
Reviewing Federated Machine Learning and Its Use in Diseases Prediction

Abstract
1. Introduction
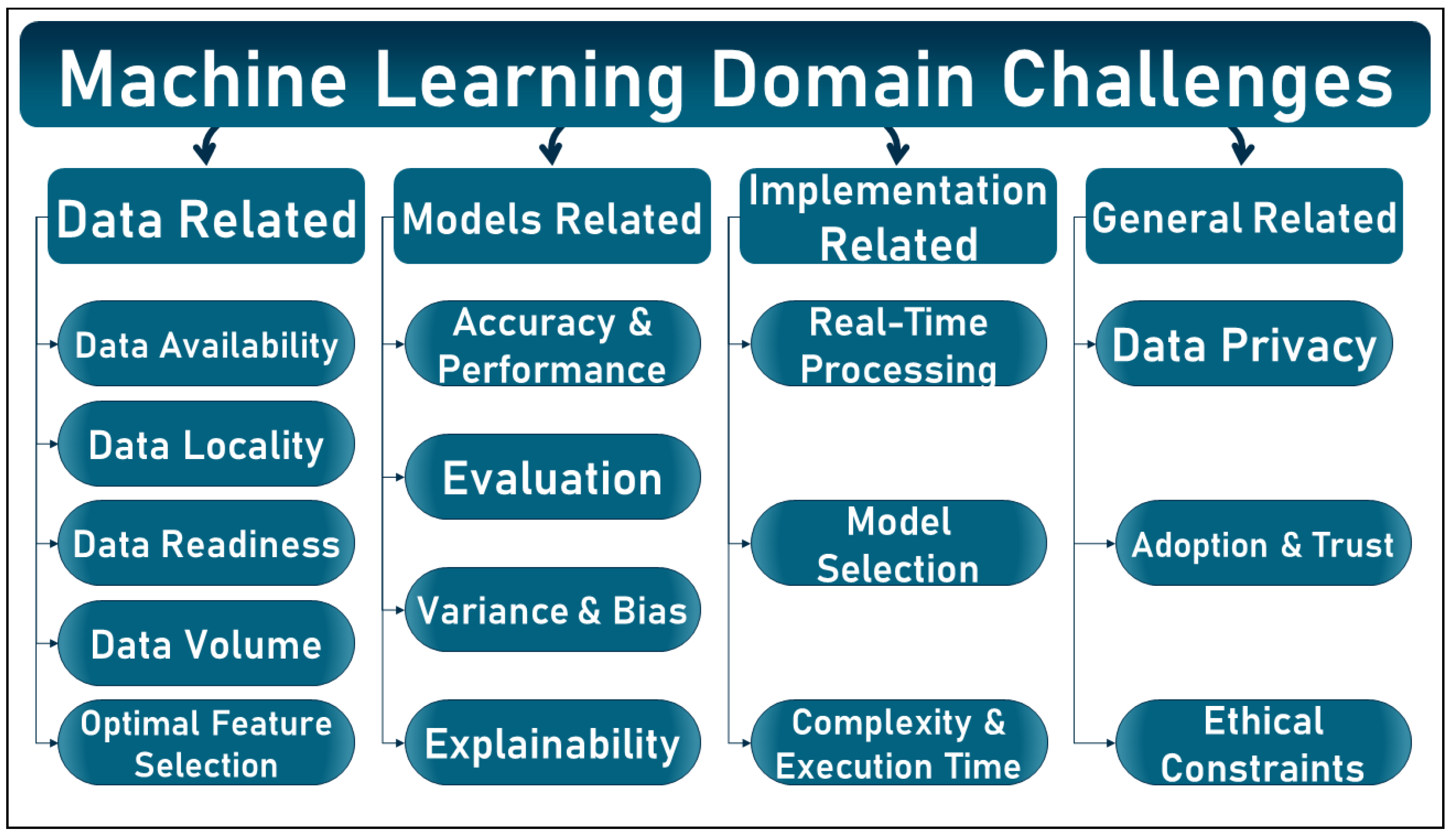
1.1. Machine Learning under The Scope: Challenges
1.1.1. Data Related Challenges
- Data availability and accessibility: to train a model, one must have the necessary data, which may not be available on the spot or may be available but inaccessible for various reasons;
- Data locality (data islands): in the real world, data are scattered in different and unrelated entities called “data islands.” Due to different regulations and laws, data related to the same subject and available on different data islands cannot be accessed for use and analysis;
- Data readiness: even if data are available and accessible, several aspects should be considered, such as:
- -
- Data heterogeneity: available data may have different characteristics or be composed of different forms. For example, health data for the same patient may be available in different forms, such as medical images, reports, videos, and structured data. The ability to deal with such heterogeneity is a challenging task;
- -
- Noise and signal artifacts: due to the interaction between data acquisition instruments and other electrical devices, data can be poisoned by noisy attributes that affect the overall results of ML models;
- -
- Missing data: data collected by measuring devices may be incomplete for various reasons;
- -
- Classes imbalance: in classification problems, the data collected for one group may dominate the data collected for other groups, affecting the learning of the smart model.
- Data volume: is the amount, size, and scope of the data. In the context of ML, size can be defined either vertically by the number of records or samples in a dataset or horizontally by the number of features or attributes it contains. Data volume presents several challenges, such as:
- -
- Course of dimensionality: dimensionality describes the number of features or attributes that are present in a dataset. Increasing dimensionality can have a negative impact on model performance;
- -
- Bonferroni principle [16]: the Bonferroni principle states that when searching for a particular type of event in a given set of data, the probability of finding that event is high. Therefore, the accuracy of a ML model subject to the Bonferroni principle may be compromised.
- Feature representation and selection: the performance of ML models heavily depends on the choice of data representation or features, so selecting the optimal features will definitely improve the overall model performance.
1.1.2. Models Related Challenges:
- Accuracy and performance: achieving the highest accuracy for ML models remains the main goal for researchers from various fields, and the highest accuracy will lead to the highest adoption and integration of this technology;
- Model evaluation: evaluating an ML model can be challenging, especially when traditional performance metrics such as accuracy, precision, and recall do not reflect a model’s feasibility;
- Variance and bias: where variance is the variability of the model prediction for a given data point or a value indicating the spread of our data, and bias is the difference between the average prediction of our model and the correct value we are trying to predict. ML models are susceptible to variance and bias, which can affect their performance, results, and confidence;
- Explainability: some of the ML models, especially deep learning models, are known by their black box identity. The lack of explanations of how they work can have a negative impact on trust in these models, even when high accuracies are achieved.
1.1.3. Implementation Related Challenges:
- Real-time processing: ML models are created and trained with available data. However, fitting these models to real-time problems presents several challenges;
- Model selection: different models can produce different results even for the same problems. For example, support vector machines (SVM) and logistic regression (LR) can lead to different results, even when working with the same data at the same point in time. Thus, selecting the optimal model and tuning its parameters are not easy tasks;
- Execution time and complexity: due to the complexity of the data or models, multiple preprocessing steps, and many other reasons, ML models can require enormous computing power and long execution times.
1.1.4. General Challenges:
- User data privacy and confidentiality: which is one of the most critical issues in the field of ML. Users tend not to share their data for various reasons, which affects the availability of the data and jeopardizes the entire ML cycle;
- User technology adoption and engagement: due to privacy issues, unclear results, lack of explanation, and other reasons, users may not accept ML being integrated into their daily routine, or even accept its results;
- Ethical constraints: various ethical constraints posed by ML have been widely discussed in the literature, such as control and morality, model ownership, environmental impact, and many others.
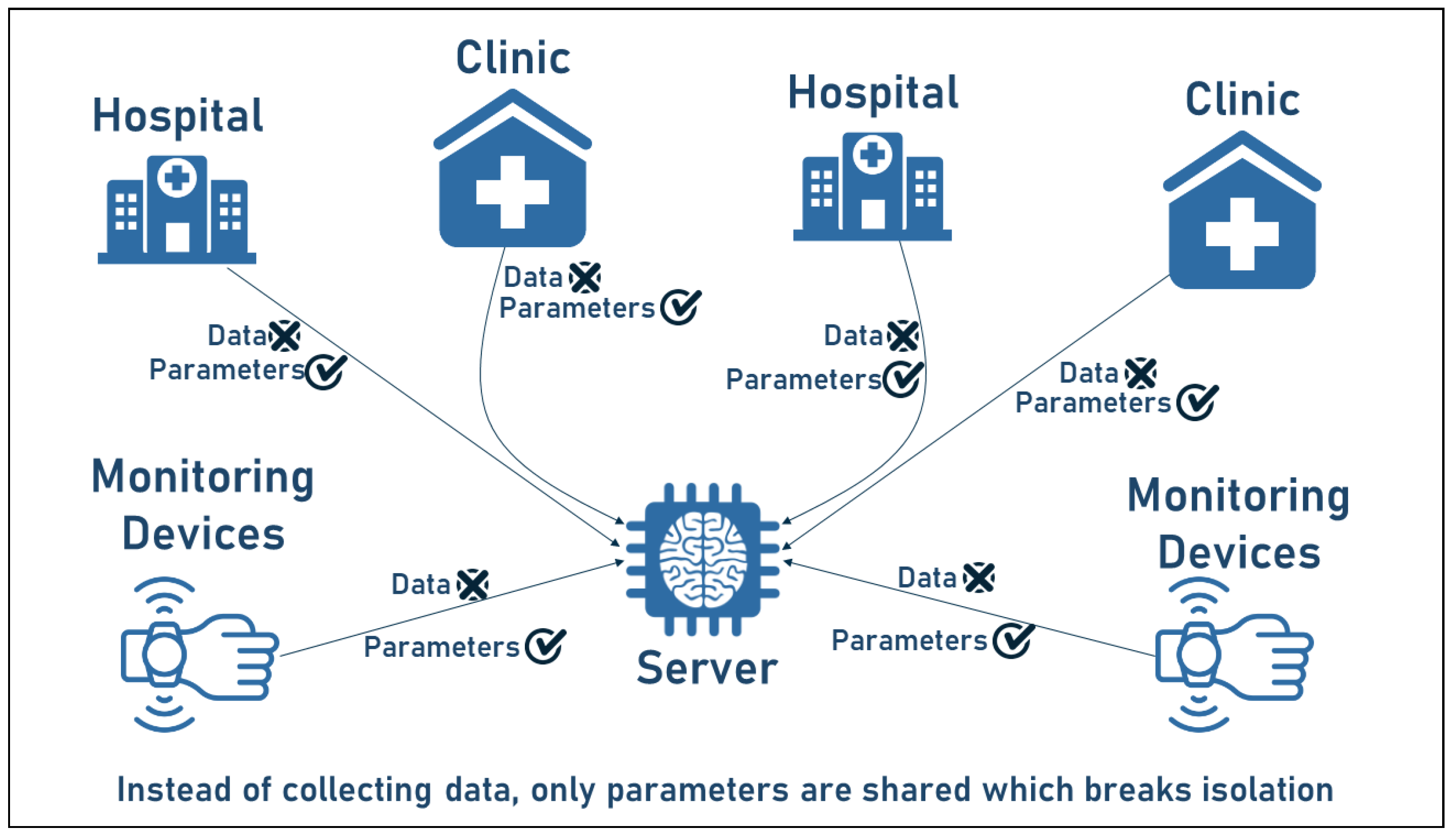
1.2. Privacy Challenge: Federated Machine Learning Motivation
Overcoming Privacy Challenges
1.3. Machine Learning and Healthcare
1.4. Outline and Main Contributions of This Article
- What is federated machine learning?
- What are the motivations for this technology?
- What are the technical perspectives on which FL is based?
- What taxonomy can be used to classify FL algorithms and techniques?
- What are the differences between FL, traditional ML (including deep learning), distributed and decentralized ML, and federated database systems?
- What are the existing FL aggregation algorithms and what is the contribution of each?
- What are the available FL frameworks?
- Proposing a novel and comprehensive taxonomy that classifies FL into the maximum number of possible categories;
- Establishing clear and precise boundaries to distinguish between FL, traditional ML, distributed and decentralized ML, and federated database systems;
- Discussing existing aggregation algorithms in FL and evaluation of the contributions of each to the field;
- Reviewing and discussing the state of the art of FL in diagnosing:
- -
- Cardiovascular disease;
- -
- Diabetes;
- -
- Cancer.
- Presenting the challenges faced by FL and the possible future perspectives that can be pursued to increase the efficiency of the technology.
2. Federated Learning
2.1. Overview and Definition(s)
2.1.1. Data Islands and Privacy Dilemma: Concept behind FL
2.1.2. Motivations behind FL Concept
2.1.3. FL Definition(s)
“Define N data owners {F1, …FN}, all of whom wish to train a machine learning model by consolidating their respective data {D1, …DN}. A conventional method is to put all data together and use D = Di ∪ … ∪ DN to train a model MSUM. A federated learning system is a learning process in which the data owners collaboratively train a model MFED, in which process any data owner Fi does not expose its data Di to others. In addition, the accuracy of MFED, denoted as VFED should be very close to the performance of MSUM, VSUM. Formally, let be a non-negative real number, if . We say the federated learning algorithm has -accuracy loss.”
