

Wrist-Based Fall Detection: Towards Generalization across Datasets



Abstract
1. Introduction
2. Related Work
2.1. Classification Models in ML
Imbalanced Learning
2.2. Types of FDS
2.2.1. Camera-Based FDS
2.2.2. Context/Ambient FDS
2.2.3. Wearables FDS
2.3. Datasets
2.4. Wrist-Based FDS
3. Selection of Datasets
3.1. Datasets
3.1.1. Dataset Up Fall
3.1.2. Dataset WEDA Fall
3.1.3. Dataset UMA Fall
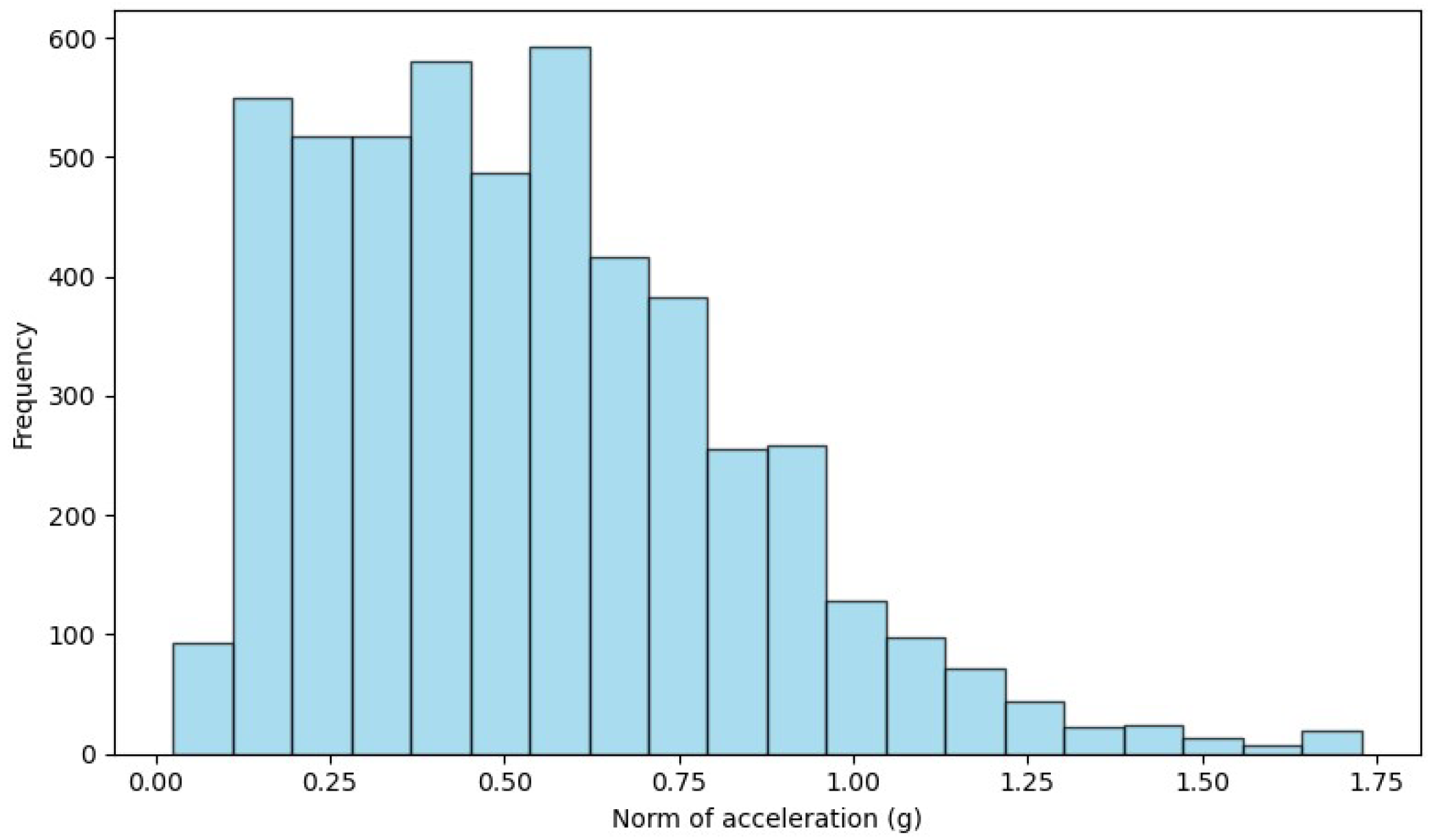
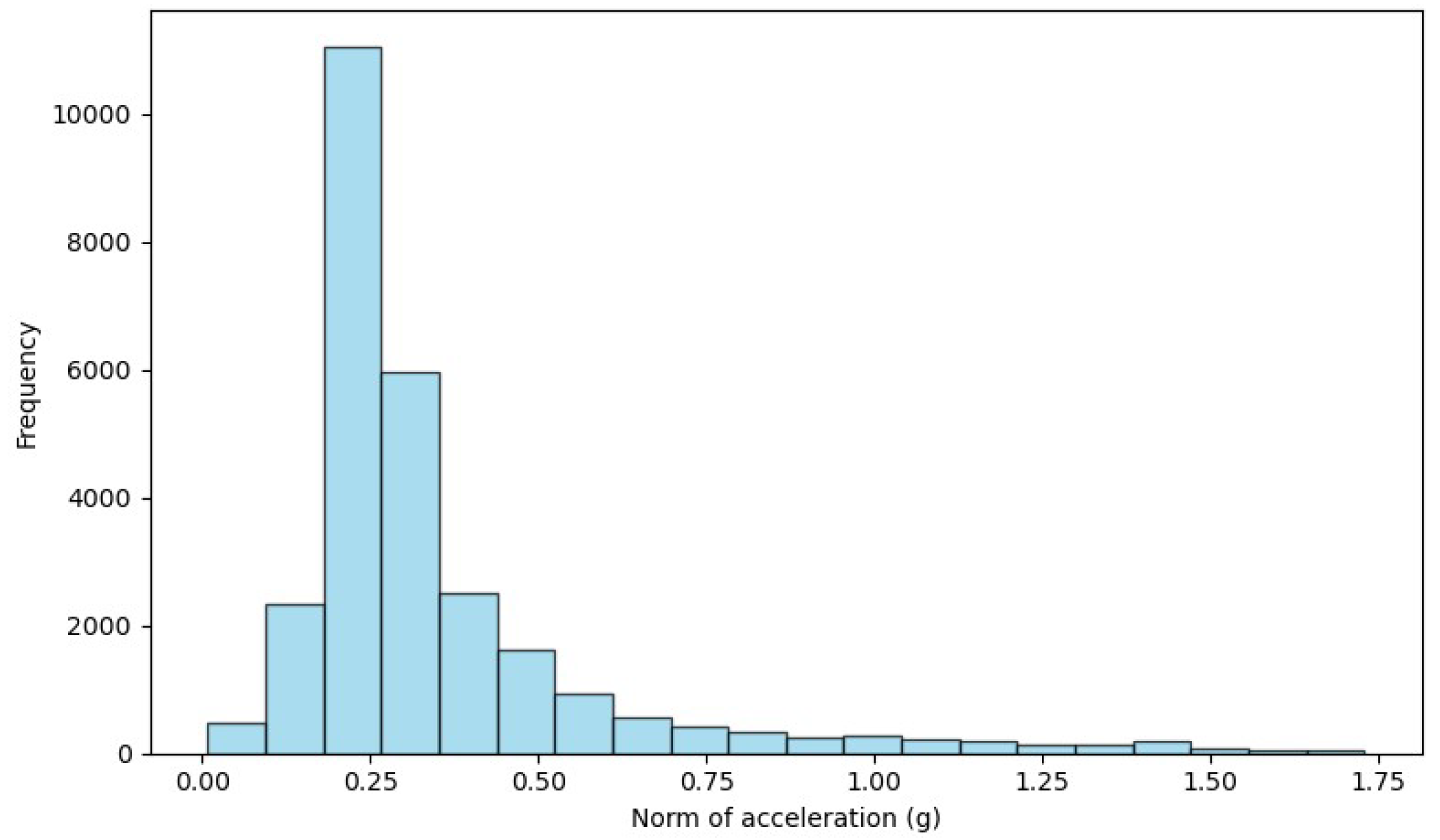
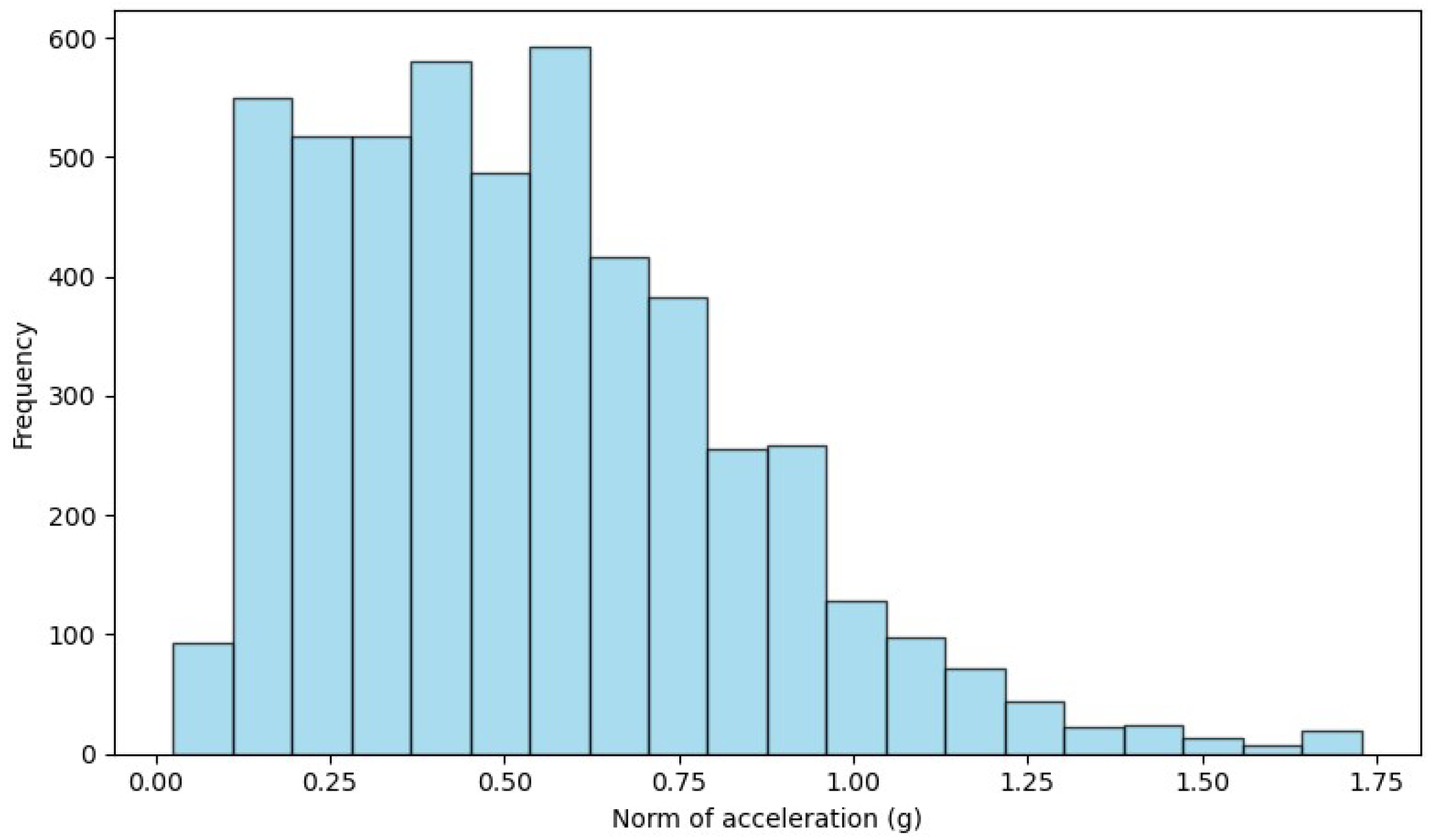
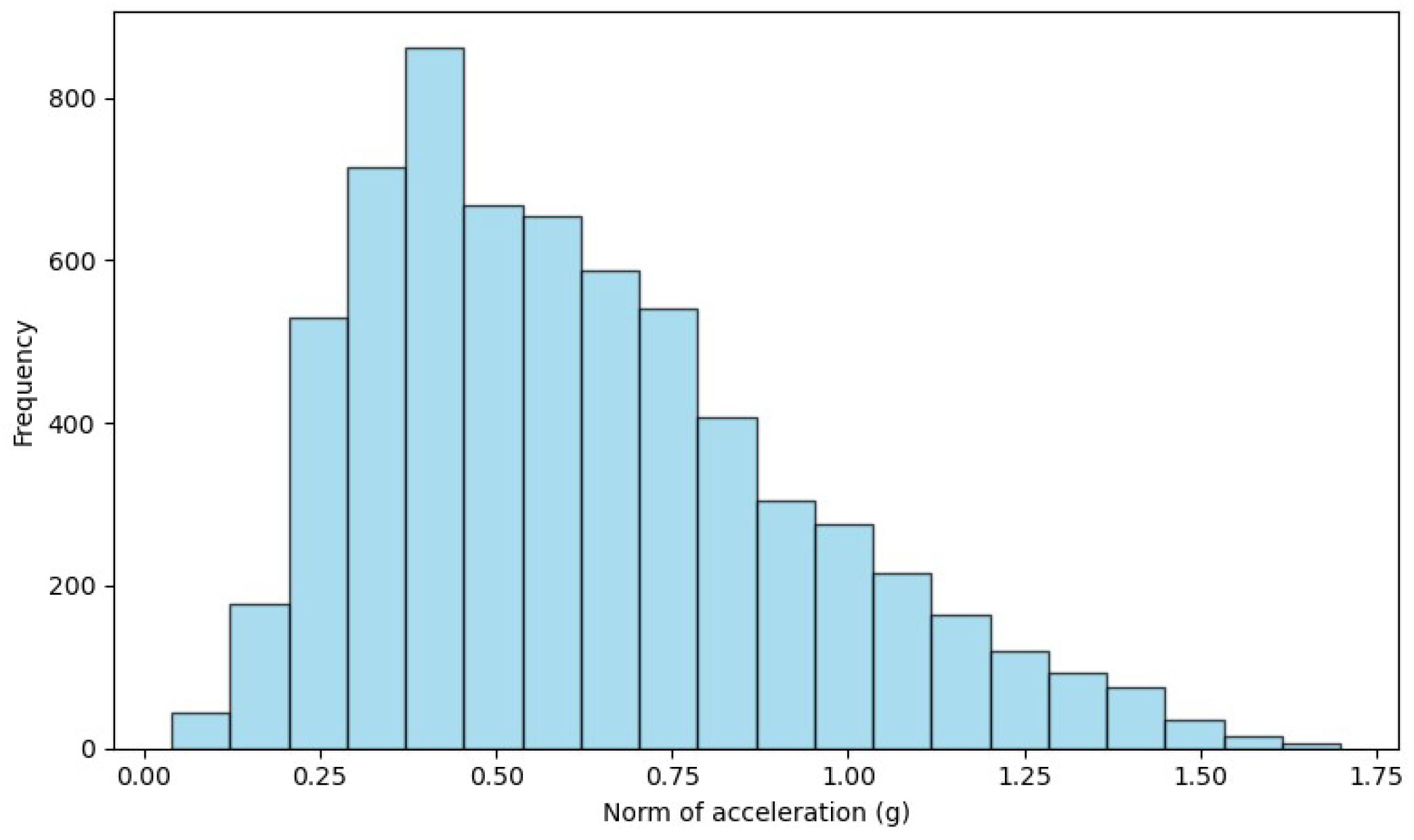
3.2. Preprocessing the Datasets
4. Results
4.1. Feature Extraction
4.2. Feature Selection
4.3. Fall Detection Models
- Train and test each dataset individually. All the datasets were labeled in a per-window method, which is the same approach on the UP-FALL dataset and explained in Section 3.2. However, we cleaned up not valide data samples and