
Modified Particle Swarm Optimization with Attention-Based LSTM for Wind Power Prediction

Abstract
:1. Introduction
2. Optimization Algorithm
2.1. Particle Swarm Optimization (PSO)
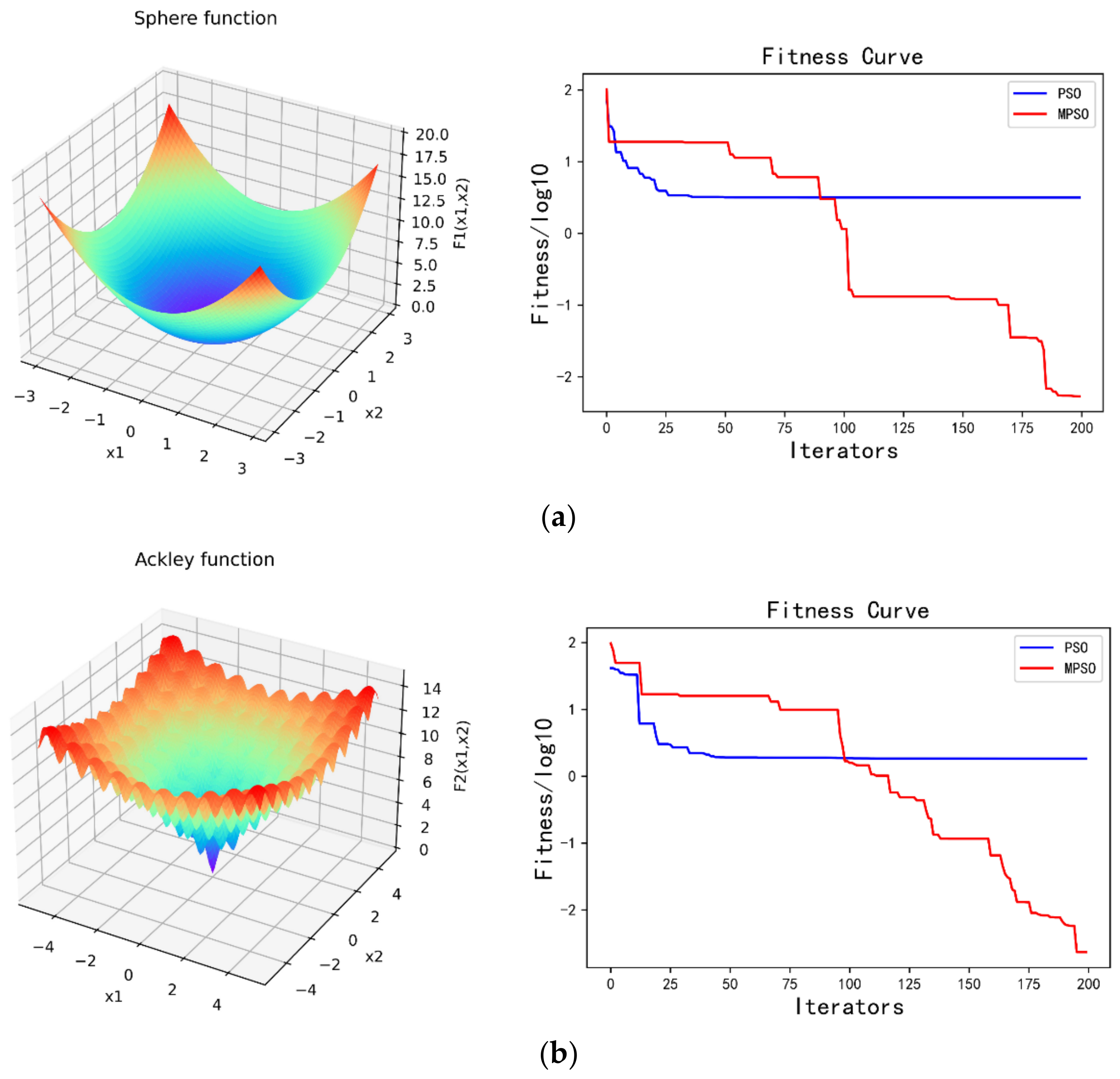
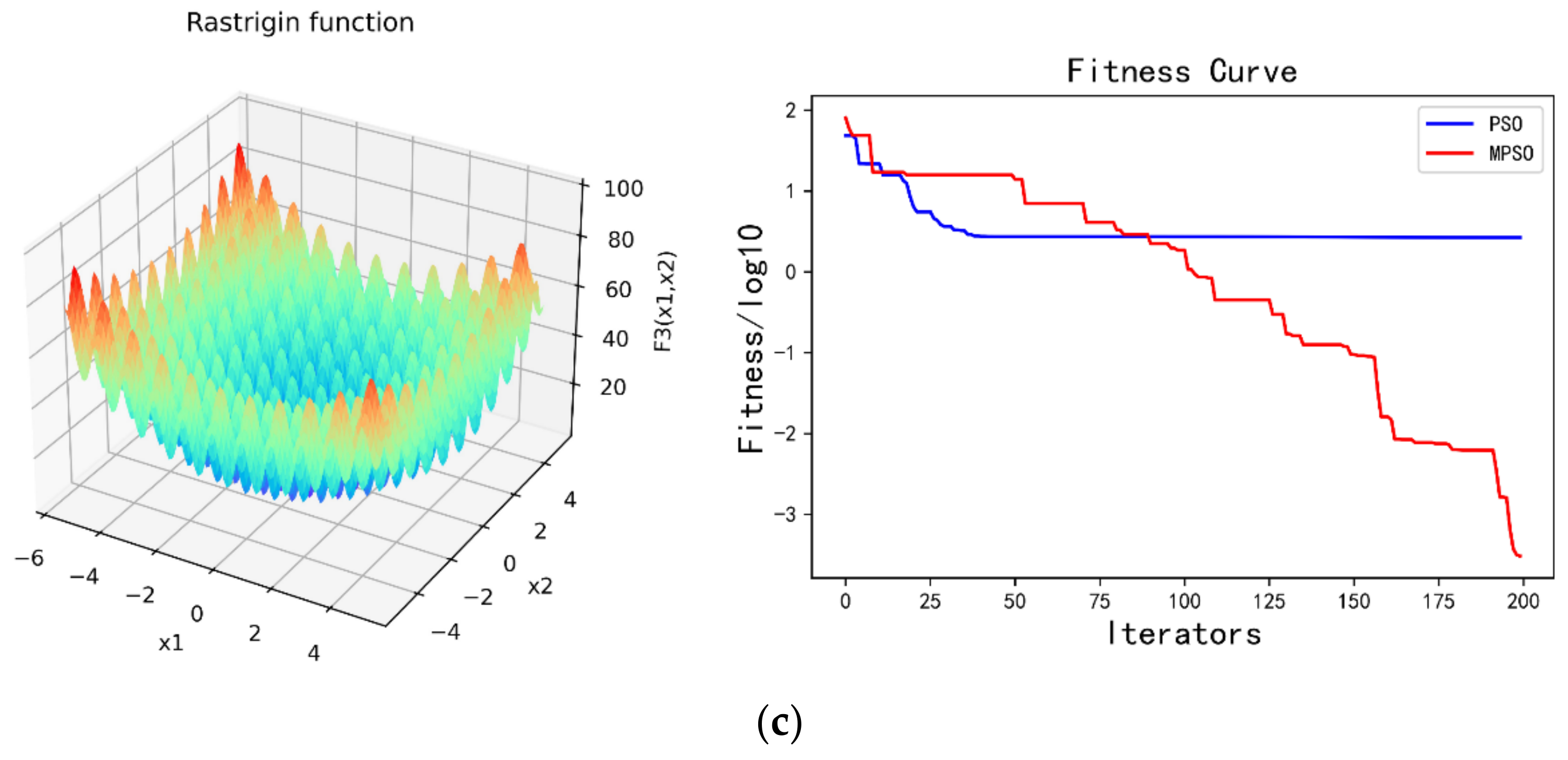
2.2. Modified Particle Swarm Optimization (MPSO)
3. LSTM Network Based on Attention Mechanism
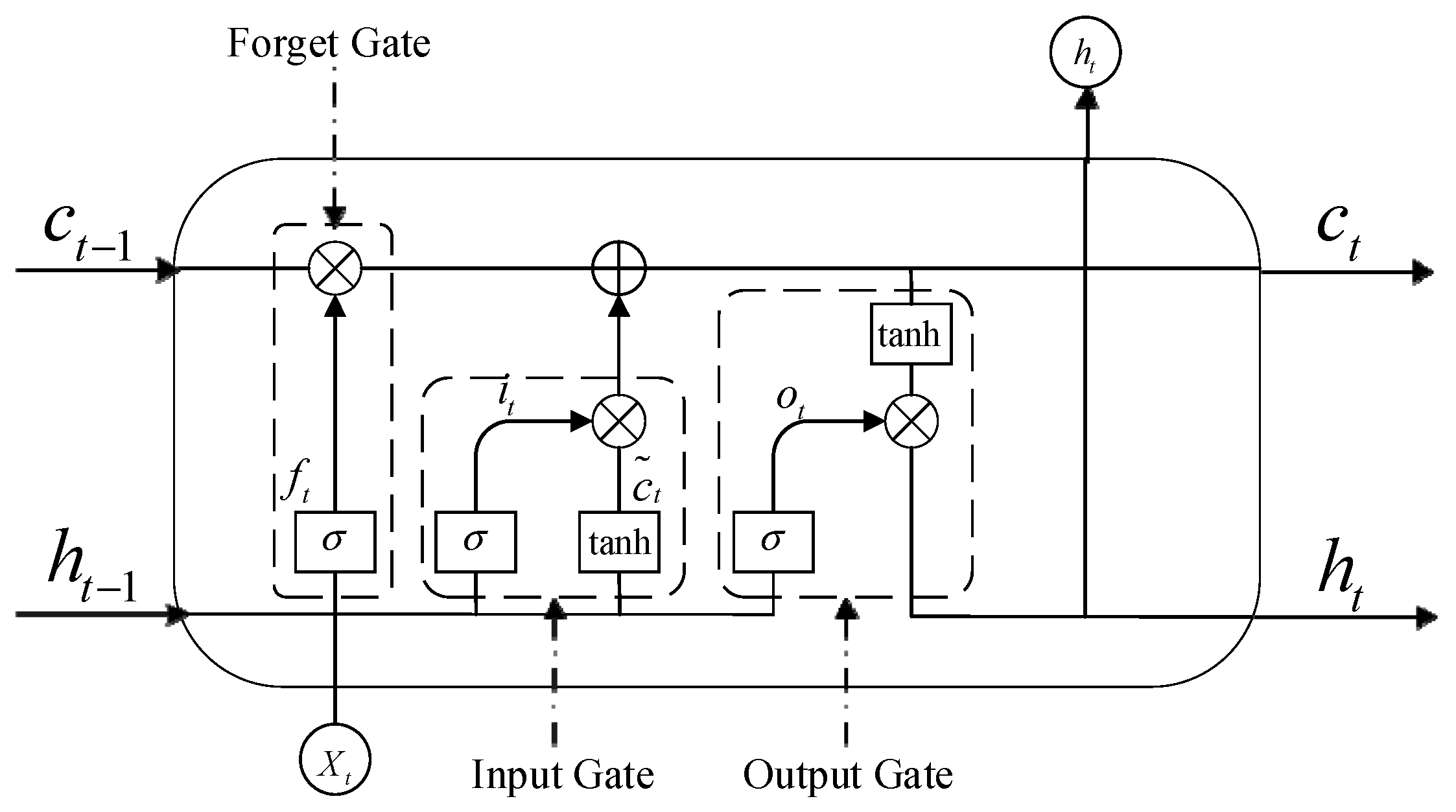
3.1. Standard LSTM Network
3.2. Attention Mechanism Model
3.2.1. Input Attention Mechanism
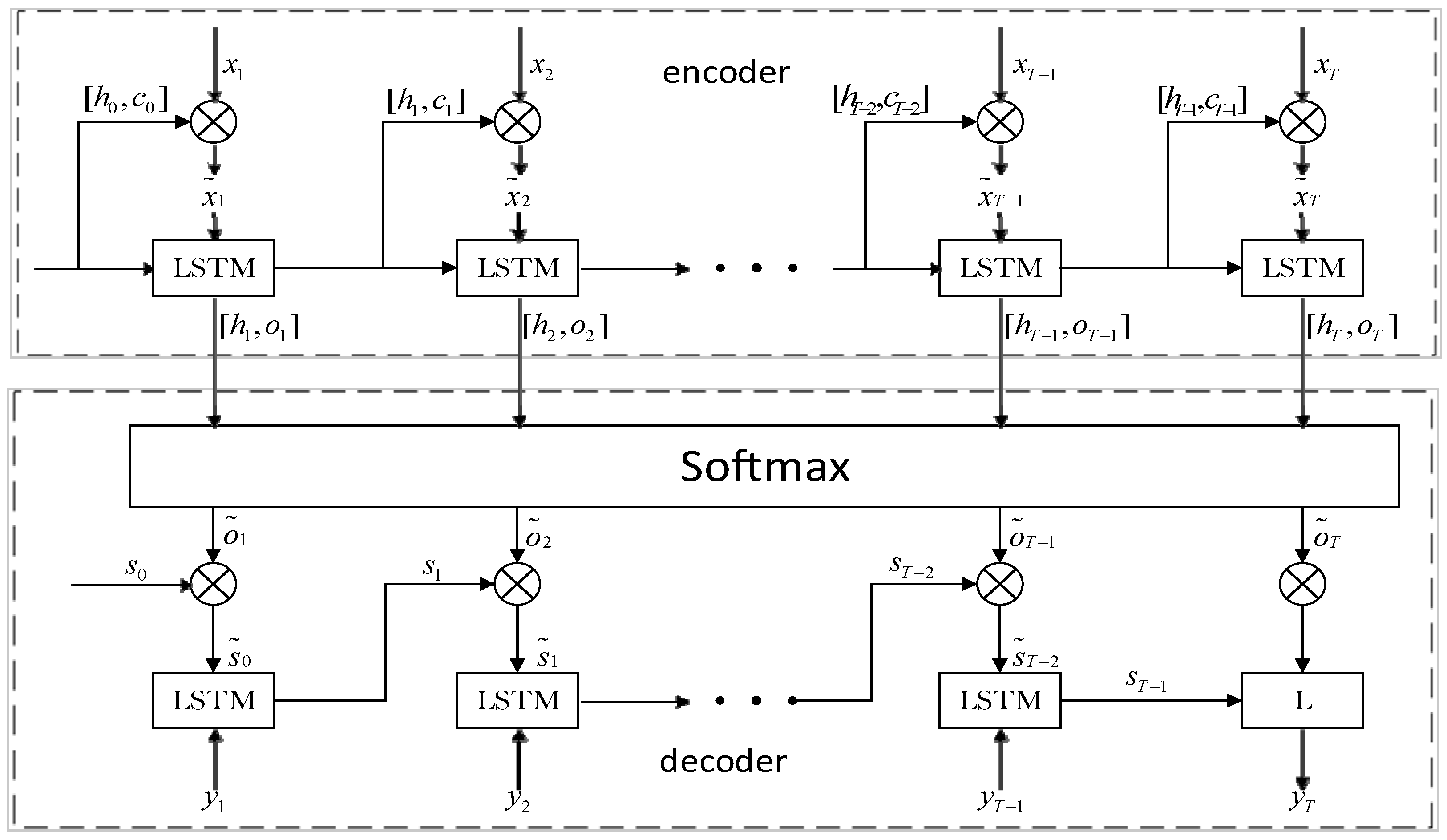
3.2.2. Similar Day Attention Mechanism
3.3. Hyperparameters on the Network
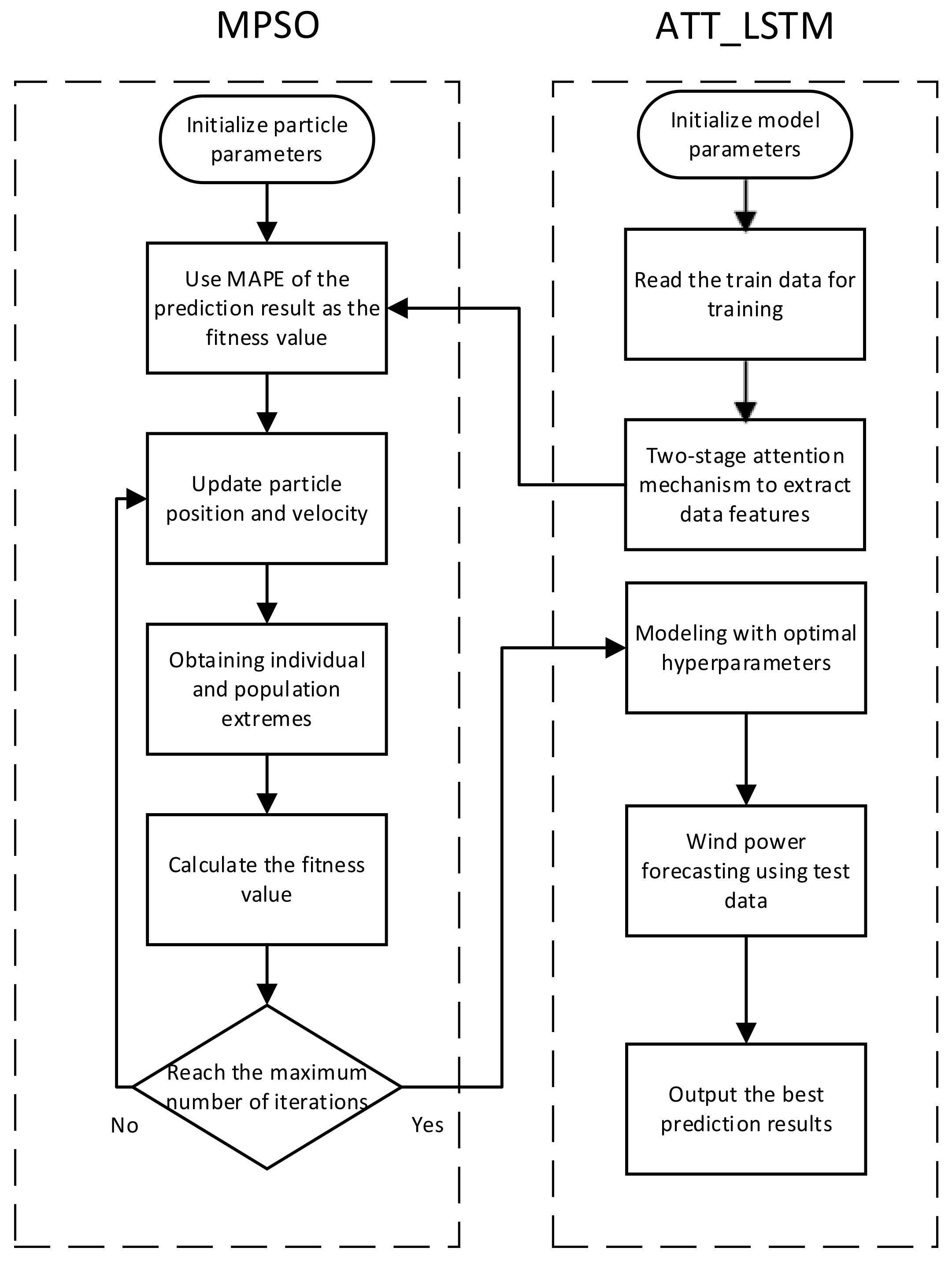
4. MPSO_ATT_LSTM Model
- Step 1:
- Pre-process the experimental data and slice the processed data into training data and test data.
- Step 2:
- Initialize the relevant parameters of the modified particle swarm optimization (MPSO). Set up the maximum number of iterations of the modified particle swarm algorithm, the maximum and minimum values of inertia weights and , the maximum and minimum values of individual particle learning rates and , the maximum and minimum values of population learning rates and , and the number of populations M. Set up the learning rate, the number of neurons in the first hidden layer and the second hidden layer, and the batch size in the LSTM model with the attention mechanism as the target optimization parameters of the improved particle swarm algorithm.
- Step 3:
- Form the corresponding particles and populations according to the parameters to be tuned, and construct the LSTM model with the attention mechanism with each particle corresponding to the initial parameters. Training is performed through the training data. As the fitness value of each particle, the mean absolute percent error (MAPE) of the results is used.
- Step 4:
- Real-time update individual particles and population optimal particle positions according to the MPSO algorithm.
- Step 5:
- Repeat the iterations until the maximum number of iterations is exceeded. Return the particle parameter corresponding to the best fitness and determine the value of the LSTM hyperparameter with the attention mechanism. Otherwise, return to step 4.
- Step 6:
- Substitute the obtained hyperparameters for the LSTM model with the attention mechanism. Wind power prediction has been performed on the test data.
