
Achieving High Efficiency and High Throughput in Erasure Code-Based Distributed Storage for Blockchain †



Abstract
1. Introduction
- The trigger-based ARQ method, which uses trigger signals much smaller than the encoded chunks, reduces the data transmission overhead for recovering the original blocks from EC-based distributed blockchain storage while maintaining the decentralization of the blockchains.
- The proposed trigger-based ARQ technique enables stable data recovery while ensuring low latency and high-throughput performance, even when node failure is frequent.
- Using the trigger-based ARQ scheme with an EC-based distribution technique, blockchains can reduce storage overhead while effectively accessing the original blocks, overcoming the limitations of conventional EC-based distributed storage.
2. Related Work
3. System Model
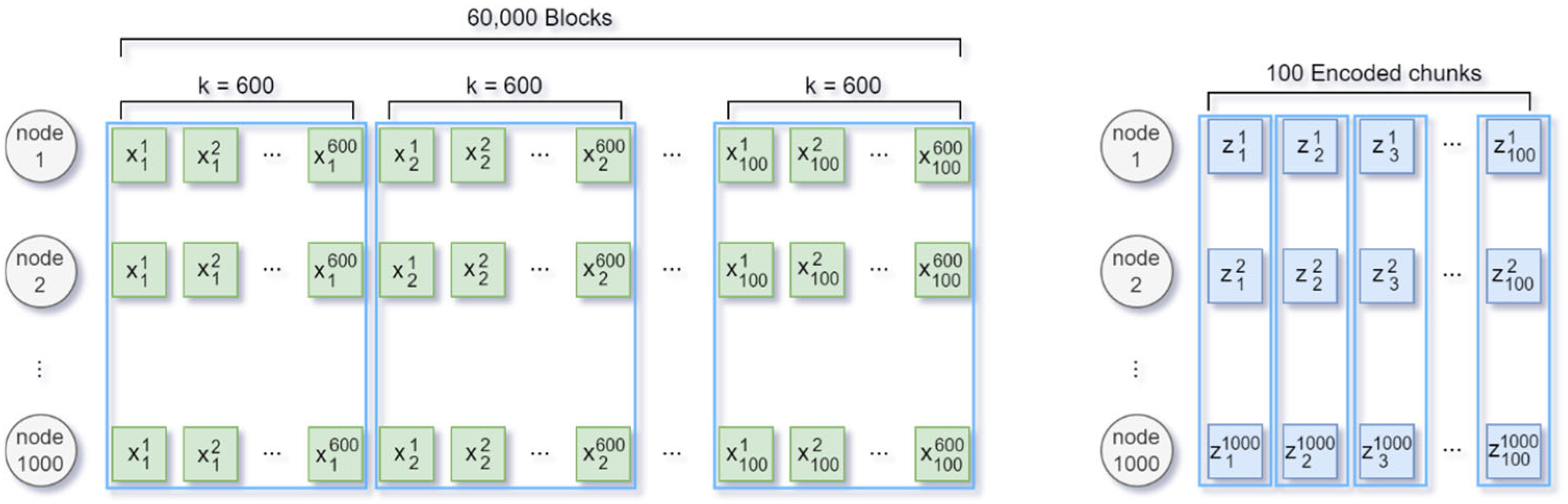
3.1. Erasure Code-Based Distributed Blockchain Storage
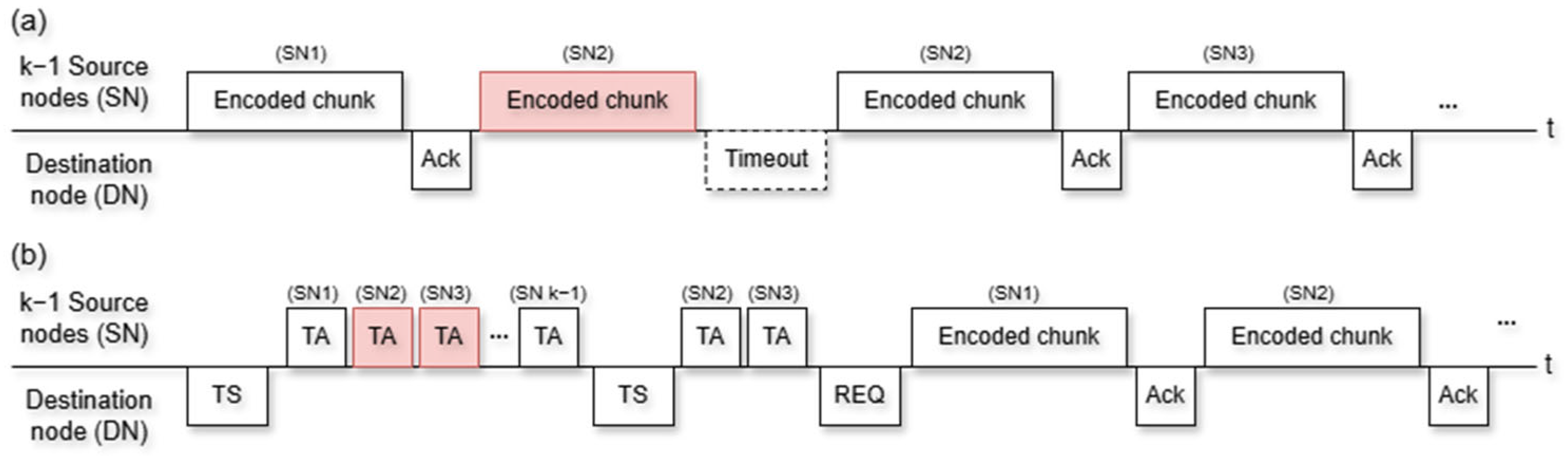
3.2. Effective Block Recovery
4. Evaluation and Analysis
4.1. Experimental Environment
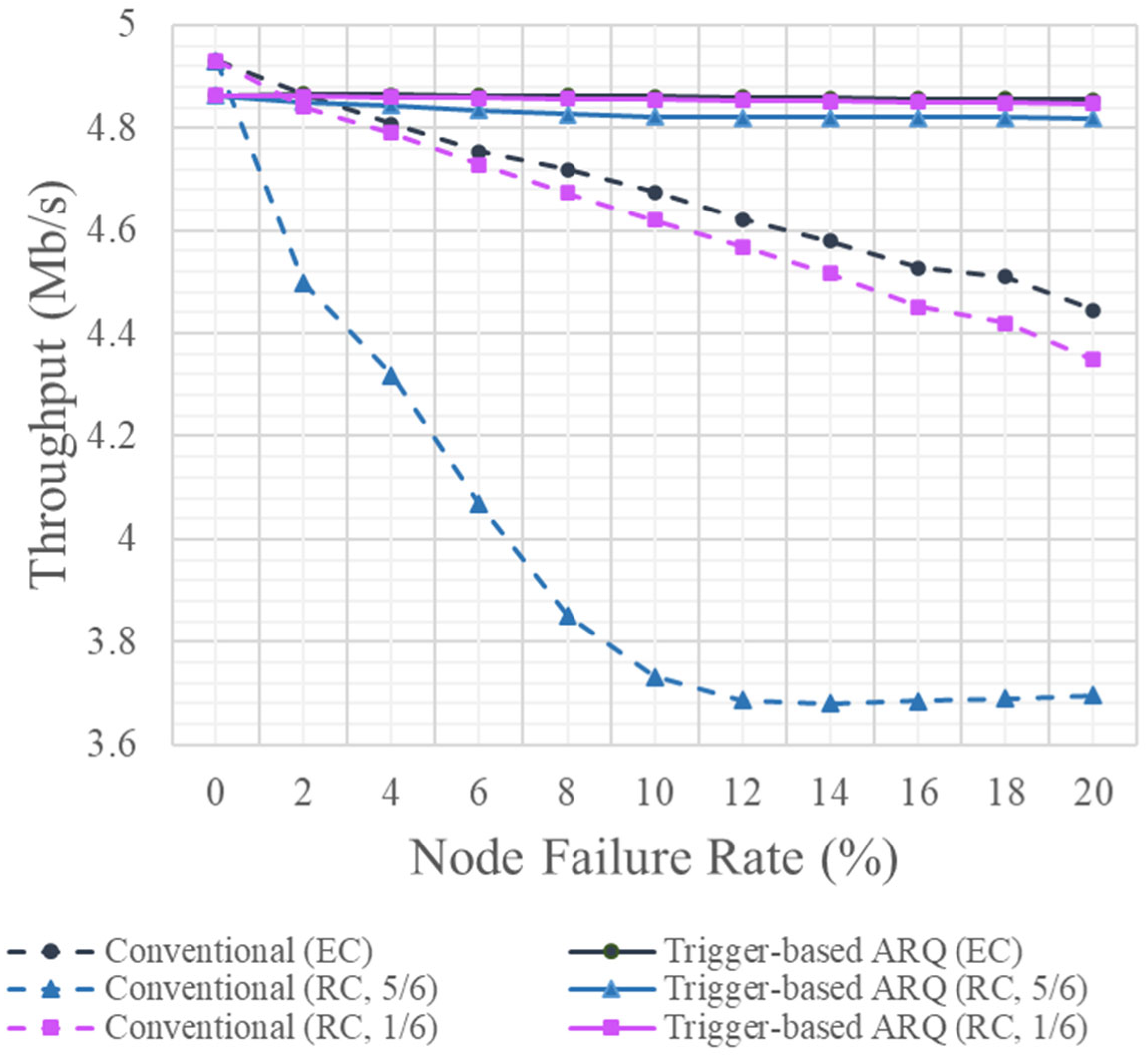
4.2. Throughput Evaluation
4.3. Storage Efficiency Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DN | Destination node |
| EC | Erasure code |
| IoT | Internet of Things |
| LRC | Local Reconstruction Codes |
| MSD | Maximum separable distance |
| MSR | Minimum storage regeneration |
| RC | Repetition code |
| RS | Reed Solomon |
| SN | Source nodes |
| TA | Trigger ACK |
References
- Khan, A.G.; Zahid, A.H.; Hussain, M.; Farooq, M.; Riaz, U.; Alam, T.M. A journey of web and blockchain towards the industry 4.0: An overview. In Proceedings of the 2019 International Conference on Innovative Computing (ICIC), IEEE, Lahore, Pakistan, 1–2 November 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Lin, Y.; Gao, Z.; Du, H.; Niyato, D.; Kang, J.; Deng, R.; Shen, X.S. A unified blockchain-semantic framework for wireless edge intelligence enabled web 3.0. IEEE Wirel. Commun. 2024, 31, 126–133. [Google Scholar] [CrossRef]