relabeled all datasets to standardize. Thus, comparisons with previous approaches serve only as reference. We do the feature selection step on each one of these datasets. Starting from 78 features, we select 27 features of UMA Fall, 28 features of UP Fall, and 28 of WEDA Fall.
- Train and test the model with all datasets combined. The combination of approaches allows a comprehensive assessment of the performance and robustness of the proposed model in different scenarios. We also do the feature selection step on the combined dataset, which results in 26 out of 78 features.
- Study of the generalization of the model. In this group of experiments, we train a model using samples of one dataset only, and test on the remaining datasets.
4.4. Model Evaluation
4.4.1. Train and Test Each Dataset Individually
4.4.2. Train and Test the Model with All Datasets Combined
4.4.3. Study of Model Generalization
- The WEDA Fall dataset stands out in the generalization of ADL, presenting high identification capacity both with and without normalization. In one notable exception, when trained by the ANN algorithm, the UMA Fall dataset demonstrates a slight advantage, revealing better generalization ability for ADL.
- The UP Fall dataset demonstrates the best generalization ability to fall activities, showing relatively high detection rates. In contrast, the UMA Fall dataset stands out in generalizing falls when used by the ANN algorithm.
- The overall performance of the model reveals that the algorithms trained with the UMA Fall dataset achieved a higher AUC-ROC compared to the other datasets, indicating a greater ability to differentiate classes. This consistency reflects the quality of the characteristics or patterns present in the data. However, a notable exception occurs in the case of the SVM algorithm with data normalization, where the UP Fall set presents a superior overall performance
4.5. Discussion
5. Conclusions and Future Work
5.1. Conclusions
5.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| ADL | Activity of Daily Living |
| ARC | Activity Recognition Chain |
| ANN | Artificial Neural Network |
| AUC | Area Under the Curve |
| AUC-ROC | Area Under the Curve ROC |
| DT | Decision Tree |
| FDS | Fall Detection System |
| kNN | K-Nearest Neighbours |
| ML | Machine Learning |
| MLP | Multi Layer Perceptron |
| RF | Random Forest |
| ROC | Receiver Operating Characteristic |
| SVM | Support Vector Machines |
References
- M Steverson. Ageing and Health. 2022. Available online: https://www.who.int/news-room/fact-sheets/detail/ageing-and-health (accessed on 1 December 2022).
- OMS. Falls, Fact Sheet. 2021. Available online: https://www.who.int/en/news-room/fact-sheets/detail/falls (accessed on 1 December 2022).
