Abstract
When reading text, observers alternate periods of stable gaze (fixations) and shifts of gaze (saccades). An important debate in the literature concerns the processes that drive the control of these eye movements. Past studies using strings of letters rather than meaningful text (‘z-reading’) suggest that eye movement control during reading is, to a large extent, controlled by low-level image properties. These studies, however, have failed to take into account perceptual grouping processes that could drive these low-level effects. We here study the role of various grouping factors in horizontal scanning eye movements, and compare these to reading meaningful text. The results show that sequential horizontal scanning of meaningless and visually distinctive stimuli is slower than for meaningful stimuli (e.g. letters instead of dots). Moreover, we found strong evidence for anticipatory processes in saccadic processing during horizontal scanning tasks. These results suggest a strong role of perceptual grouping in oculomotor control in reading.
Introduction
A guiding assumption of the approaches that emphasize the low-level impacts on reading and horizontal scanning (Vitu, O’Regan, Inhoff, & Topolski, 1995, see also Nuthmann, Engbert, & Kliegl, 2007, Rayner & Fischer, 1996) is the idea that similar patterns of saccadic processing can be observed for both meaningful and meaningless material. Similar distributions of saccade amplitudes were found for meaningful (such as text) and meaningless stimuli (such as z-strings), suggesting that the decision of where to move the eyes is unaffected by stimulus meaning. In contrast, fixation durations tend to be longer for meaningless z-texts than for actual text (Vitu, 2011, 740; for initial evidence cp. Nuthmann, Engbert, & Kliegl, 2007, Rayner & Fischer, 1996), suggesting that the decision when to move the eyes can also be influenced influenced by meaning. It seems that the string length induces a similar effect for both meaningful and meaningless scanning, demonstrating that the probability of skipping a 5 or 6 letter string is equally high for reading and scanning meaningless letter strings (Rayner & Fischer, 1996); the preferred viewing position also induces a similar effect for both meaningful and meaningless scanning: the distributions of preferred landing positions are similar in both cases (Nuthmann et al., 2007). Furthermore, the programming of regressions seem to be a more general visual process that is not strongly sensitive to language processing: the regressions seem to be largely unrelated to lexical processing (Engbert, & Kliegl, 2011, Trukenbrod & Engbert, 2007, Nuthmann, & Engbert, 2009). Although there are differences between z-reading and reading meaningful texts, e.g., differences in fixation duration- and saccade amplitudes distributions (Rayner & Fischer, 1996), there are some more basic low-level visual processes (that are not directly related to verbal processing) that seem to have strong effects on saccadic processing, i.e., the planning of the saccades. For this study, together with the results from z-reading studies (Vitu, O’Regan, Inhoff, & Topolski, 1995, Rayner & Fischer, 1996, Rayner, Pollatsek, Ashby, & Clifton Jr, 2012), we demonstrate that meaning and configuration exert a moderate degree of influence on scanning processes. We also demonstrate that in case of reading a meaningful (and grammatically correct) text, there is a link between occulomotor and visual processing, on one hand, and higher cognitive processing (lexical processing, in particular) on the other hand. Therefore, in contrast with z-reading advocates, we would rather argue in line with assumptions made by the E-Z reader model (Rayner, Pollatsek, Ashby, & Clifton Jr, 2012, Ch. 6) that the primary aim when reading meaningful text (instead of just scanning symbols) is word identification. We would therefore like to argue that eye movements in z-reading and in actual word reading may show similar properties, this similarity may occur despite highly different processes at the level of cognitive processing.
The second aspect of eye movements in scanning tasks adressed here is perceptual grouping that has been studied extensively (Treisman, 1982), but only sporadically in the context of eye movement control (e.g., Ghose, Hermens & Wagemans, 2012).
An important approach to perceptual grouping is the Gestalt approach, which postulates a series of principles along which visible elements in are likely to be grouped. Important principles that guide grouping in perceptual processing are grouping by proximity, feature similarity, connectedness, continuity, configuration, entity similarity, and figurality (e.g., Wertheimer, 1923, Palmer, 1992, Wagemans, Elder, Kubovy, Palmer, Peterson, Singh, & von der Heydt, 2012, Pomerantz & Kubovy, 1986).
While past studies of horizontal scanning have looked at the distinction between meaningful and meaningless text, they have not taken into account the role of perceptual grouping, as a process of early analysis of the available visual information. In our study, we will focus on one of the central grouping principles—similarity. According to this principle, similar elements (shape, size, color, etc.) are perceived as belonging together, all else being equal (ceteris paribus).
The role of perceptual grouping has been largely confined to a phenomenological semi-quantitative framework and, despite demonstrating some strong phenomenological effects, perceptual grouping has only recently been quantitatively replicated (for an overview see, e.g., Wagemans et al., 2012, Palmer, 1999). Grouping principles have often been studied in isolation, because of the inherent problem of quantifying the relative strength of different grouping principles, without risking an interaction of the different principles. Such interactions can be complementary, and can either be additive or non-additive, and operate on a local or a global stimulus level. Moreover, new grouping principles are still being discovered (Wagemans et al., 2012) since Wertheimer’s seminal study of 1923.
