


Short-Term Power Load Forecasting Based on PSO-Optimized VMD-TCN-Attention Mechanism



Abstract
:1. Introduction
2. Load Sequence Decomposition Based on PSO-VMD
2.1. Particle Swarm Optimization
- (1)
- First, initialize the number of independent variables of the objective function, the maximum velocity of the particle, the position information, and the maximum number of iterations of the algorithm, and set the particle population size as M.
- (2)
- Set the fitness function, define the individual extreme value as the optimal solution for each particle, find the global optimal solution, and compare it with the historical optimal solution to update the speed and position.
- (3)
- Keep updating the velocity and position by iterating Equations (1) and (2).
- (4)
- The PSO optimization is terminated when the set maximum number of iterations is reached or the error between generations satisfies the set condition.
2.2. Variational Modal Decomposition
- (1)
- Hilbert transform of the submodes to obtain the one-sided spectrum of the resolved signal:
- (2)
- Transforming the spectrum to the baseband multiplied by the estimated center frequency of the exponential signal:
- (3)
- Estimating the bandwidth by demodulating the signal Gaussian smoothing, which can be expressed as its constrained variational problem as Equation (5):
- (4)
- By introducing a quadratic penalty factor α and Lagrange multiplier, it is transformed into an unconstrained variational problem to be solved as Equation (6):
- (5)
- The value is updated continuously and iteratively by the alternating direction multiplier method:where: is the undecomposed main signal; is the set of nth modal decompositions of order; is the unit pulse signal; , , are the Fourier transforms of , , , respectively; n is the nth modal component after decomposition; is the total number of decompositions; is the central frequency of the modalities; is the bias operator; is the number of iterations; is the unit of imaginary numbers; is the convolution operator.
2.3. Sample Entropy
- (1)
- For a time series of data , a vector sequence of dimension is formed by the serial number. Where is the consecutive values starting from the i-th point.
- (2)
- Define the distance between vectors and :
- (3)
