Sensor Data Compression Using Bounded Error Piecewise Linear Approximation with Resolution Reduction


Abstract
1. Introduction
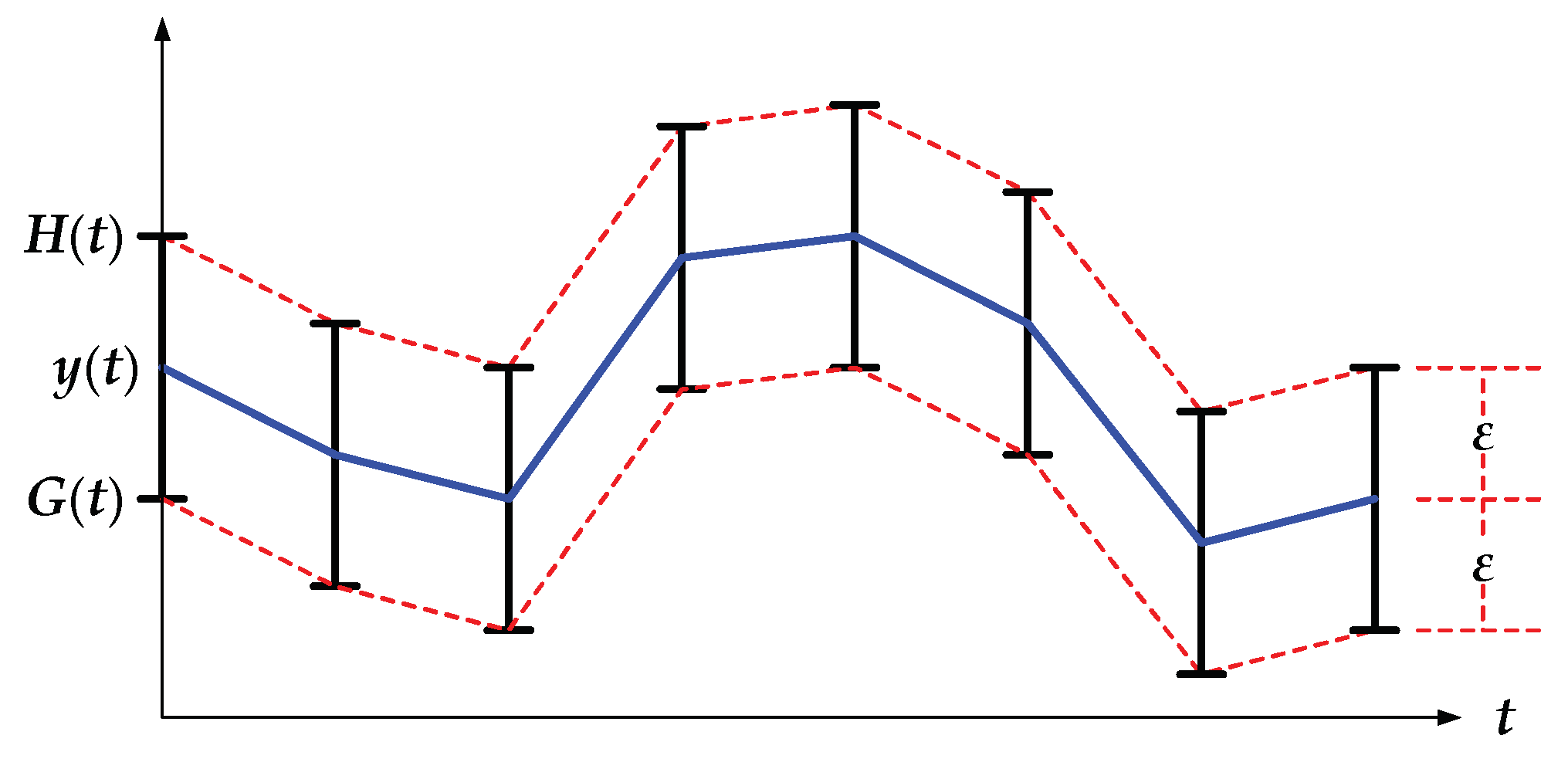
1.1. Bounded-Error Piecewise Linear Approximation (BEPLA)
1.1.1. Definition 1: Bounded-Error Approximation (BEA)
1.1.2. Definition 2: Piecewise Linear Approximation (PLA)
1.1.3. Definition 3: Bounded-Error Piecewise Linear Approximation (BEPLA)
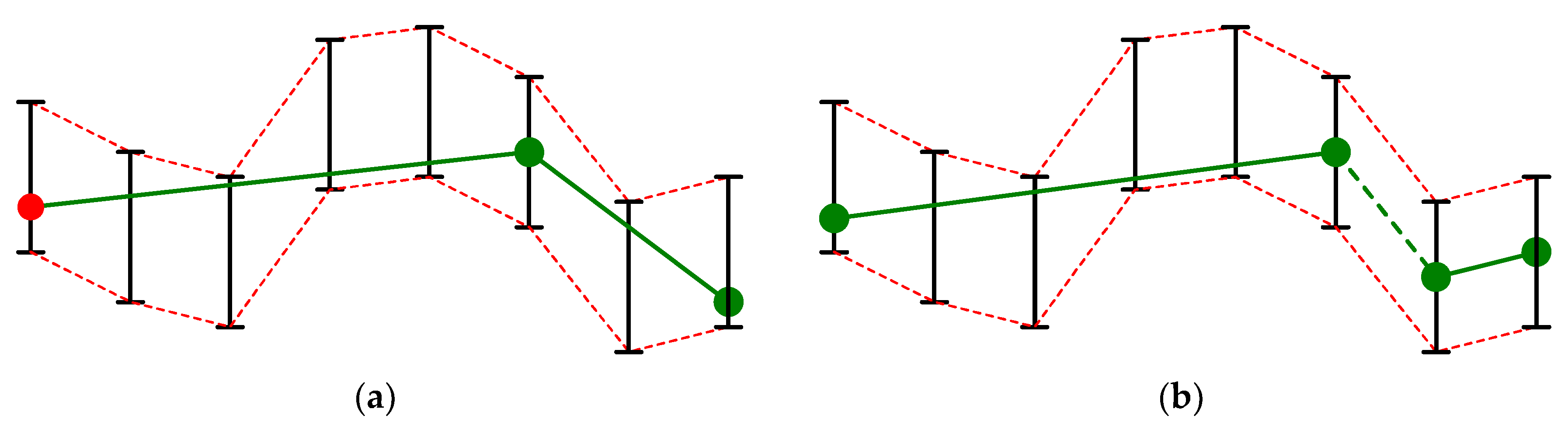
1.2. BEPLA with Resolution Reduction
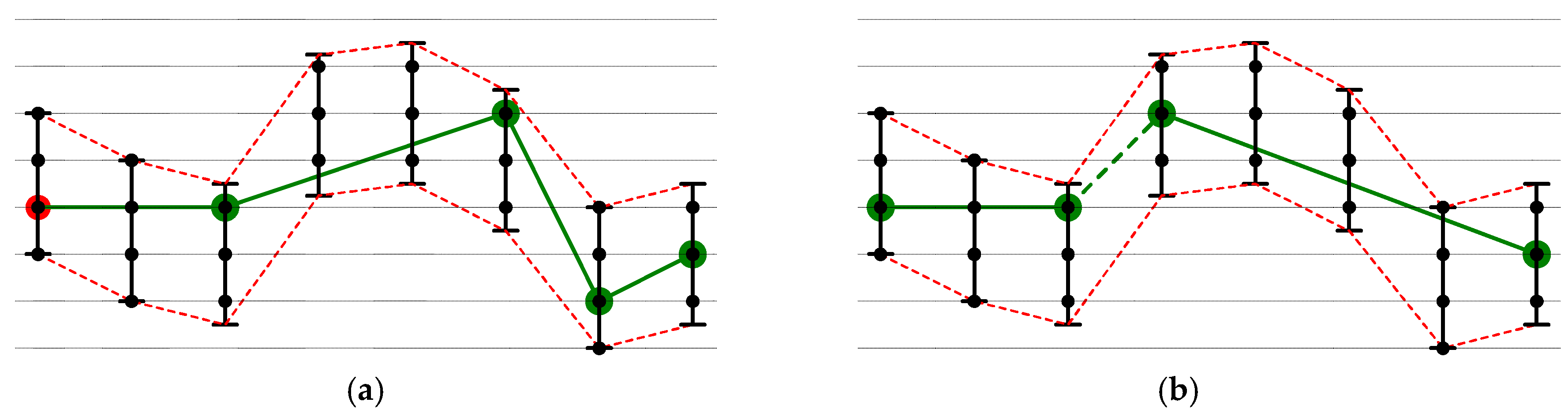
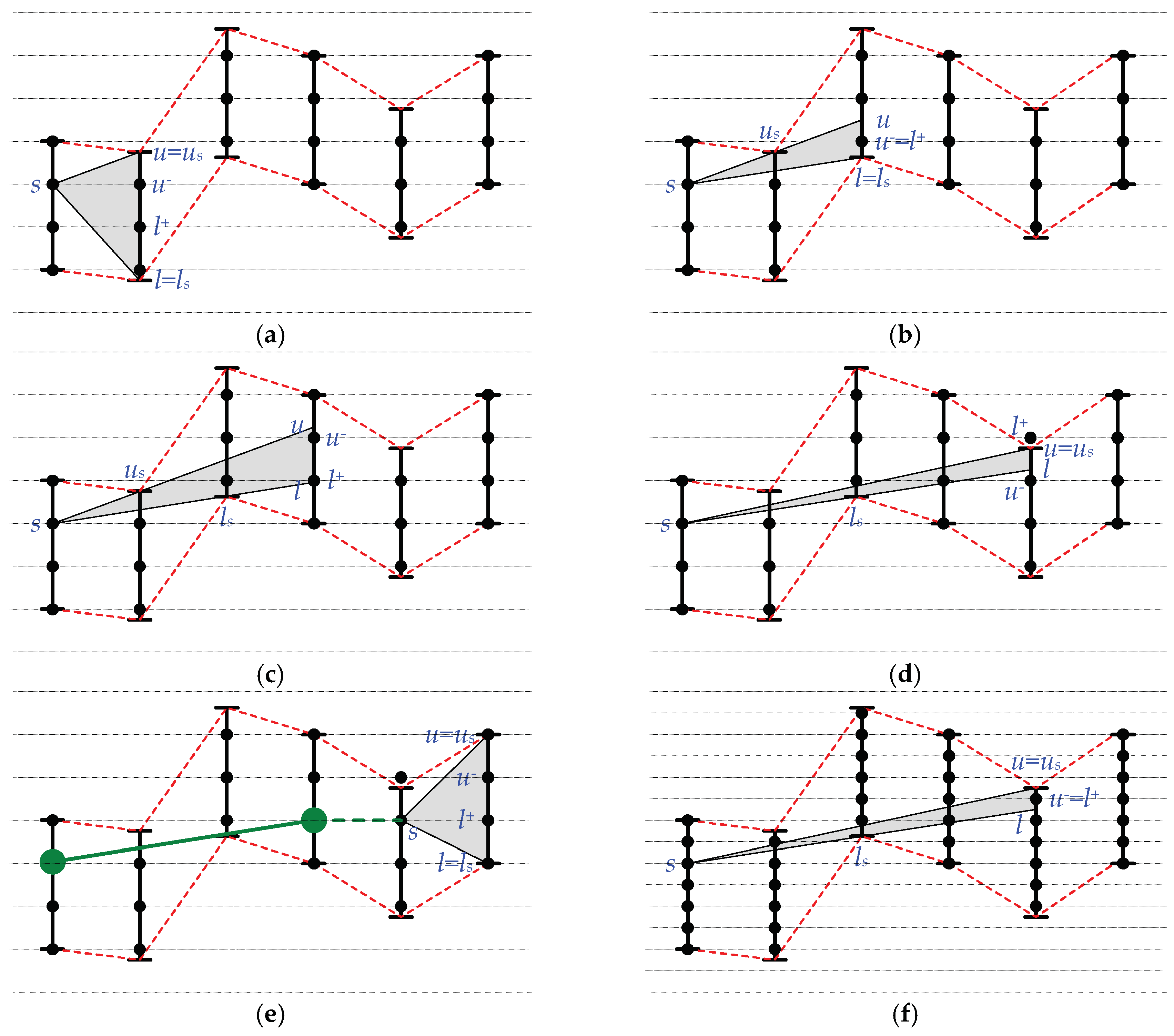
2. Method
| Algorithm 1: Swing-RR(d), given error bound ε, maximal delay delay, and resolution r bits in length |
| 1: segment.length++ // segment.length is initialized to −1 fora new window |
| 2: if (segment.length == 0) then // the first data point in this window |
| 3: segment.start s = picking up a coded data point between d + ε and d − ε; |
| 4: else if (segment.length == 1) then // the second data point in this window |
| 5: us = d + ε; ls = d − ε; |
| 6: check_range (); |
| 7: else if ((d + ε is below s→ls) or (d − ε is above s→us) |
| 8: {close this window; generate a line segment; initialize a new window;} |
| 9: else |
| 10: if (d + ε is below s→us) us = d + ε; // s→us swing down |
| 11: if (d − ε is above s→ls) ls = d − ε; // s→ls swing up |
| 12: check_range (); |
| 13: end if |
| 14: |
| 15: Function check_range () |
| 16: u = the point at d.t extended from s→us; |
| 17: l = the point at d.t extended from s→ls; |
| 18: u− = the largest coded data point smaller than or equal to u; |
| 19: l+ = the smallest coded data point larger than or equal to l; |
