Power Transformer Operating State Prediction Method Based on an LSTM Network




Abstract
:1. Introduction
2. Long Short-Term Memory Recurrent Neural Networks
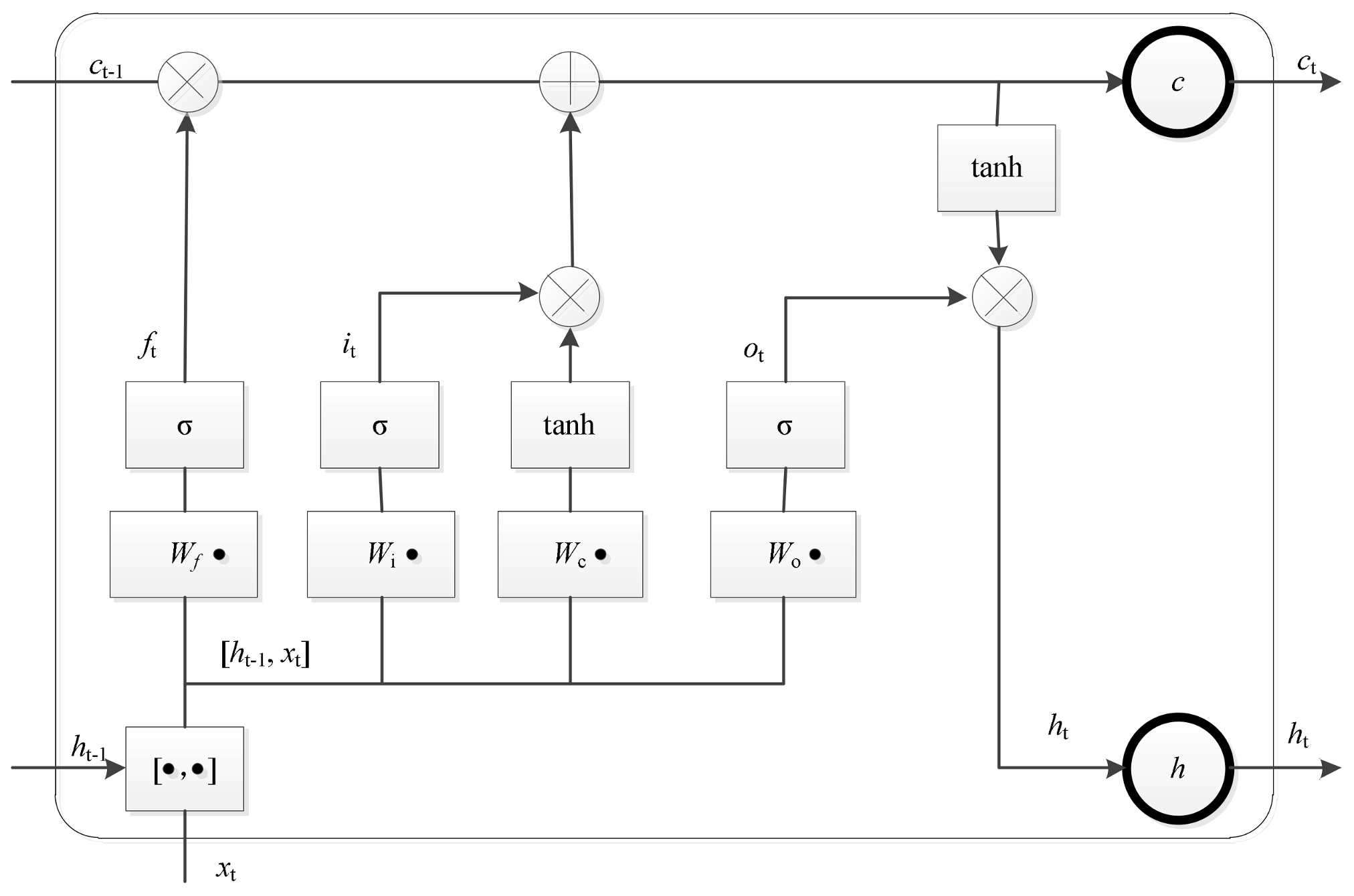
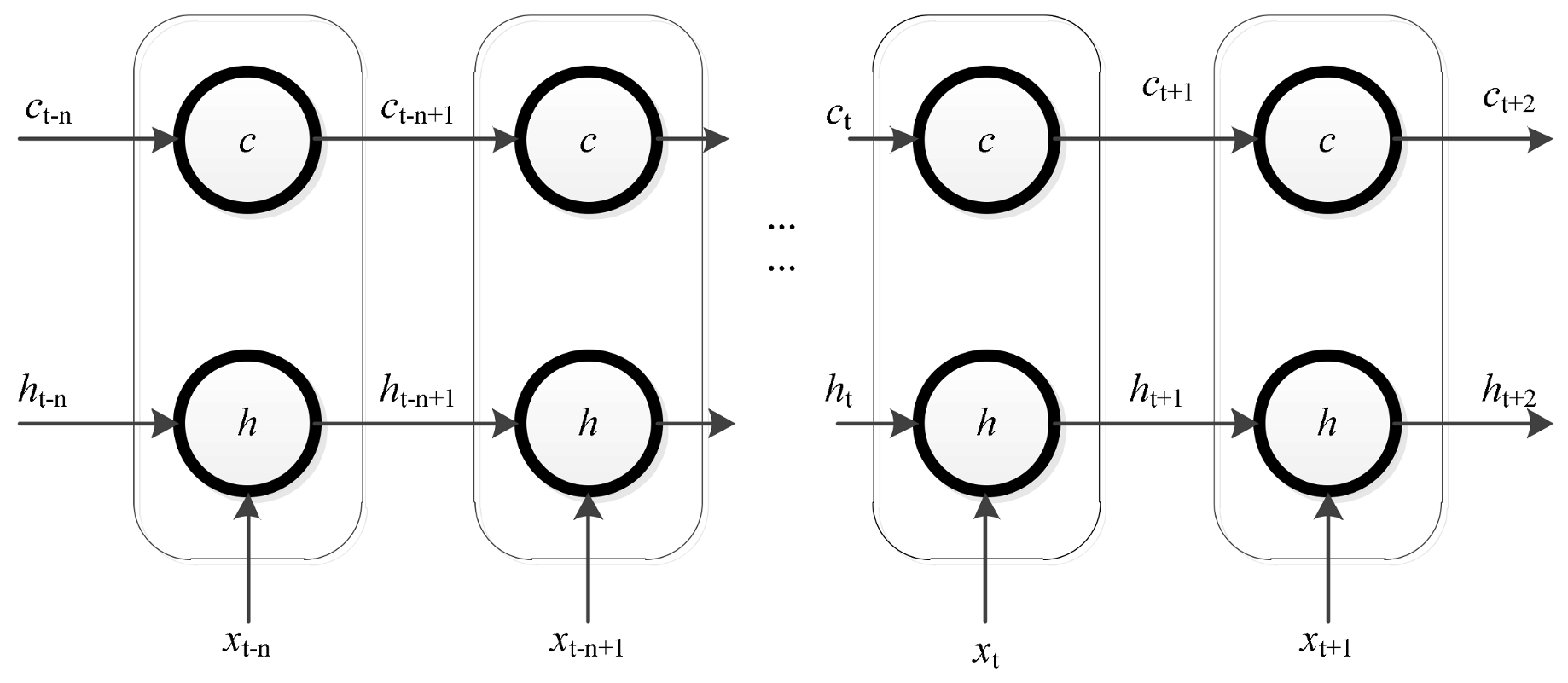
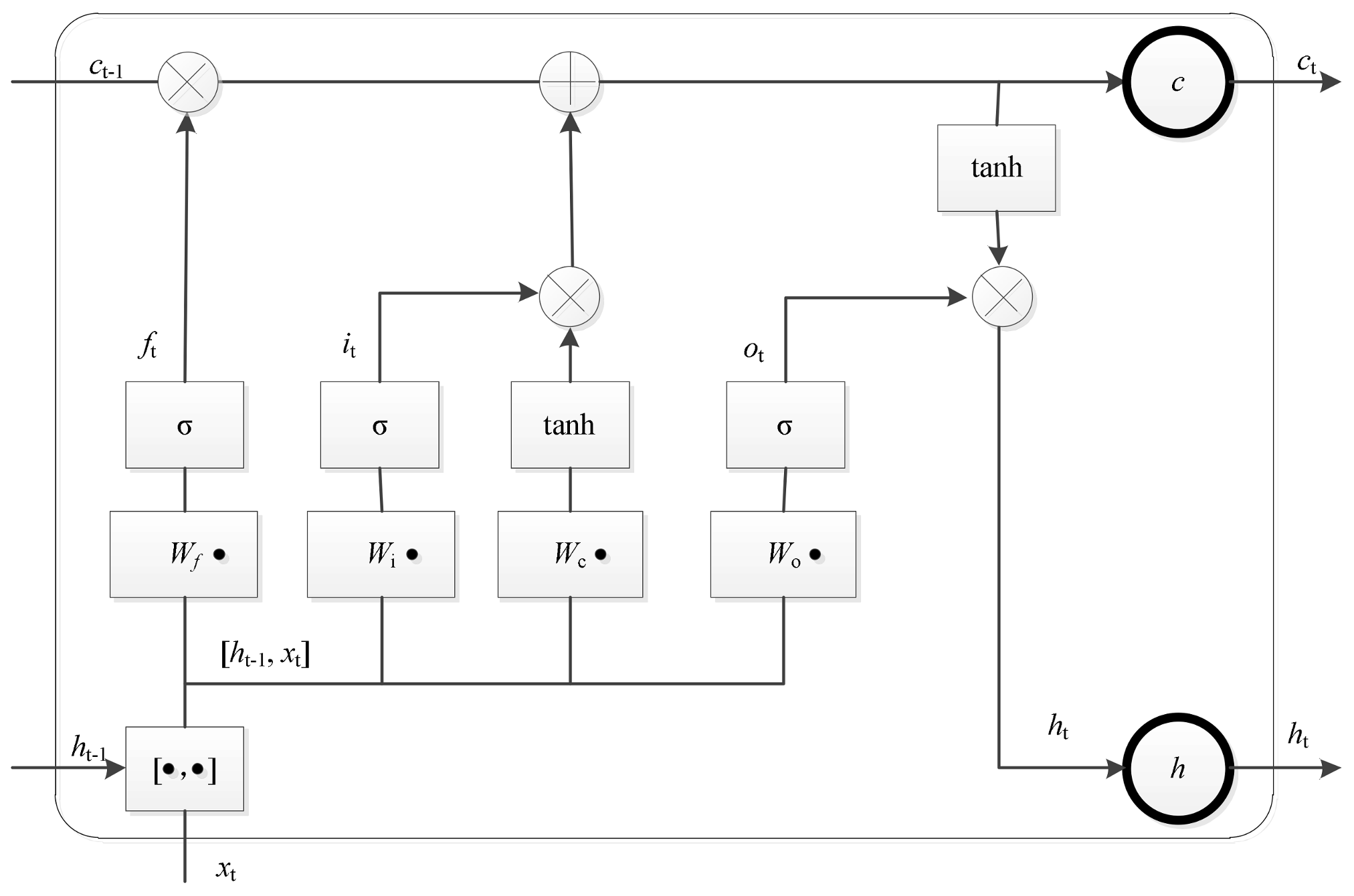
