
Representation Learning with a Variational Autoencoder for Predicting Nitrogen Requirement in Rice




Abstract
: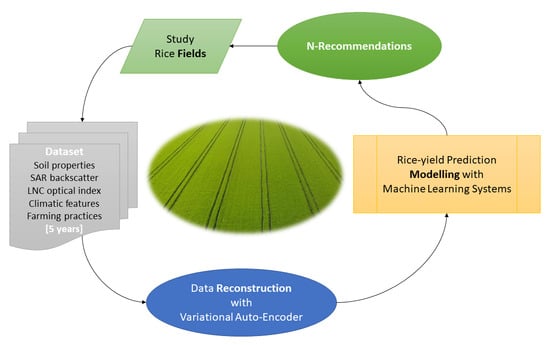
1. Introduction
2. Materials and Methods
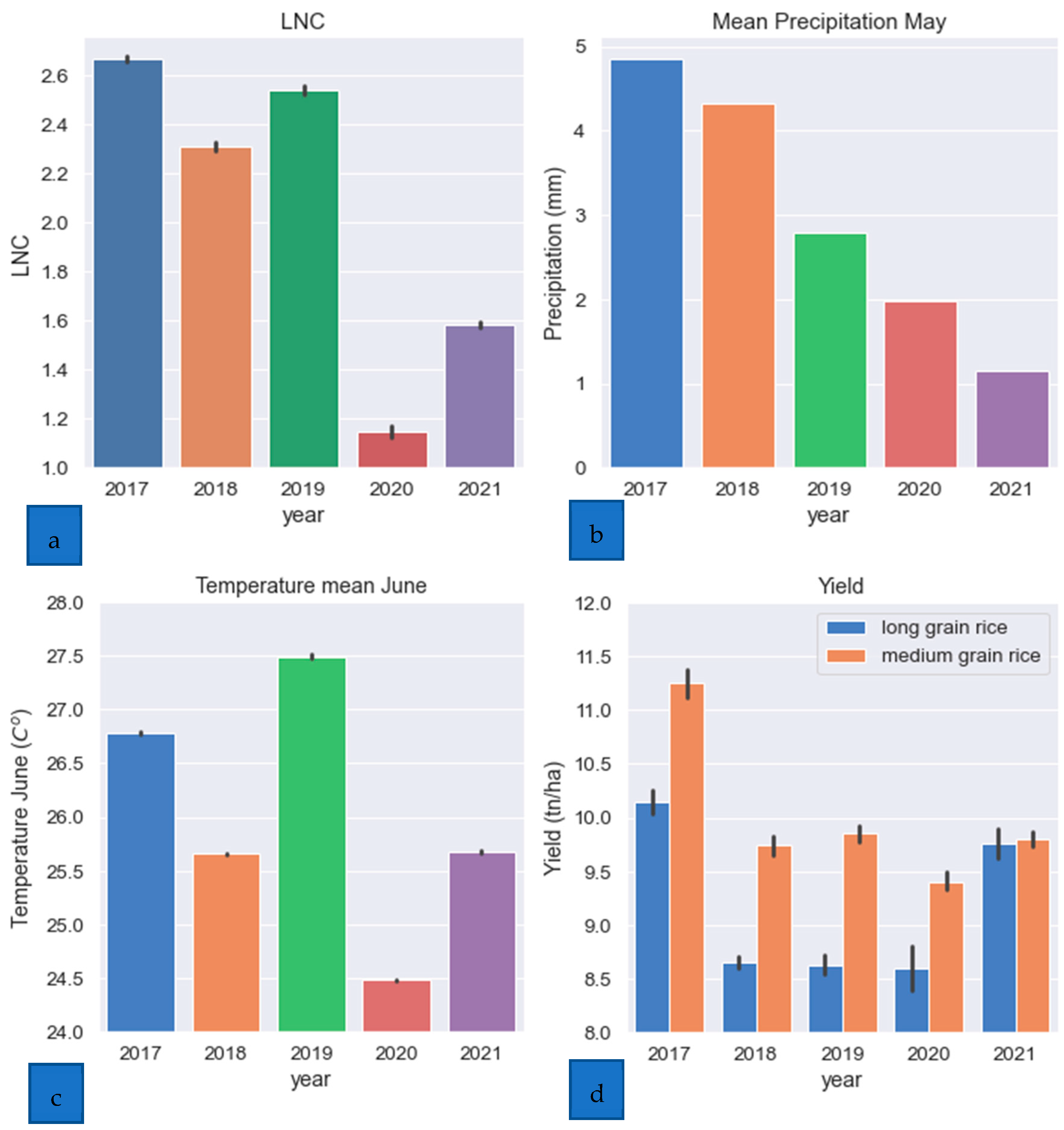
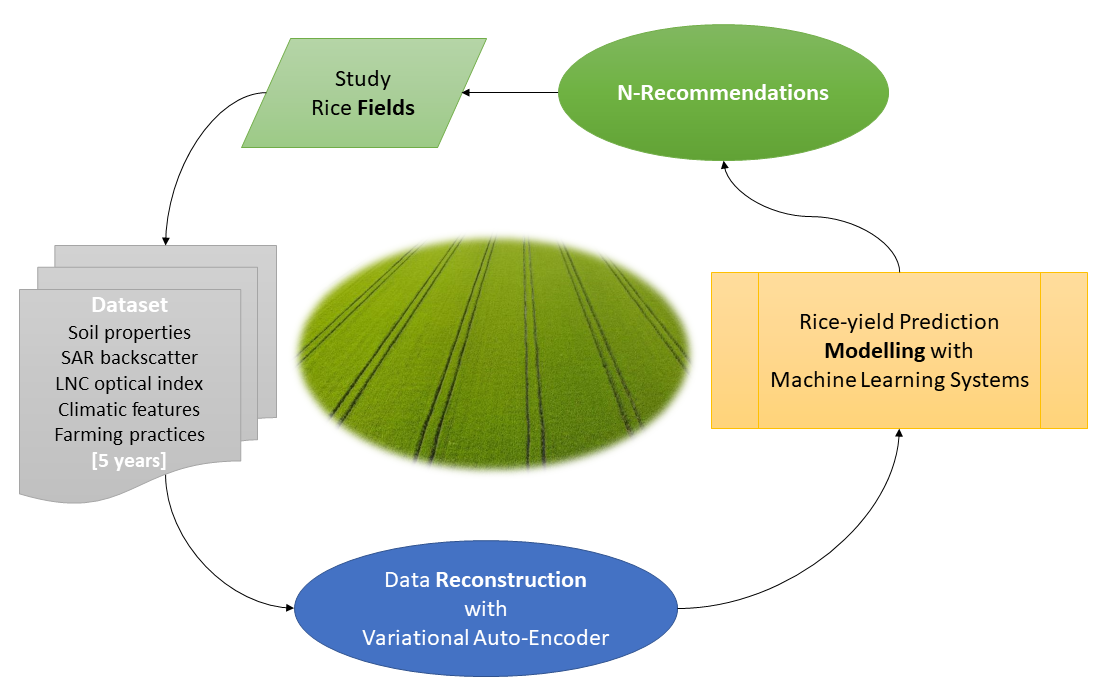
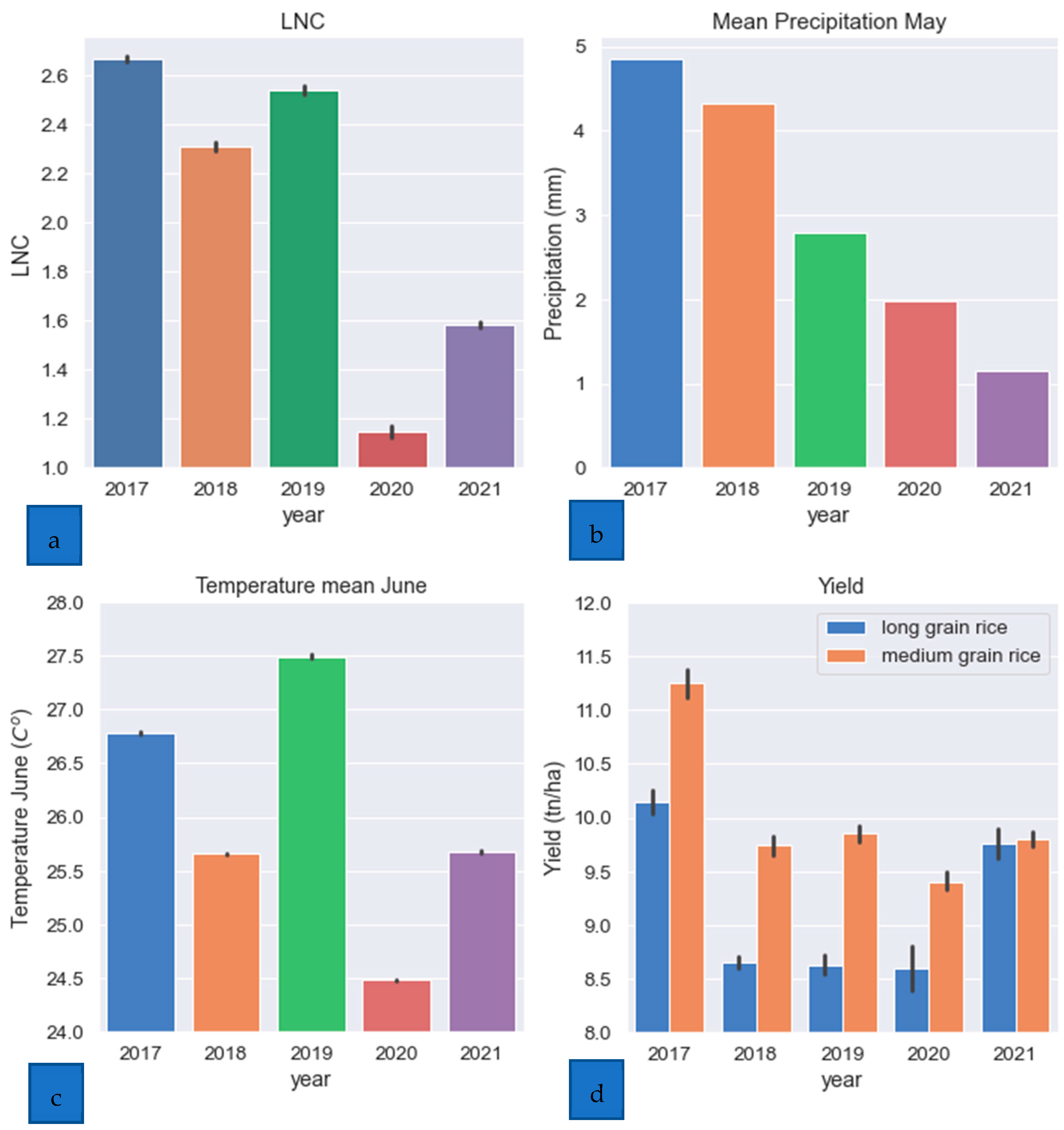
