3.1. Dataset Description
During the building’s operation, sensor data streams were continuously collected and recorded in a database between 13 September 2022 and 22 June 2023. Since the sensors began operating at different times—with some being added during the data centre’s operation and after its restructuring with new compute servers—the analysis was limited to the period from 9 March 2023 to 21 June 2023, when all of sensors were active.
The collected data required extensive preprocessing to form a coherent dataset. Given that the data were sampled at different frequencies, and some values represented derivatives of the original signals, the first step was to reconstruct the true signal values. The differences in sampling frequency were addressed by using the lowest frequency as the reference and resampling the other variables accordingly. When necessary, linear interpolation of the nearest samples was used to obtain actual values. A complete list of variables used in the experiments is provided in
Table 1.
Subsequently, the base period for system operation was determined. Based on expert knowledge, a 15 min interval was selected as the operating period, as this duration captures temperature variations caused by changes in weather conditions or shifts in the electrical energy consumption of the servers. Accordingly, the base signals were integrated or resampled; for instance, energy consumption was integrated over the 15 min period, while temperature readings were averaged. The resulting dataset formed the basis for the final analysis.
As already mentioned, the data were collected from 13 September 2022 to 22 June 2023, yielding 27,013 samples at a 15 min resolution. This period is divided into two phases:
Installation Phase: Involving the mounting of new compute servers, adjustment of sensor locations, and coordination of air conditioning devices (up to 6 March 2023).
Stable Operation Phase: Covering regular operation under stable conditions (from 7 March 2023 to 22 June 2023).
Due to the instability observed during the installation phase, our experiments focus exclusively on the stable operation phase beginning on 7 March 2023. The recorded signals are illustrated in
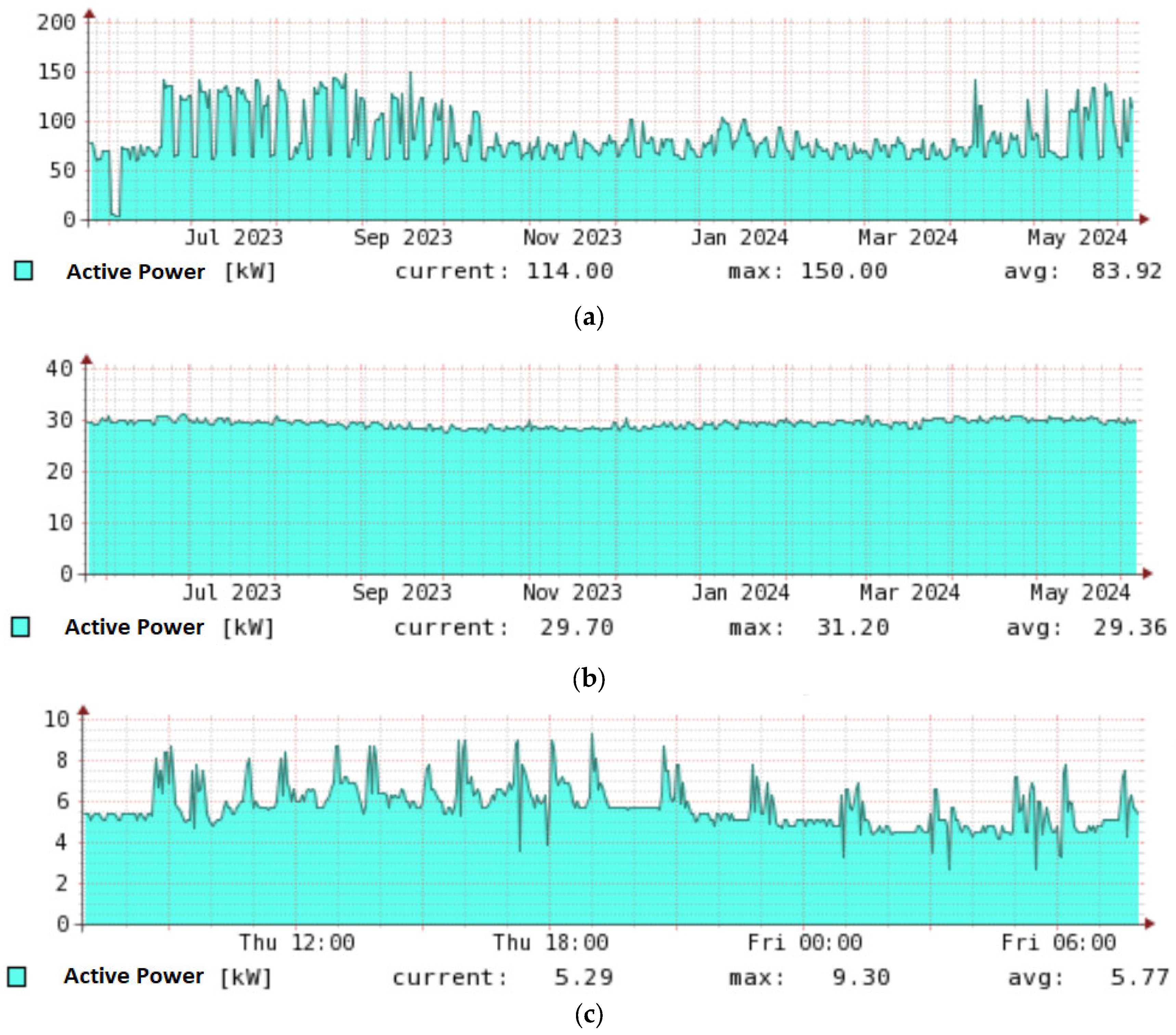
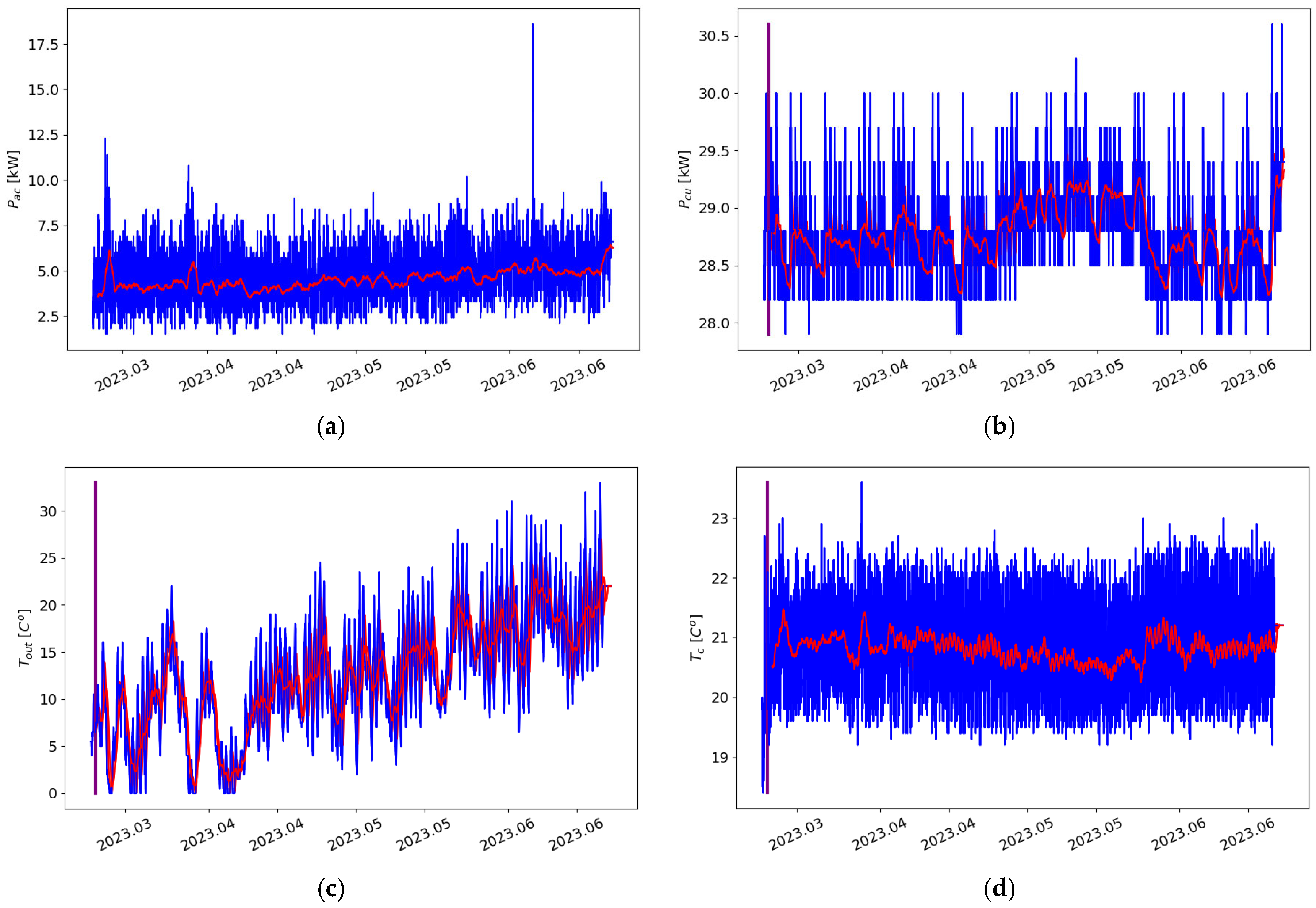
Figure 9. Specifically,
Figure 9a depicts the power consumption of the air conditioning system, which ranges from 2.5 to 7.5 kW, with notable peaks in early March, early April (reaching 10 kW), and a single peak in early June (with three samples exceeding 17 kW). The outlier recorded in June was caused by maintenance activities.
Figure 9b shows the aggregated power consumption of the compute servers, with an observed increase in May due to the replacement of computing units. Consequently, a higher
PCU was recorded during that month.
Figure 9c displays outdoor temperature variations that reflect natural weather fluctuations.
