
Short-Term Load Forecasting Models: A Review of Challenges, Progress, and the Road Ahead

 ,
,  , ,
, ,  ,
,  and
and 
Abstract
1. Introduction
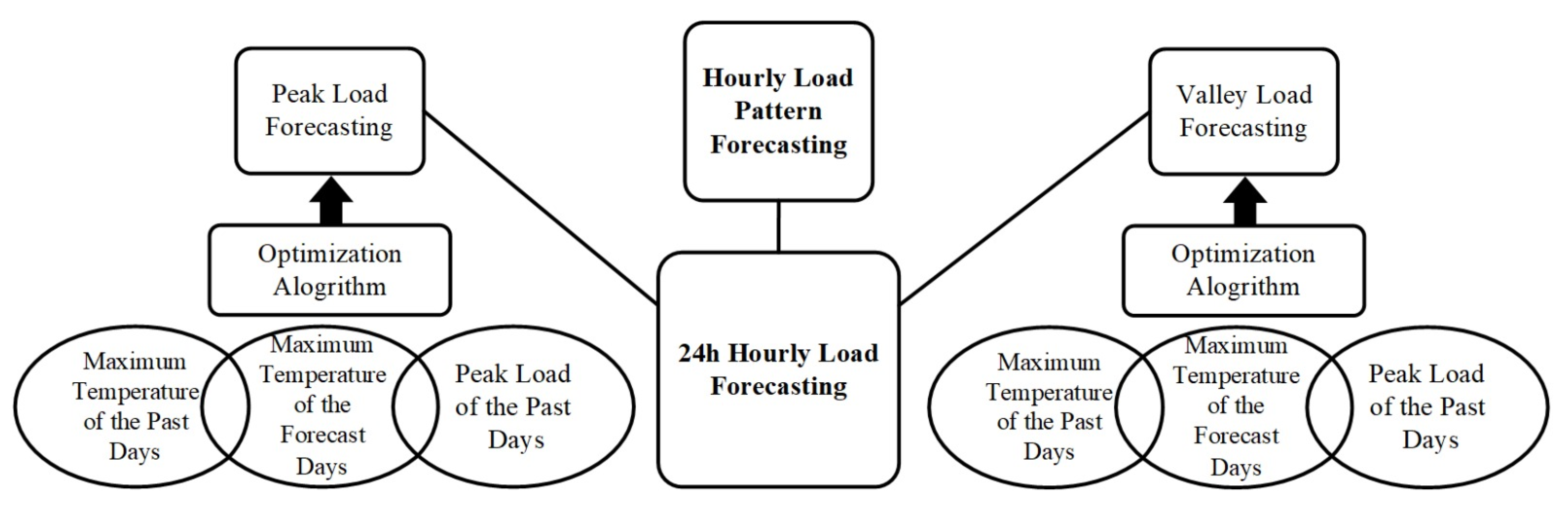
2. Challenges and Solutions
3. Development in STLF Models
3.1. Statistical Models
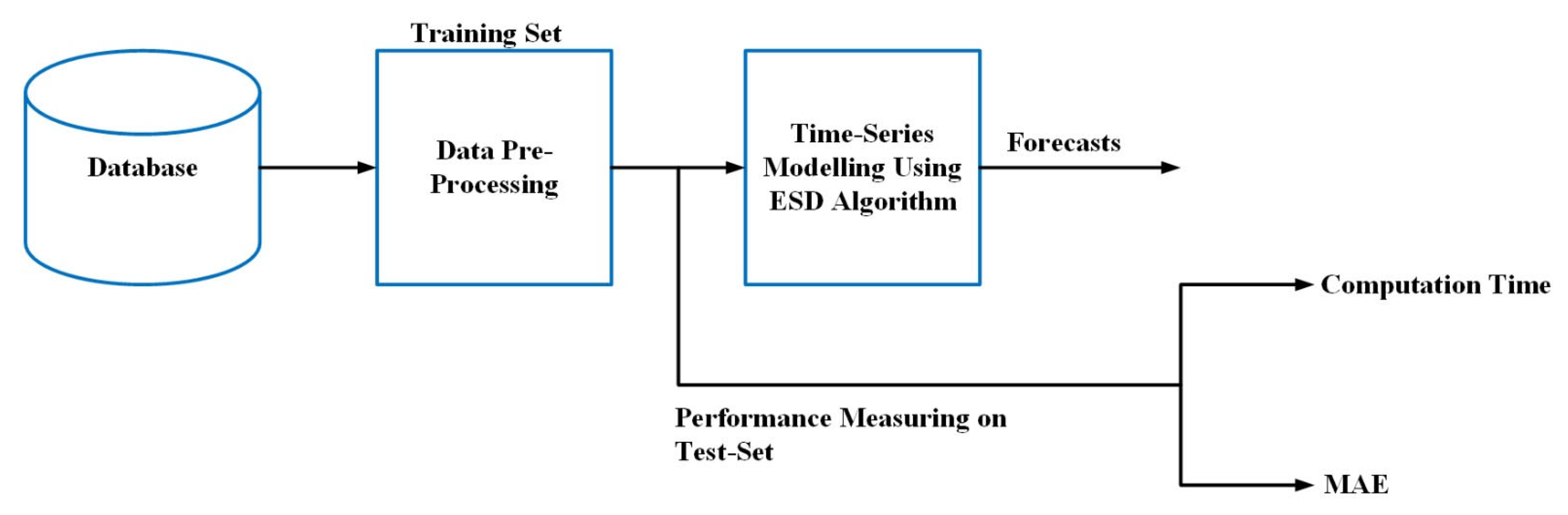
3.1.1. Autoregressive Integrated Moving Average (ARIMA) Models
- Y(t) is the value of the time series at time t;
- c is a constant;
- φ1, φ2, ..., φₚ are the autoregressive coefficients;
- p is the order of the AR model;
- ε(t) is the error term at time t.
- Y(t) is the value of the time series at time t;
- c is a constant;
- ε(t) is the error term at time t;
- θ1, θ2, …, θq are the moving average coefficients;
- q is the order of the MA model.
3.1.2. Seasonal Autoregressive Integrated Moving Average (SARIMA) Models
3.1.3. Exponential Smoothing (ES) Models
3.1.4. Generalized Linear Models (GLMs)
- β0 is the intercept;
- β1 is the coefficient for the predictor variable X1.
- µ is the expected count (mean) of the response variable;
- β0 is the intercept;
- β1 is the coefficient for the predictor variable X1.
- γ0 is the intercept for the dispersion part of the model;
- γ1 is the coefficient for the predictor variable Z1 affecting the dispersion.
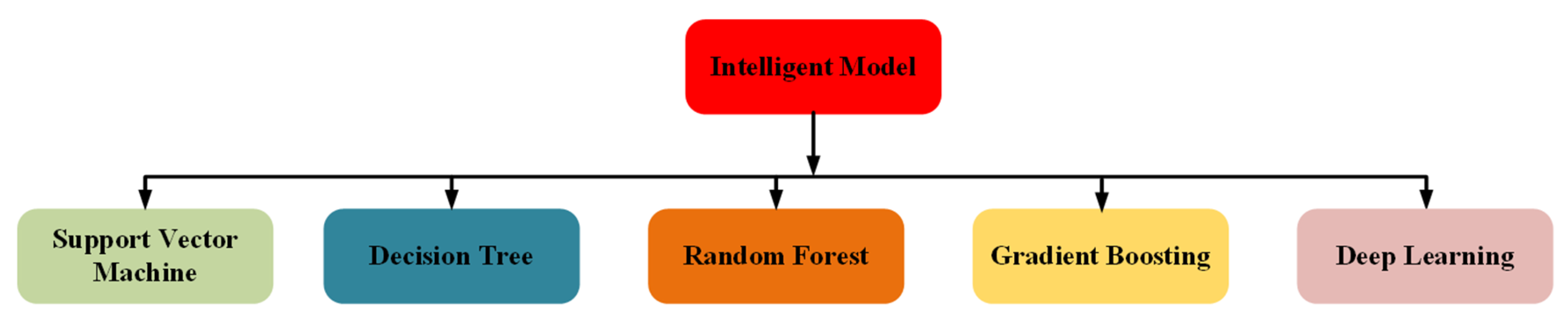
3.2. Intelligent Models
3.2.1. Support Vector Machine
- yi is the true label of the i-th data point; in the binary classification case, it takes the value of either −1 or +1.
