

A Light-Weight Artificial Neural Network for Recognition of Activities of Daily Living


Abstract
1. Introduction
2. Related Work
3. Methods
3.1. Shallow Neural Network
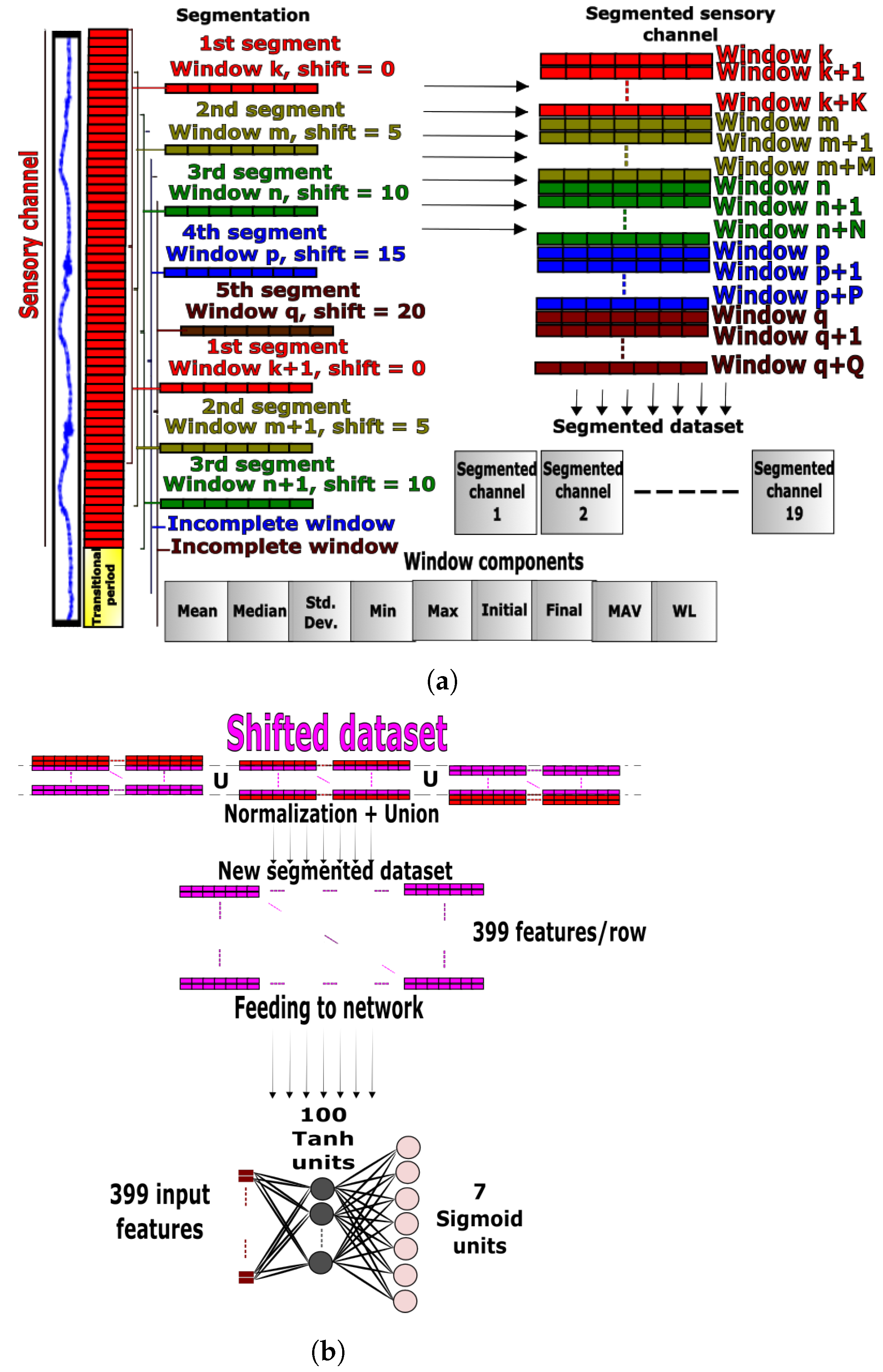
3.1.1. ANN Preprocessing
3.1.2. ANN Design
3.1.3. ANN Training
3.2. Deep Neural Network
3.2.1. DNN Preprocessing
3.2.2. DNN Design and Training
3.3. Convolutional Neural Network
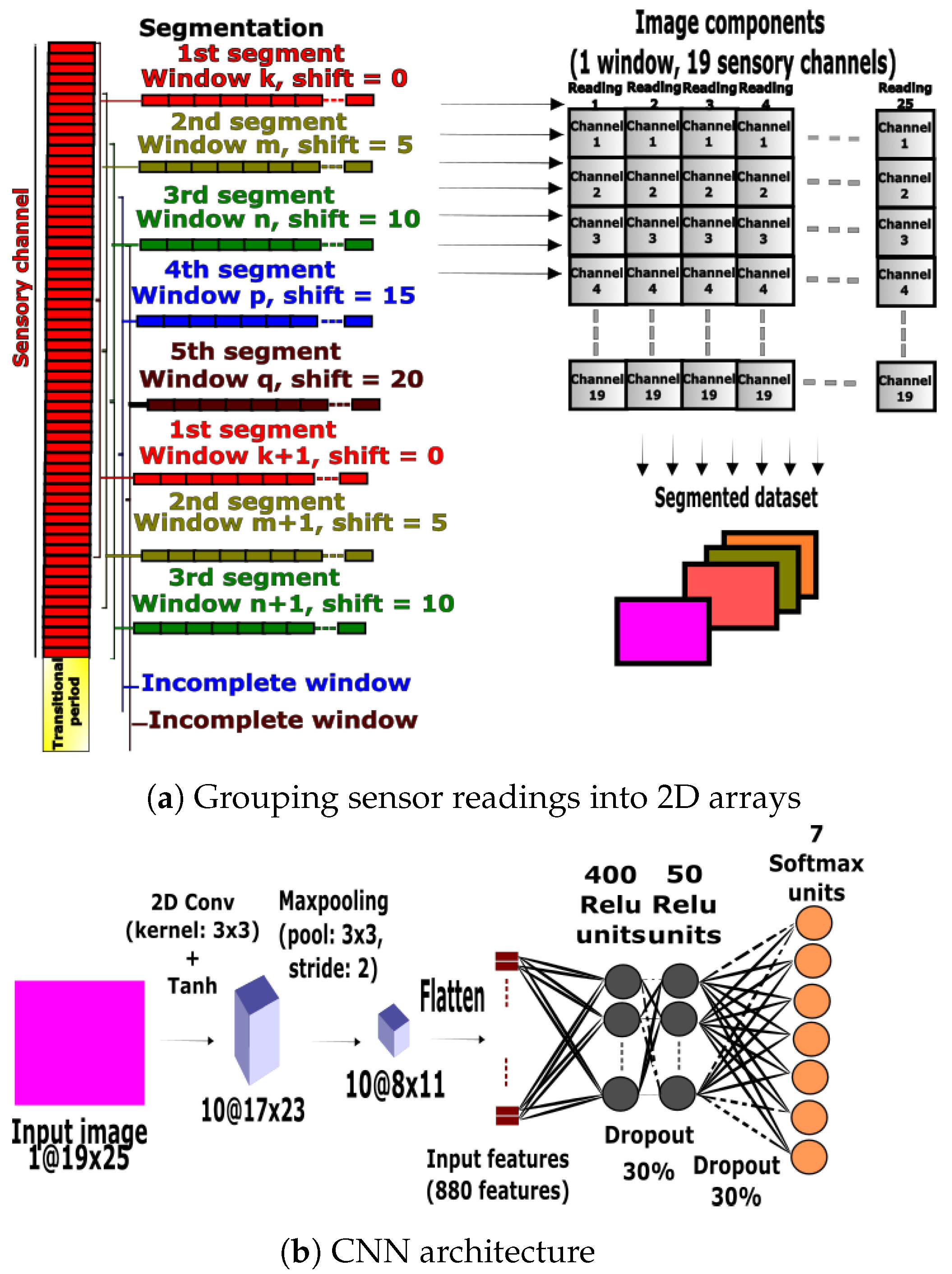
3.3.1. CNN Preprocessing
3.3.2. CNN Design and Training
3.4. Long Short-Term Network
3.4.1. LSTM Preprocessing
3.4.2. LSTM Design and Training
3.5. CNN-LSTM Hybrid Network
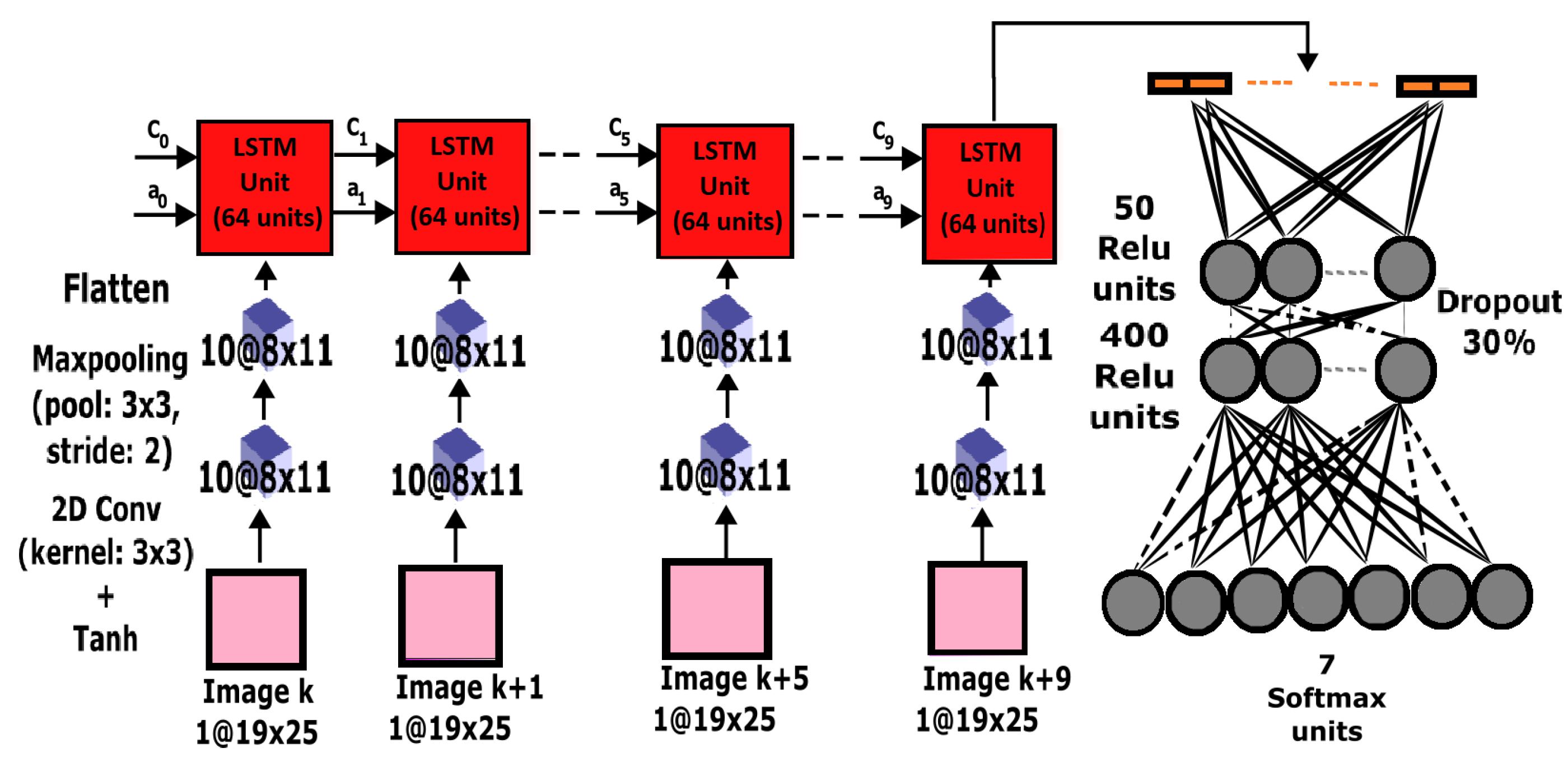
3.5.1. CNN-LSTM Preprocessing
3.5.2. CNN-LSTM Design and Training
4. Results
4.1. Activity Recognition for Seen Subjects
4.1.1. ANN Approach
4.1.2. DNN Approach
4.1.3. CNN Approach
4.1.4. LSTM Approach
4.1.5. CNN-LSTM Approach
4.1.6. Accuracy of Light-Weight ANN on Seen Subjects with Individual and Combined Sensory Channels
4.2. Activity Recognition for Unseen Subjects
4.2.1. ANN Approach
4.2.2. DNN Approach
4.2.3. CNN Approach
4.2.4. LSTM Approach
4.2.5. CNN-LSTM Approach
4.2.6. Accuracy of Light-Weight ANN on Unseen Subjects with Individual and Combined Sensors
5. Discussion
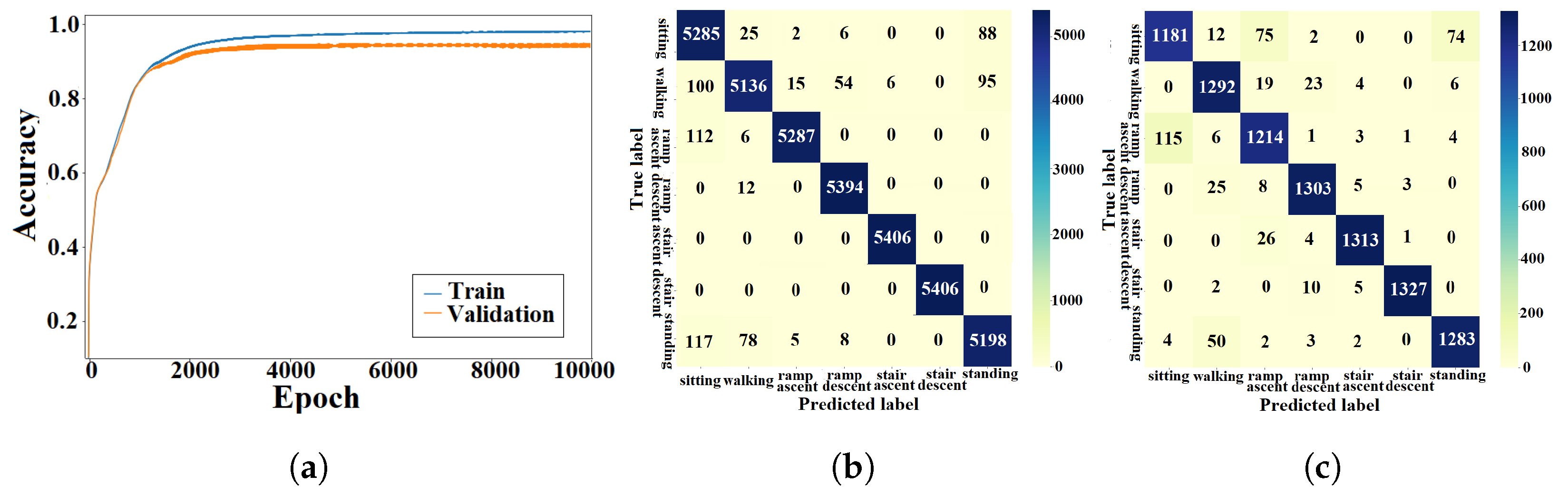
5.1. Classification Accuracy
5.2. Inference Speed
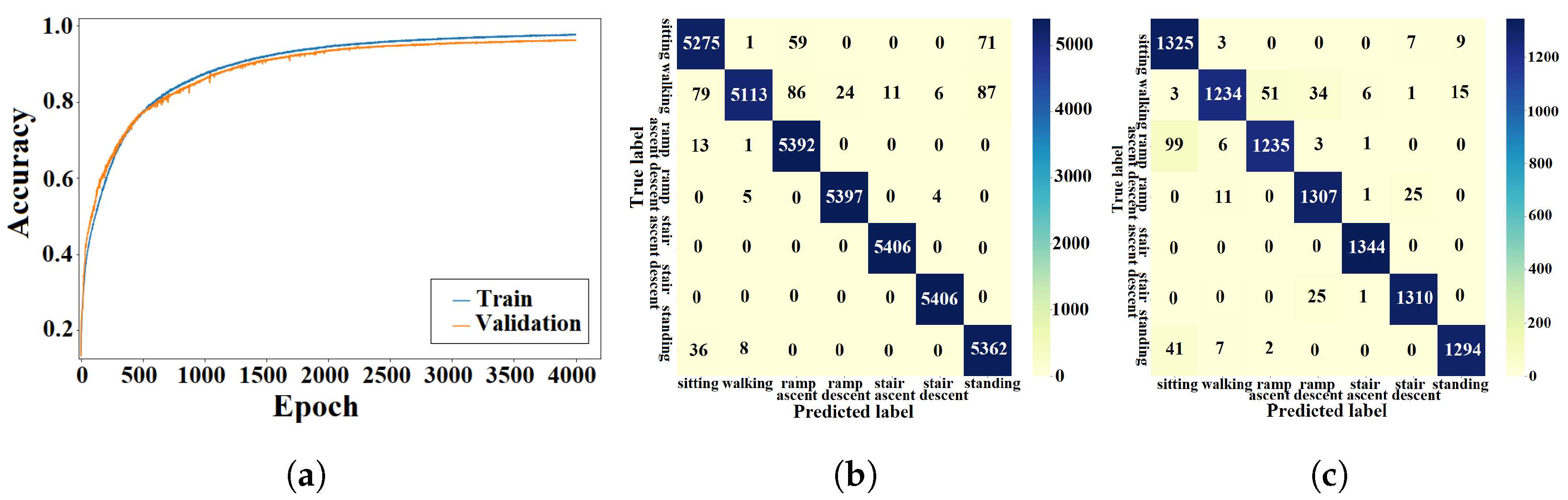
5.3. Confusion Patterns
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Debnath, B.; O’brien, M.; Kumar, S.; Behera, A. A step towards automated functional assessment of activities of daily living. In Multimodal AI in Healthcare; Springer: Berlin/Heidelberg, Germany, 2023; pp. 187–202. [Google Scholar]
- Bartholomé, L.; Winter, Y. Quality of life and resilience of patients with juvenile stroke: A systematic review. J. Stroke Cerebrovasc. Dis. 2020, 29, 105129. [Google Scholar] [CrossRef] [PubMed]
- Thayabaranathan, T.; Kim, J.; Cadilhac, D.A.; Thrift, A.G.; Donnan, G.A.; Howard, G.; Howard, V.J.; Rothwell, P.M.; Feigin, V.; Norrving, B.; et al. Global stroke statistics 2022. Int. J. Stroke 2022, 17, 946–956. [Google Scholar] [CrossRef]
