A State of Health Estimation Framework for Lithium-Ion Batteries Using Transfer Components Analysis



Abstract
1. Introduction
2. Applied Approaches
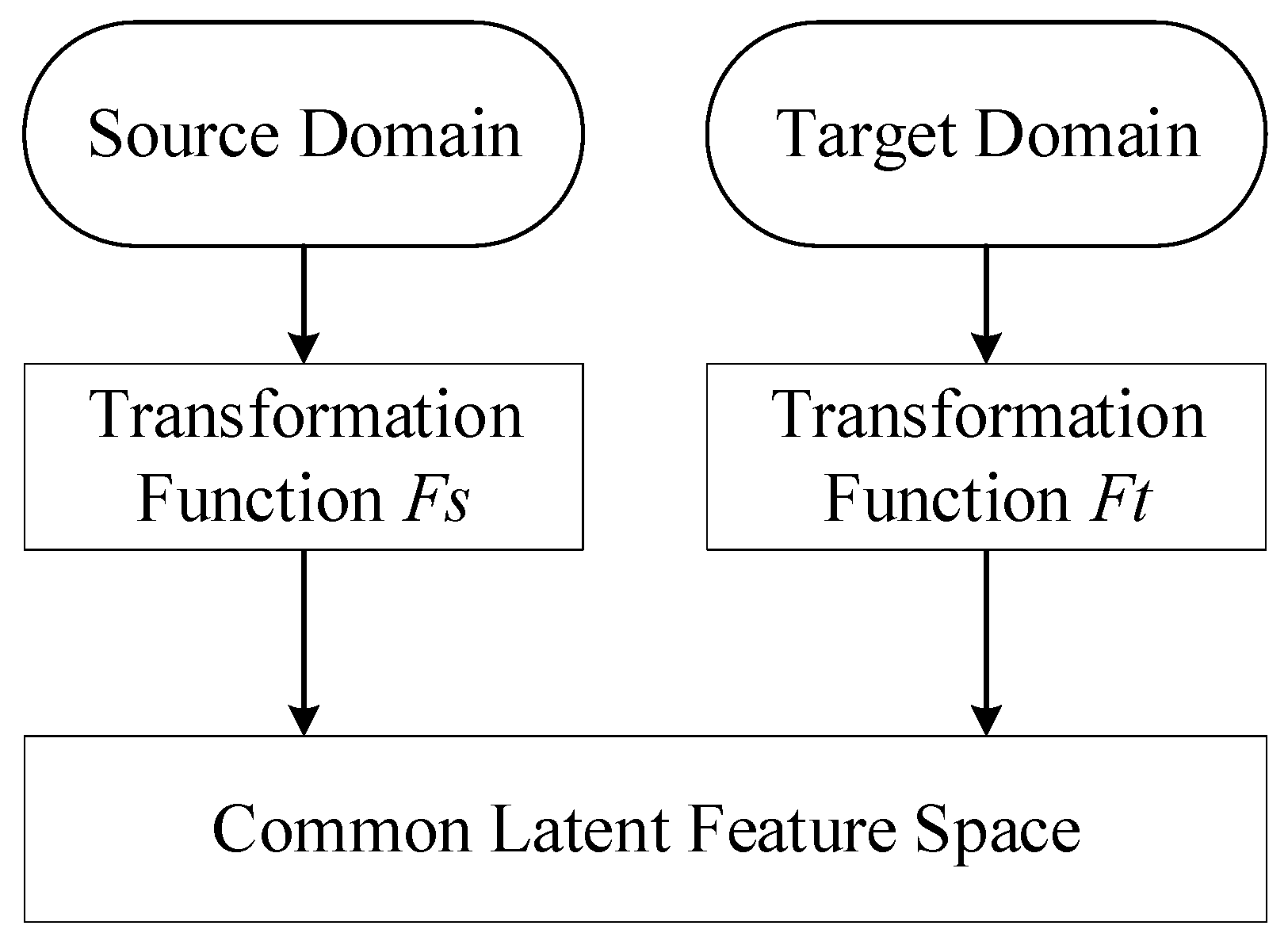
2.1. Domain Adaptation
2.2. Training Algorithm of Neural Network
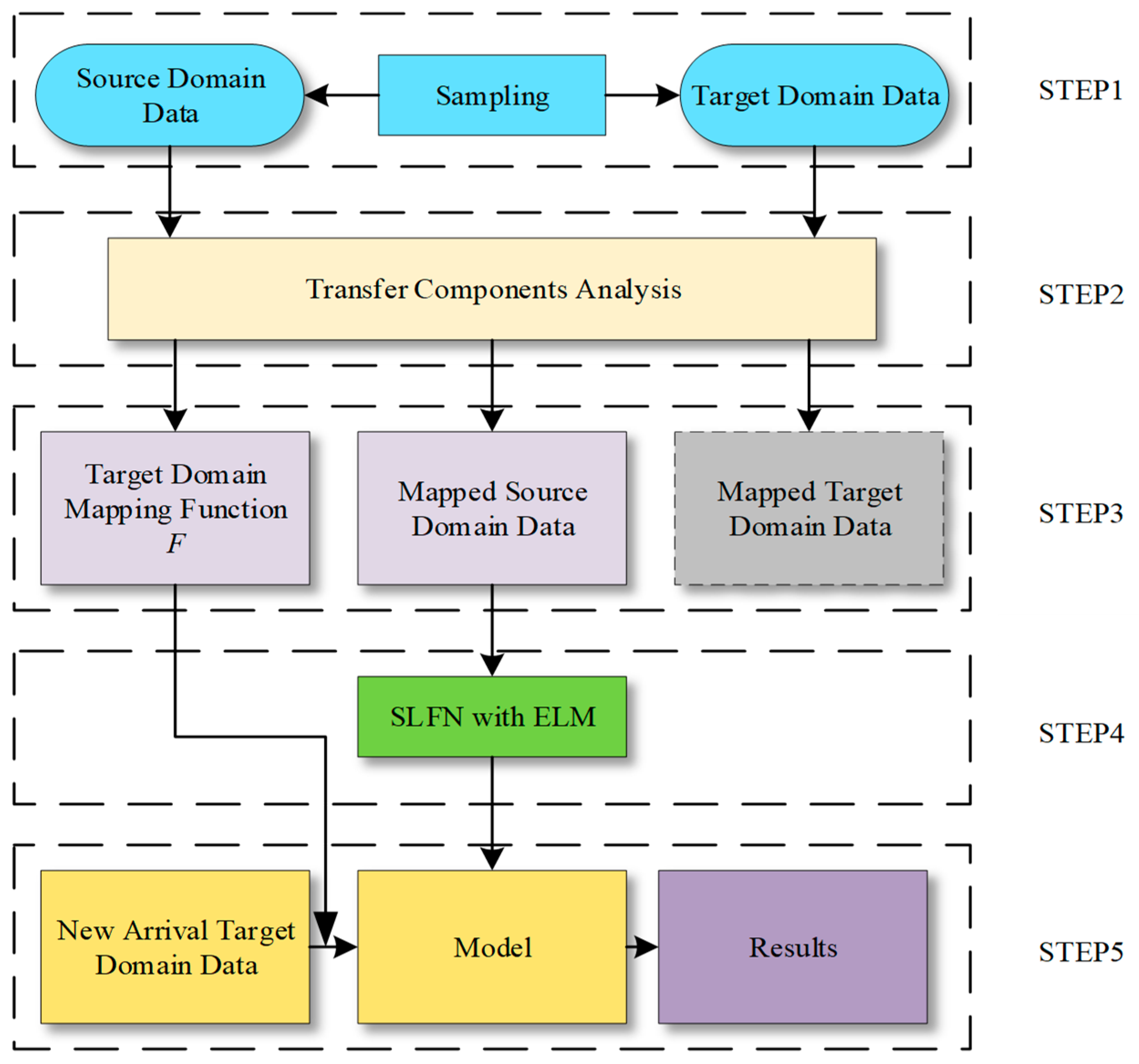
2.3. Framework for Prediction
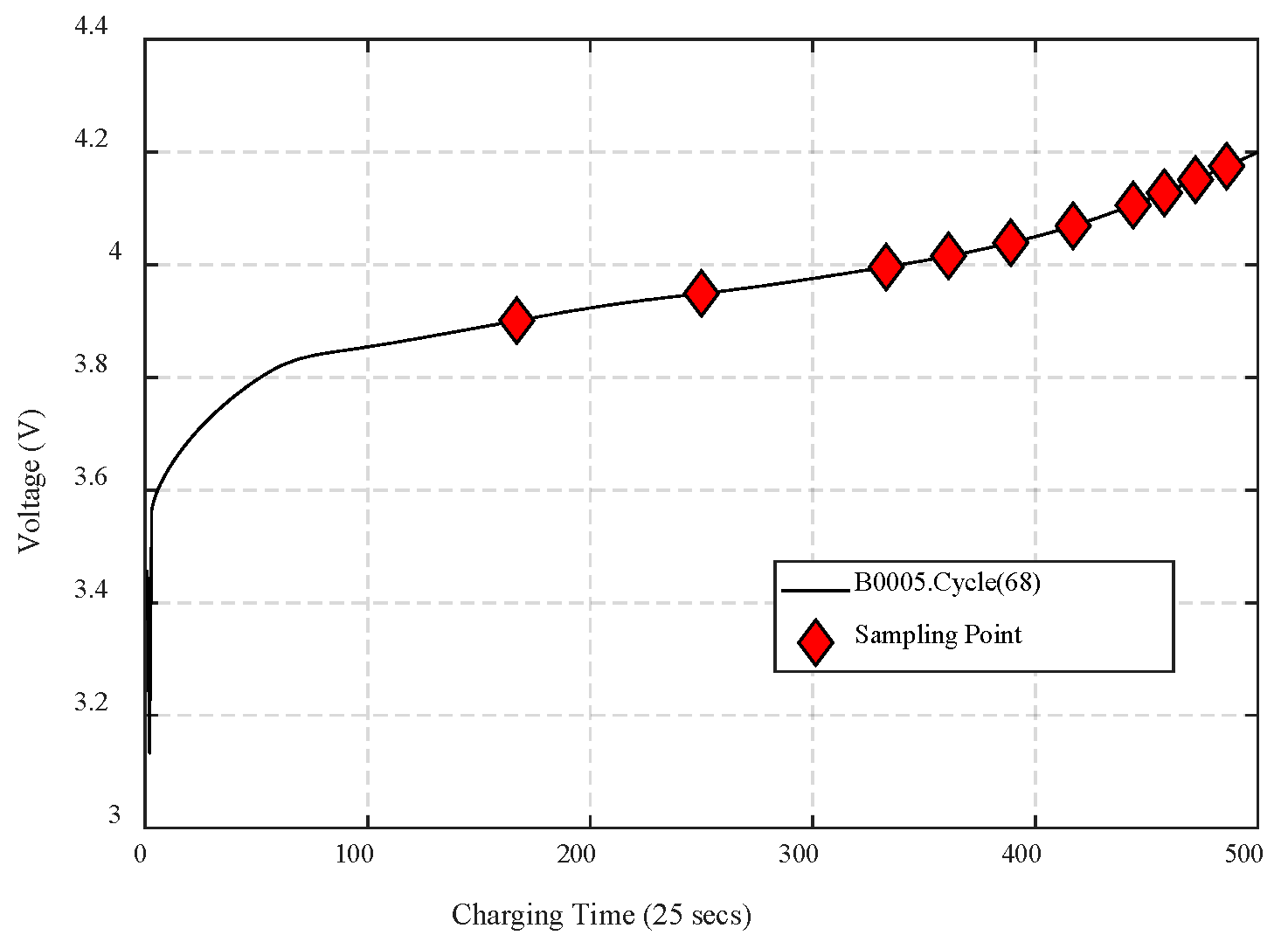
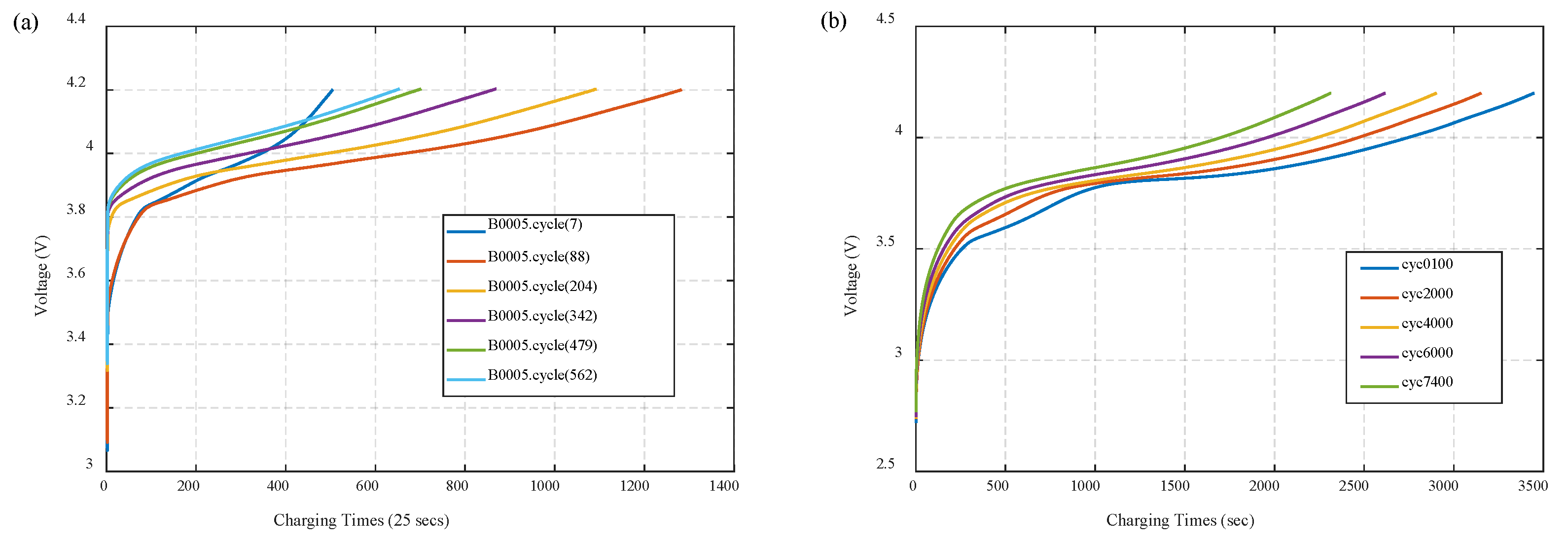
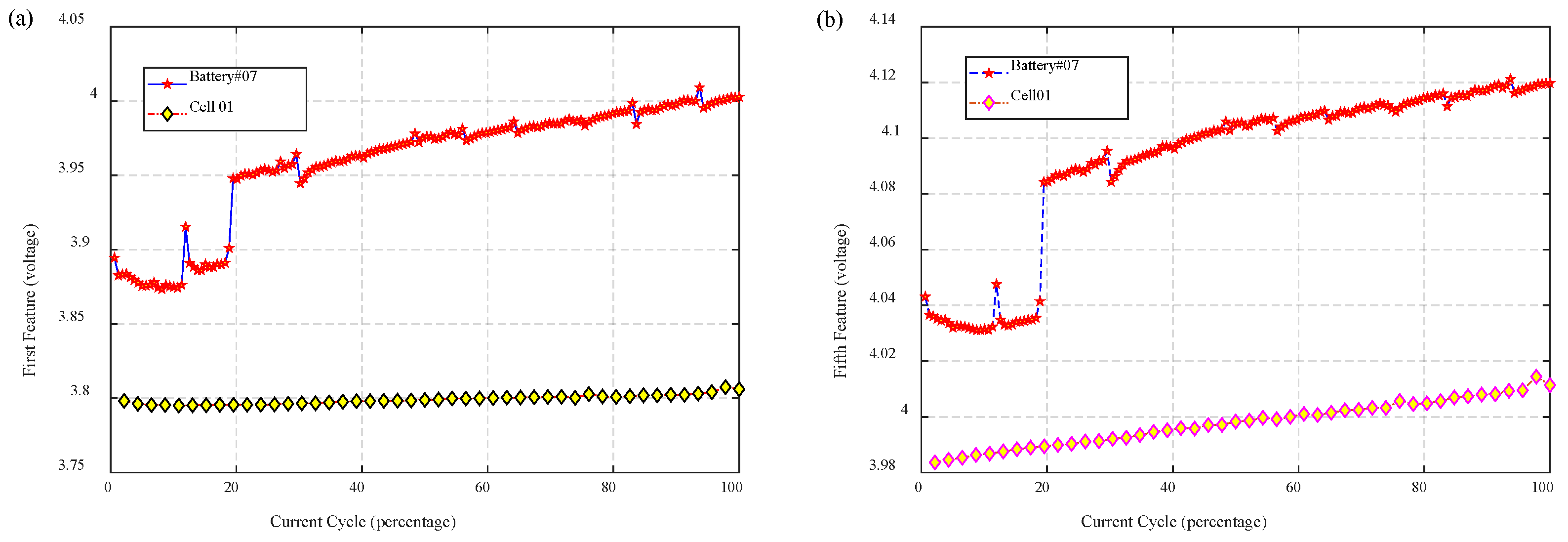
- To begin with, the complete degradation data of source battery and the previous parts of the target battery data are needed. Features are extracted from the raw data of charging voltage of batteries according to the scheme of IS. As is shown in Figure 4, the data in the middle and posterior parts, especially the latter part, have relatively large differences.