- w is the weight vector, which is orthogonal to the decision boundary (hyperplane).
- xi is the feature vector of the i-th data point.
- b is the bias term, which shifts the decision boundary away from the origin.
- w⋅xi is the dot product between the weight vector w and the feature vector xi, which represents the projection of xi onto the weight vector.
- The first step involves collecting historical electricity load data and relevant exogenous variables such as weather data, day of the week, and time of the day. These data are cleaned and preprocessed to remove any inconsistencies, outliers, or missing values, and are often normalized or standardized to improve the performance of the SVM.
- Next, the most relevant features are selected for the forecasting task. This step is crucial, as irrelevant or redundant features can negatively impact the model’s performance. Techniques such as recursive feature elimination (RFE), correlation analysis, or principal component analysis (PCA) can be applied to identify the most significant features of the problem.
- The SVM model is trained with the preprocessed data and the selected features. SVMs aim to find the optimal hyperplane that best separates the data into different classes or categories. In the case of STLF, it is a regression problem, so the model will learn to predict continuous values for the electricity load. To do this, the SVM algorithm uses kernel functions (such as linear, polynomial, or radial basis functions) to transform the input data into a higher-dimensional space, making finding the optimal separating hyperplane easier.
- To ensure the SVM model performs well on unseen data, it is validated using techniques such as cross-validation. During this process, the dataset is divided into training and validation subsets, with the model being trained on one subset and tested on the other. This helps to assess the model’s performance and generalizability. Moreover, hyperparameters such as the cost parameter (C), kernel type, and kernel parameters are tuned to find the best combination for the specific STLF problem.
- After training and tuning the SVM model, it is tested on an unseen dataset to evaluate its forecasting accuracy. Performance metrics such as mean absolute error (MAE), mean squared error (MSE), or mean absolute percentage error (MAPE) are used to quantify the model’s predictive capabilities.
- Once the SVM model has been trained, validated, and tested, it can be used to make short-term load forecasts based on new input data. The model takes in the relevant features for the desired forecasting period and outputs the predicted electricity load.
3.2.2. Decision Tree
- Gini impurity: Gini impurity measures a node’s impurity (class mixture), with lower values indicating higher purity [63]. The Gini impurity for a node with class probabilities pi is:
- b.
- Information gain: Information gain is based on entropy, which measures the randomness or uncertainty in a set. The entropy for a node with class probabilities π is:
- The first step involves collecting historical electricity load data and relevant exogenous variables such as weather data, day of the week, and time of the day. These data are cleaned and preprocessed to remove any inconsistencies, outliers, or missing values. Feature scaling is generally not required for decision trees, as they are less sensitive to the scale of input features.
- The most relevant features for the forecasting task are selected to ensure that irrelevant or redundant features do not negatively impact the model. Techniques such as recursive feature elimination (RFE), correlation analysis, or information gain can be applied to identify the most significant features of the problem.
- With the preprocessed data and selected features, the decision tree model is trained. The algorithm recursively splits the data into subsets based on the input features’ values to minimize the impurity of the resulting subsets. For a regression task such as STLF, the impurity can be measured using criteria such as mean squared error (MSE). The algorithm splits the data until a stopping criterion is reached, such as a maximum tree depth or a minimum number of samples in a leaf node.
- Decision trees can be prone to overfitting, especially when they grow too deep. To address this issue, the model is validated using techniques such as cross-validation. The dataset is divided into training and validation subsets, with the model being trained on one subset and tested on the other. This method helps assess the model’s performance and generalizability. Additionally, pruning techniques, such as cost-complexity or reduced-error pruning, can simplify the tree and reduce overfitting.
- After training and pruning the decision tree model, it is tested on an unseen dataset to evaluate its forecasting accuracy. Performance metrics such as mean absolute error (MAE), mean squared error (MSE), or mean absolute percentage error (MAPE) are used to quantify the model’s predictive capabilities [65].
- Once the decision tree model has been trained, validated, and tested, it can make short-term load forecasts based on new input data. The model takes in the relevant features for the desired forecasting period and traverses the tree from the root node to a leaf node, following the decision rules at each split. The output at the leaf node is the predicted electricity load.
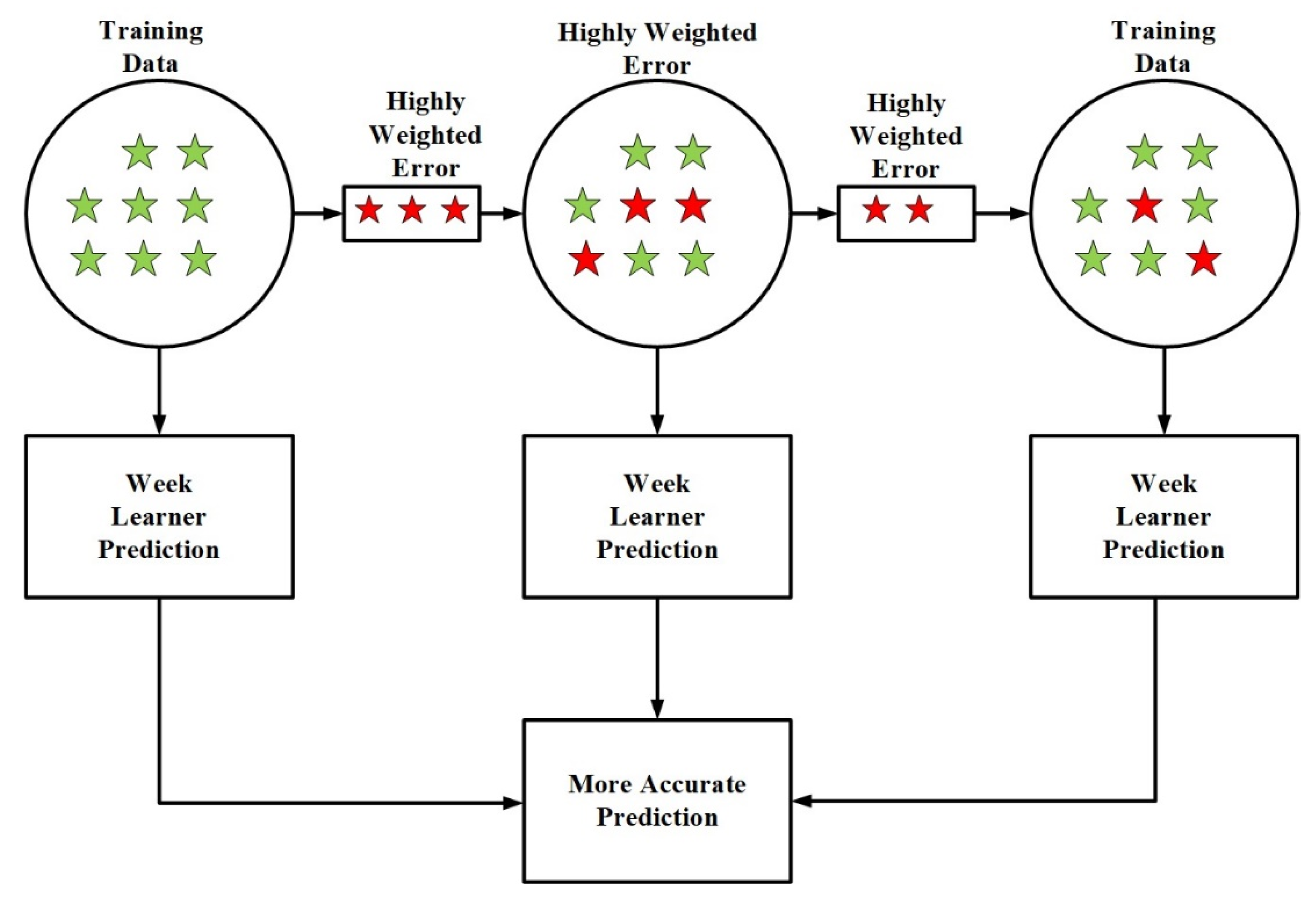
3.2.3. Random Forest and Gradient Boosting
- The first step involves collecting historical electricity load data and relevant exogenous variables such as weather data, day of the week, and time of the day. These data are cleaned and preprocessed to remove inconsistencies, outliers, or missing values. Feature scaling is generally not required for random forest as decision trees, its base learners, are less sensitive to the scale of input features.