2.1. Study Area
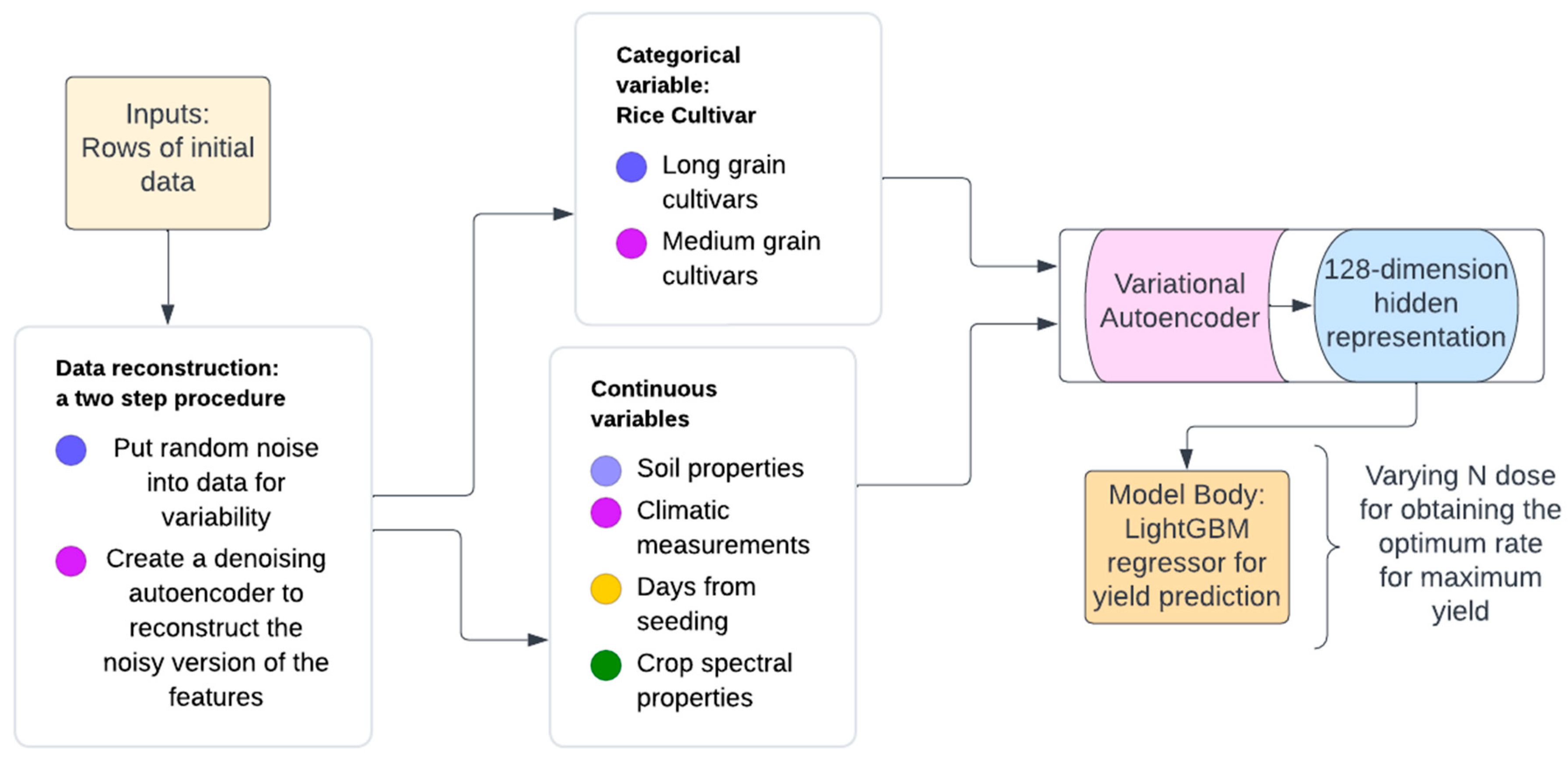
2.2. Dataset Preparation
- Soil properties
- b.
- Climatic measurements
- c.
- Farming practices
- d.
- Crop spectral properties
- e.
- Yield
2.3. Experimental Design
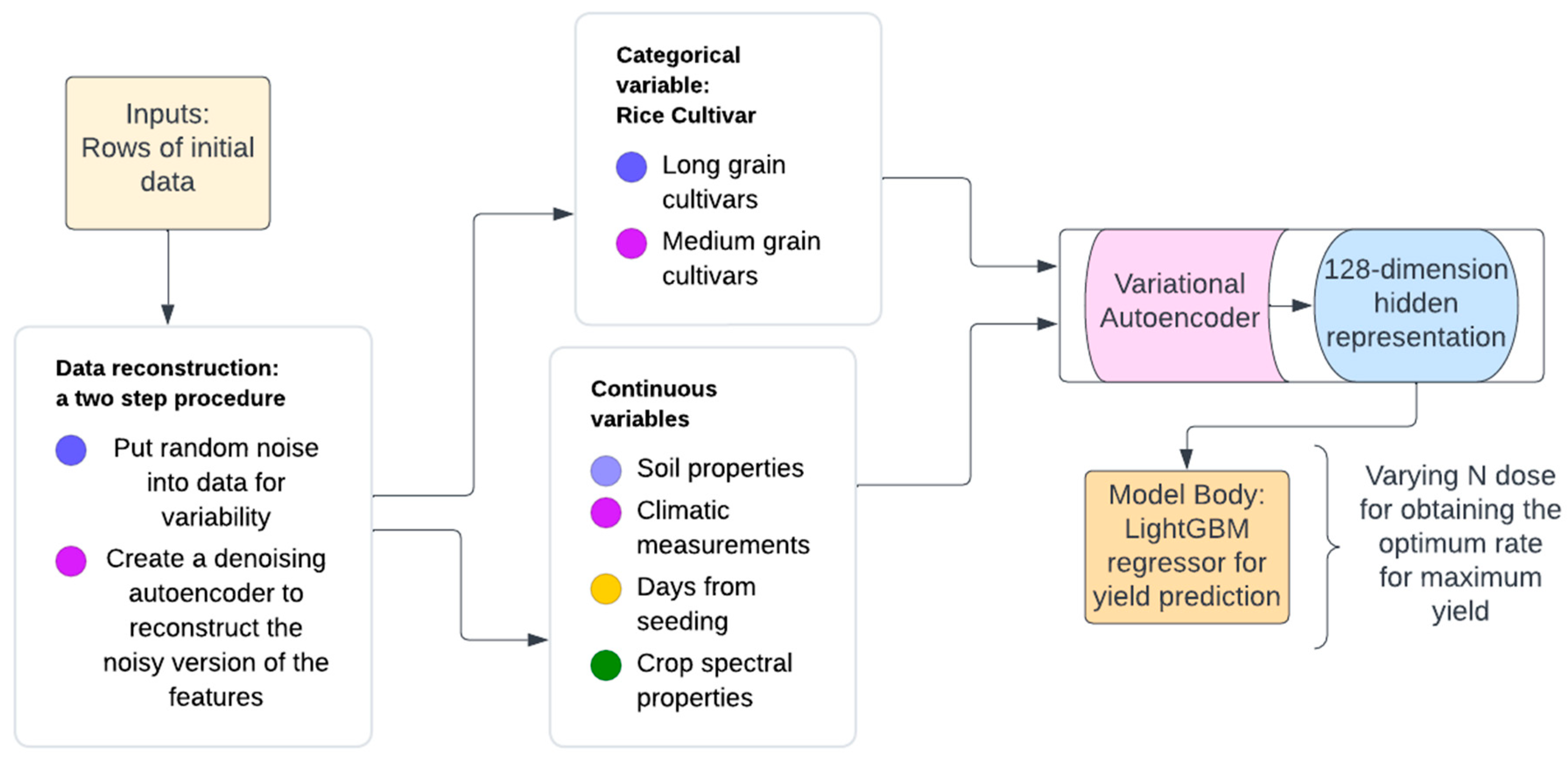
2.4. Machine Learning
- Model methodology
- b.