2.2. FL Technical Inspection
2.2.1. Underlying Architecture
- Parties: are also referred to as customers, users, or individuals, and are the data owners and beneficiaries of FL. They are indicated by:
- -
- Hardware specifications such as storage, processing, and power capacities;
- -
- Scalability and stability;
- -
- Data distribution.
- Manager: known as a server or aggregator, is the high-performance central server that acts as a model aggregator rather than a data collector;
- Communication–computation framework: the computation handles the model training and the communication handles the exchange of model parameters between the parties and the manager. Several frameworks were developed to manage the relationships between different FL entities, which are discussed in detail later;
- The parties federally train their own model using their local data without sharing it;
- The global model is updated by the locally trained models;
- The global model is then shared with the different parties/data owners;
- The above steps are repeated until the global model achieves the desired performance.
2.2.2. FL Communication-Computation Frameworks
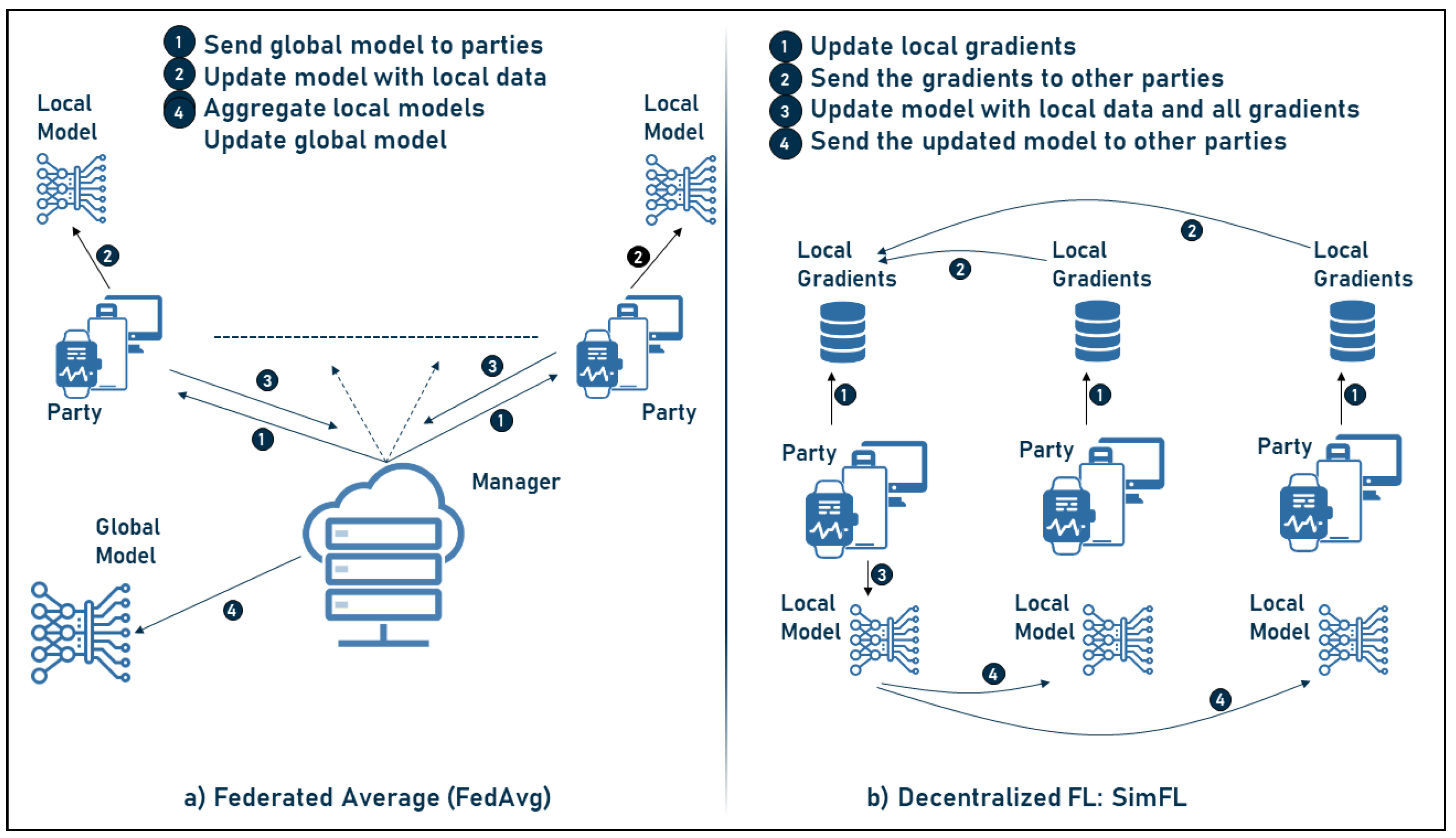
- Centralized design (client-server architecture): in this approach, data flow is often asymmetric, with the manager aggregating information from the parties and sending them back to the updated model. In addition, communication between the manager and the parties can be synchronous or asynchronous;
- Decentralized design (peer-to-peer architecture): In this approach, communication is performed between the parties themselves without the need for a central manager. This allows each party to directly update the global parameters.
- Federated average learning, which is the basis of FL and is determined in the following steps:
- -
- The manager sends the model to the parties involved;
- -
- The parties train the received model with their local data;
- -
- The updated models are sent back to the manager;
- -
- The above steps are repeated until the model achieves the desired performance.
- Decentralized federated learning SimFL, where no central manager/server is required. In this framework, the following steps are applied:
- -
- The parties first update the gradients of their local data;
- -
- Then, the gradients are sent to a selected party;
- -
- Next, the selected party uses its local data and the gradients to update the model;
- -
- Then, the model is sent to all other parties;
- -
- To ensure fairness and to use the data from the different parties, each party is selected to update the model for approximately the same number of rounds and the above steps are therefore repeated until the final model is reached.
2.3. Federated Learning Taxonomy
- Data partitioning;
- Machine learning model;
- Privacy mechanism;
- Communication architecture;
- Scale of federation;
- Motivation of federation.
2.3.1. Data Partitioning
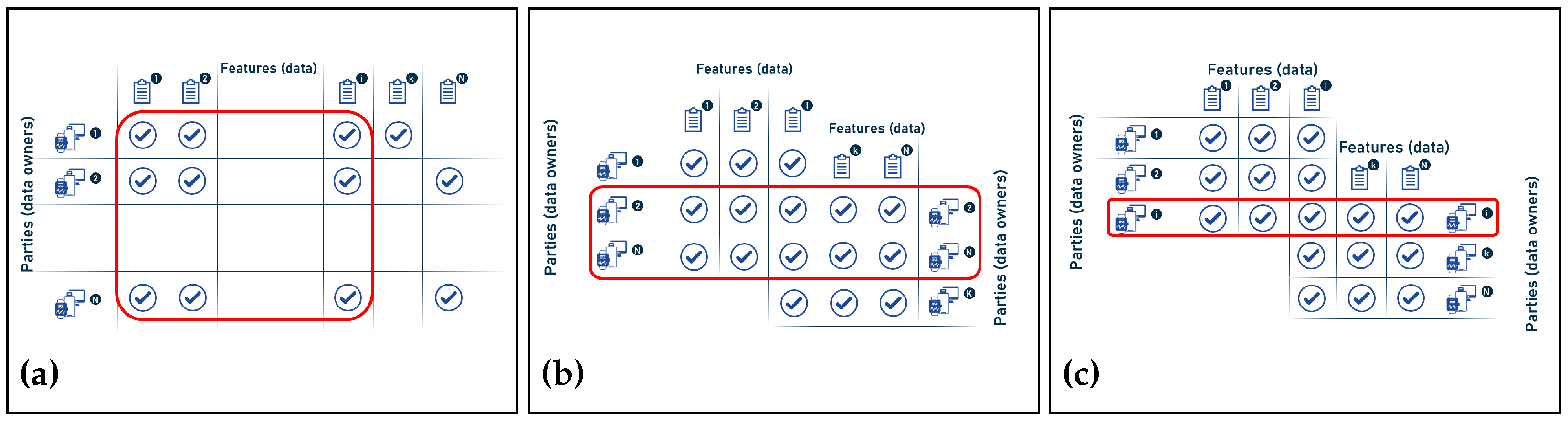
- Horizontal FL: also known as sample-based federated learning, and is the case when the data on the parties share the same feature space but differ in the samples. In other words, in horizontal FL partitioning, the datasets are partitioned horizontally (by parties), and then the part of the data that have the same features but the parties are not exactly the same is taken out for training. It is therefore characterized by the following:
- -
- Is the most commonly used data partitioning strategy in implementations of FL;
- -
- Is suitable to increase the sample size;
- -
- Can train the local models using their local data with the same architecture, since these data share the same feature space;
- -
- Simplifies the update of the global model by averaging all local models.
- Vertical FL: also known as feature-based learning, when the data share the same or similar sample space (parties) but differ in the feature space (data). In other words, in vertical FL partitioning, the dataset is split vertically (by features), then part of the data where the parties are the same but the features are not exactly the same are taken out for training:
- -
- Which is challenging in terms of implementation;
- -
- Which makes it more complex to update a global model by averaging because the data may not be similar between parties;
- -
- Which has much more room for improvement to be applied in more complicated ML approaches.
- Federated transfer learning: this is the case when the datasets scattered between the parties differ not only in the samples but also in the feature space. In this partitioning method, the data are not segmented, but the learning is transferred to overcome the lack of data or tags. Therefore, it is characterized by:
- -
- Being an effective way to protect both data security and user privacy while breaking the boundaries of data islands;
- -
- Enabling the transfer of knowledge from one domain to another for better learning outcomes;
- -
- Offering plenty of room for growth to make it more flexible with different data structures;
- -
- Triggering the issue of communication efficiency.
2.3.2. Machine Learning Models
- Linear models: support vector machines, linear regression, ridge regression, lasso regression, among others;
- Decision tree: gradient boosting, decision trees, random forests, among others;
- Neural networks: convolutional neural networks, multi-layer perceptron, deep neural networks, and others.
2.3.3. Privacy Mechanism
- The learned model: once the learned model is published, it is exposed to attacks such as model inversion attack [28] and membership inference attack [29] and others. Such attacks can potentially infer raw data by accessing the model. For example, they can determine whether a particular dataset was used in the training process. Finally, inference attacks can also be performed in the FL manager learning process, where the server has access to the parties’ local updates.
- Model aggregation: is one of the most common privacy preserving mechanisms in FL systems and the main concept behind the FL technique, where the global model is trained by aggregating the model parameters of all parties without sharing the original data in the training process;
- Cryptographic methods: In this approach, the parties must encrypt their messages before sending them to the manager or other parties, work with the encrypted messages, and decrypt the encrypted output to obtain the final result. In this context, various algorithms have been used in FL systems, such as:
- -
- Homomorphic encryption [39]: Users can compute and process the encrypted data without revealing the original data, and at the same time the user decrypted the processed data with the key, which is exactly the expected result. However, due to the additional encryption/decryption operations, homomorphic encryption incurs extremely high computational overhead;
- -
- Secure multiparty computation (SMC) [62]: in this algorithm, the server is guaranteed to learn the parties’ inputs only in their entirety. However, SMC does not provide any confidentiality guarantee for the final model, which is still vulnerable to inference and model inversion attacks and can also be a reason for additional computational overhead.
- Differential privacy [63]: is a new definition of privacy in which the final results of the model are insensitive to the changes of a particular dataset by minimizing the impact of a single dataset on the computation of the results. This method has been proven successful for data poisoning attacks, but may not be usable for model poisoning attacks.
2.3.4. Methods for Resolving Heterogeneity
- Asynchronous communication: the synchronous scheme can be easily disrupted by the diversity of devices. Therefore, asynchronous communication can help resolve this diversity;
- Device sampling: limiting the use of a party/device to only the necessary iterations, not necessarily participating in every single iteration;
- Fault-tolerant mechanism: in an environment with multiple working participants, the failure of one participant can affect the performance of the entire environment. A fault-tolerant mechanism helps prevent the entire system from collapsing if one of the parties fails;
- Model heterogeneity: is used to resolve data heterogeneity and includes three strategies:
- -
- Each individual party has its own model;
- -
- A global model that is suitable for all parties;
- -
- Relevant learning models for tasks.
2.3.5. Communication Architecture
- Centralized design: this assumes the existence of a central server that aggregates the local models trained by the parties and sends them back for updating. Communication between the manager and the local parties can be synchronous or asynchronous;
- Decentralized design: in this approach, communication is between the parties, and each can directly update the global model without the need for a central aggregation manager.
2.3.6. Scale of Federation
- Cross-silo FL: this approach is used when the participating parties are fewer in number, have relatively large amounts of data, have relatively high computational power, and are available for all rounds of learning. This approach is best suited when the participants are organizations or computers;
- Cross-Device FL: in contrast, the number of parties involved in the learning process is relatively large, they have a small amount of data, and are equipped with relatively low computing power. This approach is best suited when the participants are mobile devices.