| 20: if (l+ ≤ u−) then // there exists at least one coded data point |
| 21: segment.stop = (l+ + u−)/2; |
| 22: if (segment.length ≥ delay) // Swing-RR is forced to output a line segment |
| 23: {close this window; generate a line segment; initialize a new window;} |
| 24: end if |
| 25: else // there exist no coded data points |
| 26: {close this window; generate a line segment; initialize a new window;} |
| 27: end if |
3. Experiment
3.1. Experimental Setup
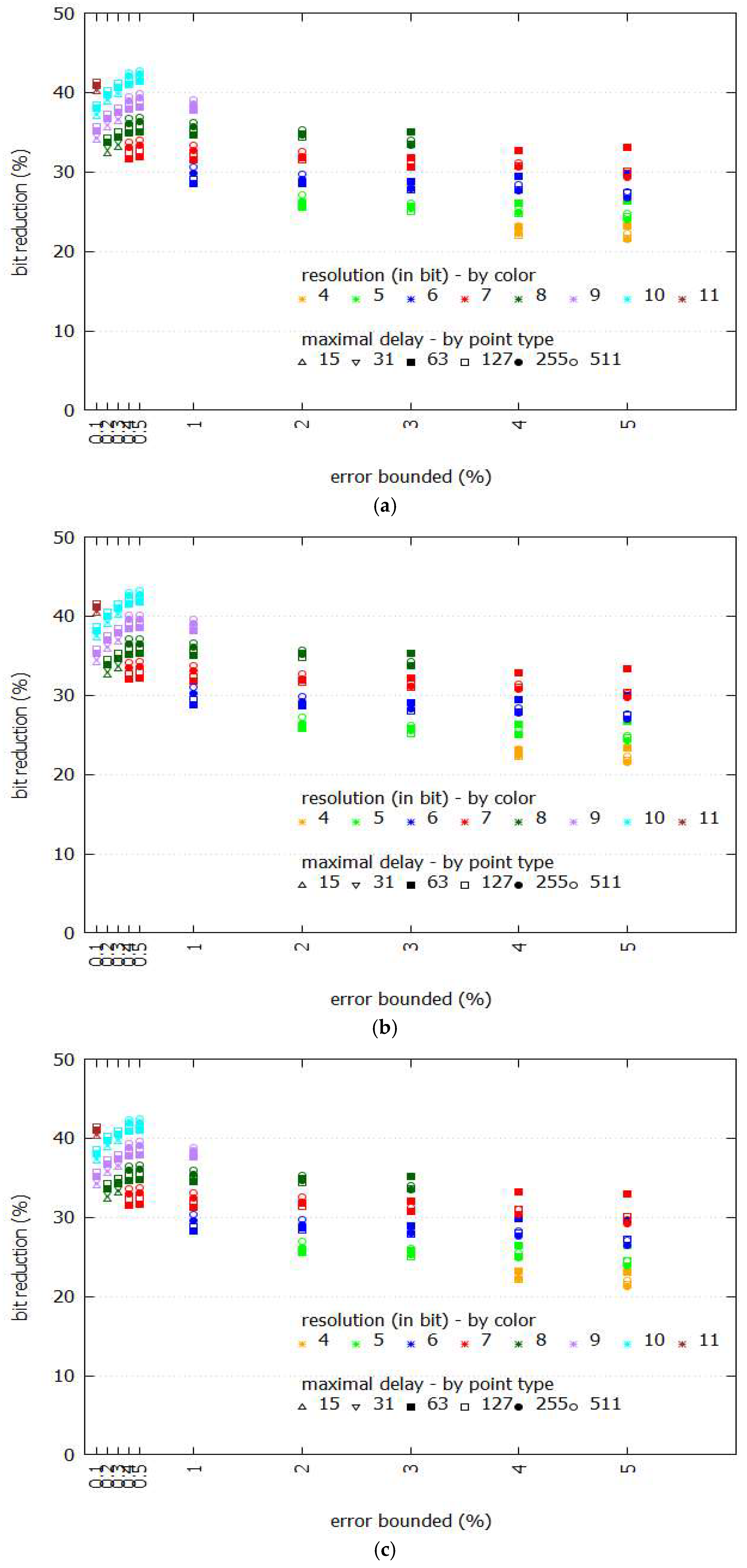
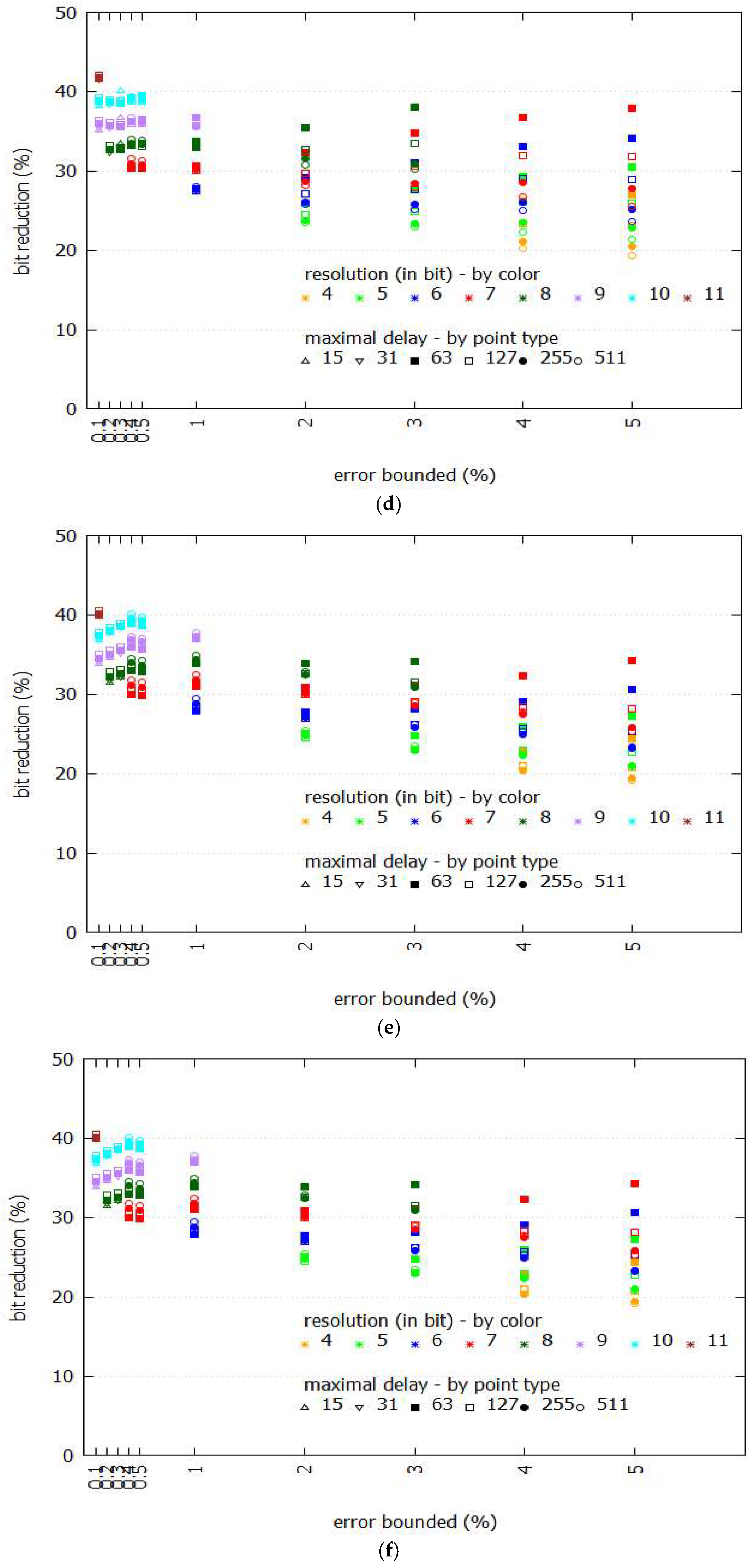
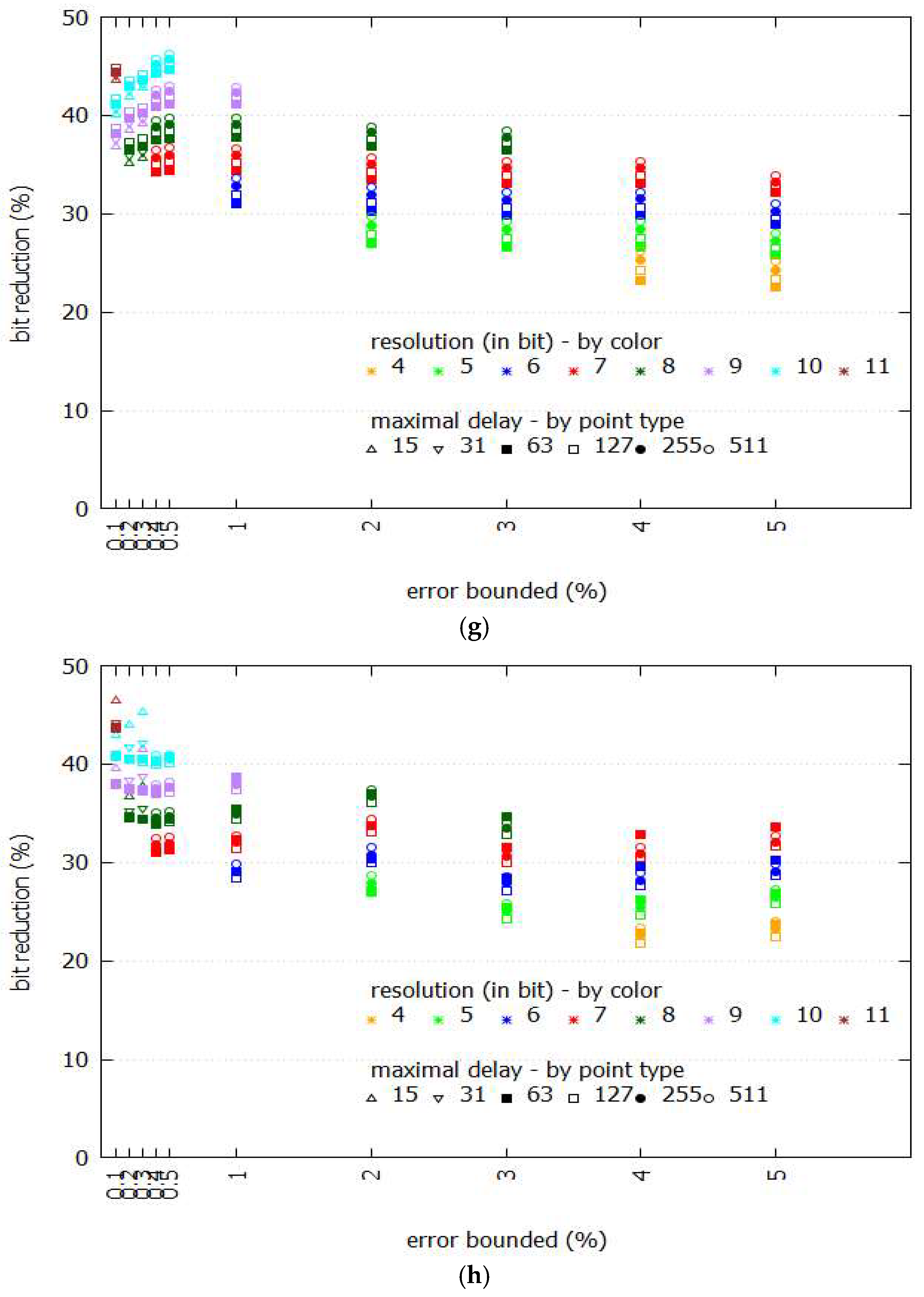
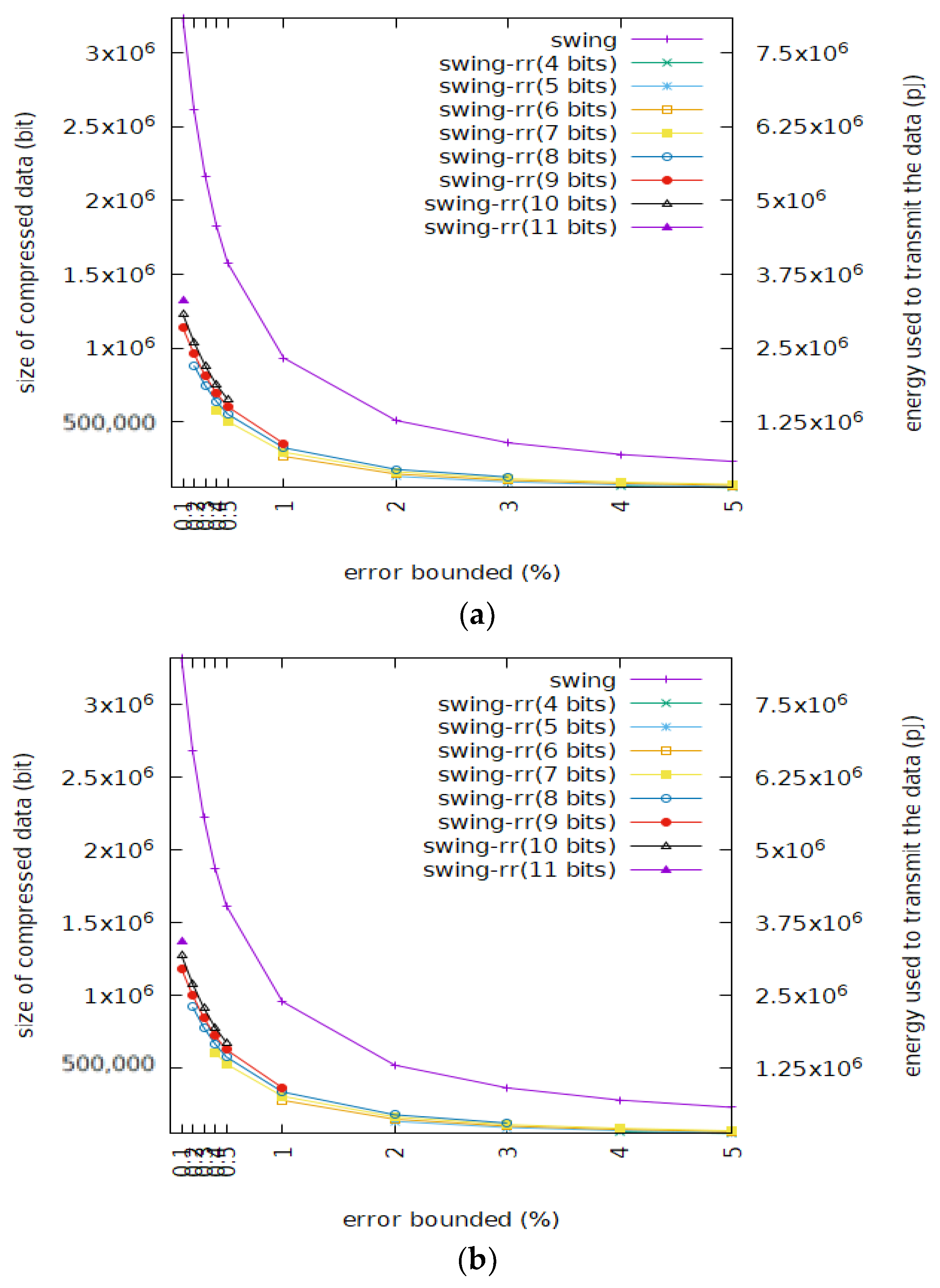
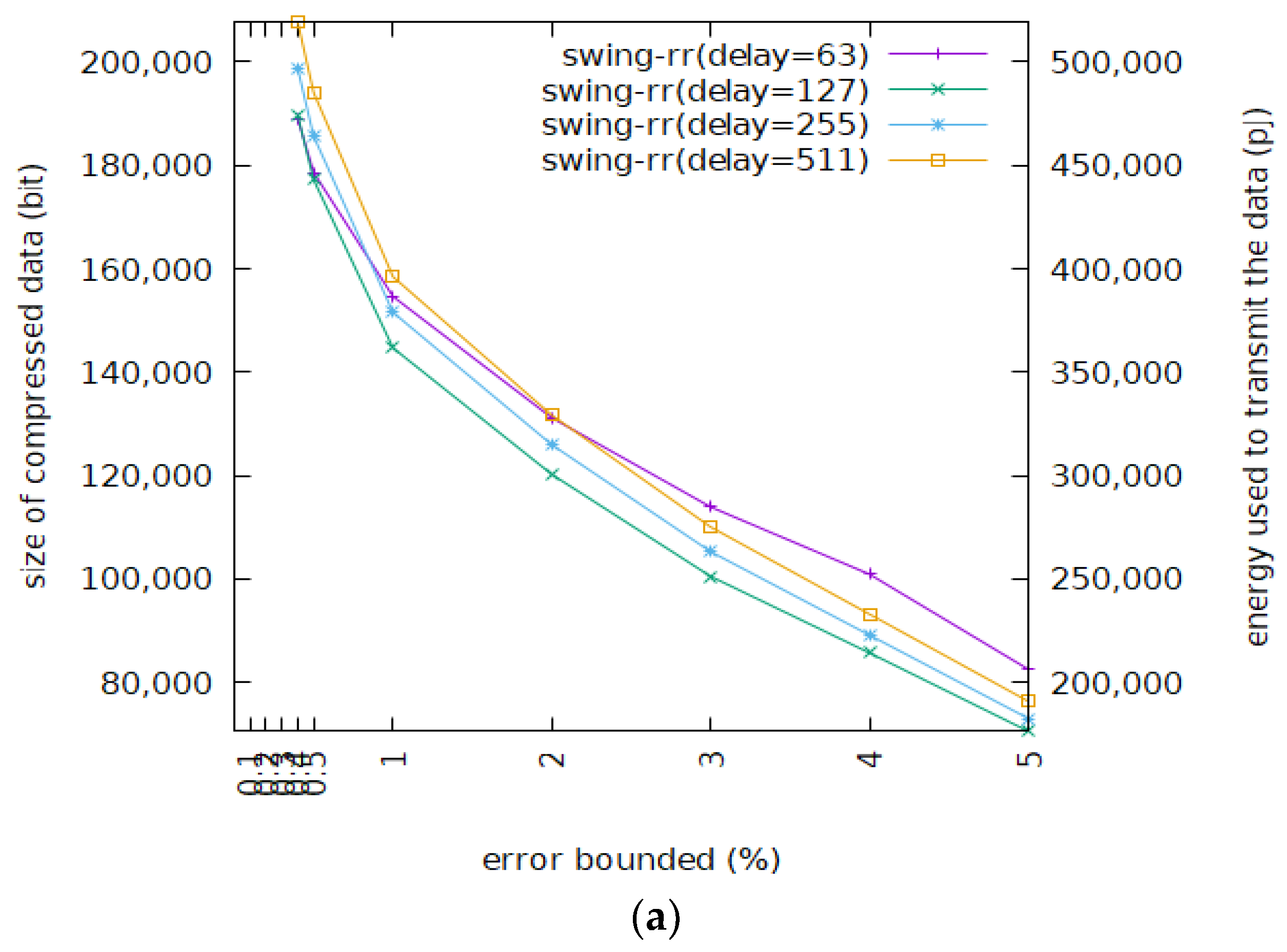
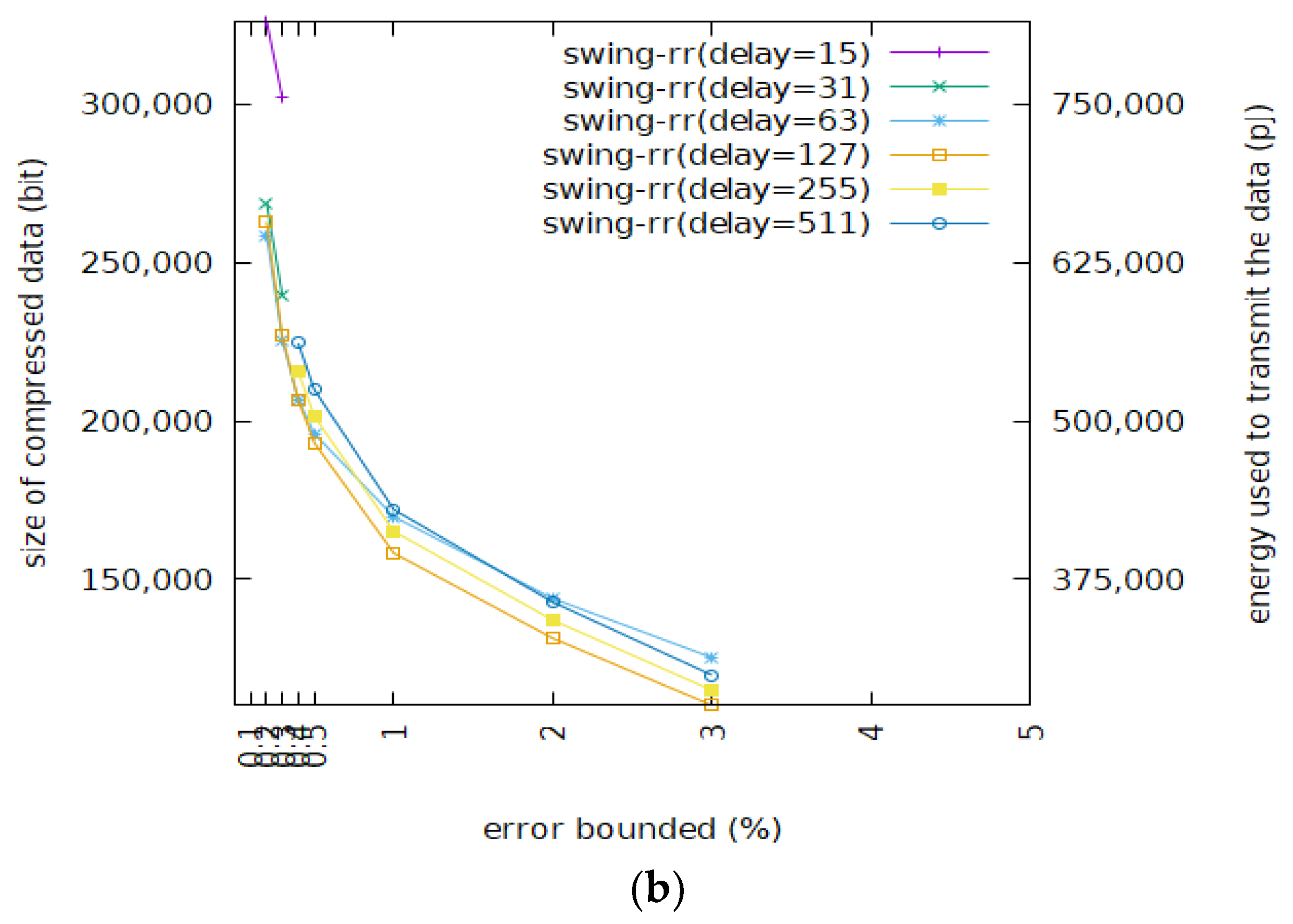
3.2. Compression Ratio
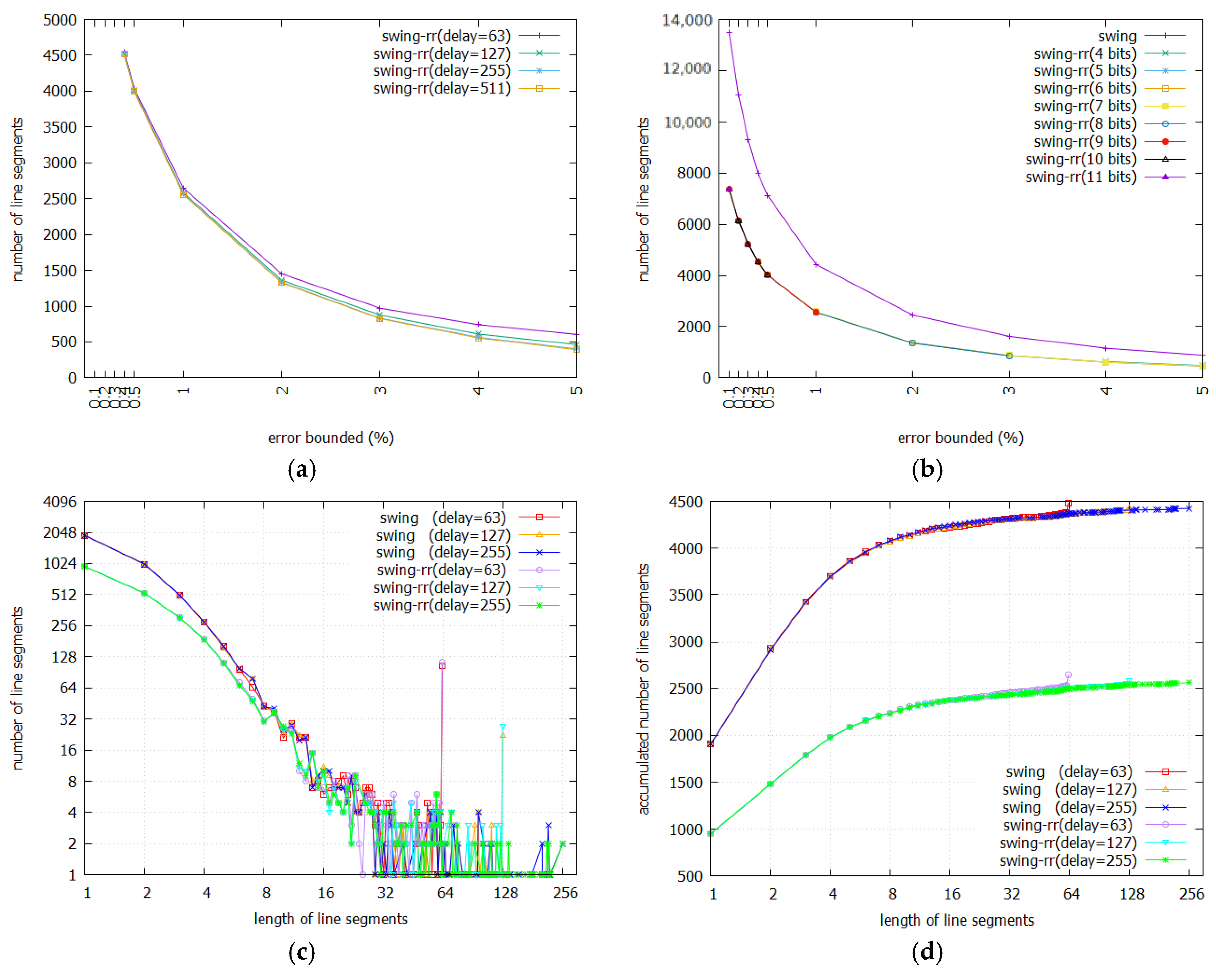
3.3. Number of Segments and Their Length
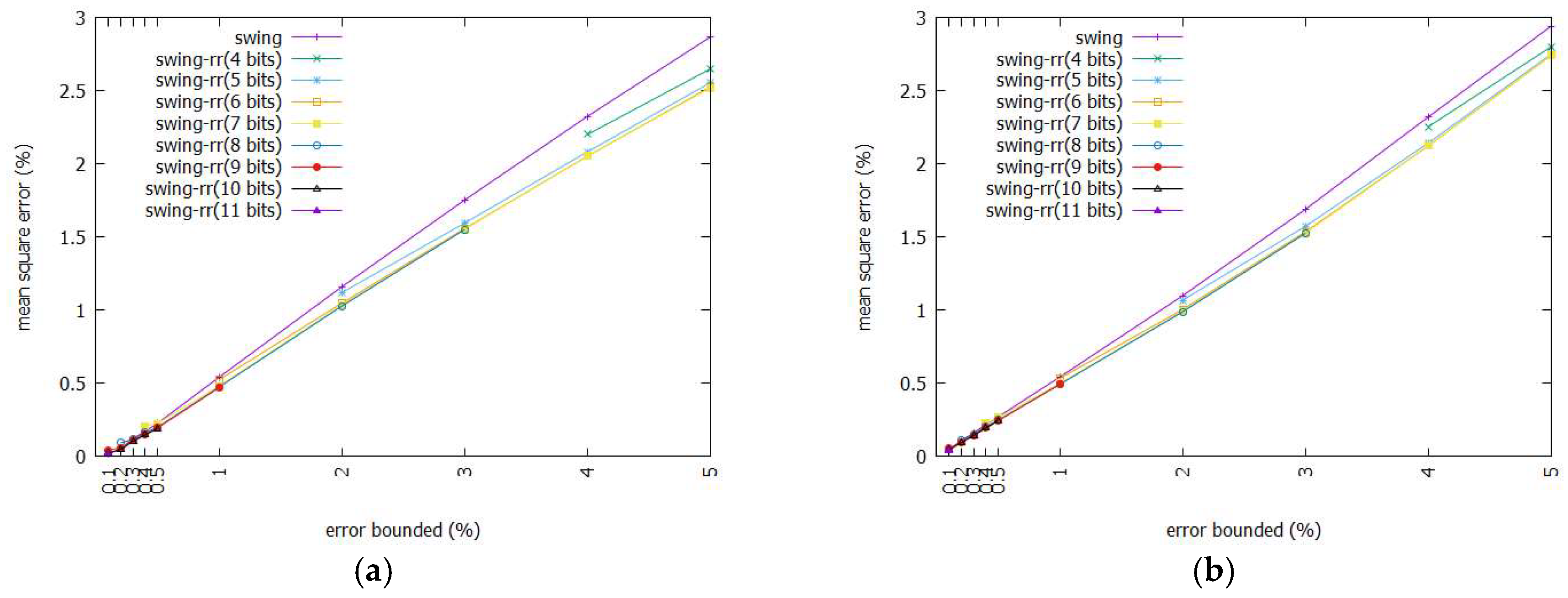
3.4. Mean Square Error
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wu, S.; Zuo, M.J. Linear and nonlinear preventive maintenance models. IEEE Trans. Reliab. 2010, 59, 242–249. [Google Scholar] [CrossRef]
- Shang, Y. Vulnerability of networks: Fractional percolation on random graphs. Phys. Rev. E 2014, 89, 012813. [Google Scholar] [CrossRef] [PubMed]
- Shehabi, A.; Smith, S.; Sartor, D.; Brown, R.; Herrlin, M.; Koomey, J.; Masanet, E.; Horner, N.; Azevedo, I.; Lintner, W. United States Data Center Energy Usage Report; LBNL-1005775; Lawrence Berkeley National Laboratory: Berkeley, CA, USA, 2016. [Google Scholar]
- Baliga, J.; Ayre, R.W.A.; Hinton, K.; Tucker, R.S. Green cloud computing: Balancing energy in processing, storage, and transport. Proc. IEEE 2011, 99, 149–167. [Google Scholar] [CrossRef]