- The employment of the TCA algorithm is shown in this step. The calculation process of TCA is shown in Section 2.1. First, the input are two feature matrices from source and target domains. Then, calculate the L and H matrices according to Equation (5) and Equation (9). Then, we need to choose a kernel function to calculate the K matrix. In this paper, the Gaussian kernel function in the radial basis function (RBF) is chosen, for its lower computational cost and shorter computation time.where is the bandwidth of the Gaussian kernel function.Then, the ranked top dth eigenvalues of are the source and target domain data we need.
- After TCA processing, the mapped source domain data, the mapped target domain data, and the function used to map the new arrival target domain data are obtained. Among them, the labels of mapped target domain data remain unknown, because the SOH of target battery is unable to obtain at this moment. For this sack, this part of the data is not used. On the other hand, the source domain data are complete after being mapped. Therefore, it can be used to train an effective model.
- In this step, an SLFN model based on the ELM training algorithm described in Section 2.2 is trained. In this paper, the activation function of the hidden layer is a sigmoid function:For any one of the mapped source domain sample data, it can be formulated as follows:Because of the regression problem, the output of the network has only one neural node and the output is the predicted value. Then, in the context of our application of ELM to predict lithium battery SOH, the output layer only needs one output neuron . It can be given as follows:where M is the number of hidden layer neurons in the SLFN and needs to be manually selected.
- In this step, new arrival target domain data are predicted by a formerly well-trained model. The trained model has different numbers of input neurons with target domain data. Therefore, new arrival target domain data should be mapped by TCA. In an experimental environment, the data sets in use have integrated data of both the source domain and target domain, which can be mapped together by TCA at once. However, in the actual application process, this is not feasible. The newly generated target domain data need to be mapped into the new space by the mapping function F in STEP3. After the new data are mapped to previous latent space, the model can be used to get the desired SOH predictions.