2.1. Long Short-Term Memory Networks
2.2. Backpropagation through Time Algorithm
3. Transformer Operating State Prediction Using the LSTM-Based Approach
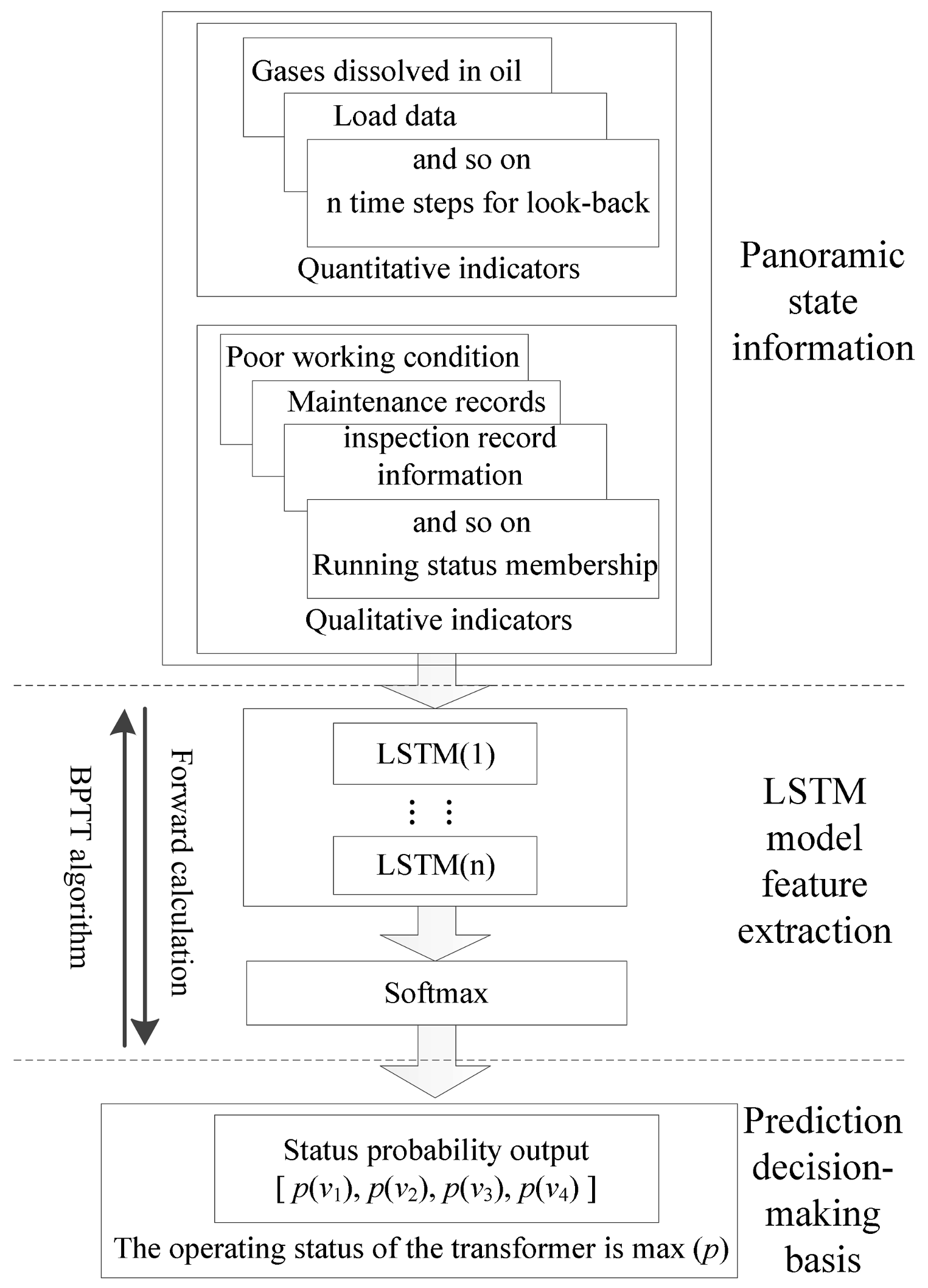
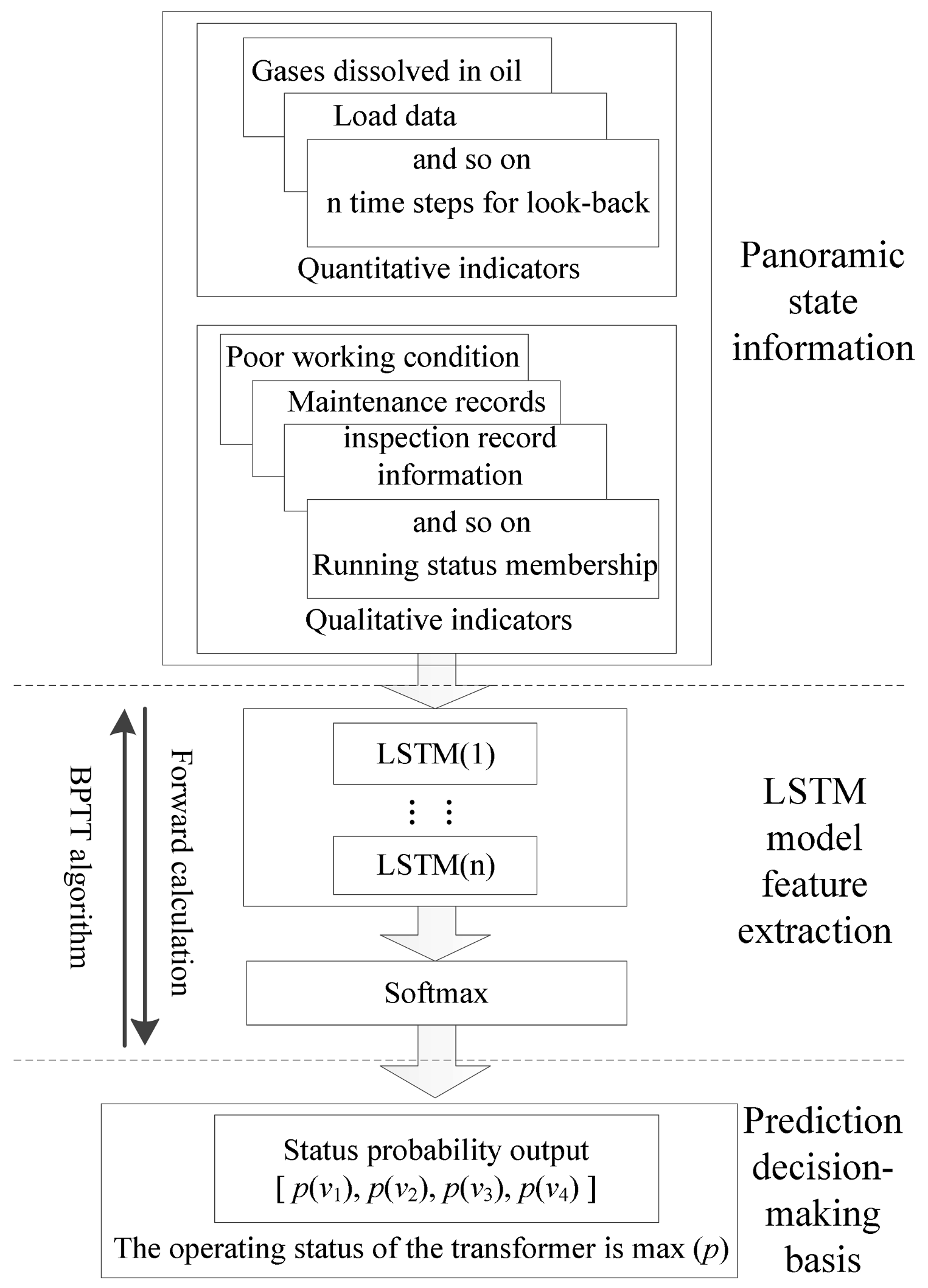
3.1. Input Characteristic Parameters Based on Panoramic Information