- Count the number of distances between and that are less than or equal to , calculate its ratio to and denote it as :
- (4)
- Define the mean value of as:
- (5)
- Increase the number of dimensions by 1 and repeat steps (1) to (4) to obtain the average value of as:
- (6)
- Define SE as:when is a finite value, SE can be estimated as:where: is the dimensionality, is the similarity tolerance, and is the length.
3. TCN-Attention Prediction Model
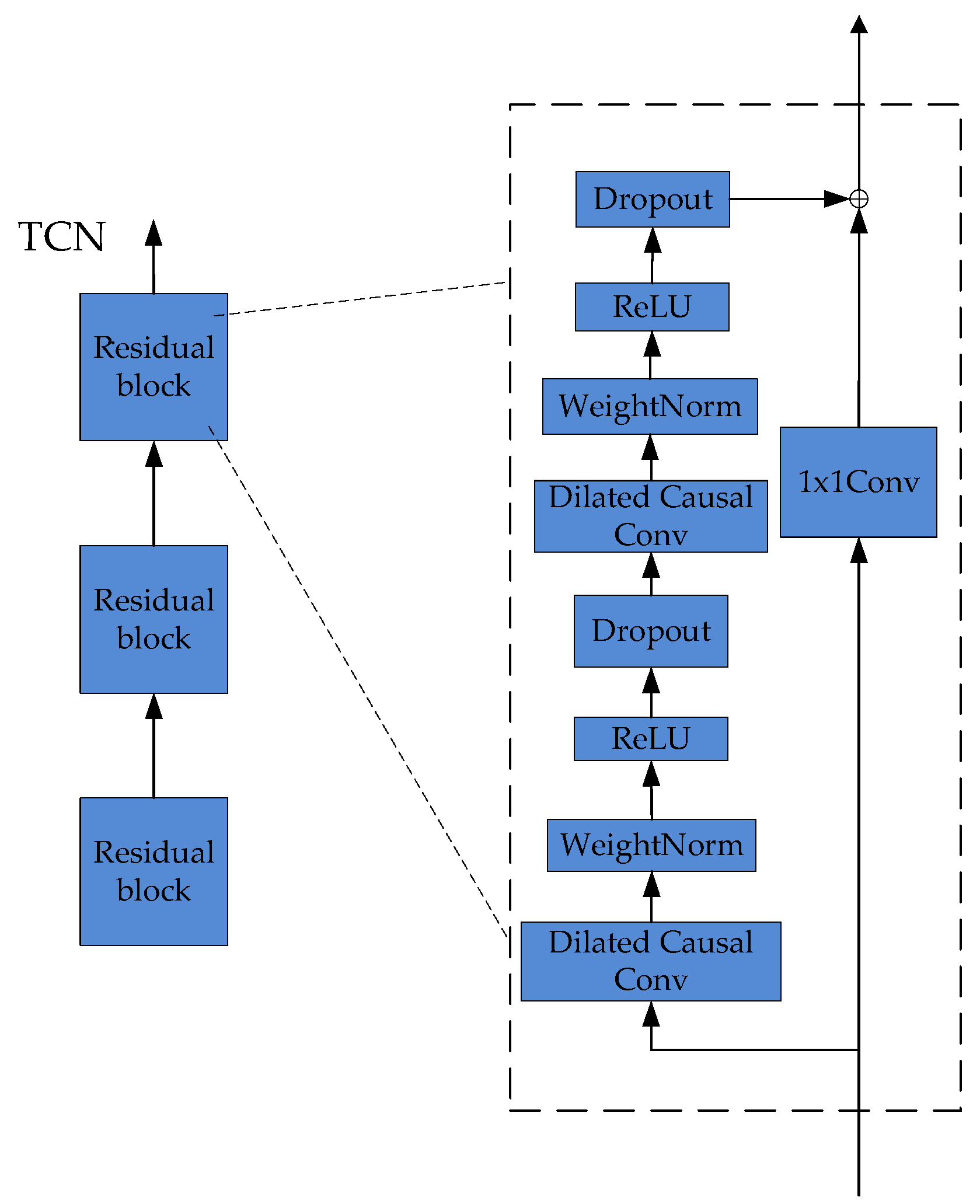
3.1. TCN
3.2. Attention Mechanism
3.3. TCN-Attention Prediction Model
4. Example Analysis
4.1. Example of Calculation
4.2. Data Pre-Processing and Model Evaluation Metrics
4.3. Power Load Decomposition and Feature Construction
4.4. TCN-Attention Model Parameter Settings and Prediction Accuracy
4.5. Analysis of the Impact of PSO Optimized VMD Decomposition on Model Prediction Accuracy
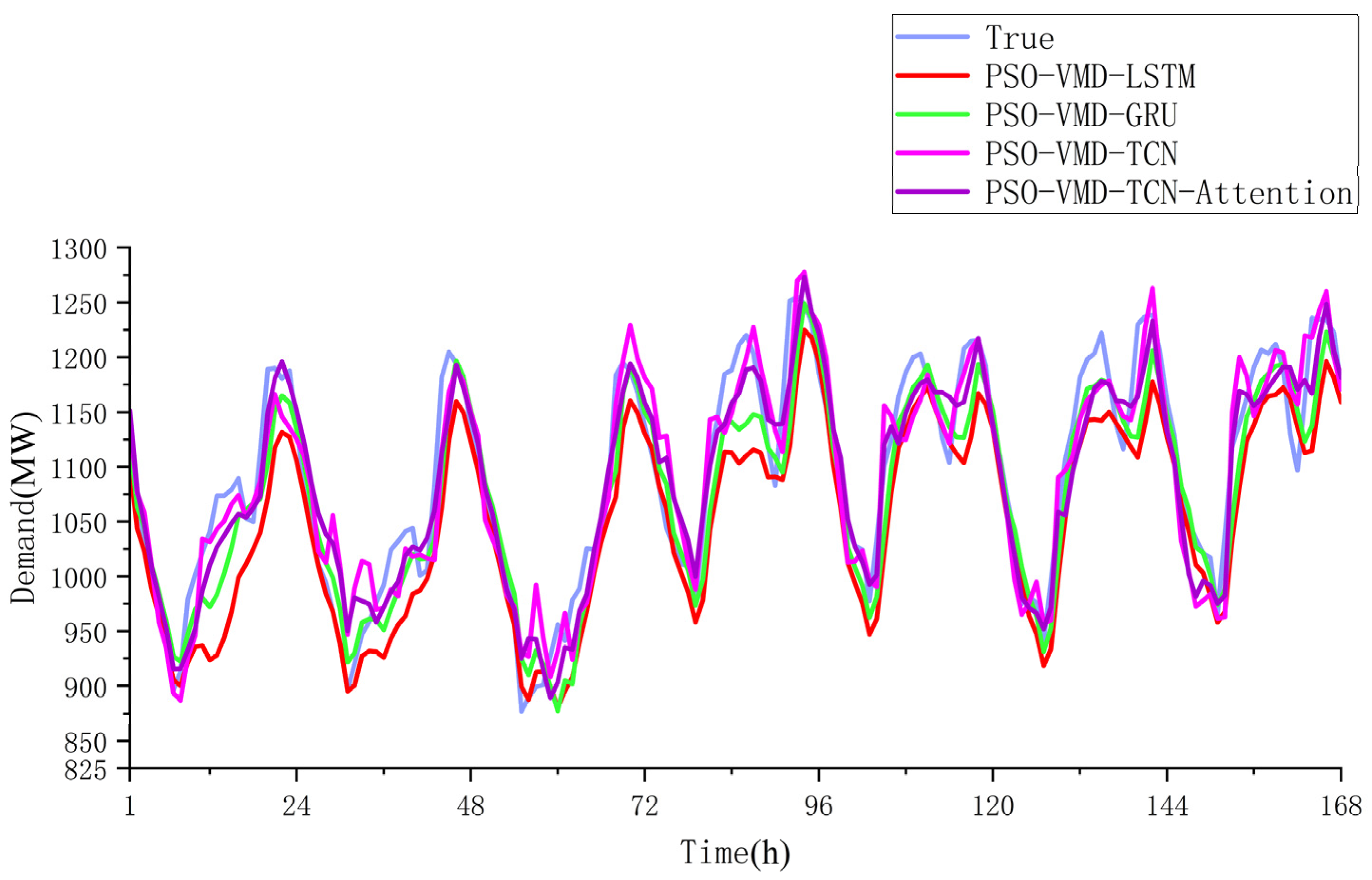
4.6. Comparative Analysis of TCN-Attention Prediction Models
5. Conclusions
- (1)
- By using the VMD decomposition method after PSO optimization to decompose the load, the proposed approach overcomes the need for manual adjustment of parameters required by the VMD decomposition method. The sample entropy is employed as the fitness function for decomposing the load component with the least time complexity, promoting the learning and feature extraction of the forecasting model. The proposed method leads to improved accuracy of the model, as evidenced by the computational analysis.
- (2)
- The presented example verifies the high prediction accuracy of the TCN-Attention model, which is benefited by several factors: the PSO-optimized VMD’s load sequence construction, TCN’s efficient learning and accurate prediction abilities on load features, and the Attention mechanism’s input sequence weight assignment.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Smil, V. Perils of long-range energy forecasting: Reflections on looking far ahead. Technol. Forecast. Soc. Chang. 2000, 65, 251–264. [Google Scholar] [CrossRef]
- Yildiz, B.; Bilbao, J.I.; Sproul, A.B. A review and analysis of regression and machine learning models on commercial building electricity load forecasting. Renew. Sustain. Energy Rev. 2017, 73, 1104–1122. [Google Scholar] [CrossRef]