Figure 9d presents the ceiling temperature of the Databox (
TC), which is critical as it often represents the highest temperature in the cold corridor. Finally,
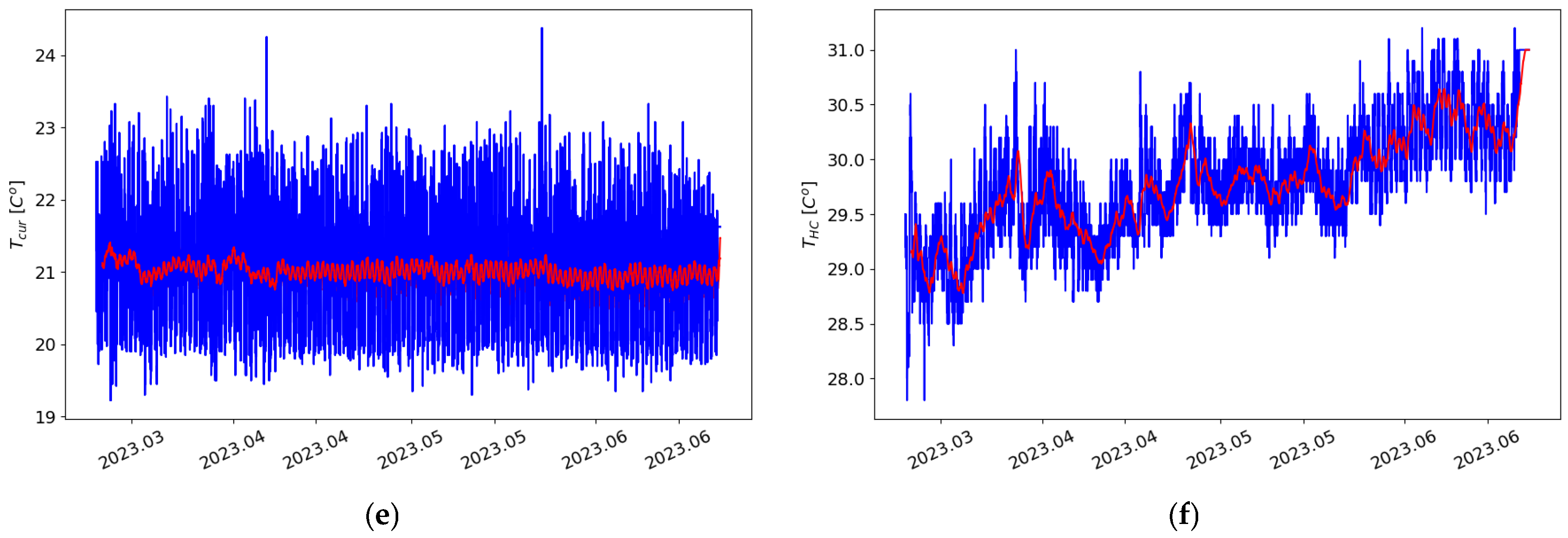
Figure 9e and
Figure 9f illustrate, respectively, the temperature recorded by the air conditioning systems controller and the temperature in the warm corridor—the variable targeted for prediction.
3.1.1. Dataset Adaptation for Machine Learning Task
The forecasting problem was defined as predicting the temperature in the warm corridor 24 h in advance with a 15 min resolution. It was assumed that cross-variate information would be available during the forecast. All of the recorded during system operation variables are presented in
Table 1, and visualized in
Figure 9. The subfigures of
Figure 9 show the recorded values marked in blue, and the red line represents the average.
The following additional variables have been employed:
DoW, which stands for day of the week;
WoH, which is employed to differentiate between days of work and weekends or holidays and
QoD—quarter-hour of the day. Since the
DoW and
QoD are cyclic variables, they were represented using sin/cos transformation using Formula (1), where
T is the period here
T = 6 for
DoW, and
T = 95 for
QoD, and
t are the values of
DoW in range
or values of
QoD in range
.
The use of cyclic representation has two advantages first it avoids the problem of dissimilarity between the end and the beginning of the cycle, so that there is a smooth transition between the following days. Secondly, the dataset has smaller number of variables when compared to the one hot encoding therefore it is easier to construct the model.
In summary, the constructed dataset used in the experiments consisted of 10,849 samples, five basic variables directly measured from the air conditioning system, and five additional features including DoWsin, DoWcos, WoH, QoDsin, and QoDcos.