3.2. Output Target Defined from the Transformer Operating Status
3.3. Methods for Indicator Quantification
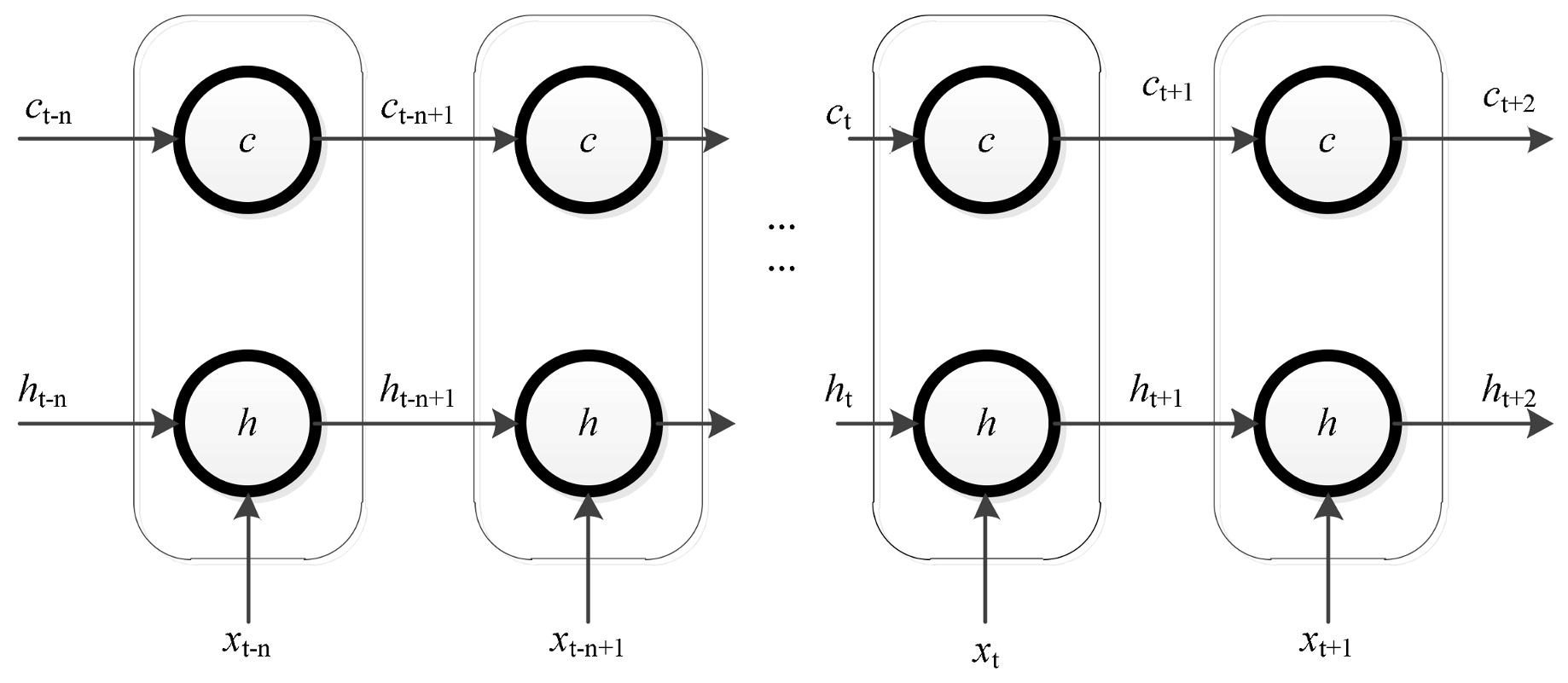
3.4. The Proposed LSTM Prediction Model
- (1)
- Samples are collected and divided into training sets and test sets.
