
Federated Learning for Predictive Maintenance and Anomaly Detection Using Time Series Data Distribution Shifts in Manufacturing Processes


Abstract
:1. Introduction
- It increases the load on the central server. When a large amount of data from multiple locations is sent to a centralized server in real time, the data processing volume becomes very large and may exceed the processing power of the central server or cause network bottlenecks. This can result in delays or loss of data, which can reduce the performance of the real-time predictive maintenance system.
- Data security issues may arise. In a centralized system, all data are sent to a central server for processing, which can lead to data security and privacy issues. Critical manufacturing process data or confidential information can be exposed, and data leaks can occur if malicious actors are involved. This can lead to a decrease in competitiveness or even costly losses for the organization [5].
- Proposal of a federated learning framework that considers time series data distribution shifts.
- Proposal of a 1DCNN-Bilstm model for time series anomaly detection and predictive maintenance of manufacturing processes.
2. Related Work
2.1. Manufacturing Processes
- Fluid transfer: Pumps are responsible for transferring liquids or gases to a desired location. They are essential for accurately and efficiently moving a variety of fluids, such as raw materials, byproducts, and solvents, in manufacturing processes.
- Pressure maintenance: Some processes require a constant specific pressure. Pumps keep liquids or gases at a specific pressure, which allows stable and efficient processes.
- Mixing and separation: Some processes require mixing or separating multiple fluids. Pumps can perform these tasks, mixing fluids in the correct proportions or separating the desired components.