3.1.2. Preliminary Dataset Analysis
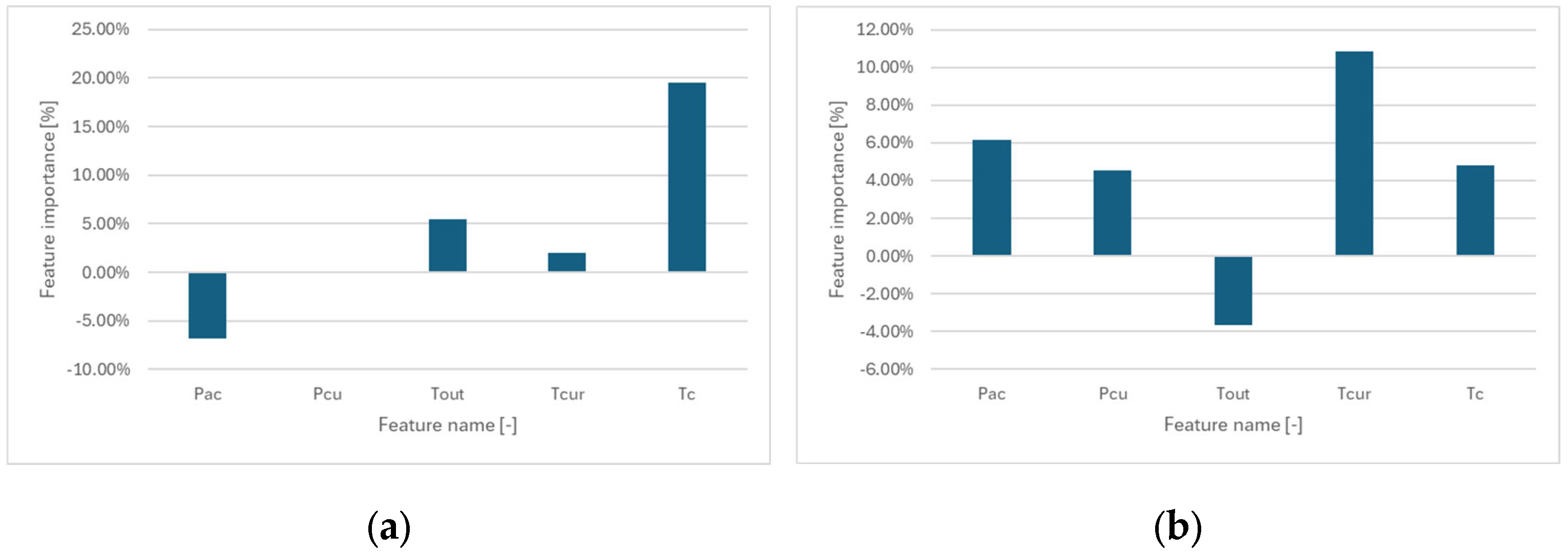
A fundamental step in constructing complex predictive models is the preliminary analysis of the available data. This process involves identifying interdependencies among input features and examining relationships between individual features and the target variable. The primary tool used for this purpose is the Pearson correlation coefficient, which captures linear relationships between variables. It is commonly complemented by the Spearman correlation coefficient, which enables the detection of nonlinear—though monotonic—dependencies.
The results of the correlation analysis are summarized in
Table 2 and
Table 3, which report the Pearson and Spearman correlation coefficients, respectively. The results indicate a generally weak correlation among the examined variables. The highest observed correlation appears between
Tcur and
TC, reaching 0.62 for Pearson and 0.59 for Spearman, suggesting a moderate dependency. This is expected, as both
Tcur and
TC, refer to temperature measurements at different points within the cooling system.
Another notable correlation is found between PAC (power consumption of the air conditioner) and TOUT (outdoor temperature), with values of 0.26 and 0.32, respectively. This relationship is intuitive, as energy consumption of the air conditioning system is influenced by the outdoor temperature.
In the analysis of the relationship between the output variable
THC (temperature in the hot corridor) and the input features, presented in
Table 4, the highest correlation was observed with the output temperature
TOUT, reaching 0.54. This was followed by a weaker correlation with
PAC, amounting to 0.23 in terms of Spearman correlation. However, the corresponding Pearson correlation was only 0.08, indicating a nonlinear but monotonic relationship between
PAC and
THC.
3.2. Methods Used in the Experiments