Another point of discussion in the field of perceptual grouping involves the the moment in time at which grouping happens. On the one hand, it has been argued that grouping is an early, pre-steady state (stochastic) process (Taylor & Aldridge, 1974). This idea also corresponds to the initial intuition by Wertheimer that grouping is an early, low-level phenomenon that provides units for further processing. To some extent, the similar, but empirically better-supported position is that of Prinzmental & Banks (1977), who emphasize that grouping is an early, pre-attention process (for a discussion cp. also Feldman, 2007, 817, 818).
On the other hand, it has been assumed that perceptual grouping is a late process, which takes place only after the perceptual steady state has been established and depth information has been extracted (Palmer, 1999, 263, for initial results cp. also Rock & Brosgole, 1964), or that grouping is a post-attention process (e.g., Mack, Tang, Tuma, Kahn, & Rock, 1992).
Finally, there is a mixed view, where it is assumed that grouping is a multi-level phenomenon possessing different temporal dynamics and strengths at different levels (Palmer, Brooks & Nelson, 2003, for other early evidence supporting the notion that retinal and perceived information interact during grouping processes cp. Beck, 1975, Olson & Attneave, 1970). We think the late processing view is the most plausible one (perceptual grouping is multi-level phenomenon) and we therefore hypothesize that, at the level of saccadic processing in horizontal scanning, grouping occurs later and is more robust than has been indicated by the psychophysical experimental paradigm (Ghose, Hermens & Wagemans, 2012).
In the present study, we aim to extend the work on z- reading, by examining how perceptual grouping influences the planning of scanning eye movements by analyzing eye movement patterns when processing stimuli with almost no contextual information and stimuli with some contextual information (both consistent and arbitrary, senseless).
We focus on the principle of grouping by similarity, which is considered to be one of the strongest grouping princples (Palmer, 1999). While past studies have examined perceptual aspects associated with grouping by similarity, we will study how perceptual grouping by similarity affects oculomotor scanning. To compare the eye movements when scanning meaningless configurations of symbols with those in reading, we use both simple perceptual elements (ranging from static dots to rows of varying or randomly ordered geometrical figures with color effects) and meaningful text and letter arrays (where we will also apply similarity cues).
Thus, we explore the way in which a participant structures gaze shifting for stimuli with varying configurational complexity (captured by different horizontally distributed patterns of grouping by similarity). An additional aim of the study is to describe the structural properties of saccadic processing and to establish how strong the grouping effects are. Instead of using z-strings that still activate restrictive lexical processing, we substituted the letter strings with figures that lack any orthographical structure and lexical meaning (i.e., geometrical figures).
Experiment
Participants
Ten subjects (seven females), aged 21-34, all from the Department of Optometry and Vision Science, at the University of Latvia, participated in both experiments reported here. All subjects had normal near distance vision. Participants were naive about our research aims, or our hypotheses until after the experiments. To establish the robustness of the effects, six participants repeated the first experiment, 2 months after the first performance.
Experimental setup
We created 11 arrays of symbols, words, and letters, which were presented one by one to the participants (in a fixed order). Participants were asked to scan the elements in each of the arrays horizontally. The arrays were presented in two separate experiments, where Experiment 1 aimed to compare meaningless and meaningful horizontal scanning eye movements. Experiment 2 was designed to examine the influence of perceptual grouping.
Apparatus
Stimuli were presented on an LCD (Hewlett Packard Compaq 1720, 17 inch, 1280 × 1024 pixels) computer screen. During the experiment the participants head was fixed (participants were asked to put their chin on the chin rest and put their forehead against a bar) and the distance from the participants’ faces to the screen was 60 cm. Eye movements were recorded with a video-oculograph iViewX Hi-Speed at 250Hz.
Data analysis
Data were analyzed with the program BeGaze2. Further statistical analysis was conducted with MS Excel and IBM SPSS software.
Using the velocity-based algorithm (developed by Smeets & Hooge, 2003), the BeGaze software divided the recorded raw eye movement data into 3 main events: fixations, saccades, and blinks. A saccadic speed threshold level of 35°/s (20% of the peak velocity onset) was chosen. Previous research has suggested that a threshold level of 25-35°/s yielded acceptable results for the greatest number of participants (Lacis, Laicane, & Skilters, 2012).
Saccade deteciton was verified using visual inspection and when it was found that small saccades were not detected, or when small eye movements during fixations were classified as saccades, the corresponding saccade and fixation data were disregarded (process illustrated in Figure 1).
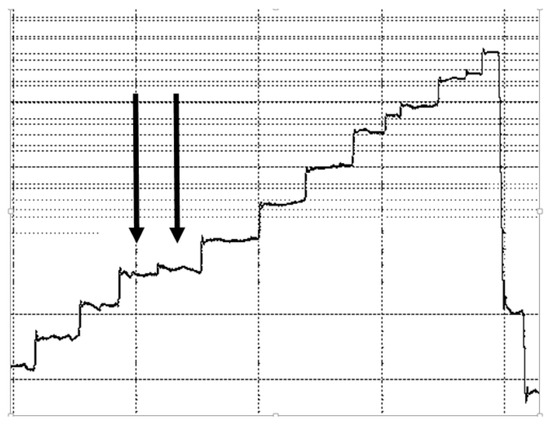
Figure 1.
Illustration of instances where automatic fixation and saccade detection yielded inaccurate results. Arrows indicate a single fixation automatically divided into two fixations. The two fixations were removed from the data analysis.
Fixations and saccades before and after blinking were removed from the data analysis, as were fixations before regressions and regressive saccades.