2.3.7. Federation Motivation
- Regulations: where laws restrict the sharing of private information between different companies, such as the GDPR, Chinese laws, or PDPA or other laws;
- Incentives: where FL is motivated by a desire to develop services.
2.4. Federated Learning: Borderlines
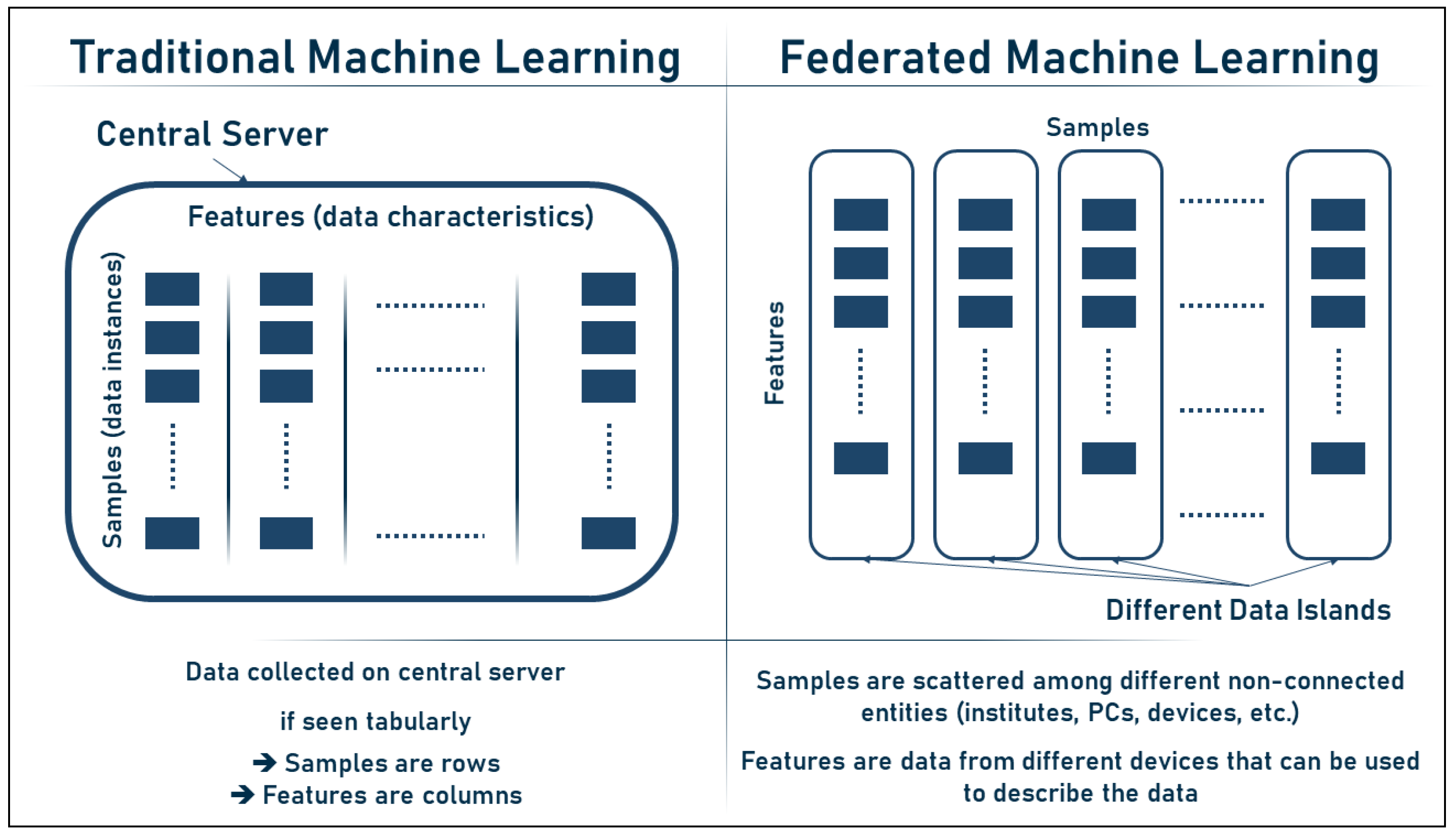
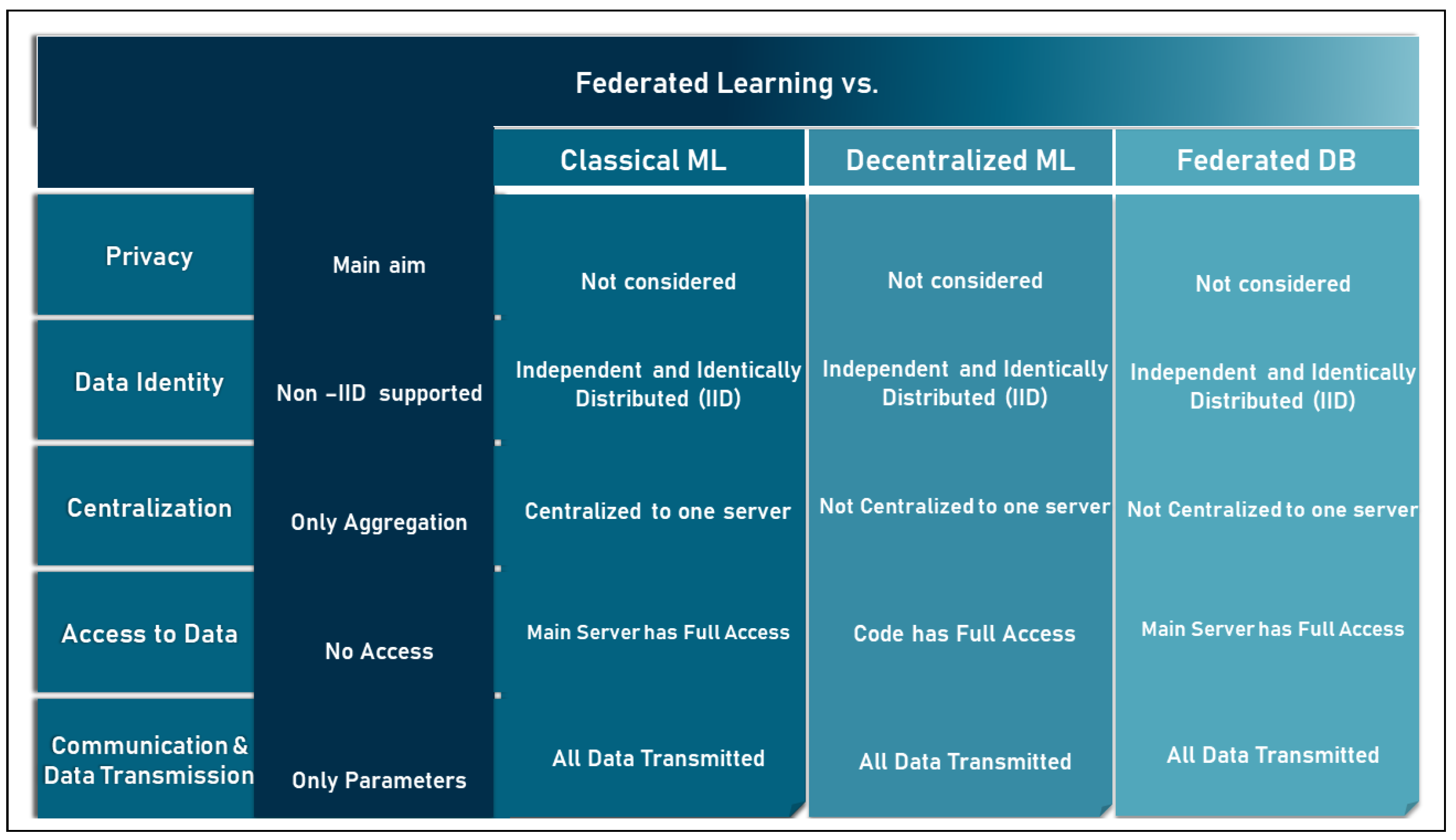
2.4.1. FL vs. Classic ML
- Motivation: classical ML focuses on the learning goal, while FL focuses on both the learning goal and privacy;
- Data identity: in classical ML, user data are described as independently and identically distributed (IID), while in FL, it is possible to deal with unbalanced non-IID data coming from different parties, be it individuals or institutions;
- Centralization: in the classical ML, all data and computations are centralized around one server, while FL provides both centralized and distributed server architecture;
- Data access: in the classic ML, the central server has full access to the user data, while this is not the case in FL;
- Communication and data transfer: in classic ML, all the user data are fully transmitted to the central server, while in FL, only minimal parameters or trained models are exchanged.
2.4.2. FL vs. Distributed and Decentralized ML
- Motivation: in distributed classical ML, the main goal is to accelerate the processing phase, while in FL, both privacy and processing phases are targeted;
- Data identity: in the distributed classical ML, the data are described as IID records, while in FL, it is unbalanced non-IID records due to heterogeneity;
- Centralization: in the distributed classical ML, no central server is included in the architecture, while in FL, both centralization and distribution are provided;
- Data access: in the distributed classic ML, the data are distributed among several servers, but the global model still has access to the user data and, moreover, some servers can have access to all the data of a user at a given time;
- Communication and data transmission: in distributed classical ML, all user data are transmitted to the network of servers, while in FL, only minimal parameters or trained models are exchanged.
2.4.3. FL vs. Federated Database System
- Motivation: in FDBS, the main goal is to perform database operations over diverse and independent databases, while the main goal of FL is to process heterogeneous and independent databases to learn from data;
- Data identity: both can support non-IID databases;
- Centralization: both support the decentralization of database storage, but in FDBS, the processing is handled by a central server;
- Data access: in FDBS, unlike FL, the processing server has access to all data;
- Communication and data transfer: in FDBS all data are transferred in contrast to FL.
2.5. FL Aggregation Algorithms: State of the Art
- Performance issues:
- -
- Suffering from ‘client-drift’ and convergence;
- -
- Tuning difficulty;
- -
- High communication and computation cost;
- -
- Significant variability in systems characteristics on each network device;
- -
- Existence of non-identically distributed data across the network;
- -
- Heterogeneity of devices, users and network channels;
- -
- Sensitivity to local models;
- -
- Scalability issues.
- Security and privacy issues: FL is still under the risk of several breaching attacks such as:
- -
- Poisoning attacks;
- -
- Inference attacks;
- -
- Backdoor attacks.
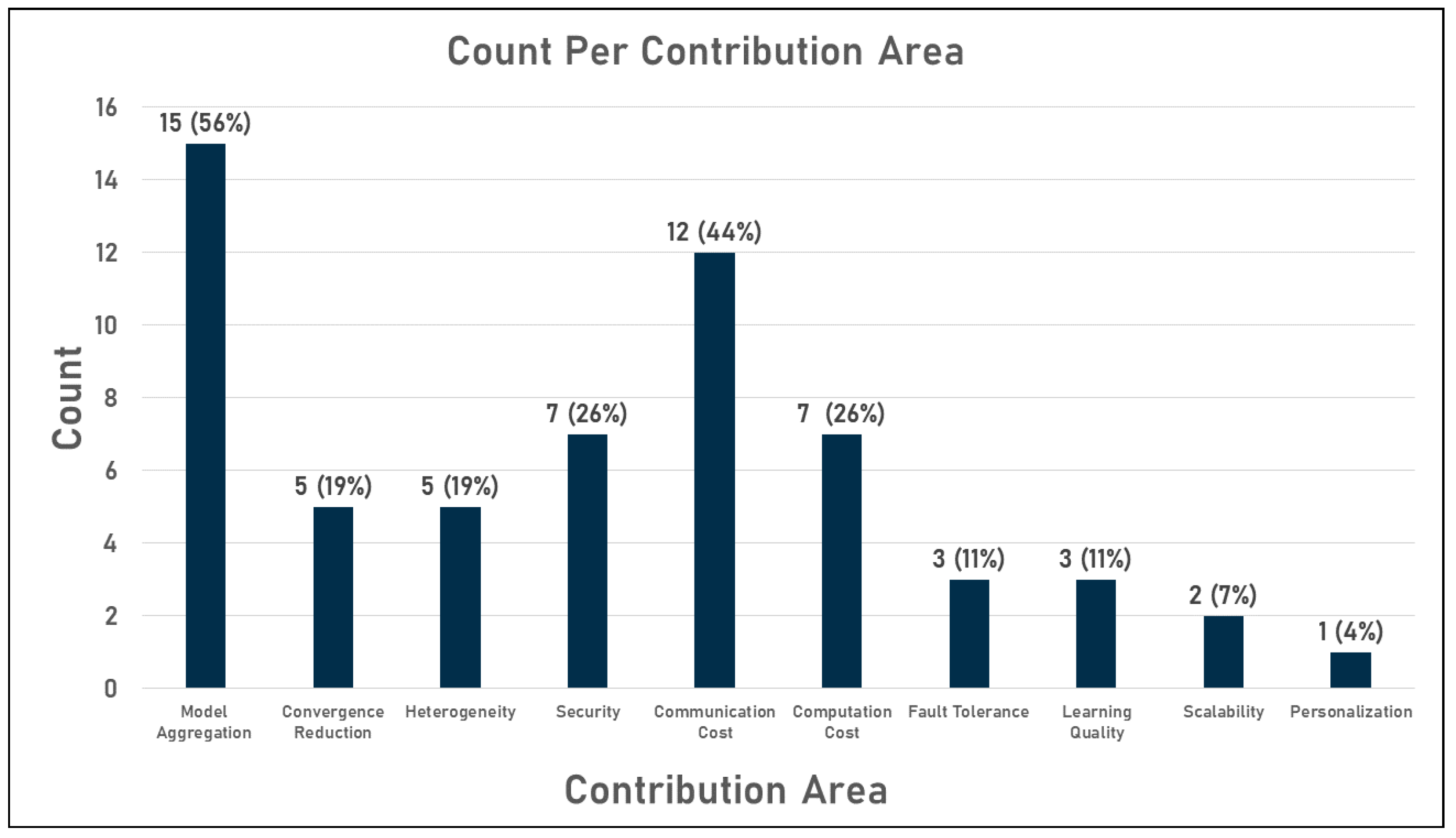
- Improving model aggregation;
- Reducing convergence;
- Handling heterogeneity;
- Enhancing security;
- Reducing communication and computations cost;
- Handling users’ failures (fault tolerance);
- Boosting learning quality;
- Supporting scalability, personalization, and generalization.