- Schoene, D.; Heller, C.; Aung, Y.N.; Sieber, C.C.; Kemmler, W.; Freiberger, E. A systematic review on the influence of fear of falling on quality of life in older people: Is there a role for falls? Clin. Interv. Aging 2019, 14, 701–719. [Google Scholar] [CrossRef]
- James, S.L.; Lucchesi, L.R.; Bisignano, C.; Castle, C.D.; Dingels, Z.V.; Fox, J.T.; Hamilton, E.B.; Henry, N.J.; Krohn, K.J.; Liu, Z.; et al. The global burden of falls: Global, regional and national estimates of morbidity and mortality from the Global Burden of Disease Study 2017. Inj. Prev. 2020, 26, i3–i11. [Google Scholar] [CrossRef]
- Brownsell, S.; Hawley, M. Fall detectors: Do they work or reduce the fear of falling? Housing Care Support 2004, 7, 18–24. [Google Scholar] [CrossRef]
- Londei, S.T.; Rousseau, J.; Ducharme, F.; St-Arnaud, A.; Meunier, J.; Saint-Arnaud, J.; Giroux, F. An intelligent videomonitoring system for fall detection at home: Perceptions of elderly people. J. Telemed. Telecare 2009, 15, 383–390. [Google Scholar] [CrossRef] [PubMed]
- Chaudhuri, S.; Thompson, H.; Demiris, G. Fall detection devices and their use with older adults: A systematic review. J. Geriatr. Phys. Ther. (2001) 2014, 37, 178. [Google Scholar] [CrossRef]
- Bourke, A.K.; Van de Ven, P.W.; Chaya, A.E.; OLaighin, G.M.; Nelson, J. Testing of a long-term fall detection system incorporated into a custom vest for the elderly. In Proceedings of the 2008 30th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Vancouver, BC, Canada, 20–25 August 2008; pp. 2844–2847. [Google Scholar]
- De Quadros, T.; Lazzaretti, A.E.; Schneider, F.K. A movement decomposition and machine learning-based fall detection system using wrist wearable device. IEEE Sens. J. 2018, 18, 5082–5089. [Google Scholar] [CrossRef]
- Martínez-Villaseñor, L.; Ponce, H.; Brieva, J.; Moya-Albor, E.; Núñez-Martínez, J.; Peñafort-Asturiano, C. UP-fall detection dataset: A multimodal approach. Sensors 2019, 19, 1988. [Google Scholar] [CrossRef] [PubMed]
- Marques, J.; Moreno, P. Online fall detection using wrist devices. Sensors 2023, 23, 1146. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Weiss, G.M.; Provost, F. The Effect of Class Distribution on Classifier Learning: An Empirical Study; Technical Report; Rutgers University: New Brunswick, NJ, USA, 2001. [Google Scholar]
- Khan, S.S.; Hoey, J. Review of fall detection techniques: A data availability perspective. Med. Eng. Phys. 2017, 39, 12–22. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Liu, X.Y.; Wu, J.; Zhou, Z.H. Exploratory undersampling for class-imbalance learning. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2008, 39, 539–550. [Google Scholar]
- Elkan, C. The foundations of cost-sensitive learning. In Proceedings of the International Joint Conference on Artificial Intelligence, Seattle, WA, USA, 4–10 August 2001; Lawrence Erlbaum Associates Ltd.: Mahwah, NJ, USA, 2001; Volume 17, pp. 973–978. [Google Scholar]
- Domingos, P. Metacost: A general method for making classifiers cost-sensitive. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 155–164. [Google Scholar]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Chaccour, K.; Darazi, R.; El Hassani, A.H.; Andres, E. From fall detection to fall prevention: A generic classification of fall-related systems. IEEE Sens. J. 2016, 17, 812–822. [Google Scholar] [CrossRef]
- Xu, T.; Zhou, Y.; Zhu, J. New advances and challenges of fall detection systems: A survey. Appl. Sci. 2018, 8, 418. [Google Scholar] [CrossRef]
- Rupasinghe, T.; Burstein, F.; Rudolph, C.; Strange, S. Towards a blockchain based fall prediction model for aged care. In Proceedings of the Australasian Computer Science Week Multiconference, Sydney, Australia, 29–31 January 2019; pp. 1–10. [Google Scholar]
- Hussain, F.; Hussain, F.; Ehatisham-ul Haq, M.; Azam, M.A. Activity-aware fall detection and recognition based on wearable sensors. IEEE Sens. J. 2019, 19, 4528–4536. [Google Scholar] [CrossRef]
- De Miguel, K.; Brunete, A.; Hernando, M.; Gambao, E. Home camera-based fall detection system for the elderly. Sensors 2017, 17, 2864. [Google Scholar] [CrossRef] [PubMed]
