Introduction
In the design research community, the benefit of using eye-tracking is distinct: it provides quantifiable information about a viewer’s visual attention in a nonintrusive manner. Its significance is based on the fact that the visual appearance of a product plays a critical role in consumer response (
Crilly, Moultrie, & Clarkson, 2004) and on the hypothesis that eye-tracking data instantly externalize what people think (
Just & Carpenter, 1980) or aim to accomplish (
Just & Carpenter, 1976).
Eye-tracking is subject to certain restrictions though: processing eye-tracking data computationally has no universal standard (
Kiefer, Giannopoulos, Raubal, & Duchowski, 2017), the link between eye-tracking measures and those of domain problems is hidden (
Mayer, 2010), experimental setups may not fully represent actual practice (
Venjakob & Mello-Thoms, 2016), and the quality of analysis often depends on the ability to build customized software (
Oakes, 2012). However, eyetrackers have been shown to provide objective measures that can be associated with high-level design problems, such as usability (
Nielson & Pernice, 2010), training effects (
Nodine, Locher, & Krupinski, 1993;
Park, DeLong, & Woods, 2012), preference (
Reid, MacDonald, & Du, 2012), and cultural influences (
Dong & Lee, 2008).
Eye-tracking data have been linked to design problems through layers of mediating parameters. Human eye movement consists primarily of two phenomena: 1) fixation—a relatively stationary period of eye movement and 2) saccades—rapid movements between fixations. The low-level parameters, e.g., fixation duration, fixated positions, and saccade amplitude, have been combined as quantitative indicators of a specified design problem. For example, changes in fixated positions were related to the specified task (
Yarbus, 1967), and the distribution of gaze durations (cumulative fixation duration within a cluster) has been found to quantify the difference between individuals with and without artistic training (
Nodine et al., 1993). The mean fixation duration and saccadic amplitude have been established to encode individualities (
Castelhano & Henderson, 2008), and the shapes of reading patterns have demonstrated the effects of cultural background (
Dong & Lee, 2008).
The limitation of this practice is that the determination of the criterion parameters for a specified problem is not always straightforward or successful. That is, the selected eye-tracking parameters were often not effective indicators of the target effect. The consequence is the lack of agreement on the mapping between parameters and design problems (
Ehmke & Wilson, 2007), and studies whose findings partially support or lie outside the scope of the initial goal (
Weber, Choi, & Stark, 2002;
Koivunen, Kukkonen, Lahtinen, Rantala, & Sharmin, 2004;
Kukkonen, 2005;
Reid et al., 2012;
Lee, Cinn, Yan, & Jung, 2015). One major cause of such phenomenon is the difficulty of dealing with multi-dimensional data; it is beyond human intuition to compare multiple highdimensional data simultaneously. For example, we can visually inspect the scanpaths of two images, but comparing multiple scanpaths in two groups is significantly more challenging (
Lorigo et al., 2008). We can compare mean fixation durations at once, but quantifying the differences of fixations over a period of time allows for multiple parameterizations, which makes it more complicated to gain insights and test hypotheses quickly. A more profound task is to relate the parameters embedded in highdimensional eye-tracking data to higher-level domain problems. The total number of combinations of parameters grows exponentially with the dimension of the parameter, and finding the relevant eye-tracking parameters through iterative testing appears to be prohibitively inefficient. It requires a more effective method to measure the relative impact of eye-tracking parameters and detect hidden patterns.
According to Arthur Samuel, machine learning is a field of study that gives computers the ability to learn without being explicitly programmed (
Simon, 2013). By virtue of its capability to identify trends and make predictions from multi-dimensional data, machine learning has significant potential for detecting new patterns and verifying existing propositions in eye-tracking studies.
Greene, Liu, & Wolfe (
2012) and
Borji & Itti (
2014) applied a classification algorithm to eye-tracking data labeled with task information and investigated the statistical foundation of the observation that the given task affects eye-tracking patterns (
Yarbus, 1967). The key advantage of machine learning lies in the order of the process; it first learns from data and then identifies the parameters relevant to the classification, rather than first predicting the potential parameters and then verifying their impact. From this perspective, a classification algorithm is a reverse approach that can identify the relevant parameters more effectively than a forward-based one where the discovery of links between eye-tracking parameters and the target effect depends heavily on the initial choice of candidate parameters (
Borji & Itti, 2014).
Motivated by the opportunities that machine learning offers, our study intends to evaluate the impact of three factors associated with viewing architectural scenes: individuality, education, and stimuli. Among the factors exogenous and endogenous to the participating individual, we designed the experiment such that eye-tracking data constituted the combined effect of natural tendency, architectural training, and image content. First, the presence of eye-tracking parameters unique to an individual has been studied extensively (
Andrews & Coppola, 1999;
Castelhano & Henderson, 2008;
Boot, Becic, & Kramer, 2009;
Mehoudar, Arizpe, Baker, & Yovel, 2014;
Greene et al., 2012;
Lee et al., 2015). We explored new eyetracking parameters that are likely to identify an individual from a larger dataset. Furthermore, the art and design community has been paying significant attention to distinguishing between “trained” and “untrained” eyes (
Nodine et al., 1993;
Weber et al., 2002;
Kukkonen, 2005;
Vogt & Magnussen, 2007;
Park et al., 2012;
Lee et al., 2015). According to the notion that evaluative discrepancy in architecture is particularly expensive (
Fawcett, Ellingham, & Platt, 2008), we aimed to identify, quantify, and visualize patterns that distinguish between majors and non-majors of architecture-related disciplines. Finally, it has been reported that the presence of image content indicative of the specified task alters what people attend to (
Yarbus, 1967;
Castelhano, Mac, & Henderson, 2009;
Tatler, Wade, Kwan, Findlay, & Velichkovsky, 2010;
Greene et al., 2012;
Borji & Itti, 2014). One of our primary focuses was the impact of image stimuli in relation to individuality or educational background. When classifications of an individual or major/non-major across all image stimuli failed to predict the identity, we compared the classification accuracy of each image and looked for the key image features that distinguished an individual or educational background.
Background
In art and design research, eye-tracking data have been used as a quantifiable measure, an objective indicator, and scientific evidence of various aesthetic rules and design heuristics. In art research, one primary question was the manner in which trained artists behave differently from novices. According to
Berlyne’s (
1971) notion of diverse vs. specific exploration,
Nodine et al. (
1993) assumed that artists shift from specific to diverse exploration when the symmetry of aesthetic composition breaks. The hypothesis was verified by artists’ dispersed, shorter gaze durations at asymmetric compositions to which nonartists were less sensitive. In subsequent research,
Vogt & Magnussen (
2007) found that artists pay more attention to structural aspects than to individual elements.
Miall & Tchalenko (
2001) focused on the actual process of painting by combining an eye-tracker with a hand-tracker and identified three distinct patterns: initial prolonged attention to the model, rapid alternation of attention between the model and the canvas for sketching, and practice strokes on the canvas. They proposed fixation stability, fixation duration, and targeting efficiency as parameters for defining the artist’s eye skills and eye–hand coordination.
