Adaptive Nonparametric Kernel Density Estimation Approach for Joint Probability Density Function Modeling of Multiple Wind Farms


Abstract
1. Introduction
2. Adaptive Multivariate Nonparametric Kernel Density Estimation Model for Multiple Wind Farms
2.1. MNKDE Model for Multiple Wind Farms
2.2. Optimal Model of Bandwidth
2.3. Improved Adaptive Strategy Based on the Optimal Bandwidth Adjustment Model
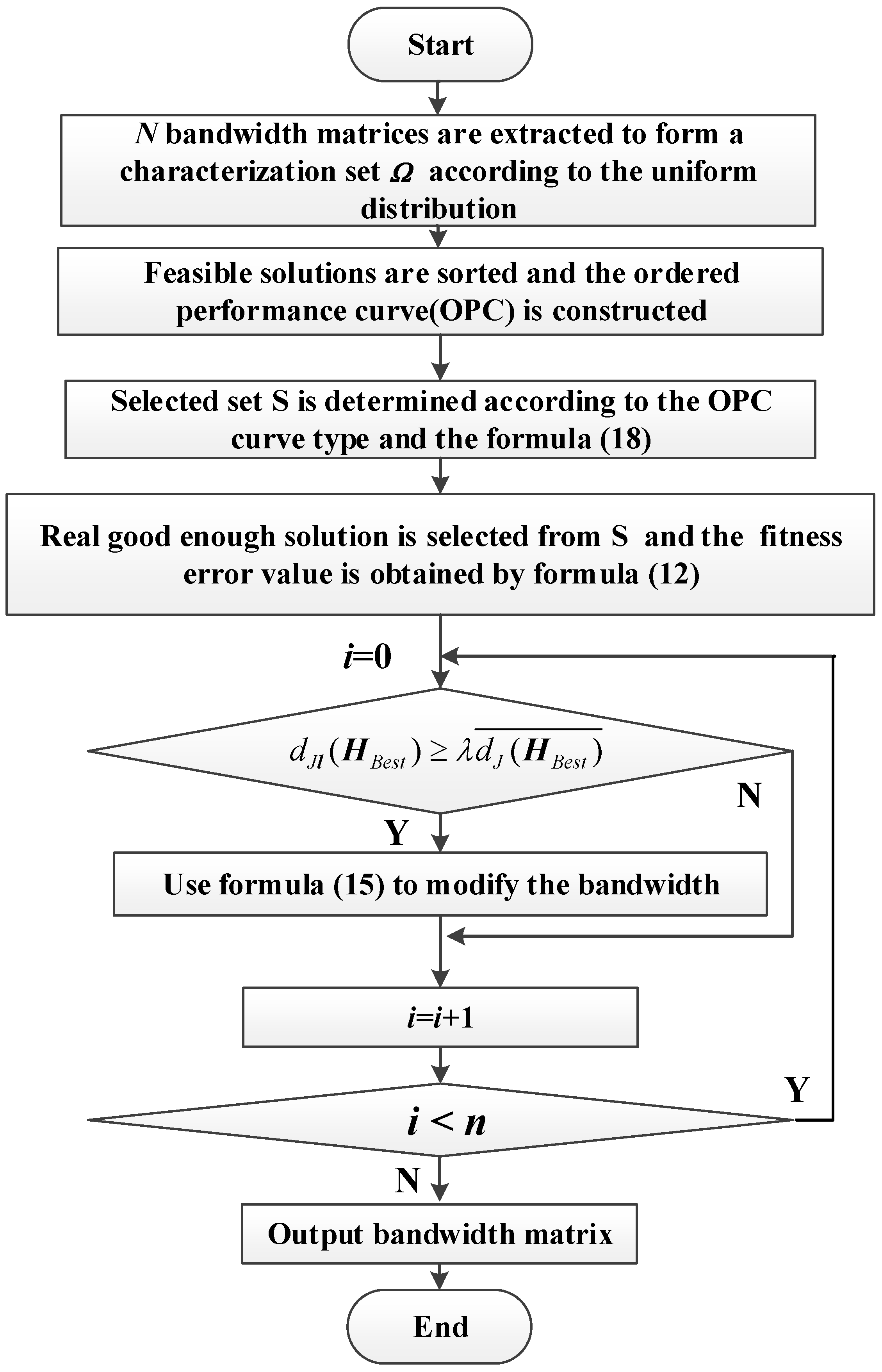
3. Solution of the Optimal Model of Bandwidth Based on Ordinal Optimization
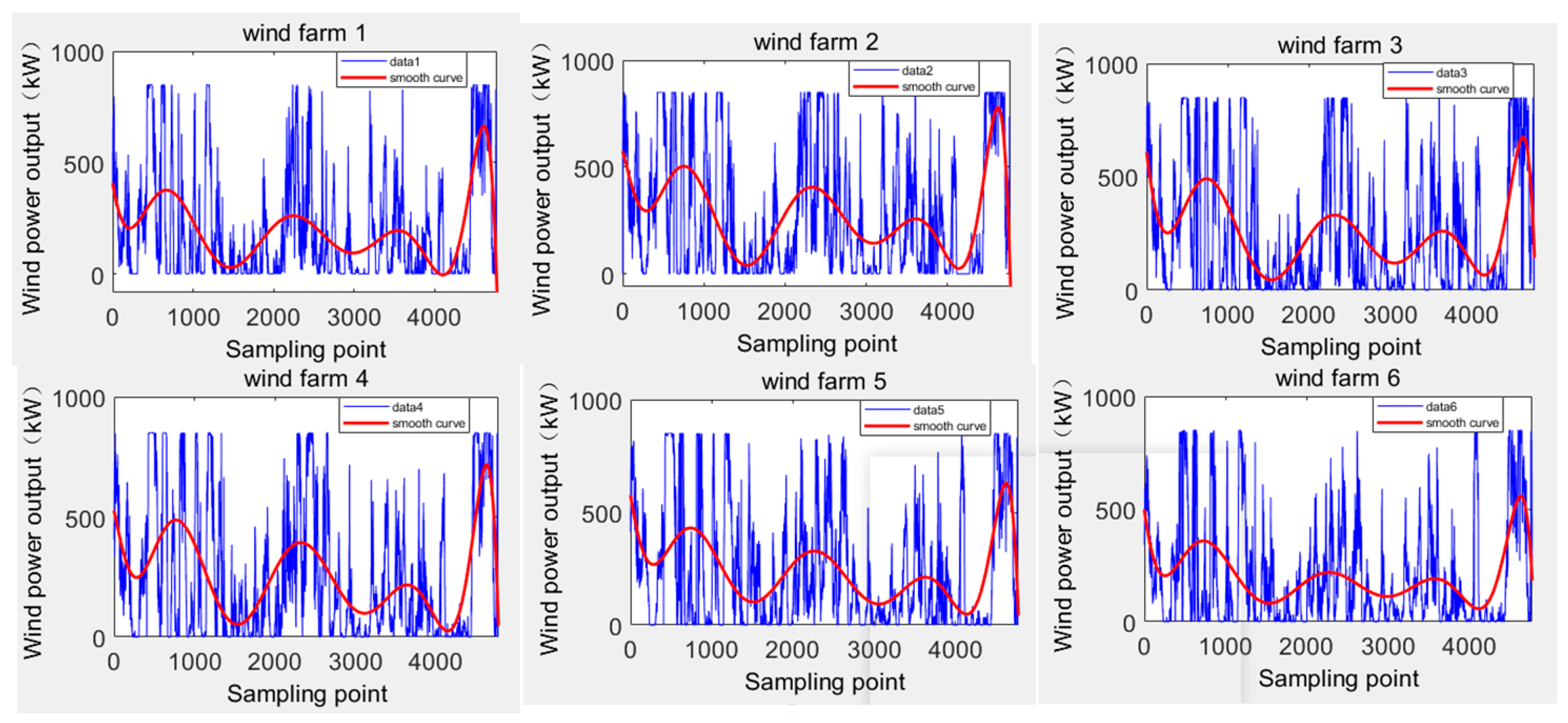
4. Scenario Study
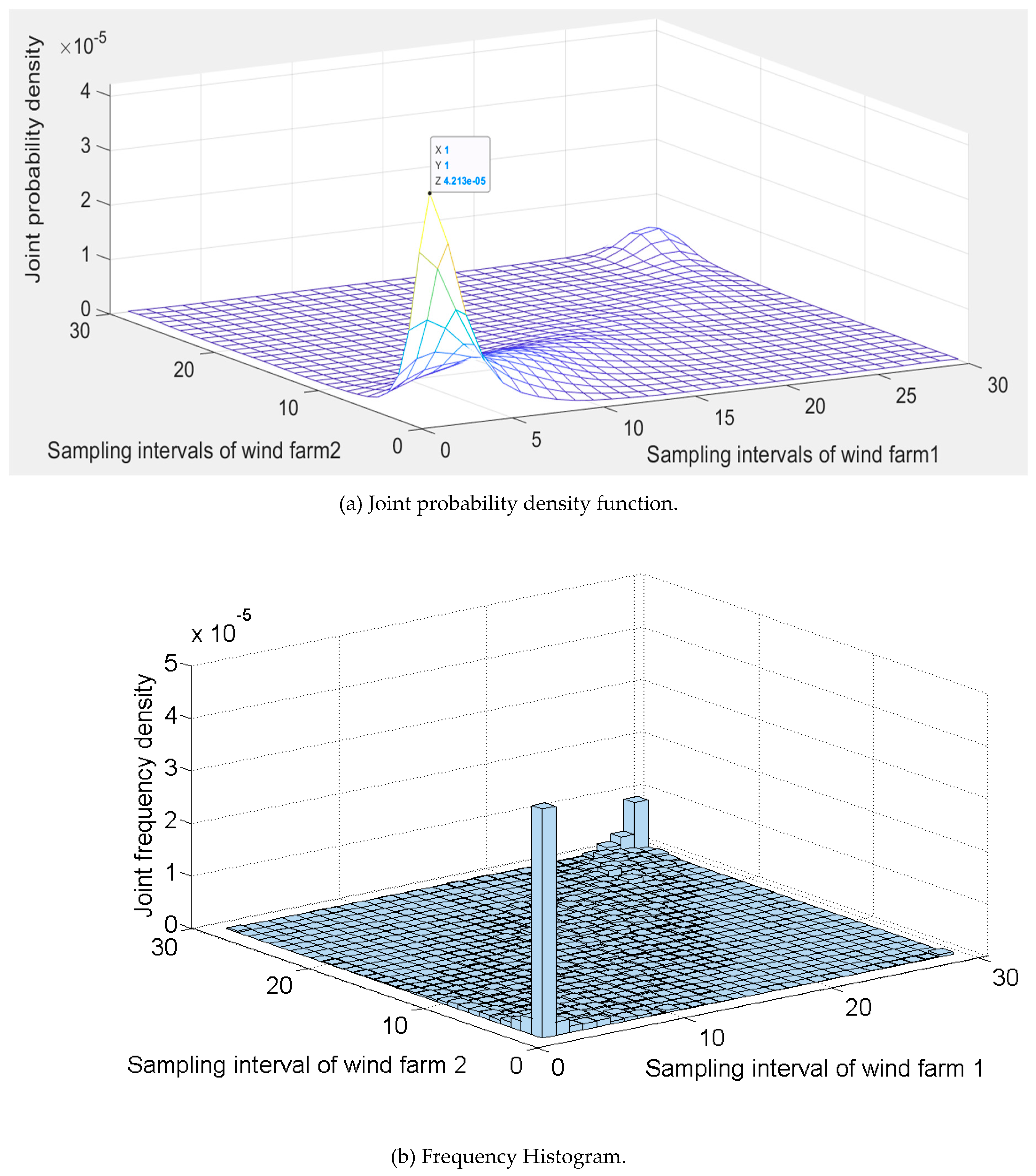
4.1. Joint Probability Density Function Modeling of Two Wind Farms
4.2. Multipart Figures
4.2.1. Validity Analysis of the Improved Adaptive Strategy for MNKDE
4.2.2. Accuracy Comparison between AMNKDE and Copula Parameter Estimation
4.2.3. Comparison of Applicability between AMNKDE and Copula Parameter Estimation
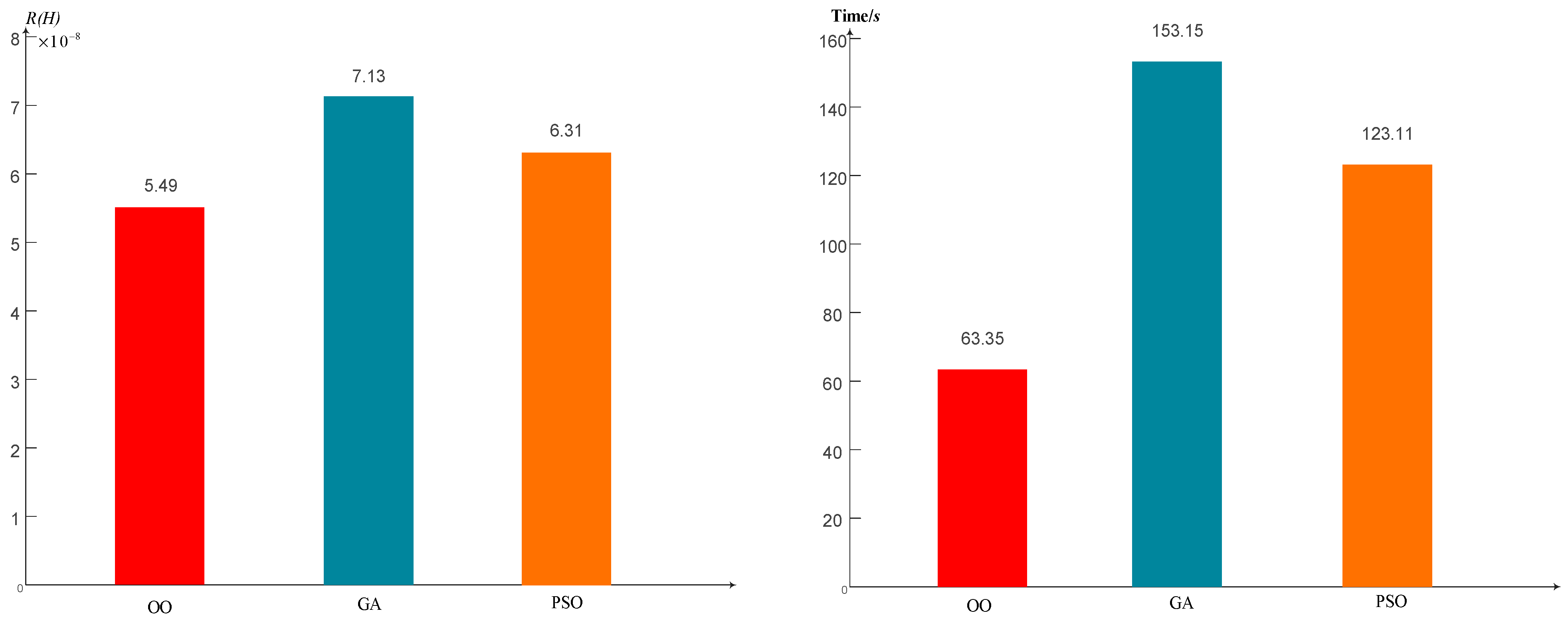
4.2.4. Comparison of Algorithms
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| probability density function | |
| H | bandwidth matrix |
| multivariate kernel function | |
| transpose of x | |
| Euclidean distance | |
| maximum distance | |
| fitness error function | |
| l | any sample intervals |
| geometric distance in l | |
| average geometric distance of the entire sample space | |
| Hl | modified bandwidth in l |
| median of the geometric distance in l | |
| number of samples in l | |
| threshold of the kernel function | |
| k | number of sample intervals needed to be adjusted |
| modified bandwidth matrix in lk | |
| measurement weight | |
| a small positive number | |
| standard deviation of measurement for each sampling interval | |
| S | number of solutions in the selected set S |