- (2)
- To reduce the influence of the data dispersion, quantitative data are normalized using the standard deviation method:where dmin k is the minimum monitoring data of the indicator k, dmax k is the maximum monitoring data of the indicator k, and dk is the monitoring data of the indicator k.
- (3)
- Quantitative data is fit to the membership function of the RDD and operating state using the SVM.
- (4)
- Qualitative indicators are quantified according to the fuzzy statistical experiment.
- (5)
- The AHP method is used to determine the weight of each indicator.
- (6)
- The comprehensive fuzzy evaluation results corresponding to v1–v4 are weighted with Steps (3) and (4) according to Step (5), and the comprehensive evaluation results are taken as the LSTM output labels.
- (7)
- According to the BPTT algorithm, the LSTM network model is trained to extract the feature relationships between the key parameters and the predicted transformer status, and the parameters of the prediction model are obtained.
- (8)
- The prediction parameters of the LSTM model are used to predict the operating state of the transformer in the test set, and the accuracy of the model is verified.
4. Case Studies and Analysis
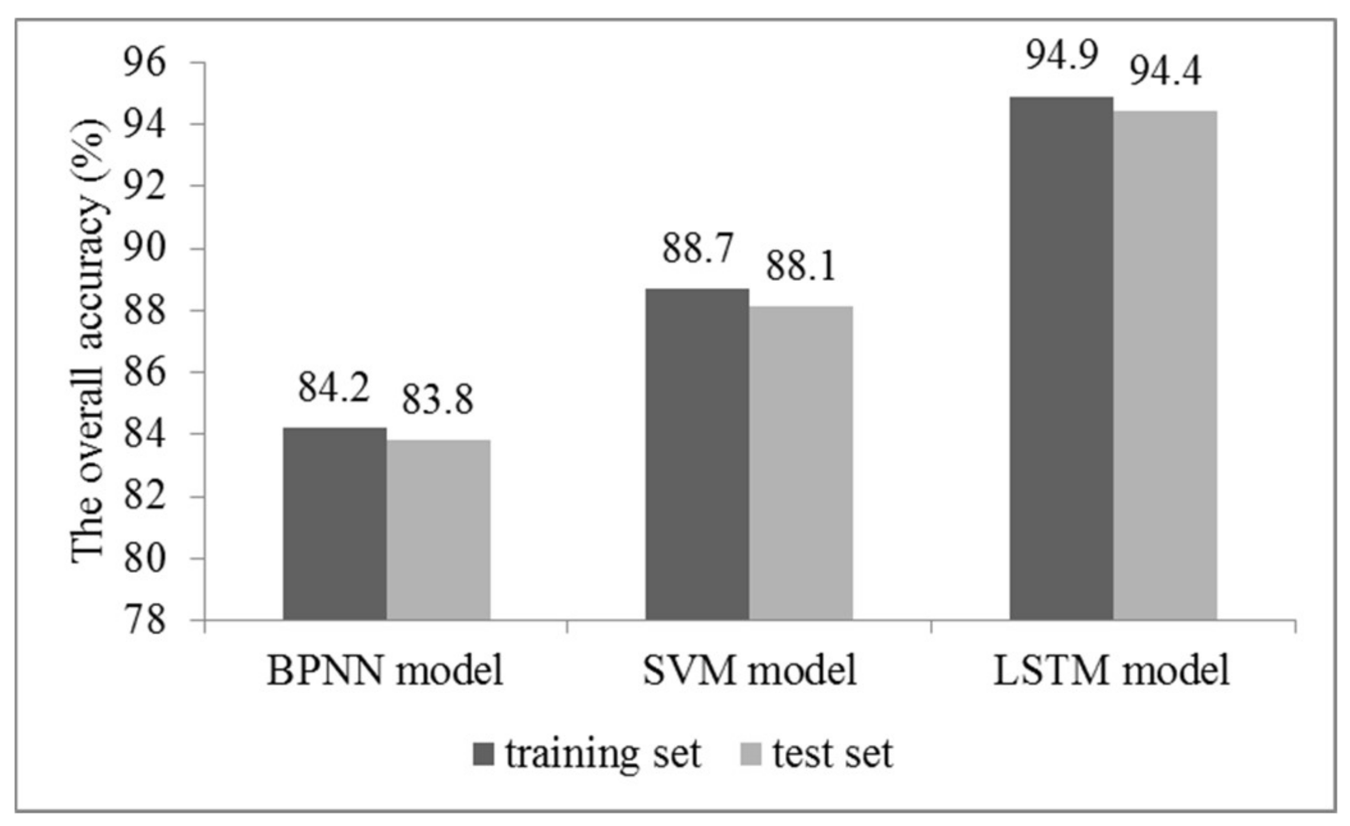
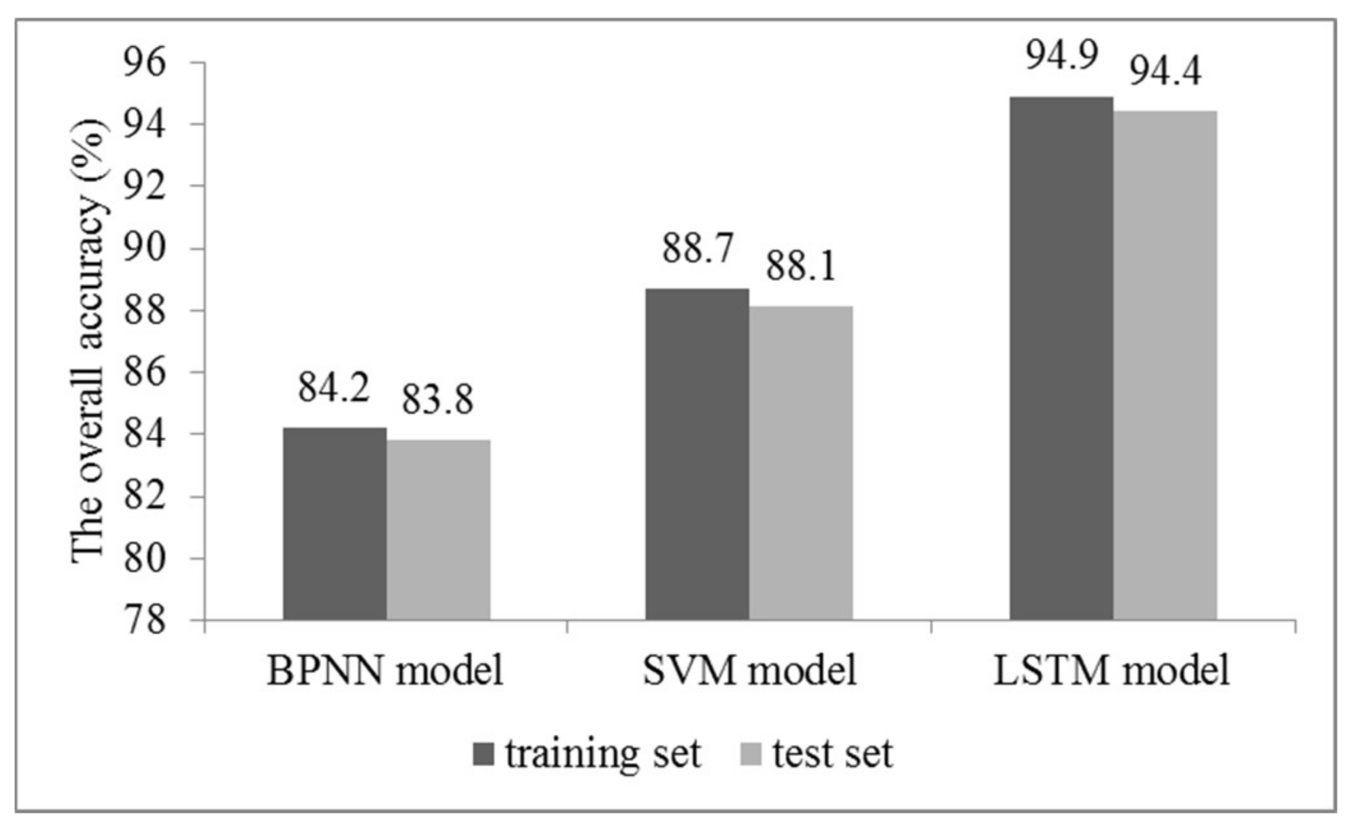
4.1. Short-Term Prediction of the Transformer Operating State
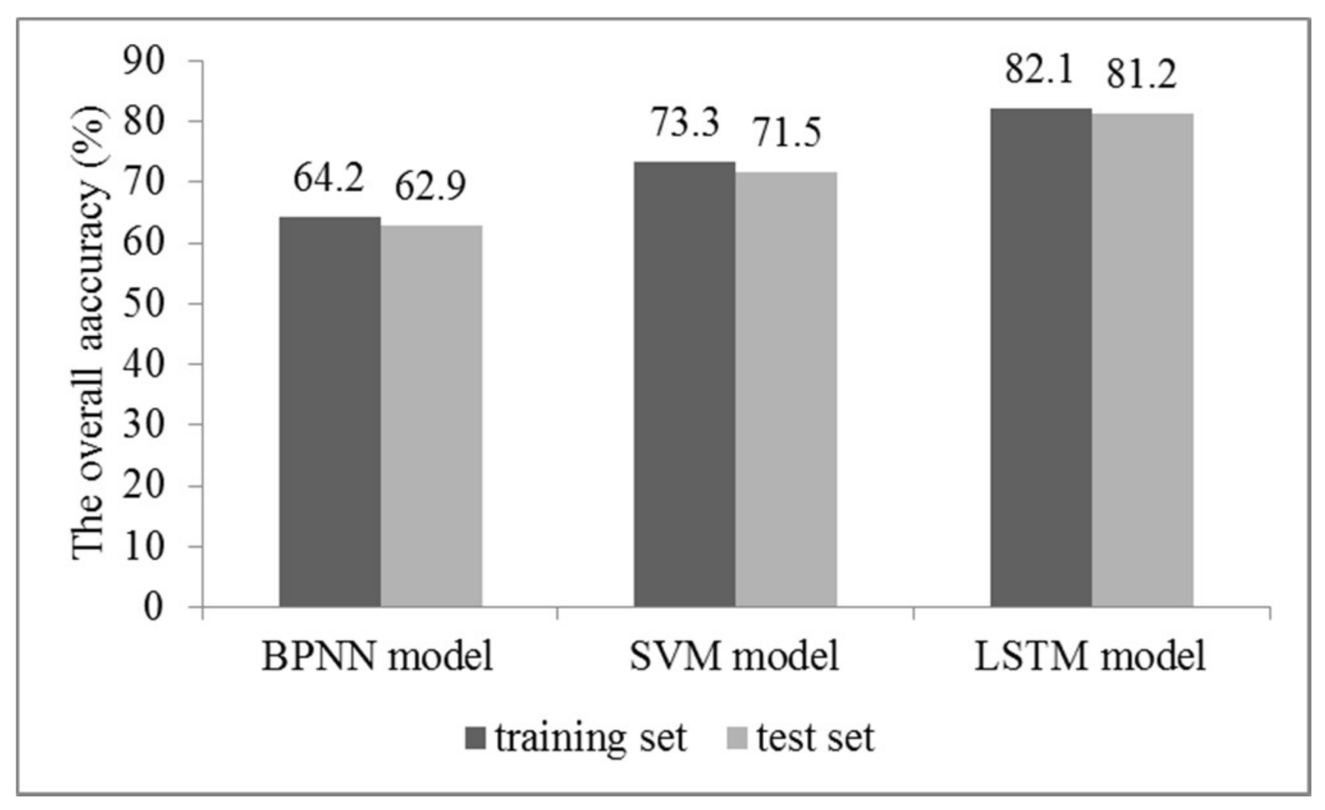
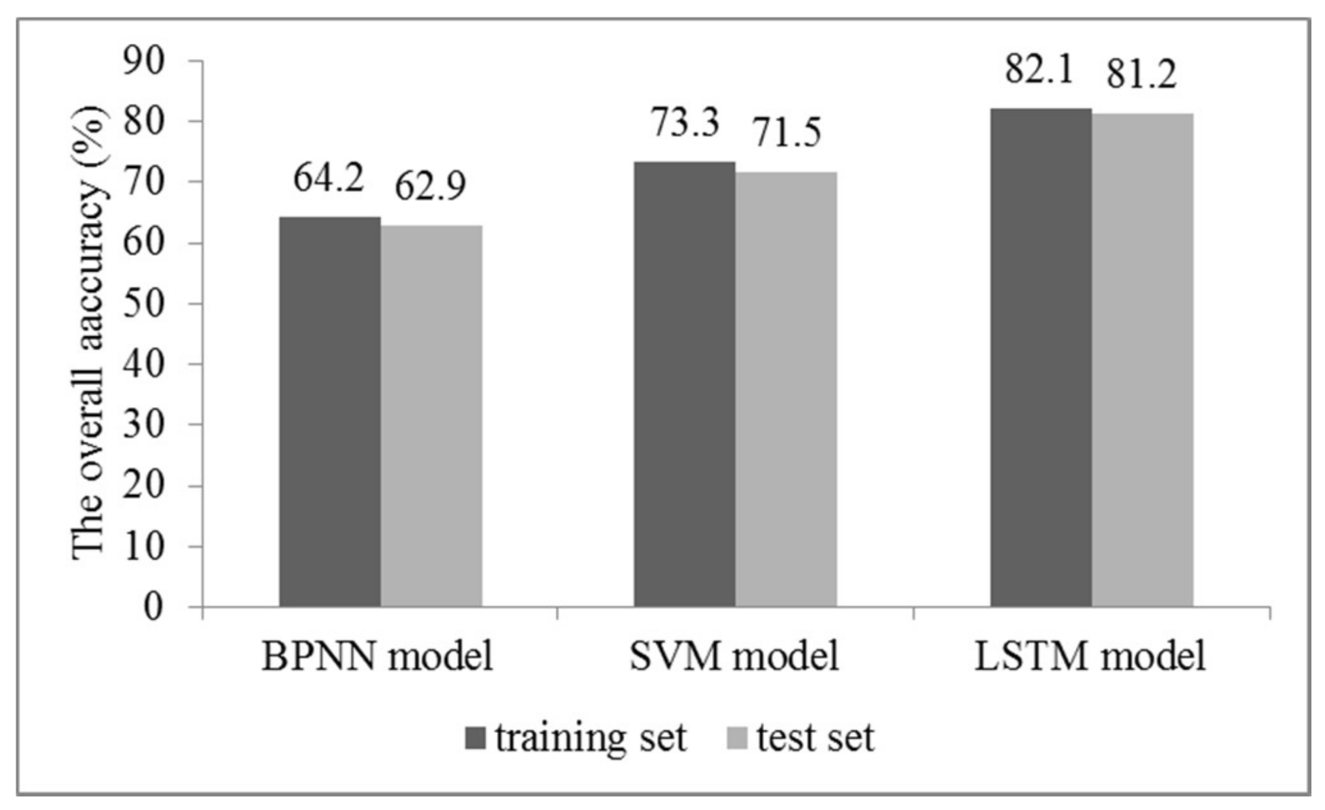
4.2. Long-Term Prediction of the Transformer Operating State
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Nomenclature
| x and xt | an input sequence, the input of recurrent neural network at time t |
| ht and zt | the hidden layer state and the output of recurrent neural network at time t |
| V, U, and W | the weight matrices of the output layer, the input layer, and the hidden layer state ht−1 as the input of recurrent neural network |
| ft, it, and ot | the state of forget gate, input gate, and output gate of LSTM at time t |
| Wf, Wi, and Wo | the weight matrices of the forget gate, input gate, and output gate of LSTM |
| bf, bi, and bo | the bias items of the forget gate, input gate, and output gate of LSTM |
| ct and bc | the memory cell state at time t and the bias of the input memory cell of LSTM |
| V and vi | transformer operating state set and transformer operating state (i = 1, 2, 3, 4) |
| r and G(∙) | the RDD of the indicator and the deterioration function |
| rl and rm | the RDD of the extremely large indicator and minimal indicator |
| al and am | the optimal value of the extremely large indicator and minimal indicator |
| bl and bm | the alarming value of the extremely large indicator and minimal indicator |
