Research and Application of a Hybrid Wind Energy Forecasting System Based on Data Processing and an Optimized Extreme Learning Machine


Abstract
1. Introduction
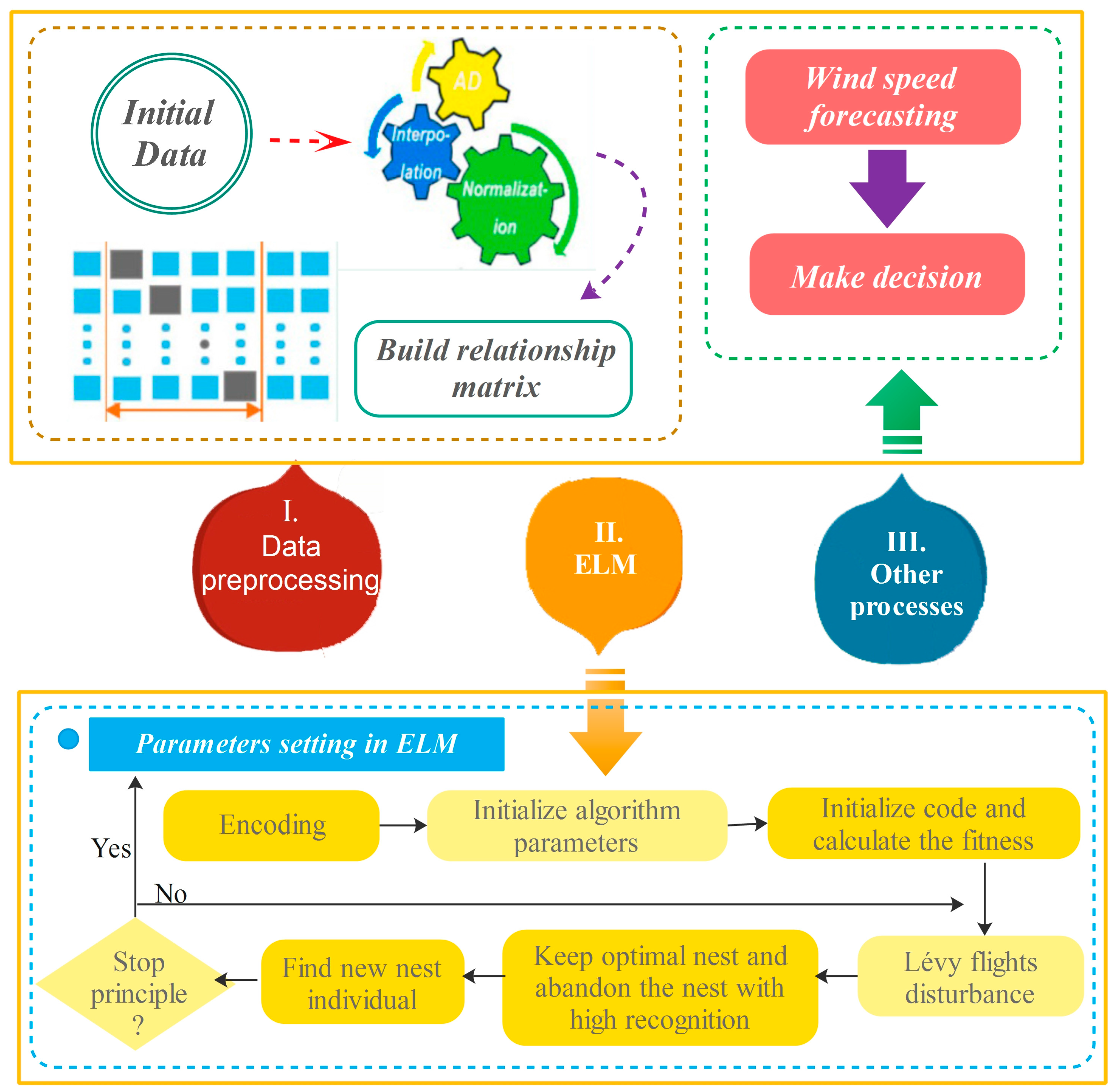
- In the data preprocessing module, the Dynamic absolute mean value method and Cubic Spline interpolation is employed to eliminate outliers and process the missing data, respectively. The Dynamic absolute mean value method can define the scope of outliers effectively by setting the value of the segmentation length and the coefficient. Cubic Spline interpolation not only can overcome the defects in high-order polynomial interpolation but also can guarantee a certain smoothness of piecewise interpolation.
- In the algorithm optimization module, the ELM algorithm is optimized by the Cuckoo Search algorithm. The Cuckoo Search algorithm is abstracted to solve various optimization problems by simulating the nest parasitic behavior in the natural world. In the paper, it is used to optimize the initial weight of ELM and then increase the forecasting accuracy.
- In the wind speed forecasting module, an innovative hybrid system which successfully takes advantages of CSELM algorithm and SGA algorithm is proposed. Then, according to this, we conduct an empirical analysis on the wind speed of Dangjin Mountain located in Akesai, China. The combined system can provide more accurate and stable wind speed forecasting results compared with traditional forecasting models.