- Zhao, J.; Liu, X.J. A hybrid method of dynamic cooling and heating load forecasting for office buildings based on artificial intelligence and regression analysis. Energy Build. 2018, 174, 293–308. [Google Scholar] [CrossRef]
- Ibrahim, B.; Rabelo, L.; Gutierrez-Franco, E.; Clavijo-Buritica, N. Machine Learning for Short-Term Load Forecasting in Smart Grids. Energies 2022, 15, 8079. [Google Scholar] [CrossRef]
- Wu, H.; Qi, F.; Zhang, X.; Liu, Y.B.; Xiang, Y.; Liu, J.Y. User-side Net Load Forecasting Based on Wavelet Packet Decomposition and Least Squares Support Vector Machine. Mod. Electr. Power 2023, 40, 192–200. [Google Scholar] [CrossRef]
- Tan, Z.; Zhang, J.; He, Y.; Zhang, Y.; Xiong, G.; Liu, Y. Short-Term Load Forecasting Based on Integration of SVR and Stacking. IEEE Access 2020, 8, 227719–227728. [Google Scholar] [CrossRef]
- Yang, D.; Yang, J.; Hu, C.; Cui, D.; Cheng, Z.G. Short-term power load forecasting based on improved LSSVM. Electron. Meas. Technol. 2021, 44, 47–53. [Google Scholar] [CrossRef]
- Gu, Y.D.; Ma, D.F.; Cheng, H.C. Power Load Forecasting Based on Similar-data Selection and Improved Gradient Boosting Decision Tree. Proc. CSU-EPSA 2019, 31, 64–69. [Google Scholar] [CrossRef]
- Wu, X.Y.; He, J.H.; Zhang, P.; Hu, J. Power System Short-term Load Forecasting Based on Improved Random Forest with Grey Relation Projection. Autom. Electr. Power Syst. 2015, 39, 50–55. [Google Scholar]
- Li, Y.; Jia, Y.J.; Li, L.; Hao, J.S.; Zhang, X.Y. Short term power load forecasting based on a stochastic forest algorithm. Power Syst. Prot. Control 2020, 48, 117–124. [Google Scholar] [CrossRef]
- Cheng, H.X.; Huang, Z. Short-term electric load forecasting model based on improved PSO optimized RNN. Electron. Meas. Technol. 2019, 42, 94–98. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, J.; Li, C.; Ji, X.; Li, D.; Huang, Y.; Di, F. Ultra Short-term Power Load Forecasting Based on Combined LSTM-XGBoost Model. Power Syst. Technol. 2020, 44, 614–620. [Google Scholar] [CrossRef]
- Peng, W.; Wang, J.R.; Yin, S.Q. Short-term Load Forecasting Model Based on Attention-LSTM in Electricity Market. Power Syst. Technol. 2019, 43, 1745–1751. [Google Scholar] [CrossRef]