The reason for excluding regressions (saccades to the left) was to minimize influences of perceptual span. Perceptual span, otherwise known as the effective visual field, describes the spatial range across which information that can be obtained during a fixation. The horizontal perceptual span in reading tasks has been found to be asymmetric; it is oriented to the right for orthographies that are printed from left to right (e.g., English) (Rayner, 1998) and oriented to the left for orthographies that are printed from right to left (e.g., Hebrew) (Pollatsek, Bolozky, Well & Rayner, 1981). Furthermore, the amount of available information in the perceptual span can influence reading speed (Pollatsek, Bolozky, Well & Rayner, 1981), as well as visual search task efficiency (Phillips & Edelman, 2007).
Our interest was mainly in the horizontal component of the gaze shifts, and therefore only this component was taken into account. To ensure correct measurement of gaze, drift correction and, if necessary, repeated calibration were performed at the start of each trial.
Together our data filtering procedures led to the removal of 62% of the fixation and saccades. These include:
- (a)
- The first and the last line of each trial (1/3 or roughly 40%); removed to exclude start and end of the trial effects.
- (b)
- Fixations before and after blinks (~10%)
A further 10-12% of the data were excluded due incorrect saccade or fixation detection (upon visual inspection).
To examine the stability of the results across sessions, six of the participants repeated the experiment after two months.
Experiment 1
To compare horizontal scanning eye movements with and without meaning or content, we designed 4 horizontal scanning tasks (henceforth: N1-N4), each consisting of one trial (stimuli illustrated in Figure 2).

Figure 2.
Stimuli. The task was to shift one’s gaze back and forth between two simple dots (N1), to scan geometrical figures aligned along a single line (N2) and aligned along 6 lines (N3), and to read a given text (N4).
Task N1 was designed to examine the role of the global effect, were eyes tend to land on the center of gravity of objects near the saccade target (Van der Stigcel, Nijboer, 2011). In task N1 participants were asked to saccade between two horizontally oriented dots, without any additional stimuli that might affect saccadic landing position. The distance between the centers of the dots was 1.9 degrees.
Task N2 was to scan a horizontal row of dots. The row had to be scanned sequentially five times. Task N2 was constructed to evaluate the parameters of horizontal scanning tasks, which, due to the organization of the stimuli, required sequential scanning eye movements to be executed in a manner similar to that for reading and scanning z-strings. The distance between the centers of the dots was 1.9 degrees, which corresponds to the average distance when reading English, i.e., 7-9 letter spaces (2 degrees) (Rayner, 1998).
Task N3 was to scan six horizontal rows of dots, line by line. Each row had to be scanned sequentially as in stimuli set N2. The horizontal distance between the centers of the dots was 1.9 degrees. The vertical distance between the lines was 0.9 degrees. The length of each row was 11 degrees. Because all the lines were visible at the same time, and transferring one’s gaze to the beginning of the next line involved a vertical component, the task bore more similarity to reading and scanning z- strings than task N2.
Task N4 was to read a given text. The text was specifically constructed so that the distance between the first letters of any two juxtaposed words was about 1.9 degrees and the vertical distance between the lines was 0.9 degrees, which corresponds to the distance between the dots in the previously mentioned dot scanning tasks (N1-N3). Hence, the vertical size of the stimuli in task N4 was about 7 degrees.
Before the experiment, all stimuli sets were presented and instructions were given to the participants. If necessary, during the experiment instructions were repeated. The general task was to execute horizontal gaze shifting from dot to dot (N1-N3), and to read a given text (N4). The stimulus presentation always began with task N1 and ended with task N4.
Results. The average saccade amplitude and the average fixation duration are the spatial (saccade amplitude) and temporal (fixation duration) aspects of programming eye movements during the task. Task N3 was chosen as the reference, in order to analyze whether global effects (N1 and N2 compared to N3) and additional visual and semantic information (N3 compared to N4) influence eye movement performance in horizontal scanning tasks.
Saccade amplitudes are highly similar across the different tasks. However, fixation durations vary across the tasks, suggesting that sequential horizontal scanning from object to object (even when using simple dots) is guided by oculomotor decision processes similar to those that occur while scanning meaningless z-strings and while reading.
Saccades. Figure 3 shows that the average saccade amplitudes range from 1.7-2.1 degrees across the four tasks. Average saccade amplitudes were slightly but not significantly shorter in tasks N2 (1.7±0.1 degrees) and N3 (1.8±0.1 degrees) and longer in tasks N1 (2.0±0.1 degrees) and N4 (2.1±0.2 degrees).

Figure 3.
Average saccade amplitudes during horizontal symbol scanning tasks (N1-N3) and while reading artificially constructed text (N4). Bars represent the SEM.
We executed one-way repeated measure ANOVA to examine the statistical significance of the observed differences in saccade amplitudes. The results did not reveal a significant effect of the task type on average saccade amplitude (F (3, 7) = 2.558, p = 0.138, partial eta square = 0.523).
Fixations. Fixation durations can be assumed to reflect information processing and saccade programming times. Because the spatial configuration across tasks was quite similar (particularly between N3 and N4), we expect the majority of any differences to be found not in saccadic amplitudes, but in fixation durations.
Figure 4 shows the average fixation durations across participants for each of the tasks. The longest fixation durations were found in the N1 task (saccading back and forth between two symmetrically aligned dots) (average fixation time for all participants was 579±63 milliseconds). In contrast, for sequential symbol scanning tasks (N2-N3) and for reading tasks (N4), the average fixation duration is half that in N1.