- The most relevant features for the forecasting task are selected to ensure that irrelevant or redundant features do not negatively impact the model. Although random forest has an inherent ability to handle many features and automatically estimate feature importance, using domain knowledge or techniques such as recursive feature elimination (RFE) and correlation analysis can help further improve model performance.
- With the preprocessed data and selected features, the random forest model is trained. The algorithm creates multiple decision trees, and each tree is trained on a different bootstrap sample of the original dataset (sampling with replacement). Additionally, a random subset of features is considered at each split in the tree construction process, which introduces further diversity among the trees and reduces overfitting.
- The cross-validation technique ensures that the random forest model performs well on unseen data. The dataset is divided into training and validation subsets, with the model being trained on one subset and tested on the other. This process helps assess the model’s performance and generalizability.
- Random forest has several hyperparameters, such as the number of trees (n_estimators), the maximum depth of the trees, and the minimum number of samples required to split a node. These hyperparameters can be tuned using techniques such as grid or random search and cross-validation to find the best combination for the specific STLF problem.
- Once the random forest model has been trained, validated, and tested, it can make short-term load forecasts based on new input data. The model takes in the relevant features for the desired forecasting period and produces a prediction from each decision tree. The final prediction is the average of the individual tree predictions, which provides a more accurate and stable forecast.
3.2.4. Multilayer Perceptron Model
- Input layer: This is the first layer of the MLP model, receiving the input data (e.g., numbers, images, and text). Each node in this layer corresponds to a single input data feature.
- Hidden layers: These are the layers between the input and output layers. They consist of neurons that learn to represent and process the data. The more hidden layers and neurons per layer, the more complex patterns the model can learn.
- Output layer: The last layer in the MLP model produces the final results or predictions. The number of nodes in this layer depends on the problem one is trying to solve. For example, if images are classified into ten categories, the output layer will have ten nodes.
- Neurons: Each neuron in the MLP model receives input from other neurons, processes it using an activation function, and sends the output to other neurons in the next layer. The activation function introduces non-linearity, which enables the MLP to learn complex patterns in the data.
- Weights and biases: Each connection between neurons has a weight that determines the strength of the association. The weights are adjusted during training to minimize the difference between the predicted and actual values. Biases are additional constants that help shift the activation function, improving the model’s learning ability.
- Training: MLP models are trained using a backpropagation algorithm, which adjusts the weights and biases by minimizing the error between the predicted and actual values. The process is iterative, involving multiple passes through the data to fine-tune the model.
- Loss function: This is a measure of how well the MLP model is performing. A lower value indicates better performance. During training, the goal is to minimize the loss of function.
- aj is the output (activation) of neuron j;
- f is the activation function;
- wij is the weight connecting input i to neuron j;
- xi is the input value for input i;
- bj is the bias term for neuron j.
- A is the activation matrix (each column represents the activation of a neuron);
- f is the activation function applied element-wise;
- W is the weight matrix;
- X is the input matrix (each column represents an input feature vector);
- B is the bias matrix.
- ai is the activation of output neuron i,
- aj is the activation of output neuron j,
3.2.5. Deep Learning Models
3.2.6. Ensemble Models
- Bragging.
- B.
- Boosting.
- C.
- Stacking.
3.3. Hybrid Models
3.3.1. ARIMA–ANN Hybrid Model
3.3.2. Wavelet-Transform-Based Hybrid Models
3.3.3. EEMD–ANN Hybrid Model
3.3.4. Fuzzy-Logic-Based Hybrid Models
3.3.5. Deep-Learning-Based Hybrid Models
3.4. Performance Comparison of STLF Models
4. The Road Ahead
- Incorporating new data sources: Traditional STLF models rely on historical load, weather, and calendar data as input features. However, the availability of new data sources, such as social media data and smart meter data, presents an opportunity to develop more accurate and robust STLF models [103]. Future studies can examine the application of machine learning algorithms to identify the most relevant data sources for predicting electricity demand and how best to incorporate these data sources into STLF models.
- Development of hybrid models: Hybrid models combine different models or techniques to address specific challenges or achieve specific goals. Hybrid models can combine traditional STLF models with models for predicting renewable energy production or demand-side management (DSM) models [104]. Future research can examine the development of more advanced hybrid models that can handle multiple input features, uncertainty quantification, and other challenges in STLF modeling.
- Integration of advanced machine learning techniques: Advanced machine learning techniques, such as deep learning and reinforcement learning, have shown great potential in improving the accuracy of STLF models. Deep learning techniques can automatically learn complex patterns and relationships in the data, while reinforcement learning can learn to optimize actions based on feedback from the environment [105]. Future work can investigate the creation of more sophisticated machine learning models that can manage vast volumes of data, combine numerous input features, and adjust to shifting energy system conditions.
- Handling of non-stationary and nonlinear load data: Traditional STLF models assume that the load data is stationary and linear. However, the load data can be non-stationary and nonlinear due to changes in consumer behavior, the introduction of new technologies, and other factors [106]. Future research can explore the development of STLF models that can handle non-stationary and nonlinear load data, either through advanced machine learning techniques or more flexible statistical models.
- Integration of probabilistic forecasting: Probabilistic forecasting measures uncertainty around the point forecast. It can help power system operators make more informed decisions in the face of uncertainty [107]. Future work can support the development of STLF models that can provide point forecasts and uncertainty estimates, such as prediction intervals or probabilistic forecasts. These uncertainty estimates can help to identify potential risks and improve the overall reliability of the power system.
- Integration of online learning: Online learning is a type of machine learning that can adapt to changing conditions in the energy system in real-time [108]. Online learning algorithms can learn from new data as it becomes available and adjust the forecast accordingly. Future studies may look toward creating STLF models that employ online learning algorithms to increase forecast precision and timeliness [109].
- Development of interpretable models: Interpretable models are models that can provide insights into the factors that are driving the forecast. Interpretable models can help power system operators understand the underlying patterns and relationships in the data and make more informed decisions about resource allocation and power generation [110]. Additional studies may examine the creation of STLF models that are easier to understand, either via the use of advanced machine learning techniques or more straightforward statistical models [111].