To develop the prediction model, we compared several well-established machine learning algorithms such as Random Forest and XGBoost with state-of-the-art techniques, including Time-Series Dense Encoder (TiDE) [
26] and Time-Series Mixer (TSMixer)—two of the most recent approaches for time series forecasting. The TiDE model was selected due to its design for long-term forecasting tasks, which aligns with our objective of forecasting across a full cycle of daily seasonality while incorporating external features, such as the day of the week. In contrast, TSMixer is a general-purpose forecasting model that is significantly more lightweight than typical transformer-based architectures, enabling more efficient training while maintaining competitive performance. On the other hand, tree-based models are feature-scale independent and are popular for their high scalability and simplicity in parameter tuning. Below is a short description of each of the models is provided.
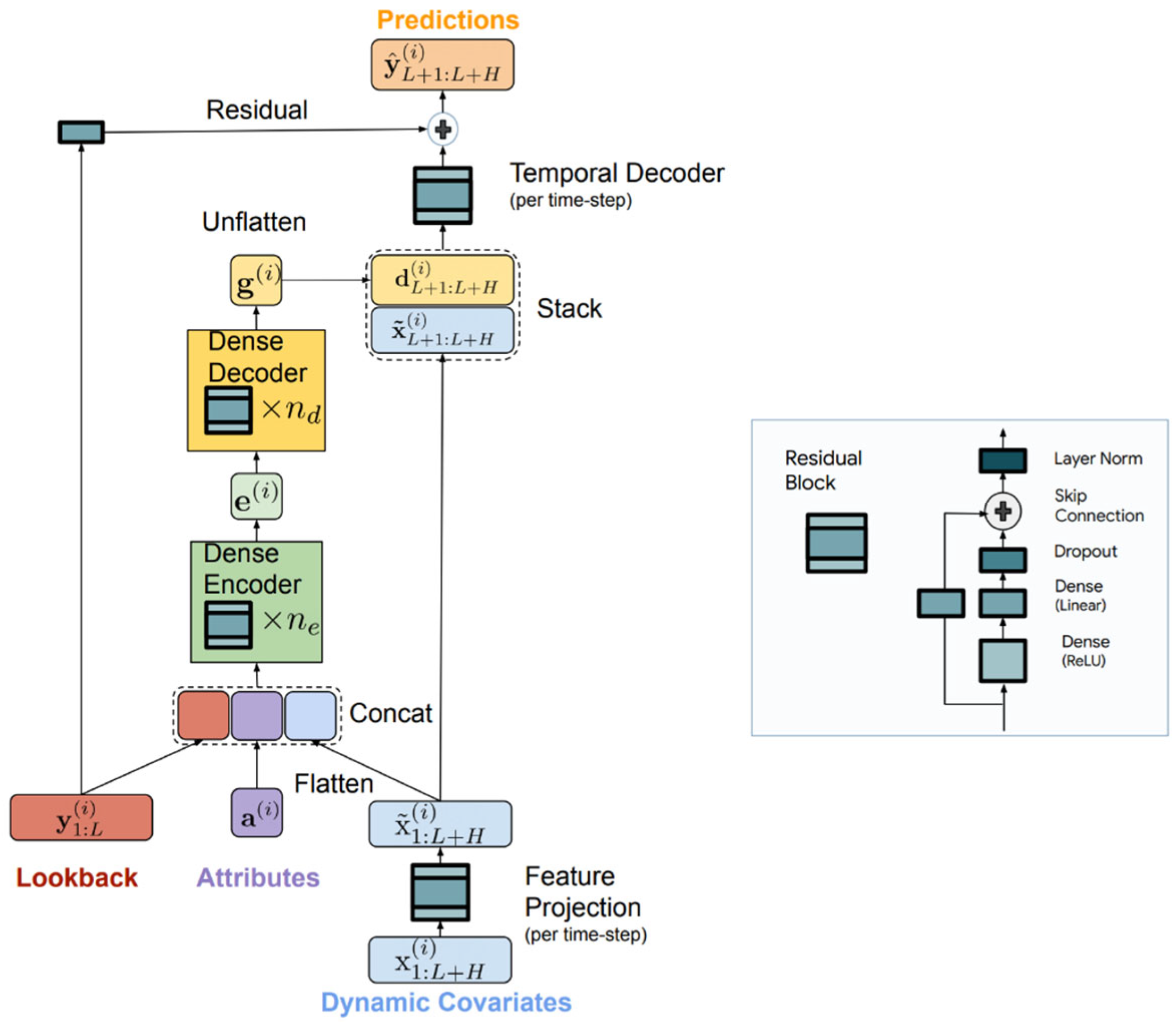
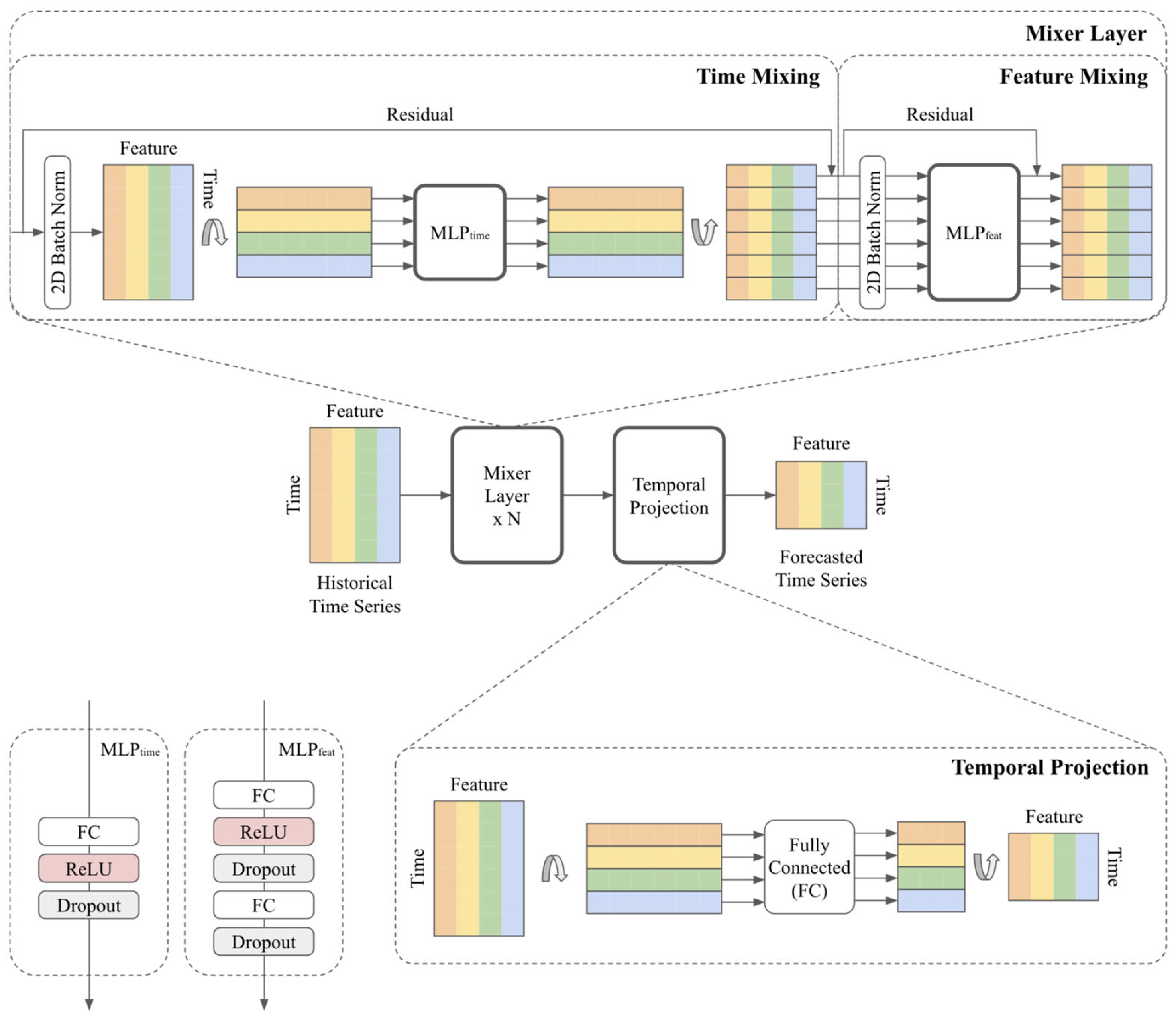
Time-Series Dense Encoder. TiDE is a novel MLP-based architecture developed in Google Research for long-term time series forecasting that efficiently incorporates both historical data and covariates. Its structure is shown in
Figure 10. The model first encodes the past observations
, and associated covariates
including fixed object properties
into a dense representation using residual MLP blocks and a feature projection step to reduce dimensionality and extract the most important properties of the signal. This encoded representation is then decoded through a two-stage process—a dense decoder followed by a temporal decoder—which combines the learned features with future covariate information to generate accurate predictions. By operating in a channel-independent manner and training globally across the dataset, TiDE effectively captures both linear and nonlinear dependencies, providing robust forecasting performance. Additionally, as shown in [
26] it outperforms other popular models such as N-HiTS [
27], DLinear [
28], LongTrans [
29], and others.