- Li, P.; He, S.; Han, P.F.; Zheng, M.M.; Huang, M.; Sun, J. Short-Term Load Forecasting of Smart Grid Based on Long-Short-Term Memory Recurrent Neural Networks in Condition of Real-Time Electricity Price. Power Syst. Technol. 2018, 42, 4045–4052. [Google Scholar] [CrossRef]
- Yang, L.; Wu, H.B.; Ding, M.; Bi, R. Short-term Load Forecasting in Renewable Energy Grid Based on Bi-directional Long Short-term Memory Network Considering Feature Selection. Autom. Electr. Power Syst. 2021, 45, 166–173. [Google Scholar]
- Wang, Z.P.; Zhao, B.; Ji, W.J.; Gao, X.; Li, X. Short-term Load Forecasting Method Based on GRU-NN. Autom. Electr. Power Syst. 2019, 43, 53–58. [Google Scholar]
- Xie, Q.; Dong, L.H.; She, X.Y. Short-term electricity price forecasting based on Attention-GRU. Power Syst. Prot. Control 2020, 48, 154–160. [Google Scholar] [CrossRef]
- Niu, D.X.; Ma, T.N.; Wang, H.C.; Liu, H.F.; Huang, Y.L. Short-Term Load Forecasting of Electric Vehicle Charging Station Based on KPCA and CNN Parameters Optimized by NSGA II. Electr. Power Constr. 2017, 38, 85–92. [Google Scholar]
- Kong, X.Y.; Zheng, F.; Cao, J.; Wang, X. Short-term Load Forecasting Based on Deep Belief Network. Autom. Electr. Power Syst. 2018, 42, 133–139. [Google Scholar]
- Liao, N.H.; Hu, Z.Y.; Ma, Y.Y.; Lu, W.Y. Review of the short-term load forecasting methods of electric power system. Power Syst. Prot. Control 2011, 39, 147–152. [Google Scholar]
- Ahmad, N.; Ghadi, Y.; Adnan, M.; Ali, M. Load Forecasting Techniques for Power System: Research Challenges and Survey. IEEE Access 2022, 10, 71054–71090. [Google Scholar] [CrossRef]
- Ye, J.H.; Cao, J.; Yang, L.; Luo, F.Z. Ultra Short-term Load Forecasting of User Level Integrated Energy System Based on Variational Mode Decomposition and Multi-model Fusion. Power Syst. Technol. 2022, 46, 2610–2618. [Google Scholar] [CrossRef]
- Wu, S.M.; Jiang, J.D.; Yan, Y.H.; Bao, W. Short-term Load Forecasting Based on VMD-PSO-MKELM Method. Proc. CSU-EPSA 2022, 34, 18–25. [Google Scholar] [CrossRef]
- Liu, K.Z.; Ruan, J.X.; Zhao, X.P.; Liu, G. Short-term Load Forecasting Method Based on Sparrow Search Optimized Attention-GRU. Proc. CSU-EPSA 2022, 34, 99–106. [Google Scholar] [CrossRef]