- A more scientific and comprehensive evaluation is conducted to estimate the performance of the developed forecasting system in this paper. The evaluation system contains the performance of the whole research process including data preprocessing, optimized algorithm and empirical forecasting results.
2. Data Preprocessing and Proposed CS-ELM Model
2.1. Multiple Patterns
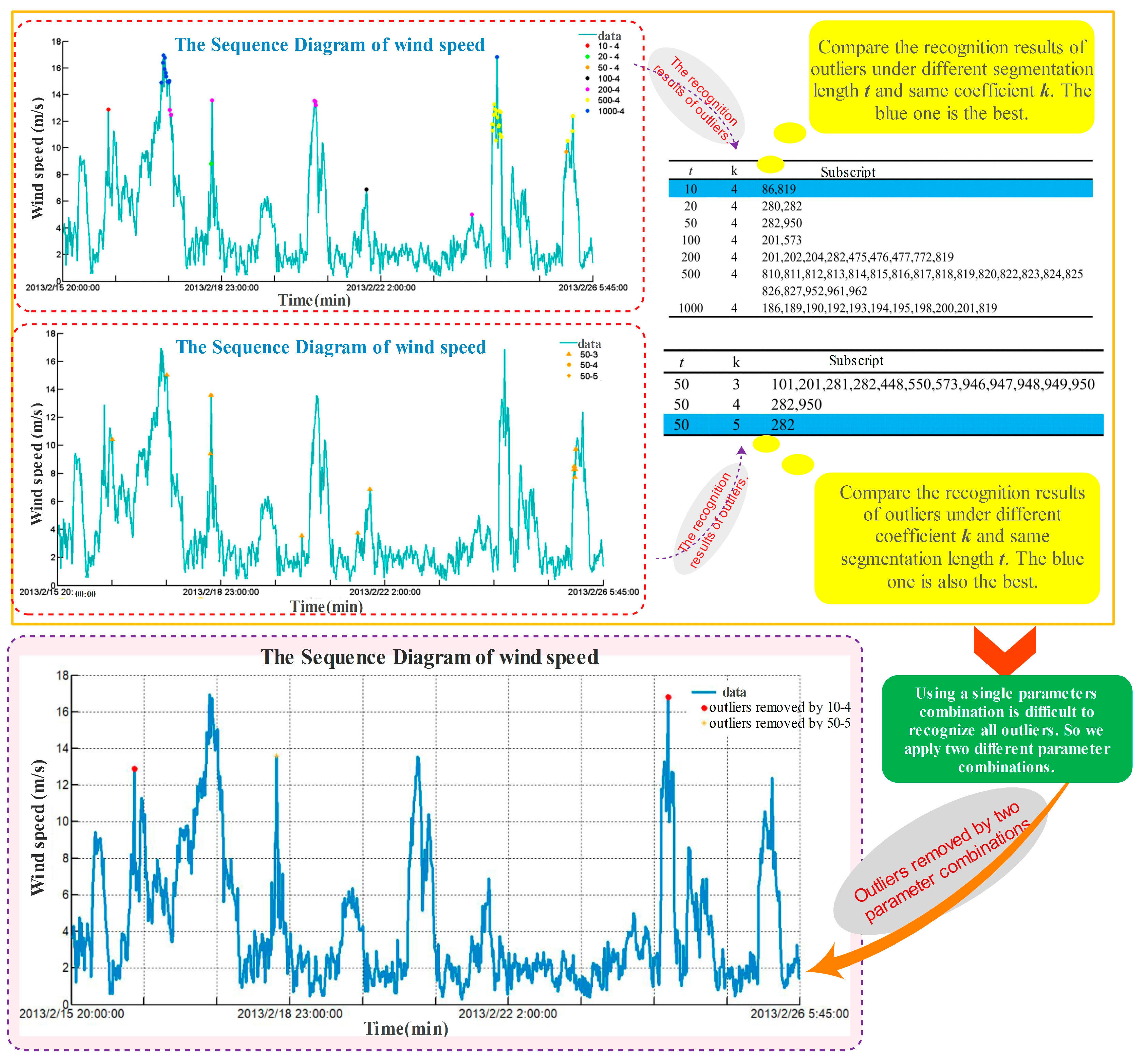
2.1.1. Dynamic Absolute Mean Value Method
2.1.2. Cubic Spline Interpolation
2.1.3. Density Function Estimation
- (a)
- Sturges’ Rule
- (b)
- Normal Reference Rule-1-D Histogram
- (c)
- Scott’s Rule
- (d)
- Freedman-Diaconis Rule
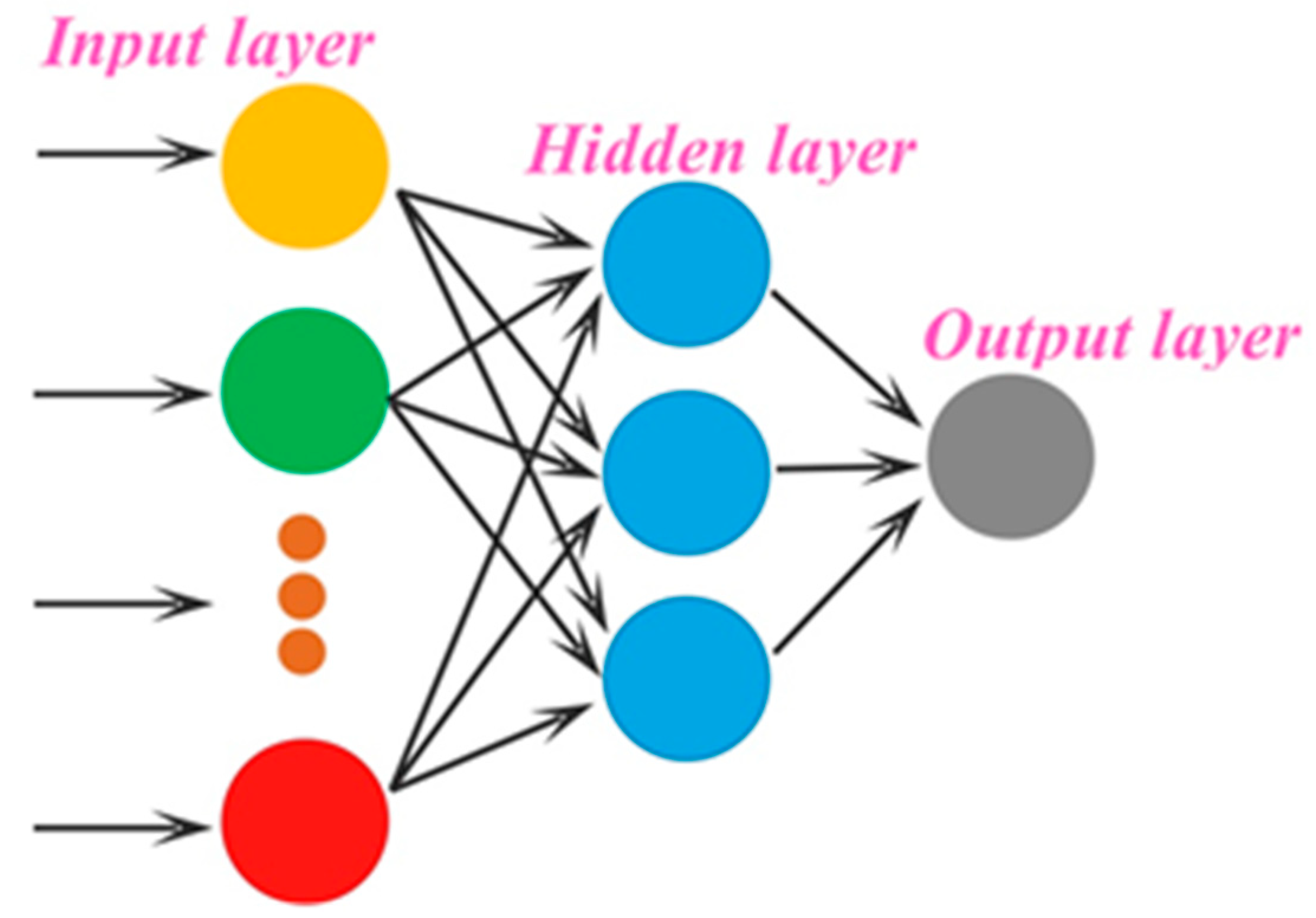
2.1.4. Extreme Learning Machine
2.1.5. Cuckoo Search
2.2. Wind Speed Empirical Analysis
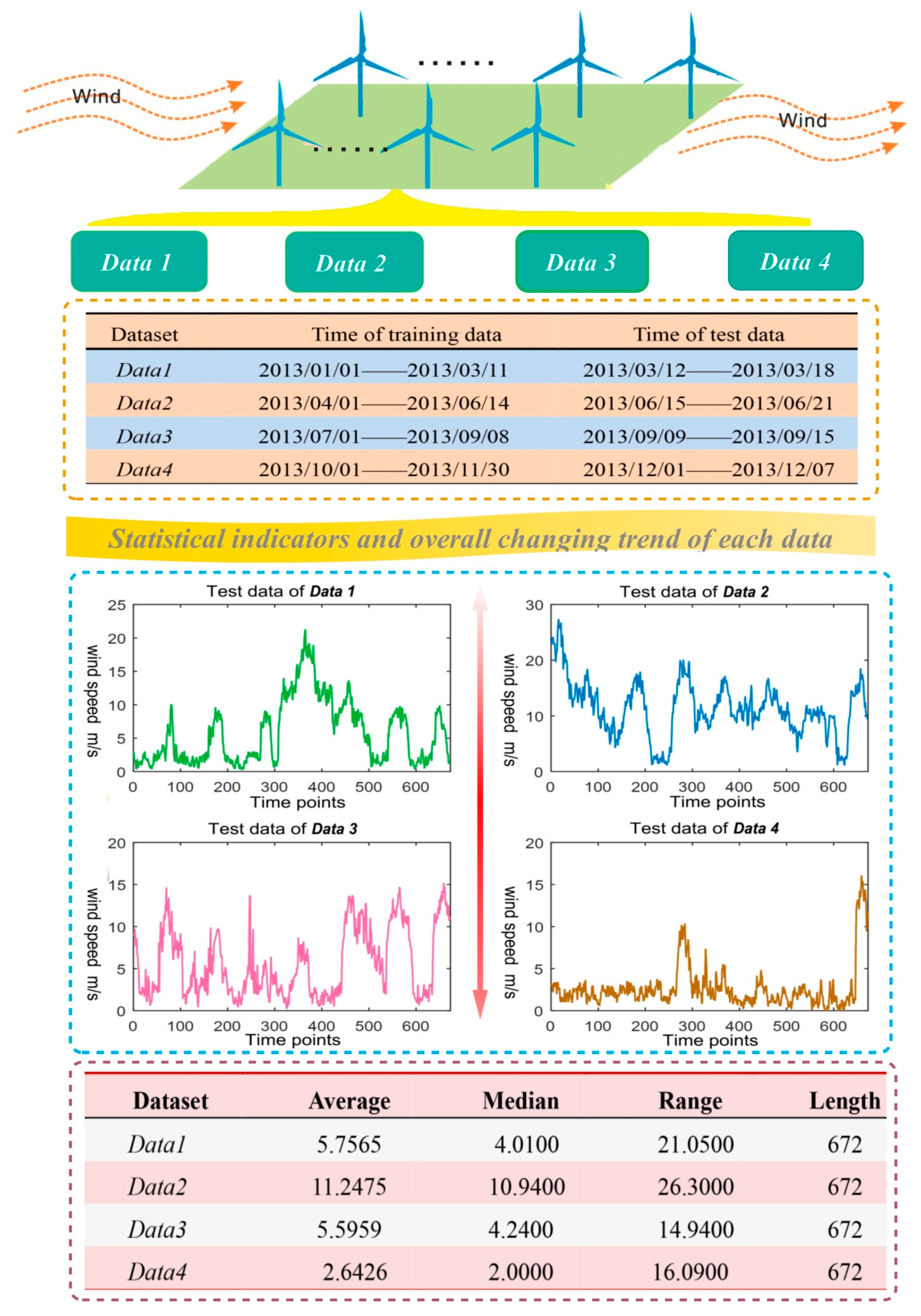
2.2.1. Data Resources
2.2.2. Prediction Evaluation Index
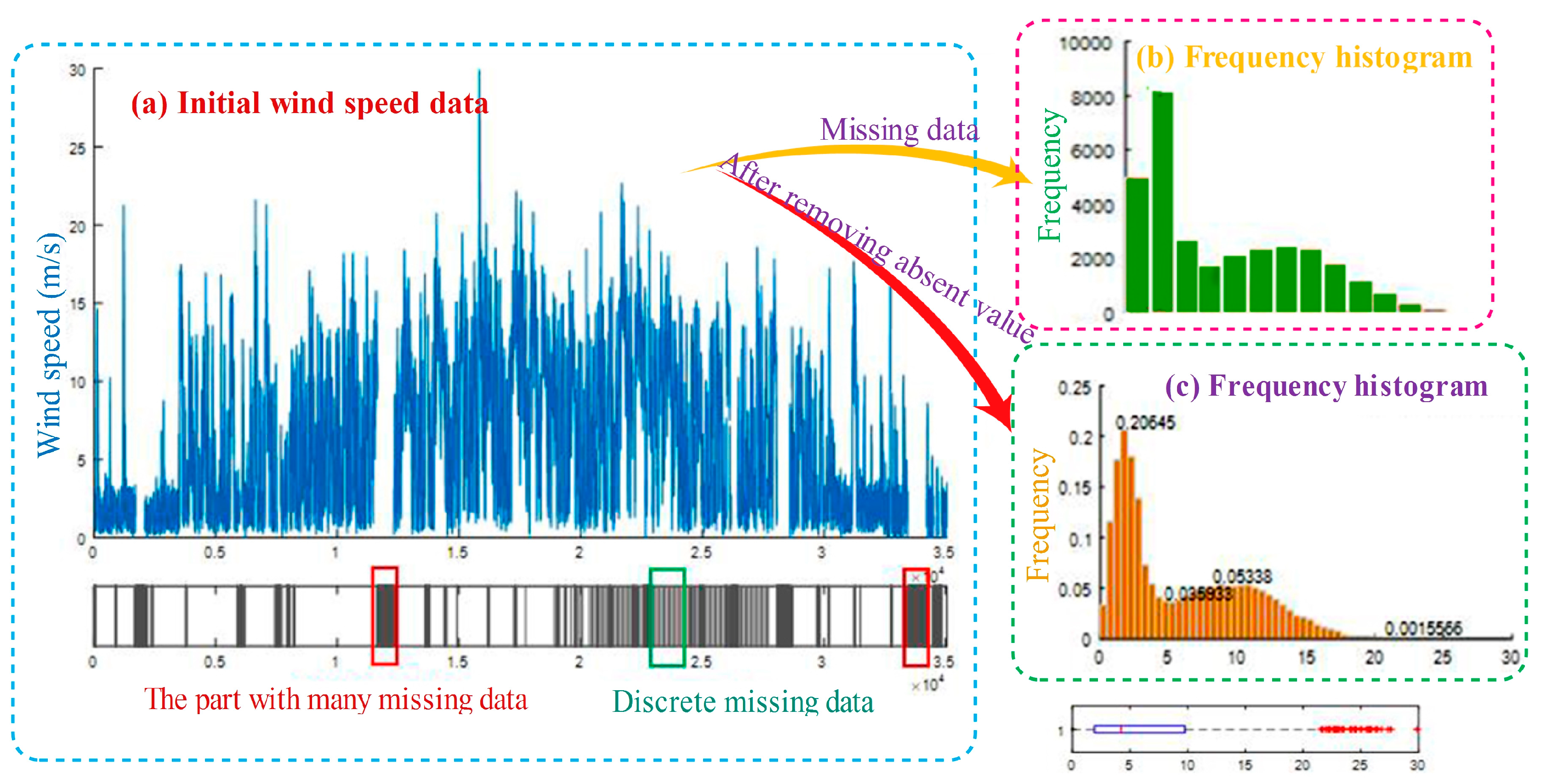
2.2.3. Statistical Analysis and Data Preprocessing
2.2.4. Model Building
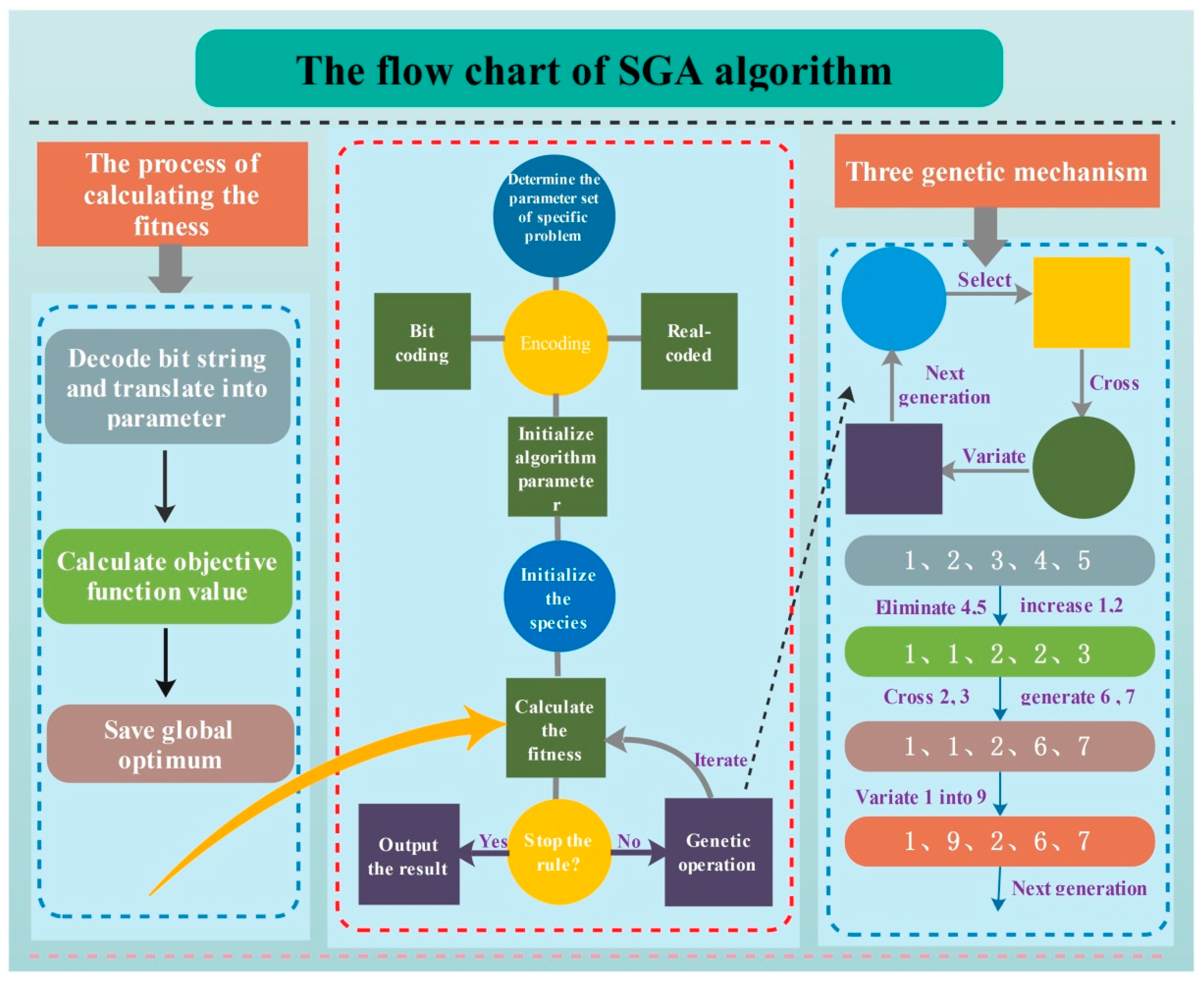
- Step 1. Data processing: The scope of the outlier to be removed can be defined by the Dynamic absolute mean value method, and after eliminating outliers, Cubic spline interpolation is used to complete data. Normalize the input data to eliminate the null column in the transformation data matrix and avoid the influence of data in results obtained by ELM as much as possible.
- Step 2. Parameter setting: Set the number of hidden layers and the activation function in ELM and the number of iterations, nest number, host recognition, boundary conditions and objective function in CS. Due to the weights in the interval [−1, 1] and the threshold in [0, 1], the parameter of the different parts of each individual coding need to be set with different scopes. The situation in which a portion of the individual is beyond the scope in iterating should employ re-initialization. The objective function decides the search trends and the results of the algorithm. The section employs 10-fold cross-validation mean square error sum as the output value of the objective function. Then, screen the optimal weight and threshold on the basis of this. As a result, the possibility of being selected is higher with higher fitness.
- Step 3. Encoding: Code for individuals where denotes the weight and denotes the threshold. In the initial phases, the first weights are initialized by the usage of the real random number in [−1, 1], but the rest part is initialized by the number in [0, 1].
- Step 4. Optimization iteration: firstly initialize the fitness of the nest, use the initial optimal nest individual and Lévy flights disturbance to generate new individuals, and calculate the fitness values of all nest individuals after disturbance. Write the fitness of nest as and the new nest fitness as . If , then replace the nest ; in every generation save the nest with small fitness, abandon the host nest with high recognition and find a new nest individual again.
- Step 5. Test: The optimized weights are used as the input weights in ELM to build the optimized wind speed prediction model.
- Step 6. Reconstructed model: Set a single point prediction threshold. If ELM forecasting values are continuously above the prediction threshold, re-optimize and adjust the weights.