- Feature engineering
- SAR backscatter vertical transmit—horizontal receive polarization rolling mean for 4 consecutive image acquisitions in June divided by the days from seeding (SAR_VH_June/Days_from_seeding);
- Variety (long grain or medium grain);
- An LNC parameter divided by the days from seeding (LNC/Days_from_seeding);
- Backscatter values obtained by the last SAR image in June divided by the days from seeding (SAR_VH_June/Days_from_seeding);
- Mean precipitation of May (Precipitation_May);
- Total N need (N_need);
- Mean temperature of July (Temperature_July);
- Mean precipitation in June (Precipitation_June);
- N rate broadcasting before seeding (Broad_N);
- Silt content in soil (Si);
- Mean temperature for June, July and August (Temperature_mean);
- Mean precipitation in July (Precipitation_July);
- Soil acidity (pH);
- Clay content in soil (C);
- Mean temperature in August (Temperature_August);
- Organic matter content in soil (OM);
- Mean precipitation in August (Precipitation_August);
- Mean precipitation of June, July, and August (Precipitaton_mean);
- Mean temperature of June (Temperature_June; and
- CaCO3 content in soil (CaCO3).
- Mean temperature anomaly of August (Temperature_August_anomaly);
- Mean temperature July anomaly (Temperature_July_anomaly);
- Mean temperature of anomalies for June, July, and August (Temperature_mean_anomaly);
- Mean temperature anomaly of May (Temperature_May_anomaly); and
- Mean temperature anomaly of June (Temperature_June_anomaly).
- c.
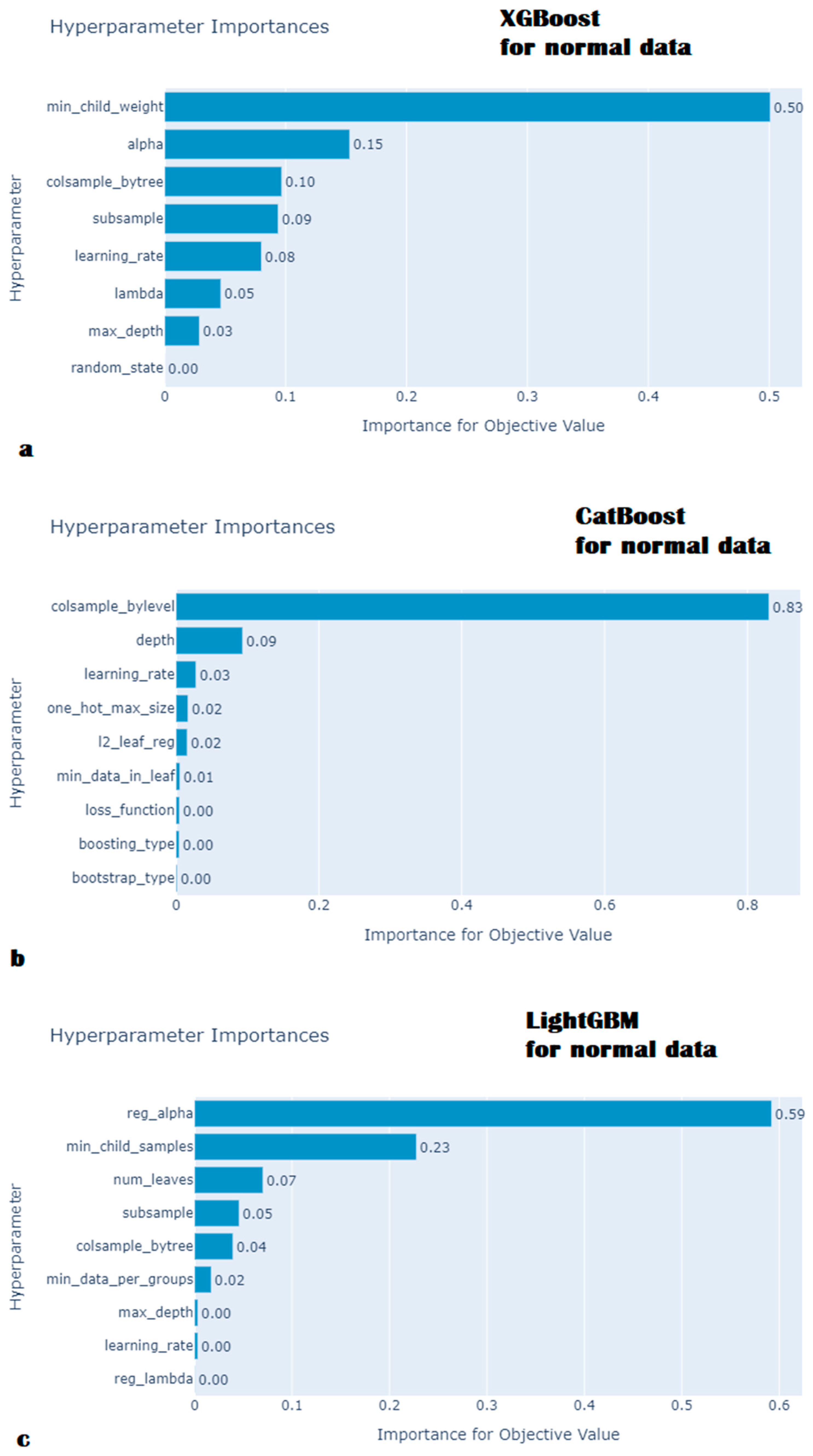
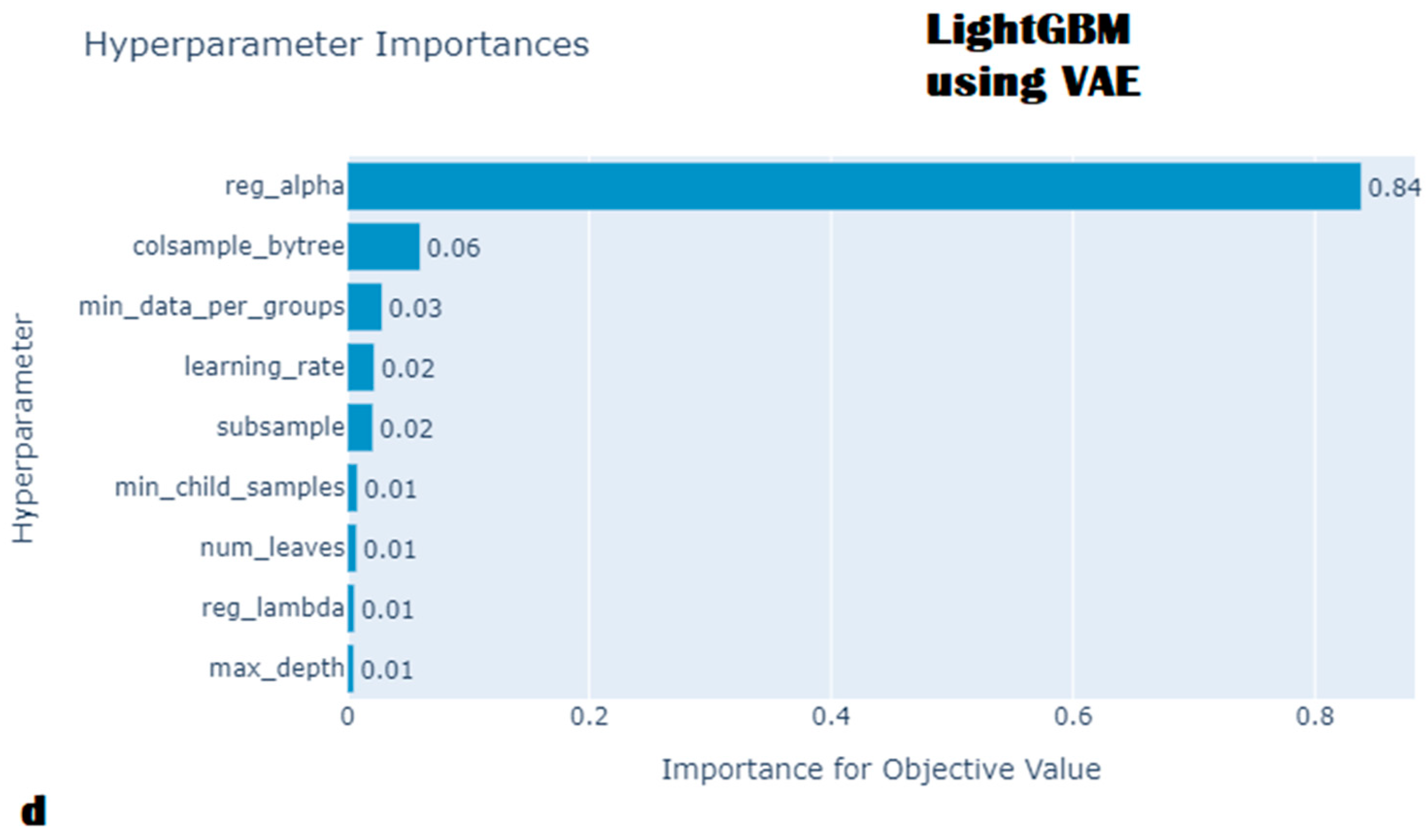
- Hyperparameter optimization
- d.
- Variational autoencoder
- e.