- Chrysanthou, M. The Effect of a Novel Orthosis on Ankle Kinematics in Simulated Sprain. Master’s Thesis, University of Twente, Enschede, The Netherlands, 2020. [Google Scholar]
- Kalita, B.; Narayan, J.; Dwivedy, S.K. Development of active lower limb robotic-based orthosis and exoskeleton devices: A systematic review. Int. J. Soc. Robot. 2021, 13, 775–793. [Google Scholar] [CrossRef]
- Wang, Y.; Cheng, X.; Jabban, L.; Sui, X.; Zhang, D. Motion Intention Prediction and Joint Trajectories Generation Towards Lower Limb Prostheses Using EMG and IMU Signals. IEEE Sens. J. 2022, 22, 10719–10729. [Google Scholar] [CrossRef]
- Ferreira, F.M.R.M.; de Paula Rúbio, G.; Dutra, R.M.A.; Van Petten, A.M.V.N.; Vimieiro, C.B.S. Development of portable robotic orthosis and biomechanical validation in people with limited upper limb function after stroke. Robotica 2022, 40, 4238–4256. [Google Scholar] [CrossRef]
- Voicu, R.A.; Dobre, C.; Bajenaru, L.; Ciobanu, R.I. Human physical activity recognition using smartphone sensors. Sensors 2019, 19, 458. [Google Scholar] [CrossRef] [PubMed]
- Akada, H.; Wang, J.; Shimada, S.; Takahashi, M.; Theobalt, C.; Golyanik, V. UnrealEgo: A New Dataset for Robust Egocentric 3D Human Motion Capture. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–17. [Google Scholar]
- Salis, F.; Bertuletti, S.; Bonci, T.; Caruso, M.; Scott, K.; Alcock, L.; Buckley, E.; Gazit, E.; Hansen, C.; Schwickert, L.; et al. A multi-sensor wearable system for the assessment of diseased gait in real-world conditions. Front. Bioeng. Biotechnol. 2023, 11, 1143248. [Google Scholar] [CrossRef]
- Zhang, Q.; Jin, T.; Cai, J.; Xu, L.; He, T.; Wang, T.; Tian, Y.; Li, L.; Peng, Y.; Lee, C. Wearable Triboelectric Sensors Enabled Gait Analysis and Waist Motion Capture for IoT-Based Smart Healthcare Applications. Adv. Sci. 2022, 9, 2103694. [Google Scholar] [CrossRef]