- Integration of ensemble methods: Ensemble methods, such as bagging and boosting, have shown great potential in improving the accuracy and robustness of STLF models. Ensemble methods can combine and overfit them and be used to select the best model for a given dataset [112]. Future work could investigate the creation of more sophisticated ensemble models capable of handling various input features, uncertainty quantification, and other difficulties in STLF modeling [113].
- Handling of data quality issues: Data quality issues, such as missing data, outliers, and measurement errors, can have a significant impact on the accuracy of STLF models [114]. Future studies could assist in creating STLF models that can deal with problems with data quality by prediction models or more sophisticated statistical models that can directly deal with missing data.
- Integration of domain knowledge: Domain knowledge, such as knowledge about consumer behavior, the energy system, and the environment, can provide valuable insights into the factors driving electricity demand [115]. Future studies can create STLF models that incorporate domain knowledge into the modeling process, either through expert systems or sophisticated machine learning methods that can add domain knowledge as different input characteristics.
- Development of adaptive models: The energy system constantly changes, and the factors driving the electricity demand can vary over time [116]. Future studies may examine the creation of STLF models that can modify their predictions in response to changing energy system conditions, either using online learning algorithms or more adaptable statistical models.
- Handling multiple time scales: The electricity demand can exhibit patterns on various time scales, such as daily, weekly, and seasonal patterns [117]. Future studies can develop STLF models that can handle multiple time scales by combining models trained on various time scales or utilizing more sophisticated machine-learning methods.
- Integration of uncertainty information: Uncertainty information, such as information about input data reliability or model accuracy, can provide valuable insights into the quality of the forecast [118]. Future studies may explore creating STLF models that can incorporate uncertainty data into the modeling process through probabilistic models or more sophisticated statistical models that can calculate forecast uncertainty [119].
- Development of models for distributed energy resources: The increasing use of distributed energy resources, such as rooftop solar panels and energy storage systems, has introduced new challenges for STLF models [120]. Future studies may develop STLF models that can account for distributed energy resources, either through models that forecast the production of renewable energy or models that forecast the effects of distributed energy resources on electricity consumption [121,122].
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cheng, L.; Yu, T. A new generation of AI: A review and perspective on machine learning technologies applied to smart energy and electric power systems. Int. J. Energy Res. 2019, 43, 1928–1973. [Google Scholar] [CrossRef]
- Ding, Y.; Zhu, Y.; Feng, J.; Zhang, P.; Cheng, Z. Interpretable spatio-temporal attention LSTM model for flood forecasting. Neurocomputing 2020, 403, 348–359. [Google Scholar] [CrossRef]
- Zakaria, A.; Ismail, F.B.; Lipu, M.H.; Hannan, M. Uncertainty models for stochastic optimization in renewable energy applications. Renew. Energy 2020, 145, 1543–1571. [Google Scholar] [CrossRef]
- Fu, H.; Baltazar, J.-C.; Claridge, D.E. Review of developments in whole-building statistical energy consumption models for commercial buildings. Renew. Sustain. Energy Rev. 2021, 147, 111248. [Google Scholar] [CrossRef]
- Lu, S.; Li, Q.; Bai, L.; Wang, R. Performance predictions of ground source heat pump system based on random forest and back propagation neural network models. Energy Convers. Manag. 2019, 197, 111864. [Google Scholar] [CrossRef]
- Ganaie, M.; Hu, M.; Malik, A.; Tanveer, M.; Suganthan, P. Ensemble deep learning: A review. Eng. Appl. Artif. Intell. 2022, 115, 105151. [Google Scholar] [CrossRef]
- Altan, A.; Karasu, S.; Zio, E. A new hybrid model for wind speed forecasting combining long short-term memory neural network, decomposition methods and grey wolf optimizer. Appl. Soft Comput. 2021, 100, 106996. [Google Scholar] [CrossRef]
- Alexander, M.; Beushausen, H. Durability, service life prediction, and modelling for reinforced concrete structures—Review and critique. Cem. Concr. Res. 2019, 122, 17–29. [Google Scholar] [CrossRef]
- Kurani, A.; Doshi, P.; Vakharia, A.; Shah, M. A Comprehensive Comparative Study of Artificial Neural Network (ANN) and Support Vector Machines (SVM) on Stock Forecasting. Ann. Data Sci. 2023, 10, 183–208. [Google Scholar] [CrossRef]
- Dagoumas, A.S.; Koltsaklis, N.E. Review of models for integrating renewable energy in the generation expansion planning. Appl. Energy 2019, 242, 1573–1587. [Google Scholar] [CrossRef]
- Zhang, R.; Chen, Z.; Chen, S.; Zheng, J.; Büyüköztürk, O.; Sun, H. Deep long short-term memory networks for nonlinear structural seismic response prediction. Comput. Struct. 2019, 220, 55–68. [Google Scholar] [CrossRef]
- Lindberg, K.B.; Seljom, P.; Madsen, H.; Fischer, D.; Korpås, M. Long-term electricity load forecasting: Current and future trends. Util. Policy 2019, 58, 102–119. [Google Scholar] [CrossRef]
- Koponen, P.; Ikäheimo, J.; Koskela, J.; Brester, C.; Niska, H. Assessing and Comparing Short Term Load Forecasting Performance. Energies 2020, 13, 2054. [Google Scholar] [CrossRef]
- Trierweiler Ribeiro, G.; Cocco Mariani, V.; dos Santos Coelho, L. Enhanced ensemble structures using wavelet neural networks applied to short-term load forecasting. Eng. Appl. Artif. Intell. 2019, 82, 272–281. [Google Scholar] [CrossRef]
- Moradzadeh, A.; Moayyed, H.; Zakeri, S.; Mohammadi-Ivatloo, B.; Aguiar, A.P. Deep Learning-Assisted Short-Term Load Forecasting for Sustainable Management of Energy in Microgrid. Inventions 2021, 6, 15. [Google Scholar] [CrossRef]
- Almalaq, A.; Edwards, G. A Review of Deep Learning Methods Applied on Load Forecasting. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 511–516. [Google Scholar] [CrossRef]
- Li, L.-L.; Zhao, X.; Tseng, M.-L.; Tan, R.R. Short-term wind power forecasting based on support vector machine with improved dragonfly algorithm. J. Clean. Prod. 2020, 242, 118447. [Google Scholar] [CrossRef]