| t | there exist at least t good enough solutions in the selected set S |
| g | size of the good enough solution subset |
References
- Wu, J.; Zhang, B.; Wang, K. Optimal economic dispatch model based on risk management for wind-integrated power system. IET Gener. Transm. Distrib. 2015, 9, 2152–2158. [Google Scholar] [CrossRef]
- Hu, D.; Ryan, S.M. Stochastic vs. deterministic scheduling of a combined natural gas and power system with uncertain wind energy. Int. J. Electr. Power Energy Syst. 2019, 108, 303–313. [Google Scholar] [CrossRef]
- Yan, J.; Liu, Y.; Han, S. Reviews on uncertainty analysis of wind power forecasting. Renew. Sustain. Energy Rev. 2015, 52, 1322–1330. [Google Scholar] [CrossRef]
- Zhang, Y.; Jian, L.; Zheng, F.; Zhang, Y.; Liu, K. Two-stage distributionally robust coordinated scheduling for gas-electricity integrated energy system considering wind power uncertainty and reserve capacity configuration. Renew. Energy 2019, 135, 122–135. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, B.; Jiang, Y.; Bie, P.; Li, H. Chance-constrained stochastic congestion management of power systems considering uncertainty of wind power and demand side response. Int. J. Electr. Power Energy Syst. 2019, 107, 703–714. [Google Scholar] [CrossRef]
- Dvorkin, Y.; Lubin, M.; Backhaus, S. Uncertainty Sets for wind power generation. IEEE Trans. Power Syst. 2016, 31, 3326–3327. [Google Scholar] [CrossRef]
- Wang, B.; Fang, B.; Wang, Y.; Liu, H.; Liu, Y. Power System Transient Stability Assessment Based on Big Data and the Core Vector Machine. IEEE Trans. Smart Grid 2016, 7, 2561–2570. [Google Scholar] [CrossRef]
- Liu, R.; Peng, M.; Xiao, X. Ultra-Short-Term Wind Power Prediction Based on Multivariate Phase Space Reconstruction and Multivariate Linear Regression. Energies 2018, 11, 2763. [Google Scholar] [CrossRef]