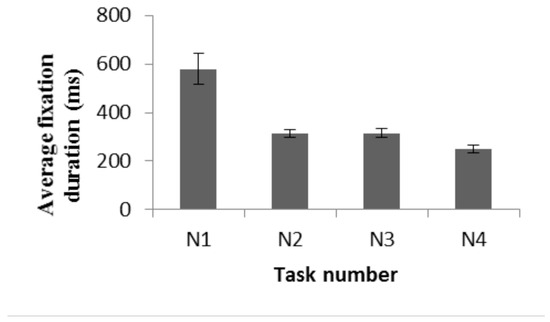
Figure 4.
Average fixation durations across participants for horizontal symbol scanning tasks (N1-N3) and while reading an artificially constructed text (N4). Bars represent the SEM.
We executed a one-way repeated measure ANOVA to compare the effect of the task on the average fixation duration. The results demonstrated a significant effect on average fixation duration, (F (3, 7) =8.480, p = 0.01, partial eta = 0.784). Post hoc tests using the Bonferroni correction revealed that the average fixation durations during tasks N1 (579±63ms) and N3 (315±19ms) are significantly different (p=0.006). No significant differences were found between tasks N2 (mean 312±16 milliseconds) and N3 (p=1.000). The slight reduction in average fixation times when comparing the results of N4 (mean 252±15 milliseconds) and N3 is also not statistically significant (p=0.09).
Experiment 2
In order to analyze the impact of increasing configurational complexity on horizontal scanning task performance, with Experiment 2 we tested seven additional horizontal scanning tasks (Figure 5) (henceforth: N5-N11).
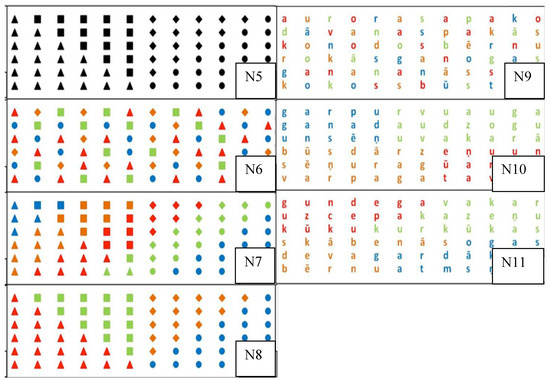
Figure 5.
Stimuli. The task was to scan geometrical figures aligned along 6 horizontal lines (N5-N8) and to scan from letter to letter (N9-N11). In tasks N5-N11, geometrical figures and letters were distributed according. to different configurational complexity. In tasks N9-N11, letters comprise meaningful texts.
Tasks N5-N8 required participants to sequentially scan six horizontal rows of objects of geometric figures. Spatially all of the objects were arranged as in task N3.
Tasks N9-N11 required participants to scan six horizontally distributed rows of letters that comprised meaningful texts. Letters were spatially arranged as in task N3.
The stimuli exhibited the following similarity principles:
- (1)
- No grouping: figures (N6) and letters (N9) were distributed and colored randomly;
- (2)
- Conflicting grouping: N7 (figures) and N10 (letters) were grouped according to geometric shape (N7) or borders of the words (N10) and color, for which the groupings did not overlap.
- (3)
- Simple grouping task: N8 (figures) and N11 (letters) were grouped according to geometric shape (N7) or borders of the words (N10) and color. In this case the groupings overlapped: the same shapes were in the same color (N7) or every letter of each word was in the same color (N10).
At the start of the experiment, all stimuli sets were presented and instructions provided to the participants. If necessary, instructions were repeated during the experiment. The general task was to execute horizontal gaze shifting from geometrical figure to geometrical figure (N5-N8) or from letter to letter (N9-N11). The speed at which one shifts one’s gaze was at the sole discretion of the participant.
Results. As before, no significant differences were found in the saccade amplitudes across the tasks. In contrast to Experiment 1, Experiment 2 did not show an effect of task on fixation durations. Fixation durations were therefore only significantly shorter when scanning letters in a meaningful text, suggesting that either the meaning of the text or letter (meaningful symbol) analysis expedites saccadic programming.
Saccades. Figure 6 shows that the average saccade amplitude during tasks N5-N11 ranges from 1.7 to 2.2 degrees. The average saccade amplitude appears to be shorter during symbol scanning tasks N5 (1.7±0.1 degrees), N6 (1.8±0.1 degrees), N7 (1.8±0.1 degrees) and N8 (1.9±0.1 degrees) than during letter scanning tasks N9 (1.9±0.1 degrees), N10 (2.0±0.1 degrees), and N11 (2.2±0.2 degrees).
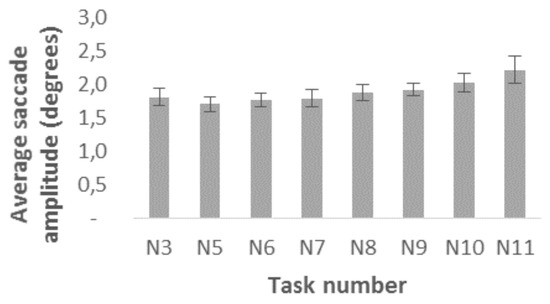
Figure 6.
Average saccade amplitudes during horizontal symbol scanning tasks (N3, N5-N8) and during letter scanning tasks (N9-N11). Bars represent the SEM.