Time-Series Mixer. TSMixer is another state-of-the-art time series forecasting model developed by Google Research [
30] (
Figure 11). It was designed for time series forecasting that applies MLP-Mixer architectures to sequential data. It is based purely on fully connected layers and constitutes an alternative to Transformer-based models, offering a simple yet effective approach to handling time series. The TSMixer consists of two blocks. The first block applies time mixing using fully connected layers (MLP layers) across time stamps. This allows the model to capture temporal dependencies in the input data. The second block is a channel mixer that is also based on fully connected layers that mix across different feature dimensions at each time step. This helps the model understand the dependencies between different input variables. TSMixer also applies a normalization layer and skip connection across blocks to support the better flow of the gradients.
The research initially considered transformer architecture, but the computational process became over-complicated due to the self-attention mechanism, and as reported in [
26,
30] both TSMixer and TiDE overcome models based on self-attention making the computational process much more tractable.
Random forest (RF) and XGBoost (XGB). Random forest is a very popular classification and regression algorithm. It is based on an ensemble of decision trees. Here, instead of a single tree, a set of trees is trained in parallel where the diversity of the trees is achieved by randomly selecting a subset of features that are used to build a single tree. A huge advantage of this method is easy parallelization, which significantly shortens the training time. On the other hand, the XGB is a version of gradient-boosted trees that applies a boosting mechanism. To overcome the limitation of a single tree model in gradient boosting the trees are sequentially constructed, that is they are added one by one considering a cost function determining training sample weights. These weights ensure that the following tree is constructed to minimize the overall error of the entire model. Additionally, XBG applies L1 and L2 regularization preventing overfitting and improving generalization. Due to the sequential construction of the decision trees in the XGB, its training time is usually longer than RF.
AutoARIMA. AutoARIMA (Auto-Regressive Integrated Moving Average) is an automated version of the standard ARIMA model used for time series forecasting. It simplifies the process of model selection by automatically identifying the best parameters (p, d, q—autoregressive, differencing and moving average terms) for the ARIMA model through a search process. The model also handles seasonal patterns and can integrate them using a seasonal version, known as SARIMA, as well as utilizing additional input variables. They were used as an indicator of the existence of a complex nonlinear relation between input and output variables.