- Li, J.; Wang, S.; Ye, L.; Fang, J. A coordinated dispatch method with pumped-storage and battery-storage for compensating the variation of wind power. Prot. Control Mod. Power Syst. 2018, 3, 21–34. [Google Scholar] [CrossRef]
- Zheng, D.; Eseye, A.; Zhang, J.; Li, H. Short-term wind power forecasting using a double-stage hierarchical ANFIS approach for energy management in microgrids. Prot. Control Mod. Power Syst. 2017, 2, 136–145. [Google Scholar] [CrossRef]
- Liao, S.; Xu, J.; Sun, Y. Control of Energy-intensive Load for Power Smoothing in Wind Power Plants. IEEE Trans. Power Syst. 2018, 33, 6142–6154. [Google Scholar] [CrossRef]
- Yang, H.; Xie, K.; Tai, H.M. Wind farm layout optimization and its application to power system reliability analysis. IEEE Trans. Power Syst. 2016, 31, 2135–2143. [Google Scholar] [CrossRef]
- Tian, P.C. Estimation of wind energy potential using different probability density functions. Appl. Energy 2011, 88, 1848–1856. [Google Scholar]
- Altunkaynak, A.; Erdik, T.; Dabanlı, İ.; Şen, Z. Theoretical derivation of wind power probability distribution function and applications. Appl. Energy 2012, 92, 809–814. [Google Scholar] [CrossRef]
- Tina, G.; Gagliano, S. Probabilistic analysis of weather data for a hybrid solar/wind energy system. Int. J. Energy Res. 2011, 35, 221–232. [Google Scholar] [CrossRef]
- Wang, C.; Li, X.H.; Tian, T.; Xu, Z.R.; Chen, R. Coordinated control of passive transition from grid-connected to islanded operation for three/single-phase hybrid multimicrogrids considering speed and smoothness. IEEE Trans. Ind. Electron. 2019. [Google Scholar] [CrossRef]