| li, lij, and wj | the score for different state levels of indicator i, the score for different state levels of indicator i given by the jth expert, and the weight of the jth expert |
| d, dk, dmin k, dmax k, and | the current monitoring value, the monitoring data of the indicator k, the minimum monitoring data of the indicator k, the maximum monitoring data of the indicator k, and the standard deviation value of dk |
| A, NP, and NT | the overall average accuracy, the number of correctly predicted samples, and the total number of samples in the dataset |
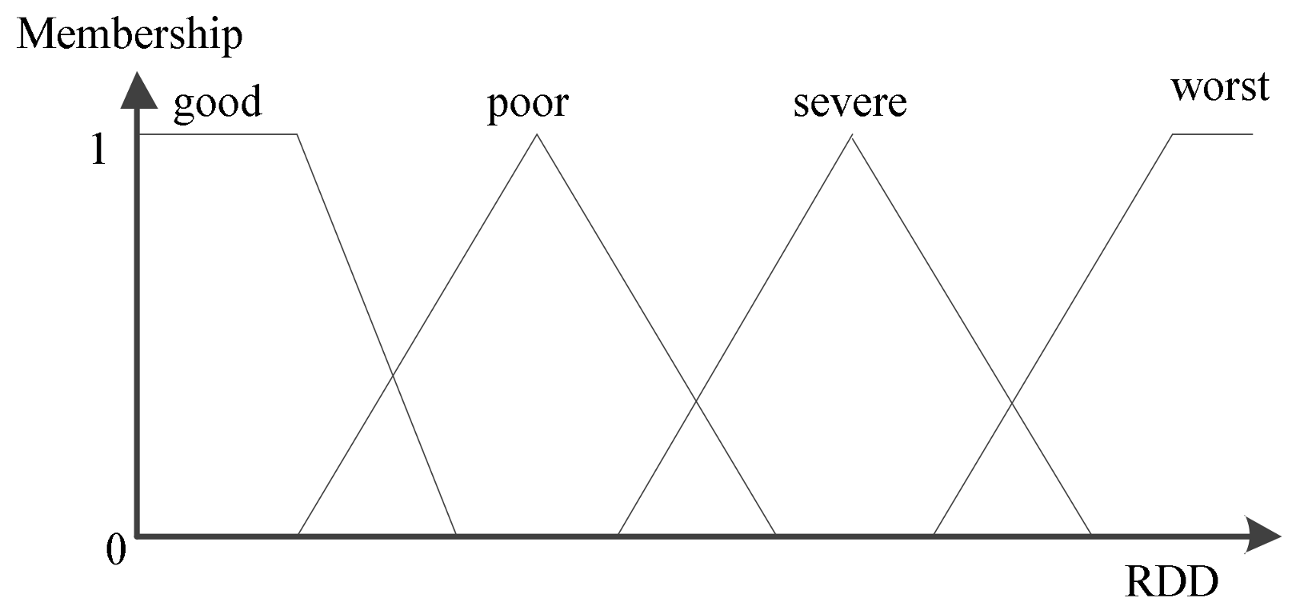
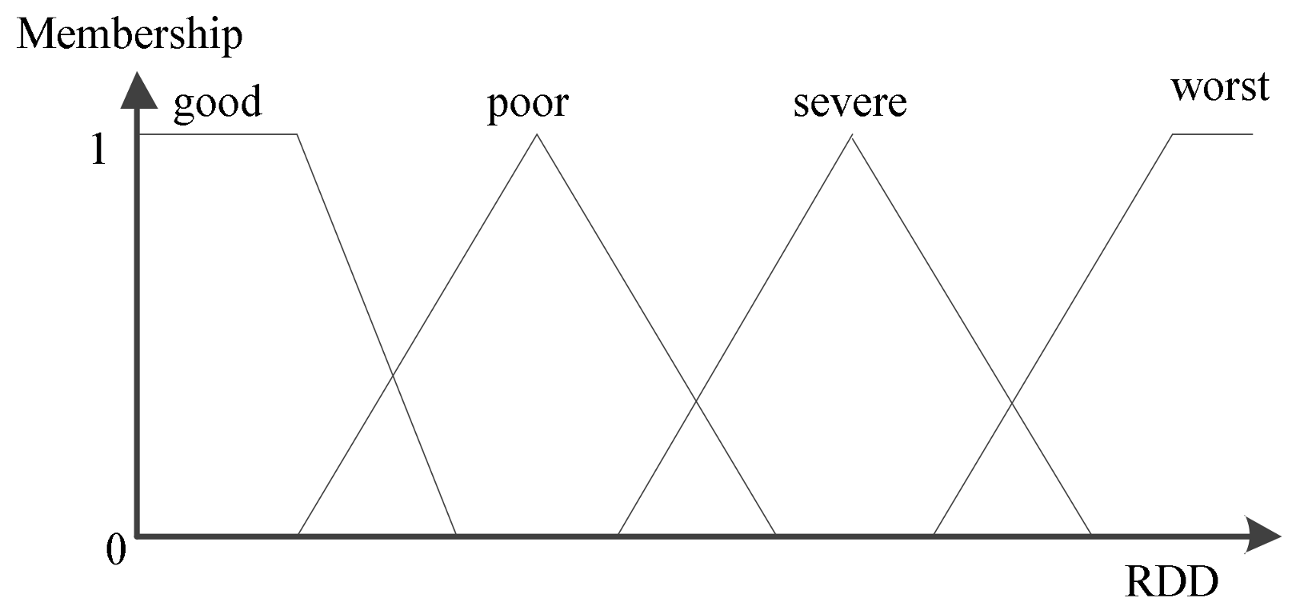
| the RDD of the gases dissolved in the oil corresponds to different operating state membership functions (i = 1, 2, 3, 4) |
References
- Kelly, J.J.; Myers, D.P. Transformer life extension through proper reinhibiting and preservation of the oil insulation. IEEE Trans. Ind. Appl. 2015, 31, 56–60. [Google Scholar] [CrossRef]
- Liao, R.J.; Bian, J.P.; Yang, L.J.; Grzybowski, S.; Wang, Y.Y.; Li, J. Forecasting dissolved gases content in power transformer oil based on weakening buffer operator and least square support vector machine—Markov. IET Gener. Transm. Distrib. 2012, 6, 142–151. [Google Scholar] [CrossRef]
- Liao, R.J.; Zheng, H.B.; Grzybowski, S.; Yang, L.J.; Tang, C.; Zhang, Y.Y. Fuzzy information granulated particle swarm optimisation-support vector machine regression for the trend forecasting of dissolved gases in oil-filled transformers. IET Electr. Power Appl. 2011, 5, 230–237. [Google Scholar] [CrossRef]
- He, Q.; Si, J.; Tylavsky, D.J. Prediction of top-oil temperature for transformers using neural networks. IEEE Trans. Power Deliv. 2000, 15, 1205–1211. [Google Scholar] [CrossRef]
- Yang, W.; Liu, Z.Z.; Chen, H.X. Research on residual flux prediction of the transformer. IEEE Trans. Magn. 2017, 53, 6100304. [Google Scholar] [CrossRef]
- Wang, F.H.; Geng, C.; Su, L. Parameter identification and prediction of Jiles—Atherton model for DC-biased transformer using improved shuffled frog leaping algorithm and least square support vector machine. IET Electr. Power Appl. 2015, 9, 660–669. [Google Scholar] [CrossRef]
- Cardelli, E.; Faba, A.; Tissi, F. Prediction and control of transformer inrush currents. IEEE Trans. Magn. 2015, 51, 1–4. [Google Scholar] [CrossRef]
- Baral, A.; Chakravorti, S. Prediction of moisture present in cellulosic part of power transformer insulation using transfer function of modified debye model. IEEE Trans. Dielectr. Electr. Insul. 2014, 21, 1368–1375. [Google Scholar] [CrossRef]
- Shaban, K.B.; El-Hag, A.H.; Benhmed, K. Prediction of Transformer Furan Levels. IEEE Trans. Power Deliv. 2016, 31, 1778–1779. [Google Scholar] [CrossRef]