In design discipline, the eye-tracking research diversified by its sub-disciplines. In the product design domain, researchers have explored the use of the eye-tracker as a tool for understanding user preference within the entire product development cycle. Using the effectiveness of the eye-tracker for measuring user attention (
Hammer & Lengyel, 1991),
Kukkonen (
2005) explored the connection between the attended area and product preference.
Reid et al. (
2012) used eye-tracking data to corroborate survey information that investigated the influence of product representation on user selection, and
Köhler, Falk, & Schmitt (
2015) proposed that eye-tracking aids the extraction of the visual impression and the emotional evaluation as part of the Kansei engineering process. In the visual communication domain, numerous studies have addressed the usability of 2D graphical user interfaces.
Nielson & Pernice (
2010) used a large set of eye-tracking data to produce design guidelines for webpage design, and
Dong & Lee (
2008) externalized how cultural background affects webpage reading behavior using eyetracking scanpath maps.
Prats, Garner, Jowers, McKay, & Pedreira (
2010) demonstrated that eye-tracking parameters can indicate the moment when shape interpretation occurs, and
Ehmke & Wilson (
2007) listed the eyetracking parameters relevant to various web usability problems. Two eye-tracking studies in the architecture domain have investigated the role of architectural elements and the impact of architectural training on viewing architectural scenes (
Weber et al., 2002;
Lee et al., 2015). A study in the fashion design domain revealed how designers and non-designers view differently in the context of participatory design (
Park et al., 2012).
Occasionally, design research that used eye-tracking data exhibited variance in the level of success, i.e., differences in the number of objectively verified hypotheses and proposed hypotheses. The characteristics of these studies are the absence of analysis on the proposed questions, lack of quantitative reasoning, and high rate of unexpected findings. For example,
Koivunen et al. (
2004) initially intended to reveal the influence of design education and rendering style; however, they observed behaviors during the first impression and different fixation durations per task.
Kukkonen (
2005) measured gaze data, preference scores, the most favored product, and individual evaluations and concluded that there is negligible correlation among them.
Reid et al. (
2012) identified that a long fixation duration can indicate either of high and low preferences, but did not provide statistical evidence or an in-depth analysis.
Lee et al. (
2015) identified potential eye-tracking parameters for differentiating individuals that were not part of their original research questions. Occasionally, an unexpected factor, e.g., image size (
Kukkonen, 2005) and presentation order (
Reid et al., 2012), was the source of the failure, but a more fundamental cause appears to be the inability to predict the affecting parameters. Whereas high-dimensional eyetracking data enable a large set of parameter combinations, their connection to high-level design issues is not revealed until we test them.
Recently, two papers have reported controversial opinions on the observation of
Yarbus (
1967) that the specified task affects the eye-tracking pattern.
Greene et al. (
2012) displayed 64 images to 16 participants with four tasks but the correct prediction rate was only marginally higher than random chance (27.1%, 95% CI = 24–31%, chance = 25%). Using the same data,
Borji & Itti (
2014) disputed the conclusion with a significantly higher prediction rate (34.12%). The element that differentiates their methods from previous ones was the adoption of machine learning, in particular a classification algorithm. More traditional approaches would have selected a set of indicative eye-tracking parameters and tested whether they fluctuate by a significant margin as the specified tasks differ. Rather, they constructed a prediction model using training data and analyzed its performance by comparing the predicted task with the actual task using validation data. The prediction model essentially draws boundaries between eye-tracking data with different tasks within the multi-dimensional parameter space. Its performance depends on how clearly the model can detect boundaries among training data and the extent to which the logic for dividing the training data is applicable to the validation data. The key difference between
Greene et al.’s (
2012) and
Borji & Itti’s (
2014) studies was the selection of the classification method for constructing the prediction model, i.e., a linear discriminant vs. the RUSBoost classifier.
In this study, we aimed to evaluate the impact of three factors, i.e., individuality, educational background, and image stimuli, by using machine learning to explore multi-dimensional data. Regarding individuality, the question has been whether endogenous eye-tracking parameters consistent across different viewing conditions exist. The motivation was to know (1) the extent to which endogenous factors affect eye-tracking patterns, and (2) the potential connection with neural substrates, such as ADHD, dementia, memory (
Castelhano & Henderson, 2008), visual search performance (
Boot et al., 2009), and visual recognition strategy (
Mehouda et al., 2014).
Andrews & Coppola (
1999) found that the mean fixation duration and saccade amplitudes formed a linear relationship in active and passive viewing tasks.
Castelhano & Henderson (
2008) demonstrated that these parameters are stable across differing image content, quality, and format.
Greene et al. (
2012) succeeded in predicting the identities of eye-tracking data using machine learning with significantly higher probability than random chance (26% vs. 6.3%). Recently,
Lee et al. (
2015) proposed the existence of additional patterns unique to certain individuals based on visual inspection. In this study, we searched for more fingerprinting patterns with higher predictability. Second, previous studies have found that groups of individuals with and without certain educational training differed in exploration patterns or cumulative fixation durations on the designated area of interest. The group with educational training focused more on the background or structural relationships among individual elements (
Nodine et al., 1993;
Weber et al., 2002;
Vogt & Magnussen, 2007) and on image content that was relevant to the focus of their training (
Park et al., 2012;
Lee et al., 2015). Observing that only a few eye-tracking parameters have been associated with group characteristics (
Nodine et al., 1993;
Weber et al., 2002;
Park et al., 2012;
Lee et al., 2015), we explored additional parameters distinguishing between major and non-major students of architecture discipline. Finally, the impact of image stimuli varied in different decoding tasks. Although it was not sufficiently strong to affect individual decoding (
Castelhano & Henderson, 2008), image content with diagnostic information relevant to the specified task was crucial in task decoding (
Borji & Itti, 2014). Image contents such as symmetry (
Nodine et al., 1993), background complexity (
Park et al., 2012), and inclusion of architectural elements (
Lee et al., 2015) were found to affect the decoding of educational background. Our focus in the case of image stimuli was to identify particular image content that attracts a particular individual or major/non-major.