- Liu, T.H.; Wei, H.K.; Zhang, K.J. Wind power prediction with missing data using Gaussian process regression and multiple imputation. Appl. Soft Comput. 2018, 71, 905–916. [Google Scholar] [CrossRef]
- Yin, H.; Zivanovic, R. Using probabilistic collocation method for neighbouring wind farms modeling and power flow computation of South Australia grid. IET Gener. Transm. Distrib. 2017, 11, 3568–3575. [Google Scholar] [CrossRef]
- Zhang, L.; Luo, Y. Combined Heat and Power Scheduling: Utilizing Building-level Thermal Inertia for Short-term Thermal Energy Storage in District Heat System. IEEE Trans. Electr. Electron. Eng. 2018, 13, 804–814. [Google Scholar] [CrossRef]
- Olauson, J.; Bergkvist, M. Correlation between wind power generation in the European countries. Energy 2016, 114, 663–670. [Google Scholar] [CrossRef]
- Luo, G.; Chen, J.; Cai, D. Probabilistic assessment of available transfer capability considering spatial correlation in wind power integrated system. IET Gener. Transm. Distrib. 2013, 7, 1527–1535. [Google Scholar]
- Xie, Z.Q.; Ji, T.Y.; Li, M.S. Quasi-Monte carlo based probabilistic optimal power flow considering the correlation of wind speeds using Copula function. IEEE Trans. Power Syst. 2018, 33, 2239–2247. [Google Scholar] [CrossRef]
- Li, C.X.; Dong, Z.Y.; Chen, G. Flexible transmission expansion planning associated with large-scale wind farms integration considering demand response. IET Gener. Transm. Distrib. 2015, 9, 2276–2283. [Google Scholar] [CrossRef]
- Hu, B.Q.; Wu, L.; Marwali, M. On the robust solution to scuc with load and wind uncertainty correlations. IEEE Trans. Power Syst. 2014, 29, 2952–2964. [Google Scholar] [CrossRef]
- Papaefthymiou, G.; Kurowicka, D. Using Copulas for modeling stochastic dependence in power system uncertainty analysis. IEEE Trans. Power Syst. 2009, 24, 40–49. [Google Scholar] [CrossRef]