- Huang, X.; Hu, T.; Ye, C.; Xu, G.; Wang, X.; Chen, L. Electric load data compression and classification based on deep stacked auto-encoders. Energies 2019, 12, 653. [Google Scholar] [CrossRef]
- Kawahara, M.; Chiu, Y.J.; Berger, T. High-speed software implementation of Huffman coding. In Proceedings of the 98th Data Compression Conference, Snowbird, UT, USA, 30 March–1 April 1998; p. 553. [Google Scholar]
- Marcelloni, F.; Vecchio, M. A simple algorithm for data compression in wireless sensor networks. IEEE Commun. Lett. 2008, 12, 411–413. [Google Scholar] [CrossRef]
- Javed, M.Y.; Nadeem, A. Data compression through adaptive Huffman coding schemes. In Proceedings of the IEEE TENCON 2000, Kuala Lumpur, Malaysia, 24–27 September 2000; pp. 187–190. [Google Scholar]
- Tharini, C.; Ranjan, P.V. Design of modified adaptive Huffman data compression algorithm for wireless sensor network. J. Comput. Sci. 2009, 5, 466–470. [Google Scholar] [CrossRef][Green Version]
- Lin, C.C.; Chuang, C.C.; Chiang, C.W.; Chang, R.I. A novel data compression method using improved JPEG-LS in wireless sensor networks. In Proceedings of the 12th International Conference on Advanced Communication Technology, Phoenix Park, Korea, 7–10 February 2010; pp. 346–351. [Google Scholar]
- Higgins, G.; Mc Ginley, B.; Glavin, M.; Jones, E. Low power compression of EEG signals using JPEG2000. In Proceedings of the 4th International Conference on Pervasive Computing Technologies for Healthcare, Munich, Germany, 22–25 March 2010. [Google Scholar]