5. Experiment
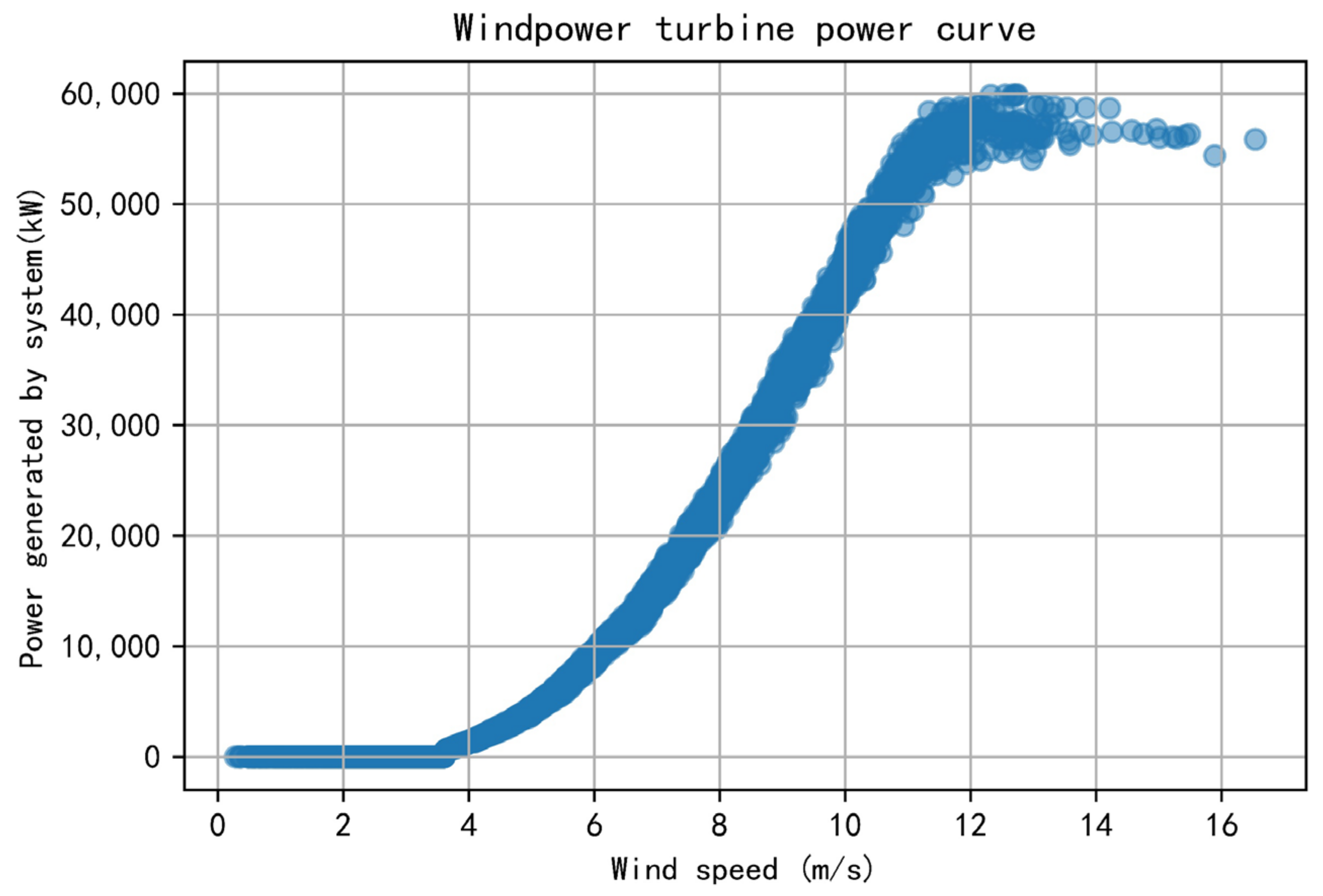
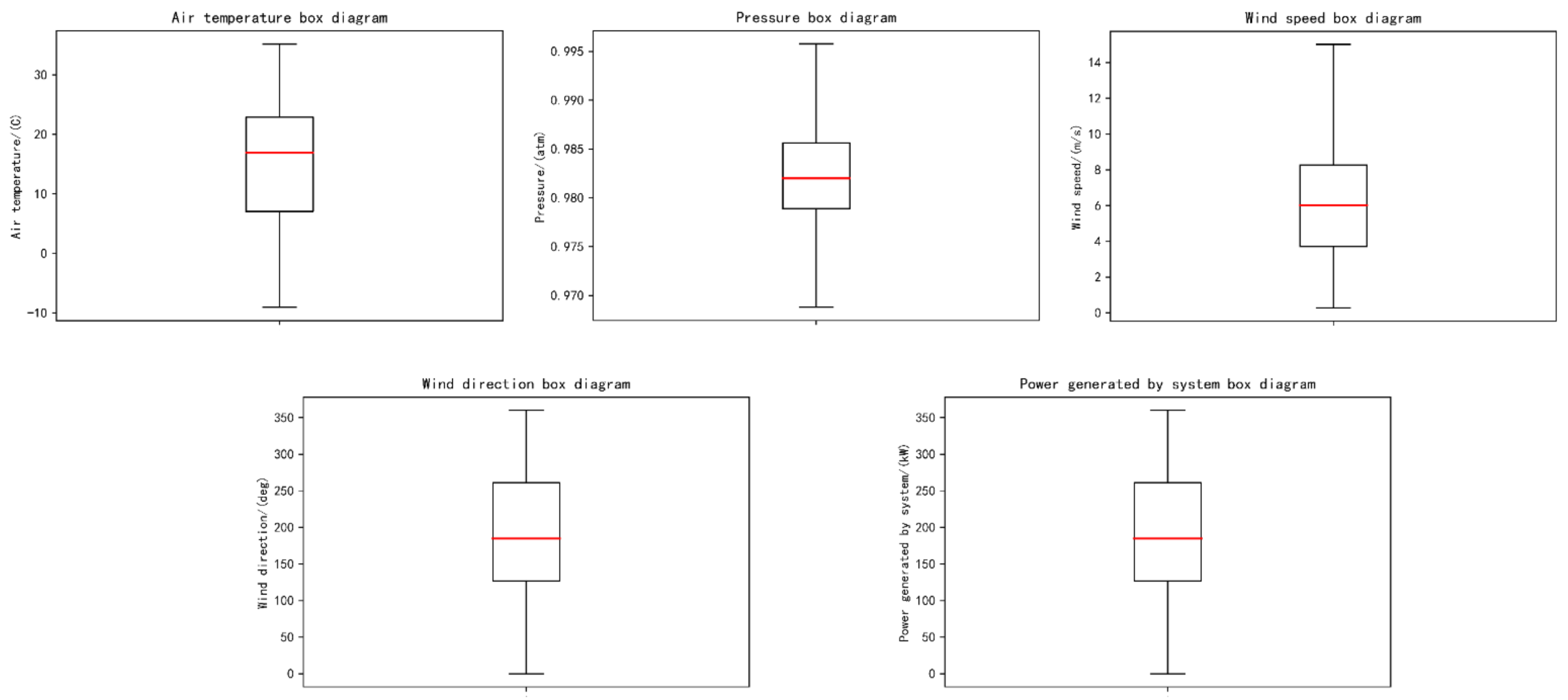
5.1. Dataset Description
- (1)
- Data cleaning: The original dataset contains some illogical or absent values. For instance, values of wind speed less than zero must be eliminated, and the missing values are filled with the mean of the upper and lower moments.
- (2)
- Data processing: Due to the fact that dataset has various units and orders of magnitude, the dataset is not comparable; they are standardized and normalized in advance. The wind direction takes values in the range of [0°, 360°]. Consequently, the wind direction data are converted to its sine and cosine values as the characteristics. Then, the transformed values are normalized to [−1, 1].