- Gill, S.; Stephen, B.; Galloway, S. Wind Turbine Condition Assessment Through Power Curve Copula Modeling. IEEE Trans. Sustain. Energy 2012, 3, 94–101. [Google Scholar] [CrossRef]
- Louie, H. Evaluation of bivariate archimedean and elliptical Copulas to model wind power dependency structures. Wind Energy 2014, 17, 225–240. [Google Scholar] [CrossRef]
- Zhang, J.; Chowdhury, S.; Messac, A. A Multivariate and Multimodal Wind Distribution model. Renew. Energy Int. J. 2013, 51, 436–447. [Google Scholar] [CrossRef]
- Wang, J.W.; Zhou, B.X.; Li, H.B. Modeling of wind farm output correlation based on comprehensive Copula function. Electr. Meas. Instrum. 2016, 53, 100–105. [Google Scholar]
- Yang, N.; Cui, J.Z.; Zhou, Z. Research on nonparametric kernel density estimation for modeling of wind power probability characteristics based on fuzzy ordinal optimization. Power Syst. Technol. 2014, 40, 335–340. [Google Scholar]
- Yang, N.; Ye, D.; Zhou, Z.; Cui, J.Z.; Chen, D.J.; Wang, X.M. Research on modelling and solution of stochastic SCUC under AC power flow constraints. IET Gener. Transm. Distrib. 2018, 12, 3618–3625. [Google Scholar]
- Soleimanpour, N.; Mohammadi, M. Probabilistic load flow by using nonparametric density estimators. IEEE Trans. Power Syst. 2013, 28, 3747–3755. [Google Scholar] [CrossRef]
- Ren, Z.Y.; Yan, W.; Zhao, X. Chronological probability model of photovoltaic generation. IEEE Trans. Power Syst. 2014, 29, 1077–1088. [Google Scholar] [CrossRef]
- Carbone, P.; Petri, D.; Barbé, K. Nonparametric probability density estimation via interpolation filtering. IEEE Trans. Instrum. Meas. 2017, 66, 681–690. [Google Scholar] [CrossRef]