Methods
We used the data generated by
Lee et al. (
2015), which is publicly available (
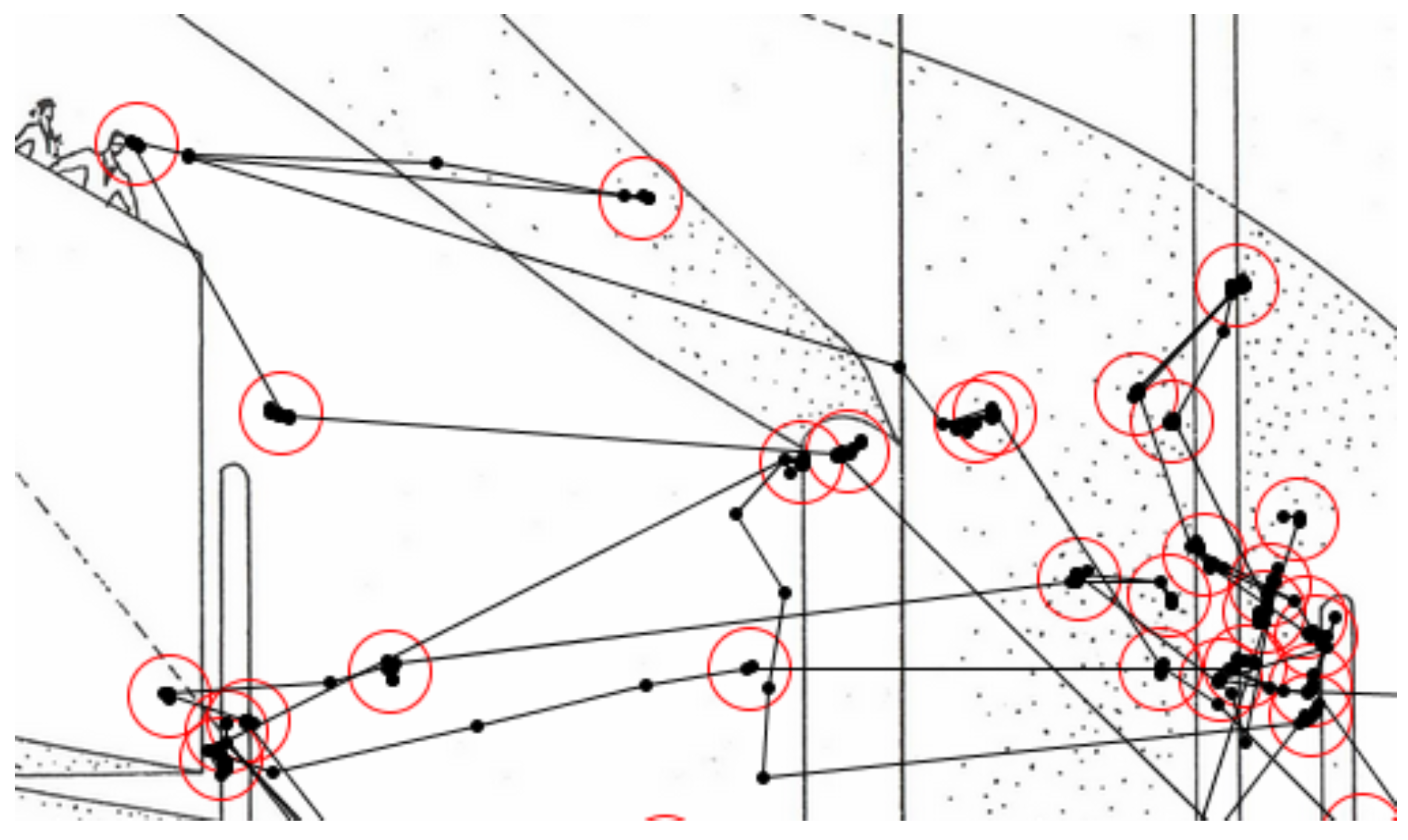
http://bit.ly/2eqb4TV), as input data. To observe the effect of architectural training on visual attention, they recorded 10-s eye-tracking patterns of 71 major/non-major participants (39 majors and 32 non-majors) on 14 images with certain architectural elements (
Appendix). The data consist of eye positions sampled with a frequency of 60 Hz in normalized coordinates: a screen space with a size of 1.0 (width) by 0.74 (height). A fixation was defined as a group of sample points whose diameter does not exceed 0.02 in normalized length and 300 ms in time between the first and last one. All other events, such as glissades and smooth pursuits as well as saccades in the traditional sense were collected into single ‘saccade’ category in our study, following the
Identification by
Dispersion
Threshold algorithm (
Figure 1,
Holmqvist & Nystrom, 2011). Hence, the definition of saccade in this paper is broader than more typical and conventional definition of saccade usually between 30-500 deg/s.
Rather than establishing candidate parameters and verifying their statistical significance, we applied machine learning to identify the distinguishing parameters and their patterns that characterize individuals and majors/non-majors. Regarding the data features for decoding individuals and majors/non-majors, we considered characteristic patterns such as oscillating movements and the extent of fixation over time proposed by
Lee et al. (
2015), as well as well-established endogenous parameters such as total fixations, mean fixation duration, and mean saccade amplitude (
Greene et al., 2012). To understand the impact of image stimuli, we also included a fixation map representing the cumulative fixation durations on each of the 10 × 10 cell grids within the image area. The complete list of features is as follows:
- (1)
Fixation data comprising average fixation duration, total fixation count, average saccade length, and total saccade count
- (2)
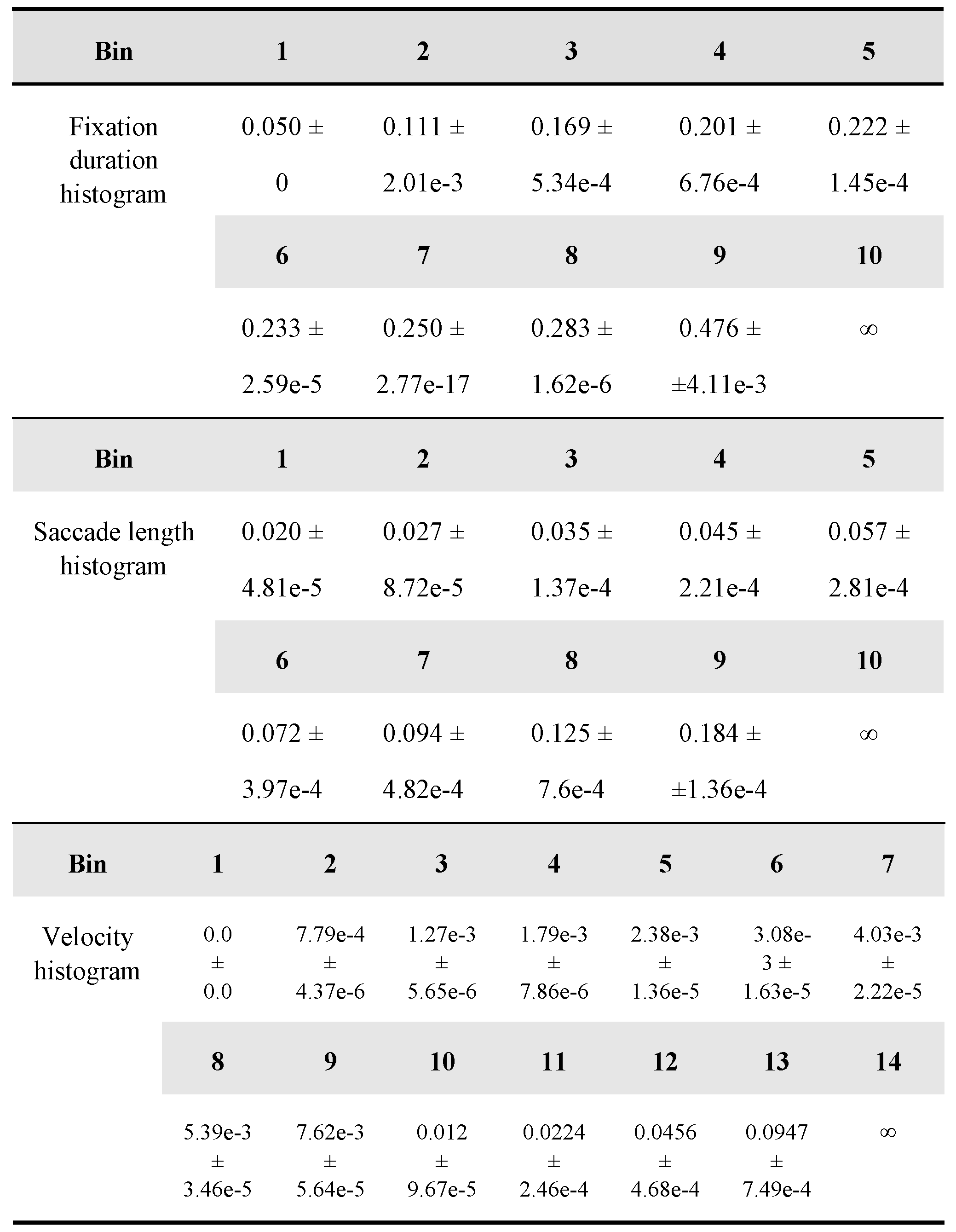
Fixation histogram data whose bins represent different ranges of fixation duration
- (3)
Saccade histogram data whose bins indicate ranges of saccade lengths
- (4)
Velocity histogram data whose bins are ranges of normalized lengths between adjacent points sampled at 60 Hz
- (5)
Fixation map data representing cumulative fixation durations on a 10 × 10 grid
Velocity histograms store normalized lengths traveled in 1/60 of a second. Because a 24.98 cm × 18.61 cm screen was placed 50 cm from the participant, velocity v (s-1) can be converted to a degree in the visual angle by using 2 tan-1 (v/2 × 24.98/50) (deg/s). The histogram consisted of 14 bins, 1 special bin reserved for zero velocity, and 13 bins for the rest. The ranges of 13 bins were determined by first sorting the data and then dividing them into 13 groups of equal sizes. Fixation and the saccade histogram consisted of 10 bins of equal sizes with no special bin.