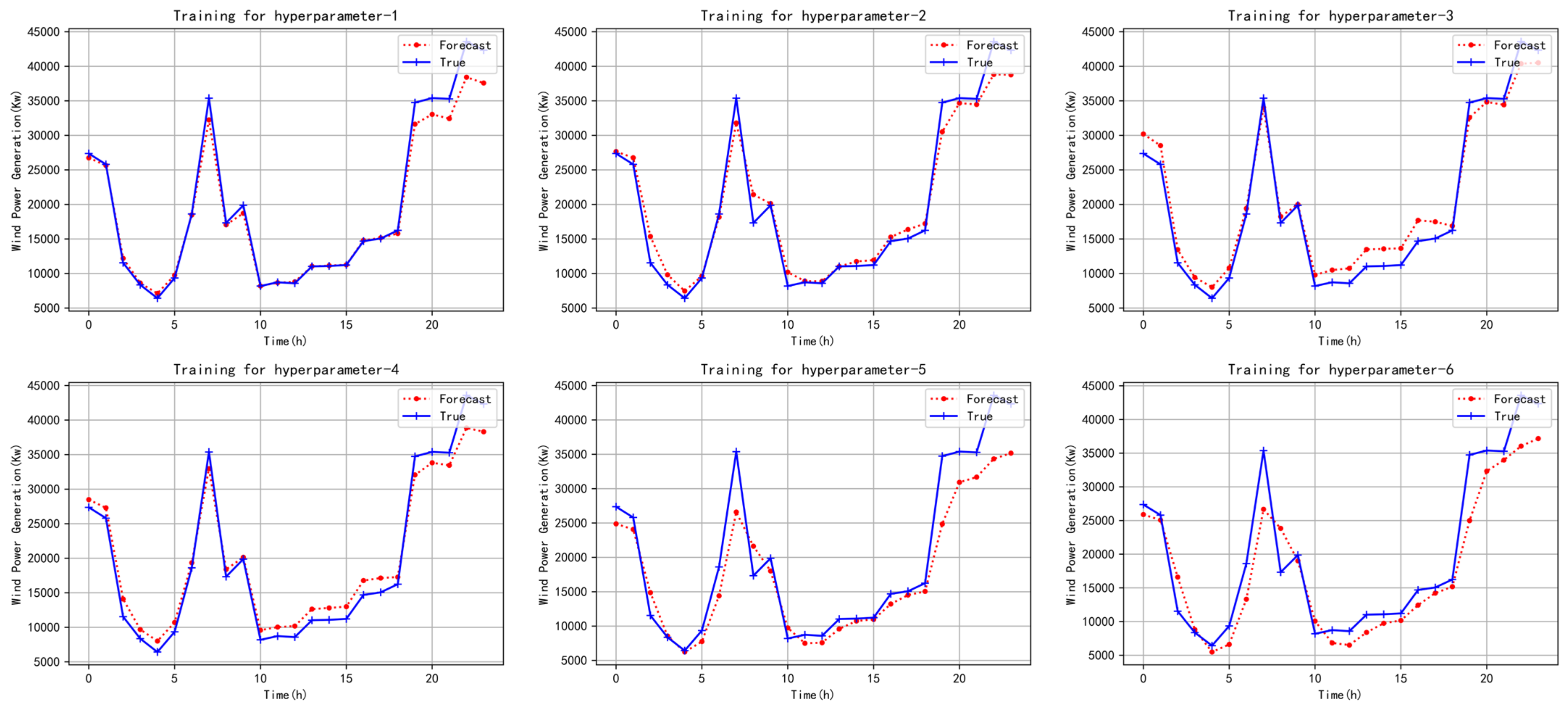
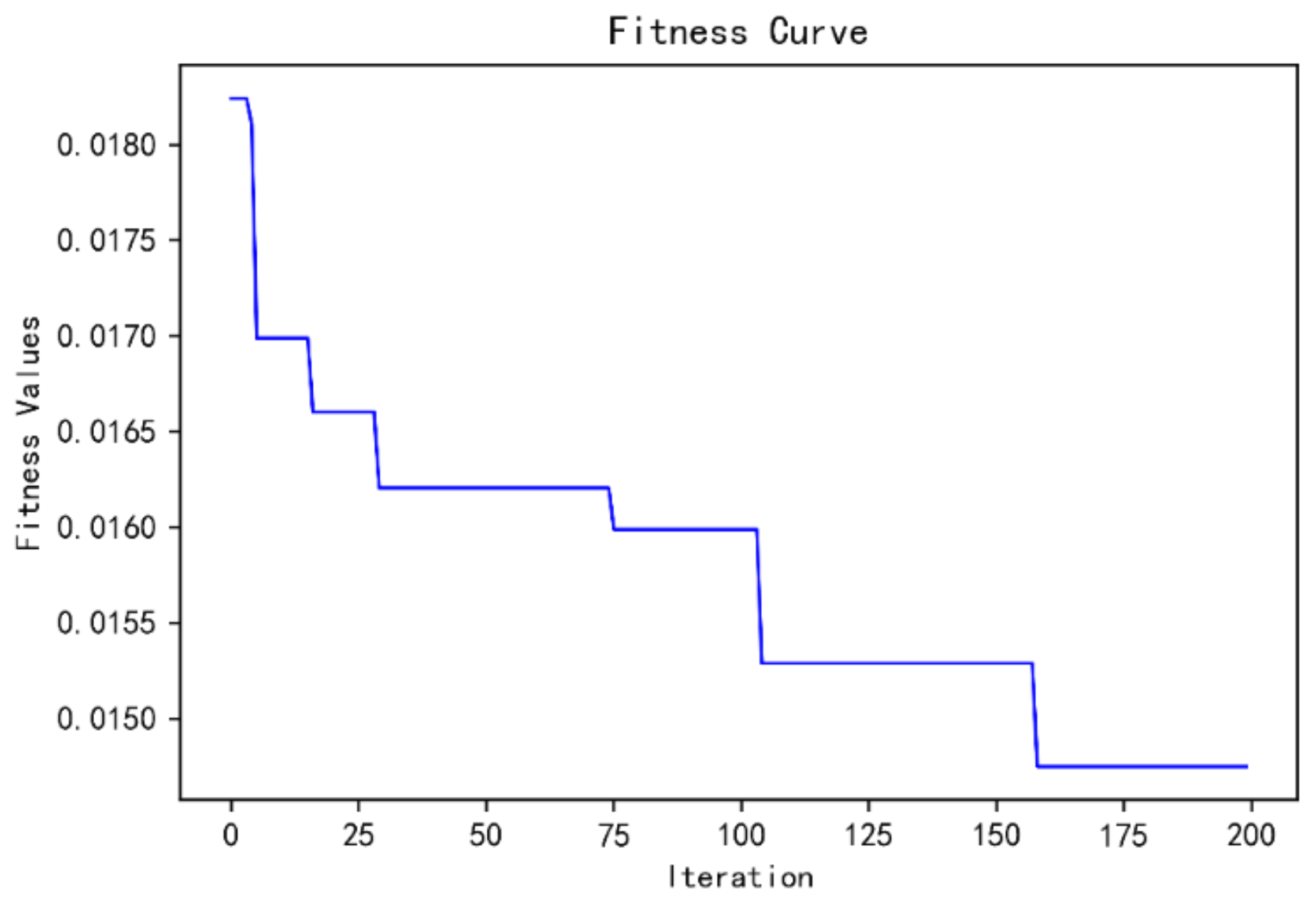
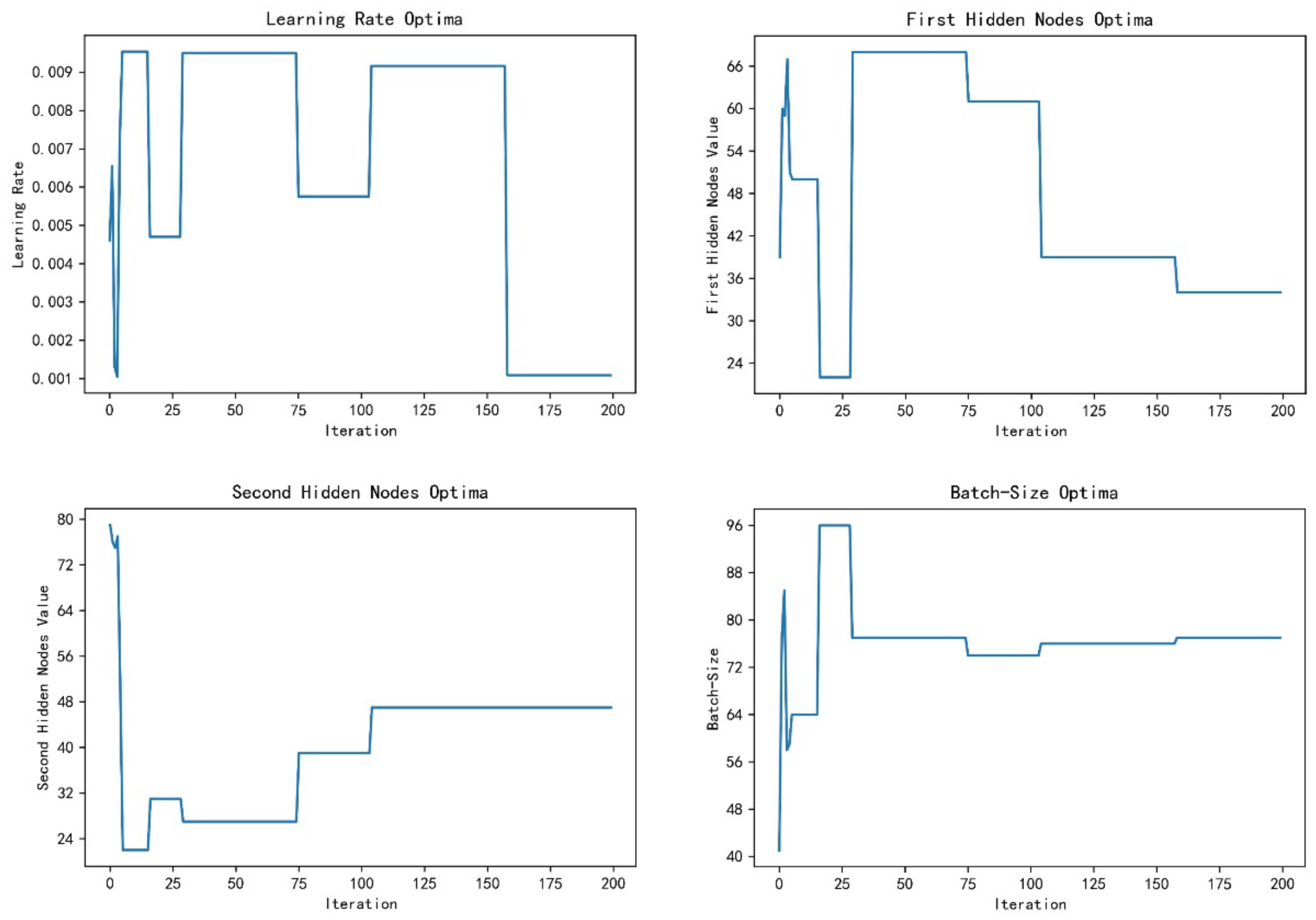
5.2. Training Process
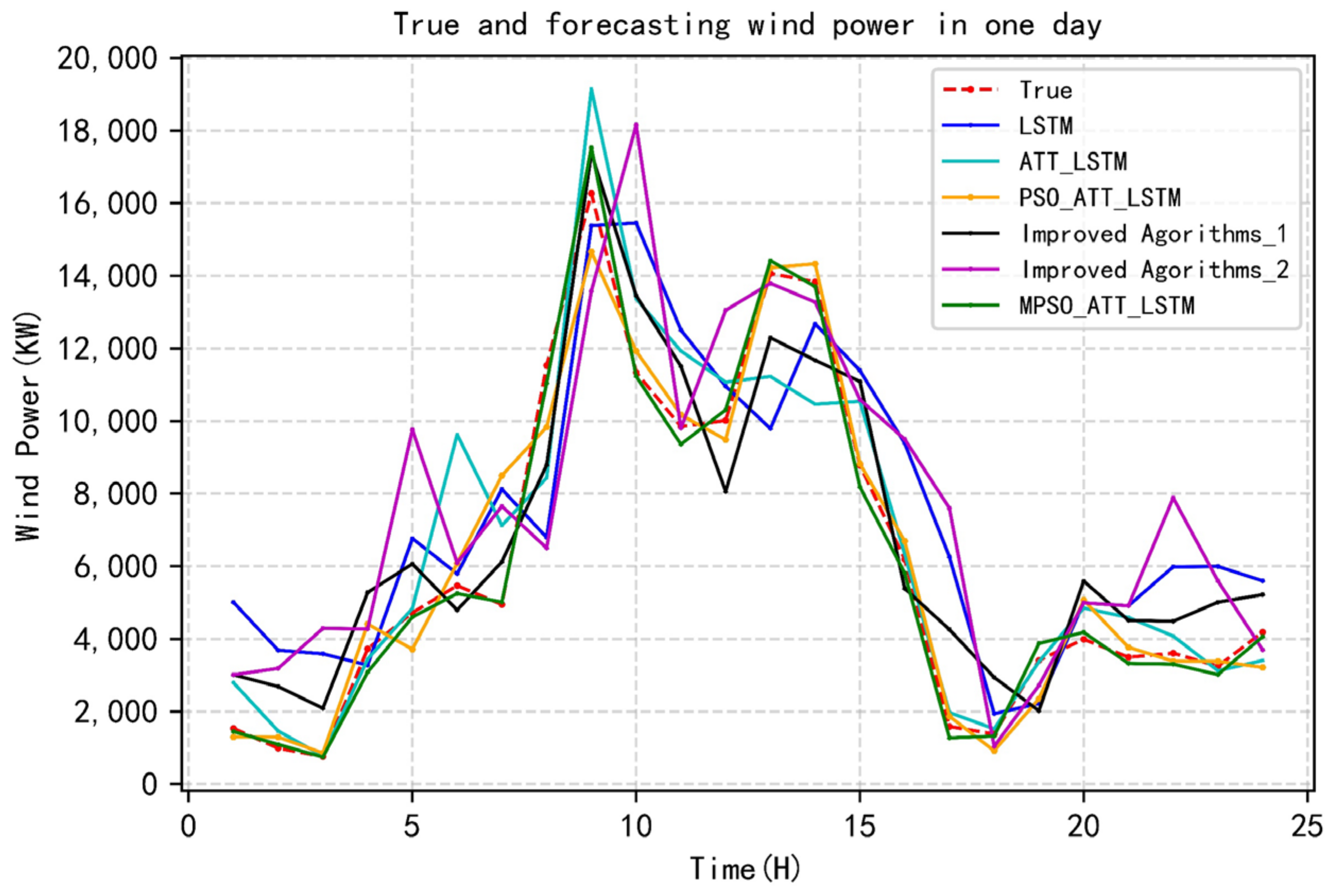
5.3. Wind Power Forecasting Assessment
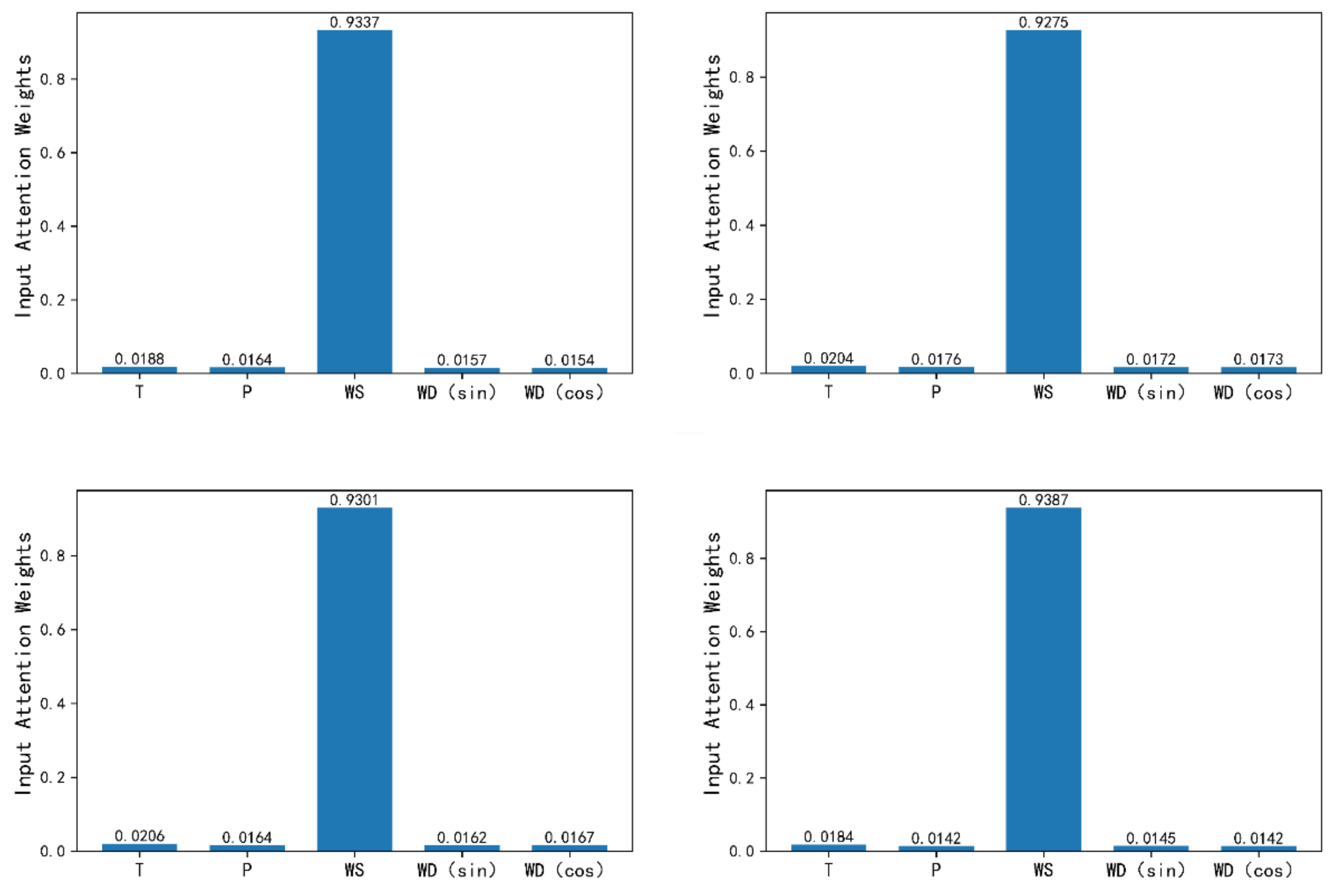
5.4. Two-Stage Attention Mechanism Explanation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gu, B.; Zhang, T.; Meng, H.; Zhang, J. Short-term forecasting and uncertainty analysis of wind power based on long short-term memory, cloud model and non-parametric kernel density estimation. Renew. Energy 2021, 164, 687–708. [Google Scholar] [CrossRef]
- Xue, F.; Duan, H.; Xu, C.; Han, X.; Shangguan, Y.; Li, T.; Fen, Z. Research on the Power Capture and Wake Characteristics of a Wind Turbine Based on a Modified Actuator Line Model. Energies 2022, 15, 282. [Google Scholar] [CrossRef]
- Ma, Y.-J.; Zhai, M.-Y. A Dual-Step Integrated Machine Learning Model for 24 h-Ahead Wind Energy Gneration Prediction Based on Actual Measurement Data and Environmental Factors. Appl. Sci. 2019, 9, 2125. [Google Scholar]
- Donadio, L.; Fang, J.; Porté-Agel, F. Numerical Weather Prediction and Artificial Neural Network Coupling for Wind Energy Forecast. Energies 2021, 14, 338. [Google Scholar] [CrossRef]
- Carvalho, D.; Rocha, A.; Gómez-Gesteira, M.; Santos, C. A sensitivity study of the WRF model in wind simulation for an area of high wind energy. Environ. Model. Softw. 2012, 33, 23–34. [Google Scholar] [CrossRef] [Green Version]
- Kumar, A.S.; Cermak, T.; Misak, S. Short-term wind power plant predicting with artificial neural network. In Proceedings of the 16th International Scientific Conference on Electric Power Engineering (EPE), Koutynad Desnou, Czech Republic, 20–22 May 2015; pp. 548–588. [Google Scholar]
- Kusiak, A.; Zheng, H.; Song, Z. Short-term prediction of wind farm power: A data mining approach. IEEE Trans. Energy Convers. 2009, 24, 125–136. [Google Scholar] [CrossRef]
- Fan, G.; Wang, W.; Liu, C.; Dai, H. Wind power prediction based on artificial neural network. Proc. CSEE 2008, 28, 118–123. [Google Scholar]
- Hu, Q. Impact of large-scale wind power access on grid dispatching operation. Sci. Technol. Wind. 2018, 14, 168. [Google Scholar]