- Delgado-García, G.; Vanrenterghem, J.; Ruiz-Malagón, E.J.; Molina-García, P.; Courel-Ibáñez, J.; Soto-Hermoso, V.M. IMU gyroscopes are a valid alternative to 3D optical motion capture system for angular kinematics analysis in tennis. Proc. Inst. Mech. Eng. Part J. Sport. Eng. Technol. 2021, 235, 3–12. [Google Scholar] [CrossRef]
- Kim, B.H.; Hong, S.H.; Oh, I.W.; Lee, Y.W.; Kee, I.H.; Lee, S.Y. Measurement of ankle joint movements using imus during running. Sensors 2021, 21, 4240. [Google Scholar] [CrossRef]
- Bangaru, S.S.; Wang, C.; Aghazadeh, F. Data quality and reliability assessment of wearable emg and imu sensor for construction activity recognition. Sensors 2020, 20, 5264. [Google Scholar] [CrossRef]
- Zheng, X.; Wang, M.; Ordieres-Meré, J. Comparison of data preprocessing approaches for applying deep learning to human activity recognition in the context of industry 4.0. Sensors 2018, 18, 2146. [Google Scholar] [CrossRef] [PubMed]
- Hudgins, B.; Parker, P.; Scott, R. A new strategy for multifunction myoelectric control. IEEE Trans. Biomed. Eng. 1993, 40, 82–94. [Google Scholar] [CrossRef] [PubMed]
- Cui, J.W.; Li, Z.G.; Du, H.; Yan, B.Y.; Lu, P.D. Recognition of Upper Limb Action Intention Based on IMU. Sensors 2022, 22, 1954. [Google Scholar] [CrossRef]
- Karakish, M.; Fouz, M.A.; ELsawaf, A. Gait Trajectory Prediction on an Embedded Microcontroller Using Deep Learning. Sensors 2022, 22, 8441. [Google Scholar] [CrossRef]
- Krichen, M.; Mihoub, A.; Alzahrani, M.Y.; Adoni, W.Y.H.; Nahhal, T. Are Formal Methods Applicable to Machine Learning and Artificial Intelligence? In Proceedings of the 2022 2nd International Conference of Smart Systems and Emerging Technologies (SMARTTECH), Riyadh, Saudi Arabia, 9–11 May 2022; pp. 48–53. [Google Scholar] [CrossRef]
- Raman, R.; Gupta, N.; Jeppu, Y. Framework for Formal Verification of Machine Learning Based Complex System-of-Systems. Insight 2023, 26, 91–102. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Hu, B.; Rouse, E.; Hargrove, L. Benchmark datasets for bilateral lower-limb neuromechanical signals from wearable sensors during unassisted locomotion in able-bodied individuals. Front. Robot. AI 2018, 5, 14. [Google Scholar] [CrossRef]