3.3. Experimental Setup
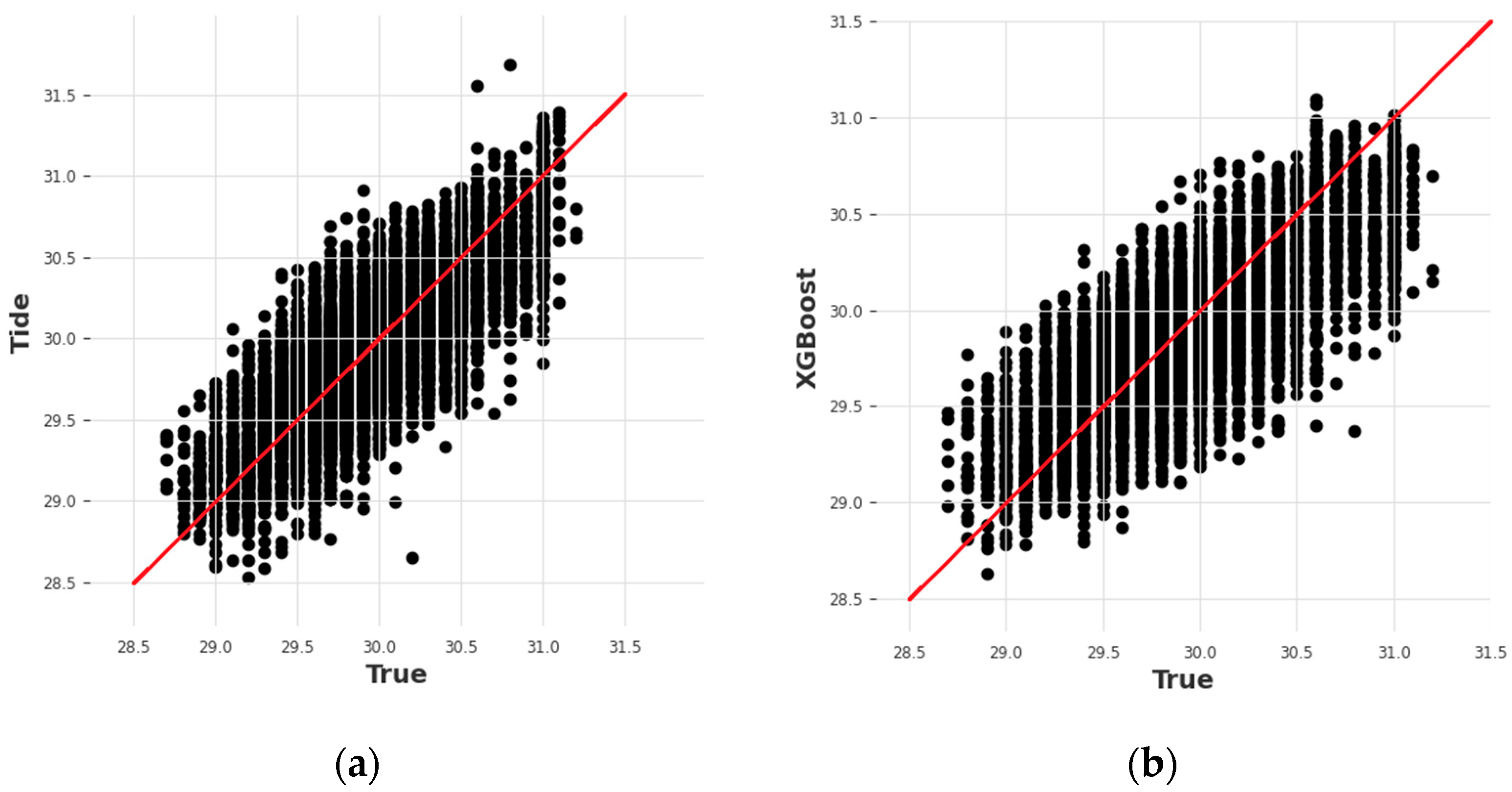
The experiments were designed to predict the temperature in the hot corridor THC from 30 April 2023 to 22 June 2023 and the remaining data starting from 7 March 2023 were used for training the model. In particular, the model was retrained for each new day using all past samples; therefore, the input data size was increased during the model evaluation. The experiments consisted of evaluating TiDE, TSMixer, XGB, RF, and AutoARIMA models, and were divided into two stages.
Stage one. The first stage was designed to find the best model parameters. That stage is particularly important for neural network models that are very sensitive to the hyperparameters setup.
For the TiDE model the learning rate (LR = {0.0001, 0.001, 0.01}), number of epochs (epochs = {20, 40, 60, 80, 100}), number of residual blocks in encoder (num. encoder = {4, 5}), the dimensionality of the decoder (decoder size = {1, 5, 8, 16, 32, 64, 128}), the width of the layers in the residual blocks of the encoder and decoder (hidden size = {16, 32, 64, 128, 256, 512}), and the dropout = {0, 0.1, 0.05, 0.1, 0.2} probability were optimized. Since the number of parameters was large the parameters were optimized sequentially tunning a particular part of the network. Initially, the number of epochs and the learning rate were tuned. Next, the decoder and encoder sizes were tunned, followed by hidden size tunning and finally setting the dropout parameter.
For the TSMixer, a similar set of parameters was optimized. That included learning rate LR = {0.0001, 0.001, 0.01}, the number of training epochs (epochs = {20, 40, 60, 80, 100}), dropout probability to avoid network overfitting dropout = {0, 0.05, 0.1, 0.2}, the number of neural network blocks number of blocks = {1, 2, 3, 4}, the size of the first feed-forward layer in the feature mixing MLP feedforward size = {1, 5, 8, 16, 32, 64, 96}, the hidden state size or the size of the second feed-forward layer in the feature mixing MLP hidden size = {16, 32, 64, 128, 256, 512}.
The tree-based models are relatively simpler to optimize and require a significantly smaller set of parameters to be tuned. For each of the tree-based families, only two parameters were optimized. For the Random Forest classifier only the tree depth and the number of trees were tuned, namely #trees = {50, 100, 200, 300} and tree_depth = {5, 10, 15}. For the XGBoost also the tree depth was tuned but smaller values were considered tree_depth = {4, 6, 8} and for the learning rate three values were evaluated LR = {0.01, 0.1, 0.3}.
The first stage of the experiment was performed for the first week of the evaluation data, which is between 30 April 2025–6 May 2025. In this stage, the AutoARIMA was excluded.