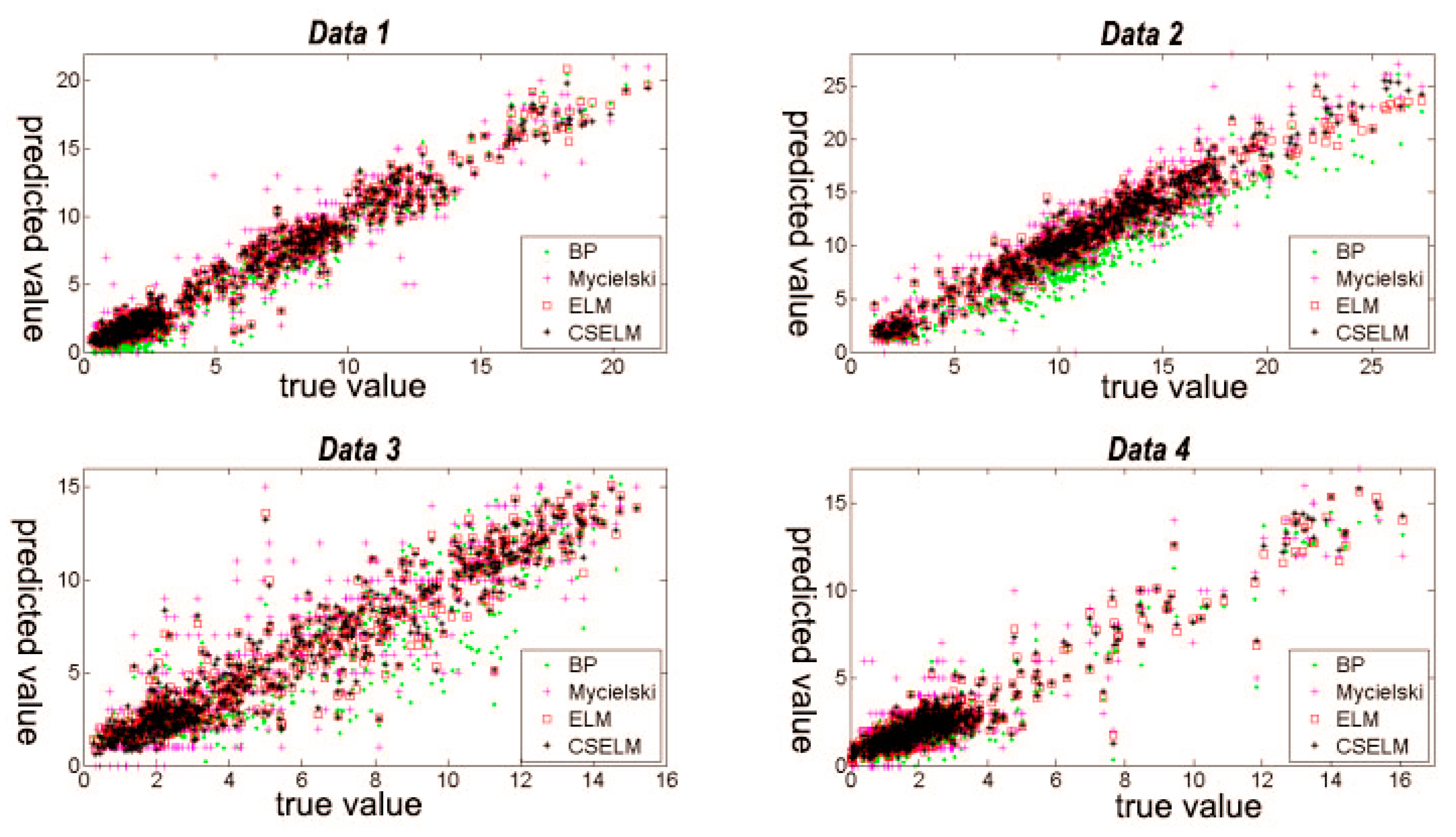
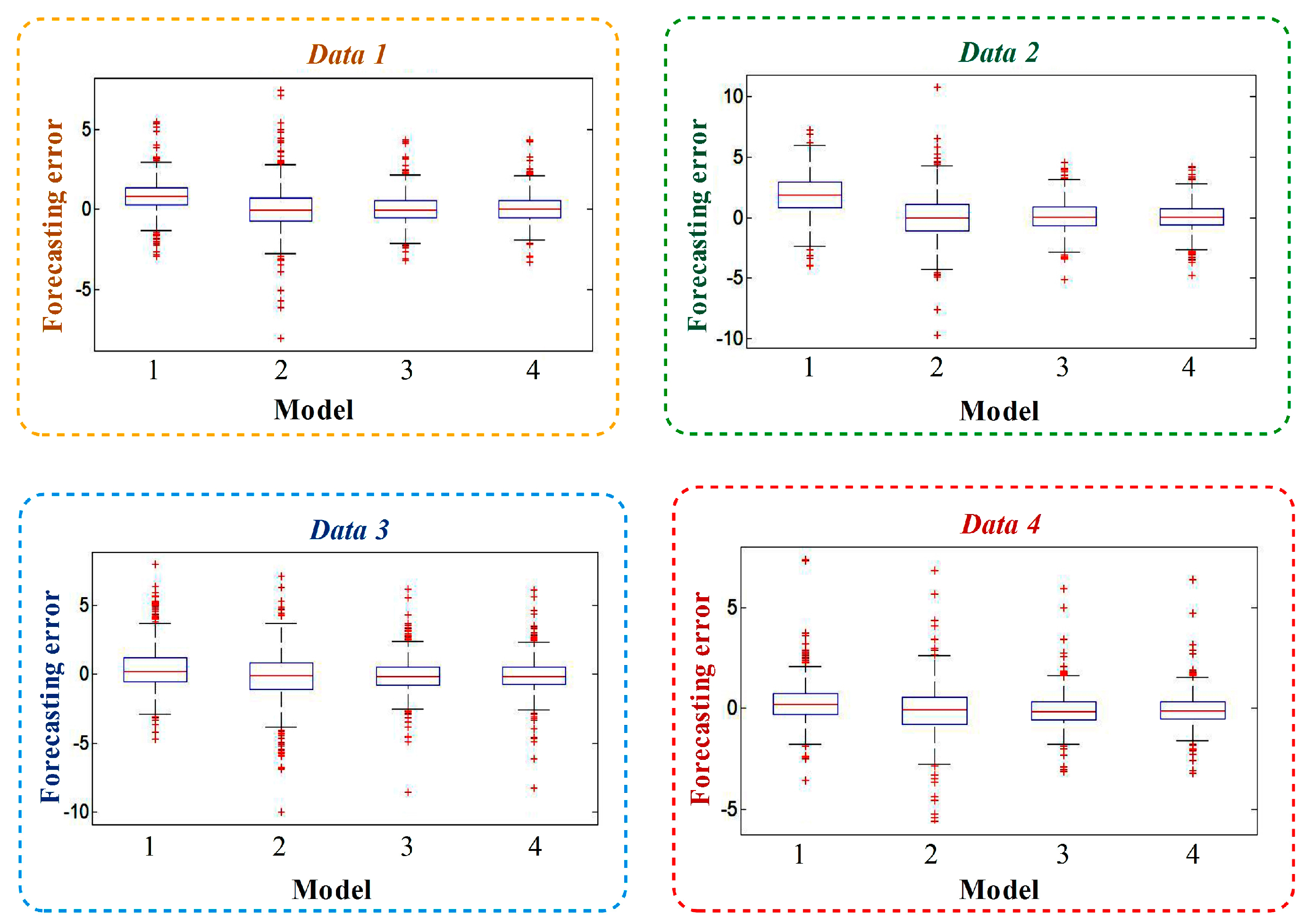
2.2.5. Model Results
- (a)
- In the first figure, the prediction result of BP is biased, and the part beyond quartiles is greater. The data of the Mycielski model beyond the upper and lower edge is more and the range of error distribution is wide, presenting an error interval that is maximized. In ELM and the CS-ELM model, the data mainly focuses on the range of −2 m/s~2 m/s, the excess part is less than BP and Mycielski, and the prediction effect is better.
- (b)
- In the second figure, the error range of the Mycielski model reaches [−10, 10], showing that the performance is very unsatisfied. The overall error is concentrated for ELM and CS-ELM.
- (c)
- In the last two figures, the result of BP is not obviously biased, and the data range beyond the top and bottom edge is less than Mycielski, so the performance is better than Mycielski. However, its error concentration is not higher than ELM and CS-ELM, leading to worse performance than ELM and CS-ELM.