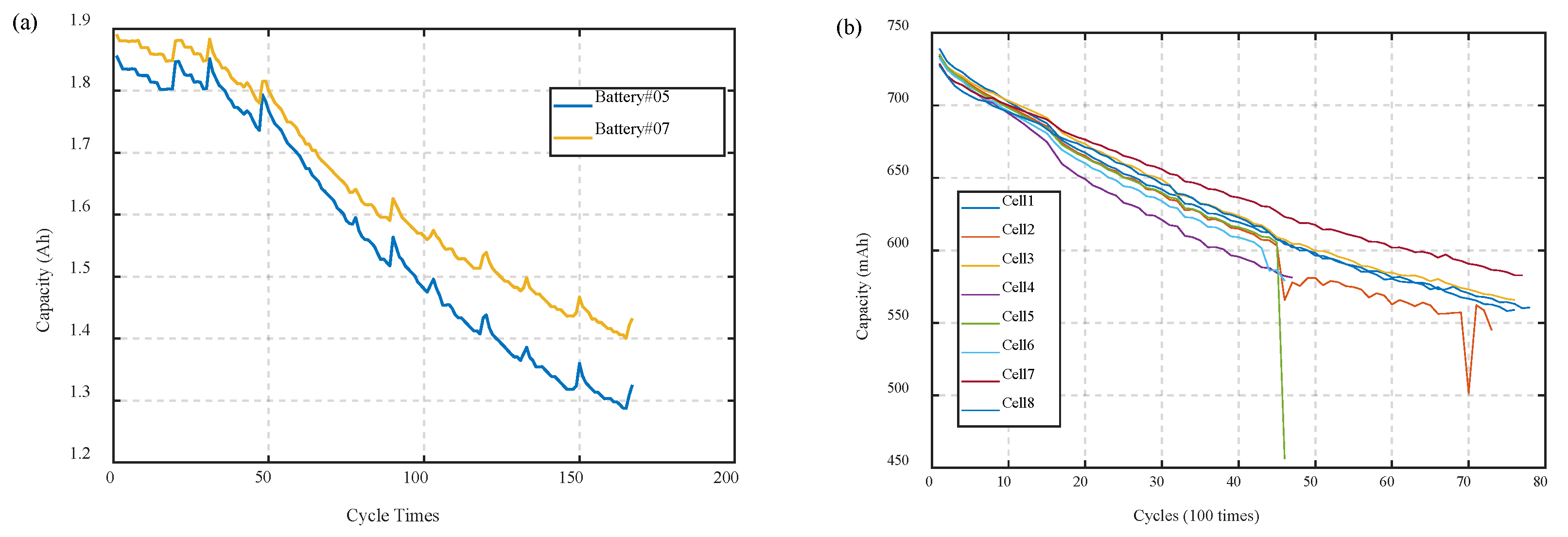
3. Battery Datasets and Experimental Setup
4. Results and Corresponding Discussion
4.1. ELM Effectiveness Experiments
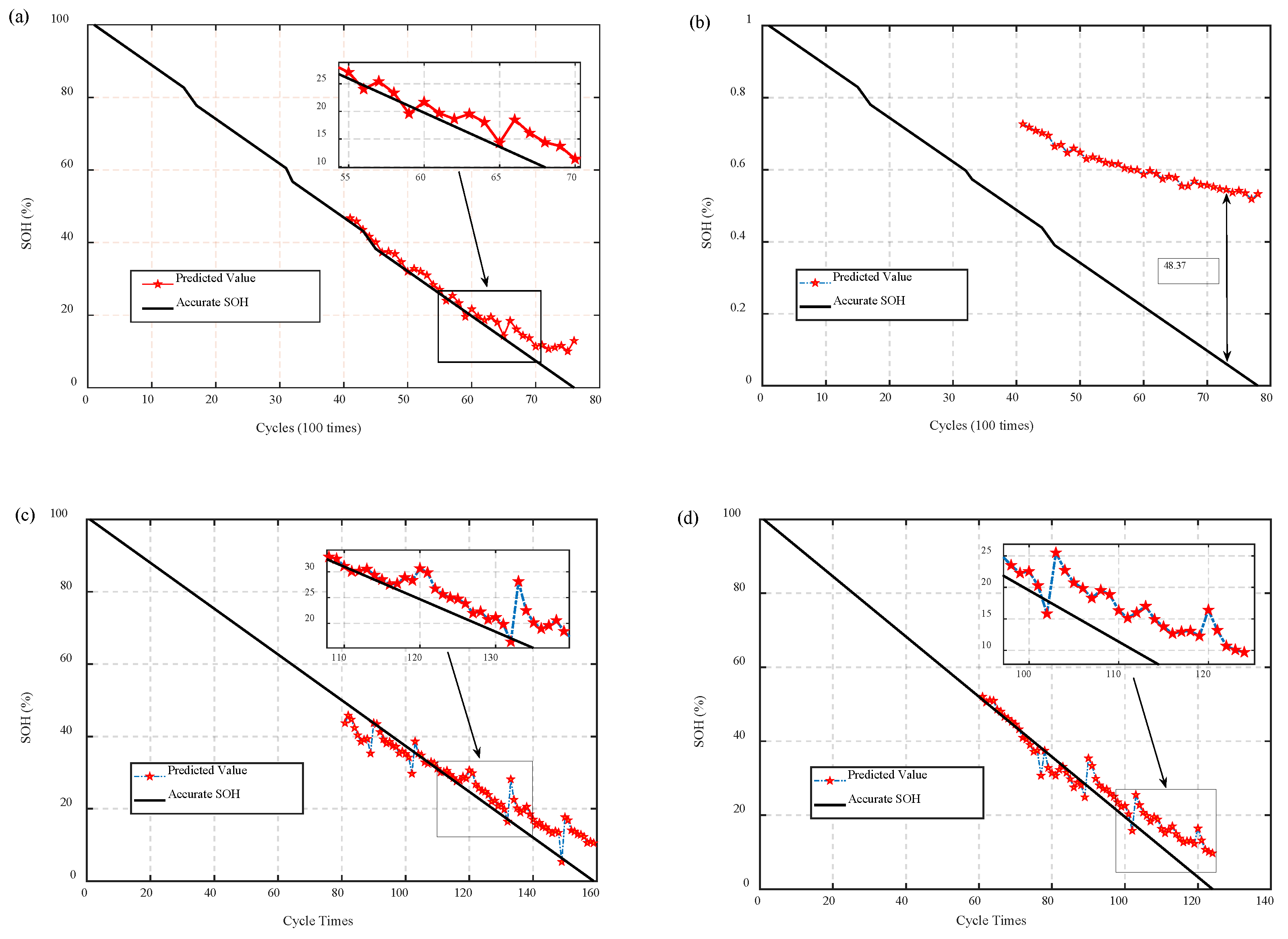
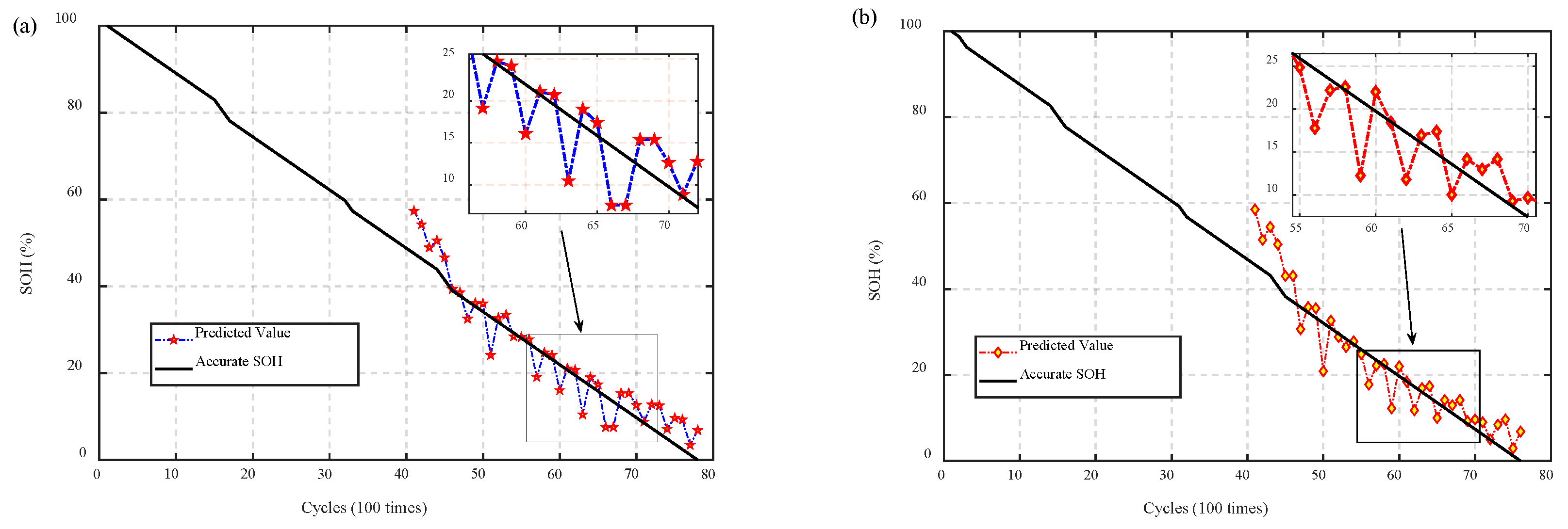
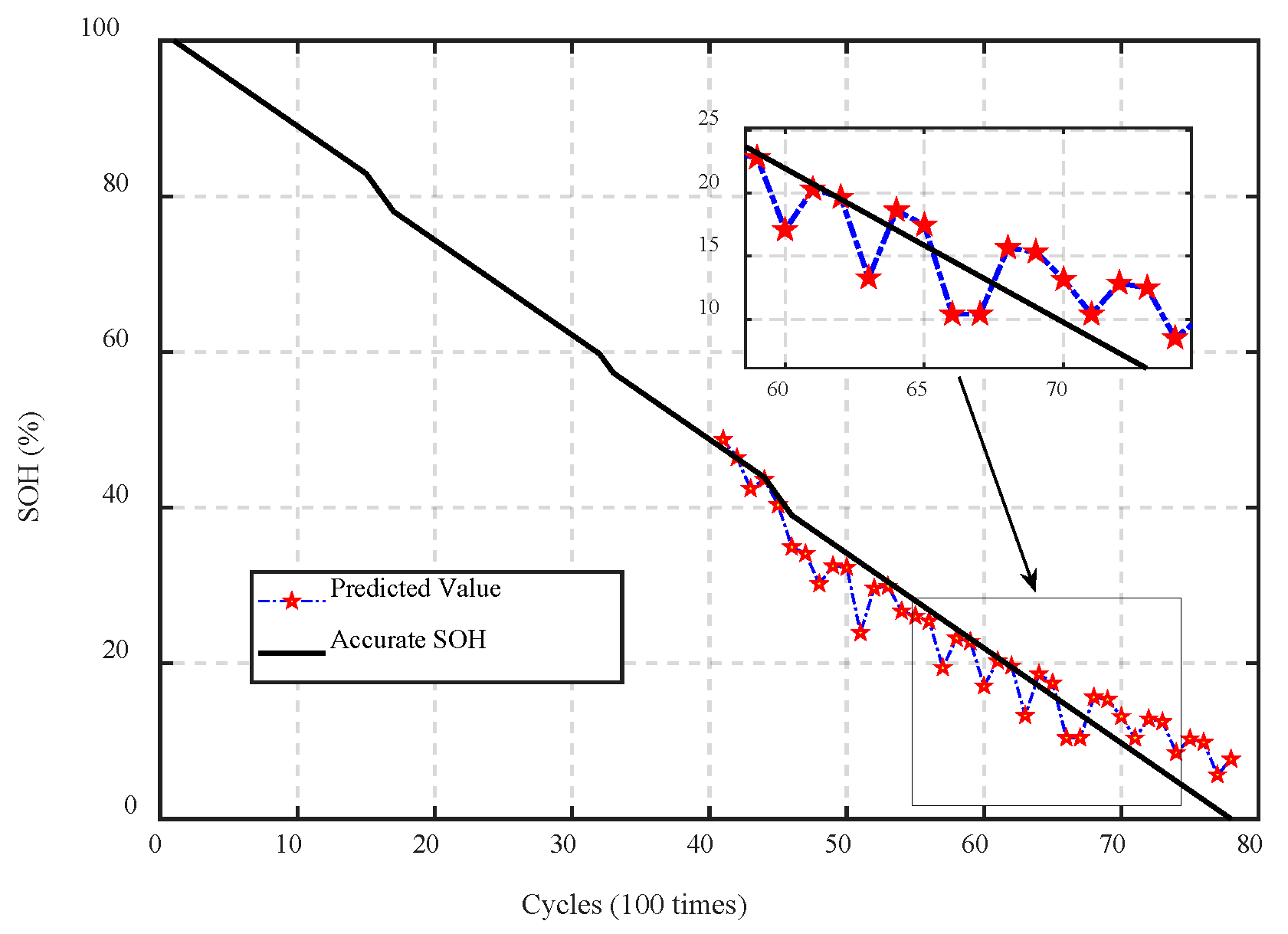
4.2. Transfer Experiment
4.3. Discussion of PCoE Dataset
4.4. Percentage of Mapping Data
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Xiong, R.; Cao, J. Critical review on the battery state of charge estimation methods for electric vehicles. IEEE Access 2018, 6, 1832–1843. [Google Scholar] [CrossRef]
- Hossain, L.S.; Hannan, M.A. A review of state of health and remaining useful life estimation methods for lithium-ion battery in electric vehicles: Challenges and recommendations. J. Clean. Prod. 2018, 205, 115–133. [Google Scholar]
- Watrin, N.; Blunier, B. Review of adaptive systems for lithium batteries State-of-Charge and State-of-Health estimation. In Proceedings of the 2012 IEEE Transportation Electrification Conference and Expo (ITEC), Dearborn, MI, USA, 18–20 June 2012. [Google Scholar]
- Zhang, J.; Lee, J. A review on prognostics and health monitoring of Li-ion battery. J. Power Sources 2011, 196, 6007–6014. [Google Scholar] [CrossRef]
- Zheng, X.; Fang, H. An integrated unscented kalman filter and relevance vector regression approach for lithium-ion battery remaining useful life and short-term capacity prediction. J. Rel. Eng. Syst. Saf. 2015, 144, 74–82. [Google Scholar] [CrossRef]
- Mingant, R.; Bernard, J. Novel state-of-health diagnostic method for Li-ion battery in service. J. Appl. Energy 2016, 183, 390–398. [Google Scholar] [CrossRef]