- Mechanical failure: When parts inside a pump wear out or break, it can cause the pump to perform poorly or stop. Examples include worn shafts and bearings, leaking seals, and broken rotors or inverters.
- Fluid-related issues: Impurities, solid particles, and corrosion from the fluid handled by the pump can build up inside the pump and affect its performance. This can impede fluid flow or damage components.
- Changes in operating conditions: Such changes can put stress on the pump. For example, fluctuations in the temperature, pressure, and flow rate of the fluid can overload the pump or make it unsuitable for the operating conditions.
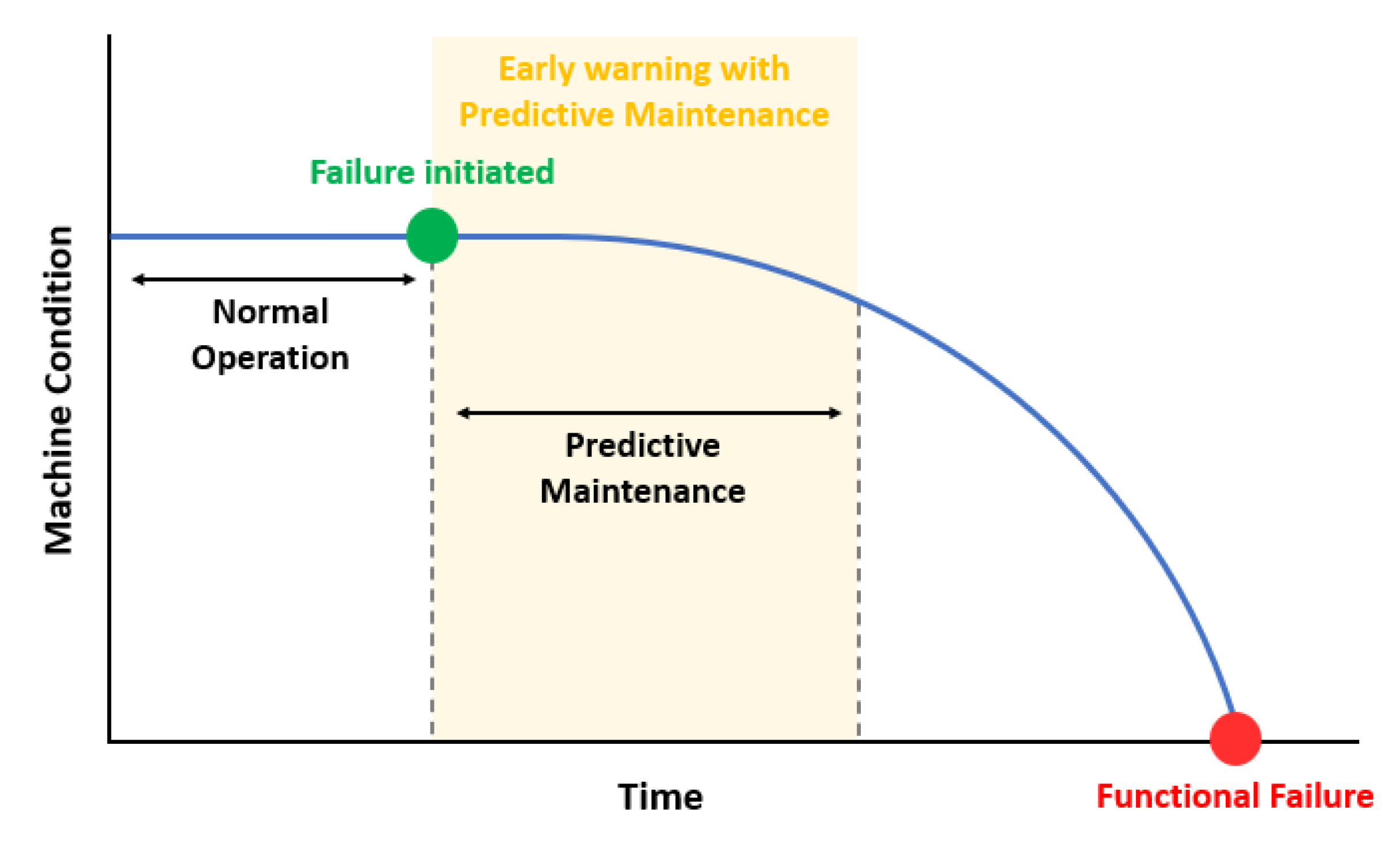
2.2. Predictive Maintenance
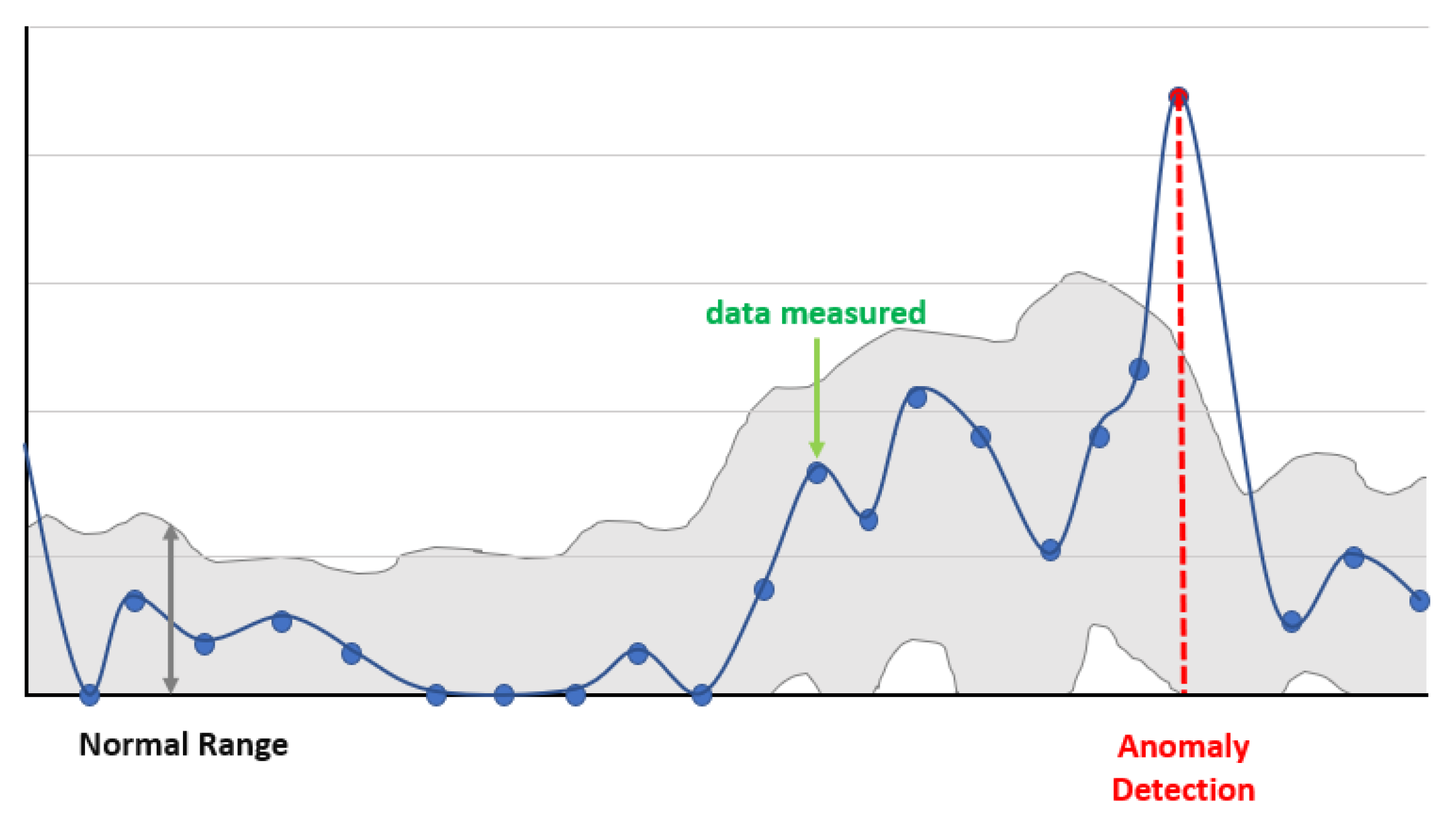
2.3. Anomaly Detection
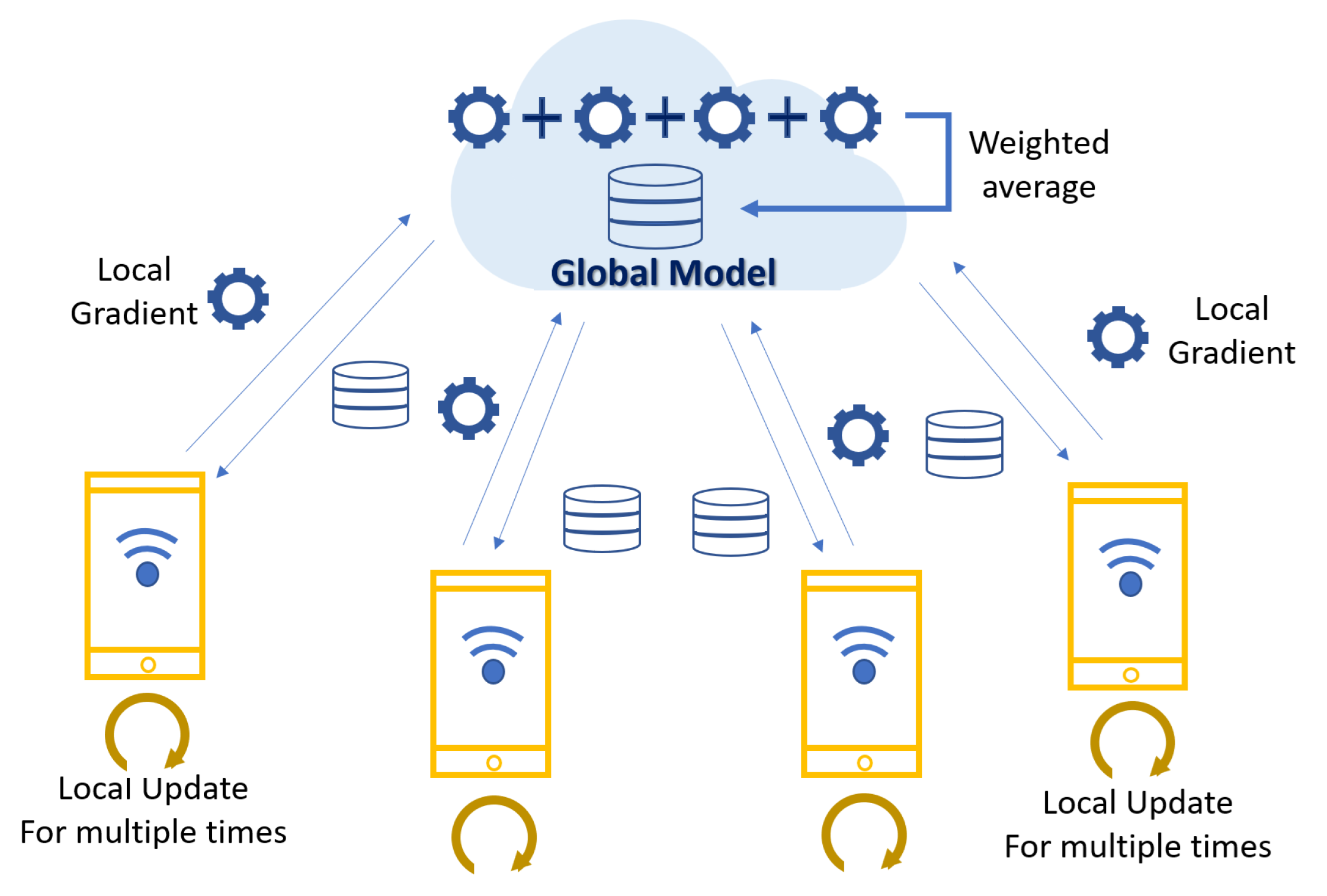
2.4. Federated Learning
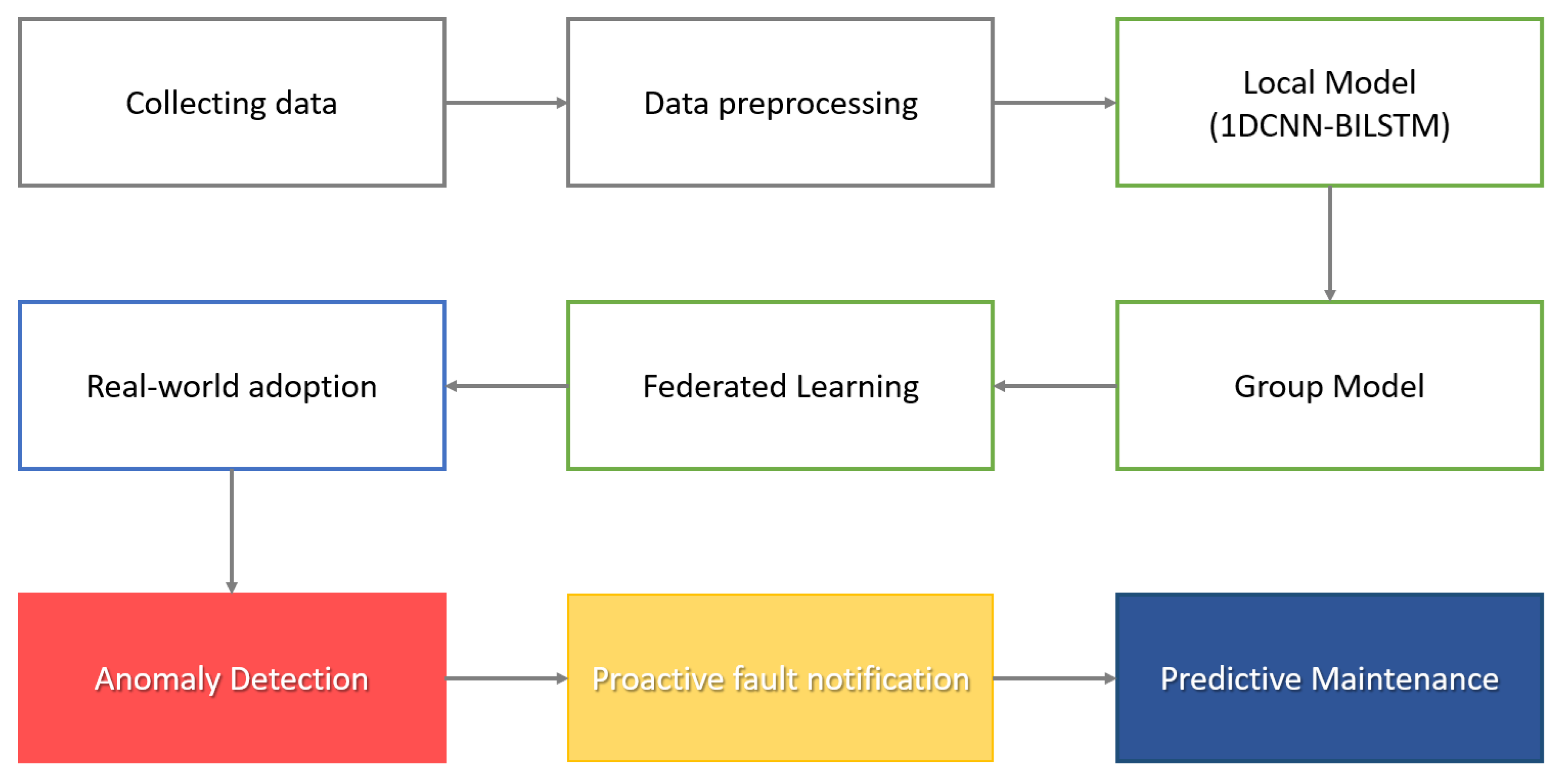
3. Federated Learning for Predictive Maintenance and Anomaly Detection