- Bendifallah, A.; Benzid, R.; Boulemden, M. Improved ECG compression method using discrete cosine transform. Electron. Lett. 2011, 47, 1–2. [Google Scholar] [CrossRef]
- Chen, J.; Ma, J.; Zhang, Y.; Shi, X. A wavelet-based ECG compression algorithm using Golomb codes. In Proceedings of the 2006 IEEE International Conference on Communications, Circuits, and Systems, Guilin, China, 25–28 June 2006; pp. 130–133. [Google Scholar]
- Fang, J.; Li, H. Hyperplane-based vector quantization for distributed estimation in wireless sensor networks. IEEE Trans. Inf. Theory 2009, 55, 5682–5699. [Google Scholar] [CrossRef]
- Wang, Y.C.; Hsieh, Y.Y.; Tseng, Y.C. Multiresolution spatial and temporal coding in a wireless sensor network for long-term monitoring applications. IEEE Trans. Comput. 2009, 58, 827–838. [Google Scholar] [CrossRef]
- Makarenko, A.; Whyte, H.D. Decentralized data fusion and control in active sensor networks. In Proceedings of the 7th International Conference on Information Fusion, Stockholm, Sweden, 28 June–1 July 2004; pp. 479–486. [Google Scholar]
- Yuan, W.; Krishnamurthy, S.V.; Tripathi, S.K. Synchronization of multiple levels of data fusion in wireless sensor networks. In Proceedings of the IEEE Global Telecommunications Conference, Riverside, CA, USA, 1 December 2003; pp. 221–225. [Google Scholar]
- Sharaf, M.A.; Beaver, J.; Labrinidis, A.; Chrysanthis, P.K. TiNA: A scheme for temporal coherency-aware in-network aggregation. In Proceedings of the 3rd ACM International Workshop on Data Engineering for Wireless and Mobile Access, Pittsburgh, PA, USA, 19 September 2003; pp. 69–76. [Google Scholar]