- Cippitelli, E.; Fioranelli, F.; Gambi, E.; Spinsante, S. Radar and RGB-depth sensors for fall detection: A review. IEEE Sens. J. 2017, 17, 3585–3604. [Google Scholar] [CrossRef]
- De Backere, F.; Ongenae, F.; Van Den Abeele, F.; Nelis, J.; Bonte, P.; Clement, E.; Philpott, M.; Hoebeke, J.; Verstichel, S.; Ackaert, A.; et al. Towards a social and context-aware multi-sensor fall detection and risk assessment platform. Comput. Biol. Med. 2015, 64, 307–320. [Google Scholar] [CrossRef]
- Muheidat, F.; Tawalbeh, L.; Tyrer, H. Context-aware, accurate, and real time fall detection system for elderly people. In Proceedings of the 2018 IEEE 12th International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 31 January–2 February 2018; pp. 329–333. [Google Scholar]
- Casilari, E.; Santoyo-Ramón, J.A.; Cano-García, J.M. Analysis of a smartphone-based architecture with multiple mobility sensors for fall detection. PLoS ONE 2016, 11, e0168069. [Google Scholar] [CrossRef]
- Özdemir, A.T. An analysis on sensor locations of the human body for wearable fall detection devices: Principles and practice. Sensors 2016, 16, 1161. [Google Scholar] [CrossRef]
- Mauldin, T.R.; Canby, M.E.; Metsis, V.; Ngu, A.H.; Rivera, C.C. SmartFall: A smartwatch-based fall detection system using deep learning. Sensors 2018, 18, 3363. [Google Scholar] [CrossRef]
- Sucerquia, A.; López, J.D.; Vargas-Bonilla, J.F. SisFall: A fall and movement dataset. Sensors 2017, 17, 198. [Google Scholar] [CrossRef]
- Medrano, C.; Igual, R.; Plaza, I.; Castro, M. Detecting falls as novelties in acceleration patterns acquired with smartphones. PLoS ONE 2014, 9, e94811. [Google Scholar] [CrossRef]
- Klenk, J.; Schwickert, L.; Palmerini, L.; Mellone, S.; Bourke, A.; Ihlen, E.A.; Kerse, N.; Hauer, K.; Pijnappels, M.; Synofzik, M.; et al. The FARSEEING real-world fall repository: A large-scale collaborative database to collect and share sensor signals from real-world falls. Eur. Rev. Aging Phys. Act. 2016, 13, 8. [Google Scholar] [CrossRef] [PubMed]
- Vavoulas, G.; Pediaditis, M.; Chatzaki, C.; Spanakis, E.G.; Tsiknakis, M. The mobifall dataset: Fall detection and classification with a smartphone. Int. J. Monit. Surveill. Technol. Res. (IJMSTR) 2014, 2, 44–56. [Google Scholar] [CrossRef]
- Frank, K.; Vera Nadales, M.J.; Robertson, P.; Pfeifer, T. Bayesian recognition of motion related activities with inertial sensors. In Proceedings of the 12th ACM International Conference Adjunct Papers on Ubiquitous Computing-Adjunct, Copenhagen, Denmark, 26–29 September 2010; pp. 445–446. [Google Scholar]
- Casilari, E.; Santoyo-Ramón, J.A.; Cano-García, J.M. Umafall: A multisensor dataset for the research on automatic fall detection. Procedia Comput. Sci. 2017, 110, 32–39. [Google Scholar] [CrossRef]
- Saleh, M.; Abbas, M.; Le Jeannès, R.B. FallAllD: An Open Dataset of Human Falls and Activities of Daily Living for Classical and Deep Learning Applications. IEEE Sens. J. 2021, 21, 1849–1858. [Google Scholar] [CrossRef]
- Igual, R.; Medrano, C.; Plaza, I. A comparison of public datasets for acceleration-based fall detection. Med. Eng. Phys. 2015, 37, 870–878. [Google Scholar] [CrossRef]
- Villar, J.R.; Chira, C.; de la Cal, E.; Gonzalez, V.M.; Sedano, J.; Khojasteh, S.B. Autonomous on-wrist acceleration-based fall detection systems: Unsolved challenges. Neurocomputing 2021, 452, 404–413. [Google Scholar] [CrossRef]
- Casilari, E.; Lora-Rivera, R.; García-Lagos, F. A study on the application of convolutional neural networks to fall detection evaluated with multiple public datasets. Sensors 2020, 20, 1466. [Google Scholar] [CrossRef]
- Kim, J.K.; Lee, K.; Hong, S.G. Detection of important features and comparison of datasets for fall detection based on wrist-wearable devices. Expert Syst. Appl. 2023, 234, 121034. [Google Scholar] [CrossRef]
- Saha, S.S.; Rahman, S.; Rasna, M.J.; Mahfuzul Islam, A.; Rahman Ahad, M.A. DU-MD: An Open-Source Human Action Dataset for Ubiquitous Wearable Sensors. In Proceedings of the 2018 Joint 7th International Conference on Informatics, Electronics & Vision (ICIEV) and 2018 2nd International Conference on Imaging, Vision & Pattern Recognition (icIVPR), Kitakyushu, Japan, 25–29 June 2018; pp. 567–572. [Google Scholar]