We executed one-way repeated measure ANOVA to compare the effect of the grouping on the average saccade amplitudes. The results reveal that visual information grouping does not have a significant effect on average saccade amplitudes either during symbol scanning (F (3, 7) =0.956, p=0.464, partial eta squared = 0,291) or during letter scanning tasks (F (2, 8) =2.383, p=0.154, partial eta squared = 0.373). This suggests that changing the shape, color, or layout of the symbols does not significantly alter the average saccade amplitudes.
Adding semantic meaning to the symbols, by replacing every symbol with a letter, increases the average saccade amplitude slightly, but no significant difference is found between letters and dots. We executed Bonferroni corrected paired-samples t-tests (corrected significance level of p<0.017) to compare the letters and dots. The only comparison that revealed a statistically significant difference was that between N7 (M=1.797, SD=0.4225) and N10 (M=2.023, SD=0.4395), when there existed stimulus shape grouping or when the borders of words did not correspond to the coloring of the symbols or letters: t(9)=-2.972, p=0.016.
Fixations. Figure 7 shows the average fixation durations during tasks N3 and N5-N11. The average fixation duration during the dot task N3 was 315±19ms.
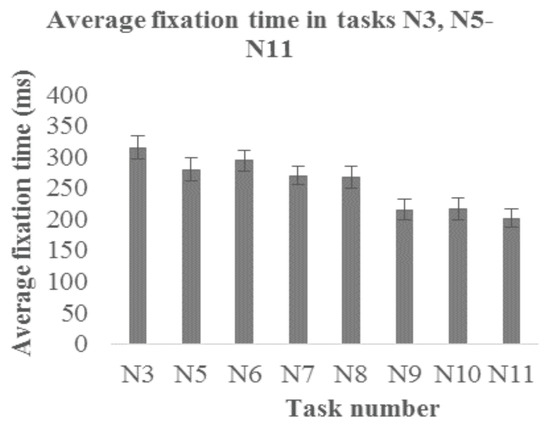
Figure 7.
Average fixation durations for the entire group during horizontal symbol scanning tasks (N3, N5-N8) and letter scanning tasks (N9-N11). Bars represent SEM.
When a set of various grayscale and colored symbols is presented, the average fixation time decreases slightly to 280±19ms in task N5, 295±17ms in task N6, 270±15ms in task N7 and 268±18ms in task N8. Similar to reading (task N4), fixation durations times appear to be shorter when symbols contain semantic meaning: the average fixation times were 215±17ms in task N9, 216±18ms in task N10, and 201±15ms in task N11.
We executed a one-way repeated measure ANOVA to compare the effect of the grouping principles (by color, by shape) on the average fixation duration. Visual information grouping did not have a significant effect on the average fixation duration during either symbol scanning (F(3,7)=2.463, p=0.147, partial eta squared= 0.514) or letter scanning tasks ( F (2, 8) =2.259, p= 0.167, partial eta sqaured=0.361).
To analyze how semantic meaning influences fixation durations, we compared the average fixation times between pairs of tasks with the same principle of symbol or letter coloration (N6 and N9, N7 and N10, N8 and N11). We performed Bonferroni corrected paired- samples t-tests (corrected significance level of p<0.017). Statistically significant differences were observed in all cases: comparing N6 (M=295, SD=53) and N9 (M=215, SD=52), t(9)=5.428, p<0.001; N7 (M=270, SD=47) and N10 (M=217, SD=57), t(9)=3.787, p=0.004; N8 (M=268, SD=56) and N11 (M=202, SD=46), t(9)=3.922, p=0.003, demonstrating changing from symbols to letters, fixation duration (reflecting processing time) is reduced.
Repeatability
In order to determine the stability of the findings over time, the experiment was repeated (for tasks N3-N5 and task N8) with six of the participants two months later. Repetition of the experiment also provided an idea about how the results are influenced by past experience with the task.
A Wilcoxon signed-rank test with a post-hoc comparison of the fixation durations (Bonferroni corrected significance level of p < 0.0017), indicated that only one participant exhibited a significant difference in fixation durations between the first and the repeated experiment, and only when performing task N6. There were no other statistically significant differences between the first and the repeated experiments.
Discussion
An important issue in the reading literature is whether eye movements during reading are controlled by low level properties of the stimuli, or whether they are determined by the meaning of the text read. Studies applying z-reading have suggested an important role of low-level features, but have not taken into account perceptual grouping aspects of the stimuli.
In the current study we analyze the oculomotor behavior in meaningful (letters and text) and meaningless (symbols) horizontal scanning tasks similar to reading. The results show no statistically significant differences when comparing the average saccade amplitudes in different horizontal scanning tasks as well as suggest no role of perceptual grouping on fixation duration during scanning of horizontally arranged stimuli. Decreased fixation durations were found when scanning words (task N4) and letters (N9-N11), compared to symbols and dots, suggesting the role of meaning.
The decreased processing times in our sequential scanning tasks (N2-N3, N5-N8), compared to scanning two stationary dots back and forth (task N1), suggest that gaze transfer in sequential horizontal object scanning is a rather automatic process that might be associated with processing a similar and ubiquitous horizontal scanning material (as when reading). The average fixation duration tends to become even shorter during simple reading tasks (N4) than during simple horizontal scanning, and that is similar to the results of other studies focusing on meaningless horizontal scanning (e.g., mindless reading where all the words are replaced with z-letter strings). The results of these studies show that average fixation durations during meaningless horizontal scanning tasks are longer that those for reading text (Vitu, O’Regan, Inhoff, Topolski, 1995).