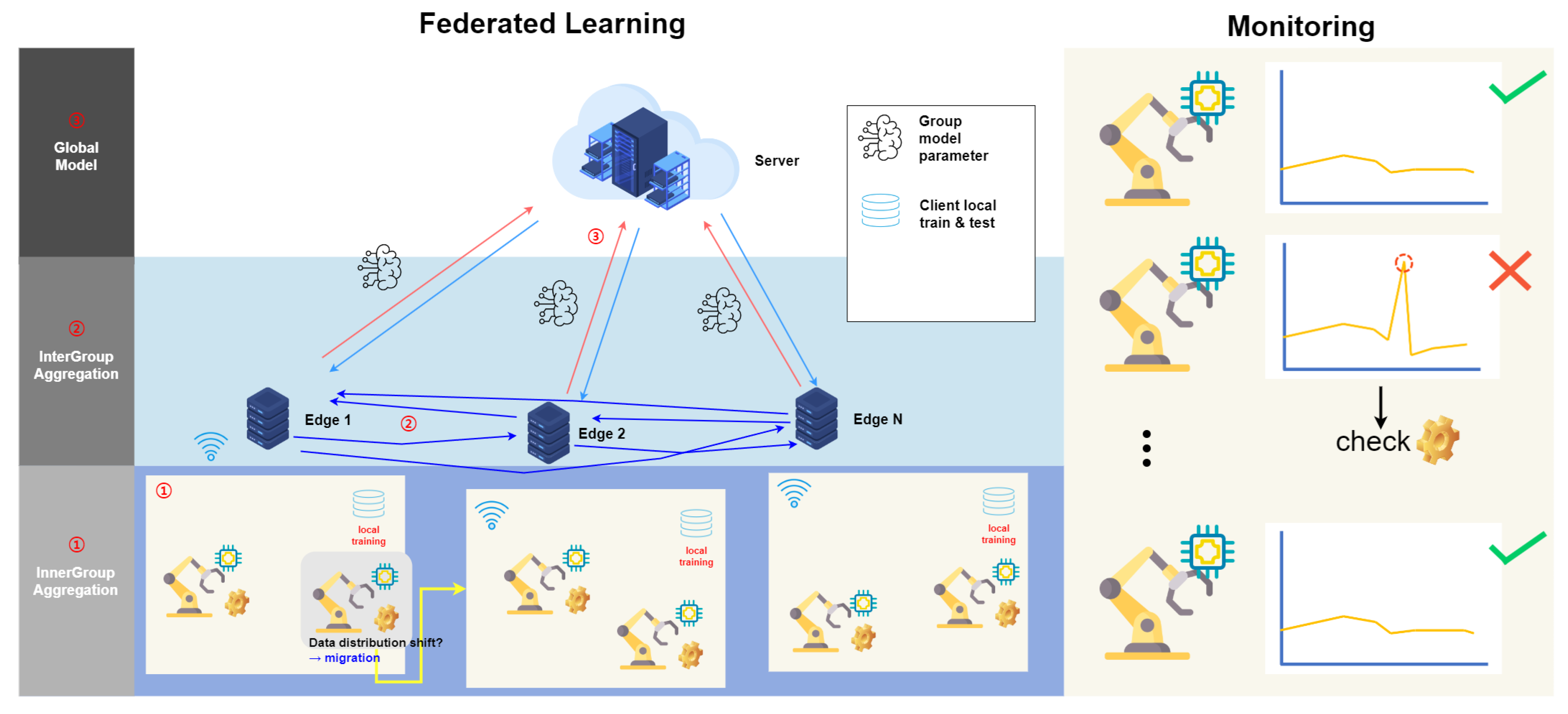
3.1. Overall Architecture
- Client:Each client has its own local dataset, which consists of data collected in a specific environment. The client trains its local model using its own dataset. The training is customized to the client’s environment, and the trained model is used for the client’s updater. Updates to the trained local model are sent to the group or secondary server. The updates contribute to the model global update through intra-group and inter-group aggregation.
- Groups:Grouping clusters clients into groups with similar characteristics. This allows similar model updates within the group. The model updates of the clients in the group are aggregated to train the group model. This takes into account the characteristics of the clients in the group, and the group model is used to initialize client updates. This model aggregates the updaters of the clients in the group to form a global model update.