- Du, Z.; Pang, X.; Qian, H. Partitionchain: A scalable and reliable data storage strategy for permissioned blockchain. IEEE Trans. Knowl. Data Eng. 2023, 35, 4124–4136. [Google Scholar] [CrossRef]
- Yun, S.W.; Lee, E.Y.; Lee, I.G. Selective layered blockchain framework for privacy-preserving data management in low-latency mobile networks. J. Internet Technol. 2023, 24, 881–891. [Google Scholar] [CrossRef]
- Luo, H.; Zhang, Q.; Sun, G.; Yu, H.; Niyato, D. Symbiotic blockchain consensus: Cognitive backscatter communications-enabled wireless blockchain consensus. IEEE/ACM Trans. Netw. 2024, 32, 5372–5387. [Google Scholar] [CrossRef]
- Gong, Y.; Yao, H.; Xiong, Z.; Chen, C.L.P.; Niyato, D. Blockchain-aided digital twin offloading mechanism in space-air-ground networks. IEEE Trans. Mob. Comput. 2024, 23, 183–197. [Google Scholar] [CrossRef]
- Hsiao, S.J.; Sung, W.T. Employing blockchain technology to strengthen security of wireless sensor networks. IEEE Access 2021, 9, 72326–72341. [Google Scholar] [CrossRef]
- Khalaf, O.I.; Abdulsahib, G.M. Optimized dynamic storage of data (ODSD) in IoT based on blockchain for wireless sensor networks. Peer-to-Peer Netw. Appl. 2021, 14, 2858–2873. [Google Scholar] [CrossRef]
- Dai, H.N.; Zheng, Z.; Zhang, Y. Blockchain for internet of things: A survey. IEEE Internet Things J. 2019, 6, 8076–8094. [Google Scholar] [CrossRef]
- Reilly, E.; Maloney, M.; Siegel, M.; Falco, G. An IoT integrity-first communication protocol via an Ethereum blockchain light client. In Proceedings of the 2019 IEEE/ACM 1st International Workshop on Software Engineering Research & Practices for the Internet of Things (SERP4IoT), IEEE, Montreal, QC, Canada, 27 May 2019. [Google Scholar] [CrossRef]