- Xu, Q.; He, D.; Zhang, N.; Kang, C.; Xia, Q.; Bai, J.; Huang, J. A short-term wind power forecasting approach with adjustment of numerical weather prediction input by data mining. IEEE Trans. Sustain. Energy 2015, 6, 1283–1291. [Google Scholar] [CrossRef]
- Hu, Q.; Zhang, R.; Zhou, Y. Transfer learning for short-term wind speed prediction with deep neural networks. Renew. Energy 2016, 85, 83–95. [Google Scholar] [CrossRef]
- Khodayar, M.; Wang, J.; Manthouri, M. Interval Deep Generative Neural Network for Wind Speed Forecasting. IEEE Trans. Smart Grid 2019, 10, 3974–3989. [Google Scholar] [CrossRef]
- Bouktif, S.; Fiaz, A.; Ouni, A.; Serhani, M. Single and multi-sequence deep learning models for short and medium term electric load forecasting. Energies 2019, 12, 149. [Google Scholar] [CrossRef] [Green Version]
- Song, H.; Dai, J.; Luo, L.; Sheng, G.; Jiang, X. Power transformer operating state prediction method based on an LSTM network. Energies 2018, 11, 914. [Google Scholar] [CrossRef] [Green Version]
- Gundu, V.; Simon, S.P. PSO–LSTM for short term forecast of heterogeneous time series electricity price signals. J. Ambient. Intell. Hum. Comput. 2021, 12, 2375–2385. [Google Scholar] [CrossRef]
- Son, N.; Yang, S.; Na, J. Hybrid Forecasting Model for Short-Term Wind Power Prediction Using Modified Long Short-Term Memory. Energies 2019, 12, 3901. [Google Scholar] [CrossRef] [Green Version]
- Viet, D.T.; Phuong, V.V.; Duong, M.Q.; Tran, Q.T. Models for Short-Term Wind Power Forecasting Based on Improved Artificial Neural Network Using Particle Swarm Optimization and Genetic Algorithms. Energies 2020, 13, 2873. [Google Scholar] [CrossRef]
- Bouktif, S.; Fiaz, A.; Ouni, A.; Serhani, M.A. Multi-Sequence LSTM-RNN Deep Learning and Metaheuristics for Electric Load Forecasting. Energies 2020, 13, 391. [Google Scholar] [CrossRef] [Green Version]
- Zou, Y.; Feng, W.; Zhang, J.; Li, J. Forecasting of Short-Term Load Using the MFF-SAM- GCN Model. Energies 2022, 15, 3140. [Google Scholar] [CrossRef]
- Zhu, A.; Zhao, Q.; Wang, X.; Zhou, L. Ultra-Short-Term Wind Power Combined Prediction Based on Complementary Ensemble Empirical Mode Decomposition, Whale Optimisation Algorithm, and Elman Network. Energies 2022, 15, 3055. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Liu, X.; Yin, G. Risk Evaluation of Major Hazardous Sources Based on Improved PSO-LSTM School of Computer Science; Beihua Institute of Aerospace Technology: Langfang, China, 2021. [Google Scholar]