- Auxiliary Server:The auxiliary server provides the group with an initial model and optimization di- rection and serves as a starting point for the group to begin training its local model. This server receives aggregated updates from within the group, performs inter-group aggregation, and combines updates from group models to form a global model of the entire system. The auxiliary server designs an algorithm for cold-starting new participants and to determine how new clients are assigned to groups to start learning.
3.2. Time Series Data Distribution Shifts
3.3. Anomaly Detection Model
- Data preprocessingFor data preprocessing, the relationship between variables is assessed through correlation analysis of data columns. Then, outliers and missing values in the data are detected and removed or replaced. PCA is used to reduce the dimensionality of the data by extracting principal components considering the correlation between variables. Since Bi-LSTM has a three-dimensional shape in the form of samples, time steps, and features, it converts the data into a sequence through a sliding window. In the sliding window, the step is set to 1/2 of the window size to reduce duplicate data.
- 1DCNN-BiLSTMThe layers of the model consist of a 1D convolution layer, maxpooling, dropout, two Bi-LSTM layers, and two hidden layers.
- 1DCNNTo extract fine-grained features of a time series, we use a one-dimensional convolutional neural network (1D CNN) on the input data using a filter. The resulting value is calculated as an output value through an activation function that uses the Rectified Linear Unit (ReLU) function. Through this process, local features of the input data are extracted and used to learn global features. After that, the size of the output value is reduced in the maxpooling layer, and the performance is improved by preventing overfitting in the dropout layer.