- Caruso, M.; Sabatini, A.M.; Knaflitz, M.; Della Croce, U.; Cereatti, A. Extension of the rigid-constraint method for the heuristic suboptimal parameter tuning to ten sensor fusion algorithms using inertial and magnetic sensing. Sensors 2021, 21, 6307. [Google Scholar] [CrossRef]
- Yan, T.; Cempini, M.; Oddo, C.M.; Vitiello, N. Review of assistive strategies in powered lower-limb orthoses and exoskeletons. Robot. Auton. Syst. 2015, 64, 120–136. [Google Scholar] [CrossRef]
- Kao, P.C.; Lewis, C.L.; Ferris, D.P. Invariant ankle moment patterns when walking with and without a robotic ankle exoskeleton. J. Biomech. 2010, 43, 203–209. [Google Scholar] [CrossRef]
- DeBoer, B.; Hosseini, A.; Rossa, C. A Discrete Non-Linear Series Elastic Actuator for Active Ankle-Foot Orthoses. IEEE Robot. Autom. Lett. 2022, 7, 6211–6217. [Google Scholar] [CrossRef]
- Del Vecchio, A.; Holobar, A.; Falla, D.; Felici, F.; Enoka, R.; Farina, D. Tutorial: Analysis of motor unit discharge characteristics from high-density surface EMG signals. J. Electromyogr. Kinesiol. 2020, 53, 102426. [Google Scholar] [CrossRef]
- Yu, T. On-Line Decomposition of iEMG Signals Using GPU-Implemented Bayesian Filtering. Ph.D. Thesis, École Centrale de Nantes, Nantes, France, 2019. [Google Scholar]
- Castillo, C.S.M.; Wilson, S.; Vaidyanathan, R.; Atashzar, S.F. Wearable MMG-plus-one armband: Evaluation of normal force on mechanomyography (MMG) to enhance human-machine interfacing. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 29, 196–205. [Google Scholar] [CrossRef] [PubMed]
- Hosseini, M.P.; Hosseini, A.; Ahi, K. A review on machine learning for EEG signal processing in bioengineering. IEEE Rev. Biomed. Eng. 2020, 14, 204–218. [Google Scholar] [CrossRef]
- De Fazio, R.; Mastronardi, V.M.; Petruzzi, M.; De Vittorio, M.; Visconti, P. Human–Machine Interaction through Advanced Haptic Sensors: A Piezoelectric Sensory Glove with Edge Machine Learning for Gesture and Object Recognition. Future Internet 2022, 15, 14. [Google Scholar] [CrossRef]