One might assume that the differences in processing times between task N1 (looking back and forth between two isolated dots) and tasks N2-N4 (scanning lines of dots) are due to subject behaviors that we observe in the context of the two-step paradigm, wherein it is necessary to change the parameters of a planned saccade (from leftward to rightward) in task N1, but not in tasks N2 to N4 (where the same saccade plan can be repeated). However, we are inclined to think that this is not the case, considering that when experiments analyzing the two- step paradigm are performed, the visual information changes during the execution of the saccade. Hence, the subject has to program a new saccade as soon as possible or even modify the saccade in progress as much as possible. Furthermore, the difference in reaction times in two-step tasks, wherein participants have to cancel an already programmed saccade, is not more than 100 ms, compared to tasks, wherein participants have to make a sequence of successive saccades (Ray, Schall & Murthy, 2004). Also, no differences have been found between the latent periods associated with undershoot and overshoot corrective saccades, wherein the direction of the saccade target is different than that for the initial saccade (Kapoula & Robinson, 1986).
Our results support the view that the planning of saccades during horizontal scanning is driven by rather robust low-level processes (and, thus, is partially consistent with the z-reading model), particularly when the spatial aspects are concerned (reflected in similar saccade amplitudes). In contrast to z-reading studies, however, our results indicate that semantics and lexical processing have a significant impact on fixation durations.
Another explanation why reading meaningful text results in a relatively faster processing time might be the familiarity of the task (e.g., everybody is familiar with reading, whereas the rest of the tasks are less familiar). However, this might not rule out the impact of lexical and syntactic factors in word identification during saccadic processing (cp. cp. Rayner, Pollatsek, Ashby, & Clifton Jr, 2012). A future desideratum would be to explore the impact of grammatical structure in more detail: eye movements over a random sequence of words or letters could be compared with a syntactically well-formed text (and, furthermore, different stages of syntactic complexity could be compared). Similarly, ‘words’ consisting of randomly shuffled letters could be compared to meaningful words. An additional variable here would be the analysis of the impact of morphological constraints on eye movements. (Our study was conducted in Latvian, which is a morphologically rich case-marked language, which provides further opportunities of studying linguistic processing).
Why are effects from perceptual grouping on saccade planning weaker than one would assume on the basis of Gestalt-theoretic ideas? We could hypothesize that saccadic processing is part of sensory processing (in the sense of Bundesen, 1990, Bundesen & Habekost, 2008); whereas, processing composition effects is part of unit generation, which is a later stage, containing categorization, recognition, and attentive selection, depending on the interplay between the strength of the sensory evidence, perceptual decision bias, and the current importance of particular kinds of objects (Bundesen & Habekost, 2008, 73). According to our results, we are not arguing that the power of composition/configuration is weaker, but we are primarily focusing on the first stage of processing; whereas, perceptual grouping is a phenomenon belonging to a higher stage of processing, containing part-whole relationships and semantics.
The general consensus is that perceptual grouping is primarily a bottom-up, attention-dependent process (Bundesesen & Habekost, 2008, for overviews cp. also Wright & Ward, 2008, Kramer, Wiegman & Kirlik, 2007, Wolfe, 2000). On the other hand, there are also top-down constraints in visual grouping: certainly one’s motivation, the task in question, one’s aim, and one’s previous experience co-determine grouping (Bundesesen & Habekost, 2008). We accept the approach by Bundesen and Habekost (2008), (see also, Bundesen, 1990), which asserts that both top-down and bottom-up processes are involved at an early stage of processing. The next higher stage of processing, where the actual grouping (in the sense of Gestalt theorists) occurs, is perceptual unit formation (Bundesen, 1990, but cp. also Palmer, 1977, Feldman, 2003) that are part-whole structures consisting of elements in a visual field that are perceived in mental sense, and not in a physical sense (Feldman, 2003, Feldman, 2007).
An alternative explanation could be that sensory processing provides material to first-stage processing, where perceptual grouping takes place; furthermore, results from perceptual grouping are transformed during the process of shape assignment (second stage), and, finally, the meaning is assigned (Pinna & Skilters, 2010). The current results are consistent with the former model, but less consistent with the latter one.
From a theoretical perspective, our current results seem to support the model for which grouping is a higher-level perceptual process. This, however, assumes that saccadic processing resides within sensory processing (Bundesen & Habekost, 2008). Our current results are less convincing for models wherein grouping is considered a primary, early-stage perceptual process (Pinna & Skilters, 2010).
Our current results are also consistent with the view that grouping occurs at different levels, concluding with a conscious level of processing, but involving interaction between bottom-up and top-down processes (Wagemans et.al, 2012). E.g., it might also be the case that other principles of grouping (proximity) are present at an earlier stage, whereas the principle of similarity—occurring at a later stage, is slower and less dominant (Ben-Av & Sagi, 1995).
Conclusions
When analysing saccadic eye movement parameters in meaningless (symbols) and meaningful (letters and words) horizontal scanning tasks, we observed that semantically meaningful symbols (letters and words) are processed more quickly (shorter fixation durations) than meaningless dots and other symbols. These effects were independent of whether the symbols were or were not grouped by similarity (one of the laws of perceptual organization).