2.3. Summary
3. Proposed Hybrid Model
3.1. Theoretical Analysis
3.1.1. Standard Genetic Algorithm
3.1.2. Stationary Time Series
3.1.3. Problem Description and Solution
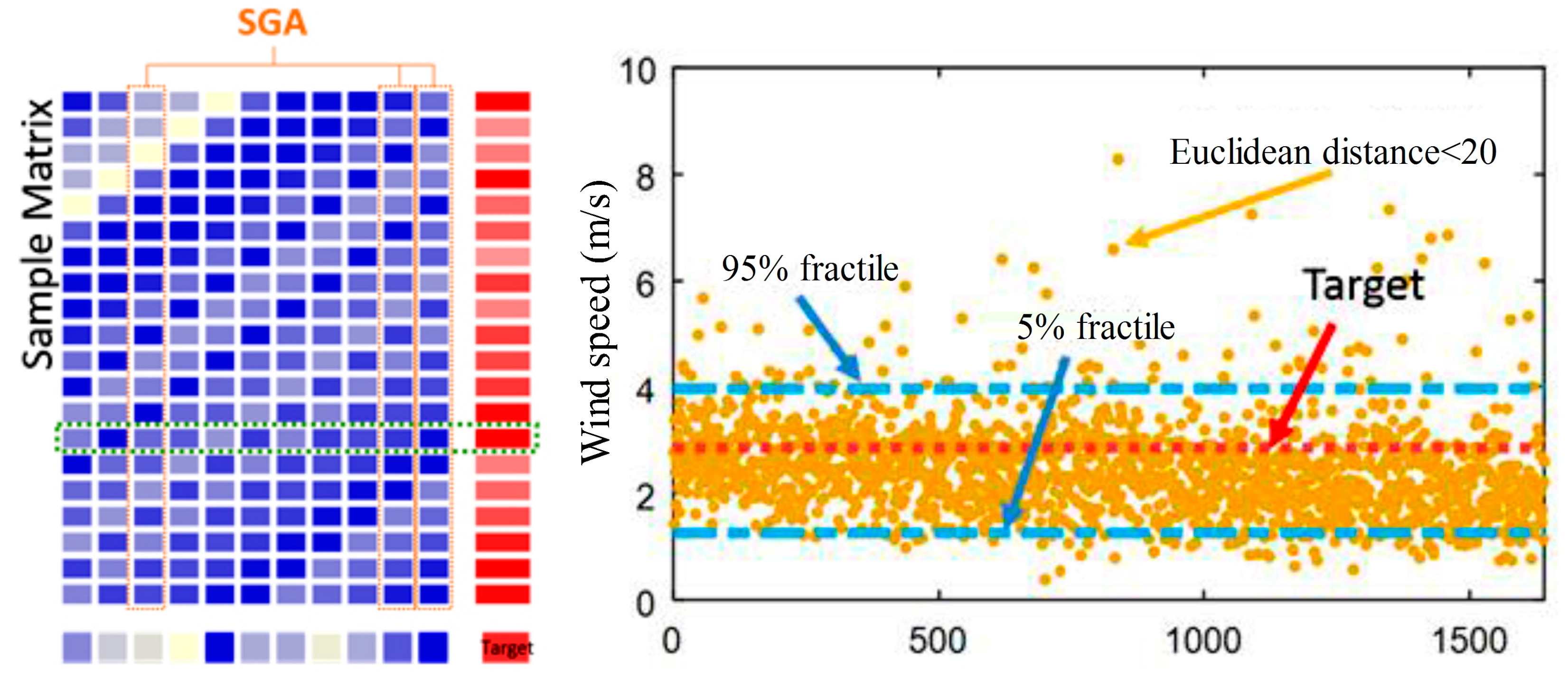
- Calculate the Euclidean distance between the test input vector and training input matrix after screening and arrange according to the values from small to large. Set a distance threshold. Lump the values less than the threshold into one class and find corresponding input vectors to form a new mapping matrix. Because each vector in the new matrix has a small distance with the test input vector, vectors therein are considered as the test input vector joined the interference. At a result, corresponding test output value which is used as a possible sample space of current prediction can be obtained. We select 5% fractile and 95% fractile of the sample as the upper and lower bounds of the confidence interval. However, due to the limited historical data, it is difficult to find close vectors and construct the sample space for the test input vector. For this reason, we can consider the spacing of part points and ignore the distance of other points, which reduces the overall distance and constructs the sample space of similar sequences. Although the SGA-CSELM model proposed in this chapter removes part variables during the input process, its result is similar to that of the CS-ELM model or even better. Thus, the SGA-CSELM screening results are adopted as a new test vector to find the possible forecast sample space again and obtain a confidence interval closer to the forecasting point. Figure 10 is an instance of the prediction point. In addition, for rare points that cannot form intervals, the moving average method is applied to obtain upper and lower boundaries.
3.2. Experiment
3.2.1. SGA-CSELM Model
- Data processing: Build the initial input and output matrix of the CSELM model and then eliminate the null columns in the matrix to ensure the continuity of the data. Normalize the data to reduce the interference of data resources on the ELM.
- SGA parameters setting: Set the appropriate fitness function , write the number of inputs requiring filtering as and compile the SGA individuals as:Set up the SGA parameters, such as the total number of individuals , number of iterations , crossover probability , mutation probability and so on.
- ELM parameters setting: Decode the output results of the ELM, extract the corresponding line of the output and input matrix as the model input, obtain the neuron number of the input layer and hidden layer and employ Sigmoid as the activation function.
- CS parameters setting: Set the number of iterations, nest number, host recognition, boundary conditions and objective function. The weight is in the interval [−1, 1], and scope of threshold is [0, 1], so the parameters represented by the different parts of each individual should be set in different ranges. Moreover, generate the portion of the individual out of range by way of re-initialization. The objective function determines the search trends and results of the algorithm, so the paper employs the mean square error of the test data fitting the value as the output value of the objective function and filters the optimal weight and threshold accordingly.
- Encoding: Apply the coding , where represents the weight and stands for the threshold value, for individuals. In the initial phase, the first weights are initialized by the usage of the real random number in [−1, 1], but the rest is initialized by the number in [0, 1].
- Optimization iteration: First, initialize the fitness of the nest, use the initial optimal nest individual and Lévy flights disturbance to generate new individuals and calculate the fitness value of all nest individuals after disturbance. Write the fitness of nest as and the new nest fitness as . If , then replace nest ; in every generation, save the nest with small fitness, abandon the host nest with high recognition and find a new nest individual again.
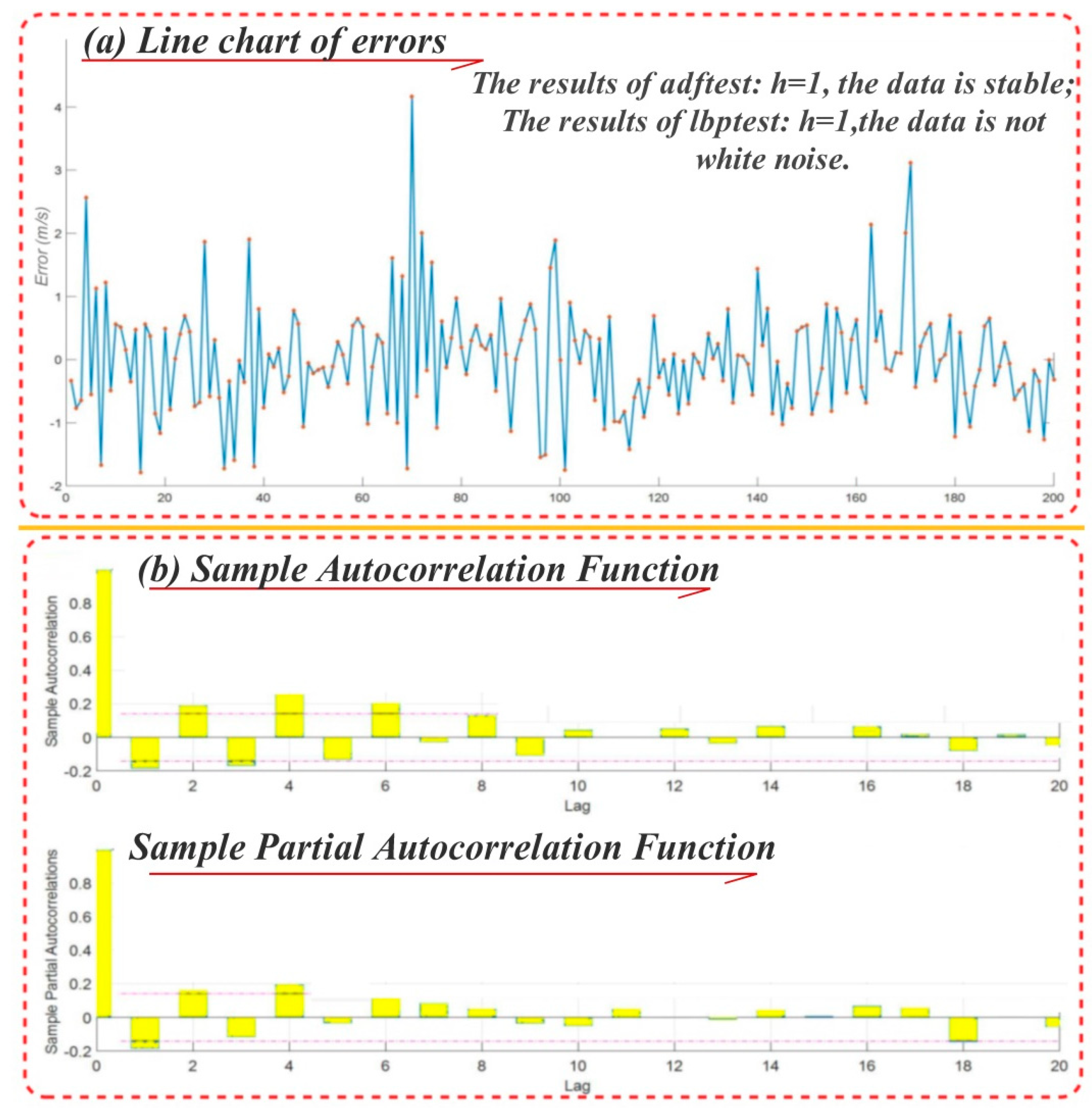
- Carry out test data fitting and obtain the training error: Set the sliding window width H, obtain the training error of the data within the widow width H used to test data and judge whether the data are white noise. If it is white noise, skip the ARMA model building steps, or establish ARMA and carry out step (8).