2.6. FL Available Frameworks/Platforms
- Tensorflow federated (TFF) algorithm [94]: an open source framework for experimenting with FL that enables developers to experiment with novel FL algorithms as well as simulating existing ones on their data;
- Federated AI technology enabler (FATE) [95]: relies on homomorphic encryption and supports a range of FL architectures and secure computation algorithms including logistic regression, tree-based algorithms, neural networks and transfer learning;
- PySyft [96]: developed by OpenMined and decouples private data from model training using federated learning, differential privacy and multiparty computation;
- Tensor/IO [97]: a lightweight cross-platform library for on-device machine learning, bringing the power of TensorFlow and TensorFlow Lite to iOS, Android, and React native applications;
- Tensorflow encrypted: provides an interface similar to that of TensorFlow and aims to make the technology readily available without requiring the user to be an expert in ML, cryptography, distributed systems, and high-performance computing;
- CoMind: built on top of TensorFlow and provides high-level APIs for implementing FL and FedAvg specifically;
- Horovod: based on the open message passing interface (MPI) and works on top of popular deep learning frameworks, such as TensorFlow and PyTorch;
- LEAF benchmark: is a modular benchmarking framework for machine learning in federated settings, with applications in FL, multi-task learning, meta-learning, and on-device learning aiming to capture the reality, obstacles, and intricacies of practical FL environments.
2.7. Training and Evaluation of Federated Learning Algorithms
- Model accuracy: in the case of FL, model accuracy is a frequent parameter used to assess performance. Precision, recall, F1-score, and area under the curve (AUC) are various ways in which a model’s efficacy may be evaluated;
- Communication overhead: since communication delays might have a negative effect on the efficiency of a federated machine learning system, it is crucial to keep this in mind. The length of time spent communicating, the number of times messages need to be sent back and forth, and the overall quantity of data communicated are all indicators of communication overhead;
- Convergence speed: the speed with which a model reaches a stable solution is known as its convergence speed. Since the models in federated machine learning need to be trained across numerous participants, this is a crucial factor to take into account;
- Privacy: since the data are being shared across several parties, privacy and security are crucial concerns in federated machine learning. Examples of privacy and security standards include data encryption, differential privacy, and safe multiparty computing.
3. Federated Learning in Action
3.1. FL: Areas of Implementation
- Smart retail: the ability to gather knowledge from different institutions enables the smart retail sector to thrive by analyzing data scattered on different islands [43];
3.2. Federated Learning and Disease Prediction
3.2.1. Federated ML and Cardiovascular Diseases: State-of-the-Art
3.2.2. Federated ML and Diabetes: State-of-the-Art
3.2.3. Federated ML and Cancer: State-of-the-Art
3.3. Discussion
3.3.1. Models Performance: Competition between FL and ML
3.3.2. Real World vs. Research Implementations
3.3.3. Dedication to Disease Diagnosis
3.3.4. Use of Smart Wearables
- Non-invasive: do not penetrate the skin to collect data;
- Compact: should not be bulky or large so as not to interfere with life activities;
- Affordable: to increase its acceptance;
- Rugged: to withstand harsh operating conditions such as light scratches or shocks;
- Easy to use: should have an intuitive interface;
- Durable power source: able to operate for a long period of time.
3.3.5. Limitations in the Use of FL for Disease Prediction
4. FL in Disease Prediction: Challenges and Future Perspectives
4.1. Challenges
- Data source-related challenges (parties embedded in FL):
- -
- Structural heterogeneity;
- -
- Statistical heterogeneity;
- -
- Data specifications—amount and readiness.
- Learning process-related challenges:
- -
- Privacy;
- -
- High communication cost;
- -
- Aggregation techniques;
- -
- Personalization techniques;
- -
- Evaluation complexity.
- Other vulnerability-related challenges:
- -
- Federated fairness;
- -
- Application areas.
4.1.1. Data Source-Related Challenges
- ⋆
- Structural heterogeneity: This is also referred to as system heterogeneity. Since federated learning mainly aims to deal with data scattered in different islands, called parties, these parties may differ in terms of network state, storage space, performance, and the processing capabilities of the devices containing the parties’ data. Therefore, due to network failures, not all devices may be ready and online at each processing iteration, which is known as device failure. On the other hand, devices with better-processing capabilities train faster than other devices, resulting in unbalanced training times. Therefore, device failure and unbalanced training times can cause some devices to lag behind the global model if they are still training with outdated parameters, with these devices being referred to as laggards.
- ⋆
- Statistical heterogeneity: Due to the differences between FL embedded parties, the data generated and collected are generally not independently and identically distributed (non-IID). Moreover, the data sizes of the different parties can be very different, resulting in an unbalanced distribution. This definitely increases the complexity in terms of analysis, modeling and evaluation.
- ⋆
- Data specifications—amount and readiness: In classical machine learning and deep learning, the amount of training data is one of the factors affecting the performance of the models, where large amounts of data can increase the accuracy of the learned model. However, in a distributed environment, the amount of data on each party is not the same, and it may be insufficient for local training on some parties, which therefore affects the accuracy. In addition, heterogeneous data on the parties may require different preprocessing steps, where some parties can process some missing data while others do not.
4.1.2. Learning Process-Related Challenges
- ⋆
- Privacy: Despite the fact that federated learning aims to building smart models that do not collect user data, it is still vulnerable to data leakage caused by attacks. This is possible because of the transmission of gradients and partial parameters, whether this is between parties and manager in the centralized architecture or between parties themselves in the decentralized architecture. Those parameters are under the risk of cracking on three levels: the inputs, learning process, or learned model, as previously discussed. Usually, attacks are performed by adversaries ranging from malicious clients in a party to a malicious party which only has black-box access to the model. The types of attacks can be summarized into the following groups [54]:
- Poisoning attacks: these are conducted by injecting noise into the FL system, and are also split into two categories:
- -
- Data poisoning attacks: these are the most common attacks against ML models and can be either targeted toward a specific class or non-targeted. In a targeted attack, the noisy records of a specific target class are injected into local data so that the learned model will act badly on this class;
- -
- Model poisoning attacks: these are similar to data poisoning attacks, where the adversary tries to poison the local models instead of the local data.
- Inference attacks: in some scenarios, it is possible to infer, conclude, or restore the party local data from the model updates during the learning process;
- Backdoor attacks: secure averaging allows parties to be anonymous during the model update process. Using the same functionality, a party or group of parties can introduce backdoor functionality in in FL global model. Then, a malicious entity can use the backdoor to mislabel certain tasks such as choosing a specific label for a data instance with specific characteristics. For sure, the proportion of the compromised devices and FL model capacity affects in the intensity of such attacks.
- ⋆
- High communication cost: this is induced by the huge number of involved devices, encryption and privacy preserving computations, local models and parameter-exchange batches. In addition, it is known that the life cycle of modern data is short and that the speed of iterative updating of data is fast, because the most important advantage is timeliness. Therefore, the cost of communication is a difficult topic that is worth studying;
- ⋆
- Aggregation techniques: in centralized federated learning, the local models are aggregated into a global model at the central server. Due to the variety of amounts of data at each party, different results of local models, communication bottlenecks and other challenges, the method behind aggregating the global model is a challenging topic. In addition, most of the existing aggregation algorithms target the aggregation itself, communication/computation cost reduction or heterogeneity the most, while other topics such as personalization and scalability are less investigated;
- ⋆
- Personalization: According to [148], there is a gap between the accuracy of local and global models, which impose personalization as a challenging topic in FL. However, there are no clear metrics to evaluate the performance of personalization techniques, which should be a hot topic for further research;
- ⋆
- Evaluation complexity: In classical ML and DL, the models are evaluated by defined metrics such as accuracy, communication cost, computation speed, among others. In contrast, the evaluation of an FL system will add more parameters to be evaluated such as privacy, additional communication cost, and robustness against attacks.
4.1.3. Other Vulnerabilities
- ⋆
- Federated fairness: fairness is an emerging area of ML, investigating how to confirm that the results of a model do not depend on sensitive attributes in a way that is considered unfair. FL creates new problems for researchers regarding fairness and requires a greater focus on improving the fairness of existing algorithms. At present, it is unclear whether existing fairness methods and frameworks that have been shown to be effective in ML will also be effective in FL;
- ⋆
- Application areas: federated learning has mainly been applied to supervised learning algorithms. Therefore, when using FL in domains that require data exploration, such as reinforcement learning, unsupervised learning, semi-supervised learning, and others, some challenges may arise;
- ⋆
- User adoption: one of the main obstacles to integrating federated machine learning into disease diagnosis is user acceptance, adoption, and participation. Although FL is known as a privacy-friendly technology, FL is still new and has mixed user adoption due to privacy concerns, discomfort, ethics, and other contextual factors.
- RQ1: Heterogeneity has a negative impact on the performance of a federated learning system. What are the solutions to deal with diversity?
- RQ2: Real-world data are noisy and usually not suitable for analysis by intelligent models. How can peripheral data be processed before these are used for model training?
- RQ3: Federated machine learning is vulnerable to security breaches and attacks. What mechanisms are in place to strengthen these algorithms against malicious entities?
- RQ4: The additional computations and sharing of models incur additional communication and computational costs in the FL system. What techniques can be used to manage the increasing costs?
- RQ5: The available aggregation algorithms consider aggregation, reduction in communication and computational costs, and privacy the most, while other issues such as personalization and scalability are the least considered. What further steps need to be taken to improve the performance of FL’s aggregation algorithms?
4.2. Future Perspectives
- ⋆
- Managing heterogeneity: Heterogeneity in federated learning systems can result from both data and hardware, which is known as statistical or structural heterogeneity. To overcome heterogeneity, federated learning researchers may consider the following:
- Structural heterogeneity:
- -
- Fault tolerance: FL considers the impact of low participation in the training process to resist device failures by storing user updates in a trusted cache architecture to mitigate their unreliable impact on the global model;
- -
- Resource allocation: to solve resource scarcity, most of the previous work is devoted to properly allocating resources to heterogeneous devices.
- Statistical heterogeneity:
- -
- Data clustering: separating independent data into multiple clusters, then processing FL on each cluster, which is not suitable for training bulk data due to conversion overhead;
- -
- Modify local training mode: put cross-entropy loss into the transfer process and assign different local update times to each party in each processing iteration;
- -
- Meta learning [150]: Improve training on non-IID data by creating a small subset of data that are shared among all edge devices.
- ⋆
- Privacy preservation enhancement: even though the main goal of FL is to preserve privacy by sharing the trained model between entities instead of raw data, the privacy preservation concept needs further enhancement, especially towards:
- Enhancing security mechanisms: by proposing new robust and feasible security mechanisms that are protected against data attacks and cracking;
- Verifying the returned model: most privacy preserving methods (FL) assume that the clients are reasonably honest. Although this is in line with training rules, curiosity in acquiring private data remains. Therefore, the returned model should be checked to determine whether it can be considered non-malicious.
- ⋆
- Communication optimization: due to the system and structural heterogeneity, as well as the decentralized nature of FL, the research area of the communication cost reduction is a hot topic to attend to. There are plenty things to be considered in this area, such as:
- Gradient aggregation: it is worthwhile to introduce adaptive weighting for each party or an ML method to learn how to aggregate these gradients in an efficient way;
- Handle heterogeneity: efficiently handling heterogeneous data and devices will definitely reduce communication rounds;
- Novel models of asynchrony: in the environment of FL, there is a large variety of devices where the synchronous scheme can be easily disrupted. Therefore, it is better to use an asynchronous scheme that can handle this diversity, solve the communication delay problem, and avoid concurrent training with heterogeneous devices; Therefore, the development of asynchronous FL platforms is a possible area of study;
- One-/few-shot learning: to minimize communication costs, reducing the number of learning rounds could be a viable solution. Some researchers are exploring the possibility of training the local models with only one iteration and updating the global model accordingly.