- BiLSTMBidirectional LSTM is used to detect anomalies in time series data. BiLSTM processes the input sequence in both directions, allowing it to take into account both the information before and after the sequence. The BiLSTM computes the input sequence as a forward hidden sequence and a backward hidden sequence in opposite directions, with each LSTM sharing equal weights in the forward and backward propagation process. The encoded vector is formed by concatenation of the final forward and backward outputs, , where ht is a vector of size 2 X h, and h is the hidden state size of the LSTM [38].The output from Bilstm was processed through a dense layer and a dropout layer, and the final output was used for anomaly detection using the softmax function.
4. Experiment and Results
4.1. Experiment Environments
4.2. Dataset
4.2.1. Data Definition and Introduction
4.2.2. Data Preprocessing
4.2.3. Data Separation
4.2.4. Learning Path for Predictive Maintenance
4.3. Performance Metrics
4.3.1. Weighted Accuracy
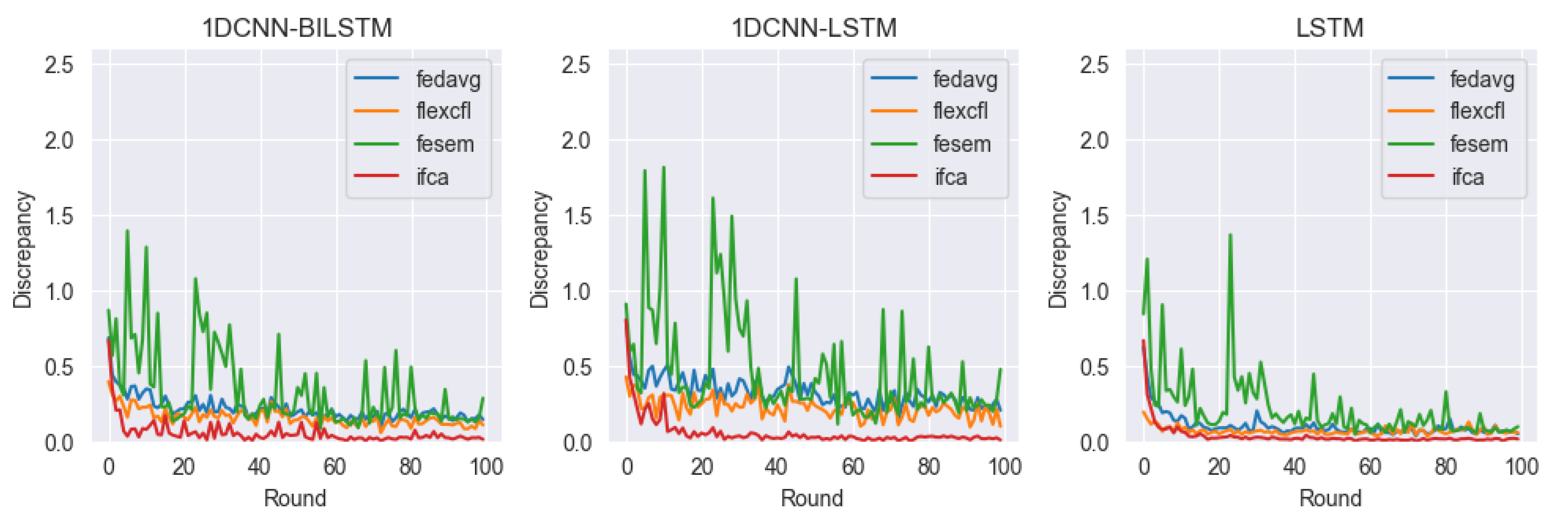
4.3.2. Data Discrepancy
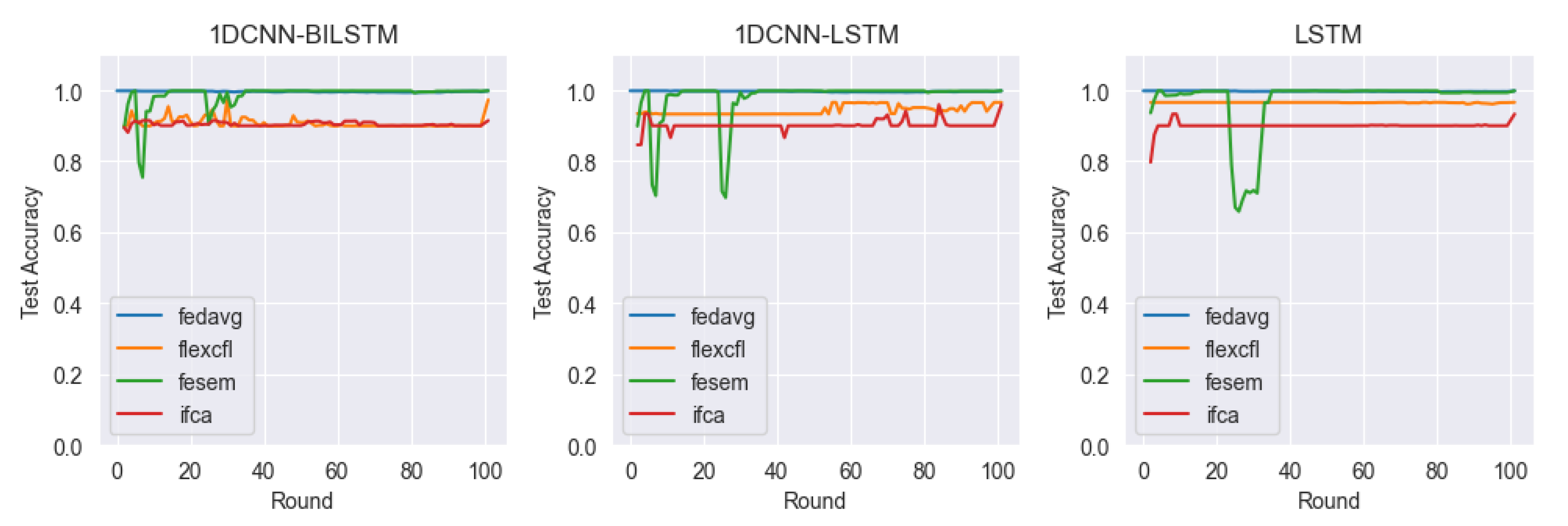
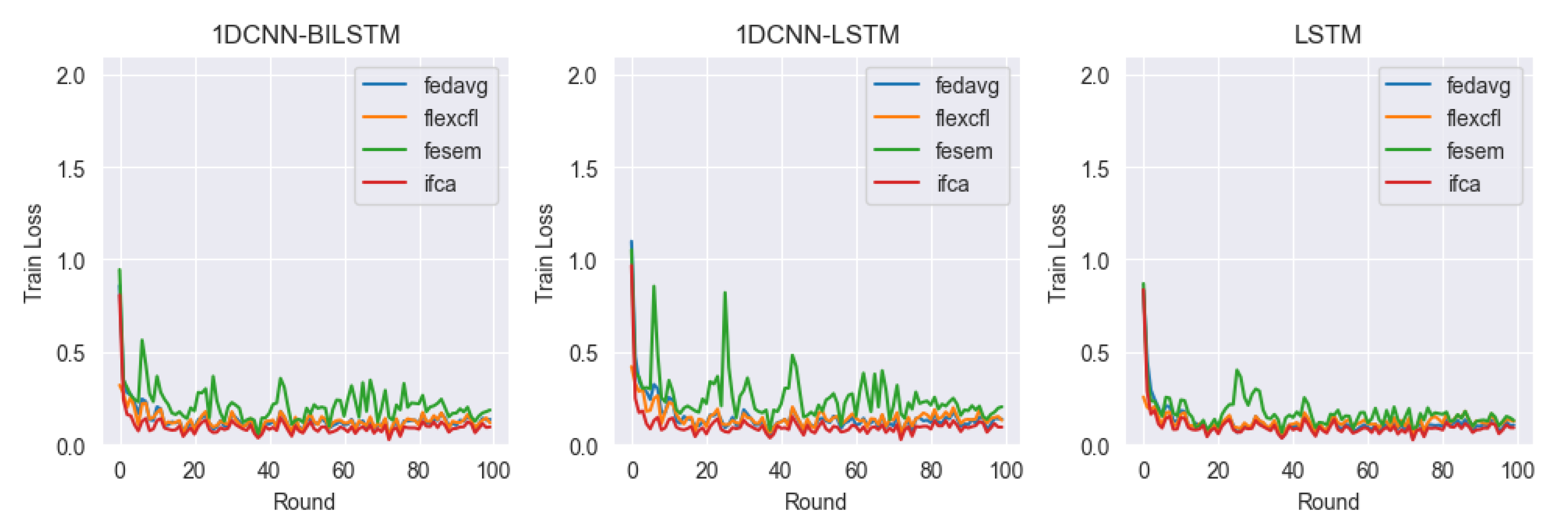
4.4. Results
- FedAvg: Vanilla FL framework. A federated learning framework that performs local training of clients in parallel and averages the central model [31].
- IFCA: A framework that optimizes model parameters for user clusters via gradient descent while estimating the user’s cluster ID [39].
- FeSEM: A distance-based CFL framework that probabilistically minimizes the expected disagreement between ℓ2 clients and groups [40].