- Identify the ARMA model: Employ the window width data to calculate the corresponding model lag intervals for endogenous to minimum BIC rule and build the ARMA model.
- Training model: Take the obtained optimizing weights as the input weights of ELM and build the SGA-CSELM hybrid wind speed forecasting model.
- Error correction: Enter the new data into the SGA-CSELM model to obtain the prediction. If there is an ARMA model, then enter the error obtain the error prediction, and correct the error in the SGA-CSELM results to obtain the Hybrid Model.
- Reconstruct model: Set the forecasting threshold of a single point. If the efficiency of the ELM exceeds the threshold continuously, then retrain the Hybrid Model.
3.2.2. Model Results
Selection Results of the Input Variable
Model Contrast Result
3.3. Summary
- Under the influence of different initial weights, the effect of the single extreme learning machine model changes greatly; nevertheless, the ELM model optimized by the cuckoo algorithm possesses both a stable result and a reliable output guarantee.
- Selecting input variables by the usage of SGA reduces the information of the part variables to some extent, but its prediction effect can still achieve results that are not weaker than those of CS-ELM, which all inputs test.
- The error of SGA-CSELM is corrected by the ARMA model, and the performance of the hybrid model after calibration is improved and declines because during the process of fixing the width of the sliding window, the error may become a white noise sequence and join the error correction, leading to poor results.
- With the screening result of SGA, by calculating the distance between the predicted sample and constructed historical data-mapping matrix, possible forecast points of the sample can be screed to be composed of points that are close. The upper and lower bounds of the prediction sample constructed by calculating the 5% and 95% fractile numerical values obtain a good result.
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ARIMA | Auto-regressive integrated moving average |
| ARMA | Auto-Regressive and Moving Average Model |
| CS | Cuckoo search |
| ELM | Extreme learning machine |
| GA | Genetic Algorithm |
| LS-SVM | Least Squares-Support Vector Machine |
| MAS | Multiple Architecture System |
| SGA | Standard Genetic Algorithm |
Nomenclature
| Evenly spaced discrete sequence | The dimension of the parameters | ||
| The difference between and | The iterative times of the algorithm | ||
| , | Threshold | The recognition rate of the host | |
| Segmentation length | target function in the CS algorithm | ||
| The coefficient determining the threshold size. | The predicted objective results | ||
| Cubic Spline interpolant function | weight | ||
| Random sample | The fitness of nest | ||
| characteristic function | The new fitness of nest | ||
| Width, the difference between and | Number of hidden layer nodes | ||
| kth subinterval | Input node | ||
| The location of the th nest in the th generation | The encoding of the kth individual | ||
| Step length controlled quantity | The ith gene of the individual k | ||
| dot product | The probability of the individual can be saved over to the next generation | ||
| The current optimal solution | Random number |
Appendix A
Appendix A.1
| Algorithm A1: Cuckoo Search Algorithm | ||||
| Input: —sequence of training data. —sequence of verification data | ||||
| Output: xb—the value of x with the best fitness value in the population of nests | ||||
| Parameters: GenMax—maximum number of iterations n—number of host nests Fi—fitness function of nest i xi—nest i pa—parameters of the cuckoo search algorithm α—step size g—current iteration number | ||||
| 1 | /* Initialize the population of n host nests xi (i = 1, 2, …, n) randomly */ | |||
| 2 | FOR EACHi: 1 ≤ i ≤ n DO | |||
| 3 | Evaluate the corresponding fitness function Fi | |||
| 4 | END FOR | |||
| 5 | WHILE (g < GenMax) DO | |||
| 6 | /* Obtain new nests by Lévy flights */ | |||
| 7 | FOR EACHi: 1 ≤ i ≤ n DO | |||
| 8 | xL = xi + α⊕Levy(λ); | |||
| 9 | END FOR | |||
| 10 | FOR EACHi: 1 ≤ i ≤ n DO | |||
| 11 | Compute FL | |||
| 12 | IF (FL < Fi) THEN | |||
| 13 | xi←xL; | |||
| 14 | END IF | |||
| 15 | END FOR | |||
| 16 | Compute FL | |||
| 17 | /* Update the best nest xp of the d generation */ | |||
| 18 | IF (Fp < Fb) THEN | |||
| 19 | xb←xp; | |||
| 20 | END IF | |||
| 21 | END WHILE | |||
| 22 | RETURNxb | |||
Appendix A.2
| Algorithm A2: CS-ELM | ||||
| Input: —sequence of training data. —sequence of verification data | ||||
| Output: —forecasting electrical load data from ELM. | ||||
| Parameters: GenMax—maximum number of iterations n—number of host nests Fi—fitness function of nest i xi—nest i pa—parameters of the cuckoo search algorithm α—step size g—current iteration number | ||||
| 1 | /* Initialize the population of n host nests xi (i = 1, 2, …, n) randomly */ | |||
| 2 | FOR EACHi: 1 ≤ i ≤ n DO | |||
| 3 | Evaluate the corresponding fitness function Fi | |||
| 4 | END FOR | |||
| 5 | WHILE (g < GenMax) DO | |||
| 6 | /* Obtain new nests by Lévy flights */ | |||
| 7 | FOR EACHi: 1 ≤ i ≤ n DO | |||
| 8 | xL = xi + α⊕Levy(λ); | |||
| 9 | END FOR | |||
| 10 | FOR EACHi: 1 ≤ i ≤ n DO | |||
| 11 | Compute FL | |||
| 12 | IF (FL < Fi) THEN | |||
| 13 | xi←xL; | |||
| 14 | END IF | |||
| 15 | END FOR | |||
| 16 | Compute FL | |||
| 17 | /* Update the best nest xp of the d generation */ | |||
| 18 | IF (Fp < Fb) THEN | |||
| 19 | xb←xp; | |||
| 20 | END IF | |||
| 21 | END WHILE | |||
| 22 | RETURNxb | |||
| 23 | Set the weight and threshold of the ELM according to xb. | |||
| 24 | Use xt to train the ELM and update the weight and threshold of the ELM. | |||
| 25 | Input the historical data into the ELM to obtain the forecasting value . | |||
References
- Zahedi, A. Australian renewable energy progress. Renew. Sustain. Energy 2010, 14, 2208–2213. [Google Scholar] [CrossRef]
- United Nations (UN). Sustainable Energy for All; United Nations: New York, NY, USA, 2012. [Google Scholar]
- Hua, Y.; Oliphant, M.; Hu, E.J. Development of renewable energy in Australia and China: A comparison of policies and status. Renew. Energy 2016, 85, 1044–1051. [Google Scholar] [CrossRef]
- Ydersbond, I.M.; Korsnes, M.S. What drives investment in wind energy? A comparative study of China and the European Union. Energy Res. Soc. Sci. 2016, 12, 50–61. [Google Scholar] [CrossRef]
- Du, P.; Wang, J.; Gou, Z.; Yang, W. Research and application of a novel hybrid forecasting system based on multi-objective optimization for wind speed forecasting. Energy Convers. Manag. 2017, 150, 90–107. [Google Scholar] [CrossRef]
- Song, J.; Wang, J.; Lu, H. Research and Application of a Novel Combined Model Based on Advanced Optimization Algorithm for Wind Speed Forecasting. Appl. Energy 2018, 215, 643–658. [Google Scholar] [CrossRef]