- Chan, W.K.; Chin, J.J.; Goh, V.T. Simple and scalable blockchain with privacy. J. Inf. Secur. Appl. 2021, 58, 102700. [Google Scholar] [CrossRef]
- Li, C.; Zhang, J.; Yang, X.; Youlong, L. Lightweight blockchain consensus mechanism and storage optimization for resource-constrained IoT devices. Inf. Process. Manag. 2021, 58, 102602. [Google Scholar] [CrossRef]
- Qi, X.; Zhang, Z.; Jin, C.; Zhou, A. BFT-Store: Storage Partition for Permissioned Blockchain via Erasure Coding. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020. [Google Scholar]
- Wang, R.; Njilla, L.; Yu, S. AC: An NDN-based blockchain network with erasure coding. In Proceedings of the 2023 International Conference on Computing, Networking and Communications (ICNC), Honolulu, HI, USA, 20–22 February 2023. [Google Scholar]
- Perard, D.; Lacan, J.; Bachy, Y.; Detchart, J. Erasure code-based low storage blockchain node. In Proceedings of the 2018 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), IEEE, Halifax, NS, Canada, 30 July–3 August 2018; pp. 1622–1627. [Google Scholar] [CrossRef]
- Xu, Y.; Huang, Y. Segment blockchain: A size reduced storage mechanism for blockchain. IEEE Access 2020, 8, 17434–17441. [Google Scholar] [CrossRef]
- Park, S.H.; Kim, S.Y.; Kim, S.H.; Lee, I.G. Trigger-based Automatic Request for Effective Data Recovery of Erasure Coded Blockchain Storage. In Proceedings of the 7th International Conference on Mobile Internet Security (Mobisec), Okinawa, Japan, 19–21 December 2023. [Google Scholar]
- Xiao, Y.; Zhou, S.; Zhong, L. Erasure coding-oriented data update for cloud storage: A survey. IEEE Access 2020, 8, 227982–227998. [Google Scholar] [CrossRef]
