

Fault Detection and Identification of Furnace Negative Pressure System with CVA and GA-XGBoost

Abstract
:1. Introduction
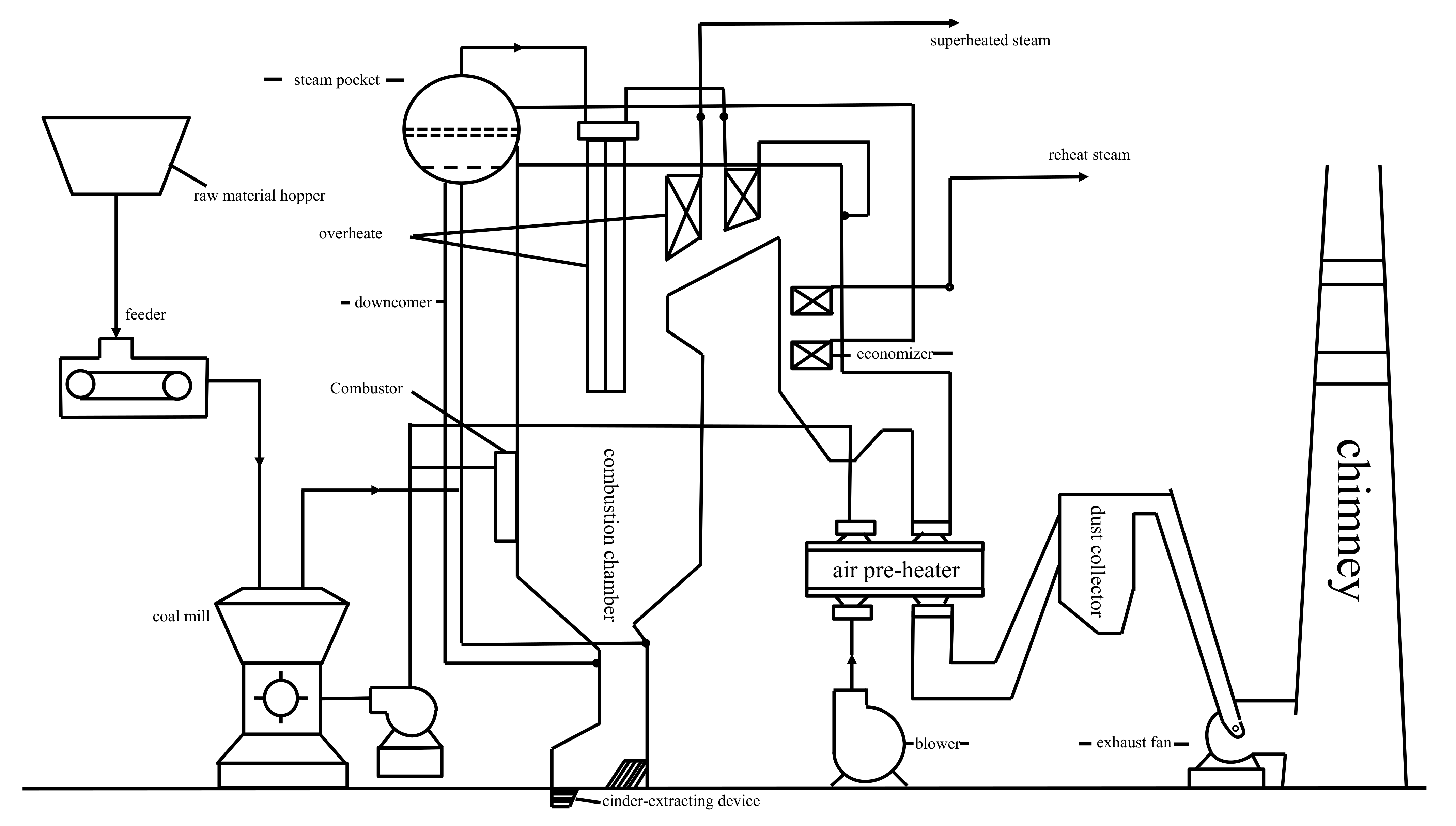
2. Background and Basic Data
3. The Proposed Fault Detection and Identification Methodology
3.1. Feature Abstraction Based on CVA
3.2. XGBoost Improved by GA
3.2.1. XGBoost
3.2.2. GA-XGBoost
| Algorithm 1. GA-XGBoost |
| Input: (crossover probability), (mutation probability), G (maximum |
| number of iterations), (Fitness limit). |
| 1. Initialize generation (learning_rate, n_estimators, max_depth, min_child_weight, |
| subsample, colsample_bytree and gamma). |
| 2. Build a XGBoost model using the individuals. |
| 3. Calculate individual fitness by Equation (13)→. |
| 4. Generate . |
| 5. While or do. |
| 6. While do. |
| 7. Select 2 individuals with the highest fitness. |
| 8. If (random(0, 1) < ) do. |
| 9. Cross operation. |
| 10. If (random(0, 1) < ) do. |
| 11. Mutation operation. |
| 12. The offspring are add to . |
| 13. end while |
| 14. |
| 15. end while |
| 16. Output best result |
3.3. The Reconstructed Variable Contribution
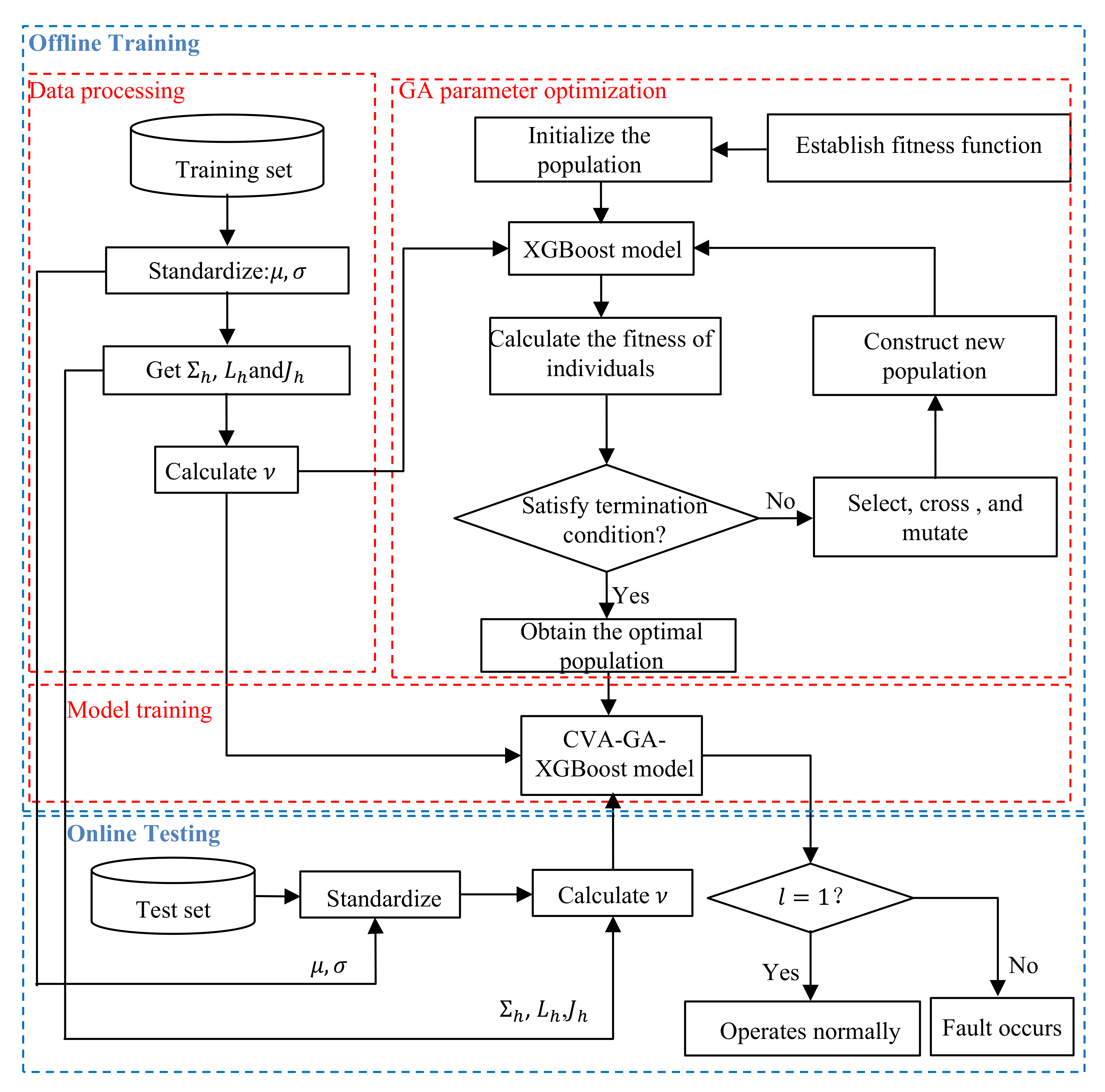
3.4. The Procedure for Fault Detection Based on CVA and GA-XGBoost
3.5. The Procedure for the Proposed Fault Identification Method
| Algorithm 2. Proposed fault identification algorithm |
| Offline modeling: |
| 1. Collect normal data sample x, standardize data, and obtain and . |
| 2. Construct and . |
| 3. Construct and . |
| 4. Perform SVD on the scaled matrix H and obtain V, U and ∑. |
| 5. Calculate and |
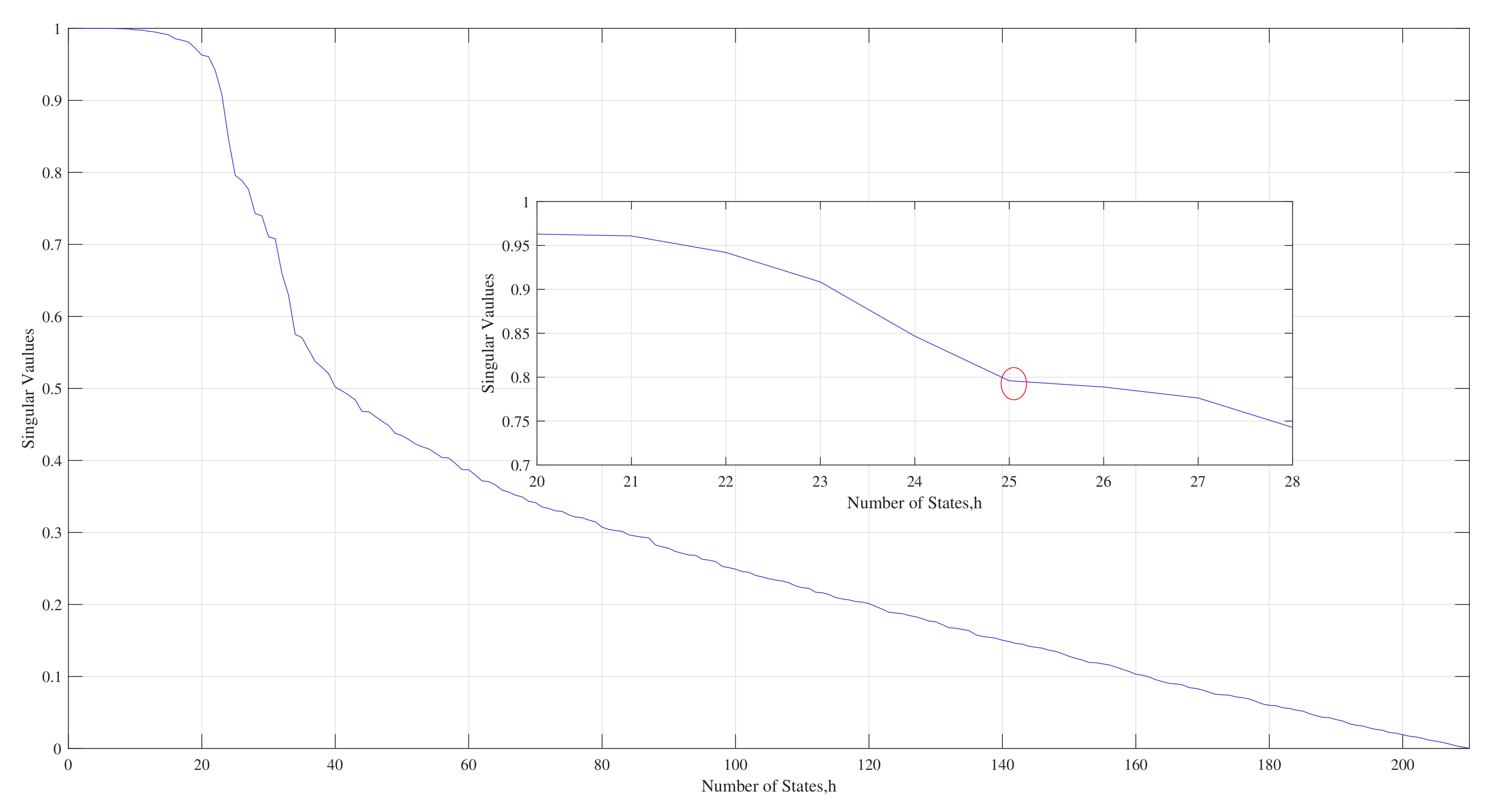