- Tian, C.; Hao, Y. A Novel Nonlinear Combined Forecasting System for Short-Term Load Forecasting. Energies 2018, 11, 712. [Google Scholar] [CrossRef]
- Wang, J.; Du, P.; Niu, T.; Yang, W. A novel hybrid system based on a new proposed algorithm—Multi-Objective Whale Optimization Algorithm for wind speed forecasting. Appl. Energy 2017, 208, 344–360. [Google Scholar] [CrossRef]
- Lynch, C.; Mahony, M.J.O.; Scully, T. Simplified Method to Derive the Kalman Filter Covariance Matrices to Predict Wind Speeds from a NWP Model. Energy Procedia 2014, 62, 676–685. [Google Scholar] [CrossRef]
- Landberg, L.; Watson, S.J. Short-term prediction of local wind conditions. Bound.-Layer Meteorol. 1970, 70, 171–195. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.; Chen, C.; Li, Y. A hybrid statistical method to predict wind speed and wind power. Renew. Energy 2010, 35, 1857–1861. [Google Scholar] [CrossRef]
- Wang, J.; Heng, J.; Xiao, L.; Wang, C. Research and application of a combined model based on multi-objective optimization for multi-step ahead wind speed forecasting. Energy 2017, 125, 591–613. [Google Scholar] [CrossRef]
- Schlink, U.; Tetzlaff, G. Wind speed forecasting from 1 to 30 minutes. Theor. Appl. Ckinatol. 1998, 60, 191–198. [Google Scholar] [CrossRef]
- Gneiting, T.; Larson, K.; Westrick, K.; Genton, M.G.; Aldrich, E. Calibrated Probabilistic Forecasting at the Stateline Wind Energy Center: The Regime-Switching Space-Time Method. J. Am. Stat. Assoc. 2006, 101, 968–979. [Google Scholar] [CrossRef]
- Torres, J.L.; Garcia, A.; de Blas, M.; de Francisco, A. Forecast of hourly average wind speed with ARMA models in Navarre (Spain). Sol. Energy 2005, 79, 65–77. [Google Scholar] [CrossRef]
- Taylor, J.W.; McSharry, P.E.; Buizza, R. Wind power density forecasting using ensemble predictions and time series models. IEEE Trans. Energy Convers. 2009, 24, 775–782. [Google Scholar] [CrossRef]
- Du, P.; Wang, J.; Yang, W.; Niu, T. Multi-step ahead forecasting in electrical power system using a hybrid forecasting system. Renew. Energy 2018, 122, 533–550. [Google Scholar] [CrossRef]
- Noorollahi, Y.; Jokar, M.A.; Kalhor, A. Using artificial neural networks for temporal and spatial wind speed forecasting in Iran. Energy Convers. Manag. 2016, 115, 17–25. [Google Scholar] [CrossRef]
- Ahmed, A.; Khalid, M. Multi-step Ahead Wind Forecasting Using Nonlinear Autoregressive Neural Networks. Energy Procedia 2017, 134, 192–204. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.; Liang, X.; Li, Y. Wind speed forecasting approach using secondary decomposition algorithm and Elman neural networks. Appl. Energy 2015, 157, 183–194. [Google Scholar] [CrossRef]
- Maatallah, O.A.; Achuthan, A.; Janoyan, K.; Marzocca, P. Recursive wind speed forecasting based on Hammerstein Auto-Regressive model. Appl. Energy 2015, 145, 191–197. [Google Scholar] [CrossRef]
- Bates, J.M.; Granger, C.W.J. The combination of forecasts. Oper. Res. Q. 1969, 20, 451–468. [Google Scholar] [CrossRef]
- Wang, J.; Liu, L.; Wang, Z. The status and development of the combination forecast method. Forecast 1997, 6, 37–38. [Google Scholar]
- Xiao, L.; Shao, W.; Liang, T.; Wang, C. A combined model based on multiple seasonal patterns and modified firefly algorithm for electrical load forecasting. Appl. Energy 2016, 167, 135–153. [Google Scholar] [CrossRef]
- Wang, J.; Yang, W.; Du, P.; Li, Y. Research and application of a hybrid forecasting framework based on multi-objective optimization for electrical power system. Energy 2018, 148, 59–78. [Google Scholar] [CrossRef]
- Xiao, L.; Wang, J.; Hou, R.; Wu, J. A combined model based on data pre-analysis and weight coefficients optimization for electrical load forecasting. Energy 2015, 82, 524–549. [Google Scholar] [CrossRef]
- Camelo, H.D.N.; Lucio, P.S.; Junior, J.B.V.L.; de Carvalho, P.C.M.; Santos, D.V.D. Innovative hybrid models for forecasting time series applied in wind generation based on the combination of time series models with artificial neural networks. Energy 2018, 151, 347–357. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, N.; Wu, L.; Wang, Y. Wind speed forecasting based on the hybrid ensemble empirical mode decomposition and GA-BP neural network method. Renew. Energy 2016, 94, 629–636. [Google Scholar] [CrossRef]
- Marsden, M. Cubic spline interpolation of continuous functions. J. Approx. Theory 1974, 10, 103–111. [Google Scholar] [CrossRef]
- Huang, G.; Zhu, Q.; Siew, C. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the IEEE International Joint Conference on Neural Networks, Budapest, Hungary, 25–29 July 2004; Volume 2, pp. 985–990. [Google Scholar]
- Wang, X.; Han, M. Improved extreme learning machine for multivariate time series online sequential prediction. Eng. Appl. Artif. Intell. 2015, 40, 28–36. [Google Scholar] [CrossRef]
- Nobrega, J.P.; Oliveira, A.L.I. Kalman filter-based method for Online Sequential Extreme Learning Machine for regression problems. Eng. Appl. Artif. Intell. 2015, 44, 101–110. [Google Scholar] [CrossRef]
- Mahdiyah, U.; Irawan, M.I.; MatulImah, E. Integrating Data Selection and Extreme Learning Machine for Imbalanced Data. Procedia Comput. Sci. 2015, 59, 221–229. [Google Scholar] [CrossRef]
- Yang, X.; Deb, S. Engineering optimization by Cuckoo Search. Int. J. Math. Model. Numer. Optim. 2010, 1. [Google Scholar] [CrossRef]
- Valian, E.; Tavakoli, S.; Mohanna, S.; Haghi, A. Improved cuckoo search for reliability optimization problems. Comput. Ind. Eng. 2013, 64, 459–468. [Google Scholar] [CrossRef]
- Daniel, E.; Anitha, J. Optimum wavelet based masking for the contrast enhancement of medical images using enhanced cuckoo search algorithm. Comput. Biol. Med. 2016, 71, 149–155. [Google Scholar] [CrossRef] [PubMed]
- Department of Comprehensive Statistics of National Bureau of Statistics. China Statistics Yearbook; China Statistics Press: Beijing, China, 2015.
- David, F.; Peris, D. On the Histogram as a Density Estimator: L2 Theory. Probability Theory and Related Fields; Springer: Berlin/Heidelberg, Germany, 2009; Volume 57, pp. 453–476. [Google Scholar]
- Liu, S.; Wang, Z. Genetic Algorithm and its application in the path-oriented test data automatic generation. Procedia Eng. 2011, 15, 1186–1190. [Google Scholar]
- Li, Y.; Li, S.; Li, X. Test Paper Generating Method Based on Genetic Algorithm. AASRI Procedia 2012, 1, 549–553. [Google Scholar]
- Wang, X.C. 43 Cases Analysis on MATLAB Neural Network; Beijing University of Aeronautics and Astronautics Press: Beijing, China, 2013. [Google Scholar]