- Viet, D.T.; Tuan, T.Q.; Van Phuong, V. Optimal placement and sizing of wind farm in Vietnamese power system based on particle swarm optimization. In Proceedings of the 2019 International Conference on System Science and Engineering (ICSSE), Dong Hoi City, Vietnam, 19–21 July 2019; pp. 190–195. [Google Scholar]
- Kennedy, J.; Eberhart, R.C. A discrete binary version of the particle swarm algorithm. In Proceedings of the Computational Cybernetics and Simulation 1997 IEEE International Conference on Systems, Man, and Cybernetics, Orlando, FL, USA, 12–15 October 1997; Volume 5, pp. 4104–4108. [Google Scholar]
- Khalil, T.M.; Gorpinich, A.V. Selective particle swarm optimization. Int. J. Multidiscip. Sci. Eng. 2012, 3, 2045–7057. [Google Scholar]
- Bengio, Y.; Simrd, P.; Frasconi, P. Learning long-term dependencies withgradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Guan, L.; Hou, C.; Han, H.; Liu, Z.; Sun, Y.; Zheng, M. Wind Power Short-Term Prediction Based on, LSTM and Discrete Wavelet Transform. Appl. Sci. 2019, 9, 1108. [Google Scholar] [CrossRef] [Green Version]
- Cho, K.; Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078,2014. [Google Scholar]
- Draxl, C.; Clifton, A.; Hodge, B.-M.; McCaa, J. The wind integration national dataset (WIND) toolkit. Appl. Energy 2015, 151, 355–366. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Peng, S.; Peng, J.; Huang, S.; Zheng, G. Wind power probability density forecasting based on deep learning quantile regression model. Electr. Power Autom. Equip. 2018, 38, 15–20. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Novelty and Advantage | Deficiency |
|---|---|---|
| Modified-LSTM [16] | Hybrid model is proposed for classification and prediction | Not compared with advanced algorithms |
| GA-PSO-ANN [17] | Using optimization algorithm to adjust neural network parameters | No optimization for neural network hyperparameters |
| Multi-Sequence LSTM-RNN [18] | Proposed multi-sequence deep learning model based on meta heuristic algorithm | Lack of data processing and feature extraction |
| MFF-SAM-GCN [19] | It can effectively capture external features that have an impact on load forecasting | The relationship between weather factors is not analyzed and extracted |
