A. Machine learning-based life cycle optimization for the carbon dioxide methanation process: Achieving environmental and productivity efficiency. J. Clean. Prod. 2023, 426, 139120. [Google Scholar] [CrossRef]
- Delanoe, P.; Tchuente, D.; Colin, G. Method and evaluations of the effective gain of artificial intelligence models for reducing CO2 emissions. J. Environ. Manag. 2023, 331, 117261. [Google Scholar] [CrossRef]
- Brander, M.; Sood, A.; Wylie, C.; Haughton, A.; Lovell, J. Electricity-Specific Emission Factors for Grid Electricity. Ecometrica. Available online: https://www.scribd.com/document/386397121/Nur/ (accessed on 13 January 2025).
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Yoon, D.H. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture, Toronto, ON, Canada, 24–28 June 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 1–12. [Google Scholar]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef]
- Howard, J.; Ruder, S. Universal Language Model Fine-Tuning for Text Classification. arXiv 2018. [Google Scholar] [CrossRef]
- Google. Google Environmental Report 2018. Available online: https://sustainability.google/reports/environmental-report-2018/#data-centers/ (accessed on 13 January 2025).
- Microsoft. Beyond Carbon Neutral. 2018. Available online: https://download.microsoft.com/download/6/7/0/6706756C-867B-4A53-BDDD-30D93650FED1/Microsoft_Beyond_Carbon_Neutral.pdf (accessed on 13 January 2025).
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Falkner, S.; Klein, A.; Hutter, F. BOHB: Robust and Efficient Hyperparameter Optimization at Scale. arXiv 2018. [Google Scholar] [CrossRef]
- Schwartz, R.; Dodge, J.; Smith, N.A.; Etzioni, O. Green AI. arXiv 2019. [Google Scholar] [CrossRef]
- Anthony, L.F.; Kanding, B.; Selvan, R. Carbontracker: Tracking and Predicting the Carbon Footprint of Training Deep Learning Models. arXiv 2020. [Google Scholar] [CrossRef]
- Schneider, I.; Xu, H.; Benecke, S.; Patterson, D.; Huang, K.; Ranganathan, P.; Elsworth, C. Life-Cycle Emissions of AI Hardware: A Cradle-To-Grave Approach and Generational Trends. arXiv 2025. [Google Scholar] [CrossRef]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and policy considerations for deep learning in NLP. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3645–3650. [Google Scholar]
- Henderson, P.; Hu, J.; Romoff, J.; Brunskill, E.; Jurafsky, D.; Pineau, J. Towards the systematic reporting of the energy and carbon footprints of machine learning. J. Mach. Learn. Res. 2020, 21, 1–43. [Google Scholar]
- Sander, J.; Cohen, A.; Dasari, V.R.; Venable, B.; Jalaian, B. On Accelerating Edge AI: Optimizing Resource-Constrained Environments. arXiv 2025. [Google Scholar] [CrossRef]
- Castellanos-Nieves, D.; García-Forte, L. Strategies of Automated Machine Learning for Energy Sustainability in Green Artificial Intelligence. Appl. Sci. 2024, 14, 6196. [Google Scholar] [CrossRef]
- Castellanos-Nieves, D.; Garcia-Forte, L. Improving automated machine-learning systems through Green AI. Appl. Sci. 2023, 13, 11583. [Google Scholar] [CrossRef]
- Herzog, B.; Schubert, J.; Rheinfels, T.; Nickel, C.; Hönig, T. GreenPipe: Energy-Efficient Data-Processing Pipelines for Resource-Constrained Systems. Available online: https://ewsn.org/file-repository/ewsn2024/ewsn24-final133.pdf (accessed on 27 May 2024).