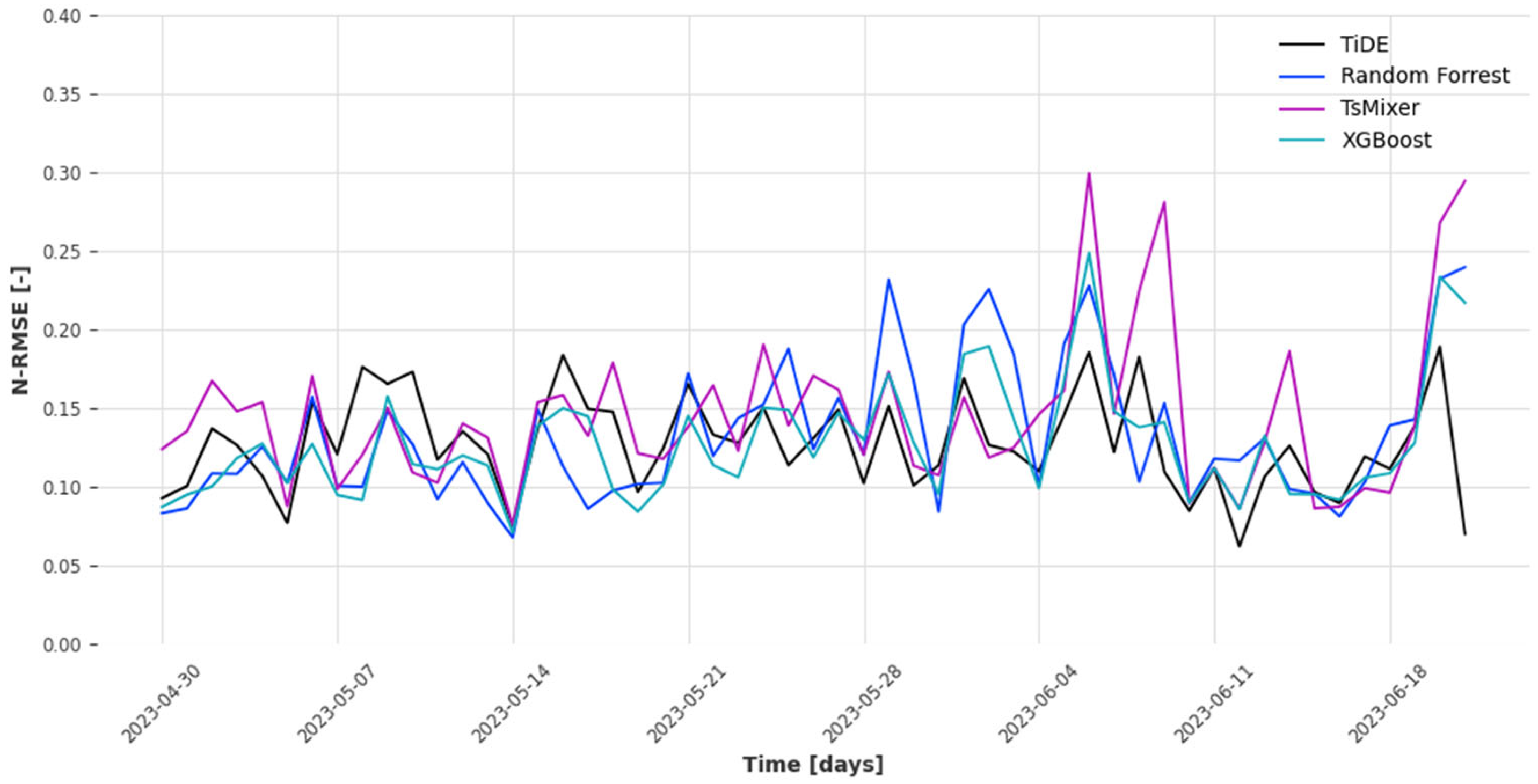
Stage two. The second stage of the research was focused on model evaluation for the entire test set. In this stage, only the model with the highest prediction accuracy was evaluated in three scenarios for each model’s family. These scenarios are presented in
Table 5. The scenarios differ in the set of variables used for evaluation and the length of the input history window. The goal of the first two scenarios was to evaluate the models with a 7-day history window and check whether the additional variables such as DoW, WoH, and QoD are useful for predicting the output. The assumption was that the 7-day history period covers one week of seasonality; therefore, the additional variables are useless.
The third scenario involved a comparison of the model’s family when the history window was set to one day, therefore it covered 96 historical samples (96 quarters within a day). In this scenario, it was assumed the use of the extended set of variables since that is the only way to represent weekly seasonality.
In all scenarios, the model forecasted the entire next day with a 15 min time resolution (a quarter of an hour resolution) that was a prediction of 96 samples at once.
For the performance evaluation, the main criteria were set to N-RMSE (Normalized Root Mean Squared Error). The N-RMSE was naturally obtained by normalizing the output variable to have 0 mean and standard deviation equal to 1. Such a measure simplifies model interpretability because performances close to 1 indicate the performance of the default regression model predicting the average value of the output (bad results). Values close to 0 signify a perfect match between predicted values and true values. N-RMSE was used for both stages of the experiments. For the second stage, two additional measures were used namely the mean absolute error (MAE) and mean absolute percentage error (MAPE) to give a full picture of the model’s performance.
The experiments were conducted using Darts Python library (version 0.32.0) for time series forecasting additionally using Scikit-Learn library (version 1.5.2) for conventional models implementation and MatPlotLib (version 3.7.1) for data visualization. All the calculations were computed on a server equipped with 2 AMD EPYC 7282 processors and 512 GB of RAM and NVIDIA RTX A4000 with 16GB VRAM.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}