| CEEMD-WOA-ELMAN [20] | A new meta-heuristic algorithm WOA is introduced to optimize the model | There is a large error between different time scales |
| MPSO_ATT_LSTM | The features between data are extracted and the hyperparameters of neural network are optimized | Discuss in part of conclusion |
| Algorithm | Parameter Setting |
|---|---|
| Common setting | Maximum iteration tmax = 200 |
| population size P = 5 | |
| PSO | |
| MPSO | |
| Test Function | Name | Best |
|---|---|---|
| (1) Unimodal test functions | ||
| Sphere | 0 | |
| (2) Multimodal test functions | ||
| Ackley | 0 | |
| Rastrigin | 0 |
| Number of Model | Learning Rate | First Hidden Layer Nodes | Second Hidden Layer Nodes | Batch-Size |
|---|---|---|---|---|
| Hyperparameter-1 | 0.001 | 64 | 128 | 32 |
| Hyperparameter-2 | 0.001 | 128 | 256 | 64 |
| Hyperparameter-3 | 0.001 | 256 | 64 | 32 |
| Hyperparameter-4 | 0.002 | 64 | 128 | 64 |
| Hyperparameter-5 | 0.002 | 128 | 256 | 128 |
| Hyperparameter-6 | 0.002 | 256 | 64 | 128 |
| Parameters of the Model | Value |
|---|---|
| LSTM layers | 2 |
| Activation function | ReLU |
| Number of first hidden nodes | 34 |
| Number of second hidden nodes | 48 |
| Dropout | 0.5 |
| Learning rate | 0.001 |
| Learning decay rate | 0.8 |
| L2 regularisation | 0.00001 |
| Length of time windows | 5 |
| Batch size | 78 |
| MAPE, % | MAE, KW | |
|---|---|---|
| LSTM | 17.2 | 2423.6 |
| ATT_LSTM | 8.2 | 621.8 |
| PSO_ATT_LSTM | 5.9 | 359.3 |
| Improved Agorithms_1 | 5.3 | 429.2 |
| Improved Agorithms_2 | 6.5 | 373.6 |
| MPSO_ATT_LSTM | 4.6 | 211.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Wang, X.; Yang, J. Modified Particle Swarm Optimization with Attention-Based LSTM for Wind Power Prediction. Energies 2022, 15, 4334. https://doi.org/10.3390/en15124334
Sun Y, Wang X, Yang J. Modified Particle Swarm Optimization with Attention-Based LSTM for Wind Power Prediction. Energies. 2022; 15(12):4334. https://doi.org/10.3390/en15124334
Chicago/Turabian StyleSun, Yiyang, Xiangwen Wang, and Junjie Yang. 2022. "Modified Particle Swarm Optimization with Attention-Based LSTM for Wind Power Prediction" Energies 15, no. 12: 4334. https://doi.org/10.3390/en15124334
APA StyleSun, Y., Wang, X., & Yang, J. (2022). Modified Particle Swarm Optimization with Attention-Based LSTM for Wind Power Prediction. Energies, 15(12), 4334. https://doi.org/10.3390/en15124334