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.; Blum, M.; Hutter, F. Auto-sklearn: Efficient and robust automated machine learning. In Automated Machine Learning; Hutter, F., Kotthoff, L., Vanschoren, J., Eds.; Springer: Cham, Switzerland, 2019; pp. 113–134. [Google Scholar]
- Patterson, D.; Gonzalez, J.; Holzle, U.; Quoc, L.; Liang, C.; Munguia, L.-M.; Rothchild, D.; So, D.R.; Texier, M.; Dean, J. The carbon footprint of machine learning training will plateau, then shrink. Computer 2022, 55, 18–28. [Google Scholar] [CrossRef]
- Patterson, D.; Gilbert, J.M.; Gruteser, M.; Robles, E.; Sekar, K.; Wei, Y.; Zhu, T. Energy and emissions of machine learning on smartphones vs. the cloud. Commun. ACM 2024, 67, 86–97. [Google Scholar] [CrossRef]
- Rafat, K.; Islam, S.; Mahfug, A.A.; Hossain, M.I.; Rahman, F.; Momen, S.; Mohammed, N. Mitigating carbon footprint for knowledge distillation based deep learning model compression. PLoS ONE 2023, 18, e0285668. [Google Scholar] [CrossRef]
- Rokh, B.; Azarpeyvand, A.; Khanteymoori, A. A comprehensive survey on model quantization for deep neural networks. ACM Trans. Intell. Syst. Technol. 2023, 14, 1–50. [Google Scholar] [CrossRef]
- Bondarenko, Y.; Nagel, M.; Blankevoort, T. Understanding and overcoming the challenges of efficient transformer quantization. arXiv 2021. [Google Scholar] [CrossRef]
- MIT News. New Tools Are Available to Help Reduce the Energy that AI Models Devour. MIT News, 2023. Available online: https://news.mit.edu/2023/new-tools-available-reduce-energy-that-ai-models-devour-1005/ (accessed on 15 January 2025).
- Liu, Y.; Lu, H.; Luo, Y.; Memaripour, A.; Merritt, A.; Pillai, S.; Zhao, X. Scaling distributed machine learning with the parameter server. In Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation, Broomfield, CO, USA, 6–8 October 2014. [Google Scholar]
- Sze, V.; Chen, Y.-H.; Yang, T.-J.; Emer, J.S. Efficient Processing of Deep Neural Networks; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Deepmind AI Reduces Energy Used for Cooling Google Data Centers by 40%. Available online: https://deepmind.google/discover/blog/deepmind-ai-reduces-google-data-centre-cooling-bill-by-40/ (accessed on 13 January 2025).
- Sarkar, S.; Naug, A.; Luna, R.; Guillen-Perez, A.; Gundecha, V.; Ghorbanpour, S.; Mousavi, S.; Markovikj, D.; Ramesh Babu, A. Carbon Footprint Reduction for Sustainable Data Centers in Real-Time. In Proceedings of the 38th Annual AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 22322–22330. [Google Scholar]
- Walsh, D.; Donti, P. Tackling Climate Change with Machine Learning. MIT Sloan. Available online: https://mitsloan.mit.edu/ideas-made-to-matter/tackling-climate-change-machine-learning (accessed on 13 January 2025).
- Pereira, R.; Couto, M.; Cunha, J.; Fernandes, J.P.; Saraiva, J. The Influence of the Java Collection Framework on Overall Energy Consumption. arXiv 2016. [Google Scholar] [CrossRef]
- Karamchandani, A.; Mozo, A.; Gómez-Canaval, S.; Pastor, A. A methodological framework for optimizing the energy consumption of deep neural networks: A case study of a cyber threat detector. Neural Comput. Appl. 2024, 36, 10297–10338. [Google Scholar] [CrossRef]
- Patterson, D.; Gonzalez, J.; Le, Q.; Liang, C.; Munguia, L.-M.; Rothchild, D.; So, D.; Texier, M.; Dean, J. Carbon Emissions and Large Neural Network Training. arXiv 2021. [Google Scholar] [CrossRef]
- Li, Y.; Hu, Z.; Choukse, E.; Fonseca, R.; Suh, G.E.; Gupta, U. EcoServe: Designing Carbon-Aware AI Inference Systems. arXiv 2025, arXiv:2502.05043. [Google Scholar] [CrossRef]
- Stanford AHA Retreat. Energy Efficiency and AI Hardware. Bill Dally. 2023. Available online: https://aha.stanford.edu/sites/g/files/sbiybj20066/files/media/file/aha-retreat-2023_dally_keynote_en_eff_ai_hw_0.pdf (accessed on 19 February 2025).