4.4.1. Test Accuracy
4.4.2. Train Loss
4.4.3. Discrepancy
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Poor, H.V. Federated learning for internet of things: A comprehensive survey. IEEE Commun. Surv. Tutor. 2021, 23, 1622–1658. [Google Scholar] [CrossRef]
- Scheffer, C.; Girdhar, P. Practical Machinery Vibration Analysis and Predictive Maintenance; Elsevier: Amsterdam, The Netherlands, 2004. [Google Scholar]
- Patel, P.; Ali, M.I.; Sheth, A. On using the intelligent edge for IoT analytics. IEEE Intell. Syst. 2017, 32, 64–69. [Google Scholar] [CrossRef]
- Ali, M.I.; Patel, P.; Breslin, J.G. Middleware for real-time event detection andpredictive analytics in smart manufacturing. In Proceedings of the 2019 15th International Conference on Distributed Computing in Sensor Systems (DCOSS), Santorini, Greece, 29–31 May 2019; pp. 370–376. [Google Scholar]
- Jiang, J.C.; Kantarci, B.; Oktug, S.; Soyata, T. Federated learning in smart city sensing: Challenges and opportunities. Sensors 2020, 20, 6230. [Google Scholar] [CrossRef] [PubMed]
- Xu, G.; Liu, M.; Wang, J.; Ma, Y.; Wang, J.; Li, F.; Shen, W. Data-driven fault diagnostics and prognostics for predictive maintenance: A brief overview. In Proceedings of the 2019 IEEE 15th International Conference on Automation Science and Engineering (CASE), Vancouver, BC, Canada, 22–26 August 2019; pp. 103–108. [Google Scholar]
- Khan, L.U.; Saad, W.; Han, Z.; Hossain, E.; Hong, C.S. Federated learning for internet of things: Recent advances, taxonomy, and open challenges. IEEE Commun. Surv. Tutor. 2021, 23, 1759–1799. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Harth, N.; Anagnostopoulos, C.; Voegel, H.J.; Kolomvatsos, K. Local & Federated Learning at the network edge for efficient predictive analytics. Future Gener. Comput. Syst. 2022, 134, 107–122. [Google Scholar]
- Pruckovskaja, V.; Weissenfeld, A.; Heistracher, C.; Graser, A.; Kafka, J.; Leputsch, P.; Schall, D.; Kemnitz, J. Federated Learning for Predictive Maintenance and Quality Inspection in Industrial Applications. arXiv 2023, arXiv:2304.11101. [Google Scholar]
- Karassik, I.J.; Messina, J.P.; Cooper, P.; Heald, C.C. Pump Handbook; McGraw-Hill Education: Berkshire, UK, 2008. [Google Scholar]
- Fausing Olesen, J.; Shaker, H.R. Predictive maintenance for pump systems and thermal power plants: State-of-the-art review, trends and challenges. Sensors 2020, 20, 2425. [Google Scholar] [CrossRef]
- Randall, R.B. Vibration-Based Condition Monitoring: Industrial, Automotive and Aerospace Applications; John Wiley & Sons: Hoboken, NJ, USA, 2021. [Google Scholar]
- Costa, V.L.; Eberhardt, B.; Chen, J.; Roßmann, J. Towards Predictive Maintenance: An Edge-based Vibration Monitoring System in Industry 4.0. In Proceedings of the 2023 International Conference on Sustainable Computing and Data Communication Systems (ICSCDS), Erode, India, 23–25 March 2023; pp. 1430–1437. [Google Scholar]
- Chong, K.E.; Ng, K.C.; Goh, G.G.G. Improving Overall Equipment Effectiveness (OEE) through integration of Maintenance Failure Mode and Effect Analysis (maintenance-FMEA) in a semiconductor manufacturer: A case study. In Proceedings of the 2015 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Singapore, 6–9 December 2015; pp. 1427–1431. [Google Scholar]
- Achouch, M.; Dimitrova, M.; Ziane, K.; Sattarpanah Karganroudi, S.; Dhouib, R.; Ibrahim, H.; Adda, M. On predictive maintenance in industry 4.0: Overview, models, and challenges. Appl. Sci. 2022, 12, 8081. [Google Scholar] [CrossRef]
- Kim, J.; Kim, D.; Je, S.; Lee, J.; Kim, D.; Ji, S. A Study on the Establishment of Prediction Conservation System for Smart Factory Facilities. In Proceedings of the Proceedings of KIIT Conference; Jeju, Republic of Korea, 1–3 December 2022, pp. 703–706.