- Yoon, S.; Shahabi, C. The clustered aggregation (CAG) technique leveraging spatial and temporal correlations in wireless sensor networks. ACM Trans. Sens. Netw. 2007, 3, 3. [Google Scholar] [CrossRef]
- Goel, S.; Imielinski, T. Prediction-based monitoring in sensor network: Taking lessons from MPEG. Comput. Commun. Rev. 2001, 31, 82–98. [Google Scholar] [CrossRef]
- Choi, K.; Kim, M.H.; Chae, K.J.; Park, J.J.; Joo, S.S. An efficient data fusion and assurance mechanism using temporal and spatial correlations for home automation networks. IEEE Trans. Consum. Electron. 2009, 55, 1330–1336. [Google Scholar] [CrossRef]
- Luo, H.; Luo, J.; Liu, Y.; Das, S.K. Adaptive data fusion for energy efficient routing in wireless sensor networks. IEEE Trans. Comput. 2006, 55, 1286–1299. [Google Scholar]
- Kumar, R.; Wolenetz, M.; Agarwalla, B.; Shin, J.; Hutto, P.; Paul, A.; Ramachandran, U. DFuse: A framework for distributed data fusion. In Proceedings of the 1st ACM International Conference on Embedded Networked Sensor Systems, Los Angeles, CA, USA, 5 November 2003; pp. 114–125. [Google Scholar]
- Jin, G.Y.; Park, M.S. CAC: Context adaptive clustering for efficient data aggregation in wireless sensor networks. Lect. Notes Comput. Sci. 2006, 3976, 1132–1137. [Google Scholar]
- Lee, S.; Yoo, J.; Chung, T. Distance-based energy efficient clustering for wireless sensor networks. In Proceedings of the 29th Annual IEEE International Conference on Local Computer Networks, Tampa, FL, USA, 16–18 November 2004; pp. 567–568. [Google Scholar]