- Mohsen, S.; Elkaseer, A.; Scholz, S.G. Human activity recognition using K-nearest neighbor machine learning algorithm. In Proceedings of the International Conference on Sustainable Design and Manufacturing, Split, Croatia, 15–17 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 304–313. [Google Scholar]
- Tran, D.N.; Phan, D.D. Human Activities Recognition in Android Smartphone Using Support Vector Machine. In Proceedings of the 2016 7th International Conference on Intelligent Systems, Modelling and Simulation (ISMS), Bangkok, Thailand, 25–27 January 2016; pp. 64–68. [Google Scholar] [CrossRef]
- Jmal, A.; Barioul, R.; Meddeb Makhlouf, A.; Fakhfakh, A.; Kanoun, O. An embedded ANN raspberry PI for inertial sensor based human activity recognition. In Proceedings of the International Conference on Smart Homes and Health Telematics, Hammamet, Tunisia, 24–26 June 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 375–385. [Google Scholar]
- Martinez-Hernandez, U.; Rubio-Solis, A.; Dehghani-Sanij, A.A. Recognition of walking activity and prediction of gait periods with a CNN and first-order MC strategy. In Proceedings of the 2018 7th IEEE International Conference on Biomedical Robotics and Biomechatronics (Biorob), Enschede, The Netherlands, 26–29 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 897–902. [Google Scholar]
- Male, J.; Martinez-Hernandez, U. Recognition of human activity and the state of an assembly task using vision and inertial sensor fusion methods. In Proceedings of the 2021 22nd IEEE International Conference on Industrial Technology (ICIT), Valencia, Spain, 10–12 March 2021; IEEE: Piscataway, NJ, USA, 2021; Volume 1, pp. 919–924. [Google Scholar]
- Ghadi, Y.Y.; Javeed, M.; Alarfaj, M.; Al Shloul, T.; Alsuhibany, S.A.; Jalal, A.; Kamal, S.; Kim, D.S. MS-DLD: Multi-Sensors Based Daily Locomotion Detection via Kinematic-Static Energy and Body-Specific HMMs. IEEE Access 2022, 10, 23964–23979. [Google Scholar] [CrossRef]