- Lew, J.S.; Liu, J.; Gong, W.; Goli, N.; Evans, R.D.; Aamodt, T.M. Anticipating and eliminating redundant computations in accelerated sparse training. In Proceedings of the 49th Annual International Symposium on Computer Architecture, New York, NY, USA, 18–22 June 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 536–551. [Google Scholar]
- Gomes Mantovani, R.; Horváth, T.; Rossi, A.L.D.; Cerri, R.; Barbon, S., Jr.; Vanschoren, J.; de Carvalho, A.C.P.L.F. Better trees: An empirical study on hyperparameter tuning of classification decision tree induction algorithms. Data Min. Knowl. Discov. 2024, 38, 1364–1416. [Google Scholar] [CrossRef]
- Dou, H.; Zhu, S.; Zhang, Y.; Chen, P.; Zheng, Z. HyperTuner: A cross-layer multi-objective hyperparameter auto-tuning framework for data analytic services. J. Supercomput. 2024, 80, 1682–1691. [Google Scholar] [CrossRef]
- Gromov, A.; Tirumala, K.; Shapourian, H.; Glorioso, P.; Roberts, D.A. The Unreasonable Ineffectiveness of the Deeper Layers. arXiv 2024. [Google Scholar] [CrossRef]
- Wu, X.; Brazzle, P.; Cahoon, S. Performance and Energy Consumption of Parallel Machine Learning Algorithms. arXiv 2023. [Google Scholar] [CrossRef]
- Chandler, J. Saving Green: Accelerated Analytics Cuts Costs and Carbon. NVIDIA Blog, 2023. Available online: https://blogs.nvidia.com/blog/spark-rapids-energy-efficiency/ (accessed on 15 January 2025).
- Helen Victoria, A.; Maragatham, G. Automatic tuning of hyperparameters using Bayesian optimization. Evol. Syst. 2021, 12, 217–223. [Google Scholar] [CrossRef]
- Xia, Y.; Zhu, M.; Kuang, L.; Ma, X. Applications classification and scheduling on heterogeneous HPC systems using experimental research. J. Digit. Inf. Manag. 2011, 9, 227–232. [Google Scholar]
- Gao, Y.; Iqbal, S.; Zhang, P.; Qiu, M. Performance and power analysis of high-density multi-GPGPU architectures: A preliminary case study. In Proceedings of the 2015 IEEE 17th International Conference on High Performance Computing and Communications, 2015 IEEE 7th International Symposium on Cyberspace Safety and Security, and 2015 IEEE 12th International Conference on Embedded Software and Systems, New York, NY, USA, 24–26 August 2015; pp. 66–71. [Google Scholar]
- Luccioni, A.S.; Viguier, S.; Ligozat, A.-L. Estimating the carbon footprint of BLOOM, a 176B parameter language model. J. Mach. Learn. Res. 2023, 24, 1–15. [Google Scholar]
- Ngufor, C.; Wojtusiak, J. Extreme logistic regression. Adv. Data Anal. Classif. 2016, 10, 27–52. [Google Scholar] [CrossRef]
- Lim, T.-S.; Loh, W.-Y.; Shih, Y.-S. A comparison of prediction accuracy, complexity, and training time of thirty-three old and new classification algorithms. Mach. Learn. 2000, 40, 203–228. [Google Scholar] [CrossRef]
- Dixit, M.; Sharma, R.; Shaikh, S.; Muley, K. Internet traffic detection using naive Bayes and k-nearest neighbors (KNN) algorithm. In Proceedings of the International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 15–17 May 2019; pp. 1153–1157. [Google Scholar]
- Analytics Vidhya. Naive Bayes Explained. 2017. Available online: https://www.analyticsvidhya.com/blog/2017/09/naive-bayes-explained/ (accessed on 13 January 2025).