- Bousdekis, A.; Lepenioti, K.; Apostolou, D.; Mentzas, G. Decision making in predictive maintenance: Literature review and research agenda for industry 4.0. IFAC-PapersOnLine 2019, 52, 607–612. [Google Scholar] [CrossRef]
- Compare, M.; Baraldi, P.; Zio, E. Challenges to IoT-enabled predictive maintenance for industry 4.0. IEEE Internet Things J. 2019, 7, 4585–4597. [Google Scholar] [CrossRef]
- Servetnyk, M.; Fung, C.C.; Han, Z. Unsupervised federated learning for unbalanced data. In Proceedings of the GLOBECOM 2020-2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Haq, I.U.; Anwar, S.; Khan, T. Machine Vision Based Predictive Maintenance for Machine Health Monitoring: A Comparative Analysis. In Proceedings of the 2023 International Conference on Robotics and Automation in Industry (ICRAI), Peshawar, Pakistan, 3–5 March 2023; pp. 1–8. [Google Scholar]
- Marchiningrum, A.U.; Albarda. Digital Twin for Predictive Maintenance of Palm Oil Processing Machines. In Proceedings of the 2022 6th International Conference on Information Technology, Information Systems and Electrical Engineering (ICITISEE), Yogyakarta, Indonesia, 13–14 December 2022; pp. 1–6. [Google Scholar]
- Calikus, E.; Nowaczyk, S.; Sant’Anna, A.; Dikmen, O. No free lunch but a cheaper supper: A general framework for streaming anomaly detection. Expert Syst. Appl. 2020, 155, 113453. [Google Scholar] [CrossRef]
- Mehra, P.; Ahuja, M.S.; Aeri, M. Time Series Anomaly Detection System with Linear Neural Network and Autoencoder. In Proceedings of the 2023 International Conference on Device Intelligence, Computing and Communication Technologies, (DICCT), Dehradun, India, 17–18 March 2023; pp. 659–662. [Google Scholar]
- Li, L.; Yan, J.; Wang, H.; Jin, Y. Anomaly detection of time series with smoothness-inducing sequential variational auto-encoder. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 1177–1191. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Kang, H.; Kang, P. Time-series anomaly detection with stacked Transformer representations and 1D convolutional network. Eng. Appl. Artif. Intell. 2023, 120, 105964. [Google Scholar] [CrossRef]
- Ruff, L.; Vandermeulen, R.; Goernitz, N.; Deecke, L.; Siddiqui, S.A.; Binder, A.; Müller, E.; Kloft, M. Deep one-class classification. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4393–4402. [Google Scholar]
- Ruff, L.; Zemlyanskiy, Y.; Vandermeulen, R.; Schnake, T.; Kloft, M. Self-attentive, multi-context one-class classification for unsupervised anomaly detection on text. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4061–4071. [Google Scholar]
- Ruff, L.; Vandermeulen, R.A.; Görnitz, N.; Binder, A.; Müller, E.; Müller, K.R.; Kloft, M. Deep semi-supervised anomaly detection. arXiv 2019, arXiv:1906.02694. [Google Scholar]
- Cheng, H.; Xu, D.; Yuan, S. Sequential Anomaly Detection with Local and Global Explanations. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; pp. 1212–1217. [Google Scholar]
- Brendan McMahan, H.; Moore, E.; Ramage, D.; Hampson, S.; Agüera y Arcas, B. Communication-efficient learning of deep networks from decentralized data. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- McMahan, B.; Ramage, D. Federated learning: Collaborative machine learning without centralized training data. Google Res. Blog 2017, 3. [Google Scholar]
- Li, L.; Fan, Y.; Tse, M.; Lin, K.Y. A review of applications in federated learning. Comput. Ind. Eng. 2020, 149, 106854. [Google Scholar] [CrossRef]
- Duan, M.; Liu, D.; Ji, X.; Wu, Y.; Liang, L.; Chen, X.; Tan, Y.; Ren, A. Flexible clustered federated learning for client-level data distribution shift. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 2661–2674. [Google Scholar] [CrossRef]
- Chiang, M.; Zhang, T. Fog and IoT: An overview of research opportunities. IEEE Internet Things J. 2016, 3, 854–864. [Google Scholar] [CrossRef]
- Mai, V.S.; La, R.J.; Zhang, T.; Huang, Y.; Battou, A. Federated Learning With Server Learning for Non-IID Data. In Proceedings of the 2023 57th Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 22–24 March 2023; pp. 1–6. [Google Scholar]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated learning in mobile edge networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef]
- Cai, L.; Zhou, S.; Yan, X.; Yuan, R. A stacked BiLSTM neural network based on coattention mechanism for question answering. Comput. Intell. Neurosci. 2019, 2019, 9543490. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, A.; Chung, J.; Yin, D.; Ramchandran, K. An Efficient Framework for Clustered Federated Learning. arXiv 2021, arXiv:2006.04088. [Google Scholar] [CrossRef]
- Xie, M.; Long, G.; Shen, T.; Zhou, T.; Wang, X.; Jiang, J.; Zhang, C. Multi-center federated learning. arXiv 2021, arXiv:2108.08647. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware Environment | Software Environment |
|---|---|
| CPU: AMD Ryzen 7 6800HS | Window 11, Tensorflow 2.11.0 |
| GPU: NVIDIA GeForce RTX 3060 | Python 3.7 |
| Model | FedAVG | FeSEM | IFCA | FlexCFL |
|---|---|---|---|---|
| 1D-BILSTM | 0.998571455 | 0.998552315 | 0.914563614 | 0.972923049 |
| 1D-LSTM | 0.998571455 | 0.998552315 | 0.959681333 | 0.965874879 |
| LSTM | 0.998571455 | 0.998552315 | 0.933049078 | 0.966081691 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahn, J.; Lee, Y.; Kim, N.; Park, C.; Jeong, J. Federated Learning for Predictive Maintenance and Anomaly Detection Using Time Series Data Distribution Shifts in Manufacturing Processes. Sensors 2023, 23, 7331. https://doi.org/10.3390/s23177331
Ahn J, Lee Y, Kim N, Park C, Jeong J. Federated Learning for Predictive Maintenance and Anomaly Detection Using Time Series Data Distribution Shifts in Manufacturing Processes. Sensors. 2023; 23(17):7331. https://doi.org/10.3390/s23177331
Chicago/Turabian StyleAhn, Jisu, Younjeong Lee, Namji Kim, Chanho Park, and Jongpil Jeong. 2023. "Federated Learning for Predictive Maintenance and Anomaly Detection Using Time Series Data Distribution Shifts in Manufacturing Processes" Sensors 23, no. 17: 7331. https://doi.org/10.3390/s23177331