- Tran, T.H.; Le, T.L.; Pham, D.T.; Hoang, V.N.; Khong, V.M.; Tran, Q.T.; Nguyen, T.S.; Pham, C. A multi-modal multi-view dataset for human fall analysis and preliminary investigation on modality. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1947–1952. [Google Scholar]
- Casilari, E.; Santoyo-Ramón, J.A.; Cano-García, J.M. Analysis of public datasets for wearable fall detection systems. Sensors 2017, 17, 1513. [Google Scholar] [CrossRef] [PubMed]
- Gasparrini, S.; Cippitelli, E.; Gambi, E.; Spinsante, S.; Wåhslén, J.; Orhan, I.; Lindh, T. Proposal and experimental evaluation of fall detection solution based on wearable and depth data fusion. In Proceedings of the International Conference on ICT Innovations, Ohrid, North Macedonia, 1–4 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 99–108. [Google Scholar]
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. (CSUR) 2014, 46, 1–33. [Google Scholar] [CrossRef]
- Qi, Y. Random forest for bioinformatics. In Ensemble Machine Learning: Methods and Applications; Springer: New York, NY, USA, 2012; pp. 307–323. [Google Scholar]
- Breiman, L. Classification and Regression Trees; Routledge: London, UK, 2017. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009; Volume 2. [Google Scholar]
- Santoyo-Ramón, J.A.; Casilari, E.; Cano-García, J.M. Analysis of a Smartphone-Based Architecture with Multiple Mobility Sensors for Fall Detection with Supervised Learning. Sensors 2018, 18, 1155. [Google Scholar] [CrossRef] [PubMed]
- Usmani, S.; Saboor, A.; Haris, M.; Khan, M.A.; Park, H. Latest research trends in fall detection and prevention using machine learning: A systematic review. Sensors 2021, 21, 5134. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Sensor | Position | ADL/Falls |
|---|---|---|---|
| Smartwatch [30] | Accelerometer | Wrist | 2456/107 |
| WEDA Fall [11] | Accelerometer | Wrist | 350/619 |
| Gyroscope | |||
| SisFall [31] | Accelerometer | Waist | 2707/1798 |
| Gyroscope | |||
| TFall [32] | Accelerometer | Thigh | 9883/1026 |
| Handbag | |||
| FARSEEING [33] | Accelerometer | Waist | 0/347 |
| Gyroscope | Thigh | ||
| UP Fall [10] | Accelerometer | Waist | 304/255 |
| Gyroscope | Ankle, Thigh | ||
| Neck, Wrist | |||
| MobilFall [34] | Accelerometer | Thigh | 342/288 |
| Gyroscope | |||
| Magnetometer | |||
| DLR [35] | Accelerometer | Waist | 961/56 |
| Gyroscope | |||
| Magnetometer | |||
| UMA Fall [36] | Accelerometer | Waist, Thigh | 322/209 |
| Gyroscope | Ankle | ||
| Magnetometer | Chest, Wrist | ||
| FallAllD [37] | Accelerometer | Wrist | - |
| Gyroscope | Waist | ||
| Magnetometer | Neck |
| 1 - Fall forward using your hands | 2 - Fall forward using your knees | 3 - Fall Back |
| 4 - Fall aside | 5 - Falling sitting on the empty chair | 6 - Walk |
| 7 - Standing | 8 - Sit | 9 - Pick up an object |
| 10 - Skip | 11 - Lay |
| 1 - Walk | 2 - Run | 3 - Going up and down the stairs |
| 4 - Sit on a chair and stand up | 5 - Sitting for a moment, try to get up and fall into a chair | 6 - Squat down, tie your shoes and stand up |
| 7 - Tripping while walking | 8 - Jump smoothly without falling (trying to reach a high object) | 9 - Hitting the table with your hand |
| 10 - Applaud | 11 - Open and close door | 12 - Falling forward when walking, caused by slipping |
| 13 - Falling to the side when walking, caused by slipping | 14 - Falling backwards when walking, caused by slipping | 15 - Falling forward when walking, caused by a trip |
| 16 - Falling backwards when trying to sit | 17 - Falling forward while sitting, caused by fainting or falling asleep | 18 - Falling backwards while sitting, caused by fainting or falling asleep |
| 19 - Falling to one side when sitting, caused by fainting or falling asleep |
| 1 - Walk | 2 - Run | 3 - Body flexion (squat) |
| 4 - Skip | 5 - Going down stairs | 6 - Climbing stairs |
| 7 - Getting in and out of bed | 8 - Sitting down and getting up from a chair | 9 - Applaud |