- Mohammadi, A.M.; Mahmood Fathy, M. The empirical comparison of the supervised classifiers performances in implementing a recommender system using various computational platforms. Int. J. Intell. Syst. Appl. 2020, 15, 11–20. [Google Scholar] [CrossRef]
- Jankowski, D.; Jackowski, K.; Cyganek, B. Learning decision trees from data streams with concept drift. Procedia Comput. Sci. 2016, 80, 1682–1691. [Google Scholar] [CrossRef]
- Bolchini, C.; Cassano, L. Machine learning-based techniques for incremental functional diagnosis: A comparative analysis. In Proceedings of the 2014 IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFT), Amsterdam, The Netherlands, 1–3 October 2014; pp. 246–251. [Google Scholar]
- Saadatfar, H.; Khosravi, S.; Joloudari, J.H.; Mosavi, A.; Shamshirband, S. A new k-nearest neighbors classifier for big data based on efficient data pruning. Mathematics 2020, 8, 286. [Google Scholar] [CrossRef]
- Dong, J.-X.; Krzyżak, A.; Suen, C.Y. A fast SVM training algorithm. In Pattern Recognition with Support Vector Machines; Lee, S.W., Verri, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2388, pp. 53–67. [Google Scholar]
- Hansch, R.; Hellwich, O. Faster trees: Strategies for accelerated training and prediction of random forests for classification of polsar images. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 4, 105–112. [Google Scholar] [CrossRef]
- Cai, L.; Barneche, A.M.; Herbout, A.; Foo, C.S.; Lin, J.; Chandrasekhar, V.R.; Aly, M.M.S. TEA-DNN: The quest for time-energy-accuracy co-optimized deep neural networks. In Proceedings of the 2019 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), Lausanne, Switzerland, 29–31 July 2019; pp. 1–6. [Google Scholar]
- Peng, Y.; Zhu, Y.; Chen, Y.; Bao, Y.; Yi, B.; Lan, C.; Guo, C. A generic communication scheduler for distributed DNN training acceleration. In Proceedings of the 27th ACM Symposium on Operating Systems Principles, Huntsville, ON, Canada, 27–30 October 2019; pp. 16–29. [Google Scholar]
- Surrisyad, H. A fast military object recognition using extreme learning approach on CNN. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 211–220. [Google Scholar] [CrossRef]
- Haryanto, T.; Wasito, I.; Suhartanto, H. Convolutional neural network for gland images classification. In Proceedings of the 11th International Conference on Information & Communication Technology and System (ICTS), Surabaya, Indonesia, 31 October 2017; pp. 55–60. [Google Scholar]
- Taylor, M.E.; Stone, P. Representation transfer for reinforcement learning. In Proceedings of the AAAI Fall Symposium: Computational Approaches to Representation Change During Learning and Development, Arlington, TX, USA, 9–11 November 2007; pp. 78–85. [Google Scholar]
- You, Y.; Li, J.; Reddi, S.; Hseu, J.; Kumar, S.; Bhojanapalli, S.; Hsieh, C.J. Large Batch Optimization for Deep Learning: Training BERT in 76 Minutes. arXiv 2019. [Google Scholar] [CrossRef]
- Izsak, P.; Berchansky, M.; Levy, O. How to Train BERT with an Academic Budget. arXiv 2021. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Technique | Energy Efficiency Characteristics |
|---|---|
| Early Stopping | Up to 80% reduction in energy used for model training [61]. |
| Knowledge Distillation | Reduces energy use and CO2 equivalent by a factor of 19 [58]. |
| Optimizing GPU Operations | Up to 75% reduction in emissions [69], and the GPU Accelerator can reduce a company’s carbon footprint by as much as 80% while delivering 5× average speedups and 4× reductions in computing costs [49,77]. |