- Qiu, J.; Wang, H.F.; Lin, D.Y.; He, B.T.; Zhang, W.F.; Xu, W. Nonparametric regression-based failure rate model for electric power equipment using lifecycle data. IEEE Trans. Smart Grid 2015, 6, 955–964. [Google Scholar] [CrossRef]
- Chowdhury, A.A.; Koval, D.O. Development of probabilistic models for computing optimal distribution substation spare transformers. IEEE Trans. Ind. Appl. 2005, 41, 1493–1498. [Google Scholar] [CrossRef]
- Zhou, D.; Wang, Z.; Li, C. Data requisites for transformer statistical lifetime modelling—Part I: Aging-related failures. IEEE Trans. Power Deliv. 2013, 28, 1750–1757. [Google Scholar] [CrossRef]
- Tokunaga, J.; Koide, H.; Mogami, K.; Hikosaka, T. Gas generation of cellulose insulation in palm fatty acid ester and mineral oil for life prediction marker in nitrogen-sealed transformers. IEEE Trans. Dielectr. Electr. Insul. 2017, 24, 420–427. [Google Scholar] [CrossRef]
- Bakar, N.A.; Abu-Siada, A. Fuzzy logic approach for transformer remnant life prediction and asset management decision. IEEE Trans. Dielectr. Electr. Insul. 2016, 23, 3199–3208. [Google Scholar] [CrossRef]
- Wouters, P.A.A.F.; van Schijndel, A.; Wetzer, J.M. Remaining lifetime modeling of power transformers: Individual assets and fleets. IEEE Electr. Insul. Mag. 2011, 27, 45–51. [Google Scholar] [CrossRef]
- Sheng, G.; Hou, H.; Jiang, X.; Chen, Y. A novel association rule mining method of big data for power transformers state parameters based on probabilistic graph model. IEEE Trans. Smart Grid 2018, 9, 695–702. [Google Scholar] [CrossRef]
- Mandic, D.P.; Chambers, J.A. Recurrent Neural Networks for Prediction: Learning Algorithms, Architectures and Stability; John Wiley: New York, NY, USA, 2001; pp. 31–46. [Google Scholar]
- Xu, C.; Wang, G.; Liu, X.; Guo, D.; Liu, T.Y. Health Status Assessment and Failure Prediction for Hard Drives with Recurrent Neural Networks. IEEE Trans. Comput. 2016, 65, 3502–3508. [Google Scholar] [CrossRef]
- Tian, Z.; Zuo, M.J. Health condition prediction of gears using a recurrent neural network approach. IEEE Trans. Reliab. 2010, 59, 700–705. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Mohamed, A.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–30 May 2013; IEEE: Vancouver, BC, Canada; pp. 6645–6649. [Google Scholar]
- Zheng, S.; Ristovski, K.; Farahat, A.; Gupta, C. Long Short-Term Memory Network for Remaining Useful Life estimation. In Proceedings of the 2017 IEEE International Conference on Prognostics and Health Management (ICPHM), Dallas, TX, USA, 19–21 June 2017; IEEE: Ottawa, ON, Canada; pp. 88–95. [Google Scholar]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-term residential load forecasting based on lstm recurrent neural network. IEEE Trans. Smart Grid 2017, 1. [Google Scholar] [CrossRef]