- Chang, R.I.; Li, M.H.; Chuang, P.; Lin, J.W. Bounded error data compression and aggregation in wireless sensor networks. In Smart Sensors Networks, Communication Technologies and Intelligent Applications; A Volume in Intelligent Data-Centric Systems; Xhafa, F., Leu, F.Y., Hung, L.L., Eds.; Elsevier: London, UK, 2017; pp. 143–157. [Google Scholar]
- Hakimi, S.L.; Schmeichel, E.F. Fitting polygonal functions to a set of points in the plane. CVGIP Graph. Models Image Proc. 1991, 53, 132–136. [Google Scholar] [CrossRef]
- Imai, H.; Iri, M. An optimal algorithm for approximating a piecewise linear function. J. Inf. Proc. 1986, 9, 159–162. [Google Scholar]
- Xie, Q.; Pang, C.; Zhou, X.; Zhang, X.; Deng, K. Maximum error-bounded piecewise linear representation for online stream approximation. VLDB J. 2014, 23, 915–937. [Google Scholar] [CrossRef]
- Zhao, H.; Dong, Z.; Li, T.; Wang, X.; Pang, C. Segmenting time series with connected lines under maximum error bound. Inf. Sci. 2016, 345, 1–8. [Google Scholar] [CrossRef]
- Elmeleegy, H.; Elmagarmid, A.K.; Cecchet, E.; Aref, W.G.; Zwaenepoel, W. Online piece-wise linear approximation of numerical streams with precision guarantees. Proc. VLDB Endow. 2009, 2, 145–156. [Google Scholar] [CrossRef]
- O’Rourke, J. An on-line algorithm for fitting straight lines between data ranges. Commun. ACM 1981, 24, 574–578. [Google Scholar] [CrossRef]
- Gritzali, F.; Papakonstantinou, G. A fast piecewise linear approximation algorithm. Signal Proc. 1983, 5, 221–227. [Google Scholar] [CrossRef]
- Luo, G.; Yi, K.; Cheng, S.W.; Li, Z.; Fan, W.; He, C.; Mu, Y. Piecewise linear approximation of streaming time series data with max-error guarantees. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Korea, 13–17 April 2015; pp. 173–184. [Google Scholar]