- Zhang, F.; Liu, G.J. Battery state estimation using unscented kalman filter. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 1863–1868. [Google Scholar]
- Fang, L.; Li, J. Online Estimation and Error Analysis of both SOC and SOH of Lithium-ion Battery based on DEKF Method. Energy Procedia 2019, 158, 3008–3013. [Google Scholar]
- Andre, D.A.; Christian, S.G. Advanced mathematical methods of SOC and SOH estimation for lithium-ion batteries. J. Power Sources 2013, 224, 20–27. [Google Scholar] [CrossRef]
- Hannan, M.A.; Lipu, M.H. Neural Network Approach for Estimating State of Charge of Lithium-ion Battery Using Backtracking Search Algorithm. IEEE Access 2018, 6, 10069–10079. [Google Scholar] [CrossRef]
- Civicioglu, P. Backtracking search optimization algorithm for numerical optimization problems. Appl. Math. Comput. 2013, 219, 8121–8144. [Google Scholar] [CrossRef]
- Jungsoo, K.; Jungwook, Y. Estimation of Li-ion Battery State of Health based on Multilayer Perceptron: As an EV Application. IFAC-PapersOnLine 2018, 51, 392–397. [Google Scholar]
- Zhiwei, H.; Mingyu, G. Online state-of-health estimation of lithium-ion batteries using Dynamic Bayesian Networks. J. Power Sources 2014, 267, 576–583. [Google Scholar]
- Zhang, Y.; Xiong, R. Long short-term memory recurrent neural network for remaining useful life prediction of lithium-ion batteries. IEEE Trans. Veh. Technol. 2018, 67, 5695–5705. [Google Scholar] [CrossRef]
- Liu, J.; Saxena, A. An adaptive recurrent neural network for remaining useful life prediction of lithium-ion batteries. In Proceedings of the Annual Conference of the Prognostics and Health Management Society, Portland, OR, USA, 10–16 October 2010. [Google Scholar]