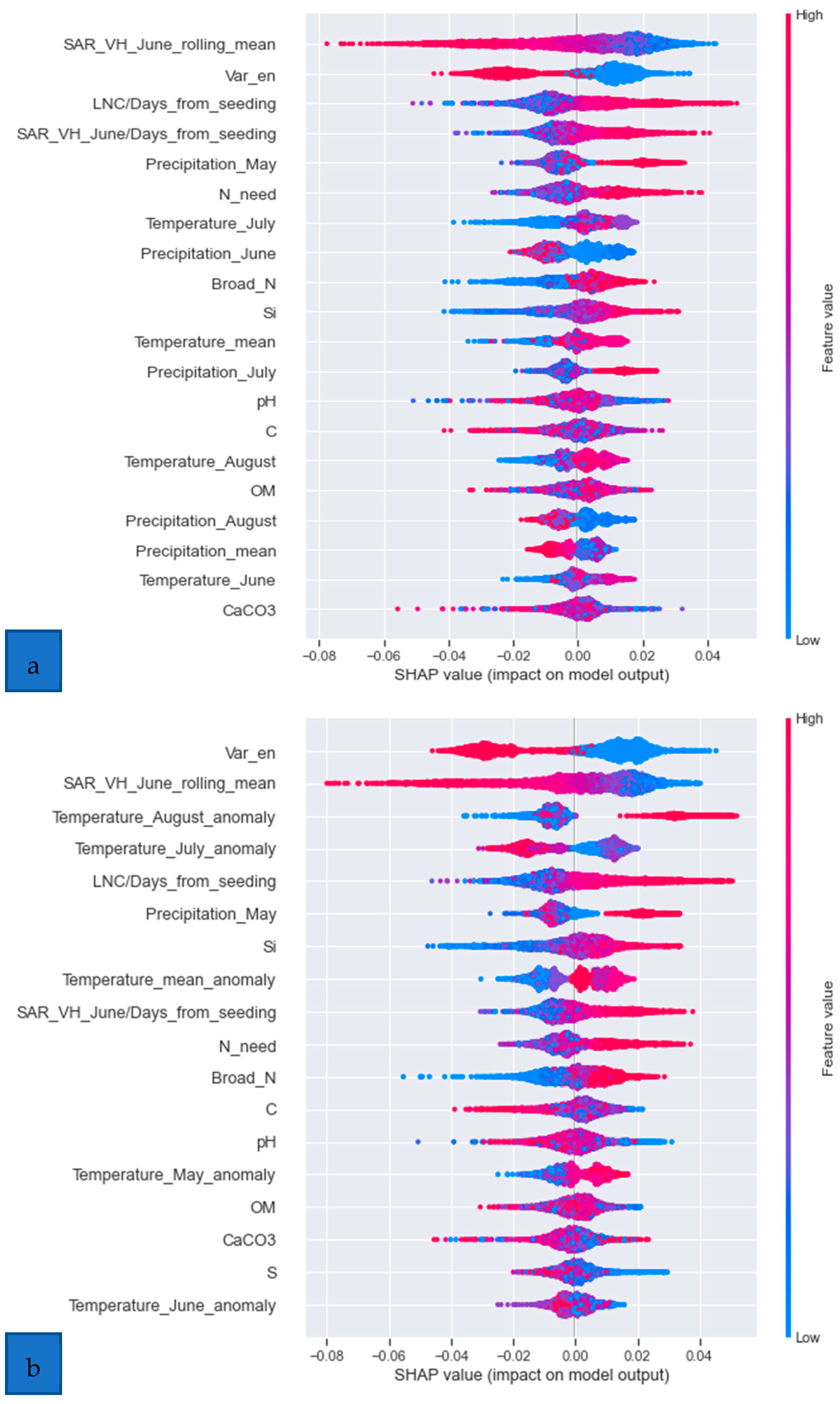
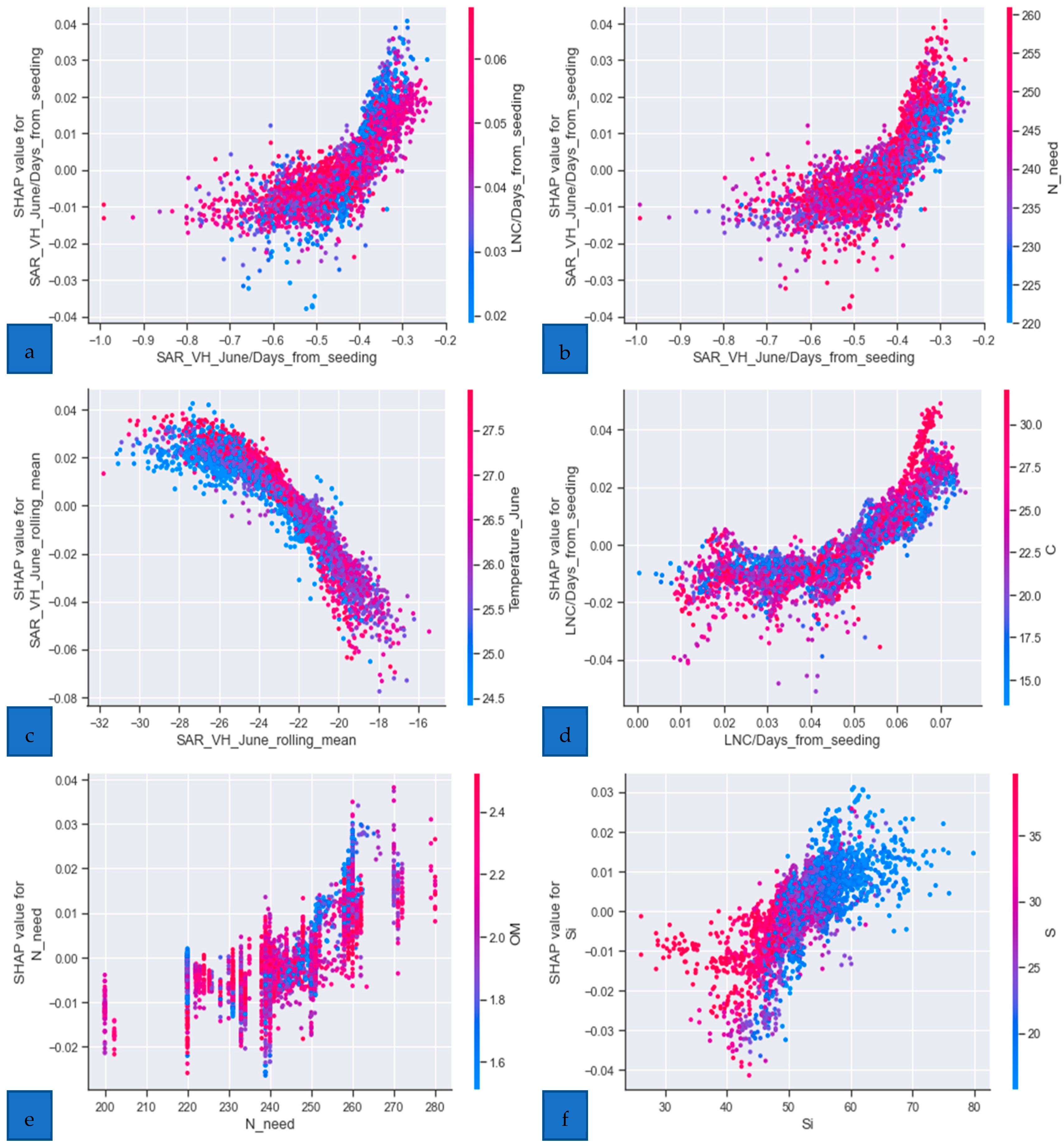
- SHAP analysis
3. Results
- Model performance
- b.