- Malash, G.F.; El-Khaiary, M.I. Piecewise linear regression: A statistical method for the analysis of experimental adsorption data by the intraparticle-diffusion models. Chem. Eng. J. 2010, 163, 256–263. [Google Scholar] [CrossRef]
- Shang, Y. Resilient multiscale coordination control against adversarial nodes. Energies 2018, 11, 1844. [Google Scholar] [CrossRef]
- Chen, Y.; Keogh, E.; Hu, B.; Begum, N.; Bagnall, A.; Mueen, A.; Batista, G. The UCR Time Series Classification Archive 2015. Available online: http://www.cs.ucr.edu/~eamonn/time_series_data/ (accessed on 7 July 2018).
- IEEE Computer Society. IEEE Standard for Floating-Point Arithmetic. Available online: IEEE Standard 754-2008. https://ieeexplore.ieee.org/document/4610935 (accessed on 7 July 2018).
- Walke, W.W.; Hidaka, Y. Next-Generation Interconnect Research at Fujitsu Laboratories. Fujitsu Sci. Technol. J. 2012, 48, 218–222. [Google Scholar]
- Clauset, A.; Shalizi, C.R.; Newman, M.E.J. Power-law distributions in empirical data. SIAM Rev. 2009, 51, 661–703. [Google Scholar] [CrossRef]
- Shang, Y. Subgraph robustness of complex networks under attacks. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 821–832. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Error Bound (%) | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 1 | 2 | 3 | 4 | 5 |
| Minimal Resolution (Bits) | 9 | 8 | 8 | 7 | 7 | 6 | 5 | 5 | 4 | 4 |
| Dataset | Length | Minimal | Maximal |
|---|---|---|---|
| Cricket_X | 117,000 | −4.766200 | 11.494000 |
| Cricket_Y | 117,000 | −9.774500 | 6.838500 |