- Wang, J.; Hu, J. A robust combination approach for short-term wind speed forecasting and analysis combination of the ARIMA (autoregressive integrated moving average), ELM (extreme learning machine), SVM (support vector machine) and LSSVM (least square SVM) forecasts using a GPR (Gaussian process regression) model. Energy 2015, 93, 41–56. [Google Scholar]
- Tsay, R.S. Analysis of Financial Time Series; Wiley: New York, NY, USA, 2002; pp. 5880–5885. [Google Scholar]
- Sun, W.; Liu, M. Wind speed forecasting using FEEMD echo state networks with RELM in Hebei, China. Energy Convers. Manag. 2016, 114, 197–208. [Google Scholar] [CrossRef]
- Zhao, J.; Guo, Z.; Su, Z.; Zhao, Z.; Xiao, X.; Liu, F. An improved multi-step forecasting model based on WRF ensembles and creative fuzzy systems for wind speed. Appl. Energy 2016, 162, 808–826. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Definition | Equation |
|---|---|---|
| MAE | Mean absolute error | |
| RMSE | Root mean square error | |
| MAPE | The average of the absolute errors | , |
| Index | Before Interpolation | After Interpolation |
|---|---|---|
| Median | 4.23 | 4.23 |
| Average | 5.99 | 6.00 |
| Range | 29.88 | 29.88 |
| Skewness | 0.74 | 0.74 |
| Kurtosis | 2.57 | 2.57 |
| Datasets | Model | RMSE | MAPE (%) | MAE |
|---|---|---|---|---|
| Data 1 | BP | 1.2937 | 37.7885 | 1.0574 |
| Mycielski | 1.3973 | 32.0933 | 0.98815 | |
| ELM | 0.95513 | 22.0223 | 0.70935 | |
| CSELM | 0.95154 | 21.9128 | 0.70312 | |
| Data 2 | BP | 2.47 | 20.8619 | 2.0638 |
| Mycielski | 1.8098 | 15.9512 | 1.3655 | |
| ELM | 1.2884 | 11.365 | 0.97447 | |
| CSELM | 1.2069 | 10.98 | 0.92169 | |
| Data 3 | BP | 1.7408 | 32.5512 | 1.231 |
| Mycielski | 1.7999 | 38.1428 | 1.2921 | |
| ELM | 1.2618 | 29.0563 | 0.88979 | |
| CSELM | 1.2582 | 27.8345 | 0.88564 | |
| Data 4 | BP | 0.83373 | 57.8981 | 0.60687 |
| Mycielski | 1.1868 | 69.887 | 0.85244 | |
| ELM | 0.80629 | 49.52 | 0.57975 | |
| CSELM | 0.78449 | 49.0454 | 0.55874 |
| Dataset | Z | Model | |
|---|---|---|---|
| Data 1 | (1,0,0,0,0,0,0,0,1,1,1) | 2.6925 × 10−4 | |
| Data 2 | (0,1,1,0,0,0,0,0,0,1,1) | 1.4634 × 10−4 | |
| Data 3 | (0,0,0,0,0,0,1,1,1,1,1) | 1.2828 × 10−4 | |
| Data 4 | (0,0,1,0,0,0,0,0,0,1,1) | 2.7143 × 10−4 |
| Model | RMSE | MAPE (%) | MAE |
|---|---|---|---|
| ELM-1 | 0.95513 | 22.0223 | 0.70935 |
| CSELM-1 | 0.95154 | 21.9128 | 0.70312 |
| ELM-2 | 1.0758 | 26.2801 | 0.80785 |
| CSELM-2 | 0.94509 | 22.1702 | 0.70205 |
| SGA-CSELM | 0.94368 | 22.0715 | 0.70112 |
| Hybrid model | 0.93729 | 22.4062 | 0.69569 |
| R | M | AIC | BIC |
|---|---|---|---|
| 0 | 0 | 525.9757 | 532.5723 |
| 0 | 1 | 522.9694 | 532.8644 |
| 0 | 2 | 520.4012 | 533.5945 |
| 0 | 3 | 520.9191 | 537.4107 |
| 1 | 0 | 521.2324 | 531.1274 |
| 1 | 1 | 510.6493 | 523.8426 |
| 1 | 2 | 511.7579 | 528.2495 |
| 1 | 3 | 513.2704 | 533.0603 |
| 2 | 0 | 517.0375 | 530.2307 |
| 2 | 1 | 511.8597 | 528.3513 |
| 2 | 2 | 513.2522 | 533.0421 |
| 2 | 3 | 514.3671 | 537.4553 |
| 3 | 0 | 516.4494 | 532.941 |
| 3 | 1 | 513.6157 | 533.4056 |
| 3 | 2 | 515.1741 | 538.2623 |
| 3 | 3 | 515.9503 | 542.3369 |
| Time | Original Data | ELM-1 | CSELM-1 | ELM-2 | CSELM-2 | SGA-CSELM | Hybrid Model | Adjusted Value |
|---|---|---|---|---|---|---|---|---|
| 0:15:00 | 1.82 | 2.87 | 2.7 | 2.19 | 2.77 | 2.86 | 2.69 | −0.17 |
| 0:30:00 | 1.55 | 1.81 | 1.72 | 2.49 | 1.95 | 1.78 | 2.05 | 0.28 |
| 0:45:00 | 1.53 | 1.6 | 1.63 | 1.96 | 1.64 | 1.68 | 1.49 | −0.19 |
| 1:00:00 | 1.14 | 1.54 | 1.51 | 1.5 | 1.52 | 1.59 | 1.74 | 0.14 |
| 1:15:00 | 0.41 | 1.11 | 1.23 | 1.35 | 1.34 | 1.22 | 1.16 | −0.06 |
| 1:30:00 | 0.45 | 0.55 | 0.62 | 1.24 | 0.66 | 0.62 | 0.76 | 0.14 |
| 1:45:00 | 1.86 | 0.76 | 0.66 | 1.2 | 0.64 | 0.71 | 0.6 | −0.11 |
| 2:00:00 | 0.71 | 2 | 1.99 | 1.41 | 1.85 | 1.93 | 1.82 | −0.11 |
| 2:15:00 | 0.63 | 0.77 | 0.93 | 1.25 | 0.95 | 0.71 | 0.95 | 0.24 |
| 2:30:00 | 0.98 | 0.88 | 0.94 | 1.16 | 0.77 | 0.9 | 0.71 | −0.2 |
| 2:45:00 | 1.13 | 1.17 | 0.96 | 1.13 | 1.03 | 1.15 | 1.25 | 0.1 |
| 3:00:00 | 1.33 | 1.15 | 1.25 | 1.03 | 1.31 | 1.21 | 1.1 | −0.11 |
| 3:15:00 | 1.54 | 1.42 | 1.43 | 1.43 | 1.39 | 1.39 | 1.42 | 0.03 |
| 3:30:00 | 1.53 | 1.78 | 1.5 | 2.13 | 1.55 | 1.57 | 1.5 | −0.07 |
| 3:45:00 | 1.57 | 1.57 | 1.61 | 1.97 | 1.64 | 1.55 | 1.58 | 0.03 |
| 4:00:00 | 0.92 | 1.61 | 1.69 | 1.48 | 1.58 | 1.59 | 1.53 | −0.06 |
| 4:15:00 | 1.18 | 0.97 | 1.05 | 1.39 | 1 | 0.99 | 1.1 | 0.11 |
| 4:30:00 | 1.5 | 1.31 | 1.24 | 1.58 | 1.36 | 1.33 | 1.19 | −0.14 |
| 4:45:00 | 1.86 | 1.59 | 1.54 | 1.64 | 1.53 | 1.52 | 1.57 | 0.05 |
| 5:00:00 | 2.61 | 1.92 | 1.95 | 1.97 | 1.9 | 1.84 | 1.72 | −0.12 |
| 5:15:00 | 2.63 | 2.65 | 2.64 | 2.44 | 2.52 | 2.54 | 2.5 | −0.05 |
| 5:30:00 | 2.02 | 2.6 | 2.59 | 2.61 | 2.55 | 2.51 | 2.52 | 0 |
| 5:45:00 | 3.01 | 1.92 | 2.04 | 2.18 | 2.01 | 1.98 | 2.03 | 0.05 |
| 6:00:00 | 2.15 | 2.98 | 2.92 | 2.28 | 2.8 | 3 | 2.8 | −0.2 |
| 6:15:00 | 1.86 | 2.01 | 1.96 | 2.4 | 2.17 | 2.03 | 2.28 | 0.26 |
| 6:30:00 | 2.02 | 1.86 | 1.94 | 2.3 | 2.01 | 1.92 | 1.73 | −0.19 |
| 6:45:00 | 1.65 | 2.1 | 2.01 | 2.2 | 1.94 | 2.02 | 2.13 | 0.1 |
| 7:00:00 | 1.7 | 1.66 | 1.7 | 1.96 | 1.76 | 1.65 | 1.6 | −0.05 |
| Dataset | Model | RMSE | MAPE (%) | MAE |
|---|---|---|---|---|
| Data 2 | ELM-1 | 1.2884 | 11.365 | 0.97447 |
| CSELM-1 | 1.2069 | 10.98 | 0.92169 | |
| ELM-2 | 1.4416 | 13.1777 | 1.1133 | |
| CSELM-2 | 1.1987 | 11.0051 | 0.91502 | |
| SGA-CSELM | 1.2077 | 10.9918 | 0.91705 | |
| Data 3 | ELM-1 | 1.2618 | 29.0563 | 0.88979 |
| CSELM-1 | 1.2582 | 27.8345 | 0.88564 | |
| ELM-2 | 1.4675 | 35.7339 | 1.0631 | |
| CSELM-2 | 1.2654 | 28.7894 | 0.8927 | |
| SGA-CSELM | 1.2652 | 26.9906 | 0.88335 | |
| Hybrid model | 1.2763 | 26.5807 | 0.89842 | |
| Data 4 | ELM-1 | 0.80629 | 49.52 * | 0.57975 |
| CSELM-1 | 0.78449 | 49.0454 * | 0.55874 | |
| ELM-2 | 0.88965 | 58.7557 * | 0.64605 | |
| CSELM-2 | 0.79179 | 47.9399 * | 0.56206 | |
| SGA-CSELM | 0.78186 | 49.0009 * | 0.55542 | |
| Hybrid model | 0.78695 | 51.3721 * | 0.55959 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Li, J.; Wang, J.; Gao, C. Research and Application of a Hybrid Wind Energy Forecasting System Based on Data Processing and an Optimized Extreme Learning Machine. Energies 2018, 11, 1712. https://doi.org/10.3390/en11071712
Wang R, Li J, Wang J, Gao C. Research and Application of a Hybrid Wind Energy Forecasting System Based on Data Processing and an Optimized Extreme Learning Machine. Energies. 2018; 11(7):1712. https://doi.org/10.3390/en11071712
Chicago/Turabian StyleWang, Rui, Jingrui Li, Jianzhou Wang, and Chengze Gao. 2018. "Research and Application of a Hybrid Wind Energy Forecasting System Based on Data Processing and an Optimized Extreme Learning Machine" Energies 11, no. 7: 1712. https://doi.org/10.3390/en11071712
APA StyleWang, R., Li, J., Wang, J., & Gao, C. (2018). Research and Application of a Hybrid Wind Energy Forecasting System Based on Data Processing and an Optimized Extreme Learning Machine. Energies, 11(7), 1712. https://doi.org/10.3390/en11071712