- ⋆
- Performance optimization: The trade-off between communication, performance, and privacy is an active research area in FL. Performance optimization can be achieved using various approaches, such as:
- Incentive mechanism: to encourage parties’ participation in the training process in a feasible way, it is important to encourage high-quality users to contribute to the process by granting them some rewards, while neglecting or rejecting untrustworthy users because the inconsistent quality of data provided by users;
- Handle party dropouts: as one of the biggest challenges in networks with a large number of devices, handling dropouts will reduce communication costs, especially related to delayed parties;
- Personalization: improving FL personalization is much needed by users and has far-reaching applications. Many involved data holders will prefer to receive more personalized models to better meet their needs.
- ⋆
- Toward unsupervised learning: unsupervised data are a large part of the data available in real life, and unsupervised learning is an area of great interest around the world. Therefore, it is of great efficiency to move towards unsupervised learning models with FL;
- ⋆
- Production of FL: due to its novelty and lack of popularity, FL still needs to be put into production so that it can gain trust and be used in more areas of life;
- ⋆
- Benchmarks: since the technology is still in its infancy, there is a large window of opportunity for benchmarking to define its future by ensuring that it is based on real-world circumstances, assumptions and datasets.
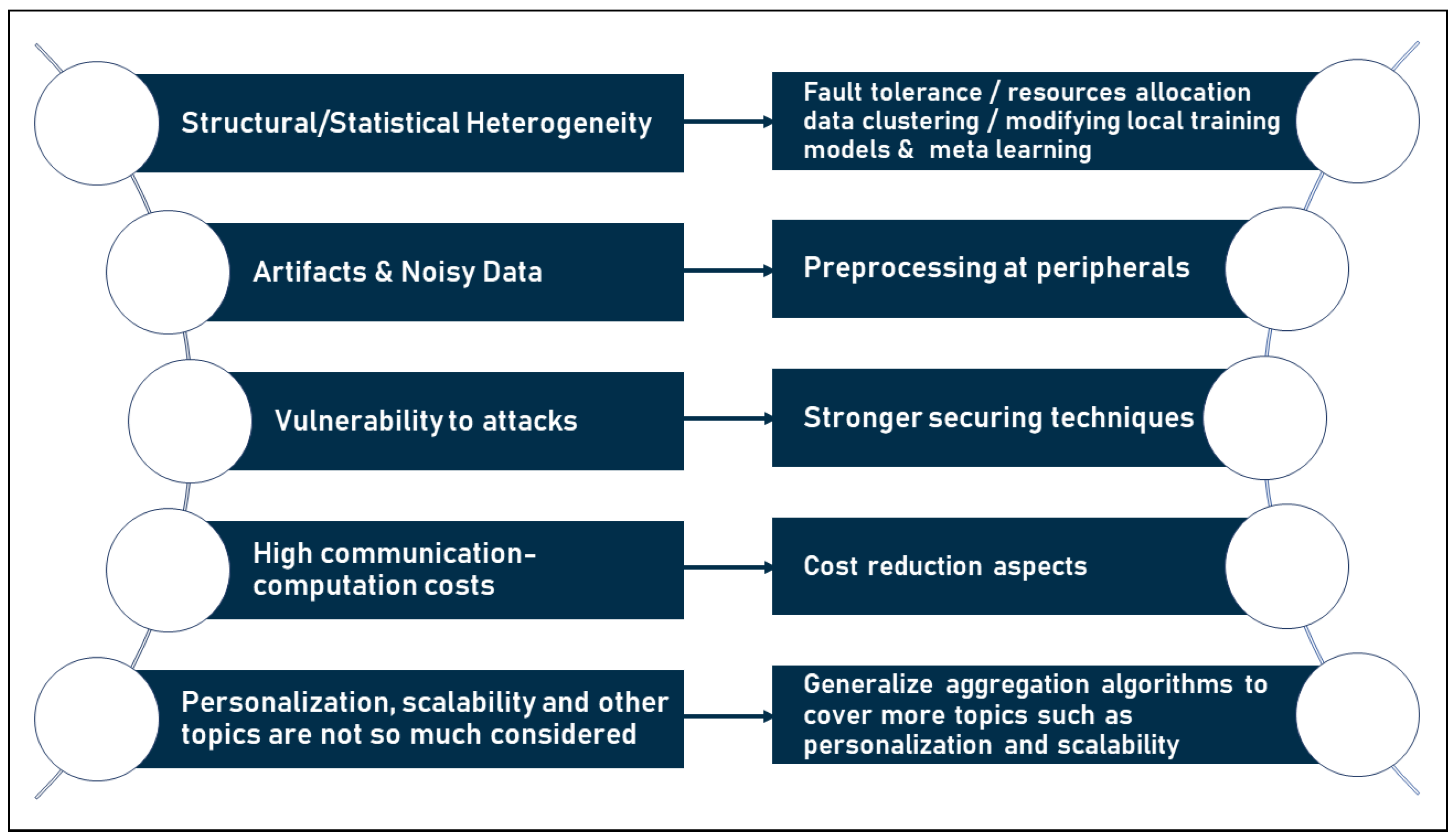
- TR1: Fault tolerance, resource allocation, data clustering, modifying local training models, and meta learning help handle heterogeneity;
- TR2: Preprocessing of data at peripherals to enhance their readiness may boost the overall model accuracy;
- TR3: More security perspectives are needed to strengthen FL against attacks;
- TR4: More communication/computation cost reduction is needed to boost the performance of FL algorithms;
- TR5: more perspectives are needed to be taken into consideration in aggregation algorithms such as privacy, personalization, and scalability.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Turing, A.M. Computing machinery and intelligence. In Parsing the Turing Test; Springer: Dordrecht, The Netherlands, 2009; pp. 23–65. [Google Scholar]
- Frankish, K.; Ramsey, W.M. (Eds.) The Cambridge Handbook of Artificial Intelligence; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Hernández-Orallo, J.; Minaya-Collado, N. A formal definition of intelligence based on an intensional variant of algorithmic complexity. Proceedings of International Symposium of Engineering of Intelligent Systems (EIS98), Tenerife, Spain, 11–13 February 1998; pp. 146–163. [Google Scholar]
- Sarker, I.H. Machine learning: Algorithms, real-world applications and research directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef] [PubMed]
- Sharma, N.; Sharma, R.; Jindal, N. Machine learning and deep learning applications-a vision. Glob. Transit. Proc. 2021, 2, 24–28. [Google Scholar] [CrossRef]
- Pallathadka, H.; Mustafa, M.; Sanchez, D.T.; Sajja, G.S.; Gour, S.; Naved, M. Impact of machine learning on management, healthcare and agriculture. Mater. Today Proc. 2021, in press. [Google Scholar] [CrossRef]
- Ghazal, T.M.; Hasan, M.K.; Alshurideh, M.T.; Alzoubi, H.M.; Ahmad, M.; Akbar, S.S.; Al Kurdi, B.; Akour, I.A. IoT for smart cities: Machine learning approaches in smart healthcare—A review. Future Internet 2021, 13, 218. [Google Scholar] [CrossRef]
- Erickson, B.J.; Korfiatis, P.; Akkus, Z.; Kline, T.L. Machine learning for medical imaging. Radiographics 2017, 37, 505. [Google Scholar] [CrossRef]
- Zantalis, F.; Koulouras, G.; Karabetsos, S.; Kandris, D. A review of machine learning and IoT in smart transportation. Future Internet 2019, 11, 94. [Google Scholar] [CrossRef]
- Xin, Y.; Kong, L.; Liu, Z.; Chen, Y.; Li, Y.; Zhu, H.; Gao, M.; Hou, H.; Wang, C. Machine learning and deep learning methods for cybersecurity. IEEE Access 2018, 6, 35365–35381. [Google Scholar] [CrossRef]
- Nagarhalli, T.P.; Vaze, V.; Rana, N.K. Impact of machine learning in natural language processing: A review. In Proceedings of the Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), IEEE, Tirunelveli, India, 4–6 February 2021; pp. 1529–1534. [Google Scholar]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef]
- Larrañaga, P.; Atienza, D.; Diaz-Rozo, J.; Ogbechie, A.; Puerto-Santana, C.; Bielza, C. Industrial Applications of Machine Learning; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- L’heureux, A.; Grolinger, K.; Elyamany, H.F.; Capretz, M.A. Machine learning with big data: Challenges and approaches. IEEE Access 2017, 5, 7776–7797. [Google Scholar] [CrossRef]
- Zhou, L.; Pan, S.; Wang, J.; Vasilakos, A.V. Machine learning on big data: Opportunities and challenges. Neurocomputing 2017, 237, 350–361. [Google Scholar] [CrossRef]
- Leskovec, J.; Rajaraman, A.; Ullman, J.D. Mining of Massive Data Sets; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Paleyes, A.; Urma, R.G.; Lawrence, N.D. Challenges in deploying machine learning: A survey of case studies. ACM Comput. Surv. (CSUR) 2020, 55, 1–29. [Google Scholar] [CrossRef]
- Char, D.S.; Shah, N.H.; Magnus, D. Implementing machine learning in health care—Addressing ethical challenges. N. Engl. J. Med. 2018, 378, 981. [Google Scholar] [CrossRef]
- Wuest, T.; Weimer, D.; Irgens, C.; Thoben, K.D. Machine learning in manufacturing: Advantages, challenges, and applications. Prod. Manuf. Res. 2016, 4, 23–45. [Google Scholar] [CrossRef]
- Injadat, M.; Moubayed, A.; Nassif, A.B.; Shami, A. Machine learning towards intelligent systems: Applications, challenges, and opportunities. Artif. Intell. Rev. 2021, 54, 3299–3348. [Google Scholar] [CrossRef]
- Albrecht, J.P. How the GDPR will change the world. Eur. Data Prot. L. Rev. 2016, 2, 287. [Google Scholar] [CrossRef]
- Parasol, M. The impact of China’s 2016 Cyber Security Law on foreign technology firms, and on China’s big data and Smart City dreams. Comput. Law Secur. Rev. 2018, 34, 67–98. [Google Scholar] [CrossRef]
- Gray, W.; Zheng, H.R. General Principles of Civil Law of the People’s Republic of China. Am. J. Comp. Law 1986, 34, 715–743. [Google Scholar] [CrossRef]
- Chik, W.B. The Singapore Personal Data Protection Act and an assessment of future trends in data privacy reform. Comput. Law Secur. Rev. 2013, 29, 554–575. [Google Scholar] [CrossRef]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the Third Theory of Cryptography Conference, TCC 2006, New York, NY, USA, 4–7 March 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- El Emam, K.; Dankar, F.K. Protecting privacy using k-anonymity. J. Am. Med. Inform. Assoc. 2008, 15, 627–637. [Google Scholar] [CrossRef]
- Li, P.; Li, J.; Huang, Z.; Li, T.; Gao, C.Z.; Yiu, S.M.; Chen, K. Multi-key privacy-preserving deep learning in cloud computing. Future Gener. Comput. Syst. 2017, 74, 76–85. [Google Scholar] [CrossRef]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), IEEE, San Jose, CA, USA, 22–26 May 2017; pp. 3–18. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics PMLR, Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Ramesh, A.N.; Kambhampati, C.; Monson, J.R.L.; Drew, P.J. Artificial intelligence in medicine. Ann. R. Coll. Surg. Engl. 2004, 86, 334. [Google Scholar] [CrossRef] [PubMed]
- Maddox, T.M.; Rumsfeld, J.S.; Payne, P.R. Questions for artificial intelligence in health care. JAMA 2019, 321, 31–32. [Google Scholar] [CrossRef] [PubMed]
- Nayyar, A.; Gadhavi, L.; Zaman, N. Machine learning in healthcare: Review, opportunities and challenges. In Machine Learning and the Internet of Medical Things in Healthcare; Academic Press: Cambridge, MA, USA, 2021; pp. 23–45. [Google Scholar]
- Moshawrab, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Smart Wearables for the Detection of Cardiovascular Diseases: A Systematic Literature Review. Sensors 2023, 23, 828. [Google Scholar] [CrossRef] [PubMed]
- Makroum, M.A.; Adda, M.; Bouzouane, A.; Ibrahim, H. Machine learning and smart devices for diabetes management: Systematic review. Sensors 2022, 22, 1843. [Google Scholar] [CrossRef]
- Moshawrab, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Smart Wearables for the Detection of Occupational Physical Fatigue: A Literature Review. Sensors 2022, 22, 7472. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Hassabis, D.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Hassabis, D.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Aono, Y.; Hayashi, T.; Wang, L.; Moriai, S. Privacy-preserving deep learning via additively homomorphic encryption. IEEE Trans. Inf. Forensics Secur. 2017, 13, 1333–1345. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Li, Q.; Wen, Z.; Wu, Z.; Hu, S.; Wang, N.; Li, Y.; Liu, X.; He, B. A survey on federated learning systems: Vision, hype and reality for data privacy and protection. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Li, L.; Fan, Y.; Tse, M.; Lin, K.Y. A review of applications in federated learning. Comput. Ind. Eng. 2020, 149, 106854. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Mammen, P.M. Federated learning: Opportunities and challenges. arXiv 2021, arXiv:2101.05428. [Google Scholar]
- Zhang, K.; Song, X.; Zhang, C.; Yu, S. Challenges and future directions of secure federated learning: A survey. Front. Comput. Sci. 2022, 16, 165817. [Google Scholar] [CrossRef]
- Asad, M.; Moustafa, A.; Ito, T. Federated Learning Versus Classical Machine Learning: A Convergence Comparison. arXiv 2021, arXiv:2107.10976. [Google Scholar]
- Mahlool, D.H.; Abed, M.H. A Comprehensive Survey on Federated Learning: Concept and Applications. arXiv 2022, arXiv:2201.09384. [Google Scholar]
- Zhang, H.; Bosch, J.; Holmström Olsson, H. Engineering Federated Learning Systems: A Literature Review. In Proceedings of the 11th International Conference, ICSOB 2020, Karlskrona, Sweden, 16–18 November 2020; Springer: Cham, Switzerland, 2020; pp. 210–218. [Google Scholar]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated learning in mobile edge networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef]
- Xu, J.; Glicksberg, B.S.; Su, C.; Walker, P.; Bian, J.; Wang, F. Federated learning for healthcare informatics. J. Healthc. Inform. Res. 2021, 5, 1–19. [Google Scholar] [CrossRef]
- Shokri, R.; Shmatikov, V. Privacy-preserving deep learning. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1310–1321. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Lyu, L.; Yu, H.; Yang, Q. Threats to federated learning: A survey. arXiv 2020, arXiv:2003.02133. [Google Scholar]
- Chen, X.; Liu, C.; Li, B.; Lu, K.; Song, D. Targeted backdoor attacks on deep learning systems using data poisoning. arXiv 2017, arXiv:1712.05526. [Google Scholar]