- Carvalho, T.P.; Soares, F.A.A.M.N.; Vita, R.; Francisco, R.D.P.; Basto, J.P.; Alcalá, S.G.S. A systematic literature review of machine learning methods applied to predictive maintenance. Comput. Ind. Eng. 2019, 137, 106024. [Google Scholar] [CrossRef]
- Chen, J.; Ran, X. Deep Learning with Edge Computing: A Review. Proc. IEEE 2019, 107, 1655–1674. [Google Scholar] [CrossRef]
- Nespoli, A.; Ogliari, E.; Leva, S.; Pavan, A.M.; Mellit, A.; Lughi, V.; Dolara, A. Day-Ahead Photovoltaic Forecasting: A Comparison of the Most Effective Techniques. Energies 2019, 12, 1621. [Google Scholar] [CrossRef]
- Mahzarnia, M.; Moghaddam, M.P.; Baboli, P.T.; Siano, P. A Review of the Measures to Enhance Power Systems Resilience. IEEE Syst. J. 2020, 14, 4059–4070. [Google Scholar] [CrossRef]
- Ahmad, T.; Zhang, D.; Huang, C.; Zhang, H.; Dai, N.; Song, Y.; Chen, H. Artificial intelligence in sustainable energy industry: Status Quo, challenges and opportunities. J. Clean. Prod. 2021, 289, 125834. [Google Scholar] [CrossRef]
- Ruano, A.; Hernandez, A.; Ureña, J.; Ruano, M.; Garcia, J. NILM Techniques for Intelligent Home Energy Management and Ambient Assisted Living: A Review. Energies 2019, 12, 2203. [Google Scholar] [CrossRef]
- Mohandes, B.; El Moursi, M.S.; Hatziargyriou, N.D.; El Khatib, S. A Review of Power System Flexibility with High Penetration of Renewables. IEEE Trans. Power Syst. 2019, 34, 3140–3155. [Google Scholar] [CrossRef]
- Liu, Z.; Jiang, P.; Zhang, L.; Niu, X. A combined forecasting model for time series: Application to short-term wind speed forecasting. Appl. Energy 2020, 259, 114137. [Google Scholar] [CrossRef]
- Laib, O.; Khadir, M.T.; Mihaylova, L. Toward efficient energy systems based on natural gas consumption prediction with LSTM Recurrent Neural Networks. Energy 2019, 177, 530–542. [Google Scholar] [CrossRef]
- Boukerche, A.; Wang, J. Machine Learning-based traffic prediction models for Intelligent Transportation Systems. Comput. Netw. 2020, 181, 107530. [Google Scholar] [CrossRef]
- Sharifzadeh, M.; Sikinioti-Lock, A.; Shah, N. Machine-learning methods for integrated renewable power generation: A comparative study of artificial neural networks, support vector regression, and Gaussian Process Regression. Renew. Sustain. Energy Rev. 2019, 108, 513–538. [Google Scholar] [CrossRef]
- Qiao, W.; Huang, K.; Azimi, M.; Han, S. A Novel Hybrid Prediction Model for Hourly Gas Consumption in Supply Side Based on Improved Whale Optimization Algorithm and Relevance Vector Machine. IEEE Access 2019, 7, 88218–88230. [Google Scholar] [CrossRef]
- Fan, C.; Wang, J.; Gang, W.; Li, S. Assessment of deep recurrent neural network-based strategies for short-term building energy predictions. Appl. Energy 2019, 236, 700–710. [Google Scholar] [CrossRef]
- Hossain, E.; Khan, I.; Un-Noor, F.; Sikander, S.S.; Sunny, S.H. Application of Big Data and Machine Learning in Smart Grid, and Associated Security Concerns: A Review. IEEE Access 2019, 7, 13960–13988. [Google Scholar] [CrossRef]
- Blaga, R.; Sabadus, A.; Stefu, N.; Dughir, C.; Paulescu, M.; Badescu, V. A current perspective on the accuracy of incoming solar energy forecasting. Prog. Energy Combust. Sci. 2019, 70, 119–144. [Google Scholar] [CrossRef]
- Wang, F.; Xuan, Z.; Zhen, Z.; Li, K.; Wang, T.; Shi, M. A day-ahead PV power forecasting method based on LSTM-RNN model and time correlation modification under partial daily pattern prediction framework. Energy Convers. Manag. 2020, 212, 112766. [Google Scholar] [CrossRef]
- Zahid, M.; Ahmed, F.; Javaid, N.; Abbasi, R.A.; Zainab Kazmi, H.S.; Javaid, A.; Bilal, M.; Akbar, M.; Ilahi, M. Electricity Price and Load Forecasting using Enhanced Convolutional Neural Network and Enhanced Support Vector Regression in Smart Grids. Electronics 2019, 8, 122. [Google Scholar] [CrossRef]
- Runge, J.; Zmeureanu, R. A Review of Deep Learning Techniques for Forecasting Energy Use in Buildings. Energies 2021, 14, 608. [Google Scholar] [CrossRef]
- Liu, H.; Chen, C.; Lv, X.; Wu, X.; Liu, M. Deterministic wind energy forecasting: A review of intelligent predictors and auxiliary methods. Energy Convers. Manag. 2019, 195, 328–345. [Google Scholar] [CrossRef]
- Lara-Benítez, P.; Carranza-García, M.; Riquelme, J.C. An Experimental Review on Deep Learning Architectures for Time Series Forecasting. Int. J. Neural Syst. 2021, 31, 2130001. [Google Scholar] [CrossRef]
- Hanifi, S.; Liu, X.; Lin, Z.; Lotfian, S. A Critical Review of Wind Power Forecasting Methods—Past, Present and Future. Energies 2020, 13, 3764. [Google Scholar] [CrossRef]
- Lim, B.; Zohren, S. Time-series forecasting with deep learning: A survey. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2021, 379, 20200209. [Google Scholar] [CrossRef]
- Fan, C.; Sun, Y.; Zhao, Y.; Song, M.; Wang, J. Deep learning-based feature engineering methods for improved building energy prediction. Appl. Energy 2019, 240, 35–45. [Google Scholar] [CrossRef]
- Muzaffar, S.; Afshari, A. Short-Term Load Forecasts Using LSTM Networks. Energy Procedia 2019, 158, 2922–2927. [Google Scholar] [CrossRef]
- Wang, K.; Qi, X.; Liu, H. Photovoltaic power forecasting based LSTM-Convolutional Network. Energy 2019, 189, 116225. [Google Scholar] [CrossRef]
- Du, S.; Li, T.; Yang, Y.; Horng, S.-J. Multivariate time series forecasting via attention-based encoder–decoder framework. Neurocomputing 2020, 388, 269–279. [Google Scholar] [CrossRef]
- Mohandes, S.R.; Zhang, X.; Mahdiyar, A. A comprehensive review on the application of artificial neural networks in building energy analysis. Neurocomputing 2019, 340, 55–75. [Google Scholar] [CrossRef]
- Mosavi, A.; Salimi, M.; Ardabili, S.F.; Rabczuk, T.; Shamshirband, S.; Varkonyi-Koczy, A.R. State of the Art of Machine Learning Models in Energy Systems, a Systematic Review. Energies 2019, 12, 1301. [Google Scholar] [CrossRef]
- Cai, M.; Pipattanasomporn, M.; Rahman, S. Day-ahead building-level load forecasts using deep learning vs. traditional time-series techniques. Appl. Energy 2018, 236, 1078–1088. [Google Scholar] [CrossRef]
- Wang, H.; Liu, Y.; Zhou, B.; Li, C.; Cao, G.; Voropai, N.; Barakhtenko, E. Taxonomy research of artificial intelligence for deterministic solar power forecasting. Energy Convers. Manag. 2020, 214, 112909. [Google Scholar] [CrossRef]
- Ahmed, R.; Sreeram, V.; Mishra, Y.; Arif, M. A review and evaluation of the state-of-the-art in PV solar power forecasting: Techniques and optimization. Renew. Sustain. Energy Rev. 2020, 124, 109792. [Google Scholar] [CrossRef]
- Van Houdt, G.; Mosquera, C.; Nápoles, G. A review on the long short-term memory model. Artif. Intell. Rev. 2020, 53, 5929–5955. [Google Scholar] [CrossRef]