In our study, we performed the classification by using each individual or major/non-major labels. Because the performance of the prediction model can vary widely according to the selected classifier (
Greene et al., 2012;
Borji & Itti, 2014), we compared the results of three classifiers: decision tree, a support vector machine (SVM) with a linear kernel (SVM.LinearSVC), and an SVM with a radial basis function kernel (SVM.SVC) implemented with the Python machine learning package (
www.scikit-learn.org). While SVM with a linear kernel was the choice of previous eye-tracking research with high-dimensional data (
Greene et al., 2012), we tested a radial kernel because it may perform better for lowerdimensional data with feature selection. Decision tree was useful to compare the importance of different features. For SVM classifiers, we applied feature selection by using the extremely randomized tree (
Geurts, Ernst, & Wehenkel, 2006) with [1.7, 1.8, 1.9, 2.0, 2.1] × mean as the threshold, [10, 30, 50, 70, 90] as the max depth, and [2, 5, 10, 15, 20] as the min_samples_split. For hyper-parameter tuning, [0.25, 0.5, 1, 2, 4] was used as the C value. For decision tree, we used [gini, entropy] as the criterion, [10, 20, … 80] as the max_depth, [auto, sqrt] as the max_features, [1, 2, …, 10] as the min_samples_leaf, and [2,3, .., 10] as the min_samples_split.
To decode the individual identities of the eye-tracking data, we compared the correct prediction rate (accuracy) against the random chance level (1/71 individuals = 1.41%). Different classifiers were compared to determine the most optimum result. To split the entire data into training and validation datasets, we adopted the leave-Nout selection scheme; 71 samples from the individualimage pairs formed the validation set and the remaining (14 − 1) × 71 samples formed the training set. With each of the 14 iterations, we chose one image out of 14 images to form a validation set. This folding scheme allowed no sample in the testing set see the target image of the validation set, ensuring that the prediction of validation set is based solely on endogenous factor (individuality) by excluding the effect of exogenous factor (image). An exhaustive alternative would have been to iterate over all the 14
71 training/validation set combinations. To decode majors/non-majors, we divided the eye-tracking data of all the participants (14 images × 71 participants) into 70/30, i.e., 70% for the training dataset and 30% for the validation dataset. As with individual decoding, we compared the performance of different classifiers averaged over 14 iterations. To estimate the statistical significance, we adopted one-way ANOVA using 14 data samples against the chance level (50%) in accordance with
Greene et al. (
2012). Please note that the histogram bin ranges were recalculated for each iteration by using the data samples in the training set only. This was done to make sure that the validation set had no effect on feature extraction (
Table 1).