- Wang, H.; Lin, A.D.; Qiu, J.; Ao, L.; Du, Z.; He, B. Research on multiobjective group decision-making in condition-based maintenance for transmission and transformation equipment based on DS evidence theory. IEEE Trans. Smart Grid 2015, 6, 1035–1045. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. A fixed size storage O (n3) time complexity learning algorithm for fully recurrent continually running networks. Neural Comput. 1992, 4, 243–248. [Google Scholar] [CrossRef]
- Ranga, C.; Chandel, A.K.; Chandel, R. Condition assessment of power transformers based on multi-attributes using fuzzy logic. IET Sci. Meas. Technol. 2017, 11, 983–990. [Google Scholar] [CrossRef]
- Li, L.; Cheng, Y.; Xie, L.J.; Jiang, L.Q.; Ma, N.; Lu, M. An integrated method of set pair analysis and association rule for fault diagnosis of power transformers. IEEE Trans. Dielectr. Electr. Insul. 2015, 22, 2368–2378. [Google Scholar] [CrossRef]
- Sun, L.; Ma, Z.; Shang, Y.; Liu, Y.; Yuan, H.; Wu, G. Research on multi-attribute decision-making in condition evaluation for power transformer using fuzzy AHP and modified weighted averaging combination. IET Gener. Transm. Distrib. 2016, 10, 3855–3864. [Google Scholar] [CrossRef]
- Zhou, J.; Xu, W. End-to-end learning of semantic role labeling using recurrent neural networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 27–31 July 2015; pp. 1127–1137. [Google Scholar]
- Ma, Y.; Hu, M. Improved analysis of hierarchy process and its application to multi-objective decision. Syst. Eng. Theory Pract. 1997, 6, 40–44. (In Chinese) [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Running Status | Maintenance Strategy |
|---|---|---|
| v1 | good | Planned maintenance |
| v2 | poor | Priority maintenance |
| v3 | severe | Maintenance as soon as possible |
| v4 | worst | Immediate maintenance |
| Index | Maintenance History |
|---|---|
| 0–0.25 | Maintenance work has no difficulty. Maintenance frequency is not very high, and no defect is left untreated. |
| 0.25–0.5 | Maintenance work has slight difficulty. Maintenance frequency is not high, and a small defect is left untreated. |
| 0.5–0.75 | Maintenance work has some difficulty. Maintenance frequency is high, and a few defects are left untreated. |
| 0.75–1 | Maintenance work is very difficult. Maintenance frequency is higher, and obvious defects/faults are left untreated. |
| Indicator | Weight | Indicator | Weight |
|---|---|---|---|
| Gas dissolved in oil | 0.335 | Corrosive gases and dust | 0.0055 |
| Dielectric loss value | 0.168 | Altitude and wind speed | 0.0076 |