- Lu, X.; Li, K.; Xu, H.; Wang, F.; Zhou, Z.; Zhang, Y. Fundamentals and business model for resource aggregator of demand response in electricity markets. Energy 2020, 204, 117885. [Google Scholar] [CrossRef]
- Huang, C.-J.; Kuo, P.-H. Multiple-Input Deep Convolutional Neural Network Model for Short-Term Photovoltaic Power Forecasting. IEEE Access 2019, 7, 74822–74834. [Google Scholar] [CrossRef]
- Sun, Y.; Haghighat, F.; Fung, B.C. A review of the-state-of-the-art in data-driven approaches for building energy prediction. Energy Build. 2020, 221, 110022. [Google Scholar] [CrossRef]
- Nam, K.; Hwangbo, S.; Yoo, C. A deep learning-based forecasting model for renewable energy scenarios to guide sustainable energy policy: A case study of Korea. Renew. Sustain. Energy Rev. 2020, 122, 109725. [Google Scholar] [CrossRef]
- Wei, N.; Li, C.; Peng, X.; Zeng, F.; Lu, X. Conventional models and artificial intelligence-based models for energy consumption forecasting: A review. J. Pet. Sci. Eng. 2019, 181, 106187. [Google Scholar] [CrossRef]
- Hafeez, G.; Alimgeer, K.S.; Khan, I. Electric load forecasting based on deep learning and optimized by heuristic algorithm in smart grid. Appl. Energy 2020, 269, 114915. [Google Scholar] [CrossRef]
- Wang, Y.; Gan, D.; Sun, M.; Zhang, N.; Lu, Z.; Kang, C. Probabilistic individual load forecasting using pinball loss guided LSTM. Appl. Energy 2019, 235, 10–20. [Google Scholar] [CrossRef]
- Ahmed, A.; Khalid, M. A review on the selected applications of forecasting models in renewable power systems. Renew. Sustain. Energy Rev. 2019, 100, 9–21. [Google Scholar] [CrossRef]
- Alhussein, M.; Aurangzeb, K.; Haider, S.I. Hybrid CNN-LSTM Model for Short-Term Individual Household Load Forecasting. IEEE Access 2020, 8, 180544–180557. [Google Scholar] [CrossRef]
- Barman, M.; Choudhury, N.B.D. Season specific approach for short-term load forecasting based on hybrid FA-SVM and similarity concept. Energy 2019, 174, 886–896. [Google Scholar] [CrossRef]
- Aslam, S.; Herodotou, H.; Mohsin, S.M.; Javaid, N.; Ashraf, N.; Aslam, S. A survey on deep learning methods for power load and renewable energy forecasting in smart microgrids. Renew. Sustain. Energy Rev. 2021, 144, 110992. [Google Scholar] [CrossRef]
- Gao, W.; Darvishan, A.; Toghani, M.; Mohammadi, M.; Abedinia, O.; Ghadimi, N. Different states of multi-block based forecast engine for price and load prediction. Int. J. Electr. Power Energy Syst. 2019, 104, 423–435. [Google Scholar] [CrossRef]
- He, F.; Zhou, J.; Feng, Z.-K.; Liu, G.; Yang, Y. A hybrid short-term load forecasting model based on variational mode decomposition and long short-term memory networks considering relevant factors with Bayesian optimization algorithm. Appl. Energy 2019, 237, 103–116. [Google Scholar] [CrossRef]
- Sajjad, M.; Khan, Z.A.; Ullah, A.; Hussain, T.; Ullah, W.; Lee, M.Y.; Baik, S.W. A Novel CNN-GRU-Based Hybrid Approach for Short-Term Residential Load Forecasting. IEEE Access 2020, 8, 143759–143768. [Google Scholar] [CrossRef]
- Ahmad, T.; Chen, H. A review on machine learning forecasting growth trends and their real-time applications in different energy systems. Sustain. Cities Soc. 2020, 54, 102010. [Google Scholar] [CrossRef]
- Deng, Z.; Wang, B.; Xu, Y.; Xu, T.; Liu, C.; Zhu, Z. Multi-Scale Convolutional Neural Network with Time-Cognition for Multi-Step Short-Term Load Forecasting. IEEE Access 2019, 7, 88058–88071. [Google Scholar] [CrossRef]
- Yang, A.; Li, W.; Yang, X. Short-term electricity load forecasting based on feature selection and Least Squares Support Vector Machines. Knowl. Based Syst. 2019, 163, 159–173. [Google Scholar] [CrossRef]
- Fazal, S.; Haque, E.; Arif, M.T.; Gargoom, A.; Oo, A.M.T. Grid integration impacts and control strategies for renewable based microgrid. Sustain. Energy Technol. Assess. 2023, 56, 103069. [Google Scholar] [CrossRef]
- Liang, Y.; Niu, D.; Hong, W.-C. Short term load forecasting based on feature extraction and improved general regression neural network model. Energy 2019, 166, 653–663. [Google Scholar] [CrossRef]
- Kim, J.; Moon, J.; Hwang, E.; Kang, P. Recurrent inception convolution neural network for multi short-term load forecasting. Energy Build. 2019, 194, 328–341. [Google Scholar] [CrossRef]
- Massaoudi, M.; Refaat, S.S.; Chihi, I.; Trabelsi, M.; Oueslati, F.S.; Abu-Rub, H. A novel stacked generalization ensemble-based hybrid LGBM-XGB-MLP model for Short-Term Load Forecasting. Energy 2021, 214, 118874. [Google Scholar] [CrossRef]
- Bermejo, J.F.; Fernández, J.F.G.; Polo, F.O.; Márquez, A.C. A Review of the Use of Artificial Neural Network Models for Energy and Reliability Prediction. A Study of the Solar PV, Hydraulic and Wind Energy Sources. Appl. Sci. 2019, 9, 1844. [Google Scholar] [CrossRef]
- Yan, K.; Li, W.; Ji, Z.; Qi, M.; Du, Y. A Hybrid LSTM Neural Network for Energy Consumption Forecasting of Individual Households. IEEE Access 2019, 7, 157633–157642. [Google Scholar] [CrossRef]
- Fajardo-Toro, C.H.; Mula, J.; Poler, R. Adaptive and Hybrid Forecasting Models—A Review. In Proceedings of the 11th International Conference on Industrial Engineering and Industrial Management. Springer International Publishing, Valencia, Spain, 5–6 July 2017; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 315–322. [Google Scholar] [CrossRef]
- Ibrahim, M.S.; Dong, W.; Yang, Q. Machine learning driven smart electric power systems: Current trends and new perspectives. Appl. Energy 2020, 272, 115237. [Google Scholar] [CrossRef]
- Du, P.; Wang, J.; Yang, W.; Niu, T. A novel hybrid model for short-term wind power forecasting. Appl. Soft Comput. 2019, 80, 93–106. [Google Scholar] [CrossRef]
- Pham, A.-D.; Ngo, N.-T.; Truong, T.T.H.; Huynh, N.-T.; Truong, N.-S. Predicting energy consumption in multiple buildings using machine learning for improving energy efficiency and sustainability. J. Clean. Prod. 2020, 260, 121082. [Google Scholar] [CrossRef]
- Sadaei, H.J.; Silva, P.C.D.L.E.; Guimarães, F.G.; Lee, M.H. Short-term load forecasting by using a combined method of convolutional neural networks and fuzzy time series. Energy 2019, 175, 365–377. [Google Scholar] [CrossRef]
- Rafi, S.H.; Masood, N.A.; Deeba, S.R.; Hossain, E. A Short-Term Load Forecasting Method Using Integrated CNN and LSTM Network. IEEE Access 2021, 9, 32436–32448. [Google Scholar] [CrossRef]
- Zhang, L.; Wen, J.; Li, Y.; Chen, J.; Ye, Y.; Fu, Y.; Livingood, W. A review of machine learning in building load prediction. Appl. Energy 2021, 285, 116452. [Google Scholar] [CrossRef]
- Tan, M.; Yuan, S.; Li, S.; Su, Y.; Li, H.; He, F.H. Ultra-Short-Term Industrial Power Demand Forecasting Using LSTM Based Hybrid Ensemble Learning. IEEE Trans. Power Syst. 2020, 35, 2937–2948. [Google Scholar] [CrossRef]