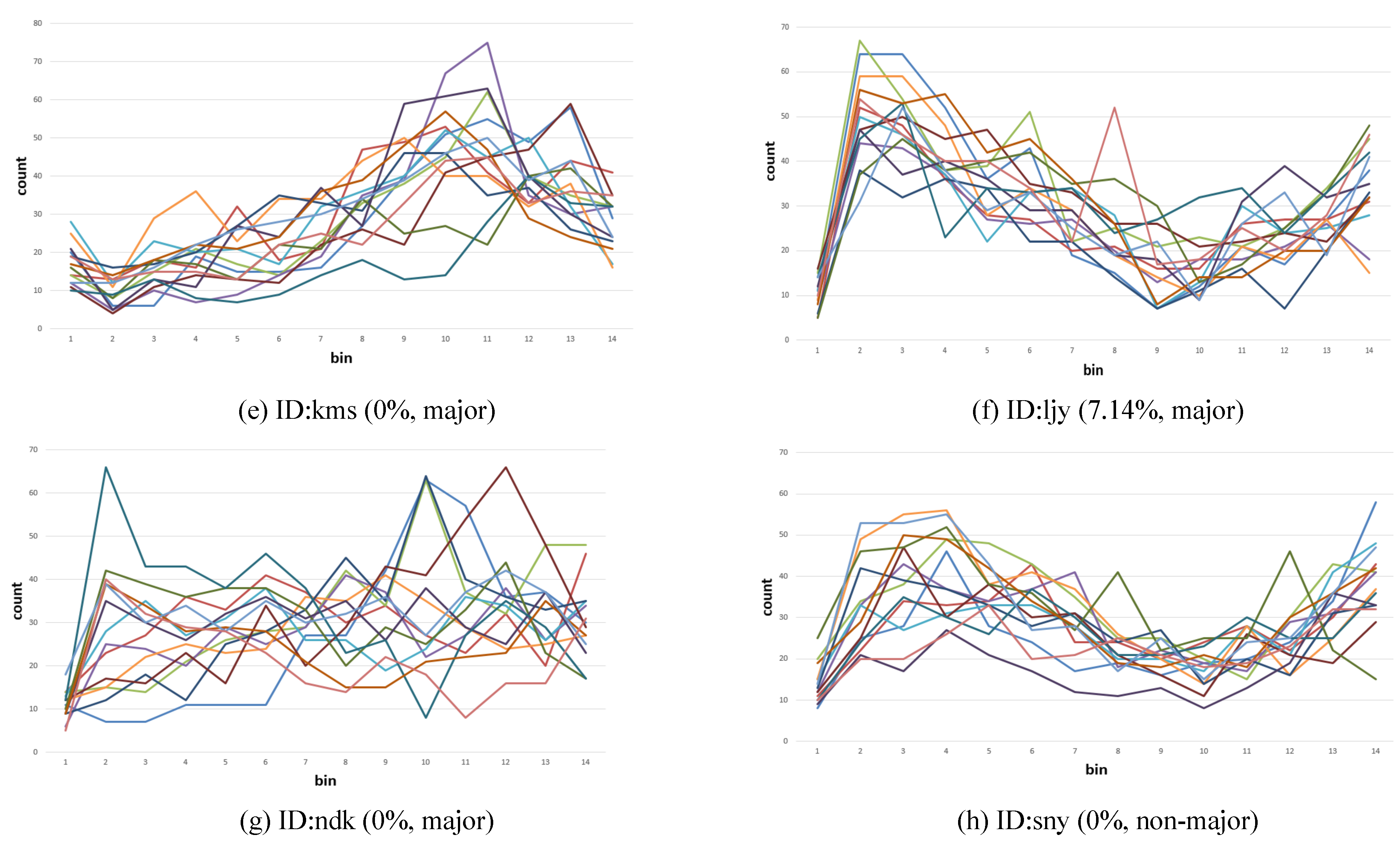
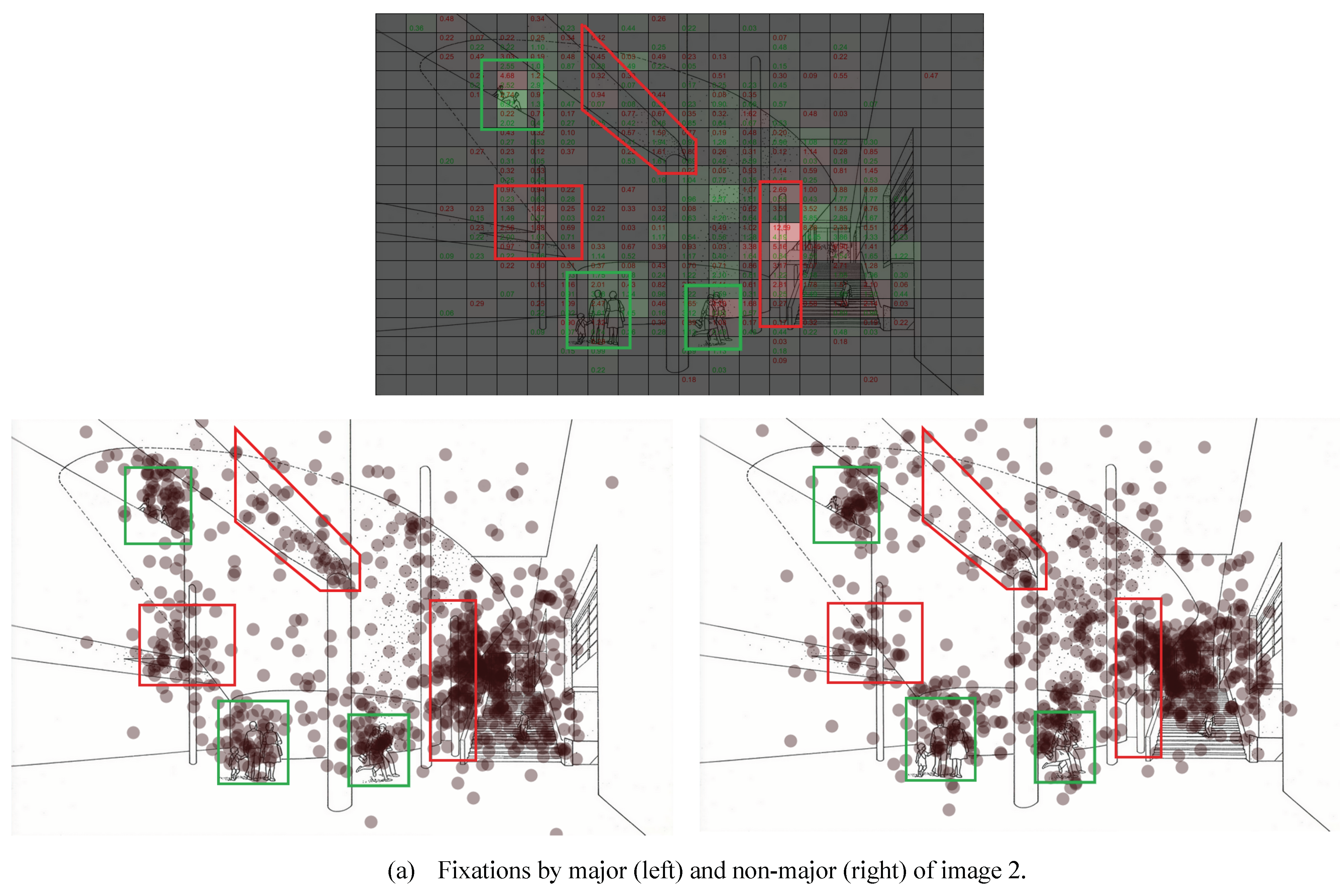
Finally, in order to investigate the effects of image stimuli, we classified 71 participants’ data for each image into major/non-major groups and identified the image content that contributed to high correct prediction rates. We ran 71 iterations per image; in each case, one of the 71 data samples formed the validation dataset and the remaining formed the training dataset. Decoding an individual per image was not feasible because there was only one sample from each participant per image, preventing division into training/validation datasets.