- Zhu, B.X.; Ren, L.L.; Hu, X. Kind of high step-up dc/dc converter using a novel voltage multiplier cell. IET Power Electron. 2017, 10, 129–133. [Google Scholar] [CrossRef]
- Kristan, M.; Leonardis, A.; Skoc, D. Multivariate online kernel density estimation with Gaussian kernels. Pattern Recognit. 2011, 44, 2630–2642. [Google Scholar] [CrossRef]
- Li, Z.H.; Tao, Y.; Abu-Siada, A. A New Vibration Testing Platform for Electronic Current Transformers. IEEE Trans. Instrum. Meas. 2019, 68, 704–712. [Google Scholar] [CrossRef]
- Pulkkinen, S.; Mäkelä, M.; Karmitsa, N. A continuation approach to mode-finding of multivariate Gaussian mixtures and kernel density estimates. J. Glob. Optim. 2013, 56, 459–487. [Google Scholar] [CrossRef]
- Chang, M.S.; Wu, X.M. Transformation-based nonparametric estimation of multivariate densities. J. Multivar. Anal. 2015, 135, 71–88. [Google Scholar] [CrossRef]
- Gramacki, A.; Gramacki, J. FFT-based fast computation of multivariate kernel density estimators with unconstrained bandwidth matrices. J. Comput. Graph. Stat. 2017, 26, 459–462. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, X.F.; Zhou, J.Q. Load Modeling Utilizing Nonparametric and Multivariate Kernel Density Estimation in Bulk Power System Reliability Evaluation. Proc. CSEE 2009, 29, 27–33. [Google Scholar]
- Zougab, N.; Smail, K.; Célestin, C. Bayesian estimation of adaptive bandwidth matrices in multivariate kernel density estimation. Comput. Stat. Data Anal. 2014, 75, 28–38. [Google Scholar] [CrossRef]
- Sreevani, N.; Murthy, C.A. On bandwidth selection using minimal spanning tree for kernel density estimation. Comput. Stat. Data Anal. 2016, 102, 67–84. [Google Scholar] [CrossRef]
- Zhao, Y.; Yang, J.G.; Li, S.X. Nonparametric disaggregation load model in power system reliability evaluation incorporating the additive correlation. IEEE Trans. Power Syst. 2008, 23, 6039–6047. [Google Scholar]