- Wang, J.; Wu, D.; Gao, Y.; Wang, X.; Li, X.; Xu, G.; Dong, W. Integral real-time locomotion mode recognition based on GA-CNN for lower limb exoskeleton. J. Bionic Eng. 2022, 19, 1359–1373. [Google Scholar] [CrossRef]
- Ghislieri, M.; Cerone, G.L.; Knaflitz, M.; Agostini, V. Long short-term memory (LSTM) recurrent neural network for muscle activity detection. J. Neuroeng. Rehabil. 2021, 18, 153. [Google Scholar] [CrossRef] [PubMed]
- Marcos Mazon, D.; Groefsema, M.; Schomaker, L.R.; Carloni, R. IMU-Based Classification of Locomotion Modes, Transitions, and Gait Phases with Convolutional Recurrent Neural Networks. Sensors 2022, 22, 8871. [Google Scholar] [CrossRef]
- Wang, H.; Zhao, J.; Li, J.; Tian, L.; Tu, P.; Cao, T.; An, Y.; Wang, K.; Li, S. Wearable sensor-based human activity recognition using hybrid deep learning techniques. Secur. Commun. Netw. 2020, 2020, 2132138. [Google Scholar] [CrossRef]
- Jain, R.; Semwal, V.B.; Kaushik, P. Deep ensemble learning approach for lower extremity activities recognition using wearable sensors. Expert Syst. 2022, 39, e12743. [Google Scholar] [CrossRef]
- Caruso, M.; Sabatini, A.M.; Laidig, D.; Seel, T.; Knaflitz, M.; Della Croce, U.; Cereatti, A. Analysis of the accuracy of ten algorithms for orientation estimation using inertial and magnetic sensing under optimal conditions: One size does not fit all. Sensors 2021, 21, 2543. [Google Scholar] [CrossRef]
- Farooq, F.; Tandon, S.; Parashar, S.; Sengar, P. Vectorized code implementation of Logistic Regression and Artificial Neural Networks to recognize handwritten digit. In Proceedings of the 2016 IEEE 1st International Conference on Power Electronics, Intelligent Control and Energy Systems (ICPEICES), Delhi, India, 4–6 July 2016; Curran Associates, Inc.: New York, NY, USA, 2016; pp. 1548–1552. [Google Scholar]
- Yuan, Y.X. A new stepsize for the steepest descent method. J. Comput. Math. 2006, 24, 149–156. [Google Scholar]
- Lerner, B.; Guterman, H.; Aladjem, M.; Dinstein, I. A comparative study of neural network based feature extraction paradigms. Pattern Recognit. Lett. 1999, 20, 7–14. [Google Scholar] [CrossRef]