| Cricket_Z | 117,000 | −4.758300 | 11.924000 |
| FaceFour | 30,800 | −4.687600 | 5.908100 |
| Lignting2 | 38,220 | −1.396000 | 23.131000 |
| Lignting7 | 22,330 | −1.781200 | 17.413000 |
| MoteStrain | 105,168 | −8.409300 | 2.468400 |
| wafer | 152,000 | −3.054000 | 11.787000 |
| Error Bound (ε) | Resolution | Maximal Delay |
|---|---|---|
| 0.1% | 9, 10, 11 | 15, 31, 63, 127 |
| 0.2% | 8, 9, 10 | 15, 31, 63, 127 |
| 0.3% | 8, 9, 10 | 15, 31, 63, 127 |
| 0.4% | 7, 8, 9, 10 | 63, 127, 255, 511 |
| 0.5% | 7, 8, 9, 10 | 63, 127, 255, 511 |
| 1% | 6, 7, 8, 9 | 63, 127, 255, 511 |
| 2% | 5, 6, 7, 8 | 63, 127, 255, 511 |
| 3% | 5, 6, 7, 8 | 63, 127, 255, 511 |
| 4% | 4, 5, 6, 7 | 63, 127, 255, 511 |
| 5% | 4, 5, 6, 7 | 63, 127, 255, 511 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, J.-W.; Liao, S.-w.; Leu, F.-Y. Sensor Data Compression Using Bounded Error Piecewise Linear Approximation with Resolution Reduction. Energies 2019, 12, 2523. https://doi.org/10.3390/en12132523
Lin J-W, Liao S-w, Leu F-Y. Sensor Data Compression Using Bounded Error Piecewise Linear Approximation with Resolution Reduction. Energies. 2019; 12(13):2523. https://doi.org/10.3390/en12132523
Chicago/Turabian StyleLin, Jeng-Wei, Shih-wei Liao, and Fang-Yie Leu. 2019. "Sensor Data Compression Using Bounded Error Piecewise Linear Approximation with Resolution Reduction" Energies 12, no. 13: 2523. https://doi.org/10.3390/en12132523
APA StyleLin, J.-W., Liao, S.-w., & Leu, F.-Y. (2019). Sensor Data Compression Using Bounded Error Piecewise Linear Approximation with Resolution Reduction. Energies, 12(13), 2523. https://doi.org/10.3390/en12132523