- Yu, J.Q.; Nie, J.K.; Zhang, A.J.; Hou, X.Y. ARIMA-GRU Short-term Power Load Forecasting Based on Feature Mining. Proc. CSU-EPSA 2022, 34, 91–99. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, J.; He, Y.; Fu, X.; Fan, L.; Yao, G.; Wen, Y. Short-Term Load Forecasting Based on the CEEMDAN-Sample Entropy-BPNN-Transformer. Energies 2022, 15, 3659. [Google Scholar] [CrossRef]
- Wang, C.; Wang, Y.; Zheng, T.; Dai, Z.M.; Zhang, K.F. Multi-Energy Load Forecasting in Integrated Energy System Based on ResNet-LSTM Network and Attention Mechanism. Trans. China Electrotech. Soc. 2022, 37, 1789–1799. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VMD | K (Modal Number) | Alpha (Bandwidth Constraint) |
|---|---|---|
| Values | 7 | 9800 |
| Number of Neurons N | Activation Function | Optimization Algorithm | Training Batch | Number of Iterations |
|---|---|---|---|---|
| 128 | Relu | Adam | 64 | 100 |
| Models | RMSE | MSE | MAE | MAPE |
|---|---|---|---|---|
| LSTM | 70.767 | 5007.971 | 57.746 | 0.053 |
| GRU | 75.950 | 5768.439 | 62.571 | 0.057 |
| TCN | 43.952 | 1931.787 | 32.267 | 0.030 |
| PSO-VMD-LSTM | 53.930 | 2908.489 | 42.399 | 0.038 |
| PSO-VMD-GRU | 37.887 | 1435.462 | 29.628 | 0.027 |
| PSO-VMD-TCN | 35.597 | 1267.151 | 29.216 | 0.027 |
| Models | RMSE | MSE | MAE | MAPE |
|---|---|---|---|---|
| PSO-VMD-LSTM | 53.930 | 2908.489 | 42.399 | 0.038 |
| PSO-VMD-GRU | 37.887 | 1435.462 | 29.628 | 0.027 |
| PSO-VMD-TCN | 35.597 | 1267.151 | 29.216 | 0.027 |
| PSO-VMD-TCN-Attention | 33.079 | 1094.231 | 27.470 | 0.025 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Geng, G.; He, Y.; Zhang, J.; Qin, T.; Yang, B. Short-Term Power Load Forecasting Based on PSO-Optimized VMD-TCN-Attention Mechanism. Energies 2023, 16, 4616. https://doi.org/10.3390/en16124616
Geng G, He Y, Zhang J, Qin T, Yang B. Short-Term Power Load Forecasting Based on PSO-Optimized VMD-TCN-Attention Mechanism. Energies. 2023; 16(12):4616. https://doi.org/10.3390/en16124616
Chicago/Turabian StyleGeng, Guanchen, Yu He, Jing Zhang, Tingxiang Qin, and Bin Yang. 2023. "Short-Term Power Load Forecasting Based on PSO-Optimized VMD-TCN-Attention Mechanism" Energies 16, no. 12: 4616. https://doi.org/10.3390/en16124616
APA StyleGeng, G., He, Y., Zhang, J., Qin, T., & Yang, B. (2023). Short-Term Power Load Forecasting Based on PSO-Optimized VMD-TCN-Attention Mechanism. Energies, 16(12), 4616. https://doi.org/10.3390/en16124616