| Data and Model Parallelization | Energy consumption reduced by up to 26× through parallel processing [76]. |
| Lifecycle Assessment | Identifies opportunities to reduce energy use and emissions throughout the model’s lifecycle. |
| Quantization | Reduces energy consumption and memory usage [59], with up to 16× reduction in memory footprint [60]. |
| Renewable Energy-Powered Data Centers | Substantial reduction in carbon footprint by using renewable energy sources. Applying DeepMind’s machine learning to Google data centers reduced the amount of energy used for cooling by up to 40% [64]. |
| Energy-Efficient Hardware | Utilizes low-power hardware to minimize energy consumption. |
| Deleting Unnecessary Layers | Simplifies architectures, reducing computational complexity and energy use. |
| Optimizing Java Code | Energy consumption reduced by 6.2% [67] to 80% through optimized code execution [68]. |
| Optimizing Data Transfer | Reduction in energy consumption [20] and carbon footprint by optimizing data transfer [66]. |
| Bayesian Hyperparameter Tuning | Significant reduction in energy consumption [78] and carbon emissions by efficiently tuning hyperparameters [73,74]. |
| Carbon-Friendly Inference Techniques | Optimizes the inference phase to minimize carbon emissions. |
| Reducing Redundant Computations | Eliminates unnecessary computations, improving efficiency and reducing energy use. |
| Method | Task Complexity | Training Time Range | Energy Consumption Estimation (kWh) |
|---|---|---|---|
| Logistic Regression/Linear Models | Non-Complex | Seconds [82] to a few minutes [83] | ~0.002 kWh |
| Naive Bayes | Non-Complex | Seconds [84] to 1 min [85] | ~0.002 kWh |
| Gradient Boosting Machines (GBMs) | Moderate | 1 to 3 min [86] | ~0.002 to 0.006 kWh |
| Decision Trees (DTs) | Non-Complex/Moderate | 5–300 s [87,88] | ~0.0001 to 0.008 kWh |
| K-Nearest Neighbors (KNNs) | Non-Complex/Moderate | 30 s [84] to 300 s [88,89] | ~0.001 to 0.008 kWh |
| Support Vector Machines (SVMs) | Moderate | 25 s [88] to 2 h [90] | ~0.001 to 0.2 kWh |
| Random Forests | Moderate/Complex | A few minutes to 3 h [91] | ~0.01 to 0.3 kWh |
| Deep Neural Networks (DNNs) | Complex/Very Complex | 35 min [92] to 115 min [83,93] | ~0.2 to 0.6 kWh |
| Bayesian Neural Networks (BNNs) | Complex | Minutes to several hours [88] | ~0.05 to 1 kWh |
| Convolutional Neural Networks (CNNs) | Complex/Very Complex | 1 h [94] to 8 h [95] | ~0.3 to 2.5 kWh |
| Reinforcement Learning (RL) | Very Complex | 14 h to 2 days [96] | ~4 to 15 kWh |
| Transformer Models (BERT, GPT) | Very Complex | 1–4 days [97,98] | ~10 to >40 kWh |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Różycki, R.; Solarska, D.A.; Waligóra, G. Energy-Aware Machine Learning Models—A Review of Recent Techniques and Perspectives. Energies 2025, 18, 2810. https://doi.org/10.3390/en18112810
Różycki R, Solarska DA, Waligóra G. Energy-Aware Machine Learning Models—A Review of Recent Techniques and Perspectives. Energies. 2025; 18(11):2810. https://doi.org/10.3390/en18112810
Chicago/Turabian StyleRóżycki, Rafał, Dorota Agnieszka Solarska, and Grzegorz Waligóra. 2025. "Energy-Aware Machine Learning Models—A Review of Recent Techniques and Perspectives" Energies 18, no. 11: 2810. https://doi.org/10.3390/en18112810
APA StyleRóżycki, R., Solarska, D. A., & Waligóra, G. (2025). Energy-Aware Machine Learning Models—A Review of Recent Techniques and Perspectives. Energies, 18(11), 2810. https://doi.org/10.3390/en18112810