- Guan, Y.; Plötz, T. Ensembles of deep lstm learners for activity recognition using wearables. In ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies; Association for Computing Machinery: New York, NY, USA, 2017; Volume 1, pp. 1–28. [Google Scholar]
- Chen, Y.; Zhong, K.; Zhang, J.; Sun, Q.; Zhao, X. LSTM networks for mobile human activity recognition. In Proceedings of the 2016 International Conference on Artificial Intelligence: Technologies and Applications, Bangkok, Thailand, 24–25 January 2016; Atlantis Press: Amsterdam, The Netherlands, 2016; pp. 50–53. [Google Scholar]
- Xia, K.; Huang, J.; Wang, H. LSTM-CNN architecture for human activity recognition. IEEE Access 2020, 8, 56855–56866. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject | Age (Years) | Height (cm) | Weight (kg) |
|---|---|---|---|
| AB156 | 26 | 193 | 77 |
| AB185 | 28 | 181 | 75 |
| AB188 | 25 | 185 | 87 |
| AB189 | 24 | 178 | 66 |
| AB190 | 23 | 160 | 54 |
| AB191 | 26 | 163 | 54 |
| AB193 | 27 | 185 | 95 |
| AB194 | 29 | 160 | 61 |
| Approach | Training Accuracy | Validation Accuracy |
|---|---|---|
| Light-weight ANN | 98.81% | 93.10% |
| DNN | 97.92% | 87.92% |
| CNN | 97.55% | 92.34% |
| LSTM | 98.34% | 92.99% |
| CNN-LSTM | 97.75% | 92.42% |
| Approach | Sitting | Walking | R. Ascent | R. Descent | S. Ascent | S. Descent | Standing |
|---|---|---|---|---|---|---|---|
| Light-weight ANN | 0.95 | 0.85 | 0.95 | 0.98 | 0.996 | 0.83 | 0.97 |
| DNN | 0.84 | 0.79 | 0.87 | 0.91 | 0.92 | 0.81 | 0.88 |
| CNN | 0.95 | 0.82 | 0.93 | 0.97 | 0.995 | 0.83 | 0.97 |
| LSTM | 0.95 | 0.84 | 0.95 | 0.97 | 0.998 | 0.81 | 0.98 |
| CNN-LSTM | 0.95 | 0.93 | 0.93 | 0.98 | 0.99 | 0.77 | 0.96 |
| Sensors | Training Accuracy | Validation Accuracy |
|---|---|---|
| IMUs only | 99.43% | 91.94% |
| Goniometers only | 73.82% | 71.51% |
| IMUs plus goniometers | 98.81% | 93.10% |
| Sensors | Sitting | Walking | R. Ascent | R. Descent | S. Ascent | S. Descent | Standing |
|---|---|---|---|---|---|---|---|
| IMUs only | 0.95 | 0.82 | 0.94 | 0.94 | 0.995 | 0.80 | 0.97 |