| 6. Determine h by the fastest descent method. |
| 7. Construct , and . |
| Online identification: |
| 1. Collect the monitoring data . |
| 2. Standardize data . |
| 3. Construct and . |
| 4. Calculate , |
| 5. Calculate . |
| 6. Calculate . |
| 7. Calculate . |
| 8. Calculate . |
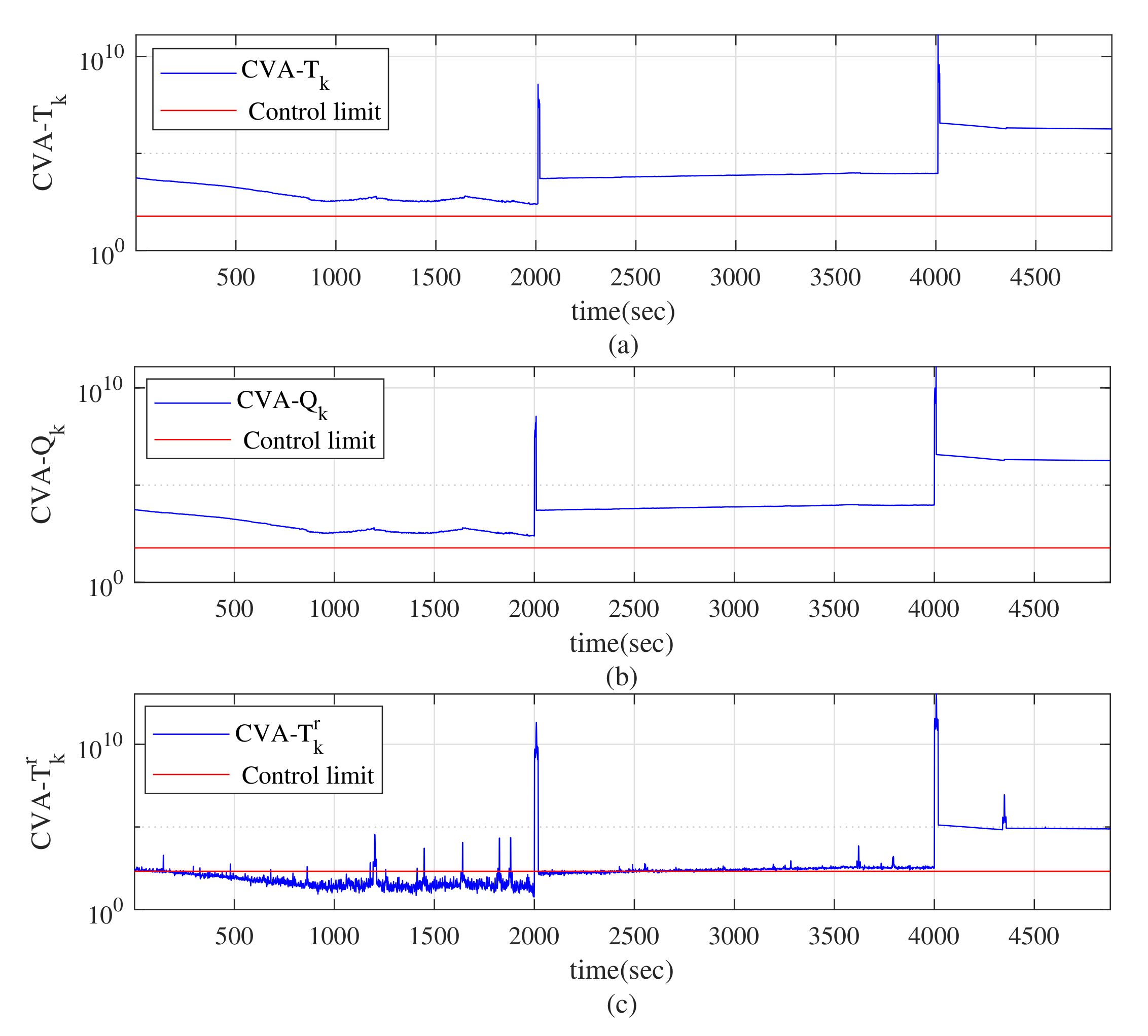
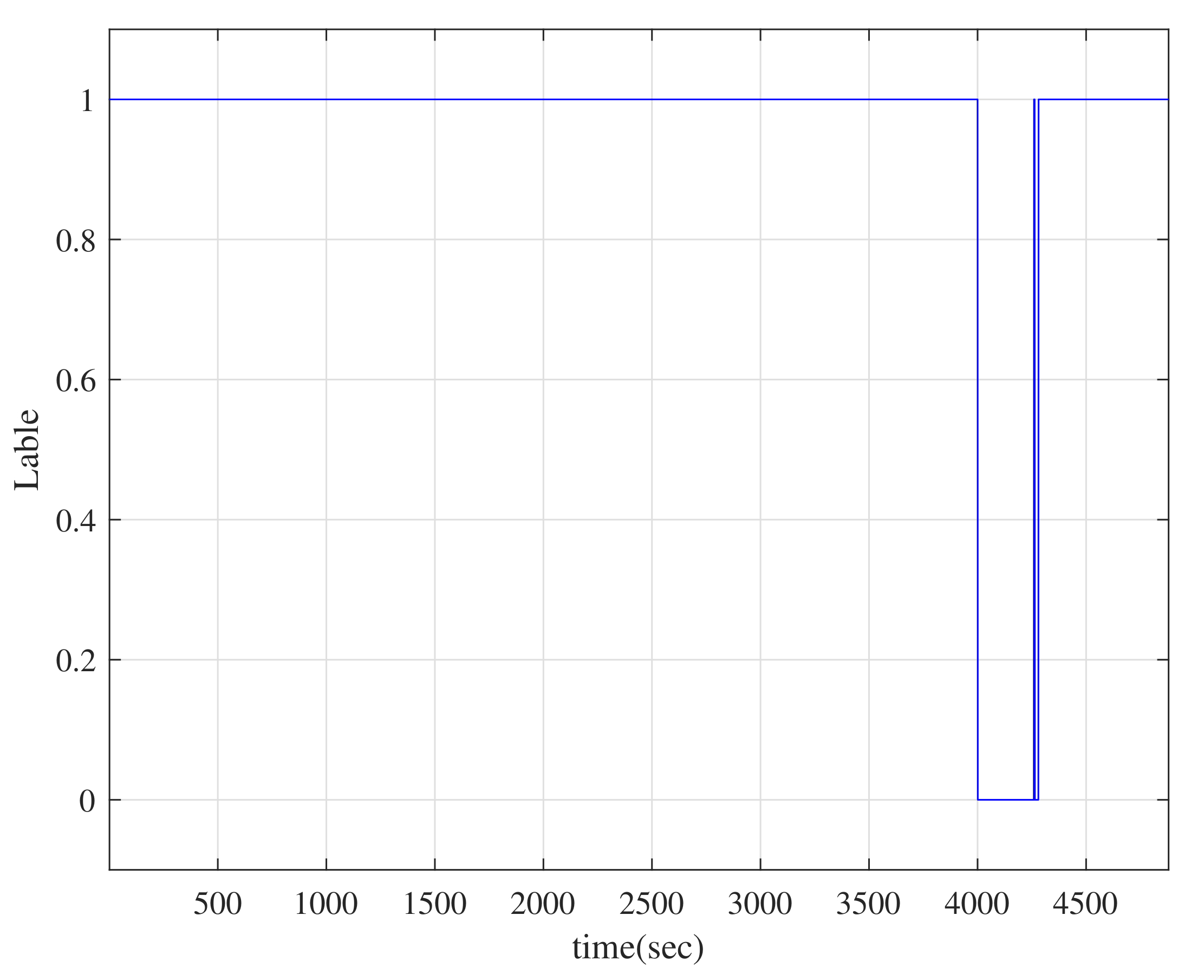
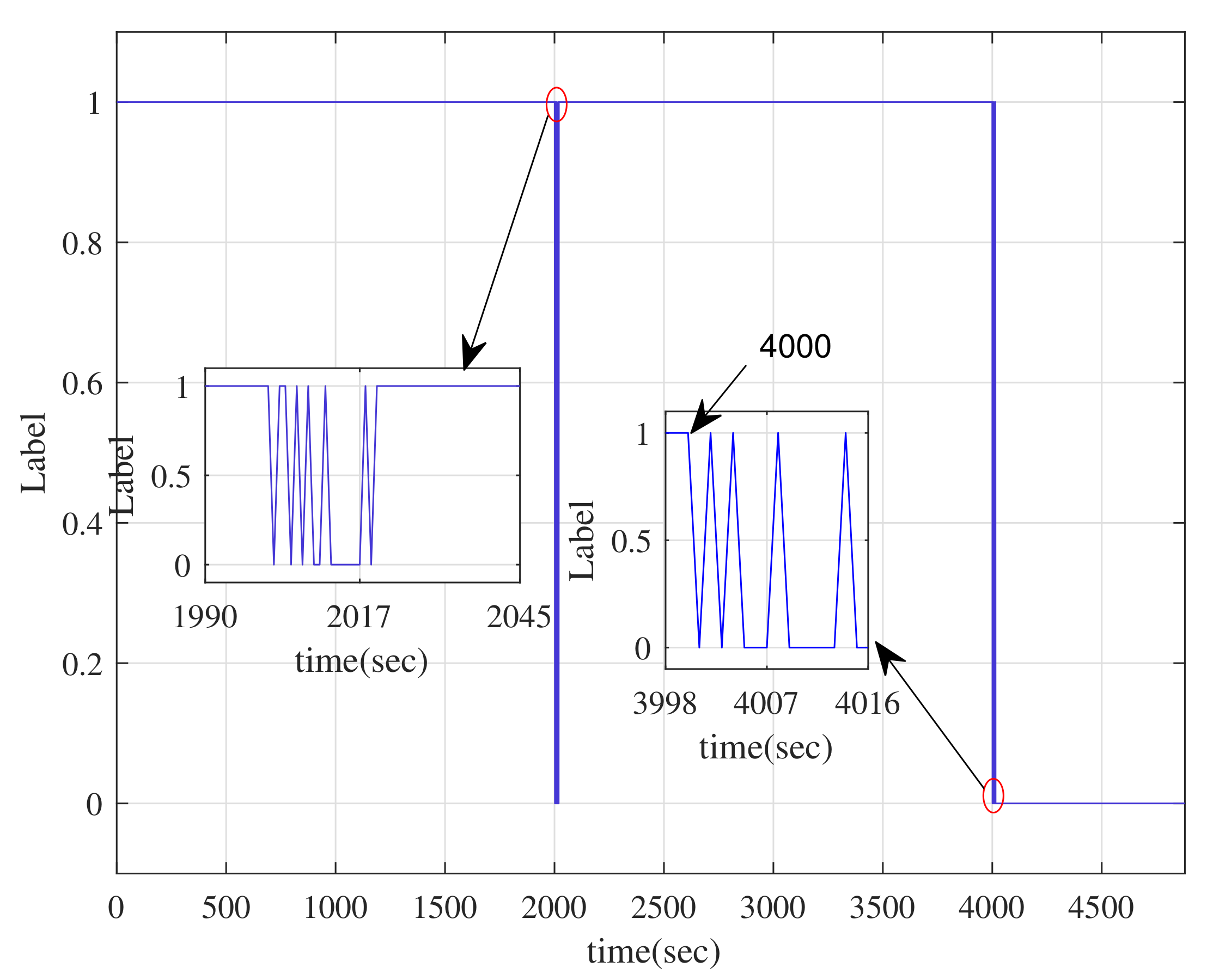
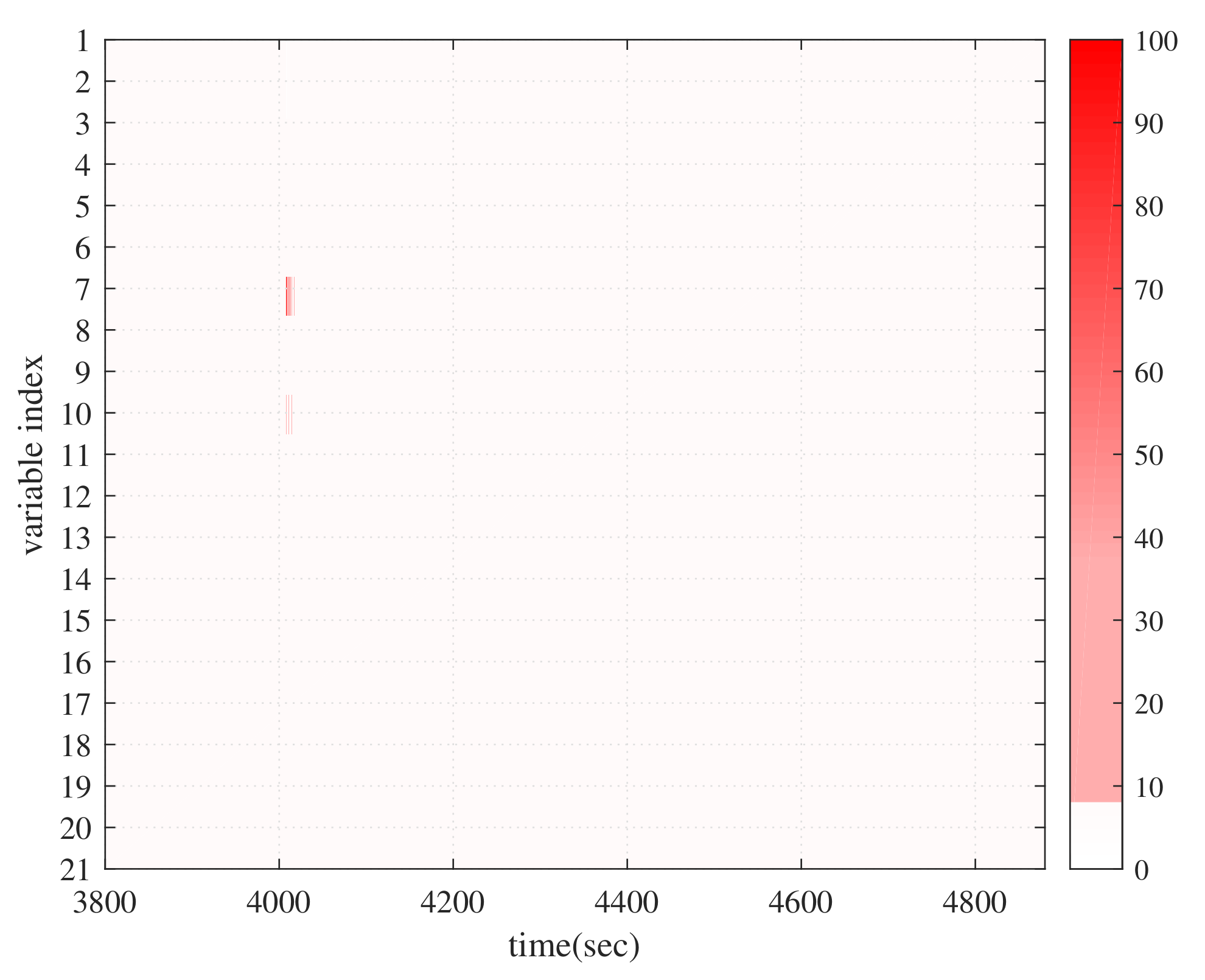
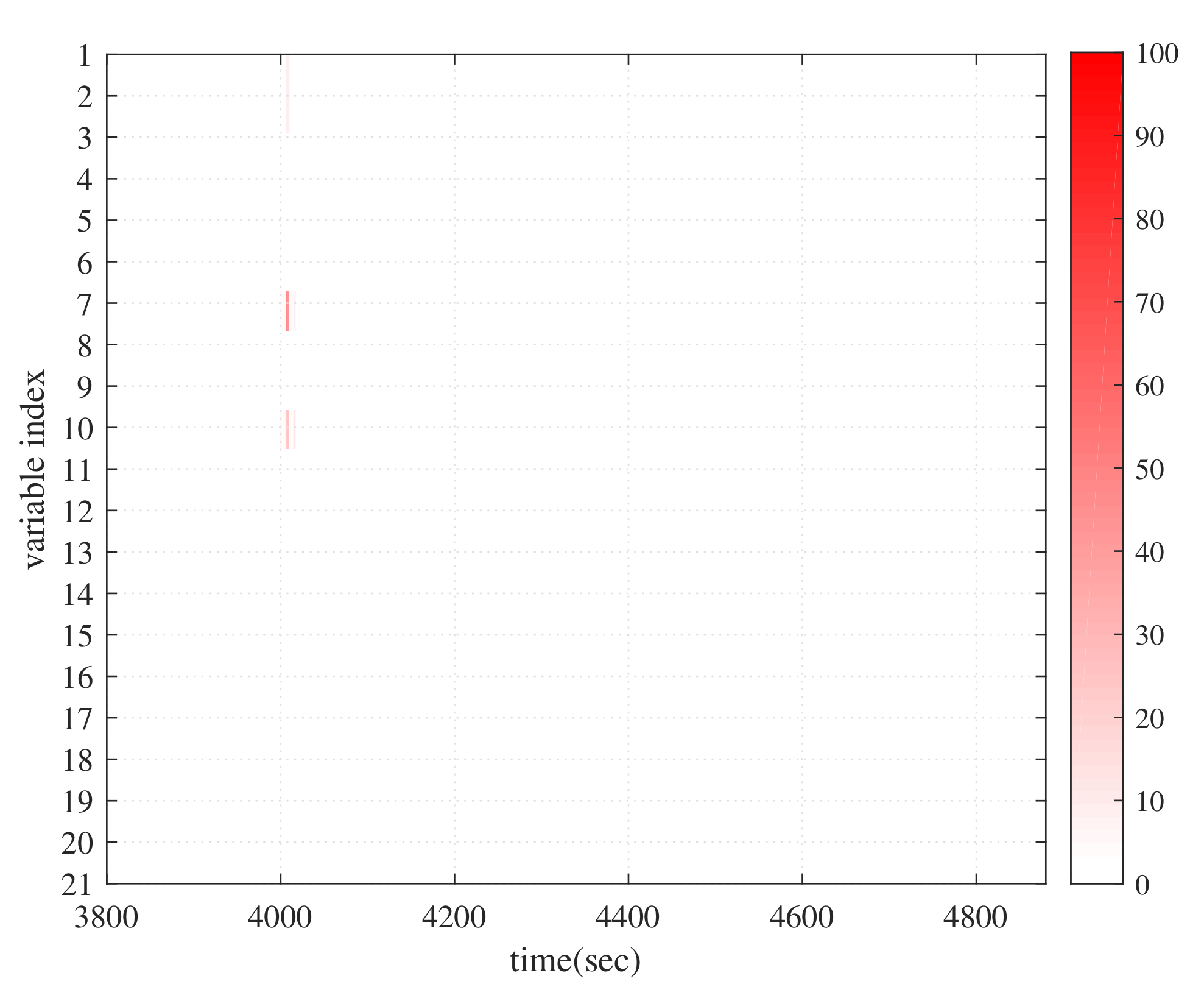
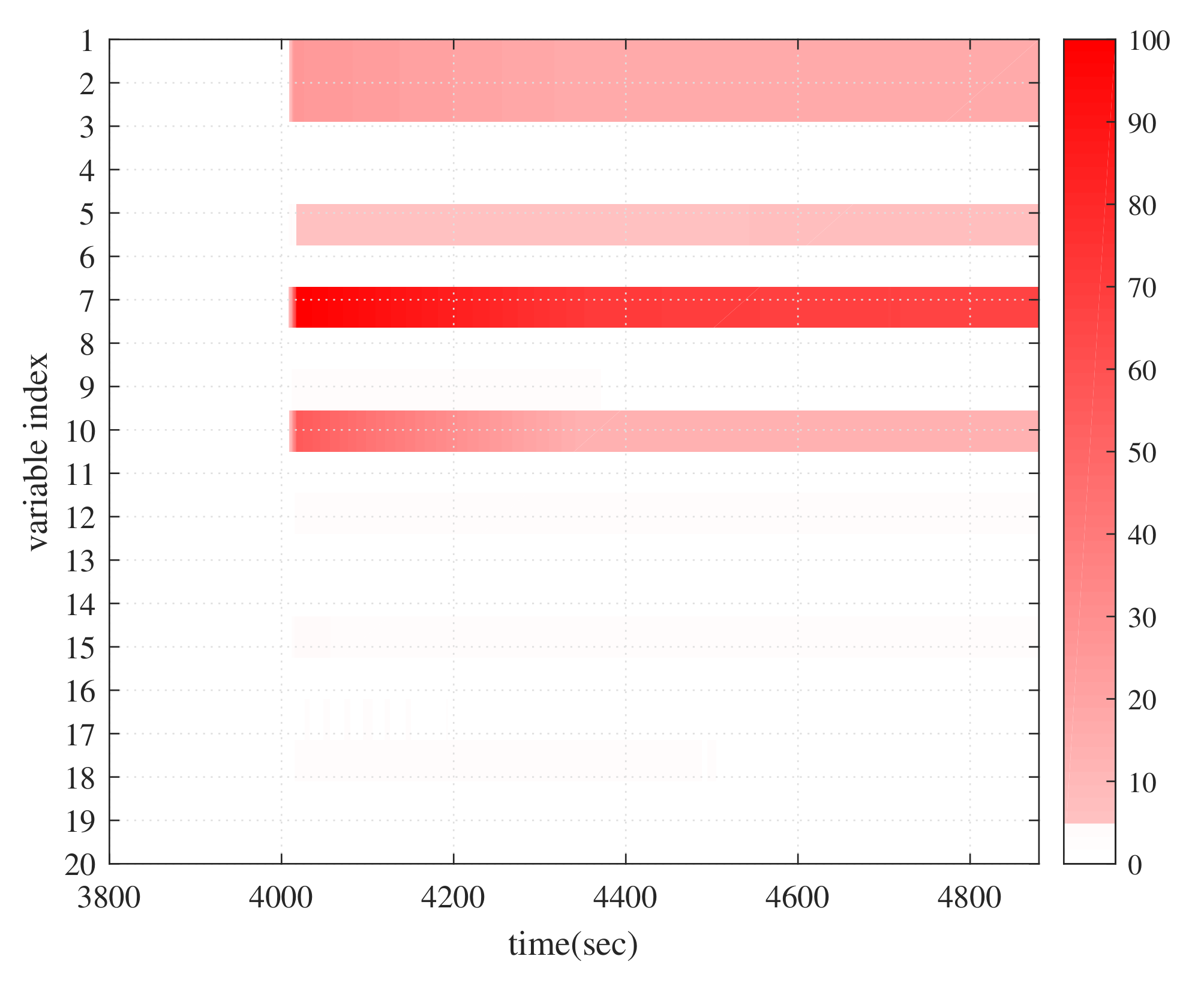
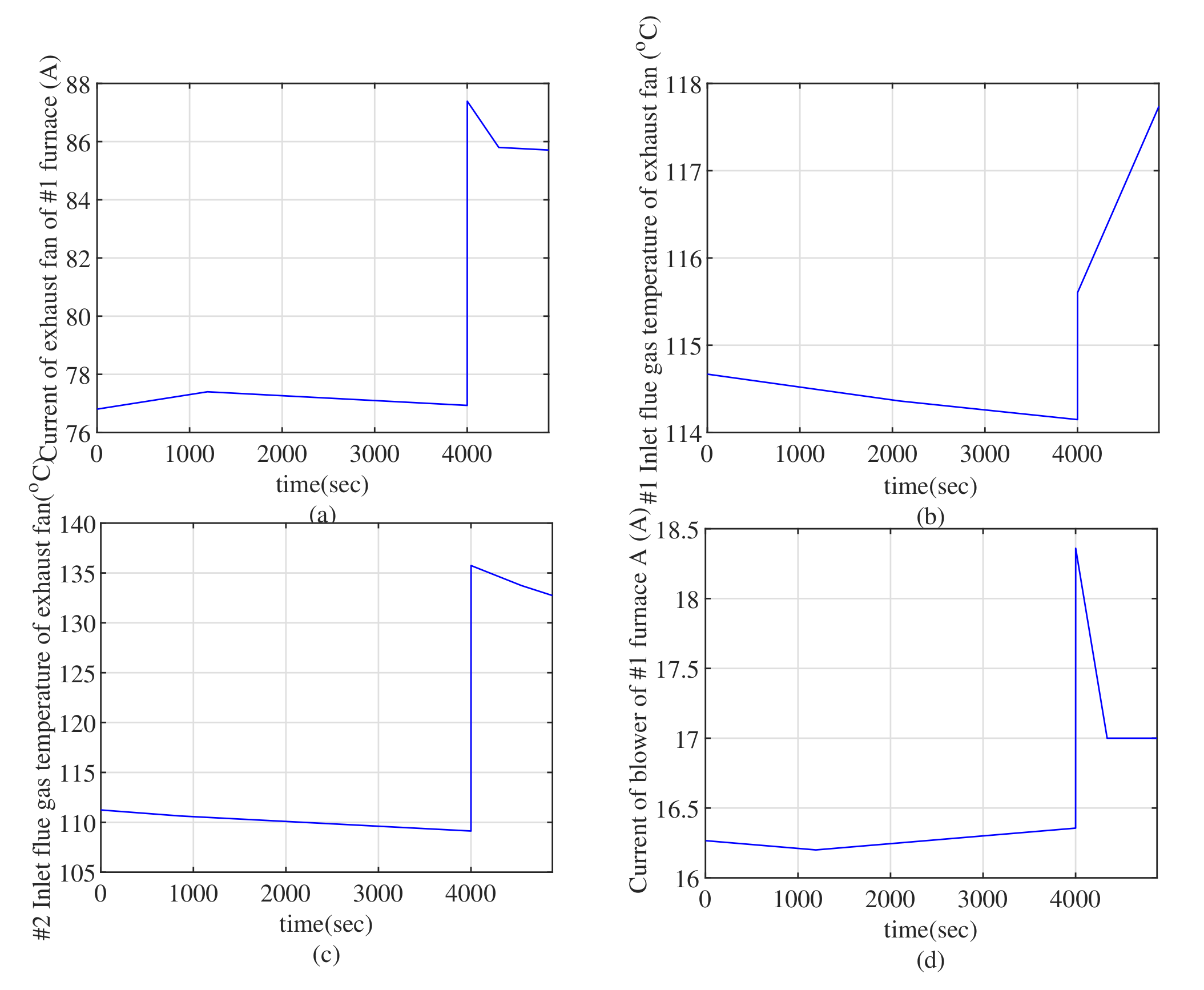
4. Application
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Khan, F.; Haddara, M.; Khalifa, M. Risk-based inspection and maintenance (RBIM) of power plants Thermal Power. In Plant Performance Analysis; Springer: London, UK, 2012; pp. 249–279. [Google Scholar]
- He, K.X.; Wang, T.; Zhang, F.K.; Jin, X. Anomaly detection and early warning via a novel multiblock-based method with applications to thermal power plants. Measurement 2022, 193, 110979. [Google Scholar] [CrossRef]
- Yu, J.; Jang, J.; Yoo, J.; Park, J.H.; Kim, S. A fault isolation method via classification and regression tree-based variable ranking for drum-type steam boiler in thermal power plant. Energies 2018, 11, 1142. [Google Scholar] [CrossRef]
- Shi, Y.H.; Wang, J.C.; Liu, Z.F. On-line monitoring of ash fouling and soot-blowing optimization for convective heat exchanger in coal-fired power plant boiler. Appl. Therm. Eng. 2015, 78, 39–50. [Google Scholar] [CrossRef]