- Van Kerm, P.; Mohammadi, M. Adaptive kernel density estimation. Stata J. 2003, 3, 148–156. [Google Scholar] [CrossRef]
- Liu, Y.S.; Lin, J.K.; Guo, L.X. A robust state estimation method based on adaptive kernel density estimation Theory. Proc. CSEE 2012, 19, 4937–4946. [Google Scholar]
- Epanecnikov, V.A. Nonparametric estimation of a multidimensional probability density. Theory Probab. Appl. 2003, 14, 156–161. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | H | Sample Interval | ||||
|---|---|---|---|---|---|---|
| Wind Farm 1 | Wind Farm 2 | |||||
| AMNKDE | [38.7,38.7] | [30,60] | [30,60] | 6.09 × 10−5 | 4.1 × 10−6 | 6.50 × 10−5 |
| [90,900] | [90,900] | |||||
| [34.5,34.5] | [0,30] | [0,30] | ||||
| [34.7,34.7] | Other interval | |||||
| Model | H | Sample Interval | |||||
|---|---|---|---|---|---|---|---|
| Wind Farm 1 | Wind Farm 2 | Wind Farm 3 | |||||
| 1 | [40.7, 40.7, 40.7] | [0,100] | [0,100] | [0,100] | 3.60 10−8 | 3.60 10−9 | 7.15 10−8 |
| [40.7, 40.7, 40.7] | [800,1000] | [800,1000] | [0,100] | 3.60 10−8 | |||
| [40.7, 40.7, 40.7] | Other interval | 2.83 10−8 | |||||
| 2 | [37,37,37] | [0,100] | [1,100] | [0,100] | 3.00 10−8 | 1.60 10−10 | 6.52 10−8 |
| [38,38,38] | [800,1000] | [800,1000] | [0,100] | 1.60 10−8 | |||
| [40.7,40.7,40.7] | Other interval | 3.20 10−8 | |||||
| Model | H | Sample Interval | |||||
|---|---|---|---|---|---|---|---|
| Wind Farm 1 | Wind Farm 2 | Wind Farm 3 | |||||
| 1 | [40.7, 40.7, 40.7] | [0,100] | [0,100] | [0,100] | 3.60 10−8 | 3.60 10−9 | 7.15 10−8 |
| [40.7, 40.7, 40.7] | [800,1000] | [800,1000] | [0,100] | 3.60 10−8 | |||
| [40.7, 40.7, 40.7] | Other interval | 2.83 10−8 | |||||