| Goniometers only | 0.88 | 0.51 | 0.69 | 0.64 | 0.62 | 0.72 | 0.82 |
| IMUs plus goniometers | 0.95 | 0.85 | 0.95 | 0.98 | 0.996 | 0.83 | 0.97 |
| Approach | Testing Accuracy |
|---|---|
| Light-weight ANN | 84.77% |
| DNN | 70.28% |
| CNN | 86.78% |
| LSTM | 86.9% |
| CNN-LSTM | 86.36% |
| Approach | Sitting | Walking | R. Ascent | R. Descent | S. Ascent | S. Descent | Standing |
|---|---|---|---|---|---|---|---|
| Light-weight ANN | 0.89 | 0.76 | 0.86 | 0.82 | 0.895 | 0.83 | 0.87 |
| DNN | 0.795 | 0.63 | 0.68 | 0.62 | 0.71 | 0.68 | 0.78 |
| CNN | 0.90 | 0.79 | 0.88 | 0.83 | 0.92 | 0.87 | 0.88 |
| LSTM | 0.898 | 0.82 | 0.89 | 0.86 | 0.897 | 0.84 | 0.85 |
| CNN-LSTM | 0.87 | 0.84 | 0.91 | 0.84 | 0.89 | 0.83 | 0.85 |
| Sensors | Testing Accuracy |
|---|---|
| IMUs only | 79.55% |
| Goniometers only | 69.96% |
| IMUs plus goniometers | 84.77% |
| Sensors | Sitting | Walking | R. Ascent | R. Descent | S. Ascent | S. Descent | Standing |
|---|---|---|---|---|---|---|---|
| IMUs only | 0.88 | 0.65 | 0.77 | 0.77 | 0.80 | 0.83 | 0.84 |
| Goniometers only | 0.84 | 0.53 | 0.69 | 0.57 | 0.67 | 0.82 | 0.73 |
| IMUs plus goniometers | 0.89 | 0.76 | 0.86 | 0.82 | 0.895 | 0.83 | 0.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohamed, S.A.; Martinez-Hernandez, U. A Light-Weight Artificial Neural Network for Recognition of Activities of Daily Living. Sensors 2023, 23, 5854. https://doi.org/10.3390/s23135854
Mohamed SA, Martinez-Hernandez U. A Light-Weight Artificial Neural Network for Recognition of Activities of Daily Living. Sensors. 2023; 23(13):5854. https://doi.org/10.3390/s23135854
Chicago/Turabian StyleMohamed, Samer A., and Uriel Martinez-Hernandez. 2023. "A Light-Weight Artificial Neural Network for Recognition of Activities of Daily Living" Sensors 23, no. 13: 5854. https://doi.org/10.3390/s23135854
APA StyleMohamed, S. A., & Martinez-Hernandez, U. (2023). A Light-Weight Artificial Neural Network for Recognition of Activities of Daily Living. Sensors, 23(13), 5854. https://doi.org/10.3390/s23135854