- Wu, J.; Zhang, C. An online method for lithium-ion battery remaining useful life estimation using importance sampling and neural networks. Appl. Energy 2016, 173, 134–140. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W. Deep Visual Domain Adaptation: A Survey. J. Neurocomput. 2018, 312, 135–153. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Pan, S.J.; Kwok, J.T. Transfer Learning via Dimensionality Reduction. In Proceedings of the 23rd National Conference on Artificial Intelligence (AAAI’08), Chicago, IL, USA, 13–17 July 2008. [Google Scholar]
- Schölkopf, B.; Smola, A. Nonlinear component analysis as a kernel eigenvalue problem. J. Neural Comput. 1998, 10, 1299–1319. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No.04CH37541), Budapest, Hungary, 25–29 July 2004. [Google Scholar]
- Huang, G.B. Learning capability and storage capacity of two-hidden-layer feedforward networks. IEEE Trans. Neural Netw. 2003, 14, 274–281. [Google Scholar] [CrossRef] [PubMed]
- Saha, B.; Goebel, K. “Battery Data Set”, NASA Ames Prognostics Data Repository. Available online: https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/#battery (accessed on 27 June 2019).
- Birkl, C. Oxford Battery Degradation Dataset 1. University of Oxford. Available online: https://ora.ox.ac.uk/objects/uuid:03ba4b01-cfed-46d3-9b1a-7d4a7bdf6fac (accessed on 27 June 2019).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set Test Set | Cell1 Cell3 | Cell1 Cell7 | Cell1 Cell8 |
|---|---|---|---|
| MAE | 1.59% | 2.57% | 2.67% |