Discussion and Conclusions
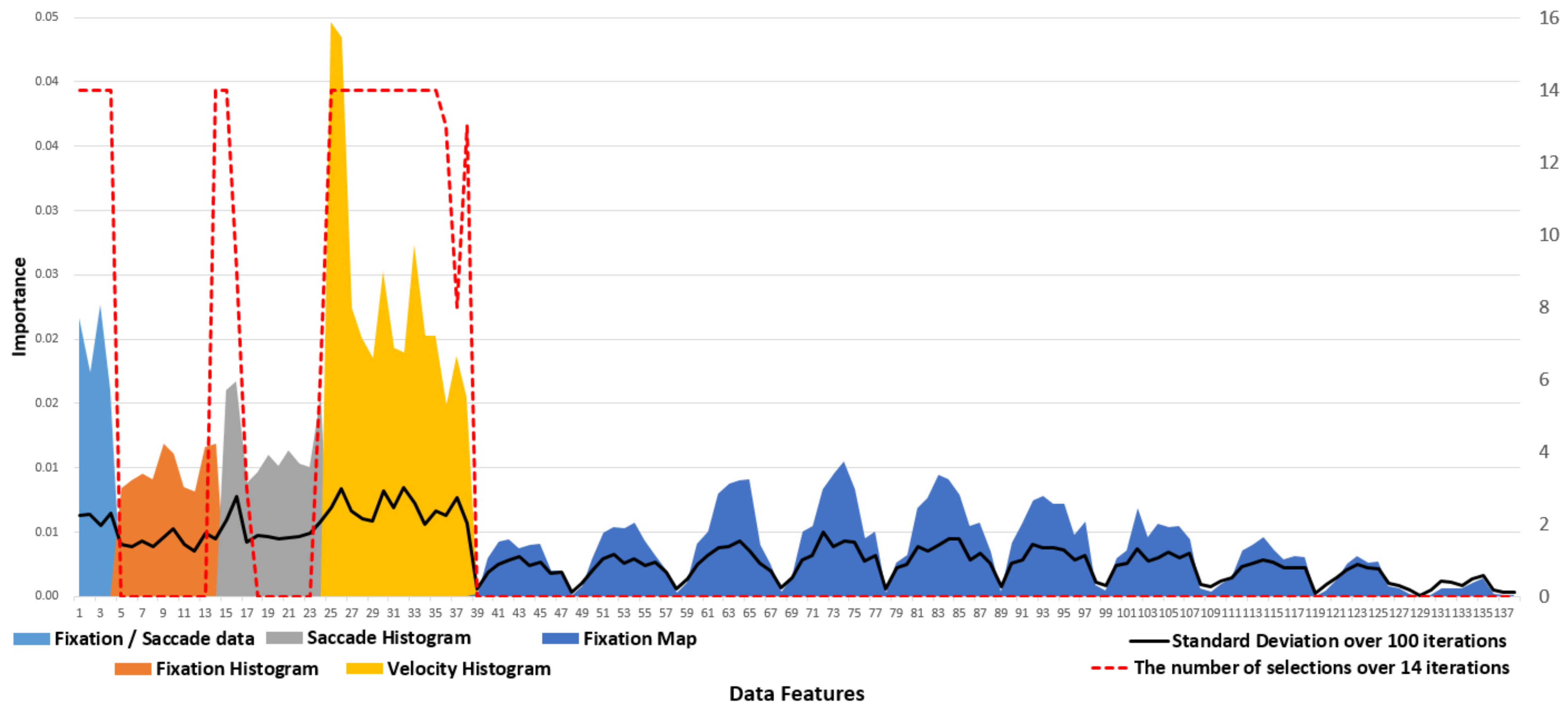
To investigate the impact of different endogenous and exogenous parameters on how we view architectural scenes, we applied a classification algorithm to multidimensional eye-tracking data obtained from students of architecture and other disciplines. We verified the effect of three factors, namely individuality, major/non-major, and image stimuli, on visual attention. The individual identity of the eye-tracking data was encoded in the velocity histogram, representing the distribution of the speed of eye movement measured at a fixed frame rate (60 Hz). The separation between the major and nonmajor groups was enabled using endogenous parameters, although it could be better explained by the differing sensitivities toward structural and symbolic image features.
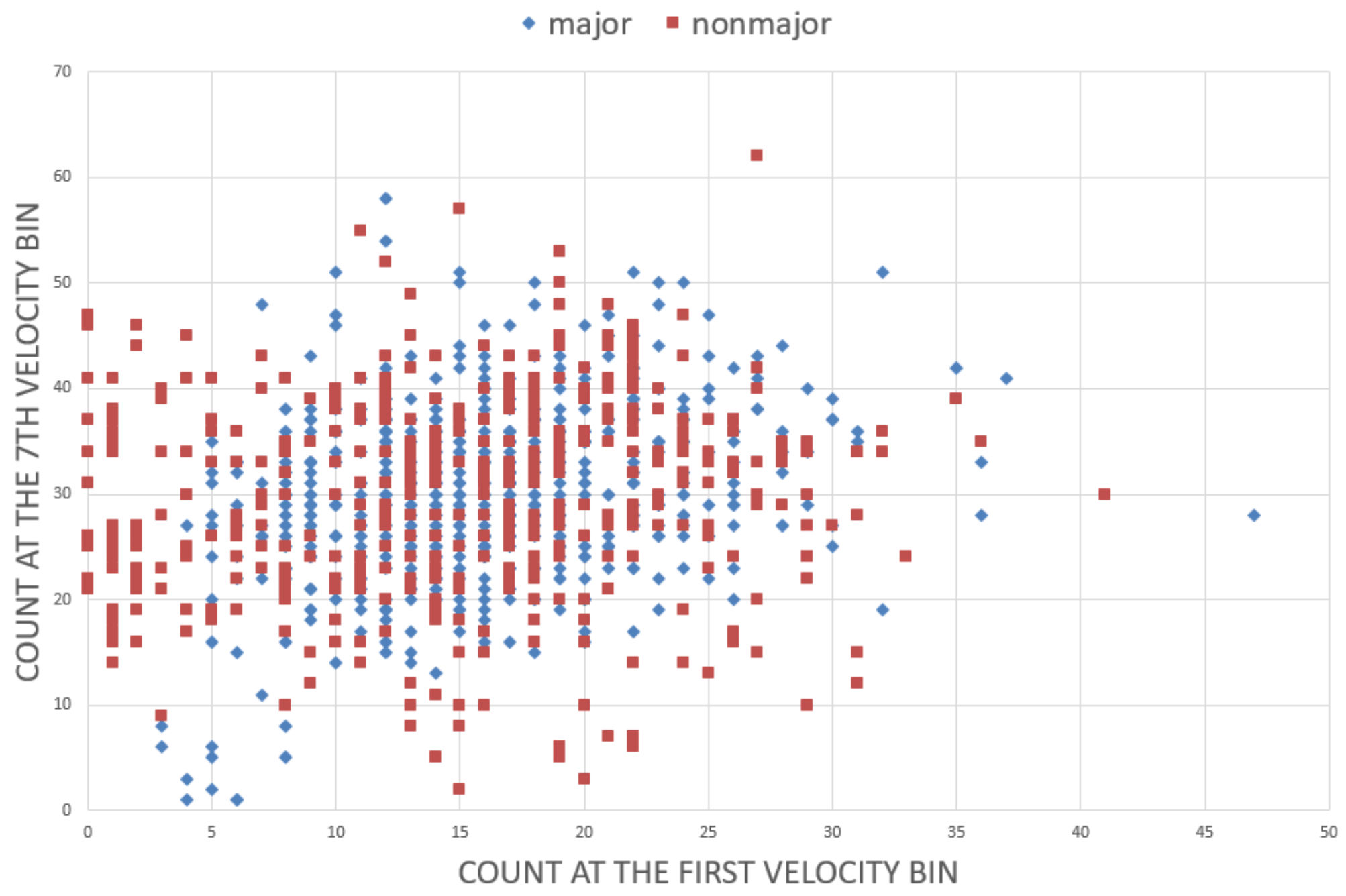
Regarding individual decoding, the classification was successful using velocity histogram when the impact of other factors such as fixation duration and count was not as much significant. This is inconsistent with previous findings where the fixation duration and saccade length were consistent across different images (
Andrews & Coppola, 1999;
Castelhano & Henderson, 2008) and the mean fixation duration, count, saccade amplitude, and coverage percent could classify individuals (
Greene et al., 2012). An explanation is that our classification algorithm required more explicit distinction between individuals in a larger pool than previous forward- or reverse-based approaches (16 by
Greene et al. (
2012) vs. 71 in our experiment). Therefore, we recommend using the velocity histogram for better individual decoding, in addition to the mean values of fixations and saccades. The use of the eye movement distances is not completely novel in eyetracking research;
Castelhano & Henderson (
2008) presented a profile of saccade distribution by length. However, their purpose was to demonstrate how natural saccade distribution could change according to the image types rather than its effectiveness in individual decoding.