- Agrawal, V.; Panigrahi, B.K.; Subbarao, P.M.V. Review of control and fault diagnosis methods applied to coal mills. J. Process. Control 2015, 32, 138–153. [Google Scholar] [CrossRef]
- Peng, X.; Ding, S.X.; Du, W.L.; Zhong, W.M.; Qian, F. Distributed process monitoring based on canonical correlation analysis with partly-connected topology. Control Eng. Pract. 2020, 101, 104500. [Google Scholar] [CrossRef]
- Forootan, M.M.; Larki, I.; Zahedi, R.; Ahmadi, A. Machine Learning and Deep Learning in Energy Systems: A Review. Sustainability 2022, 14, 4832. [Google Scholar] [CrossRef]
- Yu, K.J.; While, L.; Reynolds, M.; Liang, J.J.; Zhao, L.; Wang, Z.L. Multiobjective optimization of ethylene cracking furnace system using self-adaptive multiobjective teaching-learning-based optimization. Energy 2018, 148, 469–481. [Google Scholar] [CrossRef]
- Jagtap, H.P.; Bewoor, A.K. Use of analytic hierarchy process methodology for criticality analysis of thermal power plant equipments. Mater. Today Proc. 2017, 4, 1927–1936. [Google Scholar] [CrossRef]
- Li, W.; Peng, M.J.; Wang, Q.Z. False alarm reducing in PCA method for sensor fault detection in a nuclear power plant. Ann. Nucl. Energy 2018, 118, 131–139. [Google Scholar] [CrossRef]
- Li, W.; Peng, M.J.; Wang, Q.Z. Improved PCA method for sensor fault detection and isolation in a nuclear power plant. Nucl. Eng. Technol. 2019, 51, 146–154. [Google Scholar] [CrossRef]
- Qin, Y.H.; Lou, Z.J.; Wang, Y.Q.; Lu, S.; Sun, P. An analytical partial least squares method for process monitoring. Control Eng. Pract. 2022, 124, 105182. [Google Scholar] [CrossRef]