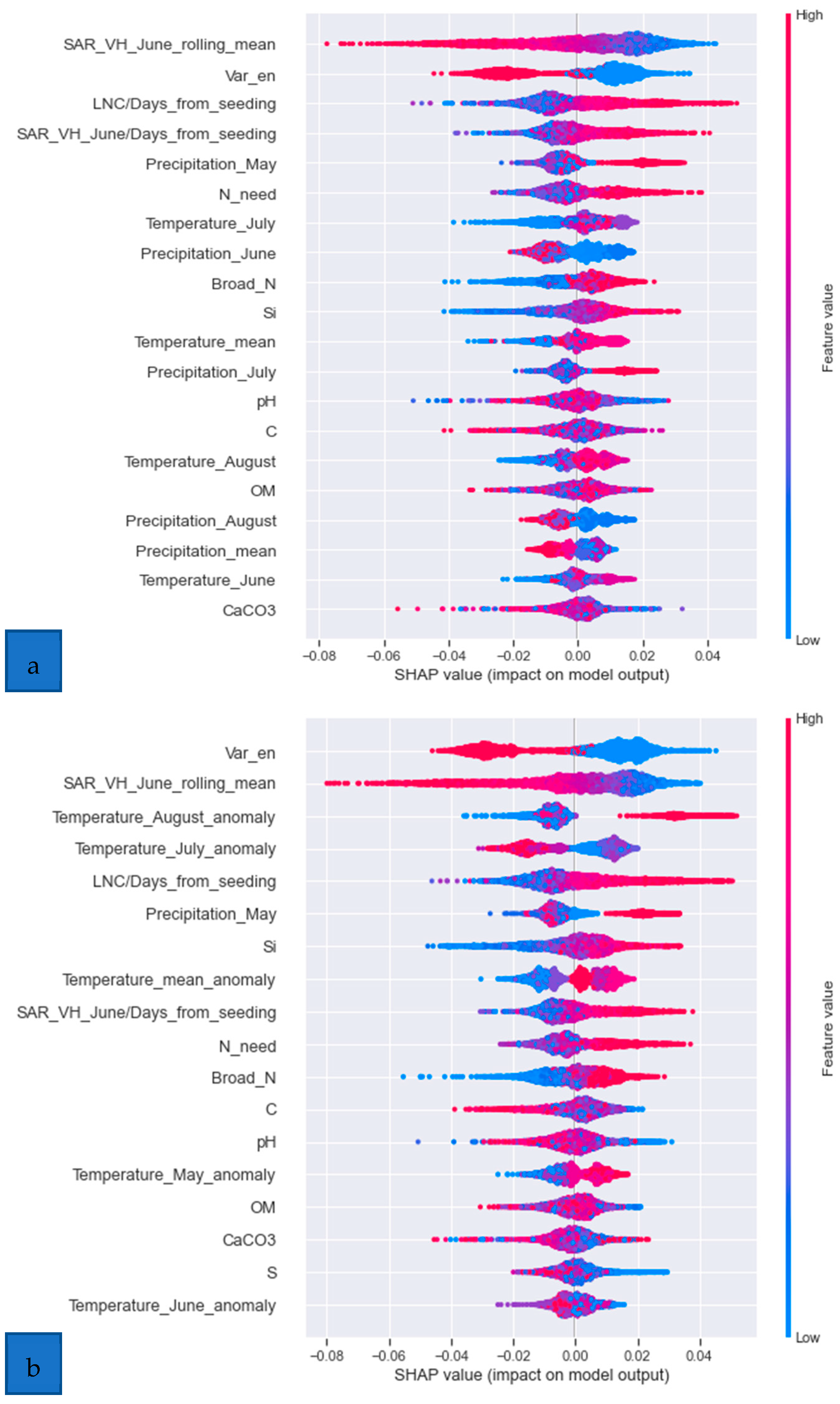
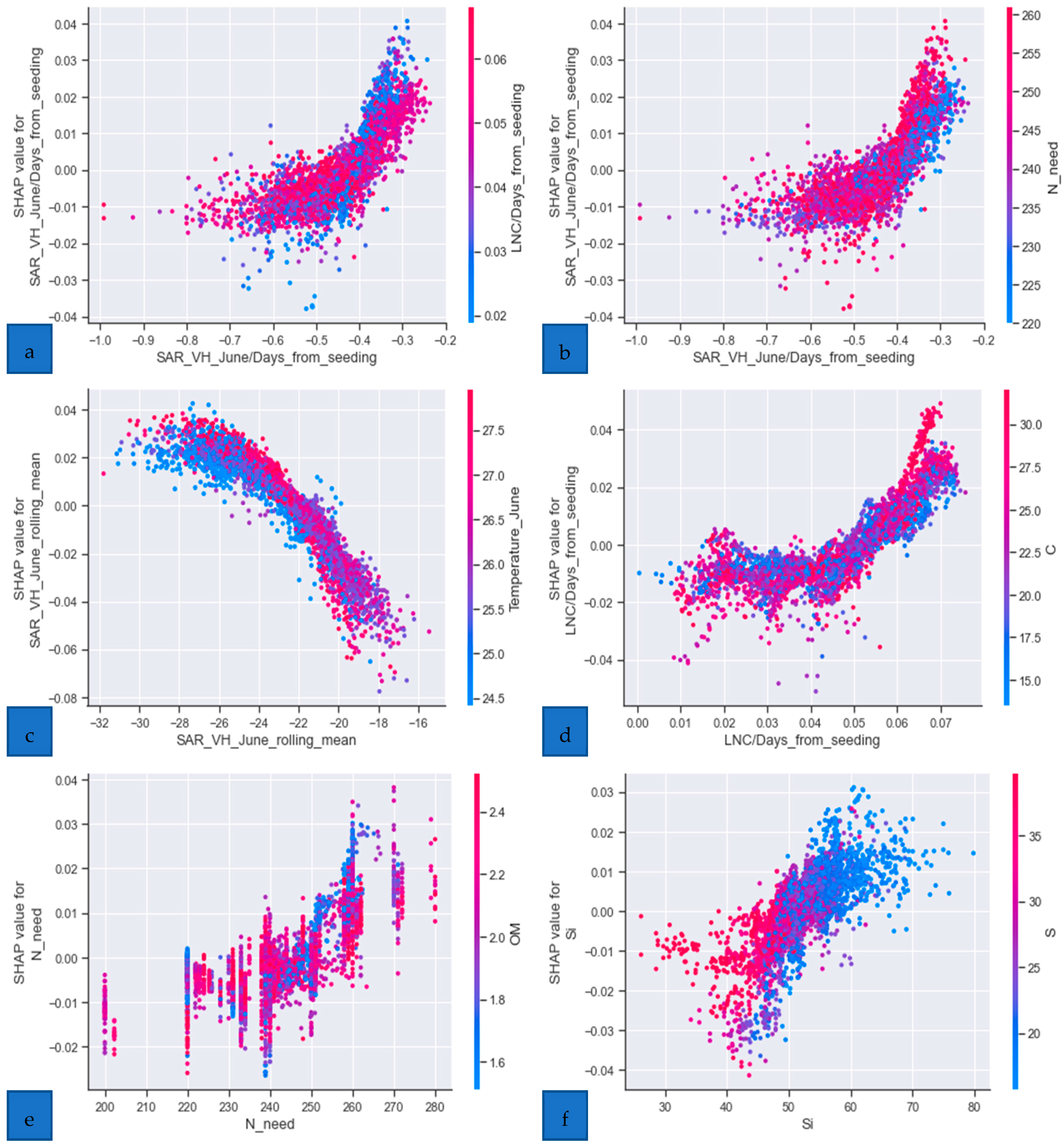
- Model explanation with SHAP
- c.
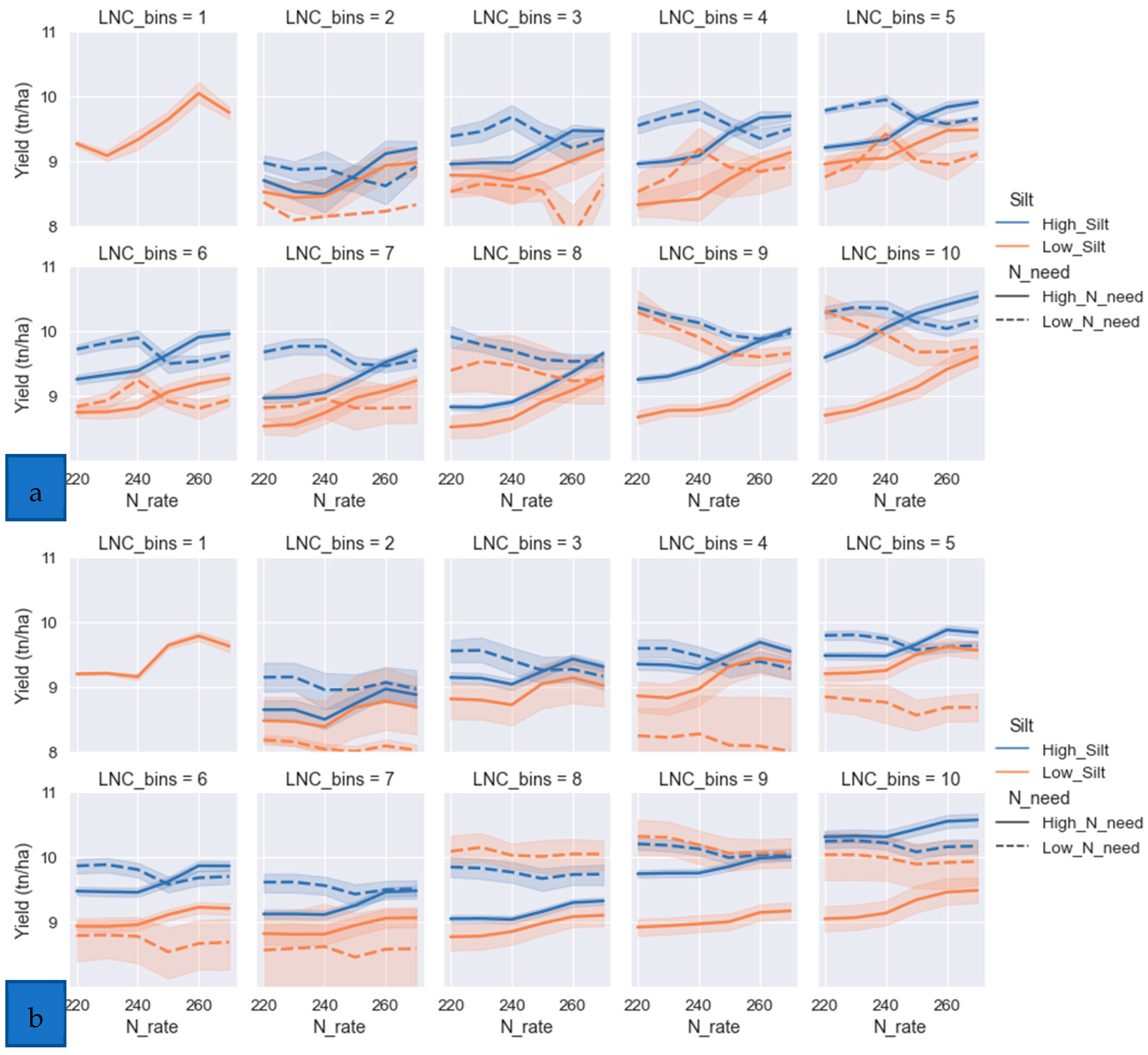
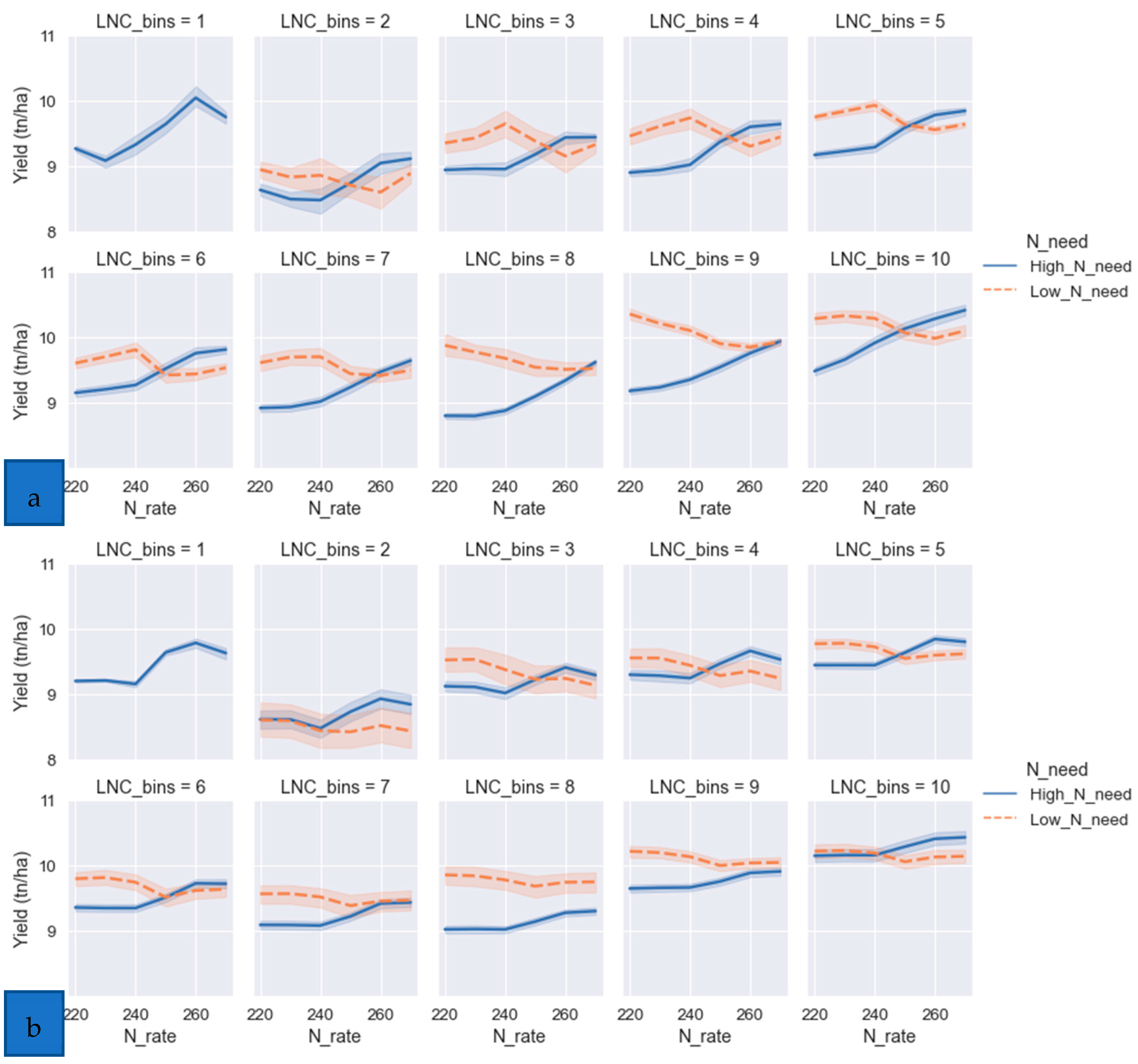
- Yield response curves to N fertilization
4. Discussion
- N need as a significant determinant of the model
- b.