Simple configurational effects that are efficient in the elementary cases of grouping by similarity indicate element aggregations, while consistently colored words are units, not only because of their coloration (where grouping by similarity corresponds to word borders), but also because they contain meaning (Palmer, 1999, 261).
Finally, our results do not necessarily imply that perceptual grouping by symmetry is less powerful, because our current results can be interpreted as early stage processing; whereas, gestalt grouping factors belong to a later stage of processing, wherein unit formation takes place (Bundesen, 1990). Furthermore, a possible constraint on this study is the focus upon horizontal scanning. It might be the case that global processing reveals more detailed grouping effects than mere horizontal scanning.
Acknowledgement
This work was supported by the European Regional Development Fund under Grant No.2013/0021/1DP/1.1.1.2.0/13/APIA/VIAA/001 and the Fulbright Scholar Program (J. Skilters). The authors are thankful to two anonymous reviewers for their constructive comments.
References
- Beck, J. The relation between similarity grouping and perceptual constancy. The American Journal of Psychology 1975, 88(3), 397–409. [Google Scholar] [CrossRef]
- Ben-Av, M. B.; Sagi, D. Perceptual grouping by similarity and proximity: Experimental results can be predicted by intensity autocorrelations. Vision Research 1995, 35(6), 853–866. [Google Scholar] [CrossRef] [PubMed]
- Bundesen, C.; Habekost, T. Principles of Visual Attention; Oxford University Press: Oxford, 2014. [Google Scholar] [CrossRef]
- Bundesen, C. A theory of visual attention. Psychological Review 1990, 97(4), 523–547. [Google Scholar] [CrossRef]
- Engbert, R.; Kliegl, R. Liversedge, S., Gilchrist, I., Everling, S., Eds.; Parallel graded attention models of reading. In The Oxford Handbook of Eye Movements; Oxford University Press: Oxford, 2011; pp. 787–800. [Google Scholar] [CrossRef]
- Feldman, J. What is a visual object? Trends in Cognitive Sciences 2003, 7(6), 252–256. [Google Scholar] [CrossRef]
- Feldman, J. Formation of visual “objects” in the early computation of spatial relations. Perception & Psychophysics 2007, 69(5), 816–825. [Google Scholar] [CrossRef]
- Finlay, J. M.; Walker, R. A model of saccade generation based on parallel processing and competitive inhibition. Behavioral and Brain Sciences 1999, 22(4), 661–721. [Google Scholar] [CrossRef] [PubMed]
- Ghose, T.; Hermens, F.; Wagemans, J. The effect of perceptual grouping on saccadic eye movements. VSS August 13. Journal of Vision 2012, 12(9), 1294. [Google Scholar] [CrossRef]
- Holmqvist, K.; Nystrom, M.; Andersson, R.; Dewhurst, R.; Jarodzka, H.; Van de Weijer, J. Eye Tracking: A Comprehensive Guide to Methods and Measures; Oxford University Press: Oxford, 2011. [Google Scholar]
- Kapoula, Z.; Robinson, D. A. Saccadic undershoot is not inevitable: Saccades can be accurate. Vision Research 1985, 26(5), 735–743. [Google Scholar] [CrossRef]
- Kramer, A. F.; Wiegman, D.; Kirlik, A. (Eds.) Attention: From Theory to Practice; Oxford University Press: Oxford, 2007. [Google Scholar]
- Lacis, I.; Laicane, I.; Skilters, J. Effect of perceptual grouping by similarity on eye movements in processing simple visual stimuli. Perception 41 ECVP Abstract Supplement 2012, 41, 170–171, [ECVP 2012: Poster]. [Google Scholar]
- Mack, A.; Tang, B.; Tuma, R.; Kahn, S.; Rock, I. Perceptual organization and attention. Cognitive Psychology 1992, 24(4), 475–501. [Google Scholar] [CrossRef]
- Navon, D. Forest before trees: The precedence of global features in visual perception. Cognitive Psychology 1977, 9(3), 353–383. [Google Scholar] [CrossRef]
- Nuthmann, A.; Engbert, R. Mindless reading revisited: An analysis based on the SWIFT model of eye-movement control. Vision Research 2009, 49, 322–336. [Google Scholar] [CrossRef]
- Nuthmann, A.; Engbert, R.; Kliegl, R. The iovp effect in mindless reading: Experiment and modeling. Vision Research 2007, 47, 990–1002. [Google Scholar] [CrossRef] [PubMed]
- Olson, R. K.; Attneave, F. What variables produce similarity grouping? The American Journal of Psychology 1970, 83, 1–21. [Google Scholar] [CrossRef]
- Op de Beeck, H. P.; Torfs, K.; Wagemans, J. Perceived Shape Similarity among Unfamiliar Objects and the Organization of the Human Object Vision Pathway. The Journal of Neuroscience 2008, 28(40), 10111–10123. [Google Scholar] [CrossRef]
- Palmer, S. E. Hierarchical structure in perceptual representation. Cognitive Psychology 1977, 9(4), 441–474. [Google Scholar] [CrossRef]
- Palmer, S. E. Common region: A new principle of perceptual grouping. Cognitive Psychology 1992, 24(3), 436–447. [Google Scholar] [CrossRef]