- Pilario, K.E.S.; Cao, Y. Canonical variate dissimilarity analysis for process incipient fault detection. IEEE Trans. Ind. Inform. 2018, 14, 5308–5315. [Google Scholar] [CrossRef]
- Chiang, L.H.; Kotanchek, M.E.; Kordon, A.K. Fault diagnosis based on Fisher discriminant analysis and support vector machines. Comput. Chem. Eng. 2004, 28, 1389–1401. [Google Scholar] [CrossRef]
- Jiang, Q.C.; Yan, X.F.; Huang, B. Review and perspectives of data-driven distributed monitoring for industrial plant-wide processes. Ind. Eng. Chem. Res. 2019, 58, 12899–12912. [Google Scholar] [CrossRef]
- Odgaard, P.F.; Bao, L.; Jorgensen, S.B. Observer and Data-Driven-Model-Based Fault Detection in Power Plant Coal Mills. IEEE Trans. Energy Convers. 2008, 23, 659–668. [Google Scholar] [CrossRef]
- Yu, Y.; Peng, M.; Wang, H.; Ma, Z. Multivariate Alarm Threshold Design Based on PCA. In International Congress and Workshop on Industrial AI; Springer: Cham, Switzerland, 2022. [Google Scholar] [CrossRef]
- Liu, G.J.; Gu, H.X.; Shen, X.C.; You, D.D. Bayesian long short-term memory model for fault early warning of nuclear power turbine. IEEE Access 2020, 8, 50801–50813. [Google Scholar] [CrossRef]
- Ajami, A.; Daneshvar, M. Data driven approach for fault detection and diagnosis of turbine in thermal power plant using Independent Component Analysis (ICA). Int. J. Electr. Power Energy Syst. 2012, 43, 728–735. [Google Scholar] [CrossRef]
- Li, D.; Hu, G.Q.; Spanos, C.J. A data-driven strategy for detection and diagnosis of building chiller faults using linear discriminant analysis. Energy Build. 2016, 128, 519–529. [Google Scholar] [CrossRef]