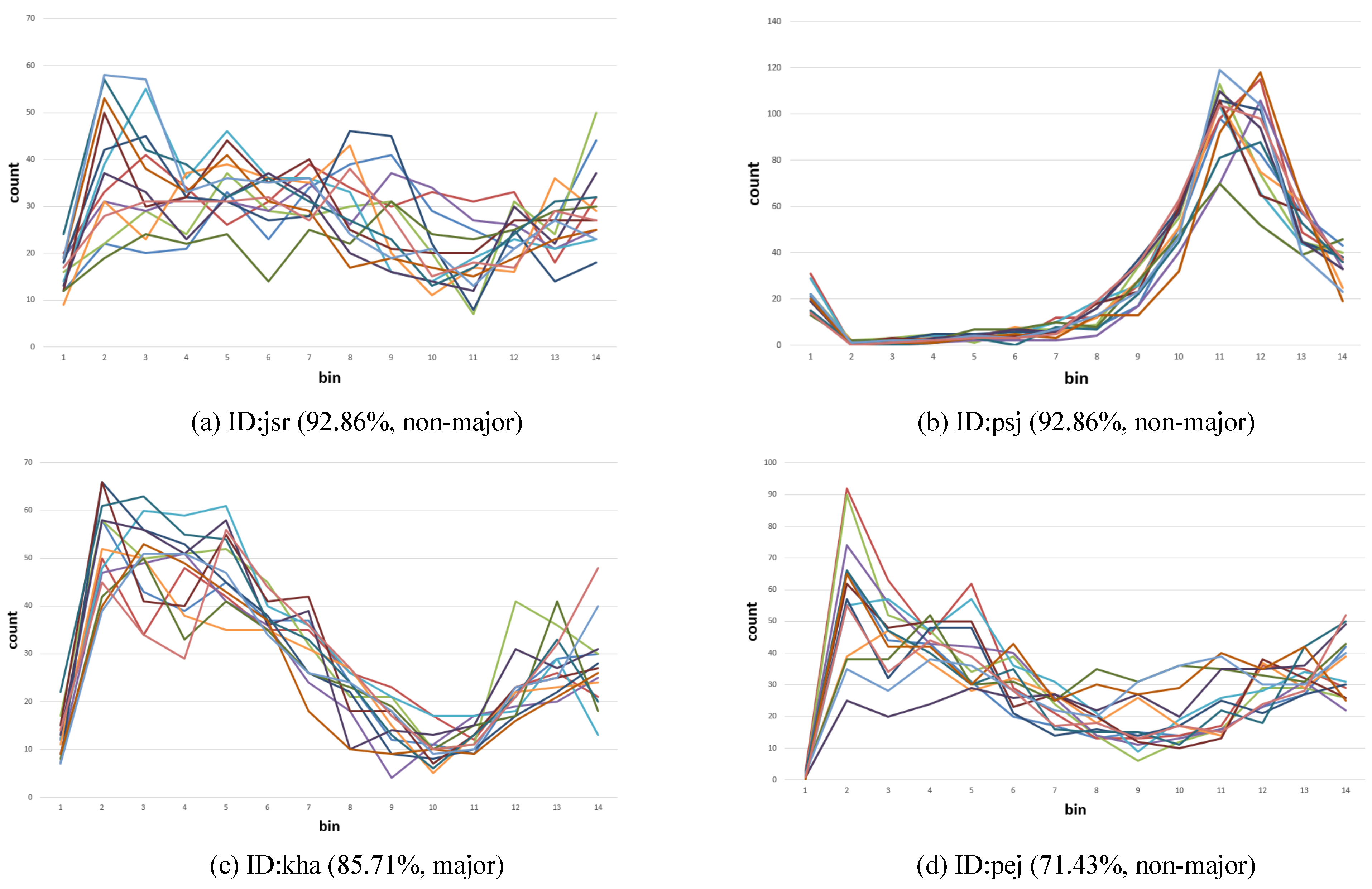
The visual analysis of the velocity histogram revealed that a sequence of spatiotemporal pattern, rather than only the distribution of speed, was unique to each individual. Whereas a histogram could capture an aspect of such a pattern, it is not straightforward to determine which parameter can summarize such a feature more effectively. It appears challenging to (1) define the length of a sequence, (2) determine the tolerance of the variation, and (3) completely accommodate spatial disposition in a smaller parameter space. We consider that this venue of exploration has a potential for future research.