- Palmer, S. E. Vision Science: Photons to Phenomenology; The MIT Press: Cambridge, MA, 1999. [Google Scholar]
- Palmer, S. E.; Brooks, J. L.; Nelson, R. When does grouping happen? Acta Psychologica 2003, 114, 311–330. [Google Scholar] [CrossRef]
- Philips, M. H.; Edelman, J. A. The dependence of visual scanning performance on saccade, fixation, and perceptual metrics. Vision Research 2008, 48(7). [Google Scholar] [CrossRef]
- Pollatsek, A.; Bolozky, S.; Well, A. D.; Rayner, K. Asymmetries in the perceptual span for Israeli readers. Brain and Language 1981, 14(1), 174–180. [Google Scholar] [CrossRef]
- Pomerantz, J. R.; Kubovy, M. Theoretical approaches to perceptual organization: Simplicity and likelihood principles. In Handbook of Perception and Human Performance; Wiley: New York, 1986; Vol 2, pp. 36-1–36-46. [Google Scholar]
- Pinna, B.; Skilters, J. Hassanien, A. E., Abraham, A., Marcelloni, F., Hagras, H., Antonelli, M., Hong, T.-P., Eds.; Perceptual Semantics: A Three-Level Approach. In Proceedings of the 10th International Conference on Intelligent Systems Design and Applications; IEEE: Cairo, Egypt, 2010; pp. 772–777. [Google Scholar] [CrossRef]
- Prinzmetal, W.; Banks, W. P. Good continuation affects visual detection. Perception & Psychophysics 1977, 21(5), 389–395. [Google Scholar] [CrossRef]
- Ray, S.; Schall, J. D.; Murthy, A. Programming of double-step saccade sequences: Modulation by cognitive control. Vision Research 2004, 44(23), 2707–2718. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Rayner, K. Eye Movements in Reading and Information Processing: 20 years of research. Psychological Bulletin 1998, 124(3), 372–422. [Google Scholar] [CrossRef] [PubMed]
- Rayner, K.; Fischer, M. H. Mindless reading revisited: Eye movements during reading and scanning are different. Perception and Psychophysics 1996, 58(5), 734–747. [Google Scholar] [CrossRef]
- Rayner, K.; Pollatsek, A.; Ashby, J.; Clifton, C., Jr. Psychology of Reading. In 2nd Edition; Psychology Press: New York, 2012. [Google Scholar]
- Reichle, E. D.; Reineberg, A. E.; Schooler, J. W. Eye Movements during Mindless Reading. Psychological Science 2010, 21(9), 1300–1310. [Google Scholar] [CrossRef]
- Rock, I.; Brosgole, L. Grouping based on phenomenal proximity. Journal of Experimental Psychology 1964, 67(6), 531–538. [Google Scholar] [CrossRef]
- Smeets, J. B.; Hooge, I. T. C. Nature of variability in saccades. Journal of Neurophysiology 2003, 90(1), 12–20. [Google Scholar] [CrossRef]
- Taylor, M. M.; Aldridge, K. D. Stochastic processes in reversing figure perception. Perception and Psychophysics 1974, 16(1), 9–27. [Google Scholar] [CrossRef]
- Treisman, A. Perceptual grouping and attention in visual search for features and for objects. Journal of Experimental Psychology: Human Perception and Performance 1982, 8(2), 194–214. [Google Scholar] [CrossRef]
- Trukenbrod, H. A.; Engbert, R. Oculomotor control in a sequential search task. Vision Research 2007, 47(18), 2426–2443. [Google Scholar] [CrossRef]
- Van der Stigchel, S.; Nijboer, T. C. W. The global effect: What determines where the eyes land? Journal of Eye Movement Research 2011, 4(2), 1–13. [Google Scholar]
- Vitu, F. Liversedge, S., Gilchrist, I., Everling, S., Eds.; On the role of visual and oculomotor processes in reading. In The Oxford Handbook of Eye Movements; Oxford University Press: Oxford, 2011; pp. 731–749. [Google Scholar] [CrossRef]
- Vitu, F.; O’Regan, J. K.; Inhoff, A. W.; Topolski, R. Mindless reading: Eye-movement characteristics are similar in scanning letter strings and reading texts. Perception and Psychophysics 1995, 57(3), 352–364. [Google Scholar] [CrossRef] [PubMed]
- Wertheimer, M. Untersuchungen zur Lehre von der Gestalt. II. Psychologische Forschung 1923, 4(1), 301–350. [Google Scholar] [CrossRef]
- Wagemans, J.; Elder, J. H.; Kubovy, M.; Palmer, S. E.; Peterson, M. A.; Singh, M.; von der Heydt, R. A century of Gestalt psychology in visual perception: I. Perceptual grouping and figure–ground organization. Psychological Bulletin 2012, 138(6), 1172–1217. [Google Scholar] [CrossRef]
- Weitnauer, E.; Carvalho, P. F.; Goldstone, R. L.; Ritter, H. Grouping by similarity helps concept learning. Proceedings: Cognitive Science; 2013; pp. 3747–3752. [Google Scholar]
- Wright, R. D.; Ward, L. Orienting of Attention; Oxford University Press: Oxford, 2008. [Google Scholar]
- Wolfe, J. M. De Valois, K. K., Ed.; Visual attention. In Seeing; Academic Press: San Diego, 2000; pp. 335–386. [Google Scholar] [CrossRef]
- Woodman, G. F.; Vecera, S. P.; Luck, S. J. Perceptual organization influences visual working memory. Psychonomic Bulletin & Review 2003, 10(1), 80–87. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
Copyright © 2015. This article is licensed under a Creative Commons Attribution 4.0 International License.