- Xia, Y.; Ding, Q.; Jing, N.; Tang, Y.; Jiang, A.; Jiangzhou, S. An enhanced fault detection method for centrifugal chillers using kernel density estimation based kernel entropy component analysis. Int. J. Refrig. 2021, 129, 290–300. [Google Scholar] [CrossRef]
- Kourti, T.; MacGregor, J.F. Multivariate SPC methods for process and product monitoring. J. Qual. Technol. 1996, 28, 409–428. [Google Scholar] [CrossRef]
- Alcala, C.F.; Qin, S.J. Reconstruction-based contribution for process monitoring. Automatica 2009, 45, 1593–1600. [Google Scholar] [CrossRef]
- Liu, J.L. Fault diagnosis using contribution plots without smearing effect on non-faulty variables. J. Process. Control. 2012, 22, 1609–1623. [Google Scholar] [CrossRef]
- Liu, J.L.; Chen, D.S. Fault isolation using modified contribution plots. Comput. Chem. Eng. 2014, 61, 9–19. [Google Scholar] [CrossRef]
- Tan, R.M.; Cao, Y. Deviation contribution plots of multivariate statistics. IEEE Trans. Ind. Inform. 2018, 15, 833–841. [Google Scholar] [CrossRef]
- Zhu, X.X.; Braatz, R.D. Two-dimensional contribution map for fault identification [focus on education]. IEEE Control Syst. Mag. 2014, 34, 72–77. [Google Scholar]
- Jiang, B.B.; Huang, D.X.; Zhu, X.X.; Yang, F.; Braatz, R.D. Canonical variate analysis-based contributions for fault identification. J. Process. Control 2015, 26, 17–25. [Google Scholar] [CrossRef]
- Li, X.C.; Yang, X.Y.; Yang, Y.J.; Bennett, L.; Collop, A.; Mba, D. Canonical variate residuals-based contribution map for slowly evolving faults. J. Process. Control 2019, 76, 87–97. [Google Scholar] [CrossRef]