- The importance of SAR backscatter on the model’s performance
- c.
- Water effect on rice productivity
- d.
- The effect of soil texture on rice productivity
- e.
- The importance of VAE for accurately predicting the N requirements
- f.
- SHAP analysis shedding light on the model
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Williams, J.F. Rice Nutrient Management in California; University of California: Oakland, CA, USA, 2010. [Google Scholar]
- Iatrou, M.; Karydas, C.; Iatrou, G.; Pitsiorlas, I.; Aschonitis, V.; Raptis, I.; Mpetas, S.; Kravvas, K.; Mourelatos, S. Topdressing nitrogen demand prediction in rice crop using machine learning systems. Agriculture 2021, 11, 312. [Google Scholar] [CrossRef]
- Iatrou, M.; Karydas, C.; Iatrou, G.; Zartaloudis, Z.; Kravvas, K.; Mourelatos, S. Optimization of fertilization recommendation in Greek rice fields using precision agriculture. Agric. Econ. Rev. 2018, 19, 64–75. [Google Scholar]
- Borgnis, F.; Pedroli, E. Technological Interventions for Obsessive–Compulsive Disorder Management. Compr. Clin. Psychol. 2022, 10, 283–306. [Google Scholar]
- Viana, C.M.; Santos, M.; Freire, D.; Abrantes, P.; Rocha, J. Evaluation of the factors explaining the use of agricultural land: A machine learning and model-agnostic approach. Ecol. Indic. 2021, 131, 108200. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22Nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Horie, T.; Nakagawa, H.; Centeno, G.; Kropff, M. The Rice Simulation Model SIMRIW and Its Testing. In Modeling the Impact of Climate Change on Rice Production in Asia CABI, UK, IRRI, Philippines; Matthews, R.B., Kropff, M.J., Bachelet, D., van Laar, H.H., Eds.; CAR international: Manila, Philippines, 1999; pp. 95–139. [Google Scholar]
- Tang, L.; Zhu, Y.; Hannaway, D.; Meng, Y.; Liu, L.; Chen, L.; Cao, W. RiceGrow: A rice growth and productivity model. NJAS Wagening. J. Life Sci. 2009, 57, 83–92. [Google Scholar] [CrossRef] [Green Version]
- Bouman, B.; Kropff, M.; Tuong, T.P.; Wopereis, S.; ten Berge, H.; van Laar, H. ORYZA2000: Modeling Lowland Rice; IRRI: Los Baños, Philippines, 2001. [Google Scholar]
- Mahmood, R.; Meo, M.; Legates, D.R.; Morrissey, M.L. The CERES-Rice Model-Based Estimates of Potential Monsoon Season Rainfed Rice Productivity in Bangladesh. Prof. Geogr. 2003, 55, 259–273. [Google Scholar]
- Gómez, D.; Salvador, P.; Sanz, J.; Casanova, J.L. Potato yield prediction using machine learning techniques and Sentinel 2 data. Remote Sens 2019, 11, 1745. [Google Scholar] [CrossRef] [Green Version]
- Boote, K.; Jones, J.; Pickering, N. Potential Uses and Limitations of Crop Models. Agron J. 1996, 88, 704–716. [Google Scholar] [CrossRef]
- Jeong, S.; Ko, J.; Yeom, J.-M. Predicting rice yield at pixel scale through synthetic use of crop and deep learning models with satellite data in South and North Korea. Sci. Total Environ. 2021, 802, 149726. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.; Deng, J.; Lu, J.; Wang, X.; Lu, B.; Tian, X.; Zhang, Y. High Nitrogen Levels Alleviate Yield Loss of Super Hybrid Rice Caused by High Temperatures During the Flowering Stage. Front. Plant Sci. 2019, 10, 357. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maina, S.C.; Bryant, R.E.; Ogallo, W.O.; Varshney, K.R.; Speakman, S.; Cintas, C.; Walcott-Bryant, A.; Samoilescu, R.-F.; Weldemariam, K. Preservation of Anomalous Subgroups On Variational Autoencoder Transformed Data. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA; pp. 3627–3631. [Google Scholar]
- Karydas, C.G.; Silleos, N.G. Precision Agriculture: Method Description—Current Status and Perspectives. In Special Conference on “Informatics in Agricultural Sector”, 2nd ed.; Matsatsinis, N., Ed.; New Technologies Publications: Chania, Greece, 2000; pp. 134–146. [Google Scholar]
- International Society of Precision Agriculture. 2022. Available online: https://www.ispag.org/ (accessed on 5 October 2022).