| 10 - Raise your hands in the air | 11 - Make a call | 12 - Open the door |
| 13 - Fall Back | 14 - Fall forward | 15 - Fall to the Side |
| Fall | ADL | Total | |
|---|---|---|---|
| UMA Fall | 384 (4.93%) | 7401 (95.07%) | 7785 |
| UP Fall | 346 (2.22%) | 15,246 (97.78%) | 15,592 |
| WEDA Fall | 605 (9.27%) | 5921 (90.73%) | 6526 |
| Joint dataset | 1335 (4.46%) | 28,568 (95.54%) | 29,903 |
| Sensor Signals | |
|---|---|
| Accelerometer: x-axis (g) | Gyroscope: x-axis (rad/s) |
| Accelerometer: y-axis (g) | Gyroscope: y-axis (rad/s) |
| Accelerometer: z-axis (g) | Gyroscope: z-axis (rad/s) |
| Maximum amplitude | Average | Root mean square |
| Minimum amplitude | Median | First Quartile |
| Number of zero crossings | Skewness | Kurtosis |
| Third Quartile | Energy | Auto-correlation |
| Standard Deviation |
| Models | Accuracy | Recall (%) | Specificity (%) | |
|---|---|---|---|---|
| Martinez et al. [10] | RF | 95.76 ± 0.18 | 66.91 ± 1.28 | 99.59 ± 0.02 |
| kNN | 94.90 ± 0.18 | 64.28 ± 1.57 | 99.50 ± 0.02 | |
| ANN | 95.48 ± 0.25 | 69.39 ± 1.47 | 99.56 ± 0.02 | |
| SVM | 93.32 ± 0.23 | 58.82 ± 1.53 | 99.32 ± 0.02 | |
| Model proposed | ANN | 78.29 ± 13.7 | 94.74 ± 3.14 | 78.01 ± 13.9 |
| SVM | 94.65 ± 1.60 | 89.51 ± 4.27 | 94.76 ± 1.62 | |
| Models | Accuracy | Recall (%) | Specificity (%) | |
|---|---|---|---|---|
| Marques et al. [11] | 3NN | 98.05 ± 0.46 | 98.24 ± 0.36 | 97.84 ± 0.83 |
| Model proposed | ANN | 99.38 ± 2.37 | 97.03 ± 0.97 | 97.18 ± 0.81 |
| SVM | 95.10 ± 0.78 | 88.87 ± 2.64 | 95.78 ± 0.91 | |
| Models | AUC (%) | (%) | |
|---|---|---|---|
| Casilari et al [28] | Thresholding | 93.5 | 85.8 |
| Model proposed | ANN | 99.8 | 92.9 |
| SVM | 95.7 | 89.2 | |
| Dataset | Algorithm | Recall (%) | Specificity (%) | AUC-ROC (%) | F1-Score (%) |
|---|---|---|---|---|---|
| UP fall | SVM | 89.51 ± 4.27 | 94.76 ± 1.62 | 95.86 ± 1.87 | 40.88 ± 8.99 |
| ANN | 94.74 ± 3.14 | 78.01 ± 13.9 | 95.13 ± 1.94 | 21.35 ± 13.2 | |
| UMA fall | SVM | 88.40 ± 3.41 | 95.78 ± 0.91 | 95.74 ± 1.06 | 43.19 ± 7.32 |
| ANN | 86.77 ± 6.15 | 97.18 ± 0.81 | 99.81 ± 0.08 | 88.63 ± 3.34 | |
| WEDA fall | SVM | 88.87 ± 2.64 | 95.78 ± 0.91 | 97.18 ± 0.81 | 77.78 ± 3.71 |
| ANN | 97.03 ± 0.97 | 97.18 ± 0.8 | 99.90 ± 0.10 | 96.80 ± 1.53 |
| Standard | Normalized | |||
|---|---|---|---|---|
| Metrics | SVM | ANN | SVM | ANN |
| Recall (%) | 87.34 ± 1.10 | 90.57 ± 3.24 | 89.18 ± 1.48 | 90.37 ± 2.07 |
| Specificity (%) | 93.58 ± 0.71 | 96.91 ± 1.26 | 88.25 ± 1.29 | 91.19 ± 2.58 |
| AUC-ROC (%) | 96.14 ± 0.65 | 98.85 ± 0.28 | 93.70 ± 0.80 | 95.67 ± 0.67 |
| F1-Score (%) | 52.30 ± 3.00 | 69.93 ± 6.60 | 40.82 ± 3.70 | 48.71 ± 6.38 |
| UMA Fall | UP Fall | WEDA Fall | ||||
|---|---|---|---|---|---|---|
| Metrics | SVM | ANN | SVM | ANN | SVM | ANN |
| Recall (%) | 80.126 | 79.600 | 89.888 | 66.632 | 61.232 | 68.904 |
| Specificity (%) | 91.902 | 94.411 | 79.545 | 86.908 | 94.118 | 93.959 |
| AUC-ROC (%) | 93.077 | 93.905 | 92.071 | 81.366 | 91.164 | 90.688 |
| F1-Score (%) | 44.470 | 52.369 | 38.626 | 38.856 | 35.631 | 38.677 |
| UMA Fall | UP Fall | WEDA Fall | ||||
|---|---|---|---|---|---|---|
| Metrics | SVM | ANN | SVM | ANN | SVM | ANN |
| Recall (%) | 63.751 | 72.666 | 90.206 | 77.735 | 60.617 | 61.975 |
| Specificity (%) | 93.492 | 88.032 | 75.218 | 81.887 | 94.608 | 94.941 |
| AUC-ROC (%) | 84.779 | 89.973 | 90.984 | 85.527 | 87.499 | 89.498 |
| F1-Score (%) | 42.632 | 34.477 | 34.712 | 37.141 | 38.524 | 36.299 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fula, V.; Moreno, P. Wrist-Based Fall Detection: Towards Generalization across Datasets. Sensors 2024, 24, 1679. https://doi.org/10.3390/s24051679
Fula V, Moreno P. Wrist-Based Fall Detection: Towards Generalization across Datasets. Sensors. 2024; 24(5):1679. https://doi.org/10.3390/s24051679
Chicago/Turabian StyleFula, Vanilson, and Plinio Moreno. 2024. "Wrist-Based Fall Detection: Towards Generalization across Datasets" Sensors 24, no. 5: 1679. https://doi.org/10.3390/s24051679
APA StyleFula, V., & Moreno, P. (2024). Wrist-Based Fall Detection: Towards Generalization across Datasets. Sensors, 24(5), 1679. https://doi.org/10.3390/s24051679