- Li, B.; Wang, Y.; Singh, A.; Vorobeychik, Y. Data poisoning attacks on factorization-based collaborative filtering. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Alfeld, S.; Zhu, X.; Barford, P. Data poisoning attacks against autoregressive models. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Bagdasaryan, E.; Veit, A.; Hua, Y.; Estrin, D.; Shmatikov, V. How to backdoor federated learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Sicily, Italy, 3–5 June 2020; pp. 2938–2948. [Google Scholar]
- Xie, C.; Huang, K.; Chen, P.Y.; Li, B. Dba: Distributed backdoor attacks against federated learning. In Proceedings of the International Conference on Learning Representations, Jakarta, Indonesia, 18–20 September 2019. [Google Scholar]
- Castro, M.; Liskov, B. Practical Byzantine fault tolerance and proactive recovery. ACM Trans. Comput. Syst. (TOCS) 2002, 20, 398–461. [Google Scholar] [CrossRef]
- Blanchard, P.; El Mhamdi, E.M.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Bayatbabolghani, F.; Blanton, M. Secure multi-party computation. In Proceedings of the 2018 ACM SIGSAC conference on computer and communications security 2018, Toronto, Canada, 15–19 October 2018; 2018. [Google Scholar]
- Dwork, C. Differential privacy: A survey of results. In Proceedings of the International Conference on Theory and Applications of Models of Computation, Xi’an, China, 25–19 April 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–19. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Zhao, S.; et al. Advances and open problems in federated learning. Found. Trends® Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Rahman, K.J.; Ahmed, F.; Akhter, N.; Hasan, M.; Amin, R.; Aziz, K.E.; Muzahidul Islam, A.K.M.; Hossain Mukta, S.; Islam, A.N. Challenges, applications and design aspects of federated learning: A survey. IEEE Access 2021, 9, 124682–124700. [Google Scholar] [CrossRef]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1175–1191. [Google Scholar]
- Pillutla, K.; Kakade, S.M.; Harchaoui, Z. Robust aggregation for federated learning. IEEE Trans. Signal Process. 2022, 70, 1142–1154. [Google Scholar] [CrossRef]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.; Suresh, A.T. Scaffold: Stochastic controlled averaging for federated learning. In Proceedings of the International Conference on Machine Learning, PMLR, Bangkok, Thailand, 18–22 November 2020; pp. 5132–5143. [Google Scholar]
- Reddi, S.; Charles, Z.; Zaheer, M.; Garrett, Z.; Rush, K.; Konečný, J.; Kumar, S.; McMahan, H.B. Adaptive federated optimization. arXiv 2020, arXiv:2003.00295. [Google Scholar]
- Hamer, J.; Mohri, M.; Suresh, A.T. Fedboost: A communication-efficient algorithm for federated learning. In Proceedings of the International Conference on Machine Learning PMLR, Bangkok, Thailand, 18–22 November 2020; pp. 3973–3983. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. In Proceedings of the Machine Learning and Systems, Austin, TX, USA, 2–4 March 2020; Volume 2, pp. 429–450. [Google Scholar]
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.; Khazaeni, Y. Federated learning with matched averaging. arXiv 2020, arXiv:2002.06440. [Google Scholar]
- Guo, H.; Liu, A.; Lau, V.K. Analog gradient aggregation for federated learning over wireless networks: Customized design and convergence analysis. IEEE Internet Things J. 2020, 8, 197–210. [Google Scholar] [CrossRef]
- Choi, B.; Sohn, J.Y.; Han, D.J.; Moon, J. Communication-computation efficient secure aggregation for federated learning. arXiv 2020, arXiv:2012.05433. [Google Scholar]
- Ye, D.; Yu, R.; Pan, M.; Han, Z. Federated learning in vehicular edge computing: A selective model aggregation approach. IEEE Access 2020, 8, 23920–23935. [Google Scholar] [CrossRef]
- Sun, J.; Chen, T.; Giannakis, G.B.; Yang, Q.; Yang, Z. Lazily aggregated quantized gradient innovation for communication-efficient federated learning. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2031–2044. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; He, L.; Lin, W.; Mao, R.; Maple, C.; Jarvis, S. SAFA: A semi-asynchronous protocol for fast federated learning with low overhead. IEEE Trans. Comput. 2020, 70, 655–668. [Google Scholar] [CrossRef]
- Sannara, E.K.; Portet, F.; Lalanda, P.; German, V.E.G.A. A federated learning aggregation algorithm for pervasive computing: Evaluation and comparison. In Proceedings of the 2021 IEEE International Conference on Pervasive Computing and Communications (PerCom), IEEE, Kassel, Germany, 22–26 March 2021; pp. 1–10. [Google Scholar]
- Chen, S.; Shen, C.; Zhang, L.; Tang, Y. Dynamic aggregation for heterogeneous quantization in federated learning. IEEE Trans. Wirel. Commun. 2021, 20, 6804–6819. [Google Scholar] [CrossRef]
- Deng, Y.; Lyu, F.; Ren, J.; Chen, Y.C.; Yang, P.; Zhou, Y.; Zhang, Y. Fair: Quality-aware federated learning with precise user incentive and model aggregation. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications, IEEE, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar]
- Park, S.; Suh, Y.; Lee, J. FedPSO: Federated learning using particle swarm optimization to reduce communication costs. Sensors 2021, 21, 600. [Google Scholar] [CrossRef]
- Varma, K.; Zhou, Y.; Baracaldo, N.; Anwar, A. LEGATO: A LayerwisE Gradient AggregaTiOn Algorithm for Mitigating Byzantine Attacks in Federated Learning. In Proceedings of the 2021 IEEE 14th International Conference on Cloud Computing (CLOUD), IEEE, Chicago, IL, USA, 5–10 September 2021; pp. 272–277. [Google Scholar]
- Hu, L.; Yan, H.; Li, L.; Pan, Z.; Liu, X.; Zhang, Z. MHAT: An efficient model-heterogenous aggregation training scheme for federated learning. Inf. Sci. 2021, 560, 493–503. [Google Scholar] [CrossRef]
- Jeon, B.; Ferdous, S.M.; Rahman, M.R.; Walid, A. Privacy-preserving decentralized aggregation for federated learning. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), IEEE, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–6. [Google Scholar]
- Wang, Y.; Kantarci, B. Reputation-enabled federated learning model aggregation in mobile platforms. In Proceedings of the ICC 2021—IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar]
- Zhao, L.; Jiang, J.; Feng, B.; Wang, Q.; Shen, C.; Li, Q. Sear: Secure and efficient aggregation for byzantine-robust federated learning. IEEE Trans. Dependable Secur. Comput. 2021, 19, 2239–3342. [Google Scholar] [CrossRef]
- So, J.; Güler, B.; Avestimehr, A.S. Turbo-aggregate: Breaking the quadratic aggregation barrier in secure federated learning. IEEE J. Sel. Areas Inf. Theory 2021, 2, 479–489. [Google Scholar] [CrossRef]
- Song, J.; Wang, W.; Gadekallu, T.R.; Cao, J.; Liu, Y. Eppda: An efficient privacy-preserving data aggregation federated learning scheme. IEEE Trans. Netw. Sci. Eng. 2022, 1. [Google Scholar] [CrossRef]
- Nguyen, J.; Malik, K.; Zhan, H.; Yousefpour, A.; Rabbat, M.; Malek, M.; Huba, D. Federated learning with buffered asynchronous aggregation. In Proceedings of the International Conference on Artificial Intelligence and Statistics PMLR, Virtual Conference, 28–30 March 2022; pp. 3581–3607. [Google Scholar]
- Elkordy, A.R.; Avestimehr, A.S. Heterosag: Secure aggregation with heterogeneous quantization in federated learning. IEEE Trans. Commun. 2022, 70, 2372–2386. [Google Scholar] [CrossRef]
- So, J.; Nolet, C.J.; Yang, C.S.; Li, S.; Yu, Q.; E Ali, R.; Guler, B.; Avestimehr, S. Lightsecagg: A lightweight and versatile design for secure aggregation in federated learning. In Proceedings of the Machine Learning and Systems, Santa Clara, CA, USA, 29 August–1 September 2022; Volume 4, pp. 694–720. [Google Scholar]
- Sheth, A.P.; Larson, J.A. Federated database systems for managing distributed, heterogeneous, and autonomous databases. ACM Comput. Surv. (CSUR) 1990, 22, 183–236. [Google Scholar] [CrossRef]
- Kumar, Y.; Singla, R. Federated learning systems for healthcare: Perspective and recent progress. In Federated Learning Systems; Springer: Cham, Switzerland, 2021; pp. 141–156. [Google Scholar]
- Google. 2019. TensorFlow Federated. Retrieved 1 July 2022. Available online: https://www.tensorflow.org/federated (accessed on 1 July 2022).
- Liu, Y.; Fan, T.; Chen, T.; Xu, Q.; Yang, Q. FATE: An Industrial Grade Platform for Collaborative Learning With Data Protection. J. Mach. Learn. Res. 2021, 22, 10320–10325. [Google Scholar]
- Ryffel, T.; Trask, A.; Dahl, M.; Wagner, B.; Mancuso, J.; Rueckert, D.; Passerat-Palmbach, J. A generic framework for privacy preserving deep learning. arXiv 2018, arXiv:1811.04017. [Google Scholar]
- GitHub—doc-ai/tensorio: Declarative, On-Device Machine Learning for iOS, Android, and React Native. Deploy. Predict. Train. GitHub. Available online: https://github.com/doc-ai/tensorio (accessed on 1 July 2022).
- Antunes, R.S.; André da Costa, C.; Küderle, A.; Yari, I.A.; Eskofier, B. Federated Learning for Healthcare: Systematic Review and Architecture Proposal. ACM Trans. Intell. Syst. Technol. (TIST) 2022, 13, 1–23. [Google Scholar] [CrossRef]
- Tan, K.; Bremner, D.; Le Kernec, J.; Imran, M. Federated machine learning in vehicular networks: A summary of recent applications. In Proceedings of the 2020 International Conference on UK-China Emerging Technologies (UCET), IEEE, Glasgow, UK, 20–21 August 2020; pp. 1–4. [Google Scholar]
- Liu, M.; Ho, S.; Wang, M.; Gao, L.; Jin, Y.; Zhang, H. Federated learning meets natural language processing: A survey. arXiv 2021, arXiv:2107.12603. [Google Scholar]
- Goecks, J.; Jalili, V.; Heiser, L.M.; Gray, J.W. How machine learning will transform biomedicine. Cell 2020, 181, 92–101. [Google Scholar] [CrossRef]
- Moshawrab, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Cardiovascular Events Prediction using Artificial Intelligence Models and Heart Rate Variability. Procedia Comput. Sci. 2022, 203, 231–238. [Google Scholar] [CrossRef]
- Brisimi, T.S.; Chen, R.; Mela, T.; Olshevsky, A.; Paschalidis, I.C.; Shi, W. Federated learning of predictive models from federated electronic health records. Int. J. Med. Inform. 2018, 112, 59–67. [Google Scholar] [CrossRef]
- Fang, L.; Liu, X.; Su, X.; Ye, J.; Dobson, S.; Hui, P.; Tarkoma, S. Bayesian inference federated learning for heart rate prediction. In Proceedings of the International Conference on Wireless Mobile Communication and Healthcare, Virtual Event, 19 November 2020; Springer: Cham, Switzerland, 2020; pp. 116–130. [Google Scholar]
- Brophy, E.; De Vos, M.; Boylan, G.; Ward, T. Estimation of continuous blood pressure from ppg via a federated learning approach. Sensors 2021, 21, 6311. [Google Scholar] [CrossRef]
- uff-Less Blood Pressure Estimation. (4 June 2017). Kaggle. Retrieved 1 July 2022. Available online: https://www.kaggle.com/datasets/mkachuee/BloodPressureDataset (accessed on 1 July 2022).