- Shan, Y.; Chen, K.; Gong, T.; Zhou, L.; Zhou, T.; Wu, Y. Geometric partitioning: Explore the boundary of optimal erasure code repair. In Proceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles, Virtual, 26–29 October 2021; ACM: New York, NY, USA, 2021; pp. 457–471. [Google Scholar] [CrossRef]
- Song, Y.; Mu, T.; Wang, B. HV-SNSP: A low-overhead data recovery method based on cross-checking. IEEE Access 2023, 11, 5737–5745. [Google Scholar] [CrossRef]
- Qiu, H.; Wu, C.; Li, J.; Guo, M.; Liu, T.; He, X.; Dong, Y.; Zhao, Y. Ec-fusion: An efficient hybrid erasure coding framework to improve both application and recovery performance in cloud storage systems. In Proceedings of the 2020 IEEE International Parallel and Distributed Processing Symposium (IPDPS), IEEE, New Orleans, LA, USA, 14 July 2020. [Google Scholar]
- Liu, Q.; Feng, D.; Jiang, H.; Hu, Y.; Jiao, T. Systematic erasure codes with optimal repair bandwidth and storage. ACM Trans. Storage 2017, 13, 1–27. [Google Scholar] [CrossRef]
- Caneleo, P.I.S.; Mohan, L.J.; Parampalli, U.; Harwood, A. On improving recovery performance in erasure code based geo-diverse storage clusters. In Proceedings of the 2016 12th International Conference on the Design of Reliable Communication Networks (DRCN), IEEE, Paris, France, 15–17 March 2016; pp. 123–129. [Google Scholar] [CrossRef]
- Meng, F.; Li, J.; Gao, J.; Liu, J.; Ru, J.; Lu, Y. Blockchain storage method based on erasure code. In Proceedings of the 2023 8th International Conference on Data Science in Cyberspace (DSC), IEEE, Hefei, China, 18–20 August 2023. [Google Scholar]
- Zhang, M.; Wu, C.; Li, J.; Guo, M. DW-LRC: A dynamic wide-stripe LRC codes for blockchain data under malicious node scenarios. In Proceedings of the 2023 IEEE 29th International Conference on Parallel and Distributed Systems (ICPADS), IEEE, Ocean Flower Island, China, 17–21 December 2023. [Google Scholar]