- Rangel-Martinez, D.; Nigam, K.D.P.; Ricardez-Sandoval, L.A. Machine learning on sustainable energy: A review and outlook on renewable energy systems, catalysis, smart grid and energy storage. Chem. Eng. Res. Des. 2021, 174, 414–441. [Google Scholar] [CrossRef]
- Pirdashti, M.; Curteanu, S.; Kamangar, M.H.; Hassim, M.H.; Khatami, M.A. Artificial neural networks: Applications in chemical engineering. Rev. Chem. Eng. 2013, 29, 205–239. [Google Scholar] [CrossRef]
- Mahadevan, S.; Shah, S.L. Fault detection and diagnosis in process data using one-class support vector machines. J. Process Control 2009, 19, 1627–1639. [Google Scholar] [CrossRef]
- Chen, K.Y.; Chen, L.S.; Chen, M.C.; Lee, C.L. Using SVM based method for equipment fault detection in a thermal power plant. Comput. Ind. 2011, 62, 42–50. [Google Scholar] [CrossRef]
- Moradi, M.; Chaibakhsh, A.; Ramezani, A. An intelligent hybrid technique for fault detection and condition monitoring of a thermal power plant. Appl. Math. Model. 2018, 60, 34–47. [Google Scholar] [CrossRef]
- Deb, C.; Zhang, F.; Yang, J.J.; Lee, S.E.; Shah, K.W. A review on time series forecasting techniques for building energy consumption. Renew. Sustain. Energy Rev. 2017, 74, 902–924. [Google Scholar] [CrossRef]
- Wang, H.; Peng, M.J.; Hines, J.W.; Zheng, G.Y.; Liu, Y.K.; Upadhyaya, B.R. A hybrid fault diagnosis methodology with support vector machine and improved particle swarm optimization for nuclear power plants. ISA Trans. 2019, 95, 358–371. [Google Scholar] [CrossRef]