- Litskas, V.D.; Aschonitis, V.G.; Lekakis, E.H.; Antonopoulos, V.Z. Effects of land use and irrigation practices on Ca, Mg, K, Na loads in rice-based agricultural systems. Agric. Water Manag. 2014, 132, 30–36. [Google Scholar] [CrossRef]
- Karydas, C.; Iatrou, M.; Iatrou, G.; Mourelatos, S. Management zone delineation for site-specific fertilization in rice crop using multi-temporal rapideye imagery. Remote Sens. 2020, 12, 2604. [Google Scholar] [CrossRef]
- Iatrou, M.; Papadopoulos, A.; Dichala, O.; Psoma, P.; Bountla, A. Determination of Soil Available Phosphorus using the Olsen and Mehlich 3 Methods for Greek Soils Having Variable Amounts of Calcium Carbonate. Commun. Soil Sci. Plant Anal. 2014, 45, 2207–2214. [Google Scholar] [CrossRef]
- Du, G.; Liu, W.; Pan, T.; Yang, H.; Wang, Q. Cooling Effect of Paddy on Land Surface Temperature in Cold China Based on MODIS Data: A Case Study in Northern Sanjiang Plain. Sustainability 2019, 11, 5672. [Google Scholar] [CrossRef] [Green Version]
- Hussain, S.; Khaliq, A.; Ali, B.; Hussain, H.A.; Qadir, T.; Hussain, S. Temperature Extremes: Impact on Rice Growth and Development. In Plant Abiotic Stress Tolerance: Agronomic, Molecular and Biotechnological Approaches; Springer International Publishing: Cham, Switzerland, 2019; pp. 153–171. [Google Scholar]
- Skofronick-Jackson, G.; Petersen, W.A.; Berg, W.; Kidd, C.; Stocker, E.F.; Kirschbaum, D.B.; Kakar, R.; Braun, S.A.; Huffman, G.J.; Iguchi, T.; et al. The Global Precipitation Measurement (GPM) Mission for Science and Society. Bull. Am. Meteorol. Soc. 2017, 98, 1679–1695. [Google Scholar] [CrossRef]
- Espino, L.; Leinfelder-Miles, M.; Brim-Deforest, W.; Al-khatib, K.; Linquist, B.; Swett, C. Rice Production Manual. In Agriculture and Natural Resources; University of California: Berkeley, CA, USA, 2018. [Google Scholar]
- Domsch, H.; Heisig, M.; Witzke, K. Estimation of yield zones using aerial images and yield data from a few tracks of a combine harvester. Precis. Agric. 2008, 9, 321–337. [Google Scholar] [CrossRef]
- Gemtos, T.; Fountas, S.; Blackmore, B.S.; Greipentrog, H.W. Precision Farming Experience in Europe and the Greek Potential. In Proceedings of the 1st Hellenic Conference in Information Technology in Agriculture (HAICTA), Athens, Greece, 6–7 June 2002. [Google Scholar]
- Evans, J.R. International Association for Ecology Photosynthesis and Nitrogen Relationships in Leaves of C3 Plants. Oecologia 1989, 78, 9–19. [Google Scholar] [CrossRef]
- Ladha, J.K.; Pathak, H.; Krupnik, T.J.; Six, J.; van Kessel, C. Efficiency of Fertilizer Nitrogen in Cereal Production: Retrospects and Prospects. Adv. Agron. 2005, 87, 85–156. [Google Scholar]
- Stroppiana, D.; Fava, F.; Boschetti, M.; Brivio, P.A. Estimation of Nitrogen Content in Crops and Pastures Using Hyperspectral Vegetation Indices. In Hyperspectral Remote Sensing of Vegetation; Thenkabail, P.S., Lyon, J.G., Huete, A., Eds.; CRC Press: Boca Raton, FL, USA, 2011; pp. 245–262. [Google Scholar]
- Karydas, C. Temporal dimensions in rice crop spectral profiles. J. Geomat. 2016, 10, 140–148. [Google Scholar]
- Westfall KLF & DGDWWMCB. Evaluating Farmer Defined Management Zone Maps for Variable Rate Fertilizer Application. Precis. Agric. 2000, 2, 201–215. [Google Scholar] [CrossRef]
- Heijting, S.; de Bruin, S.; Bregt, A.K. The arable farmer as the assessor of within-field soil variation. Precis. Agric. 2011, 12, 488–507. [Google Scholar] [CrossRef] [Green Version]
- Kumar, L.; Mutanga, O. Google Earth Engine applications since inception: Usage, trends, and potential. Remote Sens. 2018, 10, 1509. [Google Scholar] [CrossRef] [Green Version]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Amani, M.; Ghorbanian, A.; Ahmadi, S.A.; Kakooei, M.; Moghimi, A.; Mirmazloumi, S.M.; Moghaddam, S.H.A.; Mahdavi, S.; Ghahremanloo, M.; Parsian, S.; et al. Google Earth Engine Cloud Computing Platform for Remote Sensing Big Data Applications: A Comprehensive Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5326–5350. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Howard, J.; Gugger, S. Deep Learning for Coders with Fastai and PyTorch; O’Reilly Media: Sebastopol, CA, USA, 2020. [Google Scholar]
- Dorogush, A.V.; Gulin, A.; Gusev, G.; Kazeev, N.; Prokhorenkova, L.O.; Vorobev, A. Fighting Biases with Dynamic Boosting; CoRR: 2017; abs/1706.0. Available online: http://arxiv.org/abs/1706.09516 (accessed on 16 May 2022).
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Advances in Neural Information Processing Systems; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Eds.; Curran Associates, Inc.: Nice, France, 2017. [Google Scholar]
- Abdullahi, I.A.; Raheem, L.; Muhammed, M.; Rabiat, O.; Ganiyu, A. Comparison of the CatBoost Classifier with other Machine Learning Methods. Int. J. Adv. Comput. Sci. Appl. 2020, 11. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Nice, France, 2018. [Google Scholar]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-Generation Hyperparameter Optimization Framework; CoRR: 2019; abs/1907.1. Available online: http://arxiv.org/abs/1907.10902 (accessed on 10 May 2022).
- Akrami, H.; Aydore, S.; Leahy, R.M.; Joshi, A.A. Robust Variational Autoencoder for Tabular Data with Beta Divergence. Comput. Sci. 2020. Available online: http://arxiv.org/abs/2006.08204 (accessed on 17 June 2022).
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions; CoRR: 2017; abs/1705.0. Available online: http://arxiv.org/abs/1705.07874 (accessed on 30 May 2022).
- Wojtuch, A.; Jankowski, R.; Podlewska, S. How can SHAP values help to shape metabolic stability of chemical compounds? J. Cheminform. 2021, 13, 74. [Google Scholar] [CrossRef]
- Lloyd, S. N-Person Games. Def. Tech. Inf. Cent. 1952, 295–314. [Google Scholar]