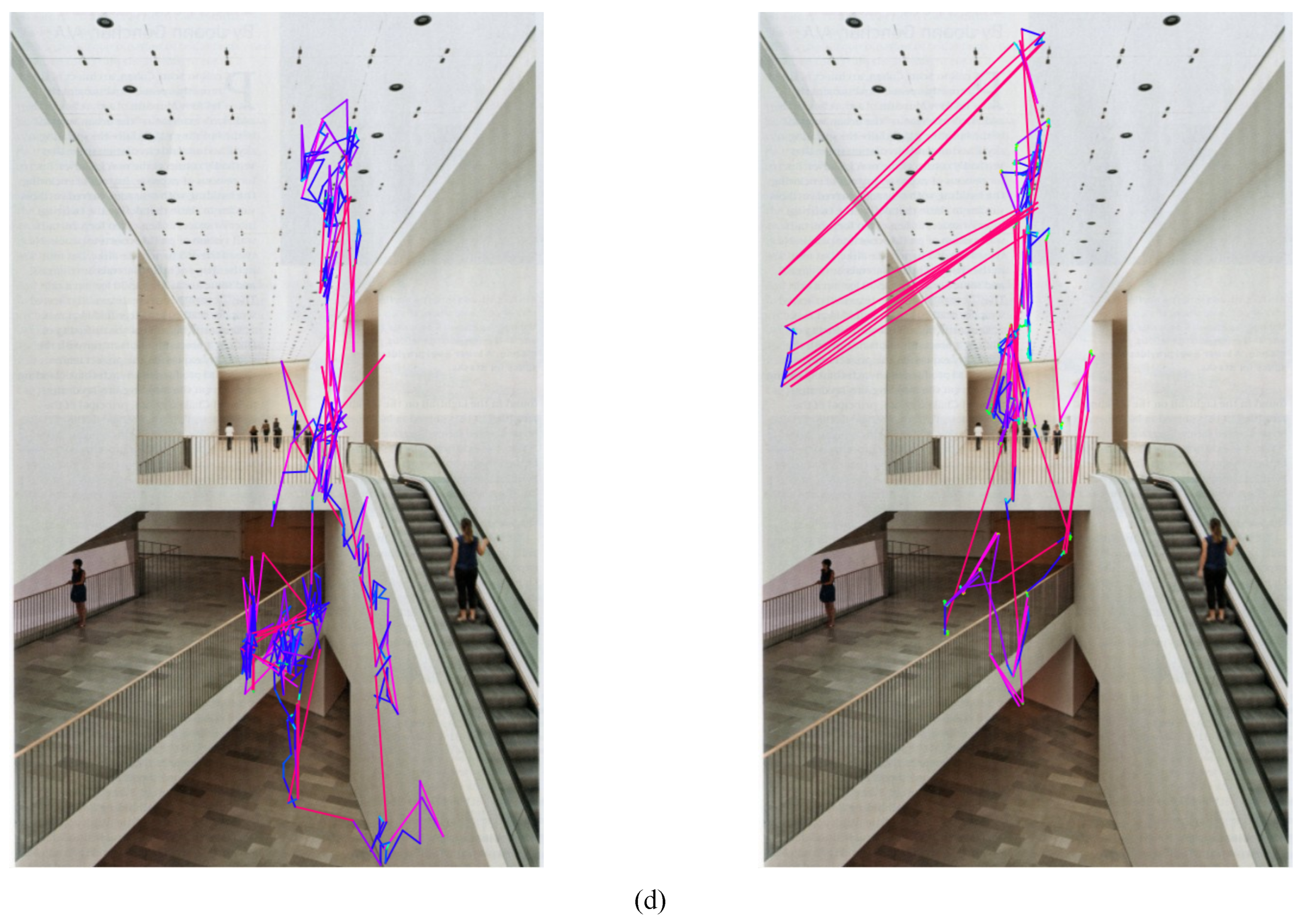
It is not evident why certain individuals exhibit stronger characteristics than others; in particular, the group of non-majors included a higher number of similar individuals than that of majors (
Figure 3). The question is whether endogenous eye-tracking parameters are innate or acquired. Previous research has concluded that fixation and saccadic measures are natural properties determined by physical, neural, developmental, and psychological constraints (
Castelhano & Henderson, 2008) and that they are consistent across substantially different image contents (
Andrews & Coppola, 1999) and tasks (
Boot et al., 2009) and an 18-month period (
Mehoudar et al., 2014). Whereas our findings imply that a longer period of training involving visual construction affects endogenous parameters, we should also consider the likelihood that individuals with certain characteristics tend to select similar disciplines. An investigation of eye-tracking patterns over a period of educational training will help find the answer to this question.
Regarding decoding majors/non-majors, the classification was statistically significant using similar data features for individual decoding. However, the prediction rate was substantially higher for majors than for nonmajors, as revealed by a 2D map whose x- and y-axes are two data features with the highest importance. The areas occupied by the two groups exhibited a large overlap, but because the majors were more narrowly clustered, the shared area had been marked as majors’ territory. It resulted in the incorrect prediction of non-majors in that area as majors. The map itself is a discovery of data features characterizing the randomness of a more heterogeneous group, but its level of distinction does not appear significant.
The analysis of image stimuli revealed that the level of attention of the majors and non-majors to certain elements differed. Whereas both groups tended to fixate on visually dense areas, the majors focused more on architectural elements (stairs, columns and beams, and truss structure) and the non-majors focused more on nonstructural elements (commercial boards and entourage objects). It is noteworthy that the division was prominent where a feature exhibited a complex shape or was in low lighting condition. To summarize, whereas the majors aimed to resolve structural uncertainty, the non-majors were affected more by direct symbolic cue (
Nodine et al., 1993;
Park et al., 2012). Its design implication is that architectural design should not only focus on organizing spaces but also consider the effect of symbols relative to visual attention. Considering that the training process is irreversible, user participation and an active use quantification method appears essential.
A limitation of the process here is that the classification performance depends highly on the resolution of the grid. In theory, a higher granularity always yields better classification results because it essentially creates more room for boundaries between different groups. Meanwhile, we also noticed a significant number of image features lying on the boundary. We recommend that a classification analysis based on boundary construction be interpreted and supplemented by other visual inspection methods. Another important point is that the reproducibility of our results will depend on the accuracy or precision of the measurement. We used raw data whose positions in normalized coordinates had a resolution in the order of 10e-4, and a timing in the order of 2.5e-6 ms, well below the frequency of the recording (60 Hz, 16.6667 ms). In our study, the first bin of the velocity histogram represents the “zero” distance between adjacent eye positions, and the existence itself along with its low to high variability across and within an individual is one proof of the soundness of the small scale data (
Figure 4 and
Figure 5).
In conclusion, the application of machine learning to eye-tracking data revealed more data features unique to an individual and provided objective measures indicating the uneven attention between groups with and without educational training. Unlike previous forward-based approaches that test the effectiveness of the selected parameters, machine learning could automatically identify the distinguishing patterns from the candidate features in high dimensional spaces. However, it is also true that machine learning is not a panacea that can reveal all the hidden eye-tracking parameters. Not only did previous studies show the effectiveness of various parameterizations, but also histogram features in our study depended largely on researchers’ insights rather than blind application of machine learning. The problem proposed as future research – investigation of better methods for capturing the spatiotemporal nature and spatial distribution of eye movement – will also require trial and error of multiple hypotheses. In conclusion, the practice of forward-based searches of eye-tracking parameters will continue to exist in the near future, but the machine learning community will keep offering strong alternatives for exploring eyetracking parameters more effectively and these alternatives would be worthwhile to consider.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}