| RMSE | 3.19% | 4.62% | 4.53% |
| Source Domain Target Domain | #05 Cell1 | #05 Cell3 | #05 Cell7 | #05 Cell8 |
|---|---|---|---|---|
| MAE | 2.10% | 2.39% | 1.79% | 1.98% |
| RMSE | 3.51% | 3.88% | 3.29% | 3.65% |
| Time Cost (s) | 0.0307 | 0.0286 | 0.0274 | 0.0283 |
| Source Domain Target Domain | #07 Cell1 | #07 Cell3 | #07 Cell7 | #07 Cell8 |
|---|---|---|---|---|
| MAE | 1.87% | 2.08% | 1.78% | 2.65% |
| RMSE | 3.16% | 3.39% | 3.62% | 4.83% |
| Time Cost (s) | 0.0287 | 0.0284 | 0.0285 | 0.0307 |
| Percentage | 30% (24/78) | 35% (27/78) | 40% (31/78) | 45% (35/78) | 50% (39/78) | 55% (43/78) | 60% (47/78) |
|---|---|---|---|---|---|---|---|
| MAE | 3.40% | 3.60% | 2.83% | 2.86% | 2.07% | 1.95% | 1.47% |
| RMSE | 5.27% | 5.66% | 4.62% | 4.81% | 3.71% | 3.56% | 2.84% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, B.; Guan, Y.; Wu, L. A State of Health Estimation Framework for Lithium-Ion Batteries Using Transfer Components Analysis. Energies 2019, 12, 2524. https://doi.org/10.3390/en12132524
Jia B, Guan Y, Wu L. A State of Health Estimation Framework for Lithium-Ion Batteries Using Transfer Components Analysis. Energies. 2019; 12(13):2524. https://doi.org/10.3390/en12132524
Chicago/Turabian StyleJia, Bowen, Yong Guan, and Lifeng Wu. 2019. "A State of Health Estimation Framework for Lithium-Ion Batteries Using Transfer Components Analysis" Energies 12, no. 13: 2524. https://doi.org/10.3390/en12132524
APA StyleJia, B., Guan, Y., & Wu, L. (2019). A State of Health Estimation Framework for Lithium-Ion Batteries Using Transfer Components Analysis. Energies, 12(13), 2524. https://doi.org/10.3390/en12132524