| 2 | [37,37,37] | [0,100] | [0,100] | [0,100] | 3.00 10−8 | 1.60 10−10 | 6.52 10−8 |
| [38,38,38] | [800,1000] | [800,1000] | [0,100] | 1.60 10−8 | |||
| [40.7,40.7,40.7] | Other interval | 3.20 10−8 | |||||
| Model | H | Sample Interval | |||||
|---|---|---|---|---|---|---|---|
| Wind Farm 4 | Wind Farm 5 | Wind Farm 6 | |||||
| 2 | [38,38,38] | [0,100] | [0,100] | [0,100] | 6.78 10−8 | 1.1 10−10 | 6.89 10−8 |
| [39,39,39] | [800,1000] | [800,900] | [0,100] | ||||
| [41.7,41.7,41.7] | Other interval | ||||||
| 3 | Copula function | 7.83 10−8 | 2.50 10−9 | 8.08 10−8 | |||
| Gumbel | 0.386 | 5.60 | |||||
| Clayton | 0.403 | 4.940 | |||||
| Frank | 0.211 | 8.586 | |||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, N.; Huang, Y.; Hou, D.; Liu, S.; Ye, D.; Dong, B.; Fan, Y. Adaptive Nonparametric Kernel Density Estimation Approach for Joint Probability Density Function Modeling of Multiple Wind Farms. Energies 2019, 12, 1356. https://doi.org/10.3390/en12071356
Yang N, Huang Y, Hou D, Liu S, Ye D, Dong B, Fan Y. Adaptive Nonparametric Kernel Density Estimation Approach for Joint Probability Density Function Modeling of Multiple Wind Farms. Energies. 2019; 12(7):1356. https://doi.org/10.3390/en12071356
Chicago/Turabian StyleYang, Nan, Yu Huang, Dengxu Hou, Songkai Liu, Di Ye, Bangtian Dong, and Youping Fan. 2019. "Adaptive Nonparametric Kernel Density Estimation Approach for Joint Probability Density Function Modeling of Multiple Wind Farms" Energies 12, no. 7: 1356. https://doi.org/10.3390/en12071356
APA StyleYang, N., Huang, Y., Hou, D., Liu, S., Ye, D., Dong, B., & Fan, Y. (2019). Adaptive Nonparametric Kernel Density Estimation Approach for Joint Probability Density Function Modeling of Multiple Wind Farms. Energies, 12(7), 1356. https://doi.org/10.3390/en12071356