| Core earthing current | 0.1023 | Load condition | 0.0068 |
| Moisture content | 0.1202 | Running temperature | 0.0189 |
| Dielectric loss of oil | 0.1058 | Abnormal noise | 0.0024 |
| Breakdown voltage | 0.0597 | Nearby short-circuit | 0.0147 |
| Air temperature | 0.0034 | Protection action | 0.012 |
| Air humidity | 0.0041 | Maintenance history | 0.0345 |
| Date | H2 | CH4 | C2H4 | C2H6 | C2H2 | TH | CO | CO2 |
|---|---|---|---|---|---|---|---|---|
| 14 March | 32.77 | 10.29 | 4.56 | 1.64 | 0.13 | 16.62 | 176.3 | 693.1 |
| 15 March | 36.58 | 10.46 | 4.87 | 1.57 | 0.15 | 17.05 | 178.7 | 698.6 |
| 16 March | 34.89 | 9.98 | 4.33 | 1.71 | 0.15 | 16.17 | 168.5 | 704.8 |
| 17 March | 33.21 | 10.9 | 4.72 | 1.68 | 0.16 | 17.46 | 174 | 707.9 |
| 18 March | 35.76 | 10.32 | 4.28 | 1.75 | 0.17 | 16.52 | 185.4 | 697.1 |
| 19 March | 38.63 | 10.65 | 4.64 | 1.8 | 0.14 | 17.23 | 171.7 | 701.7 |
| 20 March | 40.52 | 10.44 | 4.39 | 1.95 | 0.18 | 16.96 | 180.5 | 682.3 |
| 21 March | 37.97 | 10.88 | 4.61 | 1.89 | 0.17 | 17.55 | 183 | 709.3 |
| 22 March | 34.51 | 10.49 | 5.09 | 1.71 | 0.22 | 17.51 | 185.9 | 715.1 |
| 23 March | 35.39 | 10.61 | 4.68 | 1.74 | 0.21 | 17.24 | 180 | 724.8 |
| 24 March | 37.28 | 10.4 | 4.44 | 1.89 | 0.23 | 16.96 | 178.8 | 715.4 |
| 25 March | 55.07 | 15.05 | 12.71 | 4.4 | 0.48 | 32.64 | 184.3 | 720.6 |
| 26 March | 70.17 | 18.89 | 17.04 | 6.9 | 0.61 | 43.44 | 185.3 | 717 |
| Date | H2 | CH4 | C2H4 | C2H6 | C2H2 | TH | CO | CO2 |
|---|---|---|---|---|---|---|---|---|
| 15 June | 2.67 | 58.35 | 22.75 | 23.59 | 0 | 104.69 | 110.2 | 516.3 |
| 26 June | 2.37 | 66.35 | 23.28 | 25.14 | 0 | 114.76 | 116.4 | 522.6 |
| 7 July | 2.67 | 78.70 | 20.6 | 22.35 | 0 | 121.64 | 117.0 | 519.8 |
| 15 July | 2.37 | 86.05 | 20.68 | 22.19 | 0 | 128.93 | 108.1 | 514.7 |
| 24 July | 2.37 | 99.69 | 20.15 | 21.89 | 0 | 141.73 | 102.4 | 510.8 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, H.; Dai, J.; Luo, L.; Sheng, G.; Jiang, X. Power Transformer Operating State Prediction Method Based on an LSTM Network. Energies 2018, 11, 914. https://doi.org/10.3390/en11040914
Song H, Dai J, Luo L, Sheng G, Jiang X. Power Transformer Operating State Prediction Method Based on an LSTM Network. Energies. 2018; 11(4):914. https://doi.org/10.3390/en11040914
Chicago/Turabian StyleSong, Hui, Jiejie Dai, Lingen Luo, Gehao Sheng, and Xiuchen Jiang. 2018. "Power Transformer Operating State Prediction Method Based on an LSTM Network" Energies 11, no. 4: 914. https://doi.org/10.3390/en11040914
APA StyleSong, H., Dai, J., Luo, L., Sheng, G., & Jiang, X. (2018). Power Transformer Operating State Prediction Method Based on an LSTM Network. Energies, 11(4), 914. https://doi.org/10.3390/en11040914