- Nosheen, S.; Khan, J.Y. An adaptive Qos based video packet transmission technique for IEEE802.11ac WLAN. In Proceedings of the 2019 IEEE 89th Vehicular Technology Conference (VTC2019-Spring), IEEE, Kuala Lumpur, Malaysia, 28 April–1 May 2019. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| ) | 1000 |
| ) | |
| ) | |
| ) | 100 |
| ) | 1 KB |
| ACK, trigger ACK (TA) size | 14 Bytes |
| Trigger signal size | 20 Bytes |
| Data rate | 5 Mbps |
| Storage Scheme | Storage Efficiency | Throughput (Mb/s) at a Node Failure Rate of 20% | |
|---|---|---|---|
| Non-Trigger ARQ | Trigger-Based ARQ | ||
| Full-node-based storage | 1 | - | - |
| RC-based distributed storage (code rate of 5/6) | 1.2 | 3.69 | 4.81 |
| RC-based distributed storage (code rate of 1/6) | 6 | 4.34 | 4.84 |
| (1000, 600) RS-based distributed storage | 600 | 4.44 | 4.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, S.-H.; Kim, S.-Y.; Kim, S.-H.; Lee, I.-G. Achieving High Efficiency and High Throughput in Erasure Code-Based Distributed Storage for Blockchain. Sensors 2025, 25, 2161. https://doi.org/10.3390/s25072161
Park S-H, Kim S-Y, Kim S-H, Lee I-G. Achieving High Efficiency and High Throughput in Erasure Code-Based Distributed Storage for Blockchain. Sensors. 2025; 25(7):2161. https://doi.org/10.3390/s25072161
Chicago/Turabian StylePark, So-Hyun, So-Yeon Kim, So-Hui Kim, and Il-Gu Lee. 2025. "Achieving High Efficiency and High Throughput in Erasure Code-Based Distributed Storage for Blockchain" Sensors 25, no. 7: 2161. https://doi.org/10.3390/s25072161
APA StylePark, S.-H., Kim, S.-Y., Kim, S.-H., & Lee, I.-G. (2025). Achieving High Efficiency and High Throughput in Erasure Code-Based Distributed Storage for Blockchain. Sensors, 25(7), 2161. https://doi.org/10.3390/s25072161