- Gramegna, A.; Giudici, P. SHAP and LIME: An Evaluation of Discriminative Power in Credit Risk. Front. Artif. Intell. 2021, 4, 140. [Google Scholar] [CrossRef]
- Joseph, A. Shapley Regressions: A Framework for Statistical Inference on Machine Learning Models, 4th ed.; Bank of England and King’s College London: London, UK, 2019. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D Graphics Environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Waskom, M.; Botvinnik, O.; O’Kane, D.; Hobson, P.; Lukauskas, S.; Gemperline, D.C.; Augspurger, A.; Halchenko, Y.; Cole, J.B.; Warmenhoven, J.; et al. mwaskom/seaborn: V0.8.1 (September 2017). 3 September 2017. Available online: https://zenodo.org/record/883859 (accessed on 16 March 2022).
- Van Rossum, G.; Drake, F.L. The Python Tutorial; Python Software Foundation: Wilmington, DE, USA, 2010; Volume 42, pp. 1–122. Available online: http://docs.python.org/tutorial/ (accessed on 5 May 2022).
- Chakhar, A.; Hernández-López, D.; Ballesteros, R.; Moreno, M.A. Improving the Accuracy of Multiple Algorithms for Crop Classification by Integrating Sentinel-1 Observations with Sentinel-2 Data. Remote Sens. 2021, 13, 243. [Google Scholar] [CrossRef]
- Stanford, G.; Legg, J.O. Nitrogen and Yield Potential. In Nitrogen in Crop Production; ASA, CSSA, SSSA: Madison, WI, USA, 2015; pp. 263–272. [Google Scholar]
- Haque, M.A.; Haque, M. Growth, Yield and Nitrogen Use Efficiency of New Rice Variety under Variable Nitrogen Rates. Am. J. Plant Sci. 2016, 7, 612–622. [Google Scholar] [CrossRef] [Green Version]
- Tanaka, R.; Nakano, H. Barley Yield Response to Nitrogen Application under Different Weather Conditions. Sci. Rep. 2019, 9, 8477. [Google Scholar] [CrossRef] [Green Version]
- Ruan, G.; Li, X.; Yuan, F.; Cammarano, D.; Ata-Ui-Karim, S.T.; Liu, X.; Tian, Y.; Zhu, Y.; Cao, W.; Cao, Q. Improving Wheat yield Prediction Integrating Proximal Sensing and Weather Data with Machine Learning. Comput. Electron. Agric. 2022, 195, 106852. [Google Scholar] [CrossRef]
- Ranatunga, T.; Hiramatsu, K.; Onishi, T.; Ishiguro, Y. Process of Denitrification in Flooded Rice Soils. Rev. Agric. Sci. 2018, 6, 21–33. [Google Scholar] [CrossRef] [Green Version]
- Terashima, K.; Taniguchi, T.; Ogiwara, H.; Umemoto, T. Effect of Field Drainage on Root Lodging Tolerance in Direct-Sown Rice in Flooded Paddy Field. Plant Prod. Sci. 2003, 6, 255–261. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Wu, L.; Wu, X.; Ding, Y.; Li, G.; Li, J.; Weng, F.; Liu, Z.; Tang, S.; Ding, C.; et al. Lodging Resistance of Japonica Rice (Oryza sativa L.): Morphological and Anatomical Traits due to top-Dressing Nitrogen Application Rates. Rice 2016, 9, 31. [Google Scholar] [CrossRef]
- Shah, L.; Yahya, M.; Shah, S.M.A.; Nadeem, M.; Ali, A.; Ali, A.; Wang, J.; Riaz, M.W.; Rehman, S.; Wu, W.; et al. Improving Lodging Resistance: Using Wheat and Rice as Classical Examples. Int. J. Mol. Sci. 2019, 20, 4211. [Google Scholar] [CrossRef] [Green Version]
- Iatrou, M.; Papadopoulos, A. Influence of nitrogen nutrition on yield and growth of an everbearing strawberry cultivar (cv. Evie II). J. Plant Nutr. 2015, 39, 1499–1505. [Google Scholar] [CrossRef]
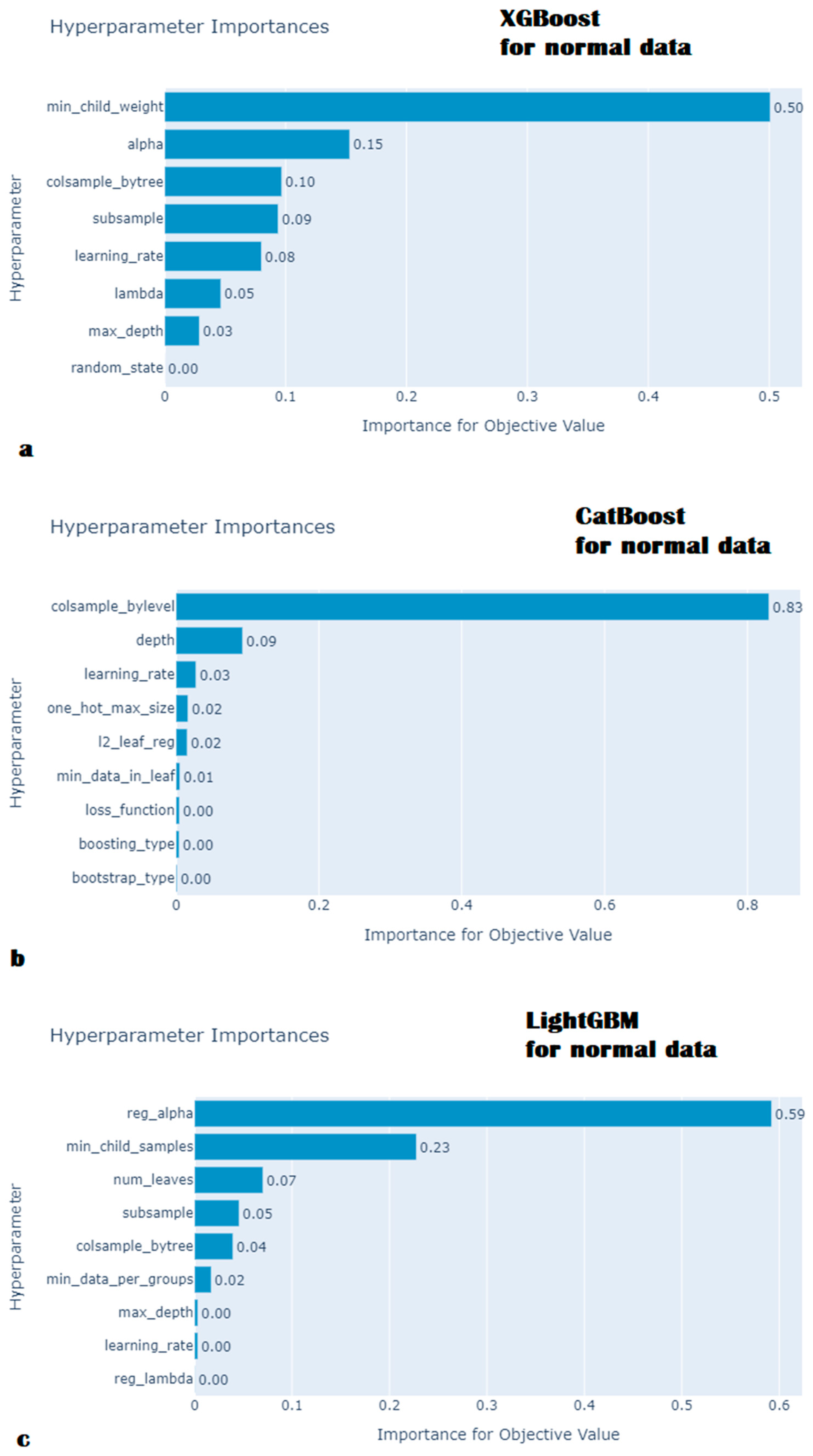
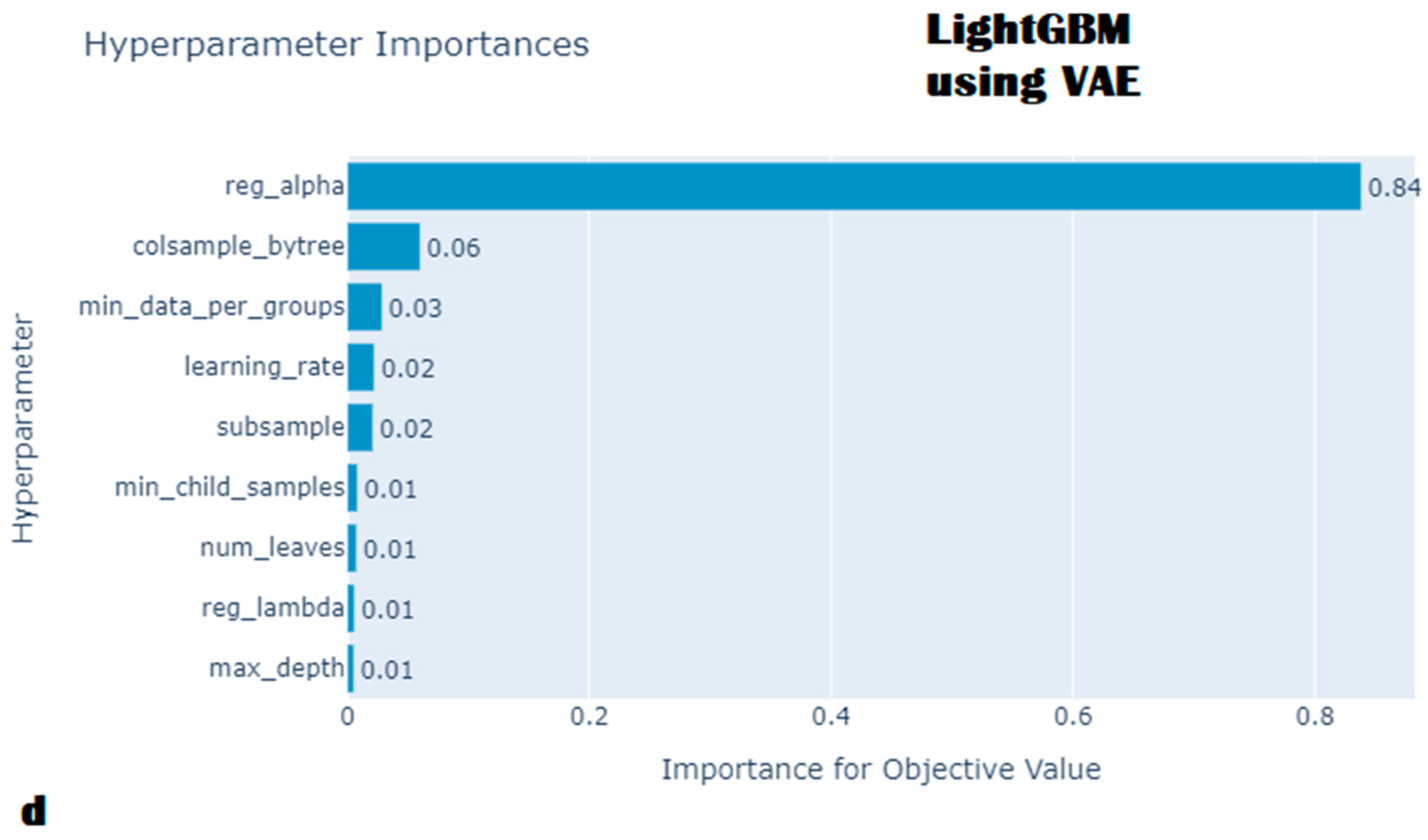


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | XGBoost | CatBoost | LightGBM |
|---|---|---|---|
| n_estimators | 10,000 | 1000 | |
| reg_lambda | 0.003 | 8.60 | |
| alpha | 0.0098 | ||
| colsample_bytree | 1 | 0.4 | |
| subsample | 0.6 | 0.7 | |
| learning_rate | 0.014 | 0.03 | 0.01 |
| max_depth | 13 | 10 | 20 |
| min_child_weight | 6 | ||
| loss_function | RMSE | ||
| l2_leaf_reg | 0.18 | ||
| colsample_bylevel | 0.096 | ||
| boosting_type | Plain | ||
| bootstrap_type | Bayesian | ||
| min_data_in_leaf | 16 | ||
| one_hot_max_size | 16 | ||
| bagging_temperature | 5.94 | ||
| depth | 10 | ||
| iterations | 1000 | ||
| reg_alpha | 0.024 | ||
| num_leaves | 851 | ||
| min_child_samples | 5 | ||
| cat_smooth | 85 | ||
| metric | RMSE | ||
| min_data_per_group | 85 |
| Hyperparameter | XGBoost | CatBoost | LightGBM |
|---|---|---|---|
| n_estimators | 10,000 | 1000 | |
| reg_lambda | 4.42 | 0.21 | |
| alpha | 0.09 | ||
| colsample_bytree | 0.8 | 0.4 | |
| subsample | 0.4 | 0.7 | |
| learning_rate | 0.012 | 0.03 | 0.014 |
| max_depth | 13 | 10 | 100 |
| min_child_weight | 1 | ||
| loss_function | RMSE | ||
| l2_leaf_reg | 0.18 | ||
| colsample_bylevel | 0.096 | ||
| boosting_type | Plain | ||
| bootstrap_type | Bayesian | ||
| min_data_in_leaf | 16 | ||
| one_hot_max_size | 16 | ||
| bagging_temperature | 5.94 | ||
| depth | 10 | ||
| iterations | 1000 | ||
| reg_alpha | 0.038 | ||
| num_leaves | 346 | ||
| min_child_samples | 14 | ||
| cat_smooth | |||
| metric | RMSE | ||
| min_data_per_group | 29 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iatrou, M.; Karydas, C.; Tseni, X.; Mourelatos, S. Representation Learning with a Variational Autoencoder for Predicting Nitrogen Requirement in Rice. Remote Sens. 2022, 14, 5978. https://doi.org/10.3390/rs14235978
Iatrou M, Karydas C, Tseni X, Mourelatos S. Representation Learning with a Variational Autoencoder for Predicting Nitrogen Requirement in Rice. Remote Sensing. 2022; 14(23):5978. https://doi.org/10.3390/rs14235978
Chicago/Turabian StyleIatrou, Miltiadis, Christos Karydas, Xanthi Tseni, and Spiros Mourelatos. 2022. "Representation Learning with a Variational Autoencoder for Predicting Nitrogen Requirement in Rice" Remote Sensing 14, no. 23: 5978. https://doi.org/10.3390/rs14235978
APA StyleIatrou, M., Karydas, C., Tseni, X., & Mourelatos, S. (2022). Representation Learning with a Variational Autoencoder for Predicting Nitrogen Requirement in Rice. Remote Sensing, 14(23), 5978. https://doi.org/10.3390/rs14235978