- Bourdeau, M.; Zhai, X.Q.; Nefzaoui, E.; Guo, X.; Chatellier, P. Modeling and forecasting building energy consumption: A review of data-driven techniques. Sustain. Cities Soc. 2019, 48, 101533. [Google Scholar] [CrossRef]
- Li, P.; Zhou, K.; Lu, X.; Yang, S. A hybrid deep learning model for short-term PV power forecasting. Appl. Energy 2019, 259, 114216. [Google Scholar] [CrossRef]
- Torres, J.F.; Hadjout, D.; Sebaa, A.; Martínez-Álvarez, F.; Troncoso, A. Deep Learning for Time Series Forecasting: A Survey. Data 2021, 9, 3–21. Available online: https://home.liebertpub.com/bigBig (accessed on 12 March 2023). [CrossRef] [PubMed]
- Ouyang, T.; He, Y.; Li, H.; Sun, Z.; Baek, S. Modeling and Forecasting Short-Term Power Load With Copula Model and Deep Belief Network. IEEE Trans. Emerg. Top. Comput. Intell. 2019, 3, 127–136. [Google Scholar] [CrossRef]
- Wang, X.; Yao, Z.; Papaefthymiou, M. A real-time electrical load forecasting and unsupervised anomaly detection framework. Appl. Energy 2023, 330, 120279. [Google Scholar] [CrossRef]
- Huang, N.; Wang, S.; Wang, R.; Cai, G.; Liu, Y.; Dai, Q. Gated spatial-temporal graph neural network based short-term load forecasting for wide-area multiple buses. Int. J. Electr. Power Energy Syst. 2023, 145, 108651. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, P.; Ma, N.; Liu, G. Robust Wavelet Transform Neural-Network-Based Short-Term Load Forecasting for Power Distribution Networks. Sustainability 2023, 15, 296. [Google Scholar] [CrossRef]
- Mehmood, M.U.; Chun, D.; Zeeshan; Han, H.; Jeon, G.; Chen, K. A review of the applications of artificial intelligence and big data to buildings for energy-efficiency and a comfortable indoor living environment. Energy Build. 2019, 202, 109383. [Google Scholar] [CrossRef]
- Li, K.; Huang, W.; Hu, G.; Li, J. Ultra-short term power load forecasting based on CEEMDAN-SE and LSTM neural network. Energy Build. 2023, 279, 112666. [Google Scholar] [CrossRef]
- Yang, D.; Guo, J.-E.; Li, Y.; Sun, S.; Wang, S. Short-term load forecasting with an improved dynamic decomposition-reconstruction-ensemble approach. Energy 2023, 263, 125609. [Google Scholar] [CrossRef]
- Bedi, J.; Toshniwal, D. Deep learning framework to forecast electricity demand. Appl. Energy 2019, 238, 1312–1326. [Google Scholar] [CrossRef]
- Ahmad, A.; Javaid, N.; Mateen, A.; Awais, M.; Khan, Z.A. Short-Term Load Forecasting in Smart Grids: An Intelligent Modular Approach. Energies 2019, 12, 164. [Google Scholar] [CrossRef]
- Hu, Y.; Li, J.; Hong, M.; Ren, J.; Lin, R.; Liu, Y.; Liu, M.; Man, Y. Short term electric load forecasting model and its verification for process industrial enterprises based on hybrid GA-PSO-BPNN algorithm—A case study of papermaking process. Energy 2019, 170, 1215–1227. [Google Scholar] [CrossRef]
- Wang, Z.; Hong, T.; Piette, M.A. Building thermal load prediction through shallow machine learning and deep learning. Appl. Energy 2020, 263, 114683. [Google Scholar] [CrossRef]
- Bouktif, S.; Fiaz, A.; Ouni, A.; Serhani, M.A. Multi-Sequence LSTM-RNN Deep Learning and Metaheuristics for Electric Load Forecasting. Energies 2020, 13, 391. [Google Scholar] [CrossRef]
- Wen, L.; Zhou, K.; Yang, S.; Lu, X. Optimal load dispatch of community microgrid with deep learning based solar power and load forecasting. Energy 2019, 171, 1053–1065. [Google Scholar] [CrossRef]
- Sun, M.; Zhang, T.; Wang, Y.; Strbac, G.; Kang, C. Using Bayesian Deep Learning to Capture Uncertainty for Residential Net Load Forecasting. IEEE Trans. Power Syst. 2020, 35, 188–201. [Google Scholar] [CrossRef]
- Nepal, B.; Yamaha, M.; Yokoe, A.; Yamaji, T. Electricity load forecasting using clustering and ARIMA model for energy management in buildings. Jpn. Arch. Rev. 2020, 3, 62–76. [Google Scholar] [CrossRef]
- Hong, T.; Xie, J.; Black, J. Global energy forecasting competition 2017: Hierarchical probabilistic load forecasting. Int. J. Forecast. 2019, 35, 1389–1399. [Google Scholar] [CrossRef]
- Zhang, Z.; Hong, W.-C. Electric load forecasting by complete ensemble empirical mode decomposition adaptive noise and support vector regression with quantum-based dragonfly algorithm. Nonlinear Dyn. 2019, 98, 1107–1136. [Google Scholar] [CrossRef]
- Shah, I.; Iftikhar, H.; Ali, S.; Wang, D. Short-Term Electricity Demand Forecasting Using Components Estimation Technique. Energies 2019, 12, 2532. [Google Scholar] [CrossRef]
- Ju, Y.; Sun, G.; Chen, Q.; Zhang, M.; Zhu, H.; Rehman, M.U. A Model Combining Convolutional Neural Network and LightGBM Algorithm for Ultra-Short-Term Wind Power Forecasting. IEEE Access 2019, 7, 28309–28318. [Google Scholar] [CrossRef]
- Qiao, W.; Yang, Z.; Kang, Z.; Pan, Z. Short-term natural gas consumption prediction based on Volterra adaptive filter and improved whale optimization algorithm. Eng. Appl. Artif. Intell. 2020, 87, 103323. [Google Scholar] [CrossRef]
- Jiang, W.; Wu, X.; Gong, Y.; Yu, W.; Zhong, X. Holt–Winters smoothing enhanced by fruit fly optimization algorithm to forecast monthly electricity consumption. Energy 2020, 193, 116779. [Google Scholar] [CrossRef]
- Liu, T.; Tan, Z.; Xu, C.; Chen, H.; Li, Z. Study on deep reinforcement learning techniques for building energy consumption forecasting. Energy Build. 2020, 208, 109675. [Google Scholar] [CrossRef]
- Gao, Y.; Ruan, Y.; Fang, C.; Yin, S. Deep learning and transfer learning models of energy consumption forecasting for a building with poor information data. Energy Build. 2020, 223, 110156. [Google Scholar] [CrossRef]
- Husein, M.; Chung, I.-Y. Day-Ahead Solar Irradiance Forecasting for Microgrids Using a Long Short-Term Memory Recurrent Neural Network: A Deep Learning Approach. Energies 2019, 12, 1856. [Google Scholar] [CrossRef]
- Chen, X.; Chen, W.; Dinavahi, V.; Liu, Y.; Feng, J. Short-Term Load Forecasting and Associated Weather Variables Prediction Using ResNet-LSTM Based Deep Learning. IEEE Access 2023, 11, 5393–5405. [Google Scholar] [CrossRef]
- Ran, P.; Dong, K.; Liu, X.; Wang, J. Short-term load forecasting based on CEEMDAN and Transformer. Electr. Power Syst. Res. 2023, 214, 108885. [Google Scholar] [CrossRef]
- Liu, C.-L.; Tseng, C.-J.; Huang, T.-H.; Yang, J.-S.; Huang, K.-B. A multi-task learning model for building electrical load prediction. Energy Build. 2023, 278, 112601. [Google Scholar] [CrossRef]
- Yang, Y.; Jinfu, F.; Zhongjie, W.; Zheng, Z.; Yukun, X. A dynamic ensemble method for residential short-term load forecasting. Alex. Eng. J. 2023, 63, 75–88. [Google Scholar] [CrossRef]