- Wang, Z.Y.; Yao, L.G.; Cai, Y.W.; Zhang, J. Mahalanobis semi-supervised mapping and beetle antennae search based support vector machine for wind turbine rolling bearings fault diagnosis. Renew. Energy 2020, 155, 1312–1327. [Google Scholar] [CrossRef]
- Chen, T.Q.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Xiang, C.; Ren, Z.J.; Shi, P.F.; Zhao, H.G. Data-Driven Fault Diagnosis for Rolling Bearing Based on DIT-FFT and XGBoost. Complexity 2021, 2021, 4941966. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Feng, Z.W.; Guan, N.; Lv, M.S.; Liu, W.C.; Deng, Q.X.; Liu, X.; Yi, W. Efficient drone hijacking detection using two-step GA-XGBoost. J. Syst. Archit. 2020, 103, 101694. [Google Scholar] [CrossRef]
- Zhang, D.H.; Qian, L.Y.; Mao, B.J.; Huang, C.; Si, Y.L. A Data-Driven Design for Fault Detection of Wind Turbines Using Random Forests and XGBoost. IEEE Access 2018, 6, 21020–21031. [Google Scholar] [CrossRef]
- Fitriah, N.; Wijaya, S.K.; Fanany, M.I. EEG channels reduction using PCA to increase XGBoost’s accuracy for stroke detection. AIP Conf. Proc. 2017, 1862, 030128. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Process Variables | Description |
|---|---|
| 1 | #1 exhaust fan blade opening |
| 2 | Current of exhaust fan of #1 furnace A (A) |
| 3 | #2 exhaust fan blade opening |
| 4 | Current of exhaust fan of #1 furnace B (A) |
| 5 | #1 inlet flue gas temperature of exhaust fan (°C) |
| 6 | #1 flue gas pressure at the outlet of dust collector (Pa) |
| 7 | #2 inlet flue gas temperature of exhaust fan (°C) |
| 8 | #2 flue gas pressure at the outlet of dust collector (Pa) |
| 9 | #1 blower blade opening |
| 10 | Current of blower of #1 furnace A (A) |