- Liu, D.; Görges, M.; Jenkins, S.A. University of Queensland vital signs dataset: Development of an accessible repository of anesthesia patient monitoring data for research. Anesth. Analg. 2012, 114, 584–589. [Google Scholar] [CrossRef]
- Tang, R.; Luo, J.; Qian, J.; Jin, J. Personalized Federated Learning for ECG Classification Based on Feature Alignment. Secur. Commun. Netw. 2021, 2021, 6217601. [Google Scholar] [CrossRef]
- Lee, E.W.; Xiong, L.; Hertzberg, V.S.; Simpson, R.L.; Ho, J.C. Privacy-preserving Sequential Pattern Mining in distributed EHRs for Predicting Cardiovascular Disease. In Proceedings of the AMIA Summits on Translational Science Proceedings, Bethesda, MD, USA, 17 May 2021; pp. 384–393. [Google Scholar]
- Raza, A.; Tran, K.P.; Koehl, L.; Li, S. Designing ecg monitoring healthcare system with federated transfer learning and explainable AI. Knowl.-Based Syst. 2022, 236, 107763. [Google Scholar] [CrossRef]
- MIT-BIH Arrhythmia Database v1.0.0. (24 February 2005). PhysioNet. Available online: https://physionet.org/content/mitdb/1.0.0/ (accessed on 1 July 2022.).
- Linardos, A.; Kushibar, K.; Walsh, S.; Gkontra, P.; Lekadir, K. Federated learning for multi-center imaging diagnostics: A simulation study in cardiovascular disease. Sci. Rep. 2022, 12, 3551. [Google Scholar] [CrossRef] [PubMed]
- Campello, V.M.; Gkontra, P.; Izquierdo, C.; Martin-Isla, C.; Sojoudi, A.; Full, P.M.; Maier-Hein, K.; Zhang, Y.; He, Z.; Lekadir, K.; et al. Multi-centre, multi-vendor and multi-disease cardiac segmentation: The M&Ms challenge. IEEE Trans. Med. Imaging 2021, 40, 3543–3554. [Google Scholar] [PubMed]
- Bernard, O.; Lalande, A.; Zotti, C.; Cervenansky, F.; Yang, X.; Heng, P.A.; Cetin, I.; Lekadir, I.; Camara, O.; Jodoin, P.M.; et al. Deep learning techniques for automatic MRI cardiac multi-structures segmentation and diagnosis: Is the problem solved? IEEE Trans. Med. Imaging 2018, 37, 2514–2525. [Google Scholar] [CrossRef] [PubMed]
- Diabetes. 2 December 2022. Available online: https://www.who.int/health-topics/diabetes#tab=tab_1. (accessed on 1 January 2023).
- Lo, J.; Timothy, T.Y.; Ma, D.; Zang, P.; Owen, J.P.; Zhang, Q.; Wang, R.K.; Beg, M.F.; Lee, A.Y.; Sarunic, M.V.; et al. Federated learning for microvasculature segmentation and diabetic retinopathy classification of OCT data. Ophthalmol. Sci. 2021, 1, 100069. [Google Scholar] [CrossRef] [PubMed]
- Islam, H.; Mosa, A. A Federated Mining Approach on Predicting Diabetes-Related Complications: Demonstration Using Real-World Clinical Data. In Proceedings of the AMIA Annual Symposium, San Diego, CA, USA, 30 October–3 November 2021; American Medical Informatics Association: Bethesda, MA, USA, 2021; Volume 2021, p. 556. [Google Scholar]
- Astillo, P.V.; Duguma, D.G.; Park, H.; Kim, J.; Kim, B.; You, I. Federated intelligence of anomaly detection agent in IoTMD-enabled Diabetes Management Control System. Future Gener. Comput. Syst. 2022, 128, 395–405. [Google Scholar] [CrossRef]
- Nielsen, C.; Tuladhar, A.; Forkert, N.D. Investigating the Vulnerability of Federated Learning-Based Diabetic Retinopathy Grade Classification to Gradient Inversion Attacks. In Proceedings of the International Workshop on Ophthalmic Medical Image Analysis, Singapore, 22 September 2022; Springer: Cham, Switzerland, 2022; pp. 183–192. [Google Scholar]
- “FGADR Dataset—Look Deeper Into Eyes.” FGADR Dataset—Look Deeper Into Eyes.|FGADR. Available online: csyizhou.github.io/FGADR/blob/NateBYWang-patch-1//FGADR (accessed on 12 January 2023).
- Liu, J.; Lu, X.; Yang, H.; Zhuang, L. A Diabetes Prediction System Based on Federated Learning. In Proceedings of the 2022 International Conference on Big Data, Information and Computer Network (BDICN), IEEE, Sanya, China, 20–22 January 2022; pp. 486–491. [Google Scholar]
- Nasajpour, M.; Karakaya, M.; Pouriyeh, S.; Parizi, R.M. Federated Transfer Learning For Diabetic Retinopathy Detection Using CNN Architectures. In Proceedings of the SoutheastCon 2022, IEEE, Mobile, AL, USA, 26 March–3 April 2022; pp. 655–660. [Google Scholar]
- Cuadros, J.; Sim, I. EyePACS: An open source clinical communication system for eye care. Stud. Health Technol. Inform. 2004, 207–211. [Google Scholar]
- Decencière, E.; Zhang, X.; Cazuguel, G.; Lay, B.; Cochener, B.; Trone, C.; Gain, P.; Ordonez, R.; Massin, P.; Klein, J.C.; et al. Feedback on a publicly distributed image database: The Messidor database. Image Anal. Stereol. 2014, 33, 231–234. [Google Scholar] [CrossRef]
- Porwal, P.; Pachade, S.; Kamble, R.; Kokare, M.; Deshmukh, G.; Sahasrabuddhe, V.; Meriaudeau, F. Indian diabetic retinopathy image dataset (IDRiD): A database for diabetic retinopathy screening research. Data 2018, 3, 25. [Google Scholar] [CrossRef]
- APTOS 2019 Blindness Detection | Kaggle. APTOS 2019 Blindness Detection | Kaggle. Available online: https://www.kaggle.com/c/aptos2019-blindness-detection (accessed on 12 January 2023).
- Chalakkal, R.J.; Abdulla, W.H.; Sinumol, S. Comparative analysis of university of Auckland diabetic retinopathy database. In Proceedings of the 9th International Conference on Signal Processing Systems, Auckland, New Zealand, 27–30 November 2017; pp. 235–239. [Google Scholar]
- Cancer. 2022. Available online: https://www.who.int/news-room/fact-sheets/detail/cancer (accessed on 13 January 2023).
- Chowdhury, A.; Kassem, H.; Padoy, N.; Umeton, R.; Karargyris, A. A Review of Medical Federated Learning: Applications in Oncology and Cancer Research. In Proceedings of the International MICCAI Brainlesion Workshop, Virtual Event, 27 September 2021; Springer: Cham, Switzerland, 2022; pp. 3–24. [Google Scholar]
- Yi, L.; Zhang, J.; Zhang, R.; Shi, J.; Wang, G.; Liu, X. SU-Net: An efficient encoder-decoder model of federated learning for brain tumor segmentation. In Proceedings of the International Conference on Artificial Neural Networks, Bratislava, Slovakia, 15–18 September 2020; Springer: Cham, Switzerland, 2020; pp. 761–773. [Google Scholar]
- Mazurowski, M.A.; Clark, K.; Czarnek, N.M.; Shamsesfandabadi, P.; Peters, K.B.; Saha, A. Radiogenomics of lower-grade glioma: Algorithmically-assessed tumor shape is associated with tumor genomic subtypes and patient outcomes in a multi-institutional study with The Cancer Genome Atlas data. J.-Neuro-Oncol. 2017, 133, 27–35. [Google Scholar] [CrossRef] [PubMed]
- Sheller, M.J.; Reina, G.A.; Edwards, B.; Martin, J.; Bakas, S. Multi-institutional deep learning modeling without sharing patient data: A feasibility study on brain tumor segmentation. In Proceedings of the International MICCAI Brainlesion Workshop, Granada, Spain, 16 September 2018; Springer: Cham, Switzerland; pp. 92–104. [Google Scholar]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Van Leemput, K.; et al. The multimodal brain tumor image segmentation benchmark (BRATS). IEEE Trans. Med. Imaging 2014, 34, 1993–2024. [Google Scholar] [CrossRef] [PubMed]
- Sheller, M.J.; Edwards, B.; Reina, G.A.; Martin, J.; Pati, S.; Kotrotsou, A.; Milchenko, M.; Xu, W.; Marcus, D.; Bakas, S.; et al. Federated learning in medicine: Facilitating multi-institutional collaborations without sharing patient data. Sci. Rep. 2020, 10, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Sheller, M.; Edwards, B.; Reina, G.A.; Martin, J.; Bakas, S. NIMG-68. Federated Learning in Neuro-Oncology for Multi-Institutional Collaborations without Sharing Patient Data. Neuro-Oncol. 2019, 21 (Suppl. S6), vi176–vi177. [Google Scholar] [CrossRef]
- Cai, X.; Lan, Y.; Zhang, Z.; Wen, J.; Cui, Z.; Zhang, W. A many-objective optimization based federal deep generation model for enhancing data processing capability in IoT. IEEE Trans. Ind. Inform. 2021, 19, 561–569. [Google Scholar] [CrossRef]
- Codella, N.C.; Gutman, D.; Celebi, M.E.; Helba, B.; Marchetti, M.A.; Dusza, S.W.; Kalloo, A.; Liopyris, K.; Mishra, N.; Halpern, A. Skin lesion analysis toward melanoma detection: A challenge at the 2017 international symposium on biomedical imaging (isbi), hosted by the international skin imaging collaboration (isic). In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), IEEE, Washington, DC, USA, 4–7 April 2018; pp. 168–172. [Google Scholar]
- Hashmani, M.A.; Jameel, S.M.; Rizvi, S.S.H.; Shukla, S. An adaptive federated machine learning-based intelligent system for skin disease detection: A step toward an intelligent dermoscopy device. Appl. Sci. 2021, 11, 2145. [Google Scholar] [CrossRef]
- Roth, H.R.; Chang, K.; Singh, P.; Neumark, N.; Li, W.; Gupta, V.; Gupta, S.; Qu, L.; Ihsani, A.; Kalpathy-Cramer, J.; et al. Federated learning for breast density classification: A real-world implementation. In Proceedings of the Domain Adaptation and Representation Transfer, and Distributed and Collaborative Learning, Lima, Peru, 4–8 October 2020; Springer: Cham, Switzerland, 2020; pp. 181–191. [Google Scholar]
- Rooijakkers, T. CONVINCED—Enabling Privacy-Preserving Survival Analyses Using Multi-Party Computation; TNO: Hague, The Netherlands, 2020. [Google Scholar]
- Sarma, K.V.; Harmon, S.; Sanford, T.; Roth, H.R.; Xu, Z.; Tetreault, J.; Xu, D.; Flores, M.G.; Ramas, A.G.; Arnold, C.W.; et al. Federated learning improves site performance in multicenter deep learning without data sharing. J. Am. Med. Inform. Assoc. 2021, 28, 1259–1264. [Google Scholar] [CrossRef] [PubMed]
- Deist, T.M.; Dankers, F.J.; Ojha, P.; Marshall, M.S.; Janssen, T.; Faivre-Finn, C.; Masciocchi, C.; Vincenzo, V.; Wang, J.; Dekker, A.; et al. Distributed learning on 20 000+ lung cancer patients—The Personal Health Train. Radiother. Oncol. 2020, 144, 189–200. [Google Scholar] [CrossRef] [PubMed]
- Wang, P.; Shen, C.; Roth, H.R.; Yang, D.; Xu, D.; Oda, M.; Misawa, K.; Chen, P.-T.; Liu, K.-L.; Mori, K.; et al. Automated pancreas segmentation using multi-institutional collaborative deep learning. In Proceedings of the Domain Adaptation and Representation Transfer, and Distributed and Collaborative Learning, MICCAI 2020, Lima, Peru, 4–8 October 2020; Springer: Cham, Switzerland, 2020; pp. 192–200. [Google Scholar]
- Lee, H.; Chai, Y.J.; Joo, H.; Lee, K.; Hwang, J.Y.; Kim, S.M.; Kim, S.-M.; Kim, K.; Nam, I.-C.; Kong, H.J.; et al. Federated learning for thyroid ultrasound image analysis to protect personal information: Validation study in a real health care environment. JMIR Med. Inform. 2021, 9, e25869. [Google Scholar] [CrossRef] [PubMed]
- Choudhury, A.; Theophanous, S.; Lønne, P.I.; Samuel, R.; Guren, M.G.; Berbee, M.; Brown, P.; Lilley, J.; van Soest, J.; Appelt, A.L.; et al. Predicting outcomes in anal cancer patients using multi-centre data and distributed learning—A proof-of-concept study. Radiother. Oncol. 2021, 159, 183–189. [Google Scholar] [CrossRef] [PubMed]