- Shahare, K.; Mitra, A.; Naware, D.; Keshri, R.; Suryawanshi, H. Performance analysis and comparison of various techniques for short-term load forecasting. Energy Rep. 2023, 9, 799–808. [Google Scholar] [CrossRef]
- Hua, H.; Liu, M.; Li, Y.; Deng, S.; Wang, Q. An ensemble framework for short-term load forecasting based on parallel CNN and GRU with improved ResNet. Electr. Power Syst. Res. 2023, 216, 109057. [Google Scholar] [CrossRef]
- Falces, A.; Capellan-Villacian, C.; Mendoza-Villena, M.; Zorzano-Santamaria, P.J.; Lara-Santillan, P.M.; Garcia-Garrido, E.; Fernandez-Jimenez, L.A.; Zorzano-Alba, E. Short-term net load forecast in distribution networks with PV penetration behind the meter. Energy Rep. 2023, 9, 115–122. [Google Scholar] [CrossRef]
- Motwakel, A.; Alabdulkreem, E.; Gaddah, A.; Marzouk, R.; Salem, N.M.; Zamani, A.S.; Abdelmageed, A.A.; Eldesouki, M.I. Wild Horse Optimization with Deep Learning-Driven Short-Term Load Forecasting Scheme for Smart Grids. Sustainability 2023, 15, 1524. [Google Scholar] [CrossRef]
- Som, T. Time Load Forecasting: A Smarter Expertise through Modern Methods; Springer Nature: Singapore, 2023; pp. 153–176. [Google Scholar] [CrossRef]
- Yadav, S.; Tondwal, B.; Tomar, A. Models of Load Forecasting. In Prediction Techniques for Renewable Energy Generation and Load Demand Forecasting; Springer: Singapore, 2023; Volume 956, pp. 111–130. [Google Scholar] [CrossRef]
- Li, D.; Tan, Y.; Zhang, Y.; Miao, S.; He, S. Probabilistic forecasting method for mid-term hourly load time series based on an improved temporal fusion transformer model. Int. J. Electr. Power Energy Syst. 2023, 146, 108743. [Google Scholar] [CrossRef]
- Shahzad, S.; Abbasi, M.A.; Chaudhry, M.A.; Hussain, M.M. Model Predictive Control Strategies in Microgrids: A Concise Revisit. IEEE Access 2022, 10, 122211–122225. [Google Scholar] [CrossRef]
- Gulzar, M.M.; Iqbal, M.; Shahzad, S.; Muqeet, H.A.; Shahzad, M.; Hussain, M.M. Load Frequency Control (LFC) Strategies in Renewable Energy-Based Hybrid Power Systems: A Review. Energies 2022, 15, 3488. [Google Scholar] [CrossRef]
- Saeed, M.H.; Fangzong, W.; Kalwar, B.A.; Iqbal, S. A Review on Microgrids’ Challenges & Perspectives. IEEE Access 2021, 9, 166502–166517. [Google Scholar] [CrossRef]
- Shahzad, S.; Abbasi, M.A.; Ali, H.; Iqbal, M.; Munir, R.; Kilic, H. Possibilities, Challenges, and Future Opportunities of Microgrids: A Review. Sustainability 2023, 15, 6366. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Refs. | Contributions | Limitations |
|---|---|---|
| [12] |
|
|
| [13] |
|
|
| [14] |
|
|
| [15] |
|
|
| [16] |
|
|
| Refs. | Model | Contributions | Applications | Limitations |
|---|---|---|---|---|
| [91] | ARIMA | Suitable for modeling time series data with trend and seasonality | Forecasting of various economic and financial data, weather forecasting, and sales forecasting | Assumes stationarity and requires careful selection of model parameters |
| [92] | SARIMA | Incorporates seasonal factors into ARIMA model | Forecasting of time series data with seasonal patterns, such as sales data during holiday seasons | Requires careful selection of model parameters |
| [93] | Exponential Smoothing | Simple yet effective method for time series forecasting | Used in various industries, such as finance, supply chain management, and marketing | Assumes no trend or seasonality in data |
| [94] | Generalized Linear Model | Extends linear regression to accommodate non-normal response variables | Used in various fields, such as medical research, environmental science, and social sciences | Assumes linearity between predictors and response variable |
| [95] | Support Vector Machine | Nonlinear classification and regression method | Used in various fields, such as finance, biology, and image recognition | Requires careful selection of model parameters |
| [96] | Decision Tree | Non-parametric method for classification and regression | Used in various fields, such as finance, marketing, and healthcare | Prone to overfitting and requires careful selection of hyperparameters |
| [97] | Random Forest | Ensemble method that uses multiple decision trees for classification and regression | Used in various fields, such as finance, marketing, and healthcare | Prone to overfitting and requires careful selection of hyperparameters |
| [98] | Gradient Boosting | Ensemble method that uses multiple weak learners to improve predictions | Used in various fields, such as finance, healthcare, and image recognition | Prone to overfitting and requires careful selection of hyperparameters |
| [99] | Deep Learning | Neural-network-based models for complex data analysis | Used in various fields, such as image recognition, natural language processing, and speech recognition | Requires large amounts of training data and computational resources |
| [100] | Ensemble Methods | Combine multiple models to improve prediction accuracy | Used in various fields, such as finance, marketing, and healthcare | Requires careful selection of models and hyperparameters |
| [101] | Multilayer Perceptron | Neural-network-based models for classification and regression | Used in various fields, such as finance, healthcare, and image recognition | Prone to overfitting and requires careful selection of hyperparameters |
| [102] | Hybrid Models | Combine multiple models or methods to improve prediction accuracy | Used in various fields, such as finance, marketing, and healthcare | Requires careful selection of models and hyperparameters |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akhtar, S.; Shahzad, S.; Zaheer, A.; Ullah, H.S.; Kilic, H.; Gono, R.; Jasiński, M.; Leonowicz, Z. Short-Term Load Forecasting Models: A Review of Challenges, Progress, and the Road Ahead. Energies 2023, 16, 4060. https://doi.org/10.3390/en16104060
Akhtar S, Shahzad S, Zaheer A, Ullah HS, Kilic H, Gono R, Jasiński M, Leonowicz Z. Short-Term Load Forecasting Models: A Review of Challenges, Progress, and the Road Ahead. Energies. 2023; 16(10):4060. https://doi.org/10.3390/en16104060
Chicago/Turabian StyleAkhtar, Saima, Sulman Shahzad, Asad Zaheer, Hafiz Sami Ullah, Heybet Kilic, Radomir Gono, Michał Jasiński, and Zbigniew Leonowicz. 2023. "Short-Term Load Forecasting Models: A Review of Challenges, Progress, and the Road Ahead" Energies 16, no. 10: 4060. https://doi.org/10.3390/en16104060
APA StyleAkhtar, S., Shahzad, S., Zaheer, A., Ullah, H. S., Kilic, H., Gono, R., Jasiński, M., & Leonowicz, Z. (2023). Short-Term Load Forecasting Models: A Review of Challenges, Progress, and the Road Ahead. Energies, 16(10), 4060. https://doi.org/10.3390/en16104060