| 11 | #2 blower blade opening |
| 12 | Current of blower of #1 furnace B (A) |
| 13 | #1 furnace A primary fan current (A) |
| 14 | #1 furnace B primary fan current (A) |
| 15 | Side A steam header pressure (MPa) |
| 16 | Side A steam header temperature (°C) |
| 17 | Compensated blower outlet air volume (t/h) |
| 18 | Oxygen content of tail flue gas (%) |
| 19 | Furnace negative pressure (Pa) |
| 20 | Generator active power (MW) |
| 21 | main steam flow (t/h) |
| Method | I | I | Detection Time |
|---|---|---|---|
| CVA- | 1 | 1 | 3.330 s |
| CVA- | 1 | 1 | 3.307 s |
| CVA- | 1 | 0.4203 | 3.561 s |
| PCA-SVM | 0.3148 | 0 | 7.304 s |
| PLS-SVM | 0 | 0 | 8.403 s |
| CVA-GA-XGBoost | 0.9955 | 0.0030 | 3.481 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ling, D.; Li, C.; Wang, Y.; Zhang, P. Fault Detection and Identification of Furnace Negative Pressure System with CVA and GA-XGBoost. Energies 2022, 15, 6355. https://doi.org/10.3390/en15176355
Ling D, Li C, Wang Y, Zhang P. Fault Detection and Identification of Furnace Negative Pressure System with CVA and GA-XGBoost. Energies. 2022; 15(17):6355. https://doi.org/10.3390/en15176355
Chicago/Turabian StyleLing, Dan, Chaosong Li, Yan Wang, and Pengye Zhang. 2022. "Fault Detection and Identification of Furnace Negative Pressure System with CVA and GA-XGBoost" Energies 15, no. 17: 6355. https://doi.org/10.3390/en15176355
APA StyleLing, D., Li, C., Wang, Y., & Zhang, P. (2022). Fault Detection and Identification of Furnace Negative Pressure System with CVA and GA-XGBoost. Energies, 15(17), 6355. https://doi.org/10.3390/en15176355