- Bharati, S.; Mondal, M.R.H.; Podder, P.; Prasath, V.S. Federated learning: Applications, challenges and future directions. Int. J. Hybrid Intell. Syst. 2022, 18, 19–35. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Pham, Q.V.; Pathirana, P.N.; Ding, M.; Seneviratne, A.; Lin, Z.; Dobre, O.; Hwang, W.J. Federated learning for smart healthcare: A survey. ACM Comput. Surv. (CSUR) 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Lo, S.K.; Lu, Q.; Wang, C.; Paik, H.Y.; Zhu, L. A systematic literature review on federated machine learning: From a software engineering perspective. ACM Comput. Surv. (CSUR) 2021, 54, 1–39. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Jiang, Y.; Konečný, J.; Rush, K.; Kannan, S. Improving federated learning personalization via model agnostic meta learning. arXiv 2019, arXiv:1909.12488. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Horizontal Transfer Learning | Vertical Transfer Learning | Federated Transfer Learning | |
|---|---|---|---|
| Data Distribution Similarity | Same | Different | Different |
| Output/Label Space Similarity | Different | Same | Same |
| Type of Task | Single task | Single ask | Federated task |
| Taxonomy | Category | Structure | Advantages |
|---|---|---|---|
| Data partitioning | Horizontal FL | Different parties and similar data features | Holds larger variety of parties |
| Vertical FL | Similar parties and different data features | Holds larger variety of data features | |
| Federated transfer learning | Different parties and different data features | Holds larger variety of parties and data features | |
| Machine learning models | Linear models | Linear regression, ride regression, lasso regression | Ease of implementation |
| Decision tree | gradient boosting, decision trees, random forests | Accurate, stable, and can map non-linear relationships | |
| Neural networks | - | Learning capabilities, highly robust and fault-tolerant | |
| Privacy mechanisms | Model aggregation | Central manager learns by aggregating the locally trained model | Avoid transmitting original data |
| Cryptographic methods | Using encryption algorithms such as homomorphic encryption and secure multi party computation (SMC) to encrypt the messages exchanged among parties | Enables the calculation and processing of encrypted data | |
| Differential privacy | Reducing the impact of a single data record on the calculation of the global model | Reduce the effect of data poisoning attacks | |
| Methods for solving heterogeneity | Asynchronous communication sampling | To resolve the heterogeneity of parties | Solve the problem of communication delays and avoid simultaneous training with heterogeneity of parties |
| Fault-tolerant mechanism | To resolve the failure of parties | Prevent whole system from collapsing if one of the parties failed | |
| Heterogeneous model | To resolve the heterogeneity of data | Resolve the issue of models diversity | |
| Communication architecture | Centralized design | Architecture controlled by a central aggregation manager/server | Reduces communication cost |
| Decentralized design | Communication performed among parties without the existence of a central manager/server | Reduces the risk of backdoor attacks | |
| Scale of federation | Cross-silo FL | Parties are less in number, hold large amounts of data and equipped with high computation power | Fits for FL among institutions |
| Cross-device FL | Parties are high in number, hold less amount of data and equipped with less computation power | Fits for FL among individuals | |
| Motivation of federation | Regulations | Motivated by laws such as GDPR and others | |
| Incentives | Motivated by desire of updating some services | Enhancing ML services |
| Ref# | Year | Given Name | Model Aggregation | Convergence Reduction | Heterogeneity | Security | Communication Cost | Computation Cost | Fault Tolerance | Learning Quality | Scalability | Personalization |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [30] | 2017 | FedAVG | ✓ | |||||||||
| [66] | 2017 | - | ✓ | ✓ | ||||||||
| [67] | 2019 | RFA | ✓ | ✓ | ||||||||
| [68] | 2020 | SCAFFOLD | ✓ | ✓ | ✓ | |||||||
| [69] | 2020 | FedOPTFedADAGARFedYOGIFedADAM | ✓ | ✓ | ✓ | |||||||
| [70] | 2020 | FedBoost | ✓ | |||||||||
| [71] | 2020 | FedProx | ✓ | ✓ | ||||||||
| [72] | 2020 | FedMA | ✓ | ✓ | ||||||||
| [73] | 2020 | - | ✓ | ✓ | ✓ | |||||||
| [74] | 2020 | - | ✓ | ✓ | ||||||||
| [75] | 2020 | - | ✓ | ✓ | ||||||||
| [76] | 2020 | LAQ | ✓ | |||||||||
| [77] | 2020 | SAFA | ✓ | ✓ | ✓ | ✓ | ||||||
| [78] | 2021 | FedDist | ✓ | ✓ | ||||||||
| [79] | 2021 | FEDHQ | ✓ | ✓ | ||||||||
| [80] | 2021 | FAIR | ✓ | ✓ | ||||||||
| [81] | 2021 | FedPSO | ✓ | ✓ | ||||||||
| [82] | 2021 | LEGATO | ✓ | ✓ | ✓ | ✓ | ||||||
| [83] | 2021 | MHAT | ✓ | ✓ | ✓ | |||||||
| [84] | 2021 | - | ✓ | |||||||||
| [85] | 2021 | - | ✓ | ✓ | ✓ | |||||||
| [86] | 2021 | SEAR | ✓ | ✓ | ||||||||
| [87] | 2021 | Turbo-Aggregate | ✓ | ✓ | ✓ | |||||||
| [88] | 2022 | EPPDA | ✓ | ✓ | ||||||||
| [89] | 2022 | FedBuff | ✓ | |||||||||
| [90] | 2022 | HeteroSAg | ✓ | ✓ | ✓ | |||||||
| [91] | 2022 | LightSecAgg | ✓ | ✓ |
| Ref | Year | Type | Parameter Studied | Predicted outcome | Model | FL Architecture | Contribution | Dataset Used | Performance |
|---|---|---|---|---|---|---|---|---|---|
| 2018 | Classification | Electronic health records | Hospitalization for CVD patients | Federated optimization scheme (cPDS) for solving sparse support vector machine | Scalability Privacy | Electronic heart records from the Boston Medical Center | Best 0.78 AUC | ||
| 2020 | Regression | Heart rate | Heart rate | Federated; earning based on sequential Bayesian method (FD Seq Bayes) Empirical Bayes-based hierarchical Bayesian method (FD HBayes-EB) | Centralized Decentralized | Privacy Scalability | Private | - | |
| 2021 | Regression | Blood pressure | Blood pressure | Time-series-to-time-series generative adversarial network (T2T-GAN) (based on LSTM) | Centralized | Novelty Privacy | Cuff-Less blood pressure estimation [106] University of Queensland vital signs dataset [107] | Mean error of 2.95 mmHg and a standard deviation of 19.33 mmHg | |
| 2021 | Classification | ECG | Arrythmias | Customized alignment Model | Centralized | Personalization Privacy | Private | Accuracy: 87.85% | |
| 2021 | Classification | Electronic health records | Cardiovascular risk | Sequential pattern mining (SPM) Based Framework | Centralized Decentralized | Privacy | Nursing Electronic Learning Laboratory (NeLL) | - | |
| 2022 | Classification | ECG | Arrythmias | 1D-convolutional neural Networks | Centralized | Privacy Explainability Communication cost reduction Personalization | MIT-BIH arrhythmia Database [111] | Accuracy: 98:9% | |
| 2022 | Classification | Cardiovascular magnetic resonance images | Hypertrophic cardiomyopathy | 3D-convolutional neural networks | Centralized | Privacy | M&M challenge [113] ACDC challenge [114] | Best 0.89 AUC |
| Ref | Model | Data Used | Performance |
|---|---|---|---|
| [116] | FL deep neural network | SFU prototype swept-source OCTA RTVue XR Avanti (OptoVue, Inc.) Angioplex (Carl Zeiss Meditec) PLEX Elite 9000 (Carl Zeiss Meditec) | Performance is comparable to conventional DL models |
| [117] | Not identified | Health Facts EMR Data dataset from Cerner | Performance is similar to the gold standard of centralized learning |
| [118] | FL convolutional neural network (CNN) FL multilayer perceptron (MLP) | Generated by simulator | FL-CNN recall: 99.24% FL-MLP recall: 98.69% performed better than traditional DL |
| [119] | Not identified | Fine-Grained Annotated Diabetic Retinopathy (FGADR) dataset [120] | Accuracy: 72% |
| [121] | Not identified | Private data collected from different healthcare facilities | - |
| [122] | Standard FL FedAVG FedProx | EyePACS [123] Messidor [124] IDRID [125] APTOS [126] University of Auckland (UoA) [127] | Standard FL Accuracy: 92.19% FedAVG Accuracy: 90.07% FedProx Accuracy: 85.81% |
| Ref | Disease | Data Used | Performance |
|---|---|---|---|
| [130] | Brain tumor | Brain MRI Segmentation Kaggle dataset [131] | FL results outperform the baseline but classical ML models competed with their results |
| [132] | Brain tumor | BraTS dataset [133] | Dice = 0.86 for both FL and ML scenarios |
| [134] | Brain tumor | BraTS dataset [133] | FL performance is similar to ML models |
| [135] | Brain tumor | Private data | Dice=0.86 for both FL and ML scenarios |
| [136] | Skin cancer | ISIC 2018 dataset [137] | Accuracy = 91% for both FL and ML scenarios |
| [138] | Skin cancer | ISIC 2019 Dermoscopy dataset [137] | Accuracy: 89% which outperformed previous implementations |
| [139] | Breast cancer | Private data from 7 different institutions | FL perform 6.3% on average better than classical ML |
| [140] | Breast cancer | Obtained from Netherlands Cancer Registry (NCR) | Not available |
| [141] | Prostate cancer | Private data | FL model exhibited superior performance and generalizability to the ML models |
| [142] | Lung cancer | Private data from 8 institutes across 5 countries | Not available |
| [143] | Pancreatic cancer | Data from hospitals in Japan and Taiwan | FL models have higher generalizability than ML models |
| [144] | Thyroid cancer | Private data from 6 institutions | DL models outperformed FL models |
| [145] | Anal cancer | Private data from 3 institutions | Not available |
| Ref | Disease | FL Beats ML (Performance) | Real-World Implementation | Disease-Oriented | Wearable |
|---|---|---|---|---|---|
| [103] | CVDs | No | No | No | No |
| [104] | No | Yes | No | Yes | |
| [105] | No | No | No | No | |
| [108] | No | No | No | No | |
| [109] | No | No | Yes | No | |
| [110] | Yes | No | No | No | |
| [112] | No | No | No | No | |
| [116] | Diabetes | Yes | No | Yes | No |
| [117] | Same | No | Yes | No | |
| [118] | Yes | No | Yes | No | |
| [119] | No | No | Yes | No | |
| [121] | Not available | No | Yes | No | |
| [122] | Yes | No | Yes | No | |
| [130] | Cancer | Yes | No | Yes | No |
| [132] | Same | No | Yes | No | |
| [134] | Same | No | Yes | No | |
| [135] | Same | No | Yes | No | |
| [136] | Same | No | Yes | No | |
| [138] | Yes | No | Yes | No | |
| [139] | Yes | No | Yes | No | |
| [140] | Not available | No | Yes | No | |
| [141] | Yes | No | Yes | No | |
| [142] | Not available | No | Yes | No | |
| [143] | No | No | Yes | No | |
| [144] | No | No | Yes | No | |
| [145] | Not available | No | Yes | No |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moshawrab, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Reviewing Federated Machine Learning and Its Use in Diseases Prediction. Sensors 2023, 23, 2112. https://doi.org/10.3390/s23042112
Moshawrab M, Adda M, Bouzouane A, Ibrahim H, Raad A. Reviewing Federated Machine Learning and Its Use in Diseases Prediction. Sensors. 2023; 23(4):2112. https://doi.org/10.3390/s23042112
Chicago/Turabian StyleMoshawrab, Mohammad, Mehdi Adda, Abdenour Bouzouane, Hussein Ibrahim, and Ali Raad. 2023. "Reviewing Federated Machine Learning and Its Use in Diseases Prediction" Sensors 23, no. 4: 2112. https://doi.org/10.3390/s23042112
APA StyleMoshawrab, M., Adda, M., Bouzouane, A., Ibrahim, H., & Raad, A. (2023). Reviewing Federated Machine Learning and Its Use in Diseases Prediction. Sensors, 23(4), 2